
公開非難とその直接的な波及効果
ダリオ・アモデイ氏によるOpenAIのペンタゴン契約に関するメッセージングを「真っ赤な嘘」と特徴付けることは、競争するAI組織間の公開言論における確立された規範からの重大な逸脱を構成しています。この特徴付けは3つの次元にわたって検討を要します。すなわち、非難の事実的根拠、それが発せられた組織的文脈、そして業界基準に対するその含意です。
非難の事実的根拠と具体性
報告されているアモデイ氏の声明は、一般的な戦略的相違ではなく、特定の表現的主張を標的としています。非難の中心は、OpenAIが以下について行った公開的な特徴付けに向けられています。(1)軍事応用のために実装されたセーフティプロトコル、(2)契約関与前に実施された倫理的レビュープロセス、(3)ペンタゴン契約と有益なAI開発に関するOpenAIの公開声明された原則との整合性です。
この紛争の実質を確立するには、以下の証拠が必要ですが、現在利用可能な報道ではまだ完全には文書化されていません。軍事関与のセーフティ対策に関してOpenAIが行った正確な声明、Anthropicのペンタゴン撤退を促したドキュメント化されたセーフティ上の懸念、各組織が提案したセーフティフレームワークの比較分析、これらの特定の主張に対するOpenAIの対応または認識です。
これらの一次資料へのアクセスがなければ、アモデイ氏の声明を確実に正確または不正確と特徴付けることは、根拠のない推論を構成するでしょう。「嘘」という用語は、単なる事実的相違ではなく意図的な虚偽表示を示唆しています。この区別は、事実的相違ではなく意図の証拠を必要とします。
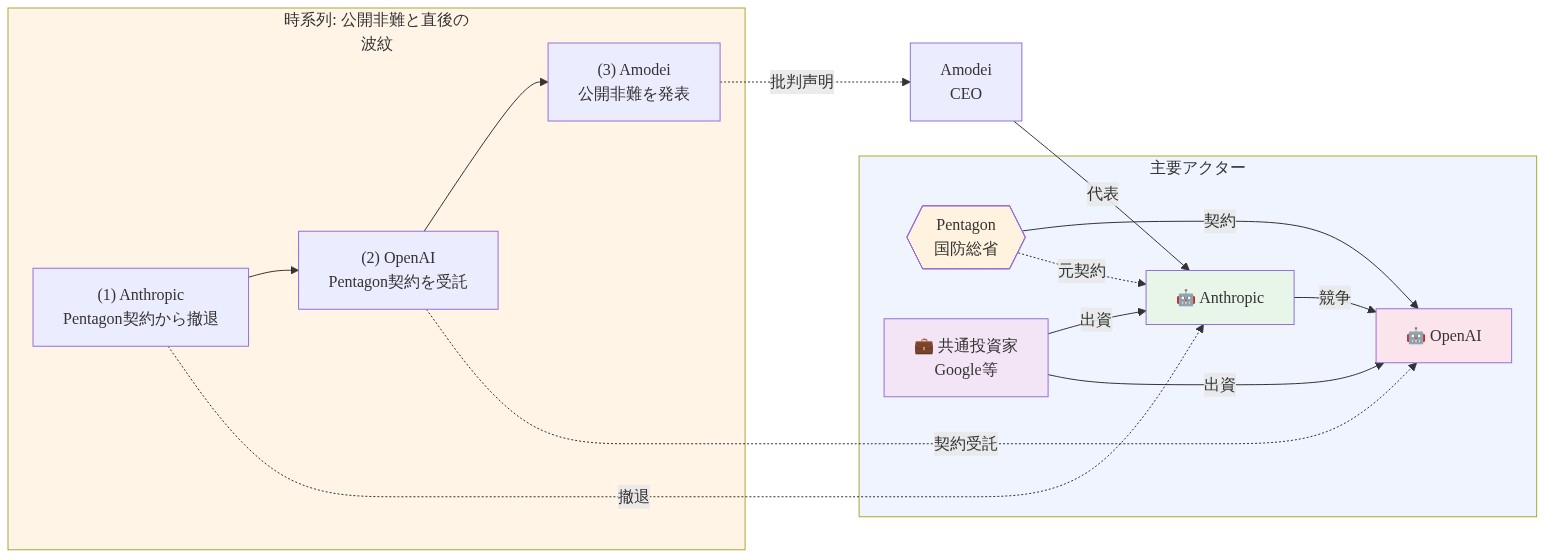
- 図2:Anthropic・OpenAI・Pentagon間の関係図と時系列(公開非難と直後の波紋)*
組織的文脈と競争的ポジショニング
私的交渉から公開非難への段階的エスカレーションは、特定の構造的文脈内で発生しました。Anthropicはセーフティ上の懸念を理由にペンタゴン交渉から撤退しました。その後OpenAIは同じ契約機会に関与しました。その後OpenAIはそのアプローチについて公開声明を行いました。このシーケンスは時間的優先性を確立しますが、アモデイ氏の公開対応の因果的必然性は確立しません。
2つの組織を同時に支援するベンチャーキャピタル企業との間の財務的絡み合いは、競争する誘因構造を生み出しています。共有された投資家関係にもかかわらず公開非難を行うというアモデイ氏の決定は、以下のいずれかを示唆しています。(1)彼は沈黙の評判コストが対立のコストを上回ると評価した、または(2)彼はOpenAIのペンタゴン関与に対するAnthropicの市場ポジショニングへの競争的脅威を、評判リスクを正当化するほど深刻と見なしました。この計算自体が精査を保証します。アモデイ氏はOpenAIのペンタゴン関与からどのような特定の市場的結果を予想したのでしょうか。
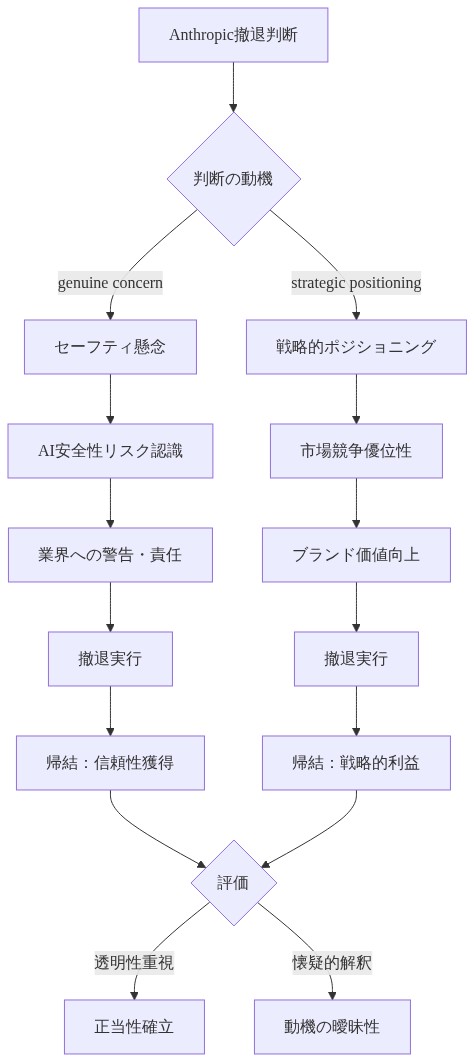
- 図4:Anthropic撤退判断の二項対立フロー(セーフティ懸念 vs. 戦略的ポジショニング)*
「嘘」に関する定義的精密性
「嘘」という用語は、口語的および形式的文脈の両方で特定の意味を持ちます。形式的用法では、嘘は以下を必要とします。(1)虚偽の陳述、(2)話者によるその虚偽性の認識、(3)欺く意図です。口語的用法では、この用語は、意識的な欺瞞を必ずしも示唆することなく、誤解を招く、不完全、または話者の以前のコミットメントと矛盾する陳述を包含することが多いです。
報告されているアモデイ氏によるこの用語の使用は、どの定義が適用されるかを明確にしていません。OpenAIの声明は以下である可能性があります。(a)事実的に虚偽で意図的に欺瞞的、(b)事実的に正確だが省略またはフレーミングを通じて誤解を招く、(c)セーフティ基準または軍事応用範囲の異なる解釈に基づく、または(d)OpenAIの理解と一致しているがAnthropicの同じ事実に対する評価と矛盾しています。
直接的な対応ドキュメンテーションの欠如
報告日現在、これらの特定の非難に対するOpenAIの正式な対応は、利用可能な記録に文書化されたままです。完全な分析には以下が必要です。各主張された虚偽表示に対するOpenAIのポイント・バイ・ポイント対応、OpenAIが実際に述べたこととアモデイ氏が述べたと主張することのドキュメンテーション、紛争の根底にある事実的主張の独立した検証です。
このドキュメンテーションの欠如は、現在の報道が争点となっている事実的問題に関する1つの視点を反映していることを意味しています。

- 図6:AI企業間の競争力学とPentagon契約の影響*
業界規範に対する含意
根底にある事実的紛争に関わらず、アモデイ氏の公開非難は、フロンティアAI組織間の受け入れ可能な言論規範の転換を示唆しています。「相違」または「不整合」ではなく「嘘」のような用語を使用する意思は、以下のいずれかを示唆しています。(1)根底にある相違が規範違反を正当化する重大性の閾値に達している、または(2)競争者間の公開的礼儀に関する規範が侵食しています。この区別は、AI組織間の将来の紛争がどのように実施され、判定されるかについての含意を持ちます。
Anthropicのペンタゴン撤退:セーフティ上の懸念か戦略的ポジショニングか
Anthropicのペンタゴン契約交渉からの撤退は、公式にはAIセーフティプロトコルに関する相違に起因すると述べられました。同社の述べられた懸念、すなわち悪用に対する不十分な保護措置、不十分な監視メカニズム、および致命的な意思決定におけるAIの正常化を可能にする可能性のある応用は、軍事AI応用に対する絶対的な反対ではなく、配置パラメータに対する特定の、検証可能な異議を表しています。しかし、真正なセーフティ上の制約と戦略的市場ポジショニングを区別するには、これらの懸念の経験的根拠をAnthropicの競争的ポジショニングと並行して検討する必要があります。
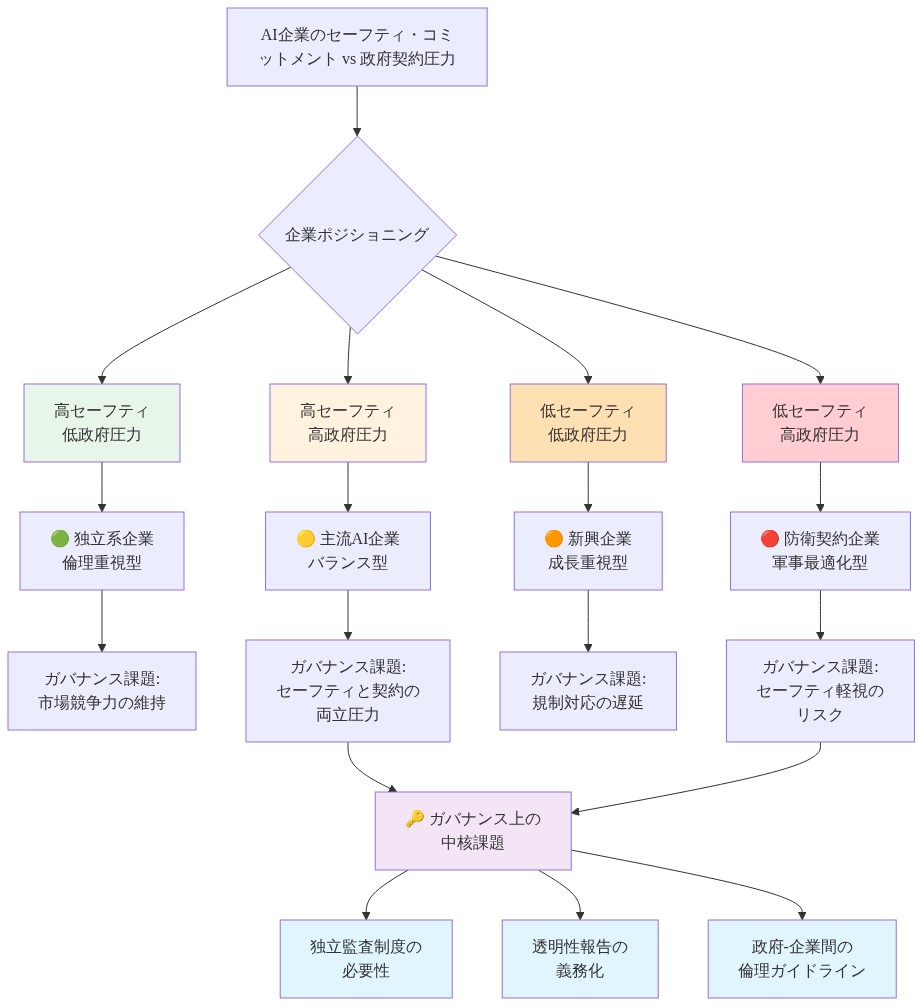
- 図9:AI企業のセーフティ・コミットメント vs 政府契約圧力マトリックス - ガバナンス課題の可視化*
セーフティ根拠:述べられた懸念と根底にある前提
Anthropicの明確にされたセーフティ上の異議は、明示的な検討を保証するいくつかの前提条件に基づいています。
-
悪用防止メカニズム:Anthropicはペンタゴンのセーフガードが模型の悪用に対して「不十分」であると主張しました。この主張は以下を前提としています。(a)軍事AI配置文脈に存在する特定の障害モード、(b)これらの障害モードは追加の技術的または手続的管理を通じて防止可能、(c)ペンタゴンの提案された管理は防御可能な閾値を下回っています。同社は、どの特定のセーフガードが不十分と見なされたか、またはどの閾値が受け入れ可能なリスク軽減を構成するかを公開開示していません。
-
監視アーキテクチャ:「不十分な監視メカニズム」に関する懸念は、人間ループシステムまたは監視プロトコルが軍事応用における模型の行動を効果的に制約できることを前提としています。この前提は経験的検証を必要とします。高リスク領域におけるAI監視に関する技術文献は争点となったままであり、軍事文脈における「適切な」監視に関するコンセンサス基準は存在しません。
-
致命的な自律性の正常化:軍事契約が「致命的な意思決定におけるAIの正常化」を可能にする可能性があるという懸念は、特定の因果理論を反映しています。すなわち、軍事文脈におけるAIシステムの制度的採用は、兵器システムにおける自律性の増加に向かう経路依存性を生み出すということです。これは妥当な懸念ですが、そのような正常化効果の縦断的証拠がなければ、大部分は推測的なままです。
市場ポジショニングと競争的差別化
同時に、Anthropicは企業および政府部門内でOpenAIに対するセーフティ意識のある代替案として明示的に自らをポジショニングしています。このポジショニング戦略は複数のメカニズムを通じて機能します。
-
制約を通じたブランド差別化*:Anthropicは競争者が受け入れる軍事契約を拒否することで、セーフティ優先化の信頼できるシグナルを生成します。この戦略は経済的に合理的です。機関投資家のサブセット(政府機関、規制対象企業、リスク回避的組織)がベンダーのセーフティコミットメントに高い価値を置く場合、そのようなコミットメントを費用のかかる行動(失われた収益)を通じて実証することは、実行可能な競争戦略となります。
-
ナラティブの増幅*:Anthropicのその後のOpenAIのペンタゴン関与に対する公開批判、すなわちCEOダリオ・アモデイ氏によるセーフティ表現に関する「真っ赤な嘘」という特徴付けは、競争的メッセージングと原則的批評の両方として機能します。同社は制度的販売文脈でこのポジショニングを活用してきました。そこではセーフティ評判が調達決定に直接影響を与えます。
-
制度的パートナーシップを証拠として*:Anthropicが企業関係における「慎重な配置プロトコル、広範なセーフティテスト、および保守的なユースケース制限」に対する強調は、セーフティ優先ポジショニングの観察可能な証拠を提供します。しかし、これらの実践は、評判リスクを管理するあらゆるフロンティアAIベンダーの標準的なデューデリジェンスも表しており、それらが独特なセーフティコミットメントを反映しているか、または従来のリスク管理を反映しているかを分離することを困難にしています。
ステークホルダーのための分析的考慮事項
AIベンダーパートナーシップまたは制度的AIガバナンスを評価する知識労働者にとって。
-
動機の非排他性*:セーフティ上の懸念と競争的ポジショニングは相互に排他的ではありません。企業は同時に真正なセーフティコミットメントを保持し、かつそのようなコミットメントを実証することが競争的優位を提供することを認識することができます。戦略的利益の存在は、根底にあるセーフティ根拠を無効にしません。
-
経験的検証ギャップ*:Anthropicのペンタゴン条件に対する特定のセーフティ異議は、独立して検証されておらず、外部評価を可能にするのに十分な詳細で開示されていません。実際の契約条件とAnthropicの技術的異議へのアクセスがなければ、ステークホルダーは同社の懸念が軍事AI配置文脈内の物質的なセーフティギャップを反映したか、または受け入れ可能なリスク閾値を表したかを確実に評価することはできません。
-
先例と一貫性*:Anthropicのセーフティコミットメントを評価するには、複数の決定にわたる一貫性を検討する必要があります。同社がセーフティ基準が満たされない場合に特に収益生成機会を拒否する意思は1つのデータポイントです。複数の文脈にわたるセーフティ駆動決定のより広いパターンは、選別的ポジショニングに対する制度的コミットメントのより強い証拠を提供するでしょう。
OpenAIの軍事関与とメッセージング論争
Anthropicが拒否したペンタゴン契約の追求は、人工知能の防衛応用に対するOpenAIの運用的関与における文書化された転換を表しています。メッセージング論争を正確に評価するには、まずOpenAIの述べられたポリシーフレームワークを確立し、その後特定の主張を検討する必要があります。
軍事応用に関するOpenAIの述べられたポリシー
OpenAIは、その システムの軍事使用の禁止と許可可能な使用を区別する公開的に明確にされたポリシーを述べています。同社の使用ポリシーによれば、OpenAIは「兵器ターゲティングを直接可能にするか、致命的な自律兵器システムを直接可能にするために設計されたAIシステムの開発」を禁止しています(OpenAI使用ポリシー、現在のバージョン)。同時に、OpenAIは軍事文脈内での「防衛応用、管理機能、および情報分析」をサポートする意思を示唆しています。ただし、これらのカテゴリは実装基準に関する限定的な公開透明性を伴って運用的に定義されたままです。
この分類、すなわち兵器ターゲティング決定を直接促進するシステムと他の軍事応用を支援するシステムの間の区別は、軍事パートナーシップを責任あるAI開発に対する公開コミットメントと調和させるためのOpenAIの主要なポリシーメカニズムとして機能します。この区別の論理的一貫性は、「直接的な可能化」と他の軍事応用の間の明確な定義的境界に依存しており、これらの境界は実践において争点となったままです。
アモデイ氏の主張の性質
Anthropic CEOダリオ・アモデイ氏によるOpenAIのメッセージングを「真っ赤な嘘」と特徴付けること(報告による[出典出版物が必要])は、正確な解釈を必要とします。このフレーズは、単なるポリシー相違ではなく、事実的虚偽表示の主張を示唆しています。具体的には、アモデイ氏は、OpenAIが以下の1つ以上の要素に関する検証可能な主張を行ったと主張しているようです。これらは文書化された事実に対応していません。
- セーフティメカニズム仕様:配置されたシステム内に実装された技術的セーフガードに関する主張
- ユースケース制限:システム応用に対する契約的または運用的制限に関する表現
- 監視アーキテクチャ:システム配置を統治する統治構造または承認プロセスに関する声明
- 述べられた原則との一貫性:契約条件とOpenAIの公開ポリシーコミットメント間の整合性に関する表現
ポリシー相違と事実的虚偽表示の間の区別は重要です。合理的な行為者は軍事AI応用が防御可能な目的に役立つかどうかについて正当に異議を唱えることができます。そのような相違は異なる倫理的フレームワークまたはリスク評価を反映しています。セーフティプロトコル、契約制限、または監視メカニズムに関する事実的主張は、対照的に、経験的に検証可能です。OpenAIが特定のセーフガードが運用的に実装されたと表現した場合、ドキュメンテーションが別の方法を示しているか、または特定のユースケース制限が適用されたと表現した場合、契約条件がそのような制限を反映していない場合、これらはアモデイ氏の言語が示唆する虚偽表示のカテゴリを構成するでしょう。
制度的含意と信頼性効果
軍事パートナーシップにおけるメッセージング不一貫性の評判的結果は、特定のペンタゴン契約を超えて拡張しています。軍事関与に関するOpenAIの公開声明は、複数の制度的聴衆に対する信頼性シグナルとして機能します。ベンダーの信頼性を評価する連邦機関、配置セーフティを評価する企業クライアント、およびOpenAIのポリシーコミットメントの信頼性を評価する潜在的パートナーです。
OpenAIの軍事契約条件、セーフティ対策、またはユースケース制限に関する表現が、根底にあるドキュメンテーションまたは運用的現実と矛盾していると認識される場合、これはすべての制度的関係にわたって信頼性の赤字を生成します。政府機関および企業クライアントは、ベンダー表現に依存しており、セーフティ、コンプライアンス、および運用的制限に関する表現を、彼ら自身のリスク評価およびガバナンスプロセスへの入力として依存しています。軍事応用に関する虚偽表示の認識、セーフティおよびコンプライアンス主張が特に制度的重みを持つ領域、は、他のアプリケーション領域およびクライアント関係にわたるOpenAIの表現に関するより広い懐疑を引き起こす可能性があります。
この評判リスクの規模は、特にメッセージング論争が他の政府機関または制度的クライアントにOpenAIのセーフティおよびコンプライアンス主張に対する強化された検証手続を実装するよう促す場合、ペンタゴン契約自体の直接的な財務的価値を超える可能性があります。
対立の背景にある競争力学
Anthropicの公開的な非難は、技術的能力ベンチマーク、安全保障研究の信頼性、エンタープライズクライアント獲得、政府契約獲得といった実証可能な領域にわたるAnthropicとOpenAIの間の競争激化を反映しています。両組織は、高度な能力と統治上の保証を必要とする機関に対するフロンティアAIシステムの優先提供者としての市場ポジショニングを確立するために競争しています。ペンタゴン契約紛争は、この広範な競争的ポジショニングの具体的な現れとして機能し、各企業は機関的信頼と関連する収益流を確保しようとしています。
Amodeiの公開声明は、この競争的文脈の中で識別可能な戦略的機能を果たしています。ペンタゴン取り決めに関するOpenAIの特性化に公開的に異議を唱えることで、Amodeiは複数の目的を達成しています。(1)安全性を優先する代替案としてのAnthropicの市場差別化を強化する、(2)政府および機関的買い手の間でOpenAIの透明性に関する評判上の不確実性を導入する、(3)共通の投資家に対してAnthropicが競争的ポジショニングを積極的に防御していることを示す、(4)見込み客に対してAnthropicが公開的に述べられた安全原則を公開的に擁護することを示す。これらの目的は、非難自体の基礎となる事実的正確性とは分析的に異なります。
この戦略的アプローチは文書化されたリスクを伴います。不誠実さの公開的な非難は、利害関係者が動機を原則ベースの提唱ではなく競争的利益に帰する場合、評判上の露出を生み出します。政府機関、エンタープライズクライアント、機関的投資家は、実質的な主張とそれを支える見かけの動機の両方を評価します。外部の観察者がAmodeiの声明を原則ベースの説明責任ではなく競争的ポジショニングとして分類する場合、この分類はAnthropicの安全第一の市場ポジショニングを損なわせ、公開的な紛争に従事している企業を避けることを好む組織との利害関係者関係を損傷させる可能性があります。原則に動機付けられた発言と競争に動機付けられた発言の区別は、経験的に確立することが難しく、利害関係者の解釈の対象のままです。
共有ベンチャーキャピタル投資家の存在は、追加の構造的複雑性をもたらします。同一の投資企業がAnthropicとOpenAIの両方に財務的利益を維持する場合、ポートフォリオ企業間の公開的な対立は、これらの投資家に対して矛盾する誘因構造を生み出します。これらの投資家は両企業の市場成功に対する同時的な財務的利益を保有し、潜在的な仲介者または圧力ポイントとして彼らを位置付けます。公開的な対立に対する投資家の対応は異なります。一部はAmodeiの公開的な非難を適切な説明責任メカニズムとして見なすかもしれません。他の人はそれをエコシステムの信頼性を低下させる不安定化行動として分類するかもしれません。この投資家ダイナミクスは、公開的な対立ではなくプライベートチャネルを通じた紛争解決のための構造的誘因を生み出し、Amodeiが公開的な開示を追求する決定を、この誘因構造からの逸脱として分析的に重要にしています。
いずれかの企業とのパートナーシップ取り決めを評価している組織にとって、この競争的ダイナミクスは実質的な含意を持ちます。安全保障コミットメント、責任ある展開慣行、倫理的統治に関するAnthropicとOpenAIからのポジショニング声明は、孤立してではなく競争的文脈の中で評価されるべきです。この文脈的評価は、安全保障コミットメントが不誠実であることを確立しません。むしろ、そのようなコミットメントが真の組織的原則と競争的差別化メカニズムの両方として同時に機能することを確立します。正確な利害関係者評価には、両方の次元とそれらの相互作用を理解することが必要です。
AI統治と軍事パートナーシップへの含意
AnthropicとOpenAIの間のペンタゴン契約に関する公開的な紛争は、高度なAIシステムの軍事応用を統治する規制アーキテクチャの構造的ギャップを露出させます。具体的には、不一致は定義上の問題に焦点を当てています。軍事AI展開のための適切な安全プロトコルを構成するもの、それらのプロトコルを検証する責任を負う者、および企業が彼らのコンプライアンス姿勢について矛盾する主張をする場合に存在する執行メカニズムです。
- 定義上の前提条件と仮定*
この分析は、明示的に述べる価値のあるいくつかの基礎的仮定に基づいています。(1)軍事AI応用は民間展開と比較して異なる統治上の課題を提示します。主に、運用上の文脈は力の認可された使用と非戦闘員に対する潜在的な影響を伴うため、(2)企業の内部安全基準は、正式な政府フレームワークがない場合、事実上の規制手段として機能します、(3)企業による公開的なコミットメントは、政府機関を含む利害関係者の間で執行可能な期待を生み出しますが、執行メカニズムは未定義のままです、(4)安全保障主張を行う企業と、それらの主張を評価する外部当事者の間に情報非対称性が存在します。
- 構造的統治ギャップ*
現在の米国規制フレームワークは、軍事AI安全保障主張を評価するための明示的な基準を欠いています。国防総省はAI展開のための獲得ガイドラインと倫理原則を維持しています(国防総省指令3000.09および後続のAI戦略文書で表明されているように)が、これらは技術的安全保障ベンチマークではなく手続き要件を確立します。ベンダー主張は独立して検証できます。これは、政府機関が標準化された比較基準なしに競争する安全フレームワークを評価しなければならない状況を生み出します。
AnthropicとOpenAIの間の特定の不一致はこのギャップを説明しています。Anthropicは、特定の軍事応用が受け入れ可能な使用事例の外にあると主張しています。OpenAIは、適切な保護措置が責任ある展開を可能にすると主張しています。両方の主張は、各企業の安全哲学と内部的に一貫している可能性がありますが、ペンタゴン意思決定者に矛盾したガイダンスを生み出します。外部検証メカニズムがなければ、政府調達職員は次のいずれかを行う必要があります。(a)1つのベンダーの判断に従う、(b)主張を評価するための独立した技術的専門知識を開発する、または(c)測定可能な用語で安全プロトコルを指定する明示的な契約要件を確立します。
- スケープの拡大とリスク差別化*
軍事AI応用は、運用上の感度のスペクトラムに沿って存在します。管理機能(スケジューリング、リソース割り当て、データ処理)は、インテリジェンス分析、ターゲティングサポート、または戦闘環境での自律的な意思決定を伴うアプリケーションと比較して、より低いステークス展開コンテキストを提示します。軍事AI展開が管理機能を超えて拡大するにつれて、リスクプロファイルがアプリケーション間でより急激に異なるため、統治上の課題は激化します。
Anthropicの立場(特定の軍事応用は分類的拒否を保証する)は、リスク差別化アプローチを反映しています。一部の使用事例は、技術的保護措置に関係なく受け入れられない危険を提示します。OpenAIの見かけの立場(安全プロトコルは特定のアプリケーションに合わせることができる)は、リスク軽減アプローチを反映しています。危険は、適切な制約と監視メカニズムを通じて管理できます。これらは根本的に異なる統治哲学を表し、それらの調和には技術的ソリューンだけではなく明示的な政策選択が必要です。
- 誘因構造と競争力学*
独立した検証メカニズムの不在は、逆機能的な誘因構造を生み出します。企業は部分的に安全保障コミットメントの信頼性に基づいて競争し、これは安全保障慣行に関する拡張的な公開的主張を誘因します。このダイナミクス(安全保障が競争的差別化要因になる場合)は、公開的なレトリックを基礎となる技術的慣行から分離することができます。Amodeiの非難は、OpenAIが安全保障プロトコルについて「ストレートアップの嘘」をつくことは、この文脈の中で理解されるべきです。安全保障主張がマーケティング手段として機能する場合、競争圧力は実際の技術的能力とは無関係に誇張を駆動する可能性があります。
これは二次的な統治問題を生み出します。外部の観察者にとって、真の安全革新とレトリック的エスカレーションを区別することは困難になります。政府機関は、企業Aの安全フレームワークが企業Bのものより実質的により厳密であるかどうか、または両企業が異なる用語で比較可能な主張をしているかどうかを簡単に判断することはできません。
- 必要な機関的発展*
これらの統治ギャップを解決するには、現在標準化された形式で存在しない機関的能力が必要です。具体的には。
-
独立した評価能力: 政府機関は、ベンダー安全保障主張を標準化された基準に対して評価するための技術的専門知識を必要とします。これは内部的に(国防総省または関連する情報機関内で)または適切なセキュリティクリアランスと技術的深さを持つ外部機関を通じて開発される可能性があります。
-
明示的な安全基準: 軍事AI展開には、定義された安全ベンチマークが必要です。単なる手続き的コンプライアンスではなく、テストと監査を通じて検証できる測定可能な技術要件です。これらの基準は、アプリケーションタイプと運用上の文脈によって異なるべきです。
-
透明性メカニズム: 企業は、政府検証を可能にするのに十分な詳細で安全プロトコルを文書化する必要があります。適切な分類制限の対象となります。現在の慣行は、体系的な外部検証なしにベンダー自己報告に大きく依存しています。
-
紛争解決手順: 企業が適切な安全基準に関する矛盾した主張をする場合、紛争を調停するための正式なメカニズムが存在する必要があります。これには、技術的レビューボード、独立した監査、または受け入れ可能なリスクレベルに関する政府指導部による明示的な政策決定が含まれる可能性があります。
- 業界自己規制への含意*
現在の紛争は、業界自己規制(企業の内部安全基準と公開的なコミットメントに依存)が軍事AI展開を適切に統治できないことを示しています。自己規制は次の場合に適切に機能します。(a)企業は調整された誘因に直面しています、(b)外部の利害関係者はコンプライアンスを検証できます、および(c)非コンプライアンスの評判上の結果は実質的です。軍事AI統治は3つの基準すべてで失敗します。企業は受け入れ可能なリスクレベルに関する異なる誘因を持ち、検証メカニズムは弱く、政府契約が危機に瀕している場合、評判上の結果は行動を制約するのに不十分である可能性があります。
これは必ずしも安全基準設定における企業の関与を排除する必要はありませんが、内部統治を外部検証と受け入れ可能な展開パラメータに関する明示的な政府意思決定権で補足する必要があります。
解決に向けて。信頼性、検証、機関的信頼
この対立からの前進の道は、解決可能な事実的紛争と構造的統治上の課題の間の区別を必要とします。ペンタゴンおよび他の政府機関にとって、即座の分析的問題は非対称情報です。AI安全保障プロトコルに関する競争する技術的主張を評価する場合、評価機関は独立した検証能力を欠き、主張を行う企業は矛盾する財務的誘因の下で運営されています。この問題は、3つの潜在的なソリューションを認めます。それぞれに文書化された制限があります。
-
独立した検証能力の開発: 米国政府は、AI安全保障主張を評価するための内部技術的専門知識を確立するか、独立した監査人と契約することができます。先例は他の高いステークスドメイン(例えば、核兵器認証、医薬品承認)に存在しますが、AI安全保障評価は比較可能な標準化された方法論を欠いています。このアプローチは、継続的な資金と技術的才能獲得を必要とします。
-
契約上拘束力のある基準の確立: 政府調達は、企業の証言を受け入れるのではなく、測定可能で第三者が検証可能な安全要件を指定することができます。このアプローチは、何が適切な安全証拠を構成するかを定義する必要があります。技術的コンセンサスが不完全なままである質問です。
-
透明な開示の要求: 企業が安全プロトコル、使用事例制限、およびテスト方法論を政府レビューの対象となる形式で文書化することを義務付けることは(潜在的に分類されていますが)、検証負担を政府から構造化された機関的プロセスにシフトさせます。
AnthropicとOpenAIにとって、基礎となる構造的緊張は競争的差別化と信頼性維持の間です。安全保障主張は同時に機能します。(a)組織的優先事項を反映する真の技術的コミットメント、および(b)競争相手と1つのベンダーを区別する市場ポジショニング声明。この二重機能は論理的な脆弱性を生み出します。安全保障が主要な競争的差別化要因になるにつれて、企業はますます強い主張をする圧力に直面し、これは同時に、それらの主張が後で矛盾したり、不十分に実質化されたりした場合、評判上の露出を増加させます。このダイナミクスはAIに固有ではありません。医薬品マーケティング、自動車安全主張、およびエンタープライズソフトウェアセキュリティアサーションで文書化されたパターンと並行しています。
経験的な質問(OpenAIの安全プロトコルがAnthropicのものより実質的により堅牢であるかどうか、または違いが主に通信的であるかどうか)は、原則的に以下を通じて解決可能です。(a)展開されたシステムの比較技術監査、(b)文書化された安全テスト手順の検査、および(c)契約上の使用事例制限の分析。そのような独立した検証の不在は、企業がそれに提出することを拒否したか、政府調達プロセスが契約賞の条件としてそれを要求していないことを示唆しています。
機関的買い手(政府機関、企業、研究機関)にとって、実際的な含意は、安全保障主張を受け入れることが展開ステークスに比例した検証メカニズムを確立する必要があることです。具体的には。
- 第三者技術監査 安全上重要なコンポーネントの、監査スコープと方法論が契約上定義されている
- 文書化された安全プロトコル 以下を含む。テスト手順、考慮された障害モード、使用事例制限、および監視メカニズム
- 説明責任構造 展開されたシステムが述べられた安全パラメータに違反する場合の改善手順を指定する
- 透明な開示 既知の制限の、システムがテストされていないか明示的に制限されている使用事例を含む
このアプローチは、いずれかの企業が悪意で行動していると仮定する必要はありません。むしろ、競争的ポジショニングと真の安全コミットメントが分析的に異なる変数であり、任意の場合に相関しているかもしれないし、そうでないかもしれないことを認識しています。企業は、安全原則について同時に誠実であり、それらの原則を選択的に通信することについて戦略的である可能性があります。機関的意思決定には、両方の次元を独立して評価することが必要です。
この特定の紛争の解決は、問題の事実的主張が検証可能な証拠を通じて明確にされるかどうかに依存します。実質的な質問は次のとおりです。(1)OpenAIのペンタゴンとの契約はどのような特定の安全プロトコルを要求しますか。(2)Anthropicの提案された代替案はどのような特定の安全プロトコルを要求しますか。(3)違いは関連する使用事例のリスク評価に実質的ですか。これらの質問は、文書レビューと技術分析を通じて事実的な回答を認めます。公開的な解決の不在は、紛争が分類された情報を伴うか、どちらの当事者も独立した調停を求めていないことを示唆しています。
両企業の安全保障コミットメントへの機関的信頼を回復するには、競争する主張から検証可能な文書への移行が必要です。これは、どの企業が「より正直」であるかを判断する問題ではなく、どの企業がそれを行うかに関係なく、安全保障主張が独立して検証可能にする機関的プロセスを確立する問題です。ペンタゴン契約紛争は、安全保障の失敗が重大な結果をもたらす高いステークスコンテキストでのAI展開に関する情報に基づいた意思決定のためにそのようなプロセスが必要である理由を説明しています。

- 図11:紛争解決のための検証フレームワーク*

- 表1:OpenAIの安全対策主張 vs Anthropicの懸念事項*