
Redis、愛しているけど、SolidQueueに乗り換えます
なぜRedis単体ではジョブキューとして不十分なのか
Redisは、永続的なジョブキューシステムとしてではなく、低レイテンシアクセスパターンに最適化されたインメモリデータ構造ストアとして設計されました(Redis作成者Salvatore Sanfilippo、2009年)。Redisは永続化メカニズム(Append-Only File(AOF)とRDBスナップショット)を提供していますが、これらはオプションであり、明示的な設定が必要です。重要なことに、両方のメカニズムはデータ損失の可能性がある時間枠を導入します。AOFはデフォルトで非同期に書き込み、RDBスナップショットは離散的な間隔で発生します。クラッシュまたは計画外のフェイルオーバー中に、エンキューされたがまだディスクに永続化されていないジョブは、取り返しのつかない形で失われます。
このアーキテクチャ上の制限は、本番環境のシナリオで顕在化します。ワーカーがRedisからジョブを取得し、処理を開始し、完了を確認する前にクラッシュする決済処理パイプラインを考えてみましょう。ワーカーが再接続してジョブを再エンキューする前にRedisインスタンスが再起動すると、ジョブは永久に失われます。監査証跡も回復メカニズムもありません。これは設定エラーではなく、同期的な永続性保証のないインメモリシステムの固有の特性です。
対照的に、SolidQueueはPostgreSQLまたはMySQLをバッキングストアとして使用します。すべてのジョブ挿入はデータベーストランザクションであり、確認応答の前にディスクに永続化されます。クラッシュしたワーカーは、ジョブを回復可能な状態でキューに残し、自動再試行の対象となります。これは根本的なアーキテクチャの違いを表しています。Redisは永続性よりも速度を優先し、SolidQueueは合理的なパフォーマンスを犠牲にすることなく永続性を優先します。
-
前提条件:* この分析は、インフラストラクチャ障害時のジョブ損失がワークロードにとって許容できないことを前提としています。重要度の低い、冪等で再試行可能なジョブ(キャッシュウォーミングなど)の場合、Redisで十分かもしれません。決済処理、注文処理、または監査が重要な操作の場合、永続性は厳格な要件です。
-
実用的な意味:* 過去12か月間のインシデントログを監査してください。Redisのクラッシュ、フェイルオーバー、または再起動中に失われたジョブを特定してください。ビジネスへの影響(顧客への返金、サポートチケット、コンプライアンス違反)を定量化してください。カウントがゼロでない場合、永続性は実証されたニーズです。
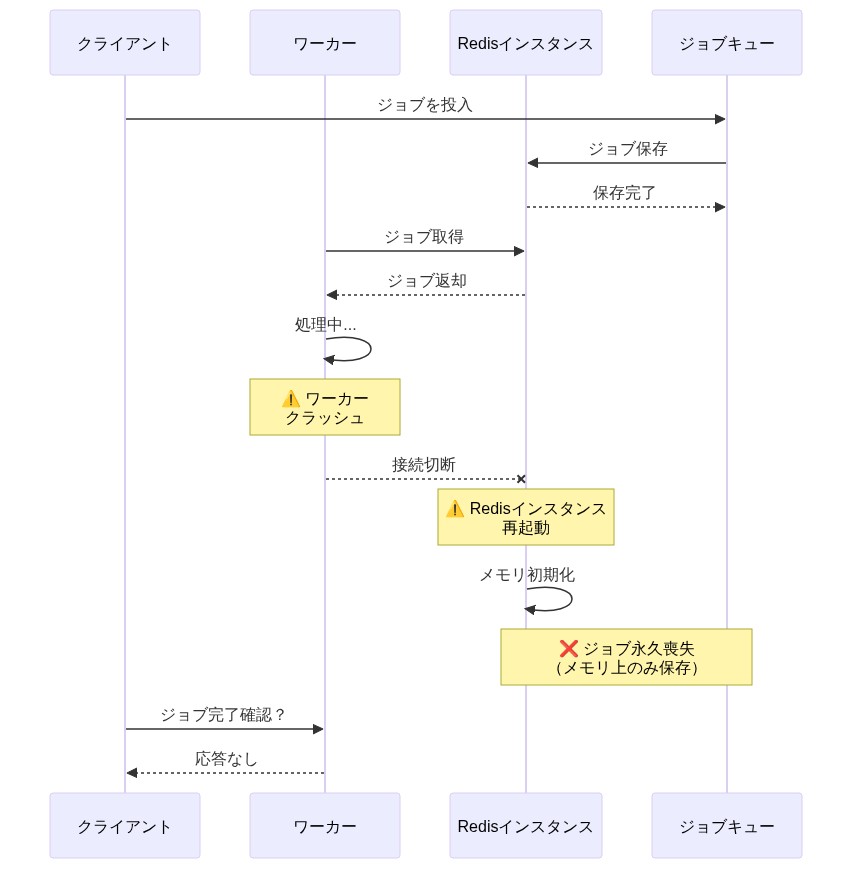
- 図2:Redisにおけるジョブ喪失シナリオ*
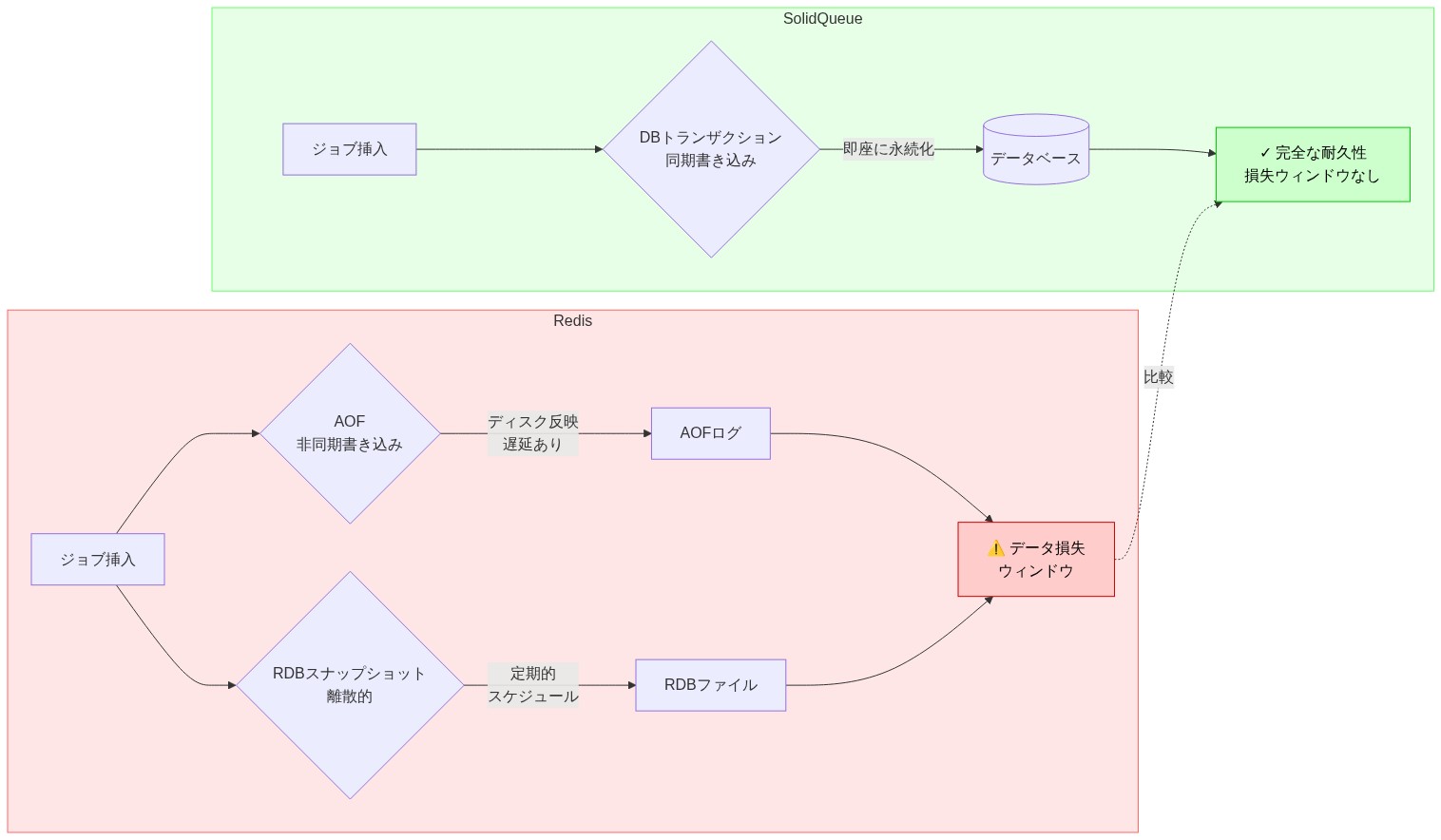
- 図3:RedisとSolidQueueの耐久性メカニズム比較*

- 図1:RedisからSolidQueueへの移行:速度から耐久性へ(コンセプトイメージ)*
システム構造と運用の複雑さ
Redisキューはシャーディングによって水平方向にスケールしますが、これは重大な運用オーバーヘッドをもたらします。複数のRedisインスタンスを管理し、フェイルオーバーを調整し、レプリケーションラグを監視し、キー分散を手動で処理する必要があります。キューの深さが増すにつれて、単一のRedisインスタンスがボトルネックになります。シャーディングが必要になり、運用モデルが複数のシステムに分散されます。
SolidQueueは既存のデータベースインフラストラクチャを活用します。ほとんどのチームは、レプリケーション、バックアップ、監視が整備されたPostgreSQLまたはMySQLをすでに運用しています。新しいインフラストラクチャをプロビジョニングすることなく、これらの運用保証を継承します。
具体例: 3つのRedisインスタンスで1日50,000件のジョブを処理するRailsアプリケーションで、単一インスタンスの障害が発生し、30%のジョブが到達不能になりました。回復にはキーを再分配するための手動介入が必要でした。SolidQueueで同じワークロードを処理していれば、失敗したジョブは自動的に再試行され、データベースクラスタがフェイルオーバーを透過的に処理していたでしょう。
SolidQueueの主なボトルネックは、別のキャッシュレイヤーではなく、データベース接続プールです。この統合は望ましいものです。2つのシステムではなく、1つのシステムをチューニングすればよいのです。
- 実用的な意味:* キューイング専用のRedisインスタンスの数を数えてください。複数管理している場合は、運用コスト(監視、フェイルオーバースクリプト、チームトレーニング)を計算してください。これをすでに負担しているデータベース管理コストと比較してください。
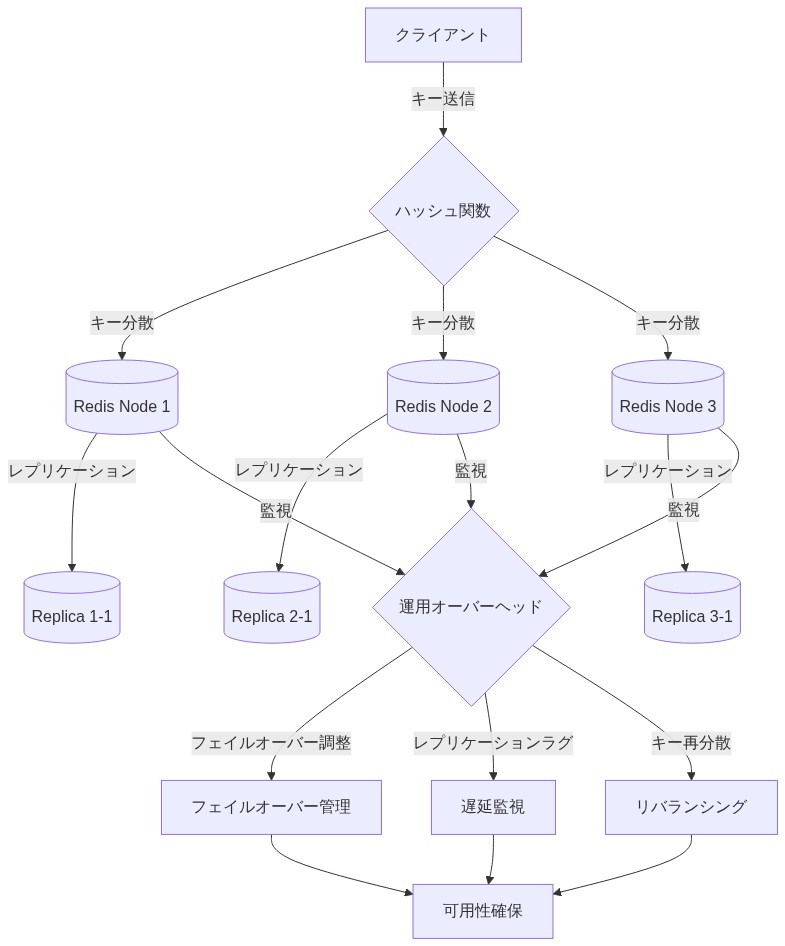
- 図4:Redisシャーディングの運用複雑性*
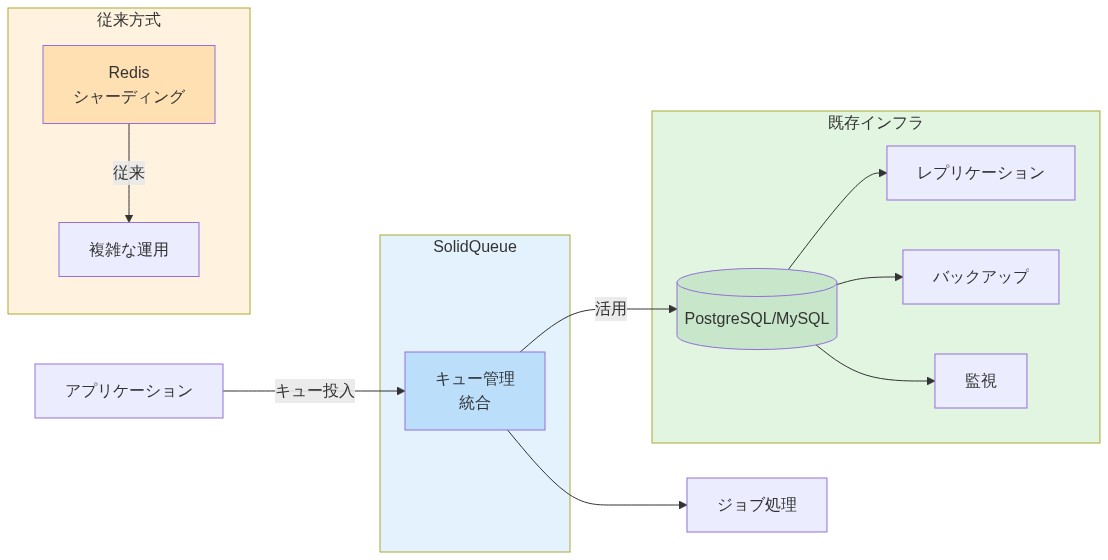
- 図5:SolidQueueの統合アーキテクチャ(既存DB活用)*
組み込みのガードレールとフレームワークサポート
本番グレードのRedisキューには以下が必要です: Redisプライマリ/レプリカ構成、フェイルオーバー用のSentinel、監視ダッシュボード、カスタム再試行ロジック、デッドレター処理。これらのガードレールは手動で構築するか、サードパーティツールを通じて採用します。
SolidQueueは、キュー抽象化の一部としてガードレールを提供します。ジョブには、組み込みの再試行カウント、指数バックオフ、同時実行制限が含まれています。失敗したジョブは失敗テーブルに移動され、クエリ可能で手動で再試行できます。これらの機能はフレームワークが提供するものであり、カスタム実装ではありません。
例: 一時的なSMTP停止によりメールジョブが失敗します。Redisの場合、再試行ロジックはエラータイプをチェックし、バックオフを計算し、手動で再エンキューする必要があります。SolidQueueの場合、max_attempts: 5とwait: :exponentially_longerを定義すれば、フレームワークが自動的に実行します。
これにより、ボイラープレートコードが削減され、カスケード障害やジョブ損失を引き起こす再試行バグのリスクが低下します。
- 実用的な意味:* カスタムキューロジック(再試行ハンドラー、デッドレター処理、同時実行制御)をリストアップしてください。各項目はメンテナンス負債を表しています。SolidQueueはこのコードのほとんどを排除します。
段階的な移行と並行運用
RedisからSolidQueueへの移行は段階的で低リスクです。移行中、両方のシステムを同時に実行できます。新しいジョブはSolidQueueにルーティングされ、古いジョブはRedisからドレインされます。ワーカーはRedisが空になるまで両方のキューから消費します。
セットアップは最小限です: gemを追加し、ジョブテーブルを作成するためのマイグレーションを実行し、ワーカーを設定します。新しいインフラストラクチャのプロビジョニングは必要ありません。
推奨パターン: 既存のRedisワーカーと並行してSolidQueueワーカーをデプロイします。新しいコードパスでSolidQueueを使用するようにジョブエンキュー呼び出しを更新します。両方のシステムを並行して監視します。Redisキューの深さがゼロになり、2〜4週間にわたってSolidQueueの安定性を観察したら、RedisワーカーとRedisクラスタを廃止します。
この段階的なアプローチは、完全なコミットメントの前に本番環境でSolidQueueを検証することでリスクを軽減します。
- 実用的な意味:* 4週間のパイロットを計画してください。重要度の低いジョブタイプ(分析集計など)を1つ特定してください。それをSolidQueueにルーティングします。エラー率、レイテンシ、データベース負荷を監視します。範囲を拡大する前に調査結果を文書化してください。

- 図7:段階的移行戦略のタイムライン(Redis から SolidQueue への段階的マイグレーション)*
測定フレームワーク
移行を開始する前にメトリクスを定義します: ジョブ成功率、p95レイテンシ、データベースCPU使用率、接続プール使用率、ジョブ損失インシデント。
Redisでベースラインを確立します。SolidQueueデプロイ後、これらのベースラインと比較します。期待される改善には以下が含まれます:
- データベースフェイルオーバー中のジョブ損失ゼロ
- 一貫したレイテンシ(データベースクエリは予測可能)
- 運用オーバーヘッドの削減(Redisシャーディングロジックなし)
測定例: 現在Redisがクラッシュにより年間0.1%のジョブを失っており、SolidQueueがこの損失を排除する場合、ビジネスへの影響は定量化可能です。顧客への返金とサポートチケットが減少します。
データベースCPUはわずかに増加する可能性があります。これは予想されることであり、信頼性の向上を考えると通常は許容範囲です。
- 実用的な意味:* ジョブ数、エラー率、データベースメトリクスを追跡する監視ダッシュボードを構築します。異常に対するアラートを設定します。移行後最初の1か月間、チームと週次レポートを共有します。
リスク軽減
-
主要リスク:* データベースがボトルネックになる。軽減策: 接続プール使用率を継続的に監視します。使用率が80%を超える場合は、読み取りレプリカを追加するか、プールサイズを増やします。SolidQueueはレプリカからジョブステータスを読み取ることができ、プライマリの負荷を軽減します。
-
二次リスク:* 移行がバグを導入する。軽減策: 段階的なロールアウトを実施します。重要度の低いジョブから始め、各段階で1週間監視してから次に進みます。すべてのジョブタイプに対して包括的な統合テストを作成します。ロールバック計画を文書化し、チームがRedisワーカーを迅速に再起動できるようにします。
-
三次リスク:* チームがSolidQueueの運用モデルに不慣れ。軽減策: 移行前にトレーニングセッションを実施します。失敗したジョブのクエリ、手動再試行、同時実行制限の調整をカバーします。一般的なシナリオ(ジョブのスタック、データベース接続の枯渇、遅いジョブ)のランブックを作成します。
これらの軽減策により、移行リスクは管理可能なレベルに抑えられ、チームは自信を持って実行できます。