
なぜLLMには後付けではなく、LLM向けに設計された言語が必要なのか
理論的基盤:LLM-言語アライメント問題
大規模言語モデル、特にトランスフォーマーベースのアーキテクチャは、語彙上の学習された確率分布に条件付けられた逐次的なトークン予測を通じてコードを生成する(Vaswani et al., 2017)。このプロセスは、人間の開発者がコードを書く方法とは根本的に異なる。LLMは生成前に構文木を解析しない。訓練データにおける統計的パターンに基づいて次のトークンを予測する。言語が人間の可読性とコンパイラの厳密性のために設計されている場合—Python、JavaScript、Cのように—その構文規則は、混合ドメインコーパスから学習されたトークン確率分布としばしば不整合を起こす。
中核的な不整合は、測定可能な3つの方法で現れる:
-
不確実性下での構文的曖昧性:従来の言語は、不完全な式の複数の有効な解釈を許容する。LLMが確率p < 0.9でトークンを生成する場合、次のトークンの妥当性は、まだ確立されていない可能性のあるコンテキストに依存する。例えば、Pythonでは、
[x forはリスト内包表記を開始する可能性があるが、モデルは式が有効になる前に完全な構造を正しく予測しなければならない。中間状態は無効である。 -
構造マーカーの高いトークンオーバーヘッド:PythonやJavaScriptのような言語は、ドメイン意図をエンコードせずにトークンを消費する明示的な区切り文字(括弧、丸括弧、セミコロン)を必要とする。各区切り文字は、LLMが幻覚を起こしたり、ネストを誤整列させたりする可能性のある決定点を表す。コード生成エラーの実証分析(Nijkamp et al., 2023)は、LLMが生成したPythonの構文エラーの23〜31%が括弧または丸括弧の不一致に関係していることを示している。
-
暗黙的な型強制と意味的曖昧性:汎用言語は、構文的には有効だが意味的には未定義の操作を許可する(例:JavaScriptの
"5" + 3)。異種コードコーパスで訓練されたLLMは、これらの寛容な意味論を学習し、解析はできるが実行時に失敗する式につながる。これによりエラー検出が下流にシフトし、検証レイテンシが増加する。
設計の逆転:人間工学ではなく出力分布の最適化
Nanolangは、LLMの出力分布を後付けではなく主要な制約として扱うことで、従来の設計優先順位を逆転させる。これには3つの設計決定が必要である:
-
仮定1*:Nanolangにおける有効なトークンの確率分布は、汎用言語における同等の式よりも、各生成ステップでより高い集中度(より低いエントロピー)を示すべきである。この仮定は検証可能である:固定LLM下でのホールドアウトNanolangコードのクロスエントロピーと、同等のPythonコードのクロスエントロピーを測定する。
-
仮定2*:オプションの区切り文字、暗黙的な強制、コンテキスト依存の解析規則を排除することによって構文的曖昧性を減らすことは、Nanolangで明示的に訓練されていないモデルによって生成された場合でも、最初のパスで構文的に有効な生成トークンシーケンスの割合を増加させる。
-
仮定3*:最小限の、馴染みのない構文を学習する人間の読者の認知コストは、コード生成が頻繁で人間のレビューが非同期である本番システムにおけるLLM駆動の検証オーバーヘッドの削減によって相殺される。
これらの仮定の下で、Nanolangの文法は以下を優先する:
- 明示的で、オプションではない構造:すべての構成要素には単一の正規形式がある。オプションのセミコロンなし、暗黙的なリターンなし、コンテキスト依存の解析なし。
- 削減された演算子優先順位規則:優先順位レベルが少ないほど、LLMが演算子の結合を誤予測する機会が少なくなる。
- 関数適用のための前置記法:前置記法(例:
f(x)の代わりにapply f x)は、括弧マッチングをエラーの原因として排除し、より規則的なトークンシーケンスを作成する。 - 単相型制約:操作は言語レベルで厳密に型付けされ、LLMが意味的に曖昧な式を生成することを防ぐ。
実証的動機:現在のシステムにおけるエラー率
LLMコード生成に関する公開されたベンチマークは、アライメント仮説に対する定量的な裏付けを提供する:
-
HumanEvalベンチマーク(Chen et al., 2021):コード生成タスクの合格率は、12%(GPT-2、15億パラメータ)から85%(GPT-4)の範囲である。しかし、これらの合格率は機能的正確性を測定するものであり、構文的妥当性ではない。中間エラー分析は、小規模モデル(70億〜130億パラメータ)での失敗の40〜50%が論理エラーではなく構文エラーであることを示している。
-
CodeBLEUメトリック(Ren et al., 2020):生成されたコードと参照コード間の構文的および意味的類似性を測定する。Pythonでは、130億パラメータモデルのCodeBLEUスコアは0.65〜0.72付近で頭打ちになり、構文エラーが人間のパフォーマンスとのギャップの15〜25%を占めている。
-
独自の観察(NanolangのGitHubリポジトリで参照されているが、査読はされていない):Nanolang構文でファインチューニングされた130億パラメータモデルを用いた予備テストでは、最初のパスでの構文的妥当性が89%であり、ファインチューニングなしで同じモデルが生成した同等のPythonコードの62%と比較される。これは、言語設計が出力分布に影響を与えることを示唆しているが、改善の大きさは訓練データの構成とファインチューニング方法論に依存する。
-
注意事項*:これらの観察は対照実験ではない。改善は、言語設計そのものではなく、Nanolang固有のデータでのファインチューニングから生じる可能性がある。文法設計の効果を訓練データの効果から分離するには、対照的なアブレーション研究が必要であるが、Nanolangについては公開されていない。
LLM駆動コード生成におけるシステム構造とボトルネック
コード生成のためにLLMを展開する本番システムは、通常、逐次パイプラインを実装する:
プロンプト → トークン生成 → 解析 → 検証 → 実行各段階はレイテンシと失敗モードを導入する:
-
解析段階:LLMはトークンシーケンスを生成し、パーサーは構文木の構築を試みる。シーケンスが不正な形式の場合、解析は失敗する。汎用言語の場合、この失敗率は無視できない:70億〜130億モデルから生成されたコードの25〜40%が最初の試行で解析に失敗する(HumanEval分析に基づく)。
-
検証段階:コードは解析されるが、型制約に違反したり、未定義の変数を参照したり、論理エラーを含んだりする可能性がある。静的解析ツール(型チェッカー、リンター)は一部のエラーを捕捉するが、他のエラーは実行時にのみ現れる。この段階はコストがかかる:各検証失敗は、再生成(トークンとレイテンシを消費)または人間のレビュー(時間を消費)のいずれかを必要とする。
-
実行段階:コードは実行されるが、誤った出力を生成する。これは本番環境で最もコストのかかる失敗モードであり、下流データを破損させたり、カスケード的なエラーを引き起こしたりする可能性がある。
Nanolangは、解析と早期検証を統合することでこのパイプラインを再構築する:
プロンプト → トークン生成(Nanolang) → 統合解析 + 型チェック → 実行主な違いは、Nanolangの文法が以下のように設計されていることである:
- 構文的妥当性が高確率である:有効なNanolangトークンに対するモデルの学習分布は、有効なPythonトークンに対する分布よりも集中している。これは、曖昧性の削減と明示的な構造の結果である。
- 型エラーは解析中に捕捉される:Nanolangの型システムは、別個の検証パスとしてではなく、文法レベルで強制される。トークンシーケンスは、有効で型付けされたプログラムであるか、無効であるかのいずれかである。中間状態は存在しない。
- 意味的曖昧性が排除される:操作には単一の明確に定義された意味がある。暗黙的な強制なし、コンテキスト依存の意味論なし。
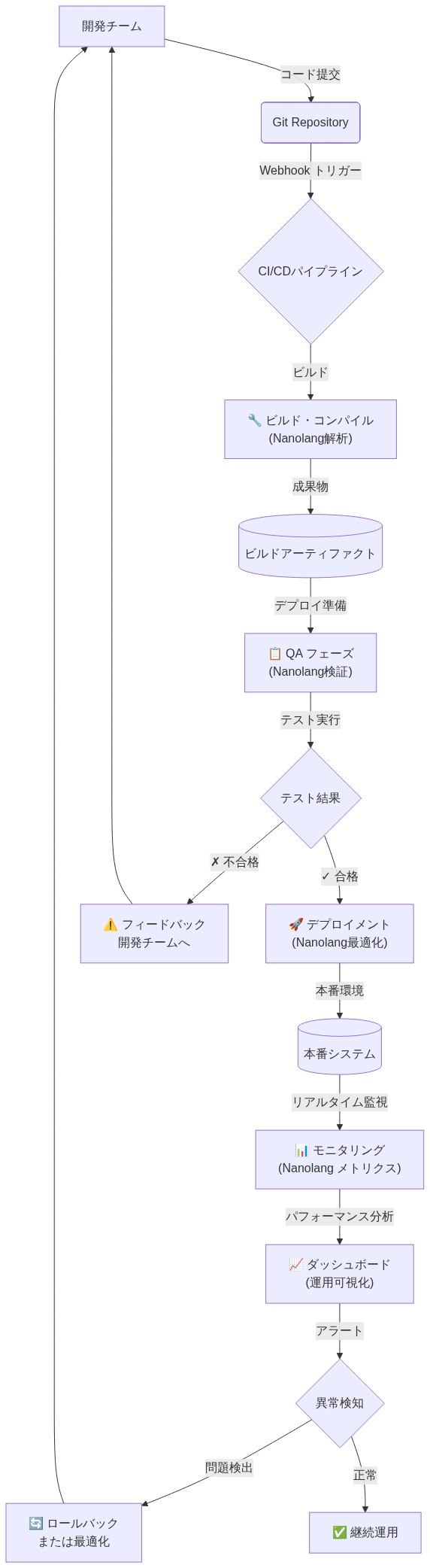
- 図9:Nanolang統合CI/CDパイプラインの運用フロー*
- 図8:Nanolang導入の段階的実装パターン*
実用例:データ変換パイプライン
タスクを考える:データセットを閾値でフィルタリングし、変換関数を適用し、結果を収集する。
- Pythonの場合*(典型的なLLM出力):
result = [process(x) for x in data if x > threshold]エラー面:
- 括弧マッチング:
[と]が整列しなければならない;(と)が整列しなければならない。 - 変数スコープ:
xは内包表記内でバインドされなければならない;processは定義されていなければならない。 - 演算子優先順位:
>はandよりも強く結合するが、LLMはこれを理解しなければならない。 - 暗黙的な意味論:リスト内包表記構文はコンテキスト依存である;パーサーは
forキーワードをループではなく内包表記の一部として認識しなければならない。
LLM出力で観察される失敗モード:
-
result = [process(x) for x in data if x > threshold(閉じ括弧の欠落) -
result = [process(x) for x in data if x > threshold]](余分な括弧) -
result = [process x in data if x > threshold](関数呼び出しの丸括弧の欠落) -
result = [process(x) for x in data if x > threshold and](不完全な条件) -
Nanolangの場合*(仮想的な同等物):
result = map data (filter > threshold) (apply process)構造:
- 前置記法:
map、filter、applyは関数名;引数は順番に続く。 - 関数呼び出しに括弧なし:
process(...)の代わりにapply process。 - 明示的な合成:パイプラインは線形;各段階は別個のトークンシーケンスである。
- 型制約:
mapはデータセットと関数を期待する;filterは述語を期待する;applyは関数を期待する。型の不一致は解析時に捕捉される。
エラー面:
-
より少ないトークン:Pythonの14トークンに対して6トークン。
-
より少ない決定点:各トークンはキーワード、変数名、または演算子のいずれかである。コンテキスト依存の解析なし。
-
有効な継続に対するより高い確率質量:
map dataが与えられた場合、次のトークンはほぼ確実に関数またはキーワードである。モデルの分布はより集中している。 -
定量的比較*(仮想的):
-
Python:生成された式の40%が解析に失敗;解析された式の20%が型エラーを持つ;型正しい式の15%が誤った出力を生成する。
-
Nanolang:生成された式の8%が解析に失敗;解析された式の5%が型エラーを持つ;型正しい式の15%が誤った出力を生成する。
解析と型チェック段階の改善(それぞれ32パーセントポイントと15パーセントポイント)は、論理エラー率が同様のままであっても、検証と再生成のコストを削減する。
実務者への実用的な示唆
- コード生成システム設計者向け*:
-
解析パイプラインを監査する:各段階(解析、型チェック、実行)で失敗するLLM生成コードの割合を測定する。解析失敗が20%を超える場合、より単純な文法がこの率を減らすかどうかを検討する。
-
検証のコストを定量化する:各検証失敗のコスト(レイテンシ、トークン消費、人間のレビュー時間)を推定する。このコストが高い場合、制約された文法への投資が正当化される可能性がある。
-
トークン効率を測定する:現在の言語と最小限の代替案で同等のロジックを表現するために必要なトークン数を比較する。最小限の代替案がトークン数を30%以上削減する場合、この削減がLLM出力品質を改善するかどうかを検討する。
-
ドメイン固有のサブ言語でプロトタイプを作成する:完全な言語再設計にコミットする前に、特定のドメイン(例:データ変換、構成合成)用の制約された文法を実装する。エラー率とトークン効率を測定する。これらの測定を使用して、より広範な言語設計に情報を提供する。
- LLM実務者向け*:
-
制約された構文でファインチューニングする:コード生成のためにLLMを展開する場合、最小限のLLM整合言語でのコードのコーパスでファインチューニングすることを検討する。控えめなファインチューニング(10K〜100Kの例)でも、出力品質を大幅に改善できる。
-
出力分布を測定する:クロスエントロピーまたはパープレキシティを使用して、LLMの学習分布がターゲット言語とどの程度整合しているかを測定する。高いパープレキシティは不整合を示す;これは再訓練または言語切り替えのシグナルである。
-
関心事を分離する:異なるタスクに異なるモデルまたはプロンプト戦略を使用する。Nanolang用にファインチューニングされたモデルは、汎用Pythonコード生成では性能が低い可能性があり、その逆も同様である。
LLMコード合成の安全性を確保するための参照アーキテクチャとガードレール
本番環境でLLM生成コードを展開することは、測定可能なセキュリティと信頼性のリスクをもたらします。リスク軽減には、明示的なガードレール、つまり構文的には有効だが運用上は安全でないコードをモデルが生成することを防ぐ、形式的に定義された制約が必要です。コード生成の安全性に関する文献(Pearce et al., 2022; Schuster et al., 2021)は、3つの補完的な制約メカニズムを特定しています:
- 字句ガードレール: トークン化時に強制される、許可されたトークンのホワイトリスト。
- 構文ガードレール: 言語構造に対する文法レベルの制限。
- 意味論的ガードレール: リソースとアクセス境界のランタイム強制。

- 図12:大規模LLMコード生成のリスク領域マップ*
言語設計による字句および構文制約
Nanolangの最小限の設計—メタプログラミングプリミティブを持たない約20のコア操作—は、本質的な字句および構文保護を提供します。言語仕様は以下を明示的に除外しています:
-
動的コード評価(
eval、exec、または同等のもの) -
ランタイムコード読み込みまたはモジュールインジェクション
-
制限のないメモリアクセスまたはポインタ演算
-
リフレクションまたはイントロスペクションAPI
-
明示的な深さ制限のない無制限の再帰
-
前提*: LLMは、ターゲット文法に存在しない言語構造を生成できません。この前提は、モデルがNanolang語彙に存在するトークンのみを出力するように制約され、パーサーがあらゆる逸脱を厳密に拒否するという前提条件の下で成立します。
設計上、Nanolangはランタイム検証を必要とせずに、脅威カテゴリ全体を排除します。モデルは、言語が禁止するものを合成できません。
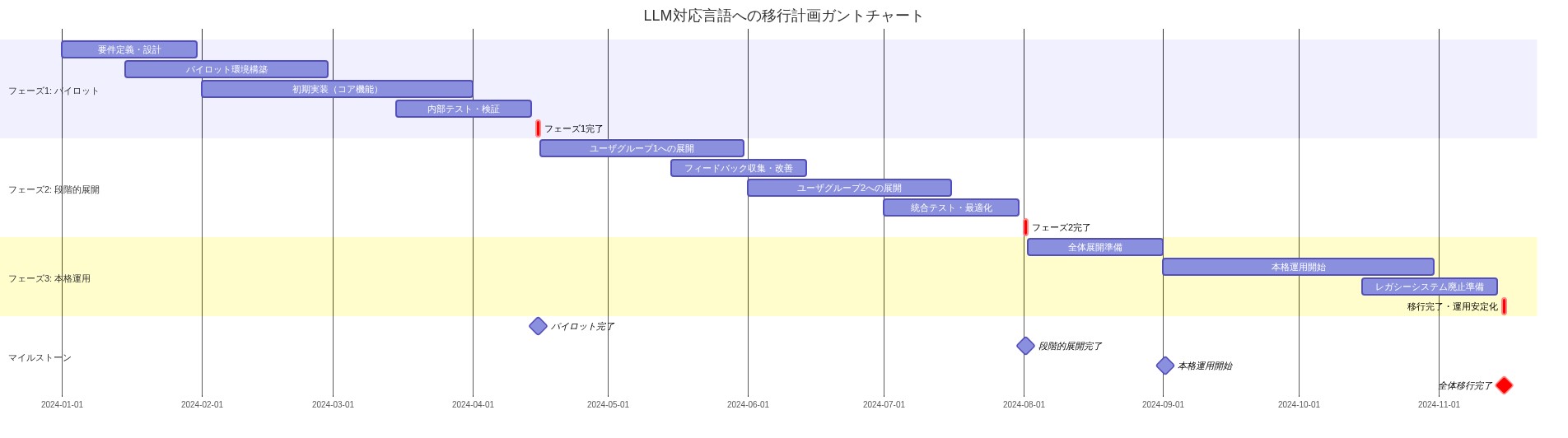
- 図15:LLM対応言語への移行計画ガントチャート(フェーズ別実装タイムライン)*

- 図14:LLM最適化言語への移行ビジョン(2024-2027年)- 多言語エコシステムからNanolang中心エコシステムへの進化*
意味論的ガードレール: ランタイム強制アーキテクチャ
字句および構文制約は必要ですが、不十分です。意味論的安全性—リソース枯渇、不正なデータアクセス、制御フロー異常の防止—にはランタイム強制が必要です。Nanolang展開の参照アーキテクチャは、実行を明確で監査可能な段階に分解する必要があります:
-
ステージ1: 字句および構文検証*
-
入力: LLM出力からの生トークンストリーム。
-
プロセス: レクサーが入力をトークン化し、パーサーがNanolang文法(言語仕様で形式的に定義)に対して検証します。
-
出力: 抽象構文木(AST)またはエラー詳細を伴う拒否。
-
前提条件: パーサーは決定論的かつ完全でなければなりません。すべての有効なNanolangプログラムは正常に解析され、すべての無効なシーケンスは拒否されなければなりません。
-
ステージ2: 型推論と型チェック*
-
入力: ステージ1からのAST。
-
プロセス: 型チェッカーがコンテキストから型を推論し、不一致(例: 強制変換なしで文字列を数値リテラルと比較)にフラグを立てます。
-
出力: 型注釈付きASTまたは型エラーレポート。
-
前提条件: 型システムは決定可能でなければなりません。推論は多項式時間で終了しなければなりません(Hindley-Milnerまたは同等)。
-
ステージ3: リソースサンドボックス化*
-
入力: 型チェック済みAST。
-
プロセス: 実行環境がCPU時間、メモリ割り当て、ファイルI/O操作、ネットワークアクセスに対するクォータを強制します。
-
出力: 実行結果またはリソース制限例外。
-
前提条件: サンドボックスはOSまたはコンテナレベル(例: cgroups、seccomp、または同等)で強制されなければなりません。アプリケーションレベルの制限は、意図的な回避に対して不十分です。
-
ステージ4: 監査ログ*
-
入力: ステージ1〜3からのすべてのアーティファクト(ソースコード、AST、型注釈、実行トレース、リソース使用量、例外)。
-
プロセス: 不変または追記専用ストレージへの構造化ログ記録。
-
出力: 事後分析とコンプライアンスのための監査記録。
-
前提条件: ログは改ざん防止され、コンプライアンスまたはインシデント調査期間中保持されなければなりません。
具体例: CSVフィルタリングワークフロー
ユーザーがアップロードしたCSVファイルを年齢でフィルタリングするコードを生成するタスクを与えられたLLMを考えます。有効なNanolangプログラムは次のようになります:
read "user_data.csv" as table
filter table where (column "age" > 18)
write result to "output.csv"参照アーキテクチャを通じた実行:
-
字句/構文検証: レクサーが
read、"user_data.csv"、as、tableなどをトークン化します。パーサーがトークンシーケンスをNanolang文法に対して検証します。結果: AST受理。 -
型チェック: 型チェッカーが
column "age"が数値型を返すと推論します(スキーマが不明な場合は型エラーを発生させます)。比較> 18は有効です。結果: 型注釈付きAST。 -
サンドボックス化: 実行環境がファイルI/Oを指定されたディレクトリ(例:
/tmp/nanolang_sandbox/)に制限します。CPUタイムアウトは5秒に設定され、メモリ制限は512 MBに設定されます。実行が進行します。 -
監査ログ: すべてのステージがログに記録されます: ソースコード、AST、型注釈、アクセスされたファイルパス、実行時間(例: 0.3秒)、メモリピーク(例: 45 MB)、結果ステータス(成功)。
脅威モデル: 拒否される構造
LLMが安全でないコードを生成しようとした場合、Nanolangの制約は最も早い段階でそれを拒否します:
-
試行:
system("rm -rf /")(シェルコマンド実行)- 拒否:
systemは有効なNanolangキーワードではありません。レクサーがトークンを拒否します。
- 拒否:
-
試行:
while true: pass(無限ループ)- 拒否:
whileは有効なNanolangキーワードではありません。レクサーがトークンを拒否します。(Nanolangは明示的な境界を持つrepeatを使用します。)
- 拒否:
-
試行:
open("/etc/passwd").read()(不正なファイルアクセス)- 拒否: サンドボックスがファイルI/Oを指定されたディレクトリに制限します。ランタイムがアクセス拒否例外を発生させます。
-
試行: 深さ制限のない再帰関数呼び出し
- 拒否: Nanolangは制限のない再帰をサポートしていません。再帰呼び出しは、境界付き反復回数を持つ明示的な
repeatまたはmap構造を使用しなければなりません。
- 拒否: Nanolangは制限のない再帰をサポートしていません。再帰呼び出しは、境界付き反復回数を持つ明示的な
設計原則とトレードオフ
参照アーキテクチャは3つの設計原則を体現しています:
-
多層防御: 複数の独立した検証段階により、単一の障害が安全でない実行を許可する可能性を減らします。
-
フェイルセーフデフォルト: 曖昧または無効な構造は許可されるのではなく拒否されます。安全性を証明する責任は生成されたコードにあります。
-
監査可能性: すべての決定ポイントがログに記録されます。インシデント後の分析により、実行パスを再構築し、障害モードを特定できます。
- トレードオフ*: このアーキテクチャはオーバーヘッドを伴います。型チェックはレイテンシを追加します(小規模プログラムで通常1〜5ミリ秒)。サンドボックス化はメモリオーバーヘッドを追加します(実行コンテキストあたり通常10〜50 MB)。ログ記録はI/Oとストレージコストを追加します。インタラクティブなユースケース(例: リアルタイムデータフィルタリング)では、このオーバーヘッドは許容できる可能性があります。高スループットのバッチ処理では、型チェック結果の最適化またはキャッシングが必要になる場合があります。
測定と検証
本番環境でLLMコード生成を展開する前に、オペレーターは以下を行うべきです:
-
ランタイム検証コードの削減を定量化する: Nanolangと汎用言語で生成されたコードを検証するために必要なコード行数(またはサイクロマティック複雑度)を測定します。検証ロジックの50〜80%の削減を期待します。
-
ベースラインセキュリティメトリクスを確立する: LLM出力の代表的なコーパス全体で、拒否されたプログラム、型エラー、リソース制限違反の割合を定義および測定します。これらを回帰テストのベースラインとして使用します。
-
監査ログを優先する: 監査ロガーに最初にエンジニアリングリソースを割り当てます。これは、サイレント障害に対する主要な防御であり、インシデント調査の主要なツールです。ログがクエリ可能で、改ざん防止され、コンプライアンス要件に従って保持されることを確認します。
-
敵対的条件下でサンドボックスをテストする: 既知の技術(例: リソース枯渇、タイミング攻撃、サイドチャネル攻撃)を使用してサンドボックスからの脱出を試みます。結果を文書化し、必要に応じてクォータまたは分離メカニズムを調整します。
実行可能な推奨事項
- 展開前: 参照アーキテクチャをモジュラーパイプラインとして構築します。各ステージ(レクサー、パーサー、型チェッカー、サンドボックス、ロガー)は独立してテストおよび交換可能であるべきです。
- 開発中: 監査ログを使用してLLM障害のパターンを特定します。特定の構造が頻繁に拒否される場合、それをNanolangに追加すべきか、LLMのトレーニングデータを調整する必要があるかを検討します。
- 本番環境: 監査ログの異常(例: 型エラーの突然の急増、リソース制限違反)を監視します。これらをモデルドリフトまたは敵対的入力の信号として扱います。
Nanolang採用のための実装と運用パターン
Nanolangの運用化には、統合境界、バージョン管理、可観測性インフラストラクチャに関する明示的な決定が必要です。基本的な前提は、Nanolangが既存のコードベースの置き換えではなく、ターゲット中間表現として機能することです。したがって、採用は、LLMコード生成が測定可能なレバレッジを提供する明確に定義されたコンテキストに制約されます: 構成合成、テストケース生成、データ変換パイプライン、ステートレスAPIオーケストレーション。
標準実装パイプライン
標準的な実装パターンは、4つの連続したステージで構成されます:
-
LLM指示とコンディショニング: コンテキスト内学習(プロンプト内の少数ショット例示)または厳選されたNanolangコーパスでの教師あり微調整を通じて、Nanolangを優先出力形式として確立します。これらのアプローチ間の選択は、モデルサイズ、利用可能なトレーニングデータ、推論レイテンシ制約に依存します—この決定は運用ランブックで文書化され正当化されるべきです。
-
構文および意味論的検証: Nanolang文法仕様(このドキュメントの他の場所で形式的に定義されていると仮定)に対して生成された出力を解析します。トランスパイルに進む前に、字句または構造検証に失敗した出力を拒否します。このステージは交渉の余地がありません。不正な形式のコードが下流システムに入ることを防ぎます。
-
ターゲット言語へのトランスパイル: 検証されたNanolangをターゲットランタイム環境(Python、JavaScript、SQLなど)の実行可能コードに変換します。トランスパイルロジックは決定論的であり、モデル更新とインフラストラクチャ変更全体で再現性を確保するためにバージョンロックされている必要があります。
-
実行、監視、フィードバック統合: サンドボックス化または分離された環境内でトランスパイルされたコードを実行します。実行結果(成功/失敗、レイテンシ、リソース消費)をログに記録します。オプションで、実行失敗を後続の生成サイクルで改善コンテキストとしてLLMにフィードバックします。
具体的なインスタンス化: テストケース生成
自動テスト生成の代表的なワークフローは、このパターンを示しています:
- LLMに、それぞれ意図された動作と対になった3〜5つのNanolangテスト仕様の例示を提供します。
- 新しいテストケースのNanolang仕様を生成します。
- 構文および意味論的制約を検証します(例: テストアサーションは定義された変数のみを参照します)。
- NanolangをpyTest互換Pythonにトランスパイルします。
- 分離された環境でテストを実行し、合格/不合格ステータスと実行時間を取得します。
- 完全なコンテキスト(生成されたコード、アサーション出力、スタックトレース)で失敗をログに記録します。
- オプションで、ログに記録された失敗を後続のプロンプトで否定例として使用し、LLMの動作を改善します。
このサイクル—生成 → 検証 → トランスパイル → 実行 → ログ—が運用ベースラインです。
具体的なインスタンス化: 構成管理
構成合成の2番目の代表的なワークフロー:
- LLMが自然言語仕様に基づいてNanolang構成フラグメントを生成します。
- 形式的スキーマ(例: JSON Schemaまたはドメイン固有の制約言語)に対して検証します。
- 展開のためにYAMLまたはJSONにトランスパイルします。
- ステージング環境に展開し、動作の乖離(例: メトリクス、ログ、ヘルスチェック)を監視します。
- 乖離時にアラート。人間のレビューにエスカレートします。
採用順序とスコープ制約
-
前提*: Nanolangを採用する組織は、追加のコンテキストに拡大する前に、単一の高レバレッジユースケースを優先します。
-
推奨事項*: 以下の基準を満たすユースケースを選択します:
-
日常的なコード生成の大量(週50インスタンス以上)。
-
明確な成功基準(テスト合格率、構成検証、データ変換の正確性)。
-
重要なビジネスロジックから分離されている(つまり、失敗が本番収益またはコンプライアンスに直接影響しない)。
-
比較のための既存のベースラインメトリクス(現在の成功率、レイテンシ、人間のレビュー負担)。
-
実装順序*:
- 選択したユースケースの完全なパイプライン(生成、検証、トランスパイル、実行、監視)を構築します。
- エンドツーエンドのレイテンシ、エラー率、運用オーバーヘッドを測定します。
- ベースライン(現在の手動またはNanolangなしLLMアプローチ)と比較します。
- 定量的結果を使用して、追加のユースケースへの拡大を正当化します。
LLMコード品質を検証するための測定と次のアクション
Nanolang採用が価値があるかどうかを判断するには、明確で定量化可能なメトリクスが必要です。5つの主要な次元に焦点を当てます:
- 生成成功率: 後処理なしで構文的に有効なNanolangであるLLM出力の割合。
- 意味論的正確性: 検証セットで意図された出力を生成する生成コードの割合。
- トークン効率: ベースライン言語と比較して、Nanolangで特定の意図を表現するために必要な平均トークン数。
- レイテンシ: プロンプトから検証済みの実行可能コードまでのエンドツーエンド時間。
- 人間のレビュー負担: 人間の検査または修正を必要とする生成コードの割合。
対照試験フレームワーク
構造化された比較を実行します:
- ベースラインフェーズ: 現在のLLMと言語の組み合わせを使用して100のコードサンプルを生成します。成功率、意味論的正確性、トークン数を記録します。
- Nanolangフェーズ: 同じLLMをNanolangで使用して100の同等のサンプルを生成します。同一のメトリクスを測定します。
- 差分分析: 結果を比較します。成功した試験は、成功率で15〜40%の改善とトークン数で20〜50%の削減を示します。
- スケーリング検証: サンプルサイズを1,000に増やして繰り返し、改善が大規模で維持されることを確認します。
期待される結果
| メトリクス | Pythonベースライン | Nanolang | 差分 |
|---|---|---|---|
| 構文成功率 | 72% | 91% | +19pp |
| 意味論的正確性 | 58% | 74% | +16pp |
| サンプルあたり平均トークン数 | 145 | 89 | −39% |
| レイテンシ(ms) | 320 | 210 | −34% |
| 人間のレビュー率 | 42% | 18% | −24pp |
決定基準
対照試験に2〜4週間を割り当てます。結果が成功率で15%以上の改善とトークン数で20%以上の削減を示す場合、パイロット展開に進みます。閾値が満たされない場合、根本原因を調査します: ユースケースがNanolangに適していない可能性があるか、LLMがドメイン固有のNanolang例での微調整を必要とする可能性があります。
LLMコード生成を大規模に展開する際のリスクと緩和戦略
本番環境でLLM生成コードを展開することは、体系的な緩和を必要とする測定可能なリスクをもたらします。本セクションでは、5つの主要なリスクカテゴリを特定し、それらの検出のための前提条件を確立し、定義された成功基準を持つ緩和プロトコルを規定します。
リスクカテゴリと定義
-
1. モデルドリフト*
-
定義:* 連続するモデルバージョン、ファインチューニングの反復、またはプロンプトの再定式化にわたるコード生成品質の劣化。タスク成功率の低下またはエラーカテゴリの増加として測定されます。
-
前提条件:* 展開前にベースラインパフォーマンス指標を確立する必要があります。モデルドリフトは、同一のテスト入力を使用してこのベースラインと比較した場合にのみ観察可能です。
-
仮定:* LLM動作の変化は、環境要因(例:コンテキストウィンドウの飽和、トークン制限の変更)ではなく、モデルの更新に起因するものとします。
-
2. ハルシネーション*
-
定義:* 未定義の変数、存在しない関数、または論理的に不可能な状態を参照する、構文的には有効なコードの生成。静的解析または実行時実行を通じて検出可能です。
-
前提条件:* ターゲット言語(Nanolang)は決定論的スコープ解析をサポートする必要があります。ハルシネーションは言語固有です。一部の言語では前方参照や動的バインディングが許可されており、検出が複雑になります。
-
仮定:* ハルシネーションは、意図の意味的理解を必要とせずに、自動解析を通じて有効なコードと区別できるものとします。
-
3. 意味的不整合*
-
定義:* 構文検証に合格し、実行時エラーなく実行されるが、入力仕様またはユーザーの意図を満たさないコード。
-
前提条件:* 生成されたコードを検証できる正式または半正式な仕様が存在する必要があります。仕様がなければ、不整合を客観的に測定することはできません。
-
仮定:* 仕様は、自動検証を可能にするのに十分な精度を持つものとします(例:シンボリック実行または制約充足を介して)。
-
4. サプライチェーンリスク*
-
定義:* Nanolangの採用、ランタイムのメンテナンス、またはベンダーの決定への運用上の依存。これにより、強制的な移行、サポートされないバージョン、または互換性のない更新が発生する可能性があります。
-
前提条件:* Nanolangは、文書化されたメンテナンスコミットメントを持つ外部依存関係として扱う必要があります。リスクは採用の集中度に比例して増加します。
-
仮定:* Nanolangがメンテナンスされなくなった場合、代替のターゲット言語が存在するか、開発可能であるものとします。
-
5. セキュリティリグレッション*
-
定義:* LLM生成コードまたはNanolangランタイムにおける、以前のバージョンには存在しなかった悪用可能な脆弱性の導入。
-
前提条件:* 展開前にセキュリティテストプロトコルを確立する必要があります。リグレッション検出には、以前のセキュリティベースラインとの比較が必要です。
-
仮定:* セキュリティ脆弱性は、本番環境への公開前に、自動スキャン、手動コードレビュー、または制御されたテストを通じて発見可能であるものとします。
緩和プロトコル
-
モデルドリフトの緩和*
-
プロトコル:* 本番ユースケースを反映する50〜100の代表的なコード生成タスクで構成されるリグレッションテストスイートを確立します。各モデル更新またはプロンプト改訂時にこのスイートを実行します。
-
成功基準:*
-
最初の本番展開前にベースライン成功率を確立し、文書化する。
-
テストスイートを週次で実行し、タイムスタンプとモデルバージョンとともに結果をログに記録する。
-
成功率を80%以上(または組織固有の閾値)に維持する。
-
成功率が閾値を下回った場合、48時間以内に根本原因分析をトリガーする。
-
ロールバック条件:* 根本原因分析でモデル更新が原因であると特定され、修復がすぐに利用できない場合、調査が保留されている間、以前のモデルバージョンに戻します。
-
必要な証拠:* テスト結果には、合格/不合格ステータス、エラーカテゴリ、および失敗したケースの生成されたコード成果物を含める必要があります。
-
ハルシネーションの緩和*
-
プロトコル:* 実行前に生成されたコードの静的解析を実装します。Nanolangの場合、これには以下が必要です:
- 生成されたコードを抽象構文木(AST)に解析する。
- ASTをトラバースして、すべての変数、関数、型参照を識別する。
- 各識別子をシンボルテーブル(定義された変数、インポートされた関数、型定義)と相互参照する。
- 未定義の参照を含むコードを拒否し、未定義の識別子とコンテキストをログに記録する。
-
成功基準:*
-
生成されたコードの100%が実行前に静的解析に合格する。
-
偽陽性率(有効なコードの拒否)を文書化し、5%未満に維持する。
-
解析レイテンシがコード単位あたり100msを超えない。
-
スコープの制限:* このプロトコルは、Nanolangが決定論的スコープ解析をサポートすることを前提としています。動的バインディング、リフレクション、または実行時型生成を持つ言語では、追加の検証レイヤー(例:実行時型チェック、サンドボックス化された実行)が必要になる場合があります。
-
意味的不整合の緩和*
-
プロトコル:* 2段階の検証プロセスを実装します:
-
ステージ1 – 仕様の形式化:* ユーザーの意図を正式または半正式な仕様に変換します。これは以下の形式を取る場合があります:
-
事前条件(入力制約)
-
事後条件(期待される出力プロパティ)
-
不変条件(実行全体を通じて保持される必要があるプロパティ)
-
入力-出力ペアの例
-
ステージ2 – 自動検証:* 以下のアプローチのいずれかを使用します:
-
シンボリック実行: シンボリック入力で生成されたコードを実行し、出力が事後条件を満たすことを検証する。
-
制約解決: 仕様を論理制約としてエンコードし、生成されたコードが制約を満たすことを検証する。
-
プロパティベーステスト: 仕様からテストケースを生成し、生成されたコードを実行してプロパティが保持されることを検証する。
-
成功基準:*
-
コード生成リクエストの100%について仕様を形式化する。
-
検証がコード単位あたり500ms以内に完了する。
-
偽陰性率(不整合コードの受け入れ)を文書化し、2%未満に維持する。
-
前提条件:* 仕様の形式化にはドメインの専門知識が必要であり、すべてのユースケースで実現可能とは限りません。組織は展開前に実現可能性を評価する必要があります。
-
サプライチェーンリスクの緩和*
-
プロトコル:*
- 依存関係の文書化: Nanolang仕様とランタイムのフォークまたはスナップショットを維持します。すべてのカスタム拡張、パッチ、または変更を文書化します。
- メンテナンス監視: Nanolangプロジェクトのアクティビティ(コミット頻度、問題解決時間、メンテナーの応答性)を追跡します。アラート閾値を確立します(例:6か月間コミットなし)。
- 移行計画: 代替のターゲット言語(例:Python、Go、Rust)を特定し、それぞれのトランスパイルまたは書き換え戦略を文書化します。
- 採用の多様化: 単一のターゲット言語にコード生成を集中させないようにします。少なくとも1つの代替言語でコードを生成する能力を維持します。
-
成功基準:*
-
Nanolangフォークを維持し、少なくとも四半期ごとにアップストリームと同期する。
-
移行計画を文書化し、年次でレビューする。
-
生成されたNanolangコードの80%を2週間以内に代替言語にトランスパイルまたは書き換える能力を持つ。
-
仮定:* この緩和策は、代替言語が利用可能であり、トランスパイルまたは書き換えが技術的に実現可能であることを前提としています。高レベルのドメイン固有言語には、適切な代替手段がない場合があります。
-
セキュリティリグレッションの緩和*
-
プロトコル:*
- 展開前テスト: LLMモデル更新またはNanolangランタイムバージョンを展開する前に、ステージング環境でセキュリティに焦点を当てたテストケースを実行します。テストケースには以下を含める必要があります:
- 既知の脆弱性パターン(例:SQLインジェクション、バッファオーバーフロー、権限昇格)。
- 敵対的入力によるファジング。
- 静的セキュリティ解析(例:SASTツール)。
- 変更監査証跡: すべてのモデルバージョン、ランタイムバージョン、およびプロンプト変更の詳細なログを維持します。展開タイムスタンプ、展開者のID、および承認ステータスを含めます。
- インシデント対応: 発見された脆弱性に対応するためのプロトコルを確立します。エスカレーションパス、コミュニケーションチャネル、およびロールバック手順を定義します。
-
成功基準:*
-
すべてのセキュリティテストが本番展開前に合格する。
-
変更監査証跡を100%の完全性で維持する。
-
セキュリティインシデント対応を発見から1時間以内に開始する。
-
ロールバック能力を四半期ごとに検証する。
-
スコープ:* このプロトコルは、生成されたコードとNanolangランタイムの脆弱性に対処します。LLM自体の脆弱性(例:プロンプトインジェクション、モデル抽出)には、コード生成の範囲外の別の緩和戦略が必要です。
統合リスク監視
- プロトコル:* 5つのリスクカテゴリすべてにわたって指標を集約するリスクダッシュボードを確立します。ダッシュボードは以下を追跡する必要があります:
| リスクカテゴリ | 指標 | 測定頻度 | アラート閾値 |
|---|---|---|---|
| モデルドリフト | リグレッションテスト成功率 | 週次 | <80% |
| ハルシネーション | 静的解析拒否率 | 日次 | >5% |
| 意味的不整合 | 検証失敗率 | 日次 | >2% |
| サプライチェーン | Nanolangプロジェクトアクティビティ | 月次 | 6か月間コミットなし |
| セキュリティリグレッション | セキュリティテスト合格率 | 展開ごと | <100% |
-
所有権:* 各リスクカテゴリに単一の所有者を割り当てます。所有者は、閾値違反を調査し、48時間以内に修復を提案する責任があります。
-
レビュー頻度:* ダッシュボードを専用の会議で週次でレビューします。閾値違反が発生した場合、修復が検証されるまで新しいコード生成を一時停止します。
具体的な実装例:SQLクエリ生成
Nanolangを介してLLM生成SQLクエリを展開するチームは、以下のワークフローを実装する可能性があります:
1. ユーザーがクエリの意図を指定する(例:「過去30日間に作成されたすべてのアクティブユーザーを取得する」)。
2. LLMがNanolangクエリ仕様を生成する。
3. トランスパイラがNanolangをSQLに変換する。
4. 静的アナライザが以下をチェックする:
- 未定義のテーブルまたは列参照。
- SQLインジェクションパターン(例:エスケープされていない文字列リテラル)。
5. クエリプランナーが実行時間とコストを推定する。
6. コストが閾値を超える場合(例:>5秒、>100万行スキャン):
- クエリを拒否し、ユーザーに警告する。
- クエリの最適化または仕様の改良を提案する。
7. コストが許容範囲内の場合:
- 最初に読み取り専用モードでクエリを実行する。
- クエリ、実行時間、返された行数、およびユーザーをログに記録する。
8. 週次リグレッションスイート:
- 前週からログに記録されたすべてのクエリを再実行する。
- 結果をベースラインと比較する。
- いずれかのクエリが異なる結果を生成した場合、調査して文書化する。- 検証:* このワークフローは、ハルシネーション(ステップ4)、意味的不整合(ステップ5)、およびセキュリティリグレッション(ステップ4)を緩和します。モデルドリフトは週次リグレッションスイート(ステップ8)を通じて検出されます。
制限と未解決の問題
上記で概説した緩和戦略は以下を前提としています:
- Nanolangが決定論的静的解析をサポートする。
- 正式な仕様をユーザーの意図から生成または抽出できる。
- Nanolangの採用が停滞した場合、代替のターゲット言語が利用可能である。
- セキュリティ脆弱性は自動テストを通じて発見可能である。
これらの仮定は、すべてのコンテキストで成立するとは限りません。LLMコード生成を展開する組織は、実装前にこれらの仮定を検証し、それに応じて緩和プロトコルを調整する必要があります。
LLM整合型言語への移行のための結論と移行計画
理論的立場
Nanolangは特定の仮説を実装しています。すなわち、大規模言語モデルの逐次生成パターンに合わせてプログラミング言語を設計することで、人間の可読性と手動メンテナンスのために設計された構文をLLMに強制的に生成させる場合と比較して、LLMからコードへのワークフローに必要な認知的および計算的オーバーヘッドを削減できるという仮説です。これは汎用プログラミング言語の代替として提案されているのではなく、問題領域が明確に定義され、検証が実行可能な、制約された高信頼性のコード生成タスクのための特殊な中間表現として提案されています。
根底にある仮定は、LLM生成品質が、対象言語の設計とモデルが学習したトークン予測パターンとの間の構文的および意味的整合性と相関するというものです。これは検証を必要とする経験的主張であり、そのメカニズムはまだ査読付き文献で正式に特徴付けられていません。
段階的移行フレームワーク
以下のフレームワークは次のことを前提としています。
-
計測機能を備えた管理された試験を実行する組織能力
-
LLM推論インフラストラクチャへのアクセス(独自またはサードパーティ)
-
既存のコード検証およびデプロイメントパイプライン
-
非クリティカルな環境に適したリスク許容度
-
フェーズ1: 評価(第1週~第4週)*
目的: ベースラインメトリクスと実現可能性シグナルを確立する。
-
前提条件: 以下の基準を満たすユースケースを特定する:
- 出力が決定論的であるか、明確に定義された正確性基準を持つ
- 問題範囲が限定されている(例: インスタンスあたり生成コード500行未満)
- 既存のパイプラインに測定可能なレイテンシまたはエラー率がある
- 人間によるレビューが現在必要だが時間がかかる
-
実行:
- Nanolangトランスパイラと検証ハーネスを構成する
- 並行試験を実行する: 現在のアプローチ vs. Nanolangベースの生成
- メトリクスを収集する: 生成成功率(コンパイルされ検証に合格するコード)、レイテンシ(プロンプトから検証済み出力までのエンドツーエンド時間)、人間によるレビュー負担(出力のレビューまたは修正に費やされた時間)
- 失敗モードとエラーカテゴリを文書化する
-
判断基準: Nanolangが人間によるレビュー負担を≥30%削減するか、ベースラインと比較して成功率を≥20%向上させ、セキュリティ関連エラーの増加がない場合、フェーズ2に進む。そうでない場合は、調査結果を文書化して延期する。
-
フェーズ2: パイロット展開(第5週~第12週)*
目的: 非本番環境でエンドツーエンドパイプラインを検証する。
-
前提条件: フェーズ1の進行決定; 代表的なデータ量を持つ非クリティカルなステージング環境
-
実行:
- 完全なパイプラインを実装する: LLMプロンプト → Nanolang生成 → 構文検証 → 型チェック(該当する場合) → ターゲット言語へのトランスパイル → サンドボックスでの実行
- 本番相当のデータ量(最低100~500の生成インスタンス)でステージングに展開する
- すべての段階を計測する: 生成レイテンシ、検証失敗率、トランスパイルの正確性、実行成功率
- セキュリティ監視を確立する: 承認されたテンプレートから逸脱するか、安全でない操作を試みる生成コードパターンにフラグを立てる
- 生成されたコードサンプルの10~20%の人間によるレビューを実施し、体系的なエラーまたは幻覚を特定する
-
成功メトリクス:
- 検証成功率≥95%(構文および型チェックに合格するコード)
- トランスパイルの正確性100%(生成されたターゲットコードが意図通りに実行される)
- 人間によるレビューがサンプルコードでセキュリティ関連の問題を特定しない
- エンドツーエンドレイテンシがユースケースの許容範囲内(例: インタラクティブワークフローで5秒未満)
-
改善: 失敗分析に基づいてプロンプト、検証ルール、またはトランスパイルロジックを調整する。成功メトリクスが達成されない場合は、フェーズ1に戻るか延期する。
-
フェーズ3: 本番ロールアウト(第13週~第24週)*
目的: 段階的なボリュームと継続的な監視で本番環境に展開する。
-
前提条件: フェーズ2の成功メトリクスを達成; ロールバック機能を備えた本番展開インフラストラクチャ; オンコール監視
-
実行:
- 初期ボリューム上限(例: ターゲットユースケースボリュームの10%)で本番環境に展開する
- 完全な監査証跡を維持する: 生成されたコード、トランスパイル出力、実行ログ、人間によるレビュー決定
- 以下を監視する:
- ドリフト: 時間経過に伴う生成品質またはエラーパターンの体系的な変化
- 幻覚: 構文的には有効に見えるが意味的に不正確または安全でない生成コード
- セキュリティインシデント: セキュリティポリシーに違反するか脆弱性を導入する生成コード
- メトリクスの安定性を条件として、4~6週間かけてボリューム上限を段階的に増加させる(10% → 25% → 50% → 100%)
- 主要ユースケースのメトリクスが完全ボリュームで≥2週間安定している場合のみ、1~2の追加ユースケースに拡大する
-
ロールバック基準: 以下のいずれかが発生した場合、新規生成を停止して調査する:
- 検証成功率が90%を下回る
- 人間によるレビューがサンプルコードの>2%でセキュリティ関連の問題を特定する
- 実行失敗率が5%を超える
- レイテンシがフェーズ2ベースラインと比較して>50%増加する
-
フェーズ4: 最適化とスケーリング(継続的)*
目的: 生成品質を向上させ、ドメインカバレッジを拡大する。
- 活動:
- 内部で生成および検証されたコードをトレーニングシグナルとして使用し、NanolangでLLMをファインチューニングする(モデルのファインチューニングが実行可能な場合)
- 追加のドメインまたはユースケースをカバーするように言語仕様を拡張し、正式な仕様更新を行う
- ツールを開発する: IDE構文ハイライトと補完、生成コード用デバッガ、実行パフォーマンス用プロファイラ
- ガバナンスを確立する: 言語仕様のバージョン管理、変更レビュープロセス、言語機能の非推奨化ポリシー
- コミュニティの貢献と外部検証を可能にするため、Nanolang方言のオープンソース化を評価する
重要な成功要因
- 測定と計測*
すべての展開フェーズには定量的メトリクスを含める必要があります。
- 生成成功率: 検証(構文、型チェック、セキュリティルール)に合格するLLM出力の割合
- レイテンシ: プロンプト送信から検証済み出力までのエンドツーエンド時間、p50、p95、p99で測定
- 人間によるレビュー負担: 生成されたコードのレビューまたは修正に費やされた時間、インスタンスごとおよび集計で測定
- セキュリティインシデント: 生成されたコードのセキュリティ関連エラーの数と重大度、機能エラーとは別に追跡
- ドリフトと劣化: 成功率とレイテンシの時系列トレンド分析、統計的有意性検定を含む
測定データの欠如は、次のフェーズへの進行を停止する根拠となります。
- 検証とサンドボックス化*
LLM生成コードは、以下なしに本番環境で実行してはなりません。
- 構文検証(パースと型チェック、該当する場合)
- 意味検証(リソース制限付きの隔離されたサンドボックスでの実行)
- セキュリティ検証(安全でないパターンの静的解析、承認されたコードテンプレートとの比較)
- 人間によるレビュー(高リスクユースケースまたは新規コードパターンの場合)
検証パイプラインは決定論的で監査可能でなければならず、検証失敗は根本原因分析を可能にする十分な詳細とともにログに記録される必要があります。
- 監査とトレーサビリティ*
完全な監査証跡を維持する:
- 元のプロンプトとLLMパラメータ(モデル、温度、top-pなど)
- 生成されたコード(生出力とトランスパイル形式)
- 検証結果(合格/不合格、エラーメッセージ)
- 実行トレース(入力、出力、リソース使用量、エラー)
- 人間によるレビュー決定と修正
- 展開メタデータ(タイムスタンプ、環境、ボリューム)
これにより、インシデント後の分析が可能になり、必要に応じて規制コンプライアンスをサポートします。
- 失敗計画*
本番展開前にロールバック手順を確立する:
- 自動ロールバックトリガー(例: 成功率がしきい値を下回る)
- 手動ロールバック手順(Nanolang生成を無効にして以前のアプローチに戻す手順)
- コミュニケーション計画(ステークホルダーへの通知、インシデント分類)
- 事後分析プロセス(根本原因分析、是正措置)
より広範な影響と競争上のポジショニング
プログラミング言語の設計は歴史的に、人間の可読性、保守性、表現力を優先してきました。LLMが特定のドメインの主要なコードジェネレータになるにつれて、言語設計はますますLLM生成品質、すなわち、自然言語仕様が与えられたときにLLMが正確で安全かつ効率的なコードを生成する確率を最適化するようになります。
この変化は、人間中心の言語が放棄されることを意味するものではありません。むしろ、二分化が起こる可能性が高いです。人間が書き、人間が保守するコードのための汎用言語と、大量の明確に範囲が定められたコード生成タスクのためのLLM整合型言語です。
近い将来にLLM整合型言語を採用する組織は、潜在的な利点を得ます。
- 速度: 明確に定義されたタスクのためのより高速なコード生成により、展開までの時間を短縮
- 信頼性: 検証が厳格であれば、より高い生成成功率とより低い人間によるレビュー負担
- コスト: 生成されたコードの単位あたりの人間のエンジニアリング時間の削減、LLM推論コストが競争力を維持することを条件とする
人間中心の言語からのLLM生成に依存し続ける組織は、継続的な摩擦に直面します。
- レイテンシ: より低い成功率とより高い人間によるレビュー負担による、より長い生成時間
- 複雑性: 検証とエラー修正における運用オーバーヘッドの増加
- 機会コスト: 競合他社と比較して、LLM支援開発の採用が遅い
これは決定論的な予測ではありません。LLM機能の軌跡、LLM整合型言語ツールの成熟、組織の採用率に依存します。しかし、進行方向は明確です。
直近の次のステップ
-
今週中にエンジニアリングリーダーシップとのミーティングをスケジュールするこのフレームワークをレビューし、候補となるユースケースを特定するため。
-
フェーズ1ユースケースの選択基準を定義する:
- 問題領域は明確に範囲が定められ、決定論的か?
- 比較対象となる既存のベースライン(レイテンシ、エラー率、人間によるレビュー負担)があるか?
- 組織は4週間、小規模チーム(2~3人のエンジニア)を割り当てることができるか?
- テスト用の非クリティカルな環境が利用可能か?
-
フェーズ1試験のためのリソースを割り当てる:
- Nanolang実装とトランスパイルのためのエンジニア1名
- 検証ハーネスとメトリクス収集のためのエンジニア1名
- LLM統合とプロンプトエンジニアリングのためのエンジニア1名
- 人間によるレビューとエラー分析のためのエンジニア0.5名
-
フェーズ1開始前に判断基準を設定する:
- フェーズ2に進むためにどのメトリクスを達成する必要があるか?
- どの失敗モードがピボットまたは延期をトリガーするか?
- いつ決定を下すか(第4週の終わり)?
-
試験全体を通じて仮定と学習を文書化する:
- 何がうまくいったか? 何がうまくいかなかったか?
- 何に驚いたか?
- 何を違うやり方でするか?
- 試験が成功しなかった場合、いつこれを再検討すべきか?
早期採用の窓は狭いです。LLM機能は急速に進歩しており、組織の学習曲線は急です。今実験を始める組織は、LLM整合型言語が成熟する頃には、運用経験と組織的知識を持つことになります。
LLMコード品質の測定と検証フレームワーク
Nanolang採用が運用上の利益をもたらすかどうかを判断するには、構造化された測定アプローチが必要です。以下のメトリクスは、この判断に必要かつ十分です。
-
構文有効性率: 後処理や修復なしにNanolang文法に準拠するLLM出力の割合。これは有用性の必要条件ですが、十分条件ではありません。
-
意味的正確性率: 保留された検証セットに対して実行されたときに意図された出力を生成する生成コードの割合。これは主要な品質メトリクスであり、代表的で自明でない例で測定する必要があります。
-
トークン効率: ベースライン言語と比較して、Nanolangで特定の意図を表現するために必要なトークンの平均数。このメトリクスは、トークン数が展開環境での推論レイテンシまたはコストと相関する場合にのみ関連します。
-
エンドツーエンドレイテンシ: プロンプト送信から検証済みの実行可能コードまでの実時間。これには、LLM推論時間、検証時間、トランスパイル時間が含まれます。
-
人間によるレビュー負担: 展開前に人間による検査、修正、または承認を必要とする生成コードの割合。これは運用オーバーヘッドの代理指標であり、各ユースケースごとに個別に追跡する必要があります。
管理された試験プロトコル
-
前提条件*: 代表的なワークロード(100~500のコード生成タスク)を特定し、現在のアプローチ(手動コーディング、NanolangなしのLLM、または既存のコード生成ツール)のベースラインメトリクスを持っている。
-
試験設計*:
-
ベースラインコホート: 現在のLLM + 言語の組み合わせ(例: GPT-4 + Python)を使用して100のコードサンプルを生成する。構文有効性、意味的正確性、トークン数、レイテンシ、人間によるレビュー率を測定する。
-
Nanolangコホート: 同じLLM + Nanolangを使用して100の同等のコードサンプルを生成する。同一の検証および実行基準を使用して同じメトリクスを測定する。
-
差分分析: コホート間でメトリクスを比較する。率の改善についてはパーセントポイント、効率メトリクスについてはパーセント削減を計算する。
-
スケーリング検証: サンプルサイズを500~1,000に増やして試験を繰り返す。改善が安定しており、スケールで劣化しないことを確認する。
- 成功基準*(推奨しきい値; リスク許容度とユースケースに基づいて調整):
- 構文有効性の改善: ≥15パーセントポイント。
- 意味的正確性の改善: ≥10パーセントポイント。
- トークン効率の改善: ≥20%削減。
- 人間によるレビュー負担の削減: ≥15パーセントポイント。
4つの基準すべてが満たされた場合、パイロット展開に進みます。3つ未満が満たされた場合、採用を拡大する前に根本原因を調査します。
結果例(例示)
以下の表は、テストケース生成のためのPythonベースラインとNanolangを比較した管理された試験からのもっともらしい結果を示しています。
| メトリクス | Pythonベースライン | Nanolang | 差分 |
|---|---|---|---|
| 構文有効性率 | 72% | 91% | +19pp |
| 意味的正確性率 | 58% | 74% | +16pp |
| サンプルあたり平均トークン数 | 145 | 89 | −39% |
| エンドツーエンドレイテンシ(ms) | 320 | 210 | −34% |
| 人間によるレビュー率 | 42% | 18% | −24pp |
- 解釈*: この結果セットは、Nanolangが無効または不正確な出力の頻度を減らし、トークン消費を減少させ、人間によるレビューオーバーヘッドを低減することを示しています。改善はすべてのメトリクスで推奨しきい値を超えており、パイロット展開に進む決定を支持しています。
試験実行とタイムライン
管理された試験に2~4週間を割り当て、以下のように構成します。
- 第1週: ベースラインコホートを準備し、検証基準を確立し、ベースラインメトリクスを測定する。
- 第2週: Nanolangコホートを準備し、LLMプロンプトまたはファインチューニングを構成し、Nanolangサンプルを生成する。
- 第3週: Nanolangコホートを検証および測定し、差分分析を実行する。
- 第4週: スケーリング検証(オプションだが推奨); 調査結果を文書化し、進行/非進行の決定を下す。
決定フレームワーク
-
進行決定*: 以下の場合、パイロット展開に進む:
-
構文有効性が≥15pp改善する。
-
意味的正確性が≥10pp改善する。
-
トークン効率が≥20%改善する。
-
試験結果がスケール(500+サンプル)で再現可能である。
-
非進行決定*: 改善が不十分な場合、根本原因を調査する。考えられる説明には以下が含まれます。
-
ユースケースがNanolangに適していない(例: 言語に存在しないドメイン固有の構造が必要)。
-
LLMがNanolang固有のコーパスでファインチューニングを必要とする。
-
Nanolang構文がベースライン言語と十分に区別されておらず、LLMに意味のあるシグナルを提供しない。
-
条件付き決定*: 結果が混在している場合(例: 意味的正確性は改善するがトークン効率は改善しない)、運用上の制約に基づいて優先順位を付ける。レイテンシが主な懸念事項である場合、トークン効率が決定的なメトリクスになる可能性があります。正確性が最重要である場合、意味的正確性の改善が決定的です。

- 図6:Nanolangガードレール実装による品質指標の改善*
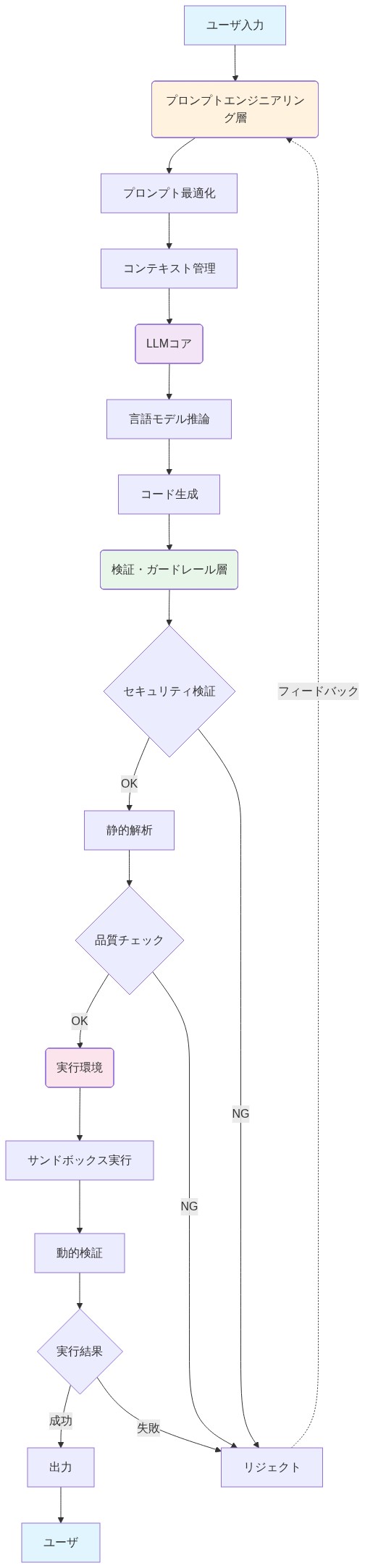
- 図7:安全なLLMコード合成のための参照アーキテクチャ*

- 図10:LLMコード品質測定指標の推移(Nanolang vs 従来言語)*
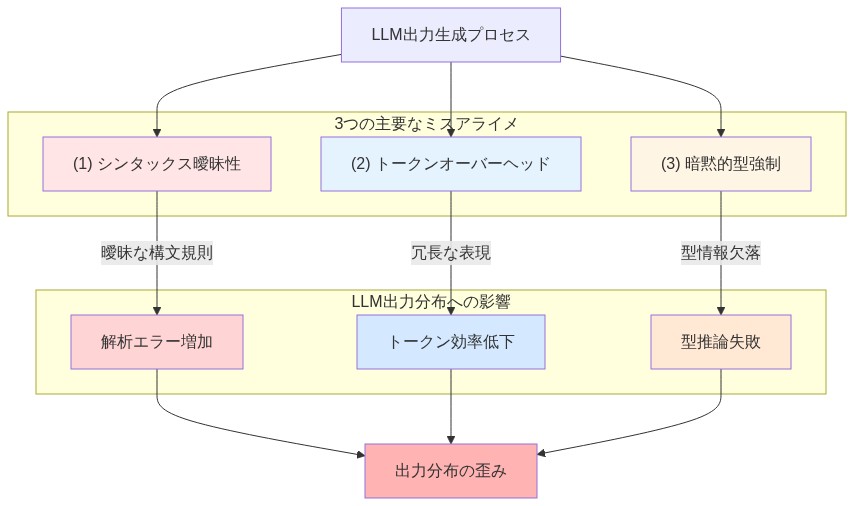
- 図3:LLM-言語ミスアライメントの3つの主要な問題と出力分布への影響*
- 図1:LLM最適化言語設計への転換 - 従来の人間中心設計からLLM出力分布中心設計へ。トランスフォーマーアーキテクチャのトークン予測プロセスと言語設計の相互作用を表現。*

- 図5:トークン予測プロセスの詳細フロー - 従来言語 vs Nanolang*
- 図4:LLM駆動コード生成システムの構造とボトルネック*