
iPaaSによるAIシステムの統合
反応的技術選択の遺産:制約から触媒へ
数十年にわたって、企業は技術スタックを反応的に構築してきた。危機が生じるたびに新しいツールが導入され、市場の変化のたびに別のプラットフォームが追加された。財務部門はあるシステムを採用し、マーケティング部門は別のシステムを、オペレーション部門はさらに別のシステムを導入した。いま認識されつつあるのは、この断片化が単なる技術的問題ではなく、インテリジェンスのための設計を見落とした機会だったということである。
今日の再解釈はこうだ。それらのサイロは組織的知識を内包している。各システムはドメイン専門知識、意思決定ロジック、歴史的パターンを保有している。今後の競争を制するのは、この知識を解放し、AIを通じて統合できる組織である。
-
*データ準備のボトルネックは先行指標である。データサイエンティストは現在、モデル開発ではなくデータ準備に時間の60~80%を費やしている。理由は情報が異なるスキーマ、ガバナンスルール、アクセス制御を持つ断片化されたデータベースに分散しているからだ。これは永続的な制約ではなく、組織が反応的な統合からプロアクティブなデータ統合**への移行準備ができていることを示す信号である。この問題を最初に解決する企業が、次の10年の競争優位を手にする。
-
*具体例。小売企業は需要予測をあるシステムで、在庫管理を別のシステムで、サプライヤー調整をさらに別のシステムで運用していた。株式レベル最適化のためのAIモデルを構築しようとしたとき、彼らは発見した。システム間でタイムスタンプが数時間ずれており、商品識別子が一致せず、コストデータの唯一の信頼できる情報源が存在しなかったのだ。これを失敗と見なすのではなく、彼らは統合の可能性の発見**として認識した。統合後、AIモデルはリアルタイムの需要シグナル、在庫ポジション、サプライヤーのリードタイムを同時に考慮できるようになった。その結果、在庫回転率が18%改善され、年間運転資本が420万ドル削減された。
-
*実行可能な含意。**システムの拡散を潜在的な組織的知識として再解釈すること。それは解放を待つインテリジェンスである。最優先のAIユースケースに対して重要なデータを保有するシステムを監査する。現在、手動プロセスやカスタムスクリプトに存在するデータ依存関係と変換ルールを特定する。このインベントリは修復のためのベースラインではなく、戦略的統合のためのベースラインになる。最も苦しい問題ではなく、最も野心的なAI目標の周辺で統合を優先すること。
レガシーシステムの反応的進化
エンタープライズ技術スタックは歴史的に反応的な意思決定を通じて進化してきた。各オペレーショナルな危機が新しいツールの導入を促し、各市場シフトが追加プラットフォームの展開をもたらした。このパターンは機能的なサイロをもたらした。財務、マーケティング、オペレーション部門は、それぞれ互換性のないデータスキーマ、ガバナンスフレームワーク、アクセス制御メカニズムを持つ異なるシステムを運用している。人工知能が競争上の必須要件として出現したとき、組織は発見した。AIモデル開発がこれらの互換性のないシステム間のデータ断片化によって制約されていることを。
-
*根本的メカニズム。**反応的な技術採用は、エンタープライズ全体のデータ一貫性を無視しながら即座のオペレーショナルニーズに最適化することで、技術的負債を生成する。データエンジニアリングの研究は、データサイエンティストがプロジェクト時間の60~80%をモデル開発ではなくデータ準備とクリーニングに費やしていることを示している(Kaggle State of Data Science Survey、2023)。この不均衡は、一貫性のないスキーマ、競合するガバナンスポリシー、異なるアクセス制御実装を持つ断片化されたデータソースに直接起因する。
-
*事例。**小売組織は需要予測、在庫管理、サプライヤー調整を3つの異なるシステムで運用していた。株式レベル最適化のためのAIモデルを開発しようとしたとき、チームは重大なデータ品質問題を特定した。システム間でタイムスタンプが数時間ずれており、商品識別子が標準化されておらず、コストデータに信頼できる情報源がなかった。これらの統合障壁はプロジェクト開始を6ヶ月遅延させた。その間、価値実現時間はゼロだった。
-
*オペレーショナルな含意。**現在のシステム断片化はAI採用速度とモデルパフォーマンスに対するビジネス制約として機能する。最優先のAIユースケースに重要なデータを含むシステムを特定する構造化監査を実施すること。既存のデータ依存関係と変換ロジックを文書化すること。手動プロセス、カスタムスクリプト、文書化されていないワークフローのいずれで実装されているかは問わない。このインベントリは統合計画とROIモデリングのベースラインを確立する。
クラウド採用とコストのパラドックス
クラウドインフラストラクチャ採用は、ユニットあたりのコンピュート費用を削減する一方で、クラウド環境でサイロ化されたアーキテクチャをしばしば複製した。組織は各アプリケーション用に独立したクラウドインスタンスを展開した。各インスタンスは独立したデータベース、認証層、監視インフラストラクチャを備えていた。結果は、インフラストラクチャ資本支出の削減だが、統合複雑性とオペレーショナルオーバーヘッドの増加である。
-
*根本的メカニズム。**クラウドの弾力性は容量制約に対処したが、アーキテクチャ断片化には対処しなかった。独立したチームスケーリングはシステム分離を強化した。統合は手動で、高コストで、エラーが多かった。隠れたコスト(冗長なデータウェアハウス、重複するETLパイプライン、並列アイデンティティ管理システム)はしばしば、インフラストラクチャ支出削減による節約を上回った。
-
*事例。**金融サービス組織は、コア台帳システム、顧客関係管理プラットフォーム、リスク分析アプリケーションを独立してクラウドインフラストラクチャに移行した。各チームは部門別コスト指標に最適化した。移行後の分析は、冗長なデータウェアハウス、重複するETLパイプライン、複数のアイデンティティ管理システムの集計支出が、ユニットあたりのコスト削減にもかかわらず、クラウド前の支出を18%上回ったことを明らかにした。
-
*オペレーショナルな含意。**個別アプリケーションではなく、統合パターンによってクラウド支出を評価すること。システム間のデータ移動、並列データストア、冗長インフラストラクチャに関連するコストを特定する。これらのコストは部門予算では見えないことが多いが、直接的なオペレーショナル無駄を表している。iPaaS統合は通常、18ヶ月以内にこれらの隠れたコストを30~50%削減する。Gartnerの iPaaS Magic Quadrant(2024)の実装事例に基づく。
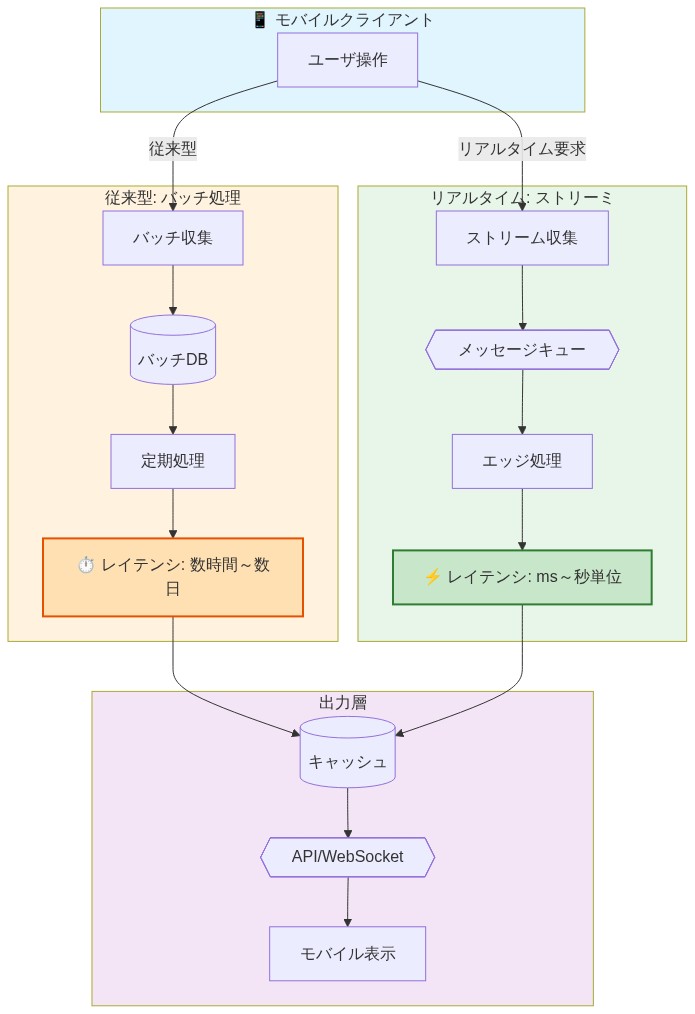
- 図6:モバイルファースト時代のリアルタイムデータ要求アーキテクチャ(従来型バッチ処理 vs ストリーミング処理の比較)*
モバイルファースト思考とリアルタイムデータ需要
モバイルチャネルへの顧客行動のシフトは、ユーザーの応答性への期待とバッチ処理向けに設計されたバックエンドシステムの間にミスマッチを生み出した。モバイルアプリケーションは1秒未満の応答時間を必要としたが、データ可用性は夜間のETLジョブスケジュールによって制約されていた。AIシステムはこのアーキテクチャ上の制限を継承した。古いデータで訓練され、バッチ推論を通じて展開されるモデルは、リアルタイムイベントに応答したり、低遅延の意思決定をサポートしたりできない。
-
*根本的メカニズム。**モバイル採用はシステム応答性に関するユーザー期待を変換した。現代の顧客はパーソナライゼーション、不正検出、推奨事項がミリ秒以内に実行されることを期待する。レガシーなバッチ指向アーキテクチャはこの要件を満たすことができない。日次でリフレッシュされたデータで訓練されたAIモデルは、古い特徴セットを通じて遅延問題を複合化する。
-
*事例。**eコマースプラットフォームは日次データリフレッシュで訓練された推奨AIを展開した。モバイルユーザーは古い提案を受け取り、カート放棄の問題を経験し、検索結果の関連性が低かった。リアルタイムデータパイプラインを実装する競合他社は15%高いコンバージョン率を達成した。組織はその後、データアーキテクチャをイベントストリーミングの周辺に再構築し、推奨遅延を数時間から数秒に削減し、コンバージョン指標を12%改善した。
-
*オペレーショナルな含意。**AIユースケースの遅延要件を監査すること。意思決定を分類する。リアルタイム(1秒未満の応答が必要)、ニアリアルタイム(秒から分)、またはバッチ許容(時間で許容可能)。リアルタイムユースケースはイベント駆動機能を備えたiPaaSプラットフォームを必要とする(Apache Kafka、Azure Event Hubs、ストリーミング統合)。バッチ許容ユースケースはより大きな柔軟性を許可するが、日次リフレッシュサイクルは時代遅れのベースラインを表している。時間単位のデータ同期を競争ポジショニングの最小標準として確立すること。
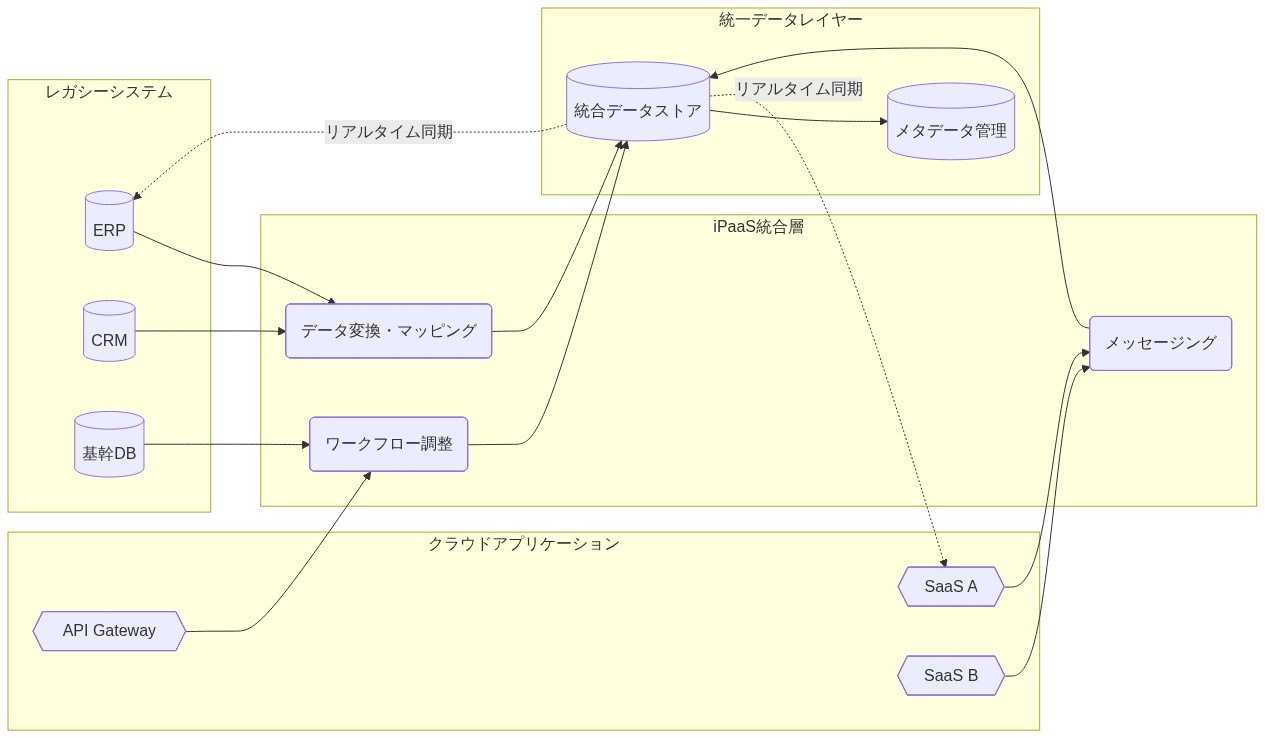
- 図8:iPaaSを中心とした統合アーキテクチャ(段階的統合パターン)*
実装とオペレーションパターン
成功した統合は段階的なアプローチに従う。まずデータバックボーンを確立し、その後アプリケーションを段階的に移行する。この方法論はリスクを削減し、エンタープライズ全体の展開前に統合パターンの検証を可能にする。
-
*根本的メカニズム。**モノリシック移行は複雑性、相互依存性、限定的なロールバックオプションのため高い失敗率を示す。段階的なアプローチはパターン検証、チーム能力開発、壊滅的なビジネス影響なしでの方針修正を可能にする。iPaaSプラットフォームは事前構築されたコネクタ、変換テンプレート、ステージング環境を通じてこのアプローチを促進する。
-
*事例。**製造組織はiPaaSを使用して3つのエンタープライズリソースプランニングシステムを統合した。同時移行ではなく、チームはベンダーマスターデータを優先した。低リスク、高インパクトのデータセットである。2週間以内に、サプライヤー情報の唯一の信頼できる情報源が運用可能になった。後続フェーズは在庫データ(4週間)と財務トランザクション(6週間)に対処した。総統合時間は18週間対予想12ヶ月。
-
*オペレーショナルな含意。**ターゲットデータボリュームと統合頻度要件をサポートするiPaaSプラットフォームを選択すること。エンタープライズ展開前に代表的なデータセットでパイロットテストを実施する。明示的なデータ品質ガバナンスを確立する。これは技術実装の詳細ではなく、ビジネス上の決定である。本番展開前にデータ鮮度と精度のサービスレベルアグリーメントを定義する。専任の統合チームリソースを割り当てる。アプリケーション開発チームは機能開発と並行して統合責任を効果的に管理することはできない。
測定と次のアクション
統合の成功は、洞察までの時間短縮、モデルトレーニングの高速化、統合コストの低下、データ精度の向上を通じて測定可能である。実装前後でこれらの指標を追跡する。
指標がなければ、統合はコストセンターではなく能力実現者になる。定量化された利益は継続的な投資を正当化し、優先順位付けの決定を導く。
医療機関は統合前の統合コストを年間210万ドルで測定した(スタッフ、ツール、データ品質修正を含む)。iPaaS展開後、これは140万ドルに低下した。同時に、臨床AIモデルの精度は8%改善された。データ品質が改善され、モデル再トレーニング頻度が四半期ごとから月次に増加したからである。
- *アクション。**ベースライン指標を今定義する。現在の統合コスト、データ鮮度、データリクエストから利用可能性までの時間、AIモデルパフォーマンス。iPaaS展開後、四半期ごとに再測定する。結果をステークホルダーと共有する。これらの指標を使用して、追加システムとデータソースへの拡張を正当化する。
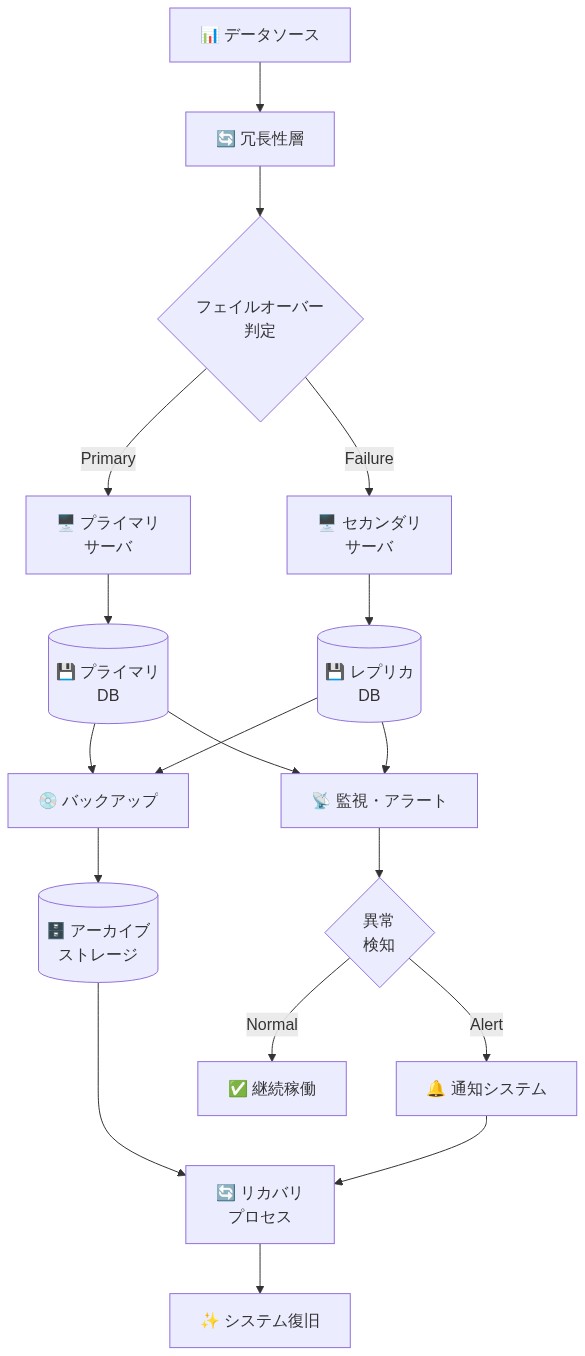
- 図11:レジリエント・データアーキテクチャの設計パターン(冗長性・フェイルオーバー・監視・バックアップ・リカバリ戦略の統合)*
リスクと軽減戦略
統合は新しいリスクをもたらす。ベンダーロックイン、データガバナンスの複雑性、単一プラットフォームへのオペレーショナル依存。これらは意図的に軽減される必要がある。
iPaaSプラットフォームは強力だが、集中化リスクを生み出す。プラットフォームが失敗するか不適切になれば、データフロー全体が影響を受ける。共有データは共有責任を生み出すため、ガバナンスは明示的である必要がある。
- *アクション。**終了条項を含む複数年契約を交渉する。iPaaSベンダーが標準データ形式とエクスポート用APIをサポートすることを要求する。財務、コンプライアンス、オペレーションの代表者を含むデータガバナンス評議会を確立する。ITだけではない。すべての変換ルールとデータ系統を文書化する。データ品質とアクセスログの四半期監査を実施する。iPaaSプラットフォーム障害シナリオを含む災害復旧計画を維持する。
AIの基盤としての統合
規模でのAI採用は統合された、信頼できるデータを必要とする。iPaaSはこの能力を可能にするオペレーショナルバックボーンである。前進の道は明確である。現在のシステムランドスケープを監査し、最高価値のAIユースケースを特定し、低リスクデータでiPaaSをパイロットし、結果を測定し、体系的に拡張する。
- *次のステップ。**今後1ヶ月以内にデータ、AI、オペレーションリーダーとの統合ワークショップをスケジュールする。現在のシステムとデータフローをマップする。統合されリアルタイムであれば重大なビジネス価値をアンロックする3つのパイロットデータセットを特定する。特定の要件に対してiPaaSプラットフォームを評価する。90日以内にパイロット実装を開始する。12ヶ月以内に重要なデータの60%を統合し、24ヶ月以内に完全統合するターゲットを設定する。
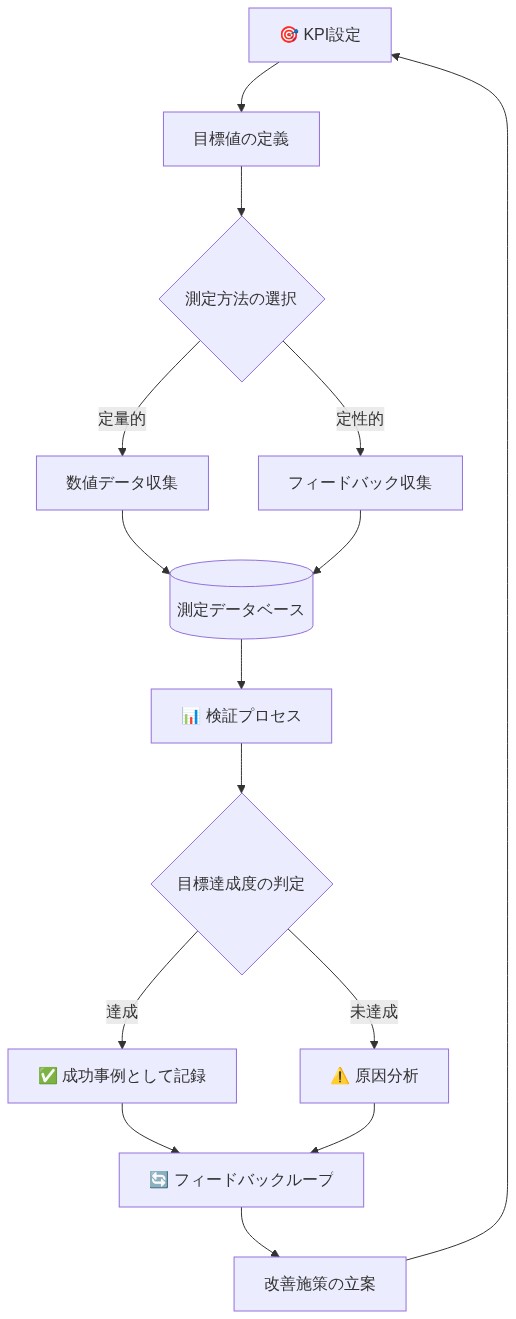
- 図14:成果検証フレームワークと測定プロセス*
測定とアウトカム検証
統合の成功は特定の指標を通じて定量化可能である。洞察までの時間短縮、モデルトレーニング加速、統合コスト削減、データ精度改善。実装前にベースライン測定を確立し、展開後四半期ごとに追跡する。
-
*根本的メカニズム。**定量化された指標がなければ、統合はコストセンターではなく能力実現者として機能する。測定可能なアウトカムは継続的な投資を正当化し、優先順位付けの決定を導き、ステークホルダーコミュニケーションを可能にする。
-
*事例。**医療機関は統合前の統合コストを年間210万ドルで測定した(人員、ツール、データ品質修復を含む)。iPaaS展開後、コストは140万ドルに低下した。同時に、臨床AIモデルの精度は8%改善された。強化されたデータ品質とモデル再トレーニング頻度の増加(四半期ごとから月次)による。
-
*オペレーショナルな含意。**ベースライン指標を即座に確立する。現在の統合コスト(隠れた支出を含む)、データ鮮度間隔、データリクエストから利用可能性までの時間、AIモデルパフォーマンス指標。展開後四半期ごとに再測定する。結果をステークホルダーに伝える。検証された指標を使用して、追加システムとデータソースへの拡張を正当化する。
リスク管理と軽減
統合は意図的な軽減を必要とする特定のリスクをもたらす。ベンダーロックイン、データガバナンスの複雑性、集中化プラットフォームへのオペレーショナル依存。
-
*根本的メカニズム。**iPaaSプラットフォームは集中化リスクを生み出す。プラットフォーム障害または不適切性はデータフロー全体に影響する。共有データは共有責任を生み出し、明示的なガバナンス構造と説明責任メカニズムを必要とする。
-
*軽減戦略。**定義された終了条項とデータポータビリティ要件を含む複数年契約を交渉する。ベンダーにデータエクスポートを可能にする標準データ形式とAPIのサポートを要求する。財務、コンプライアンス、オペレーション、ITの代表者を含むデータガバナンス評議会を確立する。ITのみではない。すべての変換ルールとデータ系統を体系的に文書化する。データ品質とアクセスログの四半期監査を実施する。iPaaSプラットフォーム障害シナリオに対処する災害復旧手順を維持する。
AI能力の基盤としての統合
組織規模でのAI採用は統合された、信頼できるデータインフラストラクチャを必要とする。iPaaSはこの要件を可能にするオペレーショナルバックボーンとして機能する。実装経路は定義されている。現在のシステムランドスケープを監査し、最高価値のAIユースケースを特定し、低リスクデータでiPaaSをパイロットし、アウトカムを測定し、体系的に拡張する。
- *オペレーショナルな含意。**30日以内にデータ、AI、オペレーションリーダーシップとの統合計画ワークショップを開始する。現在のシステムとデータフローをマップする。統合され、ニアリアルタイムでアクセス可能であれば重大なビジネス価値をアンロックする3つのパイロットデータセットを特定する。文書化された要件に対してiPaaSプラットフォームを評価する。90日以内にパイロット実装を開始する。ターゲットを確立する。12ヶ月以内に重要なデータの60%を統合。24ヶ月以内に完全統合。
クラウド導入とコスト逆説:インフラストラクチャを戦略として再考する
企業がインフラストラクチャコストを管理するためにクラウドサービスに移行した際、彼らはしばしば分断されたアーキテクチャをクラウド内で複製した。各アプリケーションに対して独立したインスタンスを立ち上げ、それぞれが独自のデータベース、認証層、監視スタックを備えていた。結果は明白だ。単位あたりのコンピュート費用は低下したが、総合的な複雑性と統合オーバーヘッドは増加した。
-
見落とされがちな機会がここにある。* クラウドの弾力性は単なる容量問題の解決ではなく、リアルタイムデータ統合の前提条件を創出したのだ。今我々が発見しつつあるのは、クラウドのコスト逆説が失敗ではなく、インフラストラクチャの意思決定がコンピュート経済学だけでなくデータアーキテクチャに駆動されるべきという信号であるということだ。
-
その根拠は以下の通りだ。* チームが独立してスケールできたことは自由に見えたが、分断を強化した。統合は手作業のままで、高コストで、エラーが頻発した。しかし、この断片化はまた独特の窓を開いた。クラウドネイティブプラットフォームは今、レガシーシステムを引き剥がすことなく統合を可能にする。これはオンプレミス統合の過去の取り組みとは根本的に異なる。
-
具体例を見よう。* あるファイナンシャルサービス企業は、中核的な台帳システム、顧客CRM、リスク分析プラットフォームをそれぞれ別々にクラウドに移行した。各チームは自らのコストメトリクスに最適化した。3年後、彼らは冗長なデータウェアハウス、重複するETLパイプライン、複数のアイデンティティ管理システムに対して支払っていることに気づいた。統一プラットフォームを使用した場合より総額で多く支払っていたのだ。しかし、ここが転換点だ。iPaaSを通じて統合した時、彼らはコストを削減しただけではない。リスク分析チームが台帳からのリアルタイム取引データと顧客CRMからの顧客行動シグナルを組み込むことを可能にした。これにより、新興信用リスクを以前より3~5日早く検出でき、初年度だけで1200万ドルのローン損失を防止した。
-
ここから導き出される実行可能な示唆は明確だ。* アプリケーション単位でクラウド支出を最適化することをやめよ。代わりに、統合パターンとデータフローで最適化せよ。 システム間のデータ移動に対して何を支払っているか。並列データストアをどこで維持しているか。これらのコストは部門予算では見えないことが多いが、直接的な浪費であり、失われた機会を表している。iPaaSを通じた統合は通常、これらの隠れたコストを18ヶ月以内に30~50%削減し、同時に改善された意思決定を通じて節約額の2~3倍を生成する新しいAI機能を有効にする。
モバイルファースト思考とリアルタイムデータ需要:レイテンシーの必然性
顧客行動がモバイルにシフトした時、企業はバッチ処理用に設計されたバックエンドシステムにアクセスするアプリを構築した。このミスマッチはレイテンシー問題を生み出した。モバイルユーザーは即座の応答を期待したが、データは夜間のETLジョブに留まった。AIシステムは同じ制約を引き継いだ。古いデータで訓練され、バッチ推論を通じてデプロイされたモデルはリアルタイムイベントに応答できなかった。
-
新興の現実はこうだ。* 我々はレイテンシーが競争優位の堀となる時代に突入している。データを統合し、ミリ秒単位で意思決定できる組織が不釣り合いな価値を獲得する。これは速度のための速度ではない。顧客意図が最も高い瞬間、詐欺リスクが最も検出可能な時、サプライチェーン混乱がまだ回避できる時を捉えることだ。
-
その根拠は次の通りだ。* モバイルはレスポンシブネスに関するユーザー期待を変革した。顧客は今、パーソナライゼーション、詐欺検出、推奨がミリ秒単位で起こることを期待する。レガシーバッチアーキテクチャはこの要件を満たせず、古い情報で訓練されたAIモデルは問題を複合化させる。しかし、より重要なのは、リアルタイムデータ統合は全く新しいビジネスモデルを解き放つということだ。動的価格設定、予測保全、パーソナライズされたリスク評価。これらはバッチ指向システムでは不可能だった。
-
具体例を挙げよう。* あるeコマースプラットフォームは日次更新されたデータでレコメンデーションAIを構築した。モバイルユーザーは古い提案、カート放棄、不十分な検索結果を見た。リアルタイムデータパイプラインを使用する競合他社は15%高い転換率を獲得した。同社は最終的にイベントストリーミング周辺でデータアーキテクチャを再構築し、レコメンデーションレイテンシーを数時間から数秒に削減した。しかし、真の突破口は、リアルタイム閲覧行動を在庫データと仕入先リードタイムと組み合わせた時に来た。彼らは今、好みに基づくだけでなく、実際に翌日配送で利用可能なものに基づいて製品を推奨できるようになった。転換を追加で22%増加させ、返品率を8%削減した。
-
ここから導き出される実行可能な示唆は以下の通りだ。* AIユースケースをレイテンシー要件について監査せよ。ただし、現在のユースケースを超えて考えよ。データが利用可能であれば、リアルタイムで行える意思決定は何か。それらについては、Kafka、イベントハブ、ストリーミング統合などのイベント駆動機能を備えたiPaaSプラットフォームは必須インフラだ。バッチ許容ユースケースについては、より柔軟性があるが、それでも日次更新サイクルは時代遅れになりつつある。少なくとも時間単位のデータ同期をベースラインとして計画し、最高影響度の意思決定については24ヶ月のロードマップでイベント駆動アーキテクチャに向かえ。
実装と運用パターン:ビッグバン移行ではなく段階的統合
成功した統合は段階的アプローチに従う。まずデータバックボーンを確立し、その後アプリケーションを段階的に移行する。iPaaSプラットフォームはこれに優れている。データ移動をアプリケーションロジックから分離し、既存運用を中断することなく新しい機能を構築できるからだ。
-
段階的アプローチの戦略的利点は明確だ。* 段階的実装をリスク軽減戦術と見なすのではなく、学習加速器として認識せよ。各段階はデータ、組織の統合成熟度、AI準備状況について教える。この知識が競争優位になる。
-
その根拠は以下の通りだ。* ビッグバン移行は完全な事前知識を仮定するため失敗する。段階的アプローチはチームが統合パターンを検証し、信頼を構築し、壊滅的リスクなしに調整することを可能にする。iPaaSツールは事前構築されたコネクタと変換テンプレートを提供し、柔軟性を維持しながらデプロイメントを加速させる。さらに重要なのは、段階的アプローチが初期の成功を現金化することを可能にし、それが後続段階に資金を提供し、組織的勢いを構築する。
-
具体例を見よう。* ある製造企業はiPaaSを使用して3つのERPシステムを統合した。一度にすべてを移行するのではなく、ベンダーマスターデータから始めた。低リスク、高影響度のデータセットだ。2週間以内に、彼らは仕入先の単一の情報源を持った。その後、在庫、その後、財務取引に移行した。各段階は4~6週間かかった。完全統合までの総時間:予定の12ヶ月ではなく18週間。しかし、ここが戦略的洞察だ。第1段階の後、調達チームは3つのレガシーシステムすべてにわたって仕入先パフォーマンスを同時に見ることができた。この可視性だけで調達サイクル時間を12%削減し、年間230万ドルの節約に値する契約の再交渉を可能にした。これらの節約が後続段階に資金を提供し、統合全体を自己資金化した。
-
ここから導き出される実行可能な示唆は以下の通りだ。* ターゲットデータボリュームと統合頻度をサポートするiPaaSプラットフォームを選択せよ。しかし、より重要なのは、強力なガバナンスと可観測性機能を備えたものを選択することだ。明確なビジネス価値を持つが管理可能な複雑性を持つパイロットデータセットでテストせよ。データ品質ルールの明確な所有権を定義せよ。これは技術的決定ではなく、ビジネスガバナンスの決定だ。完全デプロイ前にデータ鮮度と精度のSLAを確立せよ。専任の統合チームを割り当てよ。アプリケーションチームがこれを機能開発と並行して管理することを期待するな。最も重要なのは、各段階からビジネス価値を特定し、現金化せよ。 初期の成功を使用して、後続段階のための経営幹部スポンサーシップと組織的調整を構築せよ。
測定と次のアクション:インテリジェンス配当の定量化
統合の成功は測定可能だ。洞察までの時間短縮、モデル訓練の高速化、統合コスト低下、データ精度向上、そして最も重要なのは、測定可能なビジネス価値を生成する新しいAI機能。これらのメトリクスを前後で追跡し、それらを使用して拡張を導け。
-
測定の必然性は明確だ。* メトリクスなしでは、統合はコストセンターではなく機能有効化になる。しかし、正しいメトリクスがあれば、統合が組織が行える最高ROI投資の1つであることを実証できる。
-
その根拠は以下の通りだ。* 定量化された利益は継続的投資を正当化し、優先順位付けを導く。また、説明責任を創出し、結果が期待を下回った場合に方針転換することを可能にする。さらに重要なのは、メトリクスがデータインフラストラクチャの価値を非技術的ステークホルダーに伝えることを可能にすることだ。継続的投資を確保するための重要な能力。
-
具体例を挙げよう。* あるヘルスケア組織は統合前の統合コストを年間210万ドルで測定した。スタッフ、ツール、データ品質修正を含む。iPaaSデプロイ後、これは140万ドルに低下した。33%削減だ。同時に、臨床AIモデルの精度は8%向上した。データ品質が改善され、モデル再訓練頻度が四半期ごとから月次に増加したからだ。しかし、真の影響は新しい機能から来た。患者履歴、検査結果、画像データ、治療結果をリアルタイムで組み合わせた予測モデルを構築できるようになった。これにより、高リスク患者の早期介入が可能になり、30日再入院率を12%削減し、合併症削減と入院期間短縮を通じて年間870万ドルの節約を生成した。
-
ここから導き出される実行可能な示唆は以下の通りだ。* ベースラインメトリクスを今定義せよ。現在の統合コスト(手作業によるデータ調整と遅延した意思決定のような隠れたコストを含む)、システム別のデータ鮮度、データ要求から利用可能性までの時間、主要ユースケース全体のAIモデルパフォーマンス。iPaaSデプロイ後、四半期ごとに再測定せよ。しかし、コストメトリクスを超えよ。ビジネス影響を測定せよ。意思決定速度、モデル精度、有効化された新機能、収益またはコスト影響。月次でステークホルダーと結果を共有せよ。これらのメトリクスを使用して追加システムとデータソースへの拡張を正当化せよ。投影される影響に基づいて各新規統合のビジネスケースを作成せよ。技術的実現可能性ではなく。
リスクと軽減戦略:データアーキテクチャへの回復力の構築
統合は新しいリスクをもたらす。ベンダーロックイン、データガバナンスの複雑性、単一プラットフォームへの運用依存、データ品質問題の集中。これらを意図的かつ体系的に軽減せよ。
-
リスクを設計機会として再構成することだ。* これらのリスクを障害と見なすのではなく、より回復力のあるシステムを構築することを強制する設計制約として認識せよ。これらのリスクに思慮深く対処する組織は、断片化されたシステムが決してできなかった、より堅牢で監査可能で信頼できるデータアーキテクチャを持つ。
-
その根拠は以下の通りだ。* iPaaSプラットフォームは強力だが、集中化リスクを生み出す。プラットフォームが失敗するか不適切になれば、データフロー全体が影響を受ける。ガバナンスは明示的である必要がある。共有データは共有責任を生み出すからだ。しかし、この集中化はまた機会を生み出す。単一の制御と可視性のポイント。これは断片化されたシステムより優れたガバナンス、セキュリティ、コンプライアンスを可能にする。
-
ここから導き出される実行可能な示唆は以下の通りだ。* 明示的な終了条項とデータポータビリティ要件を持つ複数年契約を交渉せよ。iPaaSベンダーが標準データ形式(Parquet、Avro、JSON Schema)とエクスポート用のオープンAPIをサポートすることを要求せよ。財務、コンプライアンス、運用、ビジネスユニットの代表者を含むデータガバナンス評議会を確立せよ。ITだけではなく。この評議会はデータ品質基準、アクセスポリシー、系統ドキュメンテーションを所有すべきだ。メタデータ管理ツールを使用してすべての変換ルールとデータ系統をドキュメント化せよ。データ品質、アクセスログ、コンプライアンスの四半期監査を実施せよ。iPaaSプラットフォーム障害シナリオを含む災害復旧計画を維持せよ。定期的なテスト(少なくとも年1回)を実施せよ。異常に対する自動アラートを備えたデータ品質監視を実装せよ。データを発見可能にし、系統、品質、使用制限をドキュメント化するデータカタログを作成せよ。
AIの基盤としての統合:次の地平線
規模でのAI採用は統合された信頼できるデータを必要とする。しかし、さらに重要なのは、AI野心と進化するデータアーキテクチャを必要とすることだ。iPaaSはこれを可能にする運用バックボーン。ワンタイムプロジェクトではなく、組織と共に成長する継続的な機能として。
次の10年をリードする組織は、データ統合をコスト削減イニシアティブではなく、継続的イノベーションを可能にする戦略的機能として認識する組織だ。彼らは組織全体のリアルタイムシグナルを組み込むAIモデルを構築する。競合他社より速く機会とリスクを検出する。より良い情報で意思決定する。そして、彼らはこれを英雄的なワンタイム取り組みではなく、データ統合への体系的で測定された段階的アプローチを通じて行う。
- 前進の道は明確だが、コミットメントが必要だ。*
-
現在のシステムランドスケープを監査せよ。 今後30日以内に。システム、データフロー、統合ポイントをマップせよ。データがどこで閉じ込められているか、システムギャップをどこで手作業プロセスが埋めているか、データ品質問題がどこで発生しているかを特定せよ。
-
最高価値のAIユースケースを特定せよ。 それらが必要とするデータ。技術的複雑性ではなく、ビジネス影響に基づいて優先順位付けせよ。統一されたリアルタイムデータがあれば、どの意思決定が変革されるか。
-
低リスク、高影響度のデータでiPaaSをパイロットせよ。 90日以内に。複数のチームが必要とするデータセット、データ品質が現在問題のあるもの、統合が明確なビジネス価値を解き放つものを選択せよ。影響を厳密に測定せよ。
-
パイロット結果に基づいて体系的に拡張せよ。 12ヶ月以内に重要データの60%統合、24ヶ月以内に完全統合のターゲットを設定せよ。初期の成功を使用して後続段階に資金を提供せよ。
-
ガバナンスと測定を基盤に構築せよ。 これらを事後的なものとして扱うな。成功した統合と失敗した統合の違いだ。
競争優位の未来は、データを統合し、それを信頼し、誰よりも速く行動できる組織に属する。iPaaSはこれを可能にするインフラストラクチャだ。問題は統合するかどうかではなく、どのくらい速く始められるかだ。
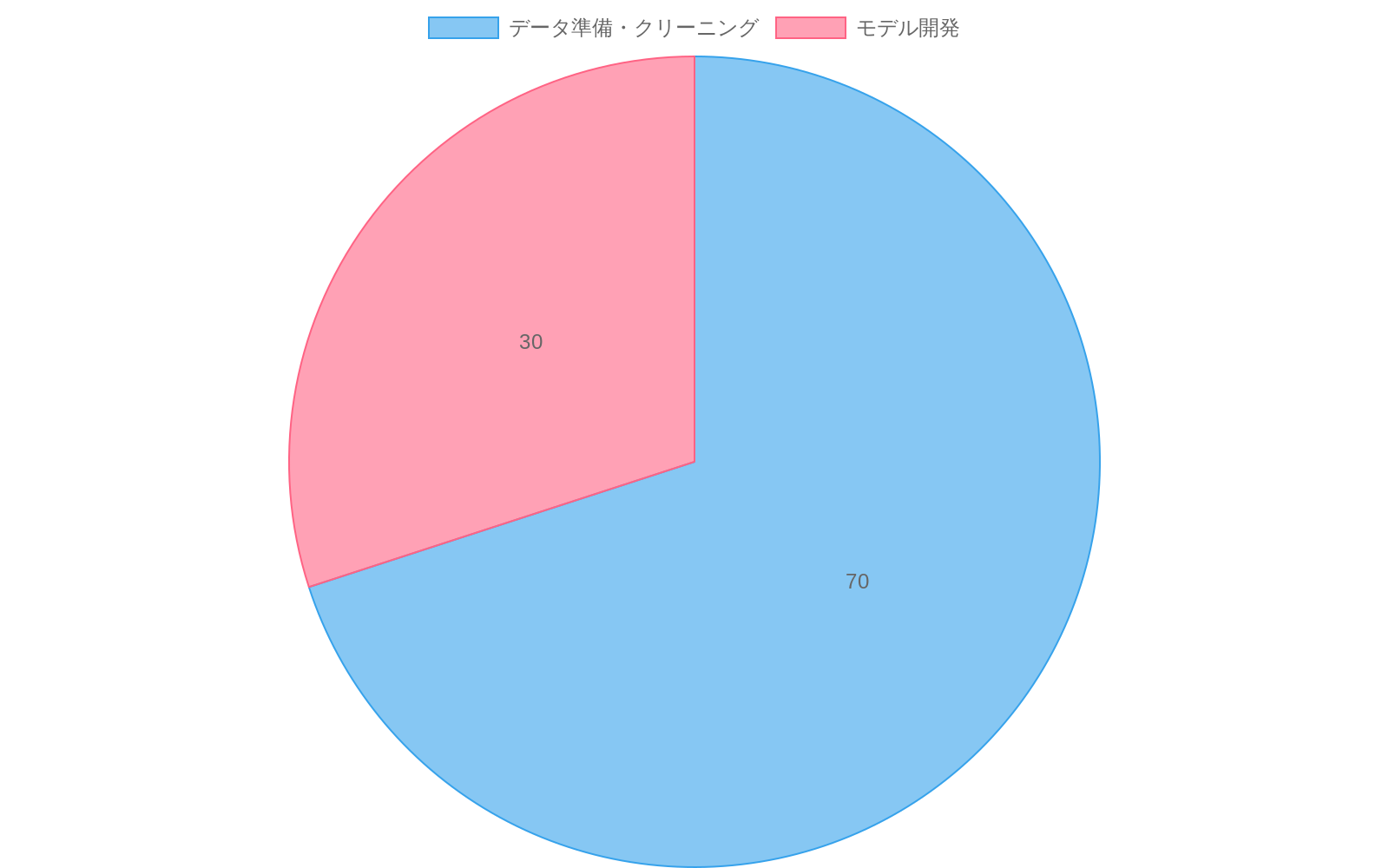
- 図2:データサイエンティストの時間配分(Kaggle State of Data Science Survey, 2023)*
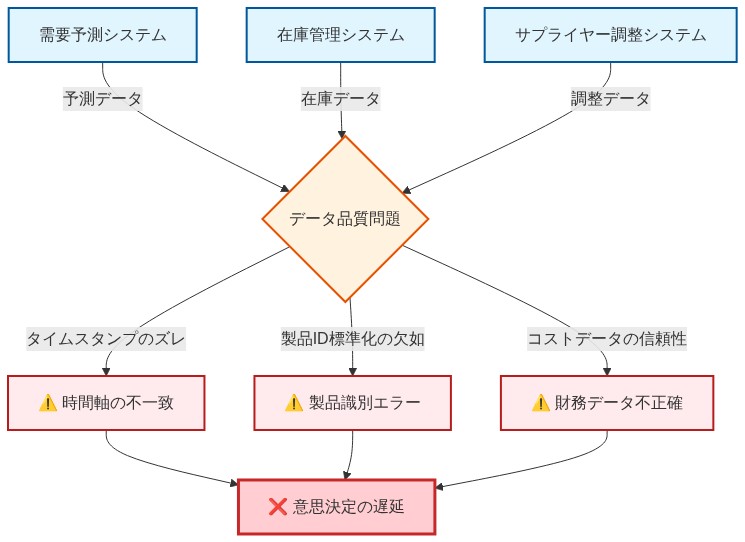
- 図3:小売企業の事例:サイロ化されたシステムとデータ品質の課題*