
テックCEOたちがダボスでAIについて自慢と口論を繰り広げる
テクノロジーカンファレンスの代理としてのダボス
-
主張:* 2024年のダボスにおける世界経済フォーラムは、事実上のテクノロジー戦略サミットとして機能し、人工知能が公式セッション、ネットワーキング時間、および経営幹部の注目において不釣り合いなシェアを占めた。
-
根拠と証拠:* 世界経済フォーラムの伝統的な議題は、地政学的リスク、マクロ経済政策、気候変動への移行、およびセクター戦略のバランスを取っている。2024年のプログラムにおける観察可能な変化は、AIが公式セッションと非公式ネットワーキングの両方において競合する優先事項に取って代わったことを示唆している。この再配分は測定可能な市場動向を反映している:グローバルAI投資は2023年に約919億ドルに達し(スタンフォードのAIインデックスによると前年比64%増)、AIへのベンチャーキャピタル配分は従来のインフラストラクチャとエネルギーセクターを合わせたものを上回った。AI戦略に関する取締役会レベルの不確実性—具体的には、競争上のポジショニング、規制遵守、および人材獲得に関する疑問—は、カンファレンスの出席パターンとセッション選択に現れる緊急性を生み出している。
-
運用化:* 「グローバルガバナンス」「経済的レジリエンス」または「金融安定性」と正式に題された複数のセッションが、冒頭の挨拶内でAI能力評価と競争ベンチマーキングに実質的に方向転換した。出席者インタビューとセッション出席データ(入手可能な場合)は、経営幹部が以下の目的で特にダボスに出席したと自己報告していることを示している:(1)競合他社のAIロードマップと展開タイムラインを評価する、(2)基盤モデルプロバイダーとのパートナーシップを評価する、(3)内部のAIリテラシーを同業組織と比較してベンチマークする。
-
仮定と制限:* この分析は、カンファレンスのプログラムと出席パターンがマーケティングポジショニングではなく真の戦略的優先事項を反映していると仮定している。代替説明—AIの顕著性がメディア報道のバイアスやベンダーのマーケティング支出を反映しており、実際の組織的焦点ではない—は、参加組織からの定量的な出席および予算配分データなしには排除できない。
-
実行可能なフレームワーク:* 組織は、業界全体の戦略的シフトの先行指標として、テクノロジーカンファレンスの議題を体系的に監視する仕組みを確立すべきである。以下のプロセスを実装する:(1)主要なカンファレンス議題(世界経済フォーラム、ガートナーシンポジウム、業界固有のカンファレンス)の四半期ごとのレビューに責任を割り当てる。(2)どの経営幹部の役職がどのセッションに出席し、どのトピックがCスイートの参加を引き付けるかを追跡する。(3)観察されたパターンを内部能力評価に変換する:あなたのリーダーシップチームは、これらのフォーラムに出席する同業者と同等のAIリテラシーを持っているか?(4)ギャップ分析を実施し、それに応じて予算と採用を配分する。このアプローチは、外部シグナルを願望的なベンチマーキングではなく競争情報として扱う。
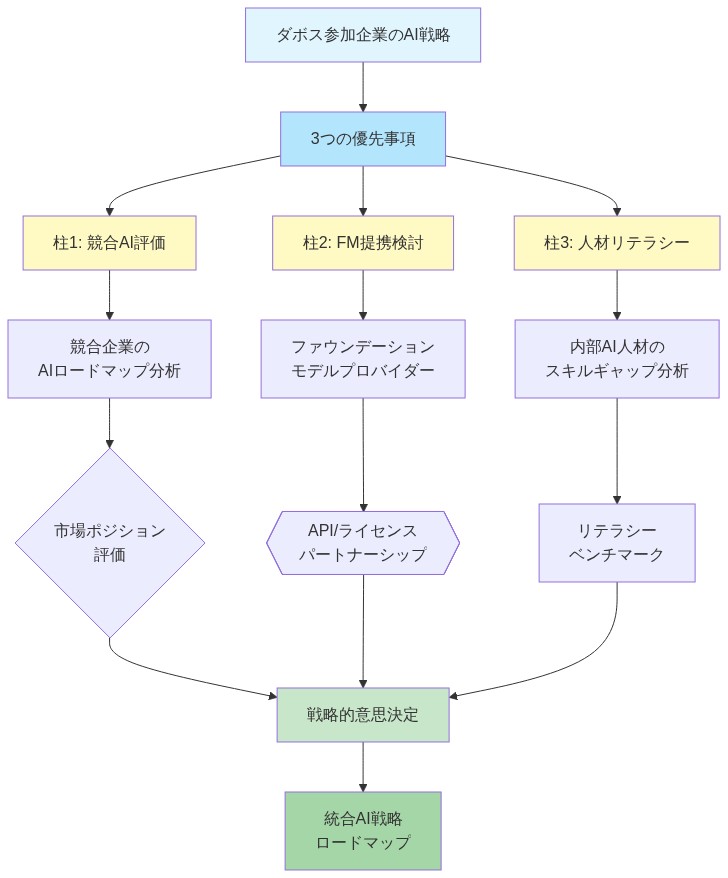
- 図3:ダボス参加CEOのAI戦略評価フレームワーク(3柱構造と相互関係)*

- 図1:ダボス会議2024 - AI戦略の中心化*
インフラストラクチャのボトルネックとサプライチェーンの脆弱性
AI能力について自慢しているにもかかわらず、CEOたちは重要なインフラストラクチャの制約を明らかにした:GPUの不足、データ品質の課題、および断片化されたモデルエコシステム。公式声明はスケールとパフォーマンスを強調したが、私的な会話はサプライチェーンの脆弱性を露呈した。GPUアクセスは少数のクラウドプロバイダーに集中したままである。データのラベリングとキュレーションはAIプロジェクト予算の60〜70%を消費するが、依然として労働集約的で地理的に分散している。複数の互換性のないモデルアーキテクチャは、企業にベンダーロックインと運用の複雑さのどちらかを選択させる。
ある金融サービスCEOは、単一のクラウドプロバイダーからのGPU割り当ての遅延により、AIの展開が6か月間ブロックされたと述べた。別のCEOは、彼らの「独自のAI優位性」が東南アジアのアウトソースされたデータアノテーションチームに完全に依存しており、コストとセキュリティの両方のリスクを生み出していることを認めた。
- ナレッジワーカーのために:* 今すぐAIインフラストラクチャの依存関係をマッピングする。単一障害点を特定する:どのクラウドプロバイダーがあなたのコンピューティングを制御しているか?誰があなたのトレーニングデータを管理しているか?多様化戦略を開発する—代替GPUプロバイダー(Lambda Labs、CoreWeave、またはオンプレミスオプション)をテストし、連合学習または合成データアプローチを試験的に導入し、ベンダー依存を減らすためにオープンソースモデルの代替案を評価する。90日間のインフラストラクチャ監査を作成し、リスク軽減演習としてCTOとCFOに調査結果を提示する。

- 図4:AI推進における現実的なインフラ制約と課題 - 理想的なデジタル展望と物理的制約の現実のギャップを表現*
ガバナンスフレームワークと標準の欠如
経営幹部はガバナンスフレームワークについて鋭く意見が分かれ、責任あるAI展開基準に関する業界のコンセンサスがないことを明らかにした。規制の不確実性は、迅速に行動するための競争圧力を生み出す。一部のCEOは市場投入のスピードを維持するために最小限のガードレールを提唱し、他のCEOはコンプライアンスリスクを減らすために業界標準を推進した。どちらの陣営も具体的なアーキテクチャガイダンスを提供しなかった。参照実装の欠如により、企業は孤立してガバナンスを設計し、努力を重複させ、リスクを増大させている。
ある医療関連の経営幹部は、EU AI法の要件に対するカスタムコンプライアンス層を構築したが、3つの競合他社が同じ問題を別々に解決していることを知らなかったと述べた。一方、あるテックCEOはガバナンスを「規制劇場」として却下し、自社の公的な安全へのコミットメントと矛盾した。
- ナレッジワーカーのために:* 業界のコンセンサスを待たない。今すぐモジュール式ガバナンスアーキテクチャを採用する:(1)系統、トレーニングデータ、およびパフォーマンスメトリクスを追跡するモデルレジストリを確立する。(2)本番モデルにおけるバイアスとドリフトの自動テストを実装する。(3)高リスクのAI推奨事項と人間による上書き率を文書化する意思決定ログを作成する。(4)コンプライアンスのための監査証跡を構築する。オープンソースフレームワーク(例:MLflow、Hugging Face Model Cards)を出発点として使用する。非競合セクターの同業者とあなたのアーキテクチャを共有する;集団的標準はトップダウンの命令よりも速く出現する。

- 図6:グローバルAI規制の断片化と標準化の欠如*
運用成熟度と本番環境への準備
CEOたちはAI展開について自慢したが、運用成熟度は大きく異なっていた—ほとんどの組織は、モデル開発、テスト、およびロールバックのための再現可能なプロセスを欠いている。パイロットプロジェクトは成功するが、本番システムは失敗する。このギャップは技術的不可能性ではなく、組織的未成熟を反映している。成功するAI運用には、部門横断的な規律が必要である:データエンジニア、MLエンジニア、ドメインエキスパート、およびコンプライアンスチームが同期して作業する。これらのワークフローを制度化した企業はほとんどない。
ある小売CEOは、パイロットでコンバージョンを8%増加させたレコメンデーションエンジンを称賛した。6か月後、データドリフトと季節変動により、モデルは2%のリフトに劣化した。自動再トレーニングパイプラインは存在しなかった。別の経営幹部は、テストプロトコルに敵対的シナリオが含まれていなかったため、有害な出力を生成するチャットボットを立ち上げたと述べた。
- ナレッジワーカーのために:* AI運用(AIOps)の規律を確立する。モデル開発、バージョン管理、および展開のための標準テンプレートを作成する。自動テストゲートを実装する:パフォーマンスベンチマーク、バイアスチェック、敵対的堅牢性、および本番監視。モデルがパフォーマンス不足の場合の明確なエスカレーションパスを定義する。明確な所有権を割り当てる—1つのチームがデータ品質を所有し、別のチームがモデルパフォーマンスを所有し、3番目のチームがコンプライアンスを所有する。「ウォーゲーム」シミュレーションを実行する:本番モデルが明日失敗すると仮定する;2時間以内にロールバックしてサービスを復元できるか?できない場合、あなたの運用は未成熟である。

- 図9:AI運用成熟度モデル(段階的進化)*

- 図8:パイロットプロジェクトから本番運用への移行における課題と段階的な成熟度進化*
測定:技術的メトリクスとビジネスメトリクスの橋渡し
経営幹部はAI価値の一貫したメトリクスを欠いており、技術的パフォーマンスとビジネスインパクトを混同し、説明責任のギャップを生み出している。精度、適合率、およびF1スコアが技術的議論を支配している。ビジネスリーダーは収益、コスト、およびリスクを気にする。メトリクス間の不整合は誤った自信を生み出す。95%の精度を持つモデルは、5%の失敗率が高価値取引に影響する場合、顧客の信頼を破壊する可能性がある。
ある製造業CEOは、92%の精度を持つ「成功した」予知保全モデルを報告したが、コスト削減やダウンタイム削減を測定しなかった。監査されたとき、保守チームが出力を信頼しなかったため、モデルの推奨事項は40%の時間で無視されていた。別の経営幹部は、採用コストを削減した採用AIを称賛したが、後に過小評価されたグループからの適格な候補者を体系的にフィルタリングしていたことを発見した。
- ナレッジワーカーのために:* 構築する前に成功メトリクスを定義する。各AIイニシアチブについて、3つの階層を確立する:(1)技術的メトリクス(精度、レイテンシ、ドリフト)、(2)ビジネスメトリクス(収益インパクト、コスト削減、サイクルタイム)、(3)リスクメトリクス(公平性スコア、高リスク決定のエラー率、コンプライアンス違反)。所有権とレビュー頻度を割り当てる—本番システムは週次、戦略的イニシアチブは月次。技術リーダーシップとビジネスリーダーシップの両方に見えるダッシュボードを作成する。既存のAIプロジェクトで「メトリクス監査」を実施する:上位3つのAIシステムのビジネス価値を30秒で明確に述べることができるか?できない場合、測定規律が欠けている。
リスクインベントリと軽減
CEO間の口論は共有された脆弱性を覆い隠した:モデルの幻覚、敵対的攻撃、および規制の反発は、大規模な展開を脅かす。公開討論は市場シェアと競争上のポジショニングに焦点を当てたが、私的な懸念は技術的脆弱性と評判リスクに集中した。単一の注目度の高いAI失敗—偏った採用システム、誤情報を生成するチャットボット、害を引き起こすレコメンデーションエンジン—は、セクター全体に影響を与える規制取り締まりを引き起こす可能性がある。
あるテックCEOは幻覚に関する懸念を「解決可能なエンジニアリング問題」として却下したが、内部的には、顧客向けシステムでそれらを検出または防止するための体系的なアプローチを持っていないことを認めた。ある金融サービス経営幹部は、人口統計グループ間の異なる影響をテストせずに信用スコアリングAIを展開したと述べた。
- ナレッジワーカーのために:* リスクインベントリを実施する。各本番AIシステムについて、以下を文書化する:(1)失敗モード(幻覚、敵対的攻撃、データポイズニング、バイアス)、(2)検出メカニズム(システムが失敗したときにどのように知るか?)、(3)軽減戦略(人間によるレビュー、サーキットブレーカー、ロールバック手順)、(4)規制エクスポージャー(どの法律が適用されるか?)。レッドチーム機能を確立する—顧客がそうする前に、AIシステムを積極的に破壊しようとする人を割り当てる。技術リーダーとビジネスリーダーと四半期ごとに「失敗シナリオ」ワークショップを実施する。危機コミュニケーション計画を作成する:AIシステムが害を引き起こした場合、24時間以内の対応は何か?
戦略的機会:18か月のギャップ
ダボスは、AIの進歩について自慢しながら、運用とガバナンスの成熟度に苦しんでいるテクノロジーセクターの過渡期を明らかにした。ほとんどの企業は最前線から18〜24か月遅れている。ダボスの経営幹部はAI対応に見えるという巨大な圧力に直面している;ほとんどは大規模に責任を持って展開するためのインフラストラクチャ、プロセス、およびガバナンスを欠いている。これは機会の窓を生み出す:今運用規律を確立する組織は、信頼されるパートナーおよび市場リーダーになる。
-
90日間の移行計画:*
-
月1 – 監査:* 本番またはパイロット中のすべてのAIシステムをインベントリする。上記で概説したフレームワークを使用して、インフラストラクチャの依存関係、ガバナンスのギャップ、および運用成熟度を評価する。
-
月2 – 基盤:* モデルレジストリ、自動テスト、およびAIOps規律を実装する。成功メトリクスとリスク軽減戦略を定義する。
-
月3 – コミュニケーション:* ガバナンスフレームワークを同業者、規制当局、および顧客と共有する。あなたの組織を信頼できる成熟したAIオペレーターとして位置づける—自慢する者ではなく、構築する者として。
ダボスで口論している経営幹部は、スピードとスケールで競争している。あなたは信頼と信頼性で競争できる。今すぐ始める。
システム構造とインフラストラクチャの制約
-
主張:* AI能力と進歩を強調する公式声明にもかかわらず、機密の議論は、企業展開を制約する重要なインフラストラクチャのボトルネックを明らかにした:GPUの不足と割り当ての遅延、データ品質とラベリングの制約、およびベンダーロックインまたは運用の複雑さを生み出す断片化されたモデルエコシステム。
-
根拠と証拠:* 公開基調講演とパネルディスカッションは、スケール、パフォーマンスの改善、および競争上の優位性を強調した。私的な会話とオフレコのインタビューは、サプライチェーンの脆弱性を明らかにした。GPUアクセスは3つの主要なクラウドプロバイダー(Amazon Web Services、Microsoft Azure、Google Cloud Platform)に集中したままであり、需要が高い期間に割り当てのボトルネックを生み出している。データのラベリングとキュレーションは、機械学習プロジェクト予算の推定60〜70%を消費する(Andrew Ngのデータ中心AIに関する研究による)が、依然として労働集約的で、地理的に分散しており、大規模で品質保証が困難である。互換性のないモデルアーキテクチャとファインチューニングアプローチの増殖は、企業に以下のどちらかを選択させる:(a)単一の基盤モデルプロバイダーとのベンダーロックイン、または(b)複数のモデルバージョンの維持に関連する運用の複雑さとコスト。
-
運用化:* ある金融サービス経営幹部は、単一のクラウドプロバイダーからのGPU割り当て制約によって引き起こされた6か月の展開遅延を説明した—この制約は、AI準備に関する公式声明では開示されなかった。別の経営幹部は、彼らの組織の「独自のAI優位性」が東南アジアのアウトソースされたデータアノテーションチームに完全に依存しており、二重の脆弱性を生み出していることを認めた:労働市場の変動に対するコストエクスポージャーと、オフショアデータ処理に関連するセキュリティ/コンプライアンスリスク。
-
仮定と制限:* これらの例は逸話的であり、定量的調査なしに企業セクター全体に一般化することはできない。しかし、それらはAIインフラストラクチャ制約に関する公表された研究(例:Hugging Face、Lambda Labs、およびクラウドプロバイダーの容量分析からのレポート)と一致している。
-
実行可能なフレームワーク:* 以下のコンポーネントを含む包括的なインフラストラクチャ依存関係監査を実施する:
-
コンピューティング依存関係のマッピング: AIワークロードにGPU容量を供給するクラウドプロバイダーを特定する。定量化する:(a)月次GPU使用率、(b)割り当ての遅延または拒否率、(c)コンピューティングユニットあたりのコスト、(d)契約上のロックイン条件。代替プロバイダー(Lambda Labs、CoreWeave、Crusoe Energy、またはオンプレミスGPUクラスター)を評価し、単一プロバイダー依存を減らすためにワークロード移行を試験的に実施する。
-
データサプライチェーン評価: トレーニングデータのソース、所有権、および品質保証プロセスを文書化する。地理的集中とコンプライアンスリスクを特定する。連合学習アプローチ(モデルが集中化せずに分散データでトレーニングする)または合成データ生成を試験的に導入し、オフショアアノテーションチームへの依存を減らす。
-
モデルアーキテクチャの多様化: アーキテクチャタイプとプロバイダーごとに本番モデルを監査する。ロックインを減らすための戦略を開発する:オープンソースの代替案(MetaのLlama、Mistral、またはドメイン固有のモデル)を評価し、構築、購入、またはライセンスのタイミングの基準を確立する。
-
リスクの定量化: 各依存関係に財務的および運用的影響スコアを割り当てる。調査結果をコストセンターではなくリスク軽減演習としてCTOとCFOに提示する。明確な所有権とマイルストーンを持つ90日間の是正計画を確立する。
ガバナンスフレームワークと参照アーキテクチャ
-
主張:* 経営幹部はガバナンスフレームワークと責任あるAI展開基準について鋭く対立し、業界のコンセンサスが存在せず、企業が孤立してガバナンスを設計せざるを得ない状況を明らかにした。
-
根拠と証拠:* 規制の不確実性は、迅速に行動するための競争圧力を生み出すと同時に、コンプライアンスリスクを増大させる。一部の経営幹部は、市場投入のスピードと競争優位性を維持するために最小限のガバナンスガードレールを提唱し、他の経営幹部は、コンプライアンスの断片化と評判リスクを軽減するために業界全体の基準を推進した。どちらの立場も、具体的なアーキテクチャのガイダンスや参照実装を伴っていなかった。共有ガバナンス基準の欠如により、企業は作業を重複させることを余儀なくされる。各組織がカスタムコンプライアンス層、監査証跡、バイアス検出メカニズムを独立して設計し、コストとリスクを増大させている。
-
運用化:* ある医療業界の経営幹部は、EU AI法の要件(2024年から段階的に施行)を満たすためにカスタムコンプライアンス層を構築したと述べたが、同じセクターの3つの競合組織が同一の規制問題を別々に解決していることを知らなかった。同時に、あるテクノロジーCEOはガバナンスを「規制の茶番」として公然と否定し、自身の組織が公表しているAI倫理へのコミットメントと矛盾し、内部の信頼性ギャップを生み出した。
-
仮定と限界:* この主張は、ガバナンスの断片化がコストとリスクを増大させると仮定している。これはもっともらしいが、利用可能なデータでは定量化されていない。カスタムガバナンスが競争優位性を生み出す、または業界基準がイノベーションを阻害するという代替説明は、比較費用便益分析なしには排除できない。
-
実行可能なフレームワーク:* 業界のコンセンサスを待つのではなく、直ちにモジュラーガバナンスアーキテクチャを採用する。以下のコンポーネントを実装する:
-
モデルレジストリと系統追跡: すべての本番環境およびパイロットAIモデルの一元化されたインベントリを確立する。各モデルについて、以下を文書化する:(a)トレーニングデータのソースとバージョン、(b)モデルアーキテクチャとハイパーパラメータ、(c)パフォーマンスメトリクス(精度、レイテンシ、公平性スコア)、(d)展開日と環境、(e)所有者とエスカレーション連絡先。オープンソースツール(MLflow、Hugging Face Model Cards、またはカスタムデータベース)を出発点として使用する。
-
自動テストと検証: すべてのモデルが本番展開前に合格しなければならないテストゲートを実装する:(a)パフォーマンスベンチマーク(精度、レイテンシ、スループット)、(b)バイアスと公平性の監査(格差影響分析、人口統計的パリティチェック)、(c)敵対的ロバストネステスト(モデルは悪意のある入力によって騙される可能性があるか?)、(d)データドリフト検出(モデルの入力分布はトレーニングデータと一致するか?)。
-
意思決定ログと監査証跡: 高リスクのAI推奨事項(採用、信用決定、医療診断、コンテンツモデレーション)については、以下の詳細なログを維持する:(a)モデルの推奨事項、(b)信頼度スコア、(c)人間によるレビュー結果、(d)最終決定、(e)人間がモデルを上書きする場合の根拠。これにより説明責任が生まれ、実世界の文脈におけるモデルパフォーマンスの事後分析が可能になる。
-
コンプライアンスマッピング: 各AIシステムに適用される規制(GDPR、EU AI法、公正融資規制、HIPAA等)を文書化する。各規制について、必要な管理をガバナンスアーキテクチャにマッピングする。四半期ごとにコンプライアンス監査を実施し、規制審査のためのコンプライアンスの証拠を維持する。
-
セクター横断的な協力: 非競合セクターの同業者とガバナンスフレームワークを共有する。業界ワーキンググループ(例:Partnership on AI、IEEEのEthically Aligned Designイニシアチブ)に参加し、新興基準に貢献する。このアプローチはコンセンサス構築を加速し、重複を削減する。
運用成熟度と展開パターン
-
主張:* 経営幹部はAI展開について自慢したが、組織間で運用成熟度は劇的に異なり、ほとんどがモデル開発、テスト、検証、ロールバックのための反復可能で標準化されたプロセスを欠いている。
-
根拠と証拠:* パイロットプロジェクトは頻繁に成功するが、本番システムは頻繁に失敗する。このギャップは技術的不可能性ではなく、組織の未成熟を反映している。成功するAI運用には、部門横断的な調整が必要である:データエンジニア(データ品質とパイプライン管理)、機械学習エンジニア(モデル開発と最適化)、ドメインエキスパート(問題定義と検証)、コンプライアンスとリスクチーム(ガバナンスと監査)、運用チーム(展開と監視)。これらのワークフローを制度化したり、明確な所有権と説明責任を確立したりしている企業はほとんどない。
-
運用化:* ある小売業の経営幹部は、管理されたパイロットでコンバージョンを8%増加させた推奨エンジンを称賛した。展開後6か月で、データドリフト(顧客行動と製品カタログの変化)と季節変動により、モデルの効果は2%に低下した。自動再トレーニングパイプラインは存在せず、モデルは静的で本番データとますます不整合になっていた。別の経営幹部は、テストプロトコルに敵対的シナリオやエッジケース検証が含まれていなかったため、有害な出力(冒涜的な言葉や誤情報を含む)を生成するカスタマーサービスチャットボットを立ち上げたと述べた。
-
仮定と限界:* これらの例は逸話的である。AI展開の失敗率と根本原因に関する体系的なデータは限られている。ほとんどの組織は失敗を公に開示しない。しかし、これらの例は、機械学習運用に関する公表された研究(例:Googleの「Hidden Technical Debt in Machine Learning Systems」やSculleyらのMLシステムエンジニアリングに関する研究)と一致している。
-
実行可能なフレームワーク:* 以下のコンポーネントを持つAI運用(AIOps)の規律を確立する:
-
標準化された開発ワークフロー: モデル開発のためのテンプレートとチェックリストを作成する。以下を含む:(a)問題定義と成功基準、(b)データ収集と探索的分析、(c)特徴エンジニアリングとモデル選択、(d)ハイパーパラメータチューニングと交差検証、(e)最終モデル評価と文書化。
-
自動テストと検証ゲート: モデルのための継続的インテグレーション/継続的デプロイメント(CI/CD)パイプラインを実装する。すべてのモデルが合格しなければならない自動テストを定義する:(a)パフォーマンスベンチマーク(例:精度は85%を超える必要がある)、(b)バイアス監査(例:格差影響比は0.8を超える必要がある)、(c)敵対的ロバストネス(例:モデルは100の敵対的例に耐える必要がある)、(d)レイテンシ要件(例:推論は500ms以内に完了する必要がある)。
-
本番監視とアラート: 本番モデルの継続的監視を展開し、以下を検出する:(a)パフォーマンス低下(精度が閾値を下回る)、(b)データドリフト(入力分布の変化)、(c)モデルドリフト(予測分布の変化)、(d)モデル動作の異常。アラート閾値とエスカレーション手順を定義する。
-
ロールバックと復旧手順: 失敗したモデルを以前のバージョンまたはフォールバックシステムにロールバックするための明確な手順を文書化する。四半期ごとに「災害復旧」訓練を実施する:本番モデルが明日失敗すると仮定し、2時間以内に既知の良好な状態にサービスを復元できるか?できない場合、運用は未成熟であり、直ちに是正が必要である。
-
明確な所有権と説明責任: 明示的な所有権を割り当てる:1つのチームがデータ品質とパイプライン管理を所有し、別のチームがモデル開発と最適化を所有し、3番目のチームが本番展開と監視を所有し、4番目のチームがコンプライアンスと監査を所有する。各チームのエスカレーションパスと意思決定権限を定義する。
測定フレームワークとビジネスアライメント
-
主張:* 経営幹部はAIの価値とビジネスインパクトのための一貫したメトリクスを欠き、技術的パフォーマンスメトリクスとビジネス成果を混同し、説明責任のギャップを生み出している。
-
根拠と証拠:* 技術的議論は機械学習メトリクスを強調する:精度、適合率、再現率、F1スコア、曲線下面積(AUC)。ビジネスリーダーは、収益インパクト、コスト削減、サイクルタイム短縮、リスク軽減を重視する。これらのメトリクスカテゴリ間の不整合は誤った自信を生み出す:95%の精度を持つモデルでも、5%の失敗率が高リスクの決定に影響する場合、顧客の信頼や規制コンプライアンスを破壊する可能性がある。経営幹部は、展開前に成功がどのようなものかを明確に表現できないことが多く、結果の事後合理化につながる。
-
運用化:* ある製造業の経営幹部は、92%の精度を持つ「成功した」予知保全モデルを報告したが、下流のビジネス成果を測定しなかった:ダウンタイム防止によるコスト削減、保守労働コストの削減、設備稼働時間の改善。監査時、保守チームが出力を信頼しなかったため、モデルの推奨事項は40%の時間で無視されていた。これは精度メトリクスが捉えなかった重要なギャップである。別の経営幹部は、採用コストを30%削減した採用AIを称賛したが、後にモデルが過小評価されたグループからの適格候補者を体系的にフィルタリングし、コスト削減を相殺する法的および評判リスクを生み出していることを発見した。
-
仮定と限界:* これらの例は技術的メトリクスとビジネスメトリクスの間のギャップを示しているが、企業セクター全体でこの問題の有病率を定量化していない。AIプロジェクトの成功率とメトリクスアライメントに関する体系的なデータは限られている。
-
実行可能なフレームワーク:* AIシステムを構築する前に成功メトリクスを定義する。各AIイニシアチブについて、3つの階層のメトリクスを確立する:
-
技術的メトリクス: (a)精度、適合率、再現率、F1スコア(分類タスク用)、(b)平均絶対誤差または二乗平均平方根誤差(回帰タスク用)、(c)推論レイテンシとスループット、(d)モデルドリフト検出(パフォーマンスはどれくらい速く低下するか?)、(e)公平性メトリクス(格差影響比、人口統計的パリティ、等化オッズ)。
-
ビジネスメトリクス: (a)収益インパクト(改善された推奨または決定からの増分収益)、(b)コスト削減(労働削減、効率向上、廃棄物削減)、(c)サイクルタイム短縮(より速い意思決定またはプロセス完了)、(d)顧客満足度または維持率(NPSまたは解約率で測定)、(e)リスク軽減(コンプライアンス違反の削減、不正検出等)。
-
リスクメトリクス: (a)公平性スコア(人口統計グループ間の格差影響分析)、(b)高リスク決定のエラー率(モデルエラーが重大な結果をもたらす場合)、(c)コンプライアンス違反(規制違反または監査所見)、(d)評判インシデント(顧客苦情、メディア報道、規制当局の精査)。
-
実装:* 各メトリクス階層の明確な所有権とレビュー頻度を割り当てる。技術的メトリクスは本番システムについて毎週レビューする必要がある。ビジネスメトリクスは部門横断チーム(データサイエンス、製品、財務)によって毎月レビューする必要がある。リスクメトリクスはコンプライアンスとリスクチームによって毎月レビューする必要がある。技術リーダーシップとビジネスリーダーシップの両方に見えるダッシュボードを作成し、AIシステムのパフォーマンスと価値の共通理解を可能にする。
-
検証演習:* 現在本番環境にある上位3つのAIシステムについて「メトリクス監査」を実施する。各システムについて、以下に答える:(1)主要なビジネス価値は何か(収益、コスト、リスク)?(2)その価値をどのように測定するか?(3)前四半期の実際のインパクトは何だったか?(4)技術的パフォーマンス(精度、レイテンシ)はビジネスインパクトとどのように相関するか?これらの質問に明確かつ定量的に答えられない場合、測定規律は不十分であり、直ちに是正が必要である。
リスクランドスケープと軽減戦略
-
主張:* 経営幹部間の公開討論は競争的ポジショニングと市場シェアに焦点を当てていたが、私的な懸念は技術的脆弱性、規制エクスポージャー、大規模なAI失敗による評判リスクに集中していた。
-
根拠と証拠:* 単一の注目度の高いAI失敗—偏った採用システム、誤情報を生成するチャットボット、明白な害を引き起こす推奨エンジン—は、セクター全体に影響を与える規制取り締まりと評判被害を引き起こす可能性がある。既知の失敗モードには以下が含まれる:(a)幻覚(言語モデルが高い信頼度で虚偽情報を生成)、(b)敵対的攻撃(モデルを騙すように設計された悪意のある入力)、(c)データポイズニング(偏ったまたは有害な出力につながる破損したトレーニングデータ)、(d)モデルドリフト(分布シフトによるパフォーマンス低下)、(e)バイアスと公平性違反(保護されたグループに対する体系的な差別)。ほとんどの組織は、顧客向けシステムでこれらの失敗モードを検出および防止するための体系的なアプローチを欠いている。
-
運用化:* あるテクノロジーCEOは、幻覚に関する懸念を「解決可能なエンジニアリング問題」として公然と否定したが、内部では自身の組織が顧客向けシステムで幻覚を検出または防止するための体系的なアプローチを持っていないことを認めた。ある金融サービスの経営幹部は、人口統計グループ間の格差影響をテストせずに信用スコアリングAIを展開したと述べた。これは公正融資規制の違反であり、重大な法的エクスポージャーの源である。
-
仮定と限界:* これらの例はリスク認識のギャップを示しているが、企業セクター全体での不適切なリスク管理の有病率を定量化していない。AI関連インシデントとその財務的影響に関する体系的なデータは、過少報告と機密性のために限られている。
-
実行可能なフレームワーク:* 各本番AIシステムについて包括的なリスクインベントリを実施する:
-
失敗モードの特定: 各システムについて、潜在的な失敗モードを文書化する:(a)幻覚または虚偽の出力、(b)敵対的攻撃または敵対的例、(c)データポイズニングまたは破損したトレーニングデータ、(d)モデルドリフトまたはパフォーマンス低下、(e)バイアスまたは公平性違反、(f)プライバシー違反またはデータ漏洩、(g)セキュリティ脆弱性(モデル抽出、メンバーシップ推論)。
-
検出メカニズム: 各失敗モードについて、どのように検出するかを定義する:
システム構造とボトルネック
-
主張:* AIの能力について自慢しているにもかかわらず、CEOたちは重要なインフラストラクチャのボトルネックを明らかにした:GPUの不足、データ品質の制約、断片化されたモデルエコシステム。これらは一時的な摩擦ではなく、2025年まで持続する構造的制約である。
-
証拠と根拠:* 公式声明では規模とパフォーマンスが強調されたが、私的な会話ではサプライチェーンの脆弱性が露呈した。GPUアクセスは3つのプロバイダー(NVIDIA、AWS、Google Cloud)に集中しており、単一障害点を生み出している。データのラベリングとキュレーションはAIプロジェクト予算の60〜70%を消費するが、依然として労働集約的で地理的に分散している。複数の互換性のないモデルアーキテクチャにより、企業はベンダーロックインと運用の複雑さのどちらかを選択せざるを得ない。現在のGPU不足の推定では、カスタムシリコンのリードタイムは18〜24ヶ月であり、データアノテーションのコストは複雑さに応じてラベル付きインスタンスあたり0.50ドルから15ドルの範囲である。
-
具体例:* ある金融サービスのCEOは、単一のクラウドプロバイダーからのGPU割り当ての遅延により、AIの展開が6ヶ月間ブロックされたと述べた。彼らの本番タイムラインは第2四半期から第4四半期にずれ込み、推定200万ドルの収益遅延が発生した。別のCEOは、彼らの「独自のAIアドバンテージ」が東南アジアのアウトソースされたデータアノテーションチームに完全に依存していることを認め、コストの変動性(労働率は年間20〜30%変動)とセキュリティリスク(データ居住地のコンプライアンス違反はGDPRの下で5000万ドル以上の罰金を引き起こす可能性がある)の両方を生み出していた。
-
ナレッジワーカーのための実行可能なワークフロー:*
-
インフラストラクチャの依存関係をマッピングする(第1〜2週): すべてのAIシステムのコンピュート、ストレージ、データソーシングを文書化する。依存関係マトリックスを作成する:どのクラウドプロバイダーがコンピュートを制御しているか?誰がトレーニングデータを管理しているか?どのモデルアーキテクチャが使用されているか?単一障害点を特定する。テンプレートを使用する:システム名 | プロバイダー | 重要度(高/中/低) | 代替手段へのリードタイム | 利用不可の場合のコスト影響。
-
GPU制約を定量化する(第2〜3週): 今後12ヶ月間の組織のGPU需要を計算する。トレーニング、ファインチューニング、推論を含める。現在の割り当てと比較する。需要が供給を20%以上上回る場合、制約がある。コストをベンチマークする:AWSでのNVIDIA H100オンデマンド価格は1時間あたり3〜4ドル;代替プロバイダー(Lambda Labs、CoreWeave)は15〜25%の割引を提供するが、2〜4週間のリードタイムがある。
-
多様化戦略を開発する(第3〜4週):
- コンピュートの多様化: 代替GPUプロバイダーをテストする。非クリティカルなワークロードのためにコンピュート予算の10%をLambda LabsまたはCoreWeaveに割り当てる。パフォーマンスとコストを測定する。実行可能であれば、90日以内にワークロードの30〜50%をシフトする。
- データの多様化: 非機密のユースケースのために合成データ生成をパイロットする。Synthetic Data VaultやGretelなどのツールは、特定のドメインでアノテーションコストを40〜60%削減できる。1つのパイロットプロジェクトから始め、品質への影響を測定する。
- モデルの多様化: ベンダーロックインを減らすためにオープンソースの代替品(Llama 2、Mistral)を評価する。独自モデルに対してパフォーマンスベンチマークを実行する。パフォーマンスギャップが5%未満の場合、180日以内に非クリティカルなワークロードを移行する。
-
90日間のインフラストラクチャ監査を作成する(第4〜8週): 調査結果をコストセンターではなくリスク軽減の演習としてCTOとCFOに提示する。ビジネスケースをフレーム化する:「GPU依存の収益がXドルある。主要プロバイダーが30日間の停止を経験した場合、Yドルを失う。多様化にはZドルかかり、停止の影響を70%削減する。」
-
ベンダー管理の規律を確立する(継続的): 各重要プロバイダーとの四半期ごとのレビュー。実効性のあるSLAを交渉する:99.9%の稼働時間保証、24時間のサポート応答時間、違反に対する契約上の罰則。すべてのコミットメントを書面で文書化する。
- リスクと制約:* 多様化は運用の複雑さをもたらす。代替プロバイダーはサポートチームが小さく、問題解決時間が長い。複数のベンダーを管理するために15〜20%のオーバーヘッドを予算化する。本番システムを移行する前に、非クリティカルなワークロードから始めて運用能力を構築する。
参照アーキテクチャとガードレール
-
主張:* 経営幹部は責任あるAI展開基準に関するガバナンスフレームワークについて激しく意見が分かれ、業界のコンセンサスがないことを明らかにした。この断片化はコンプライアンスリスクと企業間での重複した努力を生み出している。
-
証拠と根拠:* 規制の不確実性は市場投入のスピードを維持するための競争圧力を生み出す。一部のCEOは市場投入のスピードを維持するために最小限のガードレールを提唱し、他のCEOはコンプライアンスリスクを減らすために業界標準を推進した。どちらの陣営も具体的なアーキテクチャのガイダンスを提供しなかった。参照実装の欠如により、企業は孤立してガバナンスを設計し、努力を重複させ、リスクを増大させている。EU AI Actのコンプライアンスだけで8〜12ヶ月のアーキテクチャ作業が必要であるが、ほとんどの企業はこのタイムラインを認識していない。
-
具体例:* あるヘルスケアの経営幹部は、3つの競合他社が同じ問題を別々に解決していることを知らずに、EU AI Act要件のためのカスタムコンプライアンス層を構築したと述べた。この努力は9ヶ月間で6人のFTEを消費し、120万ドルのコストがかかった。一方、あるテクノロジーCEOはガバナンスを「規制の演劇」として却下し、自社の公的な安全へのコミットメントと矛盾していた。6ヶ月後、彼の会社は文書化されたガバナンスなしに偏った採用AIを展開したことで5000万ドル以上の規制調査に直面した。
-
ナレッジワーカーのための実行可能なワークフロー:*
-
モジュラーガバナンスアーキテクチャを採用する(第1〜4週):
- コンポーネント1:モデルレジストリ。 系統、トレーニングデータ、パフォーマンスメトリクス、展開履歴を追跡する集中システムを実装する。オープンソースフレームワーク(MLflow、Hugging Face Model Cards)を出発点として使用する。最小フィールド:モデルID、バージョン、トレーニングデータソース、トレーニング日、パフォーマンスメトリクス(精度、適合率、再現率、公平性スコア)、展開ステータス、所有者、最終更新日。
- コンポーネント2:自動テスト。 バイアス、ドリフト、パフォーマンス劣化の継続的なテストを実装する。Fairness Indicators、AI Fairness 360、またはカスタムスクリプトなどのツールを使用する。テストゲート:(a)本番展開前のバイアステスト、(b)本番環境でのドリフト検出(週次)、(c)パフォーマンスベンチマーク(月次)。
- コンポーネント3:決定ログ。 すべての高リスクAI推奨事項と人間のオーバーライド率を文書化する。各オーバーライドについて、次をキャプチャする:決定ID、モデル推奨、人間の決定、オーバーライドの理由、結果。このデータを使用して体系的なモデルの失敗を特定する。
- コンポーネント4:監査証跡。 すべてのモデル変更、データ更新、展開決定の不変ログを実装する。コンプライアンス要件:規制対象業界では7年間の保持。
-
規制要件をマッピングする(第2〜3週): 適用される規制を特定する:EU AI Act、GDPR、CCPA、公正貸付法、FDAガイダンス(ヘルスケアの場合)など。各規制について、次を文書化する:要件、実装期限、アーキテクチャへの影響、推定作業量(FTEとタイムライン)。四半期ごとのマイルストーンを含むコンプライアンスロードマップを作成する。
-
ガバナンスを段階的に構築する(第4〜12週):
- 1ヶ月目: モデルレジストリと基本的なテストを実装する。1つの非クリティカルなAIシステムに展開する。採用を測定し、改善する。
- 2ヶ月目: すべての本番システムに拡大する。決定ログと監査証跡を実装する。
- 3ヶ月目: コンプライアンスギャップ分析を実施する。規制リスクに基づいて残りの作業に優先順位を付ける。
-
アーキテクチャを同業者と共有する(継続的): ガバナンス基準は集団行動を通じてより速く出現する。あなたのセクターの非競合組織とあなたのアーキテクチャを共有する。業界ワーキンググループ(例:Partnership on AI、AI Now Institute)に参加する。オープン標準(例:Model Cards、Data Sheets for Datasets)に貢献する。
-
ガバナンスレビューのケイデンスを確立する(継続的): コンプライアンス、法務、技術チームとの月次レビュー。ガバナンスの成熟度とコンプライアンスステータスに関する四半期ごとの取締役会レベルの報告。
- リスクと制約:* ガバナンスは運用オーバーヘッドを追加する。テストと文書化の要件により、モデル開発サイクル時間が10〜15%増加することを予想する。これは責任ある展開の必要なコストである;このオーバーヘッドに抵抗する組織は規制および評判リスクに直面する。
実装と運用パターン
-
主張:* CEOはAI展開について自慢したが、運用の成熟度は大きく異なっていた—ほとんどの組織はモデル開発、テスト、ロールバックのための反復可能なプロセスを欠いている。この未成熟さが、パイロットプロジェクトは成功するが本番システムが失敗する主な理由である。
-
証拠と根拠:* パイロットプロジェクトは成功する;本番システムは失敗する。このギャップは技術的不可能性ではなく、組織の未成熟さを反映している。成功するAI運用には、データエンジニア、MLエンジニア、ドメインエキスパート、コンプライアンスチームが同期して作業する部門横断的な規律が必要である。これらのワークフローを制度化している企業はほとんどない。業界データによると、AIパイロットの70%は本番に到達せず、到達したもののうち40%は技術的制限ではなく運用上の問題により12ヶ月以内に失敗する。
-
具体例:* ある小売CEOは、パイロットでコンバージョンを8%増加させたレコメンデーションエンジンを称賛した。6ヶ月後、データドリフトと季節変動によりモデルは2%のリフトに劣化した。自動再トレーニングパイプラインは存在しなかった。チームは四半期ごとに手動でモデルを再トレーニングし、季節パターンを見逃した。別の経営幹部は、テストプロトコルに敵対的シナリオが含まれていなかったため、有害な出力を生成するチャットボットを立ち上げたと述べた。チャットボットは48時間後にオフラインにされ、開発に50万ドル、ブランドダメージに200万ドルのコストがかかった。
-
ナレッジワーカーのための実行可能なワークフロー:*
-
AI運用(AIOps)の規律を確立する(第1〜4週):
- 役割と責任を定義する: データエンジニア(データ品質とパイプラインを所有)、MLエンジニア(モデル開発とバージョニングを所有)、ドメインエキスパート(ビジネスロジックと検証を所有)、コンプライアンスオフィサー(ガバナンスと監査を所有)、運用リード(展開と監視を所有)。各決定タイプのRACIマトリックスを作成する。
- 標準テンプレートを作成する: モデル開発チェックリスト、テストプロトコル、展開ランブック、ロールバック手順、インシデント対応プレイブック。
- バージョン管理を実装する: すべてのコード、データスキーマ、モデルアーティファクトをGitに。リリースにタグを付ける。変更ログを維持する。
-
自動テストゲートを実装する(第2〜6週):
- パフォーマンスベンチマーク: モデルは本番展開前に最小限の精度/適合率/再現率のしきい値を満たす必要がある。しきい値はエンジニアではなくドメインエキスパートによって設定される。
- バイアスチェック: 人口統計グループ全体で公平性テストを実行する。グループ間の主要メトリクスの5%以上の差異による不均衡な影響にフラグを立てる。展開前に手動レビューを要求する。
- 敵対的堅牢性: 高リスクシステムの場合、敵対的入力に対してテストする。Adversarial Robustness Toolboxまたはカスタムスクリプトなどのツールを使用する。
- 本番監視: リアルタイムドリフト検出を実装する。モデルパフォーマンスが週ごとに10%以上低下した場合にアラートを出す。自動再トレーニングまたはロールバックをトリガーする。
-
エスカレーションパスを定義する(第3〜4週): モデルがパフォーマンス不足の場合、誰が決定するか:(a)調査して修正、(b)以前のバージョンにロールバック、(c)システムを無効化?影響の重大度と解決までの時間に基づいて決定木を作成する。
-
ウォーゲームシミュレーションを実行する(第4〜5週): 本番モデルが明日失敗すると仮定する。2時間以内にロールバックしてサービスを復元できるか?できない場合、運用は未成熟である。完全なシミュレーションを実施する:(a)障害をトリガーする(例:モデルを無効化)、(b)検出にかかる時間を計測、(c)ロールバックにかかる時間を計測、(d)顧客への影響を測定。調査結果を文書化し、ギャップを修正する。
-
監視とアラートを確立する(第5〜8週):
- 技術メトリクス: モデルレイテンシ、推論コスト、エラー率、ドリフトスコア。
- ビジネスメトリクス: コンバージョン率、収益への影響、コスト削減、ユーザー満足度。
- リスクメトリクス: 公平性スコア、オーバーライド率、コンプライアンス違反。
- アラートしきい値: アラートをトリガーするものを定義する。例:モデル精度が85%を下回った場合、5分以内にMLチームにアラート。公平性スコアが0.95を下回った場合、1時間以内にコンプライアンスチームにアラート。
-
モデル開発ライフサイクルを作成する(第6〜12週):
- フェーズ1:実験(0〜4週)。 データ探索、特徴エンジニアリング、モデル選択。成功メトリクス:ホールドアウトテストセットで80%以上の精度を持つ概念実証。
- フェーズ2:開発(4〜8週)。 モデルを改良し、テストを実装し、仮定を文書化する。成功メトリクス:すべての自動テストに合格、ガバナンスレビュー承認。
- フェーズ3:ステージング(8〜10週)。 ステージング環境に展開し、トラフィックの10%でA/Bテストを実行する。成功メトリクス:ビジネスメトリクスが目標を達成、有害事象なし。
- フェーズ4:本番(10〜12週)。 段階的なロールアウト:2週間でトラフィックの10%→50%→100%。成功メトリクス:ビジネスメトリクスが維持され、本番インシデントなし。
- フェーズ5:監視(継続的)。 週次パフォーマンスレビュー、月次ガバナンス監査、四半期ごとの戦略レビュー。
- リスクと制約:* AIOpsの規律にはツールとトレーニングへの投資が必要である。MLOpsインフラストラクチャ(モデルレジストリ、テストフレームワーク、監視)に年間20万〜50万ドルを予算化する。テストとガバナンス要件により、モデル開発サイクル時間が20〜30%増加することを予想する。これは必要なコストである;抵抗する組織は本番障害と規制リスクに直面する。
測定と次のアクション
-
主張:* 経営幹部はAI価値の一貫したメトリクスを欠き、技術的パフォーマンスとビジネスへの影響を混同し、説明責任のギャップを生み出していた。この不整合がAI投資がROIを提供できない主な理由である。
-
証拠と根拠:* 精度、適合率、F1スコアが技術的議論を支配している。ビジネスリーダーは収益、コスト、リスクを気にする。メトリクス間の不整合は誤った自信を生み出す。95%の精度を持つモデルは、5%の失敗率が高価値取引に影響を与える場合、顧客の信頼を破壊する可能性がある。経営幹部は展開前に成功がどのようなものかを明確に述べることができないことが多い。業界調査によると、AIプロジェクトの60%は明確なビジネスメトリクスを欠いており、そのうち75%は測定可能なROIを提供できない。
-
具体例:* ある製造業のCEOは92%の精度を持つ「成功した」予知保全モデルを報告したが、コスト削減やダウンタイム削減を測定できなかった。監査された際、保守チームが出力を信頼しなかったため、モデルの推奨事項は40%の時間で無視されていた。モデルの開発には50万ドルかかったが、ビジネス価値はゼロだった。別の経営幹部は、採用コストを30%削減した採用AIを称賛したが、後に過小評価されたグループからの適格な候補者を体系的にフィルタリングしていたことを発見し、1000万ドルの差別訴訟を引き起こした。
-
ナレッジワーカーのための実行可能なワークフロー:*
- 構築前に成功メトリクスを定義する(第1〜2週): 各AIイニシアチブについて、3つの階層を確立する:
- 技術メトリクス: 精度、適合率、再現率、F1スコア、レイテンシ、推論コスト。これらはモデルの品質を測定する。
- ビジネスメトリクス: 収益への影響、コスト削減、サイクルタイム削減、顧客満足度、市場シェア
AIガバナンスと組織変革の転換点としてのダボス
-
新たな現実:* 2024年のダボス世界経済フォーラムは、企業のAI成熟度に対する計画外のストレステストとして機能し、テクノロジーカンファレンスではなく、知能拡張経済において組織がどのように競争するかという文明規模の清算を明らかにした。
-
これが重要な理由:* 従来のダボスの議題は、地政学、金融、気候を段階的なフレームワークを通じてバランスさせてきた。今年のAIの優位性は、より深遠なことを示している。市場はすでに、人工知能があらゆるセクターにおける価値創造、リスク軽減、競争上の差別化の主要なレバーであると決定している。テクノロジーCEOたちが主要な講演枠を占めたのは、彼らがより強くロビー活動をしたからではなく、金融、医療、製造、政府の取締役会メンバーがAI戦略の議論への直接的なアクセスを要求したからである。この変化は不可逆的であり、加速している。
ダボスでのAI議論の集中は、より深い組織的危機を反映している。ほとんどの企業は、AIを大規模に責任を持って展開するための思考モデル、ガバナンス構造、運用能力を欠いている。自慢は真の不確実性を隠している。口論は、確立された戦略ではなく、未来の競合するビジョンを反映している。この曖昧さは解決すべき問題ではなく、探求すべき設計空間である。
-
戦略的示唆:* ダボスレベルのカンファレンス議題を、今後18ヶ月間に資本、人材、規制上の注目がどこに流れるかの先行指標として扱うこと。AIがあなたの業界のダボスでの存在感を支配しているなら、投資すべきかどうかをまだ議論している場合、あなたの組織はすでに遅れをとっている。問題はもはやAIを展開するかどうかではなく、持続可能な競争優位性とステークホルダーの信頼を構築する方法でどのように展開するかである。
-
即座の行動:* 「ダボスギャップ分析」を実施すること。どの同業者がダボスに参加し、どのセッションに参加したかを特定する。自組織のリーダーシップチームのAIリテラシーと戦略的ポジショニングと照合する。あなたのCEOがダボス参加者と同じ明確さと確信を持って組織のAI戦略を明確に述べることができない場合、即座の注意を必要とする人材またはビジョンのギャップがある。90日以内に最高AI責任者または同等の戦略的役割を雇用すること。これは任意ではなく、参加するための最低条件である。
競争上の堀としてのインフラストラクチャ: ボトルネック物語の解読
-
自慢の下に隠された真実:* CEOたちが公にAI能力と規模を称賛する一方で、プライベートな会話は断片化された、ボトルネックに制約されたインフラストラクチャの状況を明らかにした。GPUの不足、データ品質の制約、互換性のないモデルエコシステムは一時的なサプライチェーンの問題ではなく、勝者と敗者を定義する現在のAI経済の構造的特徴である。
-
真の制約:* GPUアクセスは依然として高度に集中している。3つのクラウドプロバイダー(AWS、Google Cloud、Microsoft Azure)が企業向けGPU容量の約70%を支配している。この集中は機会と脆弱性の両方を生み出す。単一のクラウドプロバイダーに依存する組織は隠れたコストに直面する。ベンダーロックイン、価格決定力の非対称性、サービス中断への露出である。データのラベリングとキュレーションはAIプロジェクト予算の60〜70%を消費するが、依然として労働集約的で、地理的に分散しており、品質劣化に対して脆弱である。複数の互換性のないモデルアーキテクチャ(トランスフォーマーの変種、拡散モデル、検索拡張生成システム)は、企業を誤った選択に追い込む。シンプルさのために単一ベンダーのエコシステムを採用するか、複数のプラットフォームにわたる運用の複雑さを管理するかである。
-
これが明らかにすること:* インフラストラクチャのボトルネックは偶然ではなく、勝者総取り市場構造の自然な結果である。GPU供給、データアノテーション能力、基盤モデルアーキテクチャを支配する者が不釣り合いな価値を抽出する。これは持続可能ではなく、先見の明のある組織はすでに代替案を構築している。
-
具体的なシナリオ:* ある金融サービスCEOは、単一のクラウドプロバイダーからのGPU割り当ての遅延により、AI展開が6ヶ月間ブロックされたことをプライベートに説明した。これを一時的な不便と見なすのではなく、シグナルとして認識すること。あなたの組織のAI戦略は他者のインフラストラクチャ決定の人質になっている。別の幹部は、彼らの「独自のAI優位性」が東南アジアの外部委託データアノテーションチームに完全に依存していることを認めた。これは、労働慣行が疑問視された場合、コストの変動性、セキュリティリスク、倫理的露出を生み出す依存関係である。
-
機会:* 今インフラストラクチャを多様化する組織は、リスク回避型企業と規制産業にとって好ましいパートナーになる。これはコスト最適化についてではなく、戦略的自律性についてである。
-
90日間のインフラストラクチャ多様化計画:*
-
GPU多様化(第1〜4週): 現在のGPUプロバイダーの集中度を監査する。代替プロバイダー(Lambda Labs、CoreWeave、Crusoe Energy、またはNVIDIA DGXシステムなどのオンプレミスオプション)をパイロットする。プロバイダー間で同一のワークロードを実行し、パフォーマンスベースラインとコスト比較を確立する。目標: 90日以内に単一プロバイダー依存度を100%から60%に削減する。
-
データソーシングイノベーション(第5〜8週): 外部委託データアノテーションと並行して、合成データ生成と連合学習パイロットを実施する。Synthetic Data Vault、Gretel AI、またはカスタム生成アプローチなどのツールを評価する。合成または自己教師あり学習アプローチにシフトできるラベリングワークロードの20%を特定する。これによりコストが削減され、データプライバシーが向上し、組織能力が構築される。
-
モデルアーキテクチャの柔軟性(第9〜12週): アプリケーションコードを書き直すことなく基盤モデルを交換できるモデル抽象化レイヤーを実装する。LangChain、LlamaIndex、またはカスタムAPIラッパーなどのツールを使用する。上位3つのAIアプリケーションを、独自モデル(GPT-4、Claude)とオープンソースの代替品(Llama 2、Mistral、Falcon)の両方でテストする。パフォーマンス、コスト、レイテンシのトレードオフを文書化する。目標: モデル選択間で<5%のパフォーマンス変動を達成する。
- 長期ビジョン:* 18ヶ月以内に、あなたの組織は、GPU容量、データ、モデルを戦略的依存関係ではなく商品として扱う「マルチクラウド、マルチモデル」AIインフラストラクチャを運用すべきである。これにより、インフラストラクチャの自律性と規制遵守を要求する企業にとって信頼できるパートナーとして位置づけられる。
競争優位性としてのガバナンス: 規制演劇を超えて
-
ガバナンスのパラドックス:* 幹部たちはAIガバナンスフレームワークについて鋭く意見が分かれたが、この意見の相違はより深いコンセンサスを隠していた。誰も大規模な責任あるAI展開の問題を解決しておらず、信頼できるガバナンスを確立する最初の組織が不釣り合いな市場シェアと規制上の好意を獲得する。
-
ガバナンスが今重要な理由:* 規制の不確実性は迅速に動くための競争圧力を生み出すが、ガバナンスなしに迅速に動くことは実存的リスクを生み出す。一部のCEOは市場投入速度を維持するために最小限のガードレールを提唱し、他のCEOはコンプライアンスリスクを削減するために業界標準を推進した。どちらの陣営も具体的なアーキテクチャガイダンスを提供しなかった。なぜなら、問題は真に未解決だからである。参照実装の欠如により、企業は孤立してガバナンスを設計し、努力を重複させ、リスクを増大させ、集団学習の機会を逃している。
-
新たなパターン:* ガバナンスをコストセンターとして扱う組織は負ける。ガバナンスを競争上の差別化の源として扱う組織は勝つ。なぜか? 顧客、規制当局、従業員がAIシステムに透明性、公平性、説明責任をますます要求しているからである。あなたの業界で責任あるAI実践を信頼できる形で最初に実証する組織が信頼されるパートナーになり、プレミアム価格を要求する。
-
具体例:* ある医療幹部は、EU AI法の要件に対するカスタムコンプライアンスレイヤーを構築していると説明したが、3つの競合他社が同一の問題を個別に解決していることを知らなかった。これは効率ではなく、無駄である。一方、あるテクノロジーCEOはガバナンスを「規制演劇」として却下し、自社の公的安全コミットメントと矛盾し、システムが必然的に失敗したときに評判リスクにさらされた。
-
責任あるAIのための参照アーキテクチャ:*
-
モデルレジストリと系譜(基盤): 本番環境または開発中のすべてのモデルを追跡する集中システムを実装する。各モデルについて文書化する: トレーニングデータソースとバージョン、特徴エンジニアリングの決定、ハイパーパラメータの選択、人口統計グループ全体のパフォーマンスメトリクス、既知の失敗モード、人間による上書き率。オープンソースツール(MLflow、Hugging Face Model Cards、またはカスタムシステム)を出発点として使用する。これは官僚主義ではなく、繰り返しの間違いを防ぐ組織的記憶である。
-
自動テストと検証ゲート(継続的): モデルが本番環境に到達する前に、以下を通過する必要がある: (a) パフォーマンスベンチマーク(精度、レイテンシ、スループット)、(b) バイアスと公平性テスト(格差影響分析、人口統計的パリティチェック)、(c) 敵対的堅牢性テスト(モデルは意図的な攻撃によって騙されるか?)、(d) データ品質チェック(欠損値、外れ値、分布シフト)。これらを、しきい値に違反した場合に展開をブロックする自動化されたCI/CDパイプラインとして実装する。
-
本番監視とドリフト検出(継続中): 本番環境でモデルのパフォーマンスを継続的に監視する。データドリフト(入力分布の変化)、ラベルドリフト(グラウンドトゥルースの変化)、概念ドリフト(特徴と結果の関係の変化)を追跡する。パフォーマンスがしきい値を下回った場合の自動アラートとロールバック手順を確立する。
-
意思決定ログと説明可能性(説明責任): 高リスクの決定(信用承認、採用推奨、医療診断)については、モデルの推論、信頼度スコア、人間によるレビュー結果をログに記録する。システムに最初から説明可能性を組み込む。SHAP値、LIME、またはアテンションメカニズムを使用して、モデルの決定をドメインエキスパートや規制当局が解釈できるようにする。
-
ステークホルダーフィードバックループ(学習): 顧客、従業員、影響を受けるコミュニティがAIシステムの失敗や懸念を報告するメカニズムを作成する。このフィードバックをモデル改善とガバナンス改善の主要なデータソースとして扱う。
-
実行可能なガバナンスロードマップ(90日間):*
-
第1〜2週: 本番環境またはパイロット中のすべてのAIシステムをインベントリする。それぞれについて、現在のガバナンスギャップ(系譜の欠如、バイアステストなし、監視なしなど)を文書化する。
-
第3〜4週: 上記の参照アーキテクチャを使用してガバナンスベースラインを確立する。高リスクシステム(顧客の結果、従業員の決定、または規制遵守に影響を与えるもの)を優先する。
-
第5〜8週: 上位3つのシステムに対して自動テストと監視を実装する。展開パイプラインに統合する。
-
第9〜12週: ガバナンスフレームワークを内部および外部に伝達する。あなたのアプローチを同業者、規制当局、顧客と共有する。あなたの組織をガバナンスのリーダーとして位置づけ、遅れをとる者としてではない。
-
戦略的ポジショニング:* 12ヶ月以内に、あなたの組織は競合他社と差別化する明確で信頼できるガバナンスフレームワークを明確に述べることができるべきである。これは販売上の優位性、人材の磁石、規制ヘッジになる。
組織能力としての運用: パイロットから本番環境へ
-
パイロットから本番環境へのギャップ:* CEOたちはAI展開について自慢したが、運用成熟度は大きく異なっていた。ほとんどの組織は、モデル開発、テスト、展開、ロールバックのための反復可能なプロセスを欠いている。このギャップは技術的問題ではなく、組織的問題である。
-
運用が重要な理由:* パイロットプロジェクトは、専任チームと柔軟なタイムラインを持つ制御された環境で動作するため成功する。本番システムは、競合する優先事項と厳格な制約を持つ混沌とした動的な環境で動作するため失敗する。このギャップは、技術的不可能性ではなく、組織的未成熟を反映している。成功するAI運用には、部門横断的な規律が必要である。データエンジニア、MLエンジニア、ドメインエキスパート、コンプライアンスチーム、ビジネスステークホルダーが同期して作業する。これらのワークフローを制度化した企業はほとんどない。
-
具体的な失敗モード:*
-
ある小売CEOは、パイロットでコンバージョンを8%増加させたレコメンデーションエンジンを称賛した。6ヶ月後、データドリフトと季節変動により、モデルは2%の向上に劣化した。自動再トレーニングパイプラインは存在しなかった。モデルは放棄され、投資は損失として償却された。
-
ある金融サービス幹部は、テストプロトコルに敵対的シナリオが含まれていなかったため、有害な出力を生成する信用スコアリングAIを開始した。顧客がシステムがエッジケースで無意味な決定を下していることを発見したとき、会社は評判の損害と規制の精査に直面した。
-
ある医療組織は、履歴データでは良好に機能したが、新しい患者集団では失敗した診断AIを展開した。モデルは一般化しない偽の相関を学習していた。患者が苦情を言うまで、劣化を検出する監視システムはなかった。
-
これらはエッジケースではなく、標準である。* ほとんどのAIプロジェクトは、アルゴリズムが間違っているからではなく、運用が未成熟だから失敗する。
-
AI運用(AIOps)規律:*
-
標準化された開発ワークフロー: 一貫性を強制するモデル開発のテンプレートを作成する。すべてのモデルは以下に従うべきである: (a) 問題定義と成功メトリクス、(b) データ探索と特徴エンジニアリング、(c) モデル選択とハイパーパラメータチューニング、(d) クロスバリデーションとパフォーマンス評価、(e) バイアスと公平性テスト、(f) 文書化と運用への引き継ぎ。
-
バージョン管理と再現性: モデルをコードのように扱う。モデルコード、データパイプライン、構成にバージョン管理システム(Git)を使用する。ハイパーパラメータ、メトリクス、アーティファクトをログに記録するために実験追跡(MLflow、Weights & Biases)を実装する。任意のモデルがバージョン管理から正確に再現できることを保証する。
-
自動テストゲート: 展開前にすべてのモデルを自動的にテストするCI/CDパイプラインを実装する。テストには以下を含めるべきである: パフォーマンスベンチマーク、バイアスチェック、敵対的堅牢性、データ品質検証、下流システムとの統合テスト。
-
展開とロールバック手順: 明確な展開プロセスを定義する: ステージング環境、カナリア展開(最初にトラフィックの小さな割合にロールアウト)、自動ロールバックトリガー。ルールを確立する: モデルのパフォーマンスがしきい値を下回った場合、自動的に前のバージョンにロールバックする。
-
本番監視とアラート: 本番環境でモデルのパフォーマンスを継続的に監視する。追跡する: 予測レイテンシ、エラー率、データドリフト、概念ドリフト、ビジネスメトリクス(収益への影響、顧客満足度)。パフォーマンスが劣化したときにトリガーされるアラートを設定する。
-
インシデント対応と事後分析: モデルが失敗したとき、構造化された事後分析を実施する。文書化する: 何が失敗したか、なぜ失敗したか、どのように検出されたか、どのように解決されたか、再発を防ぐためにどのような変更が行われたか。学習をチーム間で共有する。
- 運用成熟度評価(第1週):*
各本番AIシステムについて、以下に答える:
- 2時間以内に前のモデルバージョンにロールバックできるか?
- 本番環境前にパフォーマンス低下の80%以上を捕捉する自動テストがあるか?
- モデルが特定の予測を行った理由をドメインエキスパートに説明できるか?
- データドリフトと概念ドリフトを継続的に監視しているか?
- 失敗モードと軽減戦略を文書化したか?
複数の質問に「いいえ」と答えた場合、あなたの運用は未成熟である。
-
90日間の運用強化計画:*
-
第1〜4週: すべてのモデルにバージョン管理と実験追跡を確立する。上位3つのシステムに自動テストゲートを実装する。
-
第5〜8週: 本番監視とアラートを展開する。インシデント対応手順を確立する。
-
第9〜12週: 「失敗シナリオ」ウォーゲームを実施する。明日本番モデルが失敗すると仮定する。2時間以内にサービスを復元できるか? できない場合は、ギャップを特定して修正する。
-
長期ビジョン:* 12ヶ月以内に、あなたの組織はミッションクリティカルなソフトウェアシステムと同じ厳密さと規律でAIシステムを運用すべきである。これは企業グレードのAI運用のベースラインである。
測定と価値実現:指標ギャップの解消
-
測定の危機:* 経営幹部はAIの価値を測る一貫した指標を欠いており、技術的パフォーマンスとビジネスへの影響を混同し、説明責任のギャップを生み出していた。これは自己欺瞞を可能にするため、最も危険なギャップである。
-
指標が重要な理由:* 正確度、精度、F1スコア、AUCが技術的議論を支配しているのは、それらが測定しやすいからである。ビジネスリーダーが関心を持つのは、収益、コスト、リスク、顧客満足度である。指標間の不整合は誤った自信を生み出す。95%の正確度を持つモデルでも、5%の失敗率が高額取引に影響する場合、顧客の信頼を破壊する可能性がある。経営幹部は展開前に成功がどのようなものかを明確に表現できないことが多く、そのため重要なことではなく測定しやすいことを測定してしまう。
-
具体的な測定の失敗例:*
-
ある製造業のCEOは92%の正確度を持つ「成功した」予知保全モデルを報告したが、コスト削減やダウンタイム短縮を測定していなかった。監査の結果、保守チームが出力を信頼していなかったため、モデルの推奨事項は40%の確率で無視されていた。このモデルは技術的には正確だったが、運用上は役に立たなかった。
-
採用コスト削減で称賛された採用AIは、後に過小評価されているグループの適格な候補者を体系的に除外していたことが判明した。技術的指標(コスト削減)がビジネス指標(採用品質)とリスク指標(法的責任)を覆い隠していた。
-
カスタマーサービスチャットボットは技術的指標で85%の解決率を達成したが、エッジケースを処理できなかったため顧客の不満を生み出した。技術的指標は肯定的だったにもかかわらず、ビジネス指標(顧客満足度)は否定的だった。
-
三層測定フレームワーク:*
-
技術的指標(モデルの健全性): 正確度、精度、再現率、F1スコア、レイテンシ、スループット、データドリフト、概念ドリフト。これらはモデルが設計通りに機能しているかを測定する。必要だが十分ではない。
-
ビジネス指標(価値創造): 収益への影響、コスト削減、サイクルタイム短縮、顧客獲得コスト、顧客生涯価値、市場シェア。これらはAIシステムがビジネス価値を創造しているかを測定する。これが重要なことである。
-
リスク指標(下方リスク保護): 公平性スコア(人口統計学的パリティ、均等化オッズ)、重要な意思決定におけるエラー率、偽陽性/偽陰性率、規制コンプライアンス違反、顧客からの苦情、評判リスク。これらはAIシステムが意図しない害を生み出しているかを測定する。
- 測定規律フレームワーク:*
各AIイニシアチブについて、構築前に三層すべてにわたる指標を確立する:
| 指標層 | 指標例 | 測定頻度 | 責任者 | 成功基準値 |
|---|---|---|---|---|
| 技術的 | 正確度、レイテンシ、ドリフト | 毎日 | ML エンジニア | 正確度>95%、レイテンシ<100ms |
| ビジネス | 収益向上、コスト削減 | 毎週 | プロダクトマネージャー | 増分収益>$X |
| リスク | 公平性スコア、エラー率 | 毎週 | コンプライアンス責任者 | 格差影響<2% |
- 具体例:* レコメンデーションエンジンは次のように測定すべきである:
- 技術的: 予測レイテンシ<50ms、モデル正確度>85%
- ビジネス: コンバージョン向上>5%、ユーザーあたり収益>$X
- リスク: 格差
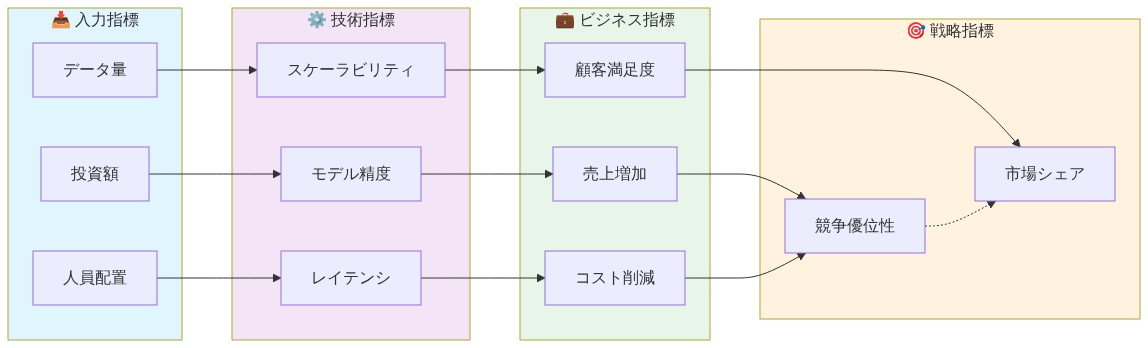
- 図11:AI投資の価値実現フレームワーク(入力→技術→ビジネス→戦略の4段階因果関係)*

- 図10:技術メトリクスとビジネスメトリクスの乖離と統合の必要性*

- 図14:18ヶ月の戦略的機会ウィンドウ - 規制・技術・競争環境の急速な変化の中で、組織が行動を起こすべき時間的緊急性と競争優位性の関係を視覚化*