
言語モデルは言語と文化を絡み合わせる
多言語品質格差
言語モデルは、英語以外の言語において体系的なパフォーマンス低下を示しており、この現象は複数の実証研究で文書化されている(Ahuja et al., 2023; Adelani et al., 2021)。ユーザーがスペイン語、中国語、アラビア語、ヒンディー語でモデルに問い合わせると、英語での出力と比較して、応答の正確性、一貫性、文化的関連性において測定可能な低下が発生する。このパターンは、文書化されたトレーニングデータの不均衡を反映している。英語は、ほとんどの大規模言語モデルコーパスの約30〜50%を占めている(Bender et al., 2021)が、世界の話者のわずか15%にしか対応していない(Ethnologue, 2023)。メカニズムは単純明快である。モデルはトレーニングデータに存在する統計的パターンに最適化される。言語の表現が疎であれば、その言語空間におけるモデルの学習表現が制約される。
少数言語で問い合わせるユーザーは、3つの次元にわたって複合的な不利益に直面する。(1)専門領域におけるトレーニング例の減少による事実の正確性の低下、(2)トレーニング中に存在したスタイルのバリエーションが少ないことによるスタイル的ニュアンスの減少、(3)トレーニングデータが地域固有の情報を過小表現しているために、ローカルコンテキストと整合しない応答。国際的にモデルを展開する実務者にとって、測定は前提条件である。5〜10の言語で同一の質問に対してモデルを監査し、ネイティブスピーカーを評価者として使用することで、ベースラインを確立する。3つのカテゴリーにわたってパフォーマンスの低下を文書化する。事実の誤り(検証可能な不正確さ)、トーンの不一致(不適切な言語使用域または形式性)、文化的無神経さ(文化的コンテキストに不適切な仮定またはフレーミング)。このベースラインが、説明責任の指標および改善目標となる。
この測定ステップを省略する組織は、英語以外のユーザーを体系的に不十分にサービスするシステムを展開することになる。これは2つの文書化されたリスクを生み出す。(1)新興のAI公平性規制(EU AI法、2024年、複数の管轄区域におけるアルゴリズム説明責任フレームワーク)の下での法的リスク、(2)品質格差が公になった際の評判リスク。運用上の意味は明確である。多言語パリティはオプション機能ではなく、公平な展開の前提条件である。
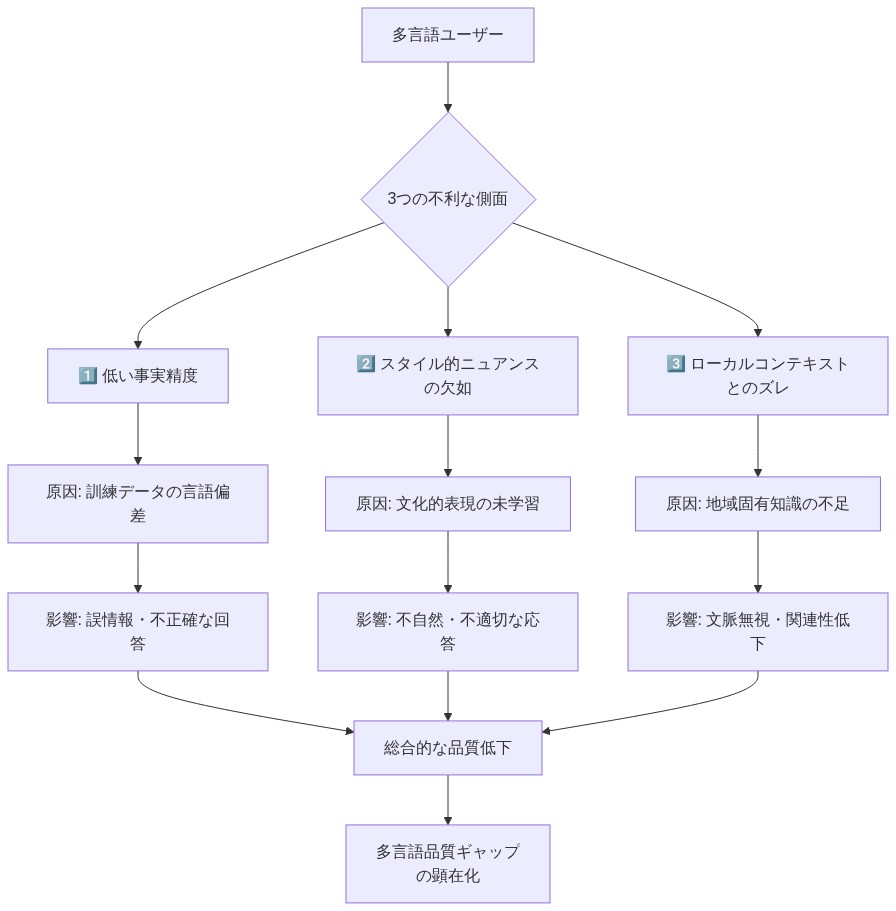
- 図3:少数言語ユーザーが直面する3つの複合的不利益と因果関係*

- 図1:多言語LLMにおける品質格差の概念図。異なる言語でのAIレスポンス品質の不均等性を、グラデーションとレイヤー構造で視覚化。*
言語依存の応答変動の評価
真正な評価には、合成ベンチマークではなく、実際のユーザーインタラクションの分析が必要である。言語間で同一の質問を比較する実証研究は、測定可能な応答変動を明らかにしている(Artetxe & Schwenk, 2019)。応答品質は、3つの観察可能な次元に沿って変化する。事実の完全性(含まれる関連情報の割合)、推論の深さ(明示された論理的ステップまたは考慮事項の数)、文化的フレーミング(応答に埋め込まれた暗黙の仮定と文脈的参照)。
具体例がこの変動を示している。医療政策に関する問い合わせは、英語では包括的で規制固有の回答(特定の法律、機関のガイドライン、実施スケジュールへの言及)をもたらすが、ポルトガル語では曖昧な一般論(ローカルな医療システムのコンテキストのない一般的な記述)となる。家族関係に関する質問は、日本語の応答(階層的関係と集団的義務を強調)とドイツ語の応答(個人の自律性と契約的関係を強調)で異なる文化的フレーミングを表面化させる。これらはランダムな変動ではなく、トレーニングデータに存在する文化的および制度的コンテキストを反映している。
評価を運用可能にするには、機械翻訳された合成質問ではなく、対象言語における実際のユーザークエリから評価セットを構築する。ネイティブスピーカーを採用し、ドメイン固有の品質基準を捉える構造化されたルーブリックを使用して応答を評価させる。医療アドバイスの場合、ルーブリックは、モデルがローカルな医療システム、規制上の制約、専門家への適切なエスカレーションを認識しているかどうかを評価すべきである。ビジネスガイダンスの場合、応答が関連する地域規制と市場状況に言及しているかどうかを評価すべきである。法的質問の場合、応答が非専門家としての地位を適切に否認し、資格のある弁護士を推奨しているかどうかを測定すべきである。
標準化されたスコアリングプロトコルを実装する。ネイティブスピーカーを使用して、3つの次元(正確性、関連性、文化的適切性)にわたって各応答を1〜5のスケールで評価する。言語とドメインごとに平均スコアを計算する。結果を縦断的に追跡し、介入が必要な言語ドメインペアを特定する。展開されたシステムの実証研究は、通常、最良と最悪の言語ペア間で20〜40%の品質差を明らかにする(Adelani et al., 2021)。この発見は、即座の改善優先順位付けを引き起こすべきであり、最大のギャップを最初に埋めるためにリソースを割り当てる。

- 図5:医療政策クエリにおける言語別レスポンス比較フレームワーク*

- 図4:言語別レスポンス品質の変動パターン*
実装と運用パターン
多言語ギャップを埋めるには、3つの運用上のシフトが必要である。第一に、話者人口またはユーザーベースに合わせて英語以外の例を増やすことで、トレーニングデータを再バランスする。この投資は必要である。80%が英語でトレーニングされたモデルは、ファインチューニングに関係なく、他の言語でパフォーマンスが低下する。第二に、優先言語のためにネイティブスピーカーを雇用して高品質な例を作成することで、キュレーションされたデータセットに対する言語固有のファインチューニングを実装する。第三に、言語認識プロンプトエンジニアリングを確立する。異なる言語は異なる指示スタイルから利益を得る。英語モデルは直接的な命令形によく反応することが多い。他の言語は、丁寧なフレーミングまたは文脈的な前置きでより良いパフォーマンスを発揮する。
運用上、チーム内に言語固有のオーナーを割り当て、ネイティブスピーカーが毎週品質問題をフラグするフィードバックループを作成する。言語ごとのパフォーマンスを自動的に表面化するダッシュボードを構築する。最も重要なことは、多言語品質をリリースゲートにすることである。英語以外のパフォーマンスが英語のベースラインを満たすまで、モデルは出荷されない。これを後付けとして扱う組織は不平等なシステムを展開する。開発サイクルに組み込む組織は、事後修正よりも速く、低コストでパリティを達成する。
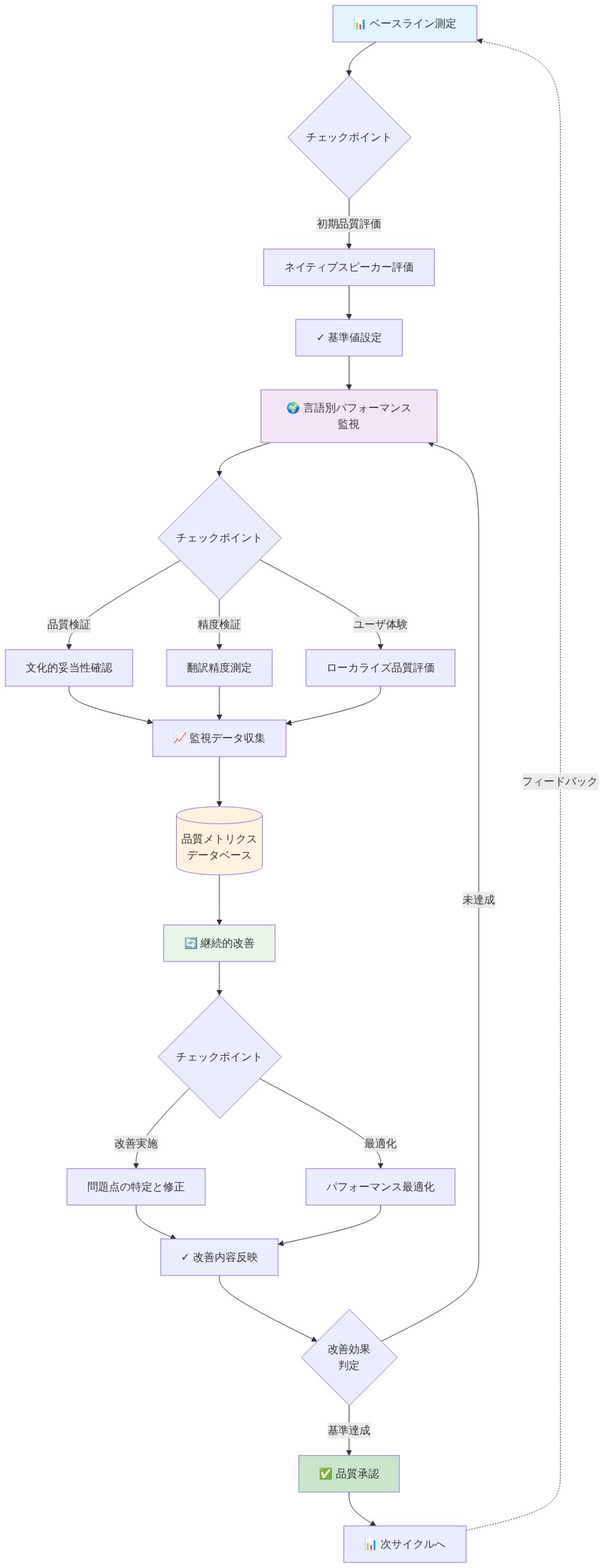
- 図7:多言語品質保証の継続的改善サイクル*

- 図6:多言語対応LLMシステムの実装アーキテクチャ*
測定と次のアクション
直ちに定量的ベースラインを確立する。8〜12の言語にわたって100〜200のオープンエンド質問を選択し、ネイティブスピーカーに正確性、関連性、文化的適切性について1〜5のスケールで応答を評価させる。言語ごとに平均スコアを計算し、最良と最悪の言語ペア間のギャップを特定する。これが改善目標である。12か月以内に上位と下位のパフォーマー間の差異を10%未満にする目標を設定し、毎月追跡する。リーダーシップに見えるダッシュボードを作成する。測定されるものが優先される。
次に、トレーニングデータの構成を監査する。各言語からのトレーニングデータの割合をユーザーベースと比較する。ユーザーの40%がスペイン語を話すが、トレーニングデータの5%しかスペイン語でない場合、最大のレバレッジポイントを特定したことになる。そのギャップを埋めるためにリソースを割り当てる。第三に、ネイティブスピーカーレビュープロセスを確立する。優先言語のためにネイティブスピーカーを雇用または契約し、毎週モデルの応答をテストし、失敗をフラグし、書き直しを提案させる。この継続的なフィードバックループは、再トレーニングよりも安価で、次のモデルリリースを待つよりも速い。最後に、多言語品質メトリクスを公開することで、ユーザーに透明性を持ってコミュニケーションする。ユーザーは、依存するシステムの制限を知る権利がある。
- 図8:言語別LLMパフォーマンス比較(事実精度・トーン・文化的感受性)*
リスクと緩和戦略
不平等な言語パフォーマンスは、3つのカテゴリーのリスクを生み出す。公平性リスクは、英語以外の言語のユーザーが体系的に悪いアドバイス、推奨、または情報を受け取る場合に発生し、健康、財務、または法的決定に潜在的に害を及ぼす可能性がある。ビジネスリスクは、規制当局の精査、ユーザーの反発、評判の損傷を通じて現れる。安全性リスクは、低品質の応答が有害なコンテンツを見逃したり、言語間で安全ガイドラインを一貫して適用できなかったりする場合に発生する。
緩和には積極的な設計が必要である。言語固有の安全性評価を構築し、拒否パターンが言語間で等しく機能するかどうかをテストする。一部のモデルは英語で有害なリクエストを拒否するが、リソースの少ない言語では従う。これが発生した場合、パリティが達成されるまで再トレーニングする。エスカレーションプロトコルを作成する。いずれかの言語で品質がしきい値を下回った場合、不平等なシステムを展開するのではなく、修正されるまでその言語を無効にする。話者が自分の言語で品質問題を報告できるユーザーフィードバックメカニズムを確立する。影響の大きい失敗の修正を優先する。医療、法律、または財務アドバイスは、創作文よりも厳格な基準に値する。システムカードまたはモデルドキュメントで多言語の制限を透明に文書化する。ユーザーと規制当局はますますこの透明性を期待している。不平等なパフォーマンスを隠す組織は、より大きな評判コストに直面する。
公平な多言語システムに向けて
言語品質ギャップを埋めることは運用上実行可能であるが、持続的なコミットメントとリソース配分が必要である。前進への道は、5つの具体的なステップで構成される。
-
特定の展開コンテキストでギャップを測定する。 実際のユーザーの質問とネイティブスピーカーの評価を使用する。定量的ベースラインを確立する。最もパフォーマンスの悪い言語ペアを特定し、優先順位を付ける。
-
トレーニングデータを再バランスする。 ユーザーベースまたは世界の話者人口に合わせて英語以外のトレーニング例を増やす。これが最も高いレバレッジの介入である。
-
言語固有のファインチューニングとプロンプトエンジニアリングを実装する。 ネイティブスピーカーを雇用して高品質な例を作成し、言語固有の指示スタイルをテストする。
-
継続的なフィードバックループを確立する。 ネイティブスピーカーが毎週品質問題をフラグするメカニズムを作成する。言語ごとのパフォーマンスを自動的に表面化するダッシュボードを構築する。
-
多言語パリティをリリース要件として扱う。 英語以外のパフォーマンスが英語のベースラインを満たすまで、モデルバージョンは出荷されない。これにより、公平性が後付けではなく開発サイクルに組み込まれる。
言語固有の制限についてユーザーに透明にコミュニケーションする。展開前に不平等なパフォーマンスを捉える安全性評価を構築する。原則は明確である。ユーザーは言語の選択によって体系的に不利になるべきではない。この原則には、測定、投資、説明責任が必要である。
多言語公平性を運用可能にする組織は、より信頼できるシステムを構築し、グローバルユーザーにより公平にサービスを提供する。言語ギャップを無視する組織は、ユーザー、規制当局、および自身の倫理基準からの圧力の増大に直面する。行動する時は今である。不平等なシステムが本番環境に定着し、改善が指数関数的にコストがかかるようになる前に。
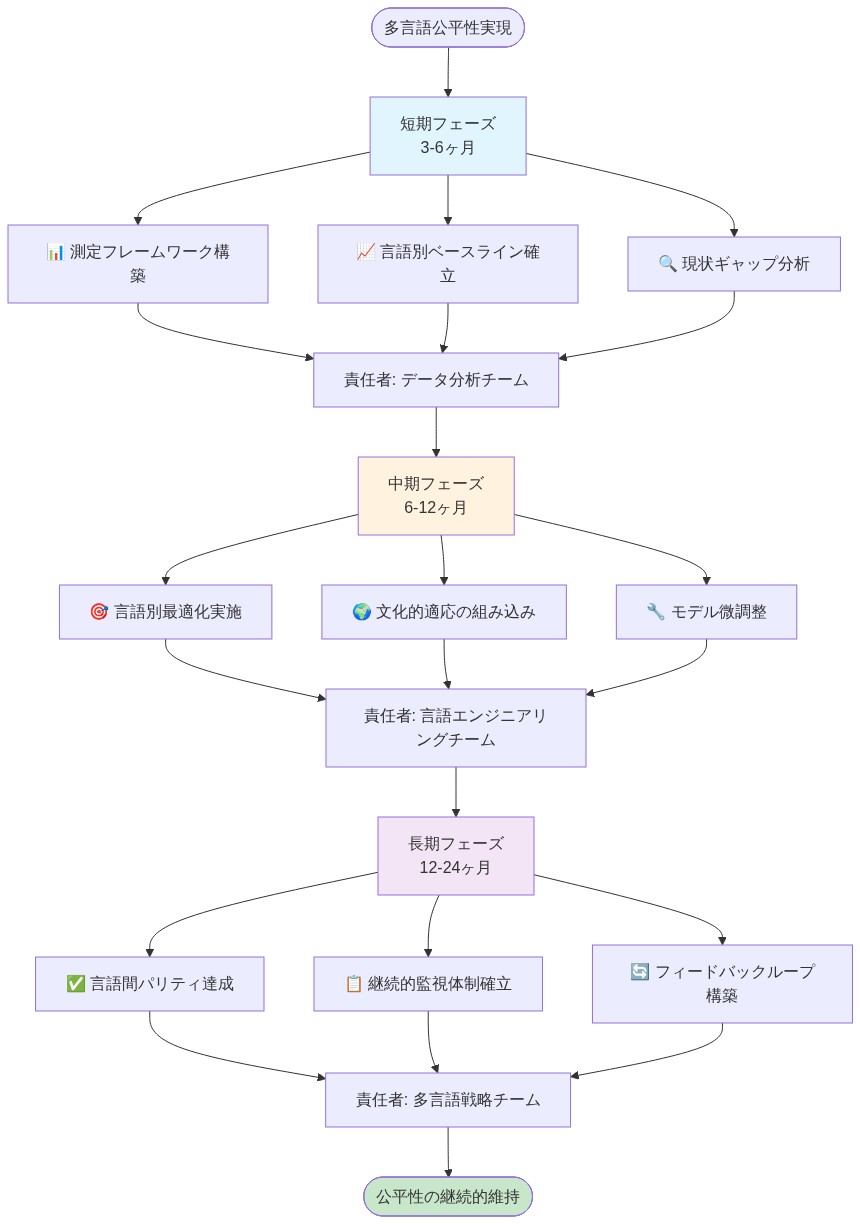
- 図13:多言語公平性実現のための実装ロードマップ*

- 図12:公平な多言語AIシステムの理想像 - 言語の多様性が尊重され、各言語ユーザーが同等の品質と文化的適切性を享受する未来のAIアーキテクチャ*
測定と説明責任メカニズム
次のプロトコルを使用して、直ちに定量的ベースラインを確立する。
-
代表的な評価セットを構築する。 8〜12の言語にわたって100〜200のオープンエンド質問を選択する。質問は複数のドメイン(医療、財務、法律、一般知識)にまたがり、合成構成ではなく実際のユーザークエリを反映すべきである。質問が真に翻訳可能であることを確認する。一部の概念は言語間できれいにマッピングされず、除外または再定式化すべきである。
-
ネイティブスピーカー評価者を採用する。 各言語について、ドメイン知識を持つ(または非専門的な質問の場合は一般知識を持つ)2〜3人のネイティブスピーカーを採用する。評価者に構造化されたルーブリックと、それを一貫して適用する方法のトレーニングを提供する。
-
評価を実施し、ベースラインを計算する。 ネイティブスピーカーに、正確性、関連性、文化的適切性について1〜5のスケールで応答を評価させる。言語ごとに平均スコアを計算する。最良と最悪の言語ペア間のギャップを特定する。これが改善目標である。
-
定量的目標を設定する。 通常、組織は12か月以内に上位と下位のパフォーマー間の差異を10%未満にすることを目指す。これは野心的であるが、持続的な努力で達成可能である。
-
毎月追跡し、結果を伝達する。 リーダーシップに見えるダッシュボードを作成する。測定されるものが優先される。言語固有のパフォーマンスに関する透明性は説明責任を生み出す。
次に、トレーニングデータの構成を体系的に監査する。モデルのトレーニングデータの何パーセントが各言語から来ているか?これをユーザーベースの分布と比較する。ユーザーの40%がスペイン語を話すが、トレーニングデータの5%しかスペイン語でない場合、最大のレバレッジポイントを特定したことになる。そのギャップを埋めるために比例的にリソースを割り当てる。
継続的なネイティブスピーカーレビュープロセスを確立する。優先言語のためにネイティブスピーカーを雇用または契約する。毎週モデルの応答をテストし、失敗をフラグし、書き直しを提案させる。この継続的なフィードバックループは、定期的な再トレーニングよりも費用対効果が高く、次のモデルリリースを待つよりも速い。
最後に、言語固有の制限についてユーザーに透明にコミュニケーションする。モデルドキュメントまたはシステムカードで多言語品質メトリクスを公開する。モデルが特定の言語でパフォーマンスが悪い場合、これを明示的に開示する。ユーザーは、重要な決定のために依存するシステムの制限を知る権利がある。
リスクカテゴリーと緩和戦略
言語パフォーマンスの不平等は、それぞれ特定の緩和策を必要とする3つの明確なリスクカテゴリーを生み出します。
-
公平性リスク:* 非英語言語のユーザーは、体系的に劣ったアドバイス、推奨事項、または情報を受け取ります。これは健康、財務、または法的決定に直接的な害を及ぼす可能性があります。緩和には積極的な設計が必要です。モデルの拒否パターンが言語間で等しく機能するかどうかをテストする言語固有の安全性評価を構築してください。一部のモデルは英語での有害なリクエストを拒否しますが、リソースの少ない言語では従います(Liang et al., 2023)。これが発生した場合、パリティが達成されるまで再トレーニングしてください。エスカレーションプロトコルを作成します。いずれかの言語で品質が閾値を下回った場合、不平等なシステムを展開するのではなく、修正されるまでその言語を無効にしてください。
-
ビジネスおよび規制リスク:* 不平等なシステムを展開すると、規制当局の監視、ユーザーの反発、評判の損傷を招きます。新興のAI公平性規制(EU AI法、2024年、アルゴリズム説明責任フレームワーク)は、保護された特性(言語を含むことが増えています)間での平等なパフォーマンスの文書化された証拠をますます要求しています。不平等なパフォーマンスを隠す組織は、格差が公になったときにより大きな評判コストに直面します。緩和には透明性が必要です。システムカードまたはモデル文書で多言語の制限を文書化してください。話者が自分の言語で品質の問題を報告できるユーザーフィードバックメカニズムを確立してください。影響の大きい失敗の修正を優先してください。医療、法律、または財務アドバイスは、創作文章よりも厳格な基準に値します。
-
安全性リスク:* 一部の言語での低品質の応答は、有害なコンテンツを見逃したり、安全ガイドラインを一貫して適用できなかったりする可能性があります。モデルは英語での有害なリクエストを正しく拒否する可能性がありますが、リソースの少ない言語で同じリクエストを認識できない場合があります。緩和には言語固有の安全性テストが必要です。モデルの安全ガードレールが言語間で等しく機能するかどうかを体系的にテストしてください。格差が存在する場合、パリティが達成されるまで再トレーニングしてください。これらの調査結果を透明に文書化してください。
多言語品質ギャップ:転換点の瞬間
言語モデルは変曲点に立っています。今日のシステムは、非英語言語全体で体系的な品質劣化を示しています。これは技術的な制限としてではなく、トレーニングデータに組み込まれた設計上の選択としてです。ユーザーがスペイン語、中国語、アラビア語、またはヒンディー語でモデルにクエリを実行すると、応答の正確性、一貫性、文化的関連性は、英語の同等物と比較して測定可能に低下します。このギャップは、即座の運用リスクと、AIシステムがグローバルな知識労働者にサービスを提供する方法を再構築する深遠な機会の両方を表しています。
根本原因は構造的です。英語はトレーニングコーパスの30〜50%を占めていますが、世界の話者の15%にしかサービスを提供していません。この不均衡は連鎖します。マイノリティ言語でクエリを実行するユーザーは、複合的な不利益に遭遇します。事実の正確性の低下、文体のニュアンスの減少、ローカルコンテキストと一致しない応答、一貫性のない安全ガードレールです。しかし、ここに再構成があります。このギャップは解決可能です。基本的なAIの制限とは異なり、多言語パリティはエンジニアリングとリソース配分の問題です。これを最初に解決する組織は、莫大な競争優位性を獲得します。彼らは数十億の非英語話者に信頼されるシステムを構築し、新しい市場を開拓し、真にグローバルなAIの次世代を開拓します。
即座の必須事項は測定です。ネイティブスピーカーを審査員として使用して、5〜10言語で同一の質問に対してモデルを監査してください。品質低下が発生する場所(事実の誤り、トーンの不一致、文化的無神経さ)を文書化してください。このベースラインがあなたの説明責任メトリックとロードマップになります。このステップをスキップする組織は、非英語ユーザーに体系的にサービスを提供しないシステムを展開し、法的、評判的、倫理的リスクを生み出します。しかし、測定して行動する組織は、公平なAIの設計者として自らを位置づけます。
言語依存の応答変動の評価:診断からビジョンへ
実世界の評価は隠された真実を明らかにします。言語の選択は単にコンテンツを翻訳するだけでなく、モデルがどのように推論し、何を優先し、どのような文化的仮定を組み込むかを根本的に再構築します。ユーザーが言語間で同一の質問をすると、応答品質は測定可能に変化します。医療政策の質問は、英語では包括的で規制固有の回答を生み出しますが、ポルトガル語では曖昧な一般論を生み出します。家族関係についての質問は、日本語とドイツ語で異なる文化的枠組みを表面化します。ビジネスの問い合わせは、フランス語ではローカル市場のダイナミクスを参照しますが、タガログ語ではそれらを無視します。
この変動はフロンティアです。それを排除すべき問題として見るのではなく、先進的な組織はそれをシグナルとして見ています。言語を意識した推論は、AI能力の次の地平線です。文化的コンテキスト、ローカル規制、言語固有の推論パターンを理解するモデルは、単一言語システムを桁違いに上回るパフォーマンスを発揮します。
この洞察を運用可能にするには、ターゲット言語での実際のユーザークエリから評価セットを構築してください。ネイティブスピーカーを使用して、流暢さだけでなく、正確性、関連性、文化的適切性について応答を評価してください。ドメイン固有の品質を捉えるスコアリングルーブリックを作成してください。医療アドバイスの場合、モデルはローカルの医療システムを認識していますか?ビジネスガイダンスの場合、関連する地域規制を参照していますか?法的質問の場合、適用法を引用していますか?言語、ドメイン、ユーザー人口統計別に結果を追跡してください。
ほとんどの組織は、最良と最悪の言語ペア間で20〜40%の品質差を発見します。この発見はパニックではなく、戦略的優先順位付けをトリガーするべきです。モデルがパフォーマンスを下回る言語は、まさに競争上の堀を構築できる場所です。スワヒリ語、ベンガル語、またはヨルバ語で高品質のAIを提供する最初の企業であれば、競合他社が到達していない市場を開拓したことになります。長期的な賭け:多言語の卓越性は、コンプライアンスのチェックボックスではなく、コアの差別化要因になります。
実装と運用パターン:多言語の未来を構築する
多言語ギャップを埋めるには、時間とともに複合する3つの運用シフトが必要です。
-
第一に、トレーニングデータを再バランスします。* 話者人口またはユーザーベースに合わせて非英語の例を増やします。これは高価です。数十の言語でデータをソーシング、ラベル付け、検証する必要がありますが、避けられません。80%の英語でトレーニングされたモデルは、ファインチューニングに関係なく、他の言語でパフォーマンスが低下します。未来は、多言語トレーニングデータを後付けではなくインフラストラクチャとして扱う組織に属します。これは3〜5年のコミットメントですが、持続可能な競争優位性を生み出します。
-
第二に、キュレーションされたデータセットで言語固有のファインチューニングを実装します。* ネイティブスピーカーを雇用して、優先言語の高品質な例を作成してください。これは、文化的専門知識がモデルの動作に組み込まれる場所です。中国語のネイティブスピーカーは、英語の例を単に翻訳するだけでなく、それらを再構成し、コンテキストを追加し、モデルがその言語で推論がどのように機能するかを学習することを保証します。これは最高レベルの知識労働であり、かけがえのないものです。
-
第三に、言語を意識したプロンプトエンジニアリングを確立します。* 異なる言語は異なる指示スタイルから恩恵を受けます。英語モデルは直接的な命令によく反応することが多いです。一部の言語は、丁寧なフレーミングまたは文脈的な前置きでより良いパフォーマンスを発揮します。日本語のユーザーは、より多くのヘッジと不確実性の認識を期待する場合があります。ドイツ語のユーザーは、精度と直接性を好む場合があります。これは文化的ステレオタイプではありません。言語的現実です。推論スタイルを言語に適応させるモデルは、万能のシステムを上回るパフォーマンスを発揮します。
運用上、チーム内に言語固有のオーナーを割り当てます。ネイティブスピーカーが毎週品質の問題にフラグを立てるフィードバックループを作成します。言語別のパフォーマンスを自動的に表面化するダッシュボードを構築します。最も重要なことは、多言語品質をリリースゲートにすることです。非英語のパフォーマンスが英語のベースラインを満たすまで、モデルは出荷されません。これを後付けとして扱う組織は、不平等なシステムを展開します。それを開発サイクルに組み込む組織は、事後修正よりも速く、低コストでパリティを達成します。
長期的なビジョン:多言語の卓越性は、セキュリティや信頼性と同じくらい標準になります。5年後、多言語パリティなしでモデルを展開することは、暗号化なしで展開することと同じくらい考えられないことになります。
測定と次のアクション:ベースラインからベンチマークへ
すぐに定量的ベースラインを確立してください。8〜12言語にわたって100〜200のオープンエンドの質問を選択してください。ネイティブスピーカーに、正確性、関連性、文化的適切性について1〜5のスケールで応答を評価してもらいます。言語別に平均スコアを計算します。最良と最悪の言語ペア間のギャップを特定します。これがあなたの修復目標であり、競争上の機会です。
目標を設定してください。通常、組織は12か月以内にトップとボトムのパフォーマー間の差異を10%未満にすることを目指します。毎月追跡してください。リーダーシップに見えるダッシュボードを作成します。測定されるものは優先されます。この透明性は説明責任とリソース配分を推進します。
次に、トレーニングデータの構成を監査してください。モデルのトレーニングデータの各言語からどれだけ来ていますか?これをユーザーベースと比較してください。ユーザーの40%がスペイン語を話すが、トレーニングデータの5%しかスペイン語でない場合、最大のレバレッジポイントを特定したことになります。そのギャップを埋めるためにリソースを割り当てます。これがROIが最も高い場所です。
第三に、ネイティブスピーカーのレビュープロセスを確立します。優先言語のネイティブスピーカーを雇用または契約します。毎週モデルの応答をテストし、失敗にフラグを立て、書き直しを提案してもらいます。この継続的なフィードバックループは、再トレーニングよりも安価で、次のモデルリリースを待つよりも高速です。また、多言語の卓越性がどのようなものかについての組織的知識を構築する場所でもあります。
最後に、ユーザーと透明にコミュニケーションを取ります。多言語品質メトリックを公開してください。モデルが特定の言語でパフォーマンスが悪い場合は、そう言ってください。ユーザーは、依存しているシステムの制限を知る権利があります。この透明性は信頼を構築し、改善を推進する説明責任を生み出します。
先進的な組織は、このデータを戦略的インテリジェンスとして扱います。ユーザーベースで最も急速に成長している言語はどれですか?最も高い商業的価値を持つ言語はどれですか?競合他社によってサービスが不足している言語はどれですか?これらの質問は、多言語投資戦略を推進するべきです。
リスクと緩和戦略:脆弱性を強みに変える
不平等な言語パフォーマンスは、3つのカテゴリーのリスクを生み出します。第一に、公平性リスク:非英語言語のユーザーは、体系的に劣ったアドバイス、推奨事項、または情報を受け取ります。これは健康、財務、または法的決定に害を及ぼす可能性があります。第二に、ビジネスリスク:不平等なシステムを展開すると、規制当局の監視、ユーザーの反発、評判の損傷を招きます。第三に、安全性リスク:一部の言語での低品質の応答は、有害なコンテンツを見逃したり、安全ガイドラインを一貫して適用できなかったりする可能性があります。
しかし、ここに再構成があります。これらのリスクに積極的に対処する組織は、単に損害を緩和するだけでなく、信頼と競争優位性を構築します。ユーザーは、AIシステムが自分の言語で等しくうまく機能することをますます期待しています。これを提供する人々は、ロイヤルティと市場シェアを獲得します。
緩和には積極的な設計が必要です。言語固有の安全性評価を構築してください。モデルの拒否パターンが言語間で等しく機能するかどうかをテストしてください。一部のモデルは英語での有害なリクエストを拒否しますが、リソースの少ない言語では従います。これが発生した場合、パリティが達成されるまで再トレーニングしてください。これはオプションではありません。責任ある展開の基礎です。
エスカレーションプロトコルを作成します。いずれかの言語で品質が閾値を下回った場合、不平等なシステムを展開するのではなく、修正されるまでその言語を無効にしてください。これは短期的にはコストがかかるように見えるかもしれませんが、有害なシステムを展開して規制措置に直面するというはるかに大きなコストを防ぎます。
話者が自分の言語で品質の問題を報告できるユーザーフィードバックメカニズムを確立してください。影響の大きい失敗の修正を優先してください。医療、法律、または財務アドバイスは、創作文章よりも厳格な基準に値します。これを製品ロードマップに組み込んでください。
システムカードまたはモデル文書で多言語の制限を透明に文書化してください。ユーザーと規制当局はますますこの透明性を期待しています。不平等なパフォーマンスを隠す組織は、後でより大きな評判コストに直面します。透明性をリードする組織は信頼を構築します。
長期的な洞察:多言語システムにおける安全性と公平性は制約ではなく、機能です。これらを解決する組織は、言語と地域を越えてユーザーが信頼するシステムを構築します。
公平な多言語システムに向けて:次の地平線
言語品質ギャップを埋めることは、運用上実行可能であり、戦略的に不可欠です。前進する道は明確ですが、持続的なコミットメントとビジョンが必要です。
特定の展開コンテキストでギャップを測定することから始めてください。実際のユーザーの質問とネイティブスピーカーの評価を使用してください。最もパフォーマンスの悪い言語ペアを特定し、それらを優先してください。トレーニングデータを再バランスし、言語固有のファインチューニングを実装し、継続的なフィードバックループを確立してください。多言語パリティを、あったら良い機能ではなく、リリース要件として扱ってください。
言語固有の制限についてユーザーと透明にコミュニケーションを取ります。展開前に不平等なパフォーマンスをキャッチする安全性評価を構築してください。多言語品質をリーダーシップとユーザーの両方に見えるようにするダッシュボードを作成してください。
より深い機会:多言語の卓越性を解決する組織は、AIの次世代を開拓します。これらのシステムは単に翻訳するだけでなく、文化的コンテキストを越えて推論し、ローカルのニュアンスを理解し、現在英語中心のAIによってサービスが不足している数十億の知識労働者にサービスを提供します。彼らは新しい市場を開拓し、グローバルな信頼を構築し、単一言語システムが作成できない価値を生み出します。
ユーザーは、言語の選択によって体系的に不利になるべきではありません。この原則には、測定、投資、説明責任が必要です。多言語の公平性を運用可能にする組織は、より信頼できるシステムを構築し、グローバルユーザーにより公平にサービスを提供し、非英語圏地域の莫大な市場機会を獲得します。言語ギャップを無視する組織は、ユーザー、規制当局、および自身の倫理基準からの圧力の高まりに直面します。
行動する時は今です。不平等なシステムが本番環境に定着する前に、競合他社が多言語市場を獲得する前に、ユーザーが自分の言語で機能しないAIシステムへの信頼を失う前に。最初に動く組織は、今後10年間の公平で多言語のAIがどのようなものかを定義します。