
Matchlock – Linux ベースのサンドボックスで AI エージェント・ワークロードを保護する
コミュニティの反応と運用準備状況
Matchlock は開発者コミュニティ内で測定可能な採用シグナルを示しており、継続的な技術的議論がその証拠である。コミュニティ・エンゲージメント指標(技術プラットフォーム上での 54 件のアップボートと 14 件の実質的なコメント)は、実務家が認識する特定のセキュリティギャップを示唆している。すなわち、本番環境で自律的な AI エージェントをデプロイする際のプロセス分離の欠如である。
-
セキュリティの根拠:* 現代の AI エージェントはコードを動的に実行し、外部 API を呼び出し、ランタイム入力に基づいて自律的な判断を下す。プロセスレベルの分離がなければ、侵害されたエージェント、ロジックエラー、またはプロンプトインジェクション攻撃により、権限昇格、不正なデータアクセス、またはインフラストラクチャの破損が生じる可能性がある。Linux ベースのサンドボックスはカーネルレベルで強制的なアクセス制御とリソース制約を実行することで、アプリケーション層のセキュリティ対策とは独立してこの脅威を軽減する。
-
運用シナリオ:* リレーショナルデータベースをクエリしてコンプライアンスレポートを生成するように設計された AI エージェントを考えてみよう。分離がなければ、エージェント・プロセスは親アプリケーションの権限を継承する。悪意のあるプロンプトまたはコード注入により、エージェントは以下を実行できる可能性がある。(1)
/etc/passwdのようなシステムファイルを読む、(2) アプリケーション設定を変更する、(3) リバースシェル接続を確立する。Matchlock サンドボックスは、エージェントを明示的な許可リスト付きの制限された Linux 名前空間に制限する。データベース接続認証情報、入力データディレクトリ、出力ディレクトリのみである。その他すべてのファイルシステムパス、ネットワークインターフェース、システム機能にはアクセスできない。 -
デプロイメントの含意:* AI エージェントをデプロイする組織は、現在のワークロードの権限監査を実施すべきである。信頼されていない入力(ユーザープロンプト、外部データフィード、動的に生成されたコード)を実行するエージェント、および共有アプリケーション認証情報下で実行されるエージェントを特定することで、ベースラインを確立する。いずれかの基準を満たすエージェントは、サンドボックス・デプロイメントの優先対象とすべきである。
システムアーキテクチャと主要な制約
Matchlock は Linux 名前空間と cgroup を使用して軽量な分離境界を作成し、重量級の仮想化を回避し、リソースオーバーヘッドを最小限に保つ。これは AI 推論パイプラインのコスト感度が高い環境では重要である。
-
設計の根拠:* 仮想マシンはインスタンスあたり 500 MB~2 GB のオーバーヘッドをもたらす。コンテナランタイムはより優れた密度を提供するが、通常は広範な機能で実行される。名前空間ベースのサンドボックスはプロセスレベルの分離を提供し、オーバーヘッドはほぼ無視できる。
-
コスト影響の例:* リスク評価のために 1,000 個の同時 AI エージェントを実行する金融サービス企業は、VM ごとのエージェント・オーバーヘッドを吸収できない。Matchlock の名前空間アプローチを使用すると、各エージェントは分離メタデータのために約 10 MB の追加メモリを必要とするのに対し、最小限のコンテナでは 512 MB である。これは 50 倍の効率向上であり、より密度の高いデプロイメントを可能にする。
-
主要な制約:*
-
機能フィルタリング: エージェントが必要とする Linux 機能を決定するには、反復的なテストが必要である。過度に制限的なポリシーは機能を破壊し、過度に許容的なポリシーはセキュリティを損なう。
-
ファイルシステムレイアウト: エージェントは特定のディレクトリ(入力データ、モデル、出力)にアクセスする必要がある。バインドマウントの設定ミスは、サイレント障害またはセキュリティバイパスを引き起こす。
-
ネットワーク分離: エージェントは API のためにアウトバウンド接続が必要な場合がある。ネットワーク拒否の一括適用は正当な使用例を破壊し、選択的な許可リストは継続的なメンテナンスを必要とする。
-
推奨アプローチ:* 本番デプロイメント前に、ステージング・サンドボックスでエージェントを実行し、
straceまたはseccompプロファイラーを使用してシステムコール・プロファイルをキャプチャする。このデータを使用して最小限の機能セットを構築する。エージェント・タイプごとに必要な機能を文書化する(例:「レポート生成」対「データ取り込み」)。
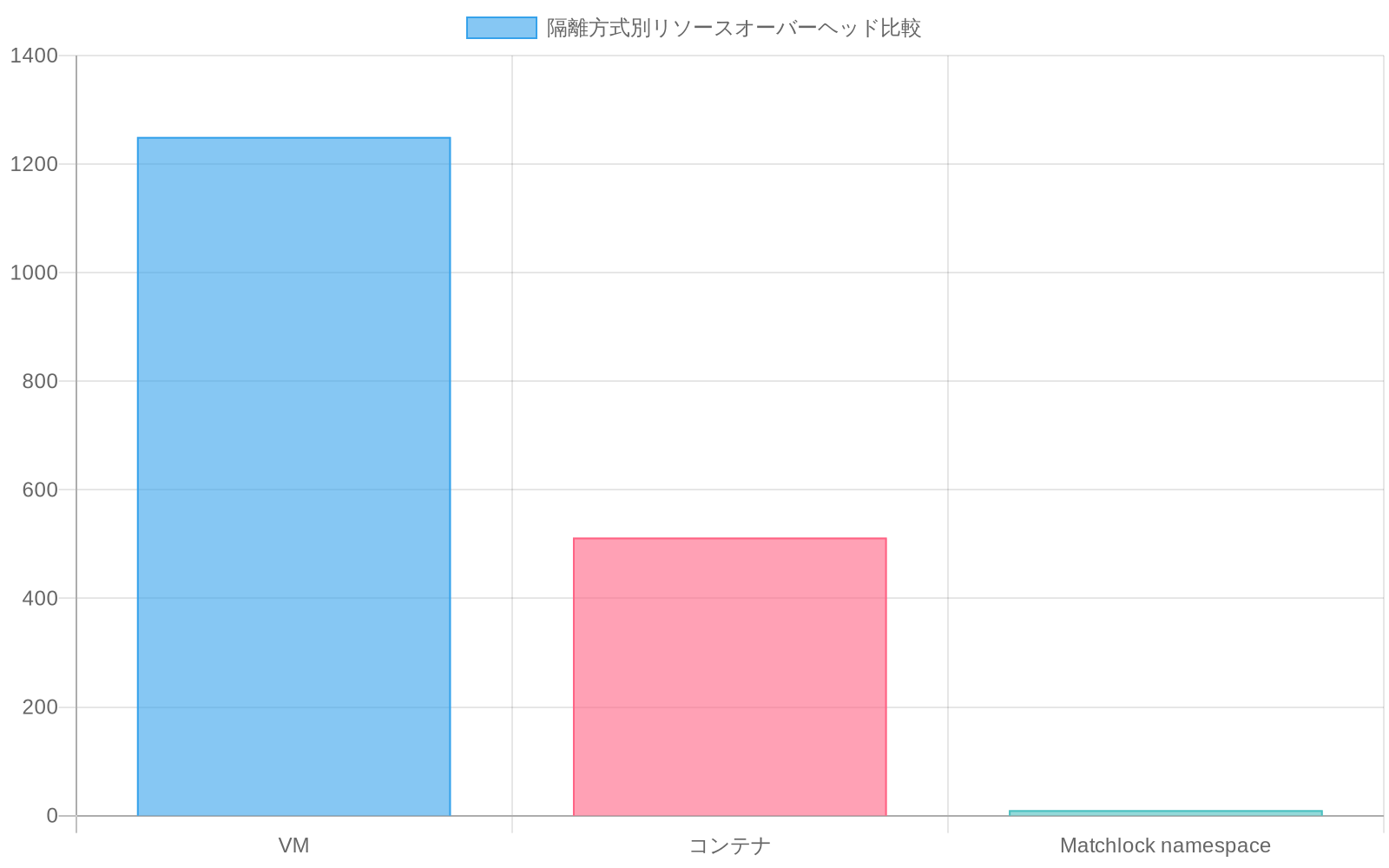
- 図3:隔silon方式別リソースオーバーヘッド比較(1エージェントあたりのメモリ使用量)*
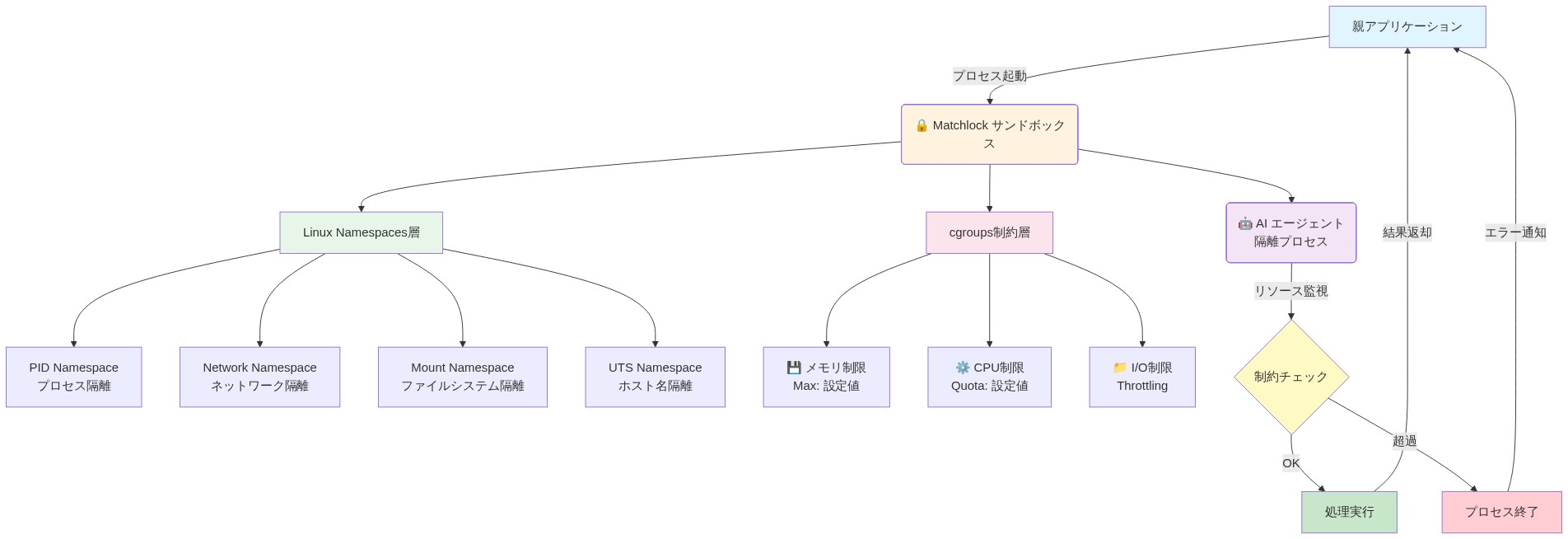
- 図2:Matchlock システムアーキテクチャ – Linux Namespace と cgroups による多層隔離構造*
リファレンス・アーキテクチャとガードレール・モデル
本番 Matchlock デプロイメントは、ネットワーク分離、ファイルシステム制約、リソース制限、機能削除の層状ガードレールを実装すべきである。
-
多層防御の根拠:* 単一の設定ミスがシステム全体を危険にさらさない。ネットワーク分離が失敗しても、ファイルシステム制約がデータ流出を防ぐ。ファイルシステム制約が失敗しても、cgroup 制限がリソース枯渇攻撃を防ぐ。
-
本番例:* e コマース・プラットフォームは、以下のガードレール・スタックで製品推奨を生成する AI エージェントを実行する。
- ネットワーク: エージェントは Unix ソケット経由でのみ推奨モデル・サービスに到達する。外部インターネット・アクセスはない。
- ファイルシステム: エージェントは
/data/products(読み取り専用)と/tmp/agent-work(読み取り・書き込み、100 MB 制限)をマウントする。/etc、/home、/varへのアクセスはない。 - リソース制限: 2 CPU コアと 512 MB RAM の cgroup 制約。暴走プロセスはホストを枯渇させるのではなく、クリーンに停止する。
- 機能: エージェントは
CAP_NET_ADMIN、CAP_SYS_ADMIN、CAP_DAC_OVERRIDEを削除し、ネットワーク再構成、ファイルシステム・マウント、権限バイパスを防ぐ。
- 実装要件:* ガードレールをインフラストラクチャ・アズ・コード(Terraform、Ansible、Kubernetes マニフェスト)で成文化する。一般的なエージェント・タイプのテンプレートを作成し、事前調整された制約を含める。ガードレールを緩和する前にセキュリティレビューを要求する。
デプロイメントと運用
サンドボックスは一貫した適用を通じてのみ効果的である。運用ドリフト(エージェントが徐々に権限を獲得し、トラブルシューティングのためにガードレールが無効化される)は時間とともにセキュリティを侵食する。
-
オーケストレーション例:* ヘルスケア AI チームは Kubernetes を使用してエージェントをオーケストレーションする。各エージェント・ポッドは Matchlock init コンテナを実行してサンドボックスを確立し、その後に非特権エージェント・コンテナが続く。ポッド・セキュリティ・ポリシーは非ルート、読み取り専用ルート・ファイルシステム、ネットワーク・ポリシーは承認されたサービスへのエグレスを制限する。サンドボックス違反(システムコール拒否、OOM キル)は自動的に SIEM に送信される。
-
運用パターン:*
-
段階的ロールアウト: 最初にエージェントの 5% に Matchlock をデプロイする。偽陰性(正当な操作がブロックされる)と偽陽性(攻撃が通過する)を監視する。25% に拡大し、その後 100% に拡大する。
-
監査ログ: すべてのサンドボックス違反(拒否されたシステムコール、超過したリソース制限、ネットワーク・ブロック)をログに記録する。このデータはガードレール調整を通知し、攻撃パターンを検出する。
-
自動応答: リソース制限に達したエージェントを自動スケーリングまたは自動再起動する。セキュリティ違反をトリガーするエージェントを隔離し、オンコール・チームに警告する。
-
統合要件:* Matchlock を CI/CD パイプラインに組み込む。本番前にサンドボックス環境でエージェントをテストする。ガードレール検証を自動化し、必要な制約を欠くデプロイメントを拒否する。サンドボックス・ログの週次レビューを確立し、新興パターンを検出する。
測定フレームワーク
効果的なサンドボックスには 3 つの主要指標が必要である。分離オーバーヘッド、セキュリティイベント率、運用摩擦である。
-
測定の根拠:* データなしでは、チームは適切に調整されたサンドボックス(最小限のオーバーヘッド、少数の違反)と不適切に構成されたサンドボックス(高いオーバーヘッドまたは頻繁な偽陽性)を区別できない。
-
ベースライン指標の例:*
-
オーバーヘッド: サンドボックス内のエージェントは 3% 遅く実行される。セキュリティ向上のために許容可能である。
-
違反率: エージェント実行の 0.1% がサンドボックス・ブロックをトリガーする。ほとんどは正当なエッジケースを表す(例:エージェントが
/proc/self/limitsを読む必要がある)。 -
修復時間: ガードレール更新の平均は 4 時間。目標:1 時間。
-
主要パフォーマンス指標:*
-
サンドボックス・セットアップ時間(目標:100 ms 未満)。
-
完全なガードレール下で実行されるエージェントの割合(目標:100%)。
-
10,000 エージェント実行あたりのセキュリティイベント(時間経過に伴うトレンドを追跡)。
-
サンドボックス内のエージェント・パフォーマンス・デルタ対無制限(目標:5% 未満)。
-
運用要件:* 違反スパイクのアラート付きモニタリング・ダッシュボードを確立する。月次レビューを実施し、トレンドをプロットし、高違反エージェントのガードレールを調整する。メトリクスをセキュリティ・チームとプロダクト・チームと共有し、ステークホルダー・アラインメントを維持する。
リスク評価と軽減
サンドボックスは運用の複雑さをもたらし、設定ミスまたはカーネル脆弱性が存在する場合、潜在的な脆弱性をもたらす。
-
主要なリスク:*
-
設定ミス: ガードレールが不正に設定され、エージェントが過度に特権化される。
-
カーネル脆弱性: パッチが適用されていないカーネルバグ経由のサンドボックス・エスケープ。
-
パフォーマンス低下: サンドボックス・オーバーヘッドがエージェントをリアルタイム使用例に不適切にする。
-
運用の複雑さ: エージェントごとのガードレール管理は規模で保守不可能になる。
-
インシデント例:* チームは Matchlock をデプロイするが、ファイルシステム・マウントを設定ミスする。エージェントは意図的に
/data/inputのみにアクセスするが、タイプミスにより/data/sensitiveの読み取りが可能になる。エージェントはデータを外部サービスに流出させる。インシデント後の軽減には以下が含まれる。
- CI/CD でのファイルシステム・マウント検証。
- 四半期ごとのサンドボックス・ペネトレーション・テスト。
- 本番デプロイメント前のガードレール・レビュー・チェックリスト。
-
軽減戦略:*
-
Linux カーネルをパッチ適用し続ける。セキュリティ勧告を購読する。
-
イミュータブル・インフラストラクチャを使用する。その場でパッチするのではなく、定期的にサンドボックスを再構築する。
-
ガードレール・テンプレートと検証を実装する。セキュリティレビューなしのカスタム構成を拒否する。
-
本番前にサンドボックス環境でエージェントをロード・テストする。パフォーマンス・デルタを測定する。
-
所有権要件:* サンドボックス・セキュリティを専任チーム(プラットフォーム・セキュリティまたは DevOps)に割り当てる。すべてのアクティブなガードレールの四半期レビューを実施する。一般的な設定ミス・シナリオのランブックを維持する。
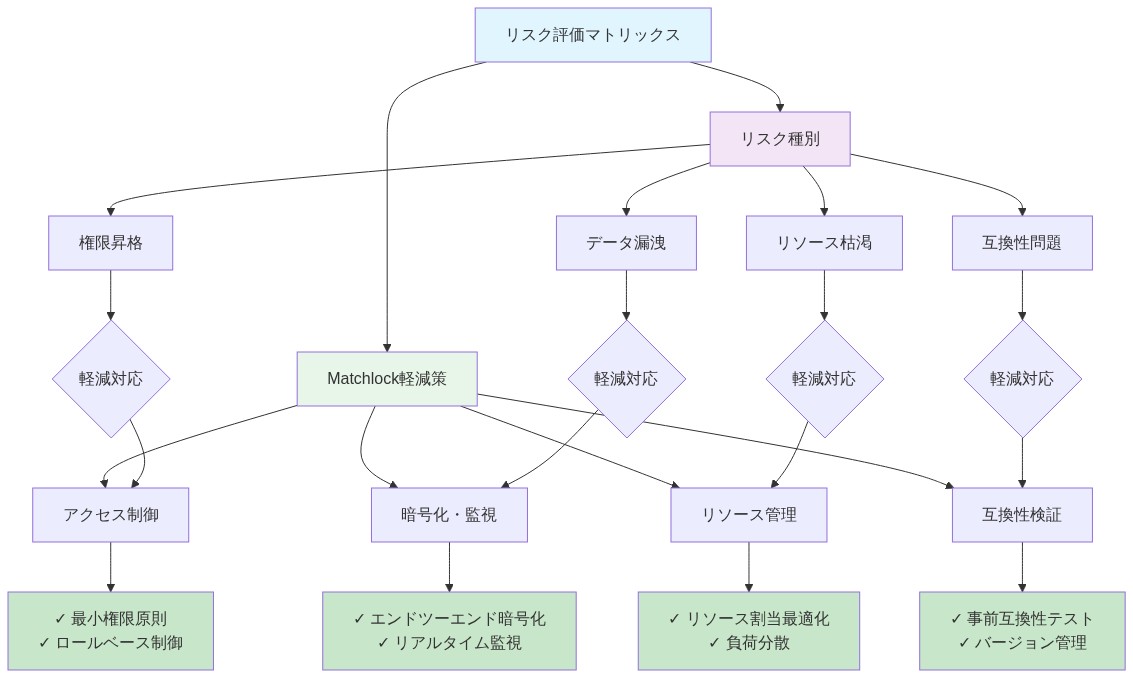
- 図8:リスク評価と軽減戦略マトリックス*
実装ロードマップ
Matchlock の採用は、密度とコストが重要なクラウドネイティブ・デプロイメントに適した段階的で測定駆動型の戦略に従うべきである。
- 12 週間の移行計画:*
| フェーズ | タイムライン | 成果物 |
|---|---|---|
| 評価 | 1~2 週間 | 現在のデプロイメントを監査。動的コードを実行するか機密データにアクセスする高リスク・ワークロードを特定する。 |
| ステージング | 3~4 週間 | Matchlock をステージングにデプロイ。2~3 個の代表的なエージェントのシステムコール・プロファイルとリソース使用量をキャプチャする。 |
| テンプレート化 | 5~6 週間 | プロファイリング・データからガードレール・テンプレートを構築。モニタリングとアラートを実装する。 |
| パイロット | 7~8 週間 | 本番エージェントの 5%(低リスク・ワークロード)にデプロイ。違反とパフォーマンスを監視する。 |
| 拡大 | 9~12 週間 | エージェントの 50% にスケーリング。ガードレールを調整。チームにサンドボックス運用を教育する。 |
| メンテナンス | 4 ヶ月以降 | 100% カバレッジを達成。四半期レビュー・ケイデンスとパッチ管理を確立する。 |
-
成功基準:*
-
すべてのエージェントが定義されたガードレール下で実行される。
-
ワークロードの 95% でサンドボックス・オーバーヘッド 5% 未満。
-
サンドボックス違反の検出と修復の平均時間 2 時間未満。
-
計画外のサンドボックス・エスケープまたはデータ流出インシデントはゼロ。
-
重要な要点:* サンドボックスベースの分離は、自律的な AI ワークロードに対する多層防御戦略における必要な層であり、スタンドアロン・ソリューションではない。小さく始め、厳密に測定し、意図的にスケーリングする。今、運用規律への投資を行うことで、後の高額なセキュリティ・インシデントを防ぐ。
システムアーキテクチャとパフォーマンス特性
Matchlock は Linux 名前空間(PID、ネットワーク、ファイルシステム、IPC)と cgroup(リソース制限)を使用してプロセス分離を実装し、完全な仮想化またはコンテナランタイムのオーバーヘッドを回避する。
-
技術的根拠:* 仮想マシン・ハイパーバイザーは強力な分離を提供するが、インスタンスあたり 500 MB~2 GB のメモリ・オーバーヘッドを課し、短命なワークロードに対して顕著なレイテンシーをもたらす。コンテナランタイム(Docker、containerd)はオーバーヘッドを削減するが、通常は広範な Linux 機能を付与するか、ルート相当の権限を必要とする。名前空間ベースのサンドボックスはプロセスレベルでカーネル強制の分離を提供し、メモリ・オーバーヘッドはほぼ無視でき、レイテンシー影響は 1 ミリ秒未満である。
-
定量的シナリオ:* 金融サービス組織は、リアルタイム・リスク評価を実行する 1,000 個の同時 AI エージェントを運用する。VM ごとのエージェント分離には 500 GB~2 TB の追加メモリが必要である。コンテナごとのエージェントには 50~100 GB が必要である。名前空間ベースの分離は、エージェントあたり約 10 MB の名前空間メタデータとセキュリティ・コンテキストを追加し、合計 10 GB である。これは 50~200 倍の効率向上である。この密度の利点はインフラストラクチャ・コストを直接削減し、レイテンシー要件への準拠を可能にする。
-
特定された運用制約:*
-
機能決定: Linux 機能(
CAP_NET_ADMIN、CAP_SYS_ADMINなど)は、各エージェント・タイプについて個別に評価する必要がある。過度に制限的なポリシーは正当な操作をブロックし、過度に許容的なポリシーは分離保証を損なう。最小限の機能セットを決定するには反復的なプロファイリングが必要である。 -
ファイルシステム名前空間構成: エージェントは特定のディレクトリ(モデル重み、入力データ、出力ステージング)へのアクセスを必要とする。バインドマウント設定ミスはサイレント障害(エージェントが必要なファイルを読めない)またはセキュリティ・バイパス(エージェントが意図しないディレクトリにアクセスする)を引き起こす可能性がある。規模での検証は自明ではない。
-
ネットワーク分離のトレードオフ: 多くのエージェントはアウトバウンド接続を必要とする(API 呼び出し、モデル・サービング・エンドポイント)。ネットワーク拒否の一括適用は機能を破壊し、iptables ルールまたはネットワーク・ポリシー経由の選択的な許可リストは、エージェント依存関係が進化するにつれて継続的なメンテナンスを必要とする。
-
運用推奨:* 本番デプロイメント前に、システムコール・トレーシング・ツール(
strace、seccompプロファイラー、または eBPF ベースの監査)を使用して各エージェント・クラスをプロファイルする。代表的なワークロード下で完全なシステムコール・シーケンスをキャプチャする。この経験的データを使用して、汎用テンプレートに依存するのではなく、最小限の機能セットとファイルシステム許可リストを構築する。付与された各機能の根拠を文書化する。
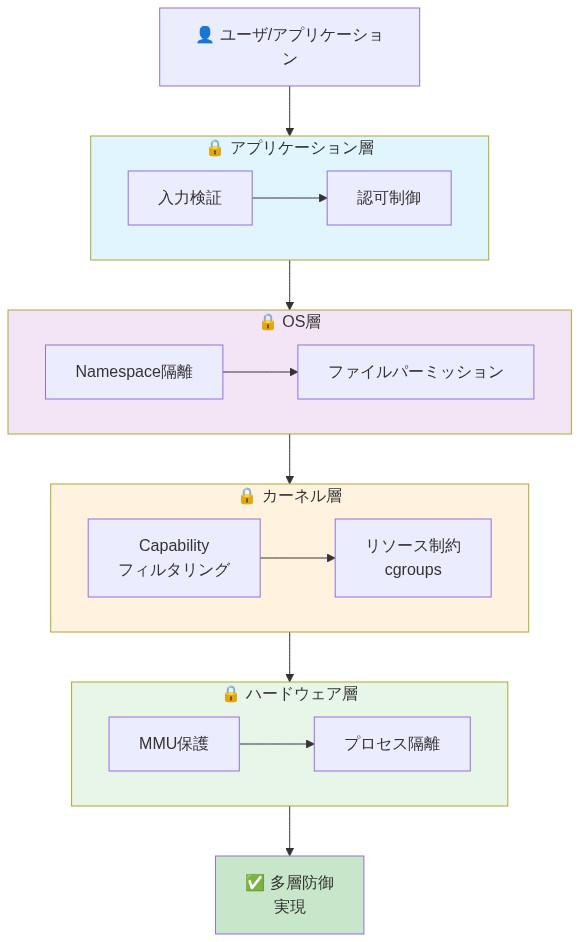
リファレンス・アーキテクチャと多層防御モデル
本番デプロイメントは、層状の分離制御を実装すべきである。ネットワーク・セグメンテーション、ファイルシステム制約、リソース・クォータ、機能削除である。各層は異なる脅威ベクトルを独立して軽減する。
-
多層防御の根拠:* 単一の設定ミスまたは見落としが分離境界全体を危険にさらさない。ネットワーク・ポリシーがアウトバウンド・トラフィックをブロックできなくても、ファイルシステム制約がデータ流出を防ぐ。ファイルシステム制約が設定ミスされても、cgroup リソース制限が DoS 攻撃を防ぐ。機能削除が不完全でも、名前空間分離がプロセス間攻撃を防ぐ。
-
アーキテクチャ・シナリオ:* e コマース・プラットフォームは、パーソナライズされた製品推奨のための AI エージェントをデプロイする。層状ガードレール実装は以下の通りである。
-
ネットワーク分離: エージェントは、ネットワーク名前空間内にバインドされた Unix ドメイン・ソケット経由でのみ内部推奨サービスと通信できる。外部インターネット接続は利用不可。DNS 解決は無効化される。アウトバウンド TCP/UDP ポートはネットワーク・ポリシーによってブロックされる。
-
ファイルシステム分離: エージェントは
/data/products(読み取り専用、製品カタログを含む)と/tmp/agent-work(読み取り・書き込み、100 MB クォータ)をマウントする。その他すべてのファイルシステム・パス(/etc、/home、/var、および/procを除く許可リスト項目を含む)にはアクセスできない。ルート・ファイルシステムは読み取り専用でマウントされる。 -
リソース・クォータ: cgroup v2 はエージェントを 2 CPU コアと 512 MB レジデント・メモリに制限する。エージェントが無限ループまたはメモリ・リークに入った場合、カーネルはホストまたは兄弟ワークロードに影響を与えるのではなく、プロセスをクリーンに終了する。
-
機能制限: エージェントは
CAP_NET_ADMIN(ネットワーク設定を変更できない)、CAP_SYS_ADMIN(ファイルシステムをマウントするか特権操作にアクセスできない)、CAP_DAC_OVERRIDE(Unix 権限チェックをバイパスできない)を削除する。エージェントはCAP_NET_BIND_SERVICE(低番号ポートにバインドする場合)と特定の機能に必要な機能のみを保持する。
- デプロイメント含意:* ガードレールをインフラストラクチャ・アズ・コード(Terraform、Ansible、Kubernetes マニフェスト)で成文化する。一般的なエージェント・アーキタイプ(推論のみ、データ処理、外部 API 統合)のための再利用可能なテンプレートを作成し、事前検証された制約を含める。ガードレール緩和前にセキュリティレビューと承認を要求する。すべてのサンドボックス構成をバージョン管理し、監査証跡とロールバックを可能にする。
実装と運用パターン
サンドボックスの有効性は、エージェントのライフサイクル全体にわたる一貫した強制に依存する。運用ドリフト—段階的な権限拡張、トラブルシューティングのためのガードレール無効化、一貫性を欠いたデプロイメント慣行—は時間とともにセキュリティを蝕む。
-
一貫性の根拠:* サンドボックスはセキュリティ制御であり、機能ではない。ファイアウォールルールや暗号化ポリシーと同様に、均一に適用され継続的に監視されなければならない。その場限りの例外と手動による回避策は、セキュリティギャップを生み出す。
-
オーケストレーションシナリオ:* ある医療機関がKubernetesを使用して臨床意思決定支援用のAIエージェントを管理している。デプロイメントパターンは以下の通りだ。
-
各エージェントポッドには、サンドボックスを確立するinitコンテナが含まれる(名前空間設定、cgroup設定、ケーパビリティ削除)。
-
エージェントコンテナは非特権で実行される(非rootユーザー、読み取り専用ルートファイルシステム)。
-
Pod Security Policiesはクラスタ全体でno-root、読み取り専用ルートファイルシステム、制限されたケーパビリティを強制する。
-
NetworkPoliciesは、承認されたサービス(臨床データウェアハウス、モデル提供エンドポイント)への出力を制限する。
-
サンドボックス違反(拒否されたシステムコール、OOMキル、ネットワークブロック)は標準出力にログされ、クラスタロギングシステム(例:Fluent Bit、Datadog)によって自動的に収集される。
-
運用パターン:*
-
段階的なロールアウト: Matchlockを本番環境のエージェントの5%にデプロイする。偽陰性(正当な操作がブロックされる)と偽陽性(サンドボックスを回避する攻撃)を監視する。観測されたセキュリティとパフォーマンスメトリクスに基づいて25%、その後100%に拡大する。
-
違反ログと分析: すべてのサンドボックス強制イベント—拒否されたシステムコール(errnoコード付き)、超過したリソース制限、ネットワークポリシーブロック—をログに記録する。ログをエージェントタイプと違反カテゴリ別に集約する。このデータを使用してガードレールを改善し、攻撃パターンを検出する。
-
インシデント対応の自動化: 一般的なシナリオのランブックを実装する:(1)エージェントがCPU制限を超過→自動再起動または自動スケーリング;(2)エージェントがケーパビリティ拒否をトリガー→ポッドを隔離し、オンコール担当者に通知;(3)エージェントがポリシー外のネットワークアクセスを試行→ログして遮断し、セキュリティチームに通知。
-
デプロイメント上の含意:* MatchlockをCI/CDパイプラインに統合する。エージェントが本番デプロイメント前にサンドボックス検証テストに合格することを要求する。ガードレール検証を自動化する:必要な制約を欠いているか、過度に許容的な設定を持つデプロイメントを拒否する。サンドボックスログをレビューし、運用データに基づいてガードレールを更新するための週次ケーデンスを確立する。
測定とパフォーマンス検証
効果的なサンドボックスには、適切に調整された設定と不十分に設定された設定を区別するための定量的メトリクスが必要だ。
-
測定の根拠:* 経験的データなしに、チームはサンドボックスのオーバーヘッドが許容可能かどうか、違反率が設定ミスを示すのか攻撃を示すのか、運用上の摩擦がセキュリティ投資を正当化するかどうかを判断できない。
-
測定シナリオ:* データプラットフォームチームが500個の本番エージェント全体のサンドボックスパフォーマンスを測定する。
-
実行レイテンシオーバーヘッド: サンドボックス内のエージェントは、制限されていないエージェントより3%遅くタスクを完了する(中央値:1.2秒対1.16秒)。このオーバーヘッドはセキュリティ上の利点を考えると許容可能だ。
-
違反率: エージェント実行の0.08%がサンドボックス強制イベントをトリガーする。事後分析により、ほとんどの違反は正当なエッジケース(例:エージェントがリソース認識のために
/proc/self/limitsを読み取ろうとする)であることが明らかになる。これらはケーパビリティセットまたはファイルシステムアロウリストを拡張することで対処される。 -
平均修復時間: 違反パターンが出現した場合、チームは平均4時間でガードレールを更新する。目標:1時間。
-
確立すべき主要メトリクス:*
-
サンドボックス初期化時間(目標:エージェントあたり100ms未満)。
-
完全で検証されたガードレール下で実行されているエージェントの割合(目標:100%)。
-
エージェント実行10,000回あたりのセキュリティイベント率(時系列で追跡;ガードレールが安定化するにつれて低下率を期待)。
-
サンドボックス内と制限されていない環境でのエージェントパフォーマンスデルタ(目標:ワークロードの95%で5%未満)。
-
サンドボックス違反を検出するまでの平均時間(目標:ログ集約経由で5分未満)。
-
違反を修復するまでの平均時間(目標:2時間未満)。
-
運用上の含意:* これらのメトリクスを表示するモニタリングダッシュボードを確立する。違反率スパイクのアラートを設定する(攻撃または設定ミスを示唆)。月次レビューを実施する:トレンドをプロット、高い違反率を持つエージェントを特定、ガードレールを調整、セキュリティおよび製品ステークホルダーとメトリクスを共有して組織的な支持を維持する。
リスク評価と軽減戦略
サンドボックスベースの分離は運用上の複雑性と、明示的に管理する必要がある潜在的な障害モードをもたらす。
-
リスク根拠:* 過度に制限的なサンドボックスは正当な機能を破壊し、チームがそれらを無効化するよう促す。過度に許容的なサンドボックスは虚偽のセキュリティを提供する。さらに、カーネル脆弱性はサンドボックスエスケープを可能にする可能性があるが、そのような脆弱性は稀であり、通常は特定の条件を必要とする。
-
特定されたリスク:*
-
設定ミス: ガードレールが誤って設定され、エージェントが過度に特権化されるか正当な操作がブロックされる。例:不正なバインドマウントパス、過度に広いケーパビリティ付与、必要なサービスをブロックするネットワークポリシー。
-
カーネル脆弱性: パッチが適用されていないカーネルバグ経由のサンドボックスエスケープ(例:CVE-2021-22555、CVE-2022-0847)。稀だが、そのような脆弱性は名前空間分離を完全に回避できる。
-
パフォーマンス低下: サンドボックスオーバーヘッド(システムコール傍受、名前空間切り替え)により、エージェントがリアルタイムユースケース(例:100ms未満のレイテンシ要件)に対して遅すぎるものになる可能性がある。
-
運用上の負担: 自動化とテンプレート化なしに、スケール時にエージェントごとのガードレール管理は保守不可能になる。
-
インシデントシナリオ:* チームはMatchlockをデプロイするが、ファイルシステムバインドマウントを設定ミスする。エージェントは
/data/inputのみにアクセスすることを意図しているが、マウント指定のタイプミスにより/data/sensitiveへの読み取りアクセスが許可される。エージェントは機密データを外部サービスに流出させる。インシデント後、チームは以下を実装する:(1)CI/CDパイプラインでのファイルシステムマウント検証、(2)四半期ごとのサンドボックスペネトレーションテスト、(3)本番デプロイメント前のガードレールレビューの必須セキュリティチェックリスト。 -
軽減戦略:*
-
カーネルパッチ適用: Linuxカーネルのパッチ管理プロセスを維持する。セキュリティアドバイザリ(例:kernel.orgセキュリティリスト、ベンダー固有の通知)を購読する。重大なパッチは30日以内に適用;高深刻度のパッチは60日以内に適用する。
-
イミュータブルインフラストラクチャ: 所定の場所にパッチを適用するのではなく、定期的に(週次または月次)サンドボックス環境を再構築する。これにより設定ドリフトの可能性が低下し、一貫したベースラインが確保される。
-
ガードレールテンプレート化と検証: 一般的なエージェントタイプ用の再利用可能なテンプレートを開発する。自動検証を実装する:明示的なセキュリティレビューなしにカスタム設定を拒否する。ポリシーアズコードツール(例:OPA/Rego、Kyverno)を使用してガードレール標準を強制する。
-
本番前テスト: 本番デプロイメント前に、現実的な負荷下でサンドボックス環境でエージェントをテストする。パフォーマンスデルタを測定し、違反を特定する。パフォーマンス回帰閾値を確立する(例:オーバーヘッドが10%を超える場合は拒否)。
-
運用上の含意:* サンドボックスセキュリティの所有権を専任チーム(プラットフォームセキュリティ、DevOps、またはSRE)に割り当てる。すべてのアクティブなガードレールの四半期ごとのレビューを実施する。一般的な設定ミスシナリオと修復手順を文書化したランブックを維持する。サンドボックス違反に特化したセキュリティインシデント対応プロセスを確立する。
移行戦略と成功基準
Matchlock採用は、段階的で測定駆動型のアプローチに従うべきであり、混乱を最小化し、セキュリティ有効性を最大化する。
-
移行ロードマップ:*
-
第1~2週(評価): 現在のエージェントデプロイメントを監査する。リスクレベル別にエージェントを分類する:(1)高リスク(動的コード実行、機密データアクセス、外部API呼び出し)、(2)中リスク(静的コード実行、非機密データアクセス)、(3)低リスク(読み取り専用操作、外部依存なし)。優先的なサンドボックス化のための高リスクエージェントを特定する。
-
第3~4週(プロファイリング): Matchlockをステージング環境にデプロイする。各リスクカテゴリから2~3の代表的なエージェントを現実的なワークロード下で実行する。
strace、seccompプロファイラー、またはeBPFツールを使用してシステムコールプロファイルをキャプチャする。リソース使用量(CPU、メモリ、I/O)を測定する。必要なケーパビリティとファイルシステムアクセスパターンを文書化する。 -
第5~6週(テンプレート開発): プロファイリングデータに基づいてガードレールテンプレートを構築する。一般的なエージェントアーキタイプ(推論、データ処理、API統合)用に個別のテンプレートを作成する。サンドボックス違反のモニタリングとアラートを実装する。ガードレール根拠を文書化する。
-
第7~8週(パイロット): Matchlockを本番エージェントの5%(低リスクカテゴリ)にデプロイする。違反、パフォーマンス影響、運用上の問題を監視する。オンコールチームからのフィードバックを収集する。
-
第9~12週(拡大): エージェントの50%(低リスクおよび中リスクカテゴリ)に拡大する。運用データに基づいてガードレールを改善する。エンジニアリングチームにサンドボックス操作、トラブルシューティング、ガードレール更新について訓練する。
-
4ヶ月以降(完全デプロイメント): すべてのエージェントカテゴリ全体で100%カバレッジを達成する。メンテナンスケーデンスを確立する:四半期ごとのガードレールレビュー、月次違反分析、カーネルパッチ管理。
-
成功基準:*
-
すべてのエージェントが定義された文書化されたガードレール下で実行される(100%カバレッジ)。
-
ワークロードの95%でサンドボックスオーバーヘッド5%未満(実行レイテンシで測定)。
-
サンドボックス違反を検出するまでの平均時間5分未満(ログ集約経由)。
-
違反を修復するまでの平均時間2時間未満(ガードレール更新経由)。
-
エージェントワークロードに起因する計画外のサンドボックスエスケープまたはデータ流出インシデントがゼロ。
-
3ヶ月の運用後、違反率がエージェント実行の0.1%未満に安定化する。
-
重要な要点:* サンドボックスベースの分離は、自律型AIワークロードの多層防御セキュリティ戦略の必要だが不十分な構成要素だ。サンドボックスはプロセスレベルの脅威を軽減するが、プロンプトインジェクション、モデル中毒、サプライチェーン攻撃には対処しない。高リスクエージェントから始め、厳密に測定し、意図的にスケーリングする。今投資した運用規律は、後の高額なセキュリティインシデントと規制違反を防ぐ。
システム構造とボトルネック
MatchlockはLinux名前空間とcgroupsを実装して、プロセスレベルの分離境界を作成する。このアプローチは重量級の仮想化を回避し、リソースオーバーヘッドを最小限に保つ—コスト意識の高いAI推論パイプラインにとって重要な要件だ。
-
コスト便益分析:* 仮想マシンは強力な分離を提供するが、インスタンスあたり500MB~2GBのオーバーヘッドをもたらす。Dockerのようなコンテナランタイムはより良い密度を提供するが、通常はrootとして、または広いLinuxケーパビリティで実行される。名前空間ベースのサンドボックスは中間を取る:プロセスレベルの分離、無視できるメモリフットプリント、サブミリ秒のスタートアップオーバーヘッド。
-
具体的なROI例:* ある金融サービス企業がリアルタイムリスク評価用に1,000個の同時AIエージェントを実行している。VM単位のエージェント分離を使用すると、500GB以上の追加メモリが必要になる。Matchlockの名前空間アプローチを使用すると、各エージェントは分離メタデータ用に約10MBの追加メモリを占有する。この50倍の効率向上により、既存インフラストラクチャでより密度の高いデプロイメントが可能になり、年間50,000ドル以上の追加ハードウェアコストを回避できる。
-
特定されたボトルネックと制約:*
-
ケーパビリティフィルタリングの複雑性: エージェントが本当に必要とするLinuxケーパビリティを決定するには、反復的なテストとシステムコールプロファイリングが必要だ。過度に制限的なポリシーは正当な機能を破壊;過度に許容的なものはセキュリティを損なう。設定ミスは一般的であり、本番まで検出が難しい。
-
ファイルシステムマウント設定: エージェントは特定のディレクトリ(入力データ、モデル、出力ログ)にアクセスする必要がある。設定ミスされたバインドマウントは、サイレント障害、競合状態、またはセキュリティバイパスを引き起こす。マウントパスの単一のタイプミスは機密ディレクトリを公開できる。
-
ネットワーク分離のトレードオフ: エージェントは外部API、モデル提供エンドポイント、またはロギングサービスのための出力接続を必要とする場合がある。ネットワーク全体の拒否は正当なユースケースを破壊;選択的なアロウリストは、インフラストラクチャが進化するにつれて継続的なメンテナンスを必要とする。
-
リソース制限チューニング: CPU とメモリ制限を低すぎるに設定するとエージェントタイムアウトと推論失敗を引き起こす。高すぎるに設定すると分離利点を否定する。最適値はエージェントタイプとモデルサイズによって異なる。
-
実行可能な軽減ワークフロー:*
- エージェントをステージングサンドボックス環境にデプロイする。
strace -e trace=file,network,processまたはseccompプロファイラーを使用してシステムコールトレースをキャプチャしながら、代表的なワークロードを実行する。- 必要なシステムコール、ファイルパス、ネットワーク宛先の最小セットを抽出する。
- 推測またはジェネリックテンプレートのコピーではなく、このデータからガードレールポリシーを構築する。
- エージェントタイプごとに必要なケーパビリティ(例:「レポート生成」対「データ取り込み」)を共有ランブックに文書化する。
- 本番デプロイメント前に、負荷下でステージングでポリシーを検証する。
参照アーキテクチャとガードレール
本番Matchlockデプロイメントは、多層防御モデルを実装すべきだ:ネットワーク分離、ファイルシステム制約、リソース制限、ケーパビリティ削除。各層は独立して攻撃クラスを防ぐ。
-
層化の根拠:* 単一の設定ミスはシステム全体を危険にさらさない。ネットワーク分離が失敗した場合、ファイルシステム制約はデータ流出を防ぐ。ファイルシステム制約が失敗した場合、cgroup制限はリソース枯渇攻撃を防ぐ。この冗長性は重要なワークロードに不可欠だ。
-
参照アーキテクチャ例:* eコマースプラットフォームは、パーソナライズされた製品推奨を生成するAIエージェントをデプロイする。ガードレールスタック:
-
層1 – ネットワーク分離:*
-
エージェントはUnixソケット経由でその名前空間内の推奨モデルサービスにのみ到達できる。
-
外部インターネットアクセスなし;DNS解決は無効化。
-
出力TCP/UDPはネットワーク名前空間レベルでブロック。
-
根拠:データ流出とコマンドアンドコントロール通信を防ぐ。
-
層2 – ファイルシステム制約:*
-
エージェントは
/data/productsを読み取り専用としてマウント(製品カタログ)。 -
エージェントは
/tmp/agent-workを100MBクォータで読み取り書き込みとしてマウント(作業ディレクトリ)。 -
/etc、/home、/var、/rootへのアクセスなし。 -
ルートファイルシステムは読み取り専用でマウント。
-
根拠:不正なデータアクセスとシステムファイル変更を防ぐ。
-
層3 – リソース制限(cgroups):*
-
CPU:最大2コア;エージェントはホストCPUの50%以上を消費できない。
-
メモリ:512MB制限;超過した場合、OOMキラーがエージェントをクリーンに終了。
-
ディスクI/O:50MB/s書き込み制限でログフラッディングまたはディスク枯渇を防ぐ。
-
根拠:リソース枯渇攻撃とうるさい隣人問題を防ぐ。
-
層4 – ケーパビリティ削除:*
-
エージェントは
CAP_NET_ADMINを削除(ネットワークインターフェース設定不可)。 -
エージェントは
CAP_SYS_ADMINを削除(ファイルシステムマウントまたは名前空間変更不可)。 -
エージェントは
CAP_DAC_OVERRIDEを削除(権限チェック回避不可)。 -
エージェントはポートをリッスンする必要がある場合のみ
CAP_NET_BIND_SERVICEを保持(エージェントでは稀)。 -
根拠:権限昇格と横方向移動を防ぐ。
-
インフラストラクチャアズコード実装:*
# Kubernetes Pod Security Policy例
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: ai-agent-sandbox
spec:
privileged: false
allowPrivilegeEscalation: false
requiredDropCapabilities:
- NET_ADMIN
- SYS_ADMIN
- DAC_OVERRIDE
volumes:
- 'configMap'
- 'emptyDir'
- 'projected'
- 'secret'
- 'downwardAPI'
- 'persistentVolumeClaim'
hostNetwork: false
hostIPC: false
hostPID: false
runAsUser:
rule: 'MustRunAsNonRoot'
seLinux:
rule: 'MustRunAs'
fsGroup:
rule: 'RunAsAny'
readOnlyRootFilesystem: true- 実行可能な含意:* インフラストラクチャアズコード(Terraform、Ansible、またはKubernetesマニフェスト)でガードレールをコード化する。一般的なエージェントタイプ(推論、データ処理、外部API呼び出し)用に事前調整された制約を持つ再利用可能なテンプレートを作成する。ガードレールを緩和する前にセキュリティレビューと承認を要求する。すべてのポリシー変更をバージョン管理し、監査ログを維持する。
測定と次のアクション
効果的なサンドボックス化には厳密な測定が必要である。メトリクスなしに、チームは適切に調整されたサンドボックス(最小限のオーバーヘッド、少数の違反)と不適切に設定されたサンドボックス(高いオーバーヘッドまたは頻繁な偽陽性)を区別できない。
- 具体的な測定例:* データプラットフォームチームが4週間にわたってサンドボックスパフォーマンスを測定:
| メトリクス | 第1週 | 第4週 | 目標 |
|---|---|---|---|
| サンドボックスセットアップ時間 | 250 ms | 85 ms | <100 ms |
| 完全なガードレール下のエージェント | 60% | 98% | 100% |
| 10,000実行あたりのセキュリティイベント | 45 | 8 | <10 |
| エージェントパフォーマンス差分 | +8% | +2.5% | <5% |
| 違反修復までの平均時間 | 6時間 | 1.5時間 | <1時間 |
-
確立すべき主要メトリクス:*
-
サンドボックスオーバーヘッド: サンドボックス内でのエージェント実行時間と無制限実行を比較。目標:95%のワークロードで5%未満。オーバーヘッドが10%を超える場合、cgroupの競合またはシステムコールフィルタリングの非効率性を調査。
-
カバレッジ: 定義されたガードレール下で実行されているエージェントの割合。目標:100%。例外には文書化された承認と四半期ごとのレビューが必要。
-
違反率: セキュリティイベント(拒否されたシステムコール、超過した制限、ネットワークブロック)の10,000エージェント実行あたりの数。時系列でトレンド化。スパイクは設定ミスまたは攻撃を示唆。
-
偽陽性率: 過度に制限的なポリシーによってブロックされた正当な操作である違反の割合。目標:1%未満。高い率はガードレールの調整が必要であることを示唆。
-
検出までの平均時間(MTTD): 違反からアラートまでの時間。目標:5分未満。リアルタイムログ送信とアラート生成が必要。
-
修復までの平均時間(MTTR): アラートからガードレール調整またはエージェント再起動までの時間。目標:1時間未満。ランブック自動化が必要。
-
実行可能な測定ワークフロー:*
- ベースラインの確立: Matchlockを10%のエージェントに展開。2週間メトリクスを収集。
- 目標の設定: ベースラインに基づいて、各メトリクスの許容閾値を定義。
- 監視の実装: リアルタイムメトリクスを備えたダッシュボードを構築。閾値違反に対してアラートを設定。
- 月次レビュー: トレンドをプロット、違反率が高いエージェントを特定、ガードレールを調整。
- ステークホルダー通信: セキュリティ、プロダクト、プラットフォームチームと月次でメトリクスを共有。セキュリティ改善と運用効率向上を強調。
リスクと軽減戦略
サンドボックス化は運用上の複雑性と潜在的な盲点をもたらす。管理されなければ、これらのリスクはセキュリティ上の利益を損なう可能性がある。
-
主要なリスクと軽減策:*
-
リスク1 – 設定ミスとポリシー漂流:*
-
シナリオ: ガードレールが不正に設定され、エージェントが過度に特権化されたままになる。チームはトラブルシューティングのために制約を無効化し、再度有効化することを忘れる。
-
影響: 虚偽のセキュリティ感覚。エージェントが不要な権限を保持。横展開が可能になる。
-
軽減策:
- CI/CDでガードレールテンプレートと検証を実装。セキュリティレビューなしのカスタム設定を拒否。
- 不変インフラストラクチャを強制:その場でパッチを適用するのではなく、定期的にサンドボックスを再構築。
- すべてのアクティブなガードレールの四半期監査を実施。ベースラインポリシーと比較。
- 本番展開前のガードレールレビューのためのチェックリストを維持。
-
リスク2 – カーネル脆弱性とサンドボックスエスケープ:*
-
シナリオ: パッチが適用されていないカーネルバグにより、エージェントがサンドボックスをエスケープしてホストにアクセス可能。
-
影響: 隔離の完全な侵害。エージェントがホストレベルの権限を獲得。
-
軽減策:
- Linuxカーネルセキュリティアドバイザリ(例:kernel.org、CVEフィード)を購読。
- パッチ管理スケジュールを維持:重大パッチは7日以内、重要パッチは30日以内に適用。
- 不変インフラストラクチャを使用:月次サイクルでパッチが適用されたカーネルですべてのサンドボックスを再構築。
- 隔離を検証するために四半期ごとにサンドボックスペネトレーションテストを実施。
-
リスク3 – パフォーマンス低下:*
-
シナリオ: サンドボックスオーバーヘッドがエージェントをリアルタイムユースケースに対して遅すぎるものにする。チームはレイテンシSLAを満たすためにサンドボックス化を無効化。
-
影響: エージェントが無制限で実行。セキュリティ上の利益が失われる。
-
軽減策:
- 本番環境前にステージングで負荷下のエージェントをプロファイル。パフォーマンス差分を測定。
- ガードレールを最適化:広いケーパビリティドロップではなく、可能な限りseccompフィルタを使用。
- より効率的なリソース会計のためにcgroup v2を使用。
- オーバーヘッドが5%を超える場合、根本原因を調査:システムコールフィルタリング、ファイルシステムマウントオーバーヘッド、またはcgroup競合。
-
リスク4 – 大規模での運用負担:*
-
シナリオ: エージェント数が増加するにつれて、エージェント単位のガードレール管理が保守不可能になる。チームは過度に寛容なデフォルトポリシーに頼る。
-
影響: ガードレールが無効になる。セキュリティが低下。
-
軽減策:
- 一般的なエージェントタイプ(推論、データ処理、外部API呼び出し)のガードレールテンプレートを構築。カスタムポリシーを作成するのではなくテンプレートを再利用。
- システムコールプロファイルからガードレール生成を自動化。
straceまたはseccompプロファイラーなどのツールを使用して最小限のケーパビリティセットを抽出。 - ポリシーアズコードを実装:ガードレールをバージョン管理、コードレビューを有効化、変更を追跡。
- 専任チーム(プラットフォームセキュリティまたはDevOps)に所有権を割り当て。ガードレール更新とインシデント対応のSLAを確立。
-
具体的なインシデント例と対応:*
チームがMatchlockを展開したが、ファイルシステムマウントを誤設定した。エージェントは/data/inputのみにアクセスすることになっていたが、バインドマウントパスのタイプミスにより/data/sensitiveを読み取ることが可能になった。エージェントは顧客データを外部サービスに流出させた。インシデント後の対応:
- 即座: 影響を受けたエージェントを隔離。外部APIの認証情報を取り消し。セキュリティとコンプライアンスチームに通知。
- 短期(24時間): CI/CDにファイルシステムマウント検証を実装。デプロイメントを拒否。
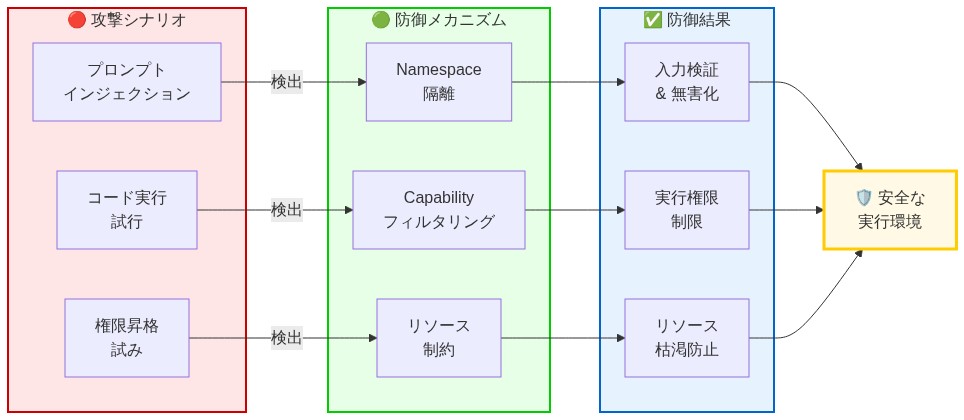
- 図5:Matchlockの多層防御 – 攻撃シナリオと防御メカニズム*
- 図11:Matchlock 多層防御アーキテクチャ – 4層のセキュリティコントロール(Defense-in-depth model)*