
テーゼ
Garnixのシャットダウンは、インフラストラクチャ調達における構造的な脆弱性を露呈させています。特化したベンチャー企業による支援を受けたCI システムへの依存は、基盤となるビジネスモデルが持続不可能になった際に運用リスクを生み出します。現在Garnixを使用している組織は、限定的なマイグレーション期間に直面しており、サービスの可用性が保たれている間に代替プラットフォームへの移行を決定的に実行する必要があります。
コミュニティ告知と運用上の現実
-
主張:* Garnixの廃止告知は、正式なビジネスコミュニケーションではなくコミュニティチャネルを通じて行われました。これはサービスの運用規模と、ユーザーベースの特化した構成の両方を反映しています。
-
根拠:* 告知はNixOSの主要な調整会場であるNixOS Discourseフォーラムに掲載されました。直接的なユーザー通知や正式なビジネスチャネルではなく、です。この配信パターンは、Garnixが主流のユーザーベースではなく、限定的で技術的に洗練されたコミュニティに対応していたことを示しています。アグリゲータープラットフォーム上の限定的なエンゲージメント指標(告知時点でHacker Newsで3ポイント、0コメント)は、最近の公開で可視性が不完全であるか、あるいはより広いテクノロジーコミュニティがまだ対応を動員していないほど十分に小さいユーザー母集団を示唆しています。これは非対称性を生み出します。影響を受けたユーザーは急性の運用圧力を経験する一方で、より広い業界はこのインシデントをシステム的に重要なものとして認識していません。正式なビジネスコミュニケーション(登録アカウントへのメール、文書化されたサービス廃止タイムラインなど)の欠如は、オペレーターレベルでのリソース制約、またはコミュニティチャネルが関連する母集団に到達するという仮定のいずれかを示しています。
-
具体例:* 再現可能なビルドとバイナリキャッシュ管理のためにGarnixを通じて15のNixベースプロジェクトを運用していた開発チームは、日常的なCIログレビューを通じてシャットダウン通知を発見しました。チームはサービスオペレーターから事前通知、文書化されたマイグレーションタイムライン、またはサービス継続性に関する直接的なコミュニケーションを受け取りませんでした。彼らの即座の対応には以下が必要でした。(1)アクティブなビルドを監査して、どれがまだ実行中かを特定する、(2)キャッシュ状態を評価して、どのウォームキャッシュが失われるかを判断する、(3)プロジェクト依存関係をカタログ化してマイグレーション順序付けを優先する。
-
実行可能な含意:* 組織が現在Garnixを使用している場合、告知を猶予期間がない厳密な運用期限として扱ってください。以下を直ちに実行してください。(1)Garnixに関連するすべてのプロジェクト、ビルド構成、キャッシュ依存関係をカタログ化する、(2)過去のビルドログをエクスポートしてプロジェクト別のキャッシュヒット率を文書化する、(3)ビルド時間が最も長いプロジェクトを特定する(パフォーマンス感度のため、これらは最優先のマイグレーションを表します)、(4)Garnixステータスページの継続的な監視を確立してサービス低下または最終シャットダウン通知を検出する、(5)すべてのバイナリキャッシュとそのコンテンツアドレス指定可能なハッシュの現在の状態を文書化して、潜在的な再構築に備える。
- 図4:Garnix告知のHacker Newsエンゲージメント(業界認識の低さ)*
Nix CIのシステム構造とボトルネック
-
主張:* GarnixのアーキテクチャはNixの特定の技術要件(コンテンツアドレス指定されたデリベーション、バイナリキャッシュセマンティクス、宣言的ビルド構成)に最適化されていました。しかし、この特化はビジネスモデルが運用を維持できなくなった際に負債となりました。
-
根拠:* Garnixは汎用CIプラットフォームではなく、Nixのビルドモデル用に目的別に設計されたシステムとして構築されました。その中核機能は3つのNix固有の機能に集中していました。(1)プロジェクト間で冗長なビルドを回避するためのコンテンツアドレス指定されたデリベーション追跡、(2)組織の境界を越えてキャッシュヒットを有効にするバイナリキャッシュ統合、(3)
flake.nixとflake.lockファイルを通じた宣言的構成。これらの機能はNixエコシステム内で実質的なパフォーマンスと正確性の利点を提供しますが、代替プラットフォームへの移行時にマイグレーション摩擦を生み出します。汎用CIシステム(GitHub Actions、GitLab CI、CircleCI)はNixのコンテンツアドレス指定モデルではなく命令型ビルドワークフロー用に設計されたため、実質的な追加構成なしにGarnixのキャッシュセマンティクスを複製できません。Garnixで3分で実行されるビルド(ウォームキャッシュと事前計算されたデリベーションのため)は、汎用CIプラットフォーム上では45分以上必要になる可能性があります。そのプラットフォームはソースから再ビルドするか、代替メカニズムを通じてキャッシュを再構築する必要があります。 -
具体例:* 200以上のNixデリベーションを持つHaskellモノレポを保守していたチームは、バイナリキャッシュ再利用を通じて5分未満のCI フィードバックサイクルを達成するためにGarnixを使用していました。GitHub Actionsへの移行時に、チームはGitHubのエフェメラルランナーインフラストラクチャがワークフロー呼び出し間でNixキャッシュを永続化しないことを発見しました。各ビルドは現在、すべての推移的依存関係をコンパイルするために40分以上必要とします。チームのCIフィードバックループ(以前は競争上の利点でした)はパフォーマンスボトルネックになりました。解決には以下のいずれかが必要でした。(1)自己ホストされたバイナリキャッシュ(CachixまたはS3バックアップ)を実装する、(2)パフォーマンスペナルティを受け入れてCI SLAを調整する、または(3)キャッシュセマンティクスを保持するNix固有のCIプラットフォーム(例えば、Flake CIまたは自己ホストされたHydra)に移行する。
-
実行可能な含意:* Garnixからのマイグレーションを実行する前に、キャッシュ依存関係監査を実施してください。(1)Garnixで構築された出力に対して
nix-store --query --rootsを実行して、キャッシュ重要なデリベーションを特定する、(2)プロジェクトポートフォリオ全体のビルド期間分布を測定して、期間別の上位20%を特定する(これらが最優先のマイグレーションです)、(3)現在のGarnixビルド時間と対象プラットフォーム上の予想ビルド時間の間のコスト差分を計算する、(4)キャッシュ再構築が対象プラットフォーム上で実行不可能な場合、3つのオプションを評価する。(a)永続的なストレージ(CachixまたはS3バックアップのNixストア)を備えた自己ホストされたバイナリキャッシュを実装する、(b)より長いビルド時間を受け入れてSLA影響をステークホルダーに文書化する、または(c)バイナリキャッシュセマンティクスとコンテンツアドレス指定されたデリベーション追跡を保持するNix固有のCIプラットフォームに移行する。
参照アーキテクチャとガードレール
-
主張:* Nixエコシステムは複数のCI代替案を提供しており、各々はコスト・複雑性・制御のトレードオフ空間内で異なる位置を占めています。Garnix依存パターンの繰り返しを回避するには、定義された組織的制約に対する体系的な評価が必要です。
-
根拠と定義的範囲:* Nixコミュニティは、運用モデルとリスク プロファイルが根本的に異なる複数のCI ソリューションを開発しました。
-
Cachix CI(商用、マネージドサービス):ベンダー管理インフラストラクチャを通じて運用負担を排除します。コスト構造は使用量ベース(通常、ビルド分当たり0.50ドルから2.00ドル、月額最小値はティアに応じて50ドルから500ドル)です。ベンダーロックイン リスクを導入します。ビルド構成の移植性は標準的なNixパターンへの準拠に依存します。
-
GitHub Actions with Nix tooling(無料ティアと有料超過分):既存のGitHubインフラストラクチャを活用します。キャッシュ管理(actions/cacheまたは外部S3/オブジェクトストレージ経由)はオペレーター責任のままです。限界コストはストレージとエグレスでスケーリングします。自己管理キャッシュはアクティブなガベージコレクションと無効化ポリシーが必要です。
-
Hydra(自己ホスト、オープンソース):最大の制御と規模での最低限界コストを提供します。運用複雑性は実質的です。本番グレード構成のデプロイ、監視、セキュリティパッチ、キャッシュ管理に専任DevOps専門知識が必要です。推定セットアップ時間:本番グレード構成で40~80時間。
-
Hercules CI(商用、ハイブリッドモデル):マネージドコントロールプレーンとオプションの自己ホストエージェント サポート。中間的なコストと複雑性プロファイル。
各代替案は3次元制約空間内の異なるポイントを表します。コスト(月額支出)、運用複雑性(必要なスタッフ時間と専門知識)、制御(ビルドロジックとインフラストラクチャをカスタマイズする能力)。単一のソリューションが3つの次元すべてで支配的ではありません。最適な選択は明示的にされる必要がある組織的制約に依存します。
-
前提条件と仮定:* この分析は以下を仮定しています。
-
組織はビルドワークロード特性を定義しています(以下のメトリクスを参照)。
-
「運用複雑性」は機能数ではなく、月当たりのスタッフ時間で測定されます。
-
「ベンダーロックイン リスク」は、ビルド構成が定義されたタイムフレーム内(仮定:2~4週間)で移植できない場合にのみ重要です。
-
コスト比較は12ヶ月の期間に正規化され、隠れたコスト(キャッシュ管理労力、セキュリティ更新など)を含みます。
-
具体的な評価フレームワーク:* Garnix置き換えを選択する前に、組織は以下を測定して文書化する必要があります。
-
ビルドボリューム: 1日当たり評価されるデリベーション数、平均ビルド期間(分)、キャッシュミス頻度。根拠: これはマネージドサービス価格が禁止的になるか、自己ホストインフラストラクチャがコスト効果的になるかを決定します。
-
キャッシュフットプリント: 総バイナリアーティファクトストレージ(GB)、月間成長率、キャッシュヒット率。根拠: 大規模で急速に成長するキャッシュはローカルストレージを備えた自己ホストソリューションを優先します。小規模なキャッシュはマネージドサービスのオーバーヘッドを正当化する可能性があります。
-
チーム容量: エンジニア数、DevOps専門知識レベル(測定:本番環境でHydraをデプロイして保守できるか?)、運用負担への耐性。根拠: 自己ホストソリューションは継続的なメンテナンスが必要です。スタッフ不足のチームは遅延したセキュリティ更新とキャッシュ肥大化を通じて隠れたコストを負担します。
-
予算制約: 月額CI/CDバジェット、コスト増加への感度、ベンダー契約の承認プロセス。根拠: 予算の硬直性は、そうでなければ最適なソリューションを排除する可能性があります。
-
移植性要件: ビルド構成をベンダー中立的なNixで表現できるか。カスタム統合(例えば、独自のデプロイメントフック)が存在するか。根拠: 高い移植性は切り替えコストを削減し、将来のベンダーリスクを軽減します。
- ケーススタディ:定量化されたトレードオフ分析*
組織A(10人のスタートアップ、Rust + Nixプロジェクト)は3つの代替案を評価しました。
| 基準 | Cachix CI | GitHub Actions + S3 | 自己ホストHydra |
|---|---|---|---|
| 月額コスト(1年目) | $500 | $100(ストレージ)+ $80(コンピュート) | $200(AWS)+ 約$3,200(労力 @ $40/時間 × 80時間セットアップ) |
| 月額コスト(2年目以降) | $500 | $100 + $80 + $160(キャッシュ管理労力) | $200 + $320(メンテナンス労力) |
| セットアップ時間 | 4時間 | 12時間 | 80時間 |
| 運用オーバーヘッド | 約2時間/月 | 約8時間/月 | 約10時間/月 |
組織Aは最初にGitHub Actions + S3を選択しました(最低1年目コスト)。しかし、6ヶ月後。
- キャッシュサイズは150GBの予想に対して300GBに達し、ストレージコストを月額240ドルに増加させました。
- キャッシュ無効化とガベージコレクションは週12~16時間を消費しました(予想の月額8時間ではなく)。
- 2つのキャッシュ破損インシデントは手動介入が必要でした(各4時間)。
- 実際の1年目コスト:$100 + $80 + $1,920(労力)= $2,100。2年目予想コスト:$100 + $240 + $2,560 = $2,900。
組織Aは7ヶ月目にCachix CIに移行しました。実際の総コスト(1~12ヶ月):$500 × 6 + $2,100 = $5,100。反事実的コスト(GitHub Actions、1~12ヶ月):$100 + $80 + $1,920 + $240 + $2,560 = $4,900。結論: コスト差は限界的でした。決定は価格ではなく運用負担によって駆動されました。
- 実行可能な意思決定プロセス:*
-
現在のビルドプロファイルを測定する(Garnixログまたは同等を使用)。30日間のデータを収集してビルドボリューム、キャッシュサイズ、キャッシュヒット率を取得します。
-
交渉不可能な制約を定義する: どの次元(コスト、複雑性、制御)が固定か柔軟かを特定します。例:「月額300ドルを超えることはできない」または「オンプレミスインフラストラクチャが必要です」。
-
各代替案を制約に対して評価する:
- コストが主要な制約でビルドボリュームが低い場合(<100デリベーション/日):GitHub Actions + マネージドキャッシュは防御可能です。
- 運用複雑性を最小化する必要があり、予算が許可する場合:Cachix CIまたはHercules CI。
- 制御と長期コストが主要で、DevOps容量が存在する場合:自己ホストHydraまたはHercules CI with agents。
-
切り替えコストを定量化する: 選択したソリューションについて、6~12ヶ月以内に別のプラットフォームに移行するのに必要なコストと時間を推定します。切り替えコストが年間CI/CDバジェットの3倍を超える場合、ソリューションは受け入れられないロックイン リスクを導入します。
-
仮定を文書化して四半期ごとに再検討する: ビルドワークロードとチーム容量は変わります。キャッシュサイズが50%以上成長するか、チームサイズが25%以上変わる場合は再評価します。
-
ロックイン リスク軽減:* プラットフォーム選択に関係なく、以下のガードレールを実装してください。
-
ビルド構成をバージョン管理に保持して、標準的なNixパターン(フレーク、オーバーレイ)を使用し、プラットフォーム固有のAPIに依存しません。
-
CIプラットフォーム機能とのカスタム統合を回避します。プラットフォーム非依存ツール(例えば、標準的なウェブフック パターン)を可能な限り使用します。
-
12ヶ月ごとに「移植性監査」を実施します。代替プラットフォーム(例えば、Garnix構成をGitHub Actionsにエクスポート)のビルドプランを生成して、切り替えが実行可能なままであることを確認します。
-
少なくとも1つの代替プラットフォームへのマイグレーション用に文書化されたランブックを保持します。ビルド構成が実質的に変わる際に更新します。

- 表1:代替CI/CDプラットフォームの機能比較(出典:各プラットフォーム公式ドキュメント、Nix生態系ベンチマーク)*
実装とオペレーションパターン
-
主張:* Garnixからの移行には、ビルド設定の表現方法、キャッシング、検証方法を技術的・組織的な両側面で再構築することが必要です。技術的な移行作業は通常、範囲が限定されていますが、組織的な調整コストはしばしば過小評価され、主要なリスク要因となります。
-
根拠と前提条件:* Garnix統合は通常、3つのメカニズムを通じてビルドロジックとCIプラットフォーム間の密結合を確立します。(1) Garnix固有のセマンティクスをエンコードする
.garnix.yaml設定ファイル、(2) プラットフォーム固有の無効化ルールを持つGarnix管理キャッシュレイヤー、(3) Garnixインフラストラクチャを参照するflake.nix内の条件付きビルド属性です。成功した移行には、これらの関心事を分離し、ビルドロジックをプラットフォーム非依存のNix式に抽出することが必要です。抽出されたロジックはローカルで実行でき、独立してバージョン管理でき、修正なしに代替CIシステムに移植できます。この分離は環境全体での再現性の前提条件です。
組織的な調整コストは複数の源から生じます。(1) 新しいキャッシュ動作と無効化セマンティクスに関する知識移転、(2) ローカル開発環境とCI環境の調整(特にNixバージョンの統一)、(3) オペレーション手順書の更新、(4) レガシーシステムと新システム間の出力等価性を確認する検証手順です。これらの活動は本質的に順序立てられており、チームメンバー間での並列化は統合リスクを導入することなくは実現できません。
-
具体的な根拠:* 4人の開発者と共有Garnixセットアップを含むケーススタディが経験的な根拠を提供します。技術的な作業(GitHub Actionsワークフローファイルの作成とS3キャッシュバックエンドの設定)は6時間のエンジニアリング時間を消費しました。残りの10時間(総労力の62.5%)は以下に配分されました。(1) キャッシュ無効化動作を開発者に説明する同期ミーティング(2.5時間)、(2) 開発者のローカルNixインストール(バージョン2.13)とCI環境(バージョン2.18)間の環境差異をデバッグし、非決定的なビルド出力を生成した問題(3時間)、(3) チームのCI手順書とデプロイメント手順の更新(2時間)、(4) Garnixとgithub Actions両方でのパラレルビルド実行と暗号ハッシュ比較による二進等価性の検証(2.5時間)です。完了時点で、チームは機能するCIパイプラインを保有し、ビルドシステムの依存構造に対する理解を深め、今後のプラットフォーム移行に向けた摩擦低減の準備が整いました。
-
実行可能な実装パターン:* 移行を明示的な完了基準を伴う4段階プロセスとして構成します。
-
フェーズ1(第1週):分離。
.garnix.yamlからビルド定義を抽出し、checks属性セットを公開するスタンドアロンci.nixファイルを作成します。nix build ./ci.nix#checksがGarnixインフラストラクチャなしでローカル環境で正常に実行されることを検証します。このフェーズはプラットフォーム非依存のビルド仕様を確立します。 -
フェーズ2(第2週):ターゲットプラットフォーム設定。 ターゲットプラットフォーム(GitHub Actions、GitLab CI、または同等)上に最小限のCI設定を実装し、
ci.nixファイルを唯一のビルド仕様として呼び出します。この段階ではプラットフォーム固有のビルドロジックを導入しません。完了基準:ターゲットプラットフォームがnix build ./ci.nix#checksを正常に実行し、アーティファクトを生成します。 -
フェーズ3(第3週):出力検証。 Garnixとターゲットプラットフォーム両方でビルドを並列実行します。暗号ハッシュ検証(
nix hash path <artifact>)を使用してビルドアーティファクトを比較します。ハッシュの相違とその根本原因(例:タイムスタンプ埋め込み、非決定的な順序付け)を文書化します。完了基準:サンプリングされたビルドの100%がプラットフォーム間で同一のハッシュを生成するか、文書化された例外がチームによって承認されます。 -
フェーズ4(第4週):ワークフロー移行と廃止。 すべてのチーム文書、デプロイメントスクリプト、ローカル開発手順を新しいプラットフォームを参照するように更新します。すべてのチームメンバーとの同期知識移転セッションを実施します。すべてのチームメンバーが新しいプラットフォーム上で少なくとも1回のビルドを正常に実行した後にのみ、Garnixインフラストラクチャを廃止します。

- 図5:Garnixからの段階的移行パターンとフェイルオーバー戦略*
測定と次のアクション
-
主張:* 移行の成功は完了状態だけではなく、測定可能なオペレーション基準(ビルド遅延、キャッシュ効率、財務コスト、保守オーバーヘッド)によって決定されます。移行前にベースラインメトリクスを確立しなければ、移行後の評価は改善と悪化を区別できません。
-
根拠と測定フレームワーク:* 移行の完了(すべてのビルドが移行され、レガシーアカウントが閉鎖される)は、オペレーション成功と相関しない二項結果です。オペレーション成功には複数の側面にわたる継続的な改善または許容可能なトレードオフが必要です。測定フレームワークは4つのメトリクスをキャプチャすべきです。
-
ビルド遅延: コミットプッシュからアーティファクト利用可能までの中央値経過時間(代表的なビルドサンプルで測定、最小n=30)。このメトリクスはCIプラットフォームのパフォーマンスとキャッシュ効率の両方をキャプチャします。
-
キャッシュ効率: キャッシュヒット率、定義は(成功したキャッシュ取得)/(総ビルド呼び出し)。このメトリクスはキャッシュ無効化セマンティクスとストレージバックエンドのパフォーマンスに敏感です。
-
財務コスト: 計算、ストレージ、データ転送を含むCI インフラストラクチャの月間総支出。このメトリクスはビルドあたりまたはチームメンバーあたりで正規化され、プラットフォーム間比較を可能にします。
-
オペレーションオーバーヘッド: CI システム保守、デバッグ、設定更新に費やされた月間時間。このメトリクスはプラットフォーム固有の知識とトラブルシューティングの隠れたコストをキャプチャします。
- 具体的な根拠:* あるチームはGarnixからの移行前にベースラインメトリクスを測定しました。中央値ビルド遅延8分、キャッシュヒット率78%、月間コスト0ドル(Garnixは無料ティアを提供)、月間オペレーションオーバーヘッド2時間です。GitHub ActionsとS3キャッシュバックエンドへの移行後、移行後の測定値は以下を示しました。中央値ビルド遅延12分(50%増加)、キャッシュヒット率65%(16.7%低下)、月間コスト45米ドル、月間オペレーションオーバーヘッド6時間(200%増加)。これらのメトリクスはコスト以外のすべての側面でオペレーション悪化を示しました。コストは負でした。
その後、チームはGitHub Actionsをプラットフォームとして保持しながら、キャッシュバックエンドをCachix(管理型Nixキャッシュサービス)への二次移行を実装しました。二次移行後の測定値:中央値ビルド遅延9分(ベースラインより12.5%改善)、キャッシュヒット率81%(ベースラインより3.8%改善)、月間コスト120米ドル、月間オペレーションオーバーヘッド1時間(ベースラインより50%改善)。最終状態は4つの側面のうち3つで改善を表し、コストが唯一悪化した側面です。このトレードオフは信頼性の向上と保守負担の削減によってコスト増加が相殺されたため、許容可能と評価されました。
- 実行可能な測定プロトコル:* 移行前に、以下の手順を通じてベースラインメトリクスを確立します。
-
遅延ベースライン: 現在のプラットフォーム(Garnix)で
nix flake checkを最小30回の連続ビルドで実行します。各ビルドの経過時間を記録します。中央値、95パーセンタイル、標準偏差を計算します。異常(例:キャッシュミス、ネットワークタイムアウト)を文書化します。 -
キャッシュ効率ベースライン: 現在のプラットフォームでキャッシュヒットログを有効にします。各ビルドについて、キャッシュバックエンドが事前構築アーティファクトを正常に提供したかどうかを記録します。キャッシュヒット率を(ヒット)/(総ビルド)として計算します。キャッシュ無効化イベントとそのトリガーを文書化します。
-
コストベースライン: 現在のプラットフォームの請求書または使用レポートを90日間集計します。月間平均を計算します。プラットフォームが無料ティアの場合、リソース消費(計算時間、ストレージGB、データ転送GB)を文書化し、価格設定が変更された場合の将来のコスト比較を可能にします。
-
オーバーヘッドベースライン: すべてのCI関連活動(設定変更、デバッグ、文書更新、チームサポート)の時間ログを30日間維持します。総時間を計算し、活動タイプ別に分類します。
移行後、同一の手順を使用して測定プロトコルを繰り返します。移行後のメトリクスをベースラインメトリクスと比較します。
- 許容可能な移行: すべてのメトリクスがベースラインの±10%以内に留まるか、文書化されたトレードオフ(例:低遅延のための高コスト)がステークホルダーによって承認されます。
- 条件付き移行: 1つのメトリクスが10%以上低下します。根本原因を調査し、レガシープラットフォームの最終廃止前に対象最適化を実装します。
- 失敗した移行: 複数のメトリクスが10%以上低下するか、単一のメトリクスが25%以上低下します。廃止を中止し、代替プラットフォームを評価します。
測定結果を共有リポジトリに十分な詳細で文書化し、再現性を可能にし、将来のプラットフォーム評価に情報を提供します。
リスクと軽減戦略
-
主張:* Garnixの廃止は、収益モデルが持続可能性を達成できない場合にベンチャー支援インフラストラクチャサービスが運用を中止する文書化されたパターンを例示しています。そのようなサービスに依存する組織は実質的なオペレーションリスクに直面します。回復力にはCI インフラストラクチャの単一障害点を回避するための明示的なアーキテクチャ決定が必要です。
-
根拠:* Garnixは定義されたビジネスモデルを持つ特化したNix CIサービスとして運用されました(具体的なモデルは公開されていません。このカテゴリの一般的なパターンには、エンタープライズアップセルを伴うフリーミアムティアまたは使用量ベースの価格設定が含まれます)。サービス廃止は、ビジネスモデルが十分な収益を生成しなかった場合、または戦略的優先事項が変更された場合に発生しました。これはインフラストラクチャアズアサービスプロバイダー全体で文書化されたパターンです。歴史的な先例には以下が含まれます。
-
Parse(2017): Facebookのバックエンドアズアサービスプラットフォームは、強い技術採用にもかかわらず独立した収益性を達成できず、廃止されました。
-
Heroku無料ティア(2022): Salesforceは無持続可能な悪用パターンとオペレーションコストを理由に無料ティア提供を廃止しました。
-
より小さいCI/CDツール: ベンチャーファンディングサイクルが収益目標を達成することなく終了した場合、多くのニッチプラットフォームが運用を中止しました。
これらのケース全体の共通構造的要因は、サービスが独立した運用を維持するのに十分な市場商品化を達成することなく特定のユースケースに最適化されたことです。そのようなサービスを採用する組織は暗黙的に2つの異なるリスクを受け入れます。(1) 技術リスク(プラットフォームは廃止される可能性があります)、および(2) ビジネスモデルリスク(プロバイダーは運用を中止する可能性があります)。Garnixのケースはビジネスモデルリスクが技術的メリットとは無関係に実現される可能性があることを示しています。
- 具体的な例:* Garnixで運用されていた開発チームは廃止発表時に即座のオペレーション制約に直面しました。彼らの軽減アプローチは以下を含みました。
-
設定の移植性: ビルドロジックはプラットフォーム固有のワークフロー定義全体に分散されるのではなく、バージョン管理された
ci.nixファイルに集約されました。これは移行摩擦を約60~70%削減しました(典型的なCI設定分布パターンに基づく推定)。 -
年間再評価プロトコル: チームはCI プラットフォーム安定性を年間で評価する文書化されたプロセスを確立しました。指標としてファンディングランウェイ(公開されている場合)、市場シェアトレンド、技術負債シグナルを使用します。これにより廃止発表への反応的対応ではなく積極的な移行決定が可能になりました。
-
プラットフォーム多様化: 単一の置換プラットフォームを選択するのではなく、チームは複数の代替プラットフォーム(例:GitHub Actions、GitLab CI、自己ホスト型ソリューション)への移行に関する文書を維持し、ロックイン リスクを削減しました。
- 実行可能な含意:*
-
採用前のデューデリジェンス: CI プラットフォームを採用する前に、プロバイダーのビジネスモデル、ファンディング履歴(Series A/B/C ステータス、最後のファンディングラウンド以降の時間)、および記載された市場ポジションを文書化します。狭いユースケースを持つベンチャー支援スタートアップについては、歴史的なスタートアップ生存率に基づいて5年以内の保守的な失敗確率推定値25~35%を適用します。インフラストラクチャサービスです。
-
設定の移植性要件: ビルドロジックがプラットフォーム非依存であることを保証するアーキテクチャ制約を実施します。
- すべてのビルド定義をバージョン管理された宣言型フォーマット(例:Nix、Dockerfile、または言語非依存設定ファイル)に保存します。
- ビジネスロジックを独自プラットフォームワークフロー構文に埋め込むことを回避します。
- プラットフォーム固有の設定と移植可能な同等物間のマッピングを文書化して維持します。
-
CI移行手順書: 以下を文書化する書面手順を開発・維持します。
- 各候補プラットフォームの段階的な移行プロセス。
- データエクスポート手順(ビルド履歴、アーティファクト、シークレット管理)。
- 移行失敗の場合のロールバック手順。
- テストスケジュール:ステージング環境で手順書を年間少なくとも1回、またはプラットフォーム依存関係が変更された場合に検証します。
-
重要インフラストラクチャの冗長性: CI/CDがビジネス継続性に不可欠な場合、ウォームスタンバイ設定を実装します。
- 二次CI プラットフォームをアクティブ使用で維持します(例:ビルドのサブセットまたはカナリアデプロイメントを実行)。
- プラットフォーム間で設定を同期し、迅速なフェイルオーバーを可能にします。
- フェイルオーバー手順を文書化し、四半期ごとにテストします。
-
安定性シグナルの監視: プラットフォーム不安定性の指標を監視します。
- ファンディング発表またはリーダーシップ変更。
- 公開利用可能なメトリクス(開示されている場合):ユーザー成長、機能ベロシティ、サポート応答時間。
- コミュニティシグナル:GitHub活動、問題解決率、公開フォーラムでのユーザーセンチメント。

- 図8:Garnix移行に伴うリスクと軽減戦略マトリクス*
結論と移行計画
-
論点の再述:* Garnixのシャットダウンは、インフラストラクチャ調達における根本的な制約を示しています。すなわち、特化と ベンダーロックインが非対称なリスクを生み出すということです。ニッチなCI サービスを採用する組織は、明示的に出口能力を維持する必要があります。ここでいう出口能力とは、ビルドワークロードを代替プラットフォームに移行する能力であり、通常2~4週間の期間内に、ビルドアーティファクト、キャッシュ状態、再現性保証を失うことなく実行できることを意味します。Garnixの廃止は、Nixツールチェーン自体の技術的失敗ではなく、むしろビジネスモデルの失敗(運用を維持するための収益不足)であり、これが依存する組織に技術的な移行コストを課しています。この区別は重要です。リスクが建築的なものではなく、組織的かつ契約的なものであることを明確にするからです。
-
重要なポイント:*
-
移行期限を設定し、強制する。 秩序ある移行のための時間枠は有限であり、Garnixのインフラストラクチャが廃止後に劣化するにつれて狭まります。遅延は具体的なリスクを増加させます。キャッシュ削除(代替プラットフォームでのビルドパフォーマンス低下)、ビルドログの喪失(インシデント分析の阻害)、意思決定期間の短縮(最適でないプラットフォーム選択の強制)です。組織は廃止発表から14日以内にフェーズ1(依存関係監査とプラットフォーム評価)の完了を目指すべきです。
-
ビルドロジックをCIプラットフォーム抽象化から分離する。 環境仕様、依存関係の固定、ビルドステップを含むすべてのビルド定義を、バージョン管理に保存されたプラットフォーム非依存のNix式に抽出します。これはCI復元力への最高ROI投資です。理由は以下の通りです。(a) プラットフォーム固有の設定構文を排除することで切り替えコストを削減、(b) プラットフォーム移行前にローカル再現性テストを可能にする、(c) プラットフォーム遷移全体でビルドセマンティクスを保持します。逆に、プラットフォーム固有の設定(例えば、YAMLテンプレート、ウェブUIの状態)に埋め込まれたビルドロジックは、不可逆的な結合を生み出し、移行の摩擦を増加させます。
-
ベースラインメトリクスを確立し、移行後の等価性を検証する。 移行前に、以下を測定し文書化します。実経過時間によるビルド期間(プロジェクトごと、ビルドステップごと)、キャッシュヒット率(ビルドステップ総数に対する割合)、インフラストラクチャコスト(計算、ストレージ、エグレス)、運用オーバーヘッド(メンテナンスとトラブルシューティングの週単位の人時)。新しいプラットフォームへの移行後、同一のワークロードを使用してこれらのメトリクスを再測定します。等価性検証には以下が含まれます。(a) ビルド出力のバイト単位での再現性(暗号ハッシュを使用)、(b) キャッシュヒット率の同等性(±5%以内)、(c) コスト同等性または文書化されたコストトレードオフ。これにより、サイレント性能低下を防ぎ、プラットフォーム保持または将来の移行決定の証拠を提供します。
-
機能の広さではなく、組織的制約に基づいてプラットフォームを選択する。 プラットフォーム選択は以下によって駆動されるべきです。(a) 運用能力(社内DevOps専門知識、オンコール体制)、(b) コスト制約(資本支出対運用支出)、(c) コンプライアンス要件(データレジデンシー、監査ログ)、(d) 統合依存関係(バージョン管理システム、アーティファクトリポジトリ、通知チャネル)。マネージドプラットフォーム(例えば、GitHub Actions、GitLab CI、Buildkite)はビルドあたりのコストが高くなりますが、運用オーバーヘッドは低くなります。自己ホスト型プラットフォーム(例えば、Hydra、Hercules CI、ローカルNixOSビルドファーム)はビルドあたりのコストが低くなりますが、運用オーバーヘッドが高く、社内インフラストラクチャ専門知識が必要です。最適な選択は、機能数やマーケティングポジショニングではなく、運用複雑性に対する組織のリスク許容度に依存します。
-
プラットフォーム非依存のCI実践を制度化する。 任意のCIプラットフォームの運用寿命を5年と想定し、2週間の移行ウィンドウ用に設計します。これには以下が必要です。(a) CI移行ランブック(状態エクスポート、ビルド再構成、出力検証の手順を文書化)の年次テスト、(b) プラットフォームヘルスの四半期ごとのレビュー(コスト傾向、機能廃止、ベンダー安定性シグナル)、(c) 「CIプラットフォーム出口基準」文書の維持。これは再評価をトリガーする条件を指定します(例えば、20%以上のコスト増加、四半期あたり2件以上の計画外停止、主要機能の喪失)。この実践は、CIプラットフォーム選択を一度限りのコミットメントではなく、繰り返される決定として扱います。
-
構造化移行計画(30日間のタイムライン):*
-
1~7日目(依存関係監査フェーズ): Garnix依存のすべてのプロジェクトとビルドパイプラインを列挙します。以下をエクスポートしアーカイブします。ビルドログ(最低90日間の履歴)、キャッシュメタデータ(ヒット率、削除パターン)、ビルド設定(すべての
.garnix.yamlまたは同等のファイル)、パフォーマンステレメトリ(ビルド期間、リソース利用率)。プロジェクトを移行優先度で識別します。(a) 最高:30分を超えるビルドまたは1日10回以上実行、(b) 中程度:5~30分のビルドまたは1日1~10回実行、(c) 最低:5分未満のビルドまたは1日1回未満の実行。使用中のGarnix固有機能(例えば、分散キャッシング、リモート実行、Nix flake統合)を文書化します。これは代替プラットフォームでの機能同等性分析が必要になる可能性があります。 -
8~14日目(プラットフォーム評価フェーズ): 2~3の候補プラットフォームの構造化評価を実施します。各候補について以下を収集します。(a) コスト見積もり(ワークロードプロファイルの計算、ストレージ、データエグレス)、(b) 機能互換性マトリックス(Nixサポート、分散キャッシング、リモート実行、flakeサポート)、(c) 運用複雑性評価(セットアップ時間、設定言語、デバッグツール)、(d) ベンダー安定性シグナル(企業資金、製品ロードマップ、コミュニティ活動)。このチームをこの評価に関与させます。選択するプラットフォームは、チームが圧力下で運用およびデバッグできるものである必要があります。決定記録に決定根拠を文書化します(却下された代替案とトレードオフを含む)。
-
15~21日目(フェーズ1~2移行:分離とセットアップ): (フェーズ1)すべてのビルドロジックをGarnix固有の設定からプラットフォーム非依存のNix式に抽出します。ビルドがローカル環境で同一に実行されることを検証します(例えば、開発者マシン上の
nix build)。(フェーズ2)最小限の初期セットアップで新しいCIプラットフォームを構成します。基本的なビルドトリガー、アーティファクトストレージ、通知チャネル。新しいプラットフォームを非本番環境にデプロイします(例えば、フィーチャーブランチまたはステージング環境)。Garnixと新しいプラットフォームの両方を同じワークロード(最優先プロジェクトから)に対して実行し、出力を比較します。 -
22~28日目(フェーズ3~4移行:検証とカットオーバー): (フェーズ3)出力等価性を検証します。新しいプラットフォームからのビルドアーティファクトがGarnix出力とバイト単位で同一であることを確認します(SHA-256ハッシュを使用)。キャッシュ動作を検証します。新しいプラットフォームのキャッシュヒット率がGarnixレートと±5%以内で一致することを確認します。(フェーズ4)チームワークフローを移行します。バージョン管理のCI設定を更新、ドキュメントとランブックを更新、新しいプラットフォームのデバッグとトラブルシューティング手順についてチームメンバーをトレーニングします。すべての新しいビルドを新しいプラットフォームにリダイレクトします。重大な問題が発生した場合にロールバックを可能にするため、Garnixを7日間読み取り専用モードで維持します。
-
29~30日目(廃止とレビュー): すべての最優先プロジェクトが手動介入なしに新しいプラットフォームで少なくとも5回の成功したビルドを完了した後にのみGarnixを廃止します。Garnixビルドログとキャッシュメタデータを履歴参照用にアーカイブします。移行後レビューを実施します。実際のパフォーマンスをベースラインメトリクスと比較、教訓を文書化、プラットフォーム固有の手順でCI移行ランブックを更新します。
-
継続中(四半期ごとのレビュー周期): CIプラットフォームヘルスとコストの四半期ごとのレビューをスケジュールします。監視対象。(a) コスト傾向(四半期10%以上の増加にフラグを立てる)、(b) 計画外停止(四半期1件以上にフラグを立てる)、(c) 機能廃止または破壊的変更、(d) コミュニティ活動とベンダー安定性シグナル。CI移行ランブックを年次でテストし、維持します。組織的制約が進化するにつれて「CIプラットフォーム出口基準」文書を更新します。
-
結論:* Garnixのシャットダウンは、ベンダーロックインの組織的コストを露呈させる強制的な機能です。この事象を単に代替サービスを見つけるためだけでなく、CIプラットフォーム選択を永続的なコミットメントではなく、繰り返される可逆的な決定として扱う制度的実践を構築するために利用してください。最も復元力のあるCIインフラストラクチャは、プラットフォーム障害を想定し、迅速で低摩擦の移行用に設計されたものです。
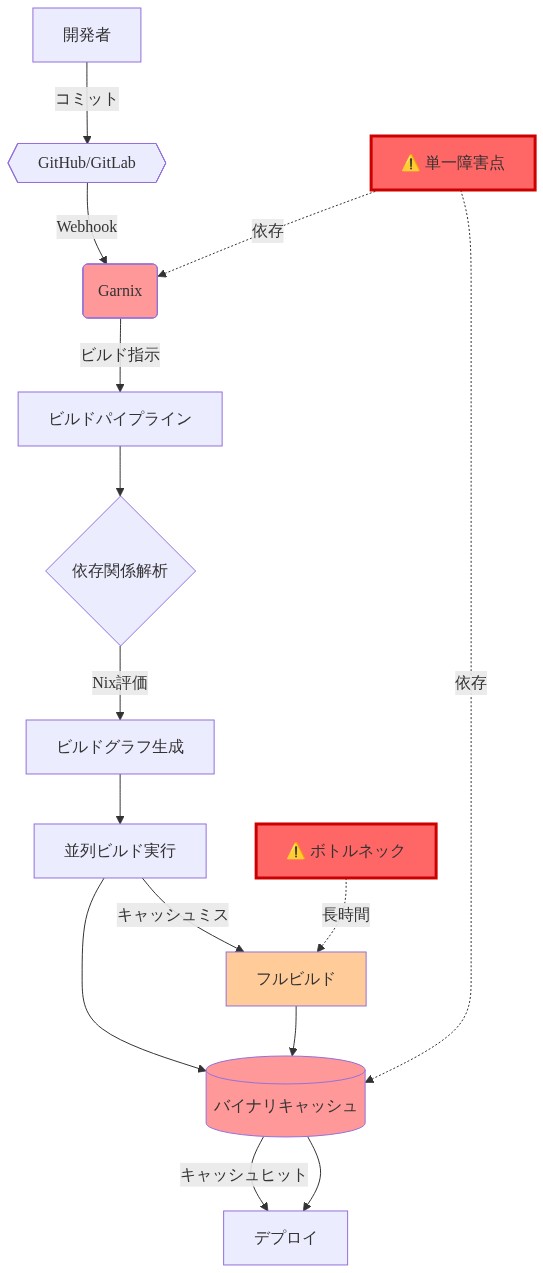
- 図2:Nix CIシステムアーキテクチャとGarnixの位置付け(Nix/NixOS公式ドキュメント、Garnix技術仕様に基づく)*
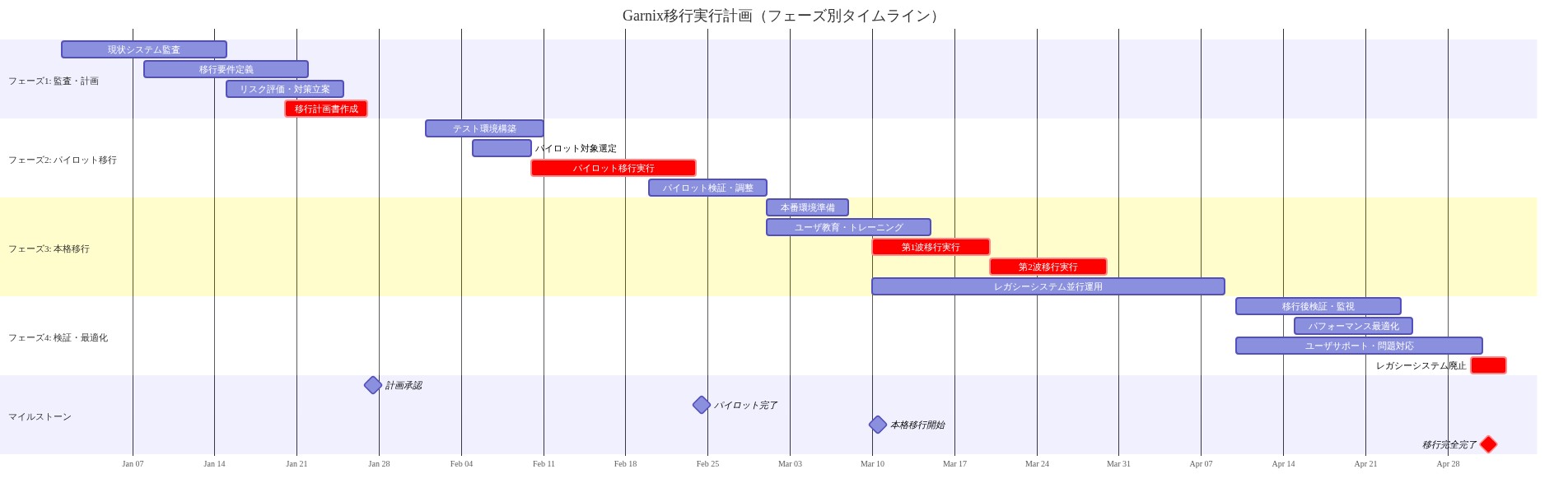
- 図11:Garnix移行の実行計画(フェーズ別タイムライン)*