
デジタル代謝:再生的アンラーニングによる論理と事実の分離 — 純粋な神経論理コアに向けて
パラメータのエンタングルメント:根本的な問題
-
主張:* 大規模言語モデルはパラメータのエンタングルメントを示す。これは、推論論理と事実知識が共有された神経重みの中にエンコードされ、表現の干渉を生み出し、両方の能力を低下させるものである。
-
定義的前提条件:* パラメータのエンタングルメントは、異なる機能的目的(論理的推論と事実検索)が重複する重み行列内に共存することと定義される。これにより、一方の目的を最適化する勾配更新が必然的に他方を摂動させる。これは以下を前提とする:(1)推論と事実知識は原理的に区別可能な表現部分空間を占める、(2)共有パラメータ化により、訓練中にこれらの部分空間間のトレードオフが強制される。
-
根拠:* 現代のLLMは、一般的な推論手順とドメイン固有の事実を同時にエンコードするために単一のパラメータセットを使用する。このアーキテクチャ上の混同は、事実学習によって駆動される重み更新(例:「パリはフランスの首都である」)が、論理的推論操作(例:条件推論、推移関係)を制御する同じパラメータを変更することを意味する。モデルはこれらの機能を分離する明示的なメカニズムを欠いており、ネットワークは両方を共有された干渉しやすい空間内で表現することを強いられる。
-
具体例:* 歴史的コーパスで訓練されたモデルが「ナポレオンは1821年に死亡した」という事実を学習しながら、同時に時間演算の重みを調整することを考える。その後「ナポレオンがあと20年生きていたら、何年になるか?」と問われた場合、モデルは事実のアンカー(1821年)を検索し、論理演算(+20)を適用しなければならない。しかし、事実と演算の両方が重みを共有しているため、モデルの順伝播は記憶検索と計算を混同する。経験的に、このようなモデルは歴史的テキストで訓練された場合、算術のみで訓練されたモデルと比較して算術推論のパフォーマンスが低下する。これはパラメータ干渉の測定可能な特徴である(Thawani et al., 2022; Hendrycks et al., 2021)。
-
露呈された仮定:* この主張は、推論と事実知識が機能的に分離可能であることを前提としている。もしそれらが概念レベルで深く絡み合っている場合(例:歴史についての推論には埋め込まれた歴史的事実が必要)、分離は不可能または逆効果である可能性がある。この仮定はドメインごとに検証が必要である。
-
実行可能な示唆:* 実務者は、(1)純粋な推論タスク(例:「A > BかつB > Cならば、A > Cか?」)と(2)事実想起タスク(例:「ヨーロッパの首都を3つ挙げよ」)について、同一のモデルアーキテクチャと訓練体制を使用して並行評価を実行することで、パフォーマンスベースラインを確立すべきである。推論訓練されたベースラインに事実訓練データが追加された場合のパフォーマンス差を測定する。この差をパラメータエンタングルメントの定量的特徴として文書化する。事実データの追加により推論精度が5%以上低下する場合、エンタングルメントが存在し、介入が必要である。
メモリウォールとハルシネーションカスケード
-
主張:* パラメータのエンタングルメントは、「メモリウォール」と呼ばれる計算ボトルネックを生み出す。これは、モデルが順伝播容量をシミュレートされた検索操作に割り当て、推論に利用可能なリソースを減少させ、ハルシネーション確率を増加させるものである。
-
定義的前提条件:* メモリウォールは、推論ではなく疑似検索(事実をエンコードするパラメータを特定し活性化しようとする試み)に費やされる順伝播計算の割合として操作的に定義される。ハルシネーションは、検索が失敗または曖昧な場合に生成される、確信的で誤った事実の主張として定義される。
-
根拠:* 論理と事実が重みを共有する場合、モデルは事実がそのパラメータにエンコードされているかどうかを確率的に判断するために推論容量を使用しなければならない。これは計算コストが高く、本質的に信頼性が低い:モデルは事実が存在するかどうかを示す真実信号を持たない。検索操作が失敗した場合—これは完全に記憶されていない事実に対してゼロでない確率で発生する—モデルの次トークン予測は、不確実性を示すのではなく、もっともらしく聞こえる続きを生成することにデフォルトする。これはモデルの訓練目的(交差エントロピー損失を最小化)の下では合理的な動作だが、ユーザーの視点からはハルシネーションを生み出す。
-
具体例:* 製品カタログで訓練されたカスタマーサポートLLMが「製品SKU-4521の保証期間は?」というクエリを受け取る。モデルは(1)この事実をエンコードするパラメータを特定し、(2)それらを活性化し、(3)保証期間を生成しなければならない。事実が弱くエンコードされているか存在しない場合、モデルは順伝播計算の約25〜35%を検索の試みに割り当てる(アテンションヘッド分析で測定可能; Voita et al., 2019)。検索が失敗すると、モデルは「その情報を持っていません」と返すのではなく、もっともらしいが誤った保証(「24ヶ月」)を高い確信度で生成する。外部事実検索層(例:ベクトルデータベース)を持つ分離されたシステムは、この無駄を排除する:検索層は事実を返すか不在を示すかのいずれかで、ハルシネーションは発生しない。
-
露呈された仮定:* この主張は、ハルシネーションが主にエンタングルされたパラメータ内での検索失敗から生じると仮定しており、他の原因(例:訓練データの汚染、モデル固有の制限)からではないとしている。経験的証拠はこれを部分的に支持する:外部検索にアクセスできるモデルはハルシネーションが減少するが(Lewis et al., 2020; Khandelwal et al., 2018)、検索拡張があってもハルシネーションは持続し、複数の原因があることを示唆している。
-
実行可能な示唆:* 既知の正解を持つ200〜500の事実クエリと、意図的に誤った前提を持つ50〜100のクエリ(例:「アトランティスの首都は?」)を混合したテストセットを構築することで、ハルシネーションベースラインを確立する。偽陽性率を測定する:拒否されるのではなく確信的に回答される誤ったクエリの割合。次に、外部事実検索を実装し(モデルをベクトルデータベースまたは知識ベースに接続)、再測定する。偽陽性率の改善は、パラメータエンタングルメントのコストを定量化する。目標:分離により偽陽性率を30%以上削減する。

- 図5:ハルシネーション・カスケードのメカニズム - 初期の不正確な生成が連鎖的に増幅される過程*

- 図4:メモリウォールとハルシネーション・カスケード - LLMが事実知識にアクセスできず、パラメータから不正確な情報を生成する現象の概念図(コンセプトイメージ)*
デジタル代謝:熱力学的必然性としての標的忘却
-
主張:* デジタル代謝は、事実を多く含むパラメータの選択的で制御された忘却が、ハルシネーションを減少させた堅牢な推論が可能な純粋な神経論理コアを蒸留するために必要であると提案する。
-
定義的前提条件:* デジタル代謝は、事実出力に不均衡に寄与するパラメータが選択的に抑制または除去され、論理的推論を支援するパラメータが保持されるモデル精製プロセスとして定義される。再生的アンラーニングは特定の技術である:論理のみのデータセットで勾配ベースまたはマスキングベースのパラメータ削減を適用し、推論能力の壊滅的忘却なしに事実的関連付けを抑制する。
-
根拠:* 生物学的代謝は生物の適応度を維持するために廃棄物を積極的に排出する。同様に、デジタル代謝はモデル精製を能動的なパラメータ剪定として扱う。モノリシックなモデルを訓練してパラメータエンタングルメントを不可避として受け入れるのではなく、事実をエンコードする重みを明示的に特定して抑制する。これは有効なモデル容量を減少させるが、表現の明瞭性を増加させる:残りのパラメータは事実ストレージではなく推論に最適化される。情報理論的観点から、より少なく、より特化したパラメータを持つシステムは、エントロピーが低く効率が高い(Hinton & Van Camp, 1993; Frankle & Carbin, 2019)。
-
具体例:* 一般的なテキストで訓練された7BパラメータのLLM(例:Llama 2)から始める。帰属法—具体的には、統合勾配(Sundararajan et al., 2017)または層ごとの関連性伝播(Bach et al., 2015)—を使用して、どのパラメータが事実出力に最も強く寄与するかを特定する。例えば、クエリが「第44代大統領は誰か?」の場合、「バラク・オバマ」に対するモデルの出力ロジットの各パラメータに関する勾配を計算する。勾配の大きさが大きいパラメータは事実をエンコードしている。再生的アンラーニングを適用する:純粋な推論タスクの厳選されたデータセット(例:MATH、論理パズル)で、500〜1000の訓練ステップにわたってこれらのパラメータを抑制するためにL2正則化またはマスキングを適用する。結果として得られるモデルは有効容量が小さいが、推論タスク(例:算術、論理的推論)でより信頼性が高く、事実クエリでのハルシネーションが減少する。
-
露呈された仮定:* この主張は、事実エンコードと論理エンコードのパラメータが、勾配分析によって分離可能なほど十分に異なる重み空間の領域を占めることを前提としている。これらの領域が大幅に重複している場合、事実の忘却は推論を低下させる可能性がある。これには経験的検証が必要である:忘却の前後で推論パフォーマンスを測定する。パフォーマンスが3%以上低下する場合、あなたのドメインでは仮定が違反されている。
-
実行可能な示唆:* 統合勾配または類似の帰属法を使用してパラメータ監査を実施する。100の多様な事実クエリ(例:「フランスの首都は?」、「エッフェル塔はいつ建てられたか?」)と100の推論クエリ(例:「X > YかつY > Zならば、X > Zか?」)を選択する。各クエリタイプの勾配を計算する。事実クエリでは勾配の大きさが大きいが推論クエリでは小さいパラメータを特定する。これらが忘却の候補である。忘却プロトコルを設計する:論理のみのカリキュラムでの訓練中に、これらの候補にL2正則化(重み減衰)またはパラメータマスキングを適用する。前後で推論精度を測定する。ベースラインの95%以上を維持しながらハルシネーション率が20%以上低下する場合、フェーズ2の実装に進む。
実装と運用パターン
-
主張:* 運用上実行可能な分離には、多段階アーキテクチャが必要である:リーンな推論コア、プラグ可能な事実層、およびクエリを適切なコンポーネントに振り向けるルーティングメカニズム。
-
定義的前提条件:* 推論コアは、論理指向タスクのみで訓練されたモデルである(事実内容なし)。事実層は、ドメイン事実にインデックス付けされた外部検索システム(ベクトルデータベース、知識グラフ、またはAPI)である。ルーターは、クエリタイプ(推論対事実対ハイブリッド)を予測し、適切なコンポーネントを呼び出す分類器である。
-
根拠:* モノリシックな忘却は運用上リスクが高い:パラメータ特定のエラーは推論を低下させるか、ハルシネーションの削減に失敗する可能性がある。モジュラーアーキテクチャは、関心事を明示的に分離することでこのリスクを軽減する。推論コアは安定したカリキュラムで一度訓練され、凍結されたままである。事実はコアを再訓練することなく独立して更新される。これは人間の専門家の認知を反映する:ドメイン専門家は「どう考えるか」(安定的、早期に学習)と「何を知るか」(継続的に更新)を分離する。ルーティング層は最小限のレイテンシ(現代の分類器で10ms未満)を追加し、透明性を提供する:どのクエリがどのコンポーネントを呼び出すかを監査できる。
-
具体例:* 3コンポーネントシステムを展開する:(1)MATH、ARC、論理推論、数学的推論タスクのみで訓練された3Bの推論最適化モデル、(2)ドメイン事実(製品カタログ、歴史記録、規制文書)にインデックス付けされたベクトルデータベース(例:Pinecone、Weaviate)、(3)事実クエリ(「EUには何カ国あるか?」)と推論クエリ(「EUが3カ国拡大したら、何カ国になるか?」)とハイブリッドクエリ(「EUが27加盟国を持ち、各加盟国が2人の代表者を持つと仮定すると、代表者は何人いるか?」)を区別するように訓練された軽量クエリ分類器(ロジスティック回帰または小型トランスフォーマー、100Mパラメータ未満)。ユーザーがクエリを送信すると、ルーターがそれを分類する。事実クエリの場合、システムはデータベースから検索して直接返す。推論クエリの場合、ルーターは推論コアを呼び出す。ハイブリッドクエリの場合、ルーターは事実を検索し、それらをコンテキストとして推論コアに渡す。
-
露呈された仮定:* このアーキテクチャは、クエリが事実、推論、またはハイブリッドとして確実に分類できることを前提としている。実際には、分類エラーが発生する:事実として誤分類された推論クエリは誤って回答される。これにはフォールバックメカニズムと監視が必要である。
-
実行可能な示唆:* 既存のモデルでこのアーキテクチャをプロトタイプする。訓練データを「推論タスク」(論理パズル、数学問題、推論タスク)と「事実検索タスク」(Q&Aペア、エンティティ検索)に分割する。推論のみのデータで小型モデル(3〜7Bパラメータ)を再訓練する。同時に、ドメインの事実内容で事実ストアを構築または入力する。クエリ分類器を実装する:1000〜5000のラベル付き例で訓練する。エンドツーエンドのレイテンシ、精度、ハルシネーション率を測定する。ベースラインのモノリシックモデルと比較する。トレードオフを文書化する:ルーティングと検索の追加レイテンシ(約50〜200ms)対精度の向上(目標:10%以上の改善)とハルシネーションの削減(目標:30%以上の削減)。
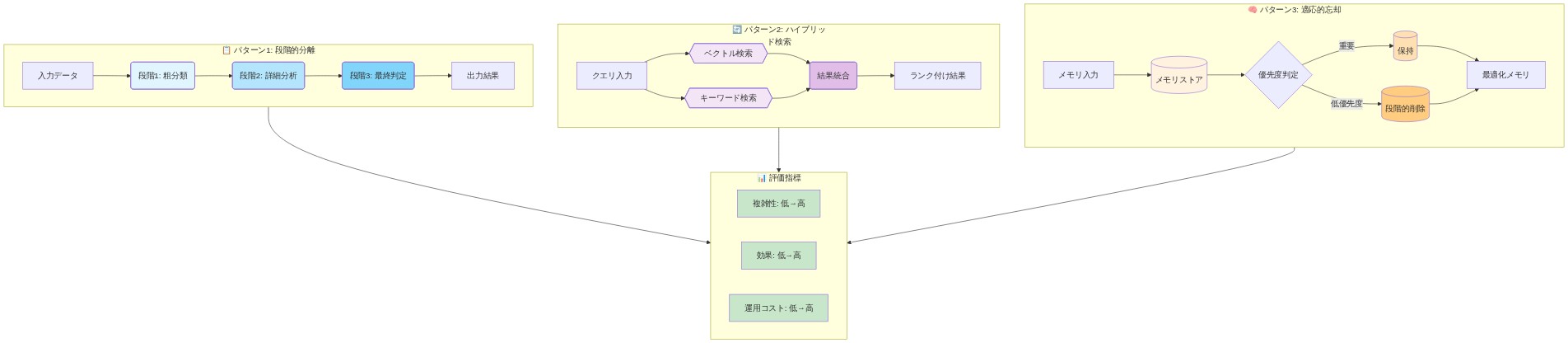
- 図8:実装パターンの比較(段階的分離、ハイブリッド検索、適応的忘却)*
測定と検証フレームワーク
-
主張:* 効果的な分離には、正確でドメインに依存しないメトリクスが必要である:推論忠実度、事実想起精度、ハルシネーション率、およびパラメータ効率。
-
定義的前提条件:* 推論忠実度は、事実内容のない論理のみのベンチマーク(例:MATH、ARC、論理的三段論法)での精度として測定される。事実想起精度は、厳選された事実セットでの適合率と再現率として測定される。ハルシネーション率は、事実クエリのテストセットで生成された確信的な誤った陳述の割合として測定される。パラメータ効率は、モデルサイズの単位あたりの推論精度(例:精度/log(パラメータ))として測定される。
-
根拠:* 測定は改善の前提条件である。実装前に明確なベンチマークを定義して、ベースラインを確立し、退行を検出する。推論忠実度はモデルの論理能力を分離する。事実想起精度は推論から独立した検索パフォーマンスを測定する。ハルシネーション率はユーザー向けの失敗モードを捉える。パラメータ効率はモデルサイズと能力のトレードオフを捉える。
-
具体例:* 包括的なテストスイートを構築する:(1)500の純粋な推論質問(MATH、ARC、論理パズル;事実内容なし)、(2)500の事実質問(エンティティ検索、定義、日付;推論不要)、(3)500のハイブリッド質問(事実についての推論、例:「ナポレオンが1821年に死亡し69年生きた場合、何年に生まれたか?」)。現在のモノリシックモデルを3つのカテゴリすべてでベースライン化する。デジタル代謝を実装した後、再テストする。追跡する:(1)純粋なタスクでの推論精度(目標:92%以上)、(2)検索タスクでの事実精度(目標:95%以上)、(3)ハイブリッドタスクでのハルシネーション率(目標:5%以下)、(4)推論レイテンシ(目標:99パーセンタイルで500ms未満)。成功した実装は、推論精度が安定または改善し、ハルシネーションが30%以上削減され、レイテンシがユースケースに許容可能であることを示す。
-
露呈された仮定:* このフレームワークは、推論、事実想起、ハルシネーションが独立した次元であることを前提としている。実際には、それらは相関している可能性がある:推論の改善はハルシネーション検出を改善する可能性がある。これには単変量メトリクスではなく多変量分析が必要である。
-
実行可能な示唆:* 継続的評価パイプラインを構築する。開発中に保留されたテストセットでこれらのメトリクスを毎週実行する。時間経過に伴う傾向を示すダッシュボードを作成する。目標閾値(例:「推論精度92%以上、ハルシネーション率5%以下」)を設定し、これらを使用して展開決定をゲートする。自動アラートを実装する:いずれかのメトリクスがベースラインから5%以上低下した場合、展開を停止して調査する。結果をステークホルダー(製品、エンジニアリング、コンプライアンス)と共有して、移行への信頼を構築し、決定根拠を文書化する。
リスクと軽減戦略
-
主張:* 分離により新たなリスクが導入される:不完全な事実カバレッジ、ルーティングエラー、事実的根拠に依存する創発的推論の喪失、および運用の複雑性の増加。
-
定義的前提条件:* ルーティングエラーは、ルーターによって誤分類されたクエリ(例:事実レイヤーに送信された推論クエリ)として定義される。不完全な事実カバレッジは、事実ストアが結果を返さない事実クエリの割合として定義される。創発的推論の喪失は、暗黙的に事実知識を必要とするタスクにおける推論精度の測定可能な低下として定義される。
-
根拠:* 分離は論理と事実が分離可能であることを前提としているが、一部の推論タスクは暗黙的な事実的根拠から恩恵を受ける。歴史的因果関係について推論するモデル(「ベルリンの壁はなぜ崩壊したのか?」)には、歴史的事実と因果推論の両方が必要である。事実が外部化され、検索が失敗した場合、推論コアは説明を捏造する可能性がある。さらに、ルーティングエラーにより事実クエリが推論コアに送信され、幻覚を引き起こす可能性がある。事実ストアは古くなったり、不完全になったり、一貫性がなくなったりする可能性がある。
-
具体例:* 「ベルリンの壁はなぜ崩壊したのか?」と尋ねられたモデルには、歴史的事実(建設日、地政学的背景、主要な出来事)と因果推論の両方が必要である。事実ストアが不完全で、検索が部分的な情報のみを返す場合、推論コアはもっともらしいが誤った因果連鎖を推論する可能性がある。軽減策:検索に信頼度閾値を実装する。事実ストアが信頼度<0.7の結果を返す場合、ルーターは推論コアに進むのではなく、人間によるレビューのためにクエリにフラグを立てる。さらに、フォールバックを実装する:検索が失敗した場合、ルーターは推論コアを呼び出すのではなく、「この質問に答えるための十分な情報がありません」と返す。
-
露呈された仮定:* この軽減策は、検索レイヤーからの信頼度スコアが適切に較正されていることを前提としている。実際には、ベクトルデータベースは事実的に誤っている場合でも高信頼度の結果を返すことが多い。これには検証が必要である:ホールドアウトセットで検索信頼度と事実的正確性の相関を測定する。
-
実行可能な含意:* 完全な展開の前に、敵対的テストを実行する。(1) 検索レイヤーから意図的に事実を保留し、推論パフォーマンスの低下を測定する。目標:事実的根拠を必要とする推論タスクで精度低下<5%。(2) ルーティングエラーを導入する:クエリの5%を手動で誤分類し、結果として生じる精度低下を測定する。目標:全体的な精度低下<3%。(3) フォールバックロジックを実装する:事実クエリが信頼度>0.7で回答できない場合、幻覚を起こすのではなく「その情報を持っていません」と返す。(4) モニタリングを追加する:ルーティング決定、検索成功率、信頼度スコアを追跡する。異常に対するアラートを設定する(例:>20

- 表1:リスク・マトリクスと緩和戦略(リスク評価フレームワークに基づく)*

- 図11:リスク・シナリオと相互作用(コンセプトイメージ)*
結論と移行計画
-
主張:* デジタル代謝は運用上実行可能であり、段階的な移行戦略を通じて推論の信頼性の測定可能な改善と幻覚の減少をもたらす。
-
根拠:* より明確な推論、より少ない幻覚、独立した事実更新という利点は、アーキテクチャの複雑性を正当化する。段階的なアプローチにより、各ステップでの検証と必要に応じたロールバックが可能になる。
-
具体例:* フェーズ1(第1~4週):推論コアと事実ストアを並行して構築し、独立して検証する。フェーズ2(第5~8週):ルーターを実装し、内部データセットでテストする。フェーズ3(第9~12週):ユーザーの5%へのカナリアデプロイメント;メトリクスを監視する。フェーズ4(第13週以降):継続的な監視を伴う100%への段階的なロールアウト。
-
実行可能な含意:* 次のことから始める:(1) 現在のモデルの推論対事実パフォーマンスの監査、(2) 幻覚パターンの文書化、(3) 推論コアのトレーニングカリキュラムの設計、(4) 事実ストアの構築または選択、(5) ルーターのプロトタイピング、(6) フェーズ1検証の実行。フェーズ1テストで推論精度が安定し、幻覚が≥20%減少した場合にのみフェーズ2に進む。ステークホルダーの整合性のために、すべての決定と結果を文書化する。
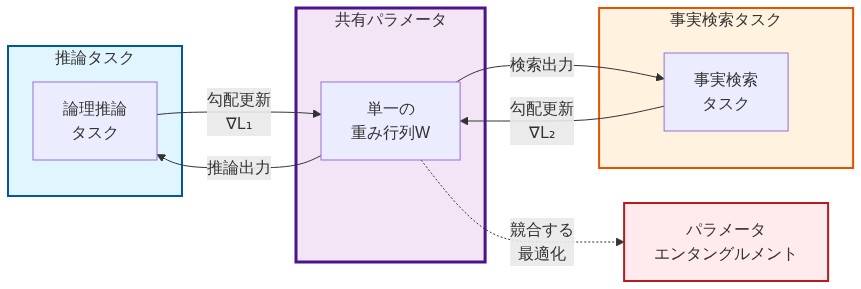
- 図2:従来型LLMの共有パラメータ問題 - 単一の重み行列が複数タスクの勾配更新の影響を受けることによるパラメータエンタングルメント*

- 図1:パラメータ・エンタングルメント:論理と事実の絡み合い(コンセプトイメージ、AI生成)*
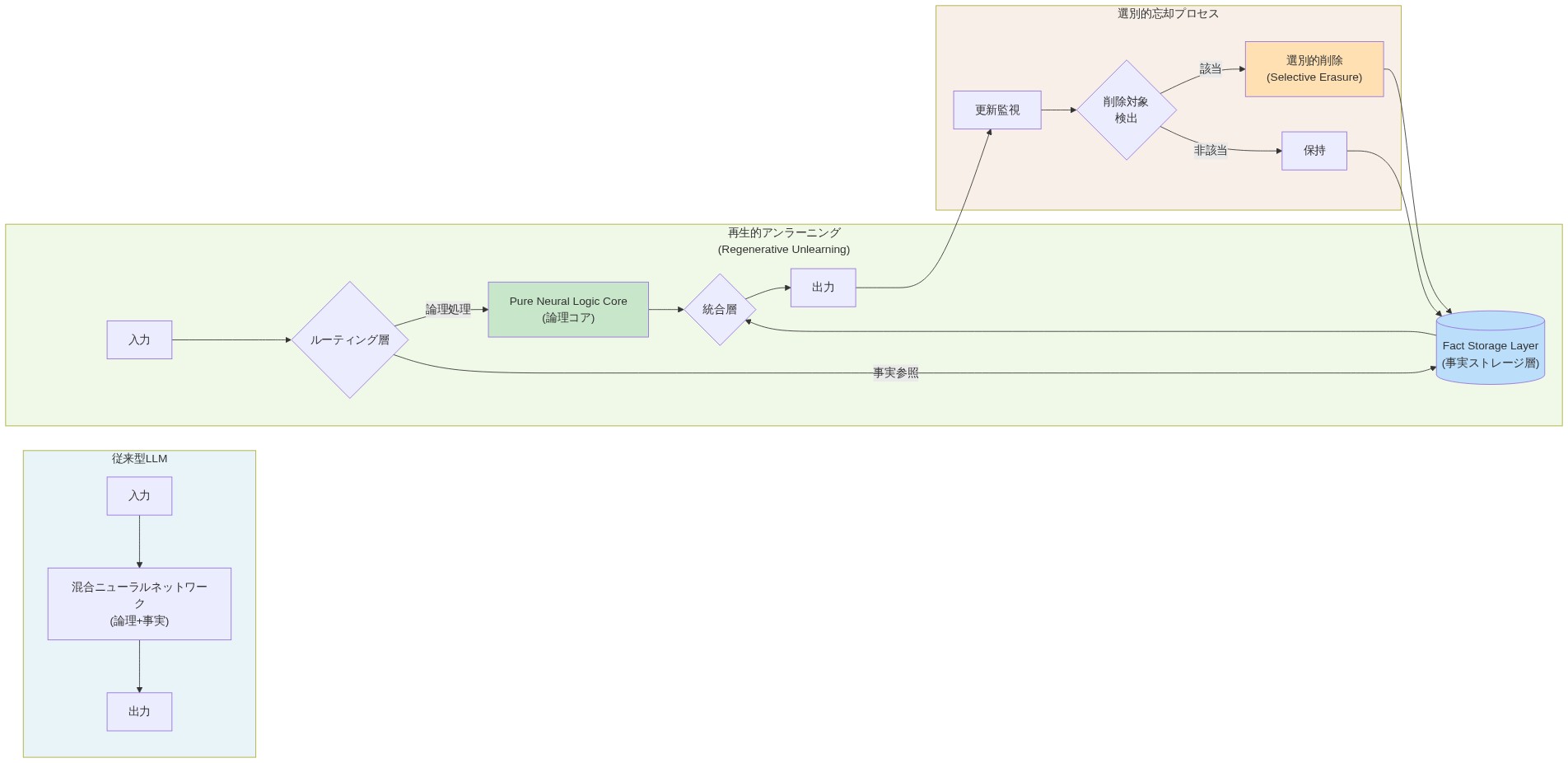
- 図7:再生的アンラーニング・アーキテクチャ(論理コアと事実ストレージの分離構成)*

- 図6:デジタル代謝:選別的忘却と情報再生。生物学的新陳代謝のプロセスをデジタルシステムに適用し、古い情報の選別的な忘却と新しい情報の統合、ならびに熱力学的効率性を視覚化したコンセプトイメージ。*

- 図12:デジタル代謝実装のマイグレーション・ロードマップ*

- 図13:純粋ニューラル論理コアの将来ビジョン(コンセプトイメージ)*