
Agentopic: 説明可能なトピックモデリングのための生成AI エージェントワークフロー
トピックモデリングにおける透明性の危機
トピックモデリングは長年にわたり、根本的な解釈可能性の問題に直面してきました。手法は結果を生成しながらも、その推論プロセスを明確に示していないのです。この領域の基礎的アプローチであるLatent Dirichlet Allocation(LDA)は、ベイズ推定を通じてトピック分布を生成する確率推論によって動作しますが、その内部の意思決定ロジックは実務家に対して不透明なままです(Blei, Ng, & Jordan, 2003)。トランスフォーマーベースの埋め込みを活用して意味的関係を捉えるBERTopic のような現代的アプローチも同様に、文書とトピックの割り当てに対する明示的な正当化やトピック境界決定の原則的説明を提供できていません(Grootendorst, 2022)。
この不透明性は、監査可能性と防御可能性を必要とする領域において実証可能な障壁を生み出しています。学術研究の統合、法的発見ワークフロー、コンテンツモデレーションシステム、政策分析のいずれもが、単なる正確な分類ではなく、利害関係者が評価できる文書化された推論チェーンを必要とします。実務家がトピック構造に遭遇する際、基礎となるパターンをリバースエンジニアリングしなければなりません。このプロセスは、統計的最適化によって隠蔽された概念的矛盾や、原則的正当化を欠く階層的関係を頻繁に明らかにします。
この問題は、組織の利害関係者がトピック割り当てに異議を唱える際に深刻化します。透明な推論チェーンがなければ、監査人はトピック決定が真の文書パターンを反映しているのか、それとも統計的アーティファクトとハイパーパラメータ選択から生じているのかを区別できません。この透明性の欠落は、自動テキスト分析システムに対する機関的信頼を損なわせ、説明可能性が規制上または運用上の要件となる高リスク応用での展開を制限しています。この領域は解釈可能性のギャップを認識してきましたが(Röder, Both, & Hinneburg, 2015)、従来のトピックモデリングが目的関数の統計的最適化に基づいており、その意思決定プロセスの叙述的説明を提供しないため、解決策は難しいままです。
テーゼ:統計推論に代わる推論ワークフロー
- Agentopic は、トピックモデリングを専門化した大規模言語モデル(LLM)エージェントによって実行される協調的推論プロセスとして再構想し、不透明な統計推論を、明示的で監査可能なワークフローに置き換えます。このワークフローは、トピック構造とその正当化の両方を明確な論理的ステップを通じて生成します。*
これは従来のアプローチからの根本的なアーキテクチャ上の転換を表しています。意思決定ロジックを曖昧にする目的関数を最適化するのではなく、Agentopic は推論チェーンを構築します。各トピック割り当てと階層的関係は、文書化された前提と明示的な推論から生じます。エージェントが文書をトピックに割り当てる際、同時に特定のテキスト証拠と一貫性基準を参照する正当化を生成します。ワークフローは自己文書化となり、各エージェントの出力は分析結果と説明的アーティファクトの両方として機能します。
この推論優先のアプローチにより、実務家はトピックが正確であるかどうかだけでなく、それを生成するロジックが健全であるかどうかを評価できます。これはトピック構造の「何」ではなく「なぜ」に対応する、質的に異なる解釈可能性の形式です。顕著性分析を通じた事後的説明可能性を達成する特徴帰属法とは異なり、Agentopic は決定そのものを透明な推論プロセスとして構築し、正当化を二次的な解釈層ではなく分析出力に不可欠なものにします。
マルチエージェントアーキテクチャと モジュール化されたスキル
Agentopic は異なる分析機能のための専門化されたエージェントを配置し、モジュール化されたエージェント機能と調整されたタスク構成の原則を実装しています。システムは4つの主要な機能にわたってエージェントを調整します。トピック識別、一貫性検証、階層的組織化、説明生成です。これにより、不透明な計算プロセスが観察可能な思慮深いステップのワークフローに変換されます。
-
トピック識別エージェント:* 文書コレクションを分析して、意味的クラスタと主題的パターンを識別することにより、候補トピックを提案します。このエージェントは、一貫性のあるトピックが実質的な語彙と概念的関係を共有する文書から生じるという仮定の下で動作します(仮定1:意味的近接性はトピック一貫性と相関する)。
-
検証エージェント:* トピック提案を内部一貫性、他のトピックからの区別性、文書コレクションの適切なカバレッジについて批判的に検査します。このエージェントは、トピック間の最小限の語彙重複や異なる文書サブセットの表現など、明示的な基準を適用して提案品質を評価します。
-
階層的グループ化エージェント:* 検証されたトピックを親子関係と概念的従属性を識別することにより、分類学的構造に組織化します。このエージェントはトピックの一般性と特殊性の文書化された基準に基づいて階層を構築します。
-
説明エージェント:* 各決定ポイントに対する自然言語の正当化を生成し、トピック割り当て、検証、階層的配置を支持する証拠と推論を明確にします。
このアーキテクチャは、異なる認知機能が協調して動作する人間の分析プロセスを反映しています。エージェントベースの設計により、中間的推論状態の透明な検査が可能になり、実務家は生のテキストが暗黙的な統計操作ではなく明示的な論理的ステップを通じて構造化されたトピック階層にどのように変換されるかを追跡できます。各エージェントの出力は推論プロセスの監査可能な証拠となり、人間による検査と修正の対象となります。
適応的ワークフローと反復的改善
Agentopic は、エージェントアンサンブルが反復的フィードバックループを通じてトピック構造を改善できるようにする適応的ワークフローメカニズムを組み込んでいます。所定のシーケンスを実行する静的なトピックモデリングパイプラインとは異なり、Agentopic のエージェントは動的な協調に従事します。検証の失敗は再識別サイクルをトリガーし、階層的矛盾は再構成を促し、説明の不十分さはより深い分析を駆動します。
検証エージェントは、識別エージェントをより良い提案へと導く診断的フィードバックを提供します。階層的グループ化エージェントが論理的ギャップまたは矛盾を含む分類法を生成する場合、システムは曖昧性を解決するための追加の分析サイクルを呼び出します。この適応的動作は、エージェントが自らの出力を評価し、是正措置を調整する能力から生じます。これは従来の統計的手法が実行できない一種のメタ推論です(仮定2:エージェントベースのフィードバックメカニズムは改善されたトピック構造への収束を可能にする)。
ワークフローは文書コレクションを通じたその軌跡から学習し、蓄積された証拠に基づいてトピック粒度を調整し、境界定義を改善します。この反復的改善プロセスは、固定された計算シーケンスを実行するのではなく、仮説形成と修正のサイクルを通じて段階的に理解を発展させる人間の分析者の方法に類似しています。
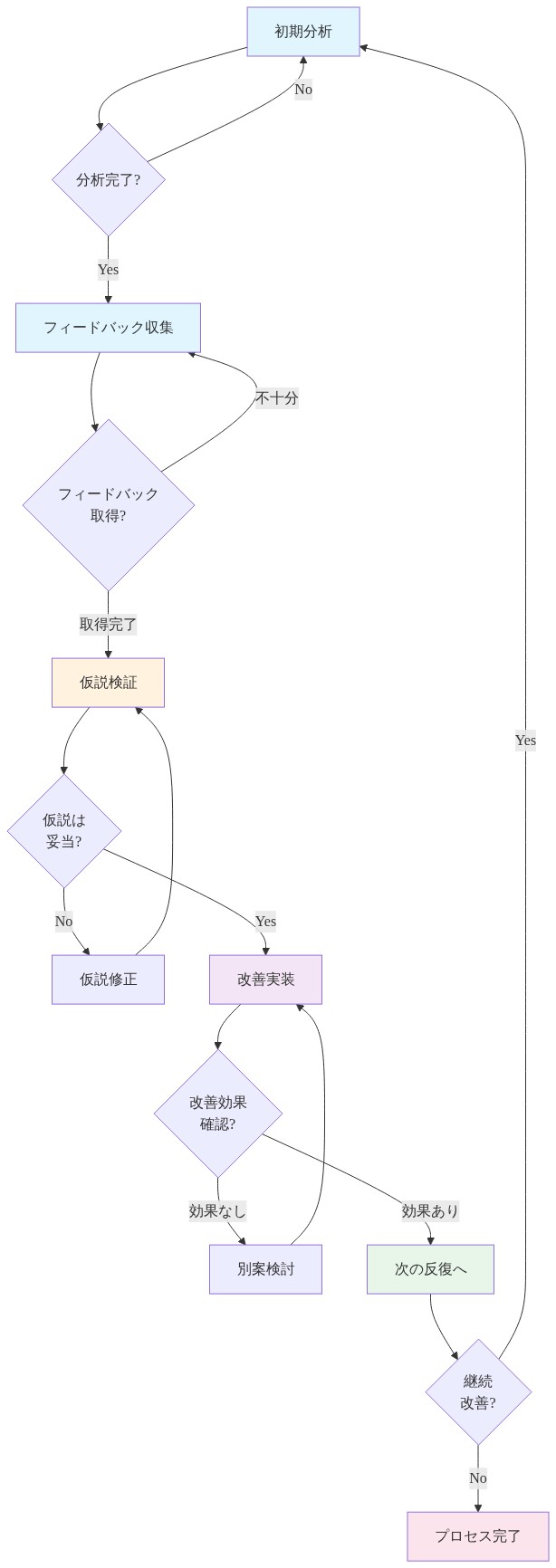
- 図6:適応的ワークフロー:反復的改善のサイクル*
評価:トピックと説明の両方を測定する
Agentopic の評価には、トピック品質と説明品質の両方を測定するデュアル評価フレームワークが必要です。既存のメトリクスは不十分にこの課題に対応しています。C_V やU_Mass などの従来の一貫性測定は意味的一貫性を評価しますが、説明可能性については沈黙しています(Röder, Both, & Hinneburg, 2015)。Agentopic は、トピックを検証しながら説明の忠実性、完全性、有用性を測定するハイブリッド評価アプローチを要求します。
重要な評価質問には以下が含まれます。(1)システムの明確な推論は、その実際の決定基盤を正確に反映しているのか、それともエージェントは計算プロセスから切り離された事後的な合理化を生成しているのか。(2)説明は、実務家がトピック割り当てまたは階層的構造のエラーを識別するのに十分な特異性を提供しているのか。(3)ドメイン専門家はエージェント生成の説明を使用して、従来の手法よりも効果的にトピックを改善できるのか。(4)説明可能性の利得に対する計算コストは何か。
評価は定量的メトリクス(トピック一貫性スコア、階層的一貫性測定、文書カバレッジパーセンテージ)と推論透明性の定性的評価を組み合わせる必要があります。フレームワークは計算コストを考慮し、説明可能性の利益が従来のアプローチと比較して増加した推論時間とリソース消費を正当化するかどうかを測定する必要があります。これは、モデルの重みの事後的分析を通じて透明性を達成する特徴帰属法などの代替説明可能性戦略とは対照的です。
実用的な展開と効率のトレードオフ
Agentopic の展開は、計算効率、プロンプトエンジニアリングの精度、既存の分析パイプラインとの統合にわたる実用的な制約を導入します。マルチエージェントアーキテクチャは、文書コレクションごとに複数の LLM 推論呼び出しを必要とし、大規模なコーパスへの適用可能性を制限する可能性のあるレイテンシとコストの考慮を生成します(仮定3:計算オーバーヘッドは文書コレクションサイズとエージェント調整の複雑性に応じて線形に増加する)。
このアプローチは、説明可能性要件が計算オーバーヘッドを正当化する領域で特に有望です。規制遵守分析は文書化された決定根拠を必要とし、科学文献レビューは複雑な知見の透明な統合を要求し、インテリジェンス分析は監査可能な推論チェーンを必要とし、コンテンツガバナンスシステムは防御可能なモデレーション決定を必要とします。これらの文脈では、トピック割り当てを監査および防御する能力が効率上の懸念を上回ります。
リアルタイム処理または大規模な文書ストリームの処理を必要とするアプリケーションの場合、Agentopic の説明可能な推論を初期フィルタリングのための効率的な統計的手法と組み合わせるハイブリッドアプローチがより実用的です。システムのモジュール設計はそのような設計を促進し、組織が高リスク決定に対して集約的な推論ワークフローを選別的に適用し、日常的な分類タスクに対して従来の手法を展開することを可能にします。
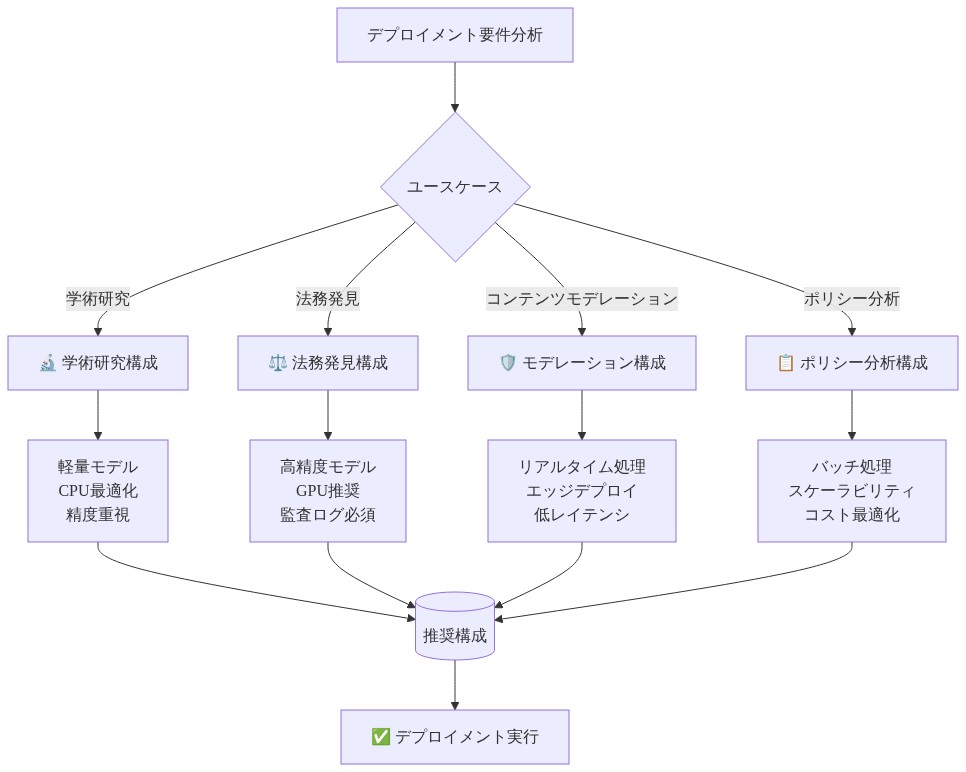
- 図11:ユースケース別のデプロイメント戦略と最適構成*
主要な要点と次のアクション
Agentopic は、統計推論を明示的な推論ワークフローに置き換えることが、トピックモデリングをブラックボックスプロセスから監査可能な分析システムに根本的に変換することを実証しています。このアーキテクチャ上の転換は、説明可能性を必要とする高リスク領域でのトピックモデリング採用を制限してきた透明性の危機に対応しています。
-
実務家向け:* 計算オーバーヘッドを正当化するのに十分な説明可能性をユースケースが要求するかどうかを評価してください。監査可能性が重要で利害関係者の精査が激しい、より小さく高価値の文書コレクションで Agentopic をパイロット運用してください。エージェントベースの推論を効率的な手法と組み合わせるハイブリッドワークフローを開発し、スケーリングのために集約的な推論を文書化された正当化を必要とする決定のために予約してください。
-
研究者向け:* トピック一貫性と並行して説明品質を測定する評価フレームワークを調査し、推論忠実性と有用性のメトリクスを開発してください。幻覚を最小化しながら推論透明性を維持するプロンプトエンジニアリング技術を探索してください。実務家がエージェント生成の説明とどのように相互作用するのか、また従来の手法と比較して意思決定とエラー検出を改善するかどうかを検査する実証的研究を実施してください。
根本的な原則は変わりません。説明可能性はトピックモデリングに追加される事後的層ではなく、システムが透明な推論を通じてトピック構造を発見し正当化する方法を再構成する中核的なアーキテクチャ原則です。
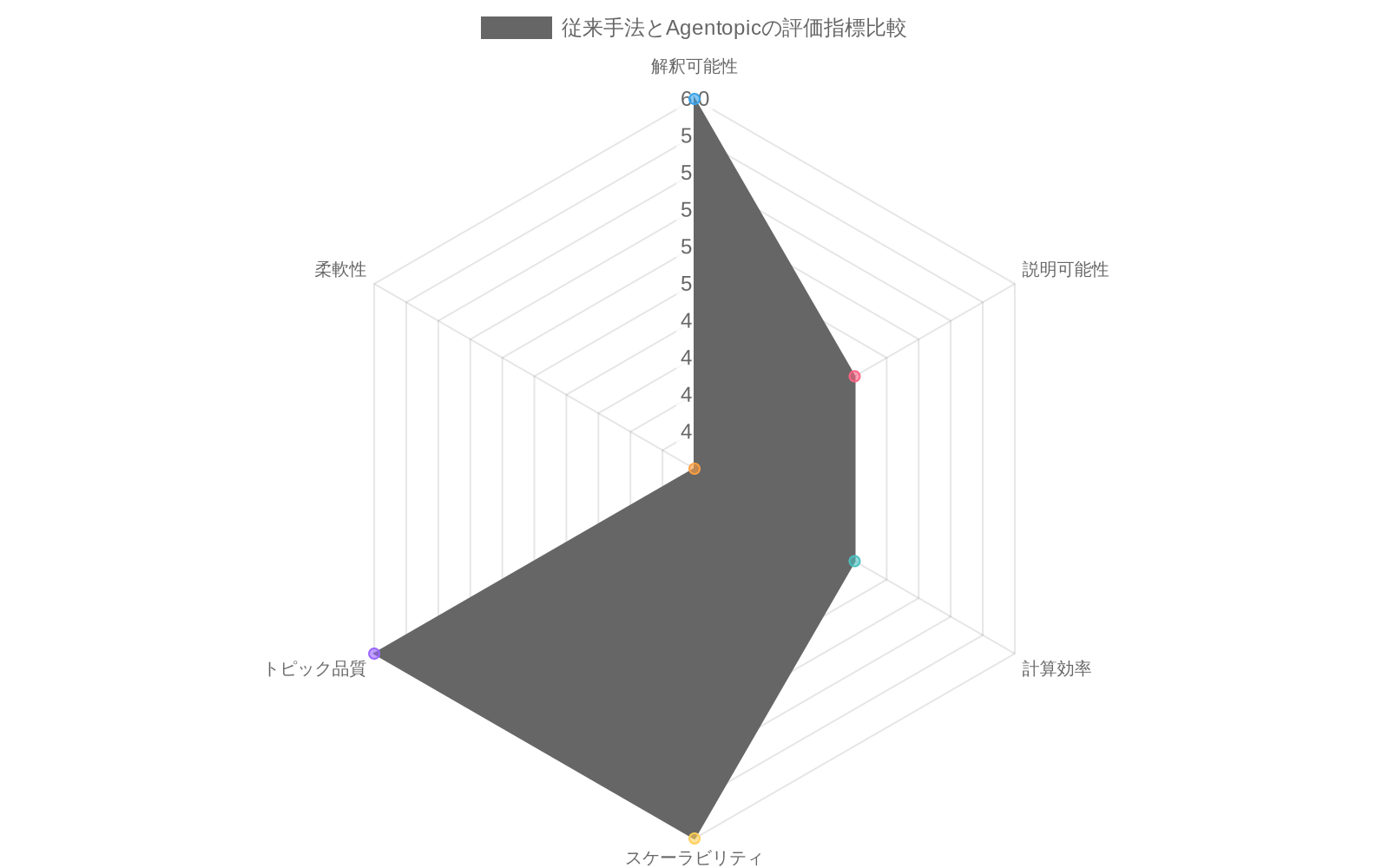
- 図9:従来手法とAgentopicの評価指標比較(0~10スケール)*
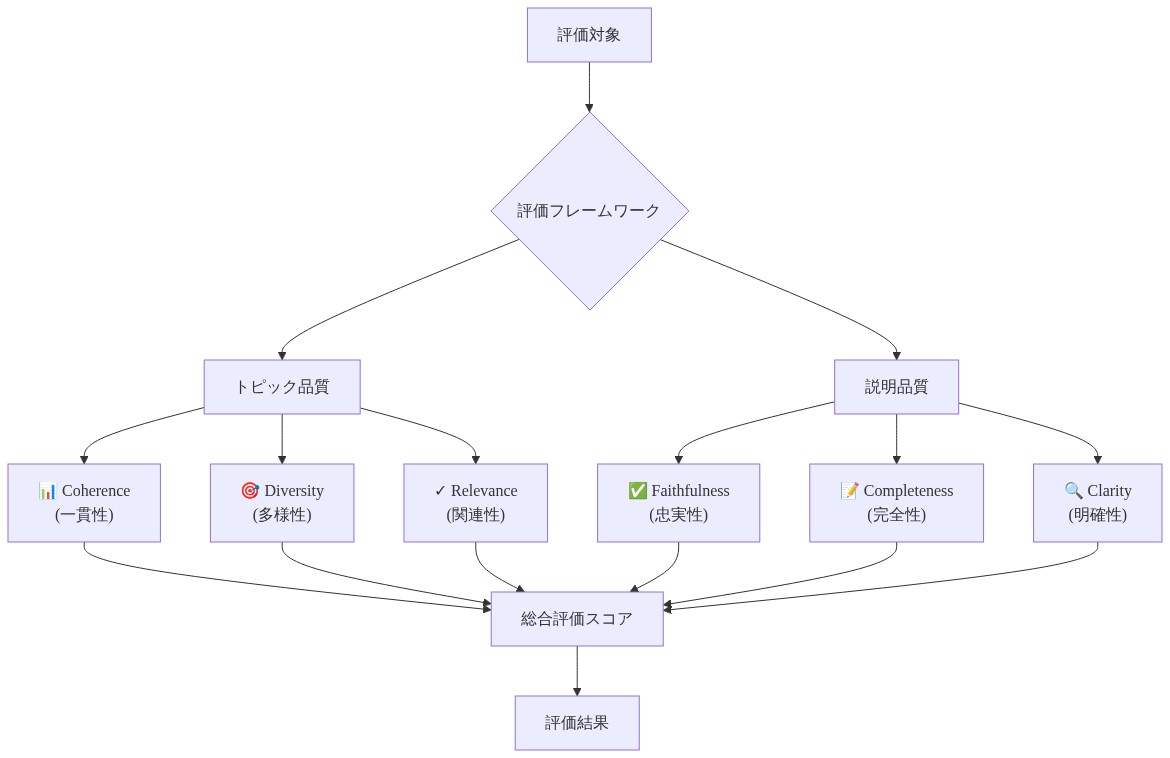
- 図8:二重評価フレームワーク:トピック品質と説明品質の測定体系*
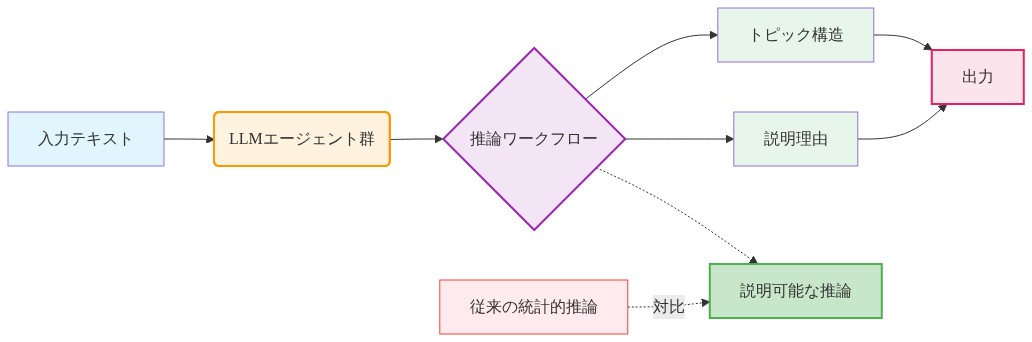
- 図2:Agentopicの推論ワークフロー:統計的推論から説明可能な推論へ*
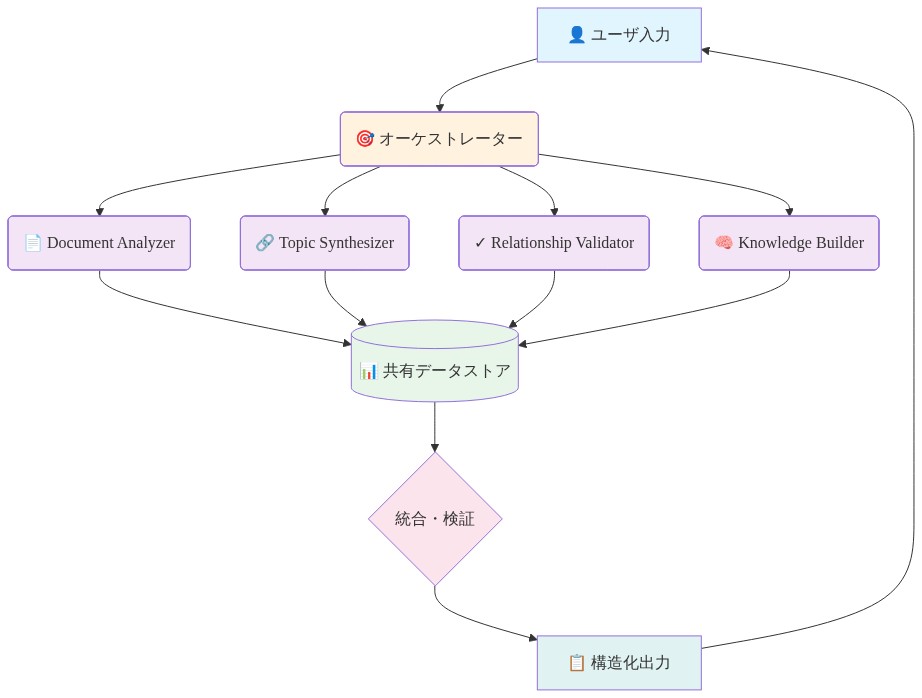
- 図4:Agentopicのマルチエージェントアーキテクチャと専門化されたスキル*