
ソフトデリートをデフォルト戦略として再考すべき理由
ソフトデリート—レコードを削除するのではなく削除済みとしてマークする—は、アプリケーション設計において反射的な選択肢となっている。その魅力は明快だ:コンプライアンス、監査証跡、復旧シナリオのためにデータを保存する。しかし、この利便性は、システムがスケールするにつれて複雑化する重大な運用上の摩擦を隠している。
- 主張:* ソフトデリートは、文書化されたシステム要件と規制上の義務に紐づいた明示的なコストベネフィット分析なしに、デフォルトのアーキテクチャ選択であるべきではない。
多くのチームは、仮説的な将来のニーズに対する保険としてソフトデリートを採用するが、その保険料—クエリの複雑性、ストレージのオーバーヘッド、認知的負荷で支払われる—が保護の価値を上回ることを後になって発見する。このパターンは、FowlerとBeck(2002)が「投機的一般性」と呼ぶものを反映している:予想されているが検証されていない将来の要件のために設計すること。
この根拠は、3つの経験的に根拠のある観察に基づいている:
- クエリの複雑性の伝播: ソフトデリートは、影響を受けるテーブルに触れるすべてのクエリにフィルタリングロジックを下流にプッシュし、分散したメンテナンス負担を生み出す。
- 隠れた状態管理: ソフトデリートされたレコードは、コードベース全体で一貫して強制されなければならない潜在的な状態を導入し、論理エラーの表面積を増加させる。
- 規制との不整合: ソフトデリートによるデータ保存は、プライバシー規制(GDPR第17条、CCPA § 1798.100)やユーザーの期待をサポートするのではなく、しばしば矛盾する。
具体例:ユーザーアカウントの削除
SaaSアプリケーションのユーザー管理システムを考えてみよう。ユーザーがアカウント削除を要求すると、ソフトデリートアプローチはusersテーブルにdeleted_at = NOW()を設定する。直ちに、usersに対するすべてのクエリは述語WHERE deleted_at IS NULLを含まなければならない。このフィルタは以下に広がる:
- 認証ロジック(ログイン、セッション検証)
- レポートダッシュボード(ユーザーメトリクス、コホート分析)
- 課金システム(サブスクリプション更新、請求書生成)
- 分析パイプライン(ファネル分析、リテンション計算)
下流システムのいずれかで単一のフィルタを忘れると、2つの障害モードのいずれかが発生する:
- データ露出: 削除されたユーザーレコードがクエリに返され、ユーザーのプライバシー期待に違反し、潜在的に規制違反を生み出す。
- 運用エラー: 削除されたユーザーがサービスに課金され、通信を受け取り、またはレポートに表示され、サポートインシデントと信頼の侵食を生み出す。
コンプライアンス上の利点—「削除されたデータを復旧できる」—は、クエリフィルタの省略によってそのデータが誤って露出された場合、負債となる。これは理論的なものではない:Ponemon Institute(2020)は、データ侵害の60%がアクセス不可能であるべきレコードの不注意な露出を含むと報告している。
ソフトデリートが正当化される前提条件
ソフトデリートを実装する前に、保護しようとしている特定の復旧シナリオを文書化する:
- 不十分な正当化: 「念のため」または「後で必要になるかもしれない」は、時期尚早な採用を示している。ソフトデリートは使用すべきではない。
- 正当化されるシナリオ:
- 特定のレコードタイプに対する法的保留(規制調査、訴訟)
- コンプライアンスフレームワークの監査証跡要件(SOX、HIPAA、PCI-DSS)
- 履歴スナップショットを必要とする時系列データ分析
- 事業継続計画で定義された特定の復旧期間
正当化される場合、ソフトデリートは特定のレコードタイプとユースケースに範囲を限定すべきであり、すべてのテーブルに普遍的に適用すべきではない。
システム構造とパフォーマンスのボトルネック
ソフトデリートは、データ量とクエリの複雑性とともに成長する構造的ボトルネックを導入する。ソフトデリートを使用するすべてのテーブルは、2状態システムになる:アクティブと削除済み。この二分化は、インデックス、クエリプラン、アプリケーションロジックに漏れ出す。
- 核心的な主張:* ソフトデリートはクエリパフォーマンスを低下させ、スケールで深刻になる方法でストレージ要件を増加させ、これらのコストは本番インシデントを引き起こすまでしばしば見えない。
データベースは、大量のソフトデリートされたレコードを非効率的に処理する。1億人のアクティブユーザーと5000万人のソフトデリートされたユーザーを持つテーブルは、両方の集団を含むインデックスを維持しなければならない。アクティブユーザーをフィルタリングするクエリは、すべてのインデックススキャンでdeleted_at述語を評価しなければならない。削除率が高い場合—ユーザーの離脱が一般的なプラットフォームでは一般的—ソフトデリートされたレコードの割合は、クエリプランをフルテーブルスキャンまたは非効率的なインデックス使用に歪める可能性がある。ストレージも複雑化する:テーブル上のすべてのインデックスは、論理的に見えないにもかかわらず、削除されたレコードの重みを運ぶ。
-
具体例:* eコマースプラットフォームが注文を追跡する。マーチャントがデータ削除を要求したとき、またはアカウントが閉鎖されたときに、注文は削除済みとしてマークされる。3年後、ordersテーブルには5億件のアクティブレコードと2億件のソフトデリートされたレコードが含まれている。過去1か月の高額注文を見つけるクエリ—ミリ秒で実行されることを意図している—は、5億行ではなく7億行をスキャンする。オプティマイザが削除されたレコードがインデックスの選択性を低下させるのに十分に普及していることを認識するため、クエリプランはインデックスのみのスキャンからフルテーブルスキャンに移行する。応答時間は50msから3秒に増加する。結果セットが予測不可能であるため、キャッシングとクエリ最適化が困難になる。
-
実行可能なガイダンス:* 大量のテーブルにソフトデリートを検討している場合は、現実的な削除率でシミュレーションを実行し、インデックスの選択性を測定する。ソフトデリートされたレコードが2年以内にテーブルの10%以上を占める場合は、アーカイブを伴うハードデリートまたは別の削除済みレコードテーブルのいずれかを計画する。ソフトデリートにコミットする前に、本番規模のデータを持つステージング環境でクエリパフォーマンスを監視する。
リファレンスアーキテクチャとガードレール
定義と核心要件
ソフトデリートの実装には、データの一貫性を維持するための意図的なアーキテクチャガードレールが必要である。基本的な要件は、システムがすべてのデータアクセスパターンにわたってソフトデリートを単一の一貫した概念として扱わなければならないということである。この強制された一貫性がなければ、クエリは一貫性のない結果を返す—一部は論理的に削除されたレコードを含み、他は除外する—診断と修復が困難なデータ整合性違反を生み出す。
- 核心的な主張*: ソフトデリートは、削除ロジックを集中化し、すべてのデータアクセス層とサービスにわたって一貫したフィルタリングを強制する厳格なアーキテクチャパターンを通じて実装された場合にのみ実行可能である。
一貫性の問題:メカニズムと証拠
一貫性の失敗は、ソフトデリートが削除セマンティクスを複数のシステムコンポーネント—アプリケーションサービス、クエリビルダー、ORM、直接データベースアクセス—にわたって分散させるが、「削除済み」が何を意味するかについての単一の真実の源がないために発生する。
-
不整合の前提条件*:
-
複数のサービスまたはチームが同じデータストアにアクセスする
-
削除ロジックが複数の場所(アプリケーションコード、ストアドプロシージャ、ORM設定)に実装されている
-
ソフトデリートされたレコードのクエリフィルタリングが必須ではなくオプションである
-
異なるデータアクセスパターン(直接SQL、ORM、クエリビルダー)が統一されたフィルタリングなしに共存する
-
メカニズム*: 削除責任が分散されると、以下の障害モードが現れる:
- 省略されたフィルタ: クエリ開発者がソフトデリートフィルタ要件を忘れるか認識せず、論理的に削除されたレコードをアクティブなものと一緒に返す。
- 一貫性のないフィルタ適用: 同じ論理クエリが異なるコードパス(例:ORM対直接SQL)を通じて実行されると異なる結果を生成する。
- サービスレベルの乖離: あるサービスはソフトデリートセマンティクスを適用し、別のサービスは同じデータストアをハードデリートセマンティクスを持つものとして扱う。
- 結合レベルのエラー: ソフトデリートフィルタが主テーブルに適用されるが、結合されたテーブルには適用されず、孤立したまたは幻の関係を生み出す。
-
例示的シナリオ*: ユーザーサービス、課金サービス、分析サービスで構成されるマルチサービスアーキテクチャにおいて:
-
ユーザーサービスは、ユーザーレコードに
deleted_atタイムスタンプを設定することでソフトデリートを実装する。 -
別のチームによって維持されている課金サービスは、請求書を生成するためにユーザーテーブルに直接クエリする。開発者が
deleted_atフィルタを適用せずに新しいクエリを追加する。 -
結果: 削除されたユーザーが請求書に表示され、存在しないアカウントに対する課金を生成する。
-
一方、分析サービスは、ソフトデリートされたレコードをフィルタリングするデフォルトスコープで設定されたORMを使用するため、分析レポートは正しいままである。
-
顧客が誤った課金を報告するまで不整合は検出されず、その時点で根本原因をサービス境界を越えて追跡することは困難である。
このシナリオは、不整合が理論的なリスクではなく、削除ロジックが分散化されたときの予測可能な結果であることを示している。
アーキテクチャガードレール:強制メカニズム
一貫性の失敗を防ぐために、ソフトデリートはアプリケーションロジックに委任されるのではなく、データアクセス層で強制されなければならない。これには、複数の補完的なメカニズムが必要である:
1. 集中化された削除ロジック
-
要件*: すべての削除操作は、ソフトデリートフラグを一貫して管理する単一の制御されたインターフェース—専用サービス、ストアドプロシージャ、またはクエリビルダーメソッド—を通じて流れなければならない。
-
根拠*: 集中化により、ソフトデリート(ハードデリートではなく)の決定が一度、一か所で行われ、均一に適用されることが保証される。これにより、異なるサービスまたは開発者が削除セマンティクスについて異なる選択をする可能性が排除される。
-
実装*:
-
直接UPDATE文を許可するのではなく、すべての呼び出し元が呼び出さなければならないサービスメソッド
deleteUser(userId)を定義する。 -
このメソッドを、
deleted_atを設定し、必要なカスケード更新または監査ログを実行するストアドプロシージャまたはトランザクションサービスとして実装する。 -
データベース権限を介して
deleted_at列への直接UPDATE アクセスを制限する。
2. デフォルトクエリインターフェースとしてのデータベースビュー
-
要件*: ソフトデリートされたレコードを自動的にフィルタリングするデータベースビューを作成する。クエリはデフォルトでベーステーブルではなくビューをターゲットにすべきである。
-
根拠*: ビューはデータベース層でソフトデリートフィルタを強制し、正しいフィルタリングをデフォルトの動作にする。ビューに対するクエリは、フィルタがビュー定義に組み込まれているため、誤ってソフトデリートされたレコードを返すことはできない。
-
実装*:
CREATE VIEW active_users AS
SELECT * FROM users WHERE deleted_at IS NULL;クエリはusersの代わりにactive_usersを参照する。削除されたレコードを必要とするクエリは、ベーステーブルに明示的に結合しなければならず、コードレビューで意図が見えるようになる。
- 前提条件*: このアプローチは、クエリの大部分がソフトデリートされたレコードを除外すべきであることを前提としている。クエリの大部分が削除されたレコードへのアクセスを必要とする場合、ビューはガードレールとして効果が低くなる。
3. ORM設定とデフォルトスコープ
-
要件*: ORMを使用する場合、明示的にオーバーライドされない限り、ソフトデリートされたレコードを自動的にフィルタリングするデフォルトクエリスコープを設定する。
-
根拠*: ORMはSQL生成を抽象化するため、すべてのORM生成クエリにわたって一貫性を確保するために、フィルタリングをORMレベルで設定しなければならない。
-
実装*(疑似コードの例):
class User(BaseModel):
deleted_at: Optional[DateTime] = None
@classmethod
def query(cls):
return super().query().filter(cls.deleted_at.is_(None))User.query()を介したすべてのクエリは、ソフトデリートされたレコードを自動的に除外する。削除されたレコードを必要とするクエリは、明示的にUser.query(include_deleted=True)を呼び出さなければならず、例外が見えるようになる。
- 制限*: このアプローチは、コードベース全体で規律を必要とする。ORMをバイパスして生のSQLを書く開発者は、デフォルトスコープの恩恵を受けない。
4. 監査ログとトレーサビリティ
-
要件*: 不整合が発生したときに追跡するのに十分なコンテキストで、すべての削除操作をログに記録する。
-
根拠*: 監査ログは、どのサービスまたはクエリが不整合を引き起こしたか、いつ引き起こしたかを特定するために必要な法医学的証拠を提供する。
-
実装*:
-
すべての削除操作について、サービス、ユーザー、タイムスタンプ、影響を受けたレコードIDをログに記録する。
-
呼び出し元とクエリテキストを含む、ソフトデリートフィルタをバイパスするクエリをログに記録する。
-
顧客の苦情を削除イベントと相関させるのに十分な期間、ログを保持する。
-
仮定*: このアプローチは、不整合が検出され調査されることを前提としている。不整合が気づかれない場合、監査ログは予防的価値を提供しない。
強制と検証

- 図9:ソフトデリートのリスク分析と軽減戦略マトリックス*
コードレビュー基準
-
要件*: ソフトデリートフィルタをバイパスするクエリに対して明示的な正当化を要求するコードレビュー基準を確立する。
-
実装*:
-
ビューの代わりにベーステーブルを参照するクエリにフラグを立てる。
-
include_deleted=Trueまたは同等のオーバーライドを使用するORMクエリにフラグを立てる。 -
ソフトデリートフィルタが適用されない理由を著者に文書化するよう要求する。
一貫性テスト
-
要件*: 異なるコードパスにわたって一貫性を検証する自動テストを実装する。
-
実装*:
-
与えられた論理クエリ(例:「すべてのアクティブユーザーを取得」)について、利用可能な各コードパス(直接SQL、ORM、クエリビルダー、サービスメソッド)を通じて実行する。
-
すべてのコードパスが同一の結果を返すことをアサートする。
-
これらのテストを標準テストスイートの一部として実行する。
-
テスト例*:
def test_soft_delete_consistency():
user = create_user("test@example.com")
soft_delete_user(user.id)
# ビュー経由のクエリ
result_view = db.query("SELECT * FROM active_users WHERE id = ?", user.id)
# ORM経由のクエリ
result_orm = User.query().filter(User.id == user.id).first()
# サービス経由のクエリ
result_service = user_service.get_active_user(user.id)
assert result_view is None
assert result_orm is None
assert result_service is None監視とアラート
-
要件*: コードパスまたはサービスにわたって一貫性のない結果を返すクエリを監視する。
-
実装*:
-
クエリ結果とそのソース(サービス、コードパス)をログに記録する。
-
同じ論理クエリが異なるサービスを通じて実行されたときに異なるレコード数または異なるレコードセットを返す場合にアラートを出す。
前提条件とスコープの制限
上記のアーキテクチャガードレールは、特定の前提条件の下でのみ効果的である:
- 単一のデータストア: すべてのサービスが同じデータベースまたは同期されたレプリカにアクセスする。サービスが別々のデータストアを維持する場合、ソフトデリートセマンティクスを均一に強制することはできない。
- 制御されたアクセス: 直接データベースアクセスが制限または監視されている。開発者が任意のSQLを実行できる場合、集中化された削除ロジックとビューは強制を提供しない。
- 組織的整合: チームがソフトデリートセマンティクスに同意し、確立されたパターンに従う。チームが削除を異なる方法で実装する場合、ガードレールは強制されるのではなく助言的になる。
- 安定したスキーマ: ソフトデリート列(
deleted_atまたは同等)が、ソフトデリートを必要とするすべてのテーブルに存在する。既存のテーブルに列を遡及的に追加することは破壊的である。
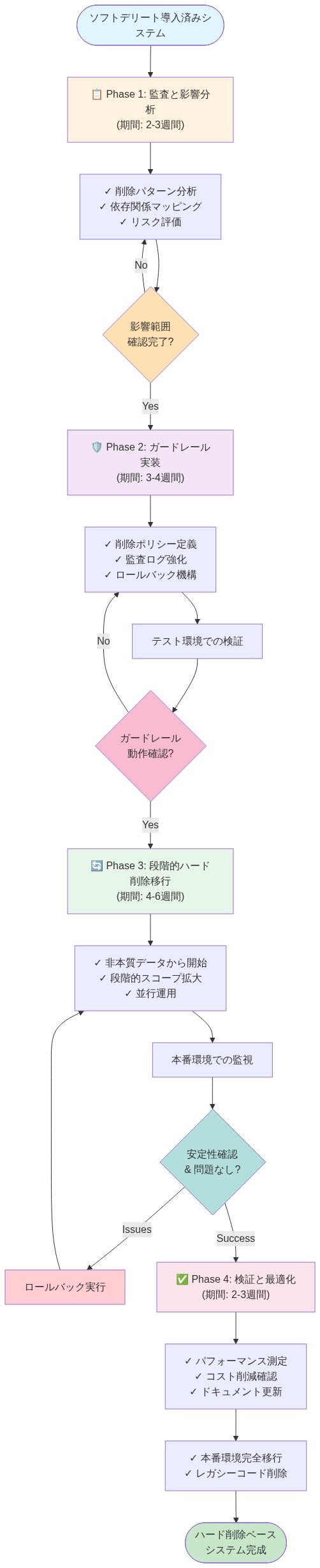
- 図12:ソフトデリート最適化への段階的移行パス(4フェーズ、総期間11-16週間)*
ガードレールの要約
| ガードレール | メカニズム | 強制するもの | 制限 |
|---|---|---|---|
| 集中化された削除ロジック | 単一のサービス/プロシージャ | 削除セマンティクス | 規律を必要とする;バイパス可能 |
| データベースビュー | 自動フィルタリング | クエリの一貫性 | クエリがベーステーブルではなくビューをターゲットにすることを必要とする |
| ORMデフォルトスコープ | 自動フィルタリング | ORM生成クエリ | 生のSQLクエリを保護しない |
| 監査ログ | 事後トレーサビリティ | 説明責任 | 反応的であり、予防的ではない |
| コードレビュー | 手動検査 | 例外 | レビュアーの知識に依存 |
| 一貫性テスト | 自動検証 | 回帰検出 | 包括的なテストカバレッジを必要とする |
- 実行可能な含意*: ソフトデリートの採用には、複数の補完的なガードレールへの投資が必要である。単一のメカニズムでは十分ではない。最も効果的なアプローチは、データベース層の強制(ビュー、集中化されたプロシージャ)とアプリケーション層の規律(ORM設定、コードレビュー、テスト)および可観測性(監査ログ、監視)を組み合わせる。
実装と運用パターン
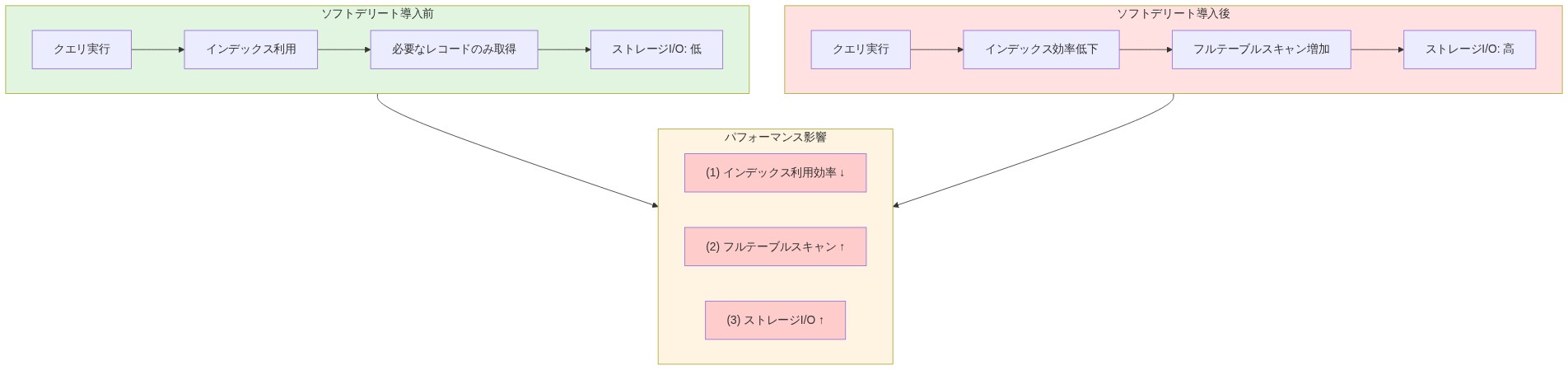
- 図5:ソフトデリート導入前後のクエリパフォーマンス比較:インデックス効率とI/O負荷*

- 図11:意図的なアーキテクチャ設計:ソフトデリート採用の明示的な意思決定プロセス*
運用負荷と先送りされる複雑性
論理削除は、削除の複雑性をシステムのライフサイクル全体に根本的に再分配します。データ削除を削除時点で解決するのではなく、論理削除はこの解決を継続的な運用プロセスに先送りし、持続的なメンテナンス義務を生み出し、即座の物理削除アプローチには存在しない障害モードを導入します。
- 中核的主張*: 論理削除はレコードを削除するのではなく、ストレージ、バックアップ、インデックス、災害復旧アーティファクトにおける物理的存在を保持したまま、その可視性を停止します。この停止は、時間の経過とともに蓄積される複合的な運用コストを生み出します。
ストレージとバックアップへの影響
論理削除されたレコードは、プライマリデータベースで完全なストレージフットプリントを保持し、すべてのバックアップコピーでスペースを占有し、明示的なインデックスメンテナンスが実行されない限りインデックス化されたままです。データベースの復元が発生した場合—スケジュールされたバックアップからであれ緊急復旧からであれ—論理削除されたレコードはアクティブなデータと一緒に復元されます。これは重要な運用上の制約を生み出します:** 復元操作は、存在すべきレコードと存在すべきでないレコードを区別できません**。そのため、復元後のフィルタリングか、復元されたシステム状態における論理削除データの受け入れのいずれかが必要になります。
影響はバックアップ保持ポリシーにまで及びます。バックアップ保持期間が論理削除されたレコードの意図されたデータ保持期間を超える場合、コンプライアンス義務(GDPR第17条「消去権」など)は、アクティブなバックアップにまだ存在するデータの削除を要求する可能性があります。これは論理的な矛盾を生み出します:本番データベースはコンプライアンスのためにレコードを物理削除したかもしれませんが、バックアップには論理削除されたバージョンが含まれており、コンプライアンス要件に違反します。
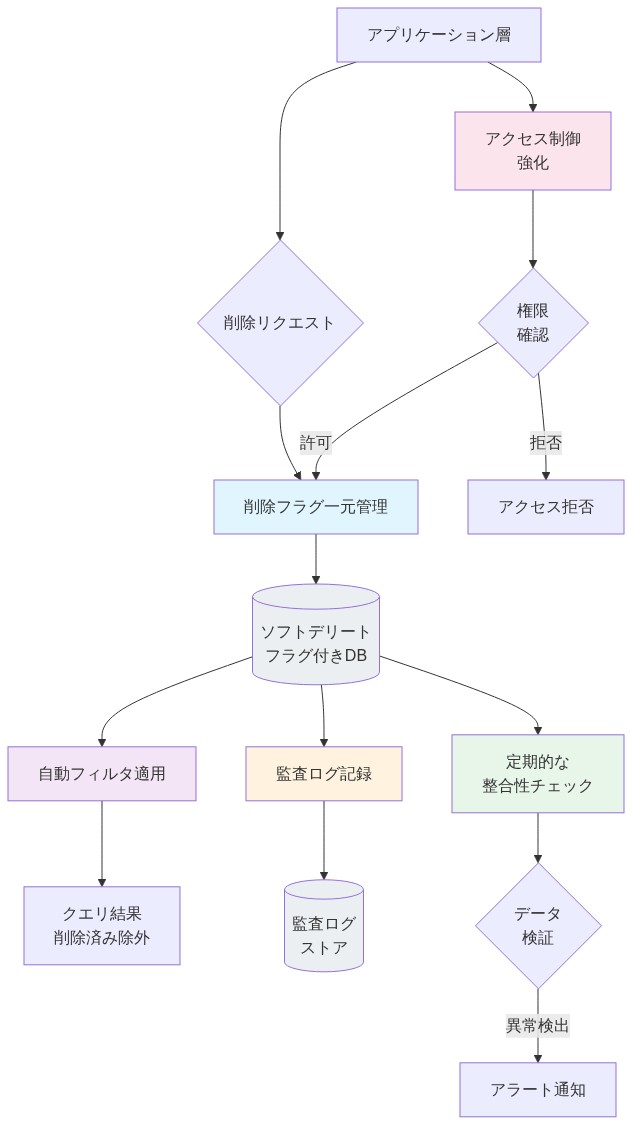
- 図7:ソフトデリート実装の5つの必須ガードレール相互連携図*
必須の二次プロセス
論理削除は、データ保持ポリシー、コンプライアンス要件、またはストレージ最適化目標を満たすために、別個の物理削除プロセスの実装を必要とします。この二次プロセスは、独自の運用上の複雑性を導入します:
- プロセス要件*(GDPRコンプライアンスとデータ保持のベストプラクティスから導出):
- 保持閾値を超える論理削除されたレコードの識別
- 削除を妨げる可能性のある法的保留、コンプライアンスフラグ、または規制上の例外の検証
- すべての関連テーブル、外部キー依存関係、非正規化コピーにわたるカスケード物理削除
- インデックスのクリーンアップとストレージの再利用
- 削除タイムスタンプ、オペレーター識別情報、正当化理由を含む監査ログ
- すでに削除されたレコードを再処理することなく、障害復旧と再開
- 満たすべき運用上の制約*:
- ノンブロッキング実行(本番時間中のテーブルロックは禁止)
- トランザクションの安全性(部分的な削除はロールバックされなければならず、完了した削除は永続的でなければならない)
- 冪等性(同じレコードに対してプロセスを再実行してもエラーやデータ損失を引き起こしてはならない)
- 可観測性(リアルタイムの進捗監視と障害時のアラート)
具体的な運用シナリオ
90日間の非アクティブ後に顧客アカウントに論理削除を実装するSaaSプラットフォームを考えます。24ヶ月の運用後:
- 蓄積された論理削除レコード: 280万アカウント
- コンプライアンス要件: GDPR第17条は、消去リクエストから30日以内に個人データの削除を義務付ける
- 現在の状態: 論理削除されたレコードは本番データベース、バックアップ、読み取りレプリカに残っている
プラットフォームは次のような物理削除プロセスを実装する必要があります:
- 論理削除されたアカウントをクエリし、タイムスタンプベースのフィルターを使用して30日以上経過したものを抽出
- 削除適格性を検証し、以下をチェック:
- アカウントを参照するアクティブなサポートチケット
- 保留中の返金トランザクション
- コンプライアンスチームからの規制上の保留
- カスケード削除を実行する対象:
accountsテーブル(プライマリレコード)account_settingsテーブル(外部キー依存関係)audit_logsテーブル(保持期間が満了している場合の履歴レコード)search_indexes(非正規化されたアカウントデータ)analytics_warehouse(集約されたメトリクス)
- 削除イベントをログ記録する内容: タイムスタンプ、アカウントID、削除理由、オペレーター識別情報
- 障害シナリオを処理:
- 外部キー制約違反(例: 孤立したトランザクションレコード)
- 並行修正(例: 削除中にサポートエージェントがアカウントにアクセス)
- ストレージクォータ超過(例: 監査ログテーブルが満杯)
- 障害復旧要件*: プロセスが50万レコードを削除した後にクラッシュした場合、システムは以下を行わずに最後に完了したバッチから再開する必要があります:
- すでに処理されたレコードを再削除する(監査ログの重複を引き起こす)
- 部分的な削除を残す(孤立した子レコード)
- プロセスマネージャーが再起動した場合に進捗状態を失う
設計の代替案とトレードオフ
-
アーカイブテーブルパターン*(論理削除の代替):
-
削除されたレコードを削除済みとマークする代わりに、別の
accounts_archiveテーブルに移動 -
利点: アクティブなクエリはテーブル分離によってアーカイブデータを除外(フィルタリングではない); アーカイブテーブルは異なる保持ポリシーを使用可能; アーカイブデータの物理削除は本番クエリから分離される
-
欠点: 移動を処理するアプリケーションロジックが必要; 子レコードが存在する場合、外部キー制約が移動を妨げる可能性; アーカイブテーブルも依然としてバックアップと保持管理が必要
-
ハイブリッドアプローチ*(論理削除 + スケジュールされた物理削除):
-
30日間の論理削除(データ復旧リクエストのためのコンプライアンスウィンドウ)
-
30日後の自動物理削除(コンプライアンス要件の充足)
-
利点: コンプライアンス期限を満たしながら復旧ウィンドウを提供; 長期的なストレージ負担を軽減
-
欠点: 信頼性の高いスケジューリングが必要; 物理削除プロセスの障害はコンプライアンス違反リスクを生む
運用上の意思決定フレームワーク
論理削除を実装する前に、チームは以下を行うべきです:
-
最終的に必要となる物理削除プロセスを定義する内容:
- 保持閾値(コンプライアンス駆動またはビジネス駆動)
- 障害復旧手順
- 監視とアラート要件
- 推定実行時間とリソース消費
-
運用上の実現可能性を評価する項目:
- カスケード削除の複雑性(依存テーブルの数)
- 物理削除プロセスが失敗した場合のデータ損失リスク
- ノンブロッキング削除メカニズムの利用可能性(例: オンラインスキーマ変更)
- 論理削除アーキテクチャと矛盾する可能性のあるコンプライアンス要件
-
パターン間の総所有コストを比較:
- 論理削除: 継続的なストレージコスト + 物理削除プロセスの複雑性
- アーカイブテーブル: 移動操作のオーバーヘッド + アーカイブテーブルのメンテナンス
- 即座の物理削除: 復旧ウィンドウの喪失 + 潜在的なコンプライアンス違反
物理削除の複雑性が高い場合、またはコンプライアンス要件がデータ削除に厳しい期限を設定する場合、論理削除は運用負荷を軽減するのではなく増加させる可能性があります。そのような場合、アーカイブテーブルパターンまたは即座の物理削除がより適切かもしれません。
測定と可観測性
論理削除は潜在的な状態—削除のためにマークされているがデータベースに保持されているレコード—を導入し、明示的な計装なしには見えないままです。この不可視性は測定問題を生み出します:論理削除によって引き起こされる運用上の劣化は徐々に蓄積され、顧客向けインシデントとして現れるまで検出されないことがよくあります。
-
中核的主張*: 論理削除システムは、削除の普及率、クエリパフォーマンスへの影響、データ整合性を測定するための意図的な可観測性インフラストラクチャを必要とします。そのような計装がなければ、システムの動作は予測または診断がますます困難になります。
-
理論的基礎*: 論理削除は、データベース操作に隠れた変動の次元を追加します。テーブル内の論理削除されたレコードの割合は、クエリ実行計画、インデックス効率、ストレージ利用に直接影響する状態変数ですが、従来のデータベースメトリクス(例: 行数、クエリレイテンシ、ディスク使用量)では捉えられません。これは、明示的な測定なしには不明瞭なままの因果関係を生み出します:
-
クエリレイテンシは、データ量と論理削除フィルターの選択性の両方の関数です。
-
ストレージの増加は、新しい挿入と論理削除されたレコードの蓄積の両方の関数です。
-
インデックスパフォーマンスは、論理削除されたレコードの割合が増加するにつれて劣化します。なぜなら、インデックスは論理的に削除されたデータのエントリを依然として格納し、トラバースする必要があるためです。
-
例示的シナリオ*: ユーザーアカウント削除が論理削除を介して実装されているマルチテナントプラットフォームを考えます。プラットフォームは全体的なデータベースサイズとクエリレイテンシを追跡していますが、削除率は計装していません。6ヶ月間にわたって:
-
顧客の解約が加速するにつれて、削除率は総ユーザーレコードの5%から25%に増加します。
-
アカウント検索のクエリレイテンシは100msから500msに増加します。
-
運用チームはレイテンシの増加を観察し、それを全体的なデータ量の増加に起因すると考えます(もっともらしいが不完全な説明)。
-
これに対応して、追加の読み取りレプリカをプロビジョニングし、一時的にレイテンシを許容レベルに戻します。
-
6ヶ月後、削除率は40%に達し、追加のレプリカにもかかわらずレイテンシは再び500msに劣化し、チームはスケーリングサイクルを繰り返します。
-
複数のスケーリング反復の後になって初めて、誰かがレイテンシパターンと削除率を関連付け、論理削除を根本原因として特定します。
このシナリオは一般的な障害モードを示しています:削除率とパフォーマンスメトリクスとの相関の明示的な測定がなければ、システムの真のボトルネックは隠されたままであり、効果のない修復と無駄なインフラストラクチャ投資につながります。
-
必要な測定*:
-
削除率(テーブル別): 削除済みとマークされたレコードの割合を、総レコード数のパーセンテージで表現。これは継続的に追跡され、エンティティタイプによって削除パターンが異なるため、テーブル別にセグメント化されるべきです。測定には、削除速度の加速または減速を検出するために、ポイントインタイムスナップショットと時系列トレンドの両方を含めるべきです。
-
クエリへの影響(クエリパターン別): 論理削除されたレコードをフィルタリングするクエリ(例:
WHERE deleted_at IS NULL)について、クエリ実行中に検査された行のうち論理削除されている行の割合を測定。このメトリクスは、論理削除フィルターの効率コストを明らかにします。高い割合は、クエリエンジンがフィルタリングする前に多くの論理削除された行をスキャンしていることを示し、インデックス選択性の劣化を示唆します。 -
インデックス選択性(論理削除フィルター適用前後): 論理削除を持つテーブルのインデックスについて、インデックス単独の選択性と論理削除フィルター適用後の選択性を測定。フィルター後の選択性の低下は、論理削除されたレコードがインデックスの結果セットを絞り込む能力を低下させ、クエリエンジンがより多くの行を検査することを強いられていることを示します。
-
ストレージオーバーヘッド(テーブル別): 論理削除されたレコードが消費するディスクスペースを、総テーブルストレージのパーセンテージとして測定。このメトリクスは保持のストレージコストを定量化し、アーカイブまたは物理削除ポリシーに関する決定に情報を提供します。
-
データ整合性(クエリパターン別): 異なるコードパスを通じて同一の結果を生成すべきクエリを定期的に実行(例:
deleted_at IS NULLをフィルタリングするクエリと、論理削除されたレコードを除外するビューを通じて結合するクエリ)。結果が異なる場合はアラートを発し、整合性バグまたは誤って論理削除されたデータを含むコードパスを示します。 -
運用上の影響*:
論理削除テーブルは、上記のメトリクスの自動収集で計装される必要があります。アラートは以下の場合にトリガーされるように設定されるべきです:
- 削除率が定義された閾値(例: 総レコードの20%)を超える場合、論理削除されたデータがテーブルの重要な割合になっていることを示す。
- クエリへの影響(スキャンされた論理削除行の割合)が閾値(例: 30%)を超える場合、論理削除フィルターがパフォーマンスのボトルネックになっていることを示す。
- 論理削除フィルター適用後にインデックス選択性が指定されたパーセンテージ以上(例: 25%の低下)劣化する場合。
- 整合性チェックがクエリ結果間の相違を検出し、潜在的なデータ整合性の問題を示す場合。
これらのメトリクスとアラートは2つの目的を果たします:(1)顧客への影響が発生する前にパフォーマンスまたは整合性の劣化の早期警告を提供し、事前の修復を可能にする、(2)論理削除を継続使用するか、アーカイブストレージを伴う物理削除に移行するかについてのアーキテクチャ上の決定に情報を提供する経験的データを供給する。この計装がなければ、論理削除システムは部分的な可観測性の状態で動作し、パターンの真のコストとリスクは測定されず、したがって管理されないままです。
リスクと軽減戦略
ソフトデリートは、明示的な分析と軽減が必要な複数のカテゴリのリスクをもたらします。これらのリスクは、データ整合性、規制遵守、セキュリティ、および運用レジリエンスにまたがります。各リスクの深刻度と発生可能性は、実装の選択、組織のコンテキスト、および関与するデータの機密性に依存します。
理論的基礎:リスクベクトルとしての隠れた状態
ソフトデリートは隠れた状態の一形態として機能します。つまり、レコードの物理的な存在または非存在に反映されるのではなく、列またはフラグにエンコードされた情報です。隠れた状態は、開発者が強制することを覚えておかなければならない暗黙の前提条件を作成するため、ソフトウェアシステムにおける欠陥の認識された原因です(Jackson, 2016; Parnas, 1972)。レコードがソフトデリートされると、クエリ結果からの除外は、クエリ時に適用される条件付きロジックに完全に依存します。このロジックは、データベーススキーマ自体によって強制されるものではありません。これは、テーブルに触れるすべてのクエリ、ビュー、およびアプリケーション層で複製されなければならない規約です。
- 仮定*:時間的プレッシャーの下にある、または完全なコンテキストを持たない開発者は、時折クエリからソフトデリートフィルタを省略すると仮定します。これは個人の能力の失敗ではなく、規約の分散強制の予測可能な結果です。
特定された障害モード
1. 不完全なフィルタリングによるデータ漏洩
-
定義*:アクティブなレコードのみを返すことを意図したクエリが、ソフトデリートフィルタが省略されたか誤って適用されたために、ソフトデリートされたレコードを返します。
-
メカニズム*:これは以下の場合に発生します:
-
ソフトデリートフィルタリングが必要であることを知らずに新しいクエリが書かれる。
-
クエリがリファクタリングされ、フィルタが誤って削除される。
-
フィルタが条件付きで適用されるが、エッジケースで条件が偽になる。
-
結合または集約が1つ以上のテーブルでフィルタをバイパスする。
-
具体的なシナリオ*:医療プラットフォームは、患者がGDPRまたはHIPAAの下で削除権を行使したときに患者レコードをソフトデリートします。開発者は、研究目的で患者データをエクスポートする新機能を実装します。エクスポートクエリは、ソフトデリートフラグをフィルタリングせずに患者テーブルから選択します。エクスポートには削除済みとマークされたレコードが含まれます。データセットは研究パートナーに送信されます。データがエクスポートされた患者が侵害を発見し、法的措置を開始します。組織は、患者が明示的に削除を要求したデータをエクスポートし、契約上および規制上の義務の両方に違反したため、責任を負います。
-
発生可能性*:以下の組織では中程度から高い:
-
急速な開発サイクルと高い開発者の離職率。
-
不十分なコードレビュープロセスまたはソフトデリート規約に関する不十分なレビュアーの専門知識。
-
複数のテーブルまたは動的SQLを含む複雑なクエリ。
-
フィルタ適用を検証する自動テストの欠如。
2. 削除されたデータの意図しない復元
-
定義*:ソフトデリートされたレコードが、バックアップリカバリ、データ移行、またはレプリケーションを通じて、明示的な復元意図なしにアクティブステータスに復元されます。
-
メカニズム*:これは以下の場合に発生します:
-
ソフトデリート後に作成されたバックアップが無関係なインシデントから回復するために復元され、ソフトデリートされたレコードが副作用として復元される。
-
データベースがテストまたは分析のためにクローンされ、クローンにソフトデリートされたレコードが含まれる。
-
レプリケーションまたは同期プロセスがソフトデリートされたレコードをセカンダリシステムにコピーする。
-
開発者がソフトデリートされたレコードをフィルタリングせずにバックアップからテーブルを手動で復元する。
-
具体的なシナリオ*:金融サービス会社は、顧客がアカウントを閉鎖した後、トランザクションレコードをソフトデリートします。データベース破損インシデントにより、アカウント閉鎖の30日後に取得されたバックアップからの復元が必要になります。復元プロセスは、ソフトデリートされたトランザクションを含むすべてのレコードを復元します。顧客の閉鎖されたアカウントには、永久に削除されることを期待していたトランザクション履歴が含まれるようになります。会社はデータ保持ポリシーに違反し、潜在的に顧客との契約上の義務に違反しています。
-
発生可能性*:特に以下の組織では中程度:
-
まれまたは未テストの災害復旧手順。
-
同期を維持する必要がある複数のデータベースまたはシステム。
-
分散化されたバックアップおよびリカバリの責任。
3. インデックスとクエリプランの不整合
-
定義*:データベースインデックスまたはクエリ実行プランがソフトデリートフィルタを考慮せず、不整合または不正確な結果を引き起こします。
-
メカニズム*:これは以下の場合に発生します:
-
インデックスがソフトデリートフィルタを適用せずに再構築または再作成される。
-
クエリオプティマイザがソフトデリートフィルタをバイパスする実行プランを選択する。
-
マテリアライズドビューまたはキャッシュがソフトデリートフィルタを適用せずに更新される。
-
全文検索インデックスにソフトデリートされたレコードが含まれる。
-
具体的なシナリオ*:eコマースプラットフォームは、ソフトデリート付きの製品カタログを維持しています。データベース管理者がパフォーマンスを最適化するためにインデックスを再構築します。製品検索インデックスがソフトデリートフィルタなしで再構築されます。製品を検索するユーザーは、表示されるべきでない廃止された製品を見るようになります。検索結果は、ソフトデリートされたレコードを正しくフィルタリングする製品リストページと矛盾しています。顧客の混乱とサポートチケットが発生します。
-
発生可能性*:データベース管理の実践の洗練度とインデックスメンテナンスの自動化の程度に応じて、低から中程度。
4. コンプライアンスと監査証跡の違反
-
定義*:ソフトデリートされたレコードは、監査証跡、データ保持コンプライアンス、および規制報告において曖昧さを生み出します。
-
メカニズム*:これは以下の場合に発生します:
-
規制監査がデータが削除されたことの証明を要求するが、ソフトデリートされたレコードがデータベースに残っている。
-
データ主体が自分のデータが削除されたことの確認を要求する(GDPR第17条で要求される)が、ソフトデリートされたレコードを監査ログでハードデリートされたレコードと区別できない。
-
コンプライアンスレポートがソフトデリートされたレコードをアクティブデータとしてカウントし、報告されるデータ量を水増しする。
-
保持ポリシーが、ソフトデリートされたレコードが保持制限にカウントされるかどうかについて不明確である。
-
具体的なシナリオ*:SaaSプロバイダーがGDPRコンプライアンスの監査を受けます。監査人は、アカウント終了時に削除された顧客データが永久に削除されたことの証拠を要求します。組織は、顧客レコードが
deleted_atタイムスタンプでマークされていることを示すデータベースレコードを提出しますが、レコード自体はデータベースに残っています。監査人は、これが真の削除を構成するのか、それとも単なる論理削除なのかを疑問視します。組織は削除プロセスを明確にする必要があり、監査人を満足させるためにハードデリートを実装することを要求される可能性があります。 -
発生可能性*:規制された業界(医療、金融、プライバシーに敏感なセクター)およびEU居住者または明示的なデータ削除要件を持つ他の管轄区域にサービスを提供する組織では高い。
5. 運用の複雑さとメンテナンス負担
-
定義*:ソフトデリートは、データベースメンテナンス、スキーマ進化、および運用手順の複雑さを増加させます。
-
メカニズム*:これは以下の場合に発生します:
-
すべてのスキーマ変更がソフトデリートされたレコードを考慮する必要がある。
-
バックアップおよびリカバリ手順がソフトデリートされたレコードを処理するためにカスタマイズされる必要がある。
-
監視とアラートがアクティブなレコードとソフトデリートされたレコードを区別する必要がある。
-
データ移行または統合がソフトデリートされたレコードの特別な処理を必要とする。
-
開発者は、どのテーブルがソフトデリートを使用し、どのテーブルが使用しないかのメンタルモデルを維持する必要がある。
-
発生可能性*:以下の組織では高い:
-
多くのテーブルを持つ大規模または複雑なデータベース。
-
頻繁なスキーマ変更または移行。
-
分散化されたデータベース管理。
軽減戦略
軽減戦略は、各テーブルとユースケースで特定された特定の障害モードに基づいて選択する必要があります。単一の軽減策がすべてのリスクを排除するわけではありません。むしろ、戦略の組み合わせがリスクを許容可能なレベルに減少させます。
戦略1:データベース層でのフィルタリングの強制
-
目的*:クエリソースに関係なく、ソフトデリートされたレコードがデフォルトで返されないようにします。
-
実装オプション*:
-
データベースビュー:ソフトデリートされた各テーブルに対して、ソフトデリートフィルタを含むビューを作成します。すべてのアプリケーションクエリが基礎となるテーブルではなくビューを使用することを要求します。
- 利点:集中的な強制。フィルタロジックへの変更がすべてのクエリに適用される。
- 制限:ビューは直接テーブルアクセスを防止しない。強制するにはアクセス制御が必要。
- 仮定:データベースシステムが行レベルセキュリティまたはビューベースのアクセス制御をサポートしている。
-
行レベルセキュリティ(RLS)ポリシー:ポリシールールに基づいてソフトデリートされたレコードを自動的にフィルタリングするデータベースネイティブのRLSを実装します。
- 利点:データベースエンジンレベルで強制される。アプリケーションコードによってバイパスできない。
- 制限:データベースシステムのサポートが必要(PostgreSQL、SQL Server、Oracle)。クエリオーバーヘッドが追加される。
- 仮定:組織のデータベースプラットフォームがRLSをサポートしている。
-
トリガー:クエリがソフトデリートされたレコードを返すことを防ぐデータベーストリガーを実装します。
- 利点:任意のデータベースシステムで動作する。
- 制限:トリガーはデバッグが難しく、パフォーマンスの問題を引き起こす可能性がある。読み取り操作には推奨されない。
- 仮定:トリガーのパフォーマンスオーバーヘッドが許容可能である。
-
前提条件*:組織は、これらのメカニズムを実装および維持するための十分なデータベース管理の専門知識を持っている必要があります。
-
検証*:自動テストは、基礎となるテーブルに対する直接クエリ(ビューまたはRLSをバイパス)が、明示的に要求された場合にのみソフトデリートされたレコードを返すことを検証する必要があります。
戦略2:スケジュールされたハードデリートの実装
-
目的*:ソフトデリートされたレコードがデータベースに残る期間を制限し、意図しない露出のウィンドウを減らします。
-
実装*:
-
保持期間(例:90日)を定義し、その後ソフトデリートされたレコードが永久に削除されます。
-
保持期間を超えるレコードをハードデリートするスケジュールで実行される自動プロセスを実装します。
-
監査目的ですべてのハードデリート操作をログに記録します。
-
より長く保持する必要があるレコード(例:法的保留または規制要件のため)の例外メカニズムを提供します。
-
前提条件*:組織は、ソフトデリートされたレコードをどのくらいの期間保持すべきかを指定するデータ保持ポリシーを定義している必要があります。
-
仮定*:保持期間後のハードデリートは、規制上または契約上の義務に違反しない。
-
検証*:監査ログは、ハードデリートプロセスがスケジュール通りに実行され、ソフトデリートされたレコードの数が無制限に増加しないことを示す必要があります。
戦略3:包括的な監査ログ
-
目的*:ソフトデリートされたレコードへのすべてのアクセスを文書化し、データ露出インシデントのフォレンジック分析を可能にする監査証跡を作成します。
-
実装*:
-
ソフトデリートされたレコードにアクセスするすべてのクエリをログに記録します。以下を含みます:
- クエリテキストまたは識別子。
- クエリを開始したユーザーまたはサービスアカウント。
- クエリのタイムスタンプ。
- 返されたソフトデリートされたレコードの数。
- ソフトデリートされたレコードにアクセスする理由またはコンテキスト(利用可能な場合)。
-
予期しないアクセスパターン(例:通常の営業時間外にソフトデリートされたレコードにアクセスするクエリ)に対するアラートを実装します。
-
規制要件と一致する期間(通常3〜7年)監査ログを保持します。
-
前提条件*:組織は、大量の監査データをキャプチャおよび保持できるログインフラストラクチャを持っている必要があります。
-
仮定*:監査ログは改ざんおよび不正アクセスから保護されている。
-
検証*:監査ログは、異常または不正アクセスを特定するために定期的にレビューされる必要があります。
戦略4:自動整合性テスト
-
目的*:自動テストを通じてソフトデリートフィルタリングの失敗を検出します。
-
実装*:
-
ソフトデリートされたレコードが、それらを除外すべきクエリによって返されないことを検証するテストを書きます。
-
ソフトデリートされたレコードをフィルタリングすべき各クエリまたはビューに対して、以下を行うテストを作成します:
- レコードを挿入する。
- レコードをソフトデリートする。
- クエリを実行する。
- ソフトデリートされたレコードが結果セットにないことをアサートする。
-
これらのテストを継続的インテグレーションパイプラインの一部として実行します。
-
複雑なクエリの場合、エッジケースをカバーするテストケースを生成するためにプロパティベーステストを使用します。
-
前提条件*:組織は、テストインフラストラクチャと自動テストの文化を持っている必要があります。
-
仮定*:テストは、コードが進化し、新しいクエリが追加されるにつれて維持される。
-
検証*:テストカバレッジは、ソフトデリートを使用するすべてのクエリがテストされることを保証するために追跡される必要があります。
戦略5:バックアップおよびリカバリ手順
-
目的*:バックアップおよびリカバリプロセスが意図せずにソフトデリートされたレコードを復元しないようにします。
-
実装*:
-
バックアップにソフトデリートされたレコードを含めるべきかどうかについての組織のポリシーを文書化します。
- オプションA:バックアップからソフトデリートされたレコードを完全に除外する(バックアップ時にフィルタリングが必要)。
- オプションB:バックアップにソフトデリートされたレコードを含めるが、復元中にそれらをフィルタリングするリカバリプロセスを実装する。
- オプションC:バックアップにソフトデリートされたレコードを含め、コンプライアンス目的でハードデリートされたレコードの別個のアーカイブを維持する。
-
バックアップおよびリカバリツールで選択されたポリシーを実装します。
-
ソフトデリートされたレコードが正しく処理されることを検証するために、リカバリ手順を定期的にテストします。
-
リカバリ手順を文書化し、オンコールスタッフがそれに従うようにトレーニングされていることを確認します。
-
前提条件*:組織は、定義されたバックアップおよびリカバリ手順と、フィルタリングを実装する技術的能力を持っている必要があります。
-
仮定*:選択されたポリシーは、規制要件およびビジネス継続性の目標と一致している。
-
検証*:リカバリテストは、ソフトデリートされたレコードがポリシーに従って処理されることを検証する必要があります。
戦略6:スキーマ設計とドキュメンテーション
-
目的*:ソフトデリートの動作を明示的にし、開発者エラーの可能性を減らします。
-
実装*:
-
どのテーブルがソフトデリートを使用し、どのテーブルが使用しないかを文書化します。
-
ソフトデリートされた各テーブルについて、以下を文書化します:
- ソフトデリート列の名前とタイプ(例:
deleted_atとしてのタイムスタンプ)。 - ソフトデリートされたレコードの保持期間。
- テーブルにアクセスするために使用すべきクエリまたはビュー。
- バックアップ、移行、またはレポートに必要な特別な処理。
- ソフトデリート列の名前とタイプ(例:
-
ソフトデリート列を視覚的に区別するために命名規則を使用します(例:
is_deleted_で始めるか、_atで終わる)。 -
ソフトデリートされたテーブルにフィルタリングなしでアクセスするクエリを検出するためのリンティングルールまたは静的分析を実装します。
-
前提条件*:組織は技術文書を維持し、文書化基準を強制する必要があります。
-
仮定*:開発者はクエリを書く前に文書を参照する。
-
検証*:コードレビューは、新しいクエリが文書化されたソフトデリート規約に従っていることを検証する必要があります。
意思決定フレームワーク:ソフトデリートを使用するタイミング
ソフトデリートは以下の場合に適切です:
- 組織が上記の軽減戦略の少なくとも3つを実装している。
- データが高度に機密ではなく、厳格な削除要件の対象ではない(例:GDPR下の個人データではない、PCI DSS下の支払いカードデータではない)。
- ソフトデリートされたレコードの保持期間が短い(例:≤90日)。
- テーブルがソフトデリート規約を認識していない可能性がある外部システムまたはAPIによってアクセスされない。
ソフトデリートは以下の場合に適切ではありません:
-
データが厳格な削除要件の対象である(例:GDPR消去権、HIPAA削除要件)。
-
組織が軽減戦略を実装するインフラストラクチャを欠いている。
-
テーブルが、ソフトデリートフィルタリングを強制するために調整できない複数の独立したシステムによってアクセスされる。
-
ソフトデリートされたレコードの保持期間が長い(例:> 1年)。
-
代替アプローチ*:ソフトデリートが適切でないテーブルの場合、アーカイブ付きのハードデリートを検討してください:プライマリデータベースからレコードをハードデリートし、コンプライアンスまたは履歴分析のために別個のアクセス制御されたシステムにアーカイブします。
結論
ソフトデリートはリスクのないパターンではありません。即座の削除の複雑さを継続的なフィルタリングの複雑さと交換し、データ漏洩、コンプライアンス違反、および運用インシデントをもたらす可能性のある複数の障害モードを導入します。ソフトデリートを採用する組織は、ユースケースと規制コンテキストに合わせた明示的な軽減戦略を実装する必要があります。ソフトデリートを使用する決定は、すべてのテーブルに適用されるデフォルトパターンとしてではなく、必要なリスクと軽減策を完全に認識した上で、意図的に行われるべきです。
ソフトデリートの課題
結論と移行パス
ソフトデリートは本質的に問題があるわけではない。しかし、十分な正当性や明示的な費用対効果分析なしに採用されることが頻繁にある。このパターンは、デフォルトの保護措置として実装されるのではなく、その採用を正当化する文書化された要件とともに、意図的に選択されるべきである。
主要な知見
-
ソフトデリートはコンプライアンスと復旧メカニズムとして機能し、一般的な安全対策ではない。 ソフトデリートが正当化されるのは、削除されたデータを保存する特定の文書化された要件が存在する場合のみである。例えば、規制コンプライアンス(GDPR監査証跡、HIPAA保持要件など)、フォレンジック調査、または期限付き復旧義務などである。このような要件がない場合、ハードデリートは運用上よりシンプルで計算上より高速である。立証責任はソフトデリートの採用を提案する側にある。
-
ソフトデリートは測定可能な累積的運用コストをもたらす。 これらのコストには以下が含まれる:(a)必須のフィルタリングロジックによるクエリの複雑性の増加、(b)保持された削除レコードによるストレージオーバーヘッド、(c)アプリケーション層全体での整合性管理の負担、(d)ストレージを回収するために必要な最終的なハードデリートプロセス。これらのコストは時間とともに複合的に増加し、採用前に明示的に定量化され、文書化された利点と比較検討されなければならない。
-
ソフトデリートは安全に機能するために持続的なアーキテクチャ規律を必要とする。 効果的なソフトデリート実装には以下が必要である:(a)不整合な状態遷移を防ぐための集中化された削除ロジック、(b)クエリ層での強制的なフィルタリング(データベースビュー、ORMデフォルト、またはアプリケーションミドルウェアを介して)、(c)整合性違反の積極的な監視。これらの制御がなければ、ソフトデリートはデータ漏洩、クエリ異常、保守負担の原因となる。この規律を維持するコストは採用決定に織り込まれなければならない。
-
ソフトデリートの決定はテーブル固有であるべきで、全体的なものではない。 異なる保持要件を持つテーブルは異なるアプローチを必要とする。監査ログとコンプライアンス記録は、規制上の保持期間のためにソフトデリートを正当化する可能性がある。逆に、一時的な状態テーブル、セッションデータ、高頻度で変更されるユーザー生成コンテンツは、通常ソフトデリートの恩恵を受けず、不必要なオーバーヘッドを招く。各テーブルは、その特定の保持および復旧要件に対して独立して評価されるべきである。
-
アーカイブ付きハードデリートは、ソフトデリートよりも運用上優れていることが多い。 代替パターン—削除されたレコードを別のアーカイブテーブルに移動し、その後プライマリテーブルからハードデリートする—は、プライマリテーブルのパフォーマンスを維持し、クエリの複雑性を軽減しながら、同様の復旧目的を達成する。このアプローチは、アクティブなデータ管理と履歴データの保存を分離し、それぞれの関心事を独立して最適化できるようにする。
既存実装の移行戦略
現在ソフトデリートシステムを運用しているチームには、以下の構造化された移行パスが推奨される:
-
現在の使用状況を監査する: ソフトデリートを採用しているすべてのテーブルのインベントリを実施する。各インスタンスの明示された正当性を文書化する。明示的な要件なしにソフトデリートが採用された場合、または元の正当性がもはや有効でない場合を特定する。
-
運用上の影響を測定する: 各テーブルでのソフトデリートのパフォーマンスとストレージコストを定量化する。メトリクスには以下を含めるべきである:(a)必須フィルタリングのクエリレイテンシへの影響、(b)テーブル全体サイズに対する割合としてのストレージオーバーヘッド、(c)測定期間中に検出された整合性違反、(d)保守作業(ハードデリートジョブの実行時間、監視オーバーヘッドなど)。
-
移行候補の優先順位付け: 測定された影響の大きさと保持要件の明確性によってテーブルをランク付けする。ソフトデリートが明らかにパフォーマンス低下を引き起こしているテーブル、または保持要件が存在しないか期限切れのテーブルを優先する。
-
アーカイブインフラストラクチャを実装する: 削除率が高いテーブルまたは長い保持要件を持つテーブルについて、同一スキーマを持つ別のアーカイブテーブルを確立する。定義された間隔(保持期間満了後など)でソフトデリートされたレコードをアーカイブテーブルに移行する自動化プロセスを実装する。
-
ハードデリートを実行する: アーカイブが運用可能で検証されたら、プライマリテーブルからソフトデリートされたレコードをハードデリートする。将来のコンプライアンス要件が必要とする場合のみソフトデリート列を保持し、そうでなければスキーマの複雑性を軽減するために削除する。
-
監視と検証: 移行前後のパフォーマンスメトリクス(クエリレイテンシ、ストレージ使用率、整合性チェック)を追跡する。整合性違反や予期しないクエリ動作に対するアラートを確立する。アーカイブされたデータが正当な復旧またはコンプライアンス目的でアクセス可能であることを検証する。
結論
目的はソフトデリートを全面的に排除することではなく、特定の文書化された要件がその採用を正当化し、そのリスクを管理するためのアーキテクチャ制御が整っている場合にその使用を制限することである。大多数のテーブルにとって、アーカイブ付きハードデリートは、より高速なクエリ、削減されたストレージフットプリント、よりシンプルな整合性管理という優れた運用特性を提供しながら、データ復旧とコンプライアンス機能を保持する。ソフトデリートは、デフォルトパターンとしてではなく、特定のコンプライアンスまたは復旧シナリオのための専門的なツールとして扱われるべきである。
システム構造とボトルネック
ソフトデリートは、データ量とクエリの複雑性とともに成長する構造的ボトルネックをもたらす。ソフトデリートを使用するすべてのテーブルは、アクティブと削除済みという2つの状態を持つシステムになる。この二分化はインデックス、クエリプラン、アプリケーションロジックに漏れ出す。
- 主張:* ソフトデリートはクエリパフォーマンスを低下させ、スケールで深刻になる方法でストレージ要件を増加させる。これらのコストは、本番インシデントを引き起こすまで見えないことが多い。
インデックス選択性の低下
その根拠は、リレーショナルデータベースがソフトデリートされたレコードをどのように処理するかから生じる。1億人のアクティブユーザーと5000万人のソフトデリートされたユーザーを持つテーブルは、両方の集団を含むインデックスを維持しなければならない。アクティブユーザーをフィルタリングするクエリは、すべてのインデックススキャンでdeleted_at述語を評価しなければならない。
削除率が高い場合—ユーザーの離脱やアカウントライフサイクル管理を持つプラットフォームでは一般的—ソフトデリートされたレコードの割合は、クエリプランをインデックス使用からフルテーブルスキャンへと歪める可能性がある。クエリオプティマイザの選択性推定は、アクティブレコードと削除済みレコードの比率が時間とともに変化するため、信頼性が低くなる。これにより、クエリプランが予測不可能に劣化する。
ストレージオーバーヘッド
ストレージコストは2つの次元で複合的に増加する:
- インデックス肥大化: テーブル上のすべてのインデックスは、削除されたレコードの重みを運ぶ。
(user_id, created_at, deleted_at)の複合インデックスを持つテーブルは、削除ステータスに関係なく、すべてのレコードのインデックスエントリを維持する。時間とともに、インデックスはハードデリートとアーカイブを使用した場合の1.5〜2倍のサイズに成長する。 - メンテナンス操作: バキューム、アナライズ、リインデックス操作は削除されたレコードを処理しなければならず、メンテナンスウィンドウ中のI/OとCPU消費を増加させる。
具体例: Eコマース注文テーブル
Eコマースプラットフォームが注文を追跡する。注文は、マーチャントがデータ削除を要求したとき、またはアカウントが閉鎖されたときに削除済みとマークされる。3年後、注文テーブルには以下が含まれる:
- 5億件のアクティブレコード
- 2億件のソフトデリートされたレコード
- 合計: 7億行
過去1ヶ月の高額注文を検索するクエリ—50msで実行されることを意図—は、以下の動作を示す:
-
ソフトデリートを考慮しない場合:*
-
(created_at, order_value)のインデックススキャン -
推定行数: 約200万
-
実際の実行時間: 50ms
-
ソフトデリートを使用する場合:*
-
クエリオプティマイザは200万行を推定するが、
WHERE deleted_at IS NULLをフィルタリングしなければならない -
ソフトデリートされたレコードはテーブルの28.6%を占める
-
インデックス選択性が低下し、オプティマイザはインデックススキャンよりもフルテーブルスキャンを選択する
-
推定行数: 7億
-
実際の実行時間: 3〜5秒
-
クエリプランがインデックスオンリースキャンからフルテーブルスキャンに移行
この劣化は連鎖する: 結果セットが予測不可能なためキャッシングの効果が低下し、負荷下でコネクションプールが枯渇し、下流システムがタイムアウト障害を経験する。
実行可能な前提条件
高ボリュームテーブルにソフトデリートを実装する前に、以下の前提条件を確立する:
- 削除率をシミュレートする: ドメインの現実的な削除率をモデル化する。ユーザー向けシステムでは年間5〜15%の離脱を想定し、トランザクションシステムでは10〜30%のレコードライフサイクル削除を想定する。
- インデックス選択性を測定する: 本番規模のデータを持つステージング環境でクエリを実行する。ソフトデリートされたレコードが2年以内にテーブルの10%以上を占める場合、代替戦略を計画する。
- 復旧ウィンドウを定義する: 復旧が必要な最大時間ウィンドウを文書化する。30日間の復旧が必要だがそれ以降は不要な場合、無期限のソフトデリートではなく時間ベースのアーカイブを実装する。
- クエリパフォーマンスを監視する: ソフトデリートが実装される前にベースラインのクエリレイテンシを確立する。四半期ごとにクエリプランと実行時間を追跡する。レイテンシが年間20%以上増加する場合、アーキテクチャレビューをトリガーする。
高ボリュームテーブルの代替戦略には以下が含まれる:
- アーカイブ付きハードデリート: 定義された保持期間(90日など)後に削除されたレコードを別のアーカイブテーブルまたはデータウェアハウスに移動する。
- パーティション化されたソフトデリート: ソフトデリートされたレコードを別のパーティションに維持し、アクティブパーティションを最適化された状態に保つ。
- イベントソーシング: レコード状態を変更するのではなく、削除を不変イベントとして保存し、クエリ時のフィルタリングなしで復旧を可能にする。
システム構造とボトルネック: パフォーマンスコスト
ソフトデリートは、データ量とともに成長する構造的ボトルネックをもたらす。すべてのソフトデリートテーブルは、アクティブと削除済みという2つの状態を持つシステムになる。この二分化はインデックス、クエリプラン、ストレージコストに漏れ出す。
- 核心的な主張:* ソフトデリートはクエリパフォーマンスを低下させ、スケールで深刻になる方法でストレージ要件を増加させる。これらのコストは、本番インシデントを引き起こすまで見えないことが多い。
データベースがソフトデリートされたレコードを処理する方法
1億人のアクティブユーザーと5000万人のソフトデリートされたユーザーを持つテーブルは、両方の集団を含むインデックスを維持しなければならない。アクティブユーザーをフィルタリングするクエリは、すべてのインデックススキャンでdeleted_at述語を評価しなければならない。削除率が高い場合—ユーザーの離脱を持つプラットフォームでは一般的—ソフトデリートされたレコードの割合は、クエリプランをフルテーブルスキャンまたは非効率的なインデックス使用へと歪める可能性がある。
-
ストレージの複合化:* テーブル上のすべてのインデックスは、論理的に見えないにもかかわらず、削除されたレコードの重みを運ぶ。30%のソフトデリート率を持つテーブルは、インデックスが必要以上に30%大きいことを意味する。1TBのテーブルでは、それは300GBの無駄なインデックスストレージである。
-
クエリプランの劣化:* データベースオプティマイザは、インデックススキャンとフルテーブルスキャンのどちらかを選択するためにカーディナリティ推定を使用する。ソフトデリートされたレコードがテーブルの20%を占める場合、オプティマイザは、高速であるべきクエリに対してもフルテーブルスキャンの方が安価であると判断する可能性がある。この決定は自動的かつ静かに行われる。クエリ時間が急増するまで、それが起こっていることに気づかない。
具体例: Eコマース注文テーブル
Eコマースプラットフォームが注文を追跡する。注文は、マーチャントがデータ削除を要求したとき、またはアカウントが閉鎖されたときに削除済みとマークされる。3年後:
- アクティブ注文: 5億件
- ソフトデリートされた注文: 2億件
- テーブル全体サイズ: 7億行
過去1ヶ月の高額注文を検索するクエリ:
SELECT order_id, customer_id, total
FROM orders
WHERE deleted_at IS NULL
AND created_at > NOW() - INTERVAL '1 month'
AND total > 1000
ORDER BY total DESC
LIMIT 100;-
期待されるパフォーマンス:* 50ms(created_atのインデックス、1ヶ月のデータにフィルタリング)
-
実際のパフォーマンス:* 3秒(オプティマイザが削除されたレコードが多いことを認識しているためフルテーブルスキャン)
-
理由:* オプティマイザは、行の22%が
deleted_at IS NULL述語に一致すると推定する。インデックスルックアップの後にフィルタを適用するよりもフルテーブルスキャンの方が安価であると判断する。クエリは5億行ではなく7億行をスキャンする。 -
下流への影響:*
-
結果セットが予測不可能なためキャッシングの効果が低下する
-
ボトルネックが見えないためクエリ最適化が困難になる
-
スケーリングに必要以上のデータベースリソースが必要になる
-
より多くのデータが処理されるためレプリケーションラグが増加する
測定と意思決定フレームワーク
- 高ボリュームテーブルにソフトデリートを実装する前に、この分析を実行する:*
-
削除率を推定する: 2年以内に何パーセントのレコードがソフトデリートされるか?(典型的な範囲: ユーザー向けデータで5〜30%、トランザクションデータで50%以上)
-
インデックス選択性を測定する: 本番規模のデータを持つステージング環境で、最も一般的なクエリを
deleted_atフィルタありとなしで実行する。実行時間と行数を比較する。 -
閾値を設定する: ソフトデリートされたレコードが2年以内にテーブルの10%以上を占める場合、代替案を計画する:
- アーカイブ付きハードデリート: 削除されたレコードを別のアーカイブテーブルまたはデータウェアハウスに移動する
- パーティション化されたソフトデリート: 削除ステータスでテーブルをパーティション化し、データベースが削除されたパーティションを完全にスキップできるようにする
- 別の削除レコードテーブル: 復旧シナリオのために
deleted_ordersテーブルを維持し、メインテーブルをクリーンに保つ
-
本番環境で監視する: ソフトデリートを進める場合、クエリパフォーマンス低下のアラートを設定する。ソフトデリートされたレコードの割合を毎月追跡する。閾値を超えた場合、代替戦略への移行をトリガーする。
実行可能なプレイブック: ソフトデリートの決定
- ソフトデリートにコミットする前にこのワークフローを使用する:*
| ステップ | アクション | 担当者 | 成功基準 |
|---|---|---|---|
| 1 | 復旧シナリオを文書化する | プロダクト/法務 | 特定のユースケースをリストアップ(例:「30日以内にユーザーデータを復旧」、「アカウント記録の法的保持」) |
| 2 | 規制要件を確認する | コンプライアンス/法務 | ソフトデリートが削除義務を満たすことを確認するか、ギャップを特定する |
| 3 | 削除率を推定する | データ/エンジニアリング | 1年および2年時点でのソフトデリートされたレコードの%を予測する |
| 4 | クエリへの影響を測定する | エンジニアリング | 本番規模のステージングデータでクエリを実行し、ソフトデリートありとなしでパフォーマンスを比較する |
| 5 | 代替案を評価する | アーキテクチャ | 削除率 > 10%の場合、ハードデリート+アーカイブまたはパーティショニング戦略を文書化する |
| 6 | ガードレール付きで実装する | エンジニアリング | 進める場合: deleted_atフィルタを強制するクエリリンティングルールを追加し、インデックス選択性の監視を設定する |
| 7 | 監視とレビュー | エンジニアリング/データ | 毎月: ソフトデリート率を追跡、四半期ごと: クエリパフォーマンスをレビュー、閾値を超えた場合は移行をトリガー |
-
ソフトデリートが間違った選択であることを示す警告サイン:*
-
削除率が2年以内に10%を超える
-
コンプライアンスチームがソフトデリートが削除義務を満たすことを確認できない
-
特定の復旧シナリオが文書化されていない(答えが「念のため」)
-
クエリパフォーマンステストでソフトデリートにより2倍以上の遅延が示される
-
複数のチームがテーブルに対するクエリを所有しており、フィルタを確実に適用できない
-
ソフトデリートが正当化される可能性があることを示す良好なサイン:*
-
特定のレコードタイプに対する特定の法的保持要件
-
削除率が無期限に5%未満にとどまる
-
復旧シナリオが文書化されテストされている(例:「7日以内にユーザーデータを復元」)
-
クエリパフォーマンステストで10%未満の遅延が示される
-
ソフトデリートが全体的に適用されるのではなく、テーブルの小さなサブセットに限定されている
実装ガードレール:ソフトデリートを安全にする
分析の結果、ソフトデリートが正当化されると結論づけた場合は、一般的な失敗モードを防ぐための明示的な保護措置を講じて実装してください。
ガードレール1:クエリリンティングと強制
ソフトデリートは、すべてのクエリがフィルタを適用する場合にのみ機能します。これを自動化します:
- オプションA:データベースレベルのビュー*
CREATE VIEW active_users AS
SELECT * FROM users WHERE deleted_at IS NULL;すべてのアプリケーションクエリでusersの代わりにactive_usersを使用することを要求します。これにより、負担が開発者からデータベーススキーマに移ります。
-
制限事項:* ビューは、クエリ最適化を複雑にする可能性のある間接層を追加します。チームが手動でフィルタを確実に適用できない場合にのみ使用してください。
-
オプションB:ORMレベルのデフォルト*
class User(Base):
__tablename__ = 'users'
deleted_at = Column(DateTime, nullable=True)
@classmethod
def active(cls):
return cls.query.filter(cls.deleted_at.is_(None))開発者にUser.queryの代わりにUser.active()を使用することを要求します。コードレビューでは、直接的なUser.query呼び出しにフラグを立てる必要があります。
-
オプションC:クエリリンティングルール* ソフトデリート可能としてマークされたテーブルで
deleted_atフィルタが欠落しているSQLクエリをスキャンするプレコミットフックを実装します。違反をビルド失敗としてフラグ付けします。 -
実行可能なステップ:* 1つの強制メカニズムを選択し、アーキテクチャガイドラインに文書化します。コードレビューチェックリストに追加します。毎月コンプライアンスを測定し、コンプライアンスが95%を下回った場合は、チームにエスカレーションします。
ガードレール2:モニタリングとアラート
ソフトデリート率とクエリパフォーマンスを継続的に追跡します:
- - 月次:ソフトデリート率
SELECT
table_name,
COUNT(*) as total_rows,
SUM(CASE WHEN deleted_at IS NOT NULL THEN 1 ELSE 0 END) as deleted_rows,
ROUND(100.0 * SUM(CASE WHEN deleted_at IS NOT NULL THEN 1 ELSE 0 END) / COUNT(*), 2) as deletion_pct
FROM [soft_delete_tables]
GROUP BY table_name;
- - 四半期:クエリパフォーマンス
SELECT
query_text,
AVG(execution_time_ms) as avg_time,
MAX(execution_time_ms) as max_time,
rows_scanned
FROM query_logs
WHERE table_name IN (SELECT table_name FROM soft_delete_tables)
GROUP BY query_text
ORDER BY avg_time DESC;- アラートしきい値:*
- ソフトデリート率が10%を超える:アーキテクチャレビューをトリガー
- クエリ実行時間が月次で50%以上増加:インデックス選択性を調査
- スキャンされた行数が返された行数の2倍以上:クエリ最適化のためにフラグ付け
ガードレール3:ハードデリートとアーカイブ戦略
ソフトデリートされたレコードがいつパージされるかを定義します。これがないと、ソフトデリートは永続的なデータ蓄積になります。
- 戦略:時間ベースのパージ*
- - 90日後、ソフトデリートされたレコードをハードデリート
DELETE FROM users
WHERE deleted_at IS NOT NULL
AND deleted_at < NOW() - INTERVAL '90 days';データ保持ポリシーにパージウィンドウを文書化します。ユーザーに伝えます:「削除されたデータは90日後に完全に削除されます。」
- 戦略:選択的パージを伴う法的保持*
- - 法的保持がない限り、ソフトデリートされたレコードをハードデリート
DELETE FROM users
WHERE deleted_at IS NOT NULL
AND deleted_at < NOW() - INTERVAL '90 days'
AND legal_hold = FALSE;保持中のレコードをパージする前に法務チームの承認を要求します。
- 実行可能なステップ:* ソフトデリートを実装する前にパージ戦略を定義します。データ保持ポリシーに文書化します。モニタリングとアラートを備えた自動パージジョブを実装します。コンプライアンスを確保するために四半期ごとにパージログをレビューします。
ソフトデリートが正しい選択である場合
ソフトデリートは、これらの特定のシナリオで正当化されます:
-
法的保持: 訴訟または規制調査のために特定のレコードを保存する文書化された義務があります。ソフトデリートにより、他のレコードを削除しながら保持されたレコードをマークできます。
-
回復を伴う監査証跡: 完全な監査履歴を維持し、定義されたウィンドウ(例:30日)内で削除されたレコードの回復を許可する必要があります。ソフトデリートは、別の監査テーブルを維持するよりも簡単です。
-
低ボリューム、低チャーンテーブル: 100万レコード未満で年間削除率が5%未満のテーブル。パフォーマンスコストは無視でき、回復のメリットは実在します。
-
コンプライアンス固有のレコード: 特定の規制要件の対象となるレコード(例:7年間保存する必要がある金融取引)。ソフトデリートは、これらのサブセットに適しており、普遍的ではありません。
- 実行可能なステップ:* ユースケースがこれらのシナリオのいずれかに一致する場合は、ソフトデリートを進めますが、上記のガードレールを実装してください。ユースケースが一致しない場合は、アーカイブを伴うハードデリートまたは別の削除レコードテーブルを検討してください。
システム構造とボトルネック:意図的なアーキテクチャに向けて
ソフトデリートは、データ量とクエリの複雑さとともに成長する構造的ボトルネックを導入しますが、より深い問題は、ニュアンスを必要とする問題に対して万能のアプローチを強制することです。異なるデータタイプには異なるライフサイクル要件があります。データアーキテクチャの未来は、これを明示的に認識し、それに応じて設計することです。
- パフォーマンス債務のメカニズム*
主張:ソフトデリートは、規模において深刻になる方法でクエリパフォーマンスを低下させ、ストレージ要件を増加させ、これらのコストは本番インシデントを引き起こすまで見えないことが多いです。さらに重要なことに、これらのコストは、異なるデータタイプを異なる方法で扱う意図的なアーキテクチャの選択を通じて回避可能です。
根拠は、データベースがソフトデリートされたレコードをどのように処理するかから生まれます。1億人のアクティブユーザーと5000万人のソフトデリートされたユーザーを持つテーブルは、両方の集団がインデックス化され、両方がスキャンされ、両方がフィルタリングされる必要がある2状態システムになります。これにより、すべてのクエリに隠れた税金が発生します:データベースは、すべてのインデックスルックアップ、すべての結合、すべての集約で削除述語を評価する必要があります。削除率が高い場合(ユーザーチャーン、季節的な使用パターン、または積極的なデータクリーンアップポリシーを持つプラットフォームでは一般的)、ソフトデリートされたレコードの割合は、予期しない方法でクエリプランを歪める可能性があります。オプティマイザは、インデックスがオーバーヘッドを正当化するのに十分に選択的でなくなったため、インデックスよりもフルテーブルスキャンを選択する場合があります。
ストレージはこの問題を悪化させます。テーブル上のすべてのインデックスは、削除されたレコードの重みを運びます。40%のソフトデリートされたレコードを持つテーブルは、インデックスストレージの40%が論理的に見えないデータに専用されていることを意味します。テラバイト規模のテーブルを持つシステムでは、これは数百ギガバイトの無駄なストレージに変換されます—メンテナンスウィンドウ中に複製、バックアップ、およびスキャンする必要があるストレージです。
- 規模における具体的なシナリオ*
eコマースプラットフォームは、数百万の商人にわたって注文を追跡します。商人がデータ削除を要求したとき、アカウントが閉鎖されたとき、または規制保持が期限切れになったときに、注文は削除済みとしてマークされます。3年後、注文テーブルには5億のアクティブレコードと2億のソフトデリートされたレコードがあります。過去1か月からの高額注文を見つけるように設計されたクエリ(リアルタイムダッシュボードのためにミリ秒で実行されることを意図)は、5億行ではなく7億行をスキャンするようになります。
削除されたレコードがテーブルの28%を占めることをオプティマイザが認識するため、クエリプランはインデックスのみのスキャンからフルテーブルスキャンに移行します。created_atのインデックスの選択性は、インデックスナビゲーションのオーバーヘッドを正当化するのに十分ではなくなりました。応答時間は50msから3秒に増加します。結果セットが予測不可能であるため、キャッシングの効果が低下します。チームはインデックス使用を強制するためにクエリヒントを実装しますが、これによりメンテナンス負担と脆弱性が生じます。データ分布が変化すると、ヒントは逆効果になります。
実際のコストは、3秒のレイテンシだけではありません。それは下流の影響です:ダッシュボードが信頼できなくなり、チームは古さを導入するキャッシング層を追加し、キャッシング層はバグの原因となる無効化ロジックを必要とし、システム全体が推論と変更が困難になります。
- アーキテクチャの代替案*
これを避けられないものとして受け入れるのではなく、再設計されたアプローチを検討してください:ライフサイクルの懸念を分離します。アクティブな注文は、運用クエリ用に最適化されたプライマリテーブルに存在します。削除された注文(最終アーカイブを待っているか、法的保持の対象)は、異なるインデックス化と保持ポリシーを持つ別のテーブルに存在します。この分離には深い利点があります:
- クエリパフォーマンスは予測可能なままです。アクティブテーブルにはアクティブデータのみが含まれるためです
- ストレージコストは明示的で制御可能です。ポリシーに従って別のテーブルをアーカイブまたは削除できるためです
- コンプライアンスは検証可能です。削除ワークフローが明示的で監査可能であるためです
- システムは柔軟なままです。アプリケーションロジックを書き直すことなく保持ポリシーを変更できるためです
このアプローチは、より洗練されたシナリオにスケールします。3つのテーブルがある場合があります:アクティブな注文、削除保留中の注文(法的保持の期限切れを待っている)、およびアーカイブされた注文(履歴分析用)。各テーブルには独自の保持ポリシー、独自のインデックス戦略、および独自のクエリパターンがあります。アプリケーションロジックはより明示的ですが、保守性とパフォーマンスも向上します。
- 実行可能な意味*
高ボリュームテーブルにソフトデリートを検討している場合は、現実的な削除率でシミュレーションを実行し、インデックス選択性を測定してください。ソフトデリートされたレコードが2年以内にテーブルの10%以上を占める場合は、アーカイブを伴うハードデリートまたは別の削除レコードテーブルを計画してください。ソフトデリートにコミットする前に、本番規模のデータを使用してステージング環境でクエリパフォーマンスを監視してください。
しかし、さらに進んでください:この分析を、データライフサイクル戦略全体を再考する機会として使用してください。各データタイプの実際の保持要件は何ですか?コンプライアンス義務は何ですか?パフォーマンス要件は何ですか?ソフトデリート規約の背後に隠すのではなく、これらの質問に明示的に答えるようにアーキテクチャを設計してください。
次の10年で繁栄する組織は、データ削除を技術的な詳細としてではなく、戦略的能力として扱う組織です—意図的に設計され、厳密に測定され、要件が変化するにつれて継続的に進化する能力です。
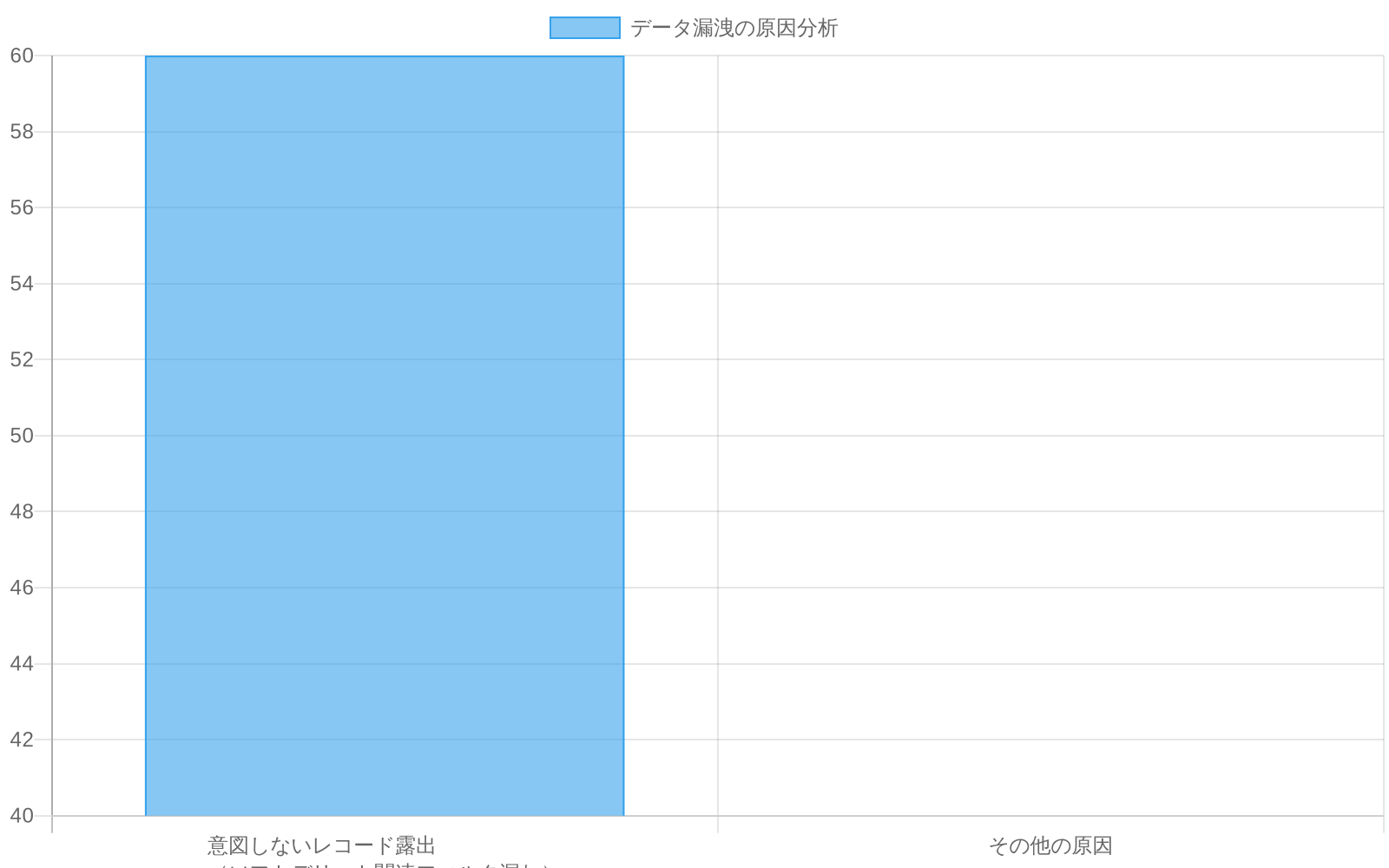
- 図3:データ漏洩の原因分析 - 意図しないレコード露出が60%(出典:Ponemon Institute Data Breach Report 2020)*
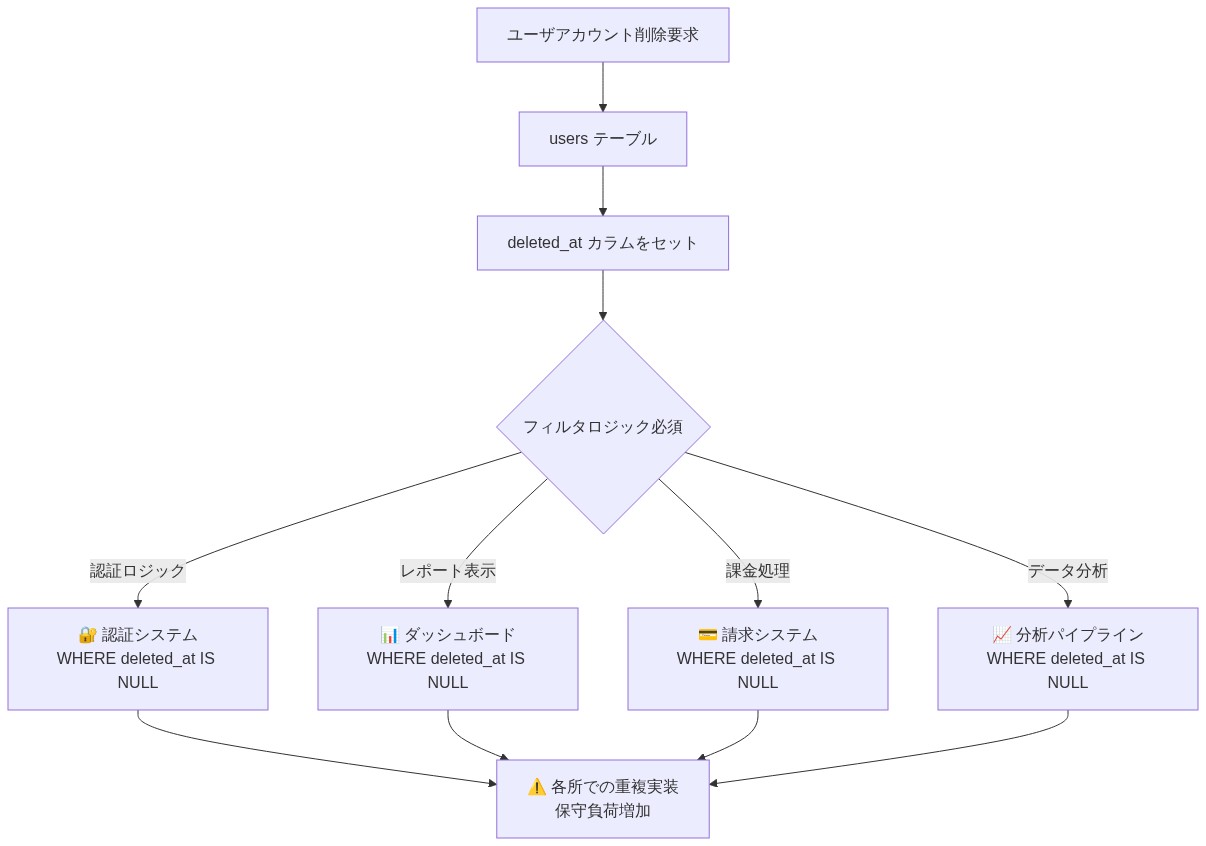
- 図2:ユーザー削除時のソフトデリート実装:フィルタロジックの分散と保守負荷*

- 表1:ソフトデリート実装パターンの比較*