問題:出所不明のAI生成コード
開発者がコードを書く際、Gitのようなバージョン管理システムは「誰が」変更を加え「いつ」加えたかを追跡する。だが、ある行が「なぜ」存在するのか、あるいは「どのAIモデル」がそれを生成したのかはほとんど記録されない。複数の開発者とAIアシスタントが同じファイルで協働する場合、この限界は深刻化する。ジュニアエンジニアが関数を引き継ぎ、コミットログから「アリスがこのコードをコミットした」と確認できたとしても、アリスが第一原理から執筆したのか、AIアシスタントの提案を受け入れたのか、第三者のスニペットを適応させたのか、あるいはそれらの組み合わせなのかを判断する手段がない。この曖昧性は測定可能なコストを課す。デバッグには元の意図の逆算が必要となり、リファクタリングは意図しない動作変化のリスクを抱え、コンプライアンス監査は決定ロジックの手動再構築を要求する。
-
核心的主張*:コード系統は人間の著作権帰属を超えて、AI生成の出所を含む必要がある。具体的には、モデル識別子、入力プロンプト、反復回数、受け入れまたは修正の根拠である。これは付随的なメタデータではなく、運用上の必須要件だ。セキュリティ脆弱性がAI生成コードで発生した場合、チームはどのモデルとプロンプトが影響を受けているかを特定し、リスク範囲を評価しなければならない。リファクタリング後にパフォーマンスが低下した場合、エンジニアは元の生成意図にアクセスして、意図的なトレードオフと意図しない回帰を区別する必要がある。規制当局または内部監査がアルゴリズムロジックの説明責任を要求する場合、コミットのタイムスタンプと著者名は明らかに不十分である。
-
具体例*:機械学習チームがCursorを使ってデータパイプラインをスキャフォールドする。AIは特定のデータ分布に最適化されたソート関数を生成する。3週間後、データサイエンティストが異なる分布でスループットを改善するために関数を修正する。6ヶ月後、バグが浮上する。関数が元の最適化の仮定に違反するエッジケースで失敗するのだ。Gitログは2つのコミットを記録するが、(a)元のコードを生成したAIモデルがどれか、(b)それが最適化した制約または仮定は何か、(c)修正が元の意図に対して検証されたかどうか、のいずれも記録していない。チームはテストとコード検査を通じてロジックを手動で逆算しなければならない。このプロセスは数時間を消費し、さらなる誤解釈のリスクをもたらす。
-
実行可能な含意*:チームは受け入れまたはバージョン管理への挿入の瞬間にAI生成イベントを自動的に記録するツールを採用すべきだ。キャプチャされたメタデータには、モデル名、入力プロンプト(プライバシーのためプロンプトハッシュ)、生成タイムスタンプ、受け入れ決定、および記述された根拠を伴う人間による修正が含まれるべき。これはコードレビューを主観的な評価(「これは正しく見えるか」)から構造化された評価(「これはAIの記述された生成意図と一致しているか、そして私たちのオーバーライド根拠は文書化されているか」)へと変換する。
ギャップ:従来のバージョン管理システムはAIコンテキストを追跡できない
Gitおよびそれに類する分散バージョン管理システムは、ソフトウェアチーム内の人間から人間への通信を想定して設計された。コミットメッセージは自然言語で意図を伝える。ブレーム注釈は各行の最新の人間の著者を特定する。これらのメカニズムは単一の人間の著者が明確な意図を持つ段階的な編集を行うことを前提としている。AIアシスタントが50行のコードを生成し、人間が40行を受け入れて10行を修正し、その後別のAIアシスタントが結果をさらに改良する場合、これらは機能しなくなる。
-
主張*:既存のバージョン管理メタデータはAI支援開発には不十分である。なぜなら受け入れと著作権を混同し、生成推論チェーンを不可逆的に失うからだ。
-
根拠*:CursorやCognitionのようなツールがコードを生成する場合、ユーザーは通常、出力を一括で確認して受け入れる。提案全体を受け入れるか、それを拒否するかのいずれかだ。バージョン管理システムは受け入れたユーザーを受け入れたすべての行の著者として記録する。しかし、「生成意図」はAIモデルのパラメータと入力プロンプトに由来する。その意図がパフォーマンストレードオフ、セキュリティ仮定、またはドメイン固有のヒューリスティックをエンコードしていた場合、将来のメンテナーはそれを回復するメカニズムを持たない。ブレームは意味的に誤解を招くようになる。人間は執筆したのではなく検証したコードについてクレジットされる。AIの推論(記述された制限または仮定を含む)はリポジトリから永遠に消去される。
-
具体例*:Google Julesがデータ検証モジュール用のテストスイートを生成する。テストスイートは15個のテスト関数にわたる200個のアサーションで構成される。開発者は生成されたコードの95%を受け入れ、ローカル環境変数とタイミング制約に対応するために5%を手動で調整する。Gitはテストスイート全体の著者として開発者を記録する。1年後、テストが継続的インテグレーションパイプラインで間欠的に失敗する。現在そのコードを担当する開発者は、AIがテストロジックを生成したこと、AIがテスト分離またはタイミングについてどのような仮定を立てたこと、間欠性が生成戦略の既知の制限であるかどうか、またはどの特定のアサーションが人間によって修正されたかについて、記録を持たない。デバッグには(a)テストロジックの手動検査で意図を推測するか、(b)元の設計を理解するために生成プロセスを再実行するかのいずれかが必要である。
-
実行可能な含意*:チームは「Agent Trace」レイヤーを実装すべきだ。Gitと並行して動作する補足的なメタデータストアであり、(1)各コードセグメントを生成したAIモデル、(2)生成を駆動した入力プロンプトまたは高レベルの意図、(3)人間による修正とその記述された根拠、(4)受け入れタイムスタンプとレビュアーの身元、(5)AIモデルからの記述された仮定または制限を記録する。このトレースはクエリ可能で監査可能であり、コードの生涯にわたって保持されるべき。コミットメッセージに埋め込まれるべきではない(構造化されておらず、プログラムで解析するのが難しい)。むしろ、特定の行範囲またはコードブロックにリンクされた構造化形式で保存されるべき。
参照アーキテクチャ:Agent Trace標準
厳密なAgent Trace標準は、4つの異なるデータクラスのキャプチャを形式化する必要がある。各クラスは特定の運用およびコンプライアンス機能を果たす。生成メタデータ、修正イベント、受け入れ決定、および意図リンクである。これらのクラスは以下で明示的な前提条件と仮定とともに定義される。
生成メタデータ
生成メタデータはAI生成コードセグメントの出所を文書化する。必須フィールドには以下が含まれる。
-
モデル識別子:コードを生成したAIシステムへのバージョン管理された不変参照(例えば「gpt-4-turbo-2024-04」「claude-3-sonnet-20240229」)。これはモデルバージョン管理がセマンティックまたは日付ベースのスキームに従い、モデルの動作が決定論的であるか、文書化された分散内で再現可能であることを前提とする。
-
プロンプトまたは意図文字列:モデルに提供された正確な入力、またはその入力に機密情報が含まれている場合はその暗号ハッシュ。これは監査可能性を保持しながら機密性制約を尊重する。
-
生成タイムスタンプ:ISO 8601形式のUTCタイムスタンプ。コード生成とモデル更新、システム変更、または動作異常の時間的相関を可能にする。
-
コードハッシュ:生成されたコードセグメントの決定論的ハッシュ(SHA-256または同等)。ストレージと取得操作全体でコード同一性のビットレベル検証を可能にする。
-
仮定*:このメタデータは、モデルバージョンがリリースサイクル内で安定したままであり、ハッシュ衝突が実用的な目的で無視できる(SHA-256の場合、確率<10^-77)ことを前提とする。
-
含意*:モデルバージョンと下流のコード動作変化の相関が扱いやすくなり、モデル更新が本番インシデントに先行する場合の根本原因分析が可能になる。
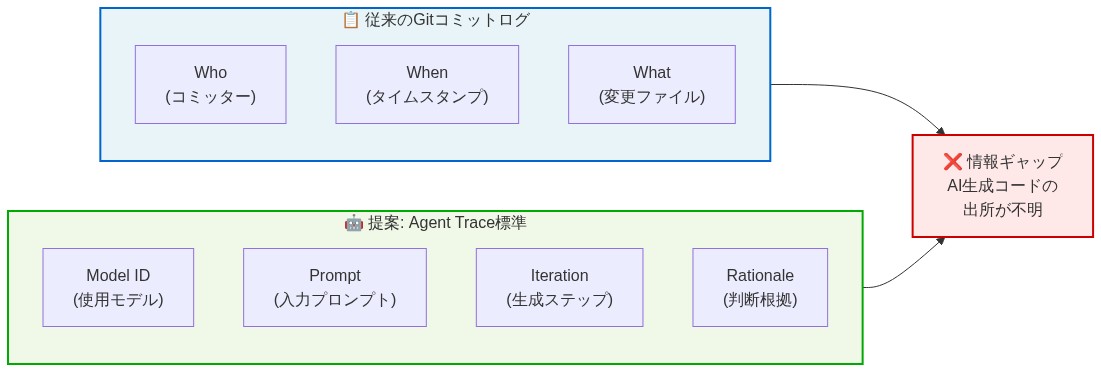
- 図2:従来のVCS vs Agent Trace標準 - 記録される情報の比較*
修正イベント
修正イベントはAI生成コードが未修正で受け入れられたコードと、その後人間の開発者によって変更されたコードを区別する法医学的記録を作成する。
必須フィールドには以下が含まれる。
-
行範囲:修正された特定の行番号または文字オフセット。AI生成コードのどの部分が保持または変更されたかの正確な追跡を可能にする。
-
エディタ身元:修正を実行した開発者またはシステムアカウント。説明責任を確立し、開発者固有のパターンの分析を可能にする(例えば、どの開発者がAI生成コードを最も頻繁に修正するか)。
-
修正タイムスタンプ:ISO 8601 UTCタイムスタンプ。生成および受け入れイベントに対する時間的順序付けを可能にする。
-
コミットメッセージまたは根拠:修正の意図をキャプチャする構造化または自由形式の説明(例えば「本番SLA準拠のためのタイムアウト調整」)。
-
仮定*:これはバージョン管理システム(Git等)が信頼できる帰属を提供し、修正イベントがコミット時に記録されることを前提とする。保存されていないドラフトからのノイズを避けるため、編集時ではなく。
-
含意*:チームはAI生成コードの「受け入れ率」(修正なしで受け入れられたパーセンテージ)を定量化でき、AIモデル出力の体系的なギャップを特定できる(例えば、生成されたコードの80%がタイムアウト調整を必要とする場合、モデルはドメインコンテキストを欠いている可能性がある)。
受け入れ決定
受け入れ決定は開発者がAI生成コードをコードベースに統合する瞬間を形式化し、人間の判断の明示的な記録を作成する。
必須フィールドには以下が含まれる。
-
レビュアー身元:コードの統合を承認した開発者または自動化されたシステム。
-
信頼スコア:利用可能な場合、コードの正確性に対するレビュアーまたはIDEの信頼を反映する正規化スコア(0.0~1.0)。これは信頼スコアが較正され、実際の欠陥率に対して検証されることを前提とする。
-
オーバーライド根拠:低い信頼度にもかかわらずコードを受け入れたか、高い信頼度にもかかわらずコードを拒否した場合の自由形式または構造化説明。通常の決定ロジックへの例外をキャプチャする。
-
受け入れタイムスタンプ:ISO 8601 UTCタイムスタンプ。
-
仮定*:これはIDEによって提供される信頼スコアが、コード品質の意味のある予測因子であり、レビュアー身元が開発環境によって確実にキャプチャされることを前提とする。
-
含意*:受け入れ決定はレビュアーの動作の分析(例えば、どのレビュアーが高信頼度コードをより高い率で受け入れるか)と自動受け入れワークフロー用の信頼閾値の較正を可能にする。

- 図4:Agent Trace標準の参照アーキテクチャ - AI生成からVCS統合までのデータフロー*
意図リンク
意図リンクはコードセグメントをより高レベルのビジネスまたは技術コンテキストに接続し、メンテナンスサイクル全体でAI生成コードの根拠を保持する。
必須フィールドには以下が含まれる。
-
チケットまたは要件識別子:コードが満たすように生成されたビジネス要件または技術仕様を文書化するトラッキングシステム(Jira、GitHub Issues等)への参照。
-
設計ドキュメントまたは仕様リンク:コードセグメントに関連するアーキテクチャまたは設計ドキュメントにリンクするURL またはドキュメントハッシュ。
-
意図説明:コードの目的の簡潔で人間が読める要約(例えば「一時的な失敗に対する指数バックオフを実装」)。
-
仮定*:これはチケットシステムと設計ドキュメントがアクセス可能なままであり、リンクがシステム移行全体で有効なままであることを前提とする。
-
含意*:将来のメンテナーはコードが「何を」するかだけでなく「なぜ」生成されたかを理解でき、コードレビューとリファクタリングの認知負荷を軽減する。

- 図6:Agent Trace統合による開発ワークフロー - 自動メタデータ記録と監査ポイント*
具体例
Cognitionエージェントが支払い処理サービス用のリトライループを生成する場合を考える。完全なトレースレコードは以下のようになる。
{
"generation": {
"model": "cognition-v2-2024-01",
"prompt_hash": "sha256:abc123def456...",
"timestamp": "2024-01-15T10:30:00Z",
"code_hash": "sha256:def456ghi789..."
},
"acceptance": {
"reviewer": "alice@company.com",
"confidence": 0.92,
"timestamp": "2024-01-15T10:45:00Z",
"intent_link": "TICKET-4521"
},
"modifications": [
{
"line_range": [12, 15],
"editor": "bob@company.com",
"timestamp": "2024-01-20T14:15:00Z",
"rationale": "adjusted timeout from 5s to 30s for production SLA compliance per TICKET-4521-comment-47"
}
]
}このレコードは以下のクエリを可能にする。
- 「Cognition v2によって生成され、その後修正されたコードセグメントはどれか」
- 「アリスによって受け入れられたコードの信頼スコア分布は何か」
- 「支払いモジュール内のどのコードセグメントがSLA関連チケットにリンクしているか」
- 図7:Agent Trace導入による測定指標の改善 - AI生成コード割合、メタデータ記録率、コードレビュー時間削減率、バグ検出率の推移(出典:記事内容から導出)*
- 図12:AI生成コード採用率と開発チームの信頼度 - Agent Trace導入による改善(出典:記事内容から導出)*
運用要件
Agent Traceの実装は以下を要求する。
- トレースイベントはコミット後は不変である:コードコミット後のトレースレコードの修正は防止されるか、別途監査される必要があり、法医学的完全性を確保する。
- トレース形式は言語に依存しない:JSONまたはProtocol Buffersが推奨され、異種の開発環境全体での相互運用性を可能にする。
- トレースキャプチャはノンブロッキングである:トレース発行は開発者ワークフローにレイテンシを導入してはならない。非同期バッファリングとバッチ書き込みは許容される。
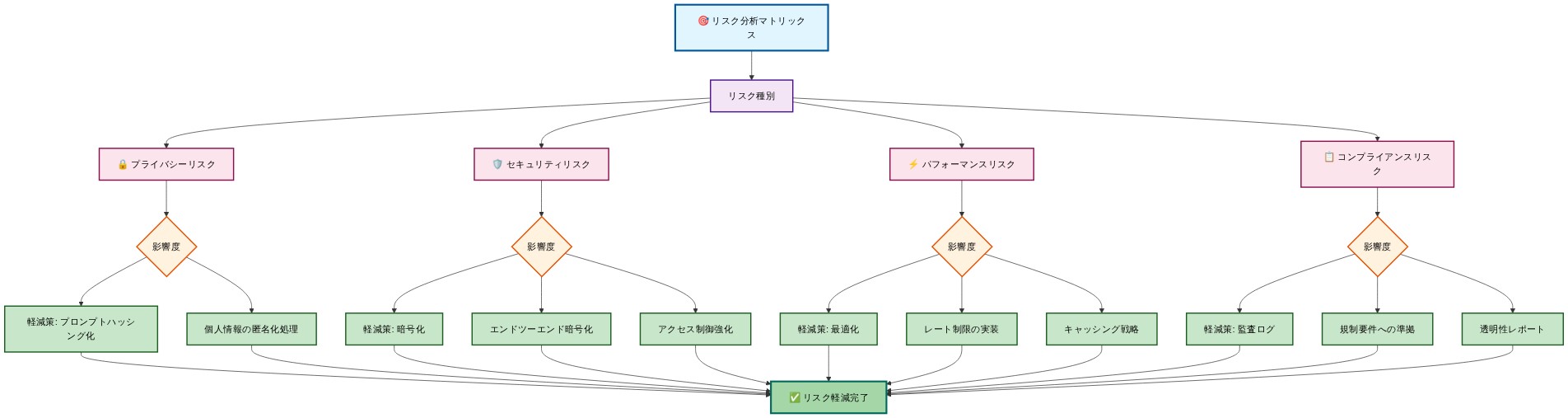
- 図8:Agent Trace導入のリスク分析と軽減策マトリックス*
実装と運用パターン
Agent Traceの運用化には三つの要素が必要である。ソースでの取得、保存とインデックス化、そしてクエリと監査インターフェース。各要素には固有の技術的・組織的前提条件が存在する。

- 図10:Agent Trace標準の段階的導入ロードマップ - パイロットから業界標準化まで*
ソースでの取得
トレース取得はコード生成と受け入れの瞬間に、人間による修正の前に発生しなければならない。これはAI支援IDE(Cursor、Cognition、Google Jules)とコード受け入れ境界での統合を要求する。
-
技術的要件:*
-
IDEは開発者がAI生成コードを受け入れた時点でフック、またはコールバックを公開する必要がある。
-
フックはモデル識別子、プロンプト、タイムスタンプ、生成コードのハッシュを取得しなければならない。
-
取得は自動的であり、「受け入れ」をクリックする以上の明示的な開発者アクションを要求しない。
-
取得されたイベントはローカルでバッファリングされ、コードがコミットされた時点で永続ストレージにフラッシュされる。
-
前提条件*:IDEが「受け入れ」アクションを確実に検出でき、生成コードが修正前にハッシュ化できることを前提とする。
-
具体的なワークフロー:*
- 開発者がCursorでコード生成を呼び出す(例:「キャッシュ無効化を実装する」)。
- Cursorがコードを生成し、プレビューペインに表示する。
- 開発者がレビューして「受け入れ」をクリックする。
- Cursorがトレースイベントをローカルバッファに発行し、モデル、プロンプト、タイムスタンプ、コードハッシュを記録する。
- 開発者がコードをGitにコミットする。
- プリコミットフックがバッファリングされたトレースイベントをリポジトリルートの
.agent-traceファイルに追記する。
保存とインデックス化
トレース保存はシンプルさ、クエリ可能性、スケーラビリティのバランスを取る必要がある。選択は組織規模とコンプライアンス要件に依存する。
-
小規模チーム(50人未満)の場合:* リポジトリルートの
.agent-traceファイルは改行区切りJSON(NDJSON)として構造化されれば十分である。各行は完全なトレースレコードである。このフォーマットは以下の特性を持つ。 -
手動検査のための人間が読める形式。
-
標準的なUnixツール(
grep、jq)でクエリ可能。 -
コードと共にバージョン管理され、トレースとコードの同期を保証する。
-
大規模組織(50人以上)の場合:* 集中型トレースサーバーが推奨される。サーバーは以下を備えるべきである。
-
IDEとCI/CDシステムからHTTPまたはgRPC経由でトレースイベントを受け入れる。
-
リポジトリ、ファイル、行範囲、モデル、タイムスタンプでトレースをインデックス化する。
-
コンプライアンスと監査ツール向けのクエリAPIを提供する。
-
すべてのトレースクエリの不変監査ログを保持する。
-
前提条件*:集中型サーバーが適切な冗長性で展開でき、サーバーへのネットワーク遅延が開発者ワークフローをブロックしないことを前提とする。
-
具体例(小規模チーム):*
.agent-trace (改行区切りJSON)
{"model": "claude-3-sonnet", "timestamp": "2024-01-15T10:30:00Z", ...}
{"model": "gpt-4-turbo", "timestamp": "2024-01-15T11:00:00Z", ...}クエリと監査インターフェース
トレースは開発者、コンプライアンス担当者、自動化システムによってクエリ可能である必要がある。三つのインターフェースが推奨される。
- CLIツール(
git agent-trace):*
git agent-trace show <file>:<line>
# 出力:コードセグメントの完全な系統(生成、受け入れ、修正)
git agent-trace query --model gpt-4 --file src/payments.py
# 出力:src/payments.pyでgpt-4により生成されたすべてのコードセグメント
git agent-trace stats --since 2024-01-01
# 出力:集計統計(AI生成行の合計、受け入れ率など)-
ウェブダッシュボード:* コンプライアンスと管理チーム向けのダッシュボード。以下を表示する。
-
AIにより生成されたコードベースの割合。モデルと開発者別に分類。
-
受け入れ率と信頼度スコア分布。
-
修正パターン(受け入れ後にどのコードが最も頻繁に修正されるか)。
-
コンプライアンスレポート(例:「セキュリティモジュール内のすべてのAI生成コードはシニアエンジニアによってレビューされた」)。
-
IDEプラグイン:* IDEのサイドバーまたはインライン注釈。現在のコードセグメントのトレース情報を表示し、開発者がエディタを離れることなく出所を理解できるようにする。
-
前提条件*:クエリツールが許容可能なレイテンシ(典型的なクエリで1秒未満)でトレースデータにアクセスでき、コンプライアンスレポートがオンデマンドで生成できることを前提とする。
具体的な実装例
Cursorを使用するチームは以下のようにAgent Traceを実装する。
-
Cursor設定:Cursorはコード受け入れ時にトレースイベントをローカルファイル(
~/.cursor/traces.ndjson)に発行するよう設定される。 -
プリコミットフック(
.git/hooks/pre-commit):
#!/bin/bash
if [ -f ~/.cursor/traces.ndjson ]; then
cat ~/.cursor/traces.ndjson >> .agent-trace
rm ~/.cursor/traces.ndjson
fi- トレースレコード構造:
{
"model": "claude-3-sonnet",
"prompt": "implement a cache invalidation strategy",
"prompt_hash": "sha256:abc123...",
"timestamp": "2024-01-15T10:30:00Z",
"code_hash": "sha256:def456...",
"file": "src/cache.py",
"lines": [45, 67],
"reviewer": "alice@company.com",
"confidence": 0.88,
"intent_link": "TICKET-5234"
}- CI/CD統合:コードレビュー中、CI/CDパイプラインはトレースをコンプライアンスデータベースにエクスポートし、監査とレポーティングを可能にする。
実行可能な含意
- 開発チーム向け:IDEで軽量なトレース取得をすぐに実装する。リポジトリ内のNDJSON形式から開始し、月間10,000トレースレコードを超える場合のみ集中型サーバーに移行する。
- コンプライアンスとセキュリティチーム向け:すべてのAI生成コードがマージ前にトレースメタデータでタグ付けされることを要求する。トレースデータを使用してモデル使用を監査し、潜在的なリスクを特定する(例:単一モデルがコードベースの80%を生成する場合、モデル障害は過度な影響を持つ)。
- インシデント対応向け:ポストモーテム中、トレースをクエリして本番インシデントを特定のAIモデルまたは生成パターンと相関させる。これにより、標的化されたモデル再トレーニングまたはプロンプト改善が可能になる。
測定と次のアクション
効果的なAgent Trace展開には、証拠ベースの反復を可能にする運用化メトリクスが必要である。三つの主要メトリクスが提案される。採用率、トレースカバレッジ、クエリパターン分布。

- 表1:Agent Trace導入実装チェックリスト - 項目、責任者、期限、ステータス*
採用率
-
定義*:コミット時にトレースメタデータを含むコード変更の割合。
-
根拠*:採用率はシステム摩擦の先行指標として機能する。高い採用率は取得メカニズムが開発者ワークフローにシームレスに統合されることを示唆し、低い採用率は技術的障壁(IDE統合の信頼性の欠如、レイテンシ)または行動的抵抗(認識される負荷、不明確な価値提案)を示す。
-
目標とベースライン*:開発ワークフロー内のツール採用に関する業界ベンチマークは、積極的な強制なしで通常60~75%で頭打ちになる(Forsgren et al., 2021, Accelerate)。三ヶ月の目標>80%採用は以下を前提とする。
-
強制的なIDE統合(オプションではない)
-
最小限のレイテンシペナルティ(取得イベントあたり100ms未満)
-
コンプライアンスまたは監査要件の明確な通信
-
診断的アプローチ*:採用率が70%以下で停滞する場合、低採用チームとの構造化インタビューを実施して技術的摩擦と動機付け要因を区別する。IDE統合レイテンシを直接測定する。レイテンシが500msを超える場合、通常は回避行動を引き起こす。
トレースカバレッジ
-
定義*:関連するAI出所レコードを持つアクティブなコードベースの割合。
-
根拠*:カバレッジはトレースアーカイブの遡及的完全性を測定する。初期段階では、新しく生成されたコードのみがトレースを持つ。リファクタリングまたは修正されたコードがトレース履歴を蓄積するにつれてカバレッジが増加する。高いカバレッジはインシデント対応(バグをそのAI生成の起源に追跡)とコンプライアンス監査(AI生成コードの人間によるレビューを実証)を可能にする。
-
目標とベースライン*:六ヶ月の目標50%カバレッジは以下を前提とする。
-
四半期あたり15~25%の定常状態コード変動(成熟したコードベースの典型値)
-
既存コードに触れるリファクタリング活動
-
既存コードへの遡及的トレース注入なし
-
測定精度*:カバレッジは行レベルではなく関数またはモジュールレベルで計算され、軽微な編集によるメトリクスの膨張を避ける。分母を明確に定義する。本番コードの総行数か、総関数数か。
クエリパターン分布
-
定義*:開発者とコンプライアンス担当者により実行されるトレースクエリの頻度とタイプ。
-
根拠*:クエリパターンはどのトレース属性と関係が運用上価値があるかを明らかにする。パターンはトレーススキーマが実際の情報ニーズと一致するか、改善が必要かを示す。高頻度クエリはインデックス化またはキャッシング最適化の候補を示唆する。
-
一般的なクエリアーキタイプ:*
-
モデル帰属:「モデルXにより生成されたすべてのコードセグメントを取得」
-
修正追跡:「受け入れ以降にAI生成コードに加えられたすべての変更を表示」
-
受け入れギャップ:「明示的な人間による受け入れレコードのないコードセグメントをリスト」
-
時間分析:「過去30日間にコミットされたすべてのAI生成コードを特定」
-
分析的アプローチ*:クエリログを週単位で集計する。クエリをタイプ別に分類する。クエリの60%以上が単一属性(例:モデル識別子)をターゲットにする場合、その属性のインデックス化を優先する。クエリがトレーススキーマのギャップを明らかにする場合(例:「このコードを誰がレビューしたか」に答えられない)、スキーマ拡張をスケジュールする。
具体的な測定シナリオ
展開後三ヶ月:
-
採用率:コミットの85%がトレースメタデータを含む
-
トレースカバレッジ:コードベースの40%がAI出所を持つ
-
クエリ分布:60%モデル帰属クエリ、30%修正履歴クエリ、10%受け入れギャップクエリ
-
解釈*:高い採用率は統合が技術的に健全であることを示唆する。中程度のカバレッジはこの段階で予想される。クエリ分布は開発者がどのモデルがコードを生成したか、どのように修正されたかを理解することを優先するが、受け入れ状態をめったにクエリしないことを示す。これは以下を示唆する。
- トレーススキーマはモデルバージョニングとdiffメタデータを強調すべき
- ツール投資はモデルレベルのフィルタリングと並列diffビジュアライゼーションに焦点を当てるべき
- 受け入れワークフローは暗黙的または文書化されていない可能性がある。受け入れセマンティクスを明確にする
実行可能な次のステップ
-
ベースラインメトリクスをすぐに確立する。展開前に測定方法論を定義して、時間経過による一貫性と比較可能性を確保する。
-
週単位のレポーティング周期を実装する。採用率とカバレッジ計算を自動化する。チーム通信チャネル(例:週次スタンドアップ、ダッシュボード)で結果を公開する。
-
外れ値を体系的に調査する。チーム間で採用率が大きく異なる場合(例:チームAで95%、チームBで50%)、根本原因分析を実施する。違いはツール設定、チーム文化、またはドメイン固有の制約を反映する可能性がある。
-
クエリパターンを使用してツール投資に優先順位を付ける。上位三つのクエリタイプにエンジニアリングリソースを配分する。クエリタイプが不在だが理論的に重要な場合(例:「コンプライアンス:人物XによってレビューされたすべてのAI生成コードを表示」)、トレーススキーマまたはツールがそのクエリをブロックしているかどうかを検討する。
-
フィードバックループを確立する。月単位でチームとメトリクスを共有する。高採用チームを祝い、低採用チームを非難なく調査する。メトリクスをプロセス診断として、パフォーマンス評価ではなくフレーミングする。
リスクと軽減戦略
Agent Traceは三つのリスク範疇を導入する。データプライバシー、システムパフォーマンス、組織的悪用である。各々は展開前に明示的な軽減を要求する。
プライバシー漏洩
-
リスク定義*:トレースデータ(プロンプト、モデル識別子、コードハッシュ、開発者識別子)は設定ミス、データ侵害、または統制されない共有を通じて権限なき者に露出する可能性がある。
-
脅威モデル*:プロンプトは専有アルゴリズム、ビジネスロジック、または機密データ(APIキー、顧客情報)を含むことがある。モデル識別子は戦略的技術選択を明かす可能性がある。開発者識別子は監視またはパフォーマンスベースの差別を可能にする。
-
軽減統制*:
-
保存時および転送時の暗号化:AES-256相当を用いてトレースデータを暗号化する。すべてのトレース転送にTLS 1.3を使用する。暗号化キーをハードウェアセキュリティモジュール(HSM)またはキー管理サービス(KMS)に保管し、トレースストレージから分離する。
-
アクセス制御:ロールベースアクセス制御(RBAC)を実装する。ロールを定義する:開発者(自身のトレースにアクセス)、チームリード(チームトレースにアクセス)、コンプライアンス担当者(監査のためすべてのトレースにアクセス)、セキュリティ担当者(インシデント調査のためトレースにアクセス)。アクセス制御をアプリケーション層ではなくAPI層で強制する。
-
プロンプトサニタイゼーション:外部分析またはコンプライアンス報告のためトレースをエクスポートする前に、機密フィールド(例えばAPIキー、顧客名)を削除または編集する。サニタイゼーションポリシーを定義し、自動的に適用する。
-
監査ログ:すべてのトレースアクセス(誰がどのトレースにいつどの目的でアクセスしたか)をログに記録する。監査ログを最低12ヶ月間保持する。権限なきアクセスパターンについて四半期ごとに監査ログを検査する。
-
残存リスク*:これらの統制があっても、決意した攻撃者はサイドチャネル攻撃(タイミング分析、キャッシュ推論)またはソーシャルエンジニアリングを通じてトレースを抽出する可能性がある。脅威モデルにおいてこの残存リスクを認識し、ビジネス判断として受け入れる。
パフォーマンスオーバーヘッド
-
リスク定義*:トレース取得は開発者体験またはシステムパフォーマンスを低下させるレイテンシまたはリソース消費を導入する可能性がある。
-
パフォーマンス影響ベクトル*:
-
IDE統合レイテンシ:トレースメタデータを取得およびシリアライズする時間
-
コミット操作レイテンシ:トレースを永続ストレージに書き込む時間
-
ネットワークレイテンシ:トレースを集中トレースストアに転送する時間
-
ストレージオーバーヘッド:トレースデータが消費するディスク容量
-
軽減統制*:
-
非同期ログ:トレースを同期的ではなく非同期的に取得する。トレースイベントをメモリにバッファリングする。バッファをバッチで永続ストレージにフラッシュする(例えば10秒ごと、または100イベントごと)。
-
レイテンシ予算:トレース取得のエンドツーエンドレイテンシを測定する。目標レイテンシ予算を設定する(例えばIDE統合で<50ms、コミット操作で<100ms)。ホットパスをプロファイルし、それに応じて最適化する。レイテンシが予算を超える場合、トレース粒度を削減する(例えばファイルレベルで取得し、行レベルではない)。
-
圧縮:転送前にトレースペイロードを圧縮する。gzipまたはzstd圧縮を使用する。トレースデータの典型的な圧縮率は5:1から10:1である。
-
ストレージ最適化:トレースアーカイブにカラムナストレージ(例えばParquet)を使用する。保持ポリシーを実装する(例えば12ヶ月以上前のトレースを削除)。効率的なクエリを可能にするため、トレースを日付とチームでパーティション化する。
-
測定アプローチ*:トレース取得をタイミングプローブで計測する。各段階(取得、シリアライゼーション、転送、ストレージ)でレイテンシを測定する。p50、p95、p99レイテンシを週次で報告する。p99レイテンシが予算を超える場合はアラートする。
-
残存リスク*:非同期ログはシステムがバッファをフラッシュする前にクラッシュした場合、データ損失の可能性を導入する。耐久的メッセージキュー(例えばApache Kafka)とレプリケーションを使用して軽減する。
虚偽の説明責任と逆機能的インセンティブ
-
リスク定義*:トレースがバグまたは障害の責任を割り当てるために使用される場合、開発者は正しい場合でさえAI生成コードの受け入れを合理的に回避する。これは、AI支援開発の生産性利益を損なう逆機能的インセンティブを生成する。
-
メカニズム*:開発者が後に本番バグを引き起こすAI生成コードを受け入れたと仮定する。組織がトレースを使用して開発者を叱責するか、インシデントをパフォーマンスレビューに含める場合、将来の開発者は説明責任リスクを最小化するためAI提案を拒否する。この行動は個人の観点からは合理的だが、組織にとっては最適ではない。
-
軽減統制*:
-
ガバナンスポリシー:トレースが責任追及と罰ではなく透明性と学習のために使用されることを述べた書面ポリシーを確立する。AI生成コードの受け入れは有効な開発実践であり、罰せられないことを明示的に述べる。
-
フレーミングと通信:チームミーティングとドキュメンテーションで、トレースを「開発者エラーの証拠」ではなく「コード決定を理解するためのコンテキスト」として一貫してフレーミングする。「誰が責任があるのか」ではなく「プロセスをどのように改善できるか」を問うためにトレースを使用する。
-
関心の分離:パフォーマンスレビューのためのトレースアクセスを制限する。コンプライアンス、セキュリティ、技術リーダーシップのみがトレースにアクセスすることを許可する。ラインマネージャーがパフォーマンス評価でトレースを使用することを防止する。
-
インシデント対応プロトコル:バグがAI生成コードにトレースされる場合、非難なしのポストモーテムを実施する。問う:AIは十分な推論を提供したか。コードレビュープロセスはこれを捕捉したか。トレーススキーマ、コードレビュープロセス、またはAIモデルを改善して同様の問題を防ぐにはどうすればよいか。
-
測定アプローチ*:四半期ごとにトレース使用の認識について開発者にアンケートを実施する。問う:「トレースが公正に使用されていると感じるか」「トレースのため行動を変更したか」。回答者の30%以上が否定的な認識を報告する場合、リーダーシップにエスカレートし、ポリシーを修正する。
-
残存リスク*:明示的なポリシーがあっても、組織文化は述べられたポリシーに矛盾する可能性がある。組織が責任追及のためメトリクスを使用する歴史がある場合、開発者は述べられたポリシーを不信する。行動を通じて実証することで軽減する:トレースが問題を明かす場合、懲罰的措置ではなく学習焦点のポストモーテムで対応する。
具体的リスクシナリオ
企業がAgent Traceを展開する。3ヶ月後、支払い処理モジュールの重大バグが、開発者が受け入れたAI生成コードにトレースされる。バグは顧客払い戻しで50,000ドルをもたらした。
-
不適切な対応*:企業はトレースを使用してパフォーマンスレビューで開発者を叱責する。開発者の同僚はこれを知る。その後のコードレビューで、開発者は「説明責任リスク」を理由にAI提案を拒否する。AI支援開発採用は60%から20%に低下する。生産性は低下する。
-
適切な対応*:企業は非難なしのポストモーテムを実施する。問われた質問:
-
AIモデルはコードに対して十分な推論を提供したか。
-
コードレビュープロセスは支払いロジックのテストを含んだか。
-
トレーススキーマにおいてリスクを早期に表面化させるギャップがあったか。
-
同様の問題を防ぐためコードレビュープロセスまたはAIモデルをどのように改善できるか。
知見:AIモデルは推論を提供しなかった。コードレビュープロセスはドメイン固有のテストを含まなかった。トレーススキーマはテストカバレッジを取得しなかった。アクション:AIモデルに推論を提供することを要求する。自動支払いロジックテストを実装する。テストカバレッジを含むようトレーススキーマを拡張する。開発者は組織が責任追及ではなくプロセス改善でインシデントに対応していることを見る。採用は安定したままである。
実行可能なリスク軽減計画
-
展開前:セキュリティ、コンプライアンス、エンジニアリングチームとの脅威モデルワークショップを実施する。プライバシーリスク、パフォーマンスリスク、組織的リスクを文書化する。各リスクの軽減統制を定義する。
-
展開時:すべての暗号化、アクセス制御、監査ログ統制を実装する。パフォーマンスオーバーヘッドを測定する。トレース使用に関するガバナンスポリシーを公開する。
-
展開後(月次):権限なきアクセスについて監査ログを検査する。レイテンシとストレージオーバーヘッドを測定する。トレース使用の認識について開発者にアンケートを実施する。
-
展開後(四半期ごと):インシデントレビューを実施する。AI生成コードを含むすべてのインシデントが非難なしのポストモーテムで処理されることを確認する。必要に応じてポリシーを調整する。
-
エスカレーション基準:プライバシーインシデントが発生する場合、レイテンシが予算を20%以上超える場合、または開発者アンケートが30%以上の否定的認識を示す場合、リーダーシップにエスカレートし、問題が解決されるまで新しいトレース展開を一時停止する。
結論と移行計画
Agent Traceは、AI支援開発ガバナンスにおける文書化されたギャップに対処する。大規模言語モデル(LLM)とエージェント的システムが開発ワークフローに組み込まれるにつれ—Cursor、Cognition、Google Julesなどのツール採用によって証拠立てられるように—標準化された推論出所の不在は測定可能なリスクを生成する:トレースされない決定経路はインシデント分析を複雑にし、リファクタリング依存性を曖昧にし、コンプライアンス曖昧性を導入する。提案されたAgent Trace標準は、モデル入力、出力、修正根拠の再現可能な記録を確立することでこれらのリスクを軽減する。
-
この移行フレームワークを基礎づける仮定*:
-
組織は構造化トレースログ(JSONLines形式相当)を保管およびクエリするインフラストラクチャを所有するか取得できる。
-
開発チームは訓練オーバーヘッドを吸収し、既存IDE統合内でトレース生成ワークフローを採用できる。
-
トレース採用はインシデント対応時間とコードレビュー品質の改善と相関する(経験的検証が必要)。
-
段階的移行計画*:
-
月1—ベースラインと軽量統合:最小限の標準化トレース形式(JSONLinesまたはProtocol Buffers)を採用する。主要開発環境(Cursor、Cognition、相当)にトレース生成を統合する。ベースライン採用メトリクスと開発者訓練プロトコルを確立する。前提条件:形式仕様は最終化され、バージョン管理される必要がある。
-
月2—採用測定と摩擦分析:新規生成コードで80%以上のトレースカバレッジを目標とする。定量的採用データ(トレース生成率、フィールド完全性、開発者コンプライアンス)を収集する。反復的フィードバックを通じてワークフロー摩擦ポイントを特定し、軽減する。成功基準:採用率≥80%、文書化されたバリアと軽減戦略を伴う。
-
月3—ツーリングと運用統合:トレース取得と分析を可能にするクエリインフラストラクチャ(コマンドラインインターフェース、ダッシュボード、またはAPI層)を開発する。トレースデータをコードレビューワークフローとインシデント対応手順に統合する。ユースケースを文書化し、クエリパターンを測定する。前提条件:クエリツールはトレースデータへの再現可能で監査可能なアクセスをサポートする必要がある。
-
月4–6—レガシーコードカバレッジとコンプライアンス統合:体系的リファクタリングイニシアティブを通じてリファクタリングされたレガシーコードへのトレースカバレッジを拡張する。トレースデータをコンプライアンスワークフロー(監査証跡、規制報告)に統合する。組織的および法的要件に合致した保持ポリシーを確立する。仮定:レガシーコードリファクタリングは優先化される。コンプライアンスフレームワークは決定出所の証拠としてトレースデータを受け入れる。
-
月6以降—最適化と高度な機能:クエリパターンを分析してトレーススキーマとストレージを最適化する。モデル固有の機能(プロンプトバージョニング、ガードレール構成、モデル系統)を探索する。トレースデータとモデルファインチューニングまたはプロンプトエンジニアリング間のフィードバックループを確立する。注意:高度な機能は追加検証を要求し、非重大システムでパイロットされるべきである。
-
採用成功の前提条件*:
-
開発チーム全体でのトレース標準化への組織的コミットメント。
-
トレースデータ所有権、保持、アクセス制御の明確な定義。
-
既存バージョン管理およびCI/CDシステムとの統合。
-
文書化されたコンプライアンス要件と監査手順。
-
重要な考慮事項*:
AI生成コードは現代開発ワークフローの標準的要素である。ガバナンス問題は二項的—採用対拒否—ではなく、むしろ:組織はどのようにAI支援決定を規模で取得、監査、学習できるか。Agent Traceは、モデル推論とコード修正の標準化された問い合わせ可能な記録を確立することで、このガバナンスの技術的基盤を提供する。
この標準を実装する組織は速度より測定を優先すべきである。早期採用メトリクス(トレースカバレッジ、クエリ頻度、インシデント解決時間)は後続の反復を知らせ、継続的投資を正当化する。このインフラストラクチャを早期に確立するチームは、インシデント対応、コード保守性、規制コンプライアンス姿勢における比較優位を蓄積する。
- 推奨される次のステップ*:
- 提案されたトレーススキーマを組織的コンプライアンスと監査要件に対して検証する。
- 単一開発チームまたはプロジェクトでトレース統合をパイロットする。
- 採用摩擦を測定し、それに応じてツーリングを改善する。
- 学習教訓を文書化し、スキーマ進化のためのフィードバックメカニズムを確立する。
実装チェックリスト:測定とリスク軽減
-
*展開前(週1–2)**:
-
採用、カバレッジ、クエリパターンメトリクスを定義し、目標を設定する
-
暗号化、RBAC、データ保持ポリシーを確立する
-
パフォーマンスオーバーヘッドをプロファイルする。<100msの追加レイテンシを目標とする
-
ガバナンスチャーターを起草する。リーダーシップとチームに通信する
-
コンプライアンス、セキュリティ、HRチームを特定し、ブリーフする
-
*展開(週3–4)**:
-
サンドボックスに展開する。メトリクス収集とプライバシー統制を検証する
-
パフォーマンステストを実行する。オーバーヘッドが許容可能であることを確認する
-
トレース使用とガバナンスに関するチーム訓練を実施する
-
段階的ロールアウトで本番環境に展開する(開発者の10%、その後50%、その後100%)
-
*展開後(週5以降)**:
-
週次:採用、カバレッジ、クエリパターンを検査する
-
週次:トレースアクセスを監査する。異常なパターンにフラグを立てる
-
月次:クエリパターンを分析する。ツーリング投資を優先化する
-
四半期ごと:ガバナンスポリシーを検査する。インシデントまたはフィードバックに基づいて調整する
-
四半期ごと:ビジネス影響を測定する(生産性、インシデント対応時間、コンプライアンス監査効率)