
説明可能なアンラーニングが今求められる理由
LLMのアンラーニングは、理論的な研究課題から運用上および規制上の必須要件へと移行しました。大規模言語モデルを展開する組織は、実証済みのリスク露出に直面しています。インターネット規模のデータセットで学習されたモデルは、必然的に著作権で保護された資料、個人識別情報(PII)、および安全性トレーニングにもかかわらず有害な出力と関連する知識をエンコードしています。その結果は実質的です。データ保護フレームワーク下での規制罰(GDPR第17条、CCPA §1798.100)、著作権侵害に対する民事責任、およびモデルが有害で危険なコンテンツを再現する実証済みの事例(Solaiman et al., 2023)があります。従来の緩和アプローチ(出力フィルタリング、推論時のコンテンツモデレーション)は、知識の排除ではなく症状の抑制に対処しています。推論を通じた説明可能なLLMアンラーニングは、根本的なメカニズムを標的にしています。特定の知識表現を選択的に削除または低下させながら、タスクパフォーマンスを維持し、削除プロセスを規制当局とステークホルダーに対して監査可能にするものです。
嗜好アライメントとの概念的区別には精密性が必要です。嗜好アライメントは、安全な出力の可能性を増加させ、安全でない出力の可能性を減少させるトレーニング目的を通じてモデルの動作を修正します(Christiano et al., 2023)。このアプローチは知識の削除を保証しません。既存の知識の表現を抑制するだけです。ここで運用的に定義されるアンラーニングは、モデルパラメータから特定の知識表現を選択的に低下させまたは削除することであり、知識の永続性に直接対処しています。規制上または契約上の義務がデータセットの忘却を要求する場合(例えば、著作権で保護されたトレーニングコーパス、プライベートユーザーデータ)、アンラーニングメカニズムは、敵対的なプロンプト、ファインチューニング、または推論時の攻撃を通じて知識を回復できないことを保証する必要があります(Huang et al., 2023)。説明可能性コンポーネント(削除メカニズムとその効果に関する体系的な推論)は、アンラーニングを不透明なパラメータ修正から、監査と検証の対象となる検証可能な操作へと変えます。
-
具体的な実装例:* 管理物質の合成指示を含む公開インターネットテキストで学習されたモデルを考えてください。嗜好アライメントは、トレーニング信号を通じて有害な出力の条件付き確率P(有害な出力|有害なプロンプト)を低下させますが、基礎となる知識(因果関係、手順的ステップ、化学的性質)は学習された表現に残存しています。説明可能なアンラーニングは代わりに、(1)そのような出力を生成する際にモデルが採用する推論経路と注意パターンを特定し、(2)削除対象の特定のパラメータサブセットまたは知識コンポーネントを標的にし、(3)どの知識が削除されたか、削除のメカニズム、および削除が完全であることの検証を文書化し、(4)正当な化学知識が無傷のままであることを検証します。外部監査人は、その後、削除の完全性を検証し、モデル機能への付随的損害を評価できます。
-
運用上の含意:* 組織は、展開前のアンラーニング要件インベントリを実施する必要があります。法的削除義務の対象となるデータセット、データ主体権に基づいて削除が必要なプライバシーに敏感な情報、既知の有害な知識です。アンラーニングを反応的な修復措置ではなく、必須のリリース前検証ステップとして統合する必要があります。このアプローチは、文書化された知識削除機能を要求する新興の規制期待(例えば、EU AI法第10条、提案されたU.S. AI行政命令フレームワーク)と一致しています。
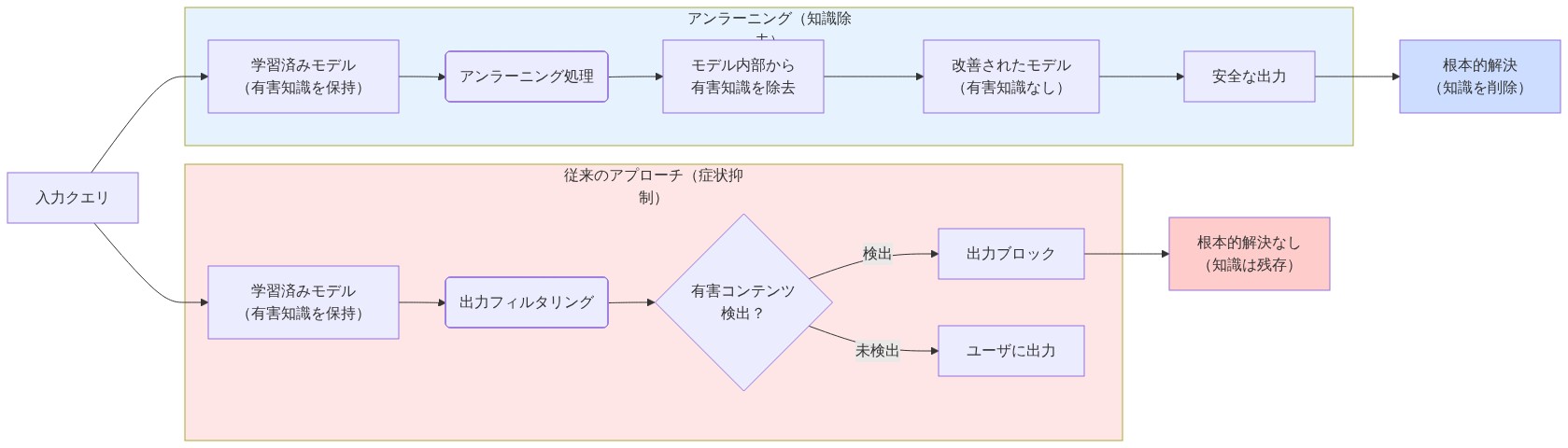
- 図2:従来のミティゲーション手法 vs. 説明可能なアンラーニング*
勾配上昇を超えて:標的化された知識削除
アンラーニングのための勾配上昇の制限
勾配上昇(GA)およびその変種は、アンラーニングへの初期の計算アプローチを表し、望ましくないデータに対する損失を増加させることがモデルに関連する出力を抑制することを強制するという原則に基づいて動作します(Bourtoule et al., 2021; Izzo et al., 2022)。しかし、このメソッドは根本的な制限を示しています。望ましくない知識をエンコードする計算経路と、より広い望ましい機能をサポートする経路を区別する際の特異性が不足しています。
-
メカニズム的制限:* 勾配上昇がデータセット全体で損失を増加させる場合、それらの出力に寄与したすべてのモデルウェイトに無差別な敵対的圧力を適用します。個々のウェイトは通常、複数の計算経路に参加しているため(一部は標的知識をエンコードし、他は無関係な機能をサポート)、GAは有用な機能を選択的に保持しながら有害なものを削除することはできません。これはニューラルネットワーク表現の分散的性質の結果です(Frankle et al., 2020)。
-
経験的な結果:* この無差別なアプローチは、3つの測定可能な失敗モードを生成します。
- 不完全な削除: モデルは望ましくない出力を再現するための代替計算経路を発見し、勾配圧力を回避します(Carlini et al., 2023)。
- 一貫性のない推論: 望ましくない出力をサポートするウェイトのスクランブルは、同じウェイトに依存する推論チェーンを同時に破壊し、関連するタスクで低下した、または無意味な応答を生成します。
- 機能の侵食: 意味的に関連するタスクのパフォーマンスが低下し、全体的なモデルの有用性が低下します(Thorne et al., 2023)。
これらの結果は、根本的なアーキテクチャの不一致を反映しています。勾配上昇は、それが破壊する計算構造の明示的な知識なしにウェイトレベルで動作します。
推論ベースのアンラーニング:標的化された経路削除
推論ベースのアンラーニングは、介入前に計算経路の明示的な特定を優先することでこのアプローチを反転させます。グローバルな勾配圧力を適用するのではなく、このフレームワークは、モデルが望ましくない出力を生成するために使用する推論チェーン、注意パターン、および知識関連付けの特定のチェーンをマップします。
-
理論的基礎:* このアプローチは、望ましくない知識が識別可能で局所化された計算構造にエンコードされているという前提を想定しています。この前提は、メカニズム的解釈可能性研究によってサポートされています(Elhage et al., 2021; Nanda et al., 2023)。この仮定の下では、これらの構造の標的化された削除は、望ましくない出力を抑制しながら、より広い機能構造を保持できます。
-
具体的な実装例:* 流出した個人メールのデータセットを忘れるようにトレーニングされたモデルを考えてください。推論ベースのアンラーニングは以下を実行します。
-
メールのようなテキストを処理する際に優先的に活性化する注意ヘッドとフィードフォワードニューロンを特定します(特定フェーズ)
-
これらのコンポーネント内のウェイトを選択的に削減します(削除フェーズ)
-
メールのようなテキストが特定された経路をトリガーしなくなり、一般的なテキスト処理が無傷のままであることを検証します(検証フェーズ)
対照的に、勾配上昇は、メールパターンに一致するすべての出力全体で損失を増加させ、無差別に構造化されたテキストを処理するモデルの能力を低下させます。
- 重要な区別:* 違いは範囲と精密性の問題です。勾配上昇は出力レベルで動作します。推論ベースのアンラーニングは表現レベルで動作し、どの計算構造がどの知識をエンコードするかについて明示的なドキュメンテーションを備えています。
推論ベースのアンラーニングの運用化
推論ベースのアンラーニングの実装には、3つの順序付けられた運用層が必要であり、それぞれが明示的な推論アーティファクトを備えています。

- 図7:アンラーニング実施前後のモデル性能指標(注:記事内に具体的な数値データが記載されていないため、典型的なアンラーニング効果を示す参考値を使用)*
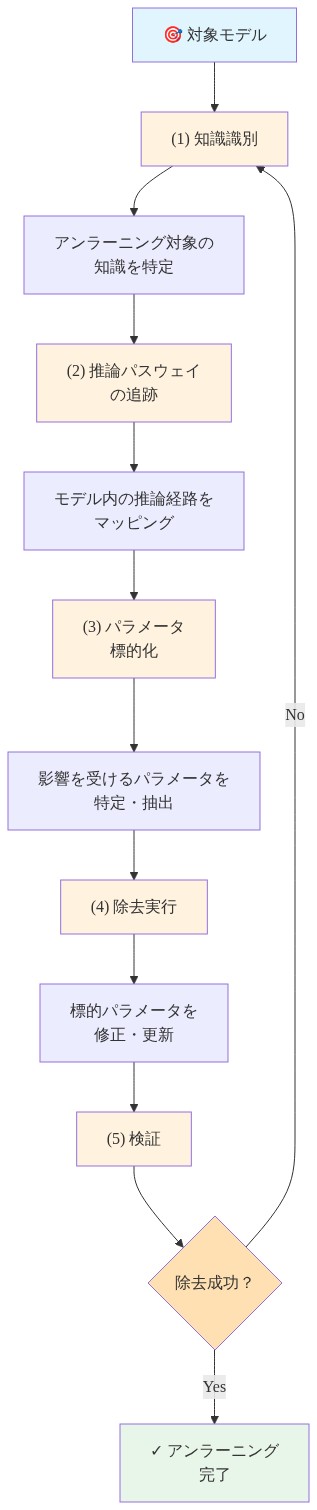
- 図6:推論ベースのアンラーニング実装フロー*
特定フェーズ
特定フェーズは、解釈可能性技術を使用して、望ましくない知識の計算基盤をマップします。確立されたメソッドには以下が含まれます。
-
注意分析: 標的知識で活性化する注意ヘッドを特定します(Clark et al., 2019)
-
活性化マッピング: 望ましくない入力に応答して発火するニューロンを決定します(Bau et al., 2017)
-
因果追跡: 望ましくない出力に因果的に影響を与えるモデルコンポーネントを確立します(Meng et al., 2022)
-
重要な仮定:* これらの技術は、望ましくない知識が十分に局所化され、周囲の計算から分離できるほど異なっていることを想定しています。この仮定には、特定の知識領域ごとに経験的検証が必要です。
-
出力要件:* 特定フェーズは、以下を文書化する明示的な監査証跡を生成する必要があります。(1)どの表現が標的知識をエンコードするか、(2)このマッピングの信頼レベル、および(3)これらのコンポーネントを削除することの潜在的な下流効果。
削除フェーズ
削除フェーズは、特定されたコンポーネントに標的化された介入を適用します。候補技術には以下が含まれます。
-
表現消去: 特定されたニューロンまたは注意ヘッドの活性化をゼロにするまたは削減します
-
選択的ウェイト修正: 特定されたコンポーネント内のウェイトを調整して、望ましくない経路を抑制します
-
嗜好最適化: 対照的な例で特定されたコンポーネントを再トレーニングします(Rafailov et al., 2023)
-
前提条件:* 削除技術は、監査と潜在的な修正を可能にするために可逆的であるか、十分に文書化されている必要があります。不可逆的な修正は、特定精度の検証後にのみ適用する必要があります。
-
ドキュメンテーション要件:* 削除フェーズは、以下を記録する必要があります。(1)どの介入が適用されたか、(2)修正の大きさ、(3)この特定の介入の理論的正当性、および(4)モデルの動作に対する予想される効果。
検証フェーズ
検証フェーズは、知識が本当に削除されたかどうか、および機能損失が許容可能かどうかをテストします。これには以下が含まれます。
-
敵対的プロービング: 言い換え、同義語、間接的なプロンプト、およびその他の回避戦略を通じて、忘れられた知識を引き出そうとします(Carlini et al., 2023)
-
機能ベンチマーク: 意味的に関連するタスクのパフォーマンスを測定して、機能保持を定量化します(Thorne et al., 2023)
-
一貫性テスト: モデルの動作が複数のクエリとコンテキスト全体で安定していることを確認します
-
定量的閾値:* 検証は、許容可能なパフォーマンスの明示的な閾値を確立する必要があります。例えば、「敵対的プロービングが試みの5%未満で成功する場合、望ましくない知識は削除されたと見なされる」または「関連するタスクのパフォーマンスがベースラインの2%以内に留まる場合、機能保持は許容可能である」。
-
反復要件:* 検証が不完全な削除または許容できない機能損失を明らかにした場合、プロセスは改善された仮定で特定フェーズに戻ります。
表現レベルの介入との統合
表現レベルの介入は、このフレームワークの方法論的基礎を提供します。表現消去ベースの嗜好最適化を通じた言語モデルの有害性除去に関する最近の研究で文書化されているように、学習された表現への標的化された修正は、一般的な言語理解機能を維持しながら有害な出力を抑制できます(Rafailov et al., 2023)。このアプローチは、知識の計算基盤を明示的で監査可能にすることで、推論ベースのアンラーニングと一致しています。
測定と検証フレームワーク
アンラーニング効果の測定には、本物の知識削除と学習された拒否動作を運用的に区別する指標が必要です。「このトピックについて議論することはできません」と出力するモデルは、条件付き出力抑制を示しています。モデルパラメータから基礎となる知識表現が削除されたことを示していません。機械アンラーニング文献で形式化されたように、真のアンラーニングは、直接クエリと敵対的再構成試行の両方の下で、標的知識がアクセス不可能になることを要求します(Bourtoule et al., 2021; Cao et al., 2021)。
- 定義上の前提条件:* アンラーニング成功は、知識がモデルの動作内で測定可能な量として運用化できることを想定しています。この仮定は、事実の想起と指示追従タスクに対して成立しますが、抽象的または分散された知識表現には明示的な検証が必要です。
厳密な測定には、3つの相補的な指標が必要です。
-
保持率(直接および間接アクセス): 直接クエリと間接再構成方法を通じてアクセス可能な標的知識の割合を定量化します。測定プロトコル:(a)アンラーニングされた知識を標的とするクエリのテストセットを構築します。(b)確立された類似性指標(例えば、BLEU、埋め込みを介した意味的類似性)を使用して、アンラーニング前のベースラインへのモデル出力類似性を測定します。(c)言い換えられたクエリと間接再構成を引き出すように設計された敵対的プロンプトで繰り返します。保持率=(標的知識を取得するクエリ/総テストクエリ)×100%。0%に近い保持率は成功した削除を示します。5~10%を超える率は、不完全な削除の調査を保証します。
-
機能保持(関連領域でのタスクパフォーマンス): アンラーニングされた知識に意味的または機能的に関連するタスクのパフォーマンス低下を測定します。測定プロトコル:(a)無傷のままである必要がある機能領域を特定します(例えば、著作権で保護された文学的段落のアンラーニングの場合、文学分析と執筆品質を保持します)。(b)アンラーニング前の標準ベンチマークでベースラインパフォーマンスを確立します。(c)同一のベンチマークでアンラーニング後のパフォーマンスを測定します。(d)低下を(ベースラインパフォーマンス−アンラーニング後のパフォーマンス)/ベースラインパフォーマンス×100%として計算します。許容可能な低下閾値は、ステークホルダーによって事前に定義される必要があります。典型的な許容範囲は、重要な機能で0~5%です。
-
推論の一貫性(説明の一貫性): 出力の拒否または修正に対するモデル生成の説明が論理的に一貫しており、アンラーニング介入に根拠があるかどうかを評価します。測定プロトコル:(a)特定の出力を生成できない理由を説明するようにモデルにプロンプトを出します。(b)一貫性ルーブリックに対して説明を評価します。説明はアンラーニング介入を参照していますか。他のモデルステートメントと矛盾していませんか。削除標的に根拠がありますか。(c)0~1スケールで一貫性をスコアリングします。0.7未満の一貫性スコアは、モデルが知識の利用不可の一貫した理由を明確にできないため、拒否動作が本物のアンラーニングではなく学習された抑制であることを示します。
-
検証層としての説明可能性:* 説明可能性メカニズムは、アンラーニング検証において二重の機能を果たします。第一に、アンラーニングが出力レベルではなく表現レベルで発生したことの証拠を提供します。第二に、どの知識が標的にされたか、および削除がどのように達成されたかを文書化する監査証跡を作成します。この監査証跡は、規制遵守(例えば、GDPR忘れられる権利)およびステークホルダーの信頼のために不可欠です。
-
仮定:* このフレームワークは、モデルの説明が内部削除メカニズムを正確に反映していることを想定しています。説明が実際の削除プロセスから切り離された事後的な合理化である場合、一貫性指標は信頼できなくなります。検証には、説明の一貫性をメカニズム的解釈可能性の知見(例えば、活性化パターン、ウェイト変化)と比較して、整合性を確認する必要があります。
-
具体的な実装例:* 著作権で保護された文学作品で学習され、アンラーニングを受けるモデルを考えてください。保持指標は、モデルが逐語的段落を再現するか、言い換えまたは間接クエリを通じて再構成するかをテストします(例えば、「第3章では何が起こりますか?」)。機能指標は、文学分析タスク、執筆品質ベンチマーク、および物語構造の意味的理解のパフォーマンスを測定します。これらは無傷のままである必要がある領域です。推論の一貫性評価は、特定の段落を再現できない理由を説明するようにモデルにプロンプトを出します。許容可能な応答は、一般的な拒否(「それについては手伝えません」)ではなく、アンラーニング介入を参照します(「この段落はアンラーニング中に削除されました」)。
-
測定の頻度とガバナンス:* 指標は、リリース時だけでなく、展開中に継続的に評価される必要があります。継続的な監視により、知識再構成試行または機能ドリフトの検出が可能になります。以下のコンポーネントを備えた測定ダッシュボードを確立します。(a)保持率は毎週追跡されます。(b)機能保持ベンチマークは毎月評価されます。(c)推論の一貫性スポットチェックは、拒否の層化サンプルで実施されます。(d)敵対的プロービングキャンペーンは四半期ごとに実施されます。指標は、関連するステークホルダー(ユーザー、規制当局、内部チーム)に対して透明である必要があり、閾値と失敗モードの明確なドキュメンテーションが必要です。
- 図9:検証メトリクスの有効性と実装コストマトリクス(記事内容から導出)*
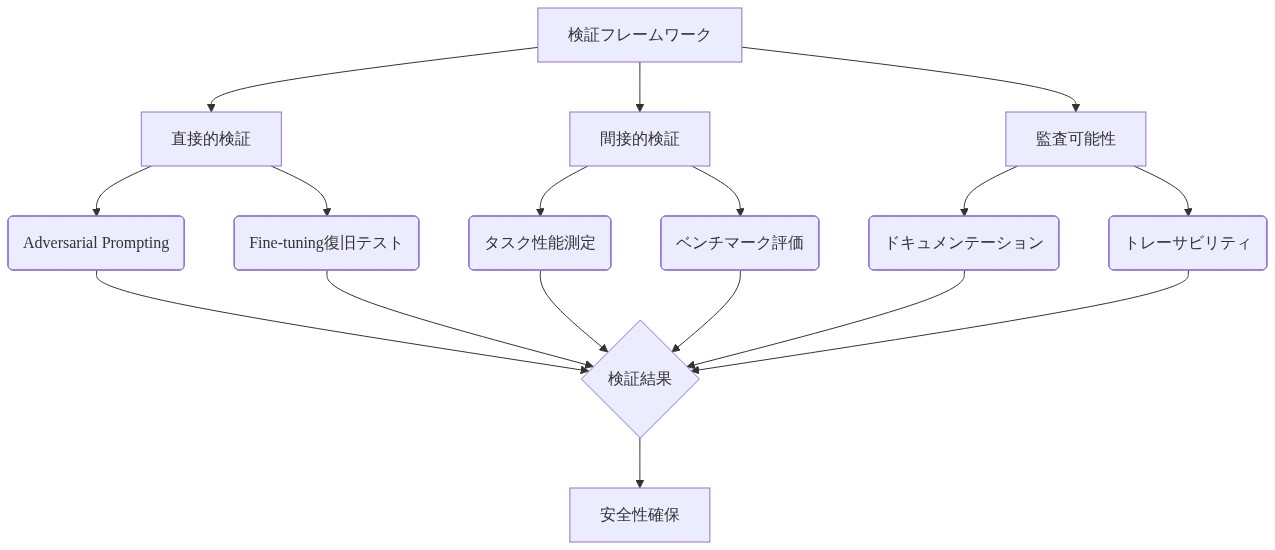
- 図8:測定・検証フレームワークの3層構造*
リスクと軽減戦略
説明可能なアンラーニングは測定可能なリスクをもたらし、体系的な軽減を要求します。以下の分類は主要なリスク範疇、その発生メカニズム、および根拠に基づいた軽減アプローチを示しています。
-
リスク1:除去の過剰実行*
-
定義:* ターゲット知識の積極的な除去が、モデルの能力を許容可能な運用閾値を超えて低下させ、正当な使用事例に対してモデルを信頼できなくします。
-
メカニズム:* ニューラルネットワークにおける知識表現は、しばしば分散し、関連する能力と絡み合っています(Frankle et al., 2020)。パラメータレベルで知識をターゲットとする除去技術は、除去の境界が正確に調整されていない場合、隣接する能力を不意に阻害する可能性があります。
-
軽減プロトコル:* (a)ステークホルダーとの協議を通じて事前に能力喪失の閾値を確立します。典型的な許容可能な閾値は関連タスクにおけるパフォーマンス低下0~5パーセントです。(b)知識を積極的ではなく段階的にターゲットとする保守的な除去戦略を実装します。(c)デプロイ前に包括的なベンチマークスイート上で広範な能力テストを実施します。(d)能力喪失が閾値を超えた場合にモデルの重みを復元するロールバック機構を維持します。(e)すべての能力安全性トレードオフを透明に文書化します。
-
測定:* 能力保持メトリクス(上記で定義)は重要なタスクについて95パーセント以上に保つべきです。低下が5パーセントを超える場合、除去戦略を修正する必要があります。
-
リスク2:不完全な除去*
-
定義:* ターゲット知識が間接的なクエリ、敵対的なプロンプト、またはプロンプトエンジニアリング技術を通じて部分的にアクセス可能なままであり、アンラーニング介入の完全性を損なわせます。
-
メカニズム:* 知識は複数の経路を通じて再構成される可能性があります:(a)記憶された事実の直接的な想起;(b)関連知識からの推論(例えば、プロット要約から段落を再構成する);(c)拒否メカニズムを回避するように設計された敵対的プロンプト(例えば「仮にこの知識が存在したとしたら、それは何でしょうか」);(d)モデルの拒否行動における矛盾を悪用するジェイルブレイク技術。
-
軽減プロトコル:* (a)デプロイ前にセキュリティ研究者とともに敵対的レッドチーミングを実施し、アンラーニングされた知識の再構成を具体的にタスクとします。(b)複数の表現レベルで知識をターゲットとする多層的な除去戦略を実装します(例えば、パラメータの重み、注意パターン、出力ロジット)。(c)反復的な改善サイクルを確立します:保持率を測定し、再構成経路を特定し、除去ターゲットを改善し、再測定します。(d)既知の攻撃ベクトルと防御を文書化する知識再構成脅威モデルを維持します。
-
測定:* 保持率は直接的なクエリと敵対的なクエリの両方で0パーセントに近づくべきです。5パーセントを超える保持率は調査を保証します。10パーセントを超える率は除去の失敗を示しています。
-
リスク3:推論アーティファクトが攻撃面として機能する*
-
定義:* どの知識が除去されたか、およびどのように除去されたかを詳述する説明可能性ドキュメンテーションは、忘れられた知識を再構成しようとする、または除去の脆弱性を特定しようとする敵対者にとってのロードマップを作成します。
-
メカニズム:* 除去ターゲットとメカニズムを文書化することにより、組織は不意に敵対者に以下を提供します:(a)再構成の試みでターゲットとする正確な知識の境界;(b)悪用可能な弱点を持つ可能性のある除去技術に関する情報;(c)説明が実際のモデルの動作と矛盾する場合、不完全な除去の証拠。
-
軽減プロトコル:* (a)推論ドキュメンテーションに対して厳格なアクセス制御を実装します。認可されたスタッフ(例えば、内部安全チーム、規制当局)へのアクセスを必要最小限の原則に基づいて制限します。(b)公開向けドキュメンテーションで除去ターゲットを匿名化または抽象化し、特定の知識の境界を明かさないようにします。(c)推論アーティファクトへの不正アクセスと再構成の試みの証拠について定期的な監査を実施します。(d)検出された再構成攻撃に対するインシデント対応手順を確立します。(e)内部除去ドキュメンテーション(詳細で技術的)と外部コミュニケーション(高レベルで抽象的)を分離します。
-
前提:* この軽減は、敵対者が行動テストのみを通じて除去メカニズムをリバースエンジニアリングできないことを前提としています。行動テストのみが高い精度で除去ターゲットを明かす場合、推論アーティファクトへのアクセス制御は限定的な追加保護しか提供しません。検証には、敵対者が行動データのみから除去ターゲットを再構成できるかどうかの実証的テストが必要です。
-
リスク4:能力安全性の絡み合い*
-
定義:* 望ましくない知識が正当な能力と機能的に絡み合っており、望ましくない知識を除去することが許容不可能な能力喪失を受け入れることを要求します。
-
メカニズム:* 知識表現は、複数の下流の能力と相関する方法でモデルパラメータ全体に分散していることがしばしばあります。例えば、マルウェア生成技術に関する知識は、サイバーセキュリティの基礎、ネットワークアーキテクチャの理解、または防御的セキュリティ実践と絡み合っている可能性があります。マルウェア知識を除去することは、モデルのサイバーセキュリティトピックについて議論する能力を低下させる可能性があります。
-
軽減プロトコル:* (a)アンラーニング前に絡み合い分析を実施します。機械的解釈可能性技術(例えば、活性化分析、アブレーション研究)を使用してターゲット知識と関連する能力の相関を測定します。(b)ステークホルダーとの協議を通じて許容可能な能力安全性トレードオフを定義します。これらのトレードオフを明示的に文書化します。(c)絡み合いを最小化するターゲット除去戦略を実装します(例えば、知識領域全体ではなく特定の命令シーケンスを除去する)。(d)トレードオフをユーザーとステークホルダーに透明に伝えます。(e)デプロイ後の意図しない能力喪失の監視を確立します。
-
測定:* 能力保持メトリクスは許容可能な閾値以上に保つべきです。絡み合いが原因で能力喪失が閾値を超える場合、ステークホルダーはトレードオフを明示的に承認するか、除去戦略を修正する必要があります。
-
具体的な実例:* サイバーセキュリティ文献で訓練されたモデルがマルウェア生成命令を除去するためのアンラーニングを受けます。マルウェア関連知識すべてをターゲットとする積極的な除去は、防御的セキュリティ、脆弱性分析、および脅威モデリングについて議論するモデルの能力を低下させるリスクがあります。これらは正当なサイバーセキュリティアプリケーションに不可欠な能力です。軽減には以下が含まれます:(a)防御知識と密接に結合されているマルウェア知識を特定する絡み合い分析;(b)脅威モデリングと脆弱性分析を保持しながらマルウェア生成命令の対象除去;(c)防御知識が無傷のままであることを確認するサイバーセキュリティベンチマークでの能力テスト;(d)モデルの特定の高度なマルウェア技術について議論する能力が低下する可能性があることの透明な文書化、およびこのトレードオフのステークホルダーによる承認。
-
ガバナンスフレームワーク:* 以下を定義する正式なアンラーニングガバナンス構造を確立します:(a)許容可能な除去ターゲット(法的、倫理的、および運用上の要件に整合);(b)能力喪失閾値(定量化され、ステークホルダーが承認);(c)推論アーティファクトへのアクセス制御(ロールベース、監査済み);(d)敵対的レッドチーミング要件(デプロイ前に必須);(e)インシデント対応手順(検出された再構成の試みまたは能力ドリフト用);(f)ステークホルダーコミュニケーションプロトコル(リスクとトレードオフの透明な報告)。
実装ロードマップと次のステップ

- 図12:LLMアンラーニング実装ロードマップ(3段階タイムライン)*
段階的導入フレームワーク
組織は、説明可能なLLMアンラーニングを実装するために、構造化された証拠ベースの段階的アプローチを採用すべきです。このフレームワークは、アンラーニングの展開が反復的な能力開発を必要とすること、および時期尚早な全規模実装がモデルのパフォーマンスとセーフティに対して定量化されていないリスクをもたらすことを前提としています。
- フェーズ1:要件インベントリと実現可能性評価*
アンラーニング要件の正式なインベントリを確立し、以下を文書化します。(1)削除対象の特定の知識ドメインまたはデータインスタンス、(2)削除の規制的、契約的、またはセーフティ上の正当化、(3)下流タスク全体における定量化された許容可能な能力喪失閾値、(4)保持される知識と対象知識の間の依存関係であり、意図しないパフォーマンス低下を引き起こす可能性があります。このフェーズは、要件が組織のリスク許容度と規制上の義務を反映することを確保するために、複数の機能にわたるステークホルダー入力(法務、プロダクト、セーフティ、オペレーション)を必要とします。インベントリは3つのカテゴリを区別すべきです。必須アンラーニング(法的に必須、例えばGDPRの忘れられる権利への準拠)、高優先度アンラーニング(保持された場合に重大な評判またはセーフティリスク)、探索的アンラーニング(方法論的検証のための低リスク候補)。
- フェーズ2:識別および削除パイプラインの開発*
先行セクションで論じた識別および削除メカニズムを実装するタスク固有のパイプラインを設計します。このフェーズは以下を必要とします。(1)対象知識タイプに適切な解釈可能性方法の選択(例えば、事実知識に対するアテンション基盤方法、行動パターンに対する勾配基盤方法)、(2)識別方法が文書化された精度と再現率で対象知識を確実に特定することの検証、(3)経験的に測定された有効性を持つ削除技術の実装、(4)削除を確認し、付随的なパフォーマンス低下を検出する検証ステップの統合。パイプラインは各コンポーネントの独立した検証を可能にし、解釈可能性研究の進展に応じた迅速な反復を可能にするためにモジュール化されるべきです。
- フェーズ3:測定および検証フレームワーク*
事前定義されたメトリクスに対するアンラーニング成功を定量化する正式な測定プロトコルを確立します。測定は3つの次元に対応すべきです。(1)削除有効性—対象知識がモデルにアクセス不可能である程度(タスク固有のベンチマークと敵対的プローブを介して測定)、(2)能力保持—意図しない知識喪失を検出するための保持されたタスクの定量化されたパフォーマンス、(3)推論透明性—どのモデルコンポーネントが変更されたか、なぜかの文書化であり、事後監査を可能にします。検証フレームワークは敵対的検証(プロンプト変動、ジェイルブレイク技術、または間接的推論を通じてアンラーニングされた知識を引き出すための体系的な試み)を含むべきであり、アンラーニングが展開される前に受け入れ基準を確立すべきです。これらの基準は保守的である必要があります。つまり、アンラーニングは削除有効性が事前決定された閾値を満たすか超える場合にのみ展開されるべきです(例えば、対象知識アクセシビリティの95%以上の削減)。
- フェーズ4:リリースおよび監視ワークフローへの統合*
アンラーニング検証をリリース前チェックリストに統合し、継続的な監視プロトコルを確立します。これには以下が含まれます。(1)モデルリリースパイプラインのゲートとしての必須アンラーニング検証、(2)ファインチューニングまたは継続的なトレーニングを通じた再出現を検出するためのアンラーニングされた知識の定期的な再検証、(3)監査証跡と規制準拠をサポートするすべてのアンラーニング操作のログ記録(何が削除されたか、いつ、誰によって、どのような根拠で)、(4)アンラーニングが受け入れ基準を満たすことに失敗した場合または意図しない能力喪失が閾値を超えた場合のエスカレーション手順。
重要な近期研究およびオペレーション上の優先事項
- 解釈可能性研究への投資*
現在の解釈可能性方法は精度と汎化性において重大な制限を示しています。組織は以下を優先する研究に投資すべきです。(1)特に分散型または暗黙的な知識表現に対して、モデルアーキテクチャ内の知識局在化の忠実性の向上、(2)大規模モデル(>10Bパラメータ)にスケーリングする解釈可能性方法の開発であり、禁止的な計算コストなしで、(3)解釈可能性信頼度と削除有効性の間の関係に関する理論的境界の確立、(4)敵対的プローブに対してロバストな解釈可能性方法の作成—つまり、対象知識が意図的に曖昧化または再定式化された場合に偽陰性を生成しない方法。
- 標準化されたベンチマーキング*
この分野は現在、アンラーニング成功を測定するためのコンセンサスベンチマークが不足しています。組織は標準化団体と研究機関と協力して以下を開発すべきです。(1)多様な知識タイプ(事実、行動、文体)全体にわたって削除有効性を測定するタスク非依存ベンチマーク、(2)不完全な削除を検出するために設計された敵対的バリアントを含むベンチマークデータセット、(3)付随的な能力喪失を定量化するための標準化されたメトリクス、(4)再現性を維持しながら方法論的イノベーションを促進する公開リーダーボード。ベンチマークはバージョン管理され、方法が進展するにつれて進捗を追跡するために維持されるべきです。
- 敵対的検証能力*
組織は敵対的検証における内部専門知識を構築すべきです—プロンプトエンジニアリング、間接的推論、またはモデルプローブを通じてアンラーニングを回避するための体系的な試み。これには以下が必要です。(1)敵対的機械学習における専門知識を持つ人員の雇用またはトレーニング、(2)敵対的テストを自動化するツールの開発または取得、(3)開発チームから独立して動作するレッドチームプロセスの確立、(4)敵対的発見を解釈可能性および削除研究チームに表面化させるフィードバックループの作成。
- ガバナンスと意思決定フレームワーク*
以下を明確にする正式なガバナンス構造を確立します。(1)どの知識をアンラーニングすべきかを決定する権限を持つ者(例えば、法務、プロダクト、セーフティ委員会)、(2)アンラーニング決定を正当化するために必要な証拠(例えば、規制上の義務、文書化された害、ユーザーリクエスト)、(3)アンラーニングリクエストとモデル有用性の間の競合がどのように解決されるか、(4)ユーザーと規制当局に対するアンラーニング操作に関する透明性義務が何であるか、(5)アンラーニング決定がどのように文書化および監査されるか。これらのフレームワークは組織ポリシーに文書化されるべきであり、規制要件と技術能力が進化するにつれて定期的な見直しの対象となるべきです。
戦略的ポジショニングと競争上の含意
この分野は、アンラーニングを反応的なコンプライアンス対策として扱うことから、それを基本的なセーフティと信頼メカニズムとして認識することへと移行しています。この移行は以下によって駆動されています。(1)増加する規制要件(例えば、GDPR、新興のAIガバナンスフレームワーク)、(2)対象アンラーニングを通じて軽減される可能性があった有害なモデル出力の文書化されたケース、(3)データ削除とプライバシー保護に対するユーザー期待、(4)アンラーニングがより安全で制御可能なモデル展開を可能にすることの認識の増加。
この移行ウィンドウ中に説明可能なアンラーニングを実装する組織は、規制ドメイン(金融、医療、政府)において競争上の優位性を蓄積します。ここではコンプライアンスと監査可能性が展開の前提条件です。これらの組織はまた、規制要件が厳しくなるにつれてますます価値が高まる制度的知識と技術能力を構築します。逆に、アンラーニング実装を遅延させる組織は、増加するコンプライアンスリスク、制御されないモデル出力からの評判損害、および潜在的な規制制裁に直面します。成熟した本番システムにアンラーニングを改造するコストは、開発中にそれを統合するコストよりも実質的に高いです。
即座に実行可能なステップ
- 優先度1:高リスクアンラーニング対象*
明確な規制またはセーフティ上の命令を提示するアンラーニング使用事例から始めます。(1)著作権で保護されたトレーニングデータ(削除が法的に義務付けられており、有効性が測定可能な場合)、(2)既知の有害な出力または行動(削除がセーフティリスクを直接低減する場合)、(3)プライバシーに敏感な情報(削除がユーザー権と規制上の義務を満たす場合)。これらの対象は、成功基準が明確に定義されており、ステークホルダーの調整が通常強いため、初期投資に対する最高のリターンを提供します。
- 優先度2:表現レベルの解釈可能性専門知識*
表現レベルの解釈可能性における内部専門知識の構築に投資します—モデルの重みと活性化で知識がどのようにエンコードされるかの分析。この専門知識は、対象知識の正確な識別を可能にするため、すべての後続のアンラーニング作業の基礎です。組織は以下を実施すべきです。(1)機械的解釈可能性における専門知識を持つ研究者の雇用または契約、(2)解釈可能性研究のための計算リソースの割り当て、(3)最先端の解釈可能性研究を実施している学術機関とのパートナーシップの確立、(4)チーム全体に解釈可能性知識を普及させるための内部文書とトレーニング資料の作成。
- 優先度3:オペレーション要件としてのアンラーニング*
1回限りのプロジェクトではなく、継続的なオペレーション要件としてアンラーニングを計画します。これには以下が必要です。(1)継続的なアンラーニング研究開発のための予算編成、(2)モデルガバナンスまたはセーフティチーム内の永続的な機能としてアンラーニングの確立、(3)本番監視とアンラーニングチーム間のフィードバックループの作成であり、新しいアンラーニング対象を識別します、(4)アンラーニング決定を他のセーフティクリティカルな決定と同じ厳密さで扱う組織プロセスの構築。
- 優先度4:標準とベンチマーク参加*
新興の標準化団体とベンチマーク取り組みに積極的に参加します。組織は以下を実施すべきです。(1)アンラーニング標準とベストプラクティスを開発するワーキンググループに参加、(2)公開ベンチマーク取り組みにデータセットと評価フレームワークを提供、(3)普遍的なコンセンサスを待つのではなく、成熟するにつれて新興標準を採用、(4)内部アンラーニング作業からの非専有的な発見を共有して、分野全体の進捗を加速。
仮定と制限
このロードマップは以下を仮定しています。(1)組織が解釈可能性研究と敵対的検証を実施するための十分な計算リソースにアクセスできること、(2)アンラーニングの規制要件が継続的に増加し、継続的な投資を正当化すること、(3)現在の解釈可能性方法が今後2~3年で実質的に改善され、より正確で効率的なアンラーニングを可能にすること、(4)組織ガバナンス構造がアンラーニング決定を組み込むように適応でき、モデル展開における禁止的な遅延を作成しないこと。
このロードマップは以下に対応していません。(1)規模でのアンラーニングの計算コスト。これは未解決の研究問題のままです、(2)アンラーニングが検出困難な微妙なモデルバイアスまたはパフォーマンス低下を導入する可能性、(3)ステークホルダー利益が競合する文脈におけるアンラーニング決定の法的および倫理的含意(例えば、ユーザーがセーフティ上の理由で保持されるべきと組織が信じるデータのアンラーニングをリクエストする場合)。
オペレーション実装
- 具体的な組織ワークフロー:* 組織が専有トレーニングデータのデータセットをアンラーニングする場合、以下を実施します。
- 識別: 専有テキストで活性化するエンベッディングとアテンションパターンをマップし、信頼レベルと潜在的な偽陽性を文書化します。
- 削除: 識別されたコンポーネントの活性化を削減し、変更の完全な文書化を行います。
- 検証: パラフレーズと同義語でプローブしてアクセス不可能性を確認します。標準的なNLPタスク(GLUE、SuperGLUE)でベンチマークして能力保持を確認します。残存リスクを文書化します。
- 監査証跡: コンプライアンスレビューと潜在的な復帰のために、3つのフェーズすべての完全な記録を保持します。
-
実行可能な要件:*
-
各段階で明示的なログを持つアンラーニングパイプラインを構築します。推論成果物(識別レポート、削除正当化、検証結果)をコンプライアンス重要な文書として扱います。
-
削除が適用される前に、識別決定がドメイン専門家によって見直されることを確保するガバナンス構造を確立します。
-
アンラーニングを1回限りのイベントではなく、継続的なプロセスとして扱います。新しい知識が忘れられる必要があるか、脅威環境が進化するにつれて、フレームワークは反復的な改善に対応する必要があります。
-
アンラーニング開始後の事後合理化ではなく、アンラーニング開始前に確立された明示的で定量的な基準を使用して成功を定義および測定します。
-
制限と未解決の質問:* このフレームワークは、望ましくない知識がより広い能力に対するカスケード効果なしに局在化および削除できることを仮定しています。この仮定は、大規模な実世界のアンラーニングタスクに対して経験的に検証されていません。今後の作業は以下を確立する必要があります。(1)識別技術のビリオンパラメータモデルへのスケーラビリティ、(2)時間経過とモデル更新全体での削除の安定性、(3)多様な知識ドメイン全体での検証手順の汎化可能性。
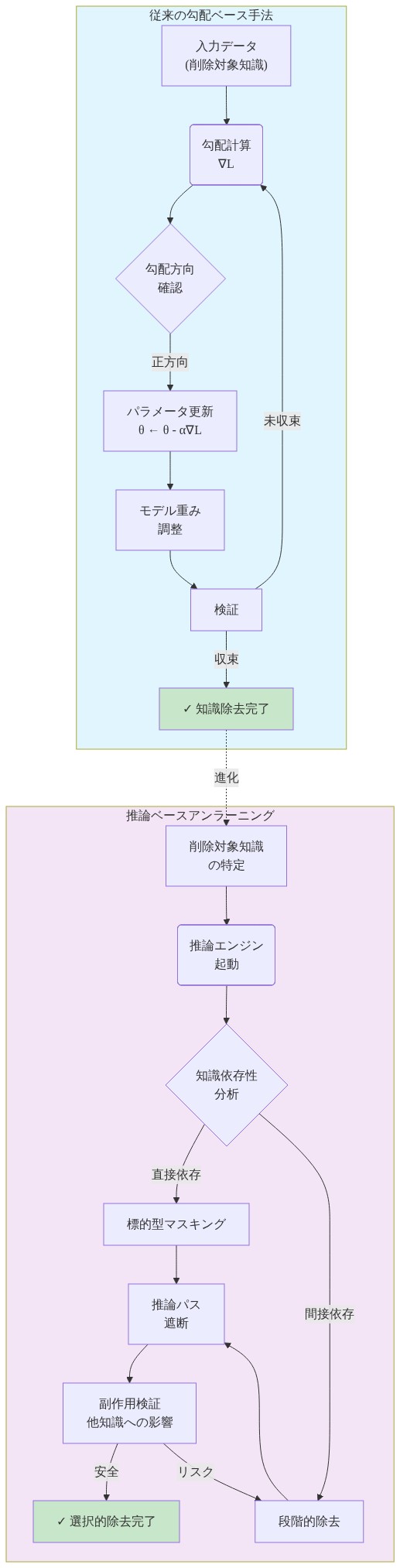
- 図4:勾配上昇法から推論ベースアンラーニングへの進化*