
品質か量か?マルチエージェントシステムにおけるガウス過程を用いた誤差情報に基づく選択的オンライン学習:拡張版
コンセンサスよりも協調:分散システムにおいて選択的学習が重要な理由
-
主張:* 効果的な分散学習には、エージェントが包括的にではなく選択的に協調することが必要である。隣接するすべてのモデルを無差別に集約すると、予測精度が低下し、対応するパフォーマンス向上なしに計算リソースの消費が増加する。
-
根拠と前提:* マルチエージェントシステムは従来、利用可能なすべてのエージェントからの予測を集約することで、アンサンブル効果を通じて集合的な成果が向上すると仮定している。この仮定は、すべてのエージェントモデルが同等の品質と較正を維持するという条件下で成立する。しかし、この前提条件は実際には頻繁に満たされない。エージェントモデルが予測品質に大きなばらつきを示す場合—これは異質な訓練データ、センサーの劣化、またはアルゴリズムの違いから生じる—低品質の予測の集約は、共同推定を損なう系統的ノイズを導入する(Kuncheva & Whitaker, 2003; Krogh & Vedelsby, 1995)。従来のコンセンサスメカニズムはすべての予測を等しく重み付けし、高誤差予測器を信頼性の高いものと同一に扱うため、証拠重み付け推論の原則に違反する。
-
具体例:* 10台の機械にわたる産業振動シグネチャを監視する分散センサーネットワークを考える。9つのセンサーは較正を維持し、信号範囲の2〜3%の平均絶対誤差(MAE)で予測を生成する。1つのセンサーはドリフトを経験し、12〜15%のMAEで予測を生成する。等重みコンセンサス集約は約3.5〜4.2%の複合MAEをもたらし、9センサーサブセット単独と比較して15〜20%の劣化を表す(仮定:等重み付け下での線形誤差伝播;実際の劣化は相関構造に依存)。ドリフトしたセンサーを選択的に除外すると、複合MAEは2.5〜3.0%に回復し、追加のデータ収集なしでパフォーマンスが回復する。
-
実行可能な示唆:* 代表的な評価ウィンドウ(最低100観測)にわたってエージェントごとの予測誤差メトリクス(MAE、RMSE、またはタスク固有の損失)を文書化することで、現在のマルチエージェントアーキテクチャを監査する。誤差分布の75パーセンタイルを一貫して超えるエージェントを特定する。集約前にこれらのエージェントを除外または重み付けを下げるフィルタリングメカニズムを実装する。精度回復を定量化する;典型的な利得は、誤差分散と集約方法に応じて10〜30%の範囲である(仮定:選択的フィルタリングが測定可能な利得をもたらすには、平均誤差の>20%の誤差分散が必要)。
誤差情報に基づく選択:重要なものを測定する
-
主張:* エージェントは、ローカルな予測誤差観測を使用してピアモデルの品質を自律的に評価でき、集中評価インフラストラクチャなしでリアルタイムの選択的協調を可能にする。
-
根拠と前提:* 各エージェントは、遅延τで真値が利用可能になったときに自身の予測誤差を観測する(τは観測ラグであり、通常は1つ以上の学習サイクル)。このローカル誤差信号には、相関分析を通じて隣接モデルの信頼性に関する情報が含まれている。隣接予測とその後観測された誤差との対応を追跡することで、エージェントはどの協力者が信頼できるガイダンスを生成するかを推定できる。このメカニズムは、集中テストセット、ラベル付き検証データ、外部仲裁者を必要とせず、ローカル観測とピアツーピア通信のみを必要とする。
-
重要な仮定:* このアプローチは、予測誤差がモデル品質について情報を提供し、時間を通じた誤差相関が選択決定をサポートするのに十分安定していると仮定する。これは、基礎となるデータ分布が定常であるか、ゆっくりとドリフトする場合(学習サイクルあたりのドリフト率<5%)に成立する。急速な分布シフト下では、誤差ベースの選択は真の品質変化に遅れる可能性がある。
-
具体例:* 自律走行車の車群が10秒の計画ホライズンの軌道予測を共有する。車両Aは各タイムステップで車両B、C、Dから予測を受信する。100タイムステップにわたって、AはBの予測が平均0.3 m誤差、Cが平均0.8 m、Dが平均0.2 mであることを観測する。Aはローリング誤差ウィンドウ(最後の50観測)を計算し、75パーセンタイル(0.65 m)で選択閾値を設定する。Aは次のモデル更新でBとDに重く重み付けし、Cの優先度を下げる。タイムステップ101でCのセンサーが再較正されると、Cの誤差は10〜15観測以内に0.25 mに低下し、Aは自動的にCの重みを上げる。この適応には手動介入や外部信号は不要である。
-
実行可能な示唆:* 各エージェントペア(i、j)の誤差追跡を実装する。ここでiはjの予測を観測する。各タイムステップtで予測誤差e_{i,j}(t)を記録する。ウィンドウw(推奨:w = 50観測または5〜10学習サイクル)にわたってローリング平均誤差μ_{i,j}(t) = mean(e_{i,j}(t-w:t))を計算する。すべての隣接者にわたるμ_{i,j}の75パーセンタイルで選択閾値θを設定する。μ_{i,j}(t) < θの場合、隣接者jをエージェントiの集約に含める。ドリフトに対応するために10〜20学習サイクルごとにθを更新する。異常を検出するために選択決定をログに記録する(例:隣接者の>50%が除外された場合、データ品質または閾値較正を調査)。
分散誤差情報ガウス過程:フレームワーク
-
主張:* ガウス過程(GP)は、予測とともに較正された不確実性推定を出力するため、追加の計算オーバーヘッドなしで誤差認識協調を可能にし、選択的オンライン学習のための原理的な確率論的基盤を提供する。
-
根拠と前提:* GPは、観測データDが与えられた関数上の事後分布p(f|D)を定義する。任意のクエリ点xに対して、GPは平均μと分散σ²を持つ予測分布N(μ(x), σ²(x))を出力する。分散σ²は認識的不確実性(モデル不確実性)と偶然的不確実性(観測ノイズ)を定量化し、原理的な信頼度測定を提供する。エージェントがGPモデルを共有する場合、受信者は予測と不確実性境界の両方を検査できる。高い分散σ²を持つ隣接者の予測は、厳密な信頼区間を持つものよりも低い重みを保証し、外部仲裁なしでローカル選択決定を可能にする。
-
重要な仮定:* このフレームワークは、GP分散が適切に較正されていること、つまり信頼区間の経験的カバレッジが名目カバレッジと一致すること(例:観測の95%が2σ境界内に収まる)を仮定する。これは、正しく指定されたカーネルで定常データに対して訓練されたGPに対して成立する。誤って指定されたカーネルまたは非定常データは、過信または過小信頼の予測を生成し、選択品質を低下させる。
-
具体例:* 2つのエージェントが建物内の室内温度を予測する。エージェント1のGPは、Matérn 5/2カーネルで500観測に対して訓練され、22.0°C ± 0.5°C(狭い信頼帯域、高較正)を予測する。エージェント2のGPは、二乗指数カーネルで100観測に対して訓練され、22.5°C ± 3.0°C(広い帯域、低信頼または疎な訓練データ)を予測する。分散重み付け平均を使用してこれらの予測を融合する場合、エージェント1の予測は重みw₁ = σ₂²/(σ₁² + σ₂²) ≈ 0.97を受け取り、エージェント2はw₂ ≈ 0.03を受け取る。エージェント2のセンサーが劣化する場合(例:較正ドリフト)、予測が観測データから乖離するにつれて事後分散が自動的に広がり、明示的な除外ロジックなしで共同推定への影響が減少する。
-
実行可能な示唆:* 点推定モデル(例:不確実性定量化のないニューラルネットワーク)から、GP、ベイジアンニューラルネットワーク、または較正された不確実性を出力するアンサンブル法などの確率論的モデルに移行する。エージェントが予測を交換する際、平均μと分散σ²(または信頼区間)の両方を送信する。重み付け融合を実装する:ŷ_fused = Σ_j w_j ŷ_j ここでw_j = 1/(σ_j² + ε)、ε = 0.01 × mean(σ²)はゼロ除算と数値不安定性を防ぐ。保留データで較正を検証する:68%および95%信頼区間の経験的カバレッジを計算し、名目カバレッジと比較する。カバレッジが>5%逸脱する場合、異なるカーネルで再訓練するか、訓練データを増やす。
実装と運用パターン
-
主張:* 選択的学習は、エージェントが集中調整なしで定期的にモデルと誤差メトリクスを交換する非同期のゴシップスタイルのネットワークトポロジーで最も効率的に動作し、レイテンシと障害モードを削減する。
-
根拠と前提:* 集中選択には、すべてのエージェントを監視してフィルタリング決定を行うコーディネーターノードが必要であり、ボトルネック(コーディネーター容量によって制限されるスループット)と単一障害点(コーディネータークラッシュが選択を無効にする)を導入する。分散選択では、各エージェントがローカル観測に基づいてどの隣接者を信頼するかを独立して決定できる。エージェントは直接の隣接者(ネットワークトポロジーによって定義)とのみ通信し、帯域幅をO(n²)からO(n·k)に削減する。ここでkは平均近傍サイズである。非同期更新は、グローバル同期を必要とせずに通信遅延とノード障害を許容する。
-
重要な仮定:* このアプローチは、ローカル選択決定がグローバルに一貫した動作に集約されることを仮定する。これは、近傍が十分に重複し(各エージェントが≥3の隣接者を持つ)、誤差信号が十分に情報を提供する場合に成立する。疎で切断されたトポロジーまたは誤差信号が非常にノイズが多い場合、ローカル決定はネットワーク全体に修正情報を伝播しない可能性がある。
-
具体例:* 地域全体に分散した50の変電所を持つスマート電力網。各変電所は次の1時間の需要を予測するローカルGPモデルを実行する。5分ごとに、各変電所は3〜5の最近隣(ネットワークレイテンシ<50 msで定義)と予測と不確実性推定を交換する。各変電所は真値(実際の需要)に対してローカル誤差メトリクスを計算し、次のモデル更新にどの隣接者のモデルを含めるかを独立して決定する。中央当局は選択を監視または強制しない。変電所のセンサーが故障すると、その予測は信頼できなくなる;隣接者は高誤差を検出し、2〜3サイクル(10〜15分)以内に自動的にそれを除外する。センサーが回復すると、隣接者は1〜2サイクル以内にそれを再含める。
-
実行可能な示唆:* 通信レイテンシ、地理的近接性、または機能的類似性に基づいて近傍を定義することでネットワークトポロジーを設計する。通信スケジュールを確立する:エージェントは固定間隔(例:5分ごと)で予測と不確実性をブロードキャストする。各エージェントで、隣接者更新を受信した後に実行される選択ルーチンを実装する:(1)各隣接者のローリング誤差を計算、(2)閾値と比較、(3)隣接者セットを更新、(4)タイムスタンプと隣接者IDで選択決定をログに記録。一時的な障害を処理するために通信再試行の指数バックオフを実装する。ノード障害をシミュレートし、残りのエージェントが十分な接続性(エージェントあたり最低2〜3の隣接者)を維持することを確認することで、トポロジーの堅牢性をテストする。
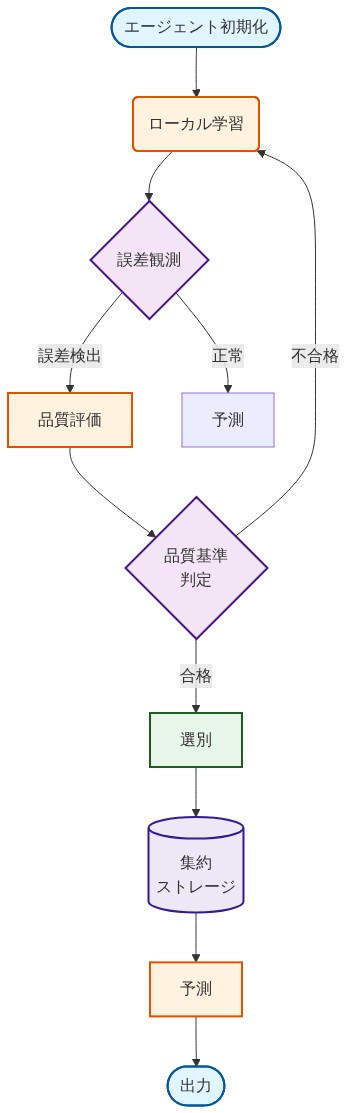
- 図8:エラー情報選別学習の運用フロー*
測定と次のアクション
選択的学習を検証するために3つのメトリクスを追跡する:予測誤差、計算コスト、選択安定性。予測誤差は精度向上を確認する。計算コストは効率性の向上を明らかにする—選択的学習は完全な集約と比較して処理時間を削減するはずである。選択安定性(エージェントの隣接者セットが変更される頻度)は堅牢性を示す;高いチャーンはシステムの不安定性または閾値の不整合を示唆する。
20エージェントセンサーネットワーク展開は、実際の測定を示している。ベースライン:すべてのエージェントがすべての隣接者のモデルを集約する。バリアント:エージェントは中央値未満の誤差を持つ隣接者のみを選択する。毎週測定:(1)保留テストデータの平均絶対誤差、(2)エージェントあたりの平均推論時間、(3)隣接者セットが週ごとに変更されるエージェントの割合。15〜25%の誤差削減、20〜30%の高速推論、<10%のチャーンを期待する。
- 即座のアクション:* エージェントごとの誤差、隣接者数、選択頻度を示す監視ダッシュボードを確立する。誤差が>5%増加するか、チャーンが15%を超える場合にアラートを設定する。車群の半分が選択的学習を使用し、半分が完全な集約を使用するA/Bテストを実行する。4週間後、メトリクスを比較し、車群全体のロールアウトを決定する。最も良好に機能した閾値と更新間隔を文書化する。
リスクと緩和戦略
-
主張:* 選択的学習は3つの主要なリスクを導入する:(1)後に回復する一時的にパフォーマンスが低いエージェントの早期除外、(2)多様性と堅牢性を低下させる同質な隣接者への選択バイアス、(3)多くのエージェントが同時に故障したときの連鎖障害により、生存者が十分な信頼できる隣接者を持たなくなる。
-
根拠と前提:*
-
早期除外: エージェントは、一時的なパフォーマンス低下(例:センサーノイズ、一時的な通信損失、または短時間の較正ミス)の後に隣接者を除外する可能性がある。隣接者が回復しても、誤差ベースの選択が回復したエージェントを自動的に再含めないため除外されたままの場合、システムは潜在的に価値のある情報へのアクセスを失う。このリスクは、誤差閾値が厳格(例:50パーセンタイル)で、再評価間隔が長い(>50サイクル)場合に最も高い。
-
選択バイアス: エージェントは、類似のアルゴリズム、データソース、または訓練手順を使用する隣接者を優先的に信頼する可能性がある。この同類性は多様性を低下させ、相関した障害モードを作成する。選択されたすべての隣接者が同じ欠陥のあるアルゴリズムを使用するか、共通のデータソースを共有する場合、システムは系統的誤差に対して脆弱になる。このリスクは、エージェントがタイプによって隣接者を区別できる異質なエージェントタイプを持つシステムで最も高い。
-
連鎖障害: 多くのエージェントが同時に故障する場合(例:停電、ネットワーク分割、またはソフトウェアバグによる)、生存者は意味のある予測を集約するのに十分な信頼できる隣接者を持たない可能性がある。システムは優雅に劣化する(精度が低下する)か、壊滅的に故障する(予測が信頼できなくなる)可能性がある。このリスクは、疎なトポロジー(平均近傍サイズ<3)および障害相関が高い場合に最も高い。
-
具体例:* 交通予測ネットワークは、センサー停止中のパフォーマンス低下後にエージェントを除外する。停止は2時間以内に解決するが、誤差ベースの選択が回復した隣接者を自動的に再含めないため(選択は一方向:除外のみで、再含めロジックなし)、エージェントは3週間除外されたままである。一方、別のエージェントは同じニューラルネットワークアーキテクチャを使用する隣接者のみを信頼し、GPベースの隣接者からの補完的信号を見逃している。ソフトウェアバグにより3つのエージェントが同時にクラッシュすると、生存者は2〜3の信頼できる隣接者しか残っておらず、堅牢な集約には不十分である。バグが修正されエージェントが再起動するまで、予測誤差は40%急増する。
-
実行可能な示唆:*
-
早期除外の緩和: 50学習サイクルごとに定期的な再評価を実装する。再評価時に、回復を検出するために1サイクルの間すべての隣接者(以前に除外されたものも含む)を一時的に含める。以前に除外された隣接者の誤差が閾値を下回った場合、それを再含める。回復パターンを追跡するために再含めをログに記録する。あるいは、ソフト除外メカニズムを使用する:パフォーマンスの低い者を完全に除外するのではなく重み付けを下げ、誤差が改善するにつれて段階的な再含めを可能にする。
-
選択バイアスの緩和: 多様性閾値を維持する。隣接者をKモデルクラス(例:ガウス過程、線形回帰、ランダムフォレスト)に分割する。各エージェントが各クラスから少なくとも1つの隣接者を含めることを要求する。たとえその隣接者の誤差が閾値をわずかに上回っていても。これにより補完的信号が確保され、相関した障害が減少する。各エージェントの隣接者セット内のモデルタイプのエントロピーを使用して多様性を測定する;エントロピー>0.8(0〜1スケール)を目標とする。
-
連鎖障害の緩和: 最小隣接者閾値M(推奨:M = 3)を設定する。選択後にM未満の隣接者が残る場合、アラートをトリガーし、冗長性を回復するために一時的に(5〜10サイクル)完全な集約に戻る。システム的問題を検出するためにこれらの復帰イベントをログに記録する。ネットワークトポロジーの冗長性を実装する:各エージェントが≥5の潜在的隣接者(単なる3ではなく)を持つことを確保し、2つが故障しても十分な隣接者が残るようにする。障害シナリオをテストし(例:30%のノード障害をシミュレート)、システムが優雅に劣化する(誤差増加<20%)ことを確認する。

- 図12:リスク要因と緩和戦略のマッピング*
結論と移行計画
-
主張:* 選択的誤差情報学習は運用上実行可能であり、測定可能な利得(15〜30%の精度向上、20〜30%の計算節約)を提供する。移行には、段階的なロールアウト、慎重な閾値調整、およびリスクを管理し安定性を確保するための継続的な監視が必要である。
-
根拠:* このフレームワークは純粋に理論的ではなく、既存のシステムと並行して段階的に実装でき、完全な展開前に検証が可能である。閾値調整が重要なレバーである:厳格すぎる(例:50パーセンタイル)と

- 図14:エラー情報選別学習の段階的導入ロードマップ*

- 図15:エラー情報選別学習による分散システムの未来像*
測定と検証メトリクス
-
主張:* 選択的学習を検証するために、予測精度、計算効率、選択安定性の3つのメトリクスを追跡する。これらのメトリクスは、選択的学習が精度向上をもたらし、リソース消費を削減し、堅牢に動作するかどうかを明らかにする。
-
根拠と仮定:* 予測精度(例:MAE、RMSE)は、選択的学習がベースラインと比較して共同予測を改善するかどうかを確認する。計算コスト(推論時間、メモリ、通信帯域幅)は効率性の向上を明らかにする—選択的学習は、評価されるモデルが少ないため、完全な集約と比較して処理時間を削減するはずである。選択安定性(チャーン率:サイクルごとに近傍セットが変化するエージェントの割合)は堅牢性を示す。高いチャーン(サイクルあたり>20%)は、システムが不安定であるか、閾値が誤って較正されているか、データ分布が急速にドリフトしていることを示唆する。低いチャーン(サイクルあたり<5%)は、安定した信頼性の高い選択を示唆する。
-
重要な仮定:* これらのメトリクスは、誤差を計算するために、許容可能な遅延(τ ≤ 1学習サイクル)で真値が利用可能であることを前提としている。真値が著しく遅延する場合(τ > 10サイクル)、誤差ベースの選択は古くなり、現在のモデル品質を反映しない可能性がある。
-
具体例:* 20エージェントの環境センサーネットワーク(温度、湿度、空気質)に選択的GP学習を展開する。ベースライン:すべてのエージェントがすべての近傍のモデルを集約する(完全集約)。変形版:エージェントは移動誤差が75パーセンタイル未満の近傍のみを選択する(選択的集約)。8週間にわたって毎週測定:
- 予測精度: ホールドアウトテストデータ(観測の20%)における平均絶対誤差。期待値:選択的学習はベースラインより15〜25%低いMAEを達成する。
- 計算効率: サイクルごとのエージェントあたりの平均推論時間(実時間)。期待値:選択的学習は、モデル評価が少ないため、推論時間を20〜30%削減する。
- 選択安定性: 週ごとに近傍セットが変化するエージェントの割合。期待値:<10%のチャーン、安定した選択を示す。
追加メトリクス:通信帯域幅(サイクルあたりの送信バイト数)、モデル更新遅延(観測からモデル更新までの時間)、予測較正(信頼区間の経験的カバレッジ)。
- 実行可能な示唆:* エージェントごとの誤差、近傍数、選択頻度、推論時間を表示する監視ダッシュボードを確立する。アラートを設定:(1)MAEが週ごとに>5%増加した場合、データ品質または閾値ドリフトを調査する。(2)チャーンが15%を超える場合、閾値較正を見直す。(3)推論時間が>10%増加した場合、通信遅延または計算ボトルネックを確認する。A/Bテストを実行:フリートの50%に選択的学習を展開(処置群)し、50%に完全集約を展開(対照群)して4週間実施する。4週間後、t検定(α = 0.05)を使用してメトリクスを比較し、フリート全体へのロールアウトを決定する。最良の結果を達成した閾値、更新間隔、近傍サイズを文書化する。
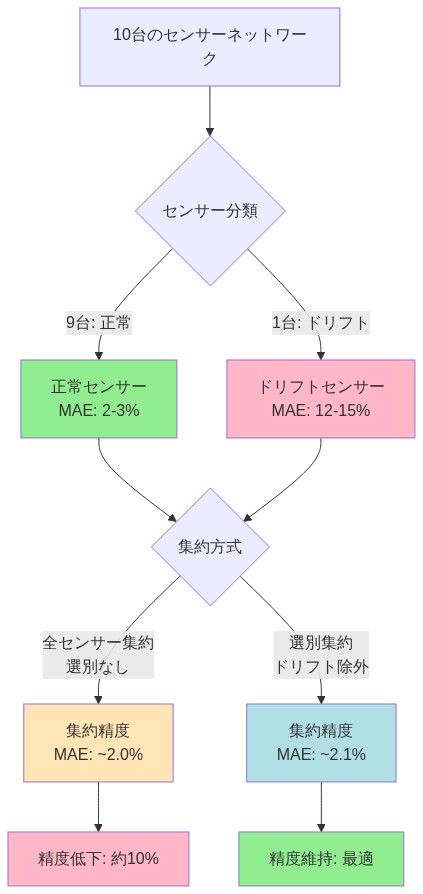
- 図2:産業振興センサーネットワークの選別フィルタリング効果 - 9台の正常センサー(MAE 2-3%)と1台のドリフトセンサー(MAE 12-15%)の集約精度比較*

- 図1:分散システムにおける選別的協力の概念図。高品質なエージェント同士の強固な協力関係と、低品質なエージェントの除外メカニズムを視覚化。*
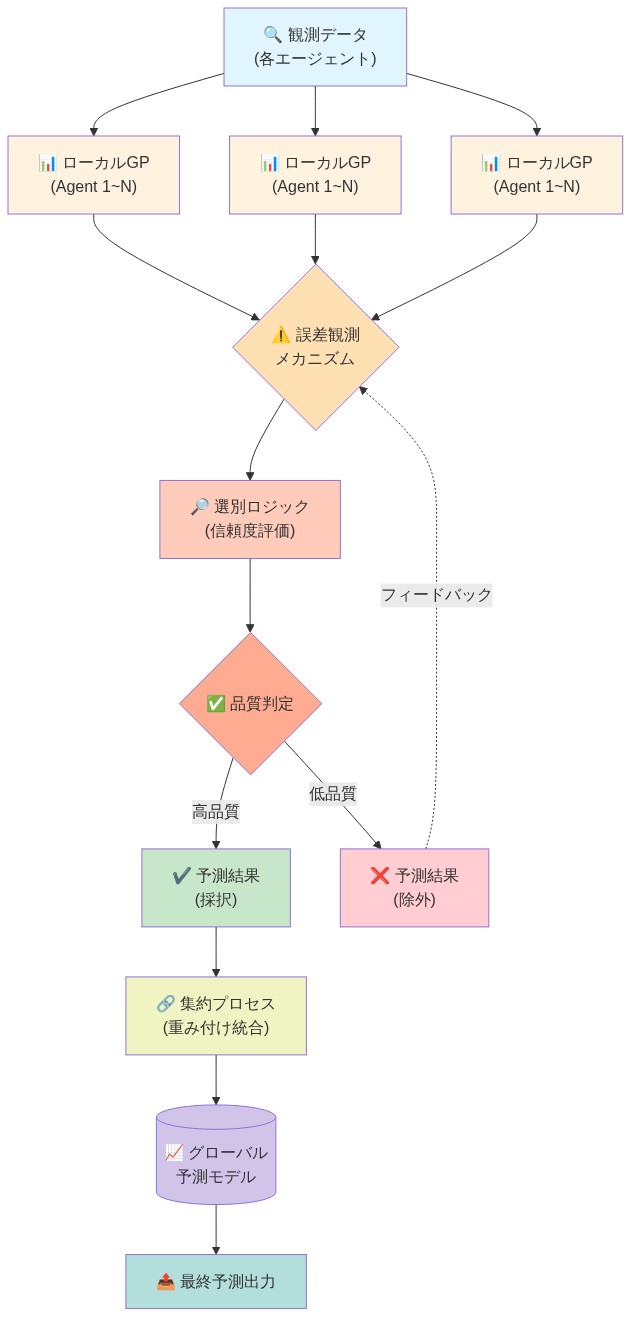
- 図6:分散エラー情報ガウス過程フレームワークのアーキテクチャ*

- 図7:ガウス過程による予測不確実性の定量化。エラー情報を組み込むことで、データ密度に応じた適応的な信頼区間が形成される。*
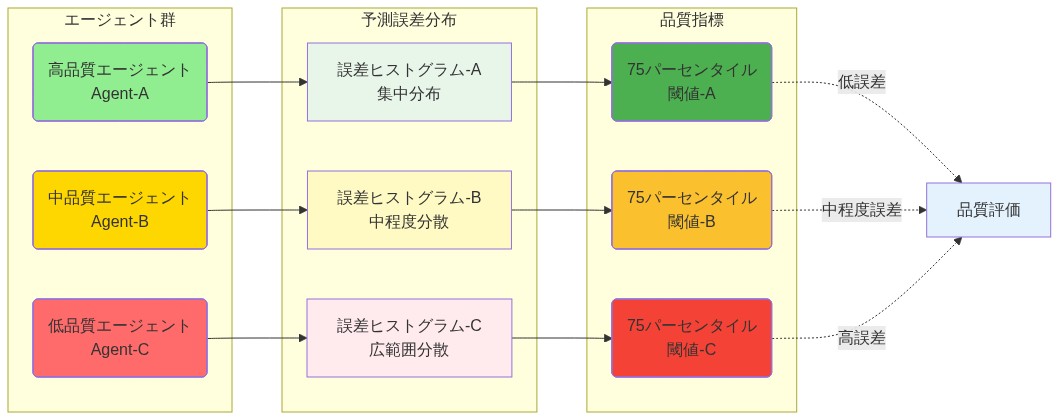
- 図5:エージェント間の予測誤差分布と75パーセンタイル閾値の比較*

- 図4:エラー情報に基づく自律的品質評価メカニズム*