
アシスタント軸:LLMのキャラクターの位置付けと安定化
アシスタント軸の定義
-
主張:* 大規模言語モデルは測定可能なスペクトル、すなわち「アシスタント軸」に沿って動作し、実世界での展開において有用性、誠実性、無害性のバランスをどのように取るかを捉えている。
-
定義上の前提条件:* アシスタント軸は、3つの主要な行動目標間のトレードオフを捉える多次元構造として定義される:(1)有用性、タスク完了率と応答の有用性として操作化される;(2)誠実性、事実の正確性と認識論的透明性(明示的な不確実性シグナリング)として操作化される;(3)無害性、高リスク要求に対する拒否率と有害な出力の不在として操作化される。これら3つの次元は直交していない;訓練目標とアライメント技術における設計選択を通じて相互作用し、互いに制約し合う(Christiano et al., 2023; Ouyang et al., 2022)。
-
根拠:* 現在のLLMは固定された行動プロファイルを持つ一枚岩的な存在ではない。それらは以下によって形成される明確な行動パターンを示す:(a)訓練データの構成とソースの重み付け、(b)明示的なアライメント技術(例:人間のフィードバックからの強化学習[RLHF]、憲法的AI)、(c)展開アーキテクチャによって課される運用上の制約。この軸は、特定のモデルが他のモデルと比較してどこに位置するかを特定し、重要なことに、訓練中に遭遇しなかった分布シフト、敵対的入力、またはリソース制約下でどのように振る舞うかを予測するための実証的フレームワークを提供する。
-
仮定:* モデルの行動は、意味のある特性評価を可能にするために、入力空間の限定された領域内で十分に安定していると仮定する。この仮定は分布内クエリに対しては成立するが、敵対的または分布外条件下では失敗する可能性がある(Hendrycks & Dietterich, 2019)。
-
例:* 最小限の安全性ファインチューニングで主に指示追従で訓練されたモデルは、高いタスク完了率(高い有用性)を達成する可能性があるが、有害な要求に対する拒否率が低い(低い無害性)ことを示す可能性がある。逆に、積極的な憲法的AI制約を受けたモデルは、稀な害を最小化するために正当な要求を高い割合で拒否する可能性がある(低い有用性、高い無害性)。どちらの立場も客観的に正しいわけではない—それぞれは開発中に行われた明示的な設計トレードオフを反映している。
-
実践への示唆:* LLMを展開するチームは、展開前段階でモデルのアシスタント軸上の位置を明示的にマッピングすべきである。モデルの既知の強み(例:ドメインXにおける技術的正確性)、文書化された失敗モード(例:ドメイン外クエリでの幻覚傾向)、特定されたエッジケース(例:一貫性のない動作を引き起こす曖昧な要求)を文書化する。これを製品、運用、法務チームの参照成果物となる1ページの「モデルプロファイル」として形式化する。この明確性は、ユーザーの期待と実際のシステム動作との間の不整合を防ぎ、展開後の驚きと責任リスクを軽減する。
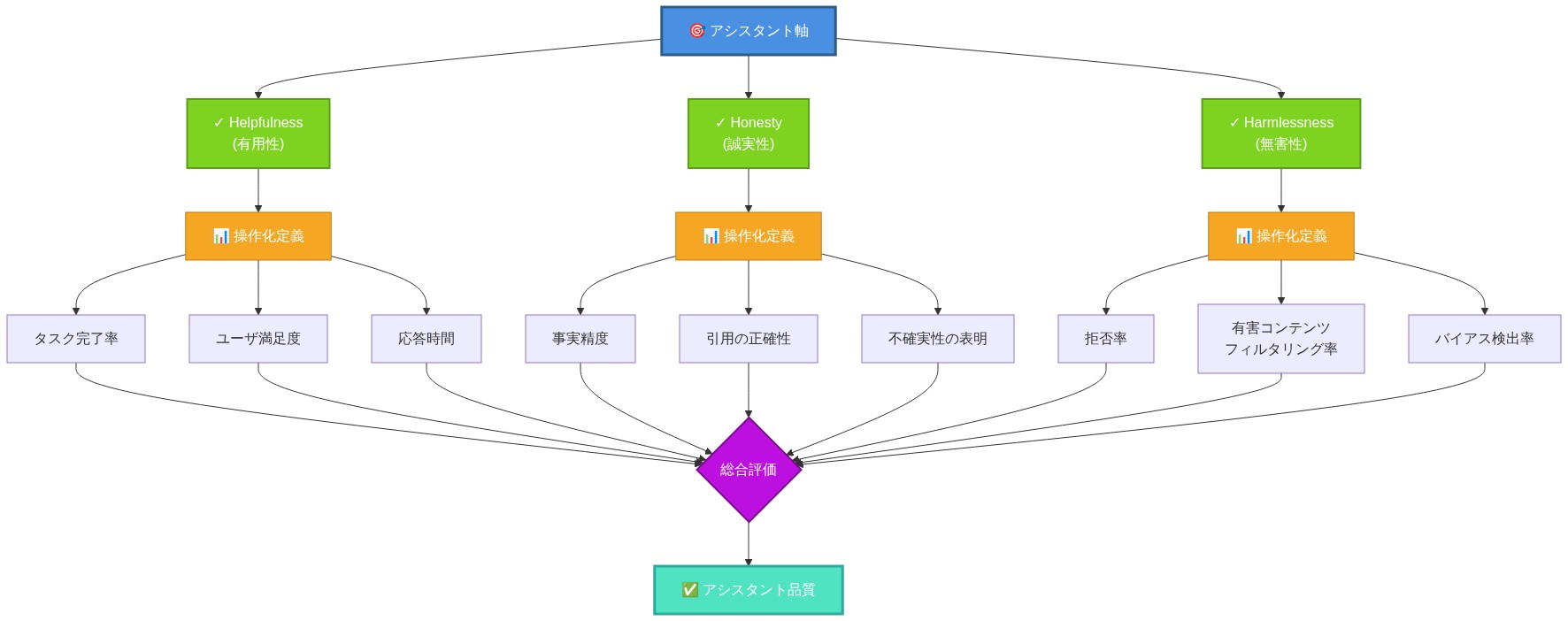
- 図2:アシスタント軸の構成要素と操作化定義*

- 図1:アシスタント軸の概念図—Helpfulness、Honesty、Harmlessnessの3次元トレードオフ空間。異なるLLMモデルがこの3次元空間内のどこに位置するかを示す。*
システム構造とボトルネック
-
主張:* LLM展開の基盤となるアーキテクチャは、モデルが相互作用全体で意図されたキャラクターをどれだけ一貫して維持できるかを制約する予測可能な摩擦点を生み出す。
-
定義上の前提条件:* 「キャラクターの一貫性」を、類似の入力に対する繰り返しの相互作用全体で、モデルの出力がその述べられた行動プロファイルと整合する度合いとして定義する。一貫性は、アシスタント軸上の意図された位置に適合する出力の割合として測定される(操作化については測定セクションを参照)。
-
根拠:* トークン制限、コンテキストウィンドウの制約、推論レイテンシは、モデルの動作に厳格な境界を作り出す。これらは理論的な制限ではない—直接的な行動上の結果を伴う工学的制約である。システムがこれらの制限に達すると、モデルが意図されたキャラクターを維持する能力は測定可能に劣化する。徹底的で包括的であるように訓練されたモデルは、トークン制限に近づくと応答を切り詰めることを余儀なくされる可能性がある。慎重であるように訓練されたモデルは、熟考中にタイムアウトし、意図された位置を反映しない可能性のあるデフォルト応答を強制される可能性がある。
-
仮定:* リソース制約下での行動劣化は予測可能なパターンに従い、実証的に測定できると仮定する。この仮定には、通常条件と制約条件下でのベースラインテストが必要である。
-
例:* 2,000トークンのコンテキストウィンドウで展開されたカスタマーサービスLLMは、平均応答長に応じて、5〜7回の交換後に会話履歴を見失う可能性がある。これにより、モデルは次のいずれかを強制される:(a)明確化の質問を再度行い、ユーザーの不満を生み出す;(b)不完全なコンテキストに基づいて仮定を行い、エラー率を増加させる;(c)以前の発言と矛盾し、信頼を損なう。これはキャラクターの欠陥やモデルの失敗ではない—アーキテクチャ上の制約の直接的な結果である。
-
実践への示唆:* 本番展開前に、ボトルネックについて展開アーキテクチャの徹底的な監査を実施する。測定すべき項目:(1)典型的なワークロード下での実際のコンテキストウィンドウ利用率(平均だけでなくパーセンタイル分布);(2)平均応答レイテンシとレイテンシ分布;(3)相互作用タイプごとに消費されるトークン予算;(4)厳格な制限(コンテキストウィンドウ、トークン予算、タイムアウト)に達する頻度。モデルの意図された動作がキャラクターの一貫性を維持するために4,000トークンのコンテキストを必要とするが、システムが2,000トークンで上限に達する場合、選択に直面する:容量を拡大する(コストへの影響を伴う)か、期待を再定義する(キャラクターへの影響を伴う)。このトレードオフを明示的に文書化する。構造的制限が一貫して達成されたときにフラグを立て、修復のためにエンジニアリングへのエスカレーションをトリガーする監視ダッシュボードを実装する。
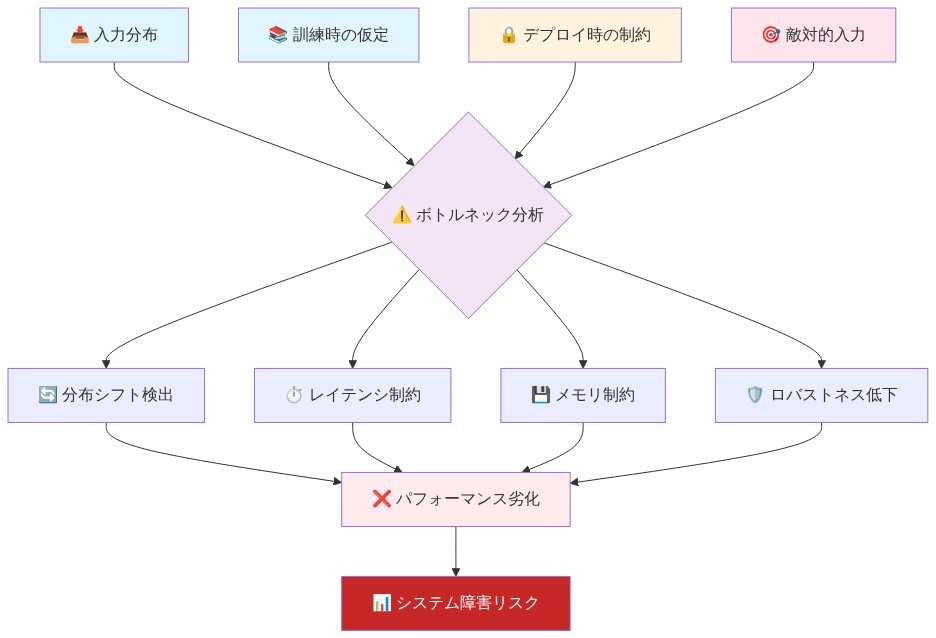
- 図4:LLMデプロイメントシステムのボトルネック構造*

- 図3:LLMの行動形成に影響する3つの要因。訓練データ構成、アライメント技術、デプロイメントアーキテクチャがモデルの位置付けに与える影響を示す概念図*
参照アーキテクチャとガードレール
-
主張:* 安定したLLMキャラクターは、モデルの重みだけからではなく、プロンプトエンジニアリング、検索拡張生成(RAG)、ポリシー実施メカニズムという階層化されたガードレールから生まれる。
-
定義上の前提条件:* 「ガードレール」を、再訓練なしにモデルの動作を形成する外部制御メカニズムとして定義する。ガードレールは3つのレベルで動作する:(1)入力レベル(システムプロンプト、入力フィルタリング)、(2)検索レベル(RAGソースのキュレーション、コンテキスト注入)、(3)出力レベル(応答フィルタリング、ポリシー実施)。ガードレールを、モデルの重みを変更するファインチューニングやアライメント技術と区別する。
-
根拠:* モデルの基本動作—事前訓練または基本アライメントされたモデルによって生成される出力の分布—は本質的に可変であり、プロンプトの変動、コンテキスト、敵対的入力に敏感である。一貫したキャラクターには、モデルの重みとは独立して動作する外部の足場が必要である。ガードレールは運用上のアンカーとして機能し、多様な入力と条件全体で、モデルの出力分布を意図された境界内に留まるように制約する。これはガードレールの制限ではない;それが核心的な機能である。
-
仮定:* ガードレールは独立して動作するように設計でき、その効果は合成的である(すなわち、複数のガードレールを予期しない相互作用なしに積み重ねることができる)と仮定する。この仮定には、各展開に対する実証的検証が必要である。
-
例:* 法的助言なしに事実に基づく判例要約を提供するように設計された法律調査アシスタントは、次のものを実装する可能性がある:(1)免責事項を含め、規範的な言語を避けるようにモデルに明示的に指示するシステムプロンプト;(2)現行判例法のキュレーションされたデータベースに応答を根拠付け、幻覚を防ぐRAG;(3)助言を与える言語パターン(例:「あなたは〜すべき」「私は推奨する」)を検出して拒否する出力フィルター。各層は意図されたキャラクターを独立して強化する。1つの層が失敗した場合(例:システムプロンプトがユーザー入力によって上書きされる)、他の層がカバレッジを提供する。
-
実践への示唆:* ガードレールを単一のゲートとしてではなく、層状に構築する。各層を個別にテストして、特定の失敗モードに対する有効性を確立する。どのガードレールがどのリスクに対処するかを文書化する(例:「RAGは最近の判例に関する幻覚を防ぐ;出力フィルターは助言提供を防ぐ」)。本番システムでは、各重要な失敗モードに対して少なくとも2つの独立した安全メカニズムを実装する—1つが失敗した場合、もう1つがカバレッジを提供する。モデルの動作がドリフトし、新しいリスクが出現し、または展開コンテキストが変化するにつれて、四半期ごとにガードレールを監査する。バージョン履歴、テスト結果、既知の制限を含むガードレールインベントリを維持する。
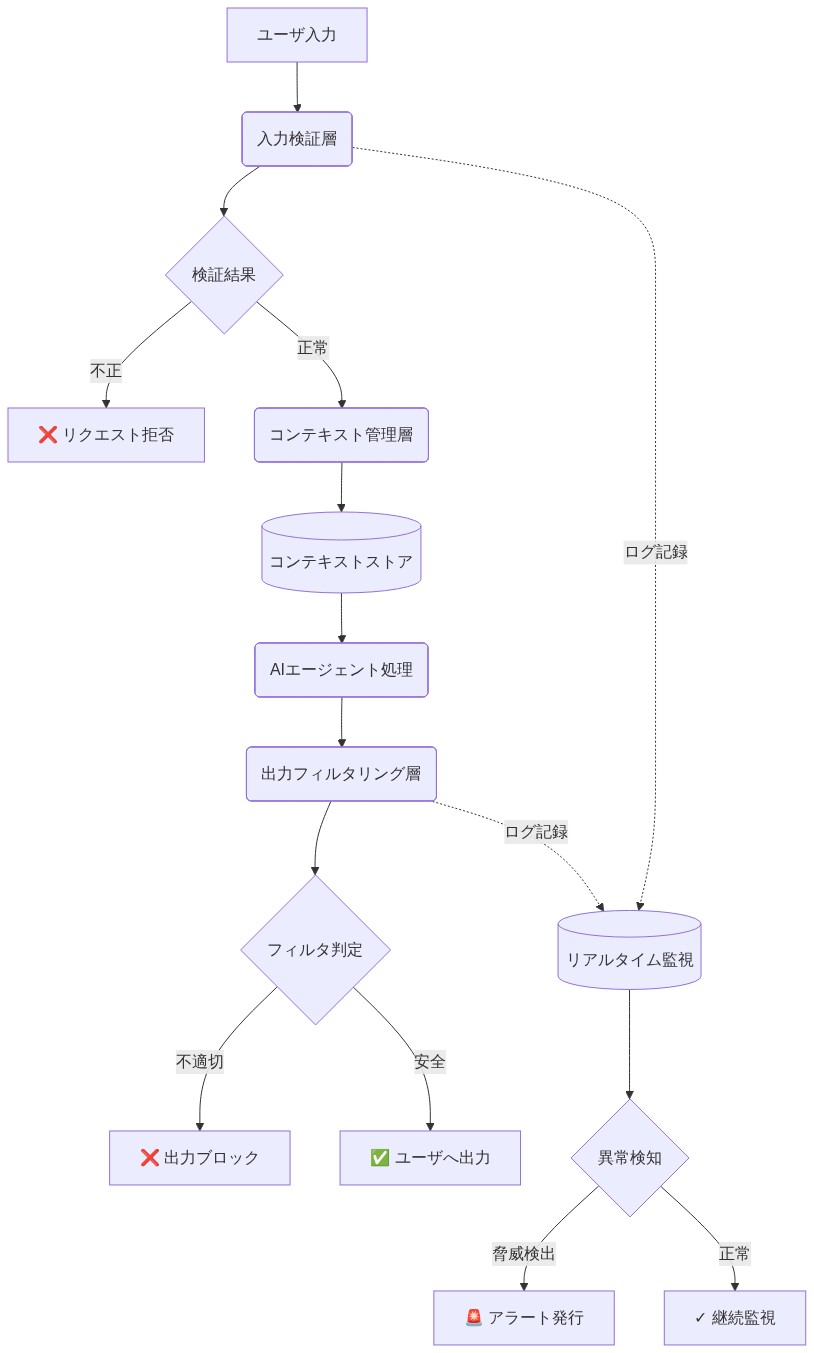
- 図6:ガードレール層のデータフロー—入力検証から出力フィルタリング、リアルタイム監視までの統合処理パイプライン*
- 図5:LLMガードレール統合参照アーキテクチャの全体像*
実装と運用パターン
-
主張:* 運用パターン—体系的なロギング、人間によるレビューワークフロー、フィードバックループ—は、モデルの意図されたキャラクターが本番環境で時間とともに持続するか侵食されるかを決定する。
-
定義上の前提条件:* 「キャラクタードリフト」を、時間の経過とともにアシスタント軸上の意図された位置からの測定可能な逸脱として定義する。ドリフトは以下を通じて発生する可能性がある:(a)ユーザー入力の分布シフト、(b)訓練中に見られなかったエッジケースの蓄積、(c)ガードレールの劣化、(d)意図しない動作を強化するフィードバックループ。
-
根拠:* 展開されたモデルは、訓練データに表現されていないエッジケース、敵対的入力、分布シフトに遭遇する。体系的なフィードバックメカニズムがなければ、モデルの動作は設計意図から乖離する。ロギングは実際の動作への可視性を生み出す;人間によるレビューはパターンを特定する;フィードバックループは再訓練、ガードレール調整、またはプロンプト改良を通じて修正を可能にする。
-
仮定:* エッジケースはサンプリングを通じて特定でき、エッジケースのパターンは実行可能である(すなわち、特定の修復を指し示す)と仮定する。この仮定には、本番トラフィックにおける十分な規模と多様性が必要である。
-
例:* 共感的だが境界を持つ(メンタルヘルス治療の助言提供を拒否する)ように設計されたHRチャットボットは、フラグが立てられた拒否がレビューまたは分析されない場合、徐々に過度に許容的になる可能性がある。ユーザーはガードレールをバイパスするために要求を言い換えることを学ぶ;モデルは後続バージョンの訓練中にこれらの言い換えられた要求に遭遇する;ガードレールが弱まる。逆に、毎週1〜2%の相互作用を体系的にサンプリングし、拒否とニアミスを分類し、エッジケースで再訓練することで、動作を意図と整合させ続ける。
-
実践への示唆:* レビューの頻度を確立する:毎週1〜2%の相互作用をサンプリングし(相互作用タイプと結果で層別化)、失敗とエッジケースを分類し、パターンをモデル開発者にルーティングする。特定から修復まで2週間以内に閉じるフィードバックループを作成する。何が再訓練をトリガーするか(例:「高リスククエリでの拒否率が5%を下回った場合、再訓練」)、ガードレール調整(例:「出力フィルターが毎週Xパターンの10インスタンス以上をキャッチした場合、フィルターを改良」)、またはプロンプト改良の決定ルールを文書化する。以下のロギングを自動化する:(a)ユーザー入力、(b)モデル出力、(c)コンテキストウィンドウの状態、(d)ガードレールの決定、(e)ユーザーフィードバックまたは人間によるレビュー結果。これにより、キャラクタードリフトが検出されたときの迅速な根本原因分析が可能になる。
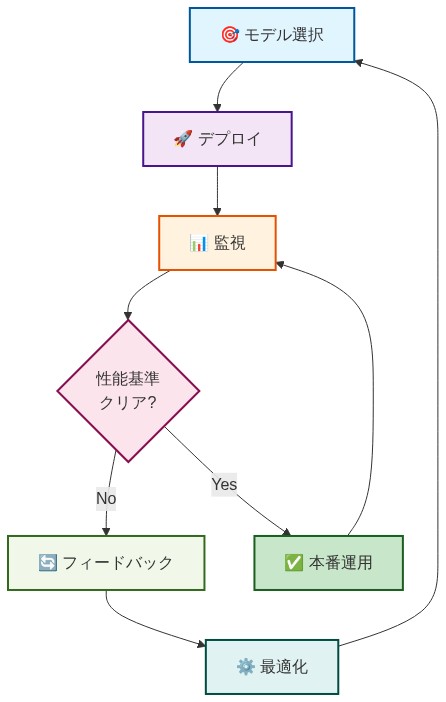
- 図8:LLM運用のライフサイクル—継続的改善ループ*

- 図7:LLMデプロイメントの実装パターン—段階的展開とテスト戦略*
測定と一貫性メトリクス
キャラクターの安定性は、単なる正確性や安全性スコアではなく、行動の一貫性メトリクスを通じて測定可能である。モデルは正確でありながら一貫性がない場合もあれば、安全でありながら役に立たない場合もある。一貫性メトリクスは、モデルが類似の入力に対して予測可能に応答し、相互作用全体で述べられた位置を維持するかどうかを捉える。
一貫性を評価するには、同じ質問の50のバリエーション(言い換え、並べ替え)でモデルをテストし、意図されたキャラクターと整合する応答の割合を計算する。85%未満のスコアは、調査を必要とする不安定性を示す。
- 実務者向け:* ユースケースに固有の3〜5の行動一貫性テストを定義し、毎月実行する。時間の経過とともに傾向を追跡する。一貫性が閾値(例:85%)を下回った場合、本番使用を一時停止して調査する。運用チームと製品チームに見えるダッシュボードを作成する。一貫性スコアを使用して、ガードレール改善のためのリソース配分を正当化する。
リスク評価と軽減
モデルのアシスタント軸上の位置が不明確、ユーザーと不整合、または一貫性なく実施されている場合、予測可能なリスクが生じる。曖昧さは責任を生み出す;ユーザーは誤った期待を抱く。一貫性のなさは信頼を侵食し、下流の害を増幅する。
医療に関する質問を時には拒否し、時には回答するモデルは混乱を生み出す。ユーザーはすべきでないときに回答に依存したり、正当な情報を不信したりする可能性がある—どちらの結果もシステムの価値を損なう。
- 実務者向け:* 立ち上げ前に「キャラクターアライメント監査」を実施する:10人のユーザーに期待される動作についてインタビューし、実際の動作と比較し、ギャップを文書化する。キャラクターの一貫性のなさが害を引き起こすシナリオをリストアップするリスク登録簿を作成する。軽減策の責任者を割り当て、四半期ごとにレビューする。モデルが何をするか、何をしないかを明確にする公開または内部のFAQを維持する。

- 図12:リスク軽減戦略マップ—脅威検出から対応までのフロー*

- 図11:LLMデプロイメントのリスク環境—多層的脅威の相互作用*
システムプロパティとしてのキャラクターの運用化
アシスタント軸を運用化するには、LLMキャラクターを後付けではなく、第一級のシステムプロパティとして扱う必要がある。キャラクターは創発的でも自己安定化するものでもない;意図的な設計、測定、保守が必要である。キャラクターを中核要件として扱うチームは、予測可能で信頼できる展開を達成する。
- 即座の行動計画:*
- プロファイルテンプレートを使用して、現在のモデルのアシスタント軸上の位置をマッピングする。
- システムのボトルネックとガードレールを監査する。
- 今月中に測定ベースラインを確立する。
- 30日以内にレビューワークフローを実装する。
- 四半期ごとのキャラクター監査を計画する。
一貫性に責任を持つ1人の責任者を割り当てる。監視と再訓練のための予算を配分する。キャラクターをコンプライアンスのチェックボックスではなく、製品要件として扱う。

- 図13:キャラクターのシステムプロパティ化—個別設定から統合プロファイルへの抽象化プロセス*
測定と次のアクション
-
主張:* キャラクターの安定性は、正確性や安全性スコアとは異なり、それらを補完する行動の一貫性メトリクスを通じて測定可能である。
-
定義上の前提条件:* 「行動の一貫性」を、意味的に同等な入力が提示されたときに、モデルがアシスタント軸上の述べられた位置と整合する出力を生成する度合いとして定義する。一貫性は、意図された動作プロファイルに適合する出力の割合として測定される。一貫性を正確性(事実内容の正しさ)および安全性(有害な出力の不在)と区別する;モデルは正確でありながら一貫性がない場合もあれば、安全でありながら役に立たない場合もある。
-
根拠:* 正確性と安全性スコアは重要な特性を捉えるが、モデルが相互作用全体で意図されたキャラクターを維持するかどうかを測定しない。モデルはクエリの95%で事実的に正確である可能性があるが、拒否、免責事項、または不確実性の処理方法において一貫性がない—信頼を損なう。一貫性メトリクスは、アシスタント軸上のモデルの位置の安定性を直接測定する。
-
仮定:* 一貫性は制御されたテストを通じて操作化でき、テスト条件下での一貫性は本番環境での一貫性を予測すると仮定する。この仮定には、テストメトリクスと本番メトリクスの間の相関分析による検証が必要である。
-
例:* 一貫性を測定するには、代表的なクエリの意味的に同等な50のバリエーション(言い換え、並べ替え、異なる詳細レベル)を作成する。各バリエーションをモデルに提示し、出力を収集する。意図されたキャラクターとの整合について出力を分析する:モデルは適切に拒否するか?免責事項を含むか?不確実性を示すか?意図されたプロファイルと整合する出力の割合を計算する。85%未満のスコアは、調査を必要とする不安定性を示す。このテストを毎月繰り返して傾向を追跡する。
-
実践への示唆:* ユースケースとアシスタント軸上の意図された位置に固有の3〜5の行動一貫性テストを定義する。毎月テストを実行する。一貫性スコアの傾向を追跡する。一貫性が閾値(例:85%)を下回った場合、本番使用を一時停止し、根本原因(ガードレールの失敗、分布シフト、モデルドリフト)を調査する。一貫性スコア、傾向、アラートを表示する運用チームと製品チームに見えるダッシュボードを作成する。一貫性スコアを使用して、ガードレール改善、再訓練、またはアーキテクチャ変更のためのリソース配分を正当化する。システムの安定性への信頼を構築するために、一貫性メトリクスをステークホルダーに公開する。
リスクと軽減戦略
-
主張:* モデルのアシスタント軸上の位置が不明確である場合、ユーザーの期待と一致していない場合、または本番環境で一貫して実施されていない場合、予測可能なリスクが生じる。
-
定義上の前提条件:* 「キャラクター不整合」を、アシスタント軸上のモデルの表明された、または意図された位置と、本番環境における実際の動作との間のギャップとして定義する。不整合は3つのカテゴリーのリスクを生み出す:(1) ユーザー期待の不一致(ユーザーがシステムの誤ったメンタルモデルを構築する)、(2) 責任リスクの露出(システムが開示または予測されていない方法で動作する)、(3) 信頼の侵食(一貫性の欠如がシステムへの信頼を損なう)。
-
根拠:* モデルのキャラクターに関する曖昧さは責任を生み出す。ユーザーは限られたインタラクションやマーケティング主張に基づいて誤った期待を構築する。一貫性の欠如は、ユーザーが動作を予測できないため、信頼を侵食する。両方とも下流の害を増幅させる:ユーザーは本来すべきでない時に出力に依存したり、正当な情報を不信したりする可能性がある。
-
仮定:* キャラクター不整合は、表明された意図、実際の動作、およびユーザーの期待の構造化された比較を通じて特定できると仮定する。これには経験的データ収集が必要である。
-
例:* 症状に関する質問に対して、時には回答を拒否し、時には詳細な情報を提供する医療情報チャットボットは混乱を生み出す。ユーザーは本来すべきでない時に回答に依存する可能性があり(健康リスクの増加)、または正当な情報を不信する可能性がある(有用性の低下)。この不整合は、不明確なガードレールまたは一貫性のないプロンプトエンジニアリングに起因する。
-
実践への示唆:* ローンチ前に「キャラクター整合監査」を実施する:(1) アシスタント軸上のモデルの意図された位置(有用性、誠実性、無害性のトレードオフ)を文書化する。(2) 10〜15人の代表的なユーザーにシステムの動作に対する期待についてインタビューする。(3) 50〜100の代表的なクエリでモデルをテストし、出力を分類する。(4) ユーザーの期待と実際の動作を比較し、ギャップを文書化する。(5) キャラクターの一貫性の欠如が害を引き起こすシナリオをリストしたリスク登録簿を作成する(例:「ユーザーが免責事項にもかかわらず医療アドバイスに依存する」)。(6) 軽減策の責任者を割り当て、四半期ごとにレビューする。(7) モデルが何をする、何をしないかを具体例とともに明確にする公開または内部FAQを維持する。動作が変化したり、エッジケースが出現したりした際にFAQを更新する。
結論と移行計画
-
主張:* アシスタント軸を運用可能にするには、LLMのキャラクターを、可用性、パフォーマンス、セキュリティと同じ厳密さの対象となる第一級のシステムプロパティとして扱う必要がある—事後的な考慮事項や創発的プロパティとしてではなく。
-
定義上の前提条件:* 「第一級のシステムプロパティ」を、以下の要件を満たすものとして定義する:(a) 開発前に明示的に指定される、(b) 本番環境で継続的に測定される、(c) 正式なガバナンスとエスカレーション手順の対象となる、(d) 専任の人員と予算でリソースが割り当てられる。
-
根拠:* キャラクターは自己安定化するものでも創発的なものでもない。意図的な設計、測定、保守が必要である。キャラクターを第一級のプロパティとして扱うチームは、予測可能で信頼できるデプロイメントを達成する。事後的な考慮事項として扱うチームは、ドリフト、不整合、責任リスクの露出を経験する。
-
仮定:* キャラクターは体系的な運用実践を通じて維持でき、保守のコストはリスクの低減とユーザー信頼の向上によって正当化されると仮定する。
-
実践への示唆:* 以下のロードマップを直ちに実施する:
-
第1〜2週:ベースラインマッピング。 モデルプロファイルテンプレート(セクション1)を使用して、現在のモデルのアシスタント軸上の位置をマッピングする。有用性、誠実性、無害性の間の意図されたトレードオフを文書化する。既知の強みと失敗モードを特定する。
-
第2〜3週:アーキテクチャ監査。 システムのボトルネックとガードレールを監査する(セクション2〜3)。コンテキストウィンドウの利用率、レイテンシ、トークン消費量を測定する。既存のガードレールをインベントリ化し、その有効性をテストする。
-
第3〜4週:測定ベースライン。 今月中に測定ベースラインを確立する(セクション4)。50以上の代表的なクエリで一貫性テストを実行する。ベースラインスコアを文書化する。一貫性の目標閾値を設定する。
-
第4〜6週:運用実装。 30日以内にレビューワークフローを実装する(セクション5)。サンプリング頻度(週次1〜2%)、分類プロセス、フィードバックループのクローズ目標(2週間)を確立する。ログ記録を自動化する。
-
継続的:四半期監査。 四半期ごとのキャラクター監査を計画する(セクション6)。一貫性メトリクス、ユーザーフィードバック、エッジケースをレビューする。必要に応じてガードレールまたはプロンプトを調整する。
一貫性とキャラクターの安定性に責任を持つ1人の責任者を割り当てる。監視インフラストラクチャ、人間によるレビュー、再トレーニングのための予算を配分する。キャラクターをコンプライアンスのチェックボックスではなく、製品要件として扱う。キャラクターメトリクスを製品ダッシュボードとステークホルダーレポートに統合する。