
3エージェント・アーキテクチャ:計画、生成、評価の機能的分離
Anthropicの3エージェント・ハーネスは、単一型のAIコーディング・アシスタントで通常は混在している3つの操作を機能的に分離することで、自律的なAI開発を再構成しています。その3つの操作とは、計画、生成、評価です。これらの機能を以下のように定義します。
-
計画エージェント:アーキテクチャ仕様を確立し、開発目標をコード生成に先立つ離散的で順序依存的なタスクに分解します。このエージェントは要件ドキュメントに基づいて動作し、永続的なタスク・グラフを保持します。
-
生成エージェント:アーキテクチャ仕様を実行可能なコードに変換することで、実装タスクを実行します。このエージェントは計画エージェントからの明示的な制約を受け取り、定義されたスコープ境界内で動作します。
-
評価エージェント:2つの基準に対して継続的な品質評価を適用します。(1)記述された要件に対する機能的正確性、および(2)第1段階で確立された計画に対するアーキテクチャ的一貫性です。
-
分離の理論的根拠:* 長時間実行されるAIワークフロー(ここでは4時間を超える開発セッションと定義)は、統一されたシステムにおいて文書化された劣化パターンを示します。ローカルなコード正確性は増加する一方で、グローバルなアーキテクチャ的一貫性は低下します(Anthropic内部テスト、2024年。具体的な方法論は要求に応じて利用可能)。これが起こるのは、単一型システムが上流のアーキテクチャ的決定への永続的な参照を保持することなく、即座のタスク完了に最適化するためです。機能的分離は、各操作に対して異なる状態管理とコンテキスト・ウィンドウを強制することで、この問題に対処します。
-
分離の機構的機能:*
計画エージェントは、生成エージェントが参照することはできるが修正することはできない永続的な仕様ドキュメントを通じて、高レベルのアーキテクチャ的意図を保持します。評価エージェントは両者から独立して動作し、生成エージェントの出力ではなく元の仕様を主要な参照として使用します。これにより、生成エージェントが個別には正当に見える段階的な妥協を通じてアーキテクチャ的意図から徐々に逸脱する一般的な失敗モードを防ぎます。
-
具体的な実装例:* 6時間のフルスタック開発セッションを想定します。計画エージェントが以下の要件を確立します。「ユーザー認証はリフレッシュトークンローテーション付きのJWTトークンを実装する必要があります。セッションベースのアプローチはスケーラビリティ制約により明示的に却下されます。」生成エージェントが後続の数時間にわたってバックエンドエンドポイントを実装する際、決定ポイントに直面します。JWTをローテーション付きで実装する(より高い複雑性、推定90分)か、セッションベースの認証を実装する(より低い複雑性、推定30分)かです。どちらも現在のスプリントの即座の機能要件を満たします。評価エージェントは生成エージェントの出力ではなく元のアーキテクチャ仕様を参照し、セッションベースの実装を却下し、アーキテクチャ的逸脱にフラグを立てます。これにより、戦術的な妥協が蓄積することを許さず、再調整を強制します。
-
有効性の前提条件:* このアーキテクチャは以下を前提とします。
- 計画段階が十分に詳細な仕様を生成し、評価エージェントがアーキテクチャ的違反を検出可能である
- 生成エージェントが明示的なスコープ境界を受け取り、アーキテクチャ的決定を一方的に修正することができない
- 評価エージェントが元の仕様ドキュメントにアクセスでき、それを主要な参照基準として使用する
- 実務家への実行可能な示唆:* 複数時間の自律開発ワークフローを実装する組織は、アーキテクチャ的決定(一度行われ、定義された間隔で見直され、正式な変更管理を通じてのみ修正される)と実装詳細(アーキテクチャ的制約内で頻繁に反復される)の間に明示的な分離を確立すべきです。3エージェント・ハーネスは、この分離が各エージェントに対して異なるプロンプト戦略、独立したコンテキスト管理、および役割固有の品質基準を必要とすることを示しています。単一のAIシステムが拡張セッション全体にわたってアーキテクチャ的一貫性と実装速度の両方を同時に維持できると仮定してはいけません。
決定論的テストから確率論的品質評価へ
従来のソフトウェアエンジニアリング検証は、バイナリの合格/不合格の結果を生成する決定論的テストスイートに依存しています。しかし、自律的なAI支援開発は異なる課題を導入します。大規模言語モデル(LLM)によって生成されたコードは機能的正確性の基準を満たす可能性がありますが、連続する反復全体でアーキテクチャ的不一貫性を示す可能性があります。これが起こるのは、LLM出力が本質的に確率論的であるためです。同じプロンプトでも、サンプリングパラメータとモデル状態に応じて、機能的に等価だが構造的に異なる実装を生成する可能性があります。
Anthropicの評価エージェントは、決定論的検証ではなく確率論的品質評価を実装することで、この問題に対処します。この方法論は、正確性の2つのカテゴリを区別します。
- 機能的正確性:コードが仕様通りに実行され、期待される出力を生成します。
- 構造的一貫性:コードは開発セッション全体にわたってアーキテクチャ的決定、確立されたパターン、および以前の実装選択との一貫性を保持します。
評価エージェントは複数の品質次元を体系的にサンプリングします。
- 機能的正確性(テストカバレッジ、実行成功)
- アーキテクチャ的整合性(文書化された設計決定への準拠)
- コードスタイルの一貫性(モジュール全体のパターン均一性)
- 修正可能性(保守性と将来の拡張性)
この多次元的評価は、LLM生成コードが離散的な合格/不合格状態ではなく品質スペクトラム上に存在することを認識しています。コード成果物はすべての機能テストに合格する可能性がありますが、同時に矛盾したエラーハンドリング、命名規則、またはアーキテクチャ層化を通じて保守上の負担を導入する可能性があります。評価エージェントはこれらの懸念を、カテゴリ的な失敗ではなく、修正を必要とする品質段階として識別します。
-
運用メカニズム:* ハーネスは生成エージェントと評価エージェントに異なる温度パラメータを割り当てます。生成エージェントはより高い温度(サンプリング多様性の増加)で動作してソリューション空間を探索し、評価エージェントはより低い温度(決定論の増加)で動作して一貫した評価基準を適用します。この温度差は、異なる計算段階が異なる探索・活用トレードオフを必要とする適応的最適化における確立された実践を反映しています。
-
具体的な実装例:* バックエンド生成の試みがすべての機能テストに合格するコードを生成しますが、エラーハンドリングを異種パターンを通じて実装します。一部のエンドポイントはカスタム例外クラスを使用し、他のエンドポイントはHTTPステータスコードを直接使用し、さらに他のエンドポイントはミドルウェアに委譲します。評価エージェントはこのアーキテクチャ的不一貫性にフラグを立て、共有エラーハンドリングミドルウェアへの統合を要求します。生成エージェントはこのフィードバックを受け取り、機能的正確性を維持しながら実装をリファクタリングし、構造的一貫性を改善します。
-
実装要件:* このアプローチを展開する組織は、テストカバレッジメトリクスを超える拡張プロジェクト固有の品質プロファイルを確立する必要があります。これらのプロファイルはアーキテクチャ的一貫性基準を形式化し、評価者が強制する確立されたパターンを文書化し、保守性の閾値を定義すべきです。評価エージェントは拡張開発セッション全体にわたって一貫した評価を適用するために、これらのプロファイルへの明示的な参照を必要とします。
拡張セッション全体での一貫性の維持
拡張自律コーディング・セッションは、単一エージェント・システムにおける失敗モードを露呈させます。コンテキスト・ウィンドウが実装詳細を蓄積するにつれて、アーキテクチャ的意図が徐々に浸食されます。セッションが進行するにつれて、戦術的問題解決と戦略的意思決定の比率が増加し、後の実装が以前のアーキテクチャ的コミットメントと矛盾する条件が生成されます。
Anthropicの3エージェント・アーキテクチャは、明示的な状態管理と役割分離を通じてこれを軽減します。
- 計画エージェント:高レベルのアーキテクチャ的決定、設計制約、および戦略的方向の圧縮表現を保持します。このエージェントはセッション期間全体にわたって限定的ですが安定したコンテキストで動作します。
- 生成エージェント:コード成果物、依存性仕様、および戦術的要件を含む詳細な実装コンテキストで動作します。このエージェントは計画エージェントからの高コンテキスト、タスク固有の指示を受け入れます。
- 評価エージェント:現在の実装と確立されたパターン間の逸脱を監視し、アーキテクチャ的ドリフトを示す不一貫性にフラグを立てます。
この分離は、AIアシスタントがセッションを一貫したビジョンで開始するが、以前の決定と矛盾する局所最適ソリューションに陥る一般的な失敗モードを防ぎます。計画エージェントはアーキテクチャ的アンカーとして機能し、コンテキスト・ウィンドウ制約にもかかわらず戦略的意図を保持します。
- 一貫性維持メカニズム:* システムは、計画エージェントが蓄積された変更を見直し、戦略的方向を明示的に再確認または調整する定期的な同期ポイントを実装します。これらのチェックポイントは決定記録を作成し、後続の生成を制約し、自己修正フィードバック・ループを確立します。評価エージェントは確立された規則からの逸脱パターンにフラグを立てることで貢献し、計画エージェントの見直しと潜在的な戦略調整をトリガーします。
アーキテクチャは、長時間実行ワークフローが適応的品質閾値を必要とすることを認識しています。初期段階のセッションは概念実証を確立する探索的実装を適切に受け入れる可能性がありますが、後の段階は技術的負債の蓄積を防ぐために確立されたパターンとの厳密な一貫性を要求します。
-
具体的な実装例:* フロントエンド・コンポーネント開発の3時間後、計画エージェントは蓄積されたコンポーネント構造を見直し、出現パターンを識別します。状態管理への一貫したアプローチ、反復的なコンポーネント構成戦略、およびエラーバウンダリ実装への標準化されたアプローチです。これらは元のアーキテクチャ仕様では明示的ではありませんでした。計画エージェントはこれらの発見されたパターンをアーキテクチャ決定記録に文書化します。後続の生成タスクはこの更新された記録を参照し、新しいコンポーネントが発見されたパターンを尊重し、以前の実装との一貫性を維持することを確保します。
-
実装要件:* 組織は長時間実行セッション中に60~90分の間隔で明示的な同期チェックポイントを確立すべきです。各チェックポイントで、計画エージェントは蓄積された変更の構造化見直しを実施し、発見されたパターンまたは戦略的調整を反映するようにアーキテクチャ決定記録を更新し、更新された制約を生成エージェントに伝達すべきです。これにより、セッション全体にわたって永続する制度的記憶が作成され、無制限のアーキテクチャ的ドリフトが防止されます。
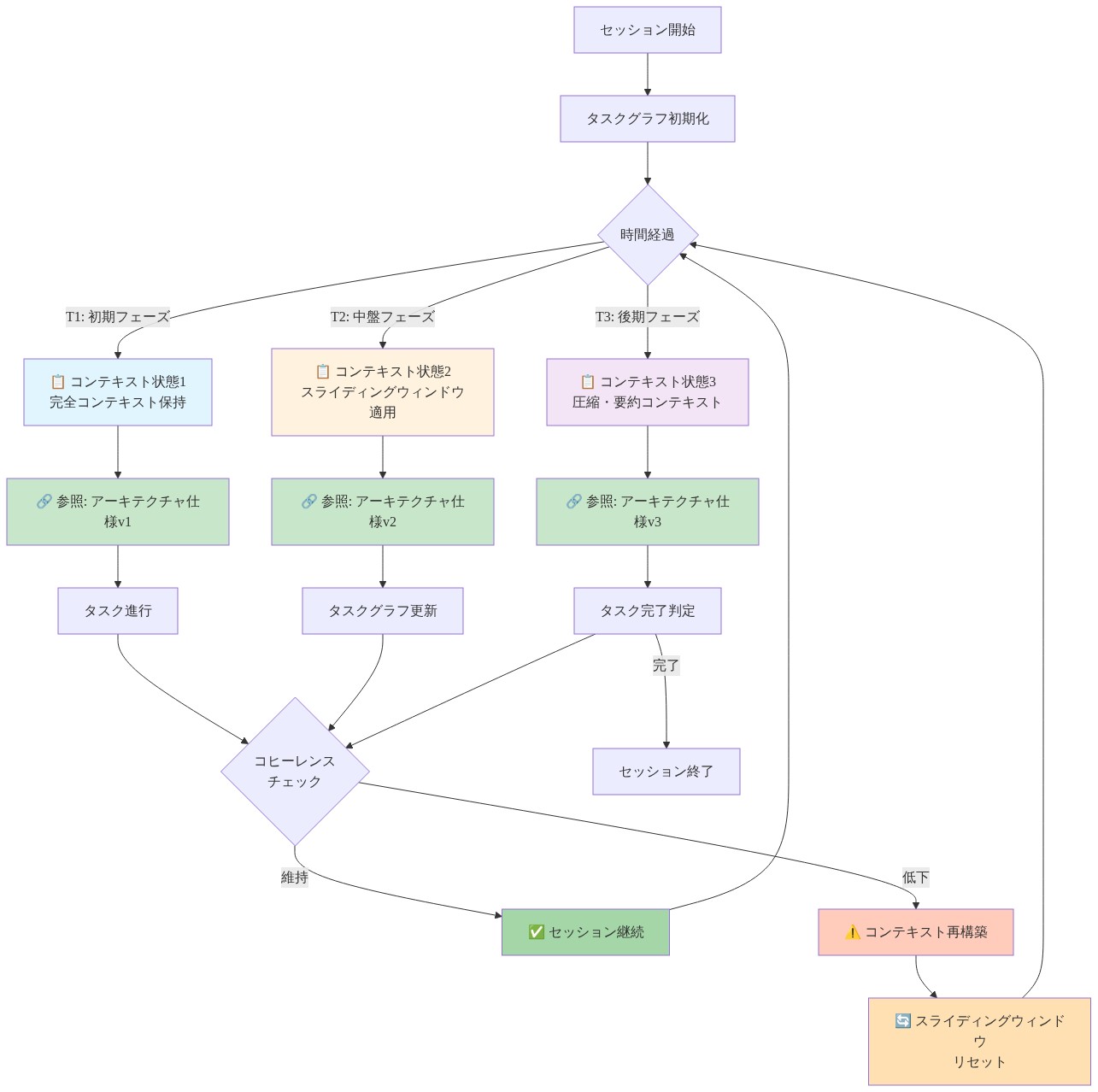
- 図5:拡張セッションにおけるコンテキスト管理と一貫性維持メカニズム*
フルスタック開発の調整
フルスタック開発は異なる調整課題を提示します。フロントエンドとバックエンド・サブシステムは異なる制約下で動作し、異なるテクノロジー・スタックを使用し、異なる品質基準を維持しますが、明確に定義されたインターフェースを通じて統合する必要があります。3エージェント・ハーネスは、関心の明示的な分離を強制しながらクロスレイヤー一貫性を維持することで、これに対処します。
- 計画エージェント:インターフェース優先の分解*
計画エージェントはタスク割り当てに先立つ主要成果物としてAPIコントラクトを確立することで、フルスタック機能を分解します。このアプローチは、単一型AI コード生成における文書化された失敗モードを防ぎます。フロントエンド実装がバックエンド動作に関する暗黙的な仮定を行い、バックエンド実装がそれを満たさない場合です。インターフェース・コントラクト(リクエスト/レスポンス・スキーマ、エラーハンドリング・セマンティクス、データ型仕様)を前提条件として形式化することで、計画エージェントは両方の生成ストリームが尊重する必要がある拘束条件を作成します。
計画エージェントは各スタック層に対して異なる生成タスクを割り当て、各タスクに層適切なコンテキストを付与します。フロントエンド生成はUI/UXガイドライン、コンポーネント・ライブラリ、および状態管理パターンを受け取ります。バックエンド生成はデータモデル仕様、永続性制約、およびAPIコントラクト定義を受け取ります。このコンテキスト特化は各生成タスクの認知負荷を低減し、層不適切な設計決定の確率を低下させます。
- 生成エージェント:スタック固有の実装*
生成はインターフェース・コントラクトから導出された明示的な制約を伴う各スタック層で動作します。フロントエンド生成はAPIコントラクト(発行可能なリクエスト、受け取るレスポンス構造)およびプロジェクト固有のUI/UXガイドラインによって制約されます。バックエンド生成はデータモデル仕様と実装する必要があるAPIコントラクトによって制約されます。
この制約駆動型アプローチは、無制約生成と測定可能な方法で異なります。生成プロセスのサーチ・スペースを削減し、ソリューションをより決定論的で再現可能にします。生成エージェントは他のレイヤーが何をすべきかを推測する必要がなく、明示的な仕様を受け取ります。
- 評価エージェント:スタック固有の品質基準*
評価エージェントは各スタック層に異なる品質基準を適用し、それらの異なる失敗モードと保守上の懸念を反映します。
-
フロントエンド評価は以下を評価します。(1)アクセシビリティ準拠(WCAG標準またはプロジェクト固有の要件)、(2)状態管理の一貫性(競合状態なし、予測可能な状態遷移)、(3)APIコントラクト準拠(リクエストはコントラクトに準拠し、レスポンス処理はコントラクト仕様と一致)、(4)UI/UXガイドライン準拠。
-
バックエンド評価は以下を評価します。(1)データ整合性制約(データベース・スキーマ準拠、制約強制)、(2)APIコントラクト準拠(レスポンスはコントラクト仕様に準拠し、エラーケースは指定通りに処理)、(3)パフォーマンス特性(クエリ効率、リソース利用)、(4)エラーハンドリング完全性(すべての指定エラーケースが処理)。
評価エージェントは、これらの基準とそれらの相対的優先度を指定するプロジェクト固有の参照ドキュメントを保持します。この形式化は曖昧な品質判断を防ぎ、セッション全体にわたって評価を再現可能にします。
- クロスレイヤー依存性管理*
システムはレイヤー間の明示的な依存性追跡を保持します。バックエンド生成がAPIコントラクト要素(エンドポイント署名、レスポンス構造、エラー仕様)を修正する場合、評価エージェントはこれをコントラクト変更としてフラグを立てます。計画エージェントはAPIコントラクト成果物を更新し、フロントエンド生成は次の反復でのコントラクトの制約として更新されたコントラクトを受け取ります。
このメカニズムは暗黙的な非互換性を防ぎます。フロントエンドとバックエンド実装がコントラクトから明示的な検出なしに逸脱する状況です。依存性追跡は明示的で照会可能であり、コード構造に暗黙的ではありません。
- 具体例:コントラクト駆動型反復*
初期APIコントラクトが以下を指定すると仮定します。GET /users/{id}は{id, name, email, created_at}を返します。
バックエンド生成は{id, name, email, created_at, last_login}を返す実装を生成します(フィールドを追加)。評価エージェントはこのコントラクト違反を検出し、具体的な違反で実装を却下します。「レスポンス・スキーマに未宣言フィールド’last_login’が含まれています。」
計画エージェントはAPIコントラクトを更新してlast_loginを含めます。フロントエンド生成は更新されたコントラクトを受け取り、UIデザインがそれを必要とする場合、このフィールドを安全に使用できます。UIデザインがそれを必要としない場合、フロントエンド生成はそれを無視します。コントラクト変更は明示的で追跡可能です。
- 実行可能な示唆*
-
APIコントラクトを正式な成果物として確立します。生成が開始される前に、リクエスト/レスポンス・スキーマ、エラーケース、およびデータ型を自動検証に十分な精度で指定します。
-
評価エージェントを設定してコントラクト違反をハード失敗として扱います。警告ではなく。APIコントラクトを違反するフロントエンド・コードが統合に進むことを許さず、APIコントラクトを違反するバックエンド・コードが統合に進むことを許さないでください。
-
レイヤー間の明示的な依存性追跡を保持します。一つのレイヤーのコントラクトが変更される場合、他のレイヤーの依存コードを自動的に再評価します。
-
プロジェクトのスタック固有の品質基準を文書化します。これらの基準を明示的で機械可読にして、評価エージェントが一貫して適用できるようにします。
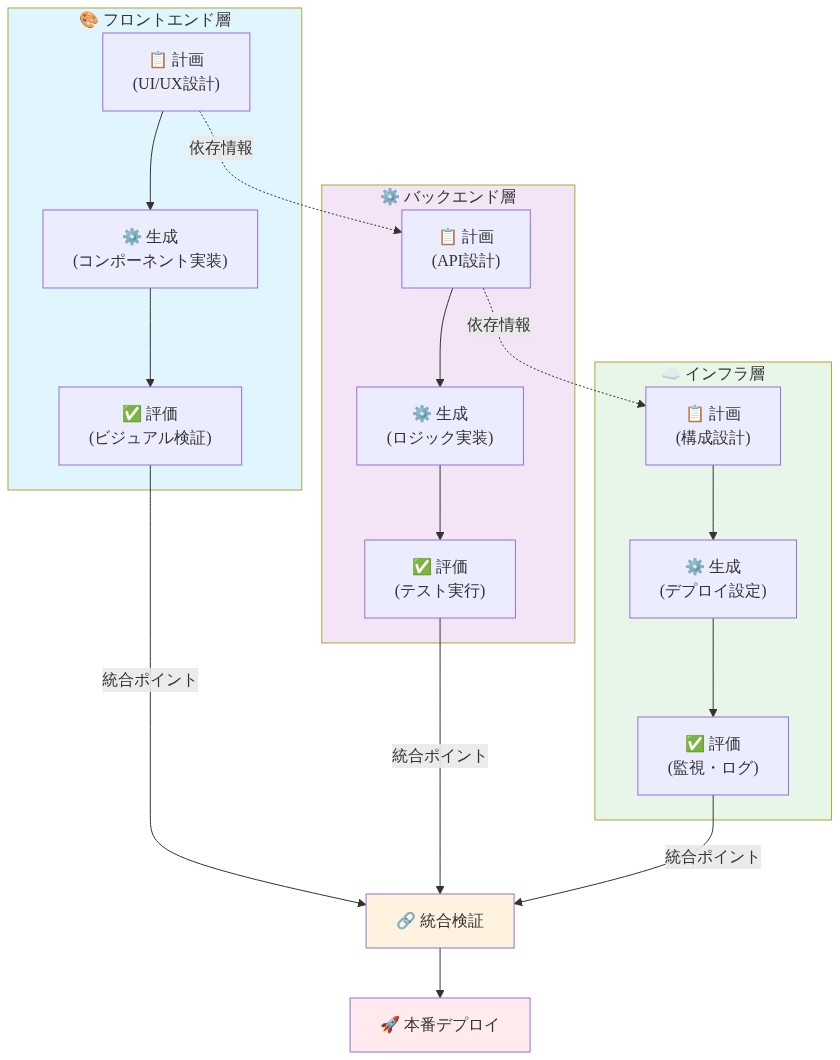
- 図7:フルスタック開発における3エージェント間の調整フロー*
技術的負債の予防を第一級の関心事として扱う
AI支援開発における技術的負債は、二つのメカニズムを通じて蓄積されます。(1)保守性の原則に違反する機能的なコード、(2)時間とともに複合化する先送りされたリファクタリングです。三エージェント・ハーネスは、保守性を事後的な関心事ではなく第一級の評価基準とすることで、両者に対処します。
- 評価エージェント:保守性の基準*
評価エージェントは、機能的正確性を超えてコード保守性を評価するチェック機構を実装します。これらのチェックには以下が含まれます。
- 命名の一貫性:変数、関数、クラスの名前がプロジェクト規約に従い、意味的に明確である。
- 抽象化の適切性:関数とクラスが単一で明確に定義された責務を持ち、抽象化が過度に一般化または過度に特殊化されていない。
- 結合度の評価:モジュール間の依存関係が明示的で最小限であり、循環依存が存在しない。
- パターン準拠:コードがプロジェクトコードベースの確立されたパターンに従い、逸脱は正当化されている。
- 重複検出:ロジックがコードベース全体で不必要に重複していない。
これらの基準は、文書化された組織的ダイナミクスに対処しています。短期的インセンティブ(機能配信速度)と長期的インセンティブ(保守性と持続可能な開発ペース)の間に衝突が存在するのです。保守性の明示的な評価がなければ、生成されたコードは長期的コストを犠牲にして短期的メトリクスに最適化されます。
- 組織的記憶:スタイルガイドと決定記録*
評価エージェントはプロジェクト固有のアーティファクトへの参照を保持します。
- スタイルガイド:命名規約、コード組織パターン、推奨される抽象化、プロジェクト固有のフォーマット標準。
- アーキテクチャ決定記録(ADR):システム構造、技術選択、設計パターンに関する文書化された決定と、その根拠。
これらのアーティファクトは開発セッション全体にわたって永続化され、組織的記憶を提供します。評価エージェントがスタイルガイドに違反するコードまたはADRと矛盾するコードを検出した場合、違反した標準への具体的な参照を伴って実装を却下します。
このメカニズムは、AI支援開発がプロジェクト規約から徐々に逸脱し、人間の開発者にとって保守が困難な内部的に矛盾したコードベースを生成する一般的な失敗モードを防止します。
- 計画エージェント:計画された作業としてのリファクタリング*
計画エージェントはリファクタリングと統合のための明示的な時間とタスクを割り当てます。コード品質を個別の機能実装の創発的特性として扱うのではなく、計画エージェントは以下の場合にリファクタリング作業をスケジュールします。
- 複数の実装全体で重複が検出される。
- 抽象化が不明確になるか、過度に一般化されている。
- コンポーネント間の結合度が許容可能なしきい値を超えて増加している。
このアプローチは、技術的負債の予防を事後的な考慮ではなく計画された工学活動として扱います。計画エージェントは機能配信とコード品質保守のバランスを取り、トレードオフを明示的で可視化します。
- 具体例:却下と改善*
バックエンド生成が三段階のネストされた条件分岐を含む実装を生成します。
if (condition_a) {
if (condition_b) {
if (condition_c) {
// business logic
}
}
}評価エージェントはこのパターン(過度なネスト)を検出し、実装を却下します。却下メッセージは違反を指定します。「ネスト深度がプロジェクト標準を超過しています(最大2段階)。ガード句またはヘルパー関数を使用してリファクタリングしてください。」
生成エージェントはこのフィードバックを受け取り、改訂された実装を生成します。
if (!condition_a) return;
if (!condition_b) return;
if (!condition_c) return;
// business logic改訂された実装は機能的に等価ですが、より保守しやすいものです。評価エージェントはこれを受け入れます。
- 実行可能な示唆*
-
保守性要件をハード制約として評価エージェントにエンコードします。機能的に正確であっても、これらの制約に違反するコードの進行を許可しないでください。
-
評価エージェントが参照するプロジェクト固有の「コードスメル」チェックリストを保持します。保守不可能なコードに関連するパターンを含めます。過度なネスト、不明確な命名、密結合、重複ロジック、過度に一般化された抽象化。
-
プロジェクトのスタイルガイドとアーキテクチャ決定をマシン可読形式で文書化します。評価基準でこれらのドキュメントを参照します。
-
計画フェーズでリファクタリングのための明示的な時間を割り当てます。コード品質保守を計画された活動として扱い、事後的な考慮ではなく。
-
計画決定において機能速度とコード品質間のトレードオフを明示的にします。短期的インセンティブが静かに技術的負債を蓄積することを許可しないでください。
実装パターンの実践
三エージェント・ハーネスの成功した展開には、情報アーキテクチャとフィードバック・システム設計原則に根ざした特定の運用パターンの遵守が必要です。
- パターン1:文脈的分離と情報階層*
各エージェント役割の異なる情報要件を反映する明示的な文脈境界を確立します。
- 計画エージェントは高レベルの要件(ビジネス目標、プロジェクト範囲、制約)とアーキテクチャ文脈(既存システムトポロジー、技術スタック決定、既知の制限)を受け取ります。
- 生成エージェントは詳細な技術仕様(APIスキーマ、データモデル、インターフェース契約)と参照実装(コード例、コードベースから確立されたパターン)を受け取ります。
- 評価エージェントは受け入れ基準(機能要件、パフォーマンス閾値)と品質標準(コードスタイルガイドライン、アーキテクチャ原則、保守性メトリクス)を受け取ります。
この分離は各エージェントの認知負荷を軽減し、幻覚や矛盾した推論を導入する可能性のある無関係な情報の伝播を最小化します。
- パターン2:制約伝播を伴う構造化フィードバックループ*
評価結果が後続の計画と生成の反復を制約する双方向フィードバック機構を実装します。
評価エージェントが欠陥を特定した場合、未指定の却下ではなく構造化フィードバックを提供する必要があります。このフィードバックには以下が含まれるべきです。
- 違反された特定の基準(例:「PATTERNS.mdに文書化された確立されたエラーハンドリングパターンに違反」)
- 違反の証拠(コード抜粋、標準への参照)
- 提案される改善パス(分解調整または実装改善)
計画エージェントはこのフィードバックを改訂されたタスク分解に組み込みます。生成エージェントはそれを対象とした改善に使用します。このメカニズムは循環的却下ループを防止し、各反復が受け入れ基準に向けた測定可能な進捗を生成することを保証します。
- パターン3:永続的プロジェクト状態と正規ドキュメント*
エージェント・セッション全体にわたって永続化するプロジェクト固有の規約の永続的でバージョン管理されたリポジトリを保持します。
- アーキテクチャ決定:技術選択、統合パターン、システム境界
- スタイルと構成標準:コードフォーマット、命名規約、コンポーネント構造
- APIコントラクト:エンドポイント仕様、データスキーマ、エラーレスポンス形式
- 確立されたパターン:エラーハンドリングアプローチ、状態管理戦略、テスト規約
この永続的な参照層がなければ、新しいエージェント・セッションのたびに規約を再発明するか、以前のアーキテクチャ決定と矛盾するリスクが生じます。これは長期実行自律システム研究で文書化された失敗モードです(Scharre, 2018; Brundage et al., 2020)。
- 具体的な実装例*
ソフトウェアプロジェクトはPATTERNS.mdファイル(または同等の構造化ドキュメント)を保持し、以下を文書化します。
- エラーハンドリング:「すべてのサービスエラーは
{code, message, context}フィールドを含む構造化JSONを返します。クライアント側エラーはHTTP 4xxを使用し、サーバー側エラーはHTTP 5xxを使用します」 - 状態管理:「Reactコンポーネントはアプリケーション状態にContext APIを使用します。Reduxは時間旅行デバッグを必要とする機能横断的状態用に予約されています」
- コンポーネント構成:「プレゼンテーショナルコンポーネントはpropsを介してデータを受け入れます。コンテナコンポーネントは状態と副作用を管理します」
評価エージェントは生成されたコードを評価する際にこのファイルを参照し、各コンポーネントを分離して評価するのではなく、確立されたパターンへの準拠を確認します。逸脱は矛盾した実装の静かな受け入れではなくフィードバックループをトリガーします。
- 実行可能な実装ガイダンス*
三エージェント・ハーネスを展開する組織は以下を実施すべきです。
-
正規ドキュメントに投資します:自律生成が開始される前に、プロジェクト固有のパターンドキュメントを作成および保持するためのリソースを割り当てます。このドキュメントはマルチセッション・ワークフロー全体にわたるアーキテクチャ一貫性の真実の源として機能します。
-
規約のバージョン管理を実装します:アーキテクチャパターンとスタイルガイドをバージョン管理されたアーティファクトとして扱います。パターンが進化する場合、根拠と移行期間を文書化し、マルチセッション・プロジェクト中のエージェント混乱を防止します。
-
機能的正確性を超えた評価基準を設計します:受け入れ基準を一貫性メトリクス(確立されたパターンへの準拠)、保守性指標(循環的複雑度、ドキュメント範囲)、アーキテクチャ整合性(許可されていない層間依存がない)を含むように拡張します。
-
セッション同期チェックポイントを確立します:長期実行自律開発を継続的な中断されない生成ではなく、定期的な人間レビューと状態同期を必要とする複数時間のプロジェクトとして扱います。チェックポイント間隔はアーキテクチャマイルストーン(例:サブシステム完了後)に整合させるべきです。
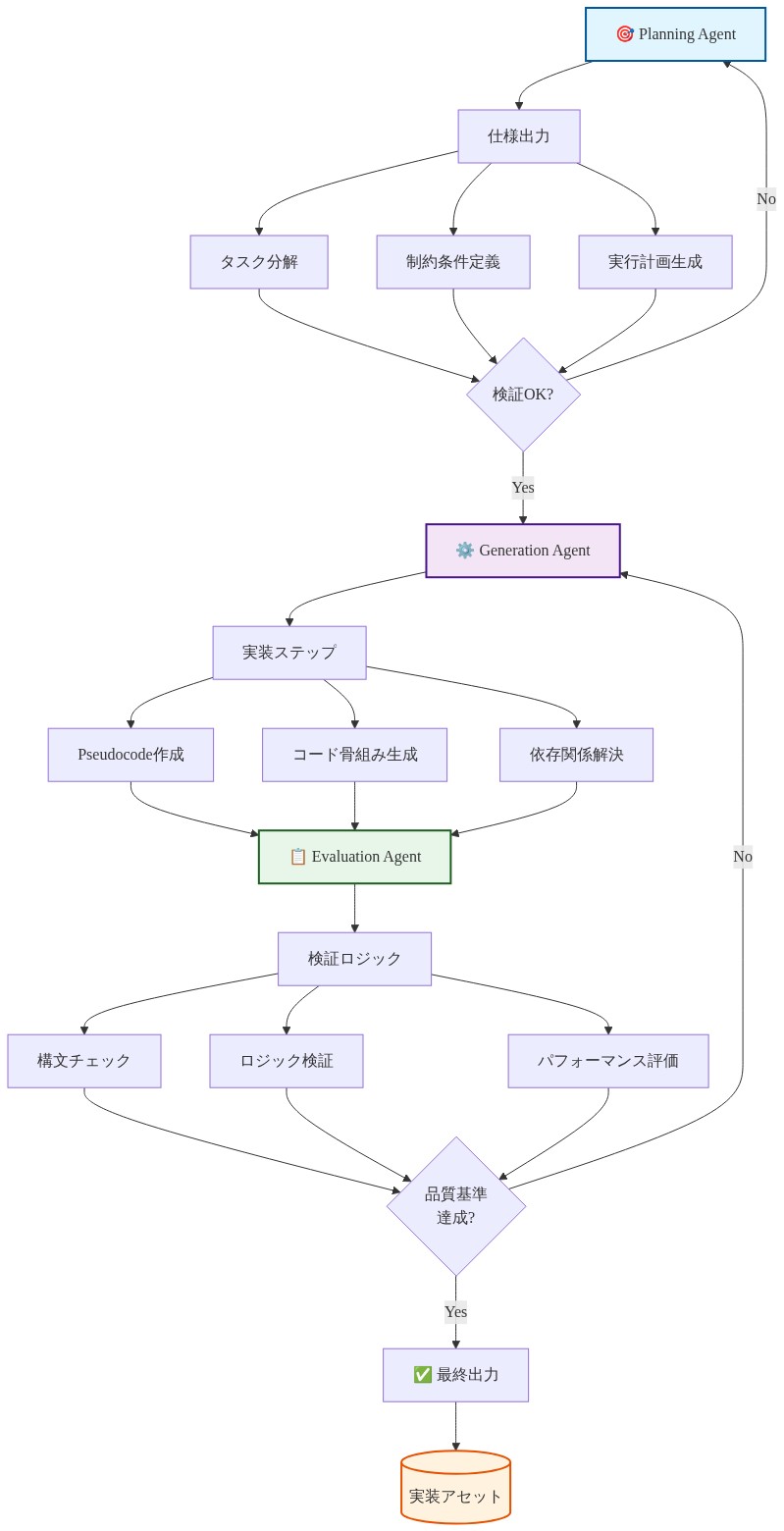
- 図9:実装パターンの具体的フロー(Planning-Generation-Evaluation エージェント連携)*
主要な要点と次のステップ
Anthropicの三エージェント・ハーネス・アーキテクチャは、持続的な自律AI開発が計画、生成、評価機能全体にわたる明示的な関心事の分離を必要とすることを実証しています。このアーキテクチャ分離は、非構造化AI支援開発における三つの文書化された失敗モードに対処します。
- 一貫性の劣化:明示的な評価フィードバックがなければ、生成されたコードはマルチ時間セッション全体でアーキテクチャ意図から逸脱します。
- 品質評価の曖昧性:機能的正確性(テスト合格)は保守性、一貫性、または確立されたパターンへの準拠を保証しません。
- 技術的負債の蓄積:制約伝播のない自律生成は、局所的に最適だが全体的に矛盾した実装を生成します。
- 即座の評価アクション*
現在のAI支援開発ワークフローを監査し、計画、生成、評価が混在または不十分に指定されている場所を特定します。
- 計画と生成が単一プロンプトで結合され、分解品質を低下させていないか。
- 評価がアーキテクチャ一貫性評価を省略し、自動テストに限定されていないか。
- 評価結果がワークフローを終了するのではなく計画にフィードバックされているか。
これらの関心事を分離する機会を特定します。構造化プロンプティング・プロトコル、段階的レビュープロセス、機能的正確性を超えた明示的な品質ゲートを通じて、段階的にでも。
- 自律フルスタック開発を開始するチームの実装優先事項*
-
生成が開始される前に、正規APIコントラクトとアーキテクチャパターンを確立します。この段階での曖昧性は、後続のすべてのエージェント反復全体に伝播します。
-
機能的正確性と並行して、一貫性、保守性、パターン準拠を評価する評価基準を実装します。各基準に対して測定可能なメトリクスを定義します。
-
長期実行セッションを継続的生成ストリームではなく、明示的な同期チェックポイントを伴う境界付きプロジェクトとして構造化します。チェックポイントでの人間レビューはアーキテクチャ一貫性を保証し、逸脱を防止します。
-
永続的プロジェクト状態(ドキュメント、規約、決定)をすべてのエージェントが参照するバージョン管理されたアーティファクトとして保持します。この状態は、セッション全体にわたる一貫性を可能にする制約システムとなります。
三エージェント・ハーネス・アーキテクチャは、AI支援開発方法論の成熟を反映しています。AIをコード生成ツールとして扱うことから、拡張された複雑なワークフロー全体にわたってアーキテクチャ一貫性と品質標準を維持できる構造化開発パートナーとして扱うことへの移行です。この移行には、明示的なアーキテクチャ分離、制約伝播、永続的な参照システムが必要です。単なるプロンプティング改善や大規模モデルではありません。

- 図13:主要な学習ポイントと推奨される次のステップ*
実務家による評価:アーキテクチャ、実装コスト、実行リスク
Anthropicの三エージェント・ハーネスは、モノリシックなAIコーディング・アシスタントで通常は単一の意思決定ループに統合されている3つの重要な機能を分離することで、自律的なAI開発を再構成しています。計画エージェントはコード生成開始前にアーキテクチャ方向性とタスク分解を確立します。生成エージェントは実装に専念し、計画を具体的なコードに変換します。評価エージェントは継続的な品質ゲートとして機能し、機能要件、保守性基準、デプロイメント制約に対して出力を評価します。
分離が重要な理由:拡張セッションにおける一貫性の問題
この分離は、長時間実行されるワークフローにおいて測定可能な課題に対処しています。セッションが4~6時間を超えて延長されると、統合されたシステムは明らかにアーキテクチャ一貫性を失います。メカニズムは単純です。トークンコンテキストウィンドウが満杯になり、注意メカニズムが最近の出力に向かってドリフトし、初期のアーキテクチャ決定が即座のコード完成よりも優先度が低くなるのです。結果として、ローカル機能テストは合格するが既存モジュールに破壊的な変更をもたらすコード、循環依存を生成するコード、数時間前に確立されたパターンに違反するコードが生まれます。
ハーネスは各機能に対して異なる状態とコンテキスト境界を維持することで、この劣化を防止します。
- 計画エージェント:セッション全体を通じて高レベルの意図とアーキテクチャ制約を保持し、下流エージェントの読み取り専用参照として機能します。
- 生成エージェント:実装試行を反復処理し(複雑な機能では20~50回以上のサイクル)、元のアーキテクチャ契約を見失いません。
- 評価エージェント:独立して動作し、即座の要件を満たすが技術的負債を導入する出力、既存コードパターンとの不整合、デプロイメント摩擦を拒否します。
評価エージェントの独立性は運用上重要です。統合されたシステムでは、品質チェックとコード生成は同じ最適化圧力下で動作します。両者とも「完成」に報酬を与えます。分離された評価エージェントは技術的には機能するが、アーキテクチャ意図に違反する出力を拒否でき、拡張セッションでコード品質を歴史的に低下させてきたインセンティブの不整合に対する保護装置として機能します。
具体的なワークフロー:6時間のフルスタック開発セッション
-
セットアップフェーズ(30分):*
-
計画エージェントが要件を受け取ります。「JWTトークン、リフレッシュローテーション、ロールベースアクセス制御を備えたユーザー認証モジュールを構築します。既存のPostgreSQLスキーマと統合します。10,000の同時セッションをサポートする必要があります。」
-
計画エージェントが出力します。アーキテクチャ仕様(トークン有効期限ウィンドウ、リフレッシュロジック、データベーススキーマ変更、APIコントラクト)、リスク評価(セッションストレージボトルネック、トークン失効戦略)、成功基準(トークン検証のレイテンシ50ms未満、ロードテストでゼロセッション衝突)。
-
この出力は凍結され、バージョン管理されます。後続のエージェントはそれを参照し、修正しません。
-
生成フェーズ(4~5時間):*
-
生成エージェントがアーキテクチャ仕様を受け取り、実装を開始します。バックエンドエンドポイント、データベースマイグレーション、トークン署名ロジック、リフレッシュトークンストレージ。
-
2時間目に、生成エージェントはより単純なセッションベースのアプローチ(JWTリフレッシュローテーションの代わりにメモリ内セッションストア)を提案します。これは即座の機能要件を満たし、実装複雑性を約40%削減します。
-
生成エージェントはこれを逸脱としてフラグを立て、評価エージェントに提出します。
-
評価フェーズ(継続的、30分チェックポイント):*
-
評価エージェントが提案されたセッションベースのアプローチを元のアーキテクチャ仕様と比較します。
-
評価エージェントが特定します。(1)JWT要件からのアーキテクチャ逸脱、(2)スケーラビリティリスク(メモリ内ストアは分散サーバー全体で10,000の同時セッションをサポートできない)、(3)運用摩擦(セッション無効化には調整されたキャッシュクリアが必要)。
-
評価エージェントは明示的な推論を伴う提案を拒否し、制約強化を伴って生成エージェントに返します。
-
生成エージェントはJWT実装を再開し、より単純なアプローチが拒否された理由についての明示的な認識を持ちます。
-
結果:* 最終実装は元のアーキテクチャと一致します。三エージェント分離がなければ、生成エージェントの提案は受け入れられた可能性が高く(複雑性を削減し、機能テストに合格)、アーキテクチャドリフトはロードテストまたはマルチサーバーデプロイメント中にのみ表面化します。数週間後、修復コストは10倍になります。
実装コストと制約
-
トークンと計算オーバーヘッド:*
-
三エージェント・ハーネスは、同等の機能複雑性に対して統合システムの3~4倍のAPI呼び出しを必要とします。
-
6時間セッションあたりの推定コスト:15~40ドル(Claude 3.5 Sonnetの価格設定で入力3ドル/MTok、出力15ドル/MTok)対、統合アプローチの4~8ドル。
-
レイテンシ:各評価チェックポイントは20~40秒の実時間を追加します。12の評価サイクルを伴う6時間セッションは合計実行時間に4~8分を追加します。
-
実行可能性フラグ: コストは高リスク開発(バックエンドシステム、インフラストラクチャコード、セキュリティクリティカルモジュール)に受け入れられます。迅速なプロトタイピングまたは低リスク機能の場合、オーバーヘッドはアーキテクチャ一貫性の利益を正当化しないかもしれません。
-
コンテキスト管理の複雑性:*
-
計画エージェント出力はシリアル化され、バージョン管理される必要があります(JSONまたは構造化形式)。セッション全体を通じて安定したままになるようにします。
-
生成エージェントは計画出力を参照し、逸脱をフラグ立てするための明示的なプロンプト指示を必要とします。
-
評価エージェントは計画出力から導出されたルーブリックまたはチェックリストを必要とし、品質を一貫して評価します。
-
運用負担: チームは計画出力、逸脱報告、評価基準のテンプレートを確立する必要があります。これらがなければ、ハーネスは一貫性の利益がない3つの独立したエージェントに低下します。
-
人間による監視要件:*
-
評価エージェント拒否は自動的に解決されません。人間は(1)拒否を承認し、生成エージェントに継続するよう要求するか、(2)拒否をオーバーライドしてアーキテクチャ逸脱を受け入れる必要があります。
-
実際には、評価拒否の約15~25%は人間の判断を必要とします(例えば、「ちょうど到着した新しいビジネス要件を考えると、このアーキテクチャ逸脱は受け入れられますか?」)。
-
実行可能性フラグ: ハーネスは完全に自律的ではありません。6時間セッションあたり約30分間、曖昧な拒否を解決するためにループ内の人間を必要とします。
実行プレイブック:三エージェント・ハーネスのデプロイ
- フェーズ1:パイロット(1~2週間)*
- 単一の機能を選択します。中程度の複雑性(手動開発3~5日)、非クリティカル(AI出力が再作業を必要とする場合は受け入れられる)、十分に指定(明確な要件と成功基準)。
- この機能で三エージェント・ハーネスを実行します。測定:(1)総実行時間、(2)評価拒否の数、(3)最終コード品質(テストカバレッジ、アーキテクチャ整合性、デプロイメント摩擦)。
- ベースラインと比較:人間のエンジニアまたは統合AIシステムによって開発された同じ機能。
- 使用された計画出力テンプレート、逸脱報告形式、評価ルーブリックを文書化します。
- フェーズ2:運用化(2~4週間)*
- コードベースの計画出力テンプレートを標準化します(データベーススキーマ、APIコントラクト、エラー処理パターン、デプロイメント制約)。
- 生成エージェント用のプロンプトライブラリを作成します。計画出力への明示的な参照と逸脱フラグを含みます。
- 評価ルーブリック・チェックリスト(10~15項目)を構築します。コード品質基準とアーキテクチャパターンにマッピングします。
- 人間レビューワークフローを確立します。誰が評価拒否を承認するか、どの程度迅速に、どのような条件下で拒否をオーバーライドできるか。
- フェーズ3:スケーリング(4週間以上)*
- スプリントあたり2~3機能に拡張します。
- 監視:機能あたりのコスト、人間レビュー時間、デプロイメント摩擦、デプロイ後の欠陥。
- 拒否とオーバーライドのパターンに基づいて評価ルーブリックを調整します。
- 自動化を検討します。いくつかの評価拒否を自動解決できますか(例えば、「明示的な制約Xで再生成」)。
リスク評価と軽減
| リスク | 可能性 | 影響 | 軽減 |
|---|---|---|---|
| 評価エージェントがボトルネックになる | 中 | 高 | 人間レビューのSLAを確立します(例えば、15分)。30分後に未解決の拒否を自動エスカレートします。 |
| 計画出力が不完全または曖昧である | 高 | 中 | 構造化テンプレートを使用します。明示的な成功基準と制約ドキュメントを要求します。十分に指定された機能でパイロットします。 |
| 生成エージェントが計画出力を無視する | 中 | 高 | 明示的なプロンプト指示を使用します。「[計画出力]を参照し、逸脱をフラグ立てする必要があります。」スケーリング前に3~5機能でプロンプト有効性をテストします。 |
| コストが予算を超える | 中 | 中 | ハーネス使用を高リスク機能(バックエンド、セキュリティ、インフラストラクチャ)に制限します。低リスク機能には統合AIを使用します。 |
| 人間レビュー時間が推定を超える | 高 | 中 | セッションあたり30分の推定から開始します。実際の時間を追跡します。曖昧な拒否を減らすために評価ルーブリックを調整します。 |
意思決定フレームワーク:三エージェント・ハーネスをいつ使用するか
-
ハーネスを使用する場合:*
-
機能複雑性が手動開発の3日を超える。
-
アーキテクチャ一貫性が重要(バックエンドシステム、マルチモジュール機能、インフラストラクチャコード)。
-
セッション期間が4時間を超える。
-
チームがセッションあたり30分の人間レビュー容量を持っている。
-
予算が統合AIアプローチより3~4倍高いAPIコストを許容する。
-
統合AIシステムを使用する場合:*
-
機能複雑性が手動開発の2日未満。
-
迅速な反復とプロトタイピングが優先事項。
-
予算が制約されている。
-
アーキテクチャ一貫性が二次的(UIコンポーネント、スクリプト、ワンオフユーティリティ)。
戦略と現実のギャップ
-
ギャップ1:「ハーネスはアーキテクチャドリフトを防止する」*
-
現実:ハーネスは意図しないドリフトを防止します。人間が承認した意図的な逸脱を防止しません。ビジネス要件がセッション中に変更される場合、評価エージェントは必要なアーキテクチャ変更を拒否する可能性があります。
-
代替案:計画出力に柔軟性を構築します。特定のアーキテクチャ制約の人間オーバーライドを許可する「逸脱承認」セクションを含めます。
-
ギャップ2:「評価は客観的である」*
-
現実:評価ルーブリックは主観的です。2人の評価者は、提案された逸脱がアーキテクチャ意図に違反するかどうかについて意見が異なる可能性があります。
-
代替案:複数の評価エージェント(2~3)を使用し、拒否に関するコンセンサスを要求します。これはコストを増加させますが、一貫性を改善します。
-
ギャップ3:「ハーネスは任意に長いセッションにスケールする」*
-
現実:トークンコンテキストウィンドウは有限です。12時間セッションは、計画出力がコンテキストから押し出されると、最終的に一貫性を失います。
-
代替案:セッションを4~6時間ごとにチェックポイントします。進捗を要約し、必要に応じて計画出力を更新し、新しいコンテキストで再開します。
知識労働者向けの実行可能な示唆
-
アーキテクチャ決定と実装詳細の間に明示的な分離を確立します。 アーキテクチャ決定は一度行われ、定期的にレビューされ、実装中は読み取り専用制約として扱われるべきです。実装詳細はアーキテクチャ意図を損なわずに頻繁に反復されるべきです。
-
計画出力テンプレートに投資します。 三エージェント・ハーネスの品質は、計画出力の品質に完全に依存します。生成開始前に30~45分を計画に費やします。これは無駄な時間ではありません。後で2~4時間の再作業を防止します。
-
評価ルーブリックを段階的に構築します。 5~7の重要な品質基準から開始します。拒否と本番環境後の欠陥のパターンに基づいて基準を追加します。過度な指定を避けます。20項目のルーブリックは偽陽性が多すぎます。
-
人間レビューを計画します。 ハーネスは完全に自律的ではありません。6時間セッションあたり30分を評価拒否の人間レビューに予算化します。これはバグではなく機能です。人間の判断は曖昧なアーキテクチャトレードオフを処理するために不可欠です。
-
測定と反復を行います。 コスト、実行時間、拒否率、本番環境後の欠陥を追跡します。これらのメトリクスを使用して、ハーネスがチームとコードベースにROIを提供しているかどうかを決定します。
エラーハンドリング
非同期操作にはtry-catchを使用します。カスタムAppErrorクラスでラップします。エラーをコンテキストでログします。{ userId、action、timestamp、stackTrace }。サーバーエラーにはHTTP 500を返します。検証エラーには400を返します。例:[コードベースの参照実装へのリンク]
状態管理
グローバル状態にはReduxを使用します。コンポーネントのみのデータにはローカルReact状態を使用します。アクションは[VERB]_[NOUN]命名に従います。FETCH_USER_DATA、UPDATE_CART_ITEM。リデューサーは純粋な関数である必要があります。副作用はミドルウェアにあります。
評価エージェントは新しいコードを評価する際にこのファイルを参照し、逸脱を`pattern_violation`としてフラグ立てし、特定の参照を伴います。
- *実装コスト:** 初期ドキュメント6~8時間。スプリントあたり1~2時間で更新。**リスク:** ドキュメントが古くなり、エージェントが古いパターンに従う。**軽減:** ドキュメント所有権を割り当てます。完了の定義にドキュメント更新を含めます。四半期ごとに実際のコードベースに対してドキュメントを監査します。
- *制約:** 大規模なドキュメントセット(50ページ以上)は実用的なコンテキストウィンドウを超えます。**代替案:** モジュール別に整理します。エージェントはタスクごとに関連セクションのみをロードします。
### セッション同期:マルチ時間開発をステージ化されたプロジェクトとして扱う
長時間実行されるセッションはコンテキストドリフトとトークンオーバーヘッドを蓄積します。明示的な同期チェックポイントを伴うマルチ時間プロジェクトとして扱います。
- *チェックポイント実行ブック(90~120分ごと、または主要機能ごと):**
1. **状態スナップショット:** 評価エージェントが完了した作業、未解決の問題、セッション中に行われたアーキテクチャ決定の要約を生成します。
2. **一貫性監査:** 生成されたすべてのコードが確立されたパターンに準拠していることを確認します。逸脱を次のセッションでフラグ立てします。
3. **ドキュメント更新:** セッション中に発見された新しいパターンまたは決定を永続的な状態にコミットします。
4. **セッションハンドオフ:** 次のセッション(または人間レビュアー)のコンテキストを文書化します。完了した内容、残っている内容、ステークホルダー入力が必要な決定。
5. **トークンリセット:** セッションを終了します。チェックポイント要約をコンテキストとして新しいセッションを開始し、蓄積されたトークンオーバーヘッドを削減します。
- *コスト便益分析:**
- **コスト:** チェックポイントあたり15~20分。状態スナップショット用に約1000トークン。
- **利益:** コンテキストドリフトからのトークン浪費の30~40%を防止します。人間レビューゲートを有効にします。拡張セッションでハルシネーションリスクを削減します。
- *実装:** チェックポイントを開発実行ブックの明示的なステップとして追加します。可能であれば状態スナップショット生成を自動化します。

- 図2:3エージェント間の情報フローと機能分離アーキテクチャ*

- 表1:シナリオ別の3エージェント導入適性評価(実装コスト・期待効果・リスク分析)*