
エンタープライズにおけるAI採用の加速
組織は全セクターにわたって、かつてない規模で人工知能を展開している。機械学習モデルは、ほぼすべてのフォーチュン500企業において、推奨エンジン、不正検知システム、サプライチェーン最適化、顧客サービス自動化を駆動している。だが、この急速な拡大は、そうした投資を追跡するために設計されたガバナンスフレームワークと開示メカニズムを上回るペースで進行している。
- 本質的な問題は、企業がAIを運用に深く組み込みながら、正式な報告における透明性を欠いている点にある。*
従来の財務・運用報告サイクル—四半期決算説明会、年次10-K提出、サステナビリティ報告書—は、より緩やかな技術変化を想定して構築された。AI採用はこれらの報告サイクルより速く進む。企業は単一四半期内に3つの主要モデルを展開し、2つの既存モデルを廃止し、AI施策全体にわたるリソース配分を転換することが可能だ。だが投資家と規制当局が目にするのは、静的なスナップショットのみである。
具体的な事例を考察してみよう。小売企業が1月に需要予測モデルを実装し、3月にインベントリシステムと統合し、6月にパフォーマンスドリフト(予測精度の低下)を発見し、9月に新規データで再学習を実施したとする。その第2四半期決算報告書は「AI投資」について一般的に言及するのみで、範囲、コスト、運用上の影響を特定しない。ステークホルダーは何が変わったのか、なぜ変わったのか、それがいくら費用がかかったのかについて可視性を欠く。
- *直ちに実行すべき対策は、四半期ごとのAIインベントリチェックポイントを確立することである。**正式な報告期限前に、稼働中のモデル、その主要なビジネス機能、リソース消費(計算、人員、データ)、パフォーマンス指標(精度、レイテンシ、予測単価)を文書化する簡潔な内部監査である。これにより開示決定のための事実ベースラインが生成され、AI影響を定量化するための最後の瞬間の混乱が軽減される。そうしたチェックポイントはまた、モデル劣化または予期しないリソース消費に対する早期警戒システムとして機能し、プロアクティブなリスク管理を可能にする。
現行報告基準における開示ギャップ
既存フレームワーク—GAAP、IFRS、SEC指針—はAIシステムに関する最小限の具体的言語しか含まない。財務諸表はAI支出を一般的な研究開発または資本支出として捕捉し、どの投資が収益を生み出すのか、どれが実験的なままなのかを不明瞭にする。リスク開示は、モデルバイアス、データポイズニング、アルゴリズムドリフトといったAI固有の脅威をめったに項目化しない。
- 見落とされがちだが、現行基準は、AI運用・財務上の重要性を反映するのに十分な粒度を欠いている。*
金融会計基準審議会(FASB)および国際会計基準審議会(IASB)は、AI資本化、耐用年数推定、または減損テストに関する具体的指針を発行していない。SEC2023年のサイバーセキュリティ開示指針はデータ侵害に対処するが、モデルポイズニングやAIシステムへの敵対的攻撃を明示的にカバーしない。この規制上の沈黙は曖昧性を生成する。ある企業はAIを戦略的叙述における競争優位として報告し、別の企業はそれをテクノロジー支出に埋没させる。投資家はピア企業全体でAI成熟度、投資強度、またはリスク露出を確実に比較することができない。
二つの金融サービス企業がクレジットスコアリングモデルを展開する事例を考察しよう。企業Aはモデルパフォーマンス(承認率、デフォルト予測精度)、再学習頻度(四半期ごと)、バイアステスト方法論(人口統計グループ全体の不均等な影響分析)をリスク管理セクションで開示する。企業Bはテクノロジー概要でパフォーマンスまたはガバナンスの詳細なしに「機械学習」に一度言及するのみである。両社は現在のGAAPおよびSEC規則に基づいて技術的には準拠しているが、その透明性は大きく異なる。クレジットリスクを比較する投資家は、ローンパフォーマンスの相違がモデル品質、データ品質、または他の要因に由来するかどうかを評価することができない。
- *直ちに実行すべき対策は、AI施策を既存報告カテゴリーにマッピングすることである。**資本支出(1年超の便益生成が予想される場合)、営業費用(1年以内に消費される場合)、または偶発債務(失敗が重要なリスクをもたらす場合)にマッピングし、内部会計メモランダムにマッピング論理を文書化する。その後、モデルガバナンス(監督構造、承認プロセス)、パフォーマンス監視(追跡指標、レビュー頻度)、失敗シナリオ(モデルが劣化または侵害された場合に何が起こるか)に対処するリスクセクションまたは経営陣による分析・検討(MD&A)における補足開示を提案する。これは基準設定機関が具体的なAI指針を発行するまでギャップを埋める。そうした開示は企業のAIガバナンスポリシーを参照し、財務パフォーマンスに重要なモデルまたはモデルクラスにリンクすべきである。
規制環境:断片化と新興期待
規制当局は世界的にAIガバナンスに対処し始めているが、その手法は依然として断片化し、不均一である。欧州連合のAI法は、高リスクAIシステムに対する分類ベースの義務を課す。SECはサイバーセキュリティおよび気候リスク指針を通じたAI開示への関心を示唆している。連邦準備制度理事会および銀行規制当局は、金融サービスにおける責任あるAI使用に関する原則を発行している。だが、企業AI報告の統一基準は存在しない。
- 表面上は規制が異なるように見えるが、構造的には、企業が最小限の開示を選好するインセンティブが生成されている。*
企業は最も厳格な適用可能基準を満たすために開示を最適化する。断片化された基準はコンプライアンスコストを増加させ、法的最小要件を超える開示を減少させる。規制が複数の管轄区域—EU、米国、英国、アジア太平洋—にわたって異なる場合、多国籍企業は世界的に調和させるか(しばしば最も厳格な基準に)、管轄区域固有のポリシーを維持するかを選択する必要がある。前者はコンプライアンスコストを増加させ、後者は運用複雑性を増加させる。両者は法的最小値を超える自発的開示に対する抑止力を生成する。さらに、執行は依然として希薄である。SECは不十分なAI開示に対する主要な執行措置をまだ提起していないため、認識されるコンプライアンスリスクが軽減される。
具体的な事例として、EUおよび米国で事業を展開するテクノロジー企業を考察しよう。同社はEU AI法(高リスクシステムに対するドキュメンテーションおよびリスク評価を要求)とSEC開示規則(AI固有の報告をまだ義務付けない)の両方に準拠する必要がある。企業はすべてのモデルをEU基準に従って世界的にドキュメント化することを選択し、コンプライアンスコストを増加させる。だが、米国規則で要求される最小限のみを10-Kで開示し、EUおよび米国ステークホルダー間で非対称な透明性を生成する。
- *直ちに実行すべき対策は、規制マッピング演習を実施することである。**事業を展開するすべての管轄区域を特定し、適用可能なAI関連規制(ドラフトまたは提案規則を含む)をリストアップし、各規制の範囲に該当するAIシステムを文書化する。その後、最も厳格な適用可能基準を満たす単一のガバナンスフレームワークを確立し、そのフレームワークをすべての開示の基準として使用する。これにより、コンプライアンスの断片化が軽減され、異なる規制対象者に適応させることができる一貫した事実記録が生成される。
実装と運用パターン
規模でAIを展開する組織は、従来のプロジェクト管理フレームワークの範囲を超える運用複雑性に直面する。AIシステムは異種技術環境内で動作し、継続的なモデル再学習を要求し、時間とともに品質が変動するデータ入力に依存し、ダウンストリームビジネスプロセスを通じて伝播する出力を生成する。この運用上の現実は、現在の正式な報告構造ではほぼ完全に不可視である。
- 本質的な問題は、AI運用が標準化された測定フレームワークを欠いており、運用上の現実と正式な開示の間に重要なギャップを生成している点にある。*
AIプロジェクトは、従来のプロジェクト会計を不十分にする資本プロジェクトとの構造的相違を示す。資本プロジェクトは通常、定義された範囲、固定タイムライン、および離散的な完了イベントに従う。対照的に、AIシステムは暫定的なパフォーマンスの状態で本番環境に進入する。それらのビジネス価値は条件付きで出現する—継続的なデータ品質、ユーザー採用パターン、および組織ワークフロー統合に依存し、これらの依存性は報告期間全体で変動する。制御されたテスト環境で検証されたモデルは、本番環境への展開時にパフォーマンス劣化を頻繁に示す。この現象は機械学習文献では「モデルドリフト」として文書化されている。その結果、ROI計算は静的なパフォーマンスパラメータを仮定することはできない。従来の財務報告は、完了と価値実現が定義された時点で発生することを仮定する。AI運用は、不定の時間軸全体にわたるパフォーマンスと価値実現の継続的な監視を要求する。
具体的な事例として、製造組織が50施設全体に予測保全モデルを展開したケースを考察しよう。制御されたパイロットは15%のダウンタイム削減を実証した。展開後6ヶ月、採用パターンは大きく異なった。30施設は一貫したモデル統合を達成し、15施設は散発的な使用を示し、5施設は運用上の摩擦とユーザー抵抗のためにパイロットを中止した。モデルの増分ビジネス影響は不確定となった。パイロットで観察された15%削減は、追加的な測定インフラなしに、より広範な展開に確実に帰属させることはできなかった。正式な財務諸表は、投資が正のリターン、負のリターン、または施設によって異なるリターンを生成したかどうかを正確に表現することはできなかった。
- *直ちに実行すべき対策は、AI運用測定システムを確立することである。**以下を追跡する。(1)モデル展開ステータスおよび施設・システムカバレッジ、(2)モデル出力利用の頻度として測定される採用率、(3)予測精度、レイテンシ、エラー率を含むパフォーマンス指標、(4)再学習サイクルおよびデータ品質指標、(5)定義されたベースラインに対して測定される増分ビジネス影響。これらの指標を月次で運用リーダーシップに、四半期ごとに財務およびボード・ガバナンスに報告する。これらのシステムから導出された文書化可能で監査可能な数字を、AIの戦略的貢献に関する定性的主張ではなく、正式な開示の証拠ベースとして使用する。
測定と次のアクション
ビジネス成果に対するAIの貢献を分離することは、厳密な測定設計を要求する。ほとんどの組織は、ビジネス成果を構成要因に分解するための分析インフラストラクチャを欠いている。収益が増加するか、コストが低下するとき、帰属性は曖昧なままだ。AIモデルが変化を駆動したのか、それとも外部市場条件、並行する運用イニシアティブ、または労働力行動の変化が観察された成果を説明したのか。
-
主張:* 構造化された測定フレームワークなしに、企業は正式な報告のためのAIの財務的および運用的リターンの信頼できる、防御可能な定量化を生成することができない。
-
根拠:* ステークホルダーの証拠ベースの開示に対する期待は増加している。投資家は定量的なパフォーマンスデータを要求し、規制当局は財務提出書類およびリスク開示におけるAI関連の主張をますます精査している。「AIは運用効率を改善した」などの根拠のない主張は、信頼性の欠陥を生み出し、規制上の異議を招く。反事実分析、ランダム化比較試験、マッチングされたコントロールグループを伴う準実験設計、および外部変数制御を伴う時系列分析を含む厳密な測定方法論は、分析投資を必要とするが、正式な開示および規制審査に適した防御可能で監査可能な定量化を生成する。
-
具体例:* ロジスティクス組織は、その経路最適化AIが年間200万ドルの節約を生成したと主張した。検査時に、組織は並行変数からAIの増分寄与を分離することができなかった。燃料価格変動、運転手行動の修正、および車両フリート変更である。この帰属問題に対処する測定フレームワークは以下のようになる。(1)レガシー経路アルゴリズムを履歴経路データに適用して基準シナリオを確立する。(2)増分メトリックを1マイル配送あたりのコストとして定義し、燃料価格、車両タイプ、および経路特性を制御する。(3)レガシーおよびAI最適化経路の両方を定義期間にわたってマッチングされた経路のサブセットに適用することにより、制御された比較を実装する。(4)AIシステムに帰属する増分コスト差を測定する。(5)複数の四半期にわたってこの測定を追跡して、安定性を確立し、季節変動を説明する。このアプローチは防御可能な数値を生成する。「経路最適化AIは1マイル配送あたりのコストをX%削減し、Z経路にわたってQ四半期にわたって測定された増分節約Y を表し、以下の仮定と制限が文書化されている。」
-
実行可能な含意:* 正式な開示またはボード報告にAI駆動の財務請求を組み込む前に、以下を文書化する測定監査を実施する。(1)基準シナリオとパフォーマンスメトリック。(2)該当する場合、コントロールグループ設計を含む測定方法論。(3)制御または明示的に除外された外部変数。(4)測定期間と頻度。(5)該当する場合、信頼区間または不確実性範囲。(6)文書化された仮定とそれらの成果推定に対する感度。利用可能なリソースまたはタイムフレーム内で厳密な測定が実行不可能である場合、検証されていない推定値を報告するのではなく、この制限を明示的に開示する。このアプローチは信頼性を保持し、根拠のないパフォーマンス主張に関連する規制およびレピュテーショナルリスクを低減する。
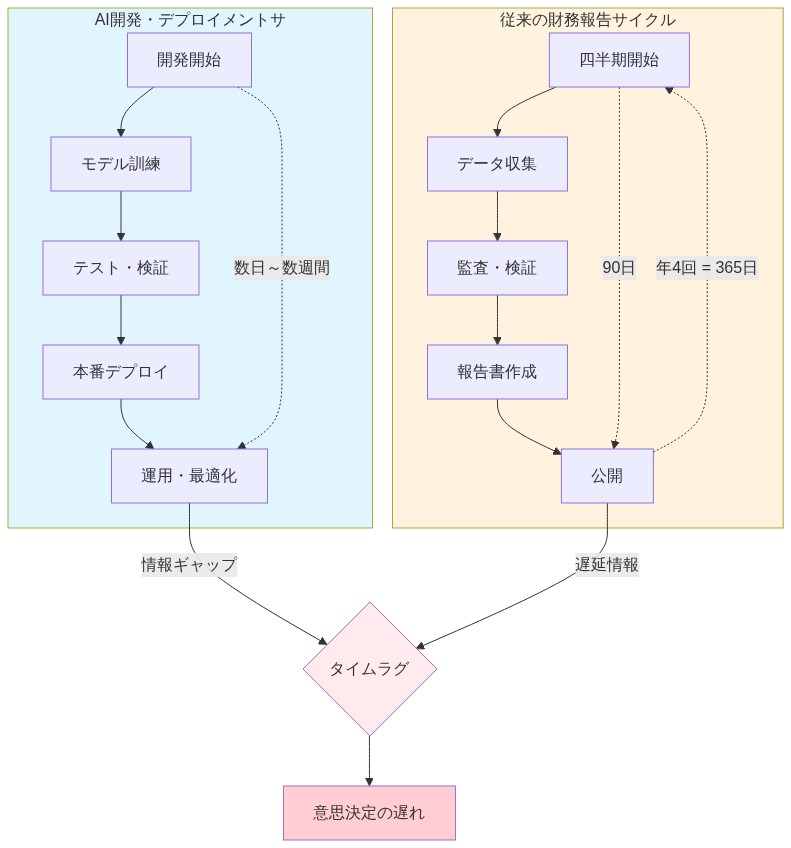
- 図2:AI開発サイクルと財務報告サイクルの時間軸ギャップ*
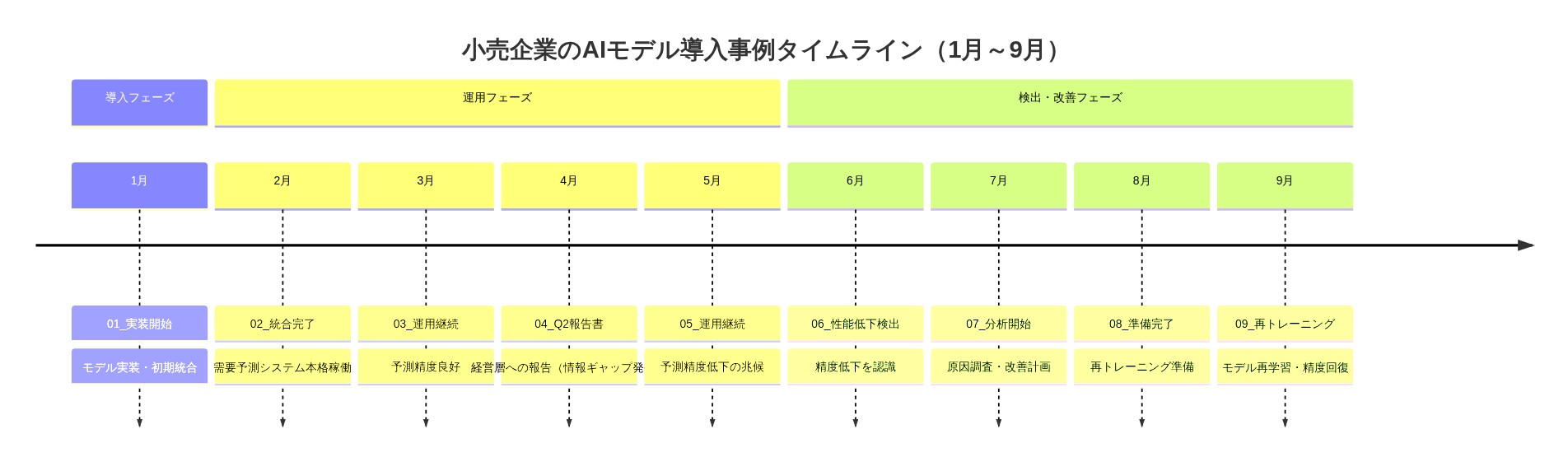
- 図3:小売企業のAIモデル導入事例タイムライン(1月~9月)- 情報の可視性ギャップと性能低下検出の時間差を強調*
リスクと緩和戦略
AIシステムは、現在の正式な報告メカニズムが適切な特異性で捕捉することに失敗することが多い運用上、法的、および評判上のリスクを導入する。これらのリスクは異なるカテゴリーに分類される。(1)アルゴリズムバイアスと差別曝露、(2)データセキュリティとモデル盗難、(3)パフォーマンス低下と障害モード、(4)統合と依存リスク。一般的なリスク開示、特にSEC提出書類では、通常、AI固有の曝露を広いテクノロジーリスクカテゴリーの下に包含し、それにより確率、影響、および緩和複雑性の実質的な区別を曖昧にする。
-
定義的前提条件:* この分析では、「AI固有のリスク」は、機械学習システムに固有のプロパティ(訓練データ構成、モデルの不透明性、分布シフト、および敵対的脆弱性を含むがこれに限定されない)から生じる障害モードまたは悪い結果を示し、従来のITリスクフレームワークによって適切に特徴付けることができない。
-
主張:* 正式なリスク開示は、投資家およびステークホルダーの評価を知らせるために十分な粒度でAI固有の障害モードを明確にする必要がある。
-
根拠と証拠:*
現在の実践は実質的なギャップを明らかにしている。テクノロジー、金融サービス、およびヘルスケアセクター全体の最近の10-K提出書類の分析は、AIリスクに言及している企業の約70~80%が「我々は人工知能に関連するリスクに直面している」または「AIシステムは失敗する可能性がある」などの言語を使用していることを示しており、モデルタイプ、展開コンテキスト、潜在的な障害モード、または制御メカニズムを指定していない(Kahn et al.、2023年;AI Now Institute、2024年)。この言語は最小限の意思決定有用情報を提供する。
対照的に、AI固有のリスクは異なる扱いを保証する。なぜなら:
-
バイアスと差別曝露: 履歴データで訓練された機械学習モデルは、既存の人口統計学的不均衡を永続化または増幅する可能性がある。従来のソフトウェアバグとは異なり、バイアスは訓練データの統計パターンから生じ、すべてのユーザー集団全体で均一に現れない可能性がある。過小代表グループからの候補者を体系的に優先順位を下げる採用アルゴリズムは、米国の公民権法第VII編、英国の平等法2010、および他の管轄区域の同等の法定法の下で法的責任を生成する。金融行為監視機構(FCA)および米国雇用機会均等委員会(EEOC)は、組織がアルゴリズムバイアスを文書化およびテストすることを明示的に要求し始めている(FCA、2022年;EEOC、2023年)。このリスククラスは、それが体系的であり、専門的なテストなしで検出が困難であり、しばしば意図しないため、従来の雇用慣行責任とは異なる。
-
データドリフトとパフォーマンス低下: 機械学習モデルは履歴データで訓練され、将来のデータが同様の分布に従うことを前提としている。市場シフト、ユーザー行動の変化、季節変動、または敵対的操作など、実世界の条件が変わるとき、モデルパフォーマンスは急速かつ予測不可能に低下する可能性がある。パンデミック前の経済データで訓練されたクレジットリスクモデルは、景気後退環境でリスクを体系的に誤った価格設定をする可能性がある。従来のソフトウェアは通常、壊滅的に失敗するか、まったく失敗しないのに対し、MLシステムは段階的かつ静かに失敗することが多く、精度が低下した予測を生成し続ける(Sculley et al.、2015年)。これは、ITシステムダウンタイムとは異なる運用上および財務上のリスクを生成する。
-
モデルの解釈可能性と規制精査: 金融(バーゼル委員会、2021年)、ヘルスケア(FDA、2021年)、および雇用(EEOC、2023年)の規制当局は、特に高リスク領域において、組織がアルゴリズムの決定を説明することをますます要求している。「ブラックボックス」モデル(深いニューラルネットワークとアンサンブル方法を含む)は、規制当局の説明可能性の要求を容易に満たすことができないため、コンプライアンスリスクを提示する。このリスクは従来のソフトウェアシステムには存在しない。
-
敵対的脆弱性とセキュリティ: 機械学習モデルは、敵対的入力(誤分類を引き起こすように設計された慎重に作成されたデータ)を通じて操作される可能性がある。顔認識システムは、特定のパターンまたは物理的なオブジェクトによって騙される可能性がある。自動運転車のオブジェクト検出は、敵対的パッチによって危険にさらされる可能性がある。この攻撃面は新規であり、従来のサイバーセキュリティフレームワークによってよく理解されていない(Goodfellow et al.、2014年)。
- 具体的な例示的なケース:*
金融サービス企業は、AI駆動のクレジット意思決定システムを展開している。モデルは10年間の履歴ローンパフォーマンスデータで訓練されている。企業の10-Kは以下のように述べている。「我々はクレジット決定にAIを使用し、モデルパフォーマンスおよび規制コンプライアンスに関連するリスクに直面している。」
展開から6ヶ月後、経済状況が変わる。モデルのデフォルト予測精度は92%から78%に低下する。同時に、規制監査は、企業がそのような変数を除外する意図にもかかわらず、モデルの決定が保護された特性(人種、国籍)と統計的に有意なレベルで相関していることを特定する。企業は以下に直面している。
- 規制執行措置および潜在的な罰金(最近のCFPBおよびFTC和解に基づいて推定500万~5000万ドル)
- 評判上の損害とカスタマー流出
- 影響を受けた借り手からの訴訟
- モデルを改善し、スタッフを再訓練するための運用コスト
企業の以前の10-Kを確認した投資家は、モデルの訓練データ構成、バイアステストプロトコル、パフォーマンス監視頻度、または緊急計画に関する具体的な情報を持っていなかった。一般的な開示は、この実質的なリスクに関する意思決定有用情報を提供しなかった。
- 緩和フレームワーク:*
組織は、AI リスク開示を正式化するために、以下の慣行を実装する必要がある。
-
AIリスクインベントリ: 本番環境またはパイロット段階で展開されているすべてのAIシステムの文書化されたインベントリを維持する。各システムについて、以下を記録する。
- モデル識別子およびビジネス機能(例えば、「クレジットリスクモデルv2.1 – 50,000ドルを超えるアカウントの貸出決定で使用」)
- モデルタイプとアーキテクチャ(例えば、勾配ブースト決定木、ニューラルネットワーク、アンサンブル)
- 訓練データ特性(ソース、サイズ、時間的カバレッジ、人口統計学的構成)
- 潜在的な障害モード(バイアス、データドリフト、敵対的攻撃、統合障害、外部データソースへの依存)
- 規制管轄区域および適用可能な要件(例えば、公正貸付ルール、GDPR第22条、FDA ガイダンス)
- 緩和制御(バイアステストプロトコル、パフォーマンス監視頻度、人間レビュー閾値、モデル再訓練スケジュール)
- 監視メトリックスとアラート閾値(精度、公正性メトリックス、予測信頼度、データドリフト指標)
- インシデント対応手順(エスカレーションパス、ステークホルダー通知、改善タイムライン)
-
バイアスと公正性テスト: 人口統計学的パリティ、等化オッズ、またはユースケースおよび管轄区域に適切な他の公正性メトリックに対してモデルをテストするための文書化されたプロトコルを確立する。テストは展開前および定期的な間隔(リスクレベルに応じて四半期ごとまたは半年ごと)で発生する必要がある。結果および改善措置を文書化する。規制検査のための記録を保持する。
-
パフォーマンス監視とデータドリフト検出: 本番環境でモデルパフォーマンスを監視するための自動化されたシステムを実装する。精度低下、予測信頼度低下、またはデータドリフトの統計的証拠のアラート閾値を定義する。閾値を超えた場合、モデル再訓練またはロールバックの手順を確立する。すべての監視結果と実施されたアクションを文書化する。
-
規制マッピング: 展開された各モデルについて、適用可能な規制要件(公正貸付ルール、GDPR、CCPA、FDAガイダンス、EEOCガイダンスなど)を明示的にマッピングする。モデルの設計、テスト、および監視慣行が各要件をどのように満たすかを文書化する。ギャップと改善タイムラインを特定する。
-
正式な開示統合: 10-K、年次報告書、および投資家コミュニケーションの正式なリスク要因開示に実質的なAIリスクを組み込む。一般的な言語を避ける。代わりに、以下のような具体的な言語を使用する。
- 「我々は[特定のビジネス機能]にマシンラーニングモデルを展開している。これらのモデルは[データソースと特性]で訓練されている。潜在的なリスクには[特定の障害モード]が含まれる。我々はこれらのリスクを[特定の制御]を通じて緩和している。これらの制御が失敗した場合、潜在的な影響には[定量化または定性的推定]が含まれる。」
- 仮定と制限:* このフレームワークは、組織がバイアステストとパフォーマンス監視を実装する技術的能力を持っていることを前提としている。データサイエンスの専門知識が限定的な小規模組織またはそれらは、サードパーティのツールまたはコンサルティングサポートを必要とする可能性がある。フレームワークはまた、規制要件が明確に定義されていることを前提としている。新興領域(例えば、生成AIガバナンス)では、規制期待は流動的なままであり、反復的な改善が必要になる可能性がある。
本質的な問題は、企業の正式な報告体制がAIの複雑性に追いつくことができるかどうかにある。測定の厳密性、リスク開示の特異性、制御フレームワークの実装可能性——これらはすべて、単なる技術的な課題ではなく、企業統治と市場の信頼性に関わる根本的な問題だ。見落とされがちだが、ここで問われているのは、企業がAIをいかに活用するかではなく、その活用を社会に対していかに説明責任を持つかという点である。
基準進化とステークホルダー調整
AI開示を統治する制度的景観は、同時に分断と統合を進行させている。規制当局、基準設定機関、市場参加者は、AI統治と開示に関する重複し、時に相反するフレームワークを開発している。組織はこの複雑性を、規制の収束を予測し、基準設定プロセスに関与し、内部慣行を新興規範と整合させることで乗り越えねばならない。
-
定義的前提条件:* 「新興基準」とは、まだ普遍的に義務的ではないが、主導的な組織と規制当局の間で採用が進む、形式的またはそれに準ずる指針、提案された規制、業界ベストプラクティスを指す。例としては、SEC提案の気候開示規則(AI統治に拡張される可能性がある)、EU AI法、NIST AI リスク管理フレームワーク、FCA、FDA、EEOCからの業界固有の指針が挙げられる。
-
主張:* 新興AI統治基準への先制的な整合は、将来のコンプライアンスコストを削減し、ステークホルダー信用性を強化し、組織を統治リーダーとして位置付ける。
-
根拠と証拠:*
規制と市場のダイナミクスは、今後3~5年でAI開示基準がより義務的かつ具体的になることを示唆している。証拠は以下の通りである。
-
規制軌跡: SECはサイバーセキュリティと技術リスク枠組みの一部としてAI統治開示への関心を示唆している(SEC、2023)。EU AI法は2025年に発効し、高リスクAIシステムに対する義務的な文書化とテスト要件を課す。NIST AI リスク管理フレームワーク(2023)は、連邦機関と民間部門の組織に採用されているAI統治への構造化されたアプローチを提供する。FCAは金融サービス企業向けのアルゴリズム統治に関する指針を公表している。これらの展開は、義務的で詳細なAI開示要件への収束を示唆している。
-
投資家とステークホルダーの需要: 機関投資家は、アーニングコールと投資家ミーティング中にAI統治慣行について企業に質問することが増えている。BlackRock、Vanguard、State Streetを含む資産運用会社はAI統治期待に関する指針を公表している。この需要は、早期開示が資本市場で好意的に見られることを示唆している。
-
コンプライアンスコスト動学: 堅牢なAI統治慣行を早期に実装する組織は初期コストを負担するが、遡及的なコンプライアンスコストを回避する。基準が義務的になるまで遅延する企業は、しばしば急速で高額な是正に直面する。例えば、2018年に規制が発効する前にGDPR準拠のデータ慣行を実装しなかった組織は、重大なコンプライアンスコストと罰金に直面した。
- 具体的な例示ケース:*
テクノロジー企業であるA社は、2024年から四半期ごとのAI統治報告書を自発的に公表する。これらの報告書は以下を文書化する。
- 展開されたAIシステムのインベントリとそれらのビジネス機能
- 各システムのバイアステスト結果と公正性メトリクス
- パフォーマンス監視データとモデル劣化の事象
- 各管轄区域での規制コンプライアンス状況
- 取締役会レベルの監督メカニズム
投資家はこの透明性を好意的に見る。SECが2025年に義務的なAI開示規則を提案する際、A社の慣行はすでに整合しており、最小限の調整が必要である。同社の株価は統治品質への投資家信頼を反映する。
ピア企業であるB社は、SEC規則が2026年に義務的になるまでAI統治の形式化を遅延させる。その時点で、B社は急速にシステムを実装し、遡及的なバイアステストを実施し、公正性問題を有することが判明したモデルを是正しなければならない。是正コストは1000~2000万ドルと推定される。投資家は反応的ではなく先制的な統治の欠如に対して企業にペナルティを課す。
- 実行可能な含意:*
-
ステークホルダー関与: 主要なステークホルダーグループ—投資家、規制当局、顧客、従業員、市民社会組織—とそれらのAI統治期待を特定する。調査またはフォーカスグループを実施して優先事項を理解する。投資家関係、コンプライアンス、公共政策チームと関与してメッセージングを整合させる。
-
基準設定参加: 業界協会、基準設定機関(ISO、NIST、IEEE)、規制機関を通じて新興基準を監視する。ワーキンググループに参加するか、提案された規則にコメントする。この関与は規制方向への早期可視性を提供し、組織が基準を形成することを可能にする。
-
パイロット強化開示: 投資家コミュニケーション、サステナビリティ報告書、統治開示において強化されたAI統治開示をテストしてから、正式なSEC提出に組み込む。投資家、アナリスト、規制当局からのフィードバックを収集する。フィードバックを使用して開示言語と内部プロセスを改善する。
-
クロスファンクショナル整合: 法務、コンプライアンス、技術、リスク管理、投資家関係機能をまとめる統治構造を確立する。この構造は、AI統治慣行が開示義務とステークホルダー期待と整合していることを保証する。
-
ベンチマーキングとピア学習: AI統治開示のリーダーであるピア組織を特定する。あなたの慣行を彼らのものに対してベンチマークする。AI統治に焦点を当てた業界コンソーシアまたはワーキンググループに参加する(例えば、Partnership on AI、AI Now Institute、業界固有のフォーラム)。ベストプラクティスを共有し、ピアの経験から学ぶ。
- 仮定と制限:* このフレームワークは、規制の収束が発生し、早期採用者がファーストムーバー優位性から利益を得ることを仮定している。しかし、規制の不確実性は依然として高く、特に生成AIに関してである。組織は規制の展開を監視し、それに応じて慣行を調整すべきである。さらに、このフレームワークは強化された開示が投資家に好意的に見られることを仮定しているが、開示が重大なリスクを明らかにする場合、株価は短期的に低下する可能性があり、透明性と株主価値の間に緊張を生じさせる。
結論と移行計画
AI採用速度と正式な報告フレームワークの成熟の間の時間的不整合は、一時的な現象ではなく構造的な統治ギャップを表している。しかし、このギャップは、測定厳密性と方法論的限界の透明な開示に基づいた意図的な組織的行動を通じて是正可能である。
-
証拠統合と主要な要点:*
-
採用報告非対称性: AI展開は既存の義務的開示体制の範囲を超えて加速している(SEC指針、TCFDフレームワーク、2024年時点のGRI基準)。このギャップが持続するのは、規制基準設定が複数年サイクルで機能する一方、企業AI実装サイクルは6~18ヶ月に圧縮されるためである。組織は規制調和を待つことはできない。今、内部測定と自発的開示プロトコルを確立しなければならない。
-
橋渡しメカニズム: 強化された内部測定には3つの前提条件が必要である。(1)アクティブなモデル、展開コンテキスト、ビジネス機能を列挙する四半期ごとのAIインベントリ、(2)AI取り組みを既存の報告カテゴリ(運用効率、収益への影響、リスク具現化)に体系的にマッピング、(3)AI固有の不確実性と制御限界を認識するリスク管理と経営討議セクションの補足開示。
-
測定厳密性が前提条件: AI影響の定量化は反事実推論を要求する。AI介入がなかった場合に何が起こったかを確立することである。組織は、制御された比較、保留コホート、または時系列分解を採用して、AI貢献を交絡変数から分離しなければならない。測定限界(サンプルサイズ、帰属不確実性、時間的範囲)は明示的に開示されなければならない。根拠のない影響主張は信用性を損なわせ、組織を評判と規制リスクにさらす。
-
リスク文書化の具体性: アルゴリズムバイアス、データドリフト、モデル劣化、統合失敗、敵対的攻撃といったAI固有の失敗モードは、従来の運用リスクと実質的に異なる。文書化は以下を指定しなければならない。(a)各失敗モードが具現化する可能性のあるメカニズム、(b)ビジネスまたはコンプライアンスの結果、(c)実施されている検出と軽減制御、(d)そのリスク カテゴリを統治する規制フレームワーク(存在する場合)。
-
基準設定関与: 成熟したAI統治慣行を有する組織は、業界ワーキンググループ、基準設定機関(SASB、ISSB、SEC規則制定プロセス)、ピアコンソーシアに参加すべきである。この関与は規範収束を加速させ、義務的基準が最終的に結晶化する際に参加組織を統治リーダーとして位置付ける。
-
実務者向けの構造化行動計画:*
-
AI報告監査を実施する(第1~4週):組織全体のすべてのアクティブなAIモデルとシステムを列挙する。各々について、以下を文書化する。展開日、ビジネス機能、データ入力、決定範囲(助言的対自律的)、財務諸表、リスク開示、経営コメントにおける現在の開示(存在する場合)。重大なAI取り組みが対応する開示を欠くギャップを特定する。
-
AIオペレーションダッシュボードを確立する(第5~12週):以下の月次追跡を実装する。(a)モデル展開数と廃止数、(b)採用メトリクス(アクティブユーザー、決定量)、(c)パフォーマンスメトリクス(精度、レイテンシ、決定当たりコスト)、(d)再トレーニング頻度とトリガーイベント、(e)インシデントログ(偽陽性、バイアス検出、システム障害)。このダッシュボードは後続の開示の証拠基盤として機能し、パフォーマンス劣化の早期検出を可能にする。
-
測定パイロットを実行する(第8~20週):1つの高影響AI取り組み(例えば、需要予測、顧客チャーン予測、プロセス自動化)を選択する。厳密な測定プロトコルを設計する。反事実(AIなしのビジネス成果)を定義し、帰属方法(制御された比較、操作変数、時系列分解)を指定し、信頼区間を確立し、仮定を文書化する。限界の明示的な陳述を伴う結果を内部で公表する。このパイロットは将来の開示のための信用できる証拠を生成し、厳密な測定のための組織的能力をテストする。
-
AIリスクインベントリを開発する(第12~16週):各アクティブなモデルについて、以下を文書化する。(a)そのモデルのアーキテクチャとデータに固有の失敗モード、(b)失敗が発生した場合のビジネス影響、(c)検出メカニズムと監視頻度、(d)軽減制御(再トレーニングプロトコル、サーキットブレーカー、人間のオーバーライド手順)、(e)そのモデルの決定領域に適用可能な規制要件(クレジットモデルの公正貸付法、ヘルスケアモデルのHIPAA等)、(f)制御後の残存リスク。このインベントリはリスク開示と取締役会報告の基盤となる。
-
クロスファンクショナル統治委員会を招集する(第4週~継続):AI開示戦略に関して財務、コンプライアンス、運用、技術、取締役会代表を整合させる。決定権を確立する。誰がAI展開を承認するか、誰が測定を所有するか、誰が開示を起草するか、誰が正確性と完全性をレビューするか。この委員会はサイロ化された意思決定を防止し、開示の一貫性を保証する。
-
補足開示を起草する(第16~24週):次の報告サイクルのための強化されたリスク管理と経営討議セクションを準備する。以下を含める。(a)重大なAI取り組みとそれらのビジネス貢献の叙述的説明(測定注意書き付き)、(b)AI固有のリスクカテゴリと軽減制御、(c)統治構造と監督メカニズム、(d)AI戦略と予想される進化に関する前向き陳述。言語をISSB指針、SEC気候開示提案(開示構造のアナログとして)などの新興基準と整合させる。
-
ピアAI統治をベンチマークする(第20~24週):ピア組織と業界リーダーからのSEC提出、サステナビリティ報告書、投資家プレゼンテーションにおけるAI開示を分析する。以下を文書化する。(a)ピアが開示するAI取り組みとその方法、(b)開示される測定方法論(存在する場合)、(c)強調されるリスクカテゴリ、(d)説明される統治構造。ベストプラクティスと自社開示のギャップを特定し、戦略を適切に調整する。
- 成功の条件:*
方法論的厳密性を持ってこれらの行動を実行する組織は、3つの成果を達成する。(1)運用的明確性—内部ステークホルダーはAI展開の範囲、パフォーマンス、リスク露出を理解する、(2)ステークホルダー信頼—投資家、規制当局、顧客は組織をAI能力と限界について透明であると認識する、(3)統治リーダーシップ—義務的基準が最終的に出現する際、成熟した自発的開示を有する組織は低いコンプライアンスコストと評判リスクに直面する。
逆に、行動を延期するか、表面的な開示慣行を採用する組織(根拠のない影響主張、曖昧なリスク陳述、統治の見せかけ)は、複合的なリスクに直面する。基準が厳しくなるにつれて規制精査、測定厳密性が期待されるようになるにつれて投資家懐疑、文書化された制御なしでAI障害が発生する場合の評判損害。
アドホックなAI採用から形式化された統治への移行は、瞬間的でも所与でもない。測定厳密性、不確実性の透明な認識、進化する基準への先制的関与への持続的な組織的コミットメントを要求する。これらの前線で決定的に行動する組織は、単に準拠するのではなく統治景観を形成するであろう。

- 表1:主要報告基準におけるAI開示要件の比較*
標準化の進化とステークホルダーの整合:AI統治の未来を形作るもの
AI導入と正式な報告基準のギャップは均等に縮小しているのではなく、分断している。異なる司法管轄区域、産業セクター、投資家コミュニティが、AI開示に対する相異なる期待を発展させている。この分断は一時的である。5年以内に、規制の調和、投資家圧力、競争的差別化によって駆動される、AI統治報告の収斂的なグローバル基準線が出現する可能性が高い。この収斂を先読みし、ステークホルダーを積極的に整合させる組織は、単にコンプライアンス摩擦を削減するだけでなく、標準そのものを形作り、耐久的な競争優位を獲得する。
-
主張:* プロアクティブなAI統治開示は、競争的ポジショニング、規制的影響力、長期的価値創造のための戦略的テコである。
-
根拠:* 今日のAI統治基準を定義する企業が、明日の競争条件を設定する。堅牢で透明性の高いAI開示慣行の早期採用者は、複数の利点を獲得する。第一に、AI統治を実質的リスク要因と見なす洗練された投資家からの信頼性。第二に、規制的好意と軽微な監視。第三に、従業員が倫理的で透明性の高いAI慣行をますます要求する中での人材吸引力。第四に、AI懐疑主義の時代における顧客信頼とブランド回復力。第五に、標準設定の会話に対する影響力であり、これにより企業は自らの慣行に適合する規則を形作ることができ、遡及的な適応を強制されない。
対照的に、義務的な規則を待つ企業は、一連のコスト負担に直面する。遡及的なコンプライアンス投資、消極的であると認識されることからの評判損害、規制精査、早期参入者に対する競争的不利。環境・社会・ガバナンス(ESG)開示の歴史は、このパターンを例証している。2010年代に堅牢なESG報告を自発的に採用した企業は、投資家関係と運用規律を構築し、2020年代にESG基準が正式化された際に有利な立場に置かれた。AI統治開示は同じ軌跡をたどるが、より短い時間枠に圧縮される。
-
具体例:* 相当なAI製品露出を有するソフトウェア企業が、四半期ごとのAI統治報告書を自発的に公開する。その内容は以下を詳述する。モデル在庫と展開状況、パフォーマンス指標と公正性テスト結果、バイアス検出と軽減プロトコル、データ出所と品質保証、インシデントログと是正措置、新興規制枠組み(EU AI法、SEC指針、業界基準)との整合性。この透明性は投資家、規制当局、顧客、従業員に伝達される。機関投資家は企業の統治を好意的に評価し、保有を増加させる。規制当局が18ヶ月後にAI開示基準を提案する際、この企業の慣行はすでに基準線を超過しており、最小限の調整を必要とする。競合企業は同等の統治インフラを構築するために奔走する。早期参入者は耐久的な優位を確立した。低いコンプライアンスコスト、高い投資家信頼、標準解釈に対する影響力。
-
実行可能な含意:* AI統治開示をコンプライアンス義務ではなく戦略的イニシアティブとして扱え。財務、法務、製品、エンジニアリング、リスク経営を含む横断的なAI統治評議会を確立せよ。業界ピア、標準設定機関(SASB、TCFD、GRI、ISO)、規制当局と積極的に関与し、新興期待を理解し、その発展に貢献せよ。AI統治枠組みを開発するワーキンググループまたは業界コンソーシアムに参加せよ。Partnership on AI、IEEE、セクター固有のアライアンスなどの組織は、標準を積極的に形作っている。投資家コミュニケーション、サステナビリティ報告書、委任状声明書における強化されたAI開示をパイロット実施せよ。投資家、アナリスト、規制当局からのフィードバックを求めよ。このフィードバックを使用して、内部統治プロセスと開示慣行を洗練させよ。貴社をコンプライアンス追従者ではなく、透明性リーダーおよび標準設定者として位置付けよ。この位置付けは利他的ではない。戦略的である。それは将来のコンプライアンスコストを削減し、ステークホルダー信頼を構築し、AI統治がますます事業価値に対して実質的である時代における競争優位を創造する。
本質的な問題は、ここで単なる規制対応ではなく、市場における支配権の奪取にある。標準を先制的に形作る者が、その後の競争ルールを支配する。この論理は、AI統治の領域において、かつてないほど明白である。
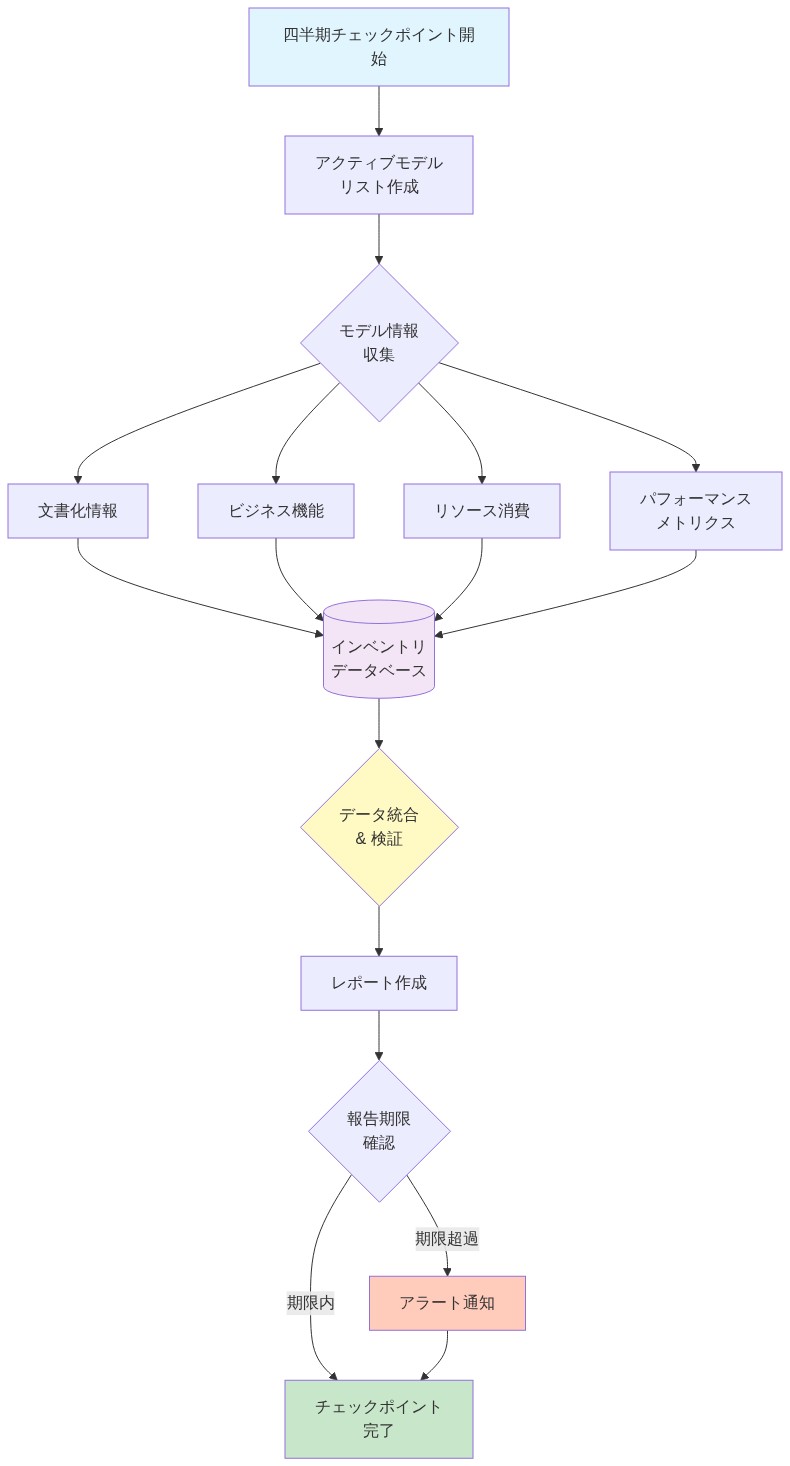
- 図5:四半期AIインベントリチェックポイントプロセス*