
LLMは400年にわたる信用詐欺である
誇大宣伝の下にあるパターン
大規模言語モデルは、何世紀にもわたる修辞的伝統を継承している。それは、確率的推論を権威ある知識として体系的に提示することである。このパターンは意図的な欺瞞ではなく、モデルのアーキテクチャと訓練目標の構造的帰結である。数十億のパラメータにわたって統計的精度で次のトークンを予測するようにシステムが最適化されると、権威ある言説を模倣する流暢なテキストを生成することに極めて熟達する。これにより、モデルの信頼性に対するユーザーの認識と、実世界の条件下での実際のモデルのパフォーマンスとの間に測定可能な信頼性ギャップが生じる。
「400年」という言及は、17世紀の百科事典編纂者から20世紀のレファレンス司書、そして現代の検索エンジンに至るまでの知識仲介者の記録された歴史を示している。彼らは、包括的で信頼できる情報へのアクセスを提供しているように見せることで、経済的・社会的価値を得てきた(Headrick, 2000; Nunberg, 2009)。LLMはこのパターンの最新の反復であり、以前のモデルからの根本的な逸脱ではなく、前例のない規模とアクセシビリティによって区別される。
-
構造的メカニズム:* LLMは訓練コーパスにおける次トークン予測精度を最適化するのであって、事実の正確性や認識論的謙虚さを最適化するのではない。数十億のトークンで訓練されたモデルは、訓練分布における統計的パターンに一致するテキストを生成することを学習する。訓練分布外のクエリ、リアルタイム情報を必要とするクエリ、またはパターン補完を超える推論を要求するクエリが提示されると、モデルは不確実性を確実にシグナルすることができない。代わりに、もっともらしく聞こえるテキストを生成する。これは「幻覚(ハルシネーション)」と呼ばれる現象である(Maynez et al., 2020; Zhang et al., 2023)。検索エンジンによって返されたテキストを事実的な回答として解釈するように条件付けられたユーザーは、確率的出力を断言として頻繁に誤解する。
-
具体例:* LLMが架空の学術論文の詳細な説明を生成し、著者名、出版年、要旨を含めている。その応答は実在の論文の説明と同一の形式である。知識労働者がこの引用をレポートに組み込む。下流の読者がそのレポートを引用し、誤った参照を伝播させる。明示的な検証が行われるまで、エラーは検出されないままである。
-
失敗の前提条件:* この失敗モードには3つの条件が必要である:(1)モデルの出力に対するユーザーの信頼、(2)検証メカニズムの欠如、(3)再検証なしでの出力の下流への伝播。これら3つすべてが現在の展開において一般的である。
-
実行可能な示唆:* 顧客向けまたは意思決定に重要な展開の前に、必須の検証ワークフローを確立する。明示的なデータ系統追跡を実装する:各応答にどの訓練データが情報を提供したか、そのデータが最後に更新されたのはいつかを文書化する。下流システムで使用される出力については、統合前に独立した事実確認を要求する。LLMの出力をデフォルトで未検証の草稿として扱い、権威ある情報源としては扱わない。
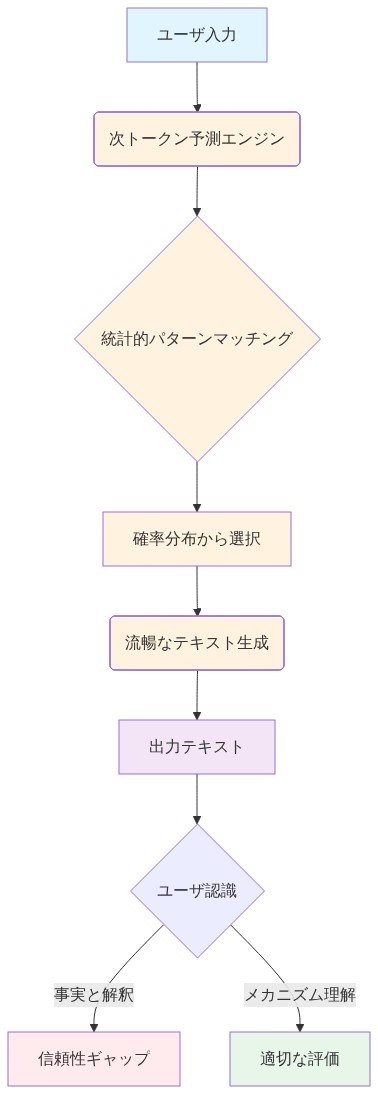
- 図2:LLMの構造的メカニズム - 次トークン予測から信頼性ギャップへ*

- 図1:LLMの信頼性ギャップ - 流暢さと正確性の乖離(コンセプトイメージ)*

- 図3:知識仲介者の400年の歴史 - 百科事典からLLMへの進化系統図。各時代の知識仲介ツールの権威的な外観と実質のギャップが繰り返されるパターンを視覚化。*
システム構造と不透明性
信用詐欺が持続するのは、アーキテクチャ自体が失敗モードを覆い隠すためである。LLMはブラックボックスとして動作し、その意思決定プロセスは作成者にとってさえ不透明なままである。この不透明性はマーケティング資産となるが、運用上の負債となる。システムは特定のトークンを選択した理由を説明できないため、推論を監査したり、エラーを根本原因まで追跡したりすることが不可能になる。
Transformerアーキテクチャは解釈可能性よりも規模と速度を優先する。注意重みは実際の推論経路への限られた洞察しか提供しない。モデルが失敗したとき、チームはそれを体系的にデバッグできない。問題を回避するために再訓練またはプロンプトエンジニアリングを行うことしかできず、技術的負債を蓄積する。
典型的な失敗シナリオ:LLM出力で訓練されたカスタマーサービスボットが矛盾したアドバイスを提供し始める。エンジニアは、問題が訓練データの矛盾、プロンプト設計、またはモデルの根本的な制限に起因するかどうかを判断できない。彼らはルールと例外を追加することに頼り、各パッチで劣化する脆弱なシステムを作成する。
運用上、モデルの入力、出力、信頼度スコアをキャプチャする観測可能性レイヤーを構築する。エッジケースを体系的にログに記録する。顧客の修正が評価指標に情報を提供するフィードバックループを確立する。高リスクの意思決定には、より小さく解釈可能なモデルを予約する。草稿生成や要約などの低リスクタスクにLLMを使用する。
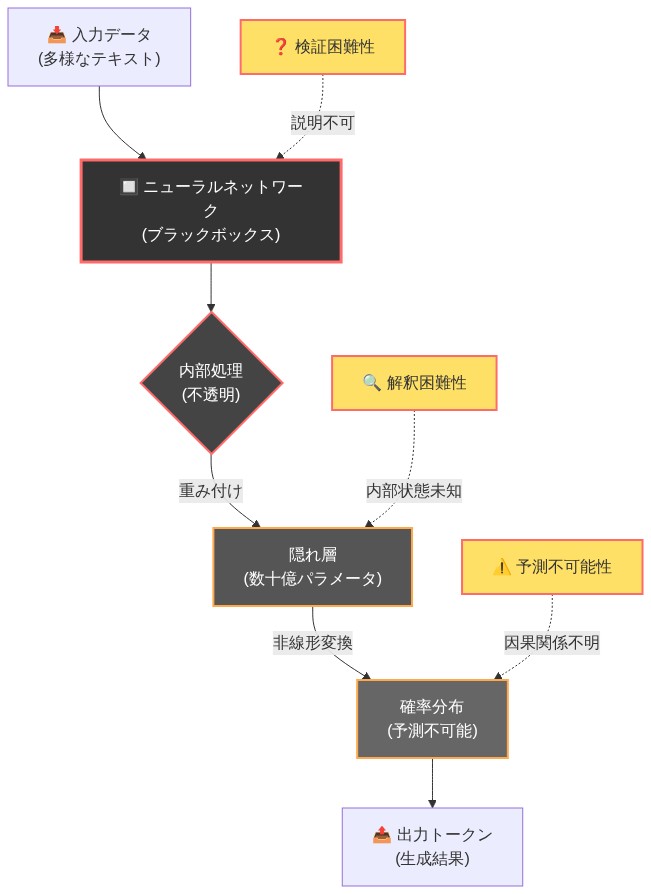
- 図4:LLMシステムの不透明性構造*
参照アーキテクチャとガードレール
効果的なLLM展開には、検証と説明責任を外部化する階層化されたガードレールが必要である。精度が重要な使用事例では、単一のLLM呼び出しでは不十分である。システムには、検索メカニズム(検証済みデータに出力を根拠付けるため)、事実確認段階(主張を検証するため)、フォールバックロジック(モデルの失敗を適切に処理するため)を含める必要がある。このアーキテクチャは、モデルが権威ある情報源ではなく、より大きな検証パイプラインの1つのコンポーネントであることを認識している。
-
設計原則:* ガードレールは責任をモデルからシステムアーキテクトに移す。ガードレールが幻覚がユーザーに到達するのを防ぐとき、失敗は事後的に発見されるのではなく、設計によって封じ込められる。
-
具体例:* 金融アドバイザリーシステムは、投資推奨の物語的説明を生成するためにLLMを使用するが、すべての数値的主張(リターン、ボラティリティ、手数料)は、ライブ市場データに接続された別の検証エンジンを通じてルーティングする。LLMは解釈的で探索的なタスクを処理し、構造化された検証は決定論的事実を処理する。LLMがファンドの年間リターンが15%であると主張する場合、検証エンジンは応答が配信される前に現在のデータに対してこれをチェックする。
-
成功の前提条件:* ガードレールには(1)明確な関心の分離(どの出力が検証を必要とするか?)、(2)権威あるデータソースへのアクセス、(3)許容可能なエラー率の定義された閾値が必要である。
-
実行可能な示唆:* 明示的な関心の分離を持つシステムを設計する。近似的、創造的、または探索的な出力が許容されるタスク(ブレインストーミング、草稿作成、要約)にLLMを予約する。決定論的または高リスクの出力には、ガードレールを備えたルールベースのシステムまたはより小さな微調整されたモデルを使用する。段階的なロールアウトを実装する:完全展開前にトラフィックの5%でガードレールをテストする。ガードレールのトリガー率を継続的に監視する。上昇率はモデルのドリフトまたは入力分布のシフトを示す。
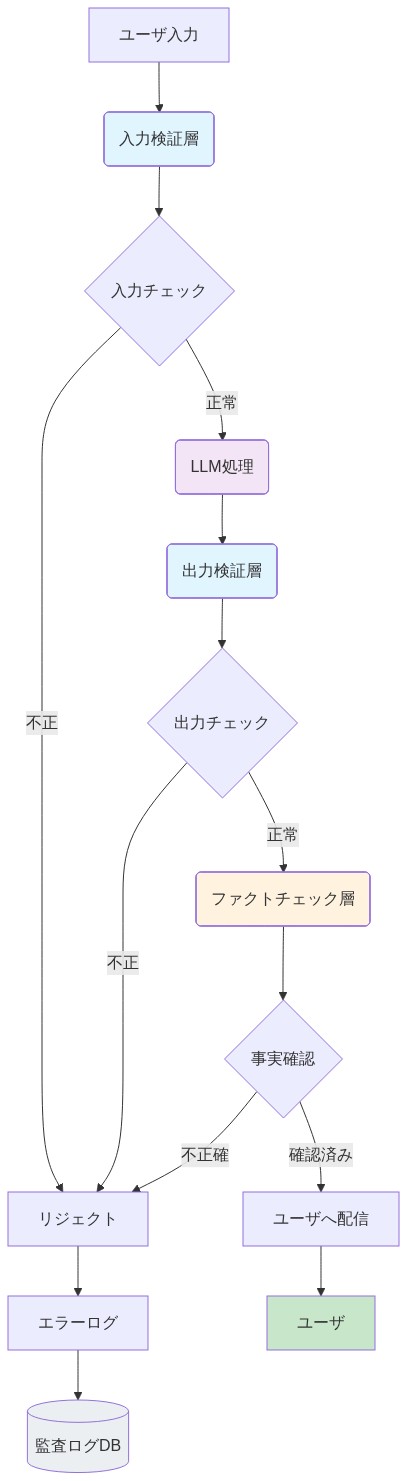
- 図5:LLM導入の参照アーキテクチャ - 多層検証フレームワーク*
実装と運用パターン
LLMシステムの運用化には、それらを決定論的APIではなく確率的インフラストラクチャとして扱うことが必要である。多くのチームは従来のソフトウェアに適用される運用規律でLLMを展開し、出力が予期せず変化または劣化すると本番インシデントに遭遇する。
-
運用上の制約:* LLMは統計モデルであり、その動作は入力分布のシフト、モデルの更新、温度設定、サンプリング戦略によって変化する。その出力は決定論的ではない。同一の入力が呼び出し間で異なる出力を生成する可能性がある。それらを安定したシステムとして扱うことは、連鎖的な失敗を招く。
-
具体例:* ある企業が1月にコンテンツモデレーションのためにGPT-4を展開する。7月までに、モデルの訓練データ分布がシフトした(モデルの更新またはユーザー入力パターンの変化のいずれかによって)。モデルは正当なコンテンツを高い率でフラグ付けし始める。バージョン管理またはA/Bテストインフラストラクチャがなければ、チームは以前のモデルバージョンに戻すことも、劣化を定量化することもできない。
-
バージョン管理要件:* モデルとプロンプトの両方を独立してバージョン管理する必要がある。プロンプトの変更は、モデルの更新と同じくらい大幅に出力分布を変更する可能性がある。
-
実行可能な示唆:* モデルとプロンプトのバージョン管理を維持する。比較のために以前のモデルバージョンを実行するシャドウインスタンスを展開する。モデル更新のためのA/Bテストインフラストラクチャを実装する。完全なロールアウト前にトラフィックのサブセットでテストする。レイテンシ、コスト、出力品質を別々の指標として追跡する。出力分布のシフト(例:応答長の突然の増加、拒否率、またはトークン使用量)に対する自動アラートを設定する。モデルの更新がパフォーマンスを劣化させた場合、数分以内に実行できるロールバック手順を確立する。
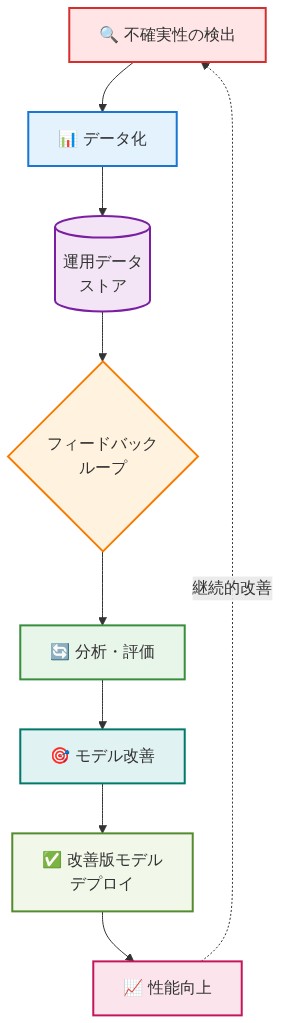
- 図7:不確実性をデータとして扱う運用パターン*
測定とベースライン
LLMのパフォーマンスを測定するには、従来の精度を超える指標が必要である。流暢さは不正確さを覆い隠す。ユーザーはすぐにエラーを検出しない可能性がある。幻覚率、レイテンシ、コスト、ユーザー満足度の独立したベースラインを確立する。
単一の指標では失敗モードを見逃す。ベンチマークで高得点を記録するモデルでも、ベンチマークが実世界の入力の多様性を捉えていないため、本番環境で幻覚を起こす可能性がある。包括的な測定には、複数の次元が必要である。
-
測定フレームワーク:* 事実の正確性(検証可能な主張は正しいか?)、一貫性(同じ質問への複数の応答は一致するか?)、較正(モデルの信頼度スコアは実際の正確性と相関するか?)、レイテンシ(応答時間は許容範囲内か?)、コスト(トークン使用量は予算内か?)を追跡する。
-
具体例:* 医療トリアージシステムは、症状の説明を生成するためにLLMを使用する。チームは、専門家の医師によって検証された応答の割合を測定する。最初の展開では、検証率は60%である。6か月後、訓練データの改善とプロンプトの調整により、検証率は85%に上昇する。チームは、検証率が80%を下回った場合にトリガーされるアラートを設定する。
-
ベースライン要件:* 展開前に、人間のパフォーマンスのベースラインを確立する。同じタスクで人間の専門家はどの程度正確か?LLMは人間のパフォーマンスを超える必要はないが、許容可能な閾値を満たす必要がある。
-
実行可能な示唆:* 展開前に、複数の次元にわたってベースライン指標を確立する。人間の専門家のパフォーマンスを測定し、それを最小閾値として使用する。本番環境で継続的な測定を実装する:応答のランダムサンプルを人間のレビュー担当者にルーティングする。時間の経過とともに指標を追跡し、劣化を検出する。ユーザーフィードバックメカニズム(親指を上げる/下げる、修正の送信)を実装し、それらを評価指標に統合する。定期的な監査を実施する:四半期ごとに、本番出力のサンプルを専門家のレビュー担当者に送信し、システムレベルのパフォーマンスを評価する。