
Docker Sandbox: MicroVM分離によるAI支援開発の隔離環境
Dockerが発表したDocker Sandboxは、Docker DesktopのWindows版およびmacOS版に統合されたセキュリティ機能である。この機能は軽量仮想マシン(MicroVM)、具体的にはLinuxkitベースのハイパーバイザーインスタンスを活用し、隔離された実行環境を構築する。技術的動機は明確に記録された課題に対処している。すなわち、開発者マシン上で実行されるAIコーディングエージェント(Claude CodeやGemini CLIなど)は、ホストシステムリソースへの無許可アクセスを軽減するため、境界を持つ実行コンテキストを必要とするのだ。
-
基本的主張:* Linuxネームスペースとcgroupsを経由したコンテナレベルの隔離はプロセスレベルの分離を提供するが、ハイパーバイザーレベルのエスケープベクトルや、信頼できない、あるいは半信頼的なコード生成ツールが昇格された能力で実行される場合の特権コンテナ脱出シナリオを防止しない。
-
根拠と証拠:* AIの言語モデルは本質的に悪意あるものではないが、セキュリティ上の含意に対する意味論的理解なしにコードを生成する。生成されたコードは無意識のうちに以下を含む可能性がある。
-
/etc/passwd、SSHキー、認証情報ストアにアクセスするファイルシステムトラバーサルパターン -
APIキーやデータベース認証情報を抽出するための環境変数列挙
-
データ流出またはリバースシェル確立を目的とするネットワーク操作
MicroVMはハイパーバイザーが強制する境界(ホストOSに応じてType 1またはType 2ハイパーバイザー)を追加し、コンテナエスケープエクスプロイトがホストカーネルに到達することを防止する。これはコンテナエスケープとは異なる。コンテナエスケープは共有カーネルネームスペース内のカーネル脆弱性または設定ミスの能力を悪用するものだ。
-
具体例:* AIエージェントがディレクトリ内のファイルをリストするPythonコードを生成する。サンドボックス隔離がなければ、エージェントは
os.listdir('/home/user/.ssh')を実行し、秘密鍵を読み取ることができる。マウントされたボリュームが/tmp/sandbox_workに制限されたMicroVMサンドボックス内では、同じコードはファイルが見つからないエラーで失敗し、エージェントのアクセスを指定された一時ディレクトリに限定する。 -
実践への含意:* 開発チームはエアギャップマシン、生成されたすべての行に対する手動コードレビュー、またはAIツールの完全な無効化を必要とせずに、AI支援コード生成ワークフローを採用できる。サンドボックスモデルはリスク段階的アプローチを可能にする。低リスク生成タスク(ボイラープレート、ドキュメント)は最小限のレビューで実行可能。高リスクタスク(認証情報処理、システム管理)は追加の制御を必要とする。
セキュリティの根拠
従来のコンテナ隔離は、信頼できない、あるいは半信頼的なコード生成ツールが開発者マシン上で実行される場合に不十分である。AIエージェントは無意識のうちに、あるいは悪意を持って機密ファイル、環境変数、またはシステムリソースにアクセスできる。MicroVMベースのサンドボックスはハイパーバイザーが強制する境界を追加し、コンテナ脱出が悪用する可能性のあるエスケープパスを防止する。
-
例:* ファイル操作コードを生成するAIエージェントは一時ディレクトリに限定され、ホストの他の場所に保存されたSSHキーや認証情報を読み取ることができない。
-
含意:* 開発チームはエアギャップマシンや生成されたすべてのスニペットに対する手動コードレビューを必要とせずに、AI支援コーディングワークフローを採用できる。
- 図2:コンテナ隔離 vs MicroVM隔離の比較(Docker Sandbox・Firecracker アーキテクチャ参考)*
開発者向けの実践的統合
Docker Sandboxは既存のDocker Desktopアーキテクチャに統合され、開発者がdocker run、composeファイル、CLIツールなどの馴染みのあるワークフローを継続しながら、自動的な隔離を得ることができる。隔離は最小限の設定変更を必要とする。
Claude Codeを使用してNode.js APIをスキャフォールドする開発者は、コード生成用のサンドボックスコンテナを指定できる。AIはそのコンテナ内で動作し、コードを共有ボリュームに出力し、開発者はそれをレビューしてメインプロジェクトに統合する。チームは軽量なポリシー(「AIが生成したコードはマージ前にサンドボックスコンテナで実行される」など)を確立すべきであり、重厚な承認ゲートではなく。
- 含意:* 開発者は実験的または信頼できないコード生成が境界を持つことに確信を持ち、明らかに安全なパターンのレビュー負担を軽減する。
ガードレール付きの参照アーキテクチャ
サンドボックスの有効性は、単なる技術的隔離ではなく、意図的なガードレール設計に依存する。無制限のネットワークアクセス、無制限のメモリ、またはホストボリュームへのアクセスを持つサンドボックスは目的を無効にする。明確なポリシーは隔離をセキュリティに変換する。
三層の参照アーキテクチャはこの層構造を示す。
- 層1(サンドボックス): AIエージェントはホストファイルアクセスなし、ネットワークはプロキシに制限、メモリは2GBでキャップされたMicroVM内で実行される。
- 層2(ステージング): 生成されたコードは一時ボリュームに書き込まれ、構文チェックされ、疑わしいパターンがスキャンされる。
- 層3(統合): 承認されたコードは人間のレビュー後、メインプロジェクトリポジトリに移動される。
サンドボックスロールごとにリソースクォータ、ネットワークポリシー、ファイルアクセスルールを定義する。MicroVM隔離と並行してDocker の--cap-drop、--memory、--networkフラグを使用し、多層防御を実施する。
運用とライフサイクル管理
サンドボックス採用は、運用チームが体系的にサンドボックスを監視、デバッグ、更新できる場合にのみスケールする。アドホックなサンドボックス使用は設定ドリフト、忘れられたインスタンス、セキュリティ態勢の盲点につながる。
スケーラブルなパターンは以下を含む。
- 開発者はAIエージェントをラッパースクリプト経由で呼び出し、自動的にタグ付きサンドボックスコンテナを作成する。
- 各サンドボックスは中央シンク(例えば、SIEMに集約されたDockerログ)にログを記録する。
- サンドボックスイメージは最新のベースOSおよびツールパッチで週単位で再構築される。
- 失敗または疑わしいサンドボックス実行はアラートをトリガーし、法医学的分析のために保持される。
サンドボックステンプレートと自動化を確立する。Docker Composeを使用してサンドボックススタックを定義し、プライベートレジストリでサンドボックスイメージをバージョン管理し、CI/CDパイプラインにサンドボックス作成を統合する。古いサンドボックスのクリーンアップを自動化し、リソースリークを防止する。
測定と可観測性
効果的なサンドボックス展開はセキュリティ価値と開発者体験への影響の両方を示すメトリクスを必要とする。測定がなければ、採用は停滞するか、オーバーヘッドとして認識される。
-
主張:* 定量的データは運用コストを正当化し、サンドボックスがインシデントを防止している場合を特定するために必要である。
-
根拠:* チームはサンドボックスモデルに対する組織的信頼を構築し、実世界の使用パターンに基づいてポリシーを改善するための証拠を必要とする。
-
推奨メトリクス:*
-
採用率: サンドボックスで実行されたAI支援コード実行の割合(目標:3ヶ月以内に80%以上)
-
防止されたインシデント: サンドボックス内で検出およびブロックされた疑わしいアクティビティの数(例えば、許可されたパス外のファイルアクセス試行、予期しないネットワーク接続)。重大度とタイプ別に分類する。
-
開発者速度: コード生成から統合までの中央値時間。サンドボックス摩擦の有無で比較する。異なるコード生成ユースケース(ボイラープレート対複雑なロジック)で個別に追跡する。
-
リソース効率: サンドボックスワークロードの平均メモリ、CPU、ディスク使用量。このデータを使用してMicroVMサイジングとリソースクォータを最適化する。
-
誤検知: サンドボックスポリシーによってブロックされた正当な操作の数。高い誤検知率は過度に制限的なポリシーを示す。
-
サンドボックス信頼性: エラーなしで完了したサンドボックス実行の割合。失敗を調査し、設定ミスまたはリソース制約を特定する。
-
データ収集アプローチ:*
-
初日からDockerの組み込みスタット(
docker stats)とログ(docker logs)を使用してサンドボックス環境にテレメトリを装備する。 -
アプリケーションレベルの可観測性で補強する。生成プロンプト、出力ハッシュ、レビュー決定をログに記録する。
-
メトリクスを監視プラットフォーム(例えば、Prometheus、Datadog)にエクスポートし、可視化とアラートを行う。
-
月単位でダッシュボード形式で開発チームとメトリクスを共有し、信頼を構築してポリシーを改善する。
-
含意:* Docker Sandbox展開前に、現在のAI支援開発実践(サンドボックスなし)のベースラインを確立する。これにより、展開前後の比較が可能になり、ROIが実証される。
リスク評価と軽減
MicroVM隔離はリスクを軽減するが、排除しない。完全な隔離は存在しない。多層防御と脅威モデリングが不可欠である。
- 残存リスクと軽減策:*
| リスク | 軽減策 |
|---|---|
| 悪意あるAIモデルがMicroVMハイパーバイザーのカーネル脆弱性を悪用するコードを生成する | Docker DesktopとホストOSをパッチ適用し続ける。MicroVMイメージの定期的なセキュリティ監査を実施する |
| 開発者が誤ってサンドボックスアクセスを機密ホストディレクトリに付与する | ポリシーアズコード(例えば、OPA/Rego)を使用して許可されたマウントパスを強制する。週単位で設定を監査する |
| AIエージェントがDNSトンネリングまたは隠蔽チャネル経由でデータを流出させる | DNSクエリを監視および制限する。予期しない送信トラフィックをブロックするネットワークポリシーを使用する |
AI支援ワークフローの脅威モデリングを実施する。コード生成ユースケースごとに許容可能なリスクレベルを定義する。予防的制御が存在する場所でも、検出的制御(ログ、アラート)を実装する。
段階的移行パス
Docker Sandbox採用は段階的であるべきであり、低リスクのユースケースから始まり、チームが運用成熟度を構築するにつれて拡大する。
- 推奨タイムライン:*
- 1~2週目: Claude Codeを使用した非重要なコード生成(例えば、ボイラープレート、テスト)で小規模チームとサンドボックスをパイロットする。
- 3~4週目: ベースラインメトリクスを確立し、パイロットフィードバックに基づいてポリシーを改善する。
- 2ヶ月目: より広い開発者集団に拡大。サンドボックス作成を標準ワークフローに統合する。
- 3ヶ月目以降: 監視を運用化し、更新を自動化し、他のAIツール(Gemini CLIなど)に拡張する。

- 図10:Docker Sandboxへの段階的移行パス(3フェーズモデル)*
重要なポイント
- Docker Sandboxは信頼できないコード生成に適したハイパーバイザーが強制する隔離を提供する。
- サンドボックスの有効性は技術的能力だけでなく、意図的なポリシー設計に依存する。
- 測定と可観測性は採用の継続とその価値の実証に重要である。
- 残存リスクは脅威モデリングと多層防御戦略を必要とする。
次のステップ
現在のAI支援開発実践を評価する。最高リスクのユースケース(例えば、ネットワークアクセスを持つAIエージェント、システムファイルを変更するコードを生成するもの)を特定する。それらのワークロードでDocker Sandboxをパイロットする。採用、インシデント、開発者体験を測定する。データに基づいてポリシーと自動化を反復する。
開発者向け:摩擦のない実践的セキュリティ
開発者はDocker Sandboxから透過的な隔離を通じて利益を得る。それは既存のDocker Desktopワークフローに統合される。サンドボックスはランタイムオプションとして動作し、別のツールや承認プロセスではない。
-
主張:* サンドボックス採用は最小限の認知的または運用的オーバーヘッドを必要とする。そうでなければ、開発者は機構を回避するか、反発する。
-
根拠:* 摩擦を課すセキュリティ制御は頻繁に無効化または回避される。Docker Sandboxは、馴染みのあるコマンド(
docker run、docker compose、CLIツール)を保持しながら隔離を追加するDocker Desktop内のオプトインまたはデフォルトランタイムモードとして設計されている。 -
運用例:* 開発者はClaude Codeを使用してNode.js REST APIをスキャフォールドする。ワークフローは以下のように進行する。
- 開発者がサンドボックスコンテナを作成する。
docker run --sandbox --name ai-gen node:18 /bin/bash - Claude Codeはこのコンテナ内で実行され、
/app/generatedにコードファイルを生成する。 - 生成されたファイルは
./generated_codeのホストマウントボリュームに書き込まれる。 - 開発者は出力をレビューし、リンターとテストを実行し、承認されたコードをメインプロジェクトに統合する。
開発者のメンタルモデルは変わらない。「コンテナを実行し、出力を取得し、レビューし、統合する」。サンドボックスは透過的である。
- 含意:* チームは軽量なポリシー(例えば、「重要なパスのAI生成コードはマージ前にサンドボックスコンテナで実行される」)を確立すべきであり、重厚な承認ゲートや別のレビューチャネルではなく。これは明らかに安全なパターン(例えば、テストボイラープレート、ドキュメント生成)のレビュー負担を軽減しながら、機密コードパスに対する制御を維持する。
参照アーキテクチャとガードレール
サンドボックスの有効性は技術的隔離の上に層状化された意図的なポリシー設計に依存する。参照アーキテクチャはMicroVM隔離と明示的なリソースおよび能力制御を組み合わせる。
-
主張:* 技術的隔離だけでは不十分である。ポリシーオーバーレイは各サンドボックスが何にアクセスでき、どのリソースを消費するかを定義する。
-
根拠:* 無制限のネットワークアクセス、無制限のメモリ割り当て、またはホストボリュームへのアクセスを持つサンドボックスは隔離目的を無効にする。明確なポリシーは技術的境界をセキュリティ保証に変換する。
-
三層参照アーキテクチャ:*
-
層1(サンドボックス実行): AIエージェントはMicroVMコンテナ内で以下を伴って実行される。
- ホストファイルシステムへの直接アクセスなし(
/sandbox/inputと/sandbox/outputのマウントボリュームのみ) - ネットワークアクセスはプロキシまたはアロウリストに制限(例えば、パッケージレジストリのみ、外部APIなし)
- メモリは2GBでキャップ。CPUは2コアに制限
- 能力がドロップされる。
--cap-drop=ALL --cap-add=NET_BIND_SERVICE(最小セット) - 可能な限りルートファイルシステムは読み取り専用
- ホストファイルシステムへの直接アクセスなし(
-
層2(ステージングと検証): 生成されたコードは一時ボリュームに書き込まれ、その後。
- 言語固有のリンター(例えば、
eslint、pylint)を使用して構文チェックされる。 - 疑わしいパターンがスキャンされる(例えば、
eval()、exec()、ハードコードされた認証情報の正規表現) - メタデータでログに記録される。タイムスタンプ、AIモデルバージョン、プロンプトハッシュ、出力ハッシュ
- 言語固有のリンター(例えば、
-
層3(統合): 承認されたコードは以下の後、メインプロジェクトリポジトリに移動される。
- 人間のレビュー(コード差分、セキュリティチェックリスト)
- 自動SAST(静的アプリケーションセキュリティテスト)スキャン
- 監査証跡を伴うバージョン管理へのコミット
-
含意:* サンドボックスロールごとにリソースクォータ、ネットワークポリシー、ファイルアクセスルールを定義する。MicroVM隔離と並行してDocker の
--cap-drop、--memory、--cpus、--networkフラグを使用し、多層防御を実施する。各ポリシーの根拠を文書化する(例えば、「メモリは2GBでキャップされている。典型的なコード生成タスクは500MB未満を必要とする。2GBはリソース枯渇攻撃を可能にすることなくヘッドルームを提供する」)。

- 図4:Docker Sandbox参照アーキテクチャ - レイヤー構造とセキュリティガードレール*
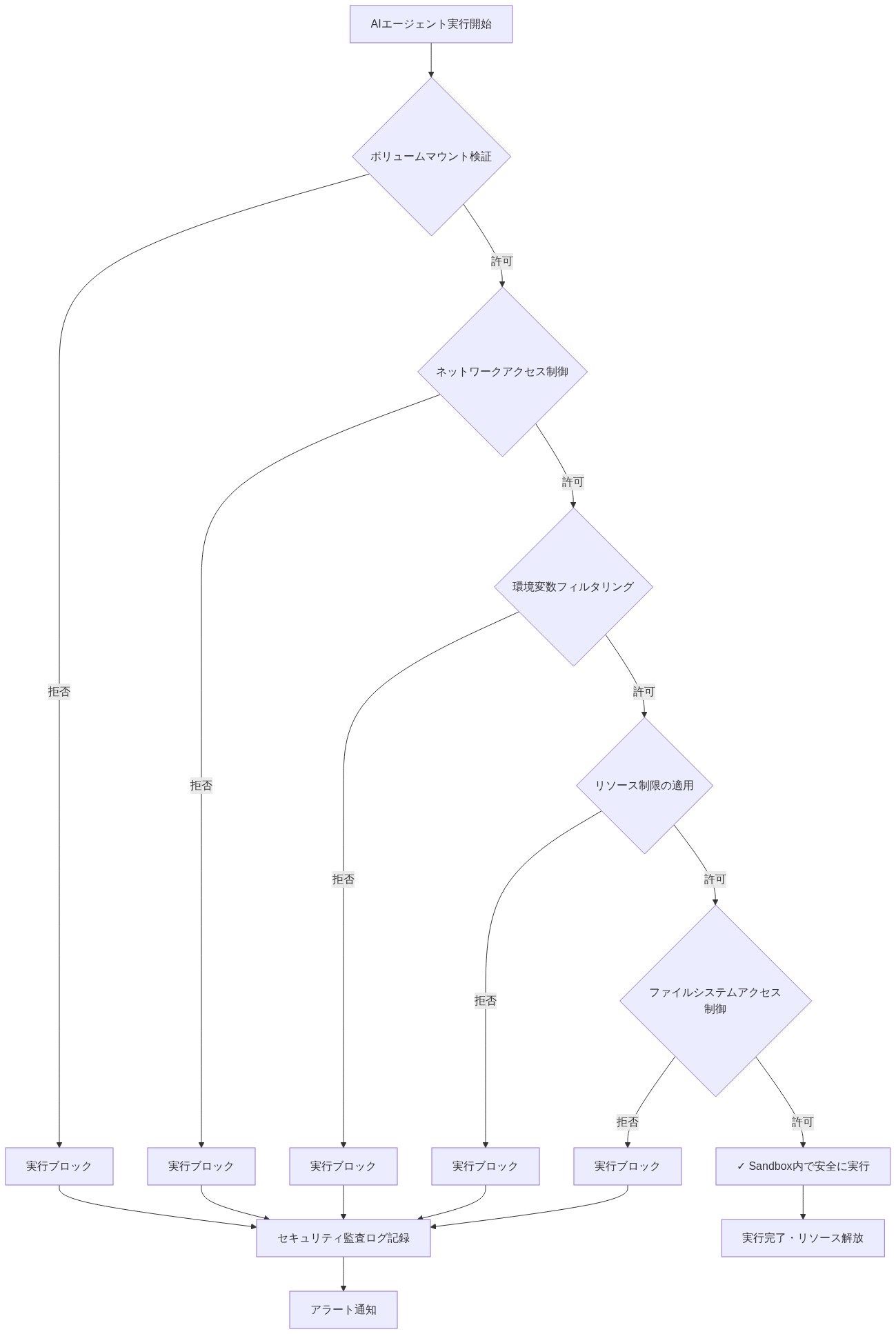
- 図5:Docker Sandboxガードレール実装フロー(AIエージェント実行時のセキュリティチェックポイント)*

- 表1:Docker Sandboxガードレール設定オプション比較(Docker Sandboxコンフィグレーションガイド)*
実装と運用パターン
Docker Sandboxの運用化はサンドボックスライフサイクル管理、ログ、CI/CDパイプラインとの統合の体系的なパターンを必要とする。アドホックなサンドボックス使用は設定ドリフトと盲点につながる。
-
主張:* サンドボックス採用は運用チームが体系的にサンドボックスを監視、デバッグ、更新できる場合にのみスケールする。
-
根拠:* 標準化されたパターンがなければ、チームは技術的負債を蓄積する。忘れられたサンドボックスインスタンスがリソースを消費し、設定が一貫性を欠き、可観測性にギャップが生じる。
-
運用パターン例:*
-
サンドボックス作成自動化: 開発者はAIエージェントをラッパースクリプト経由で呼び出し、以下を実行する。
- 一意のサンドボックスコンテナIDを生成する(例えば、
ai-gen-claude-20240115-001) - バージョン管理されたサンドボックスイメージからコンテナを作成する。
- 入出力ボリュームをマウントする。
- サンドボックス作成イベントをログに記録する(タイムスタンプ、開発者ID、AIツール、プロンプトハッシュ)
- 一意のサンドボックスコンテナIDを生成する(例えば、
-
集約ログ: 各サンドボックスは以下にログを記録する。
- Dockerのネイティブログドライバ(例えば、
json-fileまたはsplunk) - 集約ログサービス(例えば、ELK Stack、Datadog)
/sandbox/logsに書き込まれたアプリケーションレベルログ(ホストにマウント)
- Dockerのネイティブログドライバ(例えば、
-
イメージメンテナンス: サンドボックスイメージは以下である。
- 最新のベースOSパッチとツール更新で週単位で再構築される。
- コンテナイメージスキャナー(例えば、Trivy、Grype)を使用して脆弱性がスキャンされる。
- セマンティックバージョニングでタグ付けされる(例えば、
sandbox:1.2.3) - アクセス制御を伴うプライベートDockerレジストリに保存される。
-
インシデント対応: 失敗または疑わしいサンドボックス実行は以下を行う。
- アラートをトリガーする(例えば、「サンドボックスが
/sandbox/output外のファイルアクセスを試行した」) - 法医学的分析のために保持される(即座に削除されない)
- 週単位のセキュリティミーティングでレビューされる。
- アラートをトリガーする(例えば、「サンドボックスが
- 含意:* サンドボックステンプレートと自動化を確立する。Docker Composeを使用してサンドボックススタック(例えば、
docker-compose.sandbox.yml)を定義し、プライベートレジストリでサンドボックスイメージをバージョン管理し、CI/CDパイプラインにサンドボックス作成を統合する。古いサンドボックス(例えば、7日以上前のコンテナ)のクリーンアップを自動化し、リソースリークを防止する。一般的な操作のランブックを文書化する。「失敗したサンドボックスをデバッグする方法」「サンドボックスイメージを更新する方法」「サンドボックスログをレビューする方法」。
リスクと緩和戦略
Docker Sandboxはリスクを低減するが、完全には排除しない。残存する脅威には、多層防御戦略を通じた明示的な対策が必要である。
-
基本的主張:* MicroVM隔離はサプライチェーン攻撃、カーネルエクスプロイト、ハイパーバイザー脆弱性、または設定ミスを通じて回避される可能性がある。完璧な隔離メカニズムは存在しない。
-
根拠:* セキュリティは多層的な規律である。サンドボックス隔離は一つの層に過ぎず、追加の層(パッチ適用、監視、ポリシー実装)が必要である。
-
リスク行列と対策:*
| リスク | 発生可能性 | 影響度 | 対策 |
|---|---|---|---|
| 悪意あるAIモデルがMicroVMハイパーバイザーのカーネル脆弱性を悪用するコードを生成する | 低(調整された攻撃が必要) | 高(ホスト侵害) | Docker DesktopとホストOSを定期的にパッチ適用する(例:週次)。MicroVMイメージのセキュリティ監査を四半期ごとに実施する。Dockerセキュリティアドバイザリーを購読する。 |
開発者が誤ってサンドボックスアクセスを機密ホストディレクトリに付与する(例:~/.ssh、~/.aws) | 中(ヒューマンエラー) | 高(認証情報露出) | ポリシー・アズ・コード(例:OPA/Rego)を使用して許可されたマウントパスを強制する。サンドボックス設定を週次で監査する。サンドボックスベストプラクティスに関する開発者トレーニングを提供する。 |
| AIエージェントがDNSトンネリングまたは隠蔽チャネルを介してデータを流出させる | 低(高度な攻撃が必要) | 中(データ損失) | サンドボックスからのDNSクエリを監視・制限する(例:内部DNSサーバーのみをホワイトリスト化)。ネットワークポリシーを使用して予期しないアウトバウンドトラフィックをブロックする。ネットワークレベルで出口フィルタリングを実装する。 |
| サンドボックスイメージに脆弱な依存関係が含まれている | 中(サプライチェーンリスク) | 中(サンドボックス侵害、潜在的なホスト影響) | デプロイ前にサンドボックスイメージの脆弱性をスキャンする。Dockerfileで依存関係バージョンをピン留めする。最新パッチでイメージを週次で再構築する。 |
| リソース枯渇:AIエージェントが利用可能なすべてのメモリを消費し、ホスト不安定性を引き起こす | 中(設定ミスまたは悪意あるコード) | 中(サービス拒否) | サンドボックスごとに厳密なメモリ制限を強制する(例:--memory=2g)。サンドボックスの集計リソース使用量を監視する。サンドボックスメモリ合計が閾値を超えた場合にアラートを実装する。 |
| 設定ミスのあるサンドボックスがコンテナエスケープを許可する | 低(設定ミスとエクスプロイトの両方が必要) | 高(ホスト侵害) | セキュリティスキャンツール(例:docker scan、Trivy)を使用して設定ミスを特定する。ポリシー・アズ・コードを通じてサンドボックスポリシーを強制する。サンドボックス設定の定期的なセキュリティレビューを実施する。 |
- 含意:* 特定のAI支援ワークフローに対して脅威モデリングを実施する。コード生成ユースケースごとに許容可能なリスクレベルを定義する(例:「低リスク:ボイラープレート生成;高リスク:認証情報処理」)。予防的統制が存在する場所でも、検出的統制(ログ、アラート)を実装する。サンドボックス関連のセキュリティイベントに対するインシデント対応計画を確立する。
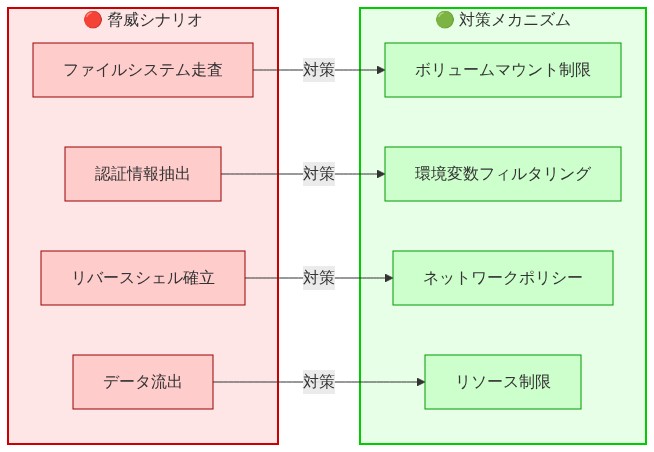
- 図9:脅威シナリオと対策メカニズムの対応図(Docker Sandboxセキュリティ脅威モデル)*
結論と移行パス
Docker Sandboxは、AI支援開発のための実用的な技術的統制を表現している。採用は段階的であるべきであり、低リスクのユースケースから始まり、チームが運用成熟度と信頼を構築するにつれて拡大する。
-
推奨される段階的移行パス:*
-
フェーズ1(1~2週目):パイロット*
-
小規模チーム(3~5名の開発者)を選定し、Claude Codeを非クリティカルなコード生成(例:ボイラープレート、ユニットテスト、ドキュメント)に使用させる。
-
テスト環境にDocker Sandboxをデプロイし、セットアップ手順と一般的な問題を文書化する。
-
ベースラインメトリクスを収集する:採用率、コード生成・レビュー時間、リソース使用量。
-
フェーズ2(3~4週目):改善*
-
パイロットチームからのフィードバックを収集し、実際の使用に基づいてサンドボックスポリシーと自動化を改善する。
-
検出・防止されたインシデントのベースラインメトリクスを確立する。
-
ランブックとベストプラクティスを文書化する。
-
フェーズ3(2ヶ月目):拡大*
-
より広い開発者層(例:全フロントエンドチーム)にDocker Sandboxをロールアウトする。
-
サンドボックス作成を標準ワークフロー(例:CI/CDパイプライン、IDE統合)に統合する。
-
開発者トレーニングとサポートを提供する。
-
フェーズ4(3ヶ月目以降):運用化*
-
サンドボックスイメージの更新とパッチ適用を自動化する。
-
サンドボックスセキュリティイベントの監視とアラートを確立する。
-
他のAIツール(Gemini CLI、GitHub Copilotなど)へのサンドボックスサポートを拡張する。
-
四半期ごとのセキュリティレビューと脅威モデリング更新を実施する。
-
重要なポイント:*
-
Docker Sandboxはハイパーバイザー強制隔離を提供する - 信頼できない、または半信頼できるコード生成に適しており、コンテナレベルの隔離を超えた防御層を追加する。
-
サンドボックスの有効性は技術的能力ではなく、意図的なポリシー設計に依存する。 サンドボックスロールごとにリソースクォータ、ネットワークポリシー、ファイルアクセスルールを定義する。
-
測定と可観測性は採用の継続と価値実証に不可欠である。 採用率、防止されたインシデント、開発者速度、リソース効率を追跡する。
-
残存リスクは脅威モデリングと多層防御戦略を必要とする。 完璧な隔離は存在しない;予防的、検出的、是正的統制を層状に配置する。
-
段階的採用は組織的リスクを低減する - チームが運用成熟度を段階的に構築することを可能にする。
- 直近のアクション項目:*
- 現在のAI支援開発実践を評価する:どのチームがAIツールを使用しているか。どのようなコードを生成しているか。最も高リスクのユースケースは何か。
- 最も高リスクのワークフロー(例:ネットワークアクセスを持つAIエージェント、システムファイルを変更するコードまたは認証情報を処理するコードを生成するもの)を特定する。
- 制御された環境でそれらのワークロードに対してDocker Sandboxをパイロットする。
- 採用率、検出されたインシデント、開発者体験を測定する。
- データに基づいてポリシー、自動化、トレーニングを反復する。