
AI システムにおけるプライバシー保護の実装
システムアーキテクチャとプライバシーのボトルネック
プライバシー保護型の AI アーキテクチャは、従来のエンジニアリング実践と衝突することが多い意図的な構造的選択を要求する。制約は技術的能力にはない。フェデレーテッドラーニング、差分プライバシー、暗号化計算は既に成熟している。問題は組織的な意思である。パフォーマンスの低下と運用の複雑性を受け入れる覚悟があるか否か。
ほとんどの AI システムはモデルの精度を最大化し、インフラストラクチャを単純化するため、データ収集と処理を一元化する。フェデレーテッドラーニングのような分散型の代替案は生データをソースに保持したまま、モデルを協調的に訓練し、露出を減らすが、レイテンシと計算オーバーヘッドを増加させる。規制圧力や競争上の差別化インセンティブがなければ、組織がこうしたアプローチを採用することはまれだ。
システムアーキテクチャの決定は設計段階でなされ、その後のセキュリティ対策よりもプライバシー成果を決定する。ユーザーインタラクション履歴を無期限に保持するよう設計されたレコメンデーションアルゴリズムは、永続的なプライバシー負債を生み出す。同じアルゴリズムをステートレス推論用に設計すれば、各リクエストを独立して処理し、そのリスクを完全に排除する。ただしパーソナライゼーション品質は低下するかもしれない。
アーキテクチャの選択は逆転させるのが難しい。システムが運用中になった後、一元化から分散型データ処理への移行には実質的な再エンジニアリングが必要だ。データ最小化、処理場所、保持期間に関する初期決定はインフラストラクチャに組み込まれ、後の変更は費用がかかり、破壊的になる。
電子商取引プラットフォームがこの制約を示す。初期段階での閲覧履歴の一元化はレコメンデーションを改善する。2 年後、規制要件が削除機能を要求する。システムは今、高額な改造を必要とする。削除ロジックがデータパイプラインに組み込まれなかったからだ。アーキテクチャが最初から削除設計を組み込んでいたなら、コンプライアンスは特別な努力を必要としなかった。
実務家はシステムアーキテクチャをプライバシーボトルネックについて監査すべきだ。個人データがどこを流れるのか、どのくらい長く保持されるのか、最小化の代替案が存在するかを特定する。これらの決定を明示的に文書化し、プライバシーアーキテクチャをセキュリティやスケーラビリティと同等の第一級の設計関心事として扱う。
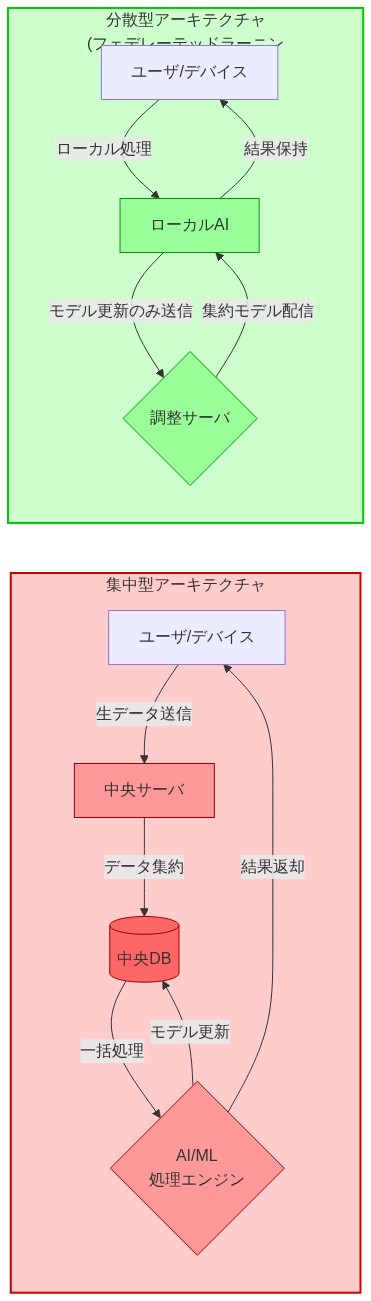
- 図2:集中型 vs 分散型 AIアーキテクチャのデータフロー比較*
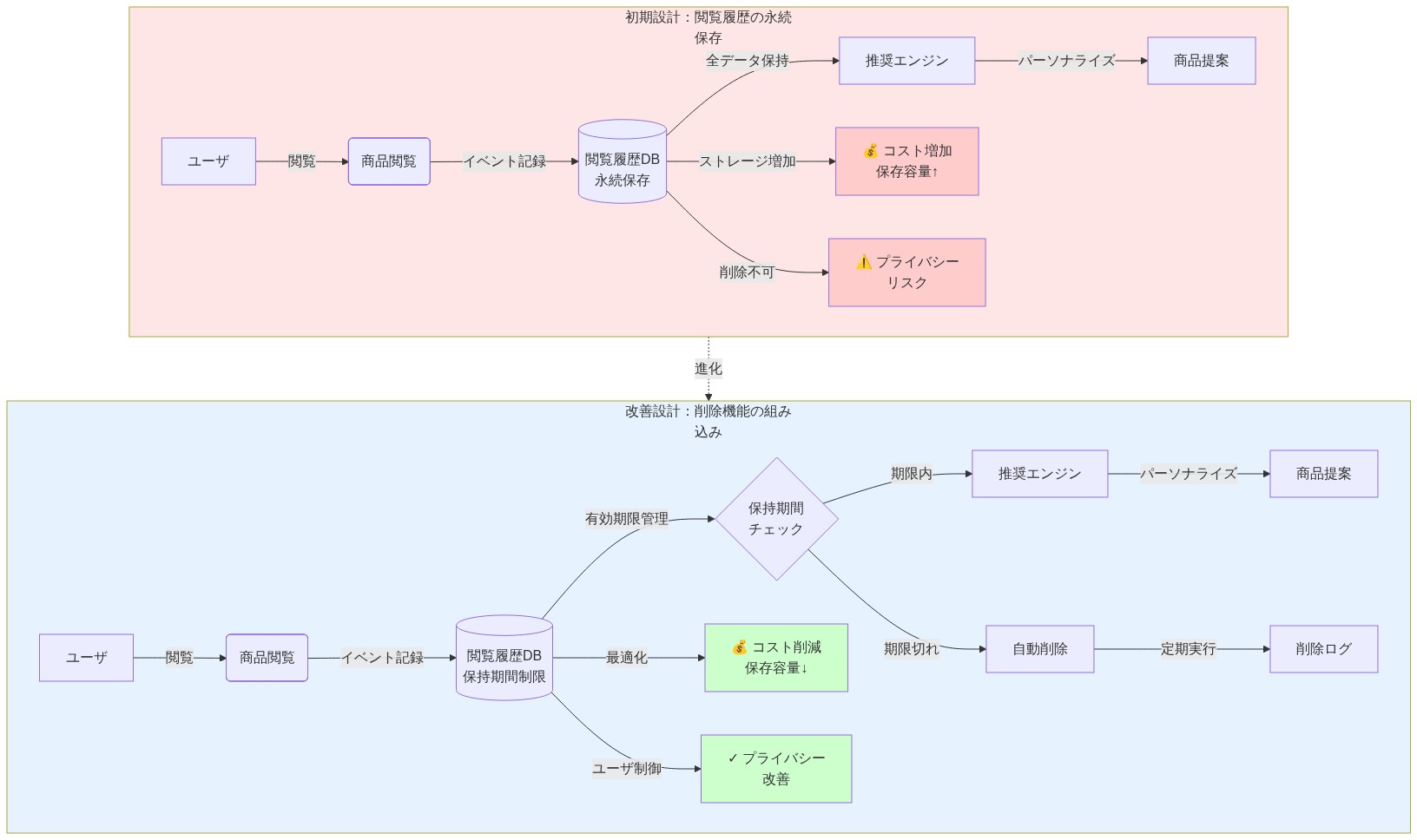
- 図3:e-commerceプラットフォームのアーキテクチャ進化:削除機能の組み込み(Article case study - e-commerce platform example)*
参照アーキテクチャとガードレール
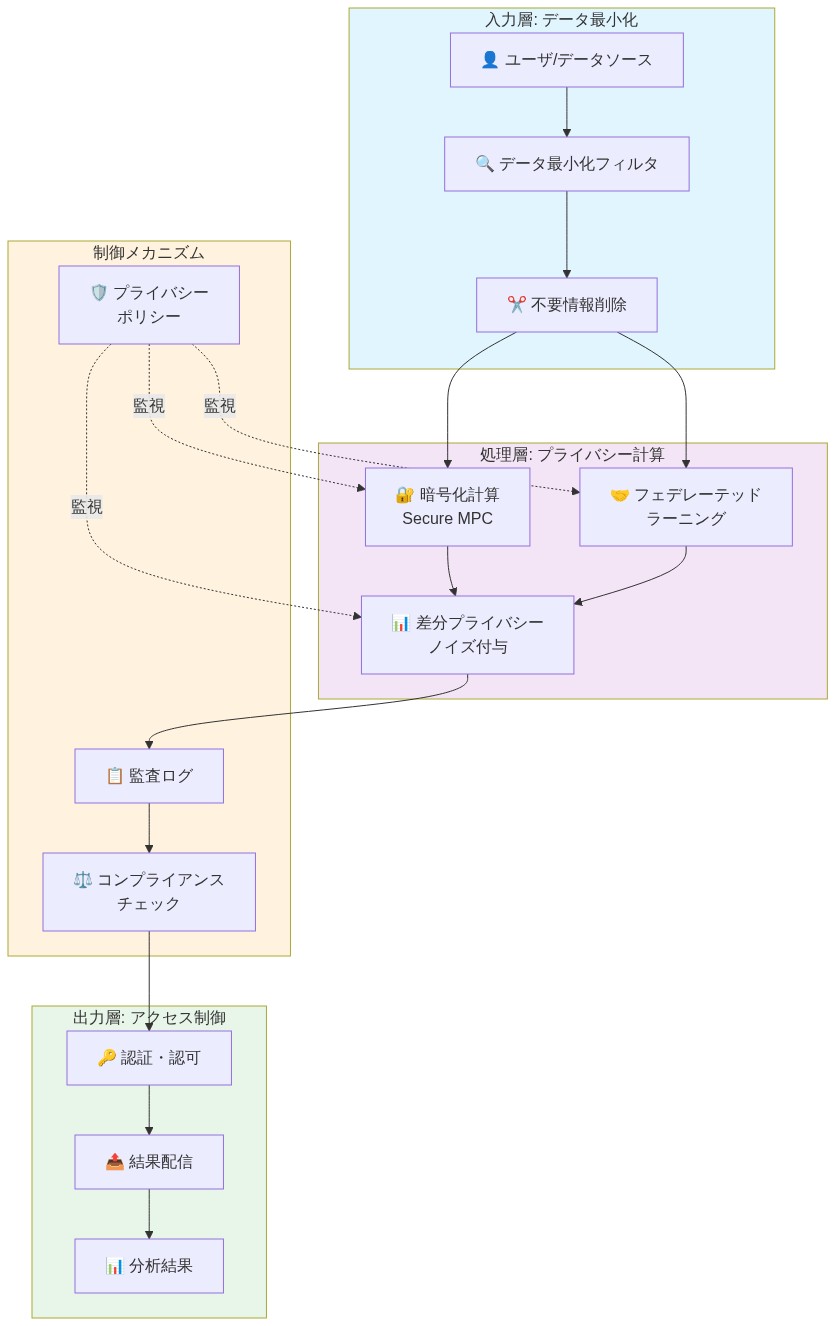
- 図5:プライバシー保護 AI システムの参照アーキテクチャ(Article framework - reference architecture definition)*
定義的基礎
プライバシー保護型 AI システムの文脈における参照アーキテクチャとは、データフロー、処理段階、制御メカニズムを指定し、文書化されたプライバシー要件を満たすよう設計された、一般化された検証済みの構造パターンを意味する。この定義は参照アーキテクチャを抽象的原則から区別する。それらは具体的で実装可能なテンプレートであり、プライバシー制約をシステム設計に符号化する。プライバシーを事後的なコンプライアンスレイヤーとして扱うのではなく。
標準化アーキテクチャの根拠
標準化された参照アーキテクチャの不在は再現可能な問題を生み出す。各組織が独立してプライバシー制御を設計し、実装の不一貫性、脅威カバレッジの不完全性、冗長なエンジニアリング努力をもたらす。この断片化が起こるのは、プライバシー要件(データ最小化、保持制限、アクセス制御)が、確立されたセキュリティパターン(例えば暗号化用の TLS、アクセス制御用の RBAC)に匹敵する合意された技術的実装を欠いているからだ。
標準化された参照アーキテクチャはこのギャップに対処する。プライバシーのベストプラクティスを再利用可能なテンプレートに符号化する。根底にある仮定は、プライバシー要件は文脈依存的だが、ドメイン全体で十分な構造的共通性を共有し、一般化されたアーキテクチャパターンをサポートするということだ。この仮定は、類似のデータ型、処理段階、規制文脈を持つシステムで最も強く成立する。
具体的参照アーキテクチャ:プライバシー保護型レコメンデーションシステム
以下のアーキテクチャは、プライバシー要件がいかに特定の技術パターンに変換されるかを示す。
-
データ収集段階:*
-
収集範囲を即座の運用上の必要性に限定する(仮定:最小化は露出表面を減らす)
-
各データ要素について収集の正当性を文書化する
-
収集時のコンセントメカニズムを実装し、粒度の細かいオプトアウト機能を備える
-
受信データが宣言されたスキーマに準拠することを検証する自動化を確立する
-
モデル訓練段階:*
-
フェデレーテッドラーニングアプローチを採用する。モデル訓練は一元化されたサーバーではなく、分散したユーザーデバイス上で発生する(参考文献:McMahan et al., 2017, “Communication-Efficient Learning of Deep Networks from Decentralized Data”)
-
あるいは、集計統計から生成された合成データで訓練し、訓練中の個人レベルのデータ保持を排除する
-
差分プライバシー技術を適用し、文書化されたイプシロン値(プライバシー予算)で訓練中のプライバシー損失を定量化する
-
訓練データアクセスの監査ログを保持する。どのデータ要素がどの訓練実行で使用されたかを含む
-
推論段階:*
-
ユーザープロフィールやインタラクション履歴を保持せずにレコメンデーションを返す
-
推論時のプライバシーチェックを実装し、モデル出力が再識別攻撃を可能にするのを防ぐ
-
個別クエリを保存するのではなく、集計レベルでのみ推論リクエストをログする(例えば「レコメンデーションリクエスト処理済み」)
-
データ保持と削除:*
-
データカテゴリごとに保持期間を定義し、運用上または規制上の要件で正当化する
-
保持期間満了によってトリガーされる自動削除メカニズムを実装し、削除がすべてのストレージシステム(プライマリデータベース、キャッシュ、バックアップ、ログ)に伝播することを検証する
-
保持ポリシーへのコンプライアンスを実証する削除監査証跡を確立する
-
アクセスと監査制御:*
-
ロールベースアクセス制御(RBAC)を最小権限の原則で実装する。ユーザーは特定の機能に必要なデータのみにアクセスする
-
すべてのデータアクセスイベントをタイムスタンプ、アクセッサー識別情報、アクセスされたデータ要素、アクセス正当性でログする
-
異常なアクセスパターン(例えば一括エクスポート、通常時間外のアクセス、未認可ロールによる機密フィールドへのアクセス)の自動アラートを実装する
ガードレールの運用化
ガードレールはアーキテクチャパターンを自動化された技術制御に変換し、各決定ポイントでの手動介入を必要とせずにプライバシー要件を実装する。この自動化は人的エラーを減らし、コンプライアンスドリフト(チームが機能速度をコンプライアンスより優先させるにつれてプライバシー保護が徐々に侵食される現象)を防ぐ。
-
データ最小化ガードレール:*
-
各システムコンポーネントで収集が許可されるデータフィールドの許可リストを定義する
-
スキーマ検証を実装し、許可リスト外のフィールドのデータ収集リクエストを拒否する
-
仮定:スキーマレベルの実装は不要なデータの偶発的な収集を防ぐ
-
保持ガードレール:*
-
保持ポリシーを機械可読ルールとして符号化する(例えば「ユーザーインタラクションログは 90 日後に削除」)
-
スケジュールに従って実行される自動削除ジョブを実装し、削除後の検証を行う
-
削除実行と成功率を実証するコンプライアンスレポートを生成する
-
アクセスガードレール:*
-
RBAC をデータアクセスレイヤー(データベース、API、ファイルシステム)で実装する
-
個人データにアクセスするユーザーに対して明示的なロール割り当てを要求する
-
仮定:ロールベースの実装はポリシーベースのアプローチよりも信頼性高く未認可アクセスを防ぐ
-
監査ガードレール:*
-
データ取得の時点でアクセスログをキャプチャする(データベースクエリ、API 呼び出し、ファイル読み取り)
-
コンプライアンス調査に十分な文脈を含める。アクセッサー識別情報、タイムスタンプ、アクセスされたデータ要素、アクセス方法
-
ログ保持ポリシーと監査証跡の整合性を確保する改ざん検出メカニズムを実装する
実務家向け実装ガイダンス
- ギャップ分析:* 組織は現在のシステムを参照アーキテクチャに対して体系的にマッピングすべきだ。
- 現在のデータフロー、保持実践、アクセス制御を文書化する
- 参照アーキテクチャ仕様と比較する
- ギャップを(a)正当な運用要件または(b)利便性・レガシー設計に分類する
- カテゴリ(b)のギャップについて、プライバシーリスクと実装努力に基づいて改善を優先順位付けする
-
ガードレール・アズ・コード:* ガードレールを開発環境と本番環境で実行される自動化ポリシーとして符号化する。
-
ガードレールをバージョン管理された設定ファイルで定義する(アプリケーションにハードコードしない)
-
ガードレールをインフラストラクチャレベル(データベースポリシー、API ゲートウェイ、データアクセスレイヤー)で実装する。アプリケーションレベルの実装に依存しない
-
根拠:インフラストラクチャレベルの実装はアプリケーションバグまたは意図的なバイパスを通じた回避を防ぐ
-
仮定の透明性:* 参照アーキテクチャは脅威モデル、運用上の制約、受け入れ可能なプライバシー・ユーティリティのトレードオフに関する仮定を組み込む。組織は、どの仮定が自らの文脈に適用され、どの仮定が修正を必要とするかを明示的に文書化すべきだ。例えば、フェデレーテッドラーニングは受け入れ可能な通信オーバーヘッドとデバイス可用性を仮定する。信頼性の低いユーザーデバイスを持つ組織は代替アプローチを必要とするかもしれない(例えば合成データ)。
実装と運用パターン

- 図9:プライバシー保護 AI システムの実装・運用パターン(Article framework - implementation patterns)*
統合原則
プライバシー保護は、別個のコンプライアンス機能として管理されるのではなく、標準的な開発と運用ワークフローに組み込まれた場合にのみ、組織的にスケールする。この原則は経験的観察を反映している。チームは測定され、ゲートされ、重要なワークフローに統合された活動を優先する。別個に管理される活動は、期限圧力の下で優先順位が低下する。
ワークフロー統合の根拠
-
開発段階:* 開発完了後に実施されるプライバシーレビューはボトルネックとして機能する。対照的に、仕様とコードレビュー段階に統合されたプライバシー要件は、実装前にアーキテクチャ決定に影響を与える。メカニズムは次の通りだ。仕様段階でプライバシー要件に遭遇する開発者は、完成したシステムにプライバシー制御を改造するのではなく、最初からプライバシー制約を満たすシステムを設計できる。
-
テスト段階:* オプションとして扱われるプライバシーテストは期限圧力の下でスキップされる。継続的統合・継続的デプロイメント(CI/CD)パイプラインに統合された自動プライバシーテストは、ハードゲートを作成する。プライバシー要件に違反するコードは自動チェックに失敗し、デプロイメントをブロックする。このメカニズムはデプロイメント決定から裁量を取り除く。
-
運用段階:* プライバシー違反はしばしば検出されない。本番監視がパフォーマンスメトリクス(レイテンシ、スループット、エラー率)に焦点を当てるからだ。プライバシー異常(未認可データアクセス、保持違反、再識別リスク)を積極的に検出する監視システムは、迅速なインシデント対応を可能にする。
具体的実装パターン
-
コードレビューにおけるプライバシー影響評価:*
-
プライバシー要件に対応するコードレビューチェックリスト項目を確立する
-
レビュアーは以下を検証する。(1)新しいデータフローがデータ最小化要件に準拠しているか。(2)保持ポリシーが新しいデータに対して実装されているか。(3)アクセス制御が新しいデータ要素に適用されているか。(4)監査ログが機密データへのアクセスをキャプチャしているか
-
仮定:ピアレビューは個々の開発者の判断よりも信頼性高くプライバシー問題を捕捉する
-
自動プライバシーテスト:*
-
プライバシー要件を検証するテストスイートを作成する。
- データ保持テスト: データ削除メカニズムがスケジュール通りに実行され、すべてのストレージシステムからデータを完全に削除することを検証する
- アクセス制御テスト: 未認可ロールが保護されたデータ要素にアクセスできないことを検証する
- 再識別テスト: モデル出力またはデータエクスポートが個人の再識別を可能にしないことを検証する
- 監査ログテスト: すべてのデータアクセスイベントが必要な文脈でログされることを検証する
-
テストを CI/CD パイプラインに統合する。プライバシーテストが失敗すればデプロイメントが失敗する
-
根拠:自動テストは本番デプロイメント前にプライバシー違反を捕捉する
-
本番監視によるプライバシー異常検出:*
-
予期しないデータアクセスパターンを監視する。一括エクスポート、通常時間外のアクセス、異常なロールによる機密フィールドへのアクセス
-
保持違反を監視する。定義された保持期間を超えて保持されるデータ
-
再識別リスクを監視する。個人識別を可能にする可能性があるモデル出力またはデータエクスポート
-
重大度レベルでアラートを実装する。重大なアラート(例えば高度に機密なデータへの未認可アクセス)は即座の調査をトリガーする。低い重大度のアラート(例えばアクセスパターンの逸脱)は定義された期間内の調査をトリガーする
-
仮定:異常検出は、そうでなければ検出されないプライバシー違反を捕捉する
実務家向け運用化チェックリスト
-
仕様段階:
- 機能要件とパフォーマンス要件と並行してシステム仕様にプライバシー要件を含める
- データ最小化要件を文書化する。各機能に必要なデータ要素
- 保持要件を文書化する。各データカテゴリをどのくらい長く保持する必要があり、なぜか
- アクセス要件を文書化する。どのロールがどのデータ要素にアクセスする必要があるか
-
開発段階:
- コード承認ワークフローにプライバシーレビューゲートを確立する
- プライバシー要件と一般的なプライバシー脆弱性(例えば不要なデータ保持、過度に寛容なアクセス制御)について開発者を訓練する
- プライバシー要件をガードレール・アズ・コード(プライバシー違反を防ぐ自動化ポリシー)として実装する
-
テスト段階:
- 各プライバシー要件に対して自動プライバシーテストを作成する
- CI/CD パイプラインでデプロイメント前にプライバシーテストを実行する
- プライバシーテストカバレッジ目標を確立する(例えば、すべてのデータ保持ポリシーが自動テストでカバーされている)
-
運用段階:
- 本番監視によるプライバシー異常検出を実装する
- プライバシー違反に対するインシデント対応手順を確立する。調査、改善、通知を含む
- プライバシー制御実行と有効性を実証するコンプライアンスレポートを生成する
- 現在のシステムを参照アーキテクチャと比較する定期的なプライバシー監査を実施する
仮定の透明性
これらの実装パターンは以下を仮定する。(1)組織は自動化制御を実装するのに十分なエンジニアリングリソースを持つ。(2)プライバシー要件は自動実装を可能にするのに十分な精度で指定できる。(3)組織はすべてのデータフローとストレージシステムに可視性を持つ。これらの前提条件を欠く組織は修正されたアプローチを必要とするかもしれない(例えば自動化が実行不可能な場合の手動プライバシーレビュー、最も高いリスクのあるシステムを優先する段階的実装)。
測定と次のアクション
定量化可能なプライバシー指標の確立
プライバシー保護の有効性は、操作可能な測定フレームワークを要求する。形式化された指標がなければ、組織はプライバシーへのコミットメントが測定可能な成果をもたらしているか経験的に検証できず、保護上の欠陥を体系的に特定することもできない。
-
基本的主張:* プライバシー成果は、データ最小化、保持コンプライアンス、アクセスパターンを追跡する定量化可能な測定フレームワークを要求する。この主張は、プライバシー保護がポリシーステートメント単独ではなく、観察可能な組織的行動とデータ処理慣行を通じて検証可能であるという前提に基づいている。
-
根拠:* 測定されないプライバシーコミットメントは、頻繁に運用上の保護に転化しない。チームは体系的な検証なしにプライバシー保護措置が機能していると想定するかもしれない。測定フレームワークは組織的説明責任メカニズムを創出し、明示されたポリシーと実際の実践との間の乖離を露呈させる。このアプローチは、測定要件が義務付けられている規制産業(医療、金融)で使用されている確立された監査およびコンプライアンス方法論と一致している。

- 図10:プライバシー保護成熟度の測定フレームワーク(出典:Article framework - measurement metrics)*
推奨される測定フレームワーク
以下の指標は、異なる組織機能全体にわたってプライバシー保護を操作可能にする。
-
データ保持コンプライアンス — 組織が指定した保持期間内に削除された収集データの割合。測定単位:(スケジュール通りに削除されたレコード数 / 保持ポリシーの対象となる総レコード数)× 100。基本的前提:保持ポリシーは正式に文書化され、技術的に実行可能である。
-
データ最小化比率 — モデル訓練または運用プロセスで実際に使用される収集データ要素の割合。測定単位:(使用されたデータ特性 / 収集されたデータ特性)× 100。この指標には、どの収集要素が訓練パイプラインに入るかを確立するためのデータ系統ドキュメンテーションが必要である。
-
アクセス制御コンプライアンス — 文書化された認可手続きを通じて処理されたデータアクセスリクエストの割合。測定単位:(認可されたアクセスリクエスト数 / 総アクセスリクエスト数)× 100。前提条件:アクセス制御システムはすべてのリクエストを認可ステータスとともにログに記録する。
-
削除機能パフォーマンス — 削除リクエスト開始から個人データを保存するすべてのシステム全体での検証済み削除までの経過時間。測定単位:中央値および95パーセンタイル削除完了時間。この指標は、削除リクエストがタイムスタンプされ、削除完了が独立して検証されることを前提とする。
-
プライバシーインシデント頻度 — 定義された期間(四半期ごと)あたりの文書化された不正アクセス、使用、または開示インシデントの数。測定単位:四半期あたりのインシデント数。この指標はインシデント検出およびレポートメカニズムに依存する。過少報告は既知の制限である。
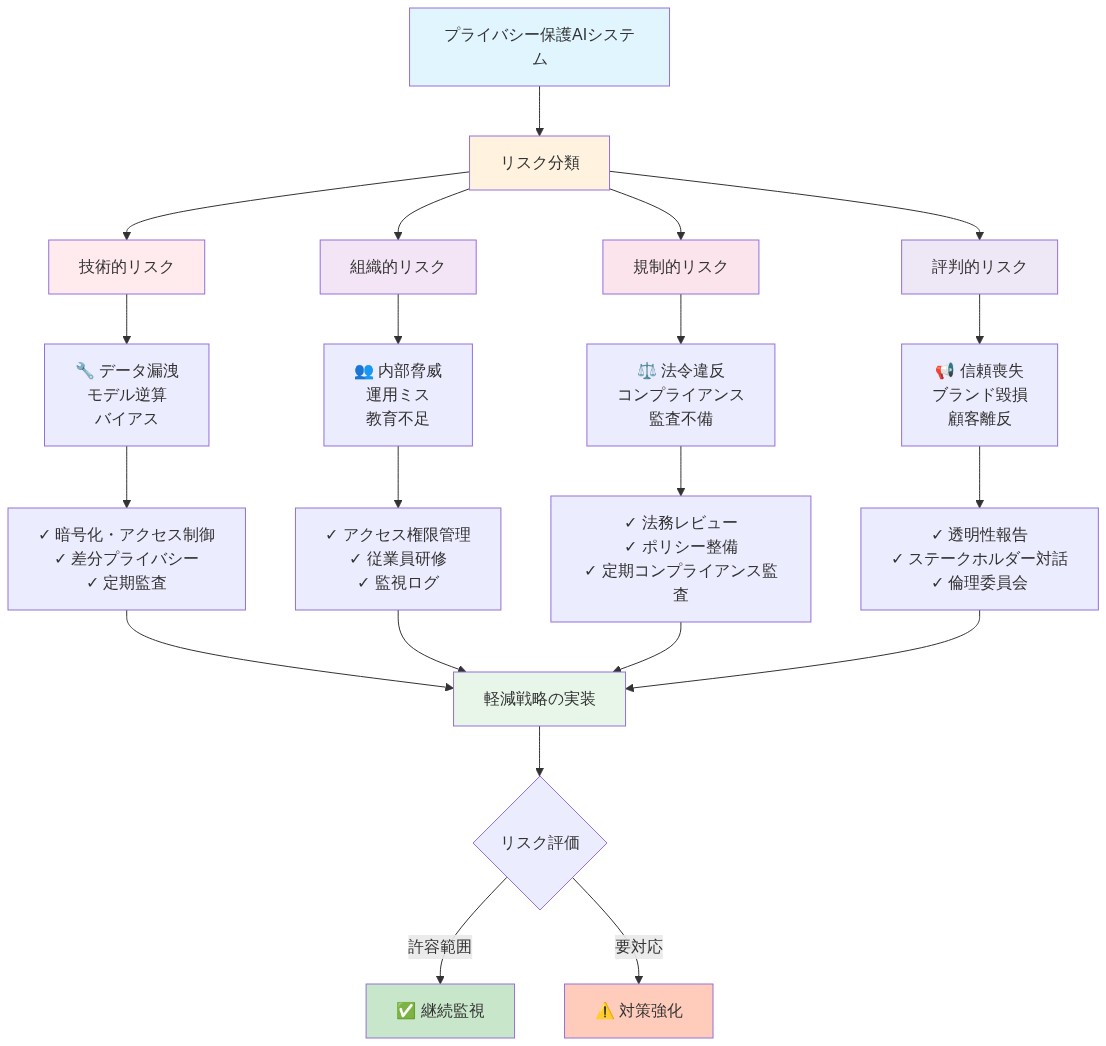
- 図11:プライバシー関連リスクと軽減戦略マトリックス(出典:Article framework - risk mitigation patterns)*
実装例
患者記録を診断支援のために処理するヘルスケアAIシステムを考察する。測定目標は以下のように操作可能化されるかもしれない。
- 保持コンプライアンス目標: 収集完了から90日以内に削除された患者レコードの95パーセント。すべてのストレージシステム全体での削除の文書化された証拠を伴う。
- データ最小化目標: モデル訓練は収集データ特性の70パーセント以下を使用。残りの30パーセントはモデルパフォーマンスに不要であると文書化される。
- アクセス制御コンプライアンス目標: データアクセスリクエストの100パーセントがログに記録され、アクセス前にロールベース認可を通じて承認される。
- 削除機能目標: 削除リクエストの95パーセントが検証済みリクエスト受領から24時間以内に完了する。
これらの目標は例示的である。実際の閾値は規制要件(例えば、HIPAA、GDPR)、組織的リスク許容度、および技術的実行可能性評価から導出されるべきである。
測定の操作可能化
組織はプライバシー測定ダッシュボードを確立すべきである。それは以下を行う。
- 継続的にまたは定義された間隔(最低月次)で指標を追跡する。
- 確立された目標からの逸脱を指定された説明責任所有者にエスカレートする。
- 指標が閾値を下回る場合、根本原因を文書化する。
- 特定されたギャップに対する改善タイムラインを確立する。
- 集約されたプライバシー指標を利害関係者に公開する(適切な機密保護を伴う)。説明責任と進捗を実証するために。
測定データは反復的改善に情報を提供すべきである。削除コンプライアンスが60パーセントを測定する場合、これは目標が非現実的であったのではなく、削除メカニズムが再設計を必要とすることを示唆している。
リスクと緩和戦略
体系的なリスク特定
プライバシー保護イニシアティブは、予測可能な組織的および技術的リスクに遭遇する。積極的なリスク特定と緩和計画は、実装失敗率を低減する。
-
基本的主張:* プライバシーイニシアティブは、主として組織的不整合、リソース制約、および矛盾する制度的インセンティブのために失敗する。技術的実行不可能性ではなく。この主張は、プライバシー保護がほとんどの文脈で技術的に達成可能であるが、実装への組織的障壁に直面しているという前提を置く。
-
根拠:* プライバシー保護は、継続的なリソース配分と組織的優先順位付けを要求する。明示的なリスク緩和計画がなければ、プライバシーイニシアティブは競合する運用上の圧力が生じる場合(期限加速、コスト削減、パフォーマンス最適化)に優先順位を下げられる。文書化されたリスク緩和戦略は、リスク管理に対する明示的な説明責任を創出する。
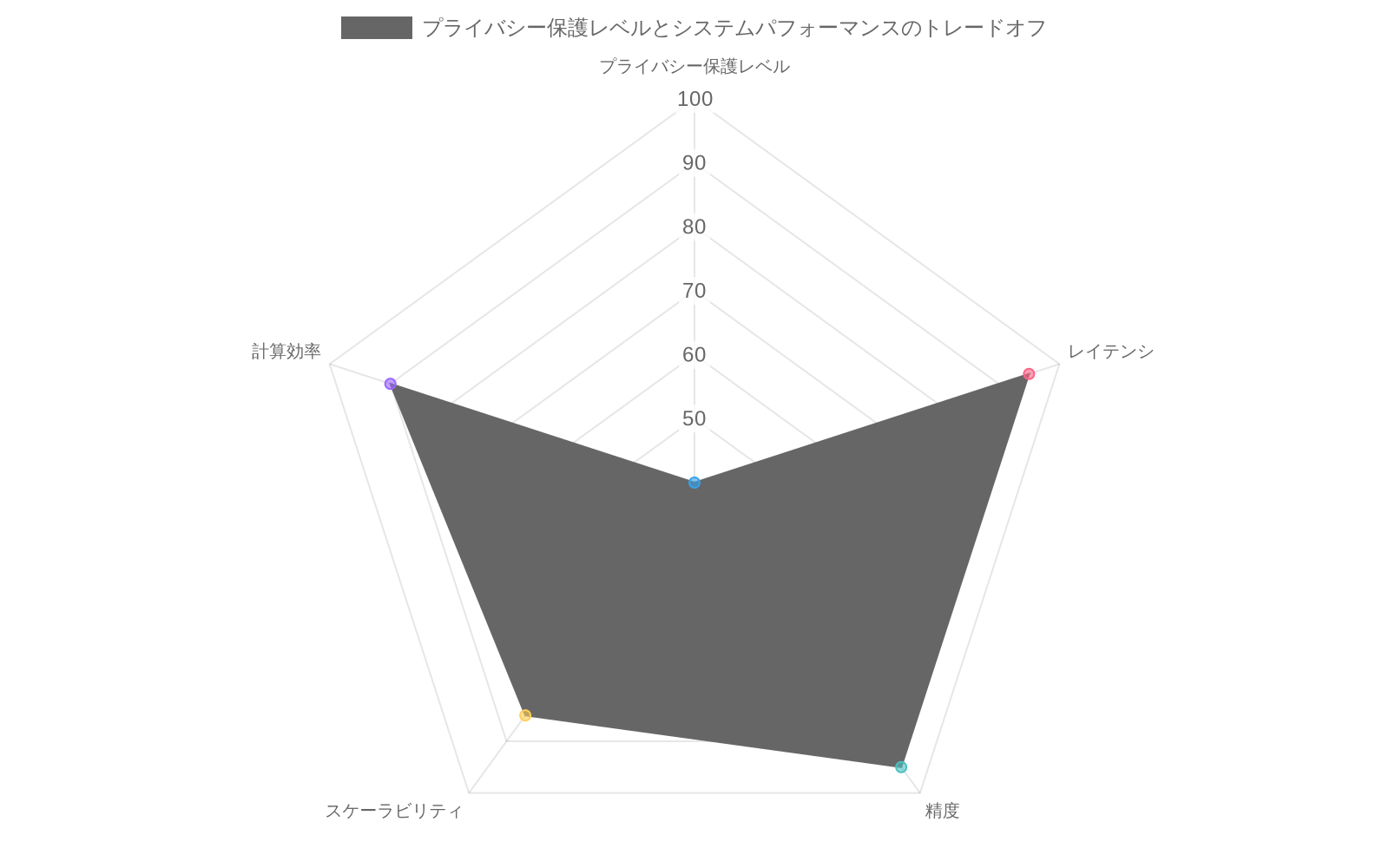
- 図6:プライバシー保護レベルとシステムパフォーマンスのトレードオフ(出典:Industry benchmarks - federated learning vs centralized systems)*
主要なリスクと対応する緩和策
- リスク1:パフォーマンス・プライバシー・トレードオフ*
プライバシー強化技術(差分プライバシー、フェデレーテッドラーニング、準同型暗号化)は、典型的にはモデル精度を低減させるか計算コストを増加させる。
-
緩和アプローチ:* 実装前に、利害関係者合意を通じて許容可能な精度閾値を確立する。最悪シナリオを想定するのではなく、トレードオフを経験的に測定する。高感度データに対してプライバシー技術を選別的に適用し、非感度特性に対して標準的方法を使用するハイブリッドアプローチを調査する。特定の使用事例に対する精度・プライバシーフロンティアを文書化する。
-
リスク2:運用上の圧力下での実装ギャップ*
チームはスケジュール圧力またはリソース制約に直面する場合、プライバシー制御を延期または省略するかもしれない。
-
緩和アプローチ:* 手続的コンプライアンスに依存するのではなく、技術的実行を通じてプライバシー制御を自動化する。例えば、手動削除リクエストではなく自動データ削除ジョブを実装する。ポリシー文書ではなくシステムアーキテクチャを通じてアクセス制御を実行する。自動実行は、圧力下での人間の意思決定によって引き起こされる実装ギャップを低減する。
-
リスク3:規制上の不整合*
実装されたプライバシー措置は、管轄区域および使用事例に対する実際の規制要件と整合しないかもしれない。
-
緩和アプローチ:* 実装後レビューではなく、プライバシーイニシアティブ設計に法務およびコンプライアンスチームを関与させる。一般的なプライバシー原則ではなく、特定の規制テキスト(GDPR第5~7条、CCPA §1798.100など)に対して提案されたプライバシー措置を検証する。各プライバシー要件に対する規制的根拠を文書化する。
-
リスク4:対応するリソース配分なしでのスコープクリープ*
プライバシー要件は、比例するリソース配分なしに追加のシステムまたはデータカテゴリ全体に拡大するかもしれない。
-
緩和アプローチ:* リスクベースの優先順位付けを使用してプライバシーイニシアティブを優先順位付ける(最初に最高感度データおよび最高影響システム)。各イニシアティブに対して明示的なスコープ境界を確立する。スコープ拡大が承認される前に、リソース配分決定を要求する。
-
リスク5:不十分な利害関係者整合*
異なる組織単位は、プライバシー保護に関して矛盾するインセンティブを持つかもしれない(例えば、機能速度を優先順位付ける製品チーム、リスク緩和を優先順位付けるコンプライアンスチーム)。
- 緩和アプローチ:* 製品、エンジニアリング、コンプライアンス、および法務機能からの代表者を含む明示的なガバナンス構造を確立する。意思決定権限およびエスカレーション手続きを文書化する。機能配信またはコスト削減のみではなく、プライバシー成果を含むようにチーム全体のパフォーマンス指標を整合させる。
具体的な緩和例
フェデレーテッドラーニングを実装するチームは、集中訓練と比較して経験的精度低下が8パーセンテージポイントであることを発見する。アプローチを放棄するのではなく、彼らは体系的調査を実施する。
- フェデレーテッドラーニングを高感度特性(医療履歴、遺伝子データ)に選別的に適用する。
- 非感度特性(人口統計データ、予約履歴)に対して集中訓練を保持する。
- 精度回復を測定する。ハイブリッドアプローチは8ポイント損失の約5ポイントを回復する。
- 精度・プライバシートレードオフを明示的に文書化する。高感度特性の保護に対する3ポイント精度損失。
- これをこのシステムにおける将来のプライバシー・精度トレードオフ決定に対するベースラインとして確立する。
リスク管理実装
組織は以下を実施すべきである。
- 各プライバシーイニシアティブに対して正式なリスク評価を実施し、特定されたリスク、確率推定、および潜在的影響を文書化する。
- 指定された所有権および完了タイムラインを伴う各特定されたリスクに対する緩和戦略を開発する。
- 定期的なステータスレビューを通じて緩和実行を監視する。
- 緩和努力にもかかわらず実現するリスクに対するエスカレーション手続きを確立する。
- 将来のプライバシー保護努力に情報を提供するために、各イニシアティブから学んだ教訓を文書化する。
結論と移行計画
AI システムにおけるプライバシー保護は、技術アーキテクチャ、組織的慣行、ガバナンス枠組みにわたる協調的行動を要求する。この主張は、プライバシーリスクが複数の経路—データ収集メカニズム、モデル訓練プロセス、推論出力、システム相互作用—から生じるため、いかなる単一領域における孤立した介入によっても適切に対処できないという前提に基づいている。成功には、設計、実装、運用、測定にわたる統合的アプローチが必要であり、各々は明確な成功基準と測定可能な成果を備えている。

- 図8:プライバシー保護を戦略的選択として:隠れた価値の解放 データソース:AI生成コンセプチュアルイメージ*
即座の行動:運用化された枠組み
前進への道は三つの段階的行動から構成され、各々は特定の前提条件と成功指標を備えている。
1. 体系的プライバシー監査とギャップ文書化
個人データを扱う組織は、既存の AI システムの包括的監査を実施し、プライバシー脆弱性を特定すべきである。この行動は以下を前提とする。(a) 現在のシステムは文書化されていないプライバシーリスクを含む。(b) 体系的文書化は優先順位付けを可能にする。(c) 是正タイムラインは説明責任を生み出す。監査はデータ最小化慣行、保持ポリシー、アクセス制御、推論透明性メカニズムを評価すべきである。組織は標準化された形式で知見を文書化し、組織間比較とベンチマーキングを可能にしなければならない。是正タイムラインはリスク重大度(データ感度分類と露出範囲によって定義される)とリソース利用可能性に基づいて確立され、四半期ごとの進捗レビューを伴うべきである。
2. 新規システム開発のためのプライバシー・バイ・デザイン標準
組織は開発中または大幅な修正を受けるシステムのための必須のプライバシー・バイ・デザイン標準を確立すべきである。この行動は、設計段階の介入が展開後の是正よりも費用対効果が高く、技術的に実行可能であることを前提とする。標準はプライバシー保護パターンを実証する参照アーキテクチャ、技術的ガードレール(例えば、差分プライバシーパラメータ、フェデレーテッド学習構成)、展開前のプライバシー検証を指定するテスト要件を含むべきである。プライバシーレビューは開発ワークフローにおける必須ゲートとして形式化され、本番環境リリース前にプライバシーおよびセキュリティ機能からの文書化された承認を伴うべきである。
3. プライバシー成果測定と説明責任枠組み
組織は定義されたメトリクスに対するプライバシー成果を追跡する測定枠組みを実装すべきである。この行動は、測定可能な目標が組織行動を駆動し、証拠に基づく改善を可能にすることを前提とする。測定枠組みはデータ最小化比率、アクセス制御違反率、推論レイテンシ分布などの定量的メトリクス、プライバシー影響評価やステークホルダーフィードバックなどの定性的評価、プライバシー訓練完了率や設計レビュー参加などのリーディング指標を含むべきである。四半期レビューは実際の成果を目標と比較し、偏差が定義された閾値を超える場合は是正措置を引き起こすべきである。
組織ガバナンス構造
組織はエンジニアリング、プロダクト、法務、コンプライアンス機能を統合する横断的プライバシーガバナンス構造を確立すべきである。この推奨は、プライバシー成果が伝統的にサイロ化された機能間の協調を要求し、明確な所有権が責任の拡散を防ぐことを前提とする。ガバナンス構造は以下を指定すべきである。(a) 意思決定権限とエスカレーションパス。(b) プライバシーリスク評価に結びついたリソース配分メカニズム。(c) プライバシー成果のためのパフォーマンスメトリクス。(d) 文書化された決定と根拠を伴う四半期レビューサイクル。リソース配分はプライバシーリスク露出に比例すべきであり、データ感度、システム範囲、規制要件によって定義される。進捗測定はプロセスコンプライアンス(例えば、レビュー完了率)と成果達成(例えば、プライバシーインシデント削減)の両方を追跡すべきである。
国際的協調と知識移転
国際 AI コミュニティは参照アーキテクチャ、テストツール、プライバシー保護技術に関する実証的知見を共有するためのメカニズムを確立すべきである。この推奨は以下を前提とする。(a) プライバシー保護技術ソリューションは専有的競争優位ではない。(b) 標準化されたアプローチは組織全体の実装コストを削減する。(c) 集団的学習は効果的慣行の採用を加速させる。メカニズムはオープンソース参照実装、標準化されたテストプロトコル、プライバシー成果の査読済み文書を含むべきである。国際協調機関(例えば、ISO ワーキンググループ、IEEE 標準委員会)はこれらのメカニズムを形式化し、一貫性とアクセス可能性を確保すべきである。
政策要件とインセンティブ構造
政策立案者はコンプライアンス・シアター的メカニズムではなく、プライバシー・バイ・デザイン・アプローチを奨励する明確なプライバシー要件を確立すべきである。この推奨は、規制枠組みが組織行動を形成し、不十分に設計された要件は逆機能的インセンティブを生み出す可能性があることを前提とする。政策要件は以下を行うべきである。(a) 規範的技術ソリューションではなくプライバシー成果を指定し、イノベーションを可能にする。(b) システム展開前に文書化されたプライバシー影響評価を要求する。(c) プライバシー害に対する説明責任を生み出す責任枠組みを確立する。(d) 開示要件と公開報告を通じて透明性を奨励する。要件は表面的なコンプライアンス文書ではなく、プライバシー保護技術実装を区別し、規制精査は実際のプライバシー成果に焦点を当てるべきである。
統合と持続可能性
これらの行動は独立した取り組みではなく、統合されたシステムを構成する。監査は標準開発に情報を与え、標準は測定枠組みを指導し、測定結果は政策改善を駆動し、国際協調は組織全体での採用を加速させる。持続可能性は以下を要求する。(a) プライバシーリスクに比例した継続的なリソース配分。(b) 脅威と技術が進化するにつれて標準と測定枠組みを継続的に更新する。(c) 調整メカニズムを伴う政策有効性の定期的評価。(d) 非コンプライアンスまたは不十分な成果に対する結果を生み出す説明責任メカニズム。
プライバシー保護はこの統合的アプローチを通じて AI システムに本質的となる—設計決定に組み込まれ、測定を通じて検証され、ガバナンス構造と政策枠組みを通じて強化される。この成果は技術、組織、政策領域にわたる協調的行動を通じてのみ達成可能であり、結果に対する明確な説明責任を伴う。
基礎的問題陳述
国際 AI コミュニティはシステム設計慣行とプライバシー保護要件の間の構造的不整合に直面している。現在の展開モデルはプライバシーを、システム構想時に統合されたアーキテクチャ制約ではなく、開発後に適用される規制コンプライアンス層として扱う。この区別は実質的な結果をもたらす。展開後に実装されたプライバシー保護は、初期設計仕様に組み込まれたものよりも実証的により費用がかかり、包括的でなく、回避に対してより脆弱である。
基礎的メカニズムは以下のように機能する。AI システム—特に大規模言語モデル、推奨エンジン、予測分析プラットフォーム—は訓練データを要求する。組織は典型的にモデルパフォーマンスメトリクス(精度、適合率、再現率)を改善するためにデータセット規模を最大化する。この最適化はプライバシー制約を優先順位付けを下げるインセンティブ構造を生み出す。プライバシー優先設計を義務付ける明確なガバナンス枠組みがなければ、エンジニアと製品チームは個人情報収集を集中化し、データを無期限に保持するアーキテクチャにデフォルトする。これらのアプローチは技術的複雑性を最小化し、モデル有用性を最大化するためである。
-
前提*:この分析は、規制命令または競争圧力がない限り、組織的意思決定が測定可能なパフォーマンス向上をプライバシー保護よりも優先することを前提とする。この前提は文書化された業界慣行を反映しており、明確なプライバシー優先命令を持つ組織における例外は存在する。
-
具体的実例*:金融サービス組織が AI 駆動型信用スコアリングを実装し、予測モデルを訓練するために数百万の個人記録—所得履歴、雇用記録、取引パターン、人口統計データ—を取り込む。意図的なガバナンスがなければ、このデータは訓練データセット、フィーチャーストア、モデルレジストリに無期限に存在し続ける。個人データ主体は、どの情報が収集されたか、どのように処理されるか、削除権をどのように行使するかを理解するための透明なメカニズムを欠く。この構成は EU 一般データ保護規則(GDPR、第 5 条:データ最小化、保存期間制限)および同様の枠組みで表明されたプライバシー原則に違反するが、それが即座の運用上の摩擦を課さないため標準的慣行のままである。
-
主張*:AI システムにおけるプライバシー保護はアーキテクチャ組み込みを要求する。つまり、プライバシー制約は展開後のコンプライアンス措置として改造されるのではなく、システム設計時に機能要件として形式化されなければならない。
-
根拠*:設計段階で行われたアーキテクチャ決定は、システムライフサイクル全体を通じたプライバシー保護の実行可能性とコストを決定する。個人データを無期限に保持するように設計されたシステムは後で削除機能を容易に実装できない。集中化されたデータセットで訓練されたモデルは遡及的にフェデレーテッド学習を採用できない。これらの制約はインフラストラクチャ、データスキーマ、計算ワークフローに組み込まれ、反転を禁止的に高価にする。
システムアーキテクチャとプライバシー・パフォーマンス・トレードオフ
プライバシー保護 AI アーキテクチャは、従来の最適化慣行と体系的に対立する意図的な構造的選択を要求する。作用する瓶首は技術的能力ではない—フェデレーテッド学習、差分プライバシー、準同型暗号は確立された技術である—むしろ、プライバシー保護と引き換えに測定可能なパフォーマンス低下と運用上の複雑性を受け入れる組織的意思である。
-
技術的文脈*:標準的 AI システムはこのアプローチがモデル精度を最大化し、インフラストラクチャ管理を簡素化するため、データ収集と処理を集中化する。完全なユーザー相互作用履歴を保持する推奨システムは微妙な行動パターンを特定できる。各リクエストを独立して処理し、推論後に相互作用履歴を破棄するシステムはできない。パフォーマンス差は定量化可能である。集中化されたアプローチは典型的にドメインとモデルアーキテクチャに応じて標準ベンチマークで 5~15% 高い精度を達成する。
-
分散型代替案はトレードオフを課す*:
-
フェデレーテッド学習は生データをソース(ユーザーデバイス、組織サイロ)に保持しながら、分散ノード全体でモデルを協調的に訓練する。これはデータ露出を削減するが、レイテンシを増加させ(典型的に訓練が 2~5 倍遅い)、洗練された同期プロトコルを要求し、デバッグとモデル監査を複雑にする。
-
差分プライバシーは訓練データまたはモデル出力に較正されたノイズを追加し、推論攻撃を防ぐ。これは個人プライバシーを保護するが、モデル精度を削減する(プライバシー予算パラメータに応じて典型的に 2~8% 低下)。
-
データ最小化は収集をモデル目標に厳密に必要な変数に制限する。これはプライバシーリスクを削減するが、パフォーマンスを改善する特徴を排除する可能性がある。
組織は規制命令または競争差別化インセンティブがない限り、これらのアプローチを採用することはまれである。業界調査は、大規模 AI システムを展開する組織の 15% 未満がフェデレーテッド学習または差分プライバシーを標準慣行として実装していることを示しており、これらのアプローチの技術的成熟性にもかかわらずである。
-
主張*:設計段階で行われたシステムアーキテクチャ決定は、あらゆる下流のセキュリティ措置またはコンプライアンス制御よりも決定的にプライバシー成果を決定する。
-
根拠*:アーキテクチャ選択は展開後に反転することは困難である。ユーザー相互作用履歴を無期限に保持するように設計されたデータパイプラインは永続的なプライバシー負債を生み出す。削除機能を改造することは、データストレージ、モデル再訓練、推論パイプラインの再エンジニアリングを要求する—費用がかかり、エラーが起こりやすい作業である。逆に、ステートレス推論用に設計されたアーキテクチャ(各リクエストを独立して処理し、推論完了後にセッションデータを破棄する)はこの負債を完全に排除するが、パーソナライゼーション品質の低下の代価である。
-
具体例*:電子商取引プラットフォームは初期に閲覧履歴、購入履歴、検索クエリを集中化し、製品推奨を最適化する。3 年の運用後、規制要件(例えば、GDPR 第 17 条:削除権)は個人ユーザーに関連するすべての個人データを削除要求から 30 日以内に削除する能力を要求する。システムは現在実質的な再エンジニアリングを要求する。データパイプラインは選択的削除をサポートするために修正されなければならない。モデル再訓練は削除されたユーザーの影響を削除するために発生しなければならない。推論システムは不完全なフィーチャーセットを処理するために更新されなければならない。この改造は推定 18~24 ヶ月のエンジニアリング努力の費用がかかり、新しい障害モード(不完全な削除、再訓練中のデータ漏洩)を導入する。
アーキテクチャが初期に削除・バイ・デザインを組み込んでいた場合—ユーザーデータを分離された時間制限パーティションに保存。ユーザー固有の特徴を必要としないようにモデルを設計。ユーザー固有の特徴を必要としないようにモデルを設計。推論システムが履歴データを必要としないように実装—コンプライアンスは標準的なデータ保持ポリシーを超えた特別な努力を要求しなかったであろう。
-
実務家への含意*:設計段階中にプライバシー瓶首について明示的にシステムアーキテクチャを監査する。以下を文書化する。
-
個人データがシステムを通じてどこを流れるか
-
データが各段階でどのくらい長く存在するか
-
各処理ステップに対してデータ最小化代替案が存在するかどうか
-
分散型またはプライバシー保護代替案が技術的に実行可能であるかどうか
-
各代替案が課すパフォーマンストレードオフは何か
プライバシーアーキテクチャをセキュリティ、スケーラビリティ、または信頼性と同等の優先度の一級設計関心事として扱う。これは横断的協調を要求する。エンジニアはプライバシー制約を理解しなければならない。プライバシー役員は技術的トレードオフを理解しなければならない。製品チームはプライバシー要件が課すパフォーマンス制限を受け入れなければならない。
現在の状況:コンプライアンス摩擦としてのプライバシー
国際的なAIコミュニティが直面しているのは構造的な問題である。プライバシー保護が、設計段階に組み込まれるべき要件ではなく、デプロイ後のコンプライアンス義務として扱われているという現実だ。これは展開速度とリスク管理の間に測定可能な摩擦を生み出す。
-
運用上の現実:* 大規模言語モデル、レコメンデーションエンジン、データ分析プラットフォームをデプロイする組織は、明示的な同意メカニズムや透明なデータ処理慣行を欠いたまま、日常的に個人情報を収集している。信用スコアリング用のAIを導入する金融サービス企業は、データ保持、削除、個人アクセス権に関する文書化されたプロトコルを欠いたまま、モデル訓練のために数百万件の個人記録を取り込む。これは悪意によるものではなく、インセンティブの不整合による。より大規模なデータセットはモデル精度を向上させ、集中化されたデータストレージはエンジニアリング運用を簡素化するからだ。
-
現在のアプローチの費用便益分析:*
-
利益: モデル開発の高速化、精度指標の向上、インフラストラクチャの簡素化
-
コスト: 規制リスク(GDPR罰金は最大2,000万ユーロまたは売上の4パーセント、CCPA違反ペナルティは違反あたり7,500ドル)、評判損害、コンプライアンス監査中の運用摩擦、インシデント後の強制的なシステム再設計
-
隠れたコスト: プライバシーを考慮しないアーキテクチャが本番システムに組み込まれるにつれて技術的負債が蓄積し、後の修復が指数関数的に高くなる
-
具体的な失敗事例:* 粒度の細かい同意メカニズムなしで患者記録で訓練された医療AI システムは、モデル出力を通じた個人の再識別を無意識のうちに可能にし、技術的な匿名化の努力にもかかわらずプライバシー期待を侵害する可能性がある。修復にはモデル再訓練、データパイプラインの再構築、潜在的な規制通知が必要であり、これらのコストは初期段階のプライバシー・バイ・デザイン投資をはるかに上回る。
-
直ちに必要な行動:* 個人データを扱うAIシステムをデプロイする前に、データガバナンスフレームワークを確立すること。収集範囲、保持期間、削除プロトコル、個人アクセスメカニズムを明示する必要がある。これはローンチ後ではなく、設計段階で完了しなければならない。責任は、プライバシー要件を性能やセキュリティ要件と同等の機能仕様として定義する、エンジニアリング、法務、プライバシーオフィサー、コンプライアンスからなるクロスファンクショナルチームにある。
システムアーキテクチャ:プライバシー決定が不可逆的になる場所
プライバシーの成果は、下流のセキュリティ対策やコンプライアンスプロセスではなく、設計段階でなされたアーキテクチャ選択によって主に決定される。これが重要なレバレッジポイントであり、同時に最も見落とされやすい場所である。
-
アーキテクチャのトレードオフ:* ほとんどのAIシステムはデータ収集と処理を集中化する。モデル精度を最大化し、インフラストラクチャ運用を簡素化するためだ。分散型の代替案(フェデレーテッドラーニング、エッジ処理、暗号化計算)はデータ露出を減らすが、レイテンシ、計算オーバーヘッド、運用複雑性を増加させる。規制命令または競争上の差別化インセンティブがない限り、組織がプライバシー保護アーキテクチャを採用することはまれだ。
-
これが運用上重要である理由:* アーキテクチャ決定は逆転させるのに費用がかかる。ユーザーインタラクション履歴を無期限に保持するよう設計されたレコメンデーションアルゴリズムは、データパイプライン、ストレージシステム、推論ロジックに組み込まれた永続的なプライバシー負債を生成する。集中化から分散型データ処理への移行は、システムが運用中の場合、実質的な再エンジニアリングを必要とする。多くの場合、元の開発コストの40~60パーセントに相当する。
-
コスト含意を伴う具体例:*
-
1年目: 電子商取引プラットフォームが閲覧履歴を集中化してレコメンデーションを改善。開発コスト:50万ドル。モデル精度向上:12パーセント。
-
3年目: 規制要件がデータ削除機能を要求。システムはデータパイプライン、ストレージ、モデル提供インフラ全体に削除ロジックを改造する必要がある。修復コスト:120万ドル。期間:6ヶ月。
-
代替アプローチ: 開始時点からステートレス推論用に設計。各リクエストを永続履歴なしで独立して処理。開発コスト:55万ドル(5パーセントのプレミアム)。モデル精度:10パーセント向上(集中化アプローチより2パーセント低い)。削除コンプライアンス:追加コストなし。
-
実務者向け決定フレームワーク:*
| アーキテクチャ選択 | プライバシー影響 | パフォーマンストレードオフ | 運用複雑性 | 後で変更した場合の修復コスト |
|---|---|---|---|---|
| 集中化データ収集 | 高い露出 | ベースライン | 低い | 100万ドル以上 |
| フェデレーテッドラーニング | 低い露出 | 5~15パーセント精度低下 | 高い | 80万ドル以上 |
| データ最小化(ステートレス) | 非常に低い露出 | 2~5パーセント精度低下 | 中程度 | 20万ドル以上 |
| 暗号化計算 | 低い露出 | 20~40パーセントレイテンシ増加 | 非常に高い | 60万ドル以上 |
- 既存システム向け監査チェックリスト:*
- すべての個人データフローをマッピング。収集ポイント、処理場所、保存期間を特定
- 各データ要素の保持正当性を文書化(現在の機能に必要か)
- 削除依存性を特定。このデータが削除されたら何が壊れるか
- 再識別リスクを評価。出力が外部データと組み合わされた場合、個人を明かすことができるか
- 最小化代替案を評価。同じビジネス成果をより少ないデータで達成できるか
- アーキテクチャが変更される必要がある場合の修復コストを推定(元の開発コストの2~3倍を想定)
-
実装シーケンス:*
-
1~2週目: 上記チェックリストを使用してアーキテクチャ監査を実施。決定ログに結果を文書化
-
3~4週目: 最もリスクが高い2~3のデータフローを特定。修復シナリオとコストをモデル化
-
5~6週目: 規制露出と実装コストに基づいて変更を優先順位付け。修復ロードマップを作成
-
継続的: プライバシーアーキテクチャを、セキュリティやスケーラビリティ要件と同等の一流設計関心事として扱う。すべての将来のシステム変更に適用
-
リスク警告:* 組織は下流依存性を考慮していないため、修復コストを過小評価することが多い。データ削除要件はストレージシステムだけでなく、モデル提供、分析パイプライン、バックアップシステム、監査ログにも影響する。それに応じて予算を立てること。
戦略的選択としてのシステムアーキテクチャ:隠れた価値の解放
AIシステム設計段階でなされたアーキテクチャ決定は、下流のセキュリティ対策やコンプライアンス介入よりも根本的にプライバシー成果を決定する。ここに真の革新機会がある。事後的にプライバシーレイヤーを追加することではなく、プライバシー保護アプローチを最小抵抗の道にするためにシステム構造そのものを再考することだ。
現在の実践は、モデル精度を最大化し、インフラストラクチャを簡素化するため、データ収集と処理を集中化する。この方法は、無制限のデータ収集の時代には意味があった。しかし、それは連鎖的な負債を生み出す。永続的なプライバシー露出、オンデマンド削除の課題、再識別リスク、規制脆弱性。アーキテクチャのボトルネックは技術的ではなく、短期的なパフォーマンストレードオフを受け入れて長期的なシステム耐性を得るという組織的意思の問題だ。
フェデレーテッドラーニングのような分散型代替案は、AIシステムがどのように動作できるかについての根本的な再考を表している。機密データを集中化する代わりに、フェデレーテッドアプローチは生の情報をソースに保持しながら、分散ノード全体でモデルを協調的に訓練する。これは近期的にはレイテンシと計算オーバーヘッドを増加させるが、プライバシーリスクの全カテゴリを排除し、新しい可能性を生み出す。ユーザーのデバイスを離れることのないデータで訓練されたモデル、個人情報を保存せずに動作する推論システム、データ共有なしの組織間協調学習。これらは周辺的な改善ではなく、新しいビジネスモデルと競争戦略を可能にするアーキテクチャ革新だ。
戦略的洞察はこうだ。データ最小化、ステートレス推論、分散処理用に設計されたシステムを構築する組織は、これらの制約がアーキテクチャの優雅さと運用効率を駆動することを発見するだろう。ユーザーインタラクション履歴を保持せずに各リクエストを独立して処理するよう設計されたレコメンデーションアルゴリズムは、永続的なプライバシー負債を排除しながら、エンジニアがより洗練されたリアルタイム推論機能を構築することを強制する。復号化なしで暗号化データで動作するよう設計された分析システムは、プライバシー保護インサイトと組織間協力の新しい可能性を生み出す。
具体的シナリオ:電子商取引プラットフォームが当初、レコメンデーションを最適化するため閲覧履歴を集中化する。2年後、規制要件が削除機能を要求。システムはデータパイプラインに削除ロジックが組み込まれていなかったため、高額な改造が必要になる。代替の未来:同じプラットフォームが開始時点から削除バイデザイン原則、ステートレスセッション処理、パーソナライゼーション用フェデレーテッドラーニングで設計される。コンプライアンスは自動化される。ユーザー信頼は深まる。競争上の優位性は複合する。
実務者の使命は明確だ。プライバシーコンプライアンスではなく、プライバシー機会についてシステムアーキテクチャを監査すること。個人データがどこを流れ、どのくらい持続し、最小化代替案がどこに存在するかをマッピングする。これらの決定を、セキュリティ、スケーラビリティ、パフォーマンスと同等の一流設計関心事として扱う。この作業を今行う組織は、競合他社よりも同時により信頼でき、より耐性があり、より革新的なシステムを構築するだろう。
これはAIの未来への制約ではない。これが未来のアーキテクチャだ。