
FedUMM: 統一マルチモーダルモデルを用いた連合学習の一般的フレームワーク
基礎アーキテクチャとしての統一マルチモーダルモデル
統一マルチモーダルモデル(UMM)は、モダリティ固有のパイプラインから統合アーキテクチャへの基礎モデル設計における構造的転換を表しています。テキスト、画像、ビデオ、オーディオに対して個別の処理経路を維持する代わりに、UMMはこれらのモダリティを単一のニューラルアーキテクチャに統合し、すべての入力タイプにわたって生成タスクと理解タスクの両方を実行できます。このアーキテクチャの統合により、冗長な特徴抽出層を排除することで全体的なモデルの複雑性が低減され、1つの統一されたパラメータ空間内でドメイン間の転移学習が可能になります。
運用上の利点は測定可能です。単一のUMMは、画像キャプショニング、ビデオコンテンツに対する視覚的質問応答、オーディオ入力に基づく条件付きテキスト生成を実行できます。すべて個別の専門家モデルを再トレーニングすることなく実行できます。UMMを導入する組織は、単一の推論パイプラインを維持することでインフラストラクチャのオーバーヘッドを削減し、統一されたパラメータ最適化から利益を得ます。ここで、1つのモダリティの改善は共有表現を通じて他のモダリティに伝播する可能性があります。
しかし、現在のUMMトレーニング方法論は、完全に集中化されたデータ収集と処理に依存しています。すべてのトレーニングデータセット(画像、テキスト、ビデオ、オーディオ)は、勾配計算とモデルの重み更新が発生する単一の計算施設に流れる必要があります。このアーキテクチャは、制御されたデータ環境を持つ研究機関には実行可能ですが、データが地理的に分散したサイト(病院、製造施設、小売チェーン、エッジデバイス)に由来し、存在する実世界のシナリオでは運用上および法的に実行不可能になります。機密性の高いマルチモーダルデータを集中化することで、3つの具体的な障壁が生じます。(1)HIPAA、GDPR、およびセクター固有のデータレジデンシー義務に基づく規制上の摩擦、(2)攻撃面の拡大と責任の露出、(3)多くの管轄区域におけるデータソブリンティ要件の違反。
-
前提条件の仮定:* この分析は、データ移動を制限する規制枠組みの下で組織が運営されている(医療、金融、重要インフラ)か、視覚的データセットの周りで競争上の機密性を維持している(製造、小売)ことを想定しています。そのような制約がない組織は、集中化されたトレーニングが運用上受け入れ可能であると判断する可能性があります。
-
実行可能な含意:* 組織は、本番規模でUMMを導入するには、トレーニングパイプライン自体のアーキテクチャの再考が必要であることを認識する必要があります。集中化されたトレーニングは、プライバシー規制産業ではもはや実行可能ではありません。次世代のUMM導入は、データのローカリティを維持しながら協調的なモデル改善を可能にする連合アプローチを要求します。
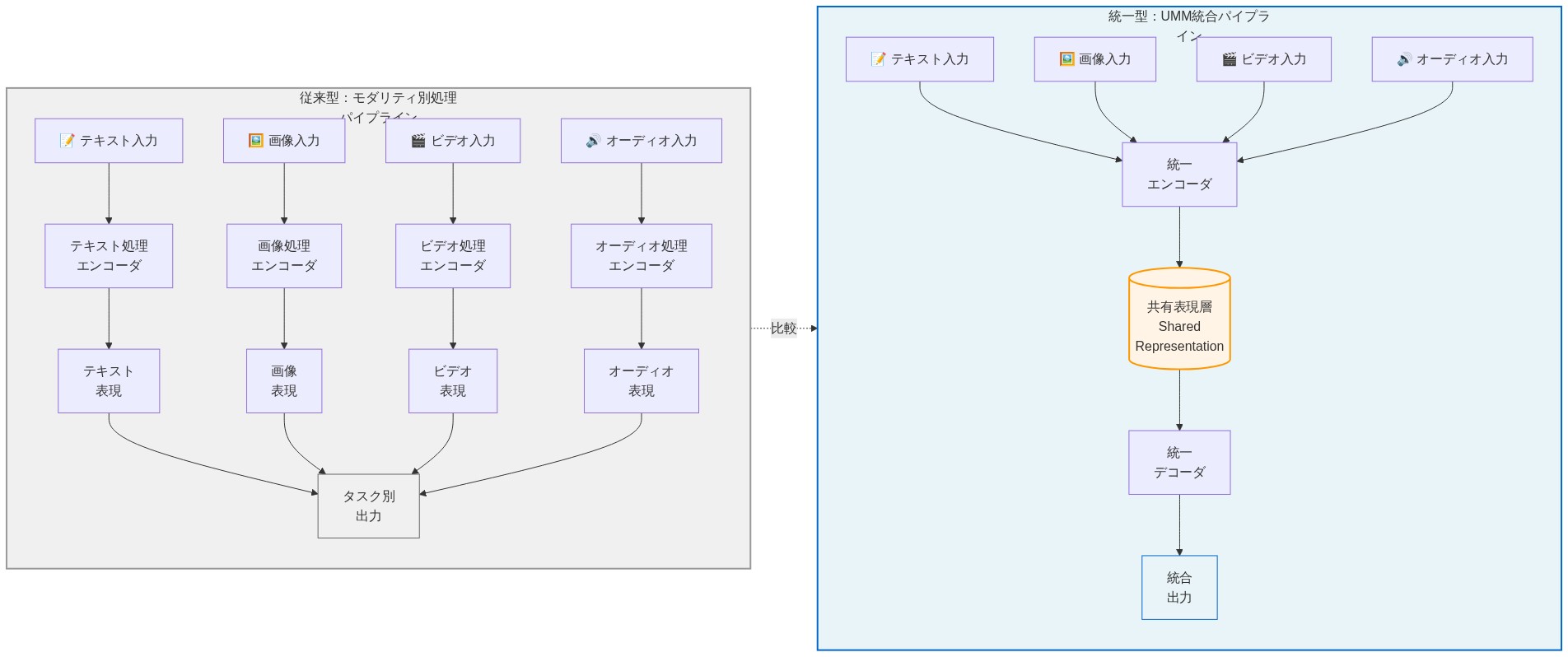
- 図2:従来型パイプライン vs. 統一マルチモーダルモデル(UMM)のアーキテクチャ比較*
実際の導入におけるプライバシーと分散の制約
集中化されたUMMトレーニングは、規制環境での採用に対する3つの具体的な運用上および法的障壁を生じさせます。
-
データ重力とネットワークの制約:* マルチモーダルデータセットをネットワーク全体で移動することは、集中化されたアーキテクチャが外部化する測定可能なレイテンシとバンド幅のコストを発生させます。毎日テラバイト単位のイメージングデータを生成する病院ネットワークは、すべてのデータが中央施設に転送される必要がある場合、ネットワークの飽和に直面します。連合アプローチは、モデル更新のみを転送します。通常、生データ量の1~5%であり、バンド幅要件を1桁削減します。
-
規制遵守要件:* ヘルスケアシステムは、明示的な患者の同意、文書化された監査証跡、およびHIPAAの最小限必要基準への準拠なしに、患者のイメージングデータを集中化されたクラウドリポジトリに統合することはできません。同様に、GDPR第32条はデータの最小化を要求します。データを集中化することはこの原則に違反します。連合トレーニングはデータをソースに保つため、EU、カナダ、および明示的なローカライゼーション義務を持つ他の管轄区域のデータレジデンシー要件を満たします。
-
競争上の機密性と知的財産保護:* 小売業者と製造業者は、視覚的データセットを独自資産として扱います。品質管理のためにコンピュータビジョンを使用する製造コンソーシアムは、競争上の製造プロセス、欠陥パターン、および製品設計を露出させることなく、共有データセンターで生のビデオフィードをプールすることはできません。連合トレーニングは、生データを露出させることなく協調的なモデル改善を可能にします。
-
具体的なシナリオ:* 10のサイトを持つ病院ネットワークは、年間約50~100テラバイトのイメージングデータを生成します。このデータを集中化してUMMトレーニングを行うことは、HIPAA制約(42 CFR §164.308)に違反し、州の違反通知法に基づく責任を生じさせ、二次使用に対する明示的な患者の同意を要求します。連合トレーニングは、各サイトでイメージングデータを保つ一方で、共有診断モデルを可能にします。
-
仮定:* この分析は、規制遵守が必須であり、オプションではないことを想定しています。規制されていないセクターの組織は、シンプルさのために集中化されたトレーニングを優先する可能性があります。
連合学習は、分散トレーニングプロトコルを実装することでこれらの制約に対処します。各サイトは独自のマルチモーダルデータでUMMをローカルにトレーニングし、重み更新を計算し、これらの更新のみを中央アグリゲータに転送します。アグリゲータは、指定されたアルゴリズム(通常は加重平均)に従って更新を組み合わせ、改善されたモデルをすべての参加サイトにブロードキャストします。生データはその発信元サイトを決して離れません。
- 実行可能な含意:* データガバナンスポリシーを直ちに監査してください。組織が複数のサイト、管轄区域、または規制ドメイン全体で運営されている場合、連合トレーニングはオプションではなく、責任あるUMM導入の前提条件です。トレーニングアーキテクチャを選択する前に、特定のユースケースのデータレジデンシー要件、同意フレームワーク、およびレイテンシ制約をマップしてください。
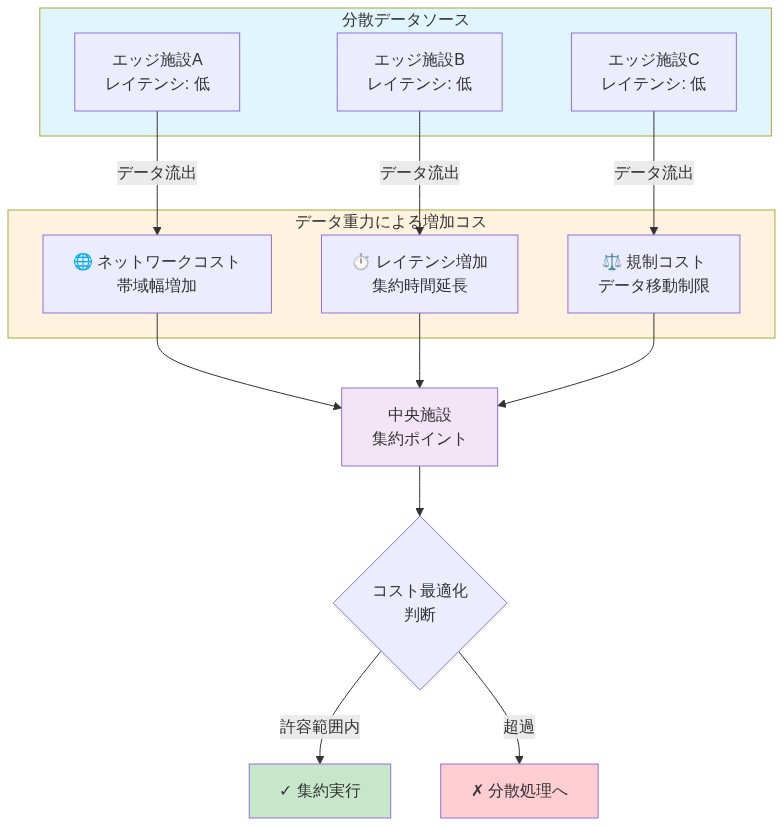
- 図4:データ重力とネットワークコストの関係性 - 分散データソースから中央施設への集約に伴う多次元コスト増加*
FedUMM: フレームワークアーキテクチャと非IIDデータ処理
FedUMMは、非IID(非独立同一分布)マルチモーダルデータで動作するUMMのために明示的に設計された連合学習フレームワークです。非IIDデータの異質性は実践における経験的規範です。1つの病院のイメージング分布(患者の人口統計、機器の種類、疾病の有病率)は別の病院のものと体系的に異なります。1つの工場の欠陥パターンは競合他社のものと異なります。1つの小売地域の製品ミックスは他の地域のものと異なります。集中化されたトレーニングはデータの同質性を想定しています。連合トレーニングは、異質性をエッジケースではなく設計要件として処理する必要があります。
- コア技術的課題:* 各サイトが画像、テキスト、ビデオの異なる分布を維持する場合、標準的な連合平均化(FedAvg)はモデルドリフトと収束失敗を引き起こす可能性があります。FedAvgはすべてのクライアント更新を等しく扱います。これはIID仮定の下でのみ適切です。非IID条件下では、この等しい重み付けにより、グローバルモデルが共有ソリューションに収束するのではなく、ローカル最適値の間で振動します。
FedUMMはこれに対処するために、ローカルデータ特性とモダリティ固有の収束メトリクスに基づいてクライアント更新に重み付けする適応的集約戦略を通じて対処します。フレームワークは各サイトのデータ分布プロパティ(クラスバランス、モダリティの有病率)を推定し、それに応じて集約の重みを調整します。より代表的なデータを持つサイトはより高い重みを受け取ります。歪んだ分布を持つサイトはより低い重みを受け取り、グローバルモデルにバイアスをかけることを防ぎます。
-
具体的な例:* 小売コンソーシアムは、3つの地域全体で製品認識のためのUMMをトレーニングします。地域Aは主に屋内照明条件を持ちます(屋内80%、屋外20%)。地域Bは屋外シーン(屋内20%、屋外80%)を持ちます。地域Cは混合条件(50/50)を持ちます。標準的なFedAvgは3つの地域の更新をすべて等しく扱い、モデルが照明条件の間で振動し、すべての環境に一般化することに失敗します。FedUMMはローカル検証メトリクスを通じてこれらの分布シフトを検出し、集約の重みを調整します(例えば、地域Aに対して0.35、地域Bに対して0.35、地域Cに対して0.30)。最終的なモデルが3つの環境すべてにわたってバランスの取れた精度で一般化することを保証します。
-
通信効率メカニズム:* FedUMMは、精度の大幅な低下なしに更新サイズを10~50倍削減する量子化と圧縮技術を実装しています。フレームワークは、完全な32ビット浮動小数点の重みを転送する代わりに、圧縮表現(16ビットまたは8ビット量子化値、スパース更新)を送信します。50のサイト全体で100のトレーニングラウンドにわたって、これはテラバイトからギガバイトへの総バンド幅要件を削減します。これはネットワーク容量が限られているサイトにとって重要な制約です。
-
仮定:* この分析は、モダリティ固有の異質性(画像、ビデオ、テキスト、オーディオモダリティ全体で異なる分布)が存在することを想定しています。フレームワークは、サイト間の異質性(異なるサイトが異なるデータ分布を持つ)とサイト内の異質性(サイト内で、異なるモダリティが異なる特性を持つ)の両方を処理する必要があります。
-
実行可能な含意:* 連合フレームワークを評価する際、非IID処理と通信効率を主要な選択基準として優先してください。ユースケースに一致する異質なデータ分布での収束速度(ラウンド数対目標精度)とバンド幅消費を示すベンチマークをリクエストしてください。フレームワークが集約精度だけでなく、モダリティごとの収束メトリクスを提供することを確認してください。
実装と運用パターン
FedUMMの導入には、3つの運用層が必要です。オーケストレーション、ローカルトレーニング、および集約です。
-
オーケストレーション層:* クライアントスケジューリングを管理します。各トレーニングラウンドに参加するサイトを決定し、遅延者(期限を逃したサイト)を処理し、フォールトトレランスを実装します。オーケストレーションは、サイト全体の可変計算容量と信頼できないネットワーク接続を考慮する必要があります。
-
ローカルトレーニング層:* 各サイトのローカルデータでUMMの前方および逆方向パスを実行します。各サイトはグローバルモデルのローカルコピーを維持し、固定数のエポックまたは時間ウィンドウでトレーニングし、重み更新を計算します。この層は、モダリティ固有の損失関数(分類用のクロスエントロピー、アライメント用の対比損失など)を実装し、モダリティ全体の可変データ可用性を処理する必要があります。
-
集約層:* 複数のサイトからの更新を組み合わせ、次のグローバルモデルを生成します。標準的な集約は加重平均です。FedUMMはこれをローカルデータ特性に基づく適応的重み付けとビザンチン堅牢な集約で拡張し、破損した更新を検出して除外します。
-
実用的な導入パターン:* プッシュベースではなくプルベースの集約モデルを実装してください。サイトは定期的に現在のグローバルモデルをリクエストし、固定時間ウィンドウ(例えば24時間)でローカルにトレーニングし、更新を送信します。このアーキテクチャはネットワークの信頼性の低さと可変計算容量を許容します。サイトが時間内にトレーニングを完了できない場合、他のサイトをブロックすることなく、そのラウンドをスキップするだけです。同期集約(すべてのサイトを待つ)はボトルネックを作成します。非同期集約(更新が到着するとグローバルモデルを更新する)はより堅牢ですが、古い更新が支配するのを防ぐために古さペナルティが必要です。
-
監視と可観測性:* ラウンドごとにサイトごとに4つのメトリクスを追跡してください。(1)ローカル損失収束(損失は単調に減少しますか?)、(2)更新の大きさ(重みはどの程度変化しますか?)、(3)通信時間(更新の転送にどのくらい時間がかかりますか?)、(4)データ分布ドリフト(ローカルデータ分布は時間とともにシフトしますか?)。異常なメトリクスを持つサイトは、データ品質の問題、設定ミス、またはネットワークの問題を示します。任意のサイトの更新の大きさが平均から3標準偏差を超える場合、自動アラートを実装してください。これは潜在的なデータ破損、ラベルシフト、またはビザンチン動作の兆候です。
-
バージョン管理と監査証跡:* 連合モデルのバージョン管理は、集中化されたトレーニングとは異なります。入力更新とモデル出力の重みのチェックサムを含むすべての集約ラウンドのレジャーを維持してください。記録してください。ラウンド番号、参加サイト、集約の重み、入力更新チェックサム、出力モデルチェックサム、収束メトリクス。これにより、規制遵守の監査証跡とラウンドが予期しない結果を生成する場合のロールバック機能が可能になります。
-
仮定:* この分析は、分散オーケストレーション用のインフラストラクチャが存在することを想定しています(例えば、Kubernetes、Apache Spark)。そのようなインフラストラクチャを持たない組織は、FedUMMを導入する前にオーケストレーションプラットフォームを構築または採用する必要があります。
-
実行可能な含意:* トレーニングが開始される前に、監視ダッシュボードとオーケストレーションインフラストラクチャを構築してください。合成データを使用してオーケストレーションロジックを検証し、ステージング環境で失敗シナリオ(ネットワーク停止、遅延者、ビザンチンクライアント)をテストしてください。一般的な運用上の問題のためのランブックを確立してください。遅延者の処理、更新の拒否、モデルのロールバック。
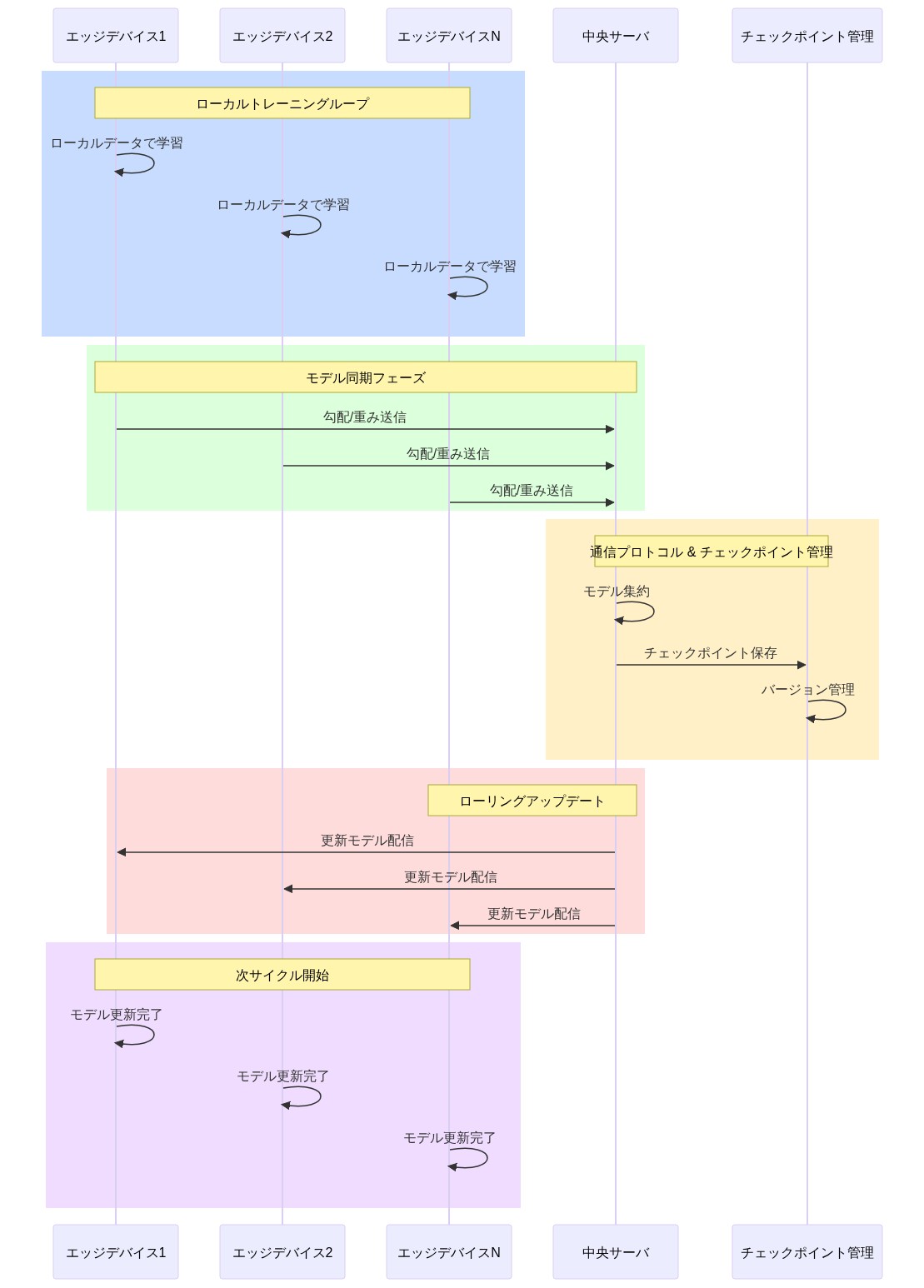
- 図7:FedUMM実装の運用パターンとトレーニングサイクル*
測定と検証戦略
連合トレーニングの成功を3つの独立した次元にわたって測定してください。収束速度、通信効率、および一般化品質。
-
収束速度:* ウォールクロック時間ではなく、ラウンド数対目標精度で測定されます。連合トレーニングは、集中化されたトレーニングよりも多くのラウンドを必要とする可能性があります(勾配の古さと異質性のため)が、サイト全体の並列化のため、より少ない総計算時間を必要とします。目標精度を事前に定義してください(例えば、保持されたテストセットで90%)。この目標が最初に達成されたラウンド番号を記録してください。集中化されたベースラインと比較してください。連合トレーニングは、異質性レベルに応じて、集中化されたトレーニングよりも10~20%以上のラウンド内で目標に到達する必要があります。
-
通信効率:* 1%の精度改善あたりのバイト数で測定されます。すべてのサイトとすべてのラウンド全体で転送されたバイト数の合計を計算し、精度改善(最終精度から初期精度を引いたもの)で割ります。連合トレーニングは、圧縮技術と異質性に応じて、生データを集中化することと比較して、転送されるバイト数を10~50倍削減する必要があります。
-
一般化品質:* 慎重な評価プロトコルが必要です。すべてのサイトからのプールされたデータで集中化されたベースラインをトレーニングしてください(プライバシーが非本番設定で許可される場合、または合成データを使用する場合)。各サイトから保持されたテストセットで連合モデルの精度を比較してください。FedUMMは、40%の非IIDデータ異質性(サイト全体のクラス分布のジェンセン・シャノン発散で測定)の下でも、すべてのサイト全体で5%以内で集中化されたパフォーマンスに一致するか、それを超える必要があります。
-
具体的な検証プロトコル:*
- 各サイトのデータをトレーニング/検証/テスト(60/20/20分割)に分割してください。
- 検証セットを使用して、連合ハイパーパラメータサーチを介してハイパーパラメータ(学習率、集約の重み、圧縮比)をチューニングしてください。
- テスト精度をサイトごとに個別に、およびサイト全体で集約して報告してください。
- サイトAが92%の精度を達成し、サイトBが85%を達成する場合、サイトBのデータ分布がサイト固有の微調整を必要とするかどうかを調査してください(受け入れ可能)またはモデルの公平性の問題を示しているかどうか(受け入れ不可)。
- 定期的な保持評価を実装してください。10ラウンドごとに、連合モデルを凍結し、トレーニング中に使用されなかった各サイトからの新しいデータで評価してください。これはデータリークと特定のクライアント分布への過剰適合を検出します。
-
公平性とバイアス評価:* 連合トレーニングは、サイトが歪んだ人口統計分布を持つ場合、バイアスを増幅する可能性があります。人口統計グループ別に精度を個別に測定してください(利用可能な場合)。人口統計グループ全体の精度分散が5%を超えないことを確認してください(または組織の公平性閾値)。分散が閾値を超える場合、過小表現グループをアップウェイトする公平性を考慮した集約を実装してください。
-
仮定:* この分析は、評価のためにラベル付きテストデータが利用可能であることを想定しています。実際には、マルチモーダルデータの基礎真実ラベルを取得することは高価です。直接評価が実行不可能な場合は、プロキシメトリクス(例えば、ダウンストリームタスクのパフォーマンス)の使用を検討してください。
-
実行可能な含意:* 導入前に成功メトリクスを定義してください。サイト全体での許容可能な精度分散(通常3~5%)、通信予算(ラウンドあたりのバイト数)、および収束速度(ラウンド数対目標)について利害関係者と同意してください。段階的なロールアウトを使用してください。3~5のサイトでパイロットを実施し、成功メトリクスに対して測定し、20以上のサイトにスケーリングしてください。
リスクと軽減戦略
統合マルチモーダルモデル(UMM)の連合学習には、3つの主要なリスクが生じます。
-
リスク1:ビザンチン型クライアントによるモデル中毒。* 悪意のある、または設定が誤ったサイトが、グローバルモデルの品質を低下させる破損した更新を送信します。破損した更新は、ランダムノイズ、ラベル反転データ、またはモデルを特定の動作に導くように設計された敵対的に作成された更新である可能性があります。標準的な連合平均化には防御がなく、単一のビザンチン型クライアントがモデルの品質を大幅に低下させる可能性があります。
-
軽減策:* ビザンチン型ロバスト集約アルゴリズム(例:Krum、マルチ-Krum、中央値ベースの集約)を実装して、外れ値の更新を検出および除外します。ロバスト中央値を>2 MAD(中央絶対偏差)超える更新にフラグを立てます。サイトごとに評判スコアを維持し、繰り返し外れ値の更新があるサイトは将来のラウンドから除外されます。具体的なしきい値:サイトの更新の大きさがラウンド内のすべての更新の95パーセンタイルを超える場合、集約に含める前に手動レビューのためにフラグを立てます。
-
リスク2:勾配反転を通じたプライバシー漏洩。* 攻撃者は、勾配反転攻撃を通じてモデル更新から訓練データを再構成できます。攻撃者が重み更新を観察する場合、それらの更新を生成する訓練データを見つけるための最適化問題を解くことができます。マルチモーダルデータの場合、これは特に懸念されます:再構成された画像またはビデオフレームは、機密情報(医療画像における患者の顔、製造業における独自製品設計)を明かす可能性があります。
-
軽減策:* 集約前に更新に差分プライバシーノイズを追加します。ノイズスケールをプライバシー予算に合わせて調整したDP-SGD(差分プライベート確率的勾配降下法)を使用します。典型的なプライバシー予算:強力なプライバシーの場合はepsilon=1-10、中程度のプライバシーの場合はepsilon=10-100。Epsilon=1は、攻撃者が特定の個人のデータが訓練セットに含まれていたかどうかを37%を超える信頼度で区別できないことを意味します。これは計算オーバーヘッド(訓練が1.5~3倍遅くなる)を追加しますが、医療および金融データには不可欠です。プライバシー会計を実装して、訓練ラウンド全体の累積プライバシー損失を追跡します。
-
リスク3:通信ボトルネックと遅延者。* サイトのネットワークが遅い、または信頼性が低い場合、連合学習は更新を待つ間停止します。単一の遅いサイトが訓練プロセス全体を遅延させる可能性があります。これはリアルタイムまたは時間に敏感なアプリケーションにとって特に問題になります。
-
軽減策:* すべてのクライアントを待つのではなく、更新が到着するにつれてサーバーがグローバルモデルを更新する非同期集約を実装します。これは収束保証を実用的なロバスト性と引き換えにします。古さペナルティを適用します:大幅に遅延しているサイトからの更新は、より低い集約重みを受け取ります。具体例:平均更新到着時間が1時間で、サイトの更新が3時間遅れて到着する場合、0.5倍の重みペナルティを適用します。
-
具体的なシナリオ:* 製造業コンソーシアムが30の工場全体で欠陥検出UMMを訓練します。工場15はネットワーク接続が悪い(衛星リンク)で、2時間遅れて更新を送信します。同期集約は、工場15を待つ毎ラウンド訓練を停止します。非同期集約は継続し、工場15の更新が到着するときに組み込み、その貢献重みに古さペナルティを適用します。訓練は無期限に停止するのではなく、100ラウンドで完了します。
-
追加リスク:データ品質とラベルノイズ。* 連合設定では、各サイトが独自のデータラベリングを管理するため、データ品質の問題が増幅されます。あるサイトは高品質のラベルを持つ可能性があります。別のサイトは、クラウドソーシングまたは自動注釈のため、ノイズの多いラベルを持つ可能性があります。ノイズの多いラベルは連合平均化を通じて伝播し、グローバルモデルの品質を低下させます。
-
軽減策:* 各サイトでラベル品質評価を実装します。確信度学習などの技術を使用して、ノイズの多いラベルを特定し、重みを下げます。サイトごとのラベル品質スコアを維持し、それに応じて集約重みを調整します。ラベル品質が高いサイトはより高い重みを受け取ります。
-
仮定:* この分析は、攻撃者が外部的であること(サイトが共謀していないこと)を想定しています。共謀しているサイトは、ビザンチン型ロバスト集約が防御できない攻撃を調整できます。
結論と移行パス
FedUMMにより、組織は機密データを一元化することなく、統合マルチモーダルモデルをデプロイできます。このフレームワークは、非IID異質性を処理し、通信オーバーヘッドを削減し、プライバシー保護を統合します。成功には3つの段階的なステップが必要です:
- データガバナンスとネットワーク制約を監査します。
- 非重要なユースケースで連合学習をパイロットして、運用専門知識を構築します。
- 適切なプライバシーおよびビザンチン型ロバスト保護を備えた連合設定に本番UMM訓練を移行します。
小さく始めます。1つのマルチモーダルタスク(画像分類、ビデオキャプション)と1つの連合シナリオ(3~5サイト)を選択します。収束、通信、および精度を測定します。運用パターンを文書化します。その後、より複雑なモデルとより大きなコンソーシアムにスケーリングします。
- 次のアクション:* データエンジニア、セキュリティ、コンプライアンス、およびML実務者を含むクロスファンクショナルチームを形成します。データレジデンシー要件をマップします。分布に一致する合成データでFedUMMをプロトタイプします。監視インフラストラクチャを設定します。ステークホルダーと成功メトリクスを定義します。60日以内にパイロットを実行します。

- 図5:FedUMMフレームワークの全体アーキテクチャと非IIDデータ処理フロー*

- 図6:非IIDデータ分布の課題とFedUMMの対応メカニズム*