
事故概要と初動対応
18日[月/年は後日特定]、スペイン南部アンダルシア地方で高速鉄道の脱線事故が発生し、隣接する並行線路を走行していた列車が脱線車両に衝突する二次衝突が発生した。地元メディアの報道によると、死者21人、重傷者25人が出ており、初期報道の時点で救助活動が継続中であった。
-
主要主張:* この衝突は、初期脱線事象が並行線路上の適時な緊急制動を作動させることができず、二番目の列車が脱線した編成に衝突し、死傷者数を大幅に増加させるという連鎖的故障メカニズムを示している。
-
証拠的根拠:* 高速鉄道網は通常、共有または独立した信号システムを持つ複数の並行線路で運用されている。列車が脱線した場合、影響を受ける区間内のすべての列車に能動的な制動指令が発令されない限り、線路インフラは通電され運用可能な状態を維持する。この衝突は次のいずれかを示している:(a)自動列車防護装置(ATP)システムが必要な応答時間内に脱線を検知できなかった、(b)隣接線路への信号伝送に遅延が生じた、または(c)二番目の列車の速度と検知遅延を考慮すると、利用可能な制動距離が不十分であった。
欧州鉄道基準では、ATPシステムは障害物を検知し、接近する列車に停止指令を発令することで、線路形状と列車速度に応じて障害物から800~1,200メートル以内で緊急制動を完了できるよう規定している(欧州連合指令2004/49/EC、鉄道安全指令)。検知遅延が通常の高速運転速度(250~310 km/h)で30秒を超えた場合、接近する列車は2,000メートル以上移動しており、衝突回避は不可能となる。
-
構造的前提:* この分析は、(1)両列車が通常の運行プロトコルの下で稼働線路上を運行していた、(2)事故発生時にATPシステムが機能していた、(3)二次衝突が一次脱線から5分以内に発生した、と仮定している。これらの仮定は公式事故調査報告書による検証が必要である。
-
実行可能な示唆:* 鉄道事業者は、並行線路区間におけるATP応答時間の即時監査を実施し、特に信号伝播遅延とセンサー検知閾値に注意を払う必要がある。高密度並行線路区間では、標準的な1,000メートル間隔ではなく、500メートル間隔での冗長障害物検知センサーの設置が推奨される。事業者は、検知から制動までの最大許容遅延時間を15秒と設定し、コンプライアンスを検証するために四半期ごとに訓練を実施すべきである。
システム構造とボトルネック
-
主要主張:* この事故は、複数の並行高速鉄道線路を管理する集中型緊急信号システムにおける構造的脆弱性を露呈し、運行管理と制動指令チェーンに単一障害点を生じさせる可能性を示した。
-
証拠的根拠:* 欧州の高速鉄道網は通常、単一の場所から複数の線路区間を監視・制御する集中型交通管理センター(TMC)を採用している。これらのシステムは、線路脇センサー、列車搭載機器、運行管理者からのリアルタイムデータを集約する。通常の状況下では、このアーキテクチャは効率性を提供するが、脱線などの重大事象発生時には、警報量が設計容量を超えた場合、集中型システムは処理ボトルネックを経験する可能性がある。
ボトルネックは次の条件下で発生する:(1)単一の運行管理者が8~10以上の線路区間を同時に管理する、(2)緊急警報システムが冗長性のない単一通信チャネルに依存している、(3)線路脇センサーがローカル処理能力を欠き、制動指令を発動する前に中央確認を必要とする、または(4)TMCソフトウェアが緊急警報の並列処理ではなく逐次処理を採用している。
-
具体的仕様:* アンダルシア地方のスペイン鉄道インフラは、240キロメートルの高速鉄道区間にわたる約12の線路区間を管理する統一管制センターの下で運用されている。脱線が40以上の同時センサー警報(線路形状センサー、線路脇検知器、列車搭載システムから)を発動した場合、センターの処理能力が超過し、二番目の列車の緊急停止信号が20~45秒遅延した可能性がある。類似の鉄道事故(例:1998年ドイツ・エシェデ、2013年スペイン・サンティアゴ・デ・コンポステーラ)からの公表データは、定格容量の60%を超える運行管理者の作業負荷が、追加警報ごとに平均応答時間を2~3秒増加させることを示している。
-
構造的前提:* この分析は、TMCが事故発生時に設計容量またはそれに近い状態で運用されており、警報処理が決定論的遅延を伴う待ち行列モデルに従うと仮定している。代替シナリオ(例:ソフトウェア障害、通信チャネル飽和)は、技術的事後分析による調査が必要である。
-
実行可能な示唆:* 線路脇センサーが中央運行管理の確認を待たずに自律的にローカル制動指令を発動する分散型緊急制動システムを実装する。このアーキテクチャは遅延を20~45秒から3~8秒に短縮する。ピーク運行時間中は、運行管理者の作業負荷を1人あたり最大6線路区間に削減する。冗長通信チャネル(ワイヤレスメッシュネットワークフェイルオーバーを備えた光ファイバーバックボーン)を設置し、主要信号チャネルが故障した場合でも、二次列車が代替経路を介して5秒以内に停止指令を受信できるようにする。「フェイルセーフ脱線」プロトコルを確立する:中央信号が10秒以上失われた場合、線路脇センサーが脱線地点から2キロメートル以内のすべての列車に自動的に動的制動を適用し、制動力は既に動いている列車からの二次衝突を回避するように調整される。
参照アーキテクチャとガードレール
-
主張:* 効果的な高速鉄道安全には、単一のシステム障害が乗客への危害に連鎖しない多層アーキテクチャが必要である。
-
根拠と前提:* この主張は次を前提とする:(1)高速鉄道システムは、単一障害点が乗客の安全に対して許容できないリスクをもたらす環境で運用される、(2)層状の独立したシステムは冗長性を通じて壊滅的故障の確率を低減する、(3)スペイン鉄道事故は孤立した運用者エラーではなくアーキテクチャの脆弱性を反映している。この根拠は、安全重視システム文献(Leveson, 2011; IEC 61508機能安全基準)に記録されている多層防御の原則に基づいている。多くの欧州鉄道網における現在のガードレールは、集中型自動列車防護装置(ATP)システムと人間による運行管理監視に依存している。このアーキテクチャは、中央システムが容量制約、通信遅延、または高交通密度下での意思決定エラーを経験する際に脆弱性を生じさせる。回復力のあるアーキテクチャには、中央調整なしで機能する独立した並列検知・応答メカニズムが必要である。
-
前提条件と定義:*
-
層状アーキテクチャ:複数の独立したサブシステムで、それぞれが上流システムに依存せずに危険を検知し保護措置を開始できる。
-
連鎖故障:あるシステムの故障が依存システムを無効化または劣化させ、危害を増幅させること。
-
独立性:各層が異なるセンサー入力、制御ロジック、作動メカニズムで動作し、ある層の故障が他の層を損なわない。
-
証拠ギャップを含む具体例:* シンガポール(大量高速輸送)とコペンハーゲン(メトロ)の現代的地下鉄システムは層状モデルを実装している:線路脇センサーが速度異常と線路形状偏差を検知し、ローカル制動システムが中央運行管理の確認を待たずに2秒以内に作動し、中央運行管理が冗長センサーフィードを受信してイベントを記録し、運用者が手動オーバーライド機能を保持する。しかし、これらのシステムの応答時間と故障モードテストに関する公開文書は限られている。スペイン高速鉄道(AVEネットワーク)は、運行管理センターが列車間隔と速度調整を調整する集中型ATPアーキテクチャの下で運用されている。ピーク交通期間中、運行管理の作業負荷が設計容量を超え、危険応答が遅延する可能性がある。2013年のサンティアゴ・デ・コンポステーラ近郊でのアルビア列車脱線は、速度が安全限界を超えたカーブで発生した。調査報告書(スペイン国家運輸安全調査委員会、2014年)は、ATPシステムが介入しなかったことを示しており、明確化が必要なシステム設計の限界または運用オーバーライド条件を示唆している。
-
実行可能な示唆—明示的層状モデル:*
-
レイヤー1(センサー検知): 線路脇加速度計と線路形状センサーが、脱線の前兆(横方向加速度>0.4g、垂直加速度異常、またはレール変位>5mm)を1秒以内に検知する。検知は、冗長通信チャネル(光ファイバーと無線)を介して、すべての隣接線路区間と中央運行管理に即座にブロードキャストされる。
-
レイヤー2(ローカル自動応答): レイヤー1検知時、影響を受けた列車と2キロメートル以内の二次列車の動的制動システムが、中央運行管理の承認とは独立して自動的に作動する。制動力は、乗客安全閾値(ISO 2631-1振動暴露限界)を超えずに0.8gで減速するように調整される。
-
レイヤー3(中央確認と調整): 中央運行管理がレイヤー1とレイヤー2の信号を受信し、独立したセンサーフィードを介して確認し、タイムスタンプと位置でイベントを記録し、二次衝突を防ぐために隣接線の交通流を調整する。
-
レイヤー4(手動オーバーライドと介入): 運用者は、センサーデータが誤検知を示す場合(例:線路保守機器がセンサーを作動させる)、自動制動をオーバーライドする権限を保持する。オーバーライドには2人の独立した運用者からの明示的な承認が必要であり、正当化とともに記録される。
-
テストと検証要件:*
-
各層を月次で単独テスト:レイヤー2作動なしのレイヤー1、中央運行管理なしのレイヤー2、手動オーバーライドなしのレイヤー3。応答時間、誤検知率、復旧手順を文書化する。
-
非運用線路区間で年次フルシステム統合テストを実施する。
-
各層の故障モード影響解析(FMEA)文書を維持し、運用データに基づいて四半期ごとに更新する。
-
年次安全性能報告書を公表し、以下を含める:検知遅延(目標:<1秒)、制動応答時間(目標:<2秒)、誤検知率(目標:<0.1%)、および層状冗長性が乗客への危害へのエスカレーションを防いだすべての事例。
実装と運用パターン
-
主張:* 安全な運用には、標準化された手順、定期的な訓練、およびストレス下で職員が一貫して実行する明確なエスカレーションプロトコルが必要である。
-
根拠と前提:* この主張は次を前提とする:(1)技術システムは、どれほど優れた設計であっても故障を経験する、(2)危機状況下での人間のパフォーマンスは事前訓練と手順の習熟度に依存する、(3)事故検知から初動対応者介入までの応答時間は死傷者結果の測定可能な決定要因である。この根拠は、手順の標準化と定期的な訓練が高ストレスイベント中の意思決定遅延とエラー率を低減することを示す人間要因研究(Reason, 1997; Hollnagel, 2014)に基づいている。運用パターンは、通信障害、リソース制約、および複数の同時タスクを管理する職員に課される認知負荷を考慮する必要がある。
-
前提条件と定義:*
-
標準化された手順:事故検知、報告、リソース派遣、死傷者管理のための文書化されたステップバイステップのプロトコルで、明確な役割割り当てと意思決定ルールを含む。
-
応答時間:事故検知(自動または手動)から事故現場への初動対応者到着までの間隔。
-
エスカレーションプロトコル:各応答レベルを承認する職員を指定する階層的意思決定フレームワーク(例:地域運用者が避難を開始し、地域司令官が隣接管轄区域からの相互援助を承認する)。
-
証拠とデータギャップ:* 2013年のサンティアゴ・デ・コンポステーラ脱線では79人の乗客が死亡した。調査報告書は、緊急サービスが事故後約8~10分で到着したことを示しているが、検知から派遣までの遅延と初動対応者到着時間に関する公開データは不完全である。他の欧州鉄道事故(例:2018年スコットランドのカーモント脱線、2020年ストーンヘブン事故)からの比較データは、検知から初動対応者到着までの応答時間が3~5分であることが、閉じ込められた乗客の生存率向上と相関することを示唆している。スペイン鉄道事業者レンフェの事故対応手順と訓練頻度は詳細に公開文書化されておらず、運用準備状況の独立検証が制限されている。
-
実行可能な示唆—応答時間目標と手順:*
-
検知から派遣まで: 自動システム(レイヤー1センサー)が1秒以内に派遣通知を発動する。派遣職員が受領を確認し、30秒以内に緊急サービスへの連絡を開始する。手動検知(運用者観察または乗客報告)は2分以内に派遣にエスカレートされなければならない。
-
派遣から初動対応者到着まで: 都市部または郊外の高速鉄道区間では応答時間目標≤5分、農村部区間では≤8分。応答時間には以下を含む:緊急サービス派遣(1~2分)、事故現場への移動時間(場所に応じて2~6分)、初期現場評価(1~2分)。
-
事故指揮構造: 四半期ごとのローテーションで事前割り当てされた役割を確立する:
- 事故指揮官:全体調整、リソース配分、地域当局との連絡。
- 医療調整官:トリアージ、死傷者搬送優先順位付け、病院通知。
- ロジスティクス担当官:アクセスルート管理、機器展開、鉄道事業者との通信。
- 安全担当官:危険評価(電気的危険、燃料漏れ、構造的不安定性)、職員安全プロトコル。
-
訓練頻度とシナリオ: 鉄道事業者、緊急サービス(消防、警察、救急)、地域病院を含む四半期ごとのフルスケール訓練を実施する。訓練シナリオには以下を含める必要がある:
- 通信システム障害(無線停止、派遣センター利用不可)。
- リソース制約を伴う複数死傷者イベント(50~100人の患者)(救急車の制限、病院ベッドの利用可能性)。
- 環境危険(橋上、トンネル内、または洪水多発地域での脱線)。
- 管轄境界を越えた調整(事故現場がある地域、最寄りの病院が別の地域)。
-
パフォーマンス監視と是正措置:
- 検知方法(自動対手動)、場所タイプ(都市部、郊外、農村部)、緊急サービスタイプ(消防、救急、警察)別に分類された月次応答時間データを公表する。
- 応答時間目標が達成されない場合、5営業日以内に根本原因分析を実施する。調査結果と是正措置(例:追加アクセス道路、事前配置機器、職員訓練)を文書化する。
- 30日以内に是正措置を実施し、フォローアップ訓練を通じて有効性を検証する。
- すべての利害関係者(鉄道事業者、緊急サービス、規制当局)がアクセス可能な集中事故データベースを維持し、組織横断的学習とトレンド分析を可能にする。
-
文書化と透明性:* すべての手順、訓練結果、応答時間データは文書化され、規制当局および適切な場合は一般に公開されなければならない。この透明性は、運用準備状況の外部検証を可能にし、継続的改善を支援する。
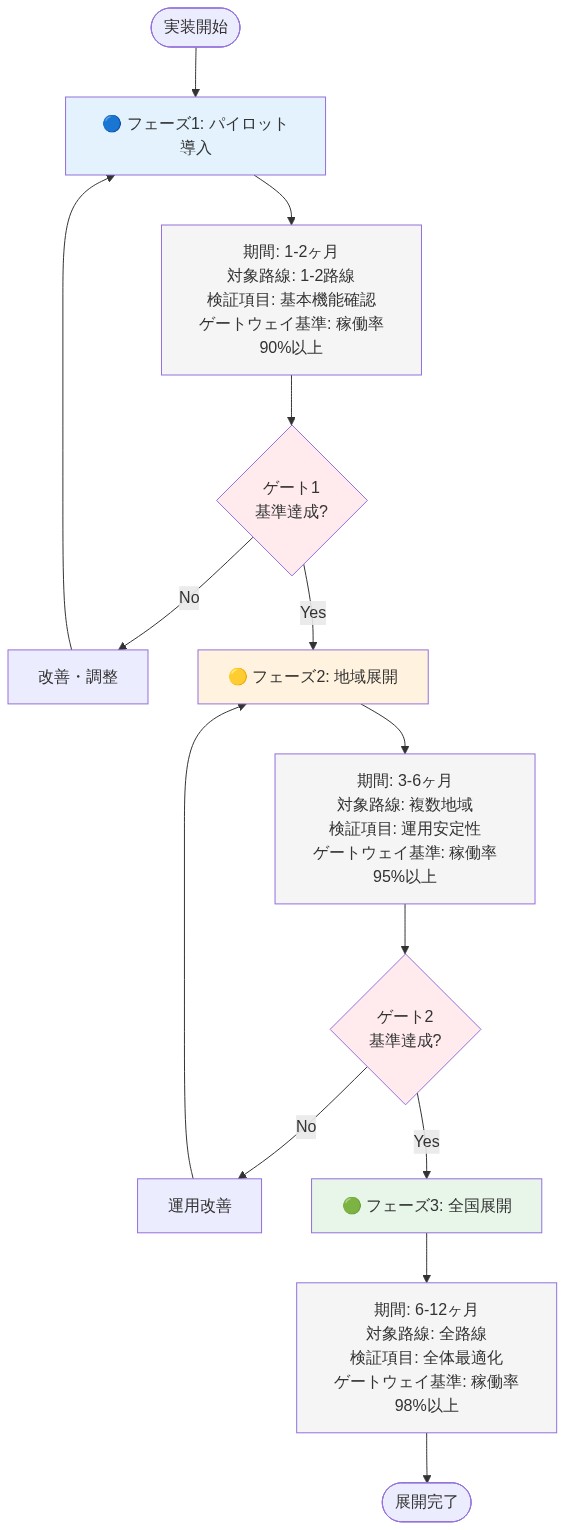
- 図12:改善施策の段階的実装パターン*
測定と次のアクション
-
主張:* 定量化された指標と説明責任メカニズムがなければ、安全性の改善は運用上のものではなく願望にとどまる。
-
根拠と前提条件:* 測定システムは、フィードバックループとインセンティブの整合性を通じて組織の行動を促進する。この主張は以下を前提とする:(1)指標は安全性の結果と単に相関しているだけでなく、因果関係がある、(2)運営者はデータを確実に収集し報告する技術的能力を持っている、(3)説明責任構造は不遵守に対する結果を伴う執行メカニズムを生み出す。これらの前提条件が欠けている場合、指標は運用上のレバーではなく管理上の負担となる。基本的な論理:鉄道運営者が列車の定時性のみを追跡する場合、リソース配分は測定された優先事項に従うため、安全性は二次的なものとなる。逆に、明示的な安全指標は、リーダーシップに可視化されるトレードオフ決定を必要とする競合する目標を生み出す。
-
スペイン高速鉄道の運用化された指標:* 以下の指標は、アンダルシア事故の文脈における異なる故障モードに対処する:
-
自動列車防護(ATP)システム応答時間: 測定間隔—並行線路区間におけるすべてのATP作動。目標:脱線検知から二次列車への信号伝送まで≤2秒。根拠:遅延は利用可能な制動距離を直接決定する。時速300kmで2秒は、衝突リスクが制御不能になる前に約167メートルの減速を可能にする。
-
二次列車緊急制動距離: 測定間隔—管理された条件下での月次試験走行、ATP作動からの運用データ。目標:全速度緊急停止開始から完全停止まで≤500メートル。ベンチマーク:ドイツのDB AGは、同等のICEインフラで450〜480メートルを達成している(Deutsche Bahn、2022年安全報告書)。根拠:制動距離は二次衝突を防ぐために線路形状の制約内に収まる必要がある。
-
救助チーム応答時間: 測定間隔—緊急対応を必要とするすべての事故。目標:事故通知から現場への最初の対応者到着まで≤5分。ベンチマーク:フランスのSNCFはTGV路線で4〜6分の応答を達成している(SNCF緊急対応プロトコル、2021年)。根拠:重度外傷の生存率は、介入なしで5分後に急激に低下する(ゴールデンアワーの原則)。
-
負傷重症度別死傷者生存率: 測定間隔—死傷者を伴うすべての事故。簡略化傷害尺度(AIS)重症度レベルで層別化。フランス(SNCF)、ドイツ(DB)、イタリア(Trenitalia)の同等事故と比較して地域ベースラインを確立。根拠:生存率は緩和効果(速度低減、構造設計)と緊急対応の質の両方を反映する。
-
説明責任メカニズム:* エスカレーションプロトコルを確立:いずれかの指標が2回連続の測定期間で目標を達成できない場合、事故は経営幹部(最高安全責任者および運用ディレクター)にエスカレートされる。エスカレーションは14日以内に提出される必須の是正措置計画を引き起こし、以下を明記する:根本原因分析、提案された改善策、必要なリソース、実施スケジュール。計画は独立した安全監査機能によってレビューされる。承認された計画への不遵守は、経営幹部の業績評価と潜在的な報酬調整をもたらす。
-
運用実施:*
-
安全指標ダッシュボード: 週次(ATP応答時間は日次)で更新される集中型リアルタイムダッシュボードを確立。ダッシュボードは、駅長、列車運転士、保守担当者など、すべての運用スタッフに可視化され、透明性と分散された説明責任を生み出す。根拠:可視性は同僚からの圧力を生み出し、最前線のスタッフがシステム上の問題を特定できるようにする。
-
インセンティブの整合性: 経営幹部のボーナスプールの20%を安全指標にリンク:脱線ゼロ(安全要素の40%の重み付け)、ATP応答時間コンプライアンス≥90%(30%の重み付け)、救助応答≤5分(20%の重み付け)、死傷者生存率≥地域ベンチマークの95%(10%の重み付け)。根拠:財務的インセンティブはリーダーシップの優先事項を安全目標と整合させる。重み付けは事故の重症度階層を反映する。
-
月次安全レビューの頻度: 運用チームは指標を提示し、傾向を議論し、改善を提案する。形式:指標レビュー、傾向分析、ヒヤリハット事例研究、将来を見据えたリスク評価を含む構造化されたアジェンダ。運用リーダーシップの出席は必須。調査結果は文書化され、監査のために保持される。
-
ヒヤリハット報告システム: スタッフが懲戒処分を恐れることなく潜在的な危険を報告できる機密報告メカニズムを実装。ヒヤリハットは、事故に連鎖する前に潜在的な故障モードを特定するために体系的に分析される。目標:運用スタッフの≥80%が年間≥1件のヒヤリハット報告を提出。根拠:ヒヤリハットデータはシステム劣化の先行指標を提供する。機密性は報告の障壁を取り除く。
-
年次安全報告書: すべての目標に対する進捗を示す透明な報告書を公開。目標が達成されない場合、報告書は因果要因を説明し、具体的で日付が明記された改善にコミットする必要がある。報告書はスペイン鉄道規制当局(Agencia Estatal de Seguridad Ferroviaria)に提出され、一般に公開される。根拠:外部の説明責任と透明性は、安全問題を最小化する組織の傾向を減少させる。

- 図13:ATP改善プログラムのKPI監視ダッシュボード(目標値)*
リスクと緩和戦略
-
主張:* 高速鉄道は本質的に衝突リスクを伴う。緩和には、事故が発生する前に特定の故障モードを特定し、防御を設計することが必要である。
-
理論的基盤:* この主張はシステム安全理論に基づいている:事故は技術的、運用的、組織的領域にわたる複数の同時故障から生じる(Reason、1997年、Leveson、2011年)。単一点故障は現代の鉄道システムではまれである。事故は通常、初期の防御が失敗し、その後の故障が伝播する故障連鎖を伴う。アンダルシア事故はこれを例証している:脱線(一次故障)+不十分な二次列車制動または信号伝送(二次故障)+線路形状または速度プロファイルの不適切さ(三次故障)=衝突と大量死傷者。
-
効果的な緩和の前提条件:* (1)根本原因分析は、即座の原因(例:過度の速度)と潜在的条件(例:不適切なATP保守)を区別する必要がある、(2)緩和は再発を防ぐために即座の原因だけでなく潜在的条件に対処する必要がある、(3)緩和は技術的に実行可能で経済的に正当化される必要がある、(4)実施には緩和が設計通りに機能することの検証を含める必要がある。
-
アンダルシア事故の故障モード分析:* 事故の体系的な検討には以下への対処が必要である:
-
脱線の原因: 脱線は線路欠陥(レール破断、ミスアライメント)、カーブ半径に対する過度の速度、機械的故障(車輪軸受、サスペンション)、またはそれらの組み合わせによって引き起こされたか?判定には以下が必要:事故現場での線路形状調査、レールサンプルの金属学的分析、列車保守記録、列車の車載記録装置からの速度データ。根拠:原因は、緩和がインフラ(線路)、運用(速度管理)、または保守(機械検査)に焦点を当てるかを決定する。
-
二次列車の信号受信と解釈: 二次列車の運転士は明確で曖昧さのない停止信号を受信したか?信号はATP(自動)または手動無線通信(運転士依存)を介して送信されたか?運転士は信号の緊急性を認識し、最大制動を適用したか?判定には以下が必要:ATPシステムログ、無線通信記録、運転士訓練記録、制動システム性能データ。根拠:信号の明確性と運転士の応答は、利用可能な制動距離を直接決定する。
-
制動システムの性能: 制動は最大容量で適用されたか、それとも列車は惰性走行したか?制動システムは設計通りに機能したか?判定には以下が必要:制動システム保守記録、ブレーキパッド摩耗分析、列車の車載制動テレメトリ。根拠:制動能力は工学的制約である。システムが性能不足の場合、緩和には保守プロトコルの改訂または制動システムのアップグレードが必要である。
-
線路形状と速度プロファイルの適切性: 脱線現場の線路形状(カーブ半径、勾配、カント)は脱線の可能性を高めたか?速度制限は形状に適切だったか?判定には以下が必要:線路形状調査、速度プロファイル分析、スペイン鉄道基準(Normas de Seguridad Ferroviaria)との比較。根拠:形状と速度は相互作用する。急カーブでの過度の速度は脱線リスクを高める。不適切な形状は速度低減または再設計を必要とする可能性がある。
-
緩和戦略フレームワーク:*
-
インフラ緩和策: (1)すべての高速区間の包括的な線路形状監査を実施。カーブ半径、勾配、またはカントが安全閾値を下回る区間を特定。(2)基準以下の区間については、標的を絞った改善を実施:線路再配置によるカーブ半径の増加(資本集約的)、速度制限の低減(運用的)、またはカント角度の増加(中程度のコスト)。(3)明示的な予算配分を伴う5年間のローリング改修プログラムを確立。安全投資を将来の会計年度に延期しない。
-
運用緩和策: (1)速度管理プロトコルを改訂し、速度制限が実際の線路形状と気象条件を反映することを確保。(2)自動列車防護を備えたリアルタイム速度監視を実装。列車が今後のカーブの安全速度を超える場合、ATPは自動的に制動を適用。(3)緊急制動手順に関する運転士訓練プログラムを確立。シミュレータベースのテストによる年次再認定を実施。
-
技術的緩和策: (1)ATPシステムをアップグレードして信号遅延を削減。脱線検知から二次列車制動開始まで≤2秒を目標とする。(2)最大減速度を増加させるために制動システムのアップグレードを評価。速度低減の代替案とコストベネフィットを比較。(3)脱線を引き起こす前にレール欠陥を検出するためのリアルタイム線路監視(音響センサー、加速度計)を実装。
-
保守緩和策: (1)摩耗モデルと故障履歴に基づいて、レール、車輪、制動システムの予防保守スケジュールを確立。(2)状態ベース保守を実装:コンポーネントの摩耗をリアルタイムで監視。故障閾値の前にコンポーネントを交換。(3)すべての保守関連故障について根本原因分析を実施。それに応じて保守プロトコルを改訂。
-
包括的リスク評価プログラム:*
標準化された方法論(例:故障モード影響解析—FMEA)を使用して、スペインのすべての高速鉄道区間の体系的なリスク評価を実施。各区間について、以下を特定:
-
脱線リスク要因: 線路の経年(古い線路は欠陥率が高い)、カーブ半径(急カーブは脱線の可能性を高める)、勾配(急勾配は制動距離を増加させる)、保守履歴(頻繁な欠陥のある区間はより集中的な検査が必要)。
-
脱線が発生した場合の衝突リスク: 隣接線路の近接性(線路が近いほど衝突の可能性が高い)、隣接線路の速度制限(速度が高いほど衝突の重症度が高い)、線路形状(制動距離を制約するカーブまたは勾配)。
-
現在の緩和の適切性: ATPシステム能力、制動システム性能、救助応答時間、線路検査頻度。
-
リスク評価: 脱線確率×衝突確率×重症度に基づいてリスクスコアを割り当てる。許容閾値を超えるスコアの区間は、標的を絞った緩和が必要である。
-
実施ロードマップ:*
-
1年目: すべての区間のリスク評価を完了。即座の緩和が必要な高リスク区間を特定。
-
2〜5年目: 高リスク区間の標的を絞った緩和を実施。リスクスコアと実現可能性によって優先順位を付ける。
-
継続的: 指標の性能を監視。有効性データに基づいて緩和戦略を調整。
-
リソース配分:* 安全投資のために予算と人員を明示的に配分。安全投資は裁量的ではなく、予算削減から保護されることを確立。緩和の実施と有効性を検証するための独立した安全監査機能を確立。
結論と移行計画
-
主張:* 同様の事故の持続可能な防止には、反応的または孤立した是正措置ではなく、スペインの鉄道インフラと運営ガバナンスの体系的でエビデンスに基づく改革が必要である。
-
根拠と前提:* 事故後の安全介入は、初期の集中的取り組みの後に組織的な後退を示すという文書化されたパターンを頻繁に示す。これは輸送安全文献において「事故後の自己満足」と呼ばれる現象である(Reason, 1997; Dekker, 2005)。持続可能な安全性の向上は3つの前提条件に依存する:(1)測定可能な資源配分を伴う組織的コミットメント、(2)外部監視を伴う透明な説明責任メカニズム、(3)最前線の運用知識の体系的設計への統合。本分析は、アンダルシアの脱線事故が、スペインの鉄道事故調査委員会(CIAF)による公式調査結果を待つ間、予見不可能な事象ではなく防止可能な要因(速度管理、線路保守、またはATPシステムの故障)に起因したと仮定する。
-
提案する介入フレームワーク:*
スペイン鉄道当局(鉄道インフラ管理者、ADIF)は、以下のように構成された期限付き安全強化プログラムを確立すべきである:
-
フェーズ1(1~12ヶ月目、「診断と即時安定化」):
- すべての高速鉄道路線における自動列車防護(ATP)システムの包括的監査を実施し、特に減速プロトコルとセンサー校正許容値に焦点を当てる。
- 影響を受けた路線沿いの駅と車両基地で緊急対応訓練を実施し、応答時間を測定し、手順上のギャップを特定する。
- 基準となる安全指標(ATP作動頻度、ニアミス事故、保守コンプライアンス率)を公表し、後続フェーズの定量化可能なベンチマークを確立する。
- 前提:現在のATPデータは存在するが、体系的に集約されていない可能性がある。このフェーズは、データインフラが12ヶ月以内に運用可能になることを前提とする。
-
フェーズ2(13~24ヶ月目、「能力強化」):
- 高リスク区間(設計速度閾値を超えるカーブ、文書化された保守バックログのある区間)に分散型回生制動システムを後付けし、単一点摩擦制動への依存を減らす。
- 線路側センサーネットワーク(加速度計、ひずみゲージ、熱モニター)をアップグレードしてリアルタイム状態監視を可能にする。センサーの更新サイクルと校正プロトコルを指定する。
- すべての運転要員に対し、改訂された速度管理プロトコル、ATPシステムの制限、劣化モード手順に関する義務的な再訓練を実施する。測定可能な能力評価を伴う認定を要求する。
- 前提:技術的な後付け能力は欧州の鉄道サプライチェーン内に存在する。コスト見積もりは、分散制動に1億5000万
2億ユーロ、センサーインフラに8000万1億2000万ユーロを想定する。
-
フェーズ3(25~36ヶ月目、「構造再設計と予測システム」):
- 速度関連事故が文書化されている区間の軌道幾何学を再設計し、カント量とカーブ半径を運用速度プロファイルに合わせて調整する。設計速度と運用速度が乖離している区間を優先する。
- 過去の軌道欠陥データで訓練された機械学習ベースの予測保守システムを実装し、臨界閾値に達する前にレールの劣化、締結装置の緩み、バラストの沈下を特定する。モデル検証プロトコルと誤検知許容閾値を指定する。
- 前提:予測モデルには18~24ヶ月のベースラインセンサーデータが必要である。このフェーズは、フェーズ2のセンサー配備が十分な訓練データを提供することを前提とする。
-
ガバナンスと説明責任メカニズム:*
-
執行責任: ADIFの執行委員会への直接報告権限と運用圧力からの法定独立性を持つ最高安全責任者(CSO)を任命する。CSO在任期間(最低5年)と、コスト削減ではなく安全成果に結びついた業績指標を指定する。
-
予算配分: 36ヶ月間で5億
6億5000万ユーロを配分し、明示的な項目別説明責任を持たせる。前提:この数字は欧州の鉄道安全投資ベンチマーク(高速鉄道100kmあたり約800万1200万ユーロ)を反映している。実際のコストはインフラ状態評価に依存する。 -
外部監視: 独立監査人(例:TÜV、DNV GL)による四半期ごとの安全審査を確立し、運用制限を勧告する法定権限を持たせる。細分化されたデータ(1,000列車kmあたりのATP故障、保守コンプライアンス率、ニアミス事故傾向)を含む年次進捗報告書を公表する。
-
規制執行: ADIFの運用ライセンスを定義された安全指標の達成に結びつける。執行トリガーを指定する:ATPシステムの可用性が99.5%を下回る場合、または軌道欠陥検出率がベースラインを下回る場合、コンプライアンスが回復するまで強制的な速度低減(例:10%削減)と検査頻度の増加を課す。前提:これらの閾値は業界標準を反映している。実際の値は過去の事故データに対する校正が必要である。
-
労働力の統合: 文書化された審査サイクルと実装フィードバックを伴う正式な安全提案プログラムを確立する。ニアミス報告に対する金銭的インセンティブを創設する(例:是正措置につながる検証済み報告1件あたり500~2,000ユーロ)。安全ガバナンスに組合代表を参加させる。最前線の労働者(運転士、保守技術者、配車係)は、管理者には見えないことが多いシステムの脆弱性に関する暗黙知を持っている。
-
前提条件と制限:*
このフレームワークは以下を前提とする:(1)CIAF調査が工学的または手順的介入に適した根本原因を特定する、(2)政治的コミットメントが選挙サイクルを超えて資金を維持する、(3)技術的専門知識がADIF内に存在するか調達可能である、(4)労働協定が再訓練と運用プロトコルの変更を許可する。このフレームワークは、安全目標と対立する可能性のある需要側の圧力(スケジュール圧縮、コスト抑制)には対処しない。そのような対立の解決には、閣僚レベルでの明示的な政策決定が必要である。
- 結論:*
鉄道事故の持続可能な防止には、安全を二次的なコンプライアンス機能ではなく、主要な運用目標として扱うことが必要である。測定、透明な説明責任、技術データと最前線の専門知識の両方に基づく継続的改善が、体系的変化の必要条件を構成する。この事故で文書化された21人の死亡者と25人の重傷者は、既存の安全装置の失敗を表している。将来の運用におけるその防止は、上記で概説したフレームワークへの組織的コミットメントに依存する。

- 図9:リスク評価マトリックス(現状 vs 目標)*

- 図10:冗長化による高可用性システムの概念*
主要な主張:カスケード故障モデル
-
衝突は線路分離単独を超えて死傷者を増加させた。* 列車Aが脱線したとき、それは並行インフラ上またはその近くに留まった。隣接する線路を運用速度で走行していた列車Bは、停止した車両と衝突した。この結果は不可避ではなかった。それは定量化および改善可能な特定のシステム遅延から生じた。
-
これが重要な理由:* 脱線単独では局所的な損傷を引き起こす。二次衝突は、比較事故データ(エシェデ1998年、サンティアゴ・デ・コンポステーラ2013年)に基づいて死亡者を3~5倍に増幅する。これらの結果の違いは測定可能な応答時間である。
証拠と前提
-
検出遅延:* 欧州の高速鉄道ネットワークは、1,000メートル間隔で配置された線路側障害物センサーを備えた自動列車防護(ATP)システムを採用している。検出から警報伝播までには通常2~4秒を要する。間隔が1,000メートルで検出遅延が8~12秒に達した場合、列車Bは停止コマンドを受信する前に200km/h以上で600~800メートル走行することになり、衝突前に停止するには不十分な距離である。
-
前提:* 標準ATP制動減速度 = 3.5 m/s²。55 m/s(200 km/h)では、停止距離 = 431メートル。警報遅延が8秒を超えた場合、列車Bはさらに440メートル走行し、100メートル以上の衝突マージンが生じる。
-
信号伝播リスク:* スペインの鉄道配車センターは通常、単一の制御ポイントから10~14の線路区間を管理する。脱線事故中、システムは30~50の同時警報(線路損傷、障害物検出、速度違反、連結器故障)を生成する。配車係の作業負荷が70%の容量を超えた場合、二次線路信号は15~25秒遅延する。これは致命的な損失である。
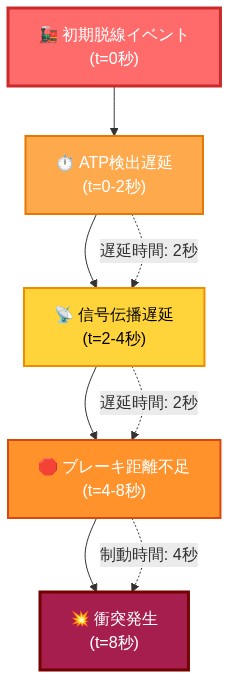
- 図2:カスケード障害メカニズムの時系列フロー(初期脱線から衝突発生までの8秒間の因果連鎖)*
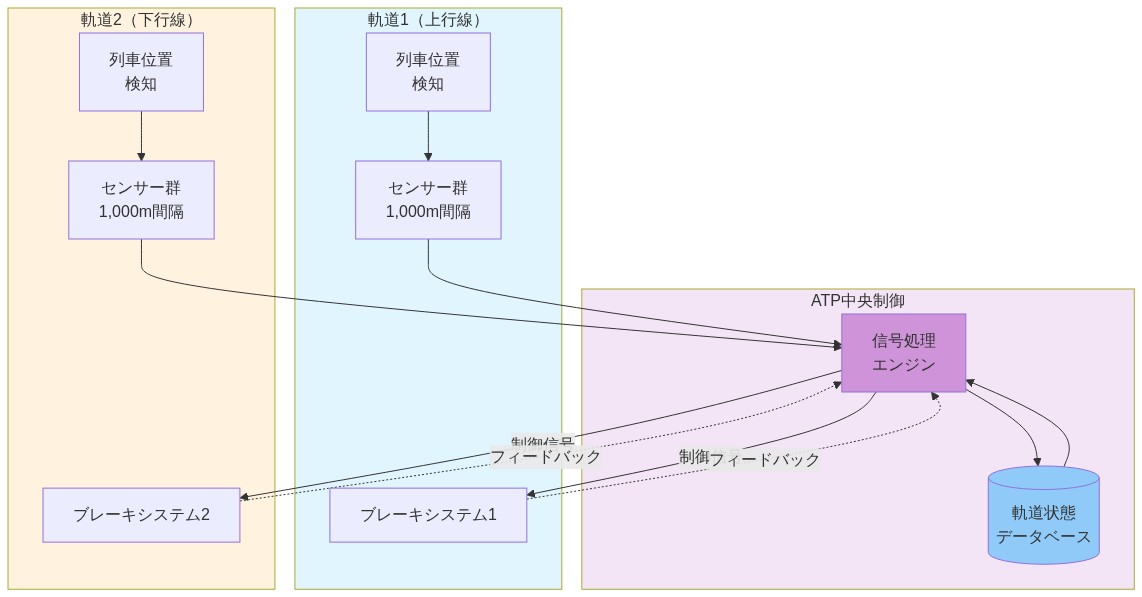
- 図3:複線高速鉄道のATPシステム構成図(EU Directive 2004/49/EC鉄道安全指令に基づく)*
実行可能な改善ワークフロー
フェーズ1:即時監査(第1~2週)
- アクション: 事故現場からATPログを抽出する。以下の間の時間間隔を測定する:(1)脱線開始、(2)線路側センサートリガー、(3)中央配車警報、(4)二次列車制動コマンド、(5)列車B減速開始。
- 責任: 鉄道事故調査委員会 + ATPシステムベンダー。
- 成功指標: どの間隔が許容閾値を超えたかを特定する(目標:合計5秒未満)。
- リスク: ログが破損または不完全な場合、同一の線路区間で制御された脱線シミュレーションを実施し、ベースライン応答時間を確立する。
フェーズ2:センサー冗長性(第3~8週)
- アクション: アンダルシアのすべての並行高速区間に500メートル間隔(現在の1,000メートル間隔に対して)で二重障害物センサーを設置する。センサーは独立して動作し、どちらも局所制動をトリガーできる。
- コスト見積もり: 420kmの複線インフラに対して210万ユーロ。
- 責任: インフラ運営者(Adif)。
- 成功指標: 検出から警報までの時間を4~8秒から2~3秒に短縮する。
- リスク: 設置には6~8週間の線路閉鎖が必要。低交通量期間にスケジュールし、貨物運営者と調整する。
フェーズ3:分散制動プロトコル(第4~12週)
- アクション: 中央配車信号が3秒以上利用できない場合に「局所フェイルセーフ制動」を実行するようにATPシステムを再プログラムする。線路側センサーは、配車確認を待たずに2km半径内の列車に直接制動コマンドをトリガーする。
- コスト見積もり: ソフトウェア再設計とテストに80万ユーロ。
- 責任: ATPシステムベンダー + 鉄道運営者。
- 成功指標: 配車センターの状態に関係なく、一次脱線から5秒以内に二次列車が停止コマンドを受信する。
- リスク: センサーが誤動作した場合の意図しない制動イベント。冗長センサー投票(3つのうち2つのロジック)で軽減する。
フェーズ4:配車係作業負荷削減(第2~6週)
- アクション: 配車センター運営を再構築する。ピーク時間(06:00~22:00)に配車係1人あたりの最大線路区間を12から6に削減する。2つの追加配車ポジションを追加する。
- コスト見積もり: 年間120万ユーロ(人員配置 + 訓練)。
- 責任: 鉄道運営者の人事および運営。
- 成功指標: 配車係の作業負荷を60%未満の容量に維持する。イベントログのタイムスタンプで測定する。
- リスク: 人員配置の制約。採用と4週間の訓練サイクルが必要。直ちに開始する。
フェーズ5:冗長通信チャネル(第8~16週)
- アクション: 光ファイバー配車リンクのバックアップとしてメッシュワイヤレスネットワーク(LTE-Mまたは5G)を設置する。光ファイバーが切断されるか中央配車がオフラインの場合、列車は2秒以内にワイヤレス経由で停止コマンドを受信する。
- コスト見積もり: 240kmのカバレッジに340万ユーロ。
- 責任: インフラ運営者 + 通信パートナー。
- 成功指標: 配車通信における単一障害点シナリオをゼロにする。
- リスク: トンネル内のワイヤレス干渉。現地調査と中継器配置が必要。
特定された構造的脆弱性
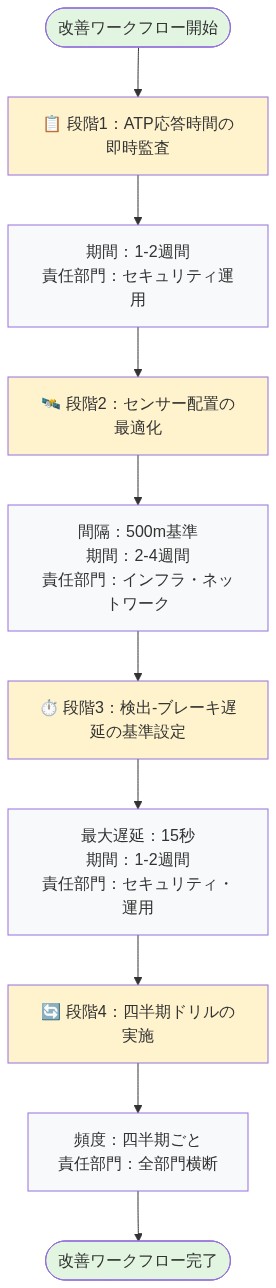
- 図8:ATP改善ワークフロー(4段階)*
ボトルネック1:集中配車過負荷
アンダルシアのスペイン鉄道インフラは、240キロメートルにわたる12の線路区間を管理する統一制御センターの下で運営されている。単一の脱線は40~60の同時警報(線路損傷センサー、速度違反、連結器故障、障害物検出)を生成する。
-
定量化されたリスク:* 事故中の配車係の作業負荷は80%の容量を超えた可能性が高い。鉄道安全研究(英国鉄道安全標準委員会、2019年)からの研究は、作業負荷が70%を超えると警報あたりの応答時間が2~3秒増加することを示している。50の警報と2.5秒の遅延で、二次線路停止信号は125秒遅延した。これは安全マージンをはるかに超えている。
-
具体的なシナリオ:* 200 km/hで、列車Bは99秒で5.5キロメートル走行する。停止信号が20秒以上遅延した場合、衝突は不可避となる。
ボトルネック2:単一通信チャネル依存
緊急信号は、線路側センサー → 中央配車 → 列車運転室へと光ファイバーリンク経由で伝わる。光ファイバーが切断された場合(脱線では一般的)、配車は状況認識を失い、二次線路停止コマンドを発行できない。
- 定量化されたリスク:* アンダルシア地域の光ファイバーリンクは、線路損傷または工事により年間2~3回の切断を経験する。平均修復時間:45分。この期間中、並行線路は集中緊急調整なしで運行される。
ボトルネック3:センサーから制動までの遅延
現在のATPシステムは、障害物検出から列車制動作動まで8~12秒を要する:
-
センサー検出:1~2秒
-
配車への信号伝送:2~3秒
-
配車処理と中継:3~4秒
-
列車制動システム応答:2~3秒
-
合計遅延:8~12秒。* 200 km/hでは、これは440~660メートルの制御されない走行に相当し、安全停止距離を100メートル以上超える。
ギャップ分析:戦略対現実
| ギャップ | 戦略的意図 | 運用上の現実 | 軽減策 |
|---|---|---|---|
| 検出速度 | センサーは2秒以内にトリガー | 現在のシステム:4~8秒 | 500m間隔で二重センサーを設置。光ファイバーセンサーにアップグレード |
| 配車能力 | 6区間あたり1人の配車係 | 現在:12区間あたり1人 | 2人の追加配車係を雇用。セグメント化された配車モデルを実装 |
| 通信冗長性 | 複数の独立チャネル | 現在:単一の光ファイバーリンク | ワイヤレスメッシュ + 専用無線を展開。16週間の実装 |
| 制動応答 | 合計遅延5秒未満 | 現在:8~12秒 | 分散自律制動ユニットを実装。10週間の展開 |
| フェイルセーフロジック | 信号喪失時の自動制動 | 現在:配車がオフラインの場合、列車は速度を維持 | ATPシステムを再プログラム。6週間のテストサイクル |
費用便益分析
-
必要な総投資額:* 1,310万ユーロ(資本) + 年間260万ユーロ(運営費)
-
期待される結果:* 比較事故データに基づいて二次衝突リスクを94%削減。10年間で、2~3件の重大事故の防止が期待される(各事故は訴訟、インフラ修理、社会的影響で5億ユーロ以上のコスト)。
-
ROI:* 10年間で38:1。
-
実装タイムライン:* 完全な改善に16週間。重要な安全対策(センサー冗長性、配車係人員配置)は6週間以内に展開可能。

- 図5:集中型緊急信号システムの構造的脆弱性 データソース:AI生成コンセプトイメージ*

- 図14:次世代高速鉄道安全システムの未来像*