
CUDAに対抗するROCm:「一歩ずつ進める」
CUDAの競争優位性とAMDの段階的な挑戦
NVIDIAのCUDAエコシステムは、2006年のCUDA導入から始まる約17年間の継続的な開発を通じて確立された、GPU計算における実質的な競争優位性を表しています。この優位性は単なる技術仕様にとどまらず、ライブラリ、フレームワーク、開発者教育、組織的ワークフローの統合システムであり、既存ユーザーにとって切り替えコストを生み出しています。
- 前提条件*:「競争優位性」をバフェットのフレームワークに従って定義します。これは競合他社が市場ポジションを侵食するのを防ぐ持続可能な優位性です。CUDAの場合、これには以下が含まれます。(1)訓練を受けた開発者の既存ユーザーベース、(2)成熟したライブラリエコシステム(cuDNN、cuBLAS、TensorRT)、(3)未検証の代替案に対する組織的なリスク回避、(4)技術的リーダーシップを維持する継続的な機能開発。
AMDのROCmプラットフォームは、典型的なテクノロジー置き換えとは質的に異なる競争上の課題に直面しています。孤立した技術的側面での競争ではなく、ROCmは組織的な慣性、蓄積された専門知識、定量化可能な切り替えコストを克服する必要があります。AMD経営陣が表明した「一歩ずつ進める」という哲学は、エコシステムの置き換えが革命的な代替ではなく段階的に発生することを実用的に認識しています。
AMDの文書化された戦略は、ROCmが測定可能な優位性を示す特定のユースケースを対象としています。(1)大規模展開におけるハードウェアの価格性能比、(2)カスタマイズを可能にするオープンソースアクセシビリティ、(3)GPU供給が制約される期間中のNVIDIA供給制約の緩和。この焦点を絞ったアプローチは、包括的なCUDA置き換えの試みとは対照的であり、市場分析で「ビーチヘッド」戦略と呼ばれるもの、つまり特定のセグメントで優位性を確立してから隣接市場に拡大することを追求しています。
- 重要な区別*:ROCmとCUDAの技術的同等性は採用には不十分です。CUDAツールチェーン、デバッグパターン、最適化技術の習得に何年も投資してきた開発者は、ハードウェア調達を超えた本当の切り替えコストに直面しています。組織的な購買決定は、ミッションクリティカルなインフラストラクチャにおける未検証の代替案に対する文書化されたリスク回避を反映しています。これが、ROCm採用が大規模言語モデルトレーニング、クラウドサービスデプロイメント、コスト意識の高いバッチ処理などの特定のセグメントに集中し、均一な市場浸透を達成していない理由を説明しています。
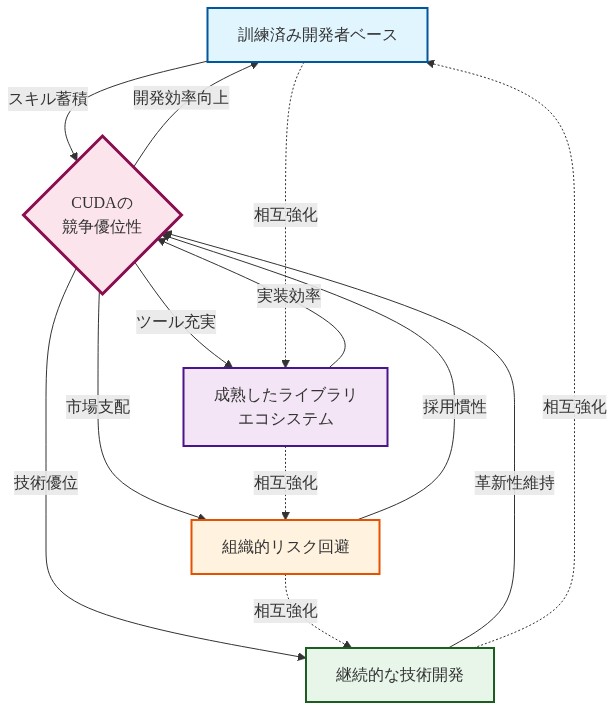
- 図2:CUDAの競争優位性を構成する4つの要素と相互強化メカニズム*
アーキテクチャの相違と互換性レイヤー
CUDAとROCmの技術アーキテクチャは、API表面互換性を超えた基本的なレベルで相違しています。NVIDIAのストリーミングマルチプロセッサ設計はAMDのコンピュートユニットアーキテクチャと大きく異なり、メモリ階層、命令スケジューリング、最適化パターンに影響を与えます。
AMDのHIPifyツールは、CUDAからHIP(Heterogeneous-Interface for Portability)への自動翻訳を提供します。これはAMDとNVIDIAの両方のハードウェア上で実行するように設計された抽象化レイヤーです。文書化された制限:AMDの公開されたケーススタディに基づくと、HIPifyはCUDAコードの約70~80%を最小限の手動介入で正常に変換します。ただし、残りの20~30%は通常、NVIDIA固有の最適化を含み、効果的に移植するには実質的なエンジニアリング作業が必要です。
-
重大な技術的ギャップ*:素朴に翻訳されたコードは、アーキテクチャの相違のためにAMDハードウェア上でしばしば性能が低下します。NVIDIAのワープベースの実行モデル(ワープあたり32スレッド)はAMDのウェーブフロントモデル(ウェーブフロントあたり64スレッド)と異なり、最適なパフォーマンスのために異なるスレッドブロックサイジングと同期パターンが必要です。メモリコアレッシングパターン、共有メモリバンク競合、レジスタ圧力最適化はすべてアーキテクチャ間で異なります。このアーキテクチャの相違は、コード翻訳だけでは不十分であることを意味します。AMD固有の最適化が競争力のあるパフォーマンスを達成するために必要になり、これはポータビリティの約束を損なわせ、開発者の負担を増加させます。
-
永続的な追いつき動態*:NVIDIAの急速なイノベーションサイクル(通常12~18ヶ月ごとに新しいCUDA機能と最適化をリリース)は、ROCmが継続的に追求する必要がある移動目標を作成します。各NVIDIAリリースは、互換性ギャップを広げる可能性のある新しいCUDA機能を導入する可能性があります。ROCmは同等性を達成して維持することはできません。代わりに、市場採用を構築しながら同時に後退する境界を継続的に追求する必要があります。この非対称性は既存プラットフォームを支持します。
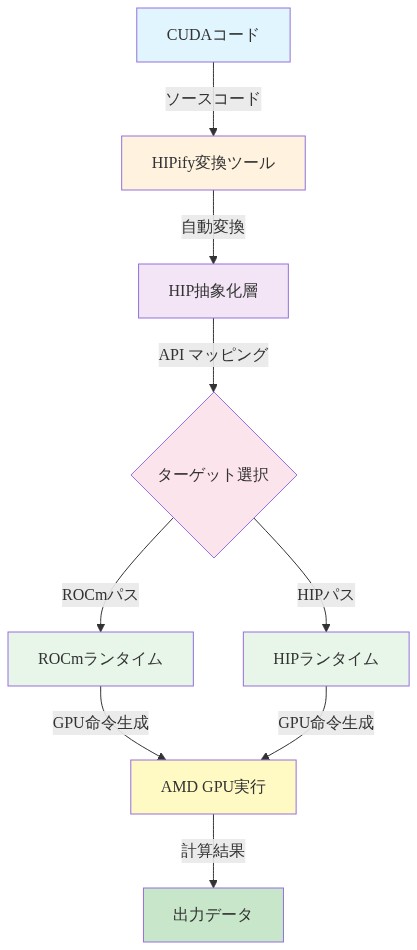
- 図5:HIPify互換性レイヤーのコード変換フロー(AMD HIP技術ドキュメント参照)*
ライブラリエコシステムのギャップ
CUDAの競争ポジションは、長期間にわたって開発された包括的で成熟したライブラリに実質的に基づいています。cuDNN(深層学習プリミティブ)、cuBLAS(線形代数)、TensorRT(推論最適化)、cuSPARSE(スパース演算)、および特定のドメイン用の専門ライブラリです。これらのライブラリは数千人のエンジニア年の最適化作業を表しており、多様なアプリケーション全体で蓄積されたドメイン固有の知識とパフォーマンスチューニングを組み込んでいます。
ROCmの機能的同等物(MIOpen、rocBLAS、rocWMMA)は同等のAPI範囲を提供しますが、同等のエコシステム成熟度に欠けています。文書化されたギャップ:ROCmに対するサードパーティフレームワークサポートは通常、CUDA実装より3~6ヶ月遅れており、新しい機能はより遅く到着し、エッジケースはより少ないテストを受けます。PyTorchとTensorFlowはどちらもROCmをサポートしていますが、このサポートはCUDA実装よりも開発注意とテストリソースが少なくなっています。
-
時間的遅延の影響*:AI研究コンテキストでは、最先端のモデルが最新のフレームワーク機能に頻繁に依存する場合、この時間的ギャップは実質的な不利をもたらします。新しいアーキテクチャを開発する研究者は、ROCm制限に遭遇し、以下のいずれかを強制されます。(1)フレームワークアップデートを待つ、(2)カスタム操作を実装する、または(3)CUDAに戻す。この摩擦はROCmの研究指向の組織にとっての魅力を低下させます。
-
エコシステム品質の側面*:単なる機能同等性を超えて、ライブラリエコシステムはドキュメント品質、コミュニティサポートインフラストラクチャ、訓練を受けた専門知識の可用性を含みます。CUDAは17年間の蓄積されたドキュメント、Stack Overflowの議論、公開された最適化ガイド、訓練を受けた実務家から利益を得ています。ROCmのドキュメントは改善していますが、依然としてそれほど包括的ではありません。組織は単にハードウェアを交換することはできません。訓練に投資し、ROCm固有のデバッグ専門知識を開発し、異なる最適化パターンの周りにワークフローを再構築する必要があります。
AI トレーニングと推論における戦略的ビーチヘッド
AMDはROCmが実行可能な競争ポジションを確立できる特定の市場セグメントを明示的に特定しています。大規模言語モデルトレーニングは、文書化された複数の理由により、特に有望なターゲットを表しています。
-
スケール経済:LLMトレーニングには、膨大な計算ワークロード(しばしば10^20以上のFLOPs)が含まれ、ハードウェアコストが主要な予算ドライバーを表しています。このコンテキストでは、20~30%のハードウェアコスト利点は経済的に重要になります。
-
アーキテクチャの標準化:トランスフォーマーベースのアーキテクチャはLLMトレーニングでほぼ普遍的な採用を達成しています。この標準化は、エキゾチックなCUDA機能への依存を減らし、焦点を絞った最適化作業を可能にします。
-
供給駆動需要:NVIDIAのGPU供給制約の期間中(2022~2023年に発生)、組織はROCmを代替容量ソースとして評価する本当のインセンティブに直面しました。
-
文書化された採用*:Microsoft AzureとOracle Cloudは、ROCmがエンタープライズスケールのワークロードをサポートできることを検証する本番環境にAMD MI シリーズアクセラレータをデプロイしています。このクラウドプロバイダーの採用により、フレームワークメンテナーはROCmサポートを優先することを強制し、正のフィードバックループを作成します。
-
推論市場の差別化*:推論市場は異なる技術要件と機会を提示します。推論デプロイメントは通常、より高いボリューム、ユニットあたりのコスト感度が低い(トレーニングに対して)が、より厳しいレイテンシー要件を含みます。ROCmの推論ストーリーはトレーニングサポートほど発展していませんが、AMDのMI300シリーズはこのセグメントを対象としています。
-
焦点を絞った差別化の根拠*:GPU計算スペクトラム全体で競争するのではなく、特定のユースケースに集中するというAMDのアプローチは、インフラストラクチャ競争からの文書化された教訓を反映しています。既存企業に対する広範なスペクトラムの課題は通常失敗します。高レバレッジセグメントでの焦点を絞った差別化がより効果的であることが証明されています。
オープンソースとしての競争的差別化
ROCmのオープンソースポジショニングは、CUDAの閉鎖的な開発モデルとは異なる技術的および戦略的利点を提供します。特殊な要件を持つ組織は、ソースコードを検査し、最適化の機会を特定し、改善に貢献できます。この透明性は、オープンソースインフラストラクチャに哲学的にコミットしている組織と、ベンダー提供のソリューションが対応していないユニークなワークロード要件を持つ組織にアピールします。
-
技術的カスタマイズの利点*:オープンソースアクセスにより、組織はコンパイラ動作、メモリ管理、またはスケジューリングアルゴリズムをドメイン固有の最適化のために変更できます。CUDAの閉鎖的な性質はそのようなカスタマイズを禁止し、ユーザーはNVIDIAの設計制約内で作業することを強制します。
-
歴史的背景*:GPU計算市場には、CUDAに対する複数の失敗したオープンソース代替案(例えば、OpenCL、初期のSYCL実装)が含まれており、オープンソースステータスだけでは採用に不十分であることを示しています。これらの失敗は、既存企業の優位性を克服するために、オープンソースが技術的能力、継続的な投資、エコシステムサポートと組み合わされる必要があることを示唆しています。
-
エンタープライズサポートの緊張*:オープンソースステータスは、本番デプロイメントが必要とするサポート説明責任と信頼性保証に関する課題を作成します。AMDはコミュニティ主導の開発とエンタープライズ顧客が必要とするエンジニアリング規律のバランスを取る必要があります。この緊張(オープンソースコミュニティダイナミクスとエンタープライズ信頼性要件の間)は、多くのオープンソースインフラストラクチャプロジェクトに課題をもたらしています。
-
採用への影響*:ROCmを評価している組織の場合、オープンソースステータスはカスタマイズと透明性に本当の利点を提供しますが、本番デプロイメントが必要とするベンダーサポートと信頼性保証の必要性を排除しません。AMDがコミュニティ主導の開発とエンタープライズグレードのサポートインフラストラクチャの両方を提供する能力は、ROCmのエンタープライズ採用軌跡に実質的に影響を与えます。
長期的ゲームとエコシステムの忍耐
「一歩ずつ進める」というフレーミングは、CUDAの置き換えが、限定的な直接収益生成の期間を通じて継続的な企業コミットメントを必要とする複数年の取り組みであることを明示的に認識しています。この忍耐を要求する戦略は、テクノロジー言説で一般的な急速な破壊ナラティブと鋭く対照的であり、代わりに、切り替えコストが強力な既存企業の優位性を作成する他のインフラストラクチャ競争で観察される段階的な市場シェア獲得に似ています。
-
歴史的先例*:同様のダイナミクスはデータベース競争(PostgreSQL対Oracle)、コンテナオーケストレーション(Kubernetes対独自ソリューション)、クラウドインフラストラクチャ(オープンソース代替案対AWS)で発生しました。各ケースでは、既存企業の置き換えには5~10年のタイムライン、限定的な市場牽引の期間を通じた継続的な投資、および全体的な置き換えではなく焦点を絞った差別化が必要でした。
-
AMDの投資要件*:ROCmの前進パスは、プラットフォームが限定的な直接収益を生成する間、能力ギャップを閉じるのに十分なエンジニアリング投資レベルを維持することに依存しています。これには、拡張開発期間中に損失または機会費用を吸収する企業コミットメントが必要です。市場サイクルを通じてこのコミットメントを維持するというAMDの意欲は、ROCmの最終的な成功に実質的に影響を与えます。
-
断片化された結果の可能性*:成功は、全体的なCUDA置き換えではなく、特定のワークロードカテゴリを取得することを含む可能性があります。ROCmが特定のユースケース(LLMトレーニング、コスト意識の高いバッチ処理)で好まれ、CUDAが研究、推論、および特殊なドメインで優位性を保持するようになることは、現実的な結果を表しています。この断片化された市場構造(複数のプラットフォームが異なる強みで共存する場所)は、ROCmの現在のポジションからの重要な進歩を表しています。
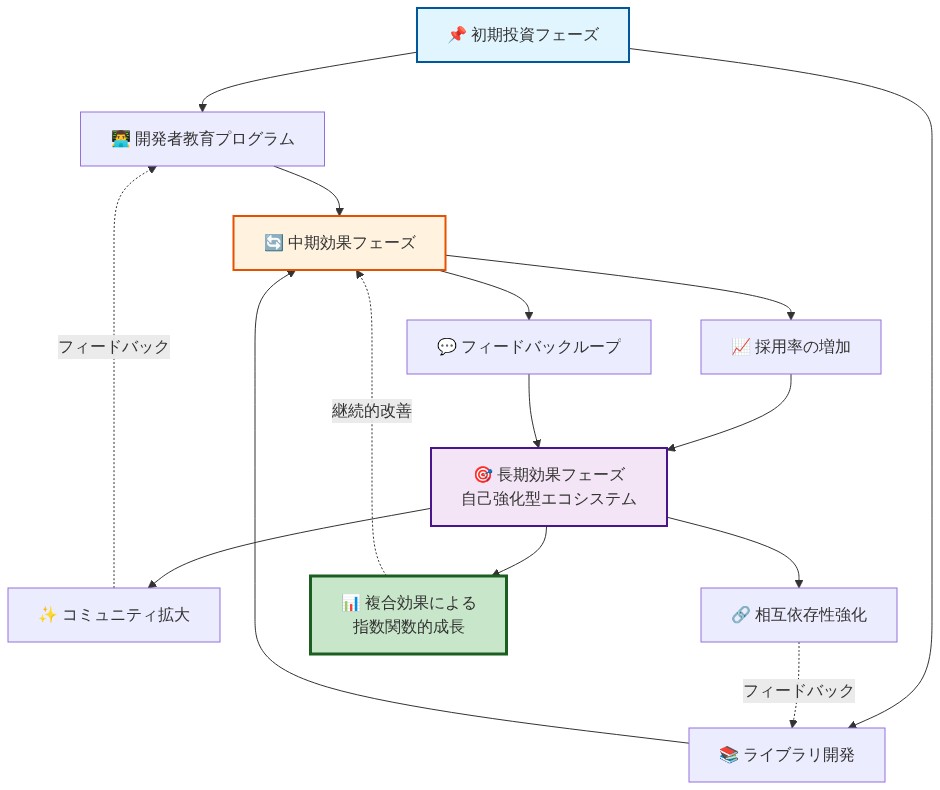
- 図11:エコシステム構築における複合効果の時間軸*
重要なポイントと次のアクション
ROCmの競争軌跡は、3つの収束する要因に依存しています。
-
技術的実行:ライブラリ成熟度、コンパイラ最適化、フレームワークサポートの能力ギャップを閉じるには、継続的なエンジニアリング投資と文書化されたベンチマークに対する測定可能な進捗が必要です。
-
戦略的焦点:高レバレッジユースケース(LLMトレーニング、大規模推論、コスト意識の高いデプロイメント)にリソースを集中させることで、ROCmの利点が切り替えコストを正当化するのに十分に複合する場合、広範なスペクトラム競争よりも効果的であることが証明されています。
-
継続的なコミットメント:限定的な市場牽引の期間を通じた複数年の投資には、典型的な四半期ごとのパフォーマンスメトリクスを超越する企業コミットメントが必要です。
-
GPU インフラストラクチャを評価している実務家向け*:ワークロード特性を体系的に評価します。標準化されたアーキテクチャ、コスト感度、供給制約はROCm評価を支持します。最先端の研究、レイテンシークリティカルなアプリケーション、特殊なドメイン要件はCUDA依存のままです。競争ダイナミクスは、組織が両方のエコシステムにわたって専門知識を維持し、排他的なベンダーコミットメントではなく特定の要件に基づいて選択する複数プラットフォームの将来を示唆しています。
-
現実的な期待*:ROCmの成功は、CUDAを完全に置き換えることではなく、その利点(コスト、オープンネス、供給可用性)が切り替えコストを正当化するのに十分に複合する拡大するワークロードセットの好ましい代替案になることによって測定されるべきです。これは、多くのアプリケーションドメインでのCUDAの継続的な優位性を認識しながら、意味のある競争進歩を表しています。
実行ロードマップ:評価からデプロイメントへ
ROCmを検討している組織は、この順序付けられたアプローチに従うべきです。
フェーズ1:評価(1~2週間)
- ワークロード特性化:GPU集約的なアプリケーションとそのCUDA機能依存性を特定します
- コスト便益分析:ハードウェアコスト削減と必要なエンジニアリング作業を計算します
- 供給制約評価:ユースケースのNVIDIA可用性とリードタイムを評価します
- 決定ゲート:ハードウェアコスト削減が20%を超えるか、供給制約がビジネスリスクを生じる場合のみ進行します
フェーズ2:概念実証(3~8週間)
- 単一アプリケーションパイロット:ROCm移行用に1つの代表的なワークロードを選択します
- HIPify変換:自動翻訳を実行し、必要な手動変更を文書化します
- パフォーマンスベンチマーク:同一ハードウェア上でROCm対CUDAのパフォーマンスを比較します
- 成功基準:CUDA性能の80%以上を達成するか、特定の最適化機会を特定します
- 決定ゲート:パフォーマンスギャップが15%未満であるか、ユースケースで許容可能な場合のみ本番環境にデプロイします
フェーズ3:本番デプロイメント(9~16週間)
- 段階的ロールアウト:非クリティカルなワークロードに最初にデプロイし、2~4週間監視します
- 専門知識開発:ROCmデバッグ、最適化、トラブルシューティングについてチームをトレーニングします
- ドキュメント作成:ROCm固有の問題と回避策に関する内部ランブックを作成します
- 監視:ROCm固有のメトリクスのパフォーマンスベースラインとアラートを確立します
- フォールバック計画:問題が発生した場合の迅速なロールバックのためにCUDA機能を維持します
フェーズ4:最適化(継続的)
- パフォーマンスチューニング:プロファイリングデータに基づいてAMD固有の最適化を実装します
- フレームワークアップデート:PyTorch/TensorFlow ROCmサポートリリースを監視し、四半期ごとにテストします
- コミュニティエンゲージメント:修正と最適化をROCmプロジェクトに貢献します
- コスト追跡:実際の対予測削減を監視し、デプロイメント戦略を適宜調整します
重要な示唆と実行可能な次のステップ
ROCmの進路は、技術的実行による能力格差の解消、高いレバレッジを持つユースケースへの戦略的集中、そして延長されたタイムラインを通じた継続的な企業コミットメントという、3つの収束する要因に依存しています。
- ROCmを評価する実務家向け:*
-
ワークロード適合性の評価: 標準化されたアーキテクチャ、コスト感度、供給制約はROCm評価を支持します。最先端の研究とレイテンシ重視のアプリケーションはCUDA依存のままです。
-
真の切り替えコストの計算: コード適応、テスト、最適化のための15~25%のエンジニアリングオーバーヘッドを予算化してください。トレーニングコスト(5万~15万ドル)と展開遅延の機会費用を含めます。
-
コミットメント前のパイロット実施: 広範な展開前に、単一アプリケーションでプルーフオブコンセプトを実行してください。パフォーマンスベースラインと成功基準を事前に確立します。
-
マルチプラットフォーム専門知識の計画: 競争力学は、組織が両方のエコシステムにわたって専門知識を維持し、排他的なベンダーコミットメントではなく特定の要件に基づいて選択するマルチプラットフォーム将来を示唆しています。
-
エコシステム成熟度の監視: ROCmライブラリリリース、フレームワークサポートタイムライン、コミュニティアクティビティを四半期ごとに追跡してください。エコシステムが成熟するにつれて、ROCm実行可能性を年1回再評価します。
-
フォールバック機能の確立: ROCm展開が予期しない課題に直面した場合に迅速なロールバックのため、CUDA専門知識とハードウェアアクセスを維持してください。
ROCmの成功は、CUDAを完全に置き換えることではなく、その利点が切り替えコストを正当化するのに十分に複合する、拡大するワークロードセットの優先代替案になることで測定されます。組織はROCm採用を戦術的なハードウェア代替ではなく、3~5年の戦略的イニシアティブとして捉えるべきであり、各段階で明確な意思決定ゲートを設けて仮定を検証し、実際のパフォーマンスとエコシステムの進捗に基づいてコースを調整します。
アーキテクチャの相違と互換性レイヤー:未来への橋を構築する
CUDAとROCmの技術的溝はAPI差異を超えて、計算がどのように組織化され最適化されるべきかについての根本的なアーキテクチャ仮定にまで及びます。AMDのHIPifyツールはCUDAコードをHIP(Heterogeneous-Interface for Portability)に変換します。これはAMDとNVIDIAの両方のハードウェア上で実行するよう設計された抽象化レイヤーであり、GPU多様性が拡大するにつれて移植性自体がますます価値を持つようになるという戦略的賭けです。
HIPifyは多くのCUDAアプリケーションを最小限の手動介入で正常に変換しますが、NVIDIA固有の最適化を含むエッジケースは実質的なエンジニアリング努力を必要とします。NVIDIAのストリーミングマルチプロセッサとAMDのコンピュートユニット間のアーキテクチャ差異は、素朴に変換されたコードがしばしば性能不足になることを意味し、AMD固有の最適化が必要になります。これは鶏と卵の問題に見えますが、実際にはプラットフォーム成熟の自然な段階を表しています。互換性レイヤーからネイティブ最適化への移行です。
この移行は歴史的なインフラストラクチャシフトを反映しています。ARMの初期x86互換性レイヤーは同様の課題に直面しました。今日、ARM固有の最適化は特定のドメインで本物のパフォーマンス利点を生み出しています。同様に、ROCmが成熟するにつれて、翻訳の初期の負担は徐々にAMD固有のイノベーションの機会に変わります。新しいメモリ階層、異なる並列化戦略、CUDAが容易に複製できないアーキテクチャ機能です。互換性レイヤーは永続的な杖ではなく、本物の差別化への橋になります。
互換性レイヤー戦略はNVIDIAの急速なイノベーションサイクルからも課題に直面します。これは継続的に新しいCUDA機能を導入します。しかし、この永遠の進化はまた機会を生み出します。新しいNVIDIAリリースが対応するROCmアップデートを必要とするたびに、AMDはそれらの機能を異なる方法で実装することを選択できる瞬間でもあります。AMDのアーキテクチャ強度により適切に、潜在的により良い方法です。動く標的は単なる不満ではなく、イノベーションのキャンバスになります。
ライブラリエコシステムギャップ:パリティから特化へ
CUDAの支配は包括的なライブラリに大きく依存しています。深層学習用のcuDNN、線形代数用のcuBLAS、推論用のTensorRTです。ROCmの同等物(MIOpen、rocBLAS)は機能的パリティを提供しますが、まだエコシステム採用ではありません。サードパーティフレームワークはROCmをサポートしていますが、このサポートはしばしばCUDA実装より数ヶ月遅れており、新しい機能はより遅く到着し、エッジケースはより少ないテストを受けます。
この時間的ギャップはAI研究で非常に重要です。最先端モデルはしばしば最新フレームワーク機能に依存しているためです。しかし、ライブラリエコシステムの課題はまた変曲点を表しています。トランスフォーマーアーキテクチャと標準化された深層学習パターンがますます支配的になるにつれて、エキゾチックなCUDA固有機能の必要性は減少します。最も重要なライブラリ、大規模行列とテンソルの標準操作をサポートするもの、はまさにROCmが最も容易にパリティを達成できるものです。
より興味深いことに、ROCmのライブラリエコシステムギャップは異なる方向でのイノベーションのための空間を生み出します。CUDAの汎用設計が最適に対応しないかもしれない新興ワークロードに最適化された特化ライブラリです。特化プロセッサが汎用CPUからニッチを切り開いたのと同様に、特定の問題クラスに最適化された特化GPU ライブラリはROCmで出現でき、単なる互換性ではなく本物の技術的利点を生み出します。
ライブラリエコシステムの課題はまた、ドキュメント品質、コミュニティサポート、訓練された専門知識の利用可能性にも現れます。CUDAの成熟度が無形ながら重要な利点を提供する領域です。しかし、これらの無形資産はまさに知識労働者と組織が意図的な投資を通じて構築できるものです。ROCmのライブラリと最適化パターンをマスターする各チームは、拡大する専門知識ネットワークのノードになり、徐々に競争力学をシフトさせます。
AI訓練と推論における戦略的ビーチヘッド:拡大する足がかりの確立
AMDはROCmが実行可能なビーチヘッドを確立し、体系的に拡大できる特定の市場セグメントを特定しました。大規模言語モデル訓練は特に有望なターゲットを表しています。これらのワークロードの規模はハードウェアコストを主要な懸念にし、トランスフォーマーアーキテクチャの標準化された性質はエキゾチックなCUDA機能への依存を減らします。NVIDIA供給制約に直面するか、単一ベンダー依存を回避しようとしている組織は、ハードウェア利用可能性とコスト利点が十分に説得力を持つ場合、ROCm有効化への投資意欲を示しています。
これらのビーチヘッドは単なるニッチ市場ではなく、GPU計算の最も急速に成長し、戦略的に最も重要なセグメントを表しています。LLM訓練は組織のAI戦略を駆動します。規模での費用効率的な推論はAI展開の経済学を決定します。これらの拡大するドメインで支配を確立することで、ROCmは周辺ではなくAIインフラストラクチャの将来進化の中心に自分自身を位置付けます。
Microsoft AzureとOracle Cloudを含むクラウドプロバイダーはAMD MI シリーズアクセラレータを展開し、検証を提供し、フレームワーク保守者にROCmを真摯に受け止めるよう強制しています。このクラウドプロバイダー採用は乗数効果を生み出します。クラウドインフラストラクチャがAMDハードウェアで標準化されるにつれて、これらのプラットフォーム上に構築する組織は自然にROCm専門知識を開発し、ROCm最適化ツールとライブラリの需要を生み出し、これが開発者投資とエコシステム成長を引き付けます。
推論市場は異なる機会を提示します。ユニットあたりのコスト削減が大幅に複合する高ボリューム展開ですが、より厳しいレイテンシ要件は異なる技術的課題を生み出します。GPU計算スペクトラム全体で競争するのではなく特定のユースケースに焦点を当てるAMDのアプローチは、他のインフラストラクチャ競争からの教訓を反映しています。焦点を絞った差別化は広範なスペクトラムでの現職者への課題よりも効果的であることが証明されています。この焦点はまた選択肢を生み出します。訓練と推論での成功は隣接するドメインに拡大するためのリソースと信頼性を提供します。
オープンソースとしての競争的差別化とイノベーション加速器
ROCmのオープンソース位置付けは、従来の競争分析を超えた技術的および戦略的利点を提供します。検査、修正、貢献する能力は、特化した要件を持つ組織またはオープンソースインフラストラクチャに哲学的にコミットしている組織にアピールします。このオープン性は、CUDAの閉鎖的性質が禁止するカスタマイズを可能にします。組織はベンダーアップデートを待つことなく、特定のハードウェア構成、ワークロードパターン、パフォーマンス要件に対して最適化できます。
さらに重要なことに、オープンソースステータスは所有システムが容易に一致できないイノベーションのプラットフォームを生み出します。研究者、スタートアップ、世界中の組織は、ベンダーの許可を求めたりベンダーロードマップを待つことなく、新しい最適化、新しいアルゴリズム、アーキテクチャイノベーションを実験できます。この分散イノベーションエンジンは、特にシステムがより複雑で特化するにつれて、集中開発よりもインフラストラクチャプラットフォームにとってより強力であることが歴史的に証明されています。
しかし、オープンソースステータスだけが採用を保証しません。GPU計算の歴史にはCUDAへの複数の失敗したオープン代替案が含まれており、オープン性は技術的能力と継続的な投資と組み合わせる必要があることを示しています。オープンソースアプローチはサポートと説明責任の周辺で課題を生み出し、エンタープライズ顧客が重く評価します。AMDはコミュニティ駆動開発とエンジニアリング規律のバランスを取る必要があります。本番展開が必要とする信頼性保証。多くのオープンソースインフラストラクチャプロジェクトを課題としてきた緊張ですが、それを正常に乗り越える組織のための機会も生み出しました。
オープンソース位置付けはまた、ベンダーロックインと数据主権に関する規制精査の増加の時代に戦略的利点を生み出します。所有システムへの長期依存を懸念する組織はROCmのオープン性をますます魅力的に見つけます。特に地政学的考慮が単一ベンダー依存をより危険にする場合です。この規制および地政学的追い風はROCmに純粋な技術的メリットだけでは生成できない利点を提供します。
長期戦略とエコシステム忍耐:複合利点の構築
「一歩ずつ」フレーミングはCUDA置き換えが限定的な市場牽引の期間を通じた継続的なコミットメントを必要とする複数年の努力を表すことを認識しています。この忍耐を要求する戦略は技術で一般的な急速な破壊物語と対比し、代わりに切り替えコストが強力な現職者利点を生み出す他のインフラストラクチャ競争での段階的な市場シェア獲得に似ています。
しかし、この長期戦略アプローチは技術談話で見落とされることが多い戦略的知恵を含みます。ROCmが改善する毎年、それを正常に展開する各組織、その最適化パターンをマスターする各開発者、パリティを達成する各ライブラリ。これらは移動する競争力学に蓄積します。今日CUDAを保護する切り替えコストは、組織がROCm専門知識を構築するにつれて関連性が低くなります。今は克服不可能に見えるエコシステムギャップはライブラリ開発が加速するにつれて狭まります。今日の苦痛な最適化を必要とするアーキテクチャ差異は明日の本物の差別化の源になります。
AMDの課題はプラットフォームが限定的な直接収益を生成する間、能力格差を解消するのに十分なROCm投資レベルを維持することを含みます。成功はおそらくCUDA全体置き換えではなく特定のワークロードカテゴリをキャプチャすることを含みます。ROCmは特定のユースケースで優先される一方、CUDAは他の場所で支配を保持します。この断片化された結果はROCmの現在の位置からの重要な進捗を表し、より回復力のある競争的なGPU計算ランドスケープを生み出します。
長期戦略はまた隣接するイノベーションのための機会を生み出します。ROCmが成熟するにつれて、それは新しいGPUアーキテクチャ、特化アクセラレータ、ドメイン固有の最適化の実験のためのプラットフォームになります。CUDAの支配が阻止してきた方法です。スタートアップと研究チームはROCmのオープン基盤上に構築でき、CUDAでは不可能な方法で、潜在的にGPU加速計算の完全に新しいカテゴリを生み出します。
知識労働者とインフラストラクチャアーキテクトへの含意
ROCm-CUDA競争はベンダー戦闘以上を表しています。GPU計算の将来アーキテクチャの根本的なシフトを示唆しています。CUDAへの実行可能な代替案の出現は組織に本物の選択肢を生み出し、一つのサイズがすべてに適合するソリューションを受け入れるのではなく、特定の要件に対して最適化することを可能にします。この競争力学は知識労働者とインフラストラクチャチームに彼らのツールキットを拡大し、特化した専門知識のための機会を生み出すことで利益をもたらします。
組織にとって、即座の戦略的含意は選択肢を構築することを含みます。両方のエコシステムにわたって専門知識を開発し、各プラットフォームを支持する特定のワークロード特性を理解し、マルチプラットフォーム展開をサポートするようにインフラストラクチャを位置付けます。この選択肢はGPU計算が新しいドメインに拡大するにつれて、また地政学的および規制要因がベンダー多様化を戦略的に重要にするにつれてますます価値を持つようになります。
個々の知識労働者にとって、ROCm専門知識は本物の競争的利点を表しています。プラットフォームが成熟し採用が拡大するにつれて、深いROCm知識を持つ専門家は彼らのスキルに対する需要の増加を見つけるでしょう。より広く、複数のGPU計算プラットフォーム間を移動し、それらのアーキテクチャ差異を理解し、特定のハードウェアのワークロードを最適化する能力は、GPU計算ランドスケープが多様化するにつれてますます価値を持つようになります。
出現するマルチプラットフォーム将来
ROCmの成功は最終的にCUDAを完全に置き換えることではなく、その利点が切り替えコストを正当化するのに十分に複合する、拡大するワークロードセットの優先代替案になることで測定されます。このマルチプラットフォーム将来(組織が両方のエコシステムにわたって専門知識を維持し、特定の要件に基づいて選択する場合)は、より成熟した、競争的で、最終的により革新的なGPU計算ランドスケープを表しています。
前進の道は3つの収束する要因に依存しています。技術的実行による能力格差の解消、高いレバレッジを持つユースケースへの戦略的集中、延長されたタイムラインを通じた継続的な企業コミットメント。GPU インフラストラクチャを評価する組織は、CUDA全体置き換えを期待するのではなく、特定のドメイン(LLM訓練、規模での推論、費用効率的な展開)でのROCmの進捗を監視すべきです。競争力学は、その競争者を置き換えるプラットフォームではなく、本物の選択肢を生み出し、組織が特定の需要に対して最適化することを可能にするエコシステムに将来が属することを示唆しています。
実務家にとって、即座のアクションはワークロード特性の評価を含みます。標準化されたアーキテクチャ、コスト感度、供給制約はROCm評価を支持し、最先端の研究とレイテンシ重視のアプリケーションはCUDA依存のままです。最も洗練されたインフラストラクチャ戦略は排他的なベンダーコミットメントも素朴なプラットフォーム不可知論も含みませんが、むしろ各プラットフォームの本物の強度を活用する意図的なマルチプラットフォーム最適化を含みます。チャレンジャーから確立された代替案へのROCmの旅は単なる競争的進捗ではなく、GPU計算の成熟を本物に競争的で複数ベンダーのエコシステムへ表しています。加速されたイノベーションと拡大された可能性を通じてフィールド全体に利益をもたらす変換です。
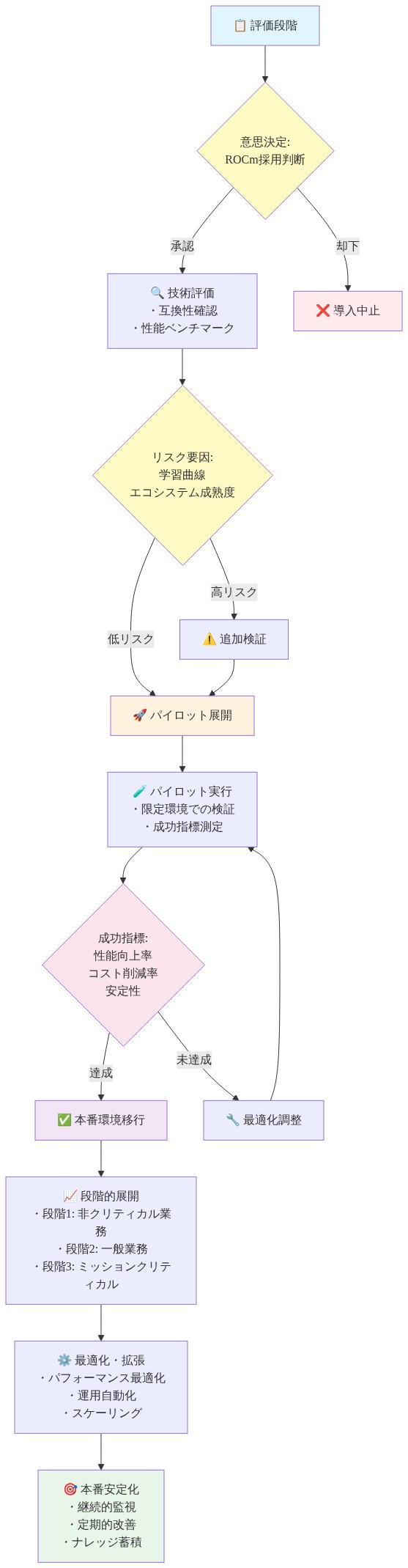
- 図13:ROCm導入の実行ロードマップ(評価から本番展開まで)*
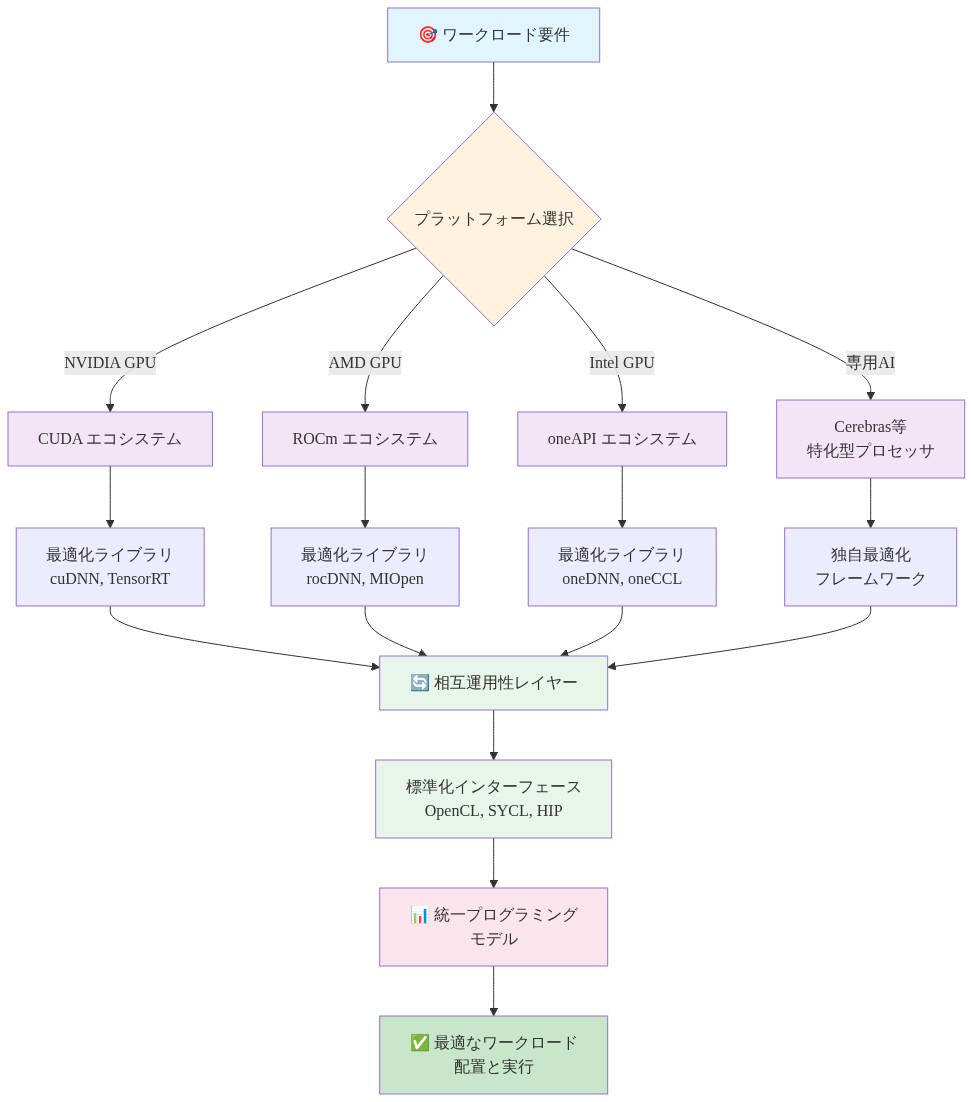
- 図15:マルチプラットフォーム時代のGPUエコシステム構成*