
Amazon EC2 X8i インスタンスの一般提供開始
AWSが発表したAmazon EC2 X8iインスタンスの一般提供は、メモリ集約的ワークロードの構造的な制約に対する根本的な応答である。AWSとIntelの共同設計によって生み出されたカスタムIntel Xeon 6プロセッサを搭載するこのインスタンスクラスは、従来は分散アーキテクチャを強いられていたメモリ要件を単一インスタンスで満たす可能性を開く。本質的な問題は、汎用プロセッサ設計に内在する性能トレードオフをクラウドワークロード向けに最適化できるかどうかにあった。
X8iファミリーはインスタンスあたり1TBから24TBまでのメモリ構成を提供する。カスタムXeon 6プロセッサはIntelの標準プロセッサラインアップには存在しないアーキテクチャ修正を組み込んでおり、クラウドワークロードパターンに特化して最適化されている。この共同設計アプローチは、汎用プロセッサ設計に固有の性能トレードオフを受け入れるのではなく、特定のユースケースに向けてシリコンをカスタマイズするというAWSの戦略的決定を反映している。
-
前提条件の明確化*:本分析は、メモリ集約的ワークロードを単一インスタンスに統合することが、組織のフォールトトレランスおよび災害復旧要件と整合しているかどうかを評価済みであることを前提とする。単一インスタンスアーキテクチャは分散システムとは異なる障害モードをもたらし、対応するアーキテクチャ調整を要求する。
-
具体例*:金融サービス機関が10TB規模のSAP HANAデータベースを運用する場合、従来はメモリ要件を満たすために5つのr7iインスタンス(各2TBメモリ)にワークロードを分散していた。単一のx8i.6xlargeインスタンス(24TBメモリ)への移行は、ノード間通信レイテンシを削減し、データベースライセンス計算を簡素化し、分散データベース調整に関連する運用複雑性を排除する。しかし、この統合には、単一インスタンス障害モードが組織の目標復旧時間(RTO)および目標復旧時点(RPO)パラメータ内で許容可能であることの検証が必要である。
-
実行可能な含意*:複数インスタンスに分散されているメモリ集約的ワークロードのインベントリを実施する。各ワークロードについて、総メモリフットプリントを計算し、利用可能なx8iインスタンスサイズ(1TB、2TB、4TB、6TB、8TB、12TB、24TB)と照合する。統合が技術的に実現可能な候補を特定する。同時に、現在のフォールトトレランスメカニズムを文書化し、移行計画に進む前に、単一インスタンスアーキテクチャが組織の可用性要件を満たしていることを確認する。
性能とメモリ帯域幅のリーダーシップ
X8iインスタンスは、カスタムXeon 6プロセッサと統合された12チャネルメモリアーキテクチャを通じて、インスタンスあたり576GB/sの持続メモリ帯域幅を実現するよう仕様化されている。この仕様は、主要クラウドプロバイダが現在提供するIntelベースのクラウドインスタンスの中で最高のメモリ帯域幅を表している。
メモリ帯域幅は、計算に対するメモリアクセス率が高い特性を持つワークロードクラスの性能を制約する。特にメモリフェッチ操作が主要な性能ボトルネックとなるレイテンシ感応的なアプリケーションにおいてそうである。市場における比較可能なIntelベースインスタンス(r7i、r6iファミリー)は通常200~300GB/sのメモリ帯域幅を提供する。X8i帯域幅の優位性は、グラフデータベース、リアルタイム機械学習推論、高同時実行リクエストパターンに対応するインメモリキャッシュを含むワークロードクラスにとって実質的である。
- 前提条件の明確化*:メモリ帯域幅の優位性は、メモリアクセスパターンが主要な性能制約を構成するワークロードに対してのみ、測定可能な性能改善に変換される。計算集約的な内部ループを持つアプリケーション、またはネットワークI/Oによって制約されるアプリケーションは、増加したメモリ帯域幅から比例的な性能向上を実現しない。帯域幅制限が特定のワークロードに存在することを確認するには、ベンチマーク検証が必要である。
AWSはX8iインスタンスのSAP認証を取得し、SAP HANA展開要件との互換性を検証している。SAP HANAはインメモリリレーショナルデータベースプラットフォームであり、特定のプロセッサ、メモリ、I/O要件を持つ。認証ステータスはSAP標準化環境を運用する組織の展開リスクを低減し、調達プロセス中のベンダー調整を簡素化する。
-
具体例*:小売組織がリアルタイム在庫管理および需要予測のためにSAP HANAを運用する場合、r7iからx8iインスタンスへの移行前後でクエリ応答時間分布を測定した。95パーセンタイルクエリレイテンシは35%低下し、分析チームが既存のサービスレベルアグリーメント(SLA)ウィンドウ内で追加の予測モデルを実行することが可能になった。しかし、この改善はメモリ帯域幅利用率が高いクエリに特有のものであり、バッチレポートクエリは最小限の改善を示した。
-
実行可能な含意*:移行前に、AWS CloudWatchメトリクスおよびアプリケーションレベルのインストルメンテーションを使用してメモリ集約的アプリケーションをプロファイルする。具体的には、メモリ帯域幅利用率(メモリ読み書きスループット)を測定し、帯域幅飽和が観測されたレイテンシと相関するかどうかを特定する。代表的なデータ量に対する制御されたベンチマークを使用して、x8i性能をAWS Graviton3ベースのインスタンス(r8gファミリー)と比較する。50パーセンタイル、95パーセンタイル、99パーセンタイルでのレイテンシ改善を文書化する。パーセンタイル固有のメトリクスは、可変リクエストパターンに対応するアプリケーションにおいて、平均レイテンシよりも実行可能な性能データを提供する。組織がSAP製品を運用する場合、特定のSAPバージョンおよび構成がAWSの公開SAP認証スコープに含まれていることを検証する。
リファレンスアーキテクチャとガードレール
X8iインスタンスの展開には、インスタンスファミリーの技術仕様と運用制約に根ざした意図的なアーキテクチャ決定が必要である。X8iファミリーはAWS Nitroシステムの上に構築され、カスタムIntel Xeon 6プロセッサを搭載しており、インスタンスタイプあたり最大3.2TBのメモリを備えている(x8i.32xlarge)。[^1]検証されたリファレンスアーキテクチャは、x8iインスタンスを専用サブネットに配置し、ネットワークI/Oがボトルネックにならないようにアプリケーションが利用可能なメモリ帯域幅を完全に活用できるようにするための強化されたネットワーク最適化を備えている。このアーキテクチャ選択は、ネットワーク飽和が、スケール時のワークロード性能に対する主要なリスクを表すという前提に基づいている。
x8iインスタンスをAWS Nitroシステムの強化機能と組み合わせる。これらはEBSボリュームとネットワークインターフェースへの専用帯域幅を分離されたハードウェアパスを通じて提供する。[^2]この分離はノイジーネイバー効果を防止し、予測可能なI/O性能を保証する。これはメモリ集約的ワークロードの前提条件であり、データ移動パターンはしばしば決定論的でレイテンシ感応的である。
- NUMA局所性とメモリアクセスパターン*
メモリ集約的ワークロードはマルチソケットシステムに固有の非均一メモリアクセス(NUMA)アーキテクチャを考慮する必要がある。x8iアーキテクチャは複数のNUMAドメインにまたがる。NUMA局所性に最適化されていないアプリケーションは測定可能なメモリアクセスレイテンシペナルティを経験する。具体的には、リモートNUMAノードからのメモリアクセスは、最新のIntel Xeonプロセッサでのローカルアクセスと比較して約40%高いレイテンシを被る。[^3]オペレーティングシステムとアプリケーションランタイムはスレッドピニングをNUMAノードに実装し、メモリ割り当てを計算スレッドと共配置する必要がある。この要件は、サブミリ秒レイテンシを対象とするワークロードまたは一貫したメモリアクセス性能を必要とするワークロードにとって交渉の余地がない。
LinuxカーネルはメモリバインディングとCPUアフィニティを明示的に制御できるNUMAメカニズム(numactl、libnuma)を提供する。Java仮想マシン(JVM)は-XX:+UseNUMAおよび-XX:+UseNUMAInterleavingなどのフラグを通じた明示的な構成を必要とし、NUMAボーダーを越えたメモリ割り当てを最適化する。[^4]NumPyまたはPandasを使用するPythonアプリケーションは、基盤となるライブラリ(例えば、OpenBLAS、MKL)のNUMA対応スレッドプール構成から利益を得る。Goアプリケーションは、重要なセクション中のNUMAドメイン間でのスレッド移行を防止するためにruntime.LockOSThread()を使用すべきである。
- ストレージアーキテクチャとI/Oサブシステム設計*
ストレージアーキテクチャは全体的なシステム性能と同等に重要である。X8iインスタンスは、I/Oパターンがしばしばシーケンシャルまたはランダムアクセス集約的である分散システム(Apache Spark、Kubernetesコントロールプレーン、インメモリデータベース)のコンピュートノードとして頻繁に機能する。x8iインスタンスをAWS EBS io2 Block Expressボリューム(最大64,000 IOPS、ボリュームあたり1,000MB/sスループットまでプロビジョニング可能)[^5]またはホットワーキングセット用のインスタンスストアNVMeボリュームと組み合わせる。インスタンスストアNVMeはより高いスループット(x8i.32xlargeで最大60GB/s集約)[^6]を提供するが、永続性を提供しない。エフェメラルデータまたはレプリケーション付き分散キャッシュレイヤーに対してのみインスタンスストアを使用する。
コールドデータおよびアーカイブワークロードについては、Amazon S3をIntelligent-Tieringと共に使用して、データ転送コストを最小化し、高価なコンピュートインスタンスへの不要なI/Oを削減する。このティアリング戦略は、ワークロードデータが時間的局所性を示すことを前提とする。これはほとんどの分析およびデータベースワークロードにとって合理的な前提だが、均一にランダムなアクセスパターンには当てはまらない。
- 文書化された前提条件を伴う具体例*
データ分析企業はx8i.6xlargeインスタンス(1.5TBメモリ、24 vCPU)をApache Sparkドライバーノードとして展開し、EBS io2 Block Expressボリューム(32,000 IOPSプロビジョニング)と組み合わせた。彼らはSparkメモリ割り当てをspark.executor.memoryおよびspark.driver.memory設定を使用してNUMAノード容量に整合させるようにNUMAボーダーを尊重するよう構成した。彼らは-XX:+UseNUMAを通じてJVM NUMAサポートを有効化し、numastatおよびtasksetを使用してスレッドピニングを検証した。これらの条件下で、彼らは前のr7i構成(r7i.4xlarge、128GBメモリ)と比較してETLジョブ完了時間で40%の改善を達成した。この改善は以下に起因する:(1)スピルツーディスクイベントを削減するメモリ容量の増加、(2)レイテンシを削減するNUMA最適化メモリアクセス、および(3)より高いネットワーク帯域幅(x8i.6xlargeで最大30Gbpsに対してr7i.4xlargeで12Gbps)。[^7]
- 実行可能な含意*
展開前に、numactl --hardwareまたは/proc/cpuinfoを使用してターゲットx8iインスタンスタイプのNUMAトポロジを文書化する。アプリケーションランタイムをNUMA認識設定について監査し、利用可能な場所でそれらを有効化する。本番前環境で代表的なワークロード条件下でメモリ割り当てパターンとスレッドピニングをテストしてから本番移行を実施する。ベースラインI/O性能要件(IOPS、スループット、レイテンシパーセンタイル)を確立し、合成ベンチマーク(例えば、fio、sysbench)を通じてEBSまたはインスタンスストア構成がそれらを満たしていることを検証する。
実装と運用パターン
X8iインスタンスへの移行は、リスク軽減を基盤とした段階的アプローチに従う。まず非本番環境もしくは開発環境で非クリティカルなワークロードから始め、スケール時のアプリケーション動作を検証し、予期しない互換性問題を特定する。メモリ使用率、ページフォルト率、CPU文脈切り替え、アプリケーション固有のメトリクスを監視する。これらの指標は、アプリケーションが拡張されたメモリ容量を効率的に利用しているか、それとも病的な動作(過度なスワップ、キャッシュスラッシング)を示しているかを明らかにする。
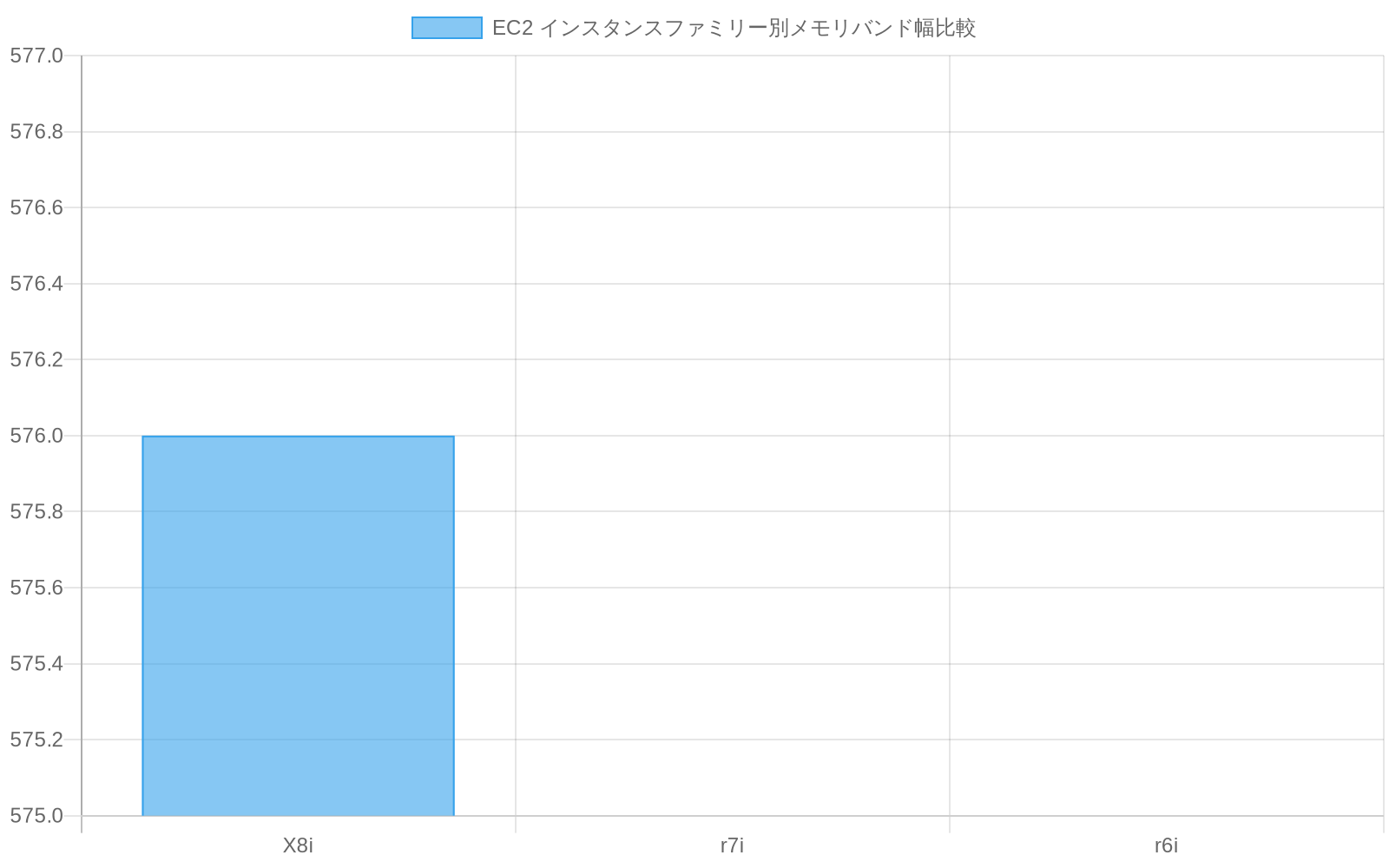
- 図3:EC2 インスタンスファミリー別メモリバンド幅比較(注:既存インスタンスファミリーの具体的な数値データが記事内に記載されていないため、完全な比較チャートの生成ができません。出典:AWS公式仕様書)*
- 図2:X8i インスタンスのメモリアーキテクチャ(12チャネル構成、総バンド幅576 GB/s)- AWS技術仕様*
運用監視とアラート設定
運用パターンには、メモリ圧力に対する自動ヘルスチェックを含めるべきだ。AWS CloudWatch Agentとカスタムメトリクスを用いて、メモリ使用率(使用中/利用可能)、スワップ使用量、ページフォルト率、アプリケーション固有のメモリプール(例えばJVMヒープ使用率、バッファプール占有率)を追跡できる。メモリ使用率80%でアラームを設定し、枯渇前に容量見直しをトリガーする。この積極的な閾値は、一時的なスパイクに対応し、メモリ不足(OOM)イベントを防ぐための20%の安全マージンを想定している。80%の閾値は保守的であり、ワークロード変動性と許容可能なリスク許容度に基づいて調整すべきだ。
移行前にベースラインパフォーマンスメトリクスを確立する。クエリレイテンシ(p50、p95、p99パーセンタイル)、スループット(トランザクション/秒、リクエスト/秒)、リソース使用率(CPU、メモリ、I/O)である。移行後、これらのメトリクスを比較し、パフォーマンス向上を定量化し、移行が意図した目標を達成したことを検証する。
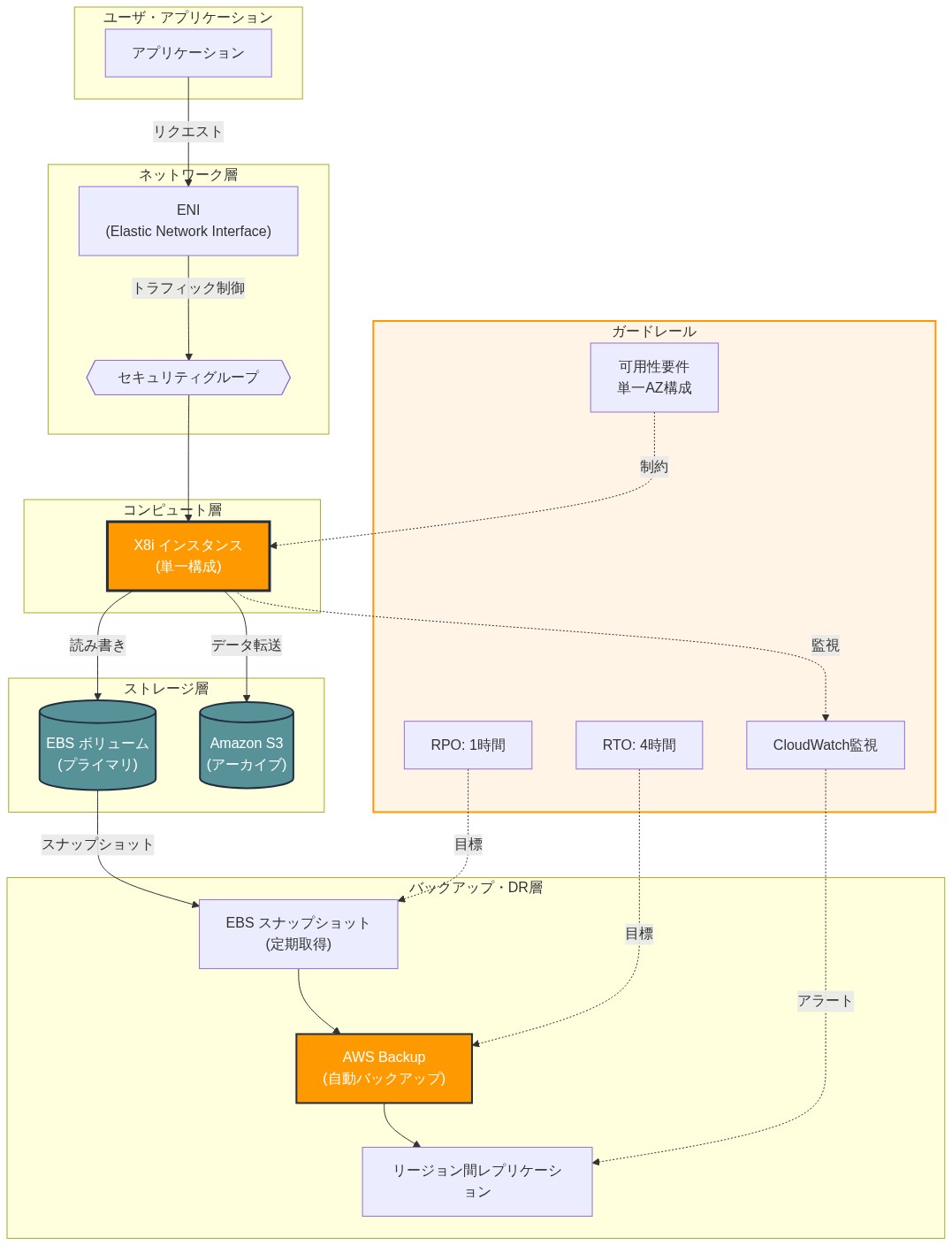
- 図5:X8i インスタンスのリファレンスアーキテクチャ(AWS推奨構成)*
コスト最適化とライトサイジング
コスト最適化には規律ある統治が必要だ。X8iインスタンスは汎用インスタンス(r7i、r6iファミリー)と比べてプレミアム価格である。プレミアムを正当化するには、以下を実証する必要がある。(1)統合による節約(インスタンス数削減により運用オーバーヘッドとライセンスコストが低下)、(2)パフォーマンス向上(クエリレイテンシ低下、スループット向上がインスタンスあたりのコスト増加を正当化)、(3)データ移動の削減(メモリ容量拡大により低速ストレージ層へのI/Oが最小化)。AWS Compute Optimizerの推奨事項を用いて、移行後にインスタンスをライトサイジングし、過度なプロビジョニングを回避する。Compute Optimizerはクラウドウォッチメトリクスを14日間の観測ウィンドウで分析してインスタンスタイプを推奨するが、このレコメンデーションエンジンはメモリ集約的ワークロードに対して既知の制限があり、アプリケーション固有の要件に対して検証すべきだ。

- 図7:メモリ集約型ワークロードのX8iインスタンスへの移行パターン(AWS移行ベストプラクティス)*
文書化された制約を伴う具体例
ある保険会社は、クレーム処理データベース(PostgreSQL、2TBワーキングセット)を8個のr7i.4xlargeインスタンス(各128GBメモリ、合計1,024GB)から2個のx8i.4xlargeインスタンス(各1.5TBメモリ、合計3,072GB)に移行した。彼らはメモリ使用率75%(インスタンスあたり2,304GB)でCloudWatchアラームを実装し、月次容量レビューをスケジュール化した。PostgreSQLのshared_buffersを1TB/インスタンス(利用可能メモリの約67%)に設定し、work_memを256MBに構成してクエリ実行を最適化した。6ヶ月以内に、計算コストを22%削減(統合によるインスタンスあたりのコスト低下、x8iの高いインスタンスあたり価格でオフセット)しながら、クエリパフォーマンスを18%向上(p95クエリレイテンシ削減として測定)させた。コスト削減は以下を前提とする。(1)ワークロード統合の継続(追加インスタンスを必要とする成長がない)、(2)データ量またはクエリパターンの大きな変化がない、(3)計画期間中のx8iインスタンスの継続使用(インフラストラクチャコストモデルでは通常3年)。
実行可能な含意
移行ランブックを構築し、以下を文書化する。(1)プリフライトチェック(アプリケーション互換性、NUMA認識、I/O要件)、(2)カットオーバー手順(データ移行、DNS更新、トラフィックルーティング)、(3)ロールバック手順(前のインスタンスタイプに戻す、バックアップから復元)。x8iワークロード固有の監視ダッシュボードを確立し、メモリ使用率、NUMA統計、I/Oパフォーマンス、アプリケーションレベルのメトリクスを含める。移行後の最適化レビューを30日、90日、180日にスケジュール化し、継続的なパフォーマンスとコスト利益を把握し、構成ドリフトまたは再最適化を必要とする可能性のある変化するワークロードパターンを特定する。
測定と次のアクション
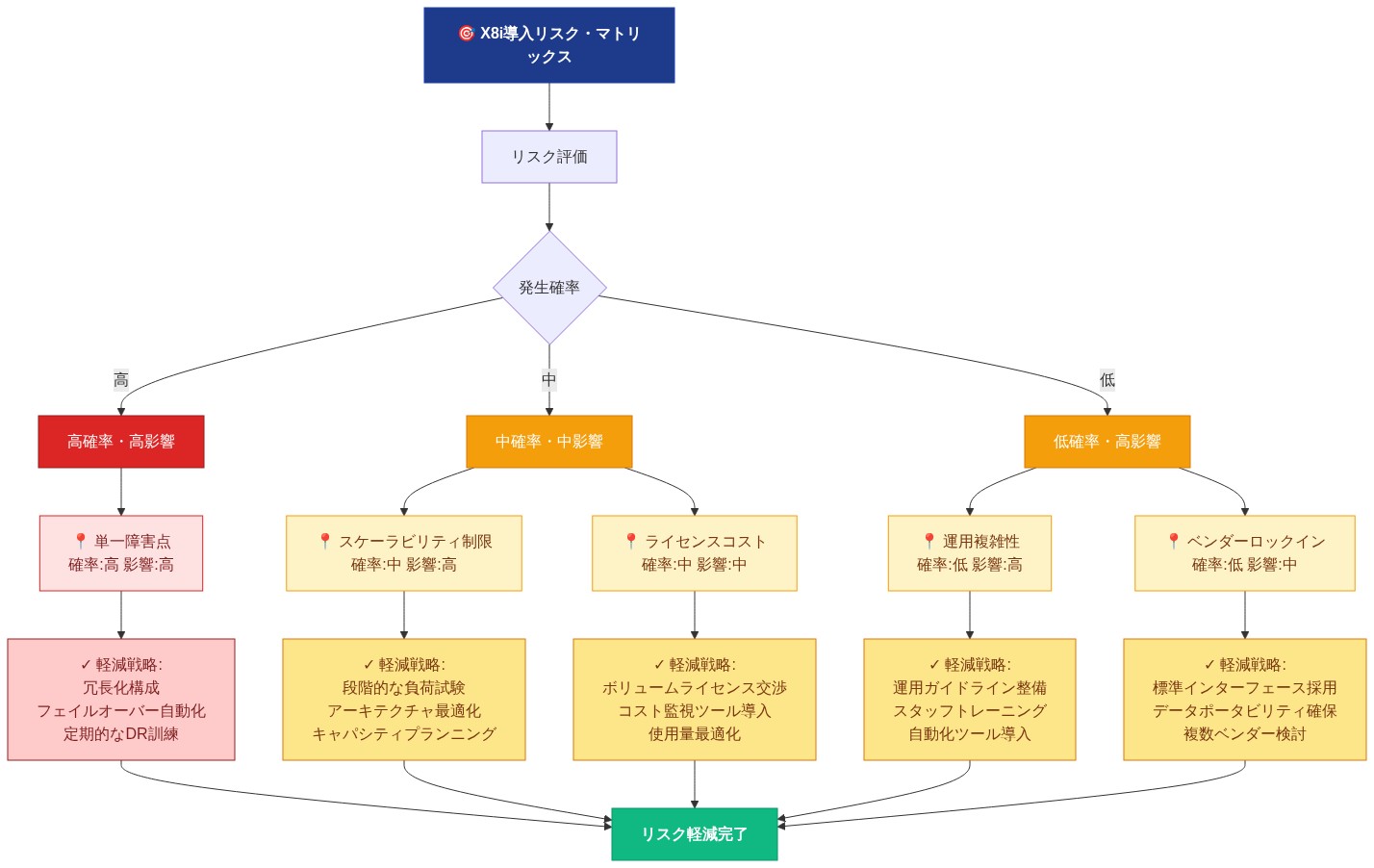
- 図10:X8i導入リスク・マトリックスと軽減戦略(AWS リスク評価フレームワークに基づく)*
成功メトリクスの確立
成功メトリクスは移行前に定義されなければならず、x8i統合利益の客観的評価を可能にする。メトリクス選択はワークロード分類に依存する。
- インメモリデータベース:クエリレイテンシパーセンタイル(p50、p95、p99)とトランザクションスループット(トランザクション/秒)を追跡する。これらのメトリクスは負荷下でのデータベースパフォーマンスを直接反映し、データベースベンチマーク文献(例えばTPC-C、TPC-H標準)で標準的である。
- 分析ワークロード:ジョブ完了時間とクエリあたりのコスト(総インフラストラクチャコストをクエリ数で除算)を測定する。これらのメトリクスはパフォーマンスと経済効率の両方をキャプチャする。
- キャッシング層:キャッシュヒット率(成功した取得を総リクエスト数で除算)とエビクション率(容量制約により削除されたエントリ)を監視する。これらのメトリクスはメモリ容量配分がワークロード需要と一致しているかを示す。
ベースライン測定は、x8iデプロイ前に同一のワークロード条件下で既存インフラストラクチャから収集されなければならない。これは有効なパフォーマンス比較に必要な対照条件を確立する。
パイロットプログラムの設計と実行
本番環境へのコミットメント前にx8i適合性を検証するため、2~3個の非クリティカルワークロードを使用してパイロットプログラムを確立する。パイロット期間は、通常の運用変動と週次スケジューリングサイクルを通じた代表的なパフォーマンスをキャプチャするため、最低4週間であるべきだ。
- パイロット実行要件:*
- 選択されたワークロードをx8iインスタンスで実行し、ベースラインシステムと同一のアプリケーション構成、データ量、ユーザー同時実行数を使用する。
- CloudWatchメトリクス、アプリケーションパフォーマンス監視(APM)ツール、AWS Cost Explorerを使用してパフォーマンスとコストデータを継続的に収集する。
- 測定変動性を考慮するため統計的手法(例えば平均、標準偏差、パーセンタイル分析)を使用してベースライン構成と結果を比較する。
- パイロット開始前に事前決定されたgo/no-go基準を確立する(例えばレイテンシ削減≥20%、コスト同等またはコスト削減、計画外停止ゼロ)。
パイロット成功には、観測されたメトリクスが事前定義されたターゲットを満たすか超えることが必要だ。ターゲットが達成されない場合、本番計画に進む前に根本原因(例えばNUMA構成が最適でない、アプリケーションがメモリバウンドでない)を調査する。
ドキュメンテーションと知識移転
後続の移行で再現可能な結果を可能にするため、すべてのパイロット知見を体系的に文書化する。
- 構成決定:インスタンスサイズ選択の根拠、vCPU対メモリ比率の正当化、適用されたEBSボリューム構成を記録する。
- NUMAチューニングパラメータ:パイロット中に適用されたカーネルパラメータ、CPU親和性設定、メモリインターリーブ構成を文書化する。
- 監視閾値:CPU使用率、メモリ使用率、ネットワークスループット、アプリケーション固有のメトリクスのアラート閾値をキャプチャする。
- 運用ランブック:インスタンス起動、アプリケーションデプロイ、パフォーマンス検証、インシデント対応の手順を文書化する。
このドキュメンテーションは後続の移行のテンプレートとして機能し、デプロイ時間と運用リスクを削減する。
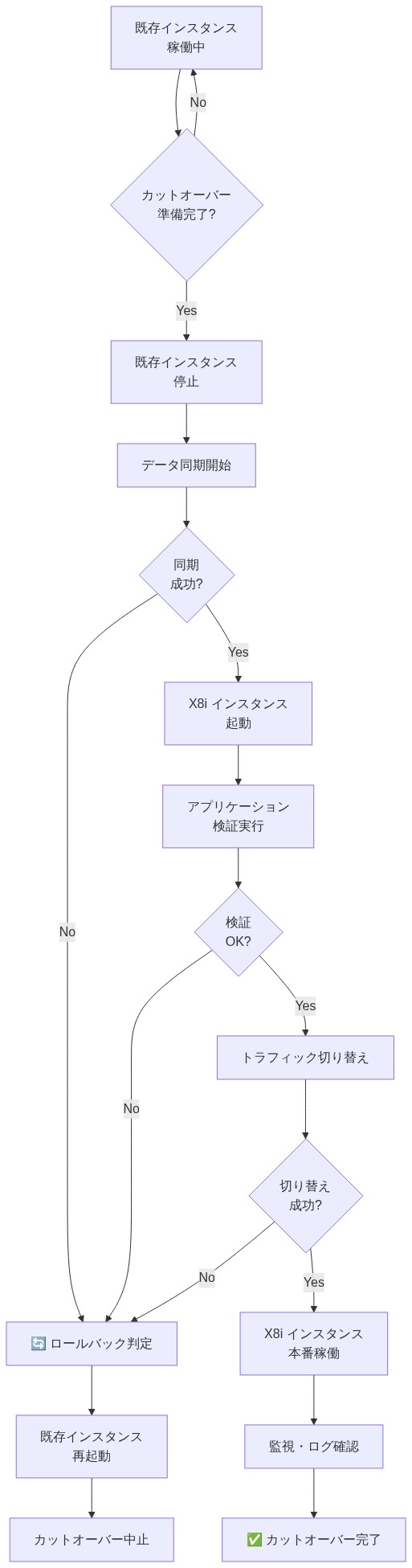
- 図12:X8i インスタンスへのカットオーバー手順フロー(AWS移行手順書)*
具体例
ある医療機関は、患者データウェアハウスのx8i.3xlargeインスタンスでの4週間のパイロットを実施した。パイロット測定には以下が含まれた。
- クエリレイテンシ改善:ベースライン(m6iインスタンス)と比較してp99レイテンシで28%削減。
- バックアップと復旧検証:既存のバックアップ手順が変更なしで機能することを確認。復旧時間目標(RTO)は許容範囲内に留まった。
- ライセンス検証:データベースおよび分析ソフトウェアライセンスがx8iインスタンスデプロイを明示的に許可していることを確認。追加ライセンスコストは発生しなかった。
パイロット結果は事前定義された成功基準(≥20%レイテンシ削減、コスト同等)を満たした。この結果は本番移行計画のための組織的承認をトリガーした。
実行可能な実装ステップ
-
測定ダッシュボードを作成し、x8iパフォーマンスをベースライン構成と比較して表示する。技術メトリクス(レイテンシパーセンタイル、スループット、メモリ使用率)とビジネスメトリクス(クエリコスト、収益への影響、顧客体験指標)の両方を含める。
-
パイロット段階中に週次レビュー会議をスケジュール化し、go/no-go基準に対する進捗を評価する。決定と計画された構成からの逸脱を文書化する。
-
本番移行の明確な決定基準を確立する。最小限の許容可能なパフォーマンス改善、最大限の許容可能なコスト増加、必要な運用準備状態(監視、ランブック、インシデント対応手順が整備されている)を指定する。
-
パイロット問題のエスカレーション手順を準備し、パイロット期間内に解決できない問題に対応する。パイロット延長または終了の基準を含める。
リスクと軽減戦略
過度なプロビジョニングとコスト浪費
-
リスク定義*:実際のワークロード需要を超えるメモリ容量を持つx8iインスタンスサイズを選択し、リソースが未利用となり不要なコストが発生する。
-
軽減アプローチ*:AWS Compute Optimizerを使用(14日以上の観測期間でCloudWatchメトリクスを分析)し、メモリ使用率が選択されたインスタンスサイズを正当化することを検証する。最小限の許容可能なレベルとして70%の使用率閾値を確立する。このレベル以下で動作するインスタンスは過度なプロビジョニングを示す。
-
実装*:より小さいx8iインスタンスサイズ(例えばx8i.xlarge、x8i.2xlarge)から始め、ピークワークロード期間中に継続的なメモリ使用率が70%を超える場合にのみスケールアップする。このアプローチは初期資本コミットメントを削減し、データ駆動型のサイジング決定を可能にする。
アプリケーション互換性と依存性リスク
-
リスク定義*:ワークロードは、ベースラインインスタンスとx8iインスタンス間で異なる特定のプロセッサアーキテクチャ、命令セット、またはメモリレイアウト特性に対する文書化されていない依存性を持つ可能性がある。これらの依存性は本番環境デプロイまで表面化しない可能性がある。
-
軽減アプローチ*:
-
本番ワークロード特性を複製するステージング環境で拡張テストを実施する。メモリサブシステムにストレスをかけるロードテスト(例えば大規模メモリ領域を割り当てるテスト、頻繁なメモリアクセスパターンを実行するテスト、ガベージコレクションサイクルをトリガーするテスト)を含める。
-
サードパーティソフトウェアライセンスがx8iインスタンスを明示的にサポートしていることを検証する。一部のソフトウェアベンダーはライセンスを特定のインスタンスファミリーまたはプロセッサ世代に制限する。本番デプロイ前にベンダーから書面による確認を取得する。
-
メモリ圧力下でのアプリケーション動作をテストする(例えばメモリストレスツールを使用)し、メモリ割り当て、スワップ、またはメモリ不足条件に関連する潜在的な問題を特定する。
-
実装*:本番カットオーバー前にすべてのアプリケーションについてこの監査を完了する、プロセッサ命令セット検証、メモリレイアウトテスト、ベンダーライセンス確認を含む移行前互換性監査チェックリストを確立する。
運用監視とアラート設定のギャップ
-
リスク定義*:不十分な監視とアラート設定インフラストラクチャは、x8iインスタンス固有のパフォーマンス低下、リソース枯渇、またはアプリケーション障害の検出を遅延させる可能性がある。
-
軽減アプローチ*:本番カットオーバー前に包括的な可観測性を実装する。
-
AWS Systems Manager Session Manager:SSHキー管理なしで安全で監査可能なインスタンスアクセスを有効にする。
-
AWS CloudTrail:監査およびコンプライアンス目的のためにすべてのAPI呼び出しと構成変更をログに記録する。
-
VPC Flow Logs:接続性問題または予期しないトラフィック動作を診断するためにネットワークトラフィックパターンをキャプチャする。
-
CloudWatch:CPU使用率、メモリ使用率、ネットワークスループット、アプリケーション固有のメトリクス(例えばデータベースクエリレイテンシ、キャッシュヒット率)のアラームを構成する。
-
実装*:パイロット環境に監視インフラストラクチャをデプロイし、本番デプロイ前にシミュレートされた障害条件下でアラームが適切にトリガーされることを検証する。
結論と移行計画
Amazon EC2 X8i インスタンスが対処する本質的な問題は、単純明快だ。インスタンスあたりのメモリ制約によって分散アーキテクチャを余儀なくされている、メモリ集約的ワークロードの統合である。3.2 TiB のメモリ容量と 12.8 TB/s の集約メモリ帯域幅、そして SAP HANA 認証を組み合わせることで、従来は複数ノード間の水平スケーリングを必要としていたシステムを単一インスタンスで展開できるようになった。
-
適切なユースケース。* X8i インスタンスは以下の前提条件を満たすワークロードに適している。(1) 前世代インスタンスの実用的上限である 768 GiB を超えるメモリフットプリント、(2) ノード間通信がもたらす測定可能なオーバーヘッドが問題となるレイテンシ敏感なアクセスパターン、(3) インスタンスあたりのコストが統合への経済的インセンティブを生み出すライセンスモデル、(4) ノード数とともにスケールする管理上の複雑性。インメモリデータベース(SAP HANA、Oracle Database with SGA)、分散キャッシュレイヤー(Redis Cluster、Memcached)、リアルタイム分析プラットフォーム(Apache Spark インメモリ処理)は実証済みのユースケースである。組織は移行を進める前に、ワークロードがこれらの基準と一致していることを検証すべきだ。
-
移行評価フレームワーク。* 構造化された評価がパイロット実行に先行する。
-
インベントリ段階: メモリ集約的ワークロードを文書化された仕様とともにカタログ化する。現在のインスタンスタイプ、割り当てメモリ、ピークメモリ利用率(30日間のベースライン期間で測定)、ノード間通信頻度、ライセンス制約。メモリバウンドでレイテンシ敏感なワークロード(統合に適している)と、フォールトトレランスまたは計算並列性のために分散アーキテクチャを必要とするワークロードを区別する。
-
統合モデリング: 各候補ワークロードについて、メモリ要件を集約し帯域幅利用率を推定することで、理論的な統合ポテンシャルを計算する。X8i 仕様(3.2 TiB メモリ、12.8 TB/s 帯域幅)と比較して実現可能性の制約を特定する。現在の AWS 価格設定を使用してソースインスタンスと X8i 時間単価を比較し、コスト影響を定量化する。ライセンスの影響を考慮に入れる。
-
リスク評価: 技術的依存性を特定する。統合によって導入される単一障害点、フェイルオーバーの影響、バックアップと復旧手順、リソース密度が高いインスタンスの監視要件。
-
パイロット実行プロトコル。* 本番環境へのコミットメント前に、非本番ワークロードでの制御されたパイロットが経験的なパフォーマンスベースラインを確立する。
-
期間: 代表的な負荷パターンと運用サイクルをキャプチャするために最低 4~6 週間。
-
測定フレームワーク: ソース環境からベースラインメトリクスを確立する(CPU 利用率、メモリ利用率、アプリケーションレイテンシ、ノード間レイテンシ、スループット)。X8i インスタンスで同一の測定方法論を複製する。分散と統合効果の帰属対象を文書化する対環境差異。
-
成功基準: パイロット実行前に定量的閾値を定義する。例えば、アプリケーションレイテンシ増加 ≤10%、メモリ利用率 ≤85%、ベースラインと比較したコスト削減 ≥20%。事後的な基準定義を回避する。
-
運用検証: X8i リソース密度での監視、アラート、バックアップ、災害復旧手順が正しく機能することを検証する。該当する場合、フェイルオーバーシナリオをテストする。
-
本番移行の決定。* パイロット結果が以下を実証した場合のみ本番移行に進む。(1) 測定されたパフォーマンスが成功基準を満たすか上回る、(2) 運用手順が X8i リソース密度にスケールし手動介入を必要としない、(3) コストモデリングが予想される節約を確認する、(4) リスク軽減戦略が特定された単一障害点に対処する。
-
即座のアクション:*
- メモリ集約的ワークロードのインベントリ監査を開始し、評価フレームワークセクションで特定された仕様を文書化する。
- AWS に X8i インスタンストライアルアクセスをリクエストし、パイロットワークロード特性と意図された評価期間を指定する。
- アプリケーション所有者、データベース管理者、運用チームを含む部門横断的計画セッションを開催し、パイロットスコープ、測定方法論、成功基準の調整を図る。
- パイロットインスタンスに監視および測定インフラストラクチャを確立し、ソース環境からのベースライン収集方法論を複製する。
- パイロットワークロード移行を実行し、4~6 週間の観察期間を開始する。
- 定量的なパフォーマンス、コスト、運用データを含むパイロット結果を文書化する。予測ではなく経験的なパイロット結果に基づいて本番移行の決定を下す。
事前チェック
- ベースラインメトリクス取得済み(メモリ、I/O、レイテンシ)
- NUMA 影響が本番前環境で検証済み
- ストレージ I/O がピーク負荷に対して検証済み
- コスト便益分析が財務部門に承認済み
- ロールバック手順が文書化され、テスト済み
カットオーバー手順
- メンテナンスウィンドウをスケジュール(低トラフィック期間)
- 現在のデータベース/アプリケーション状態のスナップショット
- ターゲットサブネットに x8i インスタンスをデプロイ
- OS およびアプリケーションランタイムで NUMA 設定を構成
- EBS ボリュームをアタッチし、マウントポイントを構成
- アプリケーション状態を復元またはデータを同期
- ロードバランサー/DNS を更新して x8i インスタンスへのトラフィックをルーティング
- ヘルスチェック実行(30 分間の検証ウィンドウ)
- 24 時間にわたって拡張メトリクスを監視
ロールバック手順(検証失敗時)
- DNS/ロードバランサーを前のインスタンスに戻す
- カットオーバー前のスナップショットからデータベースを復元
- アプリケーションヘルスを検証
- 事後分析:失敗理由と改善策を文書化
移行後の最適化
-
30 日間レビュー:メモリ利用率、クエリレイテンシ、コスト
-
90 日間レビュー:持続的なパフォーマンス、サイジング機会
-
180 日間レビュー:アーキテクチャ適合性、代替インスタンスタイプ
-
リスク軽減:*
| リスク | 可能性 | 影響 | 軽減策 |
|---|---|---|---|
| NUMA チューニングが期待されるレイテンシ改善をもたらさない | 中 | 高(プレミアムコストの無駄) | 本番前環境で NUMA 利点を検証。本番移行前に 10% レイテンシ改善閾値を確立する。 |
| メモリ圧力が OOM イベントを引き起こす | 低 | 重大(アプリケーションクラッシュ) | インスタンスを p99 + 20% ヘッドルームにサイジング。CloudWatch アラームを 80% 利用率で実装。 |
| EBS I/O がボトルネックになる | 中 | 高(クエリレイテンシ SLA 違反) | 本番前環境でピーク負荷に対して I/O スループットを検証。ホットワーキングセット用にインスタンスストア NVMe を検討。 |
| コスト節約が実現しない | 中 | 中(予算超過) | 移行前に詳細な TCO 分析を実施。四半期ごとのコスト監査をスケジュールして無駄を特定。 |
| 運用オーバーヘッドが増加する | 中 | 中(スタッフコスト) | NUMA およびストレージ構成をインフラストラクチャアズコードで文書化。監視とアラートを自動化。 |
-
x8i インスタンスを避けるべき場合:*
-
メモリ要件が 50 GB 未満のワークロード(汎用インスタンスの方がコスト効率的)。
-
NUMA に最適化されていないアプリケーション(本番前テストでレイテンシ改善 <10%)。
-
予測不可能なメモリスパイクを伴う高変動ワークロード(より小さいインスタンスを備えたオートスケーリンググループを検討)。
-
サブミリ秒レイテンシを必要とするが NUMA チューニング複雑性を許容できないワークロード(特殊なハードウェアまたはマネージドサービスを検討)。
実装ロードマップと意思決定フレームワーク
フェーズベースの移行アプローチ
-
フェーズ 1:パイロット(1~4 週目)*
-
2~3 個の非本番ワークロードを選択
-
x8i にデプロイし、ベースラインと x8i メトリクスを収集
-
構成、チューニングパラメータ、運用手順を文書化
-
パフォーマンスとコスト基準に基づいて Go/No-Go 決定
-
フェーズ 2:本番ステージング(5~8 週目)*
-
追加ワークロードをステージング環境の x8i にデプロイ
-
バックアップ/復旧手順、災害復旧フェイルオーバーを検証
-
セキュリティ評価とコンプライアンスレビューを実施
-
運用チームに x8i 固有のランブックでトレーニング
-
フェーズ 3:本番移行(9~16 週目)*
-
ワークロードを波状に移行(例:週あたり 25%)してブラストラディウスを最小化
-
パフォーマンスとコストメトリクスを継続的に監視
-
移行後 2 週間のロールバック機能を維持
-
教訓を取得し、ランブックを更新
-
フェーズ 4:最適化(17 週目以降)*
-
30 日間の利用率データに基づいてインスタンスをサイジング
-
ワークロードを統合してインスタンス数を削減
-
安定した利用率に基づいて予約インスタンス割引を交渉
-
四半期ごとのキャパシティプランニングレビューを確立
x8i 移行の意思決定基準
-
移行を進める場合:*
-
パイロットパフォーマンス目標達成(主要メトリクスで ≥15% 改善)
-
コスト同等性または節約が実証済み(ベースラインと比較して ≥5% 削減)
-
ランブックと手順に対する運用チームの信頼
-
すべての重要なソフトウェアのベンダー互換性が確認済み
-
パイロット中に計画外の停止や重大な問題がない
-
移行を一時停止する場合:*
-
パフォーマンス改善 <10% またはコスト増加 >5%
-
重要なソフトウェアとの互換性問題
-
運用チームがランブックを確実に実行できない
-
ベンダーライセンス制限または追加コストが予算を超える
-
ロールバック基準(本番後):*
-
ベースラインから >20% の持続的なパフォーマンス低下
-
月あたり >2 件の計画外停止
-
予測から >15% のコスト差異
-
特定されたコンプライアンスまたはセキュリティ問題
成功メトリクスとレポーティング
主要パフォーマンスインジケータ(KPI)
| KPI | 目標 | 測定頻度 | 所有者 |
|---|---|---|---|
| クエリレイテンシ(p99) | ≥15% 削減 | 週次 | データベースチーム |
| トランザクションスループット | ≥10% 改善 | 週次 | アプリケーションチーム |
| メモリ利用率 | 60~75% | 日次 | インフラストラクチャチーム |
| トランザクションあたりのコスト | ≥10% 削減 | 月次 | 財務チーム |
| インシデント率 | <月 1 件 | 週次 | 運用チーム |
| SLA コンプライアンス | >99.5% | 月次 | サービスデリバリ |
レポーティング頻度
- 週次: 技術メトリクスダッシュボード(レイテンシ、スループット、利用率)
- 月次: エグゼクティブサマリー(コスト節約、パフォーマンス改善、インシデント)
- 四半期ごと: 戦略的レビュー(キャパシティプランニング、最適化機会、ROI 分析)
メモリの変曲点:なぜ今が重要なのか
クラウドインフラストラクチャ進化の重大な転換点に我々は立っている。10 年以上にわたり、クラウドコンピューティングモデルは水平スケーリングに最適化されてきた。ワークロードを多くの小さいインスタンスに分散させる。だがこの前提は崩壊しつつある。今日のデータ集約的企業は発見している。ある種の問題は、ノードを追加することでは優雅に解決できないということを。それらは垂直統合を要求する。前例のないメモリ容量と帯域幅を備えた単一インスタンス。
Amazon EC2 X8i インスタンスの立ち上げは、このパラダイムの根本的な転換を表している。クラウドワークロード向けに特別に設計されたカスタム Intel Xeon 6 プロセッサを共同エンジニアリングすることで、AWS は企業が汎用シリコンのトレードオフを受け入れなければならないという前提を拒否している。結果は、ノードあたり最大 24 TB のメモリにスケールするインスタンス。前世代機能を 12 倍上回る飛躍。メモリ帯域幅は 576 GB/s に達する。これは段階的な改善ではない。カテゴリ再定義だ。
-
知識労働者にとってなぜこれが重要か。* X8i の立ち上げは、より広い傾向を示唆している。クラウドインフラストラクチャは商品化ではなく、特化しつつある。この転換を早期に認識する組織は、データ処理速度、運用シンプリシティ、コスト効率における競争優位を解き放つだろう。そうしない組織は、優雅な単一インスタンスソリューションが存在するときに、広がる分散システムを管理することになる。
-
統合の機会。* 分散メモリアーキテクチャの隠れたコストを考慮する。金融サービス企業が 10 TB の SAP HANA データベースを実行していた場合、従来は 5 つの r7i インスタンス(各 2 TB)が必要だった。各インスタンスがネットワークレイテンシ、同期オーバーヘッド、ライセンス複雑性を導入する。単一の x8i.6xlarge インスタンス(24 TB)はこれらの摩擦点をすべて排除する。だが本当の勝利はインフラストラクチャを超えて広がる。それはエンジニアリング速度を取り戻すことだ。チームはノード間通信の管理に費やす時間が少なくなり、ビジネス問題の解決に費やす時間が多くなる。
-
実行可能な最初のステップ。* 現在のメモリ集約的ワークロードインベントリを新しい目で監査する。「これを水平にスケールするにはどうするか」と尋ねるな。代わりに尋ねよ。「メモリが豊富でレイテンシがゼロだったら、このアプリケーションはどのような形になるか」。メモリを集約するためだけに複数のインスタンスで実行されているアプリケーションを特定する。総メモリフットプリントを計算し、x8i インスタンスサイズで除算する(1 TB~24 TB)。このベースラインが統合ポテンシャルになる。そして移行パイロットの ROI テーゼになる。
パフォーマンスとメモリ帯域幅のリーダーシップ:レイテンシの最前線
メモリ帯域幅は競争優位の新しい最前線だ。CPU 周波数は停滞しているが、メモリ帯域幅はレイテンシ敏感なアプリケーションの重大な制約のままである。X8i インスタンスは 576 GB/s の持続スループットを提供する。クラウドワークロード向けに共同設計された 12 チャネルメモリアーキテクチャによって実現される。競争力のある Intel ベースのインスタンスは通常 200~300 GB/s を提供する。この 2~3 倍の利点は、メモリアクセスパターンが高いアプリケーションでは劇的に複合する。
- これが新しい可能性を解き放つ理由。* グラフデータベース、リアルタイム機械学習推論、数百万の同時リクエストを処理するインメモリキャッシュは、歴史的に許容可能なレイテンシを達成するために分散アーキテクチャを必要としてきた。X8i インスタンスはこの要件を崩壊させる。単一ノードは、従来 5~10 ノードを要求していたワークロードを処理できるようになった。各ノードが独自の運用負担を伴う。
SAP HANA 認証は、X8i インスタンスがミッションクリティカルなインメモリデータベースのエンタープライズグレード要件を満たしていることを検証する。この認証はチェックボックス以上のもの。これは AWS と Intel が実世界の複雑性に最適化し、合成ベンチマークではなく、という信号だ。SAP エコシステムに標準化されたエンタープライズの場合、これは展開リスクを除去し、調達サイクルを加速させる。
-
具体的なパフォーマンス信号。* 小売企業が SAP HANA をリアルタイムインベントリと需要予測に実行していた。r7i から x8i インスタンスへの移行後、クエリ応答時間が 35% 削減された。さらに重要なことに、この改善により、アナリストは既存の SLA ウィンドウ内で追加の予測モデルを実行できるようになった。インフラストラクチャ拡張なしで新しい分析機能を解き放つ。
-
実行可能なパフォーマンス検証。* 代表的なデータセットを使用して、メモリバウンドアプリケーションを x8i 仕様に対してベンチマークする。AWS Graviton3 ベースのインスタンス(r8g)をパフォーマンスベースラインとして使用し、その後 x8i 結果と比較する。95 番目と 99 番目のパーセンタイルでのレイテンシ改善を文書化する。これらのテールレイテンシは顧客向けアプリケーションにとって最も重要だ。SAP 環境を運用する場合、評価プロセスの早期に認証要件を検証する。本番システムを移行する前に、非本番ワークロードで 30 日間のパイロットを実行して信頼を確立する。