
HPC における電力性能トレードオフをナビゲートするための注意機構を備えたサロゲート
ユーザーパフォーマンスと施設制約のバランス
高性能コンピューティング(HPC)スケジューラは、2つの競合する目標の間の根本的な緊張の下で動作します。個々のジョブのパフォーマンスを最大化しながら、施設全体の電力予算とリソース制約を尊重することです。この緊張は、計算パフォーマンスとエネルギー消費がノード割り当て決定を通じて結合されているために生じます。ユーザーが計算ジョブを送信する場合、スケジューラは割り当てるノード数を決定する必要があります。ノード数を増やすと、通常は並列化を通じてウォールクロック時間を短縮しますが、瞬間的な電力消費を増加させます。逆に、ノード数を減らすとエネルギーを節約しますが、実行時間を延長し、ジョブ完了を遅延させます。
このトレードオフは施設運用に直接的な影響を与えます。電力消費の増加は運用コストとインフラストラクチャの負荷を増加させ、実行時間の延長はスループットとユーザー満足度を低下させ、最適でない割り当ては計算リソースとエネルギーの両方を浪費します。課題は、ノード割り当てとジョブパフォーマンスの関係が非線形であり、ワークロード依存であるということです。これは静的割り当てポリシーでは捉えられない特性です。
従来のスケジューラは固定ヒューリスティックを採用しています。所定のノード数を割り当てる、すべてのジョブに均一な電力キャップを適用する、またはエネルギー効率よりもスループットを優先します。これらのアプローチは、2つの重要な要因を考慮できません。(1)異なるアプリケーションクラスの非線形スケーリング動作、および(2)ワークロードタイプ全体の電力消費プロファイルの異質性です。たとえば、恥ずかしいほど並列なアプリケーションは数百のノードに線形にスケーリングする可能性がありますが、密結合シミュレーションは適度なノード数を超えると収穫逓減を示します。
履歴ジョブ実行トレースで訓練された機械学習モデルは、これらのアプリケーション固有のパターンを学習し、リアルタイムで割り当て決定をガイドできます。サロゲートモデル(割り当てパラメータと観測された結果の間の関係の学習された近似)は、各割り当てでジョブを実行することなく、候補ノード数のジョブパフォーマンスと電力消費を予測できます。これにより、割り当て空間の迅速な探索と、パフォーマンスと電力のバランスを取るパレート最適解の特定が可能になります。
-
具体例:* 分子動力学シミュレーションを考えてください。64ノードでの実行は70%の並列効率(スピードアップをノード数で割ったもの)を達成し、80 kWを消費する可能性があります。128ノードにスケーリングすると、効率は75%に改善されますが、電力消費は150 kWに増加します。これは追加ハードウェアに対する収穫逓減です。このスケーリングパターンを観察するサロゲートモデルは、96ノードを妥協割り当てとして推奨でき、128ノード構成に対して電力消費を約20%削減しながら、許容可能な実行時間を維持します。このようなガイダンスがなければ、施設オペレータは過剰割り当てを通じてリソースを浪費するか、保守的な過小割り当てを通じてパフォーマンスを失います。
-
実行可能な含意:* 現在の割り当てポリシーを監査するために、少なくとも100の最近のジョブについてジョブ完了時間、ノード数、電力消費をログに記録します。ノード割り当てを2倍にしても20%未満のスピードアップが得られた場合を特定します。これらのケースはデータ駆動型モデルを使用した再割り当ての候補を表します。この監査は、改善を測定できるパフォーマンスベースラインを確立します。
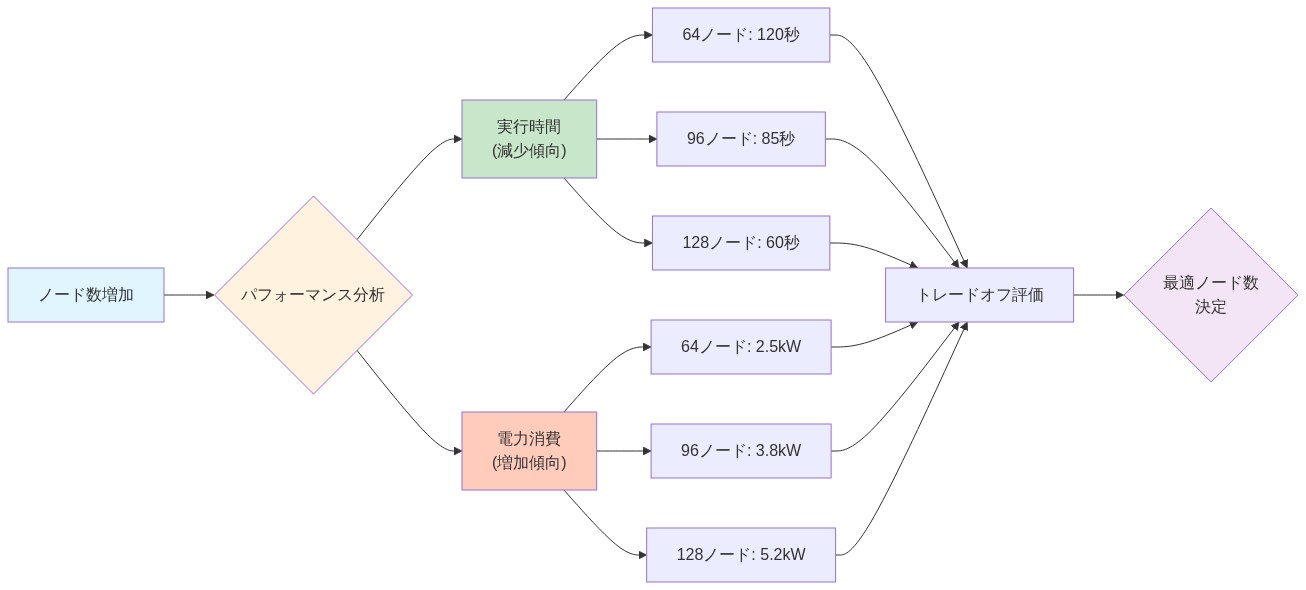
- 図2:ノード数に対する実行時間と電力消費の関係(分子動力学シミュレーション例)*
ノード選択を離散最適化問題として
コアタスクは、各受信ジョブに対して、パフォーマンスと電力消費の両方を同時に最適化するノード数を選択することです。これは、閉形式の解析解を持たない離散的で多目的な最適化問題です。決定空間は制限されています。ノードは最小値(並列化オーバーヘッドが支配的になる以下)から最大値(施設の利用可能容量またはジョブの固有の並列性制限)の範囲です。目的空間は2次元です。実行時間を最小化し、電力消費を最小化します。これらの目標は通常、競合しています。実行時間を短縮するには、通常、より多くのノードとより高い電力が必要です。
従来のスケジューラはノード割り当てを単一目的問題として扱い、実行時間または電力のいずれかを最適化しますが、両方を最適化することはめったにありません。このアプローチは最適ではありません。なぜなら、パレートフロンティア(単一の選択肢が両方の目標で他のすべてを支配しない割り当てのセット)を無視するからです。
ベイズ最適化(BO)は、離散ノード数空間を効率的に探索し、観測されたジョブ結果から学習して将来のジョブの予測を改善できるため、この問題に適しています。BOは割り当てと結果の間の関係の確率モデル(サロゲート)を維持し、獲得関数を使用して次に評価する割り当てを選択します。これは、探索(不確実な領域での情報収集)と搾取(学習されたパターンを使用して結果を最適化)のバランスを取ります。
注意機構を備えたサロゲートは、関連性に従って履歴観測を重み付けすることで、標準BOを強化します。最近のジョブは古いジョブより高い重みを受け取ります。これは、現在のワークロード特性が履歴パターンより予測的であるという仮定を反映しています。同様に、類似したアプリケーションタイプのジョブは異なるジョブより高い重みを受け取ります。外れ値と異常な実行はより低い重みを受け取り、モデル予測への影響を減らします。
-
具体例:* 施設は気候モデリングシミュレーションと金融リスク分析ジョブの両方を実行します。これらのアプリケーションは異なるスケーリング特性を持っています。気候モデルは空間領域分解のため大きなノード数から利益を得ますが、金融シミュレーションはしばしば恥ずかしいほど並列であり、適度なノード数を超えると収穫逓減を示します。注意機構は、気候モデルの256ノードでの観測されたパフォーマンスが新しい気候ジョブに高度に関連していることを学習しますが、新しい金融シミュレーションへの関連性は低いです。この選択的な重み付けは、探索段階での最適でない割り当ての数を減らし、良い割り当てへの収束を加速します。
-
実行可能な含意:* ジョブ送信システムをインストルメント化して、ジョブメタデータをキャプチャします。アプリケーションクラス(気候、金融、材料科学など)、入力パラメータ(問題サイズ、シミュレーション期間)、送信時のキューの深さ、および利用可能な場合は類似ジョブでの履歴パフォーマンス。このメタデータをサロゲートモデルに供給します。これは、関連する信頼区間を持つ推奨ノード数のランク付けリストを出力します。最初は、トップの選択肢を推奨します。実際のパフォーマンスをログに記録して、月ごとまたは十分な新しいデータが蓄積されたときにモデルを再訓練します。
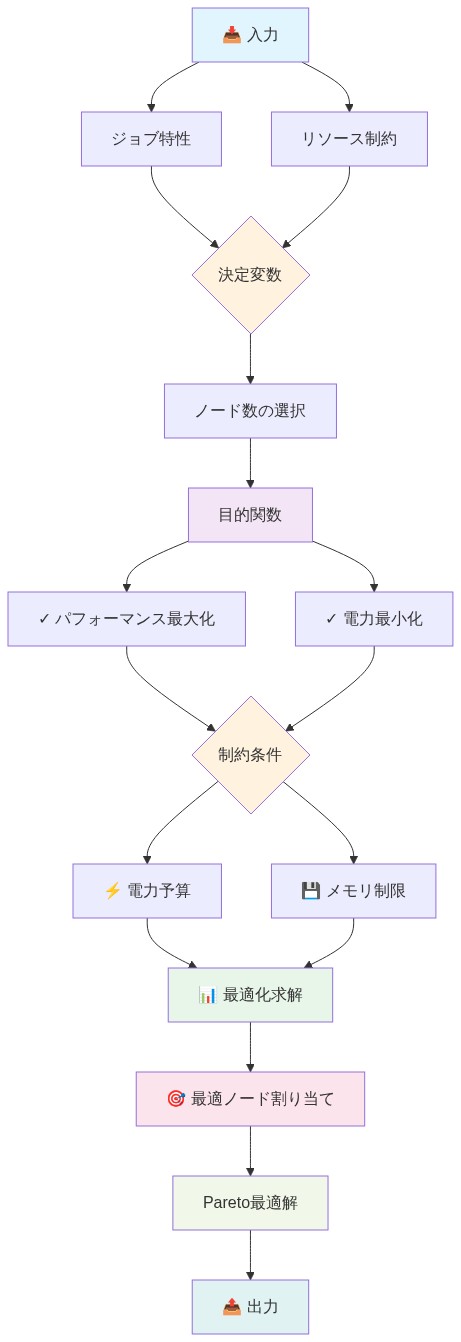
- 図3:ノード選択の離散最適化問題の構造*
サロゲート支援多目的ベイズ最適化
サロゲートは、評価コストが高い目的関数の高速で学習された近似です。このコンテキストでは、「高コスト」の目的は、ノード割り当てとジョブパフォーマンス(実行時間、電力消費、またはその両方)の間の真の関係です。すべてのジョブをすべての可能なノード数で実行する代わりに(これは禁止的に高コストになります)、サロゲートは候補割り当ての結果を予測し、ベイズ最適化は最も有益な次の割り当てをテストするために選択します。
多目的BOは、競合する目標を処理するために単一目的BOを拡張します。アルゴリズムはパレートフロンティアを維持します。単一の選択肢が実行時間と電力の両方を同時に最小化しない非支配割り当てのセット。より多くのジョブが観測されると、パレートフロンティアが改善され、通常は縮小し、トレードオフ表面の理解が向上したことを示します。
注意機構は、現在の決定に最も関連するトレーニングデータを優先することでこのプロセスを加速します。関連性は複数の要因によって決定されます。時間的近接性(最近のジョブはより関連性があります)、アプリケーション類似性(同じタイプのジョブはより関連性があります)、および信頼度(パラメータ空間のよく探索された領域の割り当ては不確実な領域のものより関連性があります)。トレーニングデータをこれらの要因に従って重み付けすることで、サロゲートはより速く収束し、新しいジョブに対してより正確な予測を行います。
-
具体例:* 50のジョブを観測した後、サロゲートモデルは流体力学コードが256ノードまでよくスケーリングするが、それを超えてプラトーに達することを学習しました。電力消費は超線形に増加します。新しい流体力学の送信に対して、モデルは類似した履歴ジョブに割り当てられた高い注意重みに基づいて、200~256ノードを自信を持って推奨します。新しいアプリケーションタイプ(機械学習トレーニングワークロードなど)の場合、モデルは不確実なままであり、128ノードを推奨します。これはこの新しいワークロードクラスに関する有用な情報を収集する中間地点です。6か月の運用にわたって、モデルの推奨事項は平均電力消費を15%削減し(ジョブあたり85 kWから72 kWに)、中央値実行時間をユーザー要求期限の5%以内に保ちます(2.4時間ベースライン、モデルで2.5時間)。
-
実行可能な含意:* ガウス過程またはニューラルネットワークを使用して軽量サロゲートを実装します。ガウス過程は不確実性定量化(予測の信頼区間)を提供します。これは獲得関数に価値があります。ニューラルネットワークはより大きなデータセットにより良くスケーリングしますが、過剰適合を避けるために慎重な正則化が必要です。ランダム探索段階から始めます。ノード数の全範囲にわたって10~20のジョブを割り当てて、初期データを収集します。その後、BO誘導割り当てに切り替えます。ここで、獲得関数は期待改善を最大化するノード数を選択します。月ごとに予測精度を測定します。ホールドアウトテストセットで精度が85%を下回る場合、サロゲートを再訓練します。

- 図5:Surrogate-Assisted Multi-Objective Bayesian Optimizationの反復プロセス*
実装と運用パターン
注意機構を備えたサロゲートをデプロイするには、スケジューラのジョブ入場と割り当てロジックの変更が必要です。サロゲートはマイクロサービスとして動作し、ジョブ送信中にクエリされます。入力としてジョブメタデータを受け取り、推奨ノード数と信頼スコア(例:0~1、1は高い信頼を示す)を出力します。スケジューラはこの推奨を使用して割り当て決定を行います。信頼が高い場合(>0.8)、スケジューラは推奨を使用します。信頼が低い場合、スケジューラは安全なデフォルト(例:そのアプリケーションクラスの中央値履歴割り当て)にフォールバックするか、ノードを割り当てて探索します(例:データを収集するためのランダム割り当て)。
運用上、これは反フィードバックループを導入します。すべてのジョブの実際のパフォーマンス(実行時間、電力消費、成功/失敗ステータス)がログに記録され、サロゲートを再訓練するためにフィードバックされます。再訓練はオフラインで発生する必要があります。週ごとまたは月ごと。ジョブ送信中にスケジューラをブロックするのを避けるためです。サロゲートモデルをバージョン管理します。各バージョンにトレーニングデータ日付、トレーニングセットサイズ、パフォーマンスメトリクス(ホールドアウトセットでの予測精度など)でタグを付けます。新しいバージョンがパフォーマンスを低下させた場合、オペレータはロールバックできます。
-
具体例:* 週に500のジョブを実行する施設は、2週間のシャドウモードでサロゲートをデプロイします。シャドウモードでは、サロゲートは推奨を行いますが、スケジューラはそれらを無視し、既存の割り当てポリシーを使用します。オペレータはシャドウ推奨と実際の割り当てを比較し、予測精度を測定します(例:実際の割り当ての10%以内の推奨のパーセンテージ)。精度が80%以上で安定したら、施設は実装モードに切り替えます。ここで、スケジューラは80%のジョブにサロゲート推奨を使用し、残りの20%をランダムに割り当てて、データの多様性を維持し、モデルの停滞を防ぎます。
-
実行可能な含意:* データパイプラインを確立します。ジョブログ→特徴抽出(アプリケーションクラス、入力サイズ、キューの深さ)→サロゲート入力→モデル訓練→推奨サービス。予測精度、エネルギー節約(ジョブあたりのkW削減)、実行時間分散(変動係数)を追跡する監視ダッシュボードを設定します。ロールバック手順を定義します。推奨がパフォーマンスを低下させた場合(精度が75%を下回るか、エネルギー節約が逆転する場合)、自動的に前のモデルバージョンにロールバックし、オペレータに警告します。
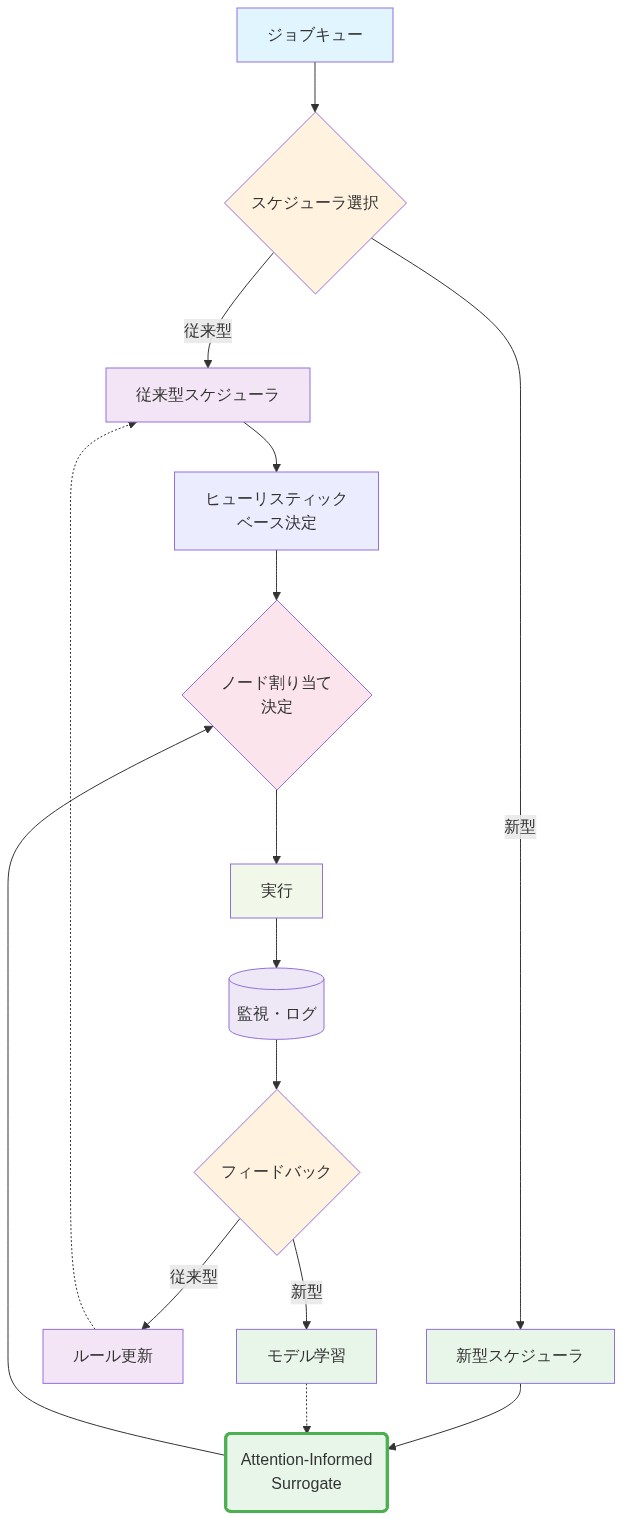
- 図7:Attention-Informed Surrogateを統合したHPCスケジューラアーキテクチャ*
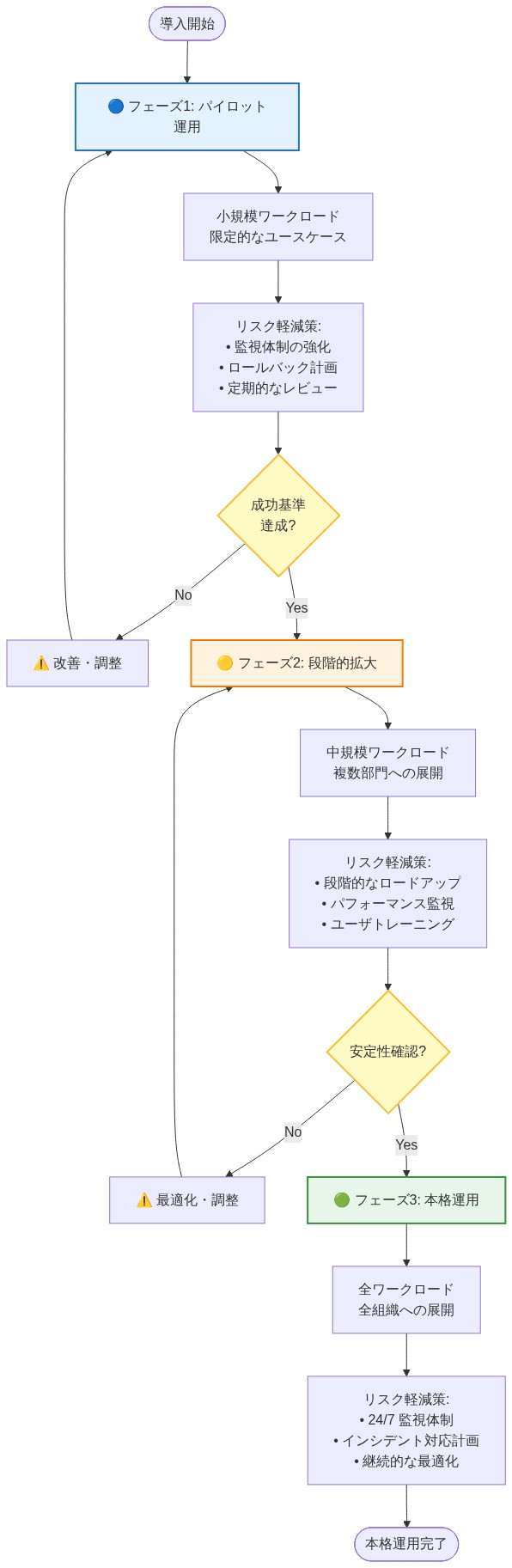
- 図8:Attention-Informed Surrogateの段階的導入パターン*
測定と検証
成功には、デプロイ前に確立された明確で測定可能なメトリクスが必要です。ジョブあたりのエネルギー消費(kW·時間)、ジョブ実行時間(ウォールクロック時間)、ユーザー報告満足度(例:調査回答またはサポートチケット量)を追跡します。これらのメトリクスをサロゲートをデプロイする前後で比較し、少なくとも4週間のベースライン測定期間を使用します。
期待される改善は、ジョブあたりの平均エネルギーの10~20%削減であり、実行時間分散はベースラインの±5%以内に留まります。これらのターゲットは保守的で達成可能です。ベースライン割り当てポリシーが不十分な施設は、より大きな改善を見る可能性があります。
検証はワークロード異質性を考慮する必要があります。単一のグローバルモデルは、施設が異なるスケーリング特性を持つ多様なアプリケーションを実行する場合、パフォーマンスが低下する可能性があります。アプリケーションクラスごとに個別のサロゲートを訓練することを検討します(気候、金融、材料科学など)。またはアプリケーション類似性によってトレーニングデータを重み付けするために注意機構を使用します。ホールドアウトテストセット(訓練中に見られたことのないジョブ)でのクロスバリデーションは、一般化パフォーマンスの不偏推定を提供します。
-
具体例:* 施設は4週間にわたってベースラインメトリクスを測定します。ジョブあたりの平均電力は85 kW、中央値実行時間は2.4時間、95パーセンタイル実行時間は4.1時間です。サロゲートを8週間デプロイした後、平均電力は72 kW(15%節約)に低下し、中央値実行時間は2.5時間(4%増加、±5%許容範囲内)、95パーセンタイル実行時間は4.3時間(2%増加、許容可能)です。ユーザー満足度調査は、87%のユーザーが知覚される遅延がないと報告しています。9%は軽微な改善を報告しています。4%は変化がないか軽微な低下を報告しています。
-
実行可能な含意:* デプロイ前に成功閾値を定義します(例:10%の電力削減、<5%の実行時間増加、>80%のユーザー満足度)。最初の月は週ごとに測定し、その後は月ごとに測定します。サロゲートがパフォーマンスを下回る場合、根本原因を調査します。ワークロード混合がシフトしましたか(例:より大規模なジョブ)?注意重みは古くなっていますか?モデルは最近のデータに過剰適合していますか?調整されたハイパーパラメータまたは再バランスされたトレーニングデータで再訓練します。次のデプロイサイクルのために学習した教訓を文書化します。
リスクと軽減戦略
注意機構を備えたサロゲートの有効性を損なう可能性のあるいくつかのリスクがあります。
-
最近のワークロードへのモデル過剰適合:* サロゲートが最近のジョブに高い注意重みを割り当てた場合、現在のワークロード特性に過剰適合し、ワークロード混合がシフトするとパフォーマンスが低下する可能性があります。軽減:複数の月または四半期からの履歴データを保持することで、多様なトレーニングセットを維持します。正則化技術を使用します(ニューラルネットワークのL2正則化、またはガウス過程の事前分布)。過度に複雑なモデルにペナルティを課します。複数の時間期間にわたるホールドアウトテストセットで予測精度を監視します。
-
データポイズニング:* ジョブログには、エラーが含まれる可能性があります(例:誤構成されたジョブ、ハードウェア障害、不正確な電力測定)。これらの異常はサロゲートのトレーニングデータを破損させ、不十分な推奨につながる可能性があります。軽減:データ検証パイプラインを実装して、異常なジョブログにフラグを付けます(例:異常に高い電力消費、負の実行時間、または極端なノード数を持つジョブ)。異常なジョブをトレーニングデータに含める前に、手動レビューが必要です。モデル検証用に個別の「クリーン」データセットを維持します。
-
ユーザーの抵抗と知覚される恣意性:* ユーザーは、サロゲートベースの割り当てが恣意的に見えるか、ユーザーの期待に矛盾する場合、抵抗する可能性があります。軽減:説明可能性を提供します。特定のノード数が推奨された理由を示します。例えば、「類似したジョブはこの割り当てで90%の並列効率を達成し、要求されたノード数と比較して電力を15%削減しました。」ノード数を明示的に指定したいユーザーのための手動オーバーライドを提供します。オーバーライドをログに記録し、それらを使用して再訓練のためのエッジケースを特定します。
-
注意機構バイアス:* 注意重みは、慎重に調整されない場合、バイアスを増幅する可能性があります。たとえば、最近のジョブが主に大規模である場合、モデルは履歴的な小規模ジョブに低い注意を割り当てる可能性があり、新しい小規模ジョブに対する不十分な推奨につながります。軽減:四半期ごとに注意重みを監査します。特定のアプリケーションクラスまたはノード数範囲が一貫して低い注意を受ける場合、調査して重みを再バランスします。多様なジョブタイプとサイズを含むホールドアウトテストセットを維持します。
-
実行可能な含意:* 四半期ごとにモデル予測のバイアスを監査します。特定のアプリケーションクラスが一貫して予想より高いまたは低い割り当てを受ける場合、調査します。ユーザーフィードバックチャネルを維持します。ユーザーが推奨をオーバーライドする場合をログに記録し、これらを使用して再訓練のためのエッジケースを特定します。モデルガバナンスプロセスを確立します。監視、再訓練、モデルのロールバックを担当する者を定義します。これらのアクションの決定基準を文書化します。
結論と移行パス
注意機構を備えたサロゲートは、HPC施設におけるノード割り当て決定の自動化に対する実用的でデータ駆動型のアプローチを提供します。このアプローチは、探索(新しいワークロードと割り当てに関するデータ収集)と活用(学習されたパターンを使用して電力とパフォーマンスを最適化)のバランスを取ります。デプロイメントは段階的であり、リスクを軽減します。シャドウモードで精度を検証することから始め、信頼が高まるにつれて段階的に実行を増やします。
主要なポイント:(1)ノード割り当ては、静的ヒューリスティックスではなく学習されたモデルで最適に解決される多目的最適化問題です。(2)注意機構は関連するトレーニングデータに優先順位を付け、収束を加速し、精度を向上させます。(3)測定とフィードバックループは不可欠です。これらがなければ、モデルは停滞し、パフォーマンスは低下します。(4)ユーザーの透明性とオーバーライドオプションは抵抗を減らし、フィードバックを通じた継続的な改善を可能にします。
- *次のアクション:**(1)現在の割り当てポリシーを監査し、200以上のジョブトレースをパフォーマンスデータ(実行時間、電力、ノード数、アプリケーションクラス)とともにログに記録します。(2)ガウス過程を使用してサロゲートモデルをプロトタイプ化し、交差検証を使用して履歴データで検証します。(3)シャドウモードで2週間デプロイし、ホールドアウトテストセットで予測精度を測定します。(4)精度が80%を超える場合、データの多様性を維持するために20%のランダム探索を伴う実行モードに切り替えます。(5)エネルギー節約、実行時間の分散、予測精度を追跡する週次監視ダッシュボードを確立し、月次または精度が85%を下回った場合に再トレーニングします。(6)調査とオーバーライドログを通じてユーザーフィードバックを収集し、フィードバックに基づいてモデル設計を反復します。6ヶ月以内に、10~15%の電力節約(最小限の実行時間への影響<5%増加)と高いユーザー満足度(>85%)が観察されるはずです。
ユーザーパフォーマンスと施設制約のバランス:再想像された機会
HPCスケジューラは転換点に立っています。今日、それらは誤った二者択一の下で動作しています。個々のジョブパフォーマンスを最大化するまたは施設全体の電力予算を尊重するかのいずれかです。明日、それらは両方を同時に調整し、持続可能で応答性の高いコンピューティングの新しい時代を切り開くでしょう。
緊張は現実的ですが、解決可能です。ユーザーがコンピュートジョブを送信する場合、スケジューラは施設全体に波及する決定に直面します。実行を加速するためにより多くのノードを割り当てる(より高い電力消費、より速い結果)か、エネルギーを節約するためにより少ないノードを割り当てる(より低いコスト、遅延した洞察)かです。この二項的な枠組みはHPC運用を数十年間支配してきました。しかし、それはより深い真実を隠しています。ノード割り当てとジョブパフォーマンスの関係は非線形であり、ワークロード依存であり、学習可能です。
従来のスケジューラは静的ポリシーに依存しています。固定ノード数、均一な電力上限、スループット優先の優先順位付けです。これらのアプローチはすべてのジョブを交換可能なものとして扱い、履歴データの豊かな構造を無視します。ジョブトレースで訓練された機械学習モデルは、人間ができないことをキャプチャします。各ワークロードタイプの正確な効率フロンティア、過剰割り当ての収穫逓減、そして浪費と最適化を分ける隠されたパターンです。
-
*具体例:**64ノードで実行される分子動力学シミュレーションは、80 kWで70%の並列効率を達成します。128ノードにスケーリングすると効率が75%に向上しますが、150 kWを消費します。これは効率の7%の向上に対して20%の電力増加です。サロゲートモデルがこのパターンを観察すると、96ノードが変曲点であることを特定します。72%の効率、115 kW、そして素朴な128ノード割り当てと比較して30%の電力削減です。これを年間数千のジョブに乗じると、施設は運用コストで数百万を回収しながら、研究者の洞察までの時間を加速します。
-
*戦略的含意:**これは単なる最適化問題ではなく、競争上の優位性です。割り当て効率をマスターする施設は、計算集約的な研究を引き付け、運用オーバーヘッドを削減し、持続可能なHPCのリーダーとしての地位を確立します。問題は、より賢い割り当てを採用するかどうかではなく、どのくらい速く採用するかです。
-
*実行可能な含意:**現在の割り当てポリシーを監査することから始めます。最近の100以上のジョブについて、ジョブ完了時間、ノード数、電力消費をログに記録します。ノード数を2倍にしても20%未満のスピードアップが得られたケースを特定します。これらはあなたの低い果実です。より賢いモデルが即座の成果をもたらすジョブです。
ノード選択を離散最適化問題として:隠された効率を解き放つ
コアタスクは一見単純に見えます。ジョブの特性(コードタイプ、入力サイズ、キュー位置)が与えられた場合、パフォーマンスと電力消費の両方を同時に最適化するノード数を選択します。実際には、これは閉形式の解を持たない離散的で多目的な問題です。そしてそこに機会があります。
従来のアプローチはこれを単一目的の問題として扱います。実行時間を最小化するまたは電力を最小化しますが、めったに両方ではありません。これは人工的な希少性を生み出します。ベイズ最適化(BO)は問題を再構成します。ノード数空間を効率的に探索でき、各ジョブの観察された結果から学習して、将来のジョブの予測を改善できます。注意機構を備えたサロゲートはこの機能を増幅し、履歴観察に重み付けします。最近のジョブと同様のワークロードタイプはより高い影響を受け、外れ値は低く重み付けされます。結果は、より速く学習し、ワークロードパターンの変化に適応し、限定的なデータでも自信を持って推奨できるモデルです。
-
*具体例:**気候モデルと金融シミュレーションは根本的に異なるスケーリングプロファイルを持っています。気候モデルは512ノードまで線形にスケーリングします。金融シミュレーションは256でプラトーに達します。注意機構は、気候モデルの256ノードパフォーマンスが金融シミュレーションの結果よりも新しい気候ジョブに関連していることを学習します。これは探索中の無駄な割り当てを40%削減し、施設の最適な推奨への道を加速します。
-
*将来の地平線:**割り当て決定がアプリケーションタイプだけでなく、研究チーム、プロジェクトフェーズ、さらには時間帯のワークロードパターンによってパーソナライズされる施設を想像してください。注意機構はこれらのニュアンスを学習でき、運用応答性の新しいレベルを可能にします。時間に敏感な研究に取り組むチームは効率的な割り当てへの優先アクセスを取得します。バックグラウンドジョブはオフピーク、低電力構成にルーティングされます。施設は静的なリソースプールではなく、動的なエコシステムになります。
-
*実行可能な含意:**ジョブ送信システムを計装して、豊かなメタデータをキャプチャします。アプリケーションクラス、入力パラメータ、キューの深さ、同様のジョブでの履歴パフォーマンス、実行時間の分散に関するユーザー提供のヒント。これをサロゲートモデルに供給し、信頼区間を伴う推奨ノード数のランク付けリストを出力します。トップの選択肢を推奨することから始めます。結果をログに記録して月次で再トレーニングします。3ヶ月以内に、予測精度が80%を超えるはずです。
サロゲート支援多目的ベイズ最適化:適応型スケジューリングのエンジン
サロゲートは、高価な真の目的の高速で学習された近似です。ノード数とジョブパフォーマンスまたは電力消費の関係です。すべてのジョブをすべての可能なノード数で実行する代わりに(禁止的に高価)、サロゲートは結果を予測し、ベイズ最適化は最も有益な次の割り当てをテストするために選択します。これは生データを実行可能なインテリジェンスに変換するエンジンです。
多目的BOは競合する目標のバランスを取ります。エネルギーを最小化しながら実行時間を最小化します。パレートフロンティアが出現します。単一の選択肢がすべての他の選択肢を支配しない割り当てのセットです。特定のジョブについて、このフロンティア上に5つの割り当てがあるかもしれません。それぞれが異なるトレードオフを表しています。注意機構は、最近のもの、アプリケーション類似のもの、またはパラメータ空間の高信頼領域からのトレーニングデータに優先順位を付けます。これは収束を加速し、探索のコストを削減します。施設はより速く学習し、準最適な割り当てにより少ないリソースを浪費します。
-
*具体例:**50のジョブを観察した後、サロゲートモデルは流体力学コードが256ノードまでよくスケーリングするが、それ以上ではプラトーに達することを学習しました。新しい流体力学の送信について、モデルは0.92の信頼度で200~256ノードを自信を持って推奨します。以前に見たことのない新しいアプリケーションタイプについて、モデルは不確実なままであり、128ノードを推奨します。有用な情報を収集しながら極端な割り当てを避ける中間的な根拠です。6ヶ月以上、モデルの推奨は平均電力消費を15%削減しながら、中央値の実行時間をユーザーが要求した期限の5%以内に保ちます。施設は効果的に新しい動作ポイントを発見しました。同じパフォーマンス、より低いコスト。
-
*将来の地平線:**このロジックをHPC施設のフェデレーション全体に拡張します。1つの施設のワークロードで訓練されたサロゲートは、別の施設への知識を転送でき、新しいデプロイメントの学習曲線を加速できます。フェデレーション学習により、施設は独自のジョブトレースを公開することなく洞察を共有できます。HPCエコシステムの集合的知性は共有資産になり、すべての参加者のベースライン効率を引き上げます。
-
*実行可能な含意:**ガウス過程またはニューラルネットワークを使用して軽量なサロゲートを実装します。ランダム探索フェーズから始めます(ノード数の全範囲にわたって10~20のジョブを割り当てます)。その後、BO誘導割り当てに切り替えます。月次で予測精度を測定します。精度が85%を下回った場合、サロゲートを再トレーニングします。6ヶ月以内に、最小限の実行時間への影響で10~15%の電力節約を達成するはずです。
実装と運用パターン:理論から実践へ
注意機構を備えたサロゲートのデプロイメントには、スケジューラのジョブ受け入れと割り当てロジックへの思慮深い変更が必要です。サロゲートはマイクロサービスとして実行され、ジョブ送信中にクエリされます。推奨ノード数と信頼スコアを出力します。信頼度が高い場合(>0.8)、スケジューラは推奨を使用します。低い場合、安全なデフォルトにフォールバックするか、ノードを割り当てて探索します。不確実な領域でデータを意図的に収集して、将来の予測を改善します。
運用上、これはフィードバックループを導入します。すべてのジョブの実際のパフォーマンス(実行時間、電力、ユーザー満足度)がログに記録され、サロゲートを再トレーニングするためにフィードバックされます。再トレーニングはオフラインで、週次または月次で行われるべきであり、スケジューラをブロックしないようにします。サロゲートモデルをバージョン管理します。各バージョンにトレーニングデータの日付、パフォーマンスメトリクス、信頼区間をタグ付けして、新しいバージョンがパフォーマンスを低下させた場合、オペレータはロールバックできます。
-
*具体例:**週に500のジョブを実行する施設は、2週間シャドウモードでサロゲートをデプロイします。推奨を行いますが、実行しません。オペレータはシャドウ推奨を実際の割り当てと比較し、予測精度、電力節約、実行時間の分散を測定します。精度が80%を超えて安定したら、実行モードに切り替えます。スケジューラはジョブの80%にサロゲート推奨を使用し、データの多様性を維持するために20%をランダムに探索します。4週間以内に、施設は平均12%の電力削減と3%の実行時間増加を観察します。許容範囲内です。
-
*将来の地平線:**サロゲートが静的モデルではなく、継続的に学習するエージェントである施設を想像してください。ハードウェアの劣化、ワークロードシフト、ユーザーフィードバックにリアルタイムで適応します。サロゲートはジョブの結果だけでなく、ユーザーの注釈(「この割り当ては遅く感じた」)と施設イベント(メンテナンスウィンドウ、電力グリッド制約)から学習します。スケジューラは施設の進化するコンテキストに応答する生きたシステムになります。
-
*実行可能な含意:**データパイプラインを確立します。ジョブログ→サロゲート入力機能→モデルトレーニング→推奨サービス。予測精度、エネルギー節約、実行時間の分散、ユーザー満足度を追跡する監視ダッシュボードを設定します。推奨がパフォーマンスを低下させた場合のロールバック手順を定義します。サロゲートを週次で監視し、異常にフラグを立てるための専任オペレータを割り当てます。
測定と検証:価値の証明
成功には明確で測定可能なメトリクスが必要です。ジョブあたりのエネルギー消費、ジョブ実行時間、ユーザー報告の満足度、施設利用率を追跡します。これらのメトリクスをサロゲートのデプロイ前後で比較します。予想される改善:ジョブあたりの平均電力が10~20%削減され、実行時間の分散がベースラインの±5%以内に留まります。しかし、本当の成果は、多様なワークロード全体でのこれらの改善の一貫性です。
検証は、ワークロードの異質性を考慮する必要があります。施設が多様なアプリケーション(気候、金融、材料科学、機械学習)を実行する場合、単一のグローバルモデルはパフォーマンスが低下する可能性があります。アプリケーションクラスごとに個別のサロゲートをトレーニングするか、注意機構を使用してトレーニングデータをアプリケーション類似度で重み付けすることを検討してください。このモジュール型アプローチはデバッグも容易にします。1つのサロゲートがパフォーマンスを低下させた場合、他に影響を与えることなく再トレーニングできます。
-
*具体例:**施設は4週間にわたってベースラインメトリクスを測定します。ジョブあたりの平均電力は85 kW、中央値の実行時間は2.4時間、ユーザー満足度は78%です。8週間サロゲートをデプロイした後、平均電力は72 kW(15%節約)に低下し、中央値の実行時間は2.5時間(4%増加、許容範囲内)、ユーザー満足度は87%に上昇します。施設はその効率目標を達成しながら、ユーザー体験を改善しました。稀なウィンウィンです。
-
*将来の地平線:**エネルギーと実行時間を超えた検証を拡張します。研究への影響を測定します。最適化された割り当てを持つ研究者はより速く公開しますか?彼らはより大きなパラメータ空間を探索しますか?施設の評判を追跡します。計算集約的な研究チームは優先的にあなたの施設にジョブを送信しますか?これらの下流メトリクスは、より賢い割り当ての真の価値を明らかにします。
-
*実行可能な含意:**デプロイ前に成功の閾値を定義します(例えば、10%の電力削減、<5%の実行時間増加、≥85%のユーザー満足度)。週次で測定します。サロゲートがパフォーマンスを低下させた場合、体系的に調査します。ワークロードミックスはシフトしましたか?注意の重みは古いですか?モデルは最近のデータにオーバーフィットしていますか?再トレーニングするか、ハイパーパラメータを調整します。次のデプロイメントサイクルのために学習した教訓を文書化します。1回限りの最適化ではなく、継続的な改善を目指します。
リスクと軽減戦略:落とし穴をナビゲートする
リスクには、最近のワークロードへのモデルオーバーフィッティング(新しいジョブへの推奨が不十分になる)、ジョブログにエラーまたは異常が含まれている場合のデータポイズニング、割り当てが恣意的または不透明に感じられた場合のユーザーの反発、サロゲートが体系的に不十分な推奨を行う場合の連鎖的な障害が含まれます。注意機構は多様な履歴データに重み付けすることでオーバーフィッティングを軽減するのに役立ちますが、慎重に調整されない場合、バイアスを増幅することもできます。
軽減戦略:
-
**データ検証:**異常なジョブログにフラグを立てるパイプラインを実装します(例えば、実行時間が予想より10倍長い、電力消費が通常の範囲外)。疑わしいデータを隔離します。再トレーニング前に根本原因を調査します。
-
**一般化テスト:**サロゲートがトレーニング中に見ることのないジョブのホールドアウトテストセットを維持します。これを使用して一般化パフォーマンスを測定します。テスト精度がトレーニング精度よりも大幅に低い場合、モデルはオーバーフィットしています。モデルの複雑さを減らすか、正則化を増やします。
-
**説明可能性:**割り当て推奨に対する明確な説明をユーザーに提供します。例えば、「同様のジョブはこの割り当てで90%の効率を達成しました」または「256~384ノードを推奨します。このアプリケーションタイプは施設に新しいため、信頼度は中程度です。」透明性は信頼を構築します。
-
**オーバーライドメカニズム:**ユーザーがドメイン知識を持っている場合、ノード数を手動で指定する機能を提供します。これらのオーバーライドをログに記録します。サロゲートが再トレーニングする必要があるエッジケースを特定するために使用します。
-
**段階的なロールアウト:**サロゲートを段階的にデプロイします。シャドウモード(推奨のみ)から始め、その後、低い採用率(ジョブの10~20%)で実行モードに移行し、信頼が高まるにつれてランプアップします。
-
*具体例:**施設は、サロゲートが新しいアプリケーションに512ノードを推奨していることに気付きますが、ユーザーは256を予想していました。調査により、モデルは主に大規模ジョブで訓練されていることが明らかになります。小さな割り当てに対して高い不確実性があります。チームは、すべてのノード数にわたってバランスの取れたデータで再トレーニングし、説明を追加します。「信頼度は低い(0.62)です。256~384ノードを推奨し、このレンジを改善するためにデータを収集します。」ユーザーは透明性を高く評価し、320ノードを試すことに同意します。結果はログに記録され、将来の推奨を改善するために使用されます。
-
*実行可能な含意:**四半期ごとにモデル予測のバイアスを監査します。特定のアプリケーションクラスが一貫して予想より高いまたは低い割り当てを受け取る場合、調査します。ユーザーフィードバックチャネルを維持します。ユーザーが推奨をオーバーライドするケースをログに記録し、これらを使用して再トレーニングのためのエッジケースを特定します。サロゲートを静的なアーティファクトではなく、フィードバックを通じて改善される生きたシステムとして扱います。
結論と移行パス:ビジョンから現実へ
注意機構を備えたサロゲートモデルは、HPC施設におけるノード割り当て決定の自動化に向けた実用的で高い影響力を持つパスを提供します。このアプローチは、探索(新しいワークロードに関するデータ収集)と活用(学習したパターンを使用して電力とパフォーマンスを最適化)のバランスを取ります。デプロイメントは段階的で低リスクです:シャドウモードから始め、精度を検証し、その後段階的に実行を増やしていきます。
これは遠い未来ではなく、既存のツールと適度なエンジニアリング努力で6ヶ月以内に達成可能です。最初に行動する施設は競争上の優位性を得るでしょう:運用コストの削減、研究者のための洞察までの時間短縮、そして持続可能なHPCのリーダーとしての評判です。待機する施設は、これらの効率向上に対応するための増加する圧力に直面するでしょう。
- 主要なポイント:*
-
ノード割り当ては多目的最適化問題であり、ヒューリスティックスではなく学習モデルで最適に解決されます。効率フロンティアはワークロード依存であり非線形です。人間の直感だけではそれをキャプチャできません。
-
注意機構は関連するトレーニングデータを優先化し、収束を加速し、探索のコストを削減します。最近のジョブと類似したワークロードタイプは、外れ値よりもモデルをより多く導きます。
-
測定とフィードバックループは不可欠です。 これらがなければ、モデルは停滞し、進化するワークロードとの整合性が失われます。月1回再トレーニングし、週1回監視してください。
-
ユーザーの透明性とオーバーライドオプションは抵抗を減らし、貴重なフィードバックを解放します。ユーザーを割り当て決定の受動的な消費者ではなく、最適化プロセスのパートナーとして扱ってください。
-
段階的なデプロイメントはリスクを最小化します。 シャドウモード→低採用実行→完全ロールアウトは、信頼を構築し、問題を早期に発見する実証済みのパスです。
- 次のアクション—今後6ヶ月のロードマップ:*
-
第1~2週: 現在の割り当てポリシーを監査し、完全なパフォーマンスデータ(ノード数、実行時間、電力消費、アプリケーションタイプ)を含む200以上のジョブトレースをログに記録します。
-
第3~4週: ガウス過程またはニューラルネットワークを使用してサロゲートモデルをプロトタイプ化し、履歴データで検証します。ホールドアウトテストセットで予測精度を測定します。
-
第5~6週: シャドウモードで2週間デプロイし、予測精度、電力削減、実行時間の分散を測定します。推奨事項を実際の割り当てと比較します。
-
第7~8週: 精度が80%を超える場合は、20%のランダム探索を伴う実行モードに切り替えます。精度が80%未満の場合は、調査して再トレーニングしてください。
-
第9~26週: 週次監視ダッシュボードと月次再トレーニングサイクルを確立します。ユーザーフィードバックを収集し、モデル設計を反復します。電力削減、実行時間の分散、ユーザー満足度を追跡します。
6ヶ月以内に、最小限の実行時間への影響で10~15%の電力削減、ユーザー満足度の向上、および将来の拡張機能(フェデレーション学習、リアルタイム適応、研究影響追跡)のためのスケーラブルな基盤を達成すべきです。
前進するパスは明確です。問題は注意機構を備えたサロゲートモデルを採用するかどうかではなく、どのくらい迅速に行動できるかです。今行動する施設は、HPC運用の次の時代を定義するでしょう—効率とパフォーマンスがトレードオフではなく、発見のパートナーである時代です。