
Amazon、さらなる大規模レイオフに備える、14,000人の雇用が危機に
市場シグナルと組織的対応
Amazonが約14,000人の従業員に影響を与える可能性のあるレイオフを発表したことは、重要な組織再編を表している。2024年1月の報道によると、これらの削減は、2022年11月に発表された約10,000人の初期削減に続くものであり、2023年を通じて追加の人員削減が行われた。[^1] 表明された理由は、Amazonの事業部門全体における業務効率と戦略的優先順位付けに集中している。
根底にある主張には明確化が必要である。Amazonの経営陣は、収益の軌跡と自動化および人工知能ツールからの予想される生産性向上を考慮すると、現在の人員配置レベルが業務要件を超えていると主張している。この主張は2つの仮定に基づいている:(1) 自動化が比例的なサービス品質低下なしに人員数を代替できること、(2) 市場状況が成長投資よりも短期的なコスト削減を正当化すること。
- ナレッジワーカーへの提言:* Amazon Web Services (AWS)に依存している組織は、ベンダー集中度の監査を直ちに実施すべきである。具体的には、どの重要なビジネス機能がAWSサポートチームに依存しているかをマッピングし、人間の介入を必要とするサービス依存関係と完全に自動化された代替手段を特定し、AWSアカウント管理との通信プロトコルを確立する。潜在的な人員移行が発生する前に、ベースラインのサービスレベル契約と応答時間メトリクスを文書化する。
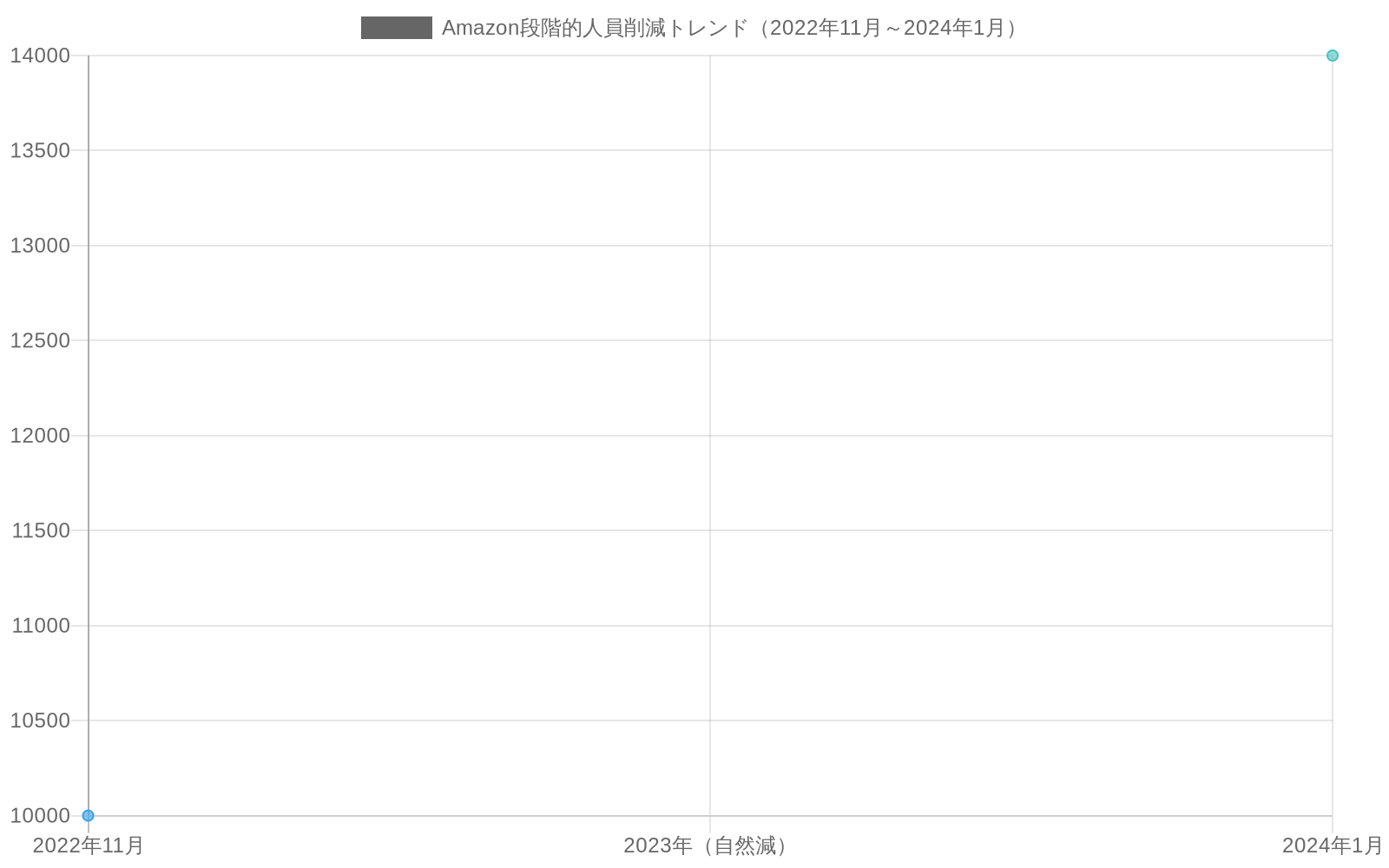
- 図2:Amazon段階的人員削減トレンド(2022年11月~2024年1月)(出典:Amazon公式発表、2024年1月報道)*

- 図1:Amazon大規模レイオフと組織再構築の概念図 - 複数事業部門の統合・最適化とAI自動化による組織変革を表現*
システム構造とボトルネック
Amazonは分散型事業単位—AWS、小売、広告、デバイスなど—を通じて運営されており、それぞれが独自の損益責任を持っている。この構造は的を絞ったコスト削減を可能にするが、共有インフラストラクチャ、セキュリティ、コンプライアンス、データセンター運用を通じて相互依存関係を生み出す。
運用上の主張:特定の部門(小売やデバイスなど)に集中したレイオフは、複数の事業単位をサポートする共有サービスを通じて連鎖する可能性がある。例えば、小売部門が3,000人の人員削減を行い、AWSが2,000人のエンジニアリングポジションを失った場合、共有インフラストラクチャチームは、比例的なリソース増加なしに残りのスタッフからの需要増加に直面する。これにより、インフラストラクチャのプロビジョニング、セキュリティレビュー、コンプライアンス認証プロセスに潜在的なボトルネックが生じる。
-
検証が必要な仮定:* 連鎖効果の大きさは、共有サービススタッフと部門固有のスタッフの比率に依存する。Amazonはこの比率を公に開示していないため、機能横断的なボトルネックの深刻度は不確実なままである。
-
ナレッジワーカーへの提言:* AWS内での組織の依存ポイントを監査する。AWSサポートチームの関与を必要とするサービス(カスタム統合、コンプライアンス認証、アーキテクチャレビュー)と完全なセルフサービス提供を特定する。潜在的な人員ギャップが発生する前に、複数のAWSアカウント担当者と直接的な関係を今すぐ確立する。サービスレベル契約とエスカレーション手順を文書化する。ミッションクリティカルなワークロードについては、マネージドサービスプロバイダーまたはマルチクラウドアーキテクチャが単一ベンダーリスクを軽減するかどうかを評価する。
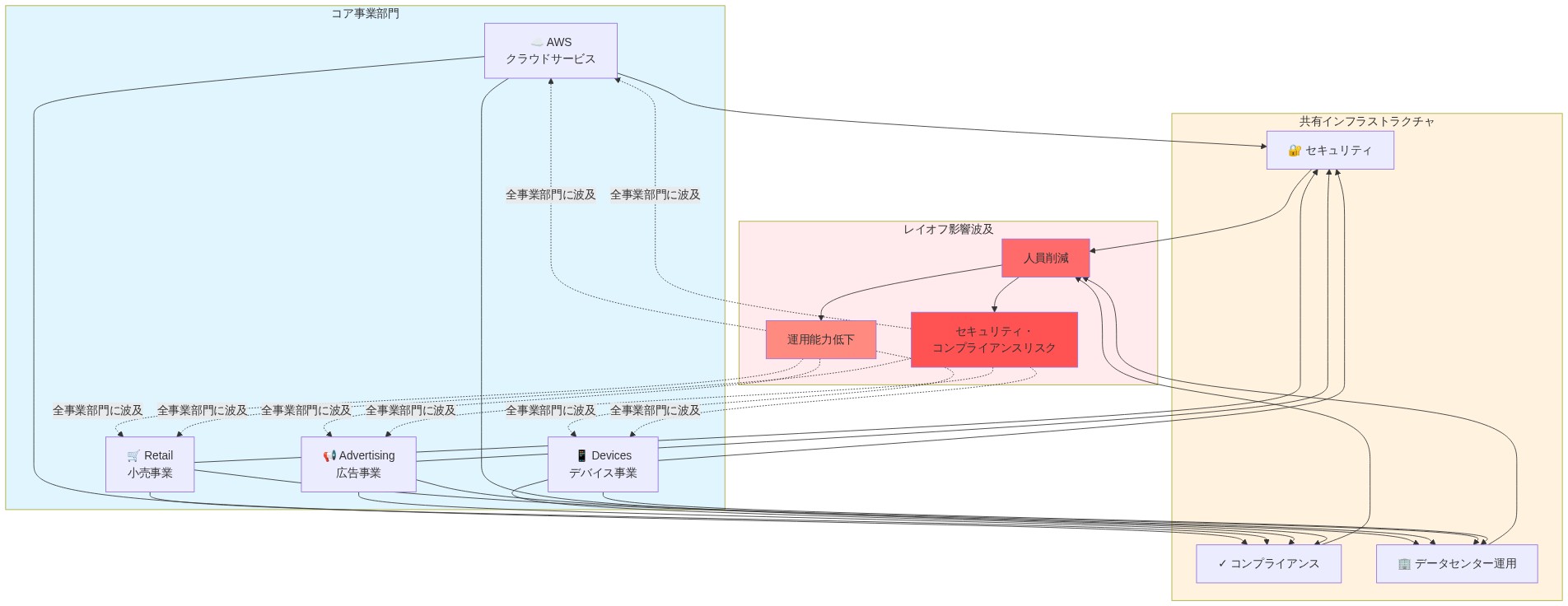
- 図3:Amazon事業部門と共有サービスの依存関係構造及びレイオフ影響の波及メカニズム*

- 図4:共有サービスのボトルネック現象 - 複数部門からの需要が限定リソースに集中し、インフラ・セキュリティ・コンプライアンス審査による遅延リスク*
参照アーキテクチャとガードレール
Amazonのコスト構造は、エンジニアリング、運用、サポート人員間の最適な比率を維持することに依存している。運用上の仮説:生成AI、インフラストラクチャ自動化、セルフサービスプラットフォームへの最近の投資を考慮すると、現在の人員数は効率性のフロンティアを超えている。
この仮説は、AIアシストによるコードレビュー、自動テスト、インテリジェントなインシデント対応システムが、20〜30%少ない人員でサービス品質を維持できるという仮定に基づいている。しかし、この仮定には実証的な検証が必要である—AmazonはAIツールがサービス品質低下なしにこれらの効率性向上を達成することを示す生産性メトリクスを公表していない。
-
具体的な参照ポイント:* AWS Lambdaとマネージドサービスは、従来のインフラストラクチャ管理と比較して運用オーバーヘッドを削減する。Amazonが大規模に自動化を展開した場合、エンジニアリングチームは理論的には人員削減で同等のサービス提供を維持できる。逆に、自動化の展開が人員削減に遅れをとる場合、サービス品質が低下する可能性がある。
-
ナレッジワーカーへの提言:* AWSセルフサービスツールと自動化フレームワークの採用を加速する。内部自動化機能を構築することで、日常的なタスクにおけるAWSプロフェッショナルサービスへの依存を減らす。サービスごとの監査を実施する:AWSサービスを「完全自動化」(Lambda、マネージドデータベース、CloudFront)と「人間集約的なサポートが必要」(カスタム統合、コンプライアンスレビュー)に分類する。可能な場合は、自動化優先のサービスにワークロードを移行する。これにより、AWSの人員配置レベルに関係なく、組織がサービス継続性を維持できる位置に立つ。
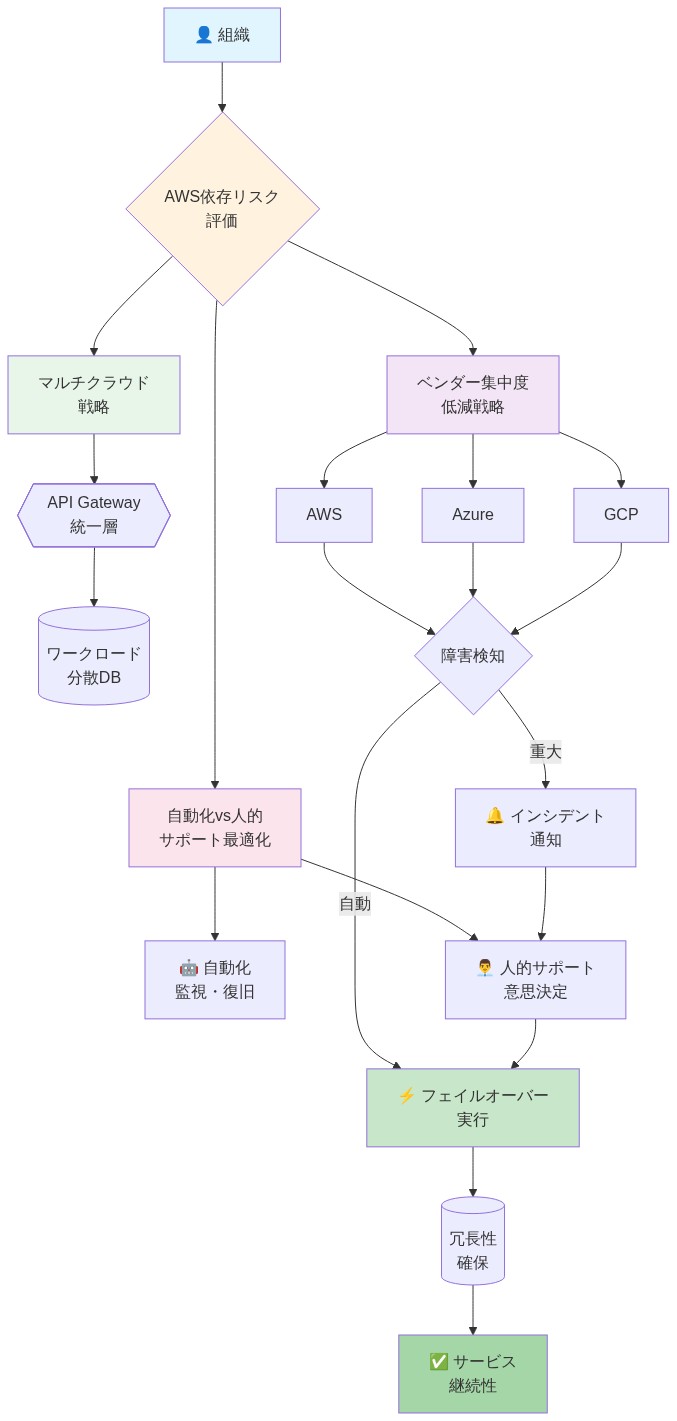
- 図5:AWS依存リスク軽減のための参照アーキテクチャ(クラウドリスク管理のベストプラクティス)*
実装と運用パターン
レイオフの実行タイミングは、サービス継続性に大きく影響する。運用上の仮定:Amazonは、即座の大量解雇を実行するのではなく、サービス中断を最小限に抑えるために、複数の四半期にわたって削減を段階的に実施する可能性が高い。
-
根拠:* 段階的アプローチにより、知識の移転、プロセスの文書化、重要な依存関係の特定が可能になる。即座の解雇は、顧客向けサービスの運用障害のリスクがあり、これによりサービスクレジット、評判の損害、競合するクラウドプロバイダーへの顧客移行の可能性が引き起こされる。
-
具体的な実装パターン:* AWSは、四半期ごとにサポートチームを10〜15%削減し、ジュニアサポート役割を統合しながら、高価値アカウントにサービスを提供するスペシャリストの保持を優先する可能性がある。エンジニアリングチームは、コアインフラストラクチャ作業ではなく、非重要プロジェクトに集中した削減が見られる可能性がある。
-
監視が必要な仮定:* これは、Amazonが即座のコスト削減よりもサービス継続性を優先することを前提としている。Amazonがこのモデルが示唆するよりも速い削減を実行する場合、サービス品質低下のリスクは大幅に増加する。
-
ナレッジワーカーへの提言:* 主要なインフラストラクチャ移行とアーキテクチャ変更を、初期の人員移行が安定した後の2024年第2〜第3四半期にスケジュールする。Amazonが初期削減を実行する第1四半期中の重要なプロジェクトを避ける。一般的なAWSサポートシナリオのための内部ランブックと文書化を今すぐ構築する—移行期間中のAWSサポートチームへの依存を減らす。マネージドサービスプロバイダーが、組織移行中に直接のAWSサポートよりも優れた継続性保証を提供するかどうかを評価する。

- 図7:ベンダー集中リスク軽減の段階的実装パターン*
測定と検証フレームワーク
組織は、レイオフが発効する前にAWSサービスの信頼性のベースラインメトリクスを確立し、人員削減が持続可能なレベルを超えた場合のサービス品質低下の検出を可能にすべきである。
-
確立すべき主要メトリクス(ベースライン:2024年1月):*
-
AWSサポートチケット解決時間(平均および95パーセンタイル)
-
サービス別APIエラー率
-
サービス可用性パーセンテージ
-
機能リリース速度(四半期ごとの新機能)
-
新しいリソースのインフラストラクチャプロビジョニング時間
-
潜在的な人員問題を示す品質低下の閾値:*
-
サポートチケット解決時間が20%以上増加
-
インシデント解決時間が2倍になる
-
サービス可用性が公表されたSLAを下回る
-
機能リリース速度が30%以上低下
-
ナレッジワーカーへの提言:* AWSサービスメトリクスの月次レビューを確立する。CloudWatch、AWS Trusted Advisor、サポートチケット履歴を使用してベースラインパフォーマンスを追跡する。これらの閾値を超える品質低下を観察した場合、インシデントを文書化し、具体的なデータを持ってアカウントマネージャーにエスカレートする。SLA違反に対するサービスクレジットを要求する。推測ではなく、観察されたサービス品質低下に基づいて、冗長性投資のビジネスケースを構築する。
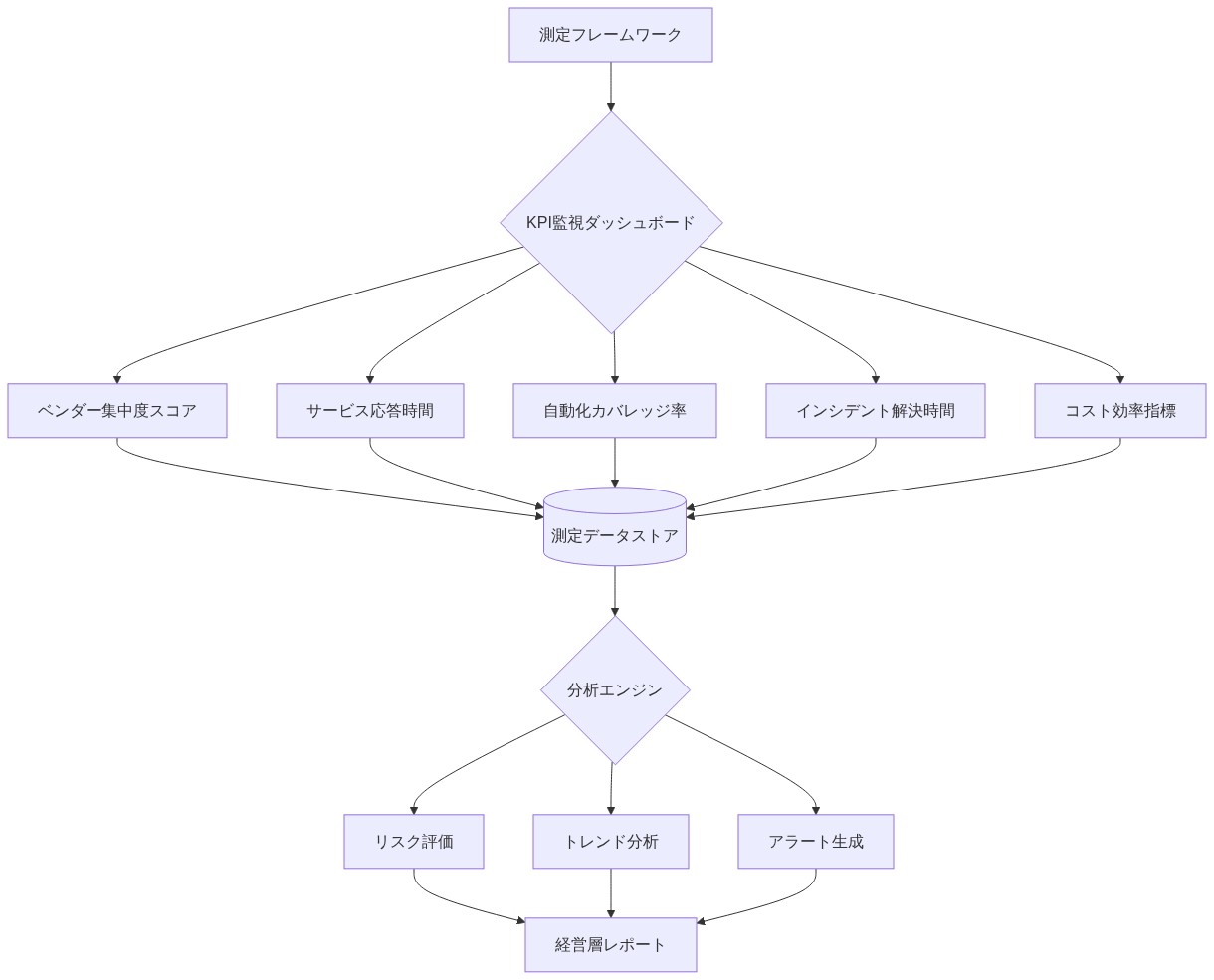
- 図8:ベンダー依存リスク測定フレームワーク(ビジネス継続性管理標準に基づく)*
リスク評価と緩和戦略
- 主要リスク:*
- 知識の喪失: Amazonが専門分野(データベース最適化、セキュリティアーキテクチャなど)で過度に積極的に削減した場合の制度的劣化
- サービス品質の低下: サポート応答性の低下または顧客ワークロードに影響を与えるインシデント解決の遅延
- 機能速度の低下: エンジニアリング能力が縮小するにつれて、AWSサービスのイノベーションが遅くなる
-
二次的リスク:*
-
セキュリティパッチまたはコンプライアンス更新の遅延
-
インフラストラクチャリソースのプロビジョニング時間の延長
-
複雑なアーキテクチャに対する専門的なサポートの可用性の低下
-
緩和戦略:*
-
戦略1: クラウドプロバイダーの多様化*
-
非重要ワークロードを代替クラウドプロバイダー(Google Cloud Platform、Microsoft Azure)に移行し、単一ベンダー依存を軽減する。これにより、AWSサービス品質が低下した場合の代替オプションが確保される。
-
戦略2: 内部能力の構築*
-
AWSサポートへの依存を減らすために、内部クラウドエンジニアリングチームに投資する。Infrastructure as Code、自動化スクリプト、監視フレームワークに関するトレーニングを実施し、一般的な問題を外部サポートなしで解決できるようにする。
-
戦略3: マネージドサービスプロバイダーとの提携*
-
AWS認定パートナーやマネージドサービスプロバイダーとの関係を確立し、Amazonの直接サポートが不十分な場合の代替サポートチャネルを提供する。これらのプロバイダーは、組織の移行期間中により安定したサービスレベルを維持できる可能性がある。
-
戦略4: サービスレベル契約の強化*
-
AWSとのサービスレベル契約を再交渉し、明確なパフォーマンス保証とペナルティ条項を含める。これにより、サービス品質が低下した場合の補償メカニズムが確保される。
-
ナレッジワーカーへの提言:* これらの緩和戦略を組織のリスク許容度と予算制約に基づいて優先順位付けする。ミッションクリティカルなワークロードには複数の緩和層を実装し、非重要システムには単一の戦略で十分な場合がある。四半期ごとにリスク評価を再検討し、観察されたAWSサービス品質の変化に基づいて戦略を調整する。

- 図11:リスク対応優先順位マトリックス(影響度×発生確率による分類)*