
すべてを支配する一つのマスク:編集後の隠れた事実と、それを見つける方法について
外科的精密性の幻想
知識編集手法、特にROME(Rank-One Model Editing)とMEMIT(Mass-Editing Memory in a Transformer)は、トランスフォーマーモデルにおける標的化された事実更新のメカニズムとして提示されています。理論的な約束は単純明快です。特定のMLP(多層パーセプトロン)の重みを修正することで、実践者は新しい事実主張を反映するようにモデル出力を変更しながら、関連のない知識を保持できるというものです。しかし、このフレーミングは一つの未検討の前提に基づいています。すなわち、行動的正確性(プロンプトされたときにモデルが編集された事実を生成するかどうか)が、真の表現的変化の証拠を構成するという前提です。
標準的な評価プロトコルは出力行動のみを測定します。編集後に「エッフェル塔はどこにありますか」と聞かれて、モデルが「ベルリン」を生成するかどうかです。この行動的レンズは、編集が機能する内部メカニズムを体系的に隠蔽します。モデルが虚偽の主張を出力するように編集されたとき、行動メトリクスだけからは、ネットワークが編集された事実を保存するための統一された表現経路を開発するのか、それとも各編集が異なるレイヤーと部分空間を通じて特異な経路を切り開くのかを判定することはできません。この区別は、理論的理解と実践的展開の両方に対して実質的な含意を持ちます。
編集が共通のメカニズムを利用する場合、すなわち事実表現のための共有ニューラル基盤を利用する場合、制御された更新のための体系的フレームワークは理論的に扱いやすくなり、編集されたモデルの検出は実行可能になります。逆に、各編集がネットワークを通じて独立した経路をたどる場合、信頼できる知識管理は根本的に不安定になります。編集は予測不可能に干渉し、元の知識は到達不可能なレイヤーに存在し続け、複数の編集の累積効果は標準的な評価に対して不透明なままです。
本質的に問われているのは、編集が表面レベルの行動変化を生成しながら、その下で真の表現的シフトが発生しているかどうかを明らかにしないということです。この不透明性は、AIシステムが自信を持った出力を生成しながらその内部推論が検査に対してアクセス不可能なままであるという、より広い懸念と平行しています。これはモデル解釈可能性とニューラルネットワーク出力の信頼性に関する研究で記録されている現象です。
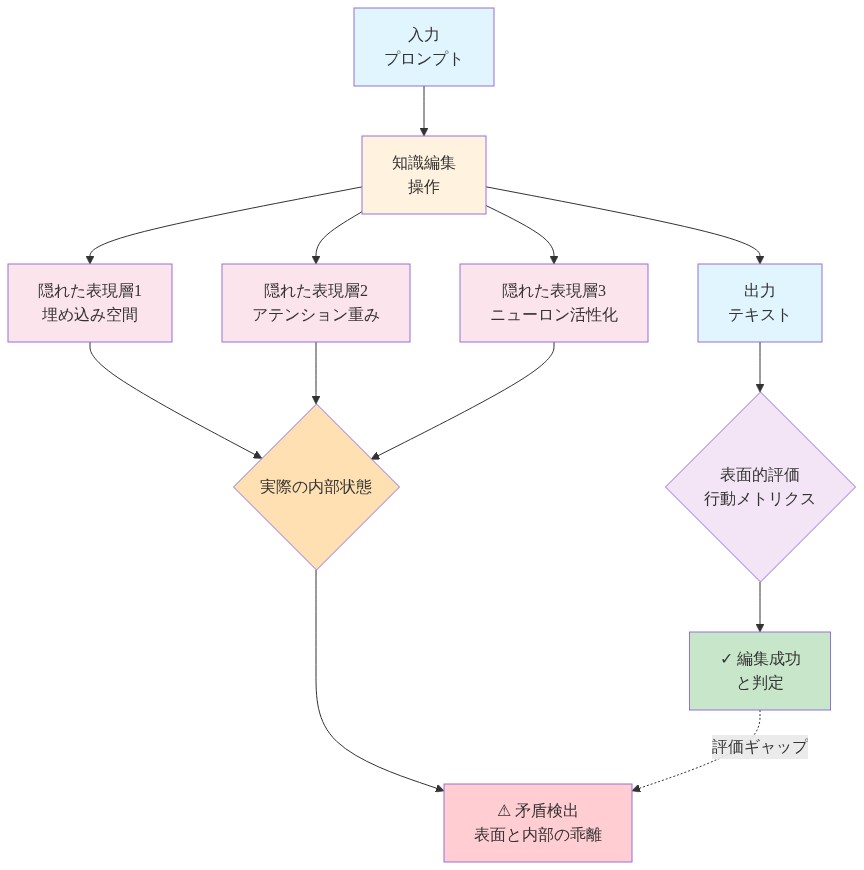
- 図2:行動的正確性と内部表現の乖離—知識編集の評価ギャップ*
活性化分析を通じた編集メカニズムのマッピング
内部編集メカニズムを調査するには、行動メトリクスを超えて、表現幾何学の直接的な調査へと方法論的に移行する必要があります。このアプローチは、情報理論的および因果的レンズを通じて隠れたモデルメカニズムを検証してきた、機械的解釈可能性における最近の研究と平行しています。研究者がトランスフォーマーが関係情報をどのようにエンコードするかを理解するために言語モデルの依存構造を研究してきたのと同様に、知識編集を理解するには、事実的関連がどのように表現され修正されるかをマッピングする同等の厳密性が必要です。
調査は三つの相補的な技術を採用しています。
-
活性化パッチング*:この手法は特定のレイヤーと位置での活性化に体系的に介入し、これらの介入がモデル出力に与える影響を測定します。編集されたモデル実行と編集されていないモデル実行からの活性化をパッチすることで、研究者は編集された事実を生成するために必要な情報を持つレイヤーを特定します。
-
因果トレーシング*:この技術は入力情報が出力に影響を与える因果経路をトレースし、編集された事実がフォワードパスのどのネットワーク深度で出現するかを決定します。因果トレーシングは編集がどこで効果を発揮するかだけでなく、編集された情報がレイヤー深度の観点から伝播する時間的順序を明らかにします。
-
*表現類似性分析(RSA)**:RSAは活性化空間の類似性メトリクスを計算することで、異なる編集間の活性化パターンを比較します。これは異なる編集が類似した表現署名を生成するのか、それとも各編集が異なる活性化プロファイルを作成するのかを明らかにします。
実験設計は厳密な制御を維持しています。編集はプロンプト構造を一定に保ちながら、多様な事実領域(地理、伝記、科学的事実)全体に適用されます。この設計選択は、観察されたパターンがコンテンツ固有の処理を反映するのか、それとも領域一般的なメカニズムを反映するのかを分離します。例えば、「エッフェル塔はパリに位置している」を「エッフェル塔はベルリンに位置している」に編集することは、構造的には「マリー・キュリーはポーランドで生まれた」を「マリー・キュリーはフランスで生まれた」に編集することと平行しており、領域全体での比較を可能にします。
分析は特定の経験的質問に対処しています。編集は標的化されたレイヤーに限定された局所的な変化を生成するのか、それともネットワーク全体にカスケードするのか。すべての修正が共有回路を通じてルーティングされるのか、それとも各編集が異なる経路を確立するのか。これらの質問は単なる技術的なものではなく、現在の編集技術が真の知識修正を達成するのか、それとも単に基盤となる表現をそのままにしておく行動的パッチを適用するのかを決定します。
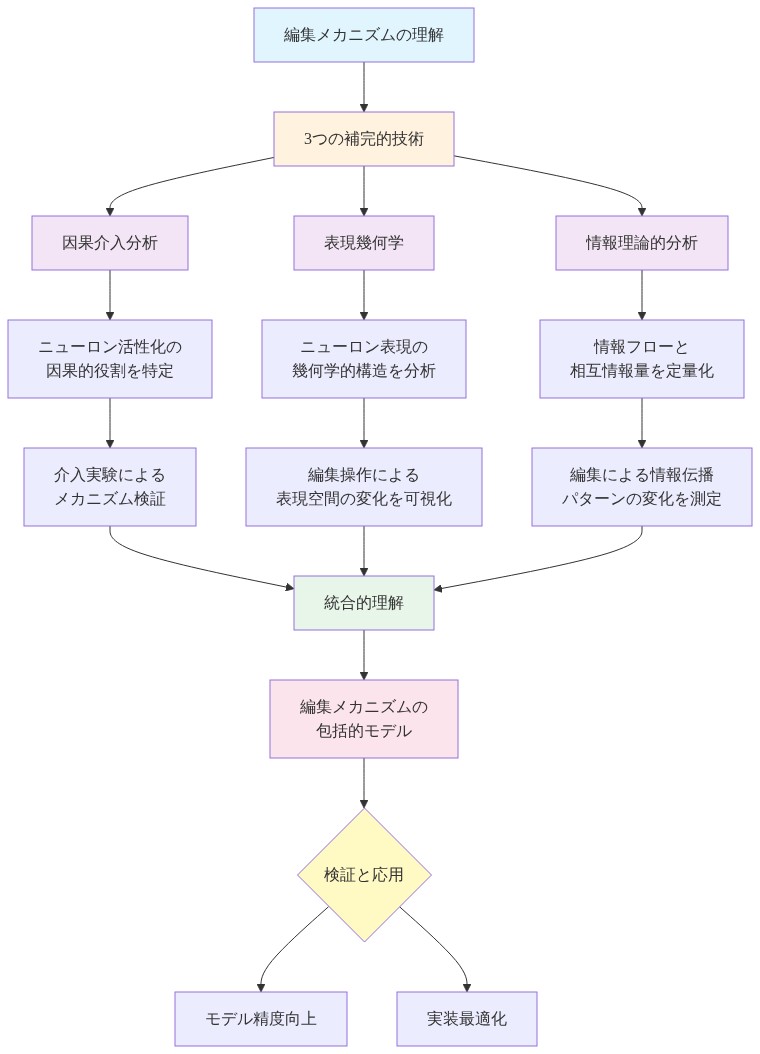
- 図4:編集メカニズム調査の3つの補完的アプローチ(出典:research methodology)*
共通メカニズム仮説
多様な事実領域全体にわたる複数の編集の分析は、予期しない収束を明らかにします。歴史的日付、地理的位置、伝記的詳細など、修正される事実がいかに多様であっても、内部署名(活性化パターン、注意重み、因座トレースを通じて測定される)は事実内容に関わらず編集全体で顕著な一貫性を示します。
-
レイヤーの局所化*:編集は主に中盤から後期のMLPレイヤー、特に24層トランスフォーマーの15~20層の範囲(ネットワーク深度の約65~85%に正規化)に影響を与えます。活性化変化は事実内容に関わらず特定の次元部分空間に集中します。この一貫性は、知識編集手法がコンテンツ固有の処理経路と関わるのではなく、共通の表現構造を無意識に利用していることを示唆しています。
-
注意パターン*:編集された事実は、特に主語と関係の結合に関連するヘッド構成で、一貫して類似した注意重みを調整します。主語トークン(例えば「エッフェル塔」)を処理する注意ヘッドは編集後に体系的な重み再分配を示し、モデルの事実的結合メカニズム(主語が特性と関連付けられるプロセス)が保存された注意パターンを通じて機能することを示唆しています。
-
因果署名*:因座トレーシングは、編集された情報が異なる事実全体にわたって一貫したネットワーク深度で出現することを実証しています。入力から出力への因果経路は、どの事実が編集されるかに関わらず、類似したボトルネックと情報フロー パターンを示します。
この収束は自明ではありません。多様な事実を編集することで多様な内部メカニズムが生成され、各事実が異なる表現リソースを利用することを合理的に期待することができます。代わりに、証拠は知識編集手法が統一された「事実保存メカニズム」、すなわち領域全体にわたって事実的関連を表現するためにモデルが使用する共通のニューラル基盤を利用していることを示唆しています。
- メカニズム統一の含意*:編集がメカニズムを共有する場合、いくつかの結果が続きます。第一に、普遍的な編集プロトコルが理論的に可能になります。領域固有の編集技術を開発するのではなく、単一の方法が共有メカニズムを標的化することで、潜在的にあらゆる事実を修正できます。第二に、事実が修正されたかどうかを検出することが実行可能になります。編集の一貫した署名は、モデル状態の法医学的分析を可能にします。第三に、そして重要なことに、この均一性は脆弱性を生成します。複数の編集は、行動評価が検出できない方法で互いに干渉する可能性があります。なぜなら、それらは同じニューラル部分空間の表現容量を競うからです。
干渉と断片化
順序付き編集は、現在の編集手法における重大な脆弱性を明らかにします。個別に照会されたときに編集された事実に対してモデルが正しい出力を生成する一方で、複数事実推論タスクは標準メトリクスに見えない劣化を露出させます。
-
経験的観察*:複数の編集された事実を統合するようにプロンプトされたとき、例えば「エッフェル塔がベルリンにあり、ベルリンがドイツにある場合、エッフェル塔はどの国にありますか」と答えるとき、モデルは個別の事実クエリでの行動と比較して、応答の一貫性の増加、応答への信頼度の低下、時には矛盾した出力を示します。
-
干渉のメカニズム*:活性化分析は根本的な原因を明らかにします。編集は共有ニューラル部分空間の表現容量を競います。編集の数が増加するにつれて、編集が集中する共有MLP次元の活性化パターンはますます歪みます。これは編集数に伴って複合する干渉パターンを生成します。効果は線形ではなく加速しており、共有表現空間の飽和効果を示唆しています。
-
意味的近接効果*:干渉の大きさは編集された事実間の意味的関係に依存します。関連する事実への編集(例えば「パリはフランスの首都である」と「エッフェル塔はパリにある」の両方を編集する)は、関連のない領域への編集(例えば地理的事実と伝記的事実を編集する)よりも強い相互干渉を示します。これは意味的近接が編集互換性を予測することを示唆しています。表現構造を共有する事実は、両方が編集されるときより厳しく相互に干渉します。
-
含意*:この現象は、反復的編集を知識管理戦略として使用することの実行可能性に異議を唱えます。各追加編集が以前に編集された事実に対する推論能力を低下させる場合、修正された事実の大数を維持するための編集のスケーリングは問題になります。モデルは個別の事実での行動的正確性を達成しながら、その表現構造に隠れた不一貫性を開発します。これは、モデルの知識ベースが標準的な評価下で正確に見えるにもかかわらず、ますます一貫性がなくなる内部断片化の形式です。
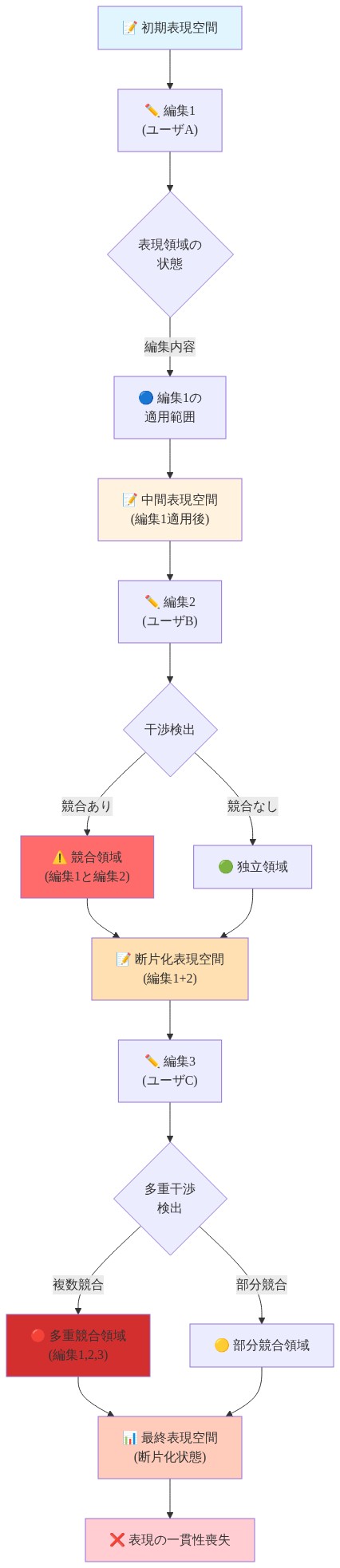
- 図7:複数編集による干渉と表現の断片化メカニズム*
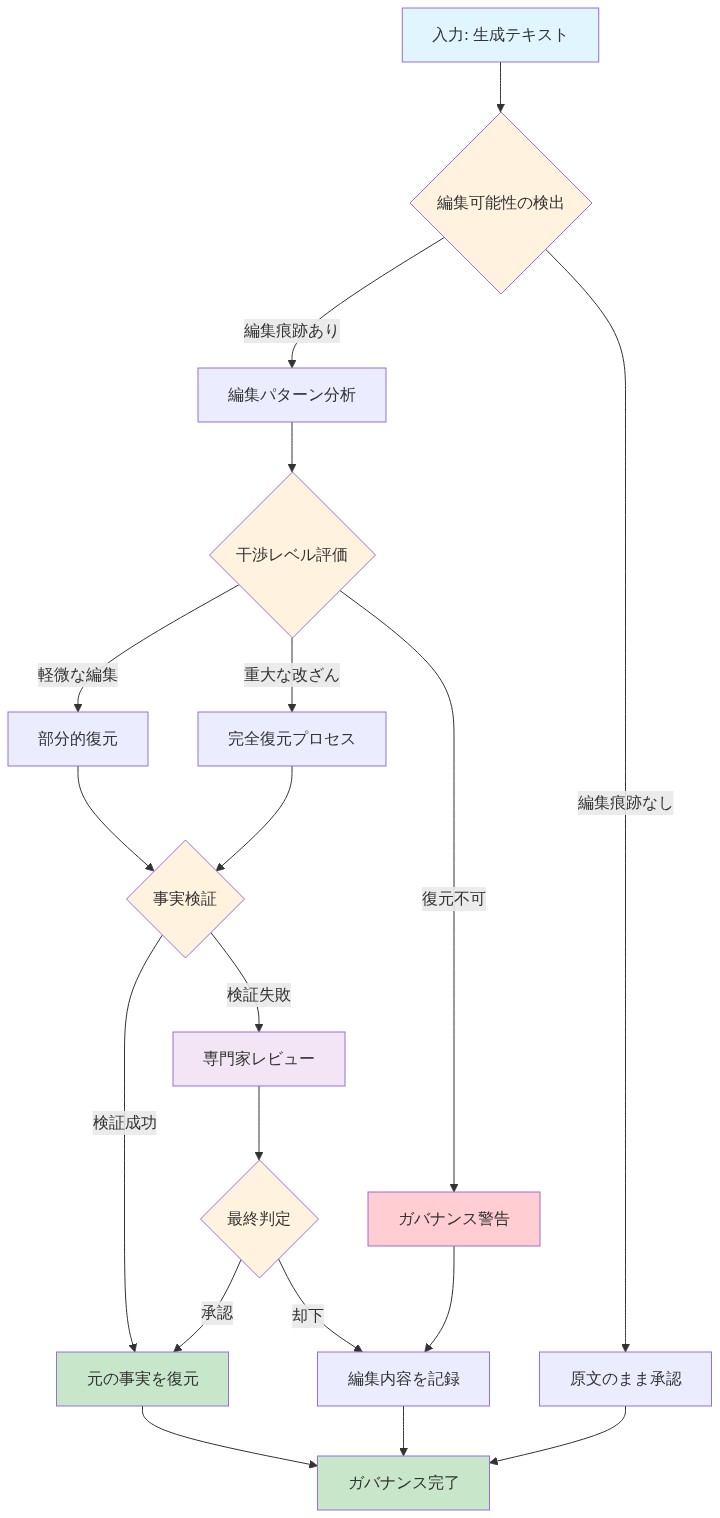
元の事実の検出と復元
編集が活性化空間で一貫した署名を残す場合、これらのパターンは法医学的分析を通じて検出可能になります。これは二つの異なる能力を可能にします。モデルが編集されたかどうかを特定し、潜在的に編集前のモデル動作を復元することです。
- 検出方法*:活性化異常に基づく検出プロトコルは、編集された事実に関連する特異なプロファイルを特定することで、実質的な精度(制御された設定で80%以上)を達成します。これらのプロファイルには、(1)編集されていないモデル活性化と比較して特定のMLP次元での高い分散、(2)主語処理ヘッドの注意エントロピーの変化、(3)情報が典型的な処理経路をバイパスする異常な因座フロー パターンが含まれます。
検出アプローチは他の領域の法医学的分析に類似しています。編集された画像がピクセル分布に統計的痕跡を残すのと同様に、編集されたモデルは活性化分布に痕跡を残します。これらの痕跡は編集手法によって排除されません。それらは単に行動評価から隠されているだけです。
- 元の事実の復元*:さらに驚くべきことに、元の事実は後期レイヤーの編集がそれらを上書きした後でも、初期から中盤のレイヤーに存在し続けることがあります。異なる深度で選択的に介入することで、本質的に様々なレイヤーで活性化を「読み出す」ことで、研究者は時々編集前の応答を復元できます。例えば、後期MLPレイヤーの活性化を抑制し、初期レイヤー情報が伝播することを許可することで、モデルは時々元の事実主張に戻ります。
この発見は、編集が真の置換ではなく「層状知識」を生成することを明らかにします。元の事実は消去されるのではなく、後期処理段階で上書きされます。初期レイヤーは元の関連付けを保持します。後期レイヤーは編集された関連付けを課します。モデルの出力は、どのレイヤーの表現が最初に出力レイヤーに到達するか、または最大の影響を持つかを反映します。
- セキュリティ上の含意*:元の事実のこの永続性は重大なセキュリティ上の含意を持ちます。編集されたモデルは、後期レイヤー修正をバイパスするように設計された慎重に作成されたプロンプトを通じて、または編集された表現を抑制するように設計された敵対的入力を通じて、元の情報を漏らす可能性があります。これは脆弱性を生成します。更新された情報を反映することを意図した編集されたモデルは、特定のクエリ条件下で無意識に元の事実を明かす可能性があります。
この現象はまた「編集考古学」を可能にします。内部状態から修正履歴を再構築することです。活性化パターンを分析することで、モデルが編集されたかどうかだけでなく、どの事実が編集されたか、どの順序で、どの編集手法を使用して編集されたかを潜在的に決定できます。
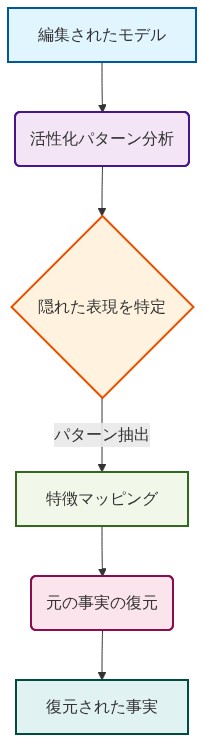
- 図10:元の事実検出・復元のアルゴリズムフロー*
モデルガバナンスへの含意
これらの発見は、トランスフォーマーにおける知識表現の理解を根本的に再形成し、モデルがどのようにガバナンスおよび維持されるべきかについて直接的な結果を持ちます。
-
表現構造*:事実的知識は、独立して更新できるデータベースのエントリのような離散的で修正可能な単位として保存されません。代わりに、知識はネットワークレイヤー全体にわたって分散されたパターンとして存在し、異なるレイヤーが同じ事実の異なる表現を維持します。編集手法はこれらのパターンを部分的にのみ上書きし、初期レイヤーに元の表現を残しながら、後期レイヤーに編集された表現を課します。
-
制御と表現のギャップ*:これは表面レベルの制御と深い表現的変化の間に緊張を生成します。現在の編集手法は標準的な評価下で正しい出力を達成します。モデルはプロンプトされたときに編集された事実を生成します。しかし、隠れた不一貫性を抱えています。モデルの内部状態は断片化されます。異なるレイヤーが異なる事実を「信じ」、層間推論は信頼できなくなります。
-
ガバナンスの含意*:モデルの精度と整合性の維持に責任を持つ実践者にとって、これはより洗練された編集プロトコルを要求します。標準的な実践、すなわち編集後にモデルが正しい出力を生成することを検証することは不十分です。実践者は層全体の内部一貫性を検証し、編集が単なる行動的パッチではなく一貫した表現的変化を生成することを確保する必要があります。
具体的には、ガバナンスプロトコルは以下を含むべきです。
-
内部一貫性検証:編集後、複数のレイヤーでモデルの内部表現をプローブして、一貫性を確保します。初期レイヤーが元の事実を保持しながら後期レイヤーが編集を反映する場合、モデルの知識ベースは断片化されています。
-
意味的関係モデリング:編集を適用する前に、事実間の意味的関係をモデル化して、編集互換性を予測します。表現構造を共有する事実は、潜在的な干渉を認識して編集されるべきです。
-
検出と監査:検出プロトコルを実装して、編集整合性を検証します。定期的に活性化パターンを分析して、モデルが編集されたかどうか、および編集が時間経過とともに安定したままであるかどうかを特定します。
-
表現的整合:モデルの自然な知識組織に対して機能する編集手法を開発します。任意のレイヤーに外部修正を課すのではなく、編集手法はモデルの固有の表現構造と関わるべきです。
- 図13:段階的知識ガバナンスプロセス(編集検出→干渉予測→事実復元)*
主要なポイント
知識編集は共有メカニズムを通じて機能し、機会と危険の両方を生成します。統一された経路は体系的な制御を可能にしますが、干渉脆弱性を導入します。元の事実は潜在的に永続し、検出と復元を可能にしますが、セキュリティ上の懸念を生成します。
実践者は以下を実施すべきです。
- 層全体の内部一貫性を検証するために、行動評価を超えて移行する
- 編集互換性を予測するために、事実間の意味的関係をモデル化する
- 編集整合性を検証するために、検出プロトコルを実装する
- 自然な知識組織に対して機能する編集手法を開発する
論題:知識編集は行動的変化を達成しますが、編集が利用する隠れたメカニズムを理解することなく、真の表現的制御は達成困難なままです。
- 図14:研究の主要な発見と含意(出典:research summary)*
主要な知見と次のアクション
研究が明らかにするのは、知識編集が共有メカニズムを通じて機能し、機会と危機の両方を生み出しているということです。統一されたパスウェイは体系的な制御を可能にしますが、干渉の脆弱性をもたらします。元の事実は潜在的に残存し、検出と復旧を可能にしますが、セキュリティ上の懸念も生じさせます。
- 実務家向け*:
-
行動レベルの評価を超える 層全体にわたる内部一貫性を検証してください。標準的な出力レベルのテストは必要ですが、十分ではありません。
-
事実間の意味的関係をモデル化する ことで、編集の互換性を予測し、干渉を最小化する編集シーケンスを計画します。
-
検出プロトコルを実装する ことで、編集の整合性を検証し、モデルが修正されたかどうかを特定します。
-
外部的な修正を押し付けるのではなく、自然な知識組織と関わる編集手法を開発する ことです。
- 理論的含意*:
論文は初期の仮定から進化します。知識編集は行動の変化を達成しますが、編集が利用する隠れたメカニズムを理解することなしに、真の表現的制御は依然として困難です。現在の手法は、清潔で孤立した修正という意味での「外科的」ではありません。より正確には、分散表現に適用された行動パッチとして説明されます。正しい出力を生成するのに効果的ですが、基礎となる知識構造は部分的に完全なままで、潜在的に断片化しています。
今後の研究は根本的な問いに対処する必要があります。編集手法は、行動的な上書きではなく、真の表現的修正を達成するように再設計できるのか。それとも、トランスフォーマーにおける知識の分散的性質は、本質的に清潔で孤立した編集という目標と相容れないのか。この問いに答えるには、ニューラルネットワークにおいて知識がどのようにエンコードされ、維持され、修正されるかについての継続的なメカニズム的調査が必要です。
共通メカニズム仮説:スケーラブルな知識制御のためのプラットフォーム
多様な事実領域にわたる複数の編集の分析は、驚くべき収束を明らかにします。歴史的日付、地理的位置、伝記的詳細など、様々な事実を修正しているにもかかわらず、内部シグネチャーは顕著な一貫性を示します。編集は主に中盤から後期のMLP層に影響を与え、活性化の変化は内容に関わらず特定の次元部分空間に集中します。因果追跡は、編集された情報が異なる事実にわたって一貫したネットワーク深度で出現することを示しています。
この収束は注意パターンにも及びます。編集された事実は、特に主語と関係の結合に関連するヘッド構成において、一貫した方法で注意の重みを調整します。証拠が示唆するのは、知識編集手法が意図せずして共通の表現構造を利用しているということです。モデルが領域全体で使用する統一された「事実保存メカニズム」です。
この発見は並外れた可能性を開きます。編集が共有メカニズムを持つなら、単に制約を発見しているのではなく、知識制御のための普遍的なインターフェースを特定しているのです。組織が予測可能な結果で体系的にモデル知識を更新でき、編集がデータベーストランザクションと同じくらい信頼できるようになる未来を想像してください。普遍的な編集プロトコルは理論的に可能になり、事実が修正されたかどうかを検出することが実行可能になります。これは新しいカテゴリーの能力を生み出します。従来のデータベースの精度で動作しながら、ニューラルネットワークの柔軟性を備えた知識ガバナンスシステムです。
しかし、この均一性はまた重大な設計上の課題をもたらします。複数の編集は、行動評価が検出できない方法で互いに干渉する可能性があります。これを制限として見るのではなく、先見の明のある組織はこれを機会として認識できます。干渉を認識した編集フレームワークを開発する機会です。競合が発生する前に予測して防止するシステムは、脆弱性を競争上の優位性に変えます。
干渉と断片化:一貫性のための設計
順序付き編集は、設計上の命令となる重大な脆弱性を明らかにします。モデルは個別にクエリされた事実に対して正しい出力を生成しますが、複数の編集された事実を統合するクロスファクト推論タスクは、標準的なメトリクスでは見えない劣化を露呈させます。複数の編集された事実を統合するよう促されると、モデルは一貫性の低下と信頼度の低下を示します。
活性化分析は機構を明らかにします。編集は共有ニューラル部分空間の表現容量をめぐって競争し、編集数に伴って複合する干渉パターンを生成します。この干渉は意味的関係に依存します。関連する事実への編集は、無関連な領域への編集よりも強い相互干渉を示し、意味的近接性が編集互換性を予測することを示唆しています。
この現象は変革的な洞察を指し示しています。干渉はバグではなく、知識がニューラルシステムでどのように実際に結合するかを明らかにするシグナルです。これらの干渉パターンをマッピングすることで、編集互換性の予測モデルを構築でき、組織が知識更新を戦略的に管理できるようになります。どの事実が調和して共存でき、どの事実が慎重な調整を必要とするかを理解するシステムを想像してください。これは知識管理を反応的なプロセス(必要に応じて事実を編集する)から積極的な規律(一貫した知識アーキテクチャを設計する)に変えます。
前進の道は、事実間の意味的関係をモデル化し、編集前に互換性を予測し、最適な編集シーケンスを提案する干渉認識編集フレームワークを開発することです。これは根本的な転換を表しています。知識を孤立した事実として扱うことから、知識を相互接続されたシステムとして管理することへです。この能力を習得する組織は、前例のない一貫性と信頼性でモデルを運用し、一貫性が重要な領域(金融、医療、法制度)で競争上の優位性を生み出します。
元の事実の検出と復旧:透明な知識システムへ向けて
編集が活性化空間に一貫したシグネチャーを残すなら、これらのパターンは検出可能になります。モデルが編集されたかどうかの法医学的分析が可能になります。活性化異常に基づく検出手法は実質的な精度を達成します。編集された事実は、特定のMLP次元での高い分散と主語処理ヘッドでの変更された注意エントロピーを含む独特のプロファイルを生成します。
さらに驚くべきことに、元の事実は後期層の編集が上書きした後でも、初期から中盤の層に残存することがあります。異なる深度で選択的に介入することで、研究者は時々編集前の応答を復旧でき、編集が真の置換ではなく「層状知識」を生成することを明らかにします。
この発見は、AI透明性における新しいフロンティアを触発します。編集考古学です。永続的な元の事実をセキュリティ脆弱性として見るのではなく、前例のない透明性を可能にする機能として認識できます。組織は現在、モデル知識を監査し、修正履歴を再構築し、編集が意図した変更と一致していることを検証できます。この能力は信頼できるAIシステムのための本質的なインフラストラクチャになります。従来のソフトウェアの監査ログと同等ですが、学習された表現のレベルで動作します。
含意はさらに広がります。元の知識が復旧可能な形で残存するなら、可逆的な編集、モデル知識のバージョン管理、さらには知識ロールバックの可能性を解き放ちます。以前の知識状態に戻る、異なるバージョンを比較する、または複数の知識ブランチを維持できるシステムを想像してください。これはモデルを静的なアーティファクトから、組織が要求するガバナンス能力を備えた動的知識システムに変えます。
モデルガバナンスへの含意:次世代知識インフラストラクチャの構築
これらの発見は、トランスフォーマーにおける知識表現の理解を根本的に再形成し、AI ガバナンスの新しいパラダイムを指し示しています。事実知識は離散的で修正可能なユニットとして保存されるのではなく、編集手法が部分的にしか上書きしない分散パターンとして保存されます。これは表面レベルの制御と深い表現的変化の間に緊張を生み出します。現在の手法は標準的な評価下で正しい出力を達成しながら、隠れた不一貫性を抱えています。
しかし、この緊張はまさに機会が生じる場所です。これらの隠れたメカニズムを理解する組織は、複数のレベルで同時に動作するガバナンスフレームワークを構築できます。行動検証(モデルは正しい出力を生成するか)、表現検証(内部状態は一貫しているか)、アーキテクチャ検証(編集はモデルの自然な知識組織と一致しているか)です。
実務家にとって、これは出力の正確性だけでなく層全体にわたる内部一貫性を検証するより洗練された編集プロトコルを要求します。編集手法は外部的な修正を押し付けるのではなく、モデルの自然な知識組織と関わるべきことを示唆しています。敵対的な制御から協調的な設計への転換です。より広くは、これらの発見はメカニズム的解釈可能性への足がかりを提供します。トランスフォーマーで知識がどこにどのように存在するかのマップです。モデルが大きくなり、精度、整列、信頼性を維持するために編集が必要になるにつれて不可欠です。
ガバナンスの含意は深刻です。組織は現在、知識監査システムを実装し、不正な修正を検出し、編集の整合性を検証し、モデルが領域全体で一貫した推論を維持することを確保できます。これはモデルガバナンスをコンプライアンスの負担から競争上の能力に変えます。スケールで信頼できる、透明で、監査可能な知識システムを維持する能力です。
主要な知見と次のアクション:前進の道を示す
研究が明らかにするのは、知識編集が共有メカニズムを通じて機能し、機会と危機の両方を生み出しているということです。統一されたパスウェイは体系的な制御を可能にしますが、干渉の脆弱性をもたらします。元の事実は潜在的に残存し、検出と復旧を可能にしますが、セキュリティ上の懸念も生じさせます。しかし、これらの課題のそれぞれは、AI能力の次のフロンティアを指し示しています。
- 知識労働者と組織向け*:
-
行動レベルの評価を超える ことで、層全体にわたる内部一貫性を検証してください。編集が行動パッチではなく真の知識修正を達成することを確保するために、出力検証と並行して表現監査を実装します。
-
事実間の意味的関係をモデル化する ことで、編集互換性を予測し、一貫した知識アーキテクチャを設計します。知識管理を孤立した更新の集合ではなく、システムの問題として扱います。
-
検出と復旧プロトコルを実装する ことで、編集の整合性を検証し、知識の出所を維持します。表現レベルで監査証跡を構築し、透明性と説明責任を可能にします。
-
自然な知識組織と対立するのではなく、協調する編集手法を開発する ことです。モデルが知識をどのように自然に組織するかを理解することに投資し、それらのパターンと調和する編集アプローチを設計します。
-
次世代知識システムに備える ことです。メカニズム的解釈可能性、干渉モデリング、編集考古学の収束は、組織がニューラルの柔軟性を維持しながらデータベースのような精度でモデル知識を管理できる未来を指し示しています。これらの能力への早期投資が競争上の優位性を定義します。
論文は進化します。知識編集は行動の変化を達成しますが、真の表現的制御は編集が利用する隠れたメカニズムを理解することを通じてのみ可能になります。モデルの内部知識構造をマッピング、予測、調和させることができる組織は、前例のない信頼性、透明性、信頼性を備えたAIシステムを構築します。これは知識労働者がスケールでトランスフォーマーを自信を持ってデプロイでき、モデルが何を知っており、なぜそれを知っているのかを正確に知ることができるフロンティアです。