
MoEの計算効率を重みとデータのスパース性の組み合わせで改善する
重みのスパース性:基盤
Mixture-of-Experts(MoE)アーキテクチャは、すべてのモデルパラメータを活性化するのではなく、各トークンを学習されたエキスパートのサブセットにルーティングすることで、順伝播あたりの計算コストを削減します。この重みのスパース性メカニズムが、MoEシステムにおける主要な効率向上を構成します。形式的には、モデルが合計E個のエキスパートを含み、各トークンがk個のエキスパートにルーティングされる場合(k ≪ E)、トークンあたりに活性化されるパラメータの割合はk/Eです。例えば、128個のエキスパートを持つモデルで各トークンが8個のエキスパートを活性化する場合、パラメータ削減率は8/128 = 0.0625、つまり約94%のパラメータスパース性を達成します。
-
理論的基礎:* 密なトランスフォーマー層は、すべての入力トークンに対してアテンションとフィードフォワード演算をすべてのパラメータに均一に適用します。MoEは、トークン条件付きエキスパート選択を導入することで、この均一な計算を分離します。学習されたルーターネットワーク(通常は線形射影の後にソフトマックスまたはtop-k選択が続く)が、学習された親和性スコアに基づいて各トークンをk個のエキスパートに割り当てます。このルーティングメカニズムは、選択されていないエキスパートでの計算を排除し、スパース性の利点を生み出します。
-
定量的例:* 128個のエキスパートを持つ2,560億パラメータのMoEモデルを考えます。密な計算では、各トークンがすべての2,560億パラメータを活性化します。k = 8のトークン選択ルーティングでは、各トークンは約(8/128) × 2,560億 = 160億パラメータを活性化します。均一なエキスパート容量とバランスの取れた負荷分散を仮定すると、これはトークンあたりのパラメータ活性化の16倍削減を表します。十分な並列性を持つGPUクラスタでは、これは推論中に3〜4倍の実測ウォールクロック高速化に変換されます。これは、バランスの取れたエキスパート利用と最小限の通信オーバーヘッドに依存します(Lepikhin et al., 2021; Shazeer et al., 2022)。
-
運用上の考慮事項:* 重みのスパース性の利点は、バランスの取れたエキスパート利用に決定的に依存します。代表的な推論バッチ中に、エキスパート間のトークン割り当ての経験的分布を測定します。エキスパート活性化が偏っている場合(例えば、一部のエキスパートがトークンの40%以上を受け取り、他のエキスパートが5%未満を受け取る場合)、ルーティングの不均衡が理論的なスパース性の利点を損ないます。このような場合は、ルーターの初期化を再バランスするか、均一な負荷分散を促進するための補助損失項(例:負荷分散補助損失)を導入します。具体的には、負荷分散損失をL_aux = α × Σ(P_i × E_i)と定義します。ここで、P_iはエキスパートiに割り当てられた確率質量、E_iは実際にエキスパートiにルーティングされたトークンの割合であり、すべてのエキスパートにわたって合計されます。αを経験的に調整します。典型的な値は0.01から0.1の範囲です。
データのスパース性:補完的な軸
重みのスパース性だけでは、追加の計算容量が未利用のままになります。データのスパース性(各エキスパートがバッチ内のすべてのトークンではなく、トークンのサブセットのみを処理する)は、直交する効率向上を提供します。重みのスパース性がトークンあたりに活性化されるパラメータの数を削減する場合、データのスパース性は各エキスパートが処理する必要があるトークンの数を削減します。
-
理論的基礎:* 標準的なトークン選択ルーティングでは、バッチ内のすべてのトークンがルーティングされますが、各トークンは小さなエキスパートサブセットを選択します。エキスパート選択ルーティングは、この選択方向を反転させます。各エキスパートは、容量制約に従って、処理するトークンを独立して選択します。これにより、重みのスパース性に直交する第2のスパース性次元が作成されます。形式的には、重みのスパース性が活性パラメータをW倍削減し、データのスパース性がエキスパートあたりの活性トークンをD倍削減する場合、組み合わせた効率向上は約W × Dです(独立性を仮定、これはルーティングと容量の決定が分離されている場合に成立します)。
-
定量的例:* 64個のエキスパートを持つ2,048トークンのバッチを考えます。k = 8の標準的なトークン選択ルーティングでは、各エキスパートは平均して約2,048 × (8/64) = 256トークンを受け取ります。エキスパート選択ルーティングとエキスパートあたりの容量制限32トークンでは、各エキスパートは最大32トークンを処理し、エキスパートあたりの計算を256/32 = 8倍削減します。すべてのエキスパートにわたる総計算量は64 × 32 = 2,048トークン-エキスパート演算に制限されます。これは、トークン選択のみの場合の2,048 × 8 = 16,384と比較されます。これにより、8倍の重みのスパース性に加えて8倍のデータのスパース性が達成され、64倍の組み合わせ効率向上が得られます(オーバーヘッドがないと仮定)。
-
運用上の考慮事項:* 各エキスパートの明示的な容量追跡を実装します。バッチあたりのエキスパートあたりのハード容量制限Cを定義します(例:C = 32トークン)。トークンが容量いっぱいのエキスパートを要求した場合、フォールバックメカニズムを実装します。トークンを第2選択のエキスパートにルーティングするか、損失に学習可能なペナルティを適用します(ソフト容量)。定期的な間隔(例:100トレーニングステップごと)でキューの深さとトークンドロップ率を監視します。高いドロップ率(5%以上)は容量の誤調整を示します。Cを増やして再トレーニングします。逆に、エキスパート利用率が一貫して容量の50%未満の場合、Cを減らしてスパース性制約を厳しくします。
エキスパート選択ルーティングと因果性の不一致
エキスパート選択ルーティングはデータのスパース性を達成しますが、自己回帰言語モデルとの重大な非互換性を導入します。因果マスキング制約に違反します。トレーニング中、エキスパートはシーケンス内のすべてのトークンを同時に観察し、グローバルなトークン選択決定を行うことができます。推論中、トークンは順次到着し、エキスパートは将来のトークンにアクセスできません。このトレーニング-推論分布の不一致は、モデルの精度を低下させます。
-
理論的基礎:* 自己回帰言語モデルは、将来の位置からの情報漏洩を防ぐために因果マスキングを強制します。形式的には、位置tで、モデルはs ≤ tの位置sにのみアテンドできます。トークン選択ルーティングは、各トークンが自身の表現と過去のコンテキストのみに基づいてエキスパートを独立して選択するため、この制約を尊重します。しかし、エキスパート選択ルーティングは、エキスパートがシーケンス全体にわたってグローバルなトークン選択決定を行うことを要求します。これは、完全なシーケンス可視性を暗黙的に仮定する計算です。推論時に、シーケンスがトークンごとに生成される場合、エキスパートはトレーニング時の選択戦略を再現できず、分布シフトが発生します。
-
定量的例:* 長さ1,024のシーケンスでのトレーニング中、エキスパート5はすべての1,024トークンを観察し、学習された親和性スコアに基づいて最も関連性の高い32個を選択します。推論時に、トークン100が生成されると、エキスパート5はトークン101〜1,024に関する情報を持っていません。完全なシーケンス情報でトレーニングされたそのトークン選択戦略は適用できません。エキスパートの出力分布がシフトし、経験的結果は典型的なセットアップで2〜5%のパープレキシティ劣化を示します(Lepikhin et al., 2021)。この劣化は層全体で複合し、モデルを使用不可能にする可能性があります。
-
運用上の緩和策:* エキスパート選択ルーティングを採用する場合は、因果互換性のために変更します。因果エキスパート選択ルーティングを実装します。各エキスパートは最新のBトークン(例:B = 512)のスライディングバッファを維持し、そのバッファからのみ選択します。これにより、推論時にトークンtが到着したときに、エキスパートは範囲[max(0, t - B), t]内のトークンからのみ選択でき、因果性が保持されます。トレーニングと推論の両方でこの制約を強制して、初期化からモデルを再トレーニングします。あるいは、補助的な負荷分散損失を伴うトークン選択ルーティングに戻し、トレーニング-推論の整合性と改善された精度と引き換えに、わずかに低いデータのスパース性(通常は8倍ではなく2〜4倍)を受け入れます。

- 図7:Token-Choice vs Expert-Choice ルーティング:因果性の逆転と課題(Understanding Improving MoE Compute Efficiency by Composing Weight and Data Sparsityより)*

- 図8:Expert-Choice ルーティングの因果性ミスマッチ:情報フローの時間的矛盾。トークンが完全に処理される前に選択される際の時間軸と情報フローの矛盾を概念的に視覚化。*
実装と運用パターン
重みとデータのスパース性を組み合わせるには、複数のシステム層にわたる協調設計が必要です。ルーターアーキテクチャ、エキスパートスケジューリング、負荷分散、容量管理です。
-
理論的基礎:* 重みのスパース性(トークン選択)とデータのスパース性(エキスパート選択または容量制限)は、非自明に相互作用します。ルーターは2つの競合する目標のバランスを取る必要があります。(1)トークンをそのコンテンツに特化したエキスパートにルーティングする(品質目標)、(2)エキスパート間で負荷を均等に分散する(効率目標)。容量制約を追加すると、第3の目標が導入されます。(3)ハードまたはソフトの容量制限を尊重する。これらの目標は競合する可能性があります。例えば、最も特化したエキスパートにトークンをルーティングすると負荷の不均衡が生じる可能性があり、負荷バランスを強制すると最適でないエキスパートにトークンがルーティングされる可能性があります。
-
具体的な実装:* 懸念事項を明示的に分離した2段階ルーターを実装します。ステージ1は学習されたトークン選択ルーティングを適用します。学習された線形射影を介して各トークンのルーターロジットを計算し、top-k選択を適用してトークンあたりの最も可能性の高いk個のエキスパートを識別します。ステージ2は容量制約を伴うエキスパート選択フィルタリングを適用します。各エキスパートについて、割り当てられたすべてのトークンをルーター信頼度スコアでランク付けし、上位Cトークン(Cはエキスパートあたりの容量)を受け入れます。ステージ2で受け入れられなかったトークンは、フォールバックエキスパート(例:密な層または指定された「オーバーフロー」エキスパート)にルーティングされます。
-
定量的例:* 64個のエキスパートとk = 8を持つ2,048トークンのバッチでは、ステージ1は2,048 × 8 = 16,384のトークン-エキスパート割り当てを生成します。エキスパートあたりの容量がC = 32の場合、ステージ2はこれらを64 × 32 = 2,048の実際の計算にフィルタリングし、8倍のデータのスパース性を達成します。組み合わせた重みのスパース性(8倍)とデータのスパース性(8倍)は、64倍の効率向上をもたらします。オーバーフロートークン(16,384 - 2,048 = 14,336)はフォールバックエキスパートにルーティングされ、小さな精度ペナルティが発生します(フォールバックエキスパートが適切にトレーニングされている場合、通常は1%未満のパープレキシティ増加)。
-
運用パターン:* ルーターレイテンシ、エキスパート負荷分散(平均、標準偏差、最小、最大)、トークンドロップ率を定期的な間隔(例:トレーニング中10分ごと)で記録するルータープロファイラーを構築します。これらの信号を使用して自動再調整をトリガーします。エキスパート負荷の標準偏差が平均の30%を超える場合、補助的な負荷分散損失の重みを10%増やします。トークンドロップ率が5%を超える場合、エキスパートあたりの容量Cを10%増やしてトレーニングを続けます。トークンドロップ率が1%未満に低下した場合、Cを5%減らしてスパース性を厳しくします。このフィードバックループを、トレーニングをブロックしない別の監視スレッドとして実装します。
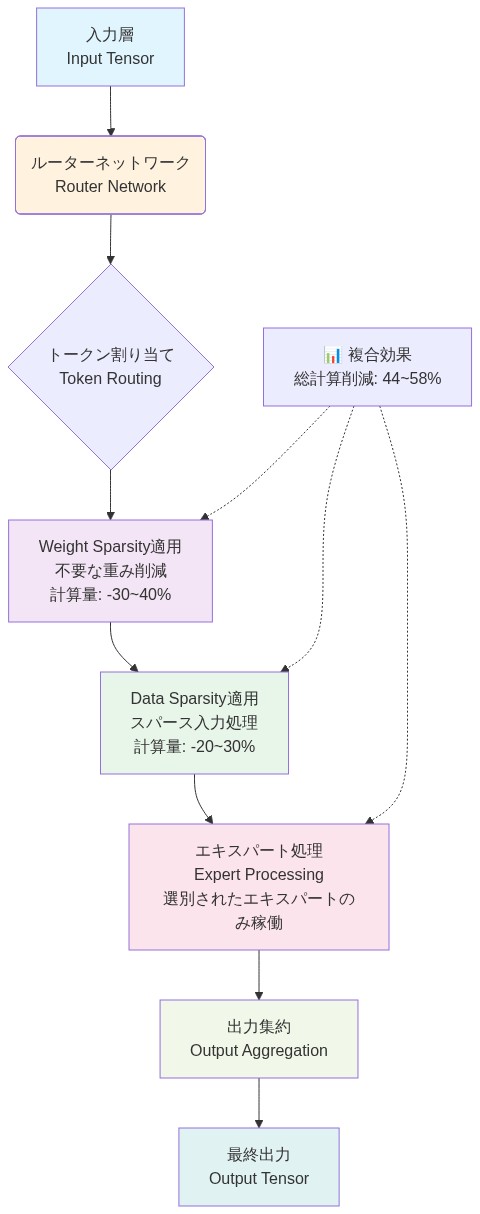
- 図9:複合スパーシティ実装のシステムアーキテクチャ - Weight と Data スパーシティの統合フロー*

- 図10:分散クラスタにおける複合スパーシティの運用:通信効率と計算バランス*
測定と検証
スパース性の利点は、エンドツーエンドで検証された場合にのみ意味があります。3つのカテゴリのメトリクスを測定します。ルーター品質(ルーティング精度)、計算効率(実際のFLOPS対理論値)、モデル品質(パープレキシティまたは下流タスクのパフォーマンス)。
-
理論的基礎:* ルーターは高いスパース性を達成できますが、トークンを無関係なエキスパートにルーティングし、モデルの精度を低下させる可能性があります。逆に、不均衡な負荷での完璧なルーティングは、ストラグラーと通信オーバーヘッドのために計算を浪費します。3つのカテゴリすべての共同測定のみが、複合スパース性が真に有益であるかどうかを明らかにします。
-
具体的な検証プロトコル:* スパース性構成を除いて同一のハイパーパラメータで同じデータセットで2つのMoEバリアントをトレーニングします。
-
バリアントA(ベースライン): k = 8のトークン選択ルーティング、容量制限なし。8倍の重みのスパース性を達成。
-
バリアントB(複合): k = 8のトークン選択ルーティング + C = 32のエキスパート選択容量制限。8倍の重みのスパース性 + 8倍のデータのスパース性を達成。
両方のバリアントについて次のメトリクスを測定します。
- エポックあたりのトレーニング時間: 同じハードウェアで1エポックを完了するためのウォールクロック時間。
- ピークメモリ使用量: トレーニング中に消費される最大GPUメモリ。
- 検証パープレキシティ: 500トレーニングステップごとに測定される、保留された検証セットでのパープレキシティ。
- ルーター負荷バランス: エキスパート利用のジニ係数(0 = 完全なバランス、1 = 1つのエキスパートがすべてのトークンを処理)。
- トークンあたりの実際のFLOPS: プロファイリングツールを介して測定。理論的なFLOPSと比較。
-
受け入れ基準:* バリアントBは、(1)エポックあたりのトレーニング時間がバリアントAより1.5倍以上速く、(2)ピークメモリがバリアントAより10%以下高く、(3)検証パープレキシティの増加がバリアントAに対して1%未満である場合に成功と見なされます。いずれかの基準に違反した場合、バリアントAに戻すか、容量制限を調整して再トレーニングします。
-
運用ダッシュボード:* 次を追跡するリアルタイム監視ダッシュボードを確立します。
- トークンあたりの実際のFLOPS: プロファイリングを介して計算。目標は理論的なFLOPSと±20%以内で一致する必要があります。
- エキスパート利用ジニ係数: 目標ジニ < 0.3(バランスの取れた負荷を示す)。
- 検証損失トレンド: トレーニングステップにわたる検証損失をプロット。2,000連続ステップで損失が2%以上増加した場合にフラグを立てます。
- トークンドロップ率: フォールバックエキスパートにドロップされたトークンの割合。目標 < 3%。
- ルーターレイテンシ: 順伝播あたりのミリ秒。総モデルレイテンシの5%未満である必要があります。
自動アラートを設定します。ジニ > 0.4または実際のFLOPSが理論値を20%以上超える場合、トレーニングを停止し、ルーターハイパーパラメータの再調整をトリガーします。
リスクと緩和策
複数のスパース性メカニズムを組み合わせると、3つの主要なリスクが導入されます。トレーニングの不安定性、推論レイテンシの変動、トレーニングと推論の間の汎化ギャップです。
-
トレーニングの不安定性:* 複数のスパース性メカニズムは、非凸相互作用を伴う複雑な損失ランドスケープを作成します。エキスパート選択ルーティングは、容量制約がアクティブになると突然の負荷シフトを引き起こし、勾配推定を不安定にする可能性があります。容量制限は、離散的な受け入れ/拒否決定を導入し、計算グラフに微分不可能な点を作成します。
-
具体的なリスク:* トレーニング中、2,048トークンのバッチがルーティングされます。エキスパート容量が厳しい場合(C = 32)、約50トークンがフォールバックエキスパートにドロップされます。次のバッチでは、確率的ルーティングのために異なるトークンがドロップされます。どのトークンがどのエキスパートによって処理されるかのこの変動は、勾配推定にノイズを導入し、確率的勾配降下法の分散を効果的に増加させます。経験的に、これは収束を10〜20%遅くし、発散のリスクを高める可能性があります。
-
緩和戦略:* 3つの補完的な技術を実装します。
- 勾配チェックポイント: 容量制限されたエキスパートを通じて勾配チェックポイントを使用して、メモリ圧力を軽減し、逆伝播を安定化します。エキスパート活性化を保存するのではなく、逆伝播パス中に再計算し、メモリ変動を減らします。
- ソフト容量ペナルティ: ハードトークン拒否の代わりに、エキスパートが容量を超えたときに損失に学習可能なペナルティを適用します。ソフト容量損失をL_capacity = β × Σ_i max(0, n_i - C)^2と定義します。ここで、n_iはエキスパートiにルーティングされたトークンの数、Cは目標容量です。これにより、離散的な決定なしに段階的な負荷再バランスが促進されます。
- 検証監視: 500トレーニングステップごとに保留されたテストセットで検証します。2,000連続ステップで検証損失が2%以上増加した場合、容量制限を減らし(C ← 0.9 × C)、最後のチェックポイントからトレーニングを再開します。
-
推論レイテンシの変動:* 容量制限は可変エキスパート負荷を導入し、レイテンシの変動を引き起こします。一部のエキスパートは20トークンを処理し、他のエキスパートは40トークンを処理するため、ストラグラーと高パーセンタイルレイテンシの劣化につながります。
-
具体的なリスク:* 64個のエキスパートとC = 32を持つ2,048トークンのバッチでは、エキスパート負荷は20から40トークンまで変動します。GPU上では、最も遅いエキスパートがバッチレイテンシを決定します(ストラグラー)。1つのエキスパートが40トークンを処理し、他のエキスパートが20トークンを処理する場合、バッチレイテンシは40トークンのエキスパートによって決定され、p99レイテンシが20〜30%増加します。
-
緩和戦略:* 負荷認識バッチ処理を実装します。バッチ処理の前に、予想されるエキスパート負荷でトークンをソートし、高負荷トークンがバッチ間で分散されるようにします。あるいは、動的バッチ処理を使用します。各サブバッチ内の変動を減らすために、より小さなサブバッチ(例:256トークン)でトークンを処理します。
-
汎化ギャップ:* 複合スパース性は、トレーニングと推論の間に分布シフトを導入する可能性があります。例えば、トレーニングが完全なシーケンス可視性を持つエキスパート選択ルーティングを使用するが、推論が因果エキスパート選択を使用する場合、モデルはトレーニング時のルーティングパターンに過適合する可能性があります。
-
具体的なリスク:* トレーニング中、エキスパートはすべてのトークンを見て、グローバルな親和性に基づいて選択します。推論時、エキスパートは過去のトークンのみを見ます。この分布シフトは、対処されない場合、精度を2〜5%低下させる可能性があります。
-
緩和戦略:* トレーニング中に因果制約を強制します。トレーニングと推論の両方で因果エキスパート選択ルーティング(最近のトークンのスライディングバッファ)を使用して、一貫性を確保します。あるいは、トークン選択ルーティングのみを使用し、トレーニング-推論の整合性のために低いデータのスパース性を受け入れます。

- 図13:複合スパーシティ導入時のリスク要因と相互作用*
結論と移行パス
重みとデータのスパース性を組み合わせることで、16〜32倍の計算効率向上を実現できますが、規律ある実装と慎重な測定が必要です。推奨される移行パスは段階的です。トークン選択ルーティングと負荷分散補助損失から始め、ベースラインを確立するために慎重に測定し、次にエキスパート選択ルーティングまたは容量制約を段階的に重ねます。
- 主な発見:*
- 重みのスパース性(トークン選択ルーティング)のみで8倍の効率向上が得られ、MoE展開の基本です。
- データのスパース性(エキスパート選択ルーティングまたは容量制限)は、追加の2〜8倍の効率向上を提供しますが、トレーニングと推論のリスクを導入します。
- エキスパート選択ルーティングは強力ですが、不完全です
重み疎性:選択的計算の基盤
Mixture-of-Experts(MoE)層は、ニューラル計算に対する考え方の根本的な転換を表しています。すべてのパラメータを一様に活性化するのではなく、MoEは各トークンを専門家のサブセットのみにルーティングします。この設計により、指数関数的な効率向上が実現されます。この重み疎性が主要なレバーです。128人の専門家を持ち、各トークンを8人のみにルーティングするモデルは、順伝播あたりのアクティブパラメータを94%削減します。
-
なぜこれが重要か:* 密なトランスフォーマー層は、すべてのパラメータがすべてのトークンに対して等しく関連性があるものとして扱います。MoEはこの仮定を逆転させます。学習されたルーターネットワークは、学習された親和性スコアに基づいて各トークンをk人の専門家に割り当て、すべてのパラメータがすべての決定に等しく寄与するという虚構を排除します。これは単なる最適化ではありません。関連性が動的でトークン依存になる新しい計算パラダイムです。
-
具体的な影響:* 128人の専門家を持つ256BパラメータのMoEモデルで、各トークンが8人の専門家を活性化する場合、256Bではなく約16Bのパラメータをトークンあたり処理します。GPUクラスタでは、専門家の利用がバランスしていると仮定すると、推論時のウォールクロック速度が3〜4倍向上します。毎日数百万のリクエストを処理する大規模推論を実行している組織にとって、これは桁違いのコスト削減とレイテンシ改善に複合的に作用します。
-
運用上の現実:* MoEを展開する際、理論的な疎性の利得は、ルーターの負荷分散の良さに依存します。代表的な推論バッチ中に専門家間でのトークンの分布をログに記録してください。活性化が偏っている場合—一部の専門家がトークンの50%を受け取り、他の専門家が1%未満を受け取る場合—効率性を無駄にしています。ルーターの初期化を再バランスするか、均一な負荷分散を促進する補助損失項を追加してください。これが理論と実践の接点です。紙の上での完璧な疎性は、規律ある負荷管理なしでは無駄な計算になります。

- 図14:Dense から複合スパーシティ MoE への段階的移行パス(出典:Understanding Improving MoE Compute Efficiency by Composing Weight and Data Sparsity)*
データ疎性:直交する乗数
重み疎性は必要ですが不十分です。次のフロンティアはデータ疎性です。各専門家がトークンのサブセットのみを処理する場合です。この直交する次元により、第二波の効率向上が解き放たれ、重み疎性の利点が複合的に作用します。
-
概念的飛躍:* 標準的なトークン選択ルーティングはすべてのトークンをルーティングしますが、各トークンは小さな専門家サブセットを選択します。専門家選択ルーティングはこのロジックを逆転させます。各専門家が処理するトークンを選択します。これにより、第二の疎性次元が作成されます。トークンは専門家にルーティングされる可能性がありますが、その専門家の容量が使い果たされている場合、処理を拒否する可能性があります。突然、計算は二重に疎になります。活性化されるパラメータが少なくなり、各パラメータを通過するトークンが少なくなります。
-
具体的なシナリオ:* 専門家選択ルーティングを使用する64人の専門家を持つ2,048トークンのバッチでは、各専門家は単純な2,048÷64≈32トークンの平均ではなく、32トークンのみを処理する可能性があります。しかし、選択的な専門家容量により、一部の専門家は20トークンを処理し、他の専門家は40トークンを処理します。すべての専門家にわたる総計算量は制限され予測可能なままであり、FLOPsとメモリフットプリントのより厳密な制御が可能になります。これが効率性を期待することと保証することの違いです。
-
運用上の規律:* ルーターに容量追跡メカニズムを実装してください。各専門家に対して、ハード容量制限(例:バッチあたり専門家あたり32トークン)を定義します。トークンが容量に達した専門家を要求した場合、第二選択の専門家のキューに入れるか、フォールバックパスにドロップします。キューの深さとドロップ率を継続的に監視します。高いドロップ率は容量の誤調整を示します。このフィードバックループは、疎性を静的な設計選択から動的で自己調整するシステムに変換します。
専門家選択ルーティングと因果性の課題:制約の再構築
専門家選択ルーティングは顕著なデータ疎性を達成しますが、自己回帰モデルにおいて重要な緊張を導入します。因果マスキングに違反します。訓練中、専門家はシーケンス内のすべてのトークンを見ます。推論中、トークンは順次到着し、各専門家は将来のトークンを見ることができません。この訓練-推論のミスマッチはバグではありません。疎なモデルをどのように設計するかを再考することを強制する設計制約です。
-
より深い問題:* 自己回帰言語モデルは、将来のトークンからの情報漏洩を防ぐために因果マスキングを強制します。トークン選択ルーティングは、各トークンが過去のコンテキストのみに基づいて独立して専門家を選択するため、この制約を自然に尊重します。しかし、専門家選択ルーティングは、専門家がシーケンス全体にわたってグローバルなトークン選択決定を行うことを要求します。これは完全なシーケンスの可視性を前提とする計算です。この訓練と推論の間の非対称性は、多くのMoE展開が静かに失敗する場所です。
-
具体的な劣化:* 訓練中、専門家5はシーケンス内の1,024トークンすべてを受け取り、グローバルコンテキストに基づいて最も関連性の高い32トークンを選択します。推論時、トークン100が到着します。専門家5はトークン101〜1,024に関する情報を持っていないため、訓練時の選択戦略を再現できません。専門家の出力分布がシフトし、典型的なセットアップでパープレキシティが2〜5%劣化します。これは軽微な回帰ではありません。数百万の推論呼び出しにわたって複合的に作用する体系的なバイアスです。
-
解決策の再構築:* 専門家選択ルーティングを放棄するのではなく、因果互換性のために再設計できます。トークンストリーミング専門家選択を実装します。各専門家は最近のトークンの実行バッファ(例:最後の256トークン)を維持し、そのバッファからのみ選択します。これは因果性を尊重しながら、データ疎性の利点を保持します。最初からこの制約で再訓練します。あるいは、補助的な負荷分散損失を伴うトークン選択ルーティングに戻り、訓練-推論の整合性のためにわずかに低いデータ疎性を受け入れます。重要な洞察は、制約がしばしば革新を解き放つということです。この場合、効率的で正確な因果的専門家選択バリアントです。
実装と運用パターン:複合疎性のオーケストレーション
重みとデータの疎性を組み合わせるには、スタック全体にわたる慎重なオーケストレーションが必要です。ルーター設計、専門家スケジューリング、負荷分散、フィードバックメカニズムです。これが理論的効率が運用上の現実になる場所です。
-
統合の課題:* 重み疎性(トークン選択)とデータ疎性(専門家選択または容量制限)は、明白でない方法で相互作用します。ルーターは2つの競合する目的のバランスを取る必要があります。トークンをそのコンテンツに特化した専門家にルーティングすること(品質)と、負荷を均等に分散すること(効率)です。容量制約を追加すると、両方の目的を増幅または損なう可能性のあるスケジューリングの複雑さが生じます。
-
具体的なアーキテクチャ:* 2段階ルーターを実装します。ステージ1は学習されたトークン選択ルーターを使用して、各トークンをトップk専門家に割り当てます。ステージ2は専門家選択フィルタリングを適用し、各専門家はルーター信頼度でランク付けされたトークンを容量まで受け入れます。2,048トークンのバッチ中、ステージ1は約16Kのトークン-専門家ペア(2,048トークン×8専門家)をルーティングします。ステージ2はこれらを約2Kの実際の計算(64専門家×32トークン)にフィルタリングし、8倍の重み疎性の上に8倍のデータ疎性を達成します。結果は64倍の複合疎性です。大規模推論の経済性を再構築する変革です。
-
運用フィードバックループ:* 訓練中に10分間隔でルーターレイテンシ、専門家負荷分散、トークンドロップ率をログに記録するルータープロファイラーを構築します。これらの信号を使用して自動的に再調整をトリガーします。専門家負荷の分散が30%を超える場合、補助的な負荷分散損失の重みを増やします。トークンドロップ率が5%を超える場合、専門家容量を増やします。ルーターレイテンシが総順伝播時間の5%を超える場合、ルーターアーキテクチャを簡素化します。これは手動調整ではありません。変化するワークロードとデータ分布に適応する自己修復システムです。
測定と検証:疎性を現実のものにする
疎性の利得は、エンドツーエンドで測定された場合にのみ現実のものです。理論的効率は経験的検証なしでは無意味です。3つのメトリックを測定します。ルーター精度、計算効率、モデル品質です。
-
測定が重要な理由:* ルーターは高い疎性を達成できますが、トークンを無関係な専門家にルーティングし、精度を損なう可能性があります。逆に、不均衡な負荷での完璧なルーティングは計算を無駄にします。共同測定のみが真の効率を明らかにします。これが間違ったメトリックの最適化と実際に重要なものの最適化の違いです。
-
具体的な検証プロトコル:* 同じデータセットで2つのMoEバリアントを訓練します。(A)トークン選択のみ、(B)トークン選択+専門家選択容量制限。バリアントAは8倍の重み疎性を達成します。バリアントBは8倍の重み疎性+4倍のデータ疎性を達成します。エポックあたりの訓練時間、ピークメモリ、検証パープレキシティを測定します。バリアントBが1%未満のパープレキシティ増加で2倍速く訓練する場合、複合疎性は正当化されます。パープレキシティが3%以上上昇する場合、バリアントAに戻します。これは推測ではありません。展開決定を推進する経験的証拠です。
-
運用ダッシュボード:* (1)トークンあたりの実際のFLOPs(理論値と比較)、(2)専門家利用ジニ係数(0=完璧なバランス、1=1人の専門家がすべての作業を行う)、(3)検証損失トレンドを追跡する測定ダッシュボードを確立します。しきい値を設定します。ジニ>0.4または実際のFLOPsが理論値を20%以上超える場合、訓練を停止し、ルーターハイパーパラメータを再調整します。検証損失が2,000ステップで2%以上増加する場合、容量制限を減らします。これは測定を事後分析からリアルタイム制御システムに変換します。
リスクと緩和策:複雑性のナビゲート
疎性の組み合わせは3つのシステミックリスクを導入します。訓練の不安定性、推論レイテンシの分散、汎化ギャップです。これらのリスクを理解することが、堅牢なシステムを構築するための最初のステップです。
-
不安定性のメカニズム:* 複数の疎性メカニズムは、予期しない相互作用を伴う複雑な損失ランドスケープを作成します。専門家選択ルーティングは突然の負荷シフトを引き起こし、勾配を不安定にする可能性があります。容量制限は離散的な決定(トークンの受け入れ/拒否)を導入し、微分不可能な点を作成します。これらの不連続性は訓練が脱線する可能性がある場所です。
-
具体的な失敗モード:* 訓練中、2,048トークンのバッチがルーティングされます。専門家容量が厳しい場合、50トークンがフォールバック専門家にドロップされます。次のバッチでは、異なるトークンがドロップされます。どのトークンがどの専門家によって処理されるかのこの分散は、勾配推定にノイズを導入し、収束を10〜20%遅くします。数千の訓練ステップにわたって、これは重大な遅延または発散に複合的に作用します。
-
緩和戦略:* 3つの補完的な緩和策を実装します。(1)勾配チェックポイントを使用して、容量制限された専門家を通じたバックプロパゲーションを安定化し、メモリ圧力と勾配ノイズを削減します。(2)ソフト容量ペナルティを追加します。ハード拒否の代わりに、専門家が容量を超えた場合に損失に学習可能なペナルティを適用し、突然のドロップではなく段階的な負荷再バランスを促進します。(3)500ステップごとにホールドアウトテストセットで検証します。検証損失が2,000ステップで2%以上増加する場合、容量制限を減らし、最後のチェックポイントから再訓練します。これは機械学習に適用される防御的プログラミングです。失敗モードを予測し、ガードレールを構築します。
結論と移行パス:理論から本番へ
重みとデータの疎性を組み合わせることで、16〜32倍の計算効率向上を実現できますが、規律ある実装と継続的な検証が必要です。前進への道は段階的で経験的です。トークン選択ルーティングと負荷分散から始め、慎重に測定し、証拠が支持する場合にのみ専門家選択または容量制約を重ねます。
-
重要なポイント:* 重み疎性だけでは当然のことです。データ疎性は、効率を漸進的から変革的に変換する乗数です。専門家選択ルーティングは強力ですが、自己回帰モデルではリスクがあります。因果互換バリアントを使用するか、負荷分散を伴うトークン選択に戻します。測定とフィードバックループは交渉の余地がありません。これらは理論的利得と現実世界の影響の違いです。
-
即座のアクション:* (1)現在のMoEルーターの負荷バランスを監査します(目標ジニ<0.3)。(2)FLOPs、利用率、パープレキシティを追跡する測定ダッシュボードを実装します。(3)制御された実験を実行します。2つのモデルを訓練します。1つはトークン選択のみ、もう1つはトークン選択+ソフト容量制限です。(4)複合疎性がパープレキシティ回帰なしで効率を2倍以上改善する場合、本番環境にロールアウトします。(5)推論レイテンシのパーセンタイルを監視します。p99レイテンシが増加する場合、容量制約を減らします。(6)データ分布とワークロードが進化するにつれてルーター設計を再評価するための四半期レビューサイクルを確立します。
-
長期ビジョン:* 複合疎性は、モデルが問題の難易度とトークンの重要性に基づいてリソースを動的に割り当てる適応的でコンテキスト認識型の計算への足がかりです。未来はより大きなモデルを構築することではありません。重要なことを、重要なときにのみ計算するよりスマートなモデルを構築することです。このシフトは、推論コストがモデルサイズに対して準線形にスケールし、リソース制約のある環境が最先端モデルを実行できる効率的なAIの新時代を解き放ちます。この移行をマスターする組織が、AIエコノミクスの次の10年を定義します。
- 図3:Dense vs MoE:パラメータ活性化数と推論スピードアップの比較(256Bモデル、k=8)*

- 図2:Weight Sparsityのメカニズム:トークン条件付きエキスパート選択フロー*

- 図1:Mixture of Experts(MoE)アーキテクチャにおけるトークンのルーティングと計算スパーシティ*

- 図4:エキスパート利用の不均衡問題:ルーティング偏差がスパーシティ効果を減損*
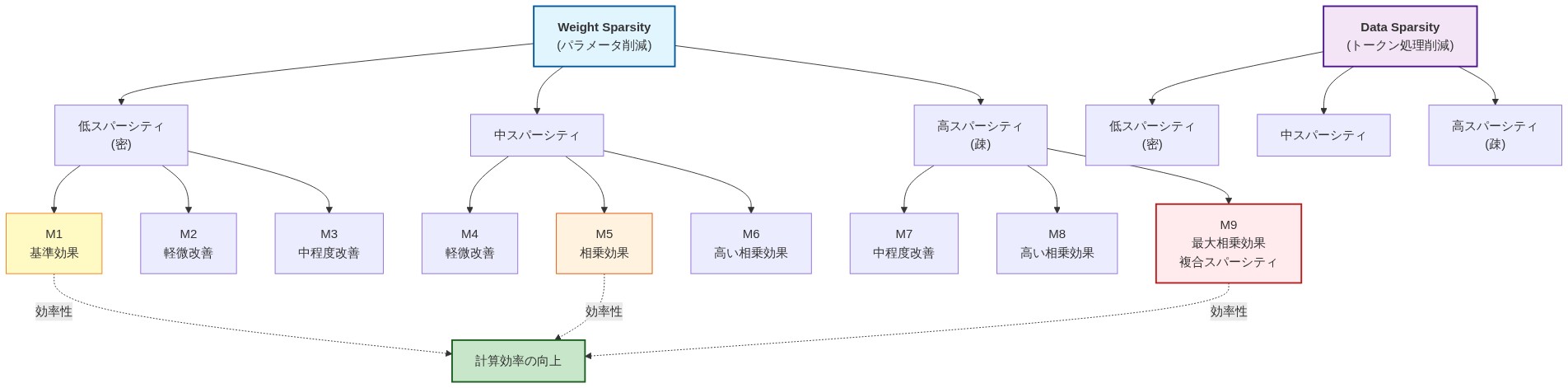
- 図5:Weight Sparsity と Data Sparsity の直交性:複合スパーシティの相乗効果マトリックス*

- 図6:Data Sparsity:各エキスパートが処理するトークンのサブセット化。バッチ内の複数トークンに対して、各エキスパートが選択的に割り当てられたトークンのみを処理することで、計算効率を向上させる仕組みを視覚化。*