
BigQueryの会話型分析機能:技術的基礎と組織的実装
自然言語とデータウェアハウスの邂逅
Google Cloudは、BigQuery内にプレビュー機能として会話型分析機能を導入した。これにより、アナリストとビジネスユーザーはSQLではなく自然言語を用いて複雑なデータセットをクエリできるようになった。この機能は大規模言語モデル(LLM)—具体的にはコード生成とセマンティック理解タスクで訓練されたモデル—を活用し、ユーザーの意図を解釈し、会話型クエリをSQLに変換し、構造化形式で結果を返す。
-
定義上の明確化:* 会話型分析機能は多段階パイプラインを通じて動作する。(1)自然言語入力の解析、(2)セマンティック意図の抽出、(3)利用可能なBigQueryデータセットに対するスキーママッピング、(4)クエリ最適化を伴うSQL生成、(5)結果のフォーマットと提示。このシステムは恣意的なクエリを実行しない。むしろ生成を認可されたデータセットに制限し、実行前に検証ルールを適用する。
-
組織的影響:* 現在、組織はボトルネックを経験している。分析能力がSQL習熟者であるデータ専門家に集中しているのだ。これは洞察生成の遅延を招き、タイムリーな分析を受ける質問の範囲を制限する。会話型分析機能は独立してクエリを定式化できるユーザー層を拡大する。ただし、正確性とガバナンスに関する重要な留保がある(後続セクションで扱う)。
-
具体例:* 小売業務マネージャーが問い合わせる。「先四半期の最高パフォーマンス製品カテゴリーは何か、また前四半期と比較してどうだったか」。システムは以下を実行しなければならない。(a)多時間的比較意図の解析、(b)関連テーブル(製品、販売トランザクション、時間ディメンション)の特定、(c)適切なジョインと集約の構築、(d)時間フィルタリングロジックの適用、(e)比較サマリーとしての結果フォーマット。これはLLMが自然言語セマンティクスだけでなく、基礎となるデータスキーマとビジネスロジックも理解することを要求する。
-
重要な仮定:* この機能は十分に文書化されたデータスキーマ、一貫した命名規則、およびLLMがクエリ生成時にアクセスできるメタデータを前提とする。文書化が不十分であるか、命名が一貫していないデータセットを持つ組織は、より高いエラー率を経験する。
-
実行可能な含意:* 実装前に、BigQueryスキーマドキュメントを監査すること。テーブルと列の名前がビジネス用語を反映していることを確認し、データセットに説明的メタデータを追加し、テーブル間の関係を文書化する。この基礎的作業は会話型分析機能の正確性を直接改善する。
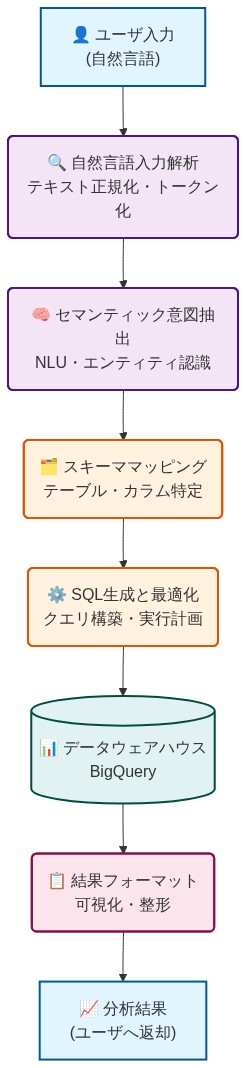
- 図2:Conversational Analyticsの処理パイプライン(Google Cloud BigQuery Conversational Analytics architecture参考)*
詳細レポート生成と予測機能
会話型分析機能は単一クエリ応答を超えて、単一の会話型インタラクション内で多次元分析レポートを生成する。ユーザーはトレンド分析、比較サマリー、前向き予測をリクエストできる。システムは複数テーブル間でデータを統合し、適切な集約を適用し、ステークホルダー消費用に出力を構造化する。
-
技術的メカニズム:* レポート生成は複数のSQLクエリを順序立てて調整することを含む。システムは以下を実行する可能性がある。(1)履歴データを取得し、ベースラインメトリクスを計算、(2)時系列分解を適用してトレンドと季節成分を分離、(3)予測モデルを適合(指数平滑化、ARIMA、または回帰ベースアプローチ)、(4)予測周辺の信頼区間を生成。各ステップはLLMが複数クエリ間でコンテキストを維持し、結果を調整することを要求する。
-
なぜこれが重要か:* 手動レポート構築はアナリストに複数クエリの作成、中間結果の検証、出力のフォーマットを要求する—矛盾しやすく、かなりのアナリスト時間を必要とするプロセス。会話型インターフェースは特定の質問に適応する文脈認識レポートを生成でき、手動作業を削減し、分析的厳密性を標準化する。
-
具体例:* サプライチェーンマネージャーが問い合わせる。「履歴需要パターンに基づいて今後3ヶ月のインベントリニーズを予測してほしい。季節トレンドを考慮に入れてくれ」。システムは以下を実行しなければならない。(a)24ヶ月以上の履歴販売データを取得、(b)時系列を分解して季節パターンとトレンド方向を特定、(c)適切な予測モデルを選択(例:季節ARIMA、または乗法的季節性を伴う指数平滑化)、(d)各月とSKUについて点予測と信頼区間を生成、(e)安全在庫レベルの推奨を伴う結果をフォーマット。
-
制限:* 予測精度はデータ品質、定常性仮定、選択されたモデルの適切性に大きく依存する。システムは時系列が構造的ブレーク、レジーム変化、または標準予測仮定に違反するその他の異常を示しているかどうかを自動的に判定できない。組織は予測をドメイン専門知識と履歴精度メトリクスに対して検証しなければならない。
-
実行可能な含意:* 反復的予測タスクについて、従来の方法を用いてベースライン精度メトリクスを確立すること。ホールドアウトテスト期間で会話型分析機能の予測をこれらのベースラインと比較する。ドメイン専門家が運用展開前に予測をレビューする人間ループ検証を実装する。システムの予測が期待と異なるケースを文書化し、これらのケースを使用してシステムの訓練データを改善する。
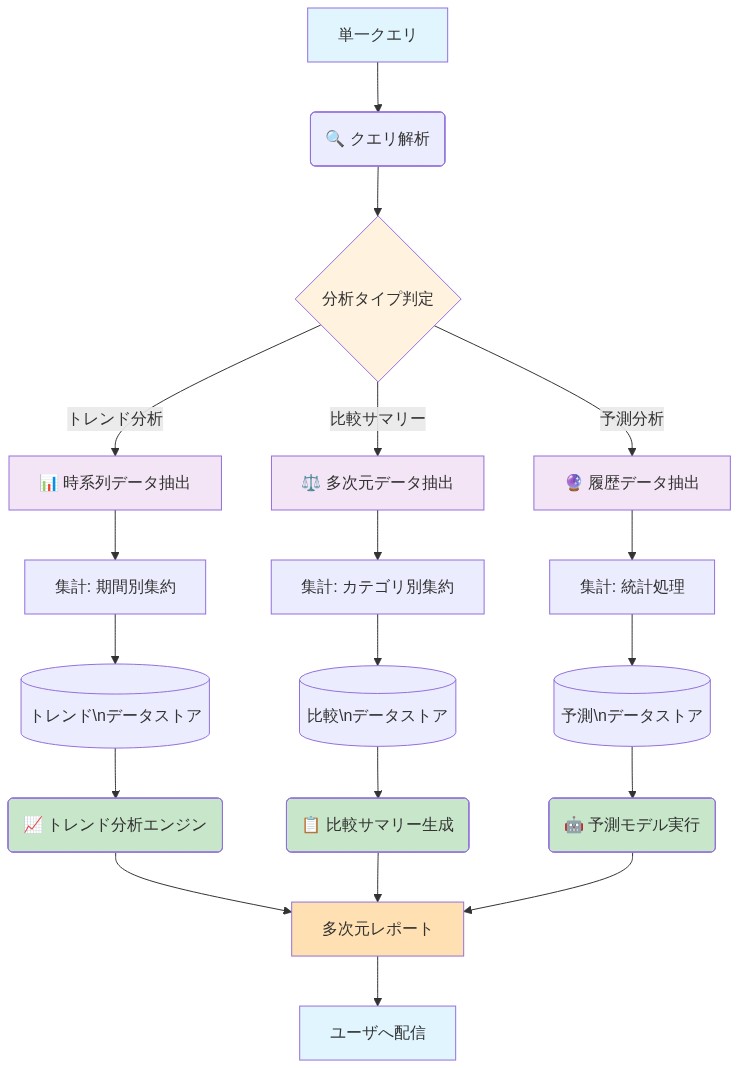
- 図4:詳細レポート生成と予測機能の統合フロー(多次元分析アーキテクチャ)*
非構造化データ分析統合
会話型分析機能は非構造化データ—テキスト文書、ログ、画像—を構造化データセットと並行して分析できる。この機能はシステムに以下を要求する。(1)非構造化ソースから特徴を抽出するために自然言語処理またはコンピュータビジョンを適用、(2)抽出された特徴を構造化メトリクスと相関、(3)モダリティ間で知見を統合。
-
技術的前提条件:* 非構造化データはBigQuery内または接続されたデータリポジトリ内で前処理およびインデックス化される必要がある。テキストデータは通常、トークン化、埋め込み生成(BERTまたはセンテンストランスフォーマーのようなモデルを使用)、およびベクトル列への保存を経る。画像はコンピュータビジョンモデルを介した特徴抽出を要求する。この前処理は会話型システムがデータをクエリできる前に発生しなければならない。
-
なぜこれが重要か:* 組織は膨大な非構造化データ—顧客通信、サポートチケット、運用ログ、製品レビュー—を蓄積しており、これは正式なデータウェアハウスから分析的に隔離されたままである。会話型分析機能はこのデータを構造化メトリクスと並行してクエリ可能にし、定量的および定性的ディメンションを組み合わせた分析を可能にする。
-
具体例:* カスタマーサクセスチームが問い合わせる。「どの顧客セグメントが最も高いチャーンリスクを持っているか、また彼らのサポートチケットの共通テーマは何か」。システムは以下を実行しなければならない。(a)トランザクションデータと予測モデルを使用して高チャーン顧客を特定、(b)関連するサポートチケットテキストを取得、(c)自然言語処理を適用してテーマを抽出(例:請求紛争、機能ギャップ、パフォーマンス問題)、(d)セグメント別にテーマ頻度を定量化、(e)テーマをチャーン指標と相関。
-
重大な制限:* テキスト分析精度は基礎となるNLPモデルの品質と訓練データの代表性に依存する。一般的な英語テキストで訓練されたモデルはドメイン固有の用語またはコンテキストを誤解する可能性がある。組織は抽出されたテーマが基礎となるテキストの人間解釈と一致することを検証しなければならない。
-
実行可能な含意:* 非構造化データを統合する前に、以下に対処するデータガバナンスフレームワークを確立すること。(1)プライバシーとコンプライアンス—個人識別情報が適切に削除または匿名化されていることを確認、(2)データ品質—テキストデータが完全で一貫してフォーマットされていることを検証、(3)モデル検証—NLP抽出テーマを文書のサンプルに対する人間アノテーションと比較。高価値非構造化データセット(例:顧客フィードバック、運用ログ)の統合を優先し、ドメイン専門家が結果を検証できる。
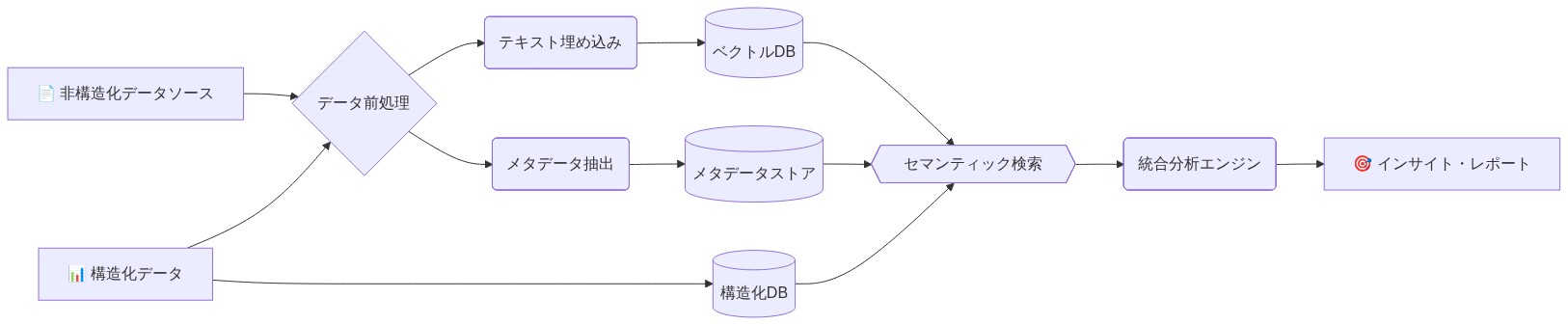
- 図6:非構造化データの統合と会話型分析への組み込み*
ガバナンスフレームワークと実装ガードレール
会話型分析機能の成功した展開は思慮深いアーキテクチャ設計と明確な運用制約を要求する。組織はデータガバナンスフレームワークを確立し、アクセス制御を定義し、正確性とコンプライアンスを確保するための検証メカニズムを実装しなければならない。システムはロールベースの権限を強制し、ユーザーが認可されたデータセットのみにアクセスし、規制要件のための監査証跡を含めるべきである。
-
ガバナンスが重要な理由:* 会話型システムは適切に制約されていない場合、機密データを不注意に公開したり、誤解を招く洞察を生成したりする可能性がある。明確なガードレールはデータセキュリティを保護し、分析的正確性を確保し、規制コンプライアンスを維持する。
-
実践的例:* 金融サービス企業はロールベースアクセス制御を伴う会話型分析機能を実装する。ジュニアアナリストは顧客デモグラフィクスとトランザクション量をクエリできるが、個人識別情報またはトランザクション詳細にはアクセスできない。システムはコンプライアンス監査証跡のためにすべてのクエリをログし、異常な結果をフラグする検証チェックを含める。
-
実装優先度:* 展開前に、データ感度レベルをマッピングしアクセスポリシーを確立すること。どのユーザーロールがどのデータセットをクエリできるかを定義する。自動検証ルールを実装—予期しない結果分布を返すクエリをフラグ、または通常の使用から逸脱するアクセスパターンをフラグ。これらのガードレールを広範なロールアウト前にパイロットユーザーでテストする。
組織的準備性とチームダイナミクス
会話型分析機能の導入は分析チーム構造とワークフローを再構成する。すべての分析をSQL開発者の専門家に集中させるのではなく、組織は分析能力をビジネスユニット全体に分散できる。これは新しい運用パターンを要求する。ビジネスユーザーに効果的な質問定式化について訓練し、システム精度を改善するためのフィードバックループを確立し、データチームの役割をクエリ実行からガバナンスとシステム最適化へと再定義する。
-
組織的シフト:* 成功した採用は技術的能力だけでなく、組織的準備性に依存する。チームは新しいワークフローに適応しなければならず、データ専門家はクエリ実行からシステム管理とデータ品質管理へと移行しなければならない。
-
実践的例:* ヘルスケア組織は段階的アプローチで会話型分析機能を実装する。第1ヶ月は臨床管理者が患者量と転帰に関する質問をよく定式化することに訓練することに焦点を当てる。第2ヶ月はユーザーが結果精度を評価するフィードバックメカニズムを導入し、基礎となるモデルの改善に供給する。第3ヶ月までに、データチームはレポート生成からデータ品質管理とシステムパフォーマンス最適化の管理へと移行する。
-
実装優先度:* ユーザー訓練、フィードバックメカニズム、データチームの進化する役割に関する明確なコミュニケーションを含む変更管理計画を設計すること。分析ニーズを明確に表現できるパワーユーザーから開始し、フィードバックを収集し、段階的に拡大する。採用メトリクス—クエリ量、ユーザー満足度、洞察までの時間改善—を確立して進捗を追跡する。
検証、精度、およびリスク軽減
組織は会話型分析機能の精度とビジネス影響を検証するための厳密な測定フレームワークを確立しなければならない。これには手動で検証されたクエリに対する会話型結果の比較、クエリパフォーマンスとコスト含意の監視、採用メトリクスの追跡が含まれる。リスク軽減戦略はハルシネーション(システムが妥当だが不正確なSQLを生成する場合)、データドリフト、および意図しないアクセスパターンに対処すべきである。
-
検証命令:* 会話型システムは自信を持って聞こえるが不正確な結果を生成できる。検証メカニズムなしに、組織は欠陥のある分析に基づいて決定を下すリスクを負う。継続的な監視はシステムが信頼できるかつ費用効果的であり続けることを確保する。
-
実践的例:* 製造企業は会話型分析機能を検証するために、サンプルクエリを会話型と手動の両方で実行する。第1週に、システムが複雑なジョインを誤解し、収益数字を膨らませた3つのインスタンスを特定する。彼らはシステムの訓練データを改善し、複数のジョインを含むクエリを人間レビュー用にフラグする検証ルールを実装する。修正後、精度はテストクエリで99.2%に達する。
-
実装優先度:* 高リスク分析について手動で検証されたクエリに対する会話型結果を比較する検証プロトコルを確立すること。クエリコストとパフォーマンスを監視—会話型システムは非効率なSQLを生成する可能性がある。採用メトリクスとユーザー満足度を追跡する。異常な結果に対する自動アラートを実装し、ユーザーが報告する不正確さがシステムを反復的に改善するフィードバックループを維持する。
戦略的採用フレームワーク
会話型分析機能は組織がデータと相互作用する方法における根本的なシフトを表す。成功はそれをSQL専門知識の代替ではなく、組織全体で分析能力を拡張する補完的ツールとして見ることを要求する。組織は高価値ユースケースを対象とするパイロットプログラムから開始し、ガバナンスフレームワークを確立し、システム精度を継続的に改善するフィードバックメカニズムを構築すべきである。
-
主要な成果:* 会話型分析機能はデータアクセスを民主化し、洞察までの時間を加速し、非構造化データを分析ワークフローに統合する。実装はガバナンス、検証、およびチームダイナミクスへの注意深い配慮を要求する。技術の価値は強力なデータ管理慣行と組織的準備性と組み合わせられるとき倍増する。
-
即座の行動計画:*
- 現在の分析ボトルネックを監査し、会話型インターフェースが手動作業を削減する3つの高価値ユースケースを特定する。
- アクセス制御、データ感度分類、および監査要件をカバーするデータガバナンスフレームワークを確立する。
- ターゲット部門から10~15人のビジネスユーザーを含むパイロットプログラムを計画し、構造化訓練とフィードバックメカニズムを含める。
- 成功メトリクス—採用率、洞察までの時間改善、分析精度—を定義し、ローンチ前にベースライン測定を確立する。
- システム検証と継続的改善にリソースを配分し、精度と信頼が反復的改善を通じて時間とともに構築されることを認識する。
参照アーキテクチャと実装ガードレール
成功した展開はデータガバナンスフレームワーク、アクセス制御、および検証メカニズムの確立を要求する。システムはロールベースの権限を強制し、監査証跡を維持し、異常または潜在的に不正確な結果をフラグする検証ルールを含めなければならない。
-
ガバナンス要件:* 組織は以下を定義しなければならない。(1)データ感度分類—どのデータセットが個人識別情報、財務データ、またはその他の規制対象コンテンツを含むか、(2)ロールベースアクセスポリシー—どのユーザーロールがどのデータセットをクエリできるか、(3)クエリ監査証跡—コンプライアンスとセキュリティレビュー用にすべてのクエリ、結果、およびユーザーをログ、(4)検証ルール—予期される分布またはアクセスパターンから逸脱する結果をフラグする自動チェック。
-
なぜこれが重要か:* 会話型システムはアクセス制御が十分に粒度化されていない場合、機密データを不注意に公開する可能性がある。検証メカニズムが不在の場合、妥当だが不正確な結果を生成することもできる。明確なガードレールはデータセキュリティを保護し、分析的正確性を確保し、規制コンプライアンスを維持する。
-
具体例:* 金融サービス企業はロールベースアクセス制御を伴う会話型分析機能を実装する。ジュニアアナリストは顧客デモグラフィクスとトランザクション量をクエリできるが、個人識別情報またはトランザクション詳細にはアクセスできない。システムはコンプライアンス監査証跡のためにすべてのクエリをログし、予期しない結果分布を返すクエリをフラグする検証チェックを含める(例:履歴パターンが非ゼロ結果を示唆する場合にゼロ結果を返すクエリ)。
-
技術的実装:* ロールベースアクセスはBigQueryのIdentity and Access Management(IAM)ポリシーを通じて強制でき、クエリ生成段階でデータセットとテーブルアクセスを制限する。監査証跡はBigQueryの監査ログを通じて維持され、すべてのクエリと結果を記録する。検証ルールはポストクエリチェックとして実装でき、結果を履歴分布またはドメイン定義閾値と比較する。
-
実行可能な含意:* 展開前に、データ感度レベルをマッピングしアクセスポリシーを確立すること。どのユーザーロールがどのデータセットをクエリできるかを定義する。自動検証ルールを実装—予期しない結果分布を返すクエリをフラグ、機密データにアクセスするクエリをフラグ、または通常の使用から逸脱するアクセスパターンをフラグ。これらのガードレールを広範なロールアウト前にパイロットユーザーでテストする。すべてのポリシーを文書化し、組織的コンプライアンス要件と一致することを確保する。
運用パターンとチームダイナミクス
会話型分析機能の導入は、分析チームの構造とワークフローを根本的に再編成する。SQL開発者による分析の一元化ではなく、組織全体のビジネスユニットに分析能力を分散させることが可能になる。これは新たな運用パターンを要求する。ビジネスユーザーに効果的な質問の定式化を訓練し、システム精度を改善するためのフィードバックループを確立し、データチームの役割をガバナンスとシステム最適化へと再定義する必要があるのだ。
-
組織的転換:* 一元化から分散型の分析への移行には、以下が必須である。(1)ビジネスユーザーの分析的思考と質問定式化能力の向上、(2)ユーザーが不正確な結果を報告するフィードバック機構の確立、(3)報告された不正確さがシステムの訓練データを改善するフィードバックループの構築、(4)データチームの責務をクエリ実行からシステムの管理、データ品質管理、ガバナンス執行へと再定義すること。
-
なぜこれが重要か:* 成功の鍵は技術的能力ではなく、組織的準備度にある。チームは新しいワークフローに適応する必要があり、データ専門家はクエリ実行からシステム管理へと転換しなければならない。この転換なしに、技術的には有能だがユーザーから信頼されない、あるいは過小利用されるシステムを導入するリスクを組織は負う。
-
具体例:* ある医療機関が段階的アプローチで会話型分析機能を導入する。第一段階(1~4週目)は臨床管理者に患者数と転帰に関する適切に構造化された質問の定式化を訓練することに焦点を当てる。第二段階(5~8週目)ではユーザーが結果精度を評価し、矛盾を報告するフィードバック機構を導入する。第三段階(9~12週目)ではデータチームをレポート生成からデータ品質管理、システムパフォーマンス最適化、ガバナンスポリシー確立へと転換させる。4ヶ月目までに、データチームの努力配分は臨時クエリ実行の20%に対してシステム管理に60%を費やすようになる。
-
測定:* 導入指標(クエリ量、ユニークユーザー数、クエリ複雑性)を追跡して、システムが意図通りに利用されているかを評価する。調査とフィードバック機構を通じてユーザー満足度を監視する。実装前後で標準的な質問に答えるのに必要な時間を比較することで、インサイト到達時間の改善を測定する。
-
実行可能な示唆:* 以下を含む変更管理計画を設計する。(1)質問定式化、結果解釈、システム制限をカバーするユーザー訓練カリキュラム、(2)ユーザーが不正確さを報告できるフィードバック機構、(3)データチームの進化する役割についての明確なコミュニケーション、(4)導入と影響を追跡するメトリクス。分析ニーズを明確に表現できるパワーユーザーから開始し、フィードバックを収集して段階的に拡大する。ローンチ前に導入とインサイト到達時間のベースラインメトリクスを確立する。
測定、検証、リスク軽減
組織は会話型分析機能の精度とビジネスインパクトを検証するための厳密な測定フレームワークを確立する必要がある。これには手動で検証されたクエリとの会話結果の比較、クエリパフォーマンスとコスト影響の監視、導入指標の追跡が含まれる。リスク軽減戦略は、システムが妥当だが不正確なSQLを生成する幻覚(ハルシネーション)、データドリフト、意図しないアクセスパターンに対処する必要がある。
-
検証方法論:* 以下の要素を含む検証プロトコルを確立する。(1)精度テスト—ビジネス質問の代表的なサンプルに対して、会話結果を手動で検証されたクエリと比較する、(2)パフォーマンス監視—クエリ実行時間とBigQueryコストを追跡して、非効率なSQL生成を特定する、(3)異常検知—履歴分布や期待範囲から逸脱する結果に対して自動アラートを実装する、(4)ユーザーフィードバック統合—ユーザーが不正確さを報告するシステムを維持し、これがモデル再訓練に組み込まれるようにする。
-
なぜこれが重要か:* 会話型システムは以下の理由で自信に満ちた不正確な結果を生成する可能性がある。(a)ユーザー意図の誤解釈、(b)不正確なスキーママッピングまたはジョイン論理、(c)有効に見えるが誤った結果を生成する幻覚SQL、(d)不適切な統計モデルの適用。検証機構がなければ、組織は欠陥のある分析に基づいて意思決定するリスクを負う。
-
具体例:* ある製造企業は会話型分析機能を、サンプルクエリを会話的にも手動でも実行することで検証する。1週目に、システムが複雑なジョインを誤解釈し、売上数値を膨らませた3つのインスタンスを特定する。具体的には、システムは注文と品目の間の一対多関係を考慮せず、二重計上をもたらした。彼らは正しいジョイン論理の例でシステムの訓練データを改善し、複数のジョインを含むクエリに人間のレビューのフラグを立てる検証ルールを実装する。修正後、テストクエリで精度は99.2%に達し、残りの0.8%はシステムエラーではなくデータ品質のエッジケースに起因する。
-
リスク軽減戦略:*
-
幻覚検知: クエリ後の検証を実装して、生成されたSQLがクエリタイプの期待パターンと一致するかを確認する。典型的なSQL構造から大きく逸脱するクエリにフラグを立てる。
-
データドリフト監視: クエリ結果が時間とともに一貫性を保つかを追跡する。結果分布の急激な変化は、データ品質の問題またはスキーマ変更を示唆する可能性がある。
-
コスト監視: クエリごとのBigQueryコストを追跡する。会話型システムは非効率なSQL(例えば、インデックス検索の代わりに全テーブルスキャン)を生成する可能性がある。コスト閾値を設定し、個別クエリが期待コストを超える場合にアラートする。
-
アクセスパターン監視: どのユーザーがどのデータセットとテーブルをクエリするかを追跡する。異常なアクセスパターン(例えば、ユーザーが以前は無視していた機密データセットを突然クエリする)は、悪用またはシステムエラーを示唆する可能性がある。
-
実行可能な示唆:* 検証プロトコルを確立する。(1)高リスク分析については会話結果を手動で検証されたクエリと比較する、(2)クエリコストとパフォーマンスを監視する、(3)導入指標とユーザー満足度を追跡する、(4)異常な結果に対して自動アラートを実装する、(5)ユーザーが不正確さを報告し、システムを反復的に改善するフィードバックループを維持する。精度と信頼は時間とともに構築されることを認識し、継続的な検証と改善にリソースを配分する。
戦略的導入と次のステップ
会話型分析機能は、組織がデータウェアハウスと相互作用する方法の転換を表している。成功には、これをSQL専門知識の代替ではなく、組織全体に分析能力を拡張する補完的ツールとして見ることが必須である。組織は高価値ユースケースを対象とするパイロットプログラムから開始し、ガバナンスフレームワークを確立し、システム精度を継続的に改善するフィードバック機構を構築すべきだ。
- 実装ロードマップ:*
-
評価段階(1~2週目): 現在の分析ワークフローを監査して、非技術ユーザーがレポートをリクエストするボトルネックを特定する。典型的な分析リクエストを満たすのに必要な時間を文書化し、会話型インターフェースが手動作業を削減する3つの高価値ユースケースを特定する。
-
ガバナンスフレームワーク(3~4週目): 以下をカバーするデータガバナンスポリシーを確立する。(a)データ感度分類、(b)ロールベースのアクセス制御、(c)監査要件、(d)検証ルール。ポリシーを文書化し、ステークホルダーの承認を得る。
-
パイロットプログラム設計(5~6週目): 対象部門から10~15人のビジネスユーザーを選定する。質問定式化、結果解釈、システム制限をカバーする訓練カリキュラムを設計する。ユーザーが不正確さを報告するためのフィードバック機構を確立する。
-
パイロット実行(7~12週目): パイロットユーザーに会話型分析機能を展開する。週次訓練セッションを実施する。システム精度、使いやすさ、ビジネスインパクトに関するフィードバックを収集する。フィードバックに基づいてシステムを改善する。
-
検証と測定(13~16週目): 会話結果を手動で検証されたクエリと比較する。導入、インサイト到達時間、分析精度のベースラインメトリクスを確立する。学習教訓を文書化する。
-
広範なロールアウト(17週目以降): パイロット結果に基づいて追加のユーザー集団に拡大する。継続的なガバナンスと検証プロセスを確立する。
-
重要なポイント:* 会話型分析機能は、厳密なガバナンス、検証、フィードバック機構とともに実装される場合、データアクセスを民主化し、インサイト到達時間を加速させる。この技術の価値は、強力なデータ管理実践と組織的準備と組み合わされるとき倍増する。成功は技術的能力だけでなく、組織的整合性、ユーザー訓練、継続的な改善に依存する。
-
即座の次のアクション:*
- 現在の分析ボトルネックを監査し、会話型インターフェースが手動作業を削減し、意思決定を加速させる3つの高価値ユースケースを特定する。
- アクセス制御、データ感度分類、監査要件、検証ルールに対応するデータガバナンスフレームワークを確立する。
- 訓練カリキュラムとフィードバック機構を含む対象部門の10~15人のビジネスユーザーとのパイロットプログラムを計画する。
- 成功メトリクス(導入率、インサイト到達時間改善、分析精度)を定義し、ローンチ前にベースライン測定を確立する。
- 精度と信頼が改善と反復的なフィードバック統合を通じて構築されることを認識し、システム検証と継続的改善にリソースを配分する。
自然言語とデータウェアハウスの邂逅—民主化のインフレクションポイント
Google CloudがBigQuery内に会話型分析機能を導入したことは、分水嶺を示す。SQLゲートキーピングの終わりの始まりである。このプレビュー機能は、アナリストとビジネスユーザーが自然言語を使用して複雑なデータセットをクエリすることを可能にし、人間とデータシステムの関係を根本的に反転させる。人間に機械構文を学ばせるのではなく、システムが人間の意図を学ぶようになるのだ。
この能力は、技術的データ専門家とビジネスステークホルダーの間の人工的障壁を溶解させる。この機能は大規模言語モデルを活用してユーザー意図を解釈し、会話クエリを最適化されたSQLに変換し、人間が読める形式でインサイトを返す。だが真の革新は、これが可能にするものにある。データ流暢性が専門的資格ではなく、普遍的な専門スキルになる未来である。
-
組織の将来にとってなぜこれが重要か:* 今日の分析ボトルネック—訓練されたSQL開発者のみがインサイトを抽出できる—は、莫大な機会費用を表している。遅延した決定、開発者の利用可能性を待つ未回答の質問、分析に時間がかかるため未検証のままのビジネス直感。これらは複利的な損失である。会話型分析機能は既存のワークフローを単に高速化するのではなく、組織が問いかけることができる質問の表面積を根本的に拡張する。財務チーム、マーケティングマネージャー、オペレーションリーダー、最前線の労働者は仮説を直接提示でき、データを静的なリソースから動的な思考パートナーへと変換する。
-
具体例—そしてそれが明かすもの:* 小売マネージャーが「先四半期の最高パフォーマンス製品カテゴリーは何か、そして前四半期と比較してどうだったか」と尋ねる。システムはこの複数部分の質問を解釈し、製品、売上、時間期間テーブル全体の適切なジョインを生成し、SQLなしでビジュアライゼーション付きのフォーマット済み比較レポートを返す。だが未来志向の洞察はここにある。このマネージャーはリアルタイムでフォローアップ質問ができるようになる。「それらのカテゴリーのうち、最も強い成長軌跡を示したのはどれか」「トップパフォーマーの在庫レベルはどうか」「これは競合ベンチマークとどう比較されるか」各質問が前のものに基づき、以前は複数のアナリストリクエストと数日の往復を要した探索的分析を可能にする。
-
実行可能な示唆—そして戦略的賭け:* 組織は現在の分析ワークフローを即座に監査して、非技術ユーザーがレポートをリクエストするボトルネックを特定すべきだ。だがそこで止まるな。潜在的需要—ビジネスユーザーが数日ではなく数分で答えを得られるなら尋ねるであろう質問—をマッピングする。ビジネスユーザーが繰り返し同じ質問をするユースケースを優先する。これらは会話型インターフェースの理想的な候補である。さらに重要なのは、分析に時間がかかるため不完全な情報で現在下されている高リスク決定を特定することだ。これらは変革の最高価値機会を表している。
詳細レポート生成と予測能力—アナリストの職人技の自動化
会話型分析機能は単純なクエリをはるかに超える。複数のテーブル全体にわたってデータを統合し、集計を適用し、出力をステークホルダー消費に対応する構造化レポートにフォーマットする包括的な分析レポートを自動的に生成する。ユーザーは多次元サマリー、トレンド分析、前向き予測を単一の会話ターンで要求できる。本質的には、アナリストの職人技全体を、眠らず、パターンを忘れないAIシステムにアウトソースするのだ。
-
なぜこれが重要か—そしてそれが示唆するもの:* 従来のBIツールは、アナリストがダッシュボードとレポートを手動で構築することを要求し、時間集約的で一貫性の欠如と認知バイアスの傾向がある。会話型インターフェースは、特定の質問に適応する文脈認識レポートを生成し、手動作業を削減し、一貫性を確保する。だが深い含意はこれだ。これらのシステムが改善するにつれ、アナリストの役割は「クエリ実行者」から「インサイト策展者」へと変換される。ボトルネックはデータアクセスからデータ解釈へと移行する。これは人間の判断が最大の価値を生み出す場所である。
-
具体例—そして隣接する機会:* サプライチェーンマネージャーが「履歴需要パターンに基づいて、季節トレンドを考慮して、今後3ヶ月の在庫ニーズを予測してほしい」と尋ねる。システムは履歴売上データを分析し、季節性を検出し、時系列予測モデルを適用し、SKU別の信頼区間と在庫レベルの推奨を含む詳細レポートを返す。だが次の反復を想像してほしい。システムは需要を予測するだけでなく、予測不確実性が最も高いSKUを特定し、潜在的なサプライチェーンリスクにフラグを立て、どの在庫決定を人間の判断にエスカレートすべきか対自動化を推奨する。これは予測を定期的な演習から継続的で適応的なプロセスへと変換する。
-
実行可能な示唆—そして戦略的ポジショニング:* 現在の予測ワークフローを評価する。アナリストが予測モデルのデータ準備に大量の時間を費やすシナリオを特定する。需要計画、チャーン予測、売上予測、容量計画。これらが即座の機会である。だが決定速度も同時にマッピングする。業界でどのくらい速く市場条件が変わるか。これらの決定を10倍速く下すことで、どの程度の競争優位を得るか。反復予測に会話型分析機能を実装して、手動作業を削減し、意思決定サイクルを加速させる。より戦略的には、自動化によって解放された時間を、シナリオ計画と戦略的先見性—競争的堀を生み出す独自の人間的作業—への投資に使用する。
非構造化データ分析の統合—最後のデータサイロを橋渡けする
会話型分析の本質的な優位性は、非構造化データを構造化データセットと並行して分析する能力にある。ユーザーは数値レコードとテキスト文書、ログ、画像を組み合わせた質問を投げかけることができ、より豊かな文脈的分析を実現する。このシステムはデータウェアハウスとドキュメントリポジトリの間隙を埋め、歴史的に分離されてきたサイロ横断的な統一クエリを可能にする。
-
なぜこれが重要か—そして何が解き放たれるのか。* 組織は膨大な非構造化データを保有している。顧客フィードバック、サポートチケット、製品レビュー、運用ログ、ソーシャルメディアの言及、内部コミュニケーション。これらは正式な分析から切り離されたままだ。このデータは数字の背後にあるなぜを含んでいる。顧客がなぜ離脱するのか、プロジェクトがなぜ失敗するのか、特定の市場がなぜ優位性を示すのか。会話型分析はこのデータを構造化メトリクスと並行してクエリ可能にし、テキストに埋もれていた洞察を解き放つ。定量分析にアクセス不可能だった知見を顕在化させる。これは根本的な転換を表している。何が起きたのかを分析する段階からなぜそれが起きたのかを理解する段階へ。
-
具体例—そして戦略的洞察。* カスタマーサクセスチームが問う。「どの顧客セグメントが最も高い離脱リスクを持ち、彼らのサポートチケットに共通するテーマは何か」。システムはトランザクションデータからの離脱指標とサポート相互作用のテキスト分析を相関させ、請求紛争や機能ギャップといった離脱する顧客に関連するパターンを特定する。だがここからさらに拡張できる。システムは離脱ドライバーのうちどれが製品変更で対処可能か、価格調整で対処可能か、カスタマーサクセス介入で対処可能かを識別できる。これは離脱分析を診断的な演習から処方的なものへと変換し、標的化された保持戦略を可能にする。
-
実行可能な含意—そして組織的変容。* ビジネス質問に関連する非構造化データソースをカタログ化する。顧客コミュニケーション、運用ログ、製品ドキュメント、市場調査、競争インテリジェンス。プライバシーとコンプライアンスのためのデータガバナンスポリシーを確立し、その後、高価値の非構造化データセットを会話型分析環境への統合を優先する。ここが戦略的な賭けだ。非構造化データを分析に正常に統合する組織は、文脈的意思決定における競争優位性を発展させるだろう。彼らは顧客が何をするかだけでなく、何を考え、何を感じているかを理解する。問題が危機になる前に特定する。競合他社が見落とす顧客フィードバックの機会を発見する。
参照アーキテクチャと実装ガードレール—システムに信頼を組み込む
会話型分析の成功した展開には、データガバナンス、アクセス制御、検証メカニズムをコンプライアンスオーバーヘッドではなく信頼インフラストラクチャとして扱う思慮深いアーキテクチャ設計が必要だ。組織はロールベースの権限を強制し、ユーザーが認可されたデータセットのみにアクセスするようにし、規制要件のための監査証跡を含め、精度を確保し誤用を防ぐ検証メカニズムを実装しなければならない。
-
なぜこれが重要か—そして隠れたリスク。* 会話型システムは適切に制約されていない場合、意図せず機密データを露出させたり、誤解を招く洞察を生成したりする可能性がある。だがより深いリスクは信頼の侵食だ。ビジネスユーザーが自信ありげだが不正確な回答を受け取れば、システムを信頼しなくなる。アクセスすべきでないデータにアクセスしたことを発見すれば、組織のデータガバナンスへの信頼を失う。明確なガードレールはデータセキュリティを保護し、分析精度を確保し、規制コンプライアンスを維持する。だがより重要なことに、広範な採用を可能にする信頼を構築する。
-
具体例—そしてガバナンスモデル。* 金融サービス企業がロールベースのアクセス制御を備えた会話型分析を実装する。ジュニアアナリストは顧客デモグラフィクスとトランザクション量をクエリできるが、個人識別情報やトランザクション詳細にはアクセスできない。システムはコンプライアンス監査証跡のためにすべてのクエリをログに記録し、異常な結果をフラグする検証チェックを含める。予期しない分布を返すクエリや通常の使用パターンから逸脱するアクセスパターン。クエリがフラグされると、結果が返される前に自動的に人間によるレビューのためにエスカレートされる。これは信頼ループを作成する。ユーザーは自分のクエリが検証され、データが保護され、システムが彼らの利益のために機能していることを知っている。
-
実行可能な含意—そしてアーキテクチャ原則。* 展開前に、データ感度レベルをマップし、アクセスポリシーを確立する。どのユーザーロールがどのデータセットをクエリできるかを定義する。自動検証ルールを実装する。予期しない結果分布を返すクエリや通常の使用パターンから逸脱するアクセスパターンをフラグする。広範なロールアウト前にパイロットユーザーでこれらのガードレールをテストする。だがより戦略的には、ガバナンスを制約ではなく機能として扱う。ユーザーにシステムがどのように彼らと組織を保護するかを伝える。検証を透明にする。これはガバナンスを制限的に感じるものから保護的に感じるものへと変換する。
運用パターンと組織ダイナミクス—分析機能の再定義
会話型分析の導入は分析チームの構造とワークフローを根本的に再形成する。すべての分析をSQL開発者の専門家に集中させるのではなく、組織はビジネスユニット全体に分析能力を分散させることができる。これは新しい運用パターンを必要とする。効果的な質問定式化についてのビジネスユーザーのトレーニング、会話型システムの精度を改善するためのフィードバックループの確立、ガバナンス、システム最適化、戦略的洞察生成に向けたデータチームの役割の再定義。
-
なぜこれが重要か—そして組織的含意。* 成功した採用は技術的能力だけでなく、組織的準備に依存する。チームは新しいワークフローに適応する必要があり、データプロフェッショナルはクエリ実行からシステムスチュワードシップとデータ品質管理へシフトしなければならない。これは深刻な変化だ。データチームはサービス機能(リクエスト実行)から戦略機能(組織がデータについてどのように考えるかの最適化)へ移行する。これは異なるスキル、異なるインセンティブ、異なるキャリアパスを必要とする。
-
具体例—そして変更管理モデル。* ヘルスケア組織が段階的アプローチで会話型分析を実装する。第1月は臨床管理者が患者数と転帰に関する適切に定式化された質問を尋ねるトレーニングに焦点を当てる。第2月はユーザーが結果精度を評価するフィードバックメカニズムを導入し、基礎となるモデルの改善に供給する。第3月までに、データチームはレポート生成からデータ品質管理とシステムパフォーマンスの最適化への管理へ移行する。システムが苦労する質問、より良いドキュメンテーションが必要なデータセット、データ品質問題を明らかにする分析パターンを特定する。彼らは真の意味でのデータサイエンティストになる。自分たちの組織のデータがどのように動作するかを研究し、それをより有用にする方法を研究する科学者。
-
実行可能な含意—そして組織設計。* ユーザートレーニング、フィードバックメカニズム、データチームの進化する役割に関する明確なコミュニケーションを含む変更管理計画を設計する。分析ニーズを明確に表現できるパワーユーザーから始め、フィードバックを収集し、段階的に拡張する。採用メトリクスを確立する。クエリ量、ユーザー満足度、洞察までの時間改善。進捗を追跡する。だがより重要なことに、データチームの再スキル化に投資する。システム最適化と戦略的分析に興奮している組織メンバーを特定し、彼らのためのキャリアパスを作成する。これは単に変更を管理することではなく、データ組織の完全な可能性を解き放つことだ。
測定、検証、リスク軽減—厳密さを通じた信頼構築
組織は会話型分析の精度とビジネスインパクトを検証するための厳密な測定フレームワークを確立しなければならない。これには手動で検証されたクエリに対する会話型結果の比較、クエリパフォーマンスとコスト含意の監視、採用メトリクスの追跡が含まれる。リスク軽減戦略はハルシネーション(システムが妥当だが不正確なSQLを生成する場合)、データドリフト、意図しないアクセスパターンに対処すべきだ。
-
なぜこれが重要か—そして信頼方程式。* 会話型システムは自信ありげだが不正確な結果を生成できる。検証メカニズムなしに、組織は欠陥のある分析に基づいて決定を下すリスクを冒す。だがより微妙に、可視的な検証なしに、ユーザーは学習された不信を発展させるだろう。結果を疑い、手動検証を求め、最終的にシステムを過小利用する。継続的な監視はシステムが信頼でき、費用対効果があることを確保し、同等に重要なことに、ユーザーに信頼性を実証する。
-
具体例—そして検証プロトコル。* 製造企業は会話型分析を検証するために、サンプルクエリを会話型と手動の両方で実行する。第1週に、システムが複雑なジョインを誤解釈し、収益数字を膨らませた3つのインスタンスを特定する。システムのトレーニングデータを洗練させ、複数のジョインを含むクエリを人間によるレビューのためにフラグする検証ルールを実装する。修正後、精度はテストクエリで99.2%に達する。だがここが戦略的洞察だ。彼らはこれらの結果を内部で公開する。ユーザーにシステムがテストされ、エラーが発見され修正され、精度が検証されたことを示す。この透明性は信頼を構築する。
-
実行可能な含意—そして測定フレームワーク。* 検証プロトコルを確立する。高リスク分析のために会話型結果を手動で検証されたクエリと比較する。クエリコストとパフォーマンスを監視する。会話型システムは非効率なSQLを生成する可能性がある。採用メトリクスとユーザー満足度を追跡する。異常な結果に対する自動アラートを実装し、ユーザーが報告する不正確さがシステムを反復的に改善するフィードバックループを維持する。透明性ダッシュボードを作成する。システム精度、検証結果、時間経過による改善を表示する。これは測定を内部コンプライアンス演習から信頼構築コミュニケーションツールへと変換する。
戦略的採用と次のステップ—会話型の未来に向けた位置付け
会話型分析は組織がデータと相互作用する方法における根本的なシフトを表している。成功はそれをSQL専門知識の代替ではなく、組織全体に分析能力を拡張し、決定がどのように下されるかを根本的に変える補完的なツールとして見ることを必要とする。早期に採用する組織は会話型分析に関する組織的筋肉記憶を発展させ、労働力全体にデータリテラシーを構築し、決定速度と洞察品質における競争優位性を創出するだろう。
-
主要なポイント—そして戦略的ビジョン。* 会話型分析はデータアクセスを民主化し、洞察までの時間を加速し、非構造化データを分析ワークフローに統合する。実装は強力なデータ管理慣行と組織的準備と組み合わせたときに、技術の価値は倍増する。だがより重要なことに、それは継続的分析へのシフトを表している。質問が尋ねられ、リアルタイムで回答される。洞察が即座に決定に情報を与える。組織が競合他社より速く学習し適応する。
-
即座の次のアクション—そして実装ロードマップ。*
(1) 分析ボトルネックを監査し、高価値のユースケースを特定する。 非技術ユーザーが現在レポートをリクエストする場所、分析に時間がかかる場所、潜在的な需要が存在する場所をマップする。会話型インターフェースが手動作業を少なくとも50%削減し、意思決定を加速させる3つのユースケースを特定する。
(2) データガバナンスフレームワークを確立する。 アクセス制御、データ感度分類、監査要件を定義する。ガバナンスを制約ではなく信頼構築機能として扱う。ガードレールがユーザーと組織をどのように保護するかを伝える。
(3) ビジネスユーザーとのパイロットプログラムを計画する。 分析ニーズを明確に表現できるターゲット部門から10~15人のパワーユーザーから始める。効果的な質問定式化と継続的改善のためのフィードバックメカニズムに関するトレーニングを含める。
(4) 成功メトリクスを定義し、ベースラインを確立する。 採用率、洞察までの時間改善、分析精度、ユーザー満足度を測定する。ローンチ前にベースライン測定を確立し、インパクトを実証できるようにする。
(5) システム検証と継続的改善にリソースを配分する。 精度と信頼は反復的な洗練を通じて時間とともに構築されることを認識する。フィードバックループ、エラー分析、モデル改善に投資する。これは1回限りの実装ではなく、継続的な最適化プロセスだ。
(6) チームの再スキル化と組織設計に投資する。 データチームがクエリ実行からシステムスチュワードシップと戦略的分析への移行を支援する。システム最適化と洞察生成に報酬を与えるキャリアパスを作成する。ここが最終的に競争優位性が生まれる場所だ。
会話型分析で成功する組織は、単にテクノロジーを展開する組織ではなく、それを組織的変容の触媒として使用する組織だ。労働力全体にデータリテラシーを構築する。意思決定サイクルを加速させる。急速に動く市場で競争するための組織的敏捷性を発展させる。そして、組織のすべてのメンバーがデータに質問を投げかけ、数日ではなく数分で回答を得ることができるようになったときに何が可能になるかを発見する。

- 図8:信頼性を組み込んだ会話型分析の参照アーキテクチャ*