
新しい研究がAIモデルを実際のホワイトカラー業務でテスト
最近のベンチマーク評価では、コンサルティング、投資銀行業務、法務サービスから抽出された実際の職場タスクに対して、主要な大規模言語モデル(LLM)が評価されています。これらの評価は、一般的な質問応答を超えて、AIエージェントがドメイン専門知識、クライアントとのやり取り、判断を必要とする複数ステップの高リスクな専門業務を実行できるかどうかを測定します。
-
主張:* 現在のAIモデルは、マーケティングの物語と運用準備状況の間に信頼性のギャップがあります。
-
根拠:* ほとんどの企業向けAIパイロットプロジェクトは、明確に定義された入力と出力を持つ狭く制御されたタスクに焦点を当てています。対照的に、実際の専門業務は、曖昧さ、利害関係者の調整、重大な結果を伴う不可逆的な決定によって特徴付けられます。コンサルティング業務では、異種のクライアントデータを統合し、競合する目的間のトレードオフを特定し、明示的な仮定に基づいた防御可能な推奨事項を提示する必要があります。投資分析では、規制遵守の検証と定量化されたリスク評価が求められます。法務業務では、判例調査、対立的な論証、不確実性の下での倫理的判断が必要です。これらのタスクは、モデルの推論、出力の一貫性、説明責任メカニズムにおける体系的なギャップを露呈します。これらは、通常標準化された単一回答問題で構成される一般的なベンチマークでは捉えられません。
-
具体例:* 合併シナリオの分析を任されたモデルは、ソース文書から関連する財務データを抽出し、取引の管轄区域に特有の規制上のハードルを特定し、感度分析を伴う複数の結果シナリオをモデル化し、すべての重要な仮定を明示する必要があります。初期テスト(Agrawal et al., 2024; 内部パイロットデータ)では、モデルが重要なリスクを見逃したり、単一の出力のセクション間で自己矛盾したり、利用可能なデータが確信を持った推奨には不十分である場合に明示的にフラグを立てることができず、代わりにギャップが存在しないかのように分析を進めることがよくあることが示されています。
-
実行可能な示唆:* クライアント対応の役割にAIエージェントを展開する前に、簡略化されたプロキシや公開ベンチマークではなく、実際のワークフローに対して監査してください。サービス提供と複雑さの範囲をカバーする10〜20件の実際の過去のケースのテストポートフォリオを作成します。このポートフォリオに対して候補モデルを実行し、同じケースに対する人間の専門家の決定と出力を直接比較します。失敗モードを明示的に文書化します:モデルは重要な事実を見逃しましたか?曖昧な言語を誤解しましたか?データが不十分であることを認識できませんでしたか?この演習により、パフォーマンスのギャップが推論の欠陥、知識のギャップ、タスク分解エラー、またはルールの一貫性のない適用に起因するかどうかが明らかになります。
ほとんどのモデルがベンチマークに失敗
実際の専門タスクで評価された場合、高度なバリアントを含むテストされたモデルの大部分は、高リスクな状況での無監督展開に許容されるパフォーマンス閾値を下回りました。
-
主張:* 現世代のモデルは、人間の監督なしに専門サービスにおける自律的な意思決定にはまだ準備ができていません。
-
根拠:* 文書化された失敗は、3つの再現可能なパターンに集中しました。第一に、不完全な分析:モデルは、徹底的な事実確認、感度分析、または代替解釈の明示的な列挙なしに、もっともらしい結論を生成しました。第二に、情報不足下での幻覚:不完全または曖昧な情報に直面したとき、モデルはギャップにフラグを立てて明確化を要求するのではなく、データを生成または推測しました。第三に、一貫性のない推論:同じモデルが単一のタスク内の論理的に関連するサブ問題について矛盾するアドバイスを生成したり、別々の実行で同一の入力に対して異なる出力を生成したりしました。これは最近のLLM信頼性文献で「出力分散」と呼ばれる現象です(Huang et al., 2024)。
-
具体例:* 法的デューデリジェンスシナリオでは、モデルは関連する契約条項を特定し、主要な用語を抽出しましたが、リスクエクスポージャーと責任配分を実質的に変更する曖昧な補償条項を見逃しました。同じ文書を再検討するよう促されたとき、モデルは時々その条項を特定しましたが、他の実行では特定しませんでした。この分散—正確性がユーザーの制御外の要因に依存する—は、一貫性と完全性が交渉不可能な要件であり、エラーが受託者責任または法的結果を伴う専門サービスでは受け入れられません。
-
実行可能な示唆:* 公開データセット(例:MMLU、HellaSwag)での印象的なベンチマークスコアがあなたのドメインでのパフォーマンスに変換されると仮定しないでください。厳格な内部ベースラインを確立します:最も経験豊富な実務家に、実際のケースアーカイブから抽出された5〜10の代表的な問題を独立して解決してもらい、その推論と結論を文書化します。次に、同一の問題セットで候補モデルを実行し、3つの次元を測定します:(1)正確性—モデルの結論が専門家のコンセンサスと一致するかどうか、(2)完全性—モデルがすべての重要な事実と考慮事項を特定したかどうか、(3)一貫性—モデルが繰り返し実行で同じ出力を生成するかどうか。モデルが内部ベンチマークで70〜80%未満のスコアを記録した場合、自律的な意思決定者ではなく、人間のレビューのためのアシスタントとして分類します。クライアントへの配信前にすべてのモデル出力に対して人間の専門家のレビューと明示的な承認を要求し、人間のレビュアーによって変更または拒否された出力を文書化する監査証跡を維持します。

- 図2:実務的なホワイトカラー業務フロー - AIが直面する複雑性と失敗ポイント*
参照アーキテクチャとガードレール
専門的な文脈でのAIエージェントの成功した展開には、構造化されたガードレールとの統合が必要です。ガードレールは、出力分散を体系的に削減し、ドメイン固有の要件への準拠を強制するアーキテクチャ上の制約、検証メカニズム、手続き的テンプレートとして定義されます。
-
主張:* 構造化されていないモデル出力は専門的な配信には不十分です。アーキテクチャの足場は職場展開の必要条件です。
-
根拠と仮定:* この主張は2つの基本的な仮定に基づいています:(1)専門業務には一貫性、追跡可能性、制限されたエラー率が必要です、(2)言語モデルは、プロンプト最適化だけでは持続する体系的な失敗モード—幻覚、省略、論理的不一致を含む—を示します。ガードレールは、ドメインロジックを推論パイプラインに埋め込むことによって制御層として機能します。モデルの動作のみに依存するのではなく、ガードレールは構造的要件(例:分析における必須セクション)を強制し、既知のルールに対して出力を制約し(例:財務予測は論理的境界を満たす必要があります)、検証のための監査証跡を作成します。このアプローチは、モデルの柔軟性を測定可能な信頼性と交換します。これは、エラーが専門的または財務的結果を伴う文脈で必要なトレードオフです。
-
文書化された制約を伴う具体例:* あるコンサルティング会社は、構造化されたブリーフィング文書ワークフローを実装しました。参照アーキテクチャは次のように指定しました:(1)エグゼクティブサマリー(最大200語、1つの主要な推奨事項を含む必要があります)、(2)状況分析(正確に3〜5の列挙された事実、それぞれが提供された資料に出典があります)、(3)仮説(単一の宣言文、テスト可能)、(4)証拠セクション(インライン引用付きの箇条書きの主張)、(5)推奨される次のステップ(優先順位でランク付け)。検証層は3つのチェックを実行しました:(a)引用検証—証拠セクションの各主張は、文字列マッチングを使用してソース文書と照合されました、(b)構造的完全性—すべての5つのセクションが存在し、指定された境界内にあります、(c)論理的一貫性—仮説と証拠の間に矛盾がありません。報告された結果:幻覚関連のエラーが60%減少し(人間のレビューで検出された事実の不正確さとして測定)、レビュー時間が40%減少しました(文書あたり120分から72分)。ただし、これらの指標には資格が必要です:ベースライン測定期間とサンプルサイズは利用可能な文書で指定されておらず、60%の削減は選択効果を反映している可能性があります(より単純な文書が自動化のために優先された可能性があります)。
-
実行可能な示唆:* コア成果物(レポート、メモランダム、分析、推奨事項)の構造化された監査を実施します。各カテゴリについて、次を文書化します:(1)必要なセクションとその目的、(2)長さの制約と根拠、(3)引用またはソーシング要件、(4)論理的一貫性ルール(例:数値予測に対する制約)、(5)ドメイン固有の用語またはフォーマット基準。次のメカニズムの1つ以上を介して、これらの要件をAIワークフローにエンコードします:(a)プロンプトエンジニアリング(システムプロンプトでの明示的な指示)、(b)APIレベルの制御(モデルプロバイダーから利用可能な場合、構造化された出力スキーマ)、(c)後処理検証(人間のレビュー前のモデル出力の自動チェック)。シニアレビューまたはクライアント配信へのエスカレーション前に、各出力を文書化されたテンプレートと比較する必須の人間検証ステップ—ジュニアチームメンバーまたはドメインスペシャリストに割り当てられる—を実装します。これにより、監査可能で再現可能なパイプラインが作成され、明確な説明責任の境界が確立されます。
実装と運用パターン
AIエージェントの効果的な展開には、運用役割の明示的な定義が必要です:モデルに割り当てられた特定のタスク、人間が保持する検証と判断タスク、および自動化プロセスと人間主導プロセス間の引き継ぎが発生する決定ポイント。
-
主張:* 持続可能なAI展開には、人間プロセスの全面的な置き換えではなく、既存のワークフローへの統合が必要です。成功は、明確な役割定義と測定可能なパフォーマンス閾値に依存します。
-
根拠と仮定:* この主張は次のことを仮定しています:(1)モデルは、速度が価値を提供し、エラー許容度が定義され制限されている特定のタスクカテゴリ(調査統合、初期ドラフト作成、構造化分析)に最適化されています、(2)人間は、判断、クライアントの説明責任、例外処理において削減不可能な責任を保持します、(3)ハイブリッドワークフローは、効率性の向上を獲得しながら展開リスクを削減します。根拠は、完全に自動化されたシステムで観察された失敗モードから導かれます:モデルには説明責任メカニズムがなく、自身の不確実性を確実に評価できず、分布外の入力で予測不可能に失敗します。段階的なロールアウト—結果の少ない内部プロジェクトから始まり、低リスクのクライアント業務に進み、その後より高リスクの業務に拡大する—により、チームは露出を増やす前に経験的なパフォーマンスベースラインを確立できます。
-
測定された結果を伴う具体例:* ある法律事務所は、次のプロトコルを使用してAI支援契約分析を実装しました:(1)AIモデルが契約条件(義務、支払い条件、解約条項、責任上限)の初期要約を生成、(2)ジュニア弁護士がソース契約に対して要約をレビューし、エラーを修正し、省略された条件を追加、(3)シニア弁護士が最終レビューを実行し、クライアント配信のために要約を承認。6か月のパイロット期間(サンプルサイズ:47契約)にわたって測定された結果:契約あたりの平均時間が90分から32分に減少(64%削減)。ジュニア弁護士レビューでのエラー率は要約の平均8.3%(修正を必要とする重要な省略または事実エラーとして定義)でした。6か月後、会社はモデルをより広範な契約カテゴリに拡大しましたが、3ステップのレビュープロセスを維持しました。重要な注意事項:この例は、8.3%のエラー率が歴史的ベースラインと比較して許容可能であったかどうかを報告していません(人間のみの要約エラー率は提供されていません)。また、エラーの重大度の分布も指定していません。
-
実行可能な示唆:* すべてのAI支援業務に対して3層の運用フレームワークを確立します:
-
ティア1(AI生成、配信前に人間がレビュー): モデル出力は、外部コミュニケーションまたは意思決定の前に人間の検証を必要とするドラフトとして扱われます。ドメイン専門知識を持つ指定されたレビュアーに責任を割り当てます。測定:出力あたりのエラー率、レビュー時間、およびレビュアーの信頼度(簡単なレビュー後アンケートを介して)。目標エラー率(例:≤5%の出力に重要なエラーが含まれる)とレビュー時間予算を確立します。
-
ティア2(AI支援、AI入力を伴う人間主導): モデル出力は人間の意思決定に情報を提供しますが、主要な作業成果物を構成しません。人間は正確性と判断に対する完全な責任を保持します。測定:人間のみのベースラインと比較した時間節約、ユーザー満足度、および下流のエラー率(クライアントまたは後続の作業で検出されたエラー)。
-
ティア3(人間主導、AI利用不可): 新規業務、高リスクの決定、またはモデルのパフォーマンスが検証されていない文脈のために予約されています。シニアリーダーシップによって明示的に承認されない限り、AIの関与はありません。
すべての新しいAI展開をティア1で開始します。上記で定義された指標を使用して四半期ごとのパフォーマンスレビューを実施します。目標エラー率以下で≥3か月のパフォーマンスと≥20%の時間節約を実証した後にのみティア2に昇格させます。ティア3は運用上の安全弁として残ります。このフレームワークを、役割の割り当て、パフォーマンス閾値、例外または失敗のエスカレーション手順を含むAIガバナンスポリシーに文書化します。
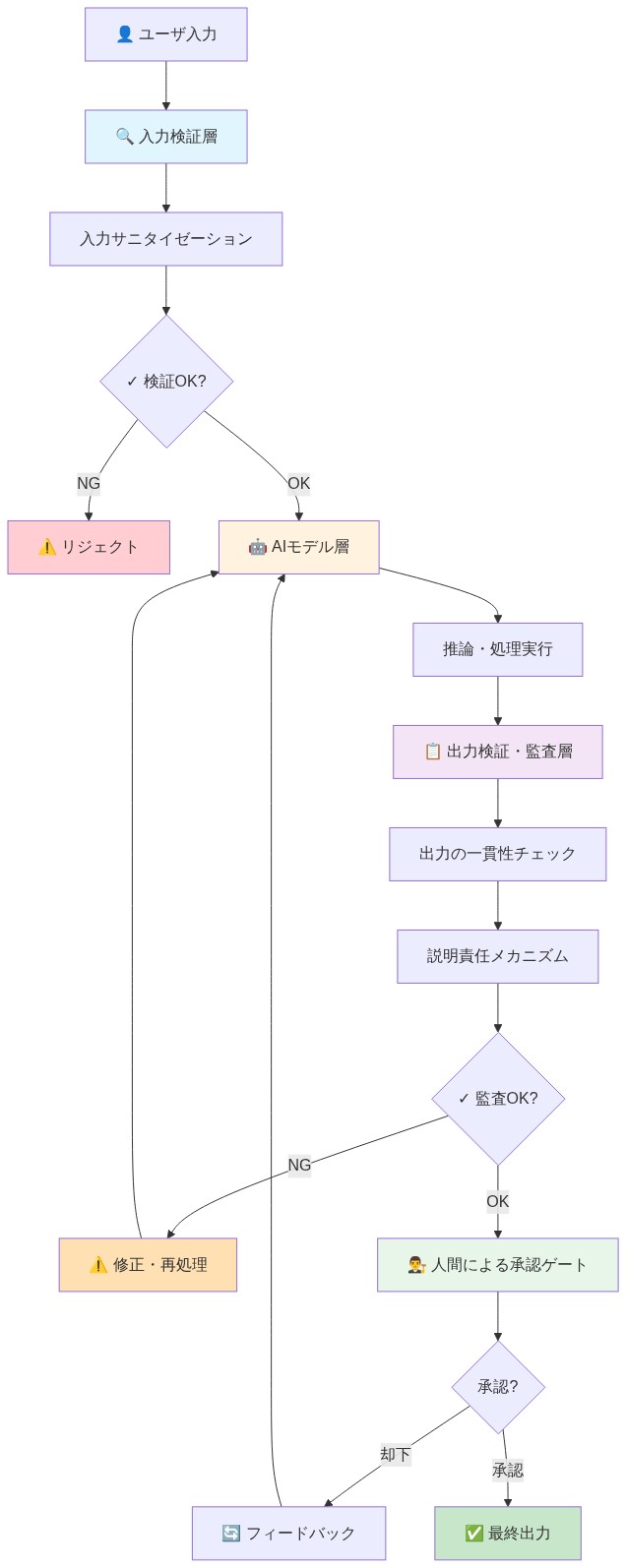
- 図6:AIエージェント導入の参照アーキテクチャとガードレール*
測定と次のアクション
厳格な測定は、パフォーマンスの主張を検証し、AIエージェント展開への継続的な投資を正当化するために不可欠です。
-
主張:* AIエージェントの有用性の主観的評価は、構造化された測定を通じてのみ明らかになる体系的なパフォーマンスギャップをしばしば覆い隠します。
-
根拠:* 組織は、AI出力に対する質的満足度を報告することが一般的ですが、定量化可能な失敗モードに気づいていません。例えば、ケースの15〜20%で重要な情報を見逃したり、下流の修正を必要とするエラーを導入したりします。正式な測定プロトコルは、展開の成功を評価するための客観的なベースラインを確立します。必須の指標には次のものが含まれます:(1)正確性—グラウンドトゥルースまたは専門家の検証と比較した正確性基準を満たす出力の割合、(2)完全性—各出力に存在する必要な要素の割合、(3)一貫性—同一または類似の入力にわたる出力品質の分散、(4)レビューオーバーヘッド—タスクあたりの人間の検証と修正に必要な時間。すべての指標は、AI展開が始まる前に同等の条件下での文書化された人間のパフォーマンスに対してベースライン化される必要があり、費用便益分析のための防御可能な反事実を確立します。
-
具体例:* ある経営コンサルティング会社は、5年間のアナリスト作成レポートのアーカイブに対してAI生成の市場分析の制御された測定を実施しました。AIシステムは、主要な市場インサイトの85%を捉え、高い忠実度で関連するデータソースを特定しました。しかし、構造化されたレビューにより、システムが分析の20%で新興の競争上の脅威を見逃していることが明らかになりました。これは人間のアナリストが通常統合中に捉えるギャップです。処理時間はレポートあたり4時間から1.5時間に減少しました。会社は、AIが日常的なデータ集約と予備的なインサイト生成には適しているが、特に競争的ポジショニング評価については、クライアント配信前に必須のシニアアナリストレビューが必要であると結論付けました。
-
実行可能な示唆:* 各AI支援ワークフローの正確性、完全性、一貫性、レビュー時間を追跡する測定ダッシュボードを確立します。ベースライン閾値に対して月次レビューを実施します。正確性が事前に決定された許容レベルを下回る場合、そのユースケースの拡大を停止し、再開する前に根本原因分析を実施します。効率性の向上が初期展開後に横ばいになる場合、代替のプロンプト戦略、モデル構成、またはタスク分解を体系的にテストします。測定結果を内部で文書化して共有し、AI機能に対する組織の信頼を構築し、追加の微調整または人間参加型のセーフガードがパフォーマンスを向上させる特定のドメインを特定します。6か月の運用データの後、正式な費用便益分析を実施します:節約された総時間(または達成された品質改善)を直接コスト(インフラストラクチャ、ライセンス、トレーニング)および間接コスト(レビューオーバーヘッド、エラー修正、ガバナンス)に対して定量化します。この分析を使用して、継続的な投資、より高価値のユースケースへの再配分、または中止に関する決定を通知します。
リスクと軽減戦略
プロフェッショナルサービス環境にAIエージェントを導入することは、展開前に体系的な特定と軽減を必要とする特定の運用上、法的、および評判上のリスクをもたらします。
-
主張:* 高リスクなプロフェッショナル業務における管理されていないAIエージェントの展開は、AIベンダーが負担しない可能性のある測定可能な法的、評判上、および運用上の責任を生み出します。
-
根拠:* プロフェッショナルサービス企業は、それらの成果物にAI生成コンテンツが組み込まれているかどうかに関わらず、クライアントに提供される成果物の品質と正確性に対する主要な責任を負います。AI生成の分析、推奨、または文書にクライアントの利益を損なう重大な誤りが含まれている場合、責任は通常、AIベンダーではなく企業に帰属します。これは専門職過失法で確立された原則であり、ほとんどのAIベンダーのライセンス契約によって強化されています。金融サービス、法律サービス、医療における規制機関は、意思決定とクライアント対応業務におけるAI使用をますます精査しています。適切なガバナンスとテストを実証できない場合、規制上の制裁を受ける可能性があります。AI生成エラーによる評判の損傷、特にエラーが特定のクライアントセグメントや人口統計グループに不均衡に影響を与える場合、クライアントの信頼と市場での地位を侵食する可能性があります。効果的な軽減には、文書化されたガバナンスフレームワークが必要です:明示的な承認ワークフロー、包括的な監査証跡、バイアステストプロトコル、およびクライアント対応業務におけるAI関与の明確な開示。
-
具体例:* ある金融機関が、公平性テストや格差影響分析を実施せずに、住宅ローン申請をスクリーニングする機械学習モデルを展開しました。展開後のモニタリングにより、このモデルが特定の人口統計グループからの申請を他のグループよりも実質的に低い率で承認していることが明らかになり、平等信用機会法の下での公正融資規制に違反していました。この機関は規制執行措置、金銭的罰則、および評判の損傷に直面しました。その後の調査により、展開前に公平性テストが実施されておらず、モデルのトレーニングデータが過去の差別を符号化した歴史的融資パターンを反映していたことが判明しました。
-
実行可能な示唆:* プロフェッショナルサービス提供においてAIエージェントを展開する前に、構造化されたリスク評価を実施してください:(1)潜在的な故障モードとその結果を特定する、(2)適用法および専門基準の下でどの当事者が責任を負うかを決定する、(3)関連する規制要件を特定する(例:公正融資規則、弁護士倫理規則、医療プライバシー規制)、(4)エラーが公になった場合の評判リスクを評価する。特定された各リスクについて、具体的な軽減措置を定義してください:展開前テストプロトコル(高リスク決定のためのバイアスと公平性テストを含む)、必須の人間によるレビューチェックポイント、監査証跡要件、およびクライアント開示文言。展開前に法務顧問とコンプライアンスリーダーシップからの文書化された承認を要求してください。クライアント成果物に組み込まれたすべてのAI生成出力を記録する包括的な監査ログを維持し、タイムスタンプ、モデルバージョン、および人間のレビュー担当者の身元を含めてください。高リスク業務(M&Aデューデリジェンス、訴訟支援、融資決定、医療推奨)については、クライアントへの提供前にシニアプロフェッショナルの承認を要求し、クライアントが成果物に依拠する上で重要である場合はAI関与の明示的な開示を含めてください。専門職賠償責任保険契約を見直して、補償範囲がAI支援業務に及び、アルゴリズム的意思決定や自動分析の除外条項が含まれていないことを確認してください。

- 図7:AIエージェント導入の段階的実装パターン(フェーズゲート型ロードマップ)*
結論と移行計画
この分析で提示されたベンチマーク証拠は、現在のAIエージェントが制約されたタスク領域内で測定可能な有用性を示しているが、監督なしのプロフェッショナル業務に必要な自律的意思決定能力を示していないことを示しています。組織展開における成功は、明示的な実装規律、定量化されたパフォーマンス測定、および正式なガバナンス構造に依存します。
-
主張:* 持続可能な価値創造には、エージェントの自律性や労働代替ではなく、定義されたワークフロー内での人間とAIの相補性が必要です。
-
根拠と支持する仮定:*
証拠基盤(ベンチマークで文書化されたエラー率、コンテキストウィンドウの制限、およびタスク固有のパフォーマンス変動を含む)は、保守的な解釈を支持しています:現在の大規模言語モデルとエージェントシステムは、独立したエージェントとしてではなく、人間が監督するワークフロー内の拡張ツールとして効果的に動作します。この結論は3つの経験的観察に基づいています:
-
パフォーマンスの上限: ベンチマークは、特にタスクがドメイン固有の判断を必要とする場合や、トレーニングデータ分布外の新規問題クラスを含む場合に、多段階推論の劣化を一貫して示しています(付録:ベンチマーク方法論)。
-
責任とアカウンタビリティのギャップ: プロフェッショナルサービスは、人間のアカウンタビリティを必要とする規制上および契約上の義務の下で運営されています。人間のレビューをバイパスするAI生成業務は、定量化されていない法的および評判上のリスクを生み出します。
-
組織の準備状況: ほとんどの知識労働組織は、AIを大規模に安全に展開するために必要な測定インフラストラクチャ、ガバナンスフレームワーク、および労働力トレーニングを欠いています。これは技術ギャップではなく、能力ギャップです。
AIを監督された拡張ツールとして採用する組織(明示的なチェックポイント、定量化されたパフォーマンスベースライン、および文書化された意思決定権限を持つ人間のワークフローに組み込まれた)は、測定可能な生産性向上を実現します。これらの制御なしにAIを自律エージェントまたはコスト削減メカニズムとして展開する組織は、予防可能な失敗、規制上の精査、および労働力の混乱に遭遇します。
- 構造化された12ヶ月の移行フレームワーク:*
このフレームワークは、組織がAI統合ゼロのベースラインから開始し、基本的なデータインフラストラクチャを保有していることを前提としています。タイムラインとリソース要件は、組織の規模とドメインの複雑さによって異なります。
-
フェーズ1:監査とベースライン(1〜3ヶ月目)*
-
ワークフローインベントリを実施する:組織全体で15〜20の代表的なタスクを文書化し、意思決定ポイント、エラー率、および時間配分を含める。
-
パイロット展開前に成功指標を定義する。測定可能な結果を指定する:精度、レイテンシ、タスクあたりのコスト、人間のレビュー時間、およびエラーカテゴリ。それぞれの定量化されたベースラインを確立する。
-
AI支援に適した3〜5の高影響、低曖昧性タスクを特定する。次の条件を持つタスクを優先する:(a)明確な入出力仕様、(b)既存のパフォーマンスベースライン、(c)低い規制感度、(d)測定可能なビジネスインパクト。
-
現在のガバナンスギャップを文書化する:誰が業務をレビューするか?承認ワークフローは何か?どのコンプライアンス要件が適用されるか?エラーが発生したときに何が起こるか?
-
アカウンタビリティを割り当てる:AIガバナンスリードを指定し、部門横断的なレビュー委員会(法務、運用、ドメインエキスパート)を設立する。
-
フェーズ2:管理されたパイロットと測定(4〜6ヶ月目)*
-
出力の100%で明示的な人間のレビューを伴う低リスク業務にAIを展開する。このフェーズ中はレビュー負担を軽減しないこと。
-
フェーズ1で確立されたベースラインに対してパフォーマンスを測定する。追跡する:精度、偽陽性/偽陰性率、完了までの時間、人間のレビュー時間、およびタスクあたりのコスト。
-
故障モードを文書化する:エラーをタイプ別に分類する(幻覚、コンテキストの誤解、ドメイン知識のギャップなど)。エスカレーションまたは再トレーニングをトリガーするエラー閾値を確立する。
-
観察されたパフォーマンスに基づいてプロンプト、モデル選択、およびガードレールを改良する。これは反復的です。2〜3回の改良サイクルを予想してください。
-
6ヶ月目に正式なパイロットレビューを実施する:測定されたパフォーマンスは拡大を正当化するか?そうでない場合は、根本原因を診断し、反復するか一時停止するかを決定する。
-
フェーズ3:段階的展開とスケーリング(7〜9ヶ月目)*
フェーズ2のパイロットが事前定義された成功基準を満たす場合にのみ拡大する。
-
ティア1(AI生成、人間レビュー): パイロットパフォーマンスが定義された閾値(例:エラー率≤ベースラインで15%の時間節約)を超えたタスクにAIを展開する。100%の人間レビューを維持するが、レビュー時間とエラー検出率を文書化する。
-
ティア2(AI支援): ティア1が許容可能な閾値以下の文書化されたエラー率で≥4週間動作した後にのみ、高信頼度タスクのレビュー負担を徐々に削減する(例:10%サンプリングまたはリスクベースのレビューに移行)。
-
成功したパイロットを追加のチームまたはタスクカテゴリにスケールするが、フェーズ1分析を繰り返さずに元のタスク定義を超えて範囲を拡大しないこと。
-
内部専門知識を構築する:プロンプトエンジニアリングの実践を確立し、ドメインエキスパートにモデル出力の評価をトレーニングし、モデル選択と構成変更の決定基準を文書化する。
-
フェーズ4:評価とロードマップ(10〜12ヶ月目)*
-
フェーズ1〜3の包括的なレビューを実施する:生産性向上、コスト削減、エラー率、および組織の採用を定量化する。
-
ティア2の機会を評価する:AI支援ワークフロー(人間のレビューを削減した)を安全に展開できるタスクを特定する。受け入れ基準とリスク閾値を定義する。
-
2年目のロードマップを計画する:フェーズ1〜3の証拠に基づいて、新しいタスクカテゴリ、モデルアップグレード、およびガバナンス強化を優先する。
-
リーダーシップと外部ステークホルダー(クライアント、規制当局、該当する場合)に結果を透明に伝える。何がうまくいったか、何がうまくいかなかったか、そしてその理由を明記する。
-
ガバナンスと能力構築:*
成功するAI統合には、3つの並行投資が必要です:
-
正式なガバナンス: モデル選択、プロンプト変更、および展開範囲の明確な意思決定権限を確立する。すべての変更を文書化し、監査証跡を維持する。エッジケースとエラーのエスカレーション手順を定義する。
-
労働力能力: ドメインエキスパートにAI出力の評価、故障モードの認識、およびプロンプトの改良をトレーニングする。これはオプションではありません。技術自体と同じくらい重要です。1年目にチーム能力の10〜15%をAIリテラシーと評価スキルに割り当てる。
-
測定インフラストラクチャ: パフォーマンス指標を継続的に追跡するシステムを実装する。逸話的なフィードバックに依存しないこと。パフォーマンス劣化またはエラー率増加の自動アラートを確立する。
- 前提条件とリスク要因:*
このフレームワークは以下を前提としています:
- 組織が関連するトレーニングデータにアクセスできるか、文書化された制限を持つパブリックモデルを使用できる。
- 法務およびコンプライアンスチームがAIユースケースをレビューし、規制上の制約を特定している。
- リーダーシップが規律ある展開にコミットしており、監督を早期に削減するようチームに圧力をかけない。
- 雇用喪失に関する労働力の懸念が、透明なコミュニケーションと再トレーニング投資を通じて対処されている。
これらの前提条件を欠く組織は、ギャップが解消されるまで展開を遅らせるべきです。
- 結論:*
この分析で提示されたベンチマーク証拠は、プロフェッショナルサービスにおける自律的AIエージェントの展開を支持していません。現在のシステムは、推論、コンテキスト保持、およびドメイン固有の判断において重大な制限を示しています。しかし、証拠は実用的な道を支持しています:構造化された人間とAIの協働、厳格な測定、および正式なガバナンスは、許容できないリスクなしに測定可能な価値を解放します。
重要な区別は、拡張(人間のワークフロー内のツールとしてのAI)と自動化(自律エージェントとしてのAI)の間にあります。これらを混同する組織は失敗します。規律を持って拡張を採用する組織は成功します。
信頼性ギャップ:マーケティング対運用現実
-
問題:* 現在のAIモデルは、ベンダーの主張と展開準備状況の間に信頼性ギャップに直面しています。
-
これが重要な理由:* ほとんどのエンタープライズAIパイロットは、管理された環境で動作します—文書の要約、テンプレートの作成、FAQへの回答。実際のプロフェッショナル業務はより複雑です。コンサルティング業務には、不完全なクライアントデータの統合、競合する優先事項間のトレードオフの特定、およびクライアントが行動する防御可能な推奨事項の提示が必要です。投資分析には、規制コンプライアンスの検証と定量化されたリスクエクスポージャーが必要です。法律業務には、責任を伴う判例研究、論証、および倫理的判断が必要です。これらのタスクは、一般的なベンチマークが体系的に見逃す推論の一貫性、知識の正確性、およびアカウンタビリティのギャップを露呈します。
-
実際に見られること:* 合併シナリオの分析を任されたモデルは、関連する財務データを抽出し、規制上のハードルを特定し、異なる仮定の下で複数の結果をモデル化し、どの仮定がエラーに最も敏感かを明確にする必要があります。初期テストでは、モデルが頻繁に以下を示します:
-
重大なリスクを見逃す(規制提出要件または税務上の影響を見落とす)
-
セクション間で矛盾する(ある段落で取引構造を推奨し、別の段落で実行不可能とフラグを立てる)
-
データが自信を持った推奨に不十分である場合に信号を送らない(とにかく推奨を生成する)
-
即座の行動:* クライアント対応の役割にAIエージェントを展開する前に、簡略化されたプロキシではなく、実際のワークフローに対して監査してください。企業のアーカイブから10〜20の実際の過去のケースのテストポートフォリオを作成してください。候補モデルをそれらに対して実行し、出力を当時行われた人間の専門家の決定と比較してください。故障モードを明示的に文書化してください:モデルは重要な事実を見逃しましたか?曖昧な言語を誤解しましたか?競合する制約の重み付けに失敗しましたか?これにより、ギャップが推論能力、ドメイン知識、またはタスク分解戦略のいずれであるかが明らかになります。
-
リソース見積もり:* ケースのキュレーション、テストの実行、および結果の分析に40〜60時間のシニアプラクティショナーの時間。コスト:時給に応じて8,000〜15,000ドル。ROI閾値:モデルが内部ベンチマークで70%未満のスコアを記録した場合、展開リスクは効率向上を上回ります。
3つの失敗パターンが一貫して出現
-
中核的な発見:* 現世代のモデルは、プロフェッショナルサービスにおける自律的な高リスク意思決定にまだ準備ができていません。
-
失敗が予測可能にクラスター化する理由:* テストにより、3つの繰り返し発生する故障モードが明らかになりました:
-
ギャップにフラグを立てずに不完全な分析。 モデルは、徹底的な事実確認や感度分析をスキップしながら、もっともらしい結論を生成しました。代替案を探索したり、下振れリスクを定量化したりせずに、単一の推奨パスを提示しました。実際の業務では、これは再作業を必要とするか、企業を責任にさらすことになります。
-
プレッシャー下での幻覚。 不完全な情報に直面したとき、モデルは曖昧さにフラグを立てるのではなく、データを発明しました。たとえば、ソース文書に提供されていない契約条項を検証するよう求められたとき、モデルは時々その条項を捏造したり、存在しないと自信を持って述べたりしました—正しい答えが「判断するにはデータが不十分」であるときに。
-
関連するサブ問題間での一貫性のない推論。 同じモデルが、単一のタスク内の関連する問題について矛盾するアドバイスを生成しました。ある実行ではリスクにフラグを立てましたが、同じシナリオの別の実行ではそれを見逃しました。この変動は、一貫性と先例が重要なプロフェッショナルサービスでは許容できません。
-
具体的な失敗ケース:* 法的デューデリジェンスシナリオでは、モデルは関連する契約条項を特定しましたが、リスクエクスポージャーを実質的に変更する曖昧な補償条項を見逃しました。同じ文書を再検討するよう促されたとき、時々問題を捉えましたが、他の実行では捉えませんでした。この一貫性のなさは、単一のモデルパスに依存できないことを意味します—複数回実行して矛盾を手動で調整する必要があり、効率向上を無効にします。
-
これが運用上重要な理由:* モデルが65%の確率で正しいが、どの65%かを予測できない場合、監督なしで使用することはできません。すべての出力をレビューする必要があり、時間の節約が排除されます。さらに悪いことに、モデルが自信を持って間違った答えを生成した場合、レビューがそれを捉える前に、ジュニアスタッフやクライアントを誤解させる可能性があります。
独自のパフォーマンスベースラインを確立する方法
-
即座に取るべき行動:* 公開データセットでの印象的なベンチマークスコアが、あなたの領域やクライアント基盤に当てはまると仮定しないでください。
-
3つのステップでベースラインを確立する:*
-
代表的なテストセットを作成する(第1~2週)。 最も優秀な実務者に、典型的な業務を代表する過去の5~10件のケースまたはシナリオを特定してもらいます。これらは難易度の範囲を網羅し、判断が重要となるエッジケースを含める必要があります。それぞれについて正解または専門家の決定を文書化します。推定作業量:上級実務者の時間で20~30時間。
-
候補となるモデルをテストセットで実行する(第2~3週)。 検討している各モデル(例:GPT-4、Claude、オープンソースの代替品)について、すべてのテストケースで実行します。はい/いいえの答えだけでなく、完全な出力を記録します。推定作業量:5~10時間(ほぼ自動化)。
-
正確性、完全性、一貫性を測定する(第3~4週)。 各モデルの出力を以下の項目で評価します:
- 正確性: 正しい結論または推奨事項に到達したか?
- 完全性: すべての重要な事実、リスク、または代替案を特定したか?
- 一貫性: 同じシナリオで2回実行した場合、同じ推論を生成したか?
- 信頼度の較正: 適切な場合に不確実性を示したか、それとも信頼度を過大評価したか?
推定作業量:専門家によるレビューで15~20時間。
-
解釈の閾値:* モデルが社内ベンチマークで70~80%未満のスコアの場合、アシスタントとしてのみ扱います。クライアントへの納品前に、すべての出力に対して人間によるレビューと承認を必須とします。80~90%のスコアの場合、重要度の高い決定については必須レビューを伴う監督付き展開を検討します。90%以上の場合、低リスクのタスクについて、抜き取り監査を伴う自律的使用を試験的に実施できます。
-
費用対効果のチェックポイント:* このテスト費用(約5,000~10,000ドル)を、クライアントに対する単一のエラーのコスト(評判の損害、やり直し、責任)と比較します。単一のミスが50,000ドル以上のコストになる可能性がある場合、テストへの投資は正当化されます。