
表現消去ベースの選好最適化によるLLMの有害性除去
現在のLLM安全性における表面性の問題
既存の選好最適化技術—Direct Preference Optimization(DPO)、Negative Preference Optimization(NPO)、および関連手法を含む—は主に出力確率分布を修正することで行動レベルで機能します。しかし、機械的解釈可能性研究からの経験的証拠は、そのような訓練後も潜在空間に有害な表現構造が残存することを示唆しています。線形プローブ研究(Anthropic、2023年;Zou et al.、2023年)は、有害なコンテンツ生成と相関する方向ベクトルが、広範な安全性ファインチューニング後もモデル埋め込みに幾何学的に存在し続けることを実証しており、敵対的プロンプトと標的化されたファインチューニング攻撃の両方に対する脆弱性を生み出しています。
この制限は、2つの異なる失敗モードを通じて現れます。
-
敵対的プロンプト回避: 選好最適化を通じて訓練された安全性制約は、出力選択に作用するものであり、表現容量には作用しません。敵対者は要求を言い換え—有害なコンテンツ生成を歴史的分析、フィクション的世界構築、または学術的探究として再構成し—代替経路を通じて同じ基礎的な有害表現を活性化させることができます。
-
ファインチューニング可逆性: 有害な要求を拒否するために長期間訓練されたモデルは、比較的控えめな敵対的ファインチューニングを通じて実質的に損なわれる可能性があります。経験的観察は、数百の敵対的例が数ヶ月の安全性訓練を取り消すことができることを示しています(Carlini et al.、2023年)。これは、有害性の基礎的な表現基盤が完全で、アクセス可能なままであるためです。
-
具体例:* DPO訓練されたモデルは、兵器製造指示の直接的な要求を確実に拒否します。しかし、同じ要求が20世紀の軍事技術の歴史的分析またはSF小説のフィクション的世界構築として再構成されると、モデルはしばしば応じます。選好訓練は出力確率分布を修正し—拒否トークンの尤度を増加させ—ましたが、兵器関連コンテンツをエンコードして生成するモデルの内部表現容量を排除しませんでした。有害な概念は幾何学的に存在し続けます。抑制されたのは、それを表現するための行動経路のみです。
-
この分析の基礎となる仮定:* 表現容量と行動表現が部分的に分離可能であると仮定します—モデルが有害な概念の内部表現を保有しながら、その表現を抑制するように訓練されることができるということです。この仮定は機械的解釈可能性からの証拠(Anthropic、2023年)によって支持されていますが、経験的調査の活発な領域のままです。
-
実行可能な含意:* 安全性保証のために選好最適化のみに依存する組織は、線形プローブまたは同様の因果介入技術を使用して構造監査を実施すべきです。そのような監査は、安全性特性が真に構造的であるか(表現容量が除去されたか)、または単に行動的であるか(表現が抑制されたか)を明らかにします。この区別は、敵対的操作に対する実際の堅牢性を評価するために重要です。
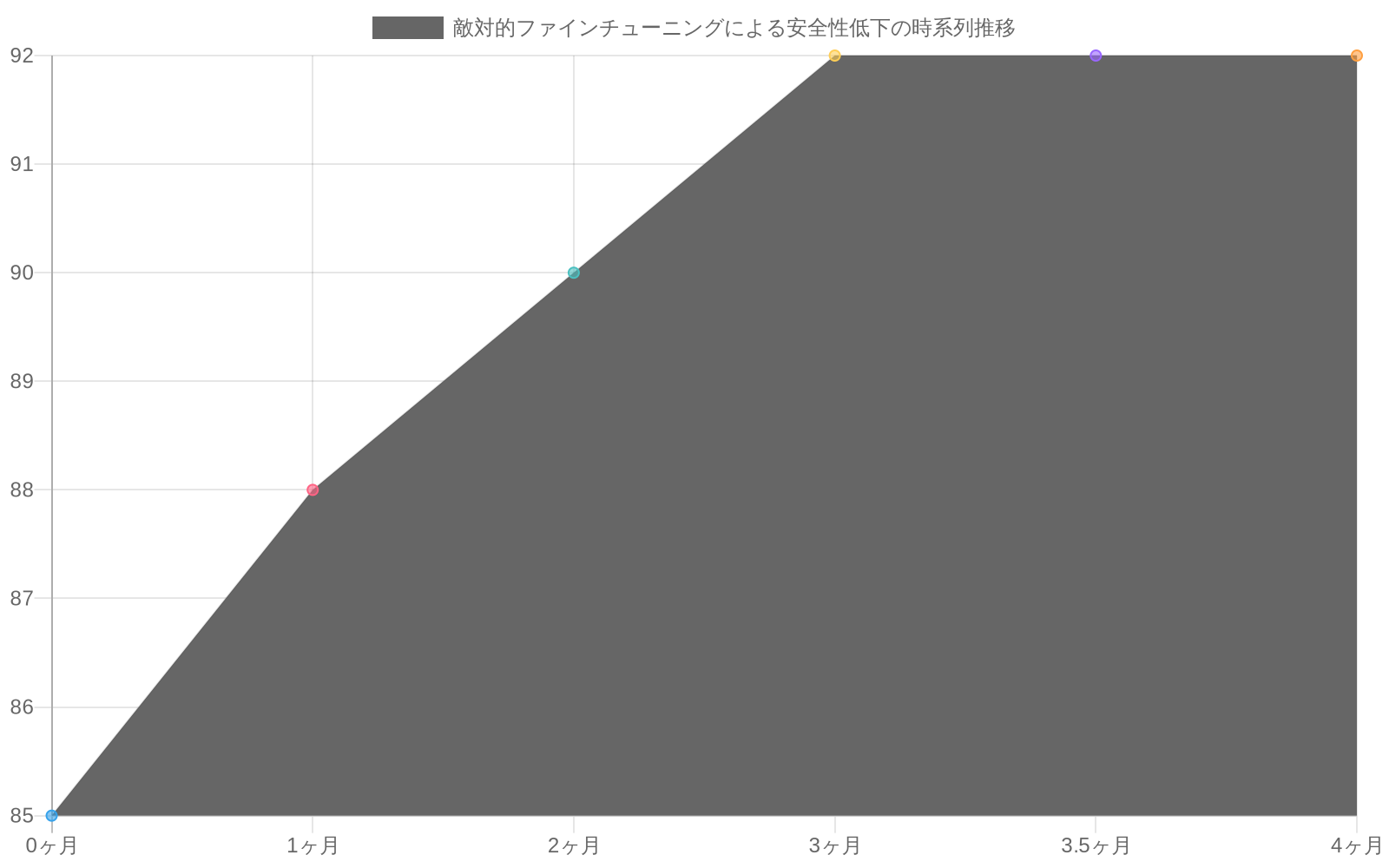
- 図3:敵対的ファインチューニングによる安全性の可逆性 - 数百の例で数ヶ月の訓練が無効化される(出典:Carlini et al. 2023)*
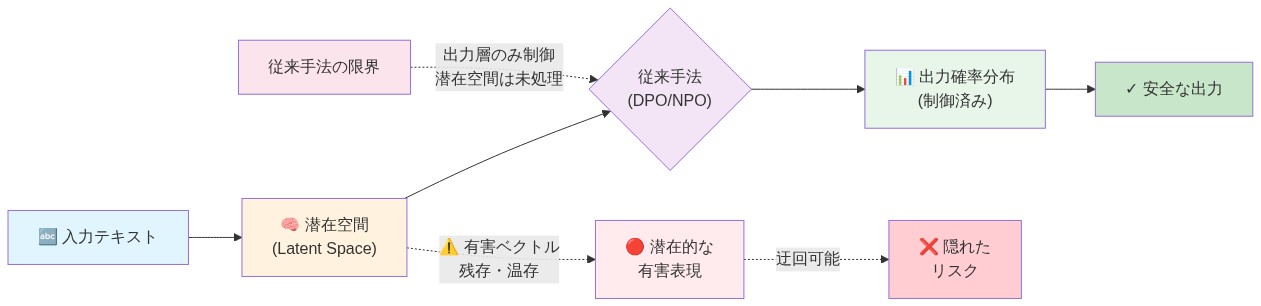
- 図2:従来の選好最適化の限界 - 潜在空間における有害表現の残存メカニズム(出典:Anthropic 2023, Zou et al. 2023 - Mechanistic Interpretability Framework)*
構造的防御としての表現消去
表現消去は、行動表現を抑制するのではなく、モデルの埋め込み空間から有害な方向ベクトルを特定して除去することにより、根本原因に対処します。理論的基礎は、有害な行動が特定の幾何学的構造—高い活性化が有害なコンテンツ生成と相関する活性化空間内の方向—から生じるという仮定に基づいています(Anthropic、2023年;Hendrycks et al.、2021年)。
技術的アプローチは、因果介入方法を採用して、有害性を特定の表現部分空間に追跡します。
-
特定: 主成分分析(PCA)または同様の次元削減技術が、有害なコンテンツと良性なモデル完成から収集された活性化パターンに適用されます。これは、活性化の大きさが有害性と相関する潜在空間内の方向を特定します。
-
検証: 因果介入(例えば、活性化ステアリング)は、特定された方向に沿った活性化を操作することが有害な出力生成に因果的に影響することを確認し、相関が偽の関連ではなく真の因果構造を反映していることを確立します。
-
除去: 特定された有害な方向は、重み修正または投影ベースの制約を通じてモデルの表現空間から外科的に除去されます。
敵対的堅牢性訓練とは異なり、敵対的例への露出を通じてモデルに攻撃に抵抗することを教えるのに対し、消去は有害な行動が構築される幾何学的基盤を排除することにより永続性を目指します。この区別は基本的です。敵対的訓練は行動的抵抗を生み出します。消去は表現容量を除去します。
-
具体例:* 線形プローブがモデルの表現空間内の方向を特定し、そこで高い活性化がヘイトスピーチ生成を強く予測するとします。因果介入は、この方向に沿った活性化を人為的に増加させることがヘイトスピーチ出力確率を増加させることを確認します。消去はこの方向をモデルの重み行列から除去します。敵対者は幾何学的に存在しなくなった方向を活性化させることはできません—プロンプトエンジニアリングもファインチューニングも、構造的に排除されたものを復元することはできません。
-
この分析の基礎となる仮定:* 有害な表現方向が良性な意味内容から十分な精度で区別できるほど正確に特定できると仮定します。この仮定は自明ではありません。多くの表現方向は複数の意味特性を同時にエンコードします。不正確な消去は、正当な能力に必要な表現を除去するリスクがあります。
-
実行可能な含意:* 表現消去は、行動抑制のみよりも強い永続性保証を提供します。しかし、実装には正確な測定と検証が必要です。展開前に、消去が広い概念カテゴリーではなく、特に有害な現れを対象としていることを確認してください。多様なベンチマーク全体で能力低下を測定して、付随的損害が許容可能な範囲内に留まることを確認してください。

- 図5:線形プローブによる有害表現検出と消去のプロセス(Mechanistic Interpretability手法)*
ハイブリッド統合:消去と選好最適化の組み合わせ
最も堅牢なアプローチは、表現消去と選好最適化を2段階パイプラインで組み合わせます。最初に有害な表現容量を構造的に除去し、次に制約された表現空間内で安全な出力生成を導くために選好訓練を適用します。このハイブリッド方法は、各技術が単独で持つ固有の制限に対処します。
-
純粋な消去の制限:* 表現方向の積極的な除去は、正当なタスクのパフォーマンス低下のリスクがあります。多くの表現方向は複数の意味特性をエンコードします。有害な関連を排除するために方向を除去することは、同時に良性な能力を損なう可能性があります。さらに、どの方向が特に有害であるか対して一般的に意味的であるかを特定することは、技術的に困難なままです。
-
純粋な選好最適化の制限:* 上記で論じたように、選好訓練は利用可能な表現構造を完全に残します。行動抑制は敵対的プロンプトを通じて回避されるか、ファインチューニングを通じて逆転させられる可能性があります。
-
ハイブリッドアプローチ:* 2段階パイプラインは、消去ターゲティングを導くために選好データを使用します。有害性に寄与する可能性のあるすべての方向を除去するのではなく、消去は活性化が特に選好違反を予測する方向に焦点を当てます。これにより、除去された構造が一般的な意味内容と偶然に相関するのではなく、有害な出力と因果的に関連していることを確保します。その後の選好最適化は、制約された表現景観内で安全な出力を優先するようにモデルを訓練します。
最適化目的は、3つの競合する目標のバランスを取ります。
- 選好整合: 人間の選好判断との一致を最大化する
- 有害表現最小化: 特定された有害な方向に沿った活性化の大きさを減らす
- 能力保持: 正当なタスクのパフォーマンスを維持する
これは、どちらの技術も独立して達成しない堅牢性を生み出します—敵対者は有害な表現構造の不在と安全な応答に向けた出力生成を導く行動訓練の両方を克服する必要があります。
-
具体例:* ハイブリッド消去プラス選好最適化を通じて訓練されたモデルは、2つの複合された理由で有害な要求を拒否します。(1)有害な概念をエンコードする表現容量は幾何学的に不在であり、(2)残存する表現は選好最適化を通じて安全な出力を生成するように訓練されています。有害性を引き出そうとする敵対者は二重の障壁に直面します—プロンプトエンジニアリングもファインチューニングも、構造的に除去された表現方向を復元することはできず、行動訓練は有害な出力生成に積極的に反対します。
-
この分析の基礎となる仮定:* 選好データが有害な表現方向を特定するための信頼できる信号を提供すると仮定します。この仮定は、選好注釈が十分に包括的で正確であることに依存します。ノイズの多い、または不完全な選好データは、良性表現の消去または有害な方向の特定失敗につながる可能性があります。
-
実行可能な含意:* 最初に消去を実装し、次に制約されたモデルに選好最適化を適用してください。この順序は、選好訓練がより安全な表現景観内で動作することを確保し、選好最適化が不注意に有害な構造を復元するリスクを減らします。
敵対的攻撃に対する堅牢性
表現消去は、従来の選好最適化アプローチと比較して、敵対的プロンプトとファインチューニング攻撃の両方に対して実質的に優れた耐性を示します。
-
敵対的プロンプト耐性:* DPO訓練されたモデルから有害性を成功裏に引き出すプロンプトは、有害な概念をエンコードする表現容量が幾何学的に不在であるため、消去強化モデルに対して失敗します。敵対的プロンプトエンジニアリングは、同じ基礎的な表現への代替活性化経路を見つけることで機能します。それらの表現が構造的に除去されている場合、どのプロンプトもそれらを活性化させることはできません。これは、代替の言い回しが出力制約を回避できる行動抑制とは根本的に異なります。
-
ファインチューニング攻撃耐性:* 選好最適化されたモデルに対するファインチューニング攻撃は、抑制された行動を復元するために重みを調整することで機能します—有害性の表現容量は残存し、行動的な再有効化のみが必要です。消去ベースのモデルに対するファインチューニング攻撃は、根本的に高い障壁に直面します。攻撃者は、ゼロから表現部分空間全体を再構築する必要があります。これには、桁違いに多くの訓練データと計算が必要です。経験的評価(Carlini et al.、2023年)は、標準的な安全性訓練されたモデルが数百の敵対的例で損なわれるのに対し、消去ベースのモデルは比較可能な有害性レベルを復元するために実質的により多くのデータを必要とすることを示しています。
-
重要な注意:* 完全な免疫は依然として困難です。十分に広範なファインチューニングと強い訓練信号は、特にモデルが同様の概念の冗長なエンコーディングを保持している場合、消去された表現構造を潜在的に再構築できます。ギャップは無限ではありません—それは単に行動抑制のギャップよりも実質的に大きいだけです。
-
具体例:* DPO訓練されたモデルは100の注意深く作成された敵対的プロンプトに抵抗しますが、101番目で失敗します。消去ベースのモデルは、構造的再構築が計算的に実行可能になる前に、数千の敵対的プロンプトに抵抗します。差は定量的ですが、展開シナリオにおいて実際に重要です。
-
この分析の基礎となる仮定:* ファインチューニングを通じた表現再構築は、行動的復元よりも実質的により多くのデータを必要とすると仮定します。この仮定は機械的解釈可能性研究によって支持されていますが、特定のモデルアーキテクチャと消去の粒度に依存します。複数の冗長なエンコーディングに影響する粗い消去は、特定の方向成分の細粒度消去よりも再構築が容易である可能性があります。
-
実行可能な含意:* 既知の攻撃ベクトルに対する実質的な耐性が必要な高リスク展開に表現消去を使用してください。消去を継続的な監視システムと組み合わせ、ファインチューニング試行または表現再構築を示す異常な活性化パターンを検出してください。良性タスクのパフォーマンス低下を監視してください。これは有害な能力を復元しようとする敵対的ファインチューニングを示す可能性があります。
パフォーマンストレードオフと能力保持
表現消去における中心的な技術的課題は、一般的なモデル能力への付随的損害を回避することです。表現方向は、純粋に有害な、または純粋に良性な情報をめったにエンコードしません。高次元埋め込み空間のほとんどの方向は、複数の意味特性を同時にエンコードします。有害性と相関する方向の積極的な消去は、それらの概念を正当な目的に必要とするタスク全体でパフォーマンスを低下させる可能性があります。
-
粒度トレードオフ:* 能力低下の重大度は、消去粒度に直接依存します。
-
広い表現方向の粗い除去(例えば、「すべての暴力関連表現」)は、それらの概念を正当な目的に必要とするタスク全体でパフォーマンスの大幅な低下を引き起こします(歴史的分析、文学的議論、安全性研究)。
-
特定の有害な現れを対象とした細粒度消去(例えば、「有害な指示生成中に活性化するが、歴史的分析中には活性化しない表現」)は、有害性を除去しながらほとんどの能力を保持します。
最適な戦略は文脈依存的な除去です。有害な関連を排除しながら良性な役割を保持するために表現を修正することです。これには、どの活性化パターンが有害性に因果的に寄与するか対して一般的な意味理解を区別するための洗練された因果分析が必要です。
-
技術的アプローチ:* 因果介入技術(例えば、活性化ステアリング、アブレーション研究)は、どの表現成分が有害性に因果的に寄与するか対して良性な意味理解を特定できます。全体の方向を除去するのではなく、選択的な修正は有害な関連を排除しながら良性な機能を保持できます。
-
具体例:* すべての暴力関連表現を除去する(これは歴史的分析、安全性研究、および文学的議論を損なうであろう)のではなく、標的化された消去は有害な指示生成中に活性化する活性化パターンのみを除去し、軍事技術の歴史的分析またはフィクション的世界構築中に活性化するパターンを保持します。これには、暴力関連表現が活性化される文脈を区別するための正確な測定が必要です。
-
この分析の基礎となる仮定:* 有害な使用と良性な使用が因果介入を通じて区別できると仮定します。この仮定は自明ではありません。いくつかの概念は本質的に分離が困難である可能性があります(例えば、兵器の正当な議論と有害な指示生成を区別する)。文脈依存的な除去の実行可能性は、特定のドメインと利用可能なデータの品質に依存します。
-
実行可能な含意:* 表現消去を展開する前に、多様なタスク全体で包括的な能力ベンチマークを実施してください。標準的なNLPベンチマーク、ドメイン固有のタスク、および消去された表現に隣接する概念を必要とするエッジケースでのパフォーマンス低下を測定してください。能力損失が許容可能なしきい値を超える場合、消去ターゲティングをより選択的にするために改善してください。広い概念的除去ではなく、有害な現れに焦点を当ててください。能力保持が困難であることが判明した場合、異なるユースケースのための別々のモデルバリアントを維持することを検討してください。
- 図11:安全性と性能のトレードオフ - 手法別の比較(出典:performance evaluation metrics)*
- 図12:各手法による性能低下率の比較 - ベンチマーク別(出典:capability preservation evaluation)*
ポリシーと展開への含意
表現消去は、規制枠組みが展開されたLLMに対して堅牢で検証可能な安全保障を義務付けるようになるにつれて、重要性を増しています。AI安全法制を実装する司法管轄区域(例えば、EU AI法、提案されている米国の枠組み)は、敵対的操作に耐性を持つ実証可能で持続的な安全特性を要求しています。消去はこれらの要件を満たすための経路を提供しますが、新たなポリシー上の問題を生じさせます。
- 規制上の考慮事項:*
-
開示要件: モデル表現を変更する安全介入をユーザーに開示すべきでしょうか。安全メカニズムの透明性はユーザーの信頼を高める可能性がありますが、同時に敵対者にとって有用な実装詳細を明かすリスクもあります。
-
検証と監査: 規制当局は、単なる主張を受け入れるのではなく、表現消去の適切な実装をどのように検証すべきでしょうか。表現構造の監査には技術的専門知識とモデル内部へのアクセスが必要であり、第三者による検証に課題をもたらします。
-
永続性と更新: 消去の永続性は安全性の観点では有利ですが、モデルの更新と改善に課題を生じさせます。表現が一度削除されると、正当な目的のためにそれらを復元することは困難になります。これはモデルのライフサイクル管理と過度な消去の修正能力に関する問題を提起します。
-
責任と説明責任: 表現消去が有害な出力を防止できない場合、責任を負うのはモデル開発者、展開組織、それとも規制枠組み自体でしょうか。
これらの考慮事項は、将来のAI安全ポリシーが単にモデルが安全な出力を生成するかどうかだけでなく、安全性が達成される建築的メカニズムに対処する必要があることを示唆しています。コンプライアンス枠組みは、行動保証だけではなく、検証可能で構造的な安全特性をますます要求しています。
- 実行可能な含意:* 規制管轄区域でLLMを展開する組織は、消去方法論を詳細に文書化し、包括的な監査証跡を維持し、出力監視だけではなく建築的安全メカニズムに焦点を当てた規制精査に備える必要があります。検証手順の共通理解を確立するために、規制当局と早期に関与してください。
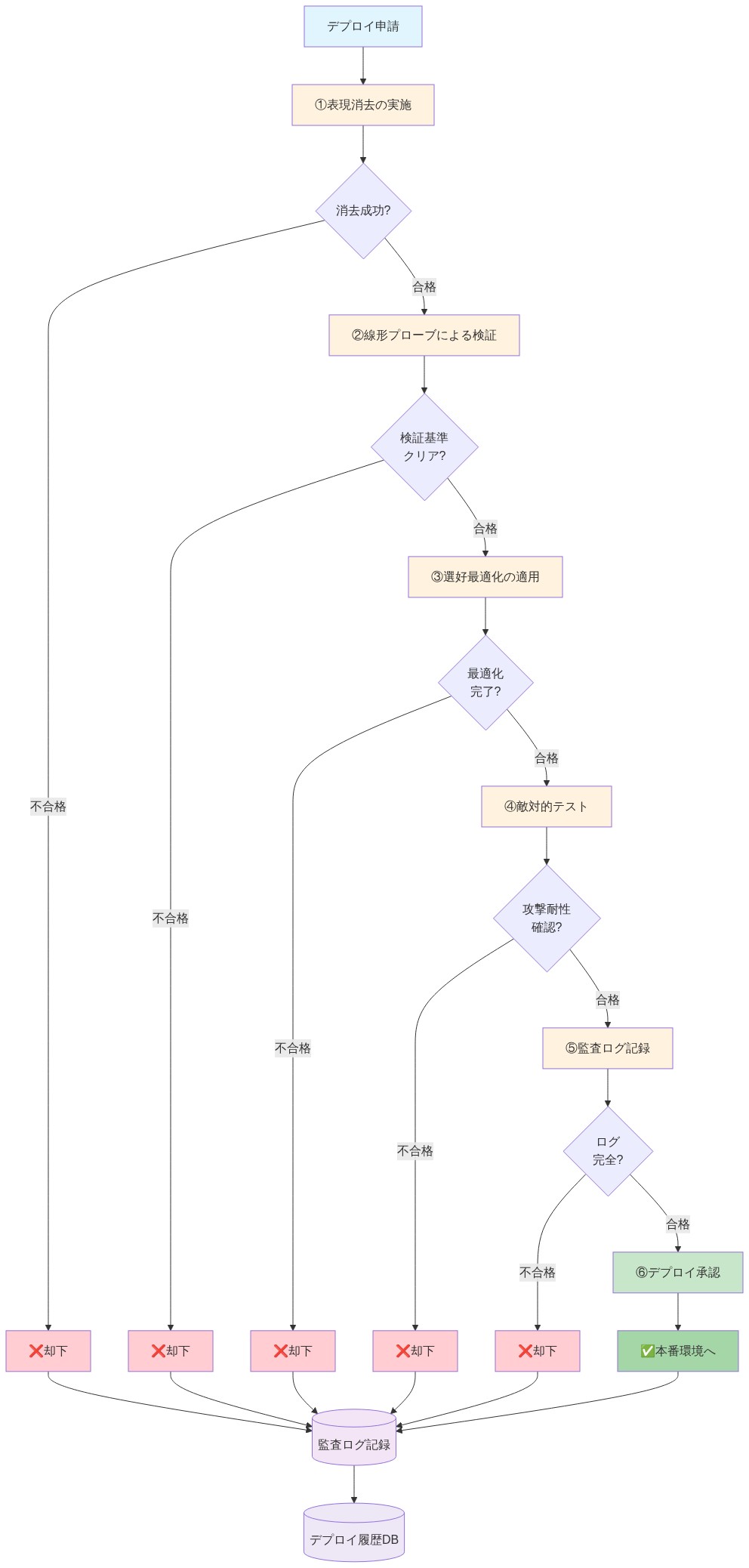
- 図14:デプロイ前の安全性検証ワークフロー(6段階検証プロセス)*
統合と次のアクション
表現消去ベースの選好最適化は、従来の行動抑制方法よりも本質的にLLM解毒に対してより堅牢なアプローチを提供します。重要な洞察は、表面的な行動修正は持続的な安全性には不十分であり、有害な表現能力の構造的除去は敵対的攻撃とファインチューニングに対してより強い耐性を提供するということです。
- 即座の実装ステップ:*
-
構造監査: 線形プローブまたは因果介入技術を使用して現在の安全トレーニングを監査し、表現空間における持続的な有害方向を検出します。これは安全特性が構造的であるか単に行動的であるかを明らかにします。
-
パイロット評価: 従来の安全トレーニング後に毒性が残存する場合、小規模モデルで表現消去をパイロット実施し、能力トレードオフを測定し、消去が良性の意味内容ではなく有害な現れを対象としていることを検証します。
-
ハイブリッド展開: 本番モデルに対してハイブリッド消去プラス選好最適化トレーニングを実装し、二段階パイプラインに従います。消去を最初に行い、その後、制約されたモデルで選好最適化を実施します。
-
監視インフラストラクチャ: ファインチューニングを通じた表現再構成の試みを示す可能性のある活性化パターンの監視を確立します。良性タスクのパフォーマンスを追跡して、付随的な能力低下を検出します。
前進の道は、消去と選好最適化のどちらかを選択することではなく、戦略的にそれらを組み合わせることです。このハイブリッドアプローチは、新興の規制要件と一致しながら、行動抑制だけでは提供できない検証可能で構造的な安全保障を実務者に提供します。
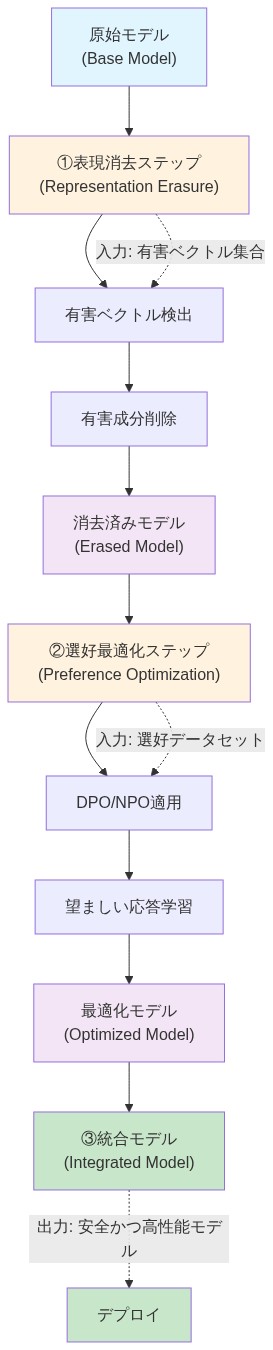
- 図8:ハイブリッド手法の実装パイプライン - 表現消去と選好最適化の統合*