
エンジニアリング支援の大規模展開に向けたマルチエージェントシステムの設計:Grabのケーススタディ
プラットフォーム組織におけるエンジニアリング支援の危機
Grabの中央データチームは、数千人の内部ユーザーに対応するデータウェアハウスプラットフォームを運用していました。そこで発生する支援リクエストの量は、手作業での対応が持続不可能なレベルに達していました。リクエストの内容は多様で、クエリ最適化、パイプライン障害診断、スキーマ設計相談、パフォーマンストラブルシューティングなど、複数のカテゴリにまたがっていました。チームが観測したのは、エンジニアリング時間の30~40%が反応的な支援業務に充てられており、これが積極的なプラットフォーム開発の取り組みを直接的に阻害していることでした。
本質的に問われているのは、スケール増加に伴う支援リクエストとエンジニアの比率が、構造的に持続不可能になるという問題です。運用上のボトルネックは二つの側面で顕在化していました。第一に、従来のチケッティングシステムは順序立てたトリアージワークフローを強制し、リクエストのルーティングと解決に遅延をもたらしていました。第二に、エンジニアリング支援は、予測可能なクエリパターンを持つカスタマーサポートとは異なり、技術的な深さ、システムレベルの推論、プラットフォーム内部に関する文脈的知識を必要としていました。従来の自動化アプローチ(スクリプト化された応答、静的ナレッジベース、単一目的のボット)は、このドメインの複雑性には不十分でした。
根本的な制約は構造的なものでした。プラットフォームのスケールが増加するにつれて、支援リクエストと利用可能なエンジニアの比率は持続不可能になりました。支援業務と開発業務の間での文脈切り替えは、チーム全体に乗算される認知コストをもたらしていました(Czerwinski et al., 2004)。カスタマーサービスの相互作用を想定して設計された従来のチャットボットは、複雑性が限定されていますが、エンジニアリング支援に必要とされる多段階の診断推論と技術的深さには対応できませんでした。
この状況が要求していたのは、以下の能力を備えたエージェントです。(1)異種のデータソースにまたがる多段階推論、(2)人間の仲介なしに本番システムとログへのアクセス、(3)微妙なエスカレーション判断、(4)決定論的な出力ではなく信頼度を校正した推奨事項の提供。
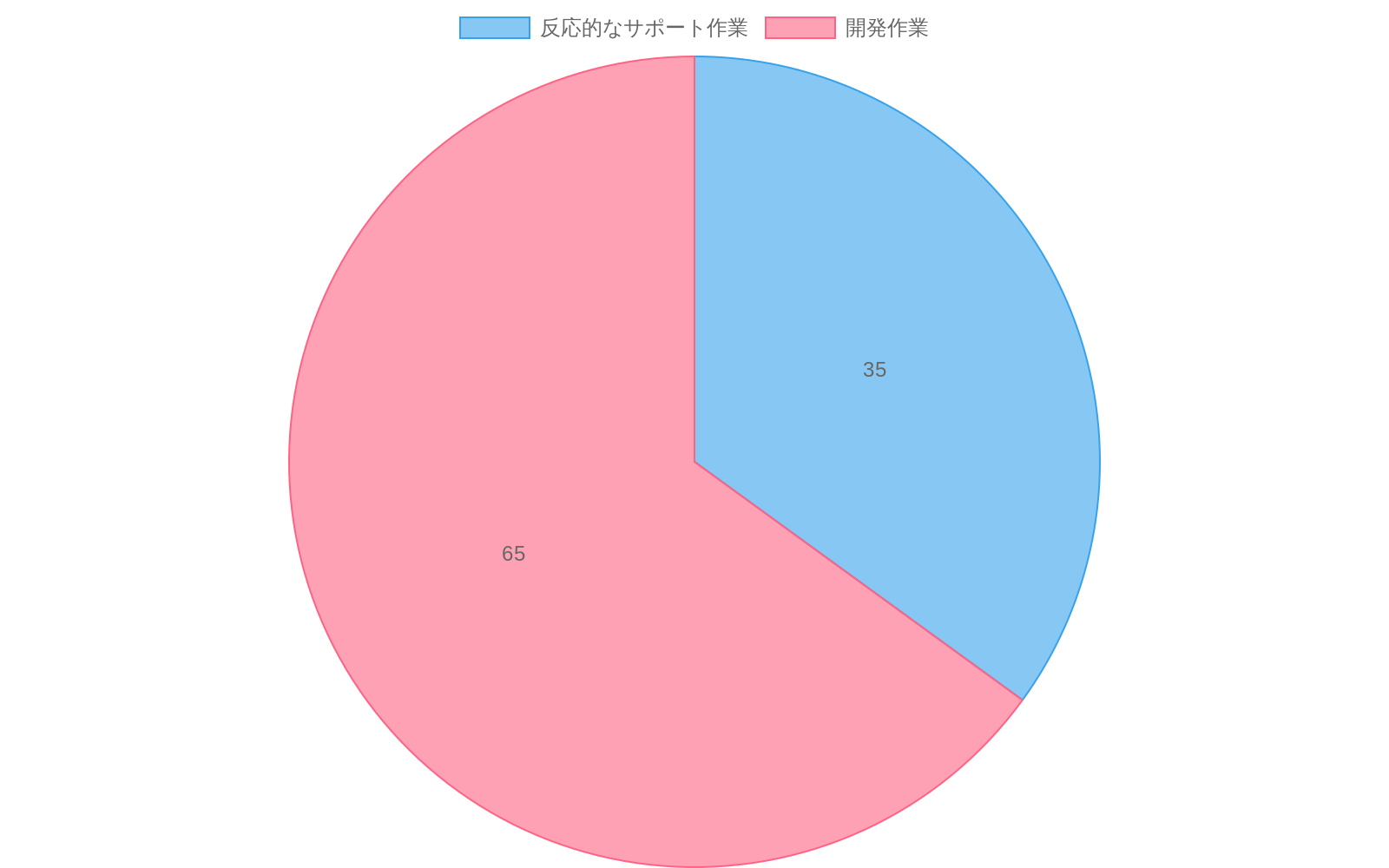
- 図2:Grabの中央データチームにおけるエンジニアリング時間配分:反応的サポート作業 vs 開発作業(出典:Grab Central Data Team内部データ)*

- 図3:従来のチケッティングシステムにおける遅延とボトルネック*
アーキテクチャ設計:調査と改善の分離
Grabの中核的な設計判断は、支援ワークフローを二つの異なるエージェントクラスに分割することでした。各クラスは異なる推論パターンとツール要件に最適化されています。この分離は、モジュール型システム設計とエージェント能力の専門化という確立された原則を反映しています。
-
*調査ワークフロー**は診断的な問題に対応します。パイプライン障害の根本原因を特定し、クエリパフォーマンス低下を分析し、データ系統の問題を追跡し、システム異常をインフラストラクチャの変更と相関させます。調査エージェントは、グラウンドトゥルースが存在する制約された問題空間(実行ログ、システムメトリクス、スキーマ履歴)で動作し、推論は診断方法論に従います。
-
*改善ワークフロー**は最適化リクエストに対応します。スキーマ改善を推奨し、インデックス戦略を提案し、アーキテクチャの変更を提案し、コスト最適化の機会を特定します。改善エージェントは、複数の有効な解決策が存在し、推奨事項がトレードオフ分析を必要とする、より制約が少ない空間で動作します。
このアーキテクチャ分離は、三つの具体的な利点をもたらします。
-
能力の専門化:調査エージェントはログ取得、メトリクス集約、時間的相関のためのツールを必要とします。改善エージェントはメタデータ分析、コストモデリング、パフォーマンスベンチマークのためのツールを必要とします。専門化されたツールセットはエージェントの決定空間を削減し、推論品質を向上させます。
-
障害の隔離:調査エージェントのエラーまたは性能低下は改善ワークフローにカスケードしないため、いずれかのエージェントクラスへの段階的な改善中もシステムの信頼性を維持します。
-
評価の明確性:成功指標はワークフロー間で異なります。調査の成功は測定可能です(根本原因が特定され、ログに対して検証されます)。改善の成功は確率的です(推奨事項が採用され、推定される利益を生み出します)。別個の評価フレームワークは指標の混同を防ぎます。
この分離はまた、人間による監視を簡素化します。エンジニアはシステム全体の複雑性を包括的に理解することなく、制約されたドメイン内でエージェント推論を検証できます。
オーケストレーション層:専門化されたエージェントの調整
Grabは、リクエスト分類、エージェント選択、エージェント間通信、結果統合を管理する中央オーケストレーション層を実装しました。オーケストレーターは、リクエスト受け入れ、エージェント割り当て、実行監視、人間へのエスカレーション間の明示的な遷移を持つステートマシンとして機能します。
-
*リクエスト分類**は、ルールベースのヒューリスティクスと過去のリクエストから学習されたパターンを使用して、ワークフロータイプ(調査対改善)を決定します。分類エラーはリクエストを不正なエージェントにルーティングします。システムは信頼度閾値を実装し、分類信頼度が定義されたレベルを下回る場合、人間によるレビューをトリガーします。
-
*エージェント選択**は以下を考慮します。(1)エージェント能力に対するリクエストの複雑性、(2)エージェントの可用性とキューの深さ、(3)類似したリクエストタイプに対する過去の成功率、(4)リソース制約。調査エージェントが飽和している場合、受信した調査リクエストはキューイングされるか、人間のエンジニアにルーティングされ、サービス品質の低下を避けます。
-
*文脈管理**は、複数段階の相互作用全体で状態を維持します。長時間実行される調査は、中間的な発見、ツール出力、推論チェーンを保持します。これにより、エージェントは高コストな操作を再実行することなく、以前の分析を参照できます。
-
*エスカレーション論理**は信頼度閾値を実装します。エージェントの推奨事項に対する信頼度が定義された閾値(技術的推奨事項の場合、通常0.65~0.75)を下回る場合、システムは不確実なガイダンスを事実として提示するのではなく、人間のエンジニアにエスカレートします。このガードレールは、高リスク文脈でユーザーに到達する自信に満ちた幻覚を防ぎます。
-
*結果統合**は複数のエージェントからの部分的な解決策を、一貫性のある応答に組み立てます。調査が根本原因を特定し、改善エージェントが軽減策を提案する場合、オーケストレーターはこれらを実行可能な推奨事項に構造化し、明示的なソース帰属を付与します。
オーケストレーターは、エージェント応答時間、エスカレーション率、解決率、エージェント推奨事項に対するエンジニア満足度を追跡する観測可能性フックを維持します。これらのメトリクスは、ルーティング論理とエージェント能力の反復的な改善に情報を提供します。
エージェント能力とツール統合
調査エージェントと改善エージェントは、ツール抽象化層を通じてGrabのデータインフラストラクチャにアクセスします。ツールは標準化されたインターフェースを持つ独立したモジュールとして実装され、エージェントが新しい方法でそれらを構成できるようにします。
-
*調査エージェントツール**には以下が含まれます。
-
クエリ実行エンジンインターフェース:実行計画、実行時統計、過去のパフォーマンストレンドを取得
-
ログ集約システム:エラーメッセージ、警告、診断イベントについて構造化ログを検索
-
監視ダッシュボード:時系列メトリクス(CPU、メモリ、I/O、クエリレイテンシ)をクエリし、タイムスタンプと相関させる
-
変更管理システム:スキーマ修正、設定変更、デプロイメントイベントを取得
-
データ系統システム:パイプライン全体のデータフローを追跡し、上流の障害を特定
-
*改善エージェントツール**には以下が含まれます。
-
メタデータリポジトリ:テーブルスキーマ、列統計、アクセスパターンをクエリ
-
コスト分析システム:代替設計のストレージとコンピュートコストを推定
-
パフォーマンスプロファイリングシステム:異なる設定下でクエリ実行をベンチマーク
-
ワークロード分析ツール:クエリパターンを特性化し、最適化の機会を特定
ツールの信頼性は重要です。エージェントは以下を適切に処理する必要があります。APIの障害(タイムアウト、レート制限)、不完全なデータ(要求された時間ウィンドウのメトリクスが欠落)、矛盾する情報(複数のソースが異なる値を報告)。システムは以下を実装します。
-
タイムアウト:ツール呼び出しは定義された期間後(通常30秒)に中止され、エージェントのブロッキングを防ぎます
-
フォールバック戦略:プライマリデータソースが失敗する場合、エージェントはセカンダリソースを試行するか、適切に性能低下します
-
明示的なエラー処理:エージェントはデータの矛盾にフラグを立て、推測するのではなく人間にエスカレートします
-
*アクセス制御**はツール層で強制されます。ほとんどのエージェントは読み取り専用で動作し、ログとメトリクスにアクセスしますが、スキーマや設定を変更することはできません。破壊的な操作(スキーマの変更、設定の修正)は明示的な人間の承認を必要とし、監査ログはすべての推奨事項と承認をキャプチャします。
-
*ツールバージョニング**は、基盤となるシステムが進化する際にエージェントが機能し続けることを保証します。APIが変更される場合、ツール定義はエージェント論理から独立して更新され、システム全体の互換性を維持します。
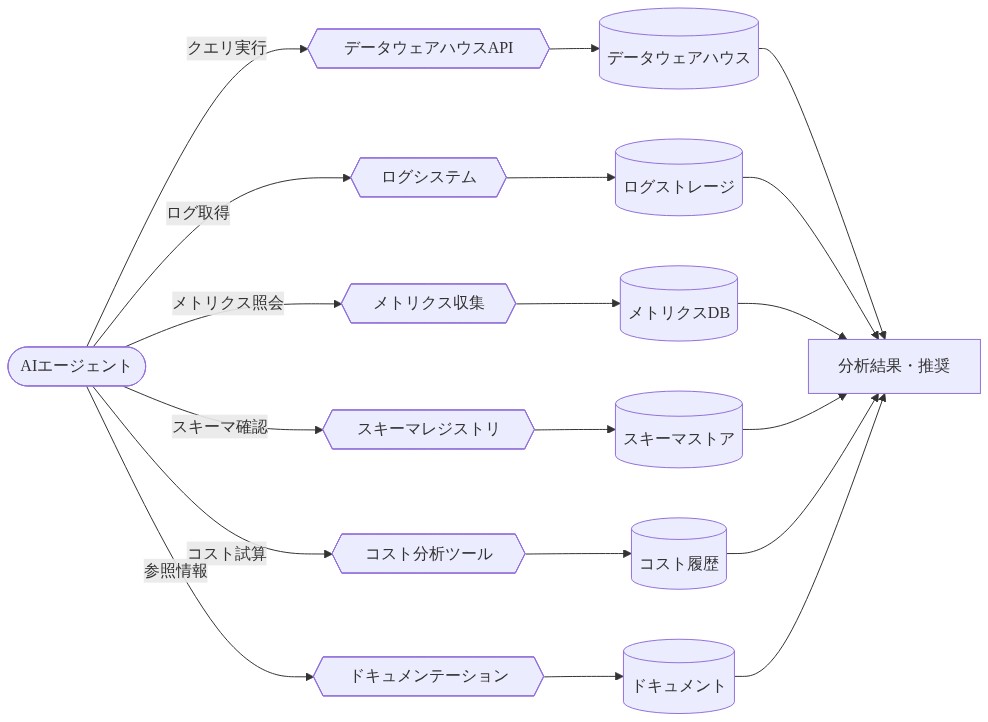
- 図7:エージェントのツール統合アーキテクチャ(Grab Multi-Agent System ツール統合設計)*
影響の測定:運用メトリクスとエンジニアリング生産性
Grabの本番デプロイメントは、マルチエージェントシステムの影響に関する経験的データを提供します。システムは受信した支援リクエストの65%を人間の介入なしに処理し、以下の特性を持ちます。
- 平均解決時間(MTTR):人間のみのベースライン(4時間)からエージェント解決リクエスト(20分)に短縮
- 月間エンジニアリング時間の回収:チーム全体で約200時間、積極的なプラットフォーム改善にリダイレクト
- リクエストタイプの分布:反復的な診断(リクエストの45%)、標準的な最適化(35%)、人間の判断を必要とする新規問題(20%)
データは、自動化の有効性に差があることを明らかにしています。最高の解決率を持つリクエストカテゴリは、共通の特性を共有しています。明確に定義された問題空間、決定論的な根本原因、明確な成功基準です。新規のアーキテクチャ決定を必要とするリクエストや、不慣れなシステムを含むリクエストは、人間に依存したままです。
-
*定性的な変化**は、効率向上と並行して出現しました。
-
エンジニアは反応的な消火活動から積極的なプラットフォーム業務へ移行
-
支援リクエストパターンは体系的な問題を表面化させました。リクエストの40%は三つの予防可能な根本原因に由来していました
-
チームはこれらの根本原因に対処し、受信するリクエスト量をさらに削減しました
-
エージェントシステム自体の保守オーバーヘッド*(モデル更新、ツール保守、オーケストレーション改善)は、エンジニアの時間の約15%を必要とします。これは意図的なトレードオフを表しています。進行中の運用負担を削減するために、自動化インフラストラクチャにエンジニアリング努力を投資します。
-
*エスカレーション分析**は、エスカレーションの35%が不十分なエージェント信頼度に起因し、40%がエージェント能力を超えるリクエスト複雑性に起因し、25%がツール障害またはデータ利用不可に起因していることを明らかにしています。この分布は、能力改善の優先順位付けに情報を提供します。
本番環境での課題:信頼性と信頼
エンジニアリング支援の重要な側面に対するAIエージェントのデプロイメントは、カスタマーサポートチャットボットに存在しない独特の課題を表面化させます。Grabは三つの主要な懸念に直面しました。本番インフラストラクチャにアクセスするエージェントの場合のシステム信頼性、技術的文脈での幻覚リスク(不正確な情報は停止を引き起こします)、エンジニア信頼の構築です。
- *信頼性制約**は広範なガードレールを必要としました。
- ほとんどのエージェントの読み取り専用アクセス、偶発的な変更を防止
- 破壊的な操作に対する必須の人間承認
- すべてのエージェント推奨事項とアクションの包括的な監査ログ
- エージェントが本番システムをリクエストで圧倒するのを防ぐサーキットブレーカー
エージェントが設定変更を推奨する場合、実行前に人間が確認して承認します。この境界は、自律的なエラーとカスケード障害の両方を防ぎます。
-
*幻覚軽減**は、モデル知識に依存するのではなく、取得されたドキュメントとクエリ結果にエージェント応答を根拠付けることを含みます。具体的なメカニズムには以下が含まれます。
-
ソース帰属:すべての主張は特定のログ、メトリクス、またはドキュメントを参照
-
信頼度スコアリング:推奨事項には明示的な信頼度推定値(0~1スケール)を含む
-
不確実性の認識:エージェントは推測するのではなく「Xを決定するための十分な情報がありません」と述べる
-
矛盾検出:複数のデータソースが矛盾する場合、エージェントは不一致にフラグを立てエスカレート
技術的文脈での幻覚は高いリスクを伴います。スキーマ設計またはクエリ最適化に関する不正確な推奨事項は、プラットフォームパフォーマンスを低下させるか、停止を引き起こす可能性があります。システムは保守的な閾値を実装します。信頼度が0.65を下回る場合、エスカレーションが発生します。
-
*信頼構築**は微妙で時間に依存することが判明しました。初期のエンジニアのスケプティシズムは信頼性の向上に伴い徐々に減少しましたが、過度な依存が二次的なリスクとして出現しました。チームは明示的なガイドラインを確立しました。エージェントは推奨事項を提供し、エンジニアが決定を下します。この境界は、過小利用と危険な過度な依存の両方を防ぎます。
-
本番環境で観測された特定の障害モード*:
-
あいまいなリクエスト解釈:エージェントが口語的な言語または文脈依存の用語を誤解
-
文脈に不適切なソリューション:技術的に正しいが、組織的制約またはビジネス文脈を無視した推奨事項
-
エッジケースの脆弱性:エージェントは訓練分布外のリクエストまたは不慣れなシステムを含むリクエストに苦労
-
ツール障害のカスケード:プライマリデータソースが失敗する場合、エージェントは適切な不確実性シグナリングなしに性能低下した推奨事項を提供することがあります
各障害は根本原因分析をトリガーし、エージェント再訓練、ツール改善、またはオーケストレーション論理調整を通じたシステム改善をもたらしました。
進化と将来の方向性
マルチエージェントシステムは、本番学習と新興能力に基づいて進化し続けています。計画された改善には以下が含まれます。
-
積極的な監視*:プラットフォームの健全性を継続的に監視し、ユーザーがリクエストを提出する前に新興の問題を特定するエージェントの開発。これはモデルを反応的な支援から予測的な介入にシフトさせます。
-
インシデント管理統合*:オンコール体制との緊密な結合、特定の問題カテゴリのインシデント対応にエージェントが参加できるようにします。エージェントは初期トリアージを実行し、診断情報を収集し、文脈が事前に組み立てられたオンコールエンジニアにエスカレートできます。
-
能力拡張*:現在人間の専門知識を必要とする、ますます洗練されたワークフローを処理するようにエージェントを拡張。これは、改善された推論能力とより包括的なツールアクセスの両方を必要とします。
-
役割進化*:エージェントがより洗練されたタスクを処理するにつれて、プラットフォームエンジニアの役割は反応的な支援からエージェント監視、能力開発、自動化が対応できない真に新規な問題の処理へシフトします。これはチーム構成とスキル要件の根本的な再構成を表しています。
この経験は、プラットフォームエンジニアリング組織に対するより広い含意を明らかにしています。
- チーム構造:マルチエージェントシステムは支援チーム構成を再形成し、支援ローテーション上のジュニアエンジニアの必要性を削減しながら、エージェントインフラストラクチャを開発・保守できるエンジニアの需要を増加させます
- スキル要件:将来のプラットフォームエンジニアはエージェント能力開発、オーケストレーション論理、人間とAIの協働パターンの能力を必要とします
- 決定境界:組織は、エージェント自律性、人間エスカレーショントリガー、高リスク推奨事項の承認ワークフローに関する明確なポリシーを確立する必要があります
同様のアプローチを採用する組織は、以下に投資すべきです。(1)洗練されたエージェント調整を可能にするオーケストレーションインフラストラクチャ、(2)明示的なエスカレーショントリガーを備えたエージェント自律性に関する明確なガードレール、(3)エージェント動作とシステムパフォーマンスに関する包括的な観測可能性、(4)利点と保守コストの両方に関する正直なメトリクス。
マルチエージェントアプローチは普遍的に適用可能ではありません。以下の場合に成功します。支援リクエストは異種ですが、明確に定義されたカテゴリに分類され、検証のためのグラウンドトゥルースが存在し、組織がエージェント保守にインフラストラクチャ開発を投資できます。以下の場合に苦労します。リクエストが非常に新規である、検証が主観的である、または組織がエージェント保守のためのエンジニアリング能力を欠いている場合です。
見落とされがちですが、より広い文脈で捉えると、この取り組みが示唆しているのは、技術組織の支援機能の本質的な変化です。エージェントが単なる効率化ツールではなく、エンジニアリング実践そのものを再形成する存在になるとき、組織は単に業務を自動化するのではなく、知識労働の性質そのものを問い直す必要があります。

- 図5:調査エージェントの診断ワークフロー(Grab Multi-Agent System設計)*
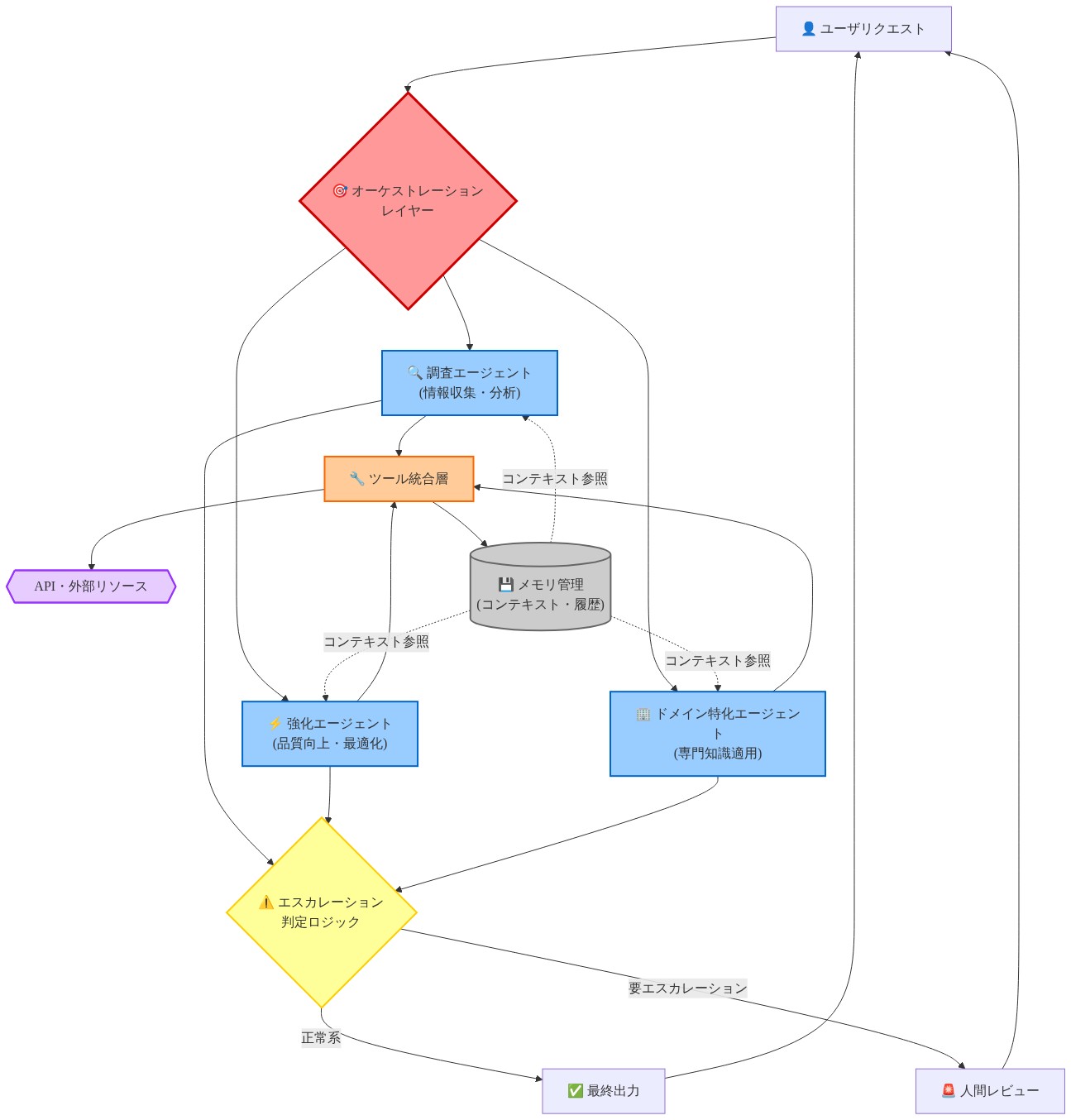
- 図6:マルチエージェントシステムのオーケストレーションレイヤー(Grab Multi-Agent System アーキテクチャ設計に基づく)*
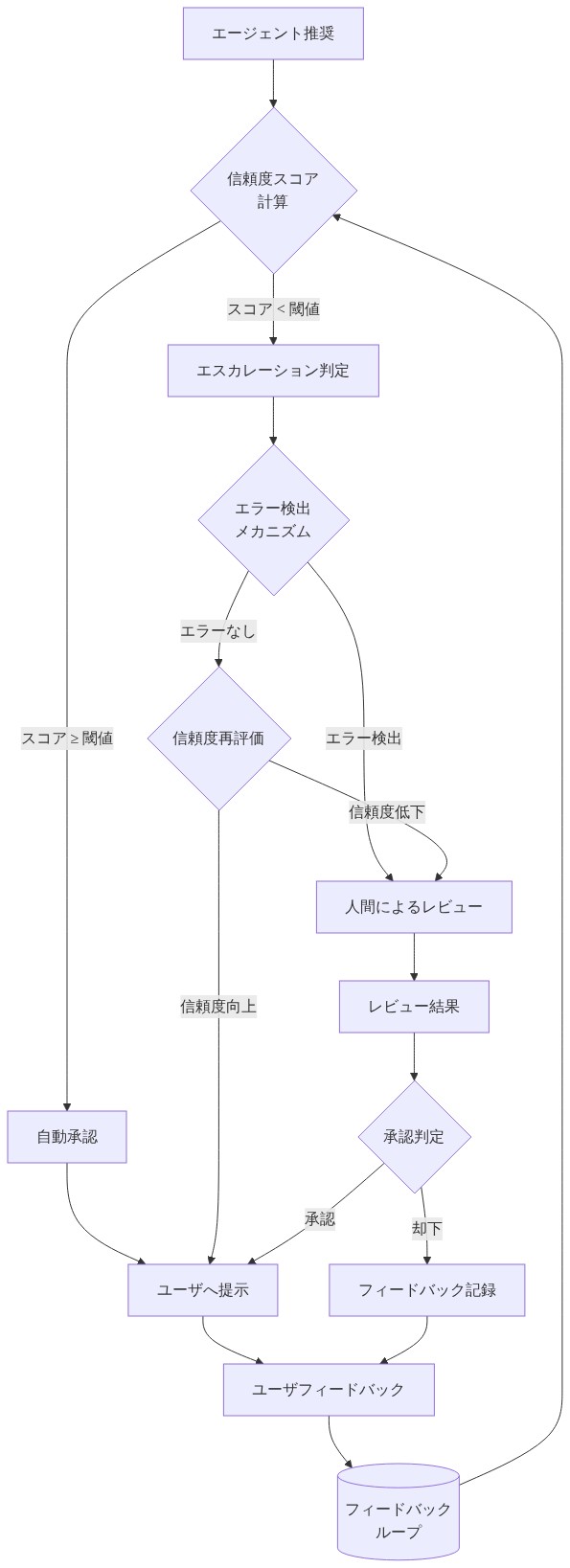
- 図11:推奨のバリデーションとエスカレーション判定フロー(Grab Multi-Agent System 信頼性設計)*