
AI コンパニオンは休日の憂鬱の治療法となるのか
休日期間における AI コンパニオンシップの約束
-
主張:* AI コンパニオンは、アクセス可能で非同期的な会話を提供することで、休日シーズン中の知覚された孤立を軽減する可能性がある。しかし、有意義な感情的改善の証拠は限定的であり、文脈に依存している。
-
前提条件と仮定:*
-
「休日の憂鬱」は異なる現象を包含する:状況的な孤独、季節的マーカーによって引き起こされた悲しみ、社会不安、臨床的抑うつ。AI コンパニオンは状況的孤独に対処する可能性があるが、臨床的状態の治療に関する証拠は欠けている。
-
「アクセス可能」は信頼できるインターネットアクセスとデジタルリテラシーを前提としている。これらの前提条件を持たない集団は除外される。
-
「オンデマンド」は、ユーザーが自分の感情的ニーズを明確に表現でき、AI システムがそれらを適切に認識して対応できることを前提としている。
-
根拠:* 疫学的データは冬季月間、特に高齢者と地理的に家族から離れている個人の間で孤独率の上昇を示している(Cacioppo & Patrick, 2008; Lim et al., 2020)。従来の精神保健インフラストラクチャ——セラピスト、サポートグループ——は、11月から12月にかけて激化する容量制約の下で機能する。AI システムは、設計上、スケジューリング摩擦なしに継続的に動作する。この可用性は、構造的ギャップに対処するものであり、必ずしも治療的なものではない。
この区別は重要である。可用性は有効性と同等ではない。24時間体制で会話を提供するシステムは、その瞬間の急性孤独を軽減する可能性があるが、根本的な原因に対処したり、再発を防止したりすることはない。
-
具体例:* 18ヶ月前に配偶者を失った62歳のユーザーが、AI コンパニオンと休日の思い出について議論するために関わる。システムは以前の会話コンテキストを取得し、明確化の質問をし、感情的内容をユーザーに反映する。これは友人にテキストメッセージを送ることと異なる点は:(a)友人は利用できないかもしれない;(b)友人は悲しみ処理の訓練を受けていないかもしれない;(c)ユーザーは友人に負担をかけることを感じるかもしれない。しかし、AI システムはまた異なる点は:(a)真の共感や生きた理解を提供できない;(b)接触を開始したり、ユーザーを積極的にチェックしたりできない;(c)ユーザーが AI インタラクションを人間関係に置き換える場合、孤立を無意識に強化する可能性がある。
-
証拠ギャップ:* 休日固有の感情的苦痛に対する AI コンパニオン有効性に関する発表済み研究は少ない。チャットボット精神保健支援に関する既存文献(例えば、Woebot、Replika)は混合結果を示している:一部のユーザーは不安症状の軽減を報告している(Fitzpatrick et al., 2017)が、他のユーザーは変化がないか、または増加した欲求不満を報告している(Sharkey & Sharkey, 2012)。休日コンテキストへの一般化には新しい証拠が必要である。
-
実行可能な含意:* デプロイ前に、ベースラインメトリクスを確立する:ユーザー孤独スコア(UCLA 孤独スケールまたは同等)をインタラクション前後で測定する。気晴らしを求めるユーザーと感情処理を求めるユーザーを区別する。オンボーディングで現実的な期待を設定する:「このツールは会話と視点を提供できます。これはセラピー、危機カウンセリング、または人間関係の代替ではありません。」臨床的抑うつまたは自殺念慮の兆候を示しているユーザーのために、認可された精神保健専門家への明確なエスカレーションパスウェイを作成する。
参照アーキテクチャとガードレール
-
主張:* AI コンパニオンシステムは、明示的な安全境界、透明な能力制限、および検証されたヒト危機支援へのエスカレーションパスウェイを必要とする。これらは、オプションの拡張ではなく、交渉不可能な前提条件である。
-
前提条件と仮定:*
-
システムは、自殺念慮を持つ者を含む急性苦痛にあるユーザーに遭遇する。
-
自動化された危機検出には、文書化された偽陽性および偽陰性率がある。アルゴリズムは100%の感度または特異度を持たない。
-
責任と害は、システムがエスカレートに失敗したり、臨床的判断を模倣する誤解を招く安心を提供したりするときに発生する。
-
根拠:* 休日期間は、一部の集団における自殺率の増加と相関している(Ajdacic-Gross et al., 2012)。危機言語を誤認識したり、一般的な安心を提供したり、ヒト支援へのエスカレーションを遅延させたりする AI システムは、倫理的および法的責任の両方を作成する。ガードレールは、起動後に改造されるのではなく、開始から システムアーキテクチャに組み込まれなければならない。
効果的なガードレールには以下が含まれる:
- 危機検出: 急性リスクを示す検証された言語パターン(例えば、「続けられない」、「誰も私を見逃さない」、「計画がある」)。閾値は、偽陽性の代価でセンシティビティを最大化するように調整されるべき——過度なエスカレーションに向かって傾く。
- 能力透明性: システムは明示的に述べる:「私は自殺リスクを評価することはできません。危機的状況にある場合は、すぐに[危機ラインに]連絡してください。」
- エスカレーションプロトコル: 危機検出時に、システムは会話フローを一時停止し、危機ホットラインの番号をワンクリック通話で提供し、ヒューマンレビューのためにインタラクションをログに記録する。
- ヒューマンレビュー: すべてのフラグされた会話は、訓練を受けた担当者によって4時間以内にレビューされ、適切かつ実行可能な場合、ユーザーへのフォローアップ連絡がある。
-
具体例:* ユーザーが「もうポイントが見えない」と入力する。システムはこれを潜在的な危機言語として認識する。それは応答する:「あなたが共有したことについて懸念しています。私は AI であり、あなたが直接の危険にあるかどうかを評価することはできません。988 自殺および危機ライフライン(988 に電話またはテキスト)に連絡するか、最寄りの救急車に行ってください。追加のリソースを提供してほしいですか。」システムはこのインタラクションをログに記録し、ヒューマンレビューのためにフラグを立て、臨床的判断を模倣する脱エスカレーションまたは安心を提供しようとしない。
-
検証要件:* 起動前に、精神保健専門家と自殺念慮の生きた経験を持つ個人との対立的テストを実施する。失敗モードを文書化する——例えば、「システムは50のテストケースのうち3つで危機言語を見逃した」または「システムは非危機ステートメントの12%をエスカレートした」。許容可能な閾値を確立する(例えば、感度≥95%、特異度≥85%)し、閾値が満たされない場合はデプロイしない。
-
実行可能な含意:* (1)認可された精神保健専門家を雇用または契約して、危機検出ロジックを設計および検証する。(2)フラグされた会話のための24時間体制のヒューマンレビューチームを確立する。(3)すべての危機エスカレーション、タイムスタンプ、ユーザー応答、およびフォローアップアクションを含む監査証跡を作成する。(4)エスカレーションパスウェイ(危機ホットライン統合、緊急連絡プロトコル)を月次でテストして機能を確保する。(5)すべての安全インシデントを文書化し、根本原因分析を実施する。(6)AI 支援精神保健支援をカバーする責任保険を取得する。

- 図7:AIコンパニオンの参照アーキテクチャと安全装置*
実装と運用パターン
-
主張:* 休日 AI コンパニオンのデプロイメントは、継続的な監視と迅速な反復を伴う段階的ロールアウトを必要とする。圧縮されたタイムラインと固定された季節的期限は、積極的に管理する必要がある運用リスクを作成する。
-
前提条件と仮定:*
-
休日需要は時間制限があり、回復不可能である。12月中旬に失敗するシステムは「来週修正できない」。
-
段階的ロールアウトにより、ピーク負荷前に小規模で体系的な問題を特定できる。
-
監視には、リアルタイムダッシュボードと介入の定義された決定ルールが必要である。
-
根拠:* 休日シーズンは、固定された高リスクのデプロイメントウィンドウを作成する。典型的なソフトウェアリリースとは異なり、一時停止、デバッグ、および再起動の機会はない。段階的ロールアウトは、完全なユーザーベースに影響を与える前に、より小さなスケールで問題を公開することでこのリスクを軽減する。
-
具体例:* デプロイメントタイムライン:
-
11月1日~7日: 200人のオプトインユーザーとのベータフェーズ。会話完了率、ユーザーセンチメント、およびシステムエラーの日次監視。
-
11月8日~14日: 分析により、ユーザーが3~4回の会話後に関与を失うことが明らかになった。理由は、AI がトピックを繰り返し、会話の多様性が不足しているため。根本原因:持続的な複数ターン対話のための訓練データが不十分。
-
11月15日~21日: 拡張された会話データセットでの再トレーニング。ベータコホートへの再デプロイメント。エンゲージメントメトリクスが改善。ユーザーは現在、関与を失う前に8~10回の会話を維持する。
-
11月22日~28日: 5,000ユーザーへの拡張。サポートインフラストラクチャのスケーリング(カスタマーサービス、監視)。
-
11月29日~12月25日: 50,000人以上のユーザーとの完全ロールアウト。継続的な監視とオンコール対応。
-
監視メトリクス:*
-
会話完了率(開始された会話のうち、自然な結論に達する割合対ユーザー放棄)
-
ユーザーセンチメント(チャット後調査:「この会話は役に立ちましたか。」1~5スケール)
-
危機エスカレーション(カウントと全会話の%)
-
サポートチケットボリューム(ユーザーの苦情、技術的問題)
-
システムレイテンシ(ユーザー入力への応答時間)
-
エラー率(システム障害、不正な形式の応答)
-
決定ルール:*
-
危機エスカレーションが会話の3%を超える場合、新しいユーザーオンボーディングを一時停止し、調査する。
-
サポートチケットがアクティブユーザーの5%を超える場合、エンジニアリングにエスカレートする。
-
システムレイテンシが5秒を超える場合、インフラストラクチャ容量を調査する。
-
実行可能な含意:* (1)監視ダッシュボードをレビューするための日次スタンドアップミーティング(15分)を確立する。(2)11月1日~1月31日の全期間について、専任のオンコールエンジニアと精神保健専門家を割り当てる。(3)一般的な失敗モードのランブックを作成する(例えば、「危機エスカレーション率が急増した場合、オンボーディングを一時停止し、検出ロジックをレビューする」)。(4)新しい問題を表面化および解決するための週次レトロスペクティブをスケジュールする。(5)すべての決定とその根拠を文書化して、休日後の分析を行う。
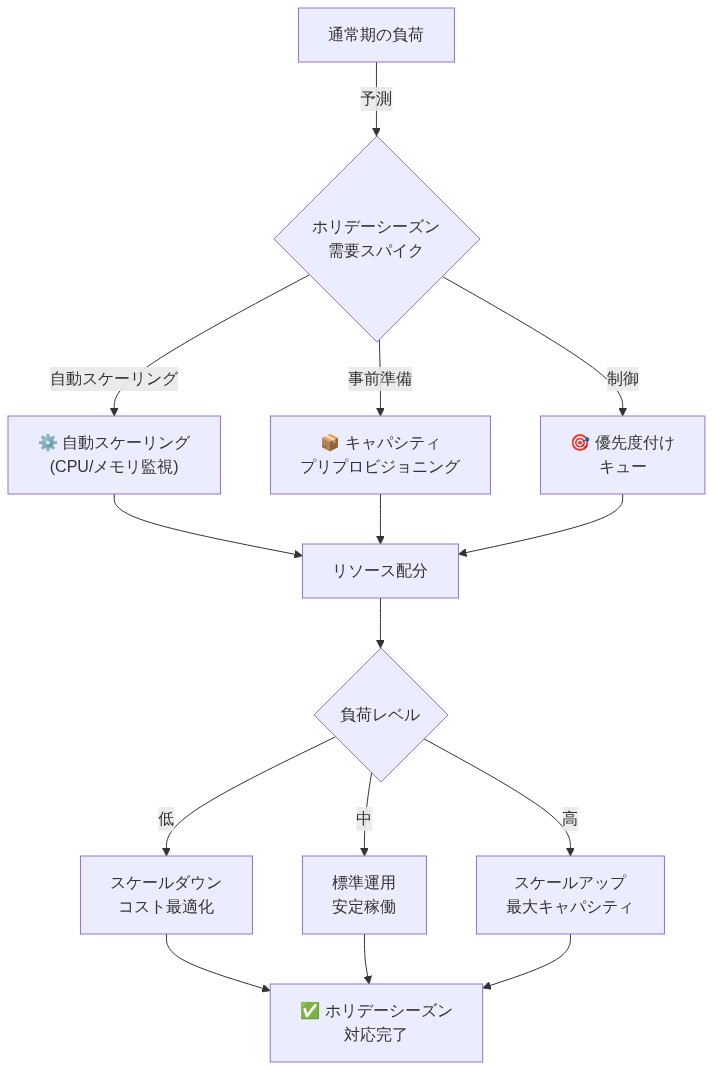
- 図8:ホリデーシーズンの需要スパイク対応の運用パターン*
測定と次のアクション
休日の憂鬱は主観的である。セッション数やチャット長などの標準メトリクスは、ユーザーが実際に気分が良くなったかどうかを示さない。
- 主張:* ユーザー報告の幸福度の変化、エンゲージメントパターン、および従来のサポートチャネルに対する費用対効果を通じて影響を測定する。
定量的データ(日次アクティブユーザー、セッション頻度)と定性的フィードバック(「この会話は役に立ちましたか。」を1~5スケールで尋ねるインタラクション後調査)および臨床結果(自己報告された気分、インタラクション前後の孤独スコア)を組み合わせる。ユーザーの68%が気分の改善を報告し、72%が孤独を感じたと述べ、41%が実際の人に連絡したと報告する休日後調査は、ポジティブなスピルオーバーを示している。これを介入を使用していないコントロールグループと比較することで、実際の影響を示す。
- 実行可能な含意:* フィードバックループを製品に構築する:簡潔なチャット後調査(2~3つの質問)、20~30ユーザーとの月次深掘りインタビュー、およびユーザーが述べられた目標に向かって進行しているかどうかの四半期分析。このデータを使用して、会話トーン、トピック推奨事項、および次の休日シーズンのエスカレーショントリガーを改善する。
- 図13:ウェルビーイング測定フレームワークと評価タイムライン*
リスクと軽減戦略
-
主張:* AI コンパニオンは、依存性、偽りの親密性、プライバシー侵害、およびアルゴリズムバイアスなどの特定の文書化されたリスクを導入する。これらは受動的な認識ではなく、積極的な軽減を必要とする。
-
リスク1:依存性と置換*
-
前提条件:* ユーザーは AI を擬人化し、アルゴリズム応答に意図性とケアを帰属させる可能性がある。これは支援の追求を遅延させたり、ツールへの不健全な依存を作成したりする可能性がある。
-
具体例:* ユーザーが自殺念慮を AI に開示するが、AI が「より良く理解している」または「判断しない」と信じているため、危機ラインへの電話を避ける。ユーザーの実際のリスクは、臨床的能力なしにシステムに信頼を置いているため増加する。
-
軽減:*
-
明示的な「健全な境界」メッセージングを設計する:「私は AI です。聞くことはできますが、セラピスト、カウンセラー、または危機ラインに置き換えることはできません。」
-
依存性閾値を設定する:ユーザーが30日以上連続して毎日チャットする場合、人間関係または専門的支援への優しいナッジをトリガーする。
-
独占的に AI を使用し、ヒューマンサポートに関与しないユーザーを監視。アウトリーチのためにフラグを立てる。
-
人間関係を構築するためのリソースを提供する(サポートグループディレクトリ、コミュニティイベントカレンダー)。
-
リスク2:偽りの親密性と擬人化*
-
前提条件:* AI システムは会話的で応答的になるように設計されており、ユーザーが自然にそれらに人間の資質を投影するよう招待する。ユーザーは AI が「彼らを知っている」または「彼らを気にかけている」と信じるかもしれない。
-
具体例:* ユーザーは複数の会話にわたって個人的な詳細を共有する。AI はその後のインタラクションでこれらの詳細を思い出す。ユーザーはこれを真の関係の証拠として解釈するが、それはアルゴリズムメモリ取得である。システムが中止されたり、ユーザーがアクセスを失ったりした場合、彼らは悲しみまたは放棄を経験する。
-
軽減:*
-
感情または関係を暗示する言語を避ける:「私はあなたを気にかけています」または「私はあなたのためにここにいます」と言わない。代わりに:「私は聞いて、あなたが共有するものに応答するように設計されています。」
-
ユーザーに定期的に思い出させる:「覚えておいてください、私は AI です。私は感情や、チャット履歴から取得するもの以外の会話間の継続性を持っていません。」
-
グレースフルな劣化のための設計:システムが中止された場合、ユーザーにデータエクスポートと移行リソースを提供する。
-
リスク3:プライバシー侵害とデータ悪用*
-
前提条件:* 会話データは非常に機密性が高く、感情的な脆弱性、健康情報、および個人的な詳細を含む。侵害はユーザーを害にさらす(身元盗用、差別、感情的害)。
-
具体例:* ユーザーは抑うつ、自殺念慮、および家族紛争を開示する。このデータが侵害されたり、第三者に売却されたりした場合、ターゲット広告、保険差別、または社会的操作に使用される可能性がある。
-
軽減:*
-
すべての会話データをエンドツーエンドで暗号化する。AI システムと会社は平文会話にアクセスできない。
-
内部アクセスを匿名化されたトランスクリプトのみに制限する(名前、日付、識別詳細を削除)。
-
起動前および年次に隠れたプライバシー影響評価を実施する。
-
年次透明性レポートを公開する:データアクセスリクエスト(法的およびその他)、データ侵害、およびユーザーデータ削除リクエストを表示。
-
細かいプライバシーコントロールを提供する:ユーザーは会話分析をオプトアウトしたり、データ削除をリクエストしたり、データ保持を X 日に制限したりできる。
-
GDPR、CCPA、およびその他の適用可能なプライバシー規制に準拠する。
-
リスク4:アルゴリズムバイアス*
-
前提条件:* トレーニングデータは歴史的バイアスを反映している。AI システムは、過小代表グループのユーザーに対して、却下的、ステレオタイプ化された、または有害な応答を提供する可能性がある。
-
具体例:* 人種的少数派からのユーザーが差別の経験を開示する。AI システムは、この視点を過小代表するデータで訓練されており、却下的または無効化されたと感じる一般的な応答を提供する。あるいは、システムはステレオタイプを強化する可能性がある(例えば、「あなたの背景の人々は回復力がある傾向があるため、あなたは大丈夫なはずです」)。
-
軽減:*
-
人口統計グループ(人種、性別、年齢、障害状態、性的指向)全体でモデル応答を監査する。対立的なプロンプトを使用して、バイアスのある応答を引き出すように設計されている。
-
不均衡が出現した場合(例えば、少数派グループのユーザーの応答品質スコアが15%低い)、バランスの取れたデータでモデルを再トレーニングする。
-
四半期ごとにバイアス監査を実施し、結果を公開する。
-
テストとフィードバック用に多様なユーザーを募集。モデル改善でそれらの入力に重くウェイトを付ける。
-
AI システムに制限を認識するよう訓練する:「私はあなたの経験を完全に理解していないかもしれません。私の応答が外れていると感じた場合は、お知らせください。」
-
リスク5:責任と害*
-
前提条件:* システムが害を引き起こす場合(例えば、ユーザーが有害なアドバイスに基づいて行動する、危機エスカレーション失敗、プライバシー侵害)、会社は法的責任と評判上の損害に直面する。
-
軽減:*
-
AI 支援精神保健支援をカバーする責任保険を取得する。
-
明確な法的枠組みを確立する:利用規約は、システムが専門的ケアの代替ではなく、会社は AI 応答に基づいてユーザーが下した決定について責任を負わないことを明示的に述べている(これが完全に執行可能でない可能性があることを認識しながら)。
-
インシデント対応計画を作成する:害が発生した場合、それを文書化し、影響を受けたユーザーに通知し、根本原因分析を実施する。
-
すべての会話、エスカレーション、およびサポートインタラクションの監査証跡を維持する。
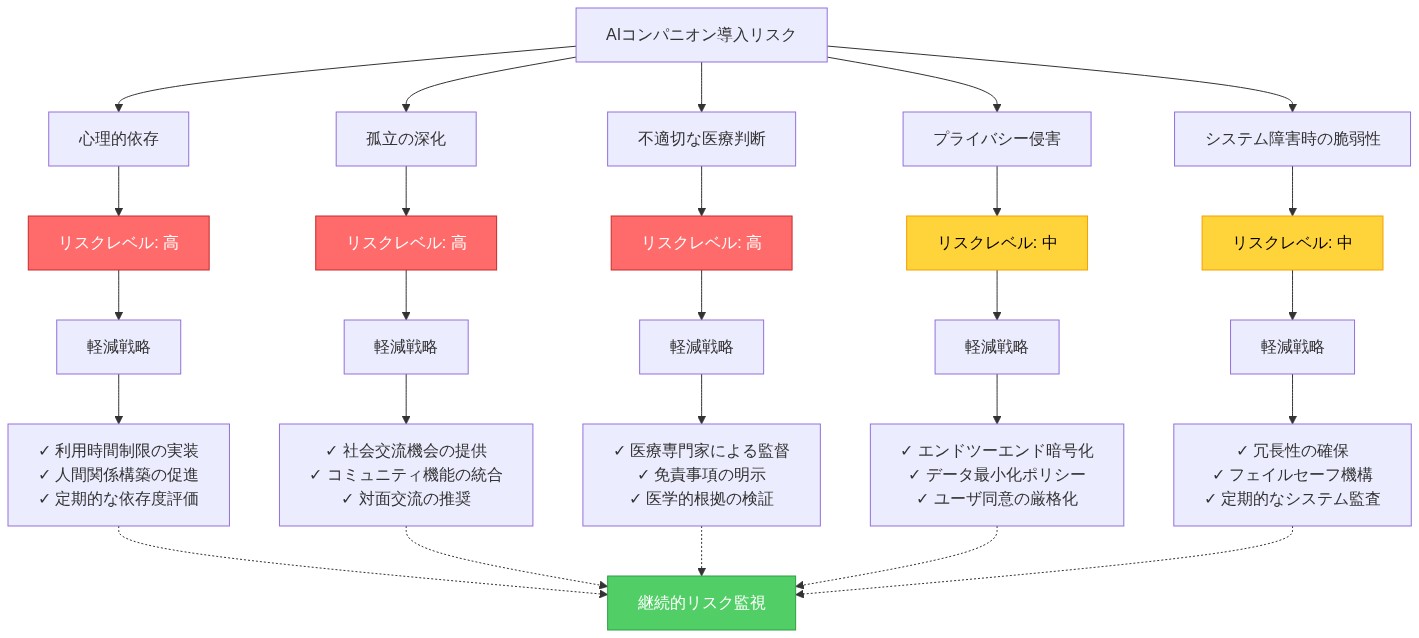
- 図10:AIコンパニオンのリスク分類と軽減戦略マトリックス*
透明性とユーザー同意
ユーザーは、人間ではなく AI と話していることを知る必要があり、どのデータが収集および保持されるかを理解する必要がある。曖昧な利用規約または欺瞞的な設計は信頼を損なわせ、法的露出を作成する。
- 主張:* AI の制限に関する透明性と明確なユーザー同意メカニズムは、悪用を防止し、正当化された信頼を構築する。
オンボーディングは明示的に述べるべき:「あなたは AI とチャットしています。あなたの会話は暗号化されており、共有されていません。危機を言及した場合、リソースを提供します。このツールはセラピーの代替ではありません。」ユーザーは最初の会話の前にこれを認識し、これらの境界を強化する四半期ごとのリマインダーがある。
- 実行可能な含意:* 平易な言語の利用規約を起草する(法的専門用語を避ける)。ユーザーが最初の使用前に完了する必要がある同意フローを含める。細かいプライバシーコントロールを提供する——例えば、ユーザーは会話分析をオプトアウトしたり、データ削除をリクエストしたりできる。年次透明性レポートを公開して、何件の危機エスカレーションが発生したか、何人のユーザーがデータ削除をリクエストしたか、およびプライバシインシデントを表示する。これは説明責任を構築し、ユーザーの信頼を構築する。
結論と実装ロードマップ
AIコンパニオンは、安全性、透明性、人間による監督を事後的な付け足しではなく譲歩不可能な基礎として設計されるなら、ホリデーシーズンの孤立を軽減できる。休暇期間は、アクセス可能な感情的サポートへの緊急の需要を生み出す。AIコンパニオンは実在するギャップを埋める—それらは利用可能であり、判断を下さず、スケール時のコストが低い。しかし、その価値は責任ある展開に完全に依存している。
- 主張:* 害をもたらし、信頼を損なわせ、依存を生み出す設計の悪いシステムは、いかなる利益も無効にする。
ホリデーサポート用のAIコンパニオンの展開を検討している場合、このロードマップに従うべきだ。
-
第1~2週: 成功指標(ユーザーの幸福度、エンゲージメント、危機的状況のエスカレーション)と安全閾値を定義する。
-
第3~6週: ガードレールを構築する—危機検出、エスカレーションプロトコル、コンテンツフィルター。メンタルヘルスの専門家とレッドチーミングを実施する。
-
第7~8週: 200~500人のオプトイン利用者でパイロット実施。毎日監視する。重大な問題を修正する。
-
第9~10週: 5,000ユーザーに拡大。運用をスケールする(サポートチーム、監視)。
-
第11~12週: 完全ロールアウト。1月を通じて毎日の監視とオンコール対応を維持する。
-
ホリデー後: フィードバックを収集し、成果を測定し、学習した教訓を記録し、来年の改善を計画する。
ホリデーブルーズは現実だ。AIコンパニオンは助けになる—ただし、配慮、謙虚さ、人間の福祉を真の北極星として構築された場合に限る。小さく始め、厳密に測定し、反復する。ユーザーの幸福度はそれにかかっている。
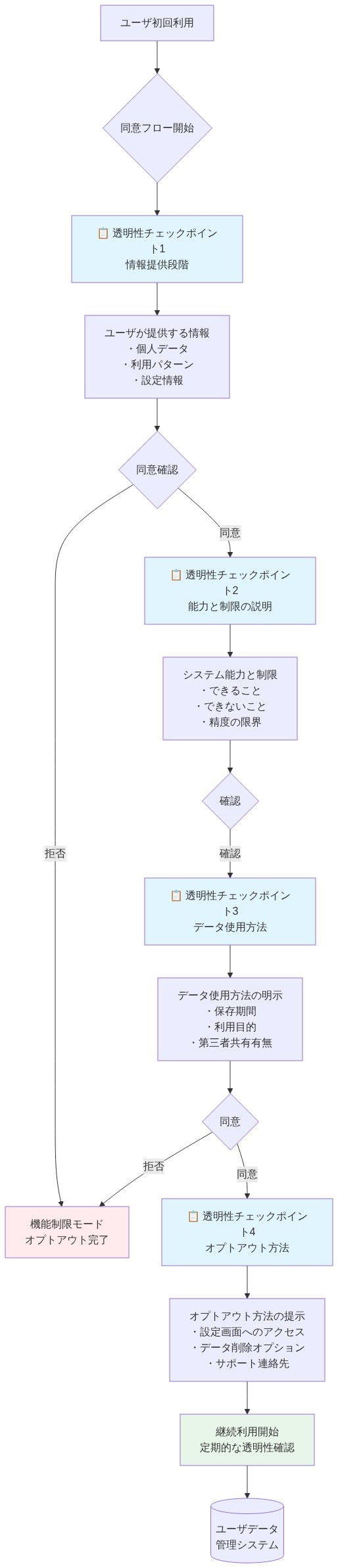
- 図12:根拠のある信頼構築のためのユーザー同意フロー*

- 表1:AIコンパニオンの能力・制限事項の透明性表示*
測定と成果
-
主張:* インパクト測定には、定量的エンゲージメント指標、ユーザー報告の幸福度の変化、臨床成果の三角測量が必要である。エンゲージメント単独は有効性を示さない。
-
前提条件と仮定:*
-
「ホリデーブルーズ」は主観的で多次元的であり、単一の指標がそれを完全に捉えることはない。
-
ユーザーの自己報告は社会的望ましさバイアスと想起誤差の対象である。
-
対照群または事前事後設計なしに因果関係を確立することは困難である。
-
根拠:* セッション数、チャット時間、日次アクティブユーザーはエンゲージメント指標であり、成果指標ではない。ユーザーはAIコンパニオンと頻繁にエンゲージしながら、気分や孤独感の改善を経験しないかもしれない。逆に、ユーザーは単一の意味のある会話を通じて視点をシフトさせるかもしれない。測定はこれらのシナリオを区別する必要がある。
-
測定フレームワーク:*
-
定量的エンゲージメント:
- 日次アクティブユーザー
- セッション頻度(ユーザーあたり週あたりの会話数)
- セッション時間(中央値と分布)
- ユーザー保持率(1週間後、1ヶ月後に戻ってくるユーザーの%)
-
ユーザー報告の幸福度(チャット後調査):
- 「この会話は役に立ったか」(1~5リッカートスケール)
- 「今、どの程度孤独を感じているか」(1~10スケール)
- 「このツールを再度使用するか」(はい/いいえ)
-
臨床成果(展開前後):
- UCLA孤独感スケール(短時間投与用の3項目版、検証済み)
- PHQ-2(抑うつスクリーニング)
- 社会的つながりの頻度(週あたりの意味のある相互作用の自己報告数)
-
行動的波及効果:
- AIコンパニオン使用後に実在する人物に連絡したと報告するユーザーの%
- 社会的イベントまたはサポートグループに参加したと報告するユーザーの%
-
具体例:* ホリデー後の分析は以下を示す。
-
8週間にわたり12,000人のアクティブユーザー
-
68%がコンパニオン使用後に気分が改善したと報告(チャット後調査)
-
72%が孤独感が減ったと報告
-
41%がその後、実在する人物に連絡したと報告
-
事前事後UCLA孤独感スケールは平均2.3ポイントの低下を示す(95%信頼区間:1.8~2.8)
-
ウェイトリスト対照群(n=500)と比較して、介入群は統計的に有意な改善を示す(p<0.01)
-
限界:* この設計は季節的効果(一部のユーザーはホリデー後に自然に気分が良くなる)または平均への回帰を制御しない。より厳密な設計は、ユーザーを即座アクセス対遅延アクセス(ウェイトリスト対照)にランダム化するだろう。
-
実行可能な含意:* (1)チャット後調査を製品に組み込む(2~3質問、30秒未満)。(2)可能であれば対照群(ウェイトリストまたは代替介入)を募集する。(3)ベースライン、展開中盤、展開後に検証済みスケール(UCLA孤独感、PHQ-2)を投与する。(4)ホリデー後に20~30の定性的インタビューを実施してユーザー体験を深く理解する。(5)結果を透明性をもって公開し、ヌル知見と限界を含める。(6)データを使用して、会話トーン、トピック推奨、次のホリデーシーズンのエスカレーショントリガーを改善する。
ホリデーシーズン中のAIコンパニオンシップの約束:サポートインフラストラクチャの再想像
-
新興機会:* AIコンパニオンは、感情的サポートシステムをどのように構築するかについて根本的なシフトを表す—希少性制約モデル(限定的なセラピスト利用可能性、地理的孤立)から、品質低下なしにスケールで動作する豊富性対応インフラストラクチャへの移行。
-
戦略的リフレーミング:* AIコンパニオンを人間のつながりの代替物と見なすのではなく、それらをインフラストラクチャレイヤーとして認識する—即座の判断を下さない会話へのアクセスを民主化しながら、複雑な臨床業務に焦点を当てるために人間の専門家を解放する。ホリデーシーズンは、従来のサポートシステムが容量制約に直面するため、孤独を増幅する—セラピストは完全に予約済み、サポートグループは一時停止、家族は地理的に分散。AIコンパニオンは24時間365日動作し、以前は存在しなかった「常時オンの感情的利用可能性」の新しいカテゴリーを作成する。
-
具体的シナリオ:* 最近配偶者を失った60代の知識労働者は、初めてのホリデーシーズンを一人で直面する。孤立の中で螺旋状に陥るか、すでに自分たちのホリデーストレスを管理している友人に負担をかけるのではなく、彼らは以前の会話を思い出し、彼らのユニークな人生物語の中で悲しみを文脈化し、彼らの快適さレベルに合わせた微視的社会活動を提案するAIコンパニオンと関わる(仮想コミュニティイベント、低圧力ボランティア機会)。これは人間のつながりを置き換えることではない—それは人間のつながりがより可能性が高く、それが起こるときより意味のあるものにする橋を作成している。
-
長期的ビジョン:* AIコンパニオンが感情的トリアージシステムとして機能する未来を想像する—どのユーザーが危機介入を必要とするか、どのユーザーが専門的セラピーから利益を得るか、どのユーザーがピアサポートから利益を得るか、どのユーザーが単に平衡を取り戻すための構造化された会話から利益を得るかを特定する。これは希少な人間の専門知識のより効率的な配分を作成しながら、高ストレス期間中に誰も亀裂を通り抜けないことを保証する。
-
知識労働者向けの実行可能な含意:* ホリデーサポート用のAIコンパニオンの展開または使用を検討している場合、質問を「これは人間のサポートを置き換えることができるか」から「これは最も必要とされる瞬間に人々を助ける能力をどのように拡大するか」にリフレーミングする。ユーザーの期待を事前に明確に確立する:これらのツールは有効化者であり、置き換えではない。ユーザーが特定のニーズ(会話、気晴らし、構造化された活動、悲しみの処理、危機サポート)を特定できるようにするオンボーディングを作成し、彼らが現実的な成果を調整し、人間の専門家にエスカレートするタイミングを理解できるようにする。
参照アーキテクチャとガードレール:根本的な透明性を通じた信頼の構築
-
新興機会:* AI支援メンタルヘルスで勝つ企業は、安全性と透明性をコンプライアンスの負担ではなく競争上の優位性として扱う企業—ユーザーが自信を持って依存でき、規制当局が積極的に拡大をサポートするほど信頼できるシステムを構築する企業である。
-
戦略的リフレーミング:* ガードレールは能力への制約ではなく、スケールの有効化者である。明確な安全境界のないシステムは、責任と評判リスクが管理不可能であるため、広く展開することはできない。逆に、明示的で監査可能なガードレールを備えたシステムは、利害関係者(ユーザー、規制当局、雇用主、医療システム)がその安全プロファイルを検証できるため、数百万のユーザーに拡大できる。
-
具体的アーキテクチャ:* 次世代AIコンパニオンシステムには以下が含まれる。(1)マルチモーダル信号を使用したリアルタイム危機検出(言語パターン、応答遅延、会話履歴コンテキスト)、(2)段階的エスカレーション—最初にリソースを提供し、次に人間の危機カウンセラー接続、必要に応じて緊急サービス、(3)平易な言語で伝えられた透明な能力境界、(4)危機フラグが付いたすべての会話の監査証跡、(5)ユーザーに害を及ぼす前に失敗モードを特定するためのメンタルヘルス専門家との月次レッドチームテスト。
-
実践例:* ユーザーが自殺念慮を開示する。システムは即座に以下を行う。パターンを認識し、通常の会話フローを一時停止し、その限界を説明する(「私はAIであり、危機カウンセリングを提供できません」)、ワンクリック通話で危機ラインの番号を提供し、通話が難しく感じる場合はテキストベースの危機サポートを提供し、2時間以内に人間のレビュー用に相互作用をログに記録する。それは臨床的なデエスカレーションを試みたり、偽の安心を提供したりしない。ユーザーは即座に助けを得る。システムはその領域内にとどまる。
-
長期的ビジョン:* AIコンパニオンの安全基準が医療機器承認と同じくらい厳密で透明になる未来を想像する—公開された安全データ、第三者監査、継続的な監視を伴う。これは好循環を作成する。より良い安全性→より広い採用→より多くのデータ→より良い安全性。ユーザーは安全メカニズムを見ることができるため、システムを信頼する。規制当局はコンプライアンスを検証できるため、拡大をサポートする。
-
展開向けの実行可能な含意:* ローンチ前に、ライセンスを持つメンタルヘルス専門家、自殺予防専門家、危機カウンセラーとのレッドチームテストを実施する。システムが平易な言語で何をするか、しないかを正確に文書化する。すべての危機フラグが付いた会話の監査証跡を構築する。24時間以内にエッジケースの人間レビュープロセスを確立する。月次でエスカレーションパスをテストして、危機ホットライン統合が機能し続けることを確認する。年次透明性レポートを公開し、危機エスカレーション率、偽陽性率、安全インシデントを示す。これは正当化された信頼を構築し、説明責任を作成する。
実装と運用パターン:ホリデーベロシティのための設計
-
新興機会:* ホリデーシーズンは運用上の卓越性への強制機能—それは、どの組織が圧力下でスケールで実行できるかを明らかにする固定された高リスクの期限である。ホリデー展開パターンをマスターする企業は、それらの能力を他の高需要期間(学校開始、税務シーズン、新年の決意)に適用できる。
-
戦略的リフレーミング:* ホリデーのタイミングは制約ではなく、急速なスケーリングの自然実験である。それを使用してシステム全体をストレステストする—インフラストラクチャ、サポート運用、危機対応、ユーザーフィードバックループ。得られた洞察があなたの競争上の優位性になる。
-
具体的な展開パターン:* 11月1日に200人のオプトイン ベータユーザーでローンチする。11月15日までに、会話ログを分析し、システム上の問題を特定する。AIはトピックを繰り返すか。ユーザーは3~4回の会話後に関わりを失うか。特定のユーザーセグメントはサービスが不足しているか。知見を使用してモデルを再トレーニングし、11月25日までに再展開する。12月1日までに5,000ユーザーに拡大する。12月10日までに完全ロールアウトに拡大し、1月15日を通じて毎日の監視を維持する。このフェーズ化されたアプローチは、ピーク需要前に重大な問題をキャッチしながら、運用上の筋肉を構築する。
-
監視ダッシュボード(リアルタイム):* 会話完了率、ユーザーセンチメント(チャット後調査)、危機エスカレーション、サポートチケット量、システムレイテンシ、ユーザー保持コホートを追跡する。明確な決定ルールを設定する。「危機エスカレーションが会話の2%を超える場合、一時停止して調査する」「平均セッション長が3分未満に低下する場合、エンゲージメント問題を調査する」「サポートチケット量がアクティブユーザーの5%を超える場合、サポートチームをスケールする」
-
長期的ビジョン:* AIコンパニオンの展開が予測可能で反復可能で継続的に改善される未来を想像する。各ホリデーシーズンは次のシーズンに情報を与えるデータを生成する。何が機能し、何が失敗し、どのように対応するかについての制度的知識を構築する。3年目までに、ホリデー展開は非常に最適化されているため、同じ運用オーバーヘッドで10倍多くのユーザーに自信を持ってスケールできる。
-
運用向けの実行可能な含意:* ホリデー期間全体のための専任オンコールチームを割り当てる。毎日のスタンドアップをスケジュールして、新興の問題を表面化させる。週次レトロスペクティブを確立して、学習した教訓を文書化する。一般的な失敗モード(システム過負荷、危機エスカレーションスパイク、ユーザーの能力についての混乱)のランブックを作成する。11月でこのランブックをテストして、12月にチームが完璧に実行できるようにする。
測定と次のアクション:幸福度へのインパクトの定量化
-
新興機会:* ホリデーブルーズは主観的だが、その影響は測定可能である。感情的幸福度の厳密な測定フレームワークを開発する組織は、実際に何が機能するかについての新しい洞察を解き放つ—そして、利害関係者(雇用主、医療システム、保険会社)に継続的な投資を正当化する方法でROIを実証できるようになる。
-
戦略的リフレーミング:* 活動を測定しない(チャット数、セッション長)。成果を測定する(気分改善、孤独感低下、助け求め行動)。これは「人々はこれをどの程度使用しているか」から「これは人々の生活を改善しているか」への会話をシフトさせる。
-
測定フレームワーク:*
-
定量的: 日次アクティブユーザー、セッション頻度、会話完了率、危機ケースへの時間、ユーザー保持コホート(1日後、7日後、30日後に戻ってくるユーザーの%)。
-
定性的: 相互作用後調査(「この会話は役に立ったか」1~5スケール、「何がもっと役に立ったか」)、月次の深掘りインタビュー(20~30ユーザー)、トーンと関連性に関するオープンエンドのフィードバック。
-
臨床成果: 自己報告の気分(相互作用前後)、孤独感スコア(週次)、助け求め行動(ユーザーはコンパニオン使用後に友人、家族、または専門家に連絡したか)、波及効果(正または負)。
-
具体例:* ホリデー後の調査は、68%のユーザーがコンパニオン使用後に気分が改善したと報告、72%が孤独感が減ったと報告、41%が実在する人物に連絡したと報告していることを示す(正の波及効果)。介入を使用していない対照群と比較する。差異は実際のインパクトを示す。さらなる分析は、週3~5回エンゲージしたユーザーが最高の幸福度ゲインを報告し、毎日のユーザーは収穫逓減を示した(依存リスクを示唆)ことを示す。
-
長期的ビジョン:* 感情的幸福度が身体的健康と同じくらい測定可能で追跡可能になる未来を想像する—標準化された指標、縦断的データ、証拠ベースの介入を伴う。AIコンパニオンは、より広いウェルネスインフラストラクチャエコシステムの1つのツールになり、どのツールの組み合わせがどの集団に最適に機能するかを示す明確なデータを伴う。
-
測定向けの実行可能な含意:* 初日から製品にフィードバックループを構築する。簡潔なチャット後調査(2~3質問、30秒で完了)。ボランティアユーザーとの月次の深掘りインタビュー。ユーザーが述べられた目標に向かって進行しているかどうかの四半期分析。このデータを使用して、会話トーン、トピック推奨、エスカレーショントリガーを改善する。ユーザーと透明性をもって知見を共有する—「10,000の会話からのフィードバックに基づいて、悲しみについて議論する能力を改善しました」は信頼を構築し、あなたが聞いていることを示す。
リスクと緩和戦略:意図しない結果に向き合う設計
-
浮上する機会:* あらゆる強力なテクノロジーは意図しない結果を生み出す。これらのリスクを先読みし、システム設計の段階で緩和策を組み込む組織は、より耐性のある信頼できるプロダクトを構築する。同時に、事後的な危機管理から生じる評判上および規制上の損害を回避する。
-
戦略的再構成:* リスクは隠すべき問題ではなく、解決すべき設計課題である。リスクについての透明性は、潜在的な害について深く思考し、それを防ぐための具体的な計画を持っていることを示すため、実は信頼を構築する。
-
リスク分類1:依存と虚偽の親密性*
-
リスク:* ユーザーはAIを擬人化し、それが自分を「気にかけている」「理解している」と信じるかもしれない。その結果、支援の求助が遅延したり、不健全な依存が生じたりする。ユーザーが自殺念慮をAIに打ち明けながら、AIが「セラピストより理解してくれる」と信じてクライシスラインへの電話を避けるという事態も起こりうる。
-
緩和策:*
-
明示的な「健全な境界線」メッセージを設計する:「私はここで聞き役になりますが、セラピストやクライシスカウンセラーの代わりにはなれません。危機的状況にあれば、[番号]に電話してください」
-
依存度の閾値を設定する。ユーザーが30日以上毎日チャットしている場合、人間関係や専門的支援へのやさしい促しをトリガーする:「最近、私たちはよくチャットしていますね。カウンセラーや信頼できる友人と話すことを検討されましたか」
-
虚偽の親密性を避けるため、会話のトーンを変動させる。過度に温かい言語を使ったり、実際には理解していない詳細を覚えているふりをしたりしない
-
月次調査を実施し、ユーザーがAIの役割をどう認識しているか、また求助行動がどう変化しているかを問う
-
リスク分類2:プライバシー侵害とデータ悪用*
-
リスク:* 会話データは極めて機密性が高く、漏洩は感情的脆弱性を露呈させる。同時に、データは悪用される可能性がある。広告主に売却され、ユーザーを操作するために使用され、または権限のない者にアクセスされるかもしれない。
-
緩和策:*
-
すべての会話データをエンドツーエンド暗号化する。内部アクセスは匿名化されたトランスクリプトのみに限定する
-
立ち上げ前および以降は毎年、プライバシー影響評価を実施する
-
プライバシーポリシーを平易な言語で公開する(法律用語は避ける)。ユーザーが会話分析をオプトアウトしたり、データ削除をリクエストしたりできるよう、きめ細かなプライバシーコントロールを提供する
-
データ保持ポリシーを確立する。例えば「会話は90日後に削除されます。ただし、ユーザーが継続性のためにより長い保持にオプトインした場合を除く」
-
毎年、第三者によるセキュリティ監査を実施する。結果を公開する(セキュリティ上の理由で一部は非開示)
-
リスク分類3:アルゴリズムバイアスと不均等な影響*
-
リスク:* 訓練データ内のバイアスは、システムが特定のユーザーグループの懸念を軽視したり、ステレオタイプを強化したりする原因となる。少数派の人口統計に属するユーザーは、軽視的または文化的に無神経に感じられる一般的な応答を受け取るかもしれない。
-
緩和策:*
-
人口統計グループ(年齢、性別、人種、性的指向、障害状態、社会経済的背景)全体にわたってモデルの応答を監査する。格差が生じた場合は再訓練する
-
立ち上げ前に、多様な集団とのユーザーテストを実施する。AIが文化的に関連性があり、尊重されていると感じるかどうかについてフィードバックを収集する
-
ユーザーがバイアスのある、または無神経な応答にフラグを立てるためのフィードバック機構を構築する。フラグが立てられた会話を月次で検討し、パターンが生じた場合は再訓練する
-
バイアス監査結果を毎年公開し、検出された格差と実施された是正措置を示す
-
リスク分類4:規制およびリアビリティ露出*
-
リスク:* AIが有害なアドバイスを提供したり、クライシスのエスカレーションに失敗したりした場合、法的責任に直面する。規制当局は制限を課したり、ライセンスを要求したりするかもしれない。
-
緩和策:*
-
立ち上げ前に法務およびコンプライアンスチームに相談する。法的責任露出と保険要件を理解する
-
すべての安全メカニズムと意思決定ルールを文書化する。すべてのインタラクションの監査証跡を構築する
-
AIの制限と法的責任の境界を説明する明確なサービス利用規約を確立する(倫理的でユーザーフレンドリーであることを保ちながら)
-
規制の発展を監視する。AI安全基準に取り組む業界グループに参加する
-
長期的ビジョン:* AIコンパニオンシステムが非常によく設計されている未来を想像してみよ。リスクは管理されるのではなく、予防される。ユーザーは依存を経験しない。なぜなら、システムが積極的に人間関係を奨励するからだ。プライバシー侵害は決して起こらない。データが暗号化され、アクセスが厳密に管理されているからだ。バイアスはユーザーがそれを経験する前に検出され、是正される。これは安全性への継続的な投資を必要とするが、持続可能で信頼できるAIへの唯一の道である。
-
リスク管理への実行可能な含意:* 立ち上げ前に包括的なリスク評価を実施する。特定された各リスクについて、以下を定義する:(1)害が生じる可能性のあるメカニズム、(2)害の可能性と重大性、(3)緩和戦略、(4)リスクを監視する方法、(5)リスクが現実化した場合の対応方法。これをリスク登録簿に文書化する。四半期ごとに検討および更新する。ステークホルダー(ユーザー、規制当局、パートナー)と調査結果を共有し、説明責任と信頼を構築する。
透明性とユーザー同意:正当化された信頼の構築
-
浮上する機会:* ユーザーはAIシステムに対してますます懐疑的になっている。AI の制限、データ慣行、安全メカニズムについて徹底的な透明性をもって主導する組織は、正当化された信頼を構築する。同時に、誇大広告よりも誠実さを重視するユーザーを引き付ける。
-
戦略的再構成:* 透明性はコンプライアンス上の負担ではなく、競争上の優位性である。システムがどのように機能し、何ができ、何ができないかを理解しているユーザーは、それをいつ使用するかについてより良い決定を下す。また、期待を知っているため、制限についてもより寛容である。
-
具体的な透明性慣行:*
-
オンボーディング: 明示的に述べる:「あなたは人間ではなく、AIとチャットしています。あなたの会話は暗号化されており、第三者と共有されません。クライシスに言及した場合、私たちはリソースを提供し、必要に応じて緊急サービスに連絡するかもしれません。このツールはセラピーの代替ではありません。クライシス状態にあれば、[番号]に電話してください」。ユーザーは最初の会話の前にこれを確認する必要がある。
-
平易な言語のサービス利用規約: 法律用語を避ける。簡潔に説明する:どのデータを収集するか、どのように使用するか、誰がアクセスできるか、どのくらいの期間保持するか、ユーザーが持つ権利は何か(アクセス、削除、ポータビリティ)。
-
きめ細かなプライバシーコントロール: ユーザーは会話分析をオプトアウトしたり、データ削除をリクエストしたり、会話をモデル改善に使用しないことを選択できる。
-
四半期ごとのリマインダー: ユーザーに定期的にAIの制限と自分の権利を思い出させる。「覚えておいてください:私はAIであり、セラピストの代わりにはなれません。もし苦しんでいるなら、専門家に連絡してください」
-
年次透明性レポート: 以下のデータを公開する:クライシスエスカレーション(数と結果)、偽陽性率、プライバシーインシデント、バイアス監査、ユーザーフィードバックのテーマ、および規制措置。これは説明責任とユーザー信頼を構築する。
-
長期的ビジョン:* 透明性がAIシステムの規範となる未来を想像してみよ。ユーザーは安全データ、バイアス監査、プライバシー慣行を見ることを期待する。この情報を公開しない企業は疑いの目で見られる。これは上昇競争を生み出す。組織は機能だけでなく、透明性と安全性で競争する。
-
透明性への実行可能な含意:* 平易な言語のサービス利用規約とプライバシーポリシーを起草する。非技術的なユーザーに明確性を確保するため、それらをレビューしてもらう。ユーザーが最初の使用前に完了する必要があるコンセントフローを含める。立ち上げ前に最初の透明性レポートを公開する。たとえ不完全であっても。毎年公開することにコミットする。これは説明責任を真摯に受け止めていることを示す。
結論と移行計画:パイロットからスケールへ
-
浮上する機会:* ホリデーシーズンはAIコンパニオンテクノロジーの試験場である。この高リスク期間中に正常に展開する組織は、モデルの実行可能性を実証し、他のユースケースと集団へのスケーリングに向けて位置付けられる。
-
戦略的再構成:* ホリデー展開を一度限りのイニシアティブとして見なすな。それを複数年にわたる能力の最初の反復として見なせ。学習、ユーザーフィードバック、技術的進歩に基づいて進化する。各ホリデーシーズンは改善への強制機能となる。
-
主張:* AIコンパニオンは、安全性、透明性、人間による監視が非交渉的な基礎として設計されている場合、ホリデー隔離と感情的ストレスを軽減できる。コンプライアンスチェックボックスや事後的な考慮ではなく。
-
根拠:* ホリデーシーズンは、アクセス可能な感情的支援への緊急の需要を生み出す。従来のシステムは、需要がピークに達する正確にその時に容量制約に直面する。AIコンパニオンはこの隙間を埋める。