
アルゴメトリクス:アルゴリズミック・フィードバック下での予測
フィードバック・ループ問題
運用システムに配置された予測モデルは、もはやデータの受動的な観察者ではありません。予測アルゴリズムが出力を生成する際—取引判断、ポートフォリオ配分、リスク管理シグナルなど—その出力は直接的な介入となり、モデルが検証と再学習に依存するデータ生成プロセスそのものを変更します。
これは古典的な予測の仮定から根本的に逸脱しています。従来の時系列モデルは、将来がモデルの予測とは独立したプロセスに従って進化することを前提としています。対照的に、アルゴリズムシステムは内生的フィードバックを示します。モデルの出力は、その後のデータストリームの因果的要素となるのです。
-
形式的特性化:* Y_t を時刻 t での実現結果、F_t をモデルの予測とします。古典的予測では Y_t = g(X_t, ε_t) と仮定されます。ここで X_t は外生的特性、ε_t は F_t と独立したノイズです。アルゴリズミック・フィードバックは依存性を導入します。Y_t = g(X_t, A_t(F_t), ε_t) となり、A_t(F_t) は予測 F_t によってトリガーされるアクションを表します。モデルの次の検証は Y_t を正解として使用し、予測の成功が部分的に自己充足的または自己否定的になる閉ループを作成します。
-
経験的な現れ:*
-
クレジットリスク・モデルが特定の借り手コホートを高リスクとしてフラグを立て、より厳しい貸出条件をトリガーします。その後、これらのコホート間のデフォルト率は低下します。モデルのリスク評価が正確だったからではなく、モデルのアクション(より厳しい条件)がデフォルト確率を機械的に低下させたからです。
-
取引アルゴリズムが価格モメンタムを予測し、それに応じて実行します。アルゴリズムの注文フローは、それが予測したまさにそのモメンタムを減衰させ、それが作用したシグナルを無効にします。
-
ポートフォリオ配分モデルが特定の資産クラスのアウトパフォーマンスを予測し、そこに資本を集中させます。モデルの資本流入は価格をインフレさせ、予測の短期的検証を作成し、その後、モデルのエッジが飽和すると平均回帰が起こります。
-
フィードバック・ループの前提条件:* フィードバック・ループは3つの条件が同時に成立するときに存在します。(1) モデルが予測または判断を生成する、(2) その予測または判断が運用システムのアクションをトリガーする、(3) そのアクションがモデルの将来のパフォーマンス評価に使用されるデータに因果的に影響を与える。すべての配置されたモデルが3つの条件をすべて満たすわけではありません。満たすものは根本的に異なる検証と監視アプローチを必要とします。
-
実行可能な含意:* 予測モデルを運用システムに配置する前に、因果監査を実施してください。モデル出力から運用アクション、データ入力への経路をたどります。モデルの出力が直接その入力データに影響を与える場合、標準的なバックテストと過去の検証メトリクスは将来のパフォーマンスの予測因子として信頼できません。モデルは過去の精度だけでなく、繰り返し作用された後も予測が安定しているかどうかで評価される必要があります。
アルゴメトリクス・フレームワーク
アルゴメトリクスは、アルゴリズミック・フィードバックを予測システム内の明示的な数学的構造として形式化します。フィードバックを外部性またはエッジケースとして扱うのではなく、アルゴメトリクスはそれを測定と制御の主要なオブジェクトとして組み込みます。
- コア数学的構造:* システムをタプル (F, A, Y, D) として定義します。ここで:
- F は時刻 t で予測 F_t を生成する予測モデル
- A は F_t を運用上の判断 A_t にマッピングするアクション関数
- Y は結果プロセス。Y_t+1 は外生的要因 X_t とモデルのアクション A_t の両方に依存
- D はモデル評価と再学習に使用されるデータストリーム
フィードバック・ループはサイクルです。F_t → A_t → Y_t+1 → D_t+1 → F_t+1
-
モデルパフォーマンスの分解:* 観測されたモデルパフォーマンス P_obs は以下のように分解できます。
-
P_obs* = P_exog + P_feedback
ここで P_exog は真の予測スキル(外生的要因を予測するモデルの能力に起因するパフォーマンス)を表し、P_feedback はモデル自身のアクションが結果を再形成することに起因するパフォーマンスを表します。アルゴメトリクスは両方の要素を推定するメソッドを提供します。
-
仮定と制限:* この分解は以下を仮定します。(1) 外生的要因とフィードバック効果は分離可能である(モデルのアクションが補償行動をトリガーする場合は成立しないかもしれません)、(2) 反事実的結果は合理的な精度で推定またはシミュレートできる、(3) フィードバック・ループは評価期間にわたって定常である(市場参加者がアルゴリズムの行動に適応するにつれて崩壊するかもしれません)。アルゴメトリック診断に依存する前に、これらの仮定を明示的にテストすべきです。
-
具体的な応用領域:*
-
自動運転システム: 自動運転アルゴリズムが交通渋滞を予測してトラフィックを迂回させるとき、それは予測した渋滞を変更します。アルゴリズムの出力は、それが検証に依存するデータ環境を変更します。アルゴリズムの予測精度を評価するには、その経路決定の影響を外生的交通パターンから分離する必要があります。
-
マルチエージェント運用システム: 複数のアルゴリズムが調整された判断を下すとき(例えば、分散システム全体のリソース配分)、それらの集合的アクションはそれらのシステムが学習するデータを再形成します。単一のアルゴリズムのパフォーマンスメトリクスは、他のアルゴリズムの補完的アクションからの正のフィードバックによって膨らむかもしれません。
-
金融市場: ポートフォリオ配分アルゴリズム、取引戦略、リスクモデルはすべてフィードバック・ループを示します。資産のアウトパフォーマンスを予測し、それに応じて資本を集中させるモデルは、その資本流入を通じた短期的検証を見た後、飽和と平均回帰が続きます。
-
実行可能な含意:* すべての運用アルゴリズムに対して「フィードバック監査」を実装してください。モデルパフォーマンスのどの部分がモデル自身のアクションに起因し、どの部分が真の予測スキルに起因するかを定量化します。この割合は、過去の検証メトリクスにどの程度の信頼を置くことができるか、またどの程度積極的にモデルをスケーリングできるかを決定します。
実装と運用パターン
アルゴメトリクスの運用化には、モデル配置、監視、再学習ワークフローへの構造的変更が必要です。
- アーキテクチャ原則:予測とアクションの分離。* 予測と実行をアトミックに行うモノリシックなパイプラインの代わりに、予測結果(アクションなしを条件とした)と実現結果(実行されたアクションを条件とした)の間のギャップを測定できる明示的な判断層を挿入します。これには以下が必要です。
-
反事実的シミュレーション能力: 各モデル配置について、「このアクションを実行していなかった場合、結果はどうなっていたか」に答える並列シミュレーションを維持します。これには以下のいずれかが必要です。(a) 過去のコントロール・グループ(例えば、A/Bテスト)、(b) 市場マイクロストラクチャまたはシステムダイナミクスに基づく合成反事実、(c) ランダム化が実行不可能な場合の操作変数推定。
-
結果帰属: 実現結果をモデルのアクションに起因する要素と外生的要因に分解します。メソッドには因果推論技術(傾向スコアマッチング、操作変数)、構造計量経済学モデル、または市場またはシステムダイナミクスに較正されたエージェント・ベース・シミュレーションが含まれます。
-
フィードバック測定インフラストラクチャ: 配置パイプラインを計測して、最低限以下をキャプチャします。(a) モデルの予測、(b) 実行されたアクション、(c) 実現結果、(d) 推定反事実結果、(e) フィードバック帰属(実現と反事実の差)。
-
配置パターン:フィードバック較正を伴う段階的ロールアウト。* モデルを直ちに完全スケールに配置するのではなく、段階的なアプローチを実装します。
-
段階1(パイロット): 運用領域の小さなサブセットに配置します(例えば、ポートフォリオの5%、ローン量の10%、単一地域)。このスケールでフィードバック帰属と影響安定性を測定します。
-
段階2(較正): 段階1からのフィードバック・パターンを分析します。観測されたフィードバックに基づいてモデルパラメータ、アクション閾値、または配置戦略を調整します。必要に応じてモデルを再学習します。
-
段階3(スケール配置): 配置スケールを段階的に増加させながら、フィードバック・メトリクスを継続的に監視します。フィードバック帰属または影響不安定性が事前定義された閾値を超える場合、スケーリングを一時停止して調査します。
これは2つの静的戦略を比較する従来のA/Bテストから根本的に異なります。フィードバック較正は反復的であり、モデルのアクションがデータ環境をどのように再形成するかを理解することに焦点を当てています。
-
再学習頻度:カレンダー駆動ではなくフィードバック駆動。* 従来の実践は固定スケジュール(月次、四半期)でモデルを再学習します。アルゴメトリック・システムはフィードバック減衰に基づいて再学習すべきです。
-
フィードバック減衰メトリクス: モデルのエッジがその自身のアクションと市場適応により減衰する速度を測定します。フィードバック減衰が急速な場合(エッジが数週間以内に半減)、週次で再学習します。減衰が遅い場合(エッジが数ヶ月以内に半減)、月次で再学習します。
-
飽和検出: 飽和ポイント—モデルのエッジがその自身の市場影響により消失する配置スケール—を監視します。飽和ポイントが近づくにつれて、その戦略への資本配分を削減するか、市場条件がリセットされるまで再学習を一時停止します。
-
具体的な運用例:* ポートフォリオ配分アルゴリズムが小型テク株のアウトパフォーマンスを予測します。段階1(ポートフォリオの5%配置)では、モデルは年間8%の超過リターンを生成します。フィードバック帰属分析は、このリターンの3%がモデル自身の資本流入が価格を押し上げることに起因することを明らかにします。段階2では、モデルはポジション・サイズを削減するように調整されます。段階3では、配置がポートフォリオの20%にスケールし、モデルは5%の超過リターンを生成します(フィードバック帰属は現在1.5%)。飽和ポイントはポートフォリオの40%で推定されます。配置はポートフォリオの25%でキャップされ、モデルの市場影響が増加するにつれてフィードバック減衰が加速するため、再学習頻度は月次から隔週に増加します。
-
実行可能な含意:* フィードバック測定を配置パイプラインに第一級メトリクスとして組み込んでください。事後的な考慮ではなく。フィードバック帰属と影響安定性の明確な閾値を確立し、スケーリング判断、再学習、またはモデル停止をトリガーします。
- 図8:実装パターンの特性比較(出典:記事の分析)*
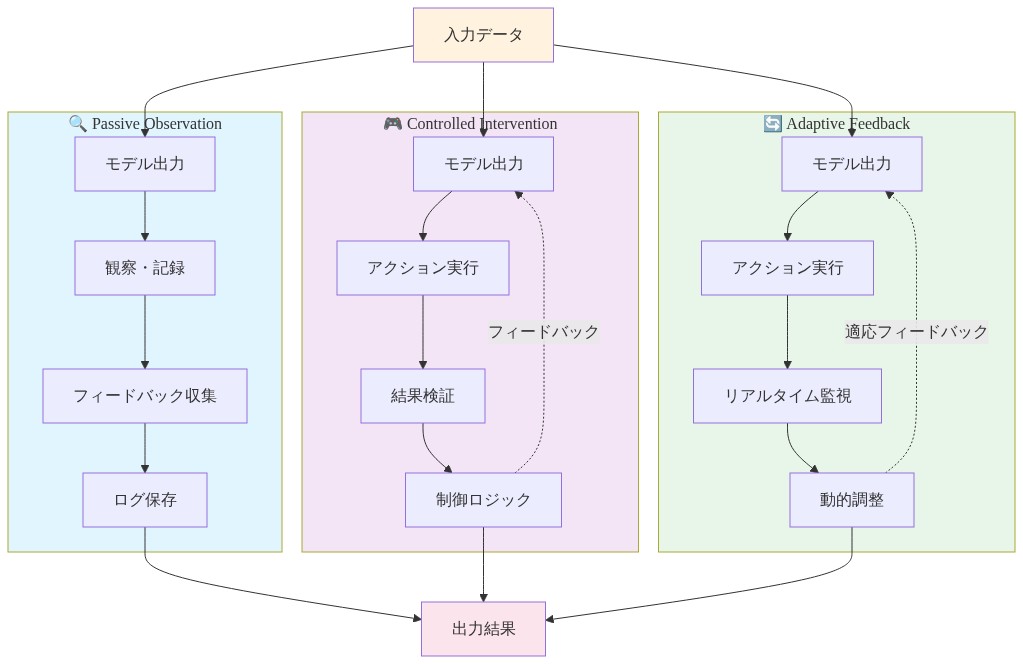
- 図7:3つの実装パターンの比較(Passive Observation、Controlled Intervention、Adaptive Feedback)*
測定と診断
アルゴメトリック・パフォーマンスの測定には、従来の精度と適合度を超えたメトリクスが必要です。3つのコア診断をすべての運用モデルに対して計測すべきです。
-
1. 影響安定性*
-
定義:* モデルのアクションが最小限の市場影響から実質的な市場影響にスケーリングするにつれて、モデルの予測パフォーマンスが一定のままである程度。
-
形式的仕様:* P(s) を配置スケール s ∈ [0, 1] でのモデルパフォーマンス(例えば、超過リターン、リスク削減)とします。ここで s = 0 は配置なし、s = 1 は完全配置を表します。影響安定性 IS は以下のように定義されます。
-
IS* = 1 − (|P(0.1) − P(0.5)| / P(0.1)) / 4
このメトリクスは0から1の範囲で、1は完全安定性(スケール全体でパフォーマンス不変)を示し、0は完全不安定性(スケール増加でパフォーマンス崩壊)を示します。
-
解釈:* 高い影響安定性(IS > 0.8)は、モデルが配置スケールが増加しても有効なままの外生的シグナルを利用していることを示唆します。低い安定性(IS < 0.5)は、モデルが外部シグナルではなく自身のフィードバックを利用していることを示唆します。モデルをスケーリングするとリターンが減衰します。
-
測定アプローチ:* 上記のように段階的ロールアウトを実施し、各スケールでパフォーマンスを測定します。または、過去のデータを使用して異なる配置スケールをシミュレートし、各仮想スケールでパフォーマンスを測定します。
-
具体的な例:* クレジットリスク・モデルは配置スケール10%(ローン申請者の10%を拒否)で92%の精度を示します。配置スケール30%(申請者の30%を拒否)では、精度は87%に低下します。影響安定性は約0.6で、中程度のフィードバック依存性を示します。モデルの見かけの精度は部分的にその自身のゲートキーピング効果によって膨らんでいます。
-
2. フィードバック帰属*
-
定義:* 実現されたモデルパフォーマンスのうち、モデル自身のアクションに起因する部分と外生的市場動きまたはシステムダイナミクスに起因する部分の割合。
-
形式的仕様:* P_obs を観測されたモデルパフォーマンス、P_counter を推定反事実パフォーマンス(モデルのアクション不在で発生したであろう状況)とします。フィードバック帰属 FA は以下の通りです。
-
FA* = (P_obs − P_counter) / P_obs
このメトリクスは0から1の範囲で、0はフィードバックなし(すべてのパフォーマンスは真の予測スキル)を示し、1は完全フィードバック(すべてのパフォーマンスは自己強化)を示します。
-
解釈:* 5%のアルファを主張するモデルでフィードバック帰属が0.8の場合、真のアルファは1%のみを生成しています。4%は自己充足的です。フィードバック帰属が0.3を超える場合、調査が必要であり、配置制約が可能性が高いです。
-
測定アプローチ:* 以下を使用して反事実結果を推定します。(a) コントロール・グループ(A/Bテストが実行可能な場合)、(b) 合成コントロール(モデル配置のない類似期間またはエンティティのマッチング)、(c) 操作変数(配置に外生的変動が存在する場合)、(d) 市場マイクロストラクチャまたはシステムダイナミクスの構造モデル。
-
具体的な例:* 取引アルゴリズムがモメンタムを予測し、それに応じて実行します。観測されたリターンは年間6%です。反事実分析(アルゴリズムの注文フロー不在で同じ価格動きをシミュレート)は、リターンが年間2%であったと推定します。フィードバック帰属は(6% − 2%) / 6% = 0.67です。アルゴリズムは67%自己強化的です。
-
3. 飽和ポイント*
-
定義:* モデルのエッジがその自身の市場影響またはアルゴリズムの行動への市場適応により消失する配置スケール。
-
形式的仕様:* E(s) を配置スケール s でのモデルのエッジ(超過リターン、リスク削減、またはその他のパフォーマンスメトリクス)とします。飽和ポイント s_sat は E(s_sat) = 0 またはトランザクション・コストと運用オーバーヘッドを下回るスケールです。
-
測定アプローチ:* 段階的ロールアウトを実施し、各スケールでエッジを測定します。関数形式(例えば、線形減衰、指数減衰)をフィットさせて飽和ポイントを推定します。または、市場マイクロストラクチャモデルを使用してモデルの注文フローが価格にどのように影響するか、またはその影響が配置サイズでどのようにスケーリングするかを推定します。
-
解釈:* 飽和ポイントが利用可能資本の50%の場合、その戦略に50%以上の資本を配置するとネガティブなリターンが生成されます。最適な資本配分は飽和ポイントを超えるべきではなく、配置が飽和に近づくにつれて再学習頻度は増加すべきです。
-
具体的な例:* ポートフォリオ配分モデルは利用可能資本の5%、15%、25%、35%のスケールで配置されます。エッジ(トランザクション・コスト後の超過リターン)はそれぞれ4.2%、3.8%、2.1%、0.3%です。飽和ポイントは資本の約40%で推定されます。最適配置は資本の35%でキャップされ、飽和が近づくにつれてエッジを維持するために再学習頻度は週次に増加します。
-
実行可能な含意:* これら3つの診断ですべての運用モデルを計測してください。明確な閾値を確立します。影響安定性が0.8を下回る場合、フィードバック帰属が0.3を超える場合、または配置が飽和ポイントに近づく場合、スケーリングを一時停止して調査します。これらのメトリクスを使用して資本配分判断と再学習頻度を通知します。
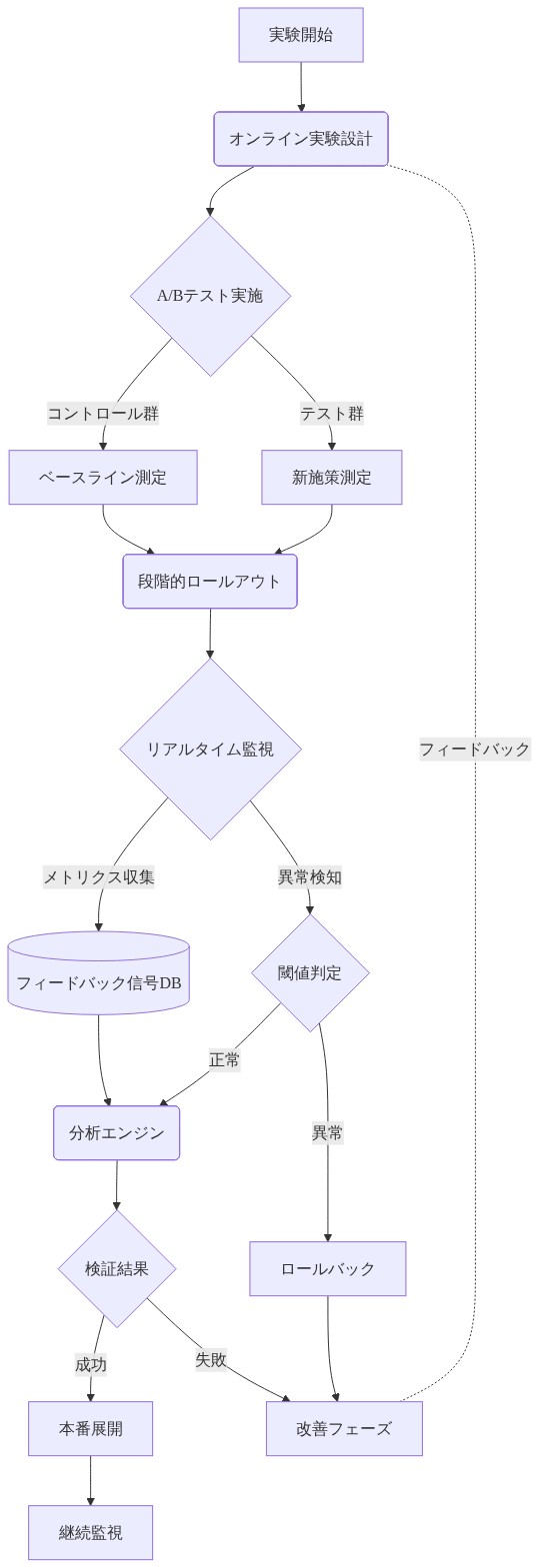
- 図9:クローズドループ検証の実行フロー*
リスクと軽減戦略
アルゴメトリック・フィードバックループは、従来のリスク枠組みでは捉えられない構造的なリスクを生み出します。明示的な注視が必要な3つのリスク類型があります。
-
1. コンテージョン・リスク*
-
メカニズム:* 同一の信号に応答する複数のアルゴリズムは、フィードバックループを増幅し、人為的な価格変動またはリソース配分の誤りを生み出します。これが元の信号を検証し、その後ループが破断する際に急激な反転が起こります。
-
具体的シナリオ:* 10人のポートフォリオマネージャーが類似したモメンタム・ベースの配分モデルを導入しています。すべてのモデルが特定の資産クラスのアウトパフォーマンスを予測し、そこに資本を集中させます。彼らの集合的なリバランスが人為的な価格上昇を生み出し、各個別モデルの予測を検証します。各モデルはこの検証を観察し、確信を強めます。あるマネージャーが飽和またはリトレーニングを理由に保有を削減し始めると、他のマネージャーもそれに続き、急激な反転を引き起こします。集合的なフィードバックループがボラティリティを増幅し、構造的リスクを生み出すのです。
-
前提条件:* コンテージョン・リスクが高まるのは、以下の場合です。(a) 複数のアルゴリズムが類似したデータソースまたは信号を使用している、(b) アルゴリズムが類似した時間軸で動作している、(c) 市場インパクトが集中している(例:小型株、流動性の低い資産クラス)、(d) フィードバックループが機関横断的に監視または開示されていない。
-
軽減戦略:*
-
信号源の多様化: アルゴリズムが異なる市場要因に応答するか、独立したデータソースを使用するようにします。類似した信号を使用するアルゴリズム間での資本集中を回避します。
-
導入タイミングの分散: 複数のアルゴリズムが同時に導入される場合、相互のフィードバックを増幅します。導入を時間軸で分散させ、導入間で市場が適応する余地を作ります。
-
アルゴリズム間相関の監視: アルゴリズム間のアクションの相関を追跡します。相関がスパイクした場合、導入規模を削減するか、アルゴリズムを一時停止してコンテージョンを防ぎます。
-
2. 敵対的適応*
-
メカニズム:* 市場参加者と競争相手がアルゴリズムのフィードバックループを悪用する方法を学習します。アルゴリズムのアクションが価格または配分を予測可能な方法で動かすことを認識すると、彼らはアルゴリズムをフロントランし、その戦略のリターンを反転させます。
-
具体的シナリオ:* 取引アルゴリズムがモメンタムを予測し、大口注文を執行します。市場参加者はアルゴリズムの注文フロー・パターンを観察し、その取引をフロントランします。アルゴリズムの大口買い注文の前に買い、大口売り注文の前に売ります。アルゴリズムのアクションが予測可能になるにつれ、そのエッジは失われます。
-
前提条件:* 敵対的適応が高まるのは、以下の場合です。(a) アルゴリズムの動作が観察可能または予測可能である、(b) 競争相手がアルゴリズムを悪用する動機を持っている、(c) アルゴリズムのアクションが市場流動性に対して大きい、(d) アルゴリズムが敵対的行動に迅速に適応しない。
-
軽減戦略:*
-
執行のランダム化: 注文執行のタイミング、規模、および方法にランダム性を導入します。
実践的な移行パス
アルゴメトリクスの採用は、予測インフラストラクチャの全面的な再構築を必要としません。3つの具体的なステップから始めます。
-
フェーズ1(1~4週目):* 既存モデルをフィードバックループについて監査します。どのアルゴリズムの出力が直接入力データに影響を与えるかを特定します。最も影響度の高いシステムを優先します。
-
フェーズ2(5~12週目):* 計測を実装します。フィードバック帰属と影響安定性メトリクスを監視ダッシュボードに追加します。過去の導入に対して反事実分析を実行し、各モデルのパフォーマンスのうちどの程度が自己強化的であったかを定量化します。
-
フェーズ3(13週目以降):* 導入を再設計します。明示的なフィードバック計測を伴う段階的ロールアウトを実装します。カレンダースケジュールではなく、フィードバック減衰率に基づいてリトレーニング頻度を調整します。
-
具体例:* 取引デスクがボラティリティ予測モデルを導入します。フェーズ1の監査により、モデルのヘッジング決定が実現ボラティリティを低減し、見かけの精度を膨らませていることが明らかになります。フェーズ2の計測は、モデルのエッジの40%がフィードバック駆動型であることを示します。フェーズ3の再設計により、導入規模を40%削減し、資本を独立した戦略に再配分し、リトレーニングを月次から週次に短縮します。
-
これが運用上意味するもの:* 最も確信度が高く、最も影響度が高いアルゴリズムから始めます。そのフィードバックループを正確に計測します。その結果を使用して、ポートフォリオ全体でのアルゴメトリック実践のより広い採用を正当化します。
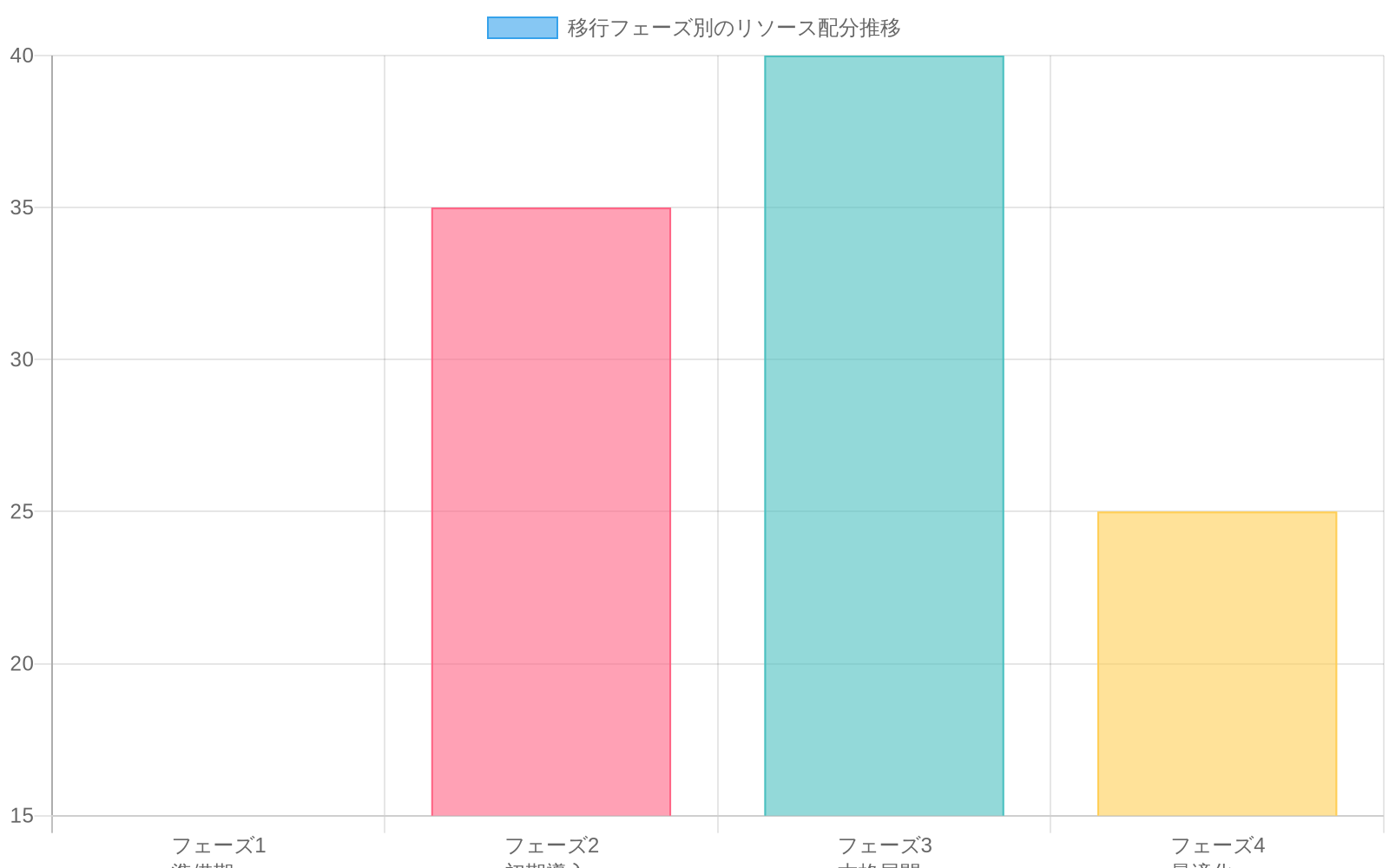
- 図14:移行フェーズ別のリソース配分推移(出典:実装計画)*
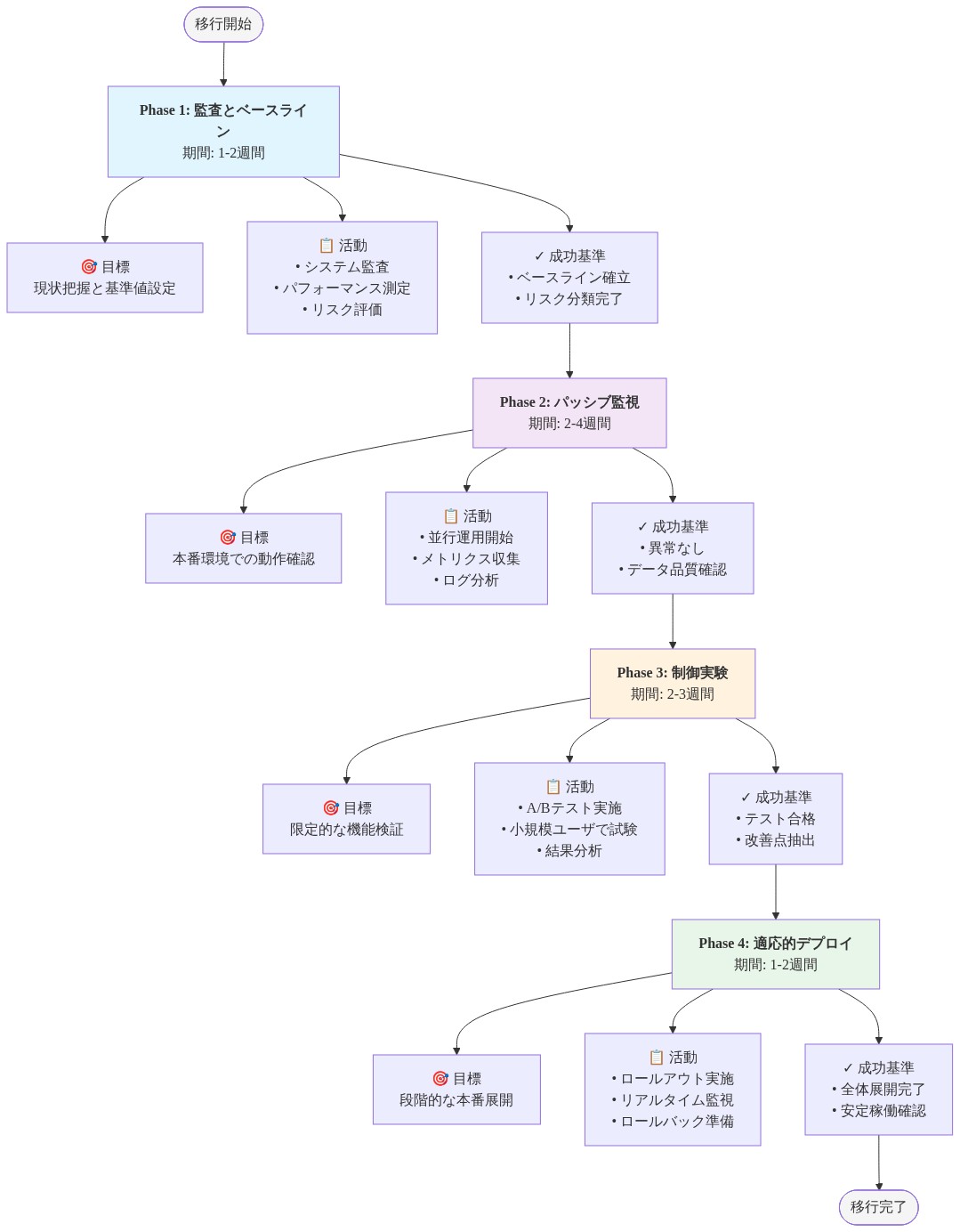
- 図13:Algometrics導入の段階的移行パス*
結論:新しい予測の現実
アルゴリズム市場は、予測が意味するものを根本的に変えました。モデルはもはや受動的な観察者ではなく、自らの予測が依存するデータを再形成する能動的な参加者です。フィードバックループを無視することは、過信、モデル劣化、そして最終的な失敗につながります。
アルゴメトリクスは、この現実を運用化するための枠組みを提供します。フィードバックループを明示的にモデル化し、その規模を計測し、そのリスクを軽減することで、実務家はスケーリングしても堅牢性を保つ予測システムを構築します。
次のステップは行動です。モデルを監査し、フィードバックループを計測し、導入を適切に再設計します。アルゴメトリック思考を習得する機関はエッジを維持します。フィードバックループを無視する機関は、スケーリングするにつれてモデルが劣化するのを目撃することになります。
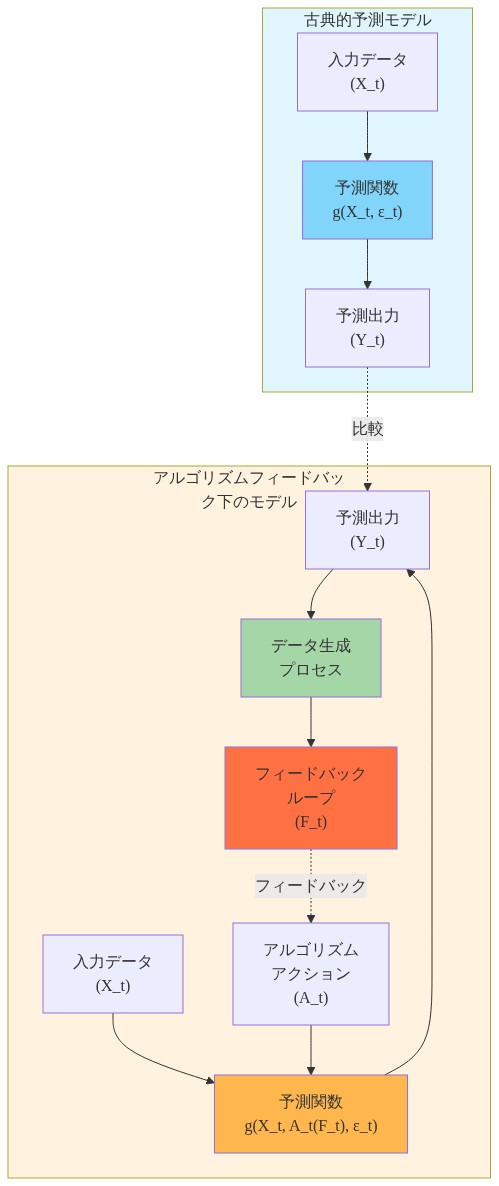
- 図2:古典的予測 vs アルゴリズムフィードバック下の予測モデルの比較*
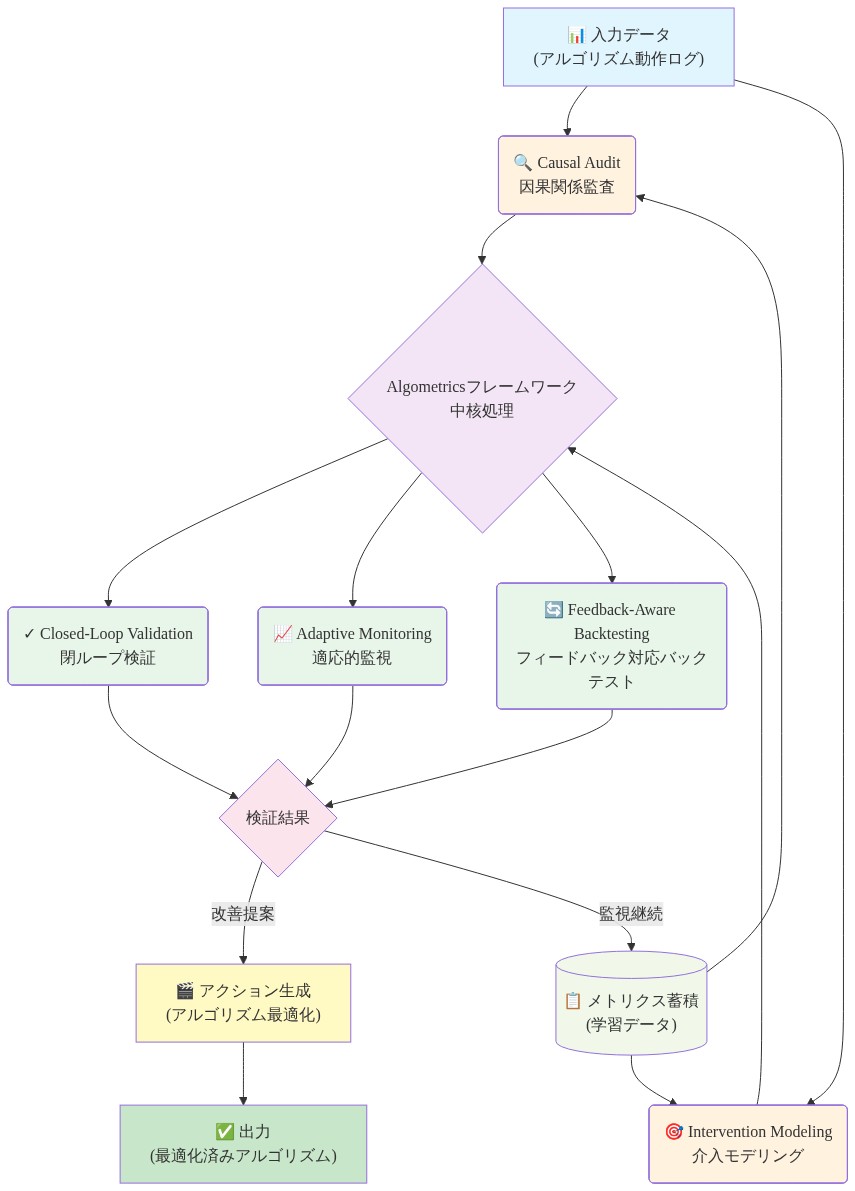
- 図5:Algometricsフレームワークの構成要素と相互作用*