
自動運転向けVLMの合成生成MCQAにおけるテキストバイアスの削減
ビジョン言語モデルにおけるテキスト悪用の問題
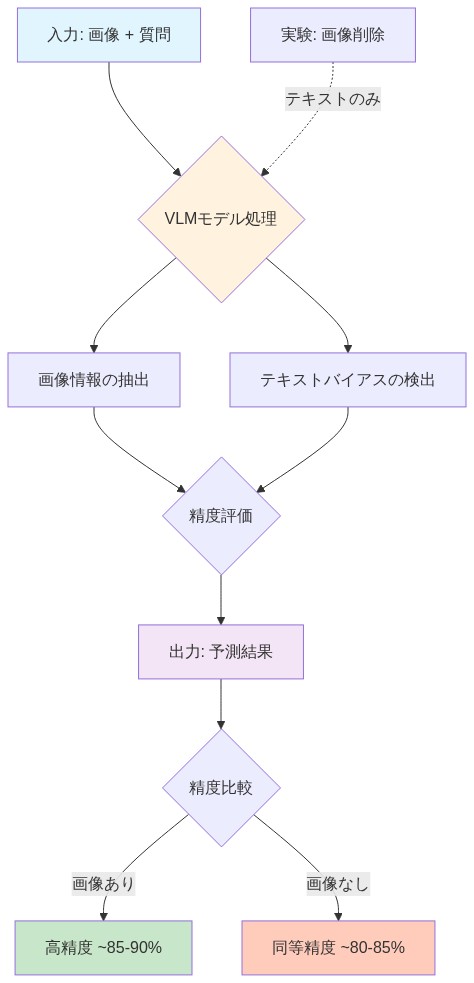
自動運転評価向けに設計されたビジョン言語モデル(VLM)は、十分に文書化された現象に根ざした根本的な検証危機に直面しています。すなわち、モデルが視覚情報を処理することなくベンチマークレベルのパフォーマンスを達成するという現象です。実証的知見は、合成生成された多肢選択問題回答(MCQA)データセットで微調整されたVLMが、視覚入力が完全に削除されたか無情報コンテンツに置き換えられた場合でも、高い精度(しばしば85~90%)を維持することを示しています(Kaur et al., 2023; Thrush et al., 2024)。このパフォーマンス維持は、モデルが真の視覚推論を実行するのではなく、質問回答構造に埋め込まれた言語パターンを悪用していることを示しています。
- 定義*:「真の視覚推論」とは、視覚情報が削除または破損された場合にほぼランダムなパフォーマンス(二項選択で約50%の精度、4択MCQAで約25%)を生成する意思決定として定義します。ただし、領域固有の事実に関する事前知識がないと仮定します。
この問題は孤立したデータセット成果物を超えています。安全性が重要なAIシステムの評価方法における体系的な失敗を表しています。モデルが画像にアクセスすることなく「前方にどのような交通標識が見えるか」という質問に答えることができる場合、評価フレームワークが知覚理解ではなく言語パターンマッチングを測定していることを示しています。この区別は自動運転にとって深刻な意味を持ちます。現実世界の安全性は、制御されたデータセット内のテキスト相関から学習された統計的ショートカットではなく、遮蔽、新規シナリオ、分布シフトの条件下での真正な視覚理解に依存しているからです。
テキストバイアスの脆弱性は、以前に文書化されたAI悪用パターンとは異なります。先行研究は、モデルが特定の領域における表面的なパターンを悪用することを特定しています(例えば、敵対的例、偽相関)。一方、VLMテキストバイアスは、ビジョン言語統合の基本的前提を直接損なっています。すなわち、モデルが堅牢な推論のために視覚と言語のモダリティを融合させることを学習するという前提です。ここでのショートカットは外部的(セキュリティバックドア)ではなく、ベンチマーク構造自体に埋め込まれており、同様の合成データセット全体で体系的に再現可能です。
訓練と評価データの間の閉ループダイナミクスにより、問題は激化します。両者が同一の生成方法論に由来する場合、モデルは一般化可能な視覚理解ではなく、データセット固有の成果物に最適化します。テンプレート駆動型アプローチを採用する合成データパイプラインは、言語モデルが容易に検出して悪用できる構造的規則性を無意識のうちにエンコードします。すなわち、一貫した質問表現、予測可能な干渉肢パターン、体系的な回答長分布です。LLMが生成した質問でさえ、言語的に自然に見えるにもかかわらず、視覚コンテンツとは独立して正答と相関する微妙な統計的フィンガープリント(例えば、意味的一貫性パターン、語彙分布)を含んでいます(Thrush et al., 2024)。
- 図2:VLMにおけるテキストバイアス搾取メカニズムのフロー図(研究知見に基づく)*
合成MCQAバイアスの構造
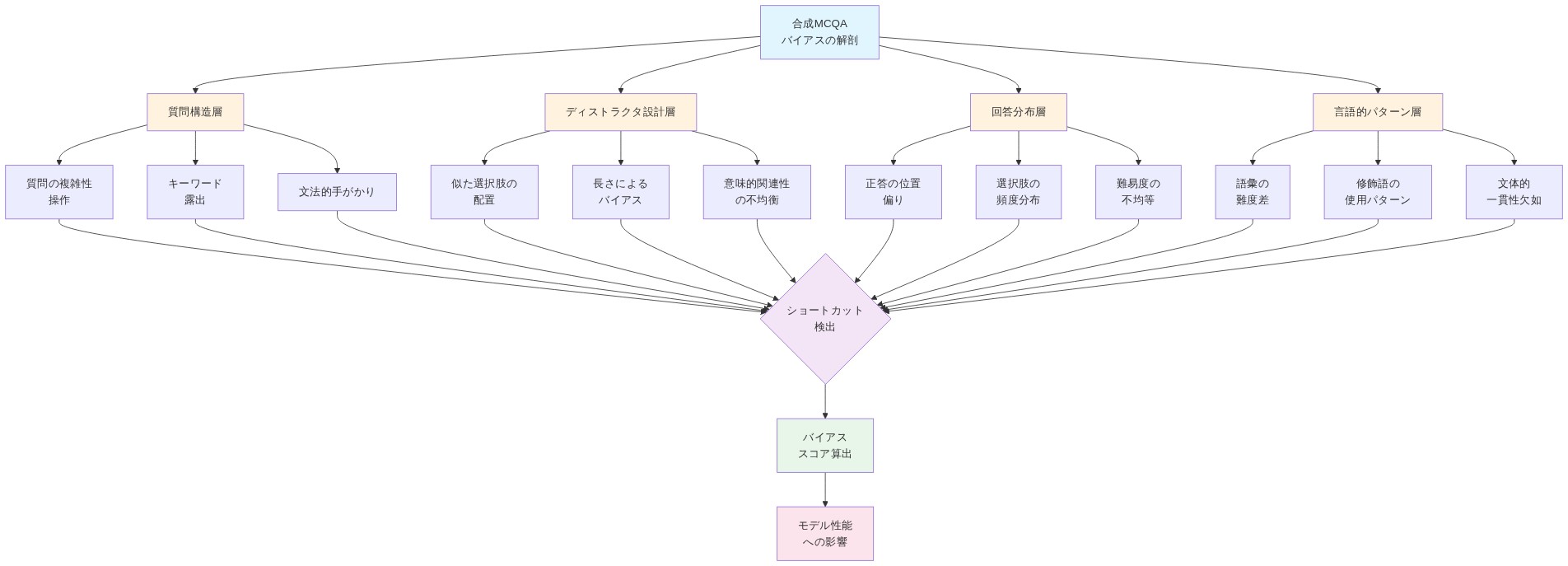
合成生成されたMCQAは、複数の測定可能な経路を通じてテキスト手がかりを導入し、モデルが視覚推論をバイパスすることを可能にします。
-
質問表現バイアス*:質問の定式化は、しばしば回答分布を狭める暗黙の前提を含みます。例えば、「どの歩行者横断標識が見えるか」という質問は、画像に歩行者横断標識が存在することを前提とし、モデルを標識関連の回答へ偏らせます。対照的に、「歩行者横断標識は存在するか」と表現された質問は、否定的な回答を許可し、確率質量をより均一に応答カテゴリ全体に分配します。
-
干渉肢の言語パターン*:干渉肢の回答は、正答とは異なる言語特性を頻繁に示します。合成MCQAデータセットの分析は、体系的なパターンを明らかにします。干渉肢は異なる語彙レジスタを採用する(例えば、形式的対日常的言語)、質問文脈に対する意味的矛盾を含む、または長さバイアスを示します(例えば、正答が干渉肢より一貫して長いまたは短い)。これらの規則性は、悪用可能な統計的署名を作成します(Kaur et al., 2023)。
-
テンプレート駆動型生成成果物*:ルールベースの生成システムは、テンプレート実装を通じて規則性をエンコードします。「前方の車両は[アクション]を実行しています。運転者は何をすべきか」というテンプレートは、自然にアクション指向の干渉肢へ偏り、正答は予測可能な統語構造に従います。テンプレートがデータセットインスタンス全体で再利用される場合、モデルはこれらのパターンを認識して悪用することを学習します。
-
実験的定量化*:制御された削除研究は、テキストバイアスの深刻さを実証しています。モデルは、マルチモーダル推論向けに設計された質問のテキストのみの変種で85~90%の精度を達成します(Thrush et al., 2024)。対照的に、堅牢なビジョン言語統合は、視覚入力なしでほぼランダムなパフォーマンスを生成すべきです。このギャップはテキスト悪用の程度を定量化します。モデルは視覚概念ではなくデータセット固有のパターンを内在化しています。
-
クロスデータセット一般化の失敗*:1つの合成MCQAコーパスで訓練されたモデルは、異なる言語分布を持つ人間検証済みデータセットで実質的に悪いパフォーマンスを示します。視覚コンテンツが意味的に類似している場合でも同様です。この非対称性は、モデルが転移可能な視覚知識ではなくテキストショートカットを内在化していることを確認します。例えば、テンプレート生成質問で訓練されたモデルは、同一の視覚概念に対処するが異なる表現慣例を使用する人間作成質問で失敗します。
- 図5:合成MCQAに隠れたショートカットの多層構造(bias analysis framework)*
主張と現実のギャップの測定
ベンチマークスコアだけでは、自動運転アプリケーション向けのVLM機能を検証できません。厳密な評価には、視覚情報の寄与を分離する体系的な削除プロトコルが必要です。
-
視覚依存性削除*:実験プロトコルは、視覚情報が削除または破損された場合のパフォーマンス低下を監視する必要があります。特定のテスト条件には以下が含まれます。(1)元のコンテンツを置き換える空白または均一な画像、(2)意味的に無関係な画像(例えば、ランダムシーン)、(3)破損した画像(例えば、ノイズ、ピクセル化)、(4)タスク関連領域がマスクされた画像。モデルがこれらの条件全体で高い精度を維持する場合、テキストショートカットへの依存を示します。精度が大幅に低下する場合、視覚処理への依存を確認します。
-
テキストバイアスの定量的閾値*:テキストのみと完全なマルチモーダル条件間の比較分析は、真の視覚推論寄与を定量化します。視覚入力を削除した場合の精度低下が15~20%未満は、深刻なテキストバイアスを示唆し、モデルが決定関連情報の80%以上をテキストから導出していることを示唆します。堅牢なビジョン言語統合は、視覚入力が削除された場合、50%以上の精度低下を生成すべきです。理想的には、ランダムチャンス(二項タスクで50%、4択MCQAで25%)に接近します。
-
クロスデータセット評価*:合成MCQAで訓練されたモデルは、異なる言語分布を持つ人間検証済みベンチマークで悪いパフォーマンスを示します。この一般化失敗は、モデルが堅牢な視覚概念ではなくデータセット固有のテキストパターンを学習していることを明らかにします。実務者は複数の独立したデータセットでモデルを評価すべきです。分布外データでの一貫したパフォーマンス低下は、テキストバイアスを示します。
-
検証プロトコルフレームワーク*:測定フレームワークは、視覚依存性とテキストショートカットへの耐性を明示的にテストする必要があります。ベンチマークメトリクスのみに依存する現在の認証アプローチは、展開準備状態の不十分な証拠を提供します。包括的な検証には以下が必要です。(1)テキストのみの削除研究、(2)クロスデータセット一般化テスト、(3)操作されたテキスト内容による敵対的評価、(4)分布シフト下でのパフォーマンス評価。
パイプライン全体にわたる軽減戦略
テキストバイアスに対処するには、データ生成、モデルアーキテクチャ、訓練手順全体にわたる調整された介入が必要です。
-
データ生成層*:
-
敵対的フィルタリング:テキストのみのベースラインモデルに対して候補をテストすることにより、視覚入力なしで回答可能な質問を特定して削除します。テキストのみのモデルが75%以上の精度を達成する質問は、修正または削除の対象としてフラグが立てられます。このフィルタリングにより、保持された質問が真に視覚情報を必要とすることが保証されます。
-
意味的干渉肢サンプリング:テンプレートベースの干渉肢生成を視覚特徴空間からのセマンティックサンプリングに置き換えます。言語ルールを通じて干渉肢を生成するのではなく、意味的に関連しているが不正確な概念に対応する視覚特徴空間の領域から不正答をサンプリングします。このアプローチは、干渉肢における体系的な言語パターンを削減します。
-
反事実データ拡張:異なる回答を必要とする異なる画像と同一の質問テキストをペアリングします。例えば、「前方の車両は何をしているか」という質問を、左折する車両、右折する車両、直進する車両を示す複数の画像と組み合わせます。この手法は、質問テキストと正答の間の偽相関を破壊し、モデルに視覚コンテンツへの依存を強制します。
-
言語多様性の注入:同一の視覚概念に対して複数の言語的定式化を生成します。単一のテンプレート構造に依存するのではなく、意味的に同等だが統語的に多様な質問バリエーションを作成します。この多様性は、モデルが特定の表現パターンを記憶することを防ぎます。
-
モデルアーキテクチャ層*:
-
モダリティドロップアウト:訓練中にランダムに視覚またはテキストモダリティを削除し、モデルに両方のソースからの情報統合を強制します。この正則化手法は、単一モダリティへの過度の依存を防ぎ、真のマルチモーダル推論を促進します。
-
注意機構の監視:クロスモーダル注意重みを分析して、モデルが視覚特徴に適切に注意を払っているかを検証します。注意がテキストトークンに不均衡に集中している場合、視覚バイパスを示唆します。注意正則化損失は、視覚領域への注意配分を明示的に奨励できます。
-
対照学習目標:視覚的に類似しているが意味的に異なるシーンを区別するようにモデルを訓練します。対照損失は、モデルが細かい視覚的差異に基づいて表現を分離することを要求し、テキスト手がかりのみへの依存を削減します。
-
訓練手順層*:
-
敵対的訓練:テキストのみのモデルが正しく分類する例にペナルティを課します。訓練損失に敵対的項を含めることで、データセット内のテキストショートカットを積極的に識別して抑制します。
-
段階的カリキュラム:簡単な視覚依存質問から始めて、徐々に複雑さを増加させます。この段階的アプローチにより、モデルは初期段階で視覚処理能力を確立し、後でテキストショートカットに依存する傾向を削減します。
-
マルチデータセット共同訓練:異なる言語分布を持つ複数のデータセットで同時に訓練します。この戦略は、モデルが単一のデータセット固有のパターンに過適合することを防ぎ、一般化可能な視覚推論能力を促進します。
これらの軽減戦略を組み合わせることで、自動運転アプリケーションに必要な真の視覚推論能力を持つVLMの開発が可能になります。各層での介入は相補的に機能し、テキストバイアスの複数の発生源に対処します。