
Show HN: Grov – AI コーディングエージェントのためのマルチプレイヤー
こんにちは HN、私は Tony です
私は、チームが現在 AI コーディングアシスタントを協調ワークフローに統合する際の文書化された非効率性に対処するために Grov を構築しました。既存の AI ツールは、ステートレスでセッション分離されたシステムとして動作します。各呼び出しは、以前の推論、アーキテクチャ上の決定、またはチームのコンテキストにアクセスすることなく開始されます。このアーキテクチャ上の制約は、測定可能な摩擦を生み出します。開発者またはチームメイトが以前に分析したコードに戻るとき、または複数のエージェントが関連する問題に取り組むとき、推論レイヤーをゼロから再構築する必要があります。
Grov の根底にある中核的な仮説は、AI の推論は一時的な出力ではなく、永続的でクエリ可能なアーティファクトとして扱われるべきだということです。エージェントの決定、その根底にある理論的根拠、およびコンテキスト上の制約を共有されたバージョン管理されたレイヤーに取り込むことで、チームはソリューションを繰り返し再導出するのではなく、セッションやチームメンバー間で知識を複利的に蓄積できます。
- 価値の前提条件:* このアプローチは、チームが推論を再利用できる、構造的に類似した反復的な問題を抱えていることを前提としています。非常に新規で一回限りの問題を抱えるチームは、限定的な利益しか得られない可能性があります。
シングルプレイヤーの問題
現在の AI コーディングアシスタントは孤立して動作します。各セッションはステートレスです。エージェントは以前の決定の記憶がなく、チームの推論にアクセスできず、共有された理解に貢献する方法もありません。ターミナルやチャットを閉じると、何ヶ月にもわたるアーキテクチャ上の決定と実装パターンがコードコメントにロックされるか、完全に失われます。
これは連鎖的な非効率性を生み出します。関連する機能に取り組むチームメイトは、コードから決定をリバースエンジニアリングするか、Slack で質問するか、AI にすでに解決された問題を再解決させる必要があります。3 人以上のチームでは、この重複は深刻になります。
-
具体例:* あなたのチームがキャッシングレイヤーを実装します。エージェント A は一貫性保証について推論し、選択を文書化します。2 日後、エージェント B が関連するパフォーマンスの問題に遭遇します。エージェント A の推論にアクセスできないため、エージェント B は分析を重複させるか、互換性のないソリューションを提案します。マルチプレイヤー AI は、エージェント A の決定コンテキストを即座に表示します。
-
これを測定する:* AI の支援を受けてチームが実装した最近の機能を 1 つ文書化してください。その推論が何回再導出または再説明されたかを追跡してください。チームの規模とスプリント数を掛けてください。それがあなたの効率性のベースラインです。
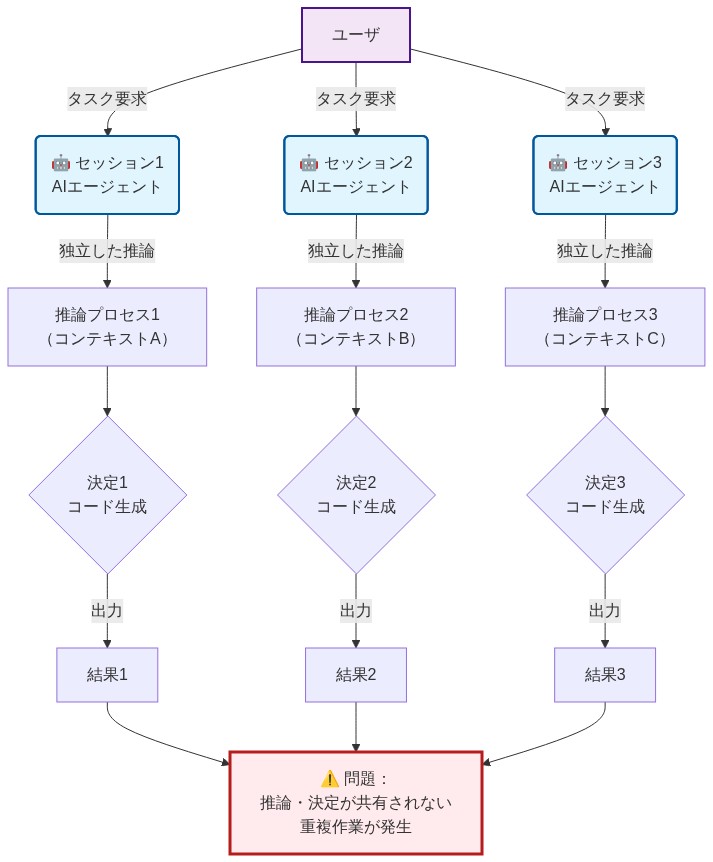
- 図2:シングルプレイヤー問題 – 孤立したセッションと推論の重複*

- 図3:推論の重複 – 同じ問題の繰り返し解決*
永続的なコンテキストと共有された推論
Grov は推論レイヤーを取り込み、永続化します。コードだけでなく、決定の背後にある理由を取り込みます。この推論レイヤーは、チームメンバーとセッション間でクエリ可能かつ構成可能になります。
エージェントが新しい問題に遭遇すると、チームがすでに確立した以前の決定、アーキテクチャ上の制約、および実装パターンにアクセスできます。これにより、AI はポイントツールからチームメモリシステムに変換されます。エージェントはコンテキストを継承し、再導出を減らし、一貫性を強制します。
-
具体例:* あなたのチームは、ローリングデプロイメントのためにデータベースマイグレーションが後方互換性を持たなければならないと確立します。この決定は、その理論的根拠とともに、Grov の推論レイヤーに取り込まれます。新しいエージェントがマイグレーションを提案すると、手動の文書化や Slack のリマインダーを必要とせずに、互換性のない点を自動的にフラグし、チームポリシーに沿った代替案を提案します。
-
候補を特定する:* チームが行った 3 つのアーキテクチャ上の決定をリストアップしてください。それぞれについて、次のように問いかけてください。AI エージェントはコードだけからこの決定を発見できるでしょうか?できない場合、それは Grov の推論レイヤーの候補です。
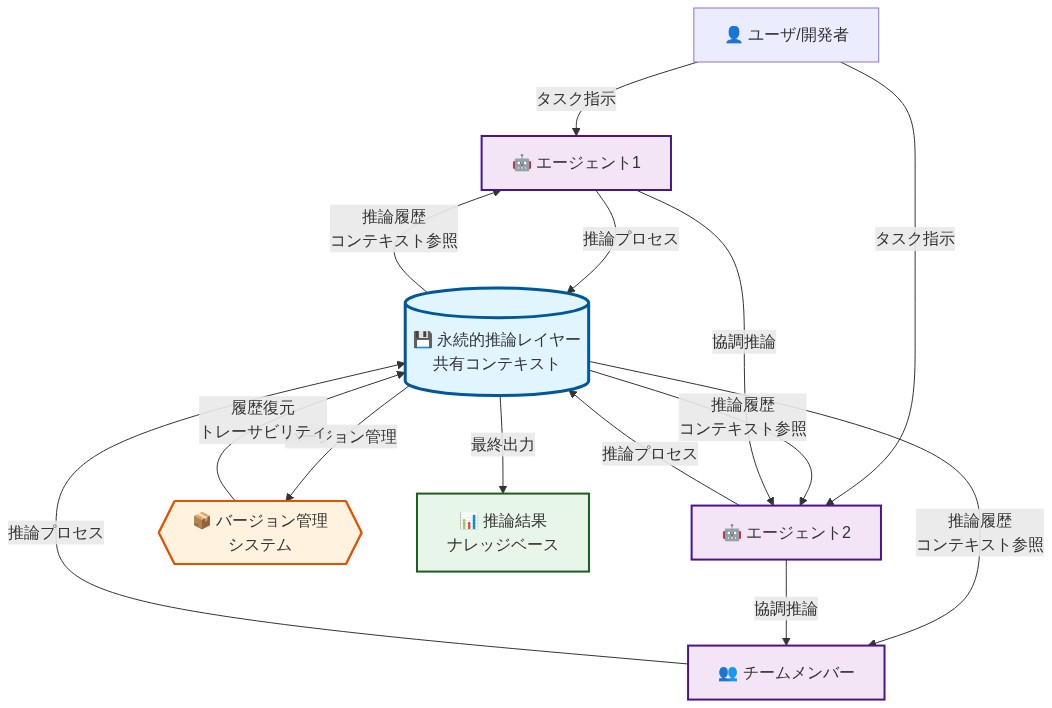
- 図4:Grovのアーキテクチャ – 永続的推論レイヤーと共有コンテキスト*
実装: 3 つのコアパターン
マルチプレイヤー AI を運用可能にするには、3 つのパターンが必要です:決定の取り込み、コンテキストの注入、および一貫性の強制。
-
*決定の取り込み**は、エージェントが何をしたかだけでなく、なぜそうしたかを記録します。考慮した制約、却下した代替案、および行った仮定を記録します。これはエージェントが作業するときに自動的に行われ、監査証跡と知識ベースを同時に作成します。
-
*コンテキストの注入**は、新しいエージェントが作業を開始する前に、以前の決定を利用可能にします。エージェントがセッションを開始すると、関連する以前の推論、チームの慣習、およびアーキテクチャ上の制約を受け取ります。これにより、エージェントは一貫性に向けてプライミングされます。
-
*一貫性の強制**は、新しい作業が確立されたパターンと矛盾する場合にフラグを立てます。新しいエージェントが以前の決定と矛盾するソリューションを提案した場合、システムは矛盾を表示し、以前の推論を説明します。
-
具体例:* あなたのチームは特定のエラー処理パターンを使用しています。新しいエージェントが異なる方法で例外処理を書くと、Grov はそれをフラグし、チームパターンを表示し、リファクタリングを提案します。時間の経過とともに、手動のコードレビューのオーバーヘッドなしに一貫性が向上します。
測定フレームワーク
マルチプレイヤー AI の価値を検証するために、3 つのメトリクスを追跡します。
-
再導出率:* エージェントが同じ問題を 2 回解決する頻度。推論レイヤーが成長するにつれて、これは減少するはずです。チームが四半期ごとに同じキャッシング問題を 3 回解決する場合、その推論を取り込むことで、そのうちの 2 つのインスタンスを排除できるはずです。
-
一貫性スコア:* 新しいコードが確立されたパターンに一致する頻度。最近のコードを監査してこれをベースライン化します。確立された慣習に従っているのは何パーセントですか?Grov を展開した後、これは測定可能に改善されるはずです。
-
コンテキストの再利用:* エージェントが以前の決定を参照する頻度。使用率が低い場合は、レイヤーが適切な決定を取り込んでいないか、適切なタイミングで表示されていないことを示唆しています。
-
1 つのメトリクスから始める:* 今週ベースラインを確立してください。1 つのチーム慣習を取り込んで Grov を展開してください。2 週間後に再測定してください。デルタを使用して、推論レイヤーの拡張を正当化してください。
リスク軽減
-
*古いまたは不正確な推論**が主要なリスクです。取り込まれた決定が古くなると、エージェントは時代遅れのパターンを伝播します。軽減策: 推論を明示的にバージョン管理します。決定が変更されたら、以前のバージョンを置き換えられたものとしてマークし、その理由を説明します。エージェントは、すべての取り込まれた決定が最新であると仮定するのではなく、バージョン管理された推論を参照する必要があります。
-
*取り込まれた推論への過度の依存**は二次的なリスクです。チームは批判的に考えることをやめ、確立されたパターンに反射的に従うかもしれません。軽減策: エージェントが以前の決定から逸脱しているときにフラグを立て、その理由を説明することを要求します。逸脱を可視化し、意図的にします。
-
具体例:* あなたのチームは同期 API パターンを確立しました。6 ヶ月後、非同期パターンに移行します。古い推論が置き換えられたものとしてマークされていない場合、エージェントは同期 API を提案し続けます。決定をバージョン管理し、置き換えられたものとしてマークし、移行を説明します。
-
広範に展開する前に:* 決定レビューのケイデンスを確立してください。四半期ごとに、取り込まれた推論の古さを監査してください。必要に応じて更新または非推奨にしてください。
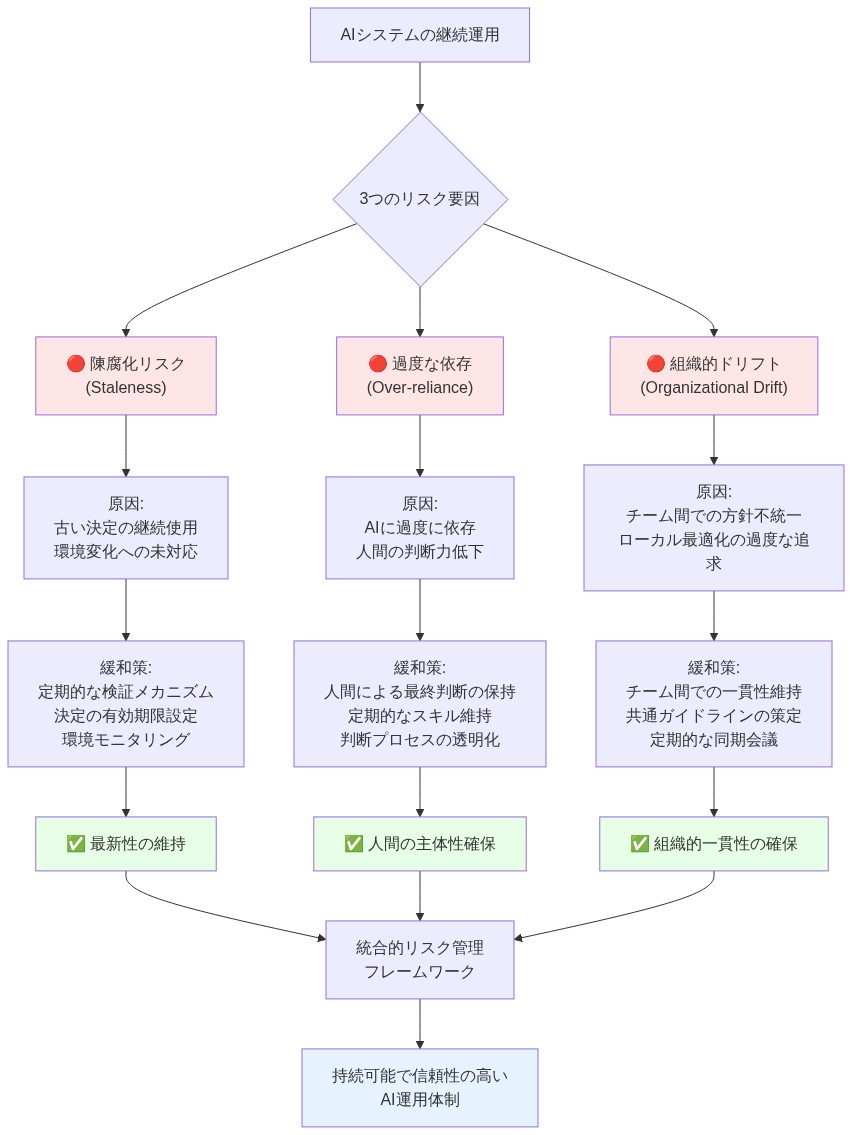
- 図8:リスク分析 – 陳腐化、過度な依存、組織的ドリフトの因果関係と緩和策*
移行と次のステップ
マルチプレイヤー AI コーディングは、時間の経過とともに価値を複利的に増やします。問題に取り組む最初のエージェントは推論を生成します。2 番目のエージェントはそれを再利用します。10 番目のエージェントは、何ヶ月にもわたって蓄積されたコンテキストから恩恵を受けます。このレバレッジは、チームの規模とプロジェクトの期間とともに成長します。
小さく始めてください: 1 つのチーム、1 つのコードベース、1 つのアーキテクチャ上の決定を選択してください。Grov で明示的に取り込んでください。新しいエージェントがそれを採用するかどうか、再導出が減少するかどうかを測定してください。そこから拡大してください。
移行パスは段階的です。現在の AI ワークフローを置き換えるのではなく、拡張します。エージェントは今日と同じように作業を続けますが、永続的な推論レイヤーにアクセスでき、作業中にそれに貢献します。四半期を経て、このレイヤーはますます価値が高まります。
- 今週:* パイロットチームと決定を特定してください。来週: Grov でそれを取り込んでください。2 週間後: 採用と一貫性を測定してください。それらの結果を使用して、拡大するかどうかを決定してください。
シングルプレイヤーの問題: 形式化
現在の AI コーディングアシスタントは、ステートレスセッションアーキテクチャと特徴付けることができるものを示しています。各エージェントの呼び出しは独立して動作し、以前の決定、チームの慣習、またはアーキテクチャ上の制約の永続的なメモリがありません。この設計上の選択は、3 つの文書化された非効率性を生み出します。
-
1. 同等の問題の再導出:* 複数のエージェントまたは開発者が構造的に類似した問題に遭遇する場合(例: キャッシングレイヤーの実装、エラー処理パターンの設計、またはデータベースクエリの最適化)、各エージェントは問題空間を独立して再分析します。この重複は測定可能です。5 人の開発者のチームがそれぞれ AI アシスタントを使用し、タスクの 30% が構造的に類似している場合、チームはタスクごとに平均約 1.2 回ソリューションを再導出します(ランダムなタスク分布を仮定)。四半期を通じて、これは大幅に複利的に増加します。
-
2. 決定コンテキストの喪失:* コードアーティファクトは何が実装されたかを保持しますが、なぜ実装されたかは保持しません。考慮された制約、却下された代替案、または行われた仮定は保持されません。チームメイトがコードを継承したり、エージェントが関連する作業に遭遇したりすると、このコンテキストは利用できません。回復には、コードコメント(多くの場合不完全)からのリバースエンジニアリングまたは元の開発者への質問(高レイテンシ、スケーラビリティの低さ)が必要です。
-
3. 一貫性のない実装:* チームが確立したパターンにアクセスできないため、新しいエージェントは以前のアーキテクチャ上の決定と矛盾するソリューションを提案する可能性があります。これにより、一貫性のなさによる技術的負債が生じ、人間が一貫性を手動で強制する必要があるため、コードレビューのオーバーヘッドが増加します。
-
具体例:* チームは、ローリングデプロイメントのために後方互換性を必要とするデータベースマイグレーション戦略を実装します。この決定は、その理論的根拠(ゼロダウンタイムデプロイメント要件、ロールバック制約)とともに、Slack スレッドまたはコードコメントに文書化されます。2 週間後に 2 番目のエージェントがマイグレーションタスクに遭遇すると、この推論にアクセスできません。より単純だが互換性のないアプローチを提案する可能性があり、チームポリシーに合わせるために人間の介入が必要になります。
-
測定ベースライン:* チームは、最近の AI 支援作業を監査することでこれを定量化できます。(1) エージェントが構造的に類似した問題を解決したインスタンスをカウントします。(2) 異なるエージェントにアーキテクチャ上の決定を再説明するのに費やした時間を測定します。(3) 一貫性を強制するために費やしたコードレビューサイクルをカウントします。このベースラインは効率性のギャップを確立します。
永続的なコンテキストと共有された推論: メカニズムと仮定
Grov は、永続的な推論レイヤー(エージェントの決定、その理論的根拠、およびそのコンテキスト上の制約のクエリ可能でバージョン管理されたリポジトリ)を導入することにより、ステートレスからステートフルエージェントアーキテクチャへの移行を運用可能にします。
- メカニズム:* エージェントがタスクを完了すると、Grov はコードアーティファクトだけでなく、次のものも取り込みます。
- エージェントが考慮した問題ステートメントと制約
- エージェントが評価した代替案とそれらが却下された理由
- 行われた仮定(例: パフォーマンス要件、互換性制約)
- エージェントが適用したチームの慣習またはアーキテクチャパターン
- 以前のパターンから逸脱する明示的な決定とその正当化
この推論レイヤーはクエリ可能になります。新しいエージェントが作業を開始すると、次のものを受け取ります。
-
現在のタスクに関連する以前の決定
-
チームが確立したアーキテクチャパターンとその理論的根拠
-
そのドメインに適用される制約または慣習
-
バージョン管理された決定履歴(現在の決定と置き換えられた決定を区別するため)
-
このメカニズムの根底にある仮定:*
- 推論は部分的に再利用可能: 構造的に類似した問題は推論コンポーネントを共有します(例: キャッシングの一貫性保証、エラー処理パターン)。この仮定は、反復的なアーキテクチャパターンを持つチームには当てはまりますが、非常に新規な作業には当てはまらない可能性があります。
- エージェントは提供されたコンテキストを効果的に使用できる: エージェントは、以前の推論を意思決定に統合できる必要があります。これには、推論が明示的で、曖昧さがなく、現在のタスクに関連している必要があります。
- チームの慣習は取り込むのに十分安定している: アーキテクチャパターンが頻繁に変更される場合、取り込まれた推論は古くなります。この仮定は、チームが十分なアーキテクチャの安定性を持っていることを必要とします。
-
具体例:* チームは、すべての API レスポンスにトレース用のリクエスト ID を含める必要があると確立します。この決定は、その理論的根拠(分散システムのデバッグ、ログの相関)とともに取り込まれます。新しいエージェントが API エンドポイントを設計すると、Grov はこの決定を表示します。エージェントは、理論的根拠を再導出したり、手動でリマインドされたりすることなく、それを組み込むことができます。
-
実行可能な意味:* Grov を採用する前に、チームのアーキテクチャ上の決定を監査してください。安定している(6 ヶ月以上変更されていない)ものはいくつありますか?複数の機能にわたって繰り返されるものはいくつありますか?安定していて繰り返される決定は、推論レイヤーの候補です。
実装パターン: 3 つのコア操作
マルチプレイヤー AI を運用可能にするには、3 つの異なるパターンが必要です:** 決定の取り込み**、コンテキストの注入、および一貫性の強制。
決定の取り込み
決定の取り込みは、エージェントのアクションの背後にある推論を発生時に記録します。これは手動の文書化ではありません。タスク実行中のエージェントの推論の自動抽出です。
- メカニズム:* エージェントがタスクを完了すると、Grov はエージェントに次のことを明確にするよう促します。
- どのような問題が解決され、どのような制約が適用されましたか?
- どのような代替案が検討され、なぜ却下されましたか?
- ソリューションの根底にある仮定は何ですか?
- このソリューションは以前のチームパターンに沿っていますか、それとも逸脱していますか?
この明確化はアーティファクトの一部になります。時間の経過とともに、チームは問題タイプ、アーキテクチャドメイン、および決定カテゴリによってインデックス付けされた推論コーパスを蓄積します。
- 仮定:* エージェントは、構造化されたクエリ可能な形式で推論を明確にできます。これは、エージェントが十分な内省能力を持ち、推論が大きなオーバーヘッドなしに抽出できることを前提としています。
コンテキストの注入
コンテキストの注入は、新しいエージェントが作業を開始する前に、以前の推論を利用可能にします。
- メカニズム:* エージェントが新しいタスクを開始すると、Grov は次の基準に基づいて関連する以前の決定を取得します。
- 問題タイプ(例:「データベースマイグレーション」、「API 設計」、「エラー処理」)
- アーキテクチャドメイン(例:「データレイヤー」、「API レイヤー」、「クライアントレイヤー」)
- 広く適用されるチームの慣習
エージェントは、このコンテキストを初期プロンプトの一部として受け取り、以前の決定との一貫性に向けてプライミングされます。
- 仮定:* 関連性マッチングは正確です。Grov が無関係な以前の決定を表示すると、エージェントは混乱したり誤解したりする可能性があります。これには、効果的なタグ付けと検索メカニズムが必要です。
一貫性の強制
一貫性の強制は、新しい作業が確立されたパターンと矛盾する場合にフラグを立てます。
-
メカニズム:* エージェントがソリューションを提案した後、Grov はそれを関連する以前の決定と比較します。新しいソリューションが逸脱している場合、Grov は次のことを行います。
-
以前の決定とその理論的根拠を表示します
-
新しいソリューションがなぜ矛盾するかを説明します
-
新しいソリューションを整合させるためにリファクタリングを提案するか、エージェントに逸脱を明示的に正当化することを要求します
-
仮定:* 逸脱は検出可能で説明可能です。これには、以前の決定が比較を可能にするのに十分具体的である必要があります。
-
具体例:* チームは、すべてのデータベースクエリにタイムアウトパラメータを含める必要があると確立しています(リソース枯渇を防ぐため)。新しいエージェントがタイムアウトなしでクエリを書くと、Grov はそれをフラグし、以前の決定を表示し、タイムアウトを追加することを提案します。エージェントがそれを省略することを主張する場合、エージェントはこのクエリが例外である理由を明示的に正当化する必要があります。
-
実行可能な意味:* 1 つのチーム慣習から始めてください。エラー処理、ログ形式、API レスポンス構造など。その理論的根拠とともに Grov で明示的に取り込んでください。その後のエージェントのうち、手動でリマインドされることなくそれを採用するものがいくつあるかを測定してください。
測定フレームワーク:3つの主要指標
Grovが価値を提供しているかどうかを評価するために、3つの指標を追跡します:** 再導出率**、一貫性スコア、コンテキスト再利用率です。
再導出率
-
定義:* エージェントが構造的に類似した問題を、過去の解決策を参照せずに独立して解決する頻度。
-
測定方法:* 問題をタイプ別にタグ付けします(例:「キャッシング実装」「エラー処理」「データベースマイグレーション」)。各問題タイプについて、四半期ごとに何回再発するかをカウントします。Grovをデプロイする前にこれをベースライン化します。デプロイ後、新しいエージェントが同じ問題タイプに対して過去の解決策を参照する頻度を測定します。
-
期待される結果:* 推論レイヤーが成長するにつれて、再導出率は低下するはずです。チームが四半期に3回「キャッシングレイヤー設計」を解決している場合、その推論を捕捉することで、再導出を四半期あたり約1回(推論を生成する最初のインスタンス)に削減できるはずです。
-
注意点:* 制約が変更された場合(例:パフォーマンス要件が変化)、一部の再導出は適切です。この指標は、新しい制約による再導出と、コンテキスト不足による再導出を区別する必要があります。
一貫性スコア
-
定義:* 確立されたチームパターンに沿った新しいコードの割合。
-
測定方法:* 最近のコード(Grov導入前のベースライン)を監査し、各実装を確立されたパターンに対して分類します。例えば、チームがエラー処理パターンを確立している場合、最近のコードを監査し、それに従っている割合を測定します。Grovをデプロイした後、この測定を繰り返します。
-
期待される結果:* 一貫性スコアは測定可能な改善を示すはずです。ベースラインが60%(最近の10の実装のうち6つが確立されたパターンに従っている)の場合、Grovをデプロイすることで、パターンが効果的に捕捉され表示されていると仮定すると、2週間以内に80%以上に増加するはずです。
-
注意点:* 一貫性が常に望ましいとは限りません。一部の逸脱は新しい制約によって正当化されます。この指標は逸脱をフラグ付けする必要がありますが、明示的に正当化されている場合はペナルティを課すべきではありません。
コンテキスト再利用率
-
定義:* エージェントが意思決定を行う際に推論レイヤーを参照する頻度。
-
測定方法:* エージェントが過去の推論にアクセスするすべてのインスタンスをログに記録します。これをエージェントの総意思決定数の割合として測定します。例えば、エージェントが1日に50の意思決定を行い、そのうち10について過去の推論を参照する場合、コンテキスト再利用率は20%です。
-
期待される結果:* 推論レイヤーが成長し、より包括的になるにつれて、コンテキスト再利用率は時間とともに増加するはずです。低いコンテキスト再利用率(<10%)は、推論レイヤーが適切な意思決定を捕捉していないか、効果的に表示されていないことを示唆しています。
-
実行可能な意味:* 今週、3つの指標すべてのベースラインを確立します。1つのチーム規約を捕捉してGrovをデプロイします。2週間後に再測定します。差分を使用して推論レイヤーの拡張を正当化します。
リスク分析と軽減戦略

- 図9:段階的ロールアウト計画 – 3フェーズの導入戦略*
リスク1:古いまたは不正確な推論
-
説明:* 捕捉された意思決定は、要件の変更、技術の進化、またはチーム慣行の変化に伴って時代遅れになる可能性があります。エージェントが時代遅れのパターンを伝播すると、技術的負債と不整合が生じます。
-
例:* チームは低レイテンシ要件のために同期APIパターンを確立しました。6か月後、要件が変更され、非同期パターンが好ましくなります。古い推論が置き換えられたとマークされていない場合、エージェントは同期APIを提案し続け、不整合が生じます。
-
軽減策:* 意思決定の明示的なバージョン管理を実装します。意思決定が変更されたら、以前のバージョンを置き換えられたとマークし、その理由を文書化します。エージェントはバージョン管理された推論を参照し、現在の意思決定と過去の意思決定を区別できる必要があります。捕捉された推論の古さを監査するために、四半期ごとの意思決定レビューの頻度を確立します。
-
前提条件:* この軽減策には規律が必要です。チームは定期的に捕捉された推論をレビューし更新することにコミットする必要があります。この規律がなければ、推論レイヤーは負債になります。
リスク2:捕捉された推論への過度の依存
-
説明:* チームは批判的評価なしに確立されたパターンに反射的に従う可能性があります。これは必要なイノベーションや新しい制約への適応を妨げる可能性があります。
-
例:* チームは特定のデータベース技術を使用する決定を捕捉しています。異なる技術を支持する新しい要件が出現したとき、チームは再評価せずに捕捉された決定に従う可能性があります。
-
軽減策:* エージェントが過去の決定から逸脱する場合にフラグを立て、逸脱を明示的に正当化することを要求します。逸脱を可視化し、意図的にします。定期的に逸脱を監査してパターンを特定します—多くのエージェントが特定の決定から逸脱している場合、その決定が時代遅れである可能性があります。
-
前提条件:* この軽減策は、エージェントが逸脱の正当化を明確に述べることができることを前提としています。また、人間がこれらの逸脱を定期的にレビューすることも前提としています。
リスク3:推論レイヤーがボトルネックになる
-
説明:* 推論レイヤーが大きく無秩序に成長すると、関連する過去の意思決定の取得が遅くなったり不正確になったりします。エージェントは無関係または矛盾する推論を受け取る可能性があり、システムへの信頼が低下します。
-
軽減策:* 推論の階層的な組織化を実装します(問題タイプ、アーキテクチャドメイン、チーム規約別)。セマンティック検索またはタグ付けを使用して、関連する意思決定を効率的に取得します。もはや関連性のない推論を定期的に統合または削除します。
-
前提条件:* これには情報アーキテクチャと取得メカニズムへの投資が必要です。
移行パスと採用戦略
マルチプレイヤーAIコーディングは時間とともに価値を複利的に増やします。問題に取り組む最初のエージェントが推論を生成します。2番目のエージェントがそれを再利用します。10番目のエージェントは数か月分の蓄積されたコンテキストから恩恵を受けます。このレバレッジはチームサイズとプロジェクト期間とともに成長します。
-
フェーズ1(第1-2週):パイロット*
-
1つのチーム、1つのコードベース、捕捉する1つのアーキテクチャ決定を特定
-
Grovで決定、その根拠、制約を明示的に文書化
-
この単一の決定を捕捉してGrovをデプロイ
-
ベースライン指標を測定:再導出率、一貫性スコア、コンテキスト再利用率
-
フェーズ2(第3-4週):測定と検証*
-
デプロイ後2週間後に指標を再測定
-
新しいエージェントが捕捉された決定を採用したかどうかを監査
-
捕捉された決定に関連する問題の再導出が減少したかどうかを特定
-
パイロットチームから定性的フィードバックを収集
-
フェーズ3(第5-8週):拡張*
-
フェーズ2が肯定的な結果を示す場合、パイロットチーム内の追加の決定に拡張
-
3-5の追加のアーキテクチャ決定またはチーム規約を捕捉
-
捕捉された推論の古さを監査するために決定レビューの頻度(例:四半期ごと)を確立
-
フェーズ4(第9週以降):より広範な採用*
-
類似のアーキテクチャパターンを持つチームから始めて、追加のチームに拡張
-
チーム間で推論を統合して共有パターンを特定
-
推論レイヤーが扱いにくくなるのを防ぐために、情報アーキテクチャと取得メカニズムに投資
-
仮定:* この段階的アプローチは、2-4週間以内に価値が実証可能であることを前提としています。パイロットフェーズで価値が明らかでない場合、アプローチの調整が必要になる可能性があります。
-
実行可能な意味:* 今週、パイロットチームと1つのアーキテクチャ決定を特定します。来週、それをGrovで捕捉します。2週間後、採用と一貫性を測定します。それらの結果を使用して拡張するかどうかを決定します。
結論
Grovは、永続的でクエリ可能な推論レイヤーを導入することで、シングルプレイヤーからマルチプレイヤーAIコーディングへのシフトを実現します。このレイヤーはコードだけでなく、意思決定の背後にある理由—考慮された制約、却下された代替案、行われた仮定—を捕捉します。この推論を新しいエージェントが利用できるようにすることで、チームはセッションやチームメンバー間で知識を複利的に増やし、再導出を削減し、一貫性を向上させ、組織的記憶を構築できます。
このアプローチにはリスクがないわけではありません。古い推論、捕捉されたパターンへの過度の依存、情報アーキテクチャの課題には積極的な管理が必要です。しかし、繰り返しのアーキテクチャパターンと十分なアーキテクチャの安定性を持つチームにとって、利点—再導出の削減、一貫性の向上、オンボーディングの高速化—は投資を正当化します。
小さく始めましょう。1つのチーム、1つのコードベース、1つの決定を選びます。それを明示的に捕捉します。新しいエージェントがそれを採用するかどうか、再導出が減少するかどうかを測定します。そこから拡張します。移行パスは段階的です。現在のAIワークフローを置き換えるのではなく、拡張します。四半期を経るごとに、推論レイヤーはますます価値あるものになり、レバレッジは複利的に増加します。
シングルプレイヤー問題:摩擦の定量化
現在のAIコーディングアシスタントは孤立して動作します。各セッションはステートレスです—エージェントは以前の決定の記憶がなく、チームの推論へのアクセスがなく、共有理解に貢献する方法がありません。ターミナルやチャットを閉じると、数か月分のアーキテクチャ決定と実装パターンがコードコメントにロックされるか、完全に失われます。
これは測定可能な非効率を生み出します。関連機能に取り組んでいるチームメイトは、コードから決定をリバースエンジニアリングするか、Slackで質問するか、AIにすでに解決された問題を再解決させる必要があります。3人以上のチームでは、この重複は深刻になります。エージェントAが特定のトレードオフで実装したバグ修正は、エージェントBがコンテキストを持たないため、エージェントBによって異なる方法で再実装されます。
-
具体的なワークフローへの影響:* チームがキャッシングレイヤーを実装します。エージェントAは一貫性保証について推論し、選択を文書化し、チャットを閉じます。2日後、エージェントBは関連するパフォーマンス問題に遭遇します。エージェントAの推論にアクセスできないため、エージェントBは分析を重複させる(推定2-4時間)か、互換性のない解決策を提案します(技術的負債を生み出す)。マルチプレイヤーAIは、エージェントAの決定コンテキストを即座に表示し、エージェントBの時間を節約し、分岐を防ぎます。
-
測定演習:* チームがAI支援で実装した最近の機能を1つ文書化します。その推論がチームメンバー間で何回再導出または再説明されたかを追跡します。チームサイズとスプリント数で乗算します。それが効率のベースラインです。10-15の主要なアーキテクチャ決定を持つコードベースに取り組む5人のチームの場合、再導出は通常、スプリントあたり3-5時間のコストがかかります。
-
対処しない場合のリスク:* 永続的な推論がなければ、チームは一貫性のない実装を通じて技術的負債を蓄積します。レビュアーが意図をリバースエンジニアリングする必要があるため、コードレビューサイクルが長くなります。新しいチームメンバーのオンボーディングには、発見可能であるべき決定の手動説明が必要です。
永続的コンテキストと共有推論:運用モデル
Grovは推論レイヤーを捕捉し永続化します—コードだけでなく、決定の背後にある理由です。この推論レイヤーは、チームメンバーとセッション間でクエリ可能で構成可能になります。
エージェントが新しい問題に遭遇すると、チームがすでに確立した過去の決定、アーキテクチャ制約、実装パターンにアクセスできます。これにより、AIはポイントツールからチームメモリシステムに変換されます。エージェントはコンテキストを継承し、手動介入なしに再導出を削減し、一貫性を強制します。
-
実際の動作:* チームは、ローリングデプロイメントのためにデータベースマイグレーションが後方互換性を持つ必要があることを確立します。この決定は、その根拠(ゼロダウンタイム要件、デプロイメント頻度、ロールバック戦略)とともに、Grovの推論レイヤーに捕捉されます。新しいエージェントがマイグレーションを提案すると、手動文書化やSlackリマインダーを必要とせずに、非互換性を自動的にフラグ付けし、チームポリシーに沿った代替案を提案します。エージェントは過去の決定を引用し、新しいアプローチがそれに違反する理由を説明できます。
-
運用上の利点:* レビュアーが一貫性を強制する必要がないため、コードレビュー時間が減少します—エージェントはすでにルールを知っています。新しいエージェントがチームコンテキストを即座に継承するため、オンボーディングが加速します。意思決定が追跡可能になります:パターンが存在する理由といつ確立されたかを確認できます。
-
実装の前提条件:* チームはGrovをデプロイする前に、3-5のコアアーキテクチャ決定を明示的に表示する必要があります。これらがシード推論レイヤーになります。このシードがなければ、Grovには注入するコンテキストがありません。チームあたり2-4時間の事前文書化を見込んでください。
-
実行可能な次のステップ:* 過去6か月間にチームが行った3つのアーキテクチャ決定を特定します。それぞれについて、次のように問います:AIエージェントはコードだけからこの決定を発見できますか?できない場合、Grovの推論レイヤーの候補があります。決定、その根拠、それが対処する制約を文書化します。これがパイロットシードです。
実装と運用パターン:3ステップワークフロー
マルチプレイヤーAIを運用化するには、3つのパターンが必要です:** 決定捕捉**、コンテキスト注入、一貫性強制。これらは自動化する必要があります。そうでなければオーバーヘッドになります。
決定捕捉
決定捕捉とは、エージェントが何をしたかだけでなく、なぜそうしたか—考慮した制約、却下した代替案、行った仮定—をログに記録することを意味します。これはエージェントが作業する際に自動的に行われ、監査証跡と知識ベースを同時に作成します。
-
実装方法:* 決定ポイントでエージェントの推論を傍受するようにGrovを構成します。エージェントが2つのアプローチの間で選択する場合、選択、考慮された代替案、根拠を捕捉します。これには最小限の構成が必要です—コードベースに関連する決定カテゴリ(API設計、エラー処理、データベースパターンなど)を定義します。エージェントは作業中に決定をログに記録します。
-
運用コスト:* 最小限。エージェントはすでに推論を生成しています。Grovはそれを捕捉します。唯一のオーバーヘッドは初期カテゴリ化です(チームあたり1-2時間)。
-
具体例:* エージェントがエラー処理を実装します。Grovは捕捉します:「(a)チーム標準が観察可能なエラーを要求し、(b)ダウンストリームサービスがエラー信号に依存し、(c)サイレント失敗が2024年第3四半期に本番インシデントを引き起こしたため、サイレント失敗ではなく構造化ログを使用したtry-catchを選択しました。」この推論は現在、クエリ可能で再利用可能です。
コンテキスト注入
コンテキスト注入とは、新しいエージェントが作業を開始する前に、過去の決定を利用可能にすることを意味します。エージェントがセッションを開始すると、関連する過去の推論、チーム規約、アーキテクチャ制約を受け取ります。これにより、エージェントは一貫性に向けてプライミングされます。
-
実装方法:* エージェントが作業を開始する前に、タスクに関連する決定についてGrovの推論レイヤーをクエリします。エージェントがAPI設計に取り組んでいる場合、過去のAPI決定を表示します。データベース操作に取り組んでいる場合、マイグレーションパターンと一貫性ポリシーを表示します。これをエージェントのプロンプトにシステムコンテキストとして注入します。
-
運用コスト:* 無視できる程度。これはクエリとコンテキスト前置操作です。レイテンシへの影響:セッションあたり<500ms。
-
具体例:* エージェントが新しいAPIエンドポイントを実装するセッションを開始します。Grovは注入します:「チームは、すべてのエンドポイントがカーソルトークン(オフセットではない)によるページネーションをサポートし、{code, message, details}形式でエラーを返し、トレース用のリクエストIDを含める必要があることを確立しています。根拠については決定[リンク]、[リンク]、[リンク]を参照してください。」エージェントは現在、コードを書く前にガードレールを持っています。
一貫性強制
一貫性強制とは、新しい作業が確立されたパターンと矛盾する場合にフラグを立てることを意味します。新しいエージェントが過去の決定と矛盾する解決策を提案する場合、システムは矛盾を表示し、過去の推論を説明します。
-
実装方法:* エージェントが作業を完了した後、一貫性チェックを実行します。実装を捕捉された推論と比較します。逸脱が存在する場合、重大度(クリティカル、警告、情報)でフラグを立てます。クリティカルな逸脱の場合、マージ前に明示的な正当化を要求します。
-
運用コスト:* 完了後に非同期で実行されます。レイテンシ:コードベースサイズに応じて1-5秒。
-
具体例:* チームは特定のエラー処理パターン(コンテキストフィールドを持つ構造化ログ)を使用しています。新しいエージェントが異なる例外処理を書きます(print文を使用した汎用try-catch)。Grovはこれを警告としてフラグ付けし、チームパターンを表示し、リファクタリングを提案します。エージェントは提案を受け入れるか、正当化してオーバーライドできます(「これはユーティリティ関数です。完全なログオーバーヘッドはここでは必要ありません」)。
-
ワークフロー統合:* 一貫性チェックはCI/CDで実行されます。逸脱は過去の決定へのリンクとともにプルリクエストコメントに表示されます。これにより、人間のレビュアーが手動で強制する必要なく、決定が可視化されます。
測定と導入メトリクス
ROIを検証するために3つのメトリクスを追跡します:** 再導出率**、一貫性スコア、コンテキスト再利用。
コンテキスト再利用
導入状況を追跡します。エージェントが推論レイヤーを参照する頻度はどのくらいですか?使用率が低い場合、レイヤーが適切な決定をキャプチャしていないか、適切なタイミングで提示されていないことを示唆しています。
-
ベースライン:* Grovを導入後、少なくとも1つのコンテキスト注入を含むエージェントセッションの数を測定します。典型的な導入ランプ:第1週でセッションの30%、第4週までに60%、第8週までに80%以上。
-
目標:* エージェントセッションの80%以上がコンテキスト注入を含むべきです。これは、エージェントが以前の推論を発見して使用していることを示します。
-
測定方法:* すべてのコンテキスト注入イベントをログに記録します。追跡:(コンテキスト注入を含むセッション / 総セッション) × 100。
-
導入シグナル:* 2週間後にコンテキスト再利用が50%未満の場合、調査します:キャプチャされた決定は関連性がありますか?適切なタイミングで提示されていますか?推論レイヤーは不完全ですか?シード決定を調整して再測定します。
実行可能な測定計画
-
第1週:* 3つのメトリクスすべてのベースラインを確立します。現在の再導出率、一貫性スコア、コンテキスト再利用(初期は0%の可能性が高い)を文書化します。
-
第2週:* シード推論レイヤー(3〜5つのコア決定)でGrovを導入します。コンテキスト再利用と一貫性スコアを測定します。
-
第4週:* 3つのメトリクスすべてを再測定します。ベースラインからのデルタを計算します。再導出率が20%以上低下し、一貫性スコアが10%以上改善し、コンテキスト再利用が50%以上の場合、追加チームに拡大します。そうでない場合は、シード決定を調整して再測定します。
-
第8週:* 完全な測定サイクル。結果を使用して、より広範な展開を正当化するか、ギャップを特定します。
リスクと軽減戦略
リスク2:キャプチャされた推論への過度の依存
-
問題:* チームが批判的に考えることをやめ、確立されたパターンに反射的に従う可能性があります。エージェントは、チームの規約に従うが特定のコンテキストに適合しないソリューションを提案する可能性があります。
-
軽減戦略:* エージェントが以前の決定から逸脱する場合にフラグを立て、理由を説明することを要求します。逸脱を可視化し、意図的にします。また、コンテキストが不適切であることを示唆する場合、エージェントがキャプチャされた推論に疑問を呈することを要求します。
-
実装:* キャプチャされた推論からのすべての逸脱をログに記録するようにGrovを構成します。エージェントの正当化を含めます。人間による検証のために、コードレビューでこれらの逸脱を表示します。逸脱頻度を追跡します。30%を超える場合、キャプチャされた推論が硬直しすぎているかどうかを調査します。
-
具体例:* チームがルールを確立しました:「すべてのデータベースクエリはプリペアドステートメントを使用する必要があります。」エージェントが、安全で検証された入力セットから動的に構築されるクエリのシナリオに遭遇します。エージェントはルールから逸脱し、理由を説明します。Grovはこれを逸脱としてフラグを立てます。人間のレビュアーが正当化を検証します。有効な場合、この例外を含めるように決定が改良されます。
-
運用コスト:* 最小限。逸脱は自動的にログに記録されます。人間によるレビューは既存のコードレビュープロセスの一部です。
リスク3:不完全または偏った推論レイヤー
-
問題:* シード推論レイヤーがすべての関連する決定をキャプチャしない場合、エージェントは重要な選択のコンテキストを欠きます。キャプチャされた推論が古いまたは偏ったアプローチを反映している場合、エージェントはそれらを伝播します。
-
軽減戦略:* 推論レイヤーのシード化にチーム全体を関与させます。1人の視点に依存しないでください。選択されたアプローチだけでなく、検討されたトレードオフと代替案を明示的にキャプチャします。
-
実装:* チームと2時間のワークショップを実施します。各コアアーキテクチャ決定について、次を文書化します:(a)選択されたアプローチ、(b)検討された代替案、(c)トレードオフ、(d)選択を推進した制約、(e)この決定がいつ行われたか。これにより、複数の視点がキャプチャされます。
-
具体例:* チームが特定のキャッシング戦略を選択しました。文書化:「複数のサービスにわたる分散キャッシングが必要であり(a)、TTLのシンプルさが運用オーバーヘッドを削減し(b)、結果整合性を許容できるため(c)、インメモリキャッシング(代替案1)およびデータベースベースのキャッシング(代替案2)よりもTTLベースの有効期限を持つRedis(選択されたアプローチ)を選択しました。トレードオフ:強い整合性保証を失います。制約:Kubernetesにデプロイするため、インメモリキャッシングはポッドの再起動後に永続化されません。」
-
運用コスト:* チームあたり事前に2〜4時間。最適でない決定を伝播する数か月を防ぎます。
リスク4:既存のワークフローとの統合摩擦
-
問題:* Grovが既存のAIツールおよびCI/CDパイプラインとスムーズに統合されない場合、導入率は低くなります。チームは孤立して作業を続けます。
-
軽減戦略:* Grovを置き換えではなく、ミドルウェアレイヤーとして導入します。エージェントは今日と同じように作業を続けますが、永続的な推論レイヤーにアクセスでき、作業中にそれに貢献します。既存のCI/CDおよびコードレビューツールと統合します。
-
実装:* GrovはAPI経由で既存のエージェントプラットフォーム(Claude、GPTなど)にフックする必要があります。一貫性チェックは既存のCI/CD(GitHub Actions、GitLab CIなど)で実行する必要があります。結果は、既存のリンターやテストと並んでプルリクエストコメントに表示される必要があります。
-
運用コスト:* 4〜8時間の統合作業。既存のツールによって異なります。
-
モニタリング:* Grovを有効にしているチームの数を測定して導入状況を追跡します。2週間後に導入率が50%未満の場合、摩擦点を調査します。一般的な問題:コンテキスト注入がレイテンシを追加する、一貫性チェックがノイズが多すぎる、統合に手動構成が必要。
導入と移行計画:段階的展開
マルチプレイヤーAIコーディングは時間とともに価値を複利的に増やします。問題に取り組む最初のエージェントが推論を生成します。2番目のエージェントがそれを再利用します。10番目のエージェントは数か月の蓄積されたコンテキストから恩恵を受けます。このレバレッジはチームサイズとプロジェクト期間とともに成長します。
フェーズ1:パイロット(第1〜4週)
-
範囲:* 1つのチーム、1つのコードベース、1〜3つのアーキテクチャ決定。
-
活動:*
-
第1週:パイロットチームとコードベースを特定します。ベースライン測定(再導出率、一貫性スコア)を実施します。
-
第2週:パイロットチームと決定キャプチャワークショップを実施します。3〜5つのコア決定を文書化します。シード推論レイヤーでGrovを導入します。
-
第3週:導入状況を監視します。コンテキスト再利用と一貫性スコアを測定します。パイロットチームからフィードバックを収集します。
-
第4週:結果を分析します。ROIを計算します。拡大するかどうかを決定します。
-
成功基準:*
-
エージェントセッションの50%以上でコンテキスト再利用。
-
ベースラインから一貫性スコアが10%以上改善。
シングルプレイヤーの罠:孤立が高コストになる理由
現在のAIコーディングアシスタントはポイントソリューション用に設計されています。チャットを開き、問題を説明し、コードを取得し、ウィンドウを閉じます。エージェントは昨日の決定の記憶を持ちません。チームメイトは今日の推論を可視化できません。エージェントAによって確立されたアーキテクチャパターンはエージェントBには見えません。これは孤立したタスクには問題なく機能します。チームでは壊滅的に崩壊します。
コスト構造は欺瞞的です。単一の再導出には数分かかります。しかし、再導出は複利的に増加します。共有コードベースで1年間作業する5人の開発者のチームでは、1回再導出するのではなく、数十回再導出します。各再導出は小さな税金です。集合的には、数か月の無駄な認知作業を表します。
より陰湿なことに、孤立は一貫性のドリフトを生み出します。共有された推論がなければ、チームは同じ問題に対して異なるソリューションに収束します。1つのエージェントがライトスルー一貫性でキャッシングを実装します。別のエージェントがライトビハインドを実装します。両方とも有効です。どちらも間違っていません。しかし、今やコードベースには2つのキャッシングパターン、2つのメンタルモデル、2つのトレードオフセットがあります。新しい開発者のオンボーディングが難しくなります。デバッグが難しくなります。リファクタリングが難しくなります。
-
具体的なシナリオ:* チームがリアルタイム通知システムを構築します。エージェントAはWebSocketsで実装し、レイテンシと接続管理を推論します。2スプリント後、エージェントBが関連機能に遭遇し、Server-Sent Eventsを提案し、同じトレードオフ分析を独立して再導出します。エージェントAの推論にアクセスできないため、エージェントBはこの決定がすでに行われたことを知る方法がありません。同じコードベースに2つの通知パターンが存在することになります。
-
複利効果:* これは1回限りのコストではありません。将来のすべての開発者、将来のすべてのエージェント、将来のすべてのリファクタリングは、両方のパターンをナビゲートする必要があります。技術的負債はコードではなく、断片化された推論です。
-
実行可能な意味:* 先月チームが行った1つのアーキテクチャ決定を文書化します。その推論が何回再説明されたかを追跡します—コードレビュー、Slack、オンボーディングで。チームサイズとプロジェクト期間で乗算します。それがあなたの効率ベースラインです。
組織記憶としての永続的推論
Grovは現在のモデルを反転させます。エージェントがステートレスツールであるのではなく、永続的な推論レイヤー—時間とともに複利的に増加する共有組織記憶—への貢献者になります。
この推論レイヤーは、何が決定されたかだけでなく、なぜをキャプチャします。エージェントがキャッシング戦略を実装するとき、考慮した制約(整合性保証、レイテンシ要件、障害モード)、拒否した代替案(およびその理由)、コードに埋め込んだ仮定をログに記録します。この推論はクエリ可能、バージョン管理可能、構成可能になります。
新しいエージェントが関連する問題に遭遇すると、ゼロから始めません。チームの蓄積された推論を継承します。キャッシングがすでに決定されたことを確認し、根拠を理解し、パターンを再利用するか、文書化された正当化で明示的に逸脱することができます。
- これにより3つの複利効果が生まれます:*
-
再導出の削減: エージェントは問題を1回解決し、その後ソリューションを参照します。2番目のエージェントは再導出しません。再利用します。10番目のエージェントは数か月の蓄積されたコンテキストから恩恵を受けます。
-
一貫性の強制: 新しい作業が確立されたパターンと矛盾する場合、システムは競合を表示し、以前の推論を説明します。一貫性は、手動の強制負担ではなく、可視性の自然な結果になります。
-
オンボーディングの加速: 新しいチームメンバー(人間またはエージェント)はチームの推論を即座に継承します。コードから決定をリバースエンジニアリングしたり、Slackで質問したりする必要はありません。コンテキストから始めます。
-
具体例:* チームは、ローリングデプロイメントのためにデータベースマイグレーションが後方互換性を持つ必要があることを確立します。この決定は、その根拠(ゼロダウンタイムデプロイメント、段階的ロールアウト、ロールバックの安全性)とともに、Grovの推論レイヤーにキャプチャされます。新しいエージェントがマイグレーションを提案すると、このコンテキストを自動的に受け取ります。エージェントが互換性のないマイグレーションを提案した場合、システムはフラグを立て、以前の推論を表示し、代替案を提案します。時間の経過とともに、互換性のないマイグレーションはまれになります—コードレビューのオーバーヘッドのためではなく、エージェントがチームの推論を継承するためです。
-
レバレッジ乗数:* 1年間作業する5人の開発者のチームでは、これは劇的に複利的に増加します。各開発者が推論レイヤーなしで決定を2回再導出する場合、10回の導出を節約したことになります。導出あたり2〜4時間で、これは20〜40時間の認知作業が回復されます。10人の開発者にスケールすると、40〜80時間について話しています。組織にスケールすると、レバレッジは組織的になります。
-
実行可能な意味:* 先四半期にチームが行った3つのアーキテクチャ決定を特定します。それぞれについて、次のように問います:AIエージェントはコードだけからこの決定を発見できますか?できない場合、Grovの推論レイヤーの候補があります。今スプリントでこれらを明示的にキャプチャし始めてください。
実装パターン:意思決定の記録、コンテキストの注入、一貫性の強制
マルチプレイヤーAIを運用可能にするには、連携して一貫性のあるシステムを構築する3つの相互連結したパターンが必要です。
- *意思決定の記録**とは、エージェントが作業する際の推論プロセスをログに記録することを意味します。これは手動のドキュメント作成ではなく、自動的に行われます。エージェントが選択肢を評価し、制約を考慮し、選択を行う際、Grovは意思決定ツリーを記録します。なぜこのアプローチが他のものより選ばれたのか?どのような制約が意思決定を促したのか?どのような前提が組み込まれていたのか?これはバックグラウンドで行われ、監査証跡と知識ベースを同時に作成します。
重要な洞察:エージェントはすでにこれらの質問を内部的に推論しています(または、すべきです)。Grovは単にその推論を明示的かつ永続的にします。エージェントの推論プロセスが組織の記憶になります。
- *コンテキストの注入**とは、新しいエージェントが作業を開始する前に、以前の意思決定を利用可能にすることを意味します。エージェントがセッションを開始すると、関連する以前の推論、チームの慣習、アーキテクチャの制約、確立されたパターンを受け取ります。これにより、手動でプロンプトを作成することなく、エージェントを一貫性に向けて準備します。
重要なのは、コンテキストの注入が選択的であることです。認証に取り組んでいるエージェントは、チームのキャッシングパターンについて知る必要はありません。Grovは問題領域に基づいて関連するコンテキストを表示し、ノイズを減らし、シグナルを改善します。
-
*一貫性の強制**とは、新しい作業が確立されたパターンと矛盾する場合にフラグを立て、パターンが存在する理由を説明することを意味します。新しいエージェントがチーム標準とは異なる方法で例外処理を書いた場合、Grovは競合を表示し、チームパターンを説明し、リファクタリングを提案します。これは懲罰的ではなく、教育的です。エージェントはチームの推論を学び、それを採用するか、正当な理由を持って明示的に逸脱するかを選択できます。
-
具体例:* あなたのチームは特定のエラー処理パターンを使用しています:構造化ロギングを持つカスタム例外タイプ、汎用的なキャッチオールハンドラーなし、一時的な障害に対する明示的な再試行ロジック。新しいエージェントが異なる方法で例外処理を書いた場合、Grovはそれにフラグを立てます。システムはチームパターンを表示し、それが選ばれた理由(デバッグ可能性、可観測性、回復力)を説明し、リファクタリングを提案します。時間の経過とともに、手動のコードレビューのオーバーヘッドなしに一貫性が向上します。新しいエージェントは、ドキュメントを読むのではなく、適用されているのを見ることでパターンを学びます。
-
実際のワークフロー:*
- エージェントAが問題に遭遇:「データベース接続の失敗をどのように処理すべきか?」
- エージェントAが選択肢を推論:指数バックオフでの再試行、サーキットブレーカー、フェイルファストなど。
- エージェントAが指数バックオフでの再試行を選択し、推論をログに記録(なぜこのアプローチか、どのような制約がそれを促したか、何が却下されたか)。
- エージェントAがソリューションを実装。Grovが意思決定を記録。
- 2週間後、エージェントBが関連する問題に遭遇:「APIタイムアウトをどのように処理すべきか?」
- エージェントBが開始する前に、Grovがコンテキストを注入:「あなたのチームは一時的な障害に対してバックオフ付き再試行パターンを確立しています。これがその推論です。」
- エージェントBはパターンを再利用するか、正当な理由を持って明示的に逸脱。
- 時間の経過とともに、チームの障害処理へのアプローチが手動の強制なしに一貫性を持つようになります。
- 実行可能な示唆:* 1つのチーム慣習から始めましょう—エラー処理、ロギング、APIレスポンス形式、またはデータベースパターン。Grovに明示的に記録します。新しいエージェントがリマインダーなしでそれを採用する回数を測定します。そのデータを使用して、推論レイヤーの拡張を正当化します。
測定フレームワーク:マルチプレイヤーAIの価値の定量化
マルチプレイヤーAIの価値は現実的ですが抽象的です。Grovはそれを具体的にする3つのメトリクスを提供します。
- 再導出率:* あなたのチームは同じ問題を何回解決していますか?これがあなたのベースラインの非効率性です。類似の問題にタグを付けます(例:「キャッシング戦略」、「エラー処理」、「APIページネーション」)。エージェントがタグ付けされた問題に遭遇する回数を追跡します。Grov導入前は、エージェントは各問題を独立して解決します。Grov導入後は、エージェントは以前のソリューションを参照します。その差があなたの再導出の節約です。
これを測定するには、エージェントセッションを追跡します。エージェントが以前の推論を参照したときにログに記録します。エージェントがソリューションを再導出したときにログに記録します。時間の経過とともに、比率は再利用に向かってシフトするはずです。
- 一貫性スコア:* 新しいコードが確立されたパターンと一致する頻度はどのくらいですか?最近のコードを監査してこれをベースライン化します。エラー処理の何パーセントがチーム標準に従っていますか?データベースクエリの何パーセントがチームのORMパターンを使用していますか?APIレスポンスの何パーセントがチームの形式に従っていますか?これがあなたの一貫性のベースラインです。
Grovを展開した後、再測定します。エージェントがチームの推論を継承するにつれて、一貫性スコアは向上するはずです。これを毎週追跡します。1か月以内に一貫性が10〜20%向上することは現実的です。
- コンテキストの再利用:* エージェントが推論レイヤーを参照する頻度はどのくらいですか?使用率が低い場合は、レイヤーが適切な意思決定を記録していないか、適切なタイミングで表示されていないことを示唆しています。使用率が高い場合は、エージェントがチームの推論を継承し、それに基づいて構築していることを示唆しています。
エージェントが以前の意思決定を参照することをログに記録することで、これを追跡します。エージェントがセッションの30%で以前の推論を参照する場合、それは健全なベースラインです。5%の場合、推論レイヤーが効果的に表示されていません。70%の場合、強力な組織の記憶を達成しています。
- 実行可能な示唆:* 今週1つのメトリクスを選びます。ベースラインを確立します。1つのチーム慣習を記録してGrovを展開します。2週間後に再測定します。差分を使用して推論レイヤーの拡張を正当化します。再導出が20%減少し、一貫性が15%向上し、コンテキストの再利用が40%に達した場合、より広範な採用のための説得力のあるケースがあります。
リスク軽減:陳腐化、過度の依存、組織的なドリフト
マルチプレイヤーAIは、シングルプレイヤーAIにはない新しいリスクをもたらします。Grovのアーキテクチャには、それぞれに対する軽減策が含まれています。
- リスク:陳腐化または不正確な推論*
記録された意思決定が時代遅れになると、エージェントは時代遅れのパターンを伝播します。あなたのチームは同期から非同期APIにシフトしましたが、古い推論はまだ同期パターンを推奨しています。エージェントは陳腐化した推論に従い、一貫性のないアーキテクチャになってしまいます。
- 軽減策:明示的なバージョン管理と非推奨化*
推論はバージョン管理されます。意思決定が変更されると、以前のバージョンは理由の説明とともに置き換えられたとマークされます。エージェントは、すべての記録された意思決定が最新であると仮定するのではなく、バージョン管理された推論を参照します。意思決定ログは次のようになります:
- v1(2024年1月): すべての外部統合に同期API。推論:よりシンプルなエラー処理、より簡単なデバッグ。
- v2(2024年4月、v1に取って代わる): 高レイテンシ統合には非同期API。推論:回復力の向上、リソース利用率の向上。低レイテンシ統合には同期APIを保持。
エージェントが統合の意思決定に遭遇すると、両方のバージョンを見て進化を理解します。時代遅れのパターンに混乱することなく、現在の推論を適用できます。
- リスク:過度の依存と批判的思考の喪失*
チームは批判的に考えることをやめ、確立されたパターンに反射的に従うかもしれません。「推論レイヤーがキャッシングを使用すると言っているので、キャッシングを使用します」—この特定の問題にキャッシングが適切かどうかを評価することなく。
- 軽減策:明示的な逸脱のログ記録と可視性*
エージェントは、以前の意思決定から逸脱している場合にフラグを立て、その理由を説明することが求められます。逸脱は可視的で意図的になります。コードレビューは次のように表示されるかもしれません:
- 以前の推論: パフォーマンスのためにすべてのデータベースクエリをキャッシュする。
- このエージェントの意思決定: このクエリはキャッシュしない。なぜなら、それはユーザー固有で頻繁に変更されるから。
- 正当化: キャッシングはパフォーマンスを向上させるよりも正確性を低下させる。
これにより、逸脱が明示的かつ教育的になります。チームは、エージェントが以前の推論を理解し、正当な理由で逸脱することを選択したことを確認します。時間の経過とともに、これはニュアンスとコンテキスト依存性を捉えたより豊かな意思決定履歴を構築します。
- リスク:組織的なドリフト*
推論レイヤーが成長するにつれて、時代遅れの組織的価値観や技術的意思決定をエンコードする可能性があります。新しいチームメンバーは、チームの現在の優先事項を反映しなくなった推論を継承します。推論レイヤーはレバレッジの源ではなく、技術的負債の源になります。
- 軽減策:四半期ごとの推論監査と明示的な非推奨化*
意思決定レビューのケイデンスを確立します。四半期ごとに、陳腐化のために記録された推論を監査します。問いかけます:この意思決定はまだ有効ですか?コンテキストは変わりましたか?これは非推奨にすべきですか?必要に応じて更新または非推奨化します。エージェントと人間が進化を理解できるように、非推奨化を可視化します。
-
具体例:* あなたのチームは「外部依存関係を最小化する」という原則を確立しました。これはスピードを最適化していたスタートアップ時代には有効でした。2年後、あなたは信頼性と保守性を最適化する確立された企業です。この原則は今や時代遅れです。明示的に非推奨化し、理由を説明し、新しい推論を導入します:「コアインフラストラクチャには十分に保守された外部ライブラリを使用する。競争上の優位性のためにのみカスタムソリューションを構築する。」
-
実行可能な示唆:* Grovを広く展開する前に、意思決定レビューのケイデンスを確立します。四半期ごとに、陳腐化のために記録された推論を監査します。必要に応じて更新または非推奨化します。これを後付けではなく、正式なプロセスにします。
組織的レバレッジ:チームから企業規模へ
マルチプレイヤーAIの価値は規模とともに複利的に増加します。Grovを持つ単一のチームは控えめな利益を見ます—再導出の減少、一貫性の向上。Grovを持つ組織は指数関数的な利益を見ます。
-
チーム規模(5〜10人):*
-
再導出が20〜30%減少。
-
一貫性が15〜25%向上。
-
オンボーディング時間が10〜20%減少。
-
企業規模(50〜100人):*
-
再導出が40〜60%減少(より多くのチーム、より多くの共有パターン)。
-
一貫性が30〜50%向上(組織標準が出現)。
-
オンボーディング時間が30〜50%減少(新しい開発者が企業の推論を継承)。
-
チーム間のコラボレーションが向上(チームは互いの推論を参照できる)。
-
組織規模(500人以上):*
-
推論が組織のIPになる。1つのチームによって確立されたパターンがすべてのチームのレバレッジになる。
-
新しい製品は既存の製品からアーキテクチャの推論を継承できる。
-
技術標準は、トップダウンの命令からではなく、記録された推論から自然に出現する。
-
組織の記憶が競争上の優位性になる。
重要な洞察:推論は複利的に増加します。最初のチームが意思決定を記録します。2番目のチームがそれらを再利用します。10番目のチームは数か月の蓄積されたコンテキストから利益を得ます。レバレッジ乗数は組織の規模とプロジェクトの期間とともに成長します。
- 実行可能な示唆:* 小規模なチームの場合は、一貫性を向上させ再導出を減らすためにGrovから始めます。大規模な組織の場合は、組織の記憶を構築しチーム間のコラボレーションを加速するためにGrovから始めます。
移行パス:中断のない段階的な採用
現在のAIワークフローを置き換えるのではなく、それを強化します。移行は段階的で中断がありません。
-
フェーズ1(第1〜2週):* 1つのチームでパイロット**
-
1つのチームと1つのコードベースを選択。
-
1つのアーキテクチャの意思決定を特定(エラー処理、キャッシング、APIパターン)。
-
Grovに明示的に記録。
-
ベースラインを測定:エージェントはこの意思決定を何回再導出しますか?実装はどのくらい一貫していますか?
-
フェーズ2(第3〜4週):測定と拡張*
-
記録された意思決定でGrovを展開。
-
採用を測定:新しいエージェントは記録された推論を何回参照しますか?
-
一貫性を測定:実装は向上しますか?
-
再導出を測定:エージェントは問題を解決する回数が減りますか?
-
結果を使用して拡張するかどうかを決定。
-
フェーズ3(第2か月):関連する意思決定への拡張*
-
フェーズ2が肯定的な結果を示す場合、同じチーム内の関連する意思決定に拡張。
-
チームごとに3〜5の意思決定を記録。
-
意思決定レビューのケイデンスを確立(月次または四半期ごと)。
-
フェーズ4(第3か月以降):チーム間の採用*
-
他のチームに拡張。
-
次のチームから始める
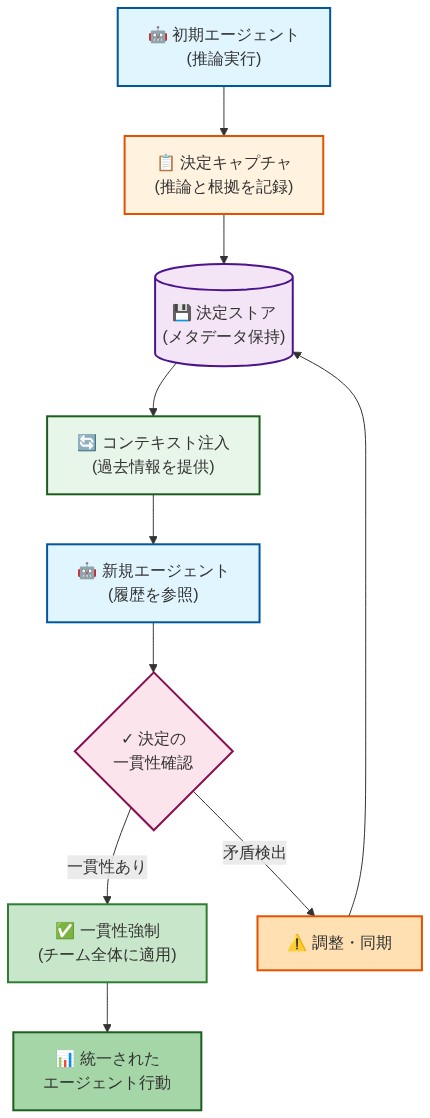
- 図6:3つのコア実装パターン – 決定キャプチャ、コンテキスト注入、一貫性強制の情報フロー*