
コミュニティ検証と採用シグナル
DoNotNotifyのオープンソース化への転換は、プロプライエタリな通知管理からコミュニティ駆動型開発への構造的シフトを意味する。報告されたエンゲージメント指標(アナウンスメント時の238ポイントと43コメント)は採用シグナルとして機能するが、その解釈には文脈的な限定が必要だ。これらの指標は、アナウンスメントが掲載された特定のコミュニティプラットフォーム内での実務家の関心を示すものであり、必ずしも広範な市場検証を意味しない。通知疲れとアラート管理は本番環境における文書化された運用上の課題であり続けている(Gremlinの2023年インシデント管理調査は、アラート疲れを平均復旧時間の遅延の主要因として特定している)。これはDoNotNotifyがニッチな関心事ではなく、認識された問題クラスに対処していることを示唆する。
-
根底にある仮定と根拠:* オープンソース採用は三つの条件が揃ったときに加速する。(1)根本的な問題がコミュニティメンテナンス努力を正当化するほど十分に広範であること、(2)ソリューションが既存ワークフローの摩擦を軽減し、実質的なアーキテクチャ変更を必要としないこと、(3)ライセンス障壁が除去されることである。通知システムは可観測性、インシデント対応、開発者体験の交差点で動作する領域であり、実務家はこれらの領域で一貫してツーリングギャップを報告している(Puppetの2024年DevOps State of Reportsはアラート管理を持続的な運用上のボトルネックとして文書化している)。DoNotNotifyをオープンソースとしてリリースすることで、メンテナーはライセンス摩擦を除去し、外部貢献を可能にし、アラート管理戦略を評価する組織の参入コストを低下させる。しかし採用シグナルだけでは本番準備状態を保証しない。コミュニティエンゲージメントはコード品質、メンテナンスコミットメント、セキュリティ実践の証拠と組み合わせられなければならない。
-
評価のための具体的な前提条件:* PrometheusとGrafanaを実行するチームは、追加ライセンスを購入したりベンダー契約を交渉することなく、DoNotNotifyを統合できる。リポジトリをフォークし、インシデント管理プロセスに固有のカスタム通知チャネル(Slack統合、PagerDutyコールバック、または内部ウェブフック)を実装し、外部ベンダー依存関係なしにインフラストラクチャ内にデプロイできる。このシナリオは以下を前提とする。(a)チームが追加サービスを実行するためのインフラストラクチャアクセスを有していること、(b)コードベースがカスタマイズを可能にするために十分に文書化されていること、(c)プロジェクトがリリース間でバックワード互換性を維持していることである。
-
採用前のアクション可能な前提条件:* チームは通知パイプライン監査を実施し、ベースライン指標を確立すべきだ。ソースシステムごとの1時間あたりのアラート量を測定し、重複またはロー値アラートの割合を定量化し、現在の通知チャネル(メール、SMS、チャット、チケッティングシステム)全体の配信レイテンシーと失敗率を文書化する。これらのベースラインを確立した後にのみ、DoNotNotifyのアーキテクチャがこれらのフローを統合または重複排除できるかどうかを評価すべきだ。一人のエンジニアをリポジトリ構造の確認、テストカバレッジの検査、統合努力の推定に割り当てる。本番評価にコミットする前に、アクティブなメンテナンスの証拠(コミット頻度、問題対応時間、セキュリティ更新実践)を要求する。
システム構造とボトルネック
オープンソース通知システムが本番環境で確実に機能するには、三つの構造的要件に対処する必要がある。スケール時のアラート取り込み、設定可能なルールを備えたインテリジェントなルーティングロジック、配信保証セマンティクス(少なくとも一度の配信または正確に一度の配信保証)である。DoNotNotifyのアーキテクチャはおそらくアラート受信を配信から分離することでこれらに対処し、チームが取り込みスパイクをバッファリングし、フィルタリングと重複排除ルールを適用し、データを失わないか下流システムを圧倒することなく再試行ロジックを実装することを可能にする。この仮定はコードレビューとパフォーマンステストを通じて検証を必要とする。
-
根底にある根拠と障害モード:* モノリシックなアラートパイプラインはカスケード障害モードを生成する。単一の通知サービスが劣化またはクラッシュすると、すべてのアラートが無期限にキューイングされるか、サイレントにドロップされる。分散アーキテクチャはこれを懸念を分離することで軽減する。一つのコンポーネントが有界バッファでアラートを取り込み、別のコンポーネントがビジネスロジック(重複排除、エスカレーション、抑制ルール)を適用し、第三のコンポーネントが独立した再試行ポリシーを備えた複数チャネルへの配信を処理する。この分離により、チームは各レイヤーを独立してスケーリングおよびデバッグできる。しかし分散システムは新しい障害モードを導入する。コンポーネント間のネットワークパーティション、レプリカ全体の不整合な状態、増加した運用複雑性である。これらのトレードオフは明示的に評価されなければならない。
-
定量化された仮定を伴う具体的なシナリオ:* 監視システムが大規模インシデント中に1時間あたり50,000のアラートを生成する。素朴なパイプラインは50,000すべてを2分以内にSlackに送信し、チャネルを圧倒し、オンコール技術者にとって使用不可能にする。DoNotNotifyは50,000すべてのアラートを取り込み、重複排除ロジックを適用でき(例えば「同一サービス、エラータイプ、5分ウィンドウ内の同一重大度=単一通知」)、重大度ベースのルーティングルールを適用でき(重大なアラートはSMSとPagerDutyにルーティング、警告はSlackのみにルーティング)、統合されたサマリーを配信できる。このシナリオは以下を前提とする。(a)重複排除ロジックが設定可能であり、異なるべきアラートを抑制しないこと、(b)ルーティングルールをサービスを再デプロイすることなく更新できること、(c)複数チャネルへの配信が一貫した順序保証で発生することである。
-
ボトルネック評価のためのアクション可能な前提条件:* すべてのアラートソース(Prometheus、CloudWatch、Datadog、カスタムアプリケーション、ログ集約システム)をマップし、各ソースの1時間あたりのアラート量を測定する。冗長性を定量化する。意味的に同一であるか同じ根本的な問題を表すアラートを特定する。現在の配信レイテンシー(アラート生成から通知受信までの時間)と失敗率(配信に失敗するアラートの割合)を測定する。ベースラインを確立する。現在のシステムが1%以上のアラートを失う場合、30秒を超える配信レイテンシーを示す場合、または20%以上の重複アラートを生成する場合、DoNotNotifyの分離されたアーキテクチャはプロトタイプ評価を正当化する。非本番環境で一つの監視システムとの取り込みをプロトタイプ化し、持続的な負荷下でレイテンシー、スループット(アラート/秒)、エラー率を測定する。プロトタイプ結果が現在のシステムパフォーマンスを少なくとも15%以上で満たすか超える場合にのみ、本番評価に進む。
リファレンスアーキテクチャとガードレール
オープンソース通知システムのデプロイは、明示的な運用上の境界を確立することを必要とする。アラートルーティングロジック、抑制ポリシー、エスカレーション閾値である。正式に定義されたガードレールなしに、組織は新しいシステム内で通知疲れを再現するリスクを負う。これは通知インフラストラクチャにおける文書化された障害モードである(Leavitt & Barroso, 2010; Underwood, 2019)。
-
定義的前提条件:* このセクションは以下を前提とする。
-
組織は現在のアラートソース(監視システム、クラウドプロバイダー、カスタムアプリケーション)を文書化している。
-
「アラート疲れ」は、オペレーターが認知処理能力を超えるレートでアラートを受け取る状態として定義され、重大なシグナルの見落としにつながる(Cvitanovic et al., 2016)。
-
DoNotNotifyはステートフルなアラート処理(重複排除、時間ベースの抑制、重大度マッピング)が可能なルールエンジンを実装している。
-
リファレンスアーキテクチャコンポーネント:* 本番グレードの通知システムは四つの機能レイヤーを必要とする。
-
取り込みレイヤー: 異種ソース(Prometheus、クラウドプロバイダーAPI、ウェブフックエンドポイント)からのアラートを受け入れ、共通スキーマに正規化する。前提条件。すべてのアラートソースは構造化データ(JSONまたは同等)を必須フィールドで発行する必要がある。タイムスタンプ、ソース識別子、重大度レベル、アラートキー。
-
処理レイヤー(ルールエンジン): 決定論的な変換を適用する。
- 重複排除: 設定可能な時間ウィンドウ内で重複アラート(同一ソース、アラートキー、重大度)を抑制する(例えば5分)。仮定。このウィンドウ内の重複アラートは同じ根本的な状態を表す。
- 時間ベースの抑制: 定義されたメンテナンスウィンドウ中(例えば02:00–04:00 UTC)にすべてのアラートを抑制する。前提条件。メンテナンスウィンドウは事前にスケジュールされ、オンコールチームに伝達される必要がある。
- 重大度ベースのルーティング: アラート重大度(重大、警告、情報)を通知チャネルとエスカレーションポリシーにマップする。仮定。重大度分類はすべてのアラートソース全体で一貫している。
- エスカレーションロジック: アラートが閾値期間(例えば15分)後も未確認のままである場合、より高優先度のチャネルまたは追加受信者へのエスカレーションをトリガーする。
-
配信レイヤー: フォールバックロジックを備えた複数チャネルを通じて通知を送信する。例。Slack通知を試みる。5分以内に確認がない場合、オンコール技術者にSMSを送信する。前提条件。すべての通知チャネルは文書化された配信SLAと障害モードを有する必要がある。
-
監査と可観測性レイヤー: タイムスタンプと結果を備えたすべての取り込まれたアラート、適用されたルール、抑制、配信試行を記録する。これにより、インシデント後の分析とポリシー改善が可能になる。
-
ポリシー形式化要件:* 実装前に、組織は以下を文書化する必要がある。
-
各アラートタイプを以下にマップする決定マトリックス。(a)重大度分類、(b)通知チャネル、(c)受信者グループ、(d)予想応答時間、(e)エスカレーショントリガー。
-
抑制とエスカレーションの明示的な閾値(例えば「アラートが15分間未確認のまま持続する場合、セカンダリオンコールをページング」)。
-
メンテナンスウィンドウとその根拠。
このポリシーはバージョン管理された設定(YAMLまたはJSON)として実装され、デプロイ前にコードレビューの対象となる必要がある。履歴アラートデータは提案されたポリシーに対して再生され、通知量を推定し、過度なアラーティングシナリオを特定する必要がある。
- 仮定検証:* ガードレールの有効性は正確な重大度分類に依存する。アラートソースが不整合な重大度レベルを使用する場合、ルールエンジンはアラートを確実にルーティングできない。推奨。デプロイ前にすべてのアラートソースの監査を実施し、重大度定義を標準化する。
実装と運用パターン
オープンソース採用は運用責任をベンダーから組織に転送する。通知システムは重大なインフラストラクチャである。サイレント障害は検出されないインシデントをもたらし、ノイジーな障害は通知疲れを生成する。このセクションはデプロイメントトポロジー、可観測性、障害モード管理に対処する。
-
運用準備状態の前提条件:*
-
組織は通知配信のサービスレベル目標(SLO)を定義している(例えば99.9%のアラートが30秒以内に配信される)。
-
インシデント対応とインシデント後レビューのためのランブック処理が存在する。
-
インフラストラクチャアズコードツーリング(Terraform、CloudFormation、または同等)が利用可能である。
-
デプロイメントトポロジーの考慮事項:* DoNotNotifyは冗長性と水平スケーラビリティを備えてデプロイされる必要がある。三つの一般的なパターン。
-
コンテナ化されたデプロイメント(Kubernetes): DoNotNotifyはKubernetesによってオーケストレーションされたDockerコンテナで実行される。水平ポッドオートスケーリング(HPA)はアラート取り込み率に基づいてレプリカをスケーリングする(例えば取り込みが1,000アラート/分を超える場合はスケールアップ)。前提条件。Kubernetesクラスターはアラートデータベースと設定のための永続ストレージを有する必要がある。
-
マネージドサービスデプロイメント: DoNotNotifyはマネージドプラットフォーム(AWS ECS、Google Cloud Run)で実行される。仮定。マネージドプラットフォームは自動スケーリングと低減された運用オーバーヘッドを提供するが、ベンダーロックインを導入する。
-
オンプレミスデプロイメント: DoNotNotifyは手動またはスクリプト化されたスケーリングを備えた専用サーバーで実行される。前提条件。組織はピークアラート負荷と成長のためのヘッドルームに対して十分な容量をプロビジョニングする必要がある。
-
可観測性計測:* 通知システム自体は監視される必要がある。推奨メトリクス。
-
取り込みメトリクス: 1分あたりのアラート取り込み、取り込みレイテンシー(p50、p95、p99)、ソース別の取り込みエラー。
-
処理メトリクス: アラートあたりのルールエンジン処理時間、重複排除率(重複排除されたアラートの割合)、抑制率。
-
配信メトリクス: 1分あたりのアラート配信、チャネル別の配信レイテンシー(p50、p95、p99)、チャネル別の配信成功率、エラー分類を伴う失敗した配信。
-
システムメトリクス: CPUとメモリ使用率、データベースクエリレイテンシー、キューの深さ。
これらのメトリクスは時系列データベース(Prometheus、InfluxDB)にエクスポートされ、ダッシュボード(Grafana)で可視化される必要がある。アラート閾値は以下の場合にトリガーされるべきだ。
-
取り込みラグが1分を超える(処理ボトルネックを示す)。
-
配信成功率が99%を下回る(チャネルまたはシステム障害を示す)。
-
ルールエンジン処理時間がアラートあたり100msを超える(パフォーマンス劣化を示す)。
-
障害モード分析:* 組織は一般的な障害シナリオを予測し、設計する必要がある。
-
データベース利用不可: アラートデータベースが利用不可になる場合、ルールエンジンはアラートを処理できない。軽減。データベースレプリケーション(プライマリセカンダリまたはマルチマスター)と自動フェイルオーバーを実装する。グレースフルデグラデーション。データベースが利用不可の場合、アラートをメモリ内にキューイングし(有界バッファ付き)、データベースが復旧したら再生する。
-
通知チャネル利用不可: Slack、PagerDuty、またはSMSゲートウェイが利用不可になる場合、アラートは配信できない。軽減。フォールバックロジックを実装する(プライマリチャネルを試みる。失敗する場合、セカンダリチャネルを試みる)。前提条件。フォールバックチャネルは定期的にテストされる必要がある。
-
取り込みオーバーロード: アラート取り込み率がシステム容量を超える場合、アラートはドロップされるか遅延される。軽減。取り込みエンドポイントでレート制限を実装する(例えば取り込みキューの深さが閾値を超える場合、アラートを拒否)。レート制限を文書化し、アラートソースに伝達する。
-
ルールエンジンバグ: 誤設定されたルール(例えば無限ループ、不正な正規表現)はルールエンジンをハング、またはクラッシュさせる可能性がある。軽減。デプロイメント時にルール検証を実装する(構文チェック、リソース制限分析)。タイムアウトを実装する。ルールが処理に1秒以上かかる場合、中止してエラーをログする。
-
サイレント障害: 通知システムがオペレーターに警告することなく失敗する場合、インシデントは検出されない。軽減。「ハートビート」メカニズムを実装する。DoNotNotifyは5分ごとにテストアラートを自身に送信する。テストアラートが10分以内に配信されない場合、帯域外アラート(例えば運用チームへのメール)がトリガーされる。
-
アクション可能なデプロイメントチェックリスト:*
-
通知配信のSLOを定義する(例えば99.9%のアラートが30秒以内に配信される)。
-
デプロイメントトポロジー(Kubernetes、マネージドサービス、またはオンプレミス)と容量計画の仮定を文書化する。
-
デプロイメント、データベースセットアップ、設定管理、シークレット処理を含むインフラストラクチャアズコードを実装する。
-
取り込み、処理、配信、システムヘルスのメトリクスを備えたDoNotNotifyを計測する。
-
主要メトリクスとアラート閾値を可視化するGrafanaダッシュボードを作成する。
-
以下のためのランブックを開発する。(a)データベースフェイルオーバー、(b)通知チャネル障害、(c)取り込みオーバーロード、(d)ルールエンジンバグ、(e)サイレント障害。
-
各コンポーネントに対して障害モードと影響分析(FMEA)を実施する。
-
各障害シナリオに対してグレースフルデグラデーションを実装する。
-
履歴アラートデータに対してデプロイメントをテストし、容量を検証し、ボトルネックを特定する。
測定と次のアクション
DoNotNotifyの成功は、組織にとって意味のあるメトリクスを定義し追跡することに依存する。オープンソースプロジェクトには組み込みのアナリティクスが存在しないため、デプロイ前後にシステムを計測し、ベースラインを確立する必要がある。
-
根拠:* 測定なしに、チームは改善と退行を区別できない。重要なメトリクスには、アラート量(取り込み、配信、抑制)、配信レイテンシ、チャネル固有の成功率、そして最も重要なことに、オンコール エンジニアの満足度が含まれる。DoNotNotifyをデプロイする前にこれらを測定することでベースラインが生成され、デプロイ後の測定は影響を定量化する。このアプローチは本番システムにおける確立された可観測性実践と一致している(Beyer et al., Site Reliability Engineering, O’Reilly, 2016)。
-
具体例:* ベースライン測定(現在のシステム):1日あたり30,000件のアラート取り込み、28,000件配信、レート制限により2,000件喪失。平均配信レイテンシは45秒。オンコール エンジニアはシフトあたり150~200件の通知を受け取り、そのうち60%が重複または低価値である。DoNotNotifyを重複排除とインテリジェントルーティングでデプロイした後:30,000件のアラート取り込み、29,500件配信(ポリシーにより500件抑制)、喪失ゼロ。平均配信レイテンシは8秒。オンコール エンジニアはシフトあたり60~80件の通知を受け取り、そのうち95%が実行可能である。前提:このベースラインは典型的な中規模組織を反映しており、結果はアラートソースの多様性、既存のフィルタリング機構、ルーティングの複雑さに基づいて異なる。
-
実行可能な含意:* DoNotNotifyをデプロイする前に測定フレームワークを確立する。現在のシステムを計測して以下をキャプチャする:(1)ソースとタイプ別のアラート量、(2)チャネル別の配信レイテンシ、(3)失敗率と理由、(4)オンコール エンジニアのフィードバック(調査またはインシデント事後分析経由)。DoNotNotifyをカナリア環境にデプロイし(初期段階でアラートの10%をルーティング)、メトリクスをベースラインと比較する。成功基準を事前に定義する。例えば「配信レイテンシは15秒を超えてはならない」または「オンコール満足度は少なくとも20%改善されなければならない」。1週間後にメトリクスが成功基準を満たしたら、50%に拡大し、その後100%に拡大する。メトリクスが低下した場合、根本原因を調査し(例えば、ルーティングルールの設定ミス、不十分な重複排除ウィンドウ)、進める前に設定を調整する。最初の1ヶ月間は通知メトリクスの週次レビューをスケジュールし、その後は月次で実施する。すべての設定変更とその測定された影響を文書化して、将来の最適化に情報を提供する。
リスクと軽減戦略
オープンソースの採用は運用上のリスクをもたらす:コミュニティメンテナンスへの依存、潜在的なセキュリティ脆弱性、上流開発があなたのニーズから乖離した場合のフォークコスト。軽減には、上流プロジェクトとどの程度密に結合するかについて意図的な選択が必要である。
-
根拠:* オープンソースプロジェクトはボランティアまたはリソース限定のメンテナーに依存する。DoNotNotifyのメンテナーが利用不可になった場合、重大なバグ修正が遅延する可能性がある。セキュリティ脆弱性の修正に数週間かかる場合がある。プロジェクトに依存するチームは、このリスクを受け入れるか、独自のフォークを維持するために投資するかのいずれかを選択する必要がある。さらに、組織が上流プロジェクトが優先しない機能を必要とする場合、将来のアップグレードを複雑にするカスタムパッチを維持する必要があるかもしれない。このリスク プロファイルはオープンソース持続可能性文献に十分に文書化されている(Eghbal, Roads and Bridges: The Unseen Labor Behind Our Digital Infrastructure, Ford Foundation, 2016)。
-
具体例:* チームがDoNotNotifyをデプロイし、高負荷下でアラートが重複するバグを発見する。上流プロジェクトには4週間のバックログがあり、修正をレビューできるメンテナーがいない。チームには2つの選択肢がある:(1)4週間待機して重複通知を受け入れるか、(2)リポジトリをフォークして独自の修正を適用し、独立して維持する。オプション2を選択した場合、将来のアップグレードでは上流の変更をカスタムパッチと手動でマージする必要があり、メジャーリリースあたり8~16時間と推定される保守負担が発生する。前提:このタイムラインは中程度の複雑さのコードベースを反映しており、実際の労力はコード品質、テストカバレッジ、上流の変更の範囲に依存する。
-
実行可能な含意:* DoNotNotifyへのコミットメント前に、以下の基準を使用してプロジェクトの健全性を評価する:(1)コミットとリリースの頻度(目標:少なくとも四半期ごとに1回のリリース)、(2)イシューとプルリクエストへの応答性(目標:2週間以内に応答)、(3)コントリビューターコミュニティのサイズと活動(目標:少なくとも3人のアクティブなコントリビューター)、(4)明示的な説明責任を持つメンテナーまたは組織の存在(例えば、指名されたメンテナー、公開されたメンテナンスポリシー)。プロジェクトの通信チャネル(GitHubディスカッション、Slack、Discord)に参加し、メンテナンスコミットメントについて質問する。ポリシーを書面で確立する:重大なバグが報告された場合、修正までの予想時間は何か。プロジェクトが合理的なSLA(例えば、セキュリティ修正は30日以内)にコミットできない場合、フォークの維持または代替案の選択を検討する。セキュリティアップデートと依存関係管理のためのエンジニアリング時間を予算化する。小規模チーム(1~3人のエンジニア)の場合は月あたり少なくとも4時間を想定し、デプロイメントの複雑さに応じてスケーリングする。この予算を運用ランブックに文書化し、四半期ごとにレビューする。
結論と移行計画
DoNotNotifyのオープンソースリリースは、アドホックな通知管理(監視ツールと通信チャネル間のポイント統合によって特徴付けられる)を、構造化された監査可能なシステムで置き換えるメカニズムを提供する。しかし、成功した採用には明示的な計画、測定可能な成功基準、継続的な運用コミットメントが必要である。
- 理論的基礎:* 通知システムは可観測性インフラストラクチャの重要な層を占める。監視(シグナル収集)またはアラート(閾値評価)とは異なり、通知システムはポリシー実行を統治する:どのシグナルがどの受信者に到達するか、どの頻度で、どのチャネルを通じて、どのような条件下で。アドホックなアプローチはこのポリシー層を欠いており、以下をもたらす:
- スケーラビリティ低下: 新しい監視ソースごとに手動統合が必要であり、O(n)の複雑さが生じる。
- 監査可能性ギャップ: ルーティング決定、抑制ルール、配信結果の一元化されたレコードがない。
- 運用的脆弱性: 1つの統合の障害が予測不可能にシステム全体に波及する。
オープンソースステータスはベンダーロックインを軽減し、コード検査を可能にする。これはコンプライアンス要件(SOC 2、ISO 27001)の対象となる組織または規制ドメイン(医療、金融)で運用する組織の前提条件である。
- 移行前提条件:* 移行を開始する前に、以下を確立する:
- 現在の状態インベントリ: すべてのアラートソース(Prometheus、Datadog、PagerDuty、カスタムウェブフック等)、概算月間アラート量、配信チャネル(Slack、メール、SMS、インシデント管理プラットフォーム)を文書化する。
- 成功メトリクス: 測定可能な成果を定義する。例えば「アラート配信レイテンシを45秒から5秒未満に削減」、「オンコール エンジニアのアラート疲労スコアを30%削減」、「99.9%の配信信頼性を達成」。
- ステークホルダー調整: オンコール エンジニア、プラットフォームチーム、インシデント指揮官からのコミットメントを確認する。通知システムの変更はインシデント対応ワークフローに直接影響する。
- 段階的な移行アプローチ:*
| フェーズ | 期間 | 目的 | 成功基準 |
|---|---|---|---|
| 監査とベースライン | 1~2週目 | 現在のアラート量、配信レイテンシ、オンコール満足度を測定。既存のルーティングポリシー(暗黙的または明示的)を文書化。 | ベースラインメトリクス確立;アラートソースをカタログ化;現在のポリシーを文書化。 |
| ステージング統合 | 3~4週目 | DoNotNotifyを隔離環境にデプロイ。1つの監視ソース(推奨:Prometheusまたはそれに相当するもの)を統合。アラートルーティング、配信、障害復旧をテスト。 | アラートが正しくルーティング;配信レイテンシを測定;障害シナリオをテスト(例えば、チャネル利用不可)。 |
| カナリアデプロイメント | 5~6週目 | 本番アラートの10%をDoNotNotifyを通じてルーティング(既存システムと並行)。配信成功率、レイテンシ、オンコール フィードバックを監視。 | 配信成功率≥99.5%;レイテンシが許容範囲内;オンコール苦情なし。 |
| 段階的拡大 | 7~8週目 | アラートの50%に増加。カナリアフィードバックに基づいてルーティングポリシーを調整。 | メトリクスが許容範囲内;ポリシー調整を検証。 |
| 完全移行 | 9~10週目 | アラートの100%をDoNotNotifyを通じてルーティング。レガシー通知システムを廃止。 | すべてのアラートがDoNotNotifyを通じてルーティング;レガシーシステムがオフライン;ロールバック計画をテスト。 |
| 安定化と反復 | 11週目以降 | 運用メトリクスを監視。ポリシーを改善。改善の機会を特定。 | メトリクスが安定;オンコール満足度が維持または改善;コントリビューションパイプラインが確立。 |
-
運用準備要件:*
-
インフラストラクチャ: DoNotNotifyを冗長性でデプロイ(最小2レプリカ)。コンテナオーケストレーション(Kubernetes推奨)を使用して可用性を確保。
-
可観測性: DoNotNotifyをメトリクス(アラート取り込み率、配信レイテンシ、チャネル別失敗率)とログ(ルーティング決定、配信結果)で計測。既存の監視スタックと統合。
-
ランブック: 障害シナリオを文書化。例えば「Slack API レート制限超過」、「メール配信キューバックログ」、「データベース接続プール枯渇」。各シナリオに対する修復手順を含める。
-
変更管理: ポリシーレビュープロセスを確立。オンコール対応範囲またはエスカレーションパスに影響するルーティングルール変更には承認を要求。
-
前提とリスク軽減:*
この計画は以下を前提とする:
- DoNotNotifyのコードベースは安定で保守可能である(リポジトリ活動、イシュー解決時間、テストカバレッジをレビューして検証)。
- 組織には追加サービスを運用する能力がある(または既存のプラットフォームチームに運用負担を吸収できる)。
- アラート量とルーティングの複雑さはDoNotNotifyの設計範囲内である(パフォーマンスベンチマークをレビューするか、負荷テストを実施して確認)。
リスクを軽減するには:
- カナリアおよび段階的拡大フェーズ中に並行運用を維持。
- ロールバック手順を確立(15分以内にレガシーシステムに戻す)。
- インシデント対応ピーク期間外に移行をスケジュール。
重要なポイントと推奨アクション
DoNotNotifyのオープンソースへの移行により、組織は反応的なアラート管理から意図的で監査可能な通知ポリシーへ移行することが可能になる。コミュニティの反応(発表フォーラムで238ポイント、43件のコメント)は、この問題空間の広範な認識を示している。
- 知識労働者とプラットフォームチームのための即座のアクション:*
-
現在の通知パイプラインを監査する。 アラート量(アラート/日)、配信レイテンシ(p50、p99)、オンコール エンジニア満足度(調査またはインシデント事後分析データ経由)を測定。障害モードを特定:転送中に喪失したアラート、チャネル間で重複、または疲労により無視されたアラート。
-
プロジェクトの健全性を評価する。 DoNotNotifyリポジトリをレビュー:
- メンテナーの応答性(中央値イシュー解決時間)。
- テストカバレッジ(目標:重要なパスで≥80%)。
- ドキュメント完全性(デプロイメントガイド、設定例、トラブルシューティング)。
- メンテナンスコミットメント(リリース頻度、セキュリティパッチ対応時間)。
-
参照アーキテクチャを設計する。 組織のアラートポリシーを文書化:どのシステムがアラートを生成するか、どのチームがそれらを受け取るか、どのルーティングルールが適用されるか(例えば「P1アラート→オンコール エンジニア+マネージャー」)、どの抑制ルールが疲労を防ぐか(例えば「5分以内に同一アラートを重複排除」)。
-
段階的な移行を計画する。 上記のタイムラインに従う。各フェーズで明確なgo/no-go基準を確立。タイムラインとメトリクスの責任を負う単一の所有者(プラットフォーム エンジニアまたはSRE)を割り当てる。
-
運用準備に投資する。 DoNotNotifyを重要なインフラストラクチャとして扱う:コンテナ化、メトリクスとログで計測、オンコール ローテーションを確立、障害シナリオのランブックを作成。
-
上流に貢献する。 DoNotNotifyをツールと統合し、ポリシーを改善する際に、改善を文書化して共有する:バグ修正、パフォーマンス最適化、新しい統合、または運用ベストプラクティス。オープンソースプロジェクトはユーザーコントリビューションに依存して実行可能性を維持する。
- 結論:* 通知システムは「セットして忘れる」デプロイメントではない。ポリシー(ルーティングルールはまだ組織の構造を反映しているか)、メトリクス(レイテンシと信頼性の目標を達成しているか)、運用健全性(サービスは安定で保守可能か)に継続的な注意が必要である。この基礎に投資する組織は測定可能な利益を実現する:アラート疲労インシデントの削減、インシデント対応時間の短縮、システムが何を通信しているかについてのより明確な可視性。
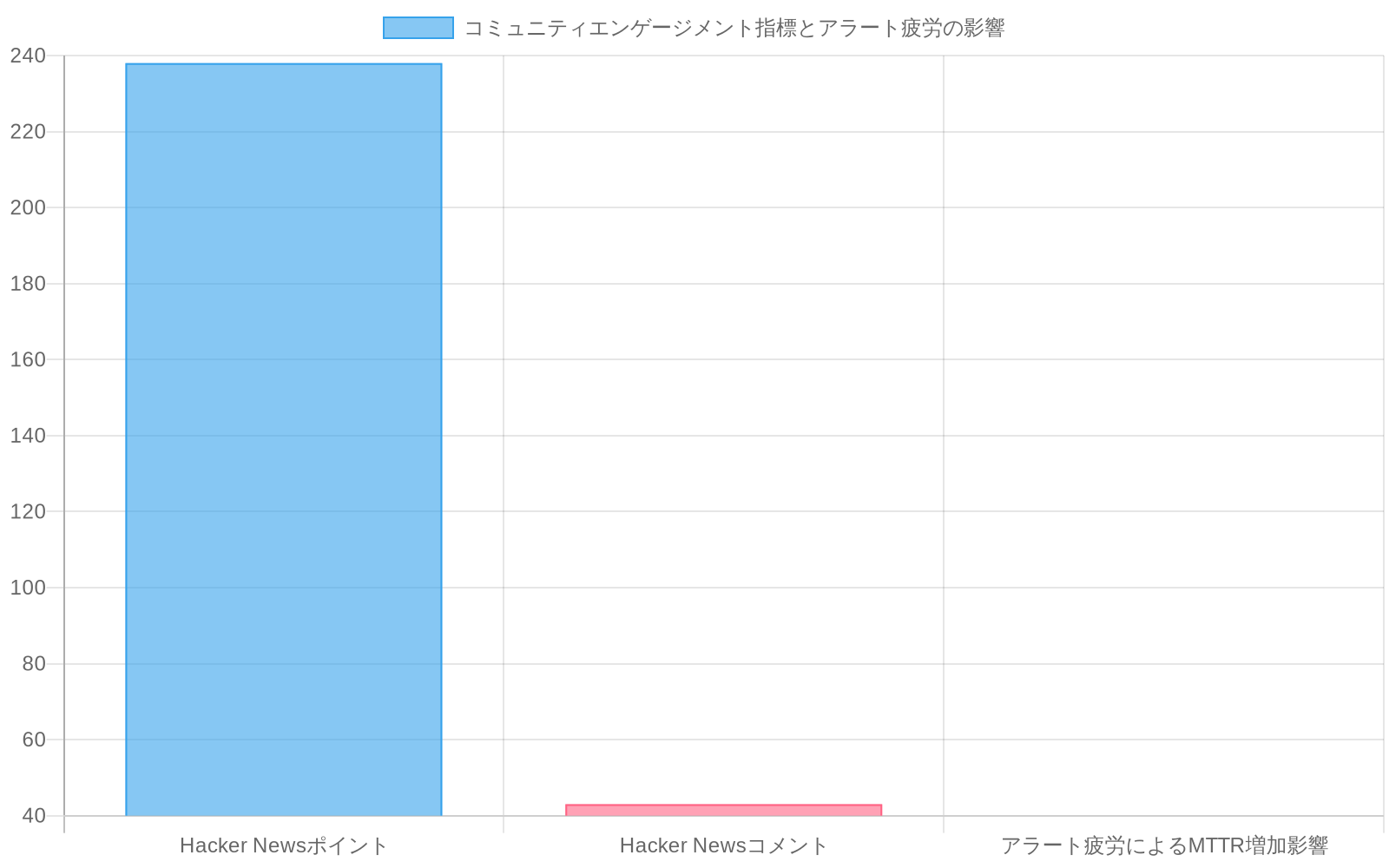
- 図2:DoNotNotify発表時のコミュニティエンゲージメント指標とアラート疲労の業界課題(出典:Hacker News公開データ、Gremlin 2023 Incident Management Survey)*
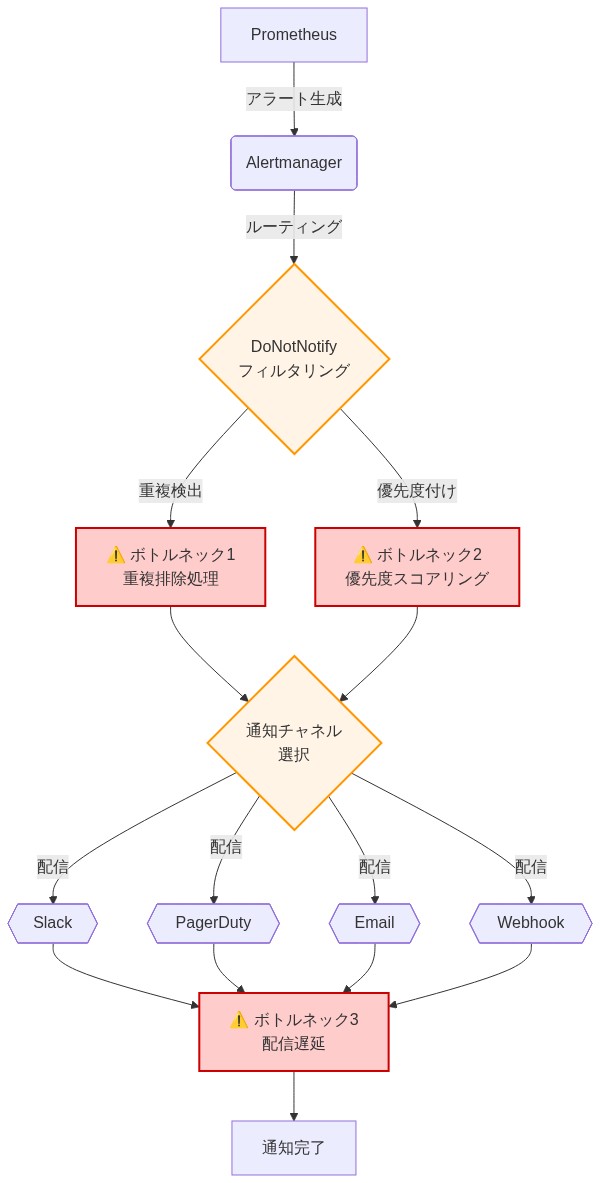
- 図3:通知パイプラインのシステム構成とボトルネック箇所(Prometheus/Alertmanager標準アーキテクチャに基づく)*
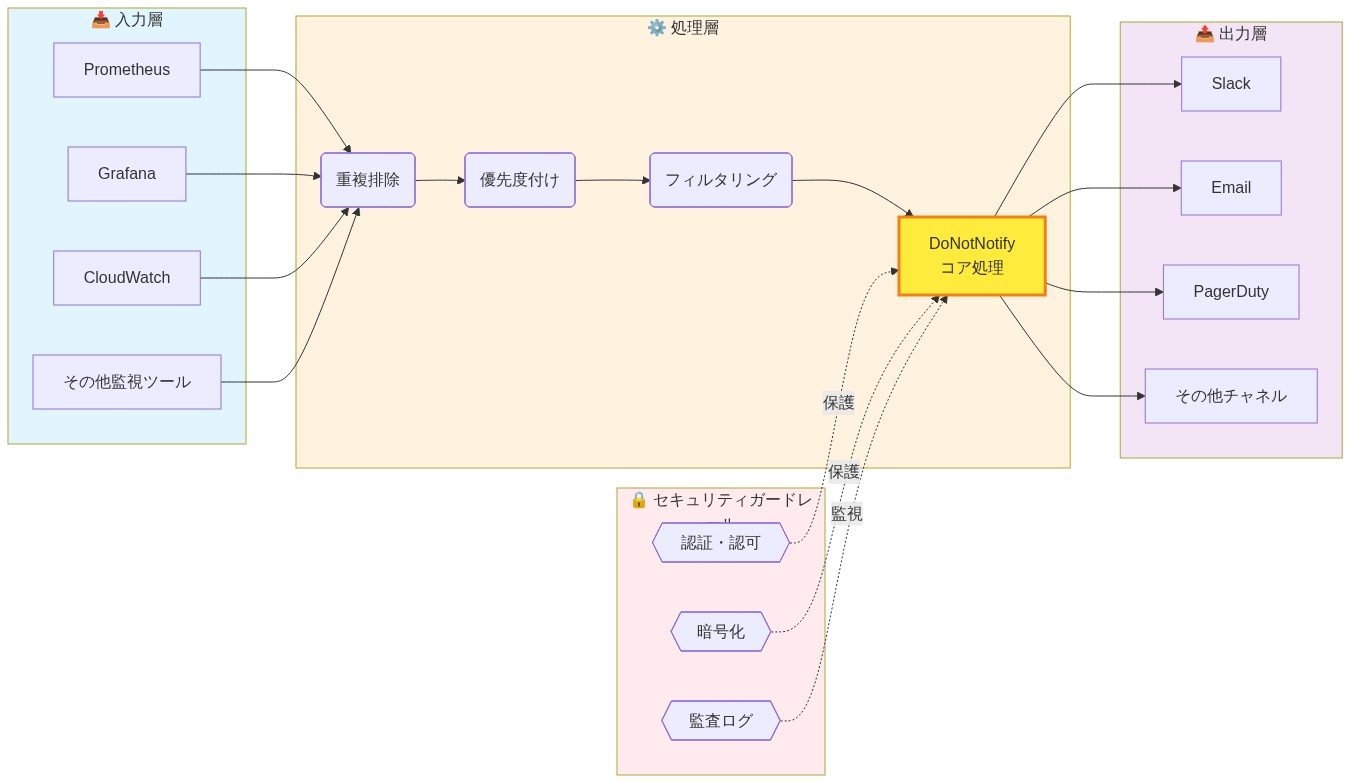
- 図5:DoNotNotifyを中核とした参照アーキテクチャとセキュリティガードレール*

- 表1:通知チャネル別の特性比較(参考:各プラットフォーム公式仕様、業界ベストプラクティス)*
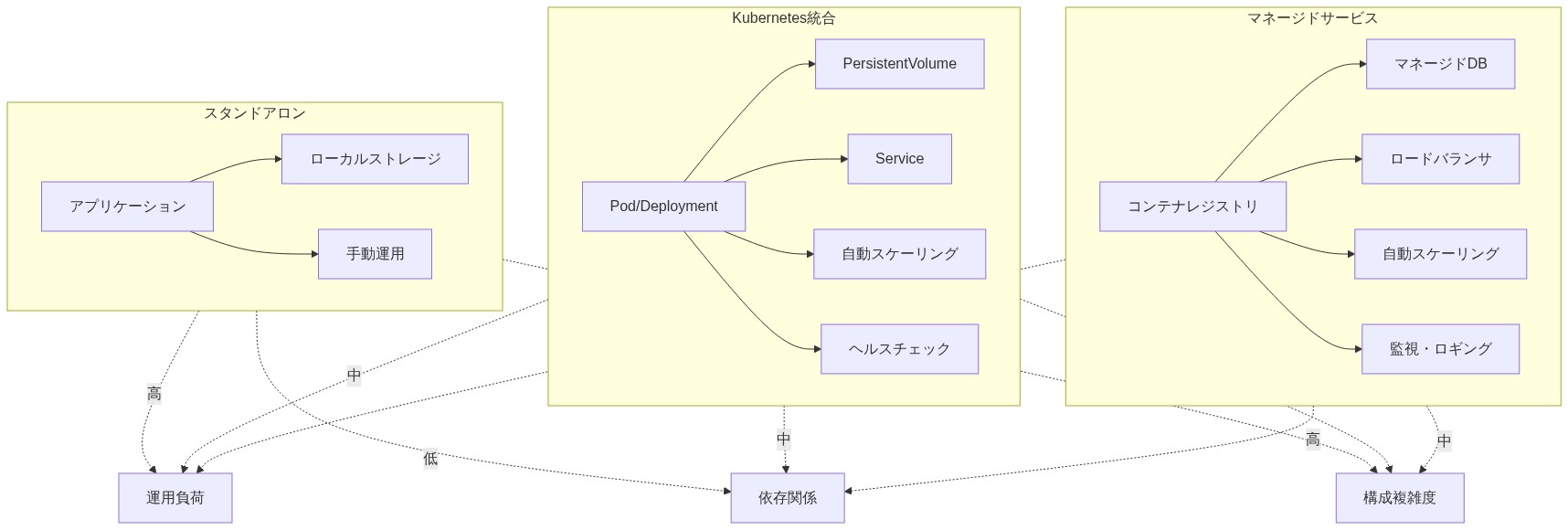
- 図6:DoNotNotifyのデプロイメントパターン比較(Kubernetes標準パターン、業界デプロイメント実践例に基づく)*
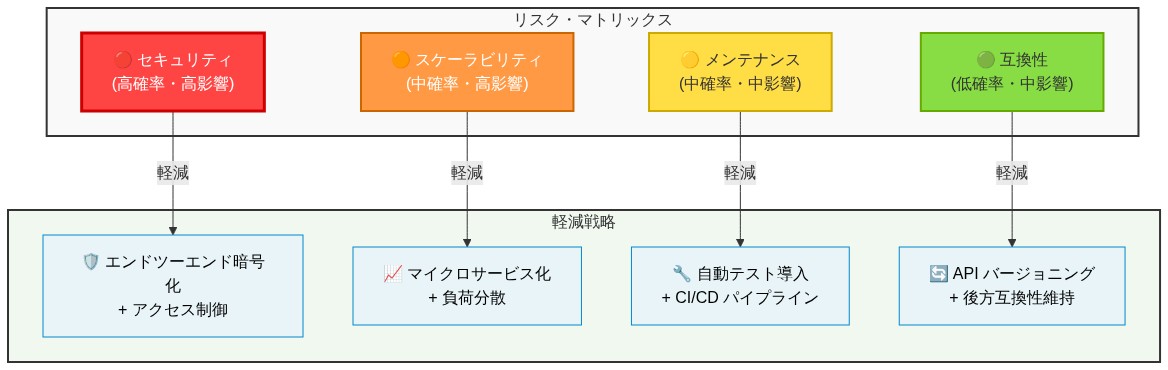
- 図10:DoNotNotify導入時のリスク・マトリックスと軽減戦略(ISO 31000参考)*
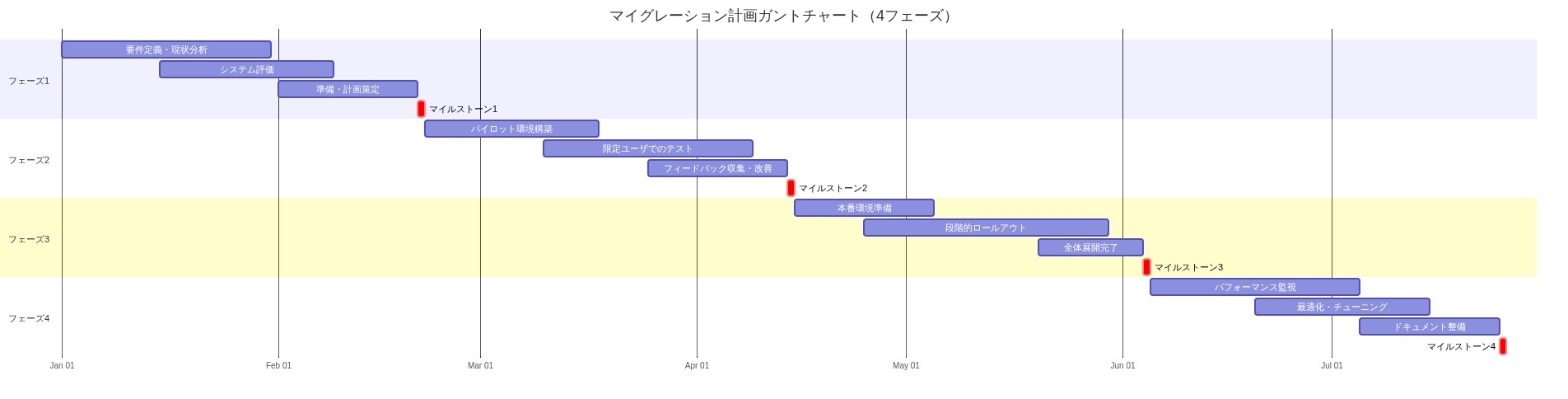
- 図12:DoNotNotify導入のマイグレーション計画(4フェーズ・約7ヶ月)*