
ザ・ダウンロード:AIの追跡を試みること、そして次世代原子力発電
AIの進歩追跡:標準的メトリクスが不十分である理由
-
主張:* AI研究・展開コミュニティは、フロンティアモデルにおける真の能力向上を測定するための正式な合意メカニズムを欠いており、能力評価とリスク特性化における体系的な盲点をもたらしている。
-
根拠と前提:* フロンティアモデル開発者(OpenAI、Google DeepMind、Anthropic)が新しい大規模言語モデルをリリースする際、業界の評価は通常、標準化されたベンチマークスイート—MMLU(Massive Multitask Language Understanding)、GSM8K(Grade School Math)、HumanEval(コード生成)—を能力の定量的代理として依拠している。これらのベンチマークは固定テストセット上の狭い領域タスク性能に最適化されている。しかし本質的な問題は、このアプローチが文書化された制限を示していることにある。(1)ベンチマークは新規推論よりも暗記とパターンマッチングに報酬を与える;(2)本番環境下でのみ現れる創発的行動を捉えない;(3)幻覚、敵対的脆弱性、分布シフト下での性能低下を含む失敗モードに対する信号を提供しない。標準化テストで95%の精度を達成するモデルでも、訓練分布外の意味的に類似したタスクで実質的な失敗率を示すか、ベンチマーク複雑性を超える推論チェーンで破局的に失敗する可能性がある。
-
具体的証拠:* GPT-4の2022年12月リリースは、従来のベンチマーク改善(通常5~15パーセントポイント)が下流ユーザーが経験的に観察した推論チェーン能力と領域横断的転移における質的飛躍と相関しなかったため、研究コミュニティ内で重大な議論を生成した。逆に、宣伝された能力改善の一部—限定的なベンチマーク利得として測定された—は本番環境では無視できるものであることが判明した。ベンチマーク性能と観察された有用性の間のこの乖離は、公開されたスコアが展開関連能力の不完全な代理として機能することを示唆している。
-
前提条件と制限:* 本分析は以下を前提とする:(1)ベンチマークスイートはモデル能力が進化する一方で静的なままであり、測定遅延を生じさせる;(2)開発者は楽観的な能力主張を支持するインセンティブ構造を有する;(3)組織はベンダー主張を独立して検証するための内部評価インフラを欠いている。本分析は領域固有ベンチマーク(例えば医学推論、法的分析)に対応していない。これらは本番タスクに対してより高い忠実度を示す可能性がある。
-
実行可能な含意:* フロンティアAIシステムを評価する組織は、公開ベンチマークを超える カスタム評価フレームワークを実装すべきである。実際のユースケースと展開コンテキストに関連する失敗モードを反映する領域固有テストスイートを構築せよ。精度メトリクスのみならず以下も追跡すること:レイテンシ分布、入力分布全体での一貫性、失敗パターン頻度、敵対的またはアウト・オブ・ディストリビューション入力下での動作。公開ベンチマークが測定しないものを明示的に文書化すること—推論の透明性、プロンプト変動への堅牢性、多段階推論を必要とするタスク上の性能、リソース制約下での動作。これにより、ベンダー主張と観察された性能を比較するための内部基準が生成され、採用リスクが低減される。
独立評価:METRと制度的距離
モデル開発者は能力を楽観的に提示するための構造的インセンティブを有する。METR(フロンティアモデル評価)は、展開前のフロンティアモデルの透明で再現可能な評価を提供するために出現し、ベンチマークゲーミングではなくフロンティア能力—新規問題解決を必要とするタスク—に焦点を当てている。
METRのフレームワークは、複数選択肢の質問に答えるのではなく、モデルが自律的に現実世界のタスク(セキュリティ脆弱性の発見、研究の実施)を完了できるかどうかをテストする。これは従来のベンチマークに見えない能力上限を明らかにし、安全上重要な失敗モードを特定する。
- 実務家向け:* 高リスク応用でフロンティアモデルを採用する前に、独立評価データを要求せよ。ベンダーに第三者評価の共有を要求するか、独自の評価を委託せよ。内部チームの場合、モデル開発から評価機能を分離した制度的距離を確立せよ—ビルダーとアセッサー間に直接的インセンティブの乖離を作成せよ。評価方法論を文書化し、モデルが進化する際に結果が比較可能なままであるようにバージョン管理を維持せよ。これはモデル能力への過信と過小評価からの機会喪失の両方から保護する。
運用インフラストラクチャと隠れた採用コスト
フロンティアAIの展開には、プロンプトエンジニアリング、検索拡張生成(RAG)、ファインチューニングワークフロー、フォールバックメカニズムにわたる慎重なオーケストレーションが必要であり、ほとんどの組織はこれを過小評価している。「テストでモデルが機能する」と「本番環境で確実に機能する」の間のギャップは実質的であり、監視、再訓練、失敗回復要件全体で複雑性が複合する。
金融サービス企業がGPT-4をカスタマーサポートに展開した際、汎用プロンプトは尤もらしいが不正確な規制助言を生成した。これを修正するには、ファクトチェックパイプラインの構築、承認された回答のベクトルデータベースの維持、エッジケースに対する人間ループレビューの実装が必要であり、展開努力を3倍にした。
- 実務家向け:* 採用前にインフラ準備状況を監査せよ。モデルをバージョン管理し、ロールバックできるか。モデル出力のログと監視があるか。分布シフトまたは性能低下を検出できるか。一般的な失敗モードに対する運用プレイブックを構築し、展開とは別にモデル監視の明確な所有権を割り当てよ。継続的メンテナンスの予算を立てよ—フロンティアモデルは静的なアーティファクトではない。
展開メトリクスを超えた成果メトリクス
組織は展開メトリクス(稼働時間、レイテンシ、スループット)から、AIが実際にビジネス結果またはユーザー体験を改善するかどうかを明らかにする成果メトリクスへシフトしなければならない。展開メトリクスはシステムが実行中であることを示す;成果メトリクスはそれが価値があるかどうかを示す。
カスタマーサービスチームはAIチャットボット成功を「エスカレーションなしで処理されたメッセージ」で測定した。このメトリクスはエスカレーションを困難にすることで劇的に改善した。「解決に対する顧客満足度」と「解決までの時間」を測定することで、チャットボットが正当な問題を転送することで実際に体験を低下させていることが明らかになった。
- 実務家向け:* 展開前に成果メトリクスを定義せよ。各AIシステムについて以下を特定せよ:何を解決しているのか。それが解決されたかどうかをどう測定するのか。受け入れ可能なトレードオフは何か(速度対精度、カバレッジ対精度)。AIなしでベースライン性能を確立せよ。展開後継続的に測定し、必要に応じて閾値を調整せよ。メトリクスが現実世界への影響と乖離する際にチームがフラグを立てられるようにフィードバックループを作成せよ。
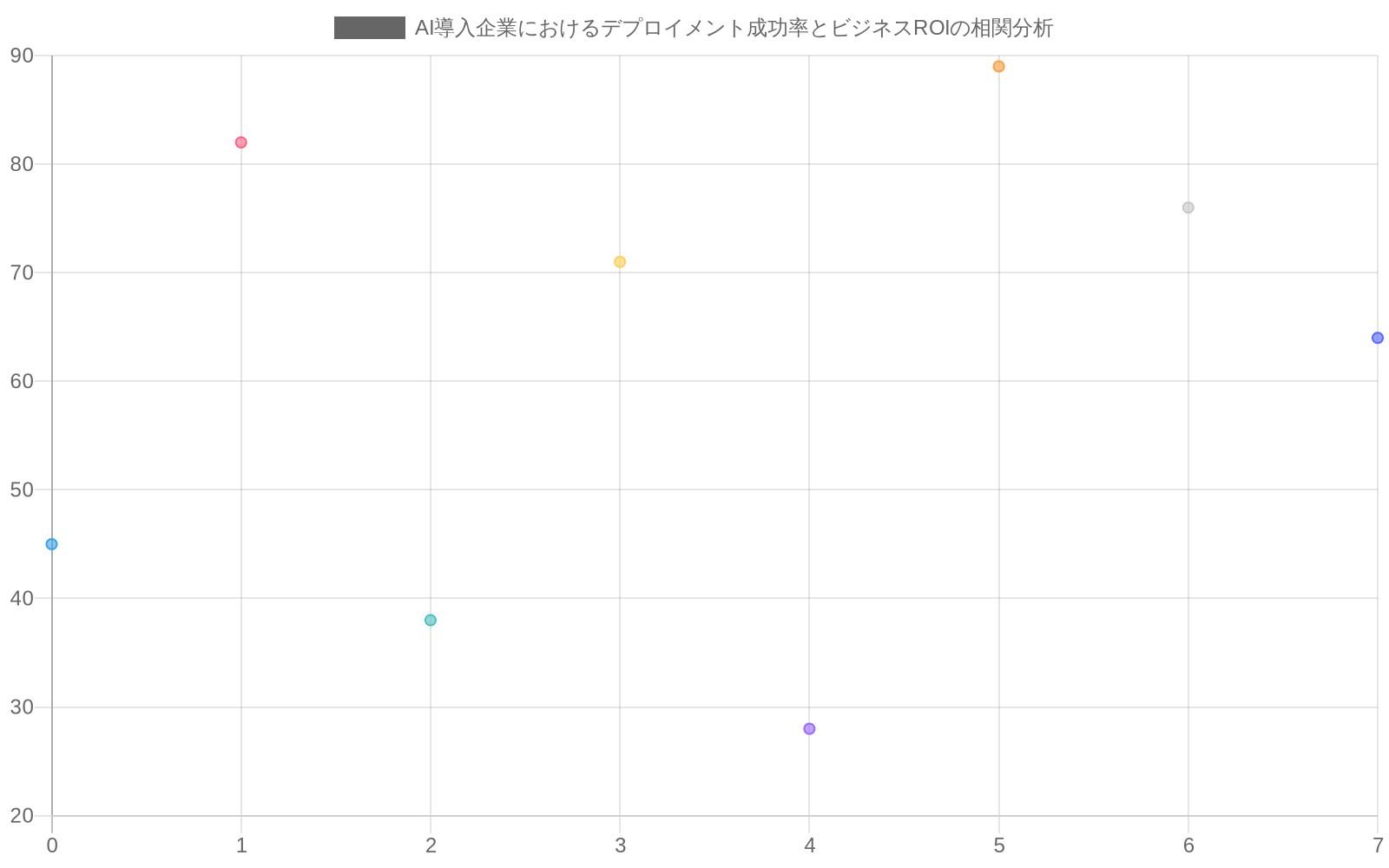
- 図9:AI導入企業におけるデプロイメント成功率とビジネスROIの相関分析(出典:企業導入事例、業界調査レポート)*
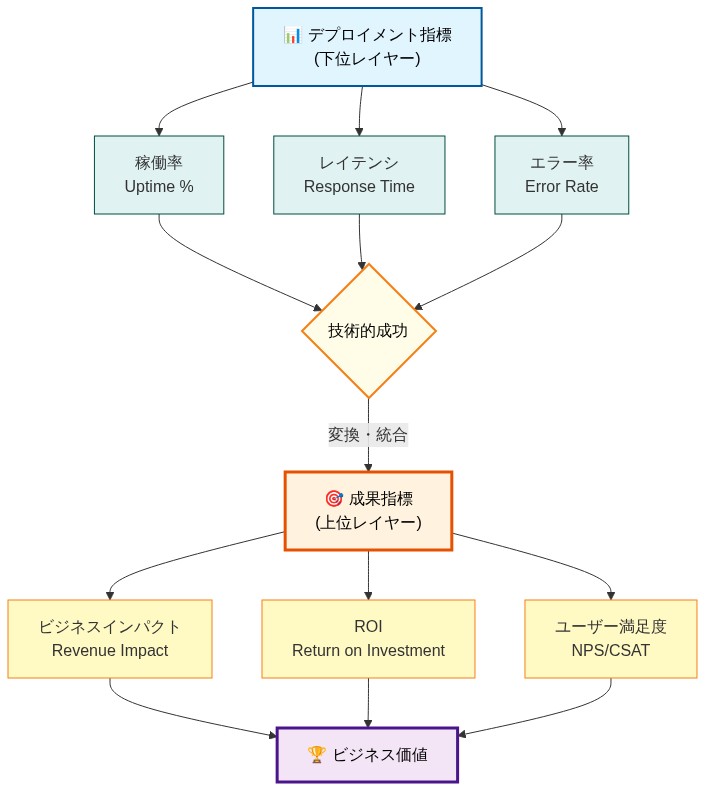
- 図8:デプロイメント指標から成果指標への転換 - 階層的価値創造フロー*
新規失敗モードとリスク軽減
フロンティアAIシステムは従来のソフトウェアが失敗しない方法で失敗する:尤もらしい虚偽を幻覚させ、スケール時に創発的バイアスを示し、アウト・オブ・ディストリビューション入力で予測不可能に低下する。これらのリスクはシステムが自律的に、または大量に動作する際に複合する。
歴史的データで訓練された採用AIは、過剰適格候補者からの履歴書をダウンランクすることを学習し、歴史的バイアスを再現した。システムは訓練目的によって「正しく」機能したが、公平性原則に違反した。これを検出するには標準QAではなく領域専門知識と敵対的テストが必要であった。
- 実務家向け:* 展開前にレッドチーミング演習を実施せよ。失敗モードを調査する多様なチームを集めよ:敵対的入力でどうなるか。性別グループ別にどのように性能が変動するか。スケール時にどうなるか。既知の制限を文書化し、ユーザーに伝えよ。サーキットブレーカーを実装せよ—信頼度が低下するか出力が予期されたパターンから逸脱する際に人間レビューをトリガーするルール。高リスク決定に対して人間監視を維持せよ。継続的監査の予算を立てよ。一度限りのコンプライアンスチェックではなく。
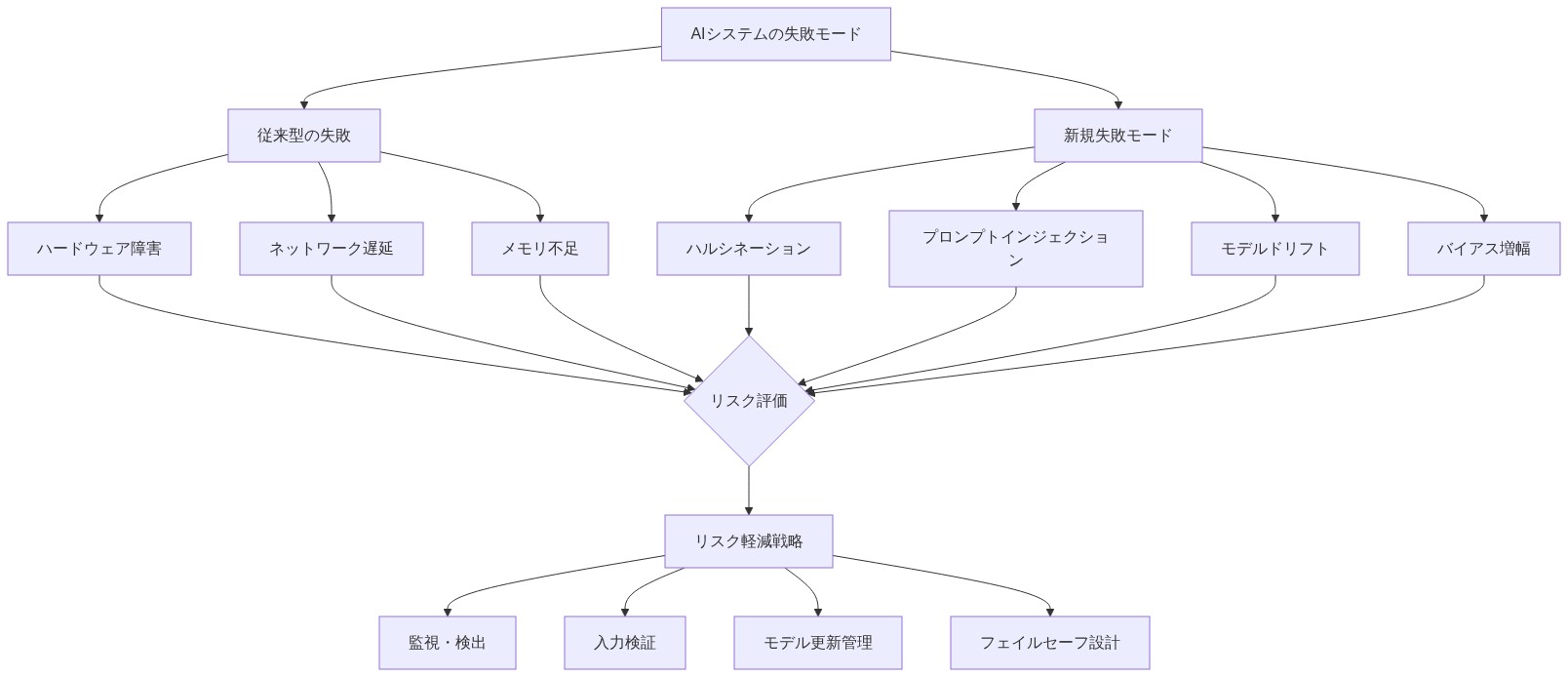
- 図11:AIシステムの失敗モード分類とリスク軽減戦略*
AIエネルギー需要と次世代原子力発電
AIのエネルギー需要は原子力発電を実行可能なエネルギー源として再燃させ、並行するインフラ課題を生成している。フロンティアモデルの訓練と実行は膨大な電力を消費し、データセンターエネルギー需要成長を駆動する。同時に、次世代原子力技術—小型モジュール炉、先進冷却—が技術的に実行可能で経済的に競争力を持つようになっている。両者とも長期計画、規制明確性、資本配置を必要とする。
主要クラウドプロバイダーはデータセンターを原子力エネルギーで電力供給することにコミットし、炉オペレーターとの長期契約に署名した。これは従来の再生可能エネルギーだけではAIインフラ需要を確実かつ費用効果的に満たすことができないという賭けを反映している。
- 実務家向け:* スケール時のAI展開のエネルギー調達とカーボンフットプリントを監査せよ。プロバイダーのエネルギーミックスを理解せよ。持続可能性がステークホルダーにとって重要な場合、再生可能または原子力エネルギーを提唱せよ。AIエネルギー消費測定・報告のための業界標準に参加せよ。インフラチームの場合、電力消費トレンドを監視せよ—これらは容量制約とコスト圧力を信号し、価格設定と可用性を駆動する。
体系的採用:実験から規律へ
責任あるAI採用は、アドホック実験から体系的能力評価と運用成熟度への移行を必要とする。フロンティアAI環境は反応的アプローチには速すぎる。明確な評価基準、運用規律、成果焦点メトリクスを確立する組織はリスクを管理しながら価値を抽出する。AIをプラグアンドプレイ技術として扱う組織は高額な失敗に直面する。
- 次のステップ:* (1)現在のAIシステムを監査せよ—何を測定し、なぜか。(2)独立評価能力を構築するか第三者とパートナーシップを結べ。(3)信頼性、監視、失敗回復のための運用基準を確立せよ。(4)ビジネス目的に結びついた成果メトリクスを定義せよ。(5)高リスク展開に対してレッドチーム演習を実施せよ。(6)エネルギーとインフラスケーリングを計画せよ。(7)学習教訓を文書化し、チーム全体で共有せよ。これは一度限りのイニシアティブではなく継続的な作業である。このプロセスを体系化する組織がリードし、他は追従する。
独立評価の役割:METRと制度的ゲートキーピング
-
主張:* 独立第三者評価組織は、特にフロンティアモデルが高リスク文脈で展開される場合、信頼できる能力評価のための制度的に必要なゲートキーパーになりつつある。
-
根拠と前提:* モデル開発者は能力を楽観的に提示するための構造的インセンティブに直面する:競争圧力、投資家期待、能力リーダーシップからの評判上の利益。METR(フロンティアモデル評価、旧Alignment Research Center)は、この不整合に対する制度的対応として出現し、広範な展開前のフロンティアモデルの透明で再現可能な評価を提供する。彼らの評価フレームワークはベンチマーク性能ではなくフロンティア能力—新規条件下での真の問題解決を必要とするタスク—を優先する。このアプローチは以下を前提とする:(1)独立評価者は能力を過度に述べるための弱い財務的インセンティブを有する;(2)透明な方法論は再現性と外部検証を可能にする;(3)フロンティア能力評価は標準ベンチマークに見えない安全上重要な失敗モードを明らかにする。
-
具体的証拠:* METRの評価方法論は、固定テストセットからの複数選択肢の質問に答えるのではなく、モデルが現実世界のタスク(コード内のセキュリティ脆弱性の特定、文献研究の実施、新規数学問題の解決)を自律的に完了できるかどうかをテストする。このアプローチは能力上限を明らかにし、失敗モード—推論エラーからの回復不能性や訓練分布を超えるタスク複雑性時の低下—を特定し、標準化ベンチマークが表面化しない。公開されたMETR評価は、モデルがベンチマークスコアが示唆するよりも低いフロンティア能力を示した事例を文書化し、展開決定に対する是正信号を提供している。
-
前提条件と制限:* 本分析は独立評価者がモデル開発者からの制度的独立性を維持することを前提とする。以下に対応していない:(1)スケーラビリティ制約—独立評価はリソース集約的であり、モデルリリースサイクルに遅れる可能性がある;(2)潜在的利益相反—評価者がモデル開発者から資金を受け取る場合;(3)スケール時またはスペシフィック展開条件下でのみ出現する能力を評価する課題。
-
実行可能な含意:* 高リスク応用(医療、金融、重要インフラ、自律システム)でフロンティアモデルを採用する前に、ベンダーに独立評価データを提供させるか、第三者評価を委託せよ。評価基準を事前に確立せよ:あなたのユースケースに関連するフロンティア能力は何か。受け入れ不可能な失敗モードは何か。内部チームの場合、モデル開発と評価機能間の分離を制度化せよ—展開成功に対する直接的インセンティブを持たないチームに評価所有権を割り当てよ。評価方法論を文書化し、モデルが進化する際に結果が比較可能なままであるようにバージョン管理を維持せよ。この制度的構造はモデル能力への過信と過小評価からの機会喪失の両方から保護する。
実装と運用成熟度
-
主張:* フロンティアAIシステムの展開には、ほとんどの組織が現在欠いている運用インフラストラクチャとガバナンスメカニズムが必要であり、実質的な隠れた採用コストと展開リスクを生成している。
-
根拠と前提:* フロンティアモデルは複数層にわたる慎重なオーケストレーションを要求する:プロンプトエンジニアリング(入力仕様の反復的精緻化)、検索拡張生成(RAG)パイプライン(外部知識ベースとの統合)、ファインチューニングワークフロー(タスク固有モデル適応)、フォールバックメカニズム(モデル信頼度が低い場合の段階的低下)。「制御されたテストで適切に性能する」と「本番環境でスケール時に確実に性能する」の間のギャップは実質的であり、しばしば過小評価される。本分析は以下を前提とする:(1)組織は通常、監視、再訓練、失敗回復複雑性を過小評価する;(2)本番展開はテストに存在しない分布シフトとエッジケースを導入する;(3)運用失敗はシステムが大量に、または高レイテンシ感度で動作する際に複合する。
-
具体的証拠:* 金融サービス組織がファクトチェックインフラを実装せずにGPT-4をカスタマーサポートに展開した。モデルは尤もらしいが事実上不正確な規制助言を生成し、コンプライアンスリスクと顧客害をもたらした。是正には以下が必要であった:ファクトチェックパイプラインの構築(承認された規制ガイダンスのベクトルデータベース)、検索拡張生成の実装により応答を検証されたソースに根拠付け、エッジケースに対する人間ループレビューの確立。これらの運用要件は初期推定を超えて展開努力とタイムラインを3倍にした。
-
前提条件と制限:* 本分析は組織が運用インフラストラクチャ構築のための技術専門知識にアクセスできることを前提とする。以下に対応していない:(1)小規模組織のリソース制約;(2)領域固有運用要件(例えば医療システムはカスタマーサービスと異なる規制要件に直面する);(3)フロンティアモデルが成熟する際の進化する運用ベストプラクティスの性質。
-
実行可能な含意:* フロンティアモデルを採用する前に、正式なインフラ準備状況監査を実施せよ:サービス中断なしでモデルをバージョン管理しロールバックできるか。モデル出力と失敗モードに対する包括的なログと監視があるか。リアルタイムで分布シフトまたは性能低下を検出できるか。信頼度が低下するか出力が予期されたパターンから逸脱する際に人間レビューをトリガーするサーキットブレーカーを実装できるか。一般的な失敗モードへの対応を文書化する運用プレイブックを構築せよ。展開チームとは別にモデル監視の明確な所有権を割り当てよ。継続的メンテナンスの予算を立てよ—フロンティアモデルは静的なアーティファクトではなく、使用パターンが進化し新規失敗モードが出現する際に継続的な監視、再訓練、適応を必要とする。
測定とアウトカム評価
-
主張:* 組織は導入中心のメトリクス(システム可用性、レイテンシ)から結果中心のメトリクス(ビジネスインパクト、ユーザー体験)への転換を迫られている。AI価値を正確に評価し、システムパフォーマンスと組織目標のズレを識別するためだ。
-
根拠と前提:* 導入メトリクス(稼働率、レイテンシ、スループット)はシステムが機能しているかを示すが、それが価値をもたらすかについては何も語らない。結果メトリクスは、AIが実際にビジネス成果、ユーザー体験、意思決定の質を改善するかを明かす。この転換には三つの要件がある。(1)導入前に成功基準を定義すること、(2)AI導入前のベースラインパフォーマンスを確立すること、(3)導入後の継続的測定とフィードバックループによる閾値調整である。本分析は、結果メトリクスが測定可能であり、組織がアウトカムに対するAIの因果的寄与を分離できることを前提としている。
-
具体的証拠:* カスタマーサービス組織はAIチャットボットの成功を「人間へのエスカレーションなしで処理されたメッセージの割合」で測定した。このメトリクスは劇的に改善した。だが調査の結果、改善はチャットボット能力の向上ではなく、エスカレーションを意図的に困難にしたことから生じていた。代替アウトカム「解決に対する顧客満足度」「解決までの時間」「再接触率」を測定すると、チャットボットが正当な問題を回避することでカスタマー体験を悪化させていたことが判明した。導入メトリクスは負のアウトカムを隠蔽していた。
-
前提条件と制限:* 本分析は以下を前提とする。(1)結果メトリクスが確実に定義・測定可能であること、(2)組織が交絡因子からAIの因果的寄与を分離できること、(3)アウトカムを継続的に追跡する測定システムが整備されていることである。以下には対応しない。(1)定量化困難なアウトカム(新規領域での意思決定品質など)、(2)導入後の長期フィードバックループでアウトカムインパクトが顕在化する場合、(3)結果メトリクスがパフォーマンスインセンティブになった場合のゲーミングの可能性。
-
実行可能な含意:* 導入後ではなく導入前に結果メトリクスを定義せよ。各AIシステムについて明示的に指定すること。何の問題を解決しているのか。それが解決されたかをどう測定するのか。受け入れ可能なトレードオフは何か(速度対精度、カバレッジ対精度)。AI導入前のベースラインパフォーマンスを確立し、反事実的比較を可能にせよ。導入後は継続的に測定し、必要に応じて閾値を調整せよ。運用チームがメトリクスと現実のインパクトのズレを指摘できるフィードバック機構を構築せよ。定期的な監査を実施し、ユースケースの進化に伴い結果メトリクスが組織目標と整合し続けることを確認せよ。
リスク特性化と軽減
-
主張:* フロンティアAIシステムは標準的なソフトウェアリスク枠組みが十分に特性化できない失敗モードをもたらす。新規の軽減戦略とガバナンス構造が必要だ。
-
根拠と前提:* AIシステムは従来のソフトウェアに存在しない失敗モードを示す。ハルシネーション(もっともらしいが虚偽の情報生成)、創発的バイアス(歴史的バイアスの大規模再現)、分布シフト下での予測不可能な性能低下(訓練分布から逸脱した入力での性能崩壊)である。これらのリスクはシステムが自律的に、大量に、高リスク文脈で動作する場合に複合化する。本分析は以下を前提とする。(1)標準的なQAとテスト手順はこれらの失敗モードを確実に検出しないこと、(2)敵対的テストとレッドチーミングは導入前に脆弱性を露呈させられること、(3)高リスク決定には人間の監視が必要であることである。
-
具体的証拠:* 採用組織は歴史的採用データで訓練されたAIシステムを導入した。システムは過度に適格な候補者の履歴書をダウンランクすることを学習し、採用決定における歴史的バイアスを再現した。システムは訓練目標(歴史的採用パターンの予測)に対して「正しく」機能したが、公正性原則と法的要件に違反した。この失敗モードの検出には採用実務の領域専門知識と敵対的テストが必要だった。標準的なソフトウェアQA手順では不十分だ。
-
前提条件と制限:* 本分析は以下を前提とする。(1)導入前にレッドチーミング演習を実施できること、(2)組織が敵対的テストのための領域専門知識と多様な視点にアクセスできること、(3)失敗モードが十分に特性化され、サーキットブレーカーの実装が可能であることである。以下には対応しない。(1)大規模運用下または特定の導入条件下でのみ顕在化する失敗モード、(2)フロンティアモデルにおける新規失敗モード予測の困難さ、(3)小規模組織のリソース制約。
-
実行可能な含意:* 高リスク文脈でフロンティアAIを導入する前に、構造化されたレッドチーミング演習を実施せよ。多様なチーム(領域専門家、潜在的ユーザー、敵対的テスター)を集め、失敗モードを探索せよ。敵対的入力でどうなるか。人口統計グループまたは入力分布全体でパフォーマンスはどう変動するか。システムが大規模に、またはリソース制約下で動作するとどうなるか。既知の制限を文書化し、ユーザーとステークホルダーに明示的に伝達せよ。サーキットブレーカーを実装せよ。信頼度が低下する、出力が予期されたパターンから逸脱する、またはシステム動作が分布シフトを示唆する場合に人間レビューをトリガーする自動化ルールだ。重大な結果をもたらす決定には人間の監視を維持せよ。一度限りのコンプライアンスチェックではなく、継続的な監査とレッドチーミングに予算を配分せよ。新規失敗モードが顕在化した際に迅速に対応できるガバナンス構造を確立せよ。
エネルギーインフラと原子力発電:並行するスケーリング課題
-
主張:* フロンティアAIのエネルギー需要はインフラ制約を生み出しており、原子力発電を実行可能なエネルギー源として再び浮上させている。AI導入とエネルギー生成の両者に並行するスケーリング課題を確立する。
-
根拠と前提:* フロンティアモデルの訓練と運用は膨大な電力を消費する。単一の大規模言語モデルの訓練には、モデルスケールとハードウェア効率に応じて1,000~10,000 MWhのエネルギーが必要とされる推定値がある。AIを駆動するデータセンターは電力需要の測定可能な成長を促進している。同時に、次世代原子力技術——小型モジュール炉(SMR)、先進冷却システム、受動的安全設計——が技術的に実現可能かつ経済的に競争力を持つようになっている。AI スケーリングと原子力導入の両者は以下を必要とする。(1)長期資本計画、(2)規制の明確性と合理化された承認プロセス、(3)グリッド統合と信頼性保証である。本分析は以下を前提とする。(1)従来の再生可能エネルギー源(風力、太陽光)はAIインフラのピーク需要を確実に満たせないこと、(2)原子力発電は炭素低排出のベースロード容量を提供すること、(3)AI と原子力導入は類似した制度的および規制的障壁に直面することである。
-
具体的証拠:* 主要なクラウドインフラプロバイダーはデータセンターに原子力エネルギーで電力を供給するコミットメントを発表し、原子力事業者と長期電力購入契約を締結している。これらのコミットメントは明示的な賭けを反映している。(1)従来の再生可能エネルギーだけではAIインフラ需要を確実に満たせないこと、(2)原子力発電は費用競争力のあるベースロード容量を提供すること、(3)長期エネルギー契約は運用上の不確実性を低減することである。米国とヨーロッパの規制変更は先進炉設計の原子力ライセンスを加速させており、エネルギー需要圧力の制度的認識を示唆している。
-
前提条件と制限:* 本分析は以下を前提とする。(1)AIからのエネルギー需要は継続的に成長すること、(2)原子力発電は代替案に対して経済的に実行可能であること、(3)原子力導入への規制障壁が対処されることである。以下には対応しない。(1)将来のAIエネルギー効率改善に関する不確実性、(2)再生可能エネルギー貯蔵における潜在的な技術的ブレークスルー、(3)原子力導入への政治的および社会的障壁、(4)代替案に対する原子力発電の完全なライフサイクルカーボンフットプリント。
-
実行可能な含意:* 大規模にAIを導入する組織はエネルギー調達とカーボンフットプリントを監査せよ。インフラプロバイダーのエネルギーミックスと長期エネルギー戦略を理解せよ。持続可能性とカーボン削減がステークホルダーにとって重要であれば、再生可能または原子力発電の調達を主張せよ。AIエネルギー消費の測定と報告のための業界標準開発に参加せよ。標準化されたメトリクスは比較を可能にし、効率改善を促進する。インフラと運用チームの場合、電力消費トレンドを監視せよ。それらは容量制約とコスト圧力を示し、価格設定、可用性、導入決定を駆動する。組織およびインdustry レベルでのエネルギー政策議論に参加し、エネルギーインフラ計画がAI導入タイムラインと整合することを確認せよ。
統合と組織的準備態勢
-
主張:* 責任あるフロンティアAI採用は、アドホックな実験から体系的な能力評価、運用成熟度、結果焦点型ガバナンスへの転換を必要とする。技術的実装ではなく制度的変化を要求する。
-
根拠と前提:* フロンティアAI環境は急速に進化しており、新規モデル、能力、失敗モードが四半期単位で出現する。反応的でアドホックなAI採用アプローチは複合的リスクを生み出す。能力過大評価、運用失敗、検出されない失敗モード、システムパフォーマンスと組織目標のズレである。形式的な評価基準、運用規律、結果焦点型測定を確立する組織はリスク管理しながら価値を抽出する。フロンティアAIをプラグアンドプレイ技術として扱う組織は高額な失敗と評判損害に直面する。本分析は以下を前提とする。(1)組織学習は可能かつ必要であること、(2)体系的アプローチは失敗リスクを低減すること、(3)制度的構造は責任あるAI採用を支援するよう設計できることである。
-
前提条件と制限:* 本分析は組織が体系的アプローチを実装するための十分なリソースと専門知識を有することを前提とする。以下には対応しない。(1)小規模組織またはリソース限定セクターのリソース制約、(2)AI ガバナンスに関する組織的コンセンサス構築の困難さ、(3)フロンティアモデルが成熟するにつれてのベストプラクティスの進化する性質。
-
実行可能な含意:* 体系的AIガバナンスへの構造化された移行計画を確立せよ。
-
現状を監査せよ: 既存のAIシステムをインベントリ化せよ。各システムについて文書化せよ。何を測定しているか。なぜか。結果は組織目標とどう比較されるか。どの失敗モードが顕在化したか。
-
評価能力を構築せよ: 独立した評価機能を確立するか提携せよ。高リスク導入の評価基準を定義せよ。導入前にレッドチーミング演習を実施せよ。
-
運用ベースラインを確立せよ: インフラ準備態勢を監査せよ。一般的な失敗モードの運用プレイブックを構築せよ。監視、ロギング、サーキットブレーカーを実装せよ。モデル監視の明確な所有権を割り当てよ。
-
結果メトリクスを定義せよ: 各AIシステムについて、ビジネス目標に結びついた成功基準を指定せよ。AI導入前のベースラインを確立せよ。導入後は継続的に測定せよ。
-
リスク特性化を実施せよ: ユースケースに固有の失敗モードを識別せよ。軽減戦略を実装せよ。既知の制限を文書化し、ステークホルダーに伝達せよ。
-
インフラスケーリングを計画せよ: エネルギー調達とカーボンフットプリントを監査せよ。エネルギーインフラ計画をAI導入タイムラインと整合させよ。
-
学習を制度化せよ: 教訓を文書化し、チーム全体で共有せよ。運用経験が評価とガバナンスに情報を与えるフィードバックループを確立せよ。定期的な監査を実施し、ガバナンス構造が組織目標と整合し続けることを確認せよ。
これは一度限りの作業ではない。モデル、ユースケース、組織目標が進化するにつれての継続的な規律だ。このプロセスを体系化する組織は責任あるAI採用でリードする。他の組織は後追いし、危機を反応的に管理する。今構築する制度的構造が、フロンティアAIが継続的に進化する中での組織の適応能力を決定する。
独立評価の役割:METRおよびそれ以降
- 問題:* モデル開発者は能力を楽観的に提示するインセンティブを持つ。
フロンティアモデルベンダーは何が測定され、結果がどう伝達されるかをコントロールする。これは好意的な解釈に向けた構造的バイアスを生み出す。METR(フロンティアモデル評価)のような独立した第三者評価組織は、導入前に透明で再現可能な評価を提供するために出現した。従来のベンチマークゲーミングではなく、フロンティア能力(新規問題解決)に焦点を当てる。
-
これが重要な理由:* METRの評価フレームワークは、複数選択問題に答えるのではなく、モデルが自律的に現実世界のタスクを完了できるかをテストする。セキュリティ脆弱性の発見、研究の実施、新規問題の解決である。これは従来のベンチマークに見えない能力の天井を明かし、本番環境で重要な安全上の重大な失敗モードを識別する。
-
何をすべきか:*
-
高リスク採用前に独立評価データを要求せよ。 ベンダーに第三者評価の共有を要求するか、自ら委託せよ。ミッション上重要なアプリケーション(医療、金融、法律)では、独立評価は譲歩不可能だ。
-
ビルダーとアセッサー間の制度的距離を確立せよ。 モデル開発チームから分離された評価機能を作成せよ。これは利益相反を防ぎ、モデルが進化する中で評価の信頼性を確保する。
-
評価方法論を標準化せよ。 モデルをどう評価するかを文書化し、結果がバージョンとベンダー全体で比較可能なままであることを確認せよ。これは評価が動く標的になることを防ぐ。
-
業界評価基準に参加せよ。 新興基準(例えば、NIST AI リスク管理フレームワーク)に参加するか貢献せよ。これは重複を低減し、組織全体での比較可能性を改善する。
- コストとタイムライン:* 独立評価の委託はスコープに応じて50,000~500,000ドルのコストがかかる。内部評価能力の構築には2~4 FTEが必要だ。ROI:単一の高リスク導入失敗(規制罰金、顧客害、評判損害)を回避することは通常、投資を正当化する。
実装と運用パターン
- 問題:* フロンティアモデルはほとんどの組織が欠く運用インフラを必要とする。
「モデルがテストで機能する」と「モデルが本番環境で確実に機能する」の間のギャップは実質的だ。フロンティアモデルは慎重なオーケストレーションを要求する。プロンプトエンジニアリング、検索拡張生成(RAG)、ファインチューニングワークフロー、フォールバック機構、監視、失敗復旧である。組織は一貫してこの複雑さを過小評価する。
-
これが重要な理由:* 金融サービス企業はGPT-4をカスタマーサポートに導入し、モデルがもっともらしいが不正確な規制アドバイスを生成することを発見した。これを修正するには、ファクトチェックパイプラインの構築、承認回答のベクトルデータベース維持、エッジケースの人間ループレビュー実装、分布外入力の監視確立が必要だった。導入努力は3倍になった。このインフラなしでは、システムはコンプライアンスと責任リスクを生み出していただろう。
-
何をすべきか:*
-
導入前にインフラ準備態勢を監査せよ。 以下ができるか。
- モデルをバージョン管理し、ロールバックするか。
- モデル出力をログし、監視するか。
- パフォーマンス低下または分布シフトを検出するか。
- 高リスク決定に対して人間ループレビューを実装するか。
- モデル失敗から連鎖的システム失敗なしで復旧するか。
いずれかの質問への答えが「いいえ」なら、本番導入の準備ができていない。
-
一般的な失敗モードの運用プレイブックを構築せよ。 文書化せよ。
- モデルがハルシネーションまたは作話しているかをどう検出するか。
- 信頼度が閾値を下回る場合のエスカレーション手順。
- パフォーマンスが低下した場合のロールバック手順。
- データ分布がシフトした場合の再訓練ワークフロー。
- 失敗をステークホルダーに通知するコミュニケーションプロトコル。
-
モデル監視の明確な所有権を割り当てよ。 導入から分離せよ。この人/チームはアラート、パフォーマンス追跡、失敗調査を所有する。モデルを構築したチームから独立して報告する。
-
継続的メンテナンスに予算を配分せよ。 フロンティアモデルは静的な成果物ではない。以下に計画せよ。
- 継続的な監視とアラート。
- データ分布がシフトする際の定期的な再訓練。
- 失敗分析に基づくプロンプトエンジニアリング改善。
- 使用が成長するにつれてのインフラスケーリング。
- コストとタイムライン:* 本番グレードの運用インフラ構築には8~16週間と2~4 FTEが必要だ。継続的メンテナンスには1~2 FTEが必要だ。これはしばしば総導入コストの30~50%である。
ダウンロード:AIの追跡を試みること、そして次世代原子力発電
測定と次のアクション
- 問題:* デプロイメント指標はビジネスインパクトを測定しない。
アップタイム、レイテンシ、スループットといったデプロイメント指標は、システムが稼働しているかどうかを示すにすぎず、それが価値あるものかどうかは示さない。組織はしばしば誤った指標を最適化し、AIシステムが現実世界の成果を悪化させている局面を見落とす。
-
なぜこれが重要か:* あるカスタマーサービスチームはAIチャットボットの成功を「エスカレーションなしで処理されたメッセージ数」で測定していた。この指標は劇的に改善した。エスカレーションを困難にすることで。顧客満足度と解決までの時間を測定すると、チャットボットは正当な問題を回避することで実際には体験を悪化させていたことが判明した。チームはビジネス価値と逆方向に動く指標を最適化していたのである。
-
何をすべきか:*
-
デプロイメント前にアウトカム指標を定義する。 各AIシステムについて以下を明示する:
- 何の問題を解決しようとしているのか
- それが解決されたかどうかをどう測定するか
- 許容できるトレードオフは何か(速度対精度、カバレッジ対精度)
- 許容できない失敗モードは何か
-
AI導入前のベースライン性能を確立する。 現在の状態(人間の性能、既存システムの性能)を測定し、改善を定量化できるようにする。
-
デプロイメント後も継続的に測定する。 アウトカム指標を四半期ごとではなく、週単位または日単位で追跡する。これにより劣化を早期に検出できる。
-
フィードバックループを構築する。 指標が現実世界のインパクトから乖離したら調査する。モデルが変わったのか。ユーザー行動が変わったのか。ビジネスコンテキストが変わったのか。これらの洞察を使って指標とモデルを改善する。
-
ユースケースとユーザーグループ別に指標をセグメント化する。 単一の集計指標は不均衡を隠す。異なる顧客セグメント、ユースケース、データ分布について別々にパフォーマンスを追跡する。
- コストとタイムライン:* アウトカム指標の定義には2~4週間を要する。継続的測定の実装には計測と分析に1~2 FTE(フルタイム相当)を要する。ROI:パフォーマンス劣化の早期検出は高額な失敗と無駄な投資を防ぐ。
リスクと軽減戦略
- 問題:* フロンティアAIシステムは従来のソフトウェアとは異なる方法で失敗する。
AIシステムは尤もらしい虚偽を生成し、スケールで予期しないバイアスを示し、分布外の入力で予測不可能に劣化する。これらのリスクはシステムが自律的に、または大量に動作する場合に複合する。標準的なリスク枠組みはこれらの失敗モードを見落とす。
-
なぜこれが重要か:* 歴史的データで訓練された採用AIは、過度に適格な候補者の履歴書をランク下げることを学習し、歴史的採用バイアスを再現した。システムはその訓練目的に従って「正しく」機能したが、公正性原則に違反し、法的責任を生じさせた。これを検出するには標準的なQAではなく、ドメイン専門知識と敵対的テストが必要だった。
-
何をすべきか:*
-
デプロイメント前にレッドチーミング演習を実施する。 多様なチーム(ドメイン専門家、倫理学者、潜在的な敵対者)を集めて失敗モードを調査する:
- モデルを破壊するために設計された敵対的入力ではどうなるか
- パフォーマンスは人口統計グループ、地域、データ分布によってどう変わるか
- スケール時(大量、エッジケース)ではどうなるか
- 最も有害な失敗モードは何か
-
既知の制限を文書化する。 モデルカードを作成して以下を明示する:
- モデルが何をするように設計されたか
- 何をするように設計されていないか
- 既知の失敗モードとその頻度
- 人口統計グループとデータ分布全体でのパフォーマンス
- 推奨されるユースケースとアンチパターン
-
サーキットブレーカーを実装する。 人間のレビューをトリガーするルールを定義する:
- 信頼度がX%を下回ったらエスカレーション
- 出力が予期されたパターンから逸脱したらフラグ
- 入力分布がシフトしたらモニタリングチームに警告
- エラー率が閾値を超えたらシステムを一時停止
-
高リスク決定については人間の監視を維持する。 人々の生活、生計、または法的権利に影響を与える決定は、人間のレビューなしに自動化しない。あなたのコンテキストで「高リスク」が何を意味するかを定義する。
-
継続的な監査に予算を配分する。 人口統計グループ、ユースケース、データ分布全体でモデルパフォーマンスの四半期または半年ごとの監査を実施する。コンプライアンスを一度限りのチェックボックスとして扱わない。
- コストとタイムライン:* レッドチーミング演習は範囲に応じて2万~10万ドルの費用がかかる。サーキットブレーカーの実装には2~4週間を要する。継続的な監査には0.5~1 FTE を要する。ROI:単一の高リスク失敗(規制罰金、差別訴訟、顧客被害)を回避することは通常、投資を正当化する。
原子力発電とエネルギー需要:並行する課題
- 問題:* AIのエネルギー需要は原子力発電を実行可能なエネルギー源として再燃させており、並行するインフラ課題を生み出している。
フロンティアモデルの訓練と実行は膨大な電力を消費する。大規模言語モデルの単一の訓練実行は1000MWh以上を消費できる。AIを支える データセンターは年間15~20%のペースでエネルギー需要増加を駆動している。同時に、次世代原子力技術(小型モジュール炉、先進冷却)は技術的に実現可能で経済的に競争力を持つようになっている。両者とも長期計画、規制の明確性、資本配置を必要とする。
-
なぜこれが重要か:* 大手クラウドプロバイダーはデータセンターを原子力エネルギーで供給することを約束し、炉オペレーターと長期契約を締結した。これは従来の再生可能エネルギーだけではAIインフラ需要を確実かつ費用効果的に満たせないという賭けを反映している。大規模でAIをデプロイする組織は、コスト、持続可能性、運用復元力に影響を与えるエネルギー調達決定に直面する。
-
何をすべきか:*
-
エネルギー調達とカーボンフットプリントを監査する。 以下を理解する:
- クラウドプロバイダーのエネルギーミックス(石炭、天然ガス、再生可能エネルギー、原子力)
- AIシステムのエネルギー消費(訓練、推論、ストレージ)
- トランザクションまたは出力あたりのカーボンフットプリント
- これが代替案(人間労働、従来のソフトウェア)とどう比較されるか
-
持続可能性がステークホルダーにとって重要な場合、再生可能エネルギーまたは原子力エネルギーを支持する。 クラウドプロバイダーと協力して:
- ワークロードをより清潔なエネルギーを持つ地域にシフト
- 再生可能エネルギークレジットを購入
- 原子力発電開発を支援
- カーボンインパクトを測定・報告
-
AIエネルギー消費測定の業界標準に参加する。 組織がエネルギー使用をどのように測定・報告するかを標準化する取り組みに参加する。これにより比較可能性が向上し、業界全体の効率改善が促進される。
-
電力消費トレンドを監視する。 これらは容量制約とコスト圧力を示し、価格設定と可用性を駆動する。プロバイダーのエネルギーコストが急上昇したら、価格上昇またはサービス劣化を予想する。
-
インフラスケーリングを計画する。 大規模でAIをデプロイしている場合、エネルギーは制約になる。インフラチームと協力して以下を計画する:
- 電力需要の増加
- 冷却要件
- 地理的分散(より安価または清潔なエネルギーへのアクセス)
- 長期エネルギー契約
- コストとタイムライン:* エネルギー調達の監査には2~4週間を要する。エネルギー監視の実装には1~2週間を要する。既存のモニタリングシステムに統合されている場合、継続的な追跡には最小限の労力を要する。ROI:エネルギーコストと持続可能性インパクトを理解することは、価格設定、ポジショニング、長期戦略を知らせる。
結論と移行計画
- 問題:* 責任あるAI採用には、アドホックな実験から体系的な能力評価と運用成熟度への移行が必要である。
フロンティアAIの風景は反応的なアプローチには速すぎる。明確な評価基準、運用規律、アウトカム重視の指標を確立する組織は、リスクを管理しながら価値を抽出する。AIをプラグアンドプレイ技術として扱う組織は高額な失敗に直面する。
- 何をすべきか:*
-
現在のAIシステムを監査する。 以下を文書化する:
- どのシステムを実行しているか
- 何を測定しており、なぜか
- 指標とビジネスインパクト間にどのようなギャップが存在するか
- どのような運用インフラが整備されているか
- どのようなリスクにさらされているか
-
独立した評価能力を構築するか、第三者とパートナーシップを結ぶ。 ビルダーとアセッサー間に制度的距離を確立する。評価方法論を標準化する。
-
運用ベースラインを確立する。 モデルをバージョン管理、監視、ロールバックできるか。失敗を検出できるか。カスケード失敗なしに回復できるか。できなければ、スケーリング前にこのインフラを構築する。
-
ビジネス目標に結びついたアウトカム指標を定義する。 測定しやすいものではなく、重要なものを測定する。ベースラインを確立する。継続的に追跡する。
-
高リスクデプロイメントについてレッドチーム演習を実施する。 失敗モードを調査する。制限を文書化する。サーキットブレーカーを実装する。人間の監視を維持する。
-
エネルギーとインフラスケーリングを計画する。 エネルギー調達を理解する。成長に備える。トレンドを監視する。
-
学習した教訓を文書化し、チーム間で共有する。 フィードバックループを作成する。プロセスを改善する。組織的学習を構築する。
-
タイムライン:* これは一度限りの作業ではない。モデルとユースケースが進化するにつれて継続的な規律である。ステップ1~2から始める(4~8週間)。ステップ3~5を並行して実装する(8~16週間)。ステップ6~7は継続的である。
-
ROI:* このプロセスを体系化する組織がリードする。より速くAIをデプロイし、リスクが低く信頼度が高い。失敗を早期に検出する。より多くの価値を抽出する。他の組織は追いかけ、より高いコストを支払い、より高いリスクを受け入れる。体系的な能力評価と運用成熟度への投資は、失敗の回避とスケーリングの加速で自らを正当化する。
AIの進捗追跡:標準指標が不足する理由――そして次に何が来るか
- 機会:* フロンティアAIのコンセンサス指標の欠如は解決すべき問題ではなく、競争優位が生まれるホワイトスペースである。
今日のAI評価の風景は初期インターネットを反映している。私たちはプロキシ(MMLU、GSM8K、HumanEval)を使用しており、これらは狭いタスク性能を測定する一方で、実際に仕事を再形成する能力を見落とす。このギャップは一時的である。今、独自の評価フレームワークを構築する組織は、競合他社がベンチマーク劇場に閉じ込められている間に、AIを効果的にデプロイするための制度的知識を所有する。
-
なぜこれが重要か:* OpenAI、Google、またはAnthropicがフロンティアモデルをリリースすると、業界は公開スコアを能力プロキシとして固視する。これらの指標は狭いタスク最適化に報酬を与えるが、体系的に創発的行動――小説的な推論チェーン、予期しない失敗モード、本番環境の驚き――を見落とす。これらが現実世界の価値を決定する。GPT-4のリリースはこれを例証した。従来のベンチマークは推論連鎖能力の質的飛躍をキャプチャできなかった。下流ユーザーは公開スコアに反映されていない能力を発見し、一方で他の宣伝された改善は実践では周辺的であることが判明した。ベンチマークが測定するものと重要なもの間のギャップが、未来が構築される場所である。
-
次の地平線:* 前向きな組織は、カスタム評価をコンプライアンスチェックボックスではなく、中核的能力として扱うべきである。仮説的なものではなく、実際のユースケースを反映するドメイン固有のテストスイートを構築する。精度だけでなく、失敗パターン、レイテンシ一貫性、入力分布全体での堅牢性を追跡する。ベンチマークが体系的に測定しないものを文書化する:推論の透明性、敵対的復元力、分布シフト下での行動、段階的な劣化。これは時間とともに複合する内部ベースラインを作成する。モデルが進化するにつれて、評価フレームワークは戦略的資産になる――市場に見えない能力軌跡を明らかにするレンズ。
-
実行可能なパス:* モデル開発から分離された専用評価機能を確立する。ビルダーとアセッサー間に制度的距離を作成する。テストスイートをコードと同じくらい厳密にバージョン管理する。これはオーバーヘッドではなく、持続可能なAI採用の基礎である。
独立評価をインフラとして:METRと信頼性レイヤー
- シフト:* 第三者評価組織は本質的インフラになりつつある――監査役ではなく、ベンダー主張と組織的現実間の能力翻訳者として。
モデル開発者は能力を楽観的に提示するための構造的インセンティブに直面している。これは悪意ではなく、競争市場の性質である。METR(フロンティアモデル評価)は、デプロイメントが臨界質量に達する前にフロンティアモデルの透明で再現可能な評価を提供するために出現した。彼らの作業はベンチマーク最適化ではなく、フロンティア能力――セキュリティ脆弱性の発見、小説的研究の実施、開放的問題の解決を要するタスク――に焦点を当てている。これは新しいカテゴリーの制度的行為者を表す:独立した能力評価者。
-
なぜこれが重要か:* METRの評価フレームワークは、複数選択肢の質問に答えるのではなく、モデルが現実世界のタスクを自律的に完了できるかどうかをテストする。これは従来のベンチマークに見えない能力の天井を明らかにし、現実的な条件下でのみ出現する安全性に関わる失敗モードを特定する。結果:過度に楽観的な採用者と、フロンティア能力を過小評価する者の両方を保護する信頼性レイヤー。
-
次の地平線:* AIシステムがより重要になるにつれて、独立評価は専門職に進化する。以下を見る可能性が高い:(1)セクター固有の評価基準(医療AIは金融AIは自律システムと異なる);(2)時間とともに能力ドリフトを追跡する継続的評価フレームワーク;(3)十分にリソースを持つ組織を超えて評価を民主化するオープンソース評価ツールキット;(4)高リスクデプロイメントに対して第三者評価を義務付ける規制枠組み。今、これらの基準構築に参加する組織は、次の十年の評価インフラを形作る。
-
実行可能なパス:* 高リスク応用でフロンティアモデルを採用する前に、独立評価データを要求する。ベンダーに第三者評価を共有させるか、自分で実施する。内部チームについては、独立した予算と報告ラインを持つ別個の機能として評価を確立する。方法論を文書化して、モデルが進化するにつれて結果が比較可能なままになるようにする。これは過度な自信と見落とされた機会の両方から保護する。
運用成熟度:フロンティアAIデプロイメントの隠れたコスト
- 機会:* ほとんどの組織はフロンティアAIデプロイメントをソフトウェア問題として扱う。実際には運用インフラ問題である――そしてそこに持続可能な競争優位が存在する。
フロンティアモデルは慎重なオーケストレーションを要求する:プロンプトエンジニアリング、検索拡張生成(RAG)、ファインチューニングワークフロー、フォールバックメカニズム、モニタリングパイプライン、失敗回復プロトコル。「モデルはテストで機能する」と「モデルは本番環境で確実に機能する」間のギャップが、ほとんどのAIイニシアティブが失敗する場所である。組織は監視、再訓練、失敗回復インフラの複雑性を体系的に過小評価する。
-
なぜこれが重要か:* 金融サービス企業がGPT-4をカスタマーサポートにデプロイしたとき、汎用プロンプトは尤もらしいが不正確な規制アドバイスを生成することを発見した。これを修正するには、ファクトチェックパイプラインの構築、承認された回答のベクトルデータベースの維持、エッジケースの人間ループレビューの実装、規制ドリフトの監視の確立が必要だった。デプロイメント労力は3倍になった。これはエッジケースではなく、規範である。運用準備を体系化する組織は、より速くデプロイし、リスクが低く、より多くの価値を抽出する。
-
次の地平線:* AIの運用成熟度は異なる規律に進化する。以下を見る可能性が高い:(1)異なるモデルタイプとユースケースの標準化された運用フレームワーク;(2)システムメトリクスではなくモデル行動を追跡するAI固有の可観測性ツール;(3)パフォーマンスドリフトを検出・修正する自動再訓練パイプライン;(4)モデルが失敗したときに段階的に劣化する段階的フォールバックアーキテクチャ;(5)モデルライフサイクル管理を所有するクロスファンクショナルチーム。今、このインフラを構築する組織は、他が複製する参照実装になる。
-
実行可能なパス:* フロンティアモデルを採用する前に、インフラ準備を監査する。モデルをバージョン管理・ロールバックできるか。モデル出力の包括的なロギングと監視があるか。分布シフトまたはパフォーマンス劣化を検出できるか。一般的な失敗モードの運用プレイブックを構築する。デプロイメントから分離されたモデル監視の明確な所有権を割り当てる。継続的なメンテナンスに予算を配分する――フロンティアモデルは静的なアーティファクトではない。運用成熟度を競争的な堀として扱う。
ダウンロード:AIの追跡を試みること、そして次世代原子力の地平
成果指標:デプロイメント成功からビジネスインパクトへ
- 転換点:* 組織はAIシステムが稼働しているかどうかを測定することから、それが価値を生み出しているかどうかを測定することへ移行しなければならない。
デプロイメント指標(稼働率、レイテンシ、スループット)はシステムが機能していることを示す。それがどれほど価値あるかは教えてくれない。成果指標こそが、AIが実際にビジネス成果、ユーザー体験、組織能力を改善しているかを明かす。これは各ユースケースごとに成功を異なる形で定義することを要求する。ほとんどの組織はこのステップを飛ばしている。
-
なぜこれが重要か:* あるカスタマーサービスチームはAIチャットボットの成功を「エスカレーションなしで処理されたメッセージ数」で測定していた。この指標はエスカレーションを難しくすることで劇的に改善した。「解決に対する顧客満足度」と「解決までの時間」を測定する指標に切り替えたとき、チャットボットは正当な問題を回避することでユーザー体験を低下させていることが明らかになった。システムは間違った成果に最適化していたのである。このパターンは組織全体で繰り返される。ダッシュボードでは良好に見える指標が、現実世界のインパクトから乖離している。
-
次の地平:* AIの成果測定はますます洗練されていくだろう。以下のような展開が予想される。(1)AI決定を下流の成果に結びつけるリアルタイムフィードバックループ。(2)他の変数からAIの貢献を分離する因果推論フレームワーク。(3)遅延的または間接的な効果を捉える長期インパクト追跡。(4)異なる優先順位を反映するステークホルダー固有の成果指標(速度対精度、カバレッジ対精度)。(5)指標が予想されるパターンから乖離したときの自動アラート。この測定インフラを構築する組織は、AIの実際のインパクトに対して前例のない可視性を得るだろう。
-
実行可能な道筋:* デプロイメント前に成果指標を定義すること。各AIシステムについて以下を特定する。何を解決しようとしているのか。それが解決されたかどうかをどう測定するのか。許容できるトレードオフは何か。AIなしでのベースライン性能を確立する。デプロイメント後は継続的に測定し、必要に応じて閾値を調整する。チームが指標と現実世界のインパクトの乖離を報告できるようにフィードバックループを構築する。成果測定を一度限りの検証ではなく、継続的な規律として扱うこと。
新しい故障モード:標準的なリスク枠組みが見落とすものを予測する
- 機会:* フロンティアAIシステムは従来のソフトウェアとは異なる方法で故障する。これらの故障モードを予測する組織は、競合他社が高くつく驚きに直面する一方で、レジリエンスを構築するだろう。
AIシステムは標準的なリスク枠組みが見落とす方法で故障する。もっともらしい虚偽を幻覚する、大規模で予期しないバイアスを示す、分布外の入力に遭遇したときに予測不可能に性能が低下する、敵対的条件下で予期しない振る舞いを示す。これらのリスクはシステムが自律的に、または大量に動作するときに複合化する。決定論的ソフトウェア向けに設計された従来のQAプロセスは不十分である。
-
なぜこれが重要か:* 歴史的データで訓練された採用AIは、過度に適格な候補者の履歴書をランクダウンすることを学習し、訓練データに埋め込まれた歴史的バイアスを再現していた。システムはその訓練目的によって「正しく」機能していたが、公正性原則と法的要件に違反していた。この故障モードを検出するには、標準的なQAではなく、ドメイン専門知識と敵対的テストが必要だった。故障モードは大規模に現れるまで、つまり数百人の候補者に影響を与えるまで見えなかった。
-
次の地平:* AIリスク管理は専門的な規律へと進化するだろう。以下のような展開が予想される。(1)故障モードを体系的に調査するレッドチーミング標準フレームワーク。(2)敵対的テストをモデル評価の中核部分として。(3)デプロイメント前に人口統計的不均衡を検出するバイアス監査ツール。(4)信頼度が低下したり出力が予想されるパターンから乖離したりしたときに人間のレビューをトリガーするサーキットブレーカーアーキテクチャ。(5)故障モード文書化を義務付ける規制枠組み。(6)AI固有のリスクをカバーする保険商品。今からレッドチーミング能力を構築する組織は、他社が採用する参照実装となるだろう。
-
実行可能な道筋:* デプロイメント前にレッドチーミング演習を実施すること。多様なチームを集めて故障モードを調査する。敵対的入力ではどうなるか。人口統計グループごとに性能はどう変わるか。大規模ではどうなるか。既知の制限は何か。調査結果を文書化し、ユーザーに伝える。サーキットブレーカーを実装する。信頼度が低下したり出力が予想されるパターンから乖離したりしたときに人間のレビューをトリガーするルール。高リスク決定については人間の監視を維持する。一度限りのコンプライアンスチェックではなく、継続的な監査に予算を配分する。故障モード予測を継続的な実践として扱うこと。
エネルギーインフラとAIスケーリング:並行する加速
- 機会:* AIのエネルギー需要は原子力を実行可能なインフラとして再び点火している。この収束は、早期に整列する組織にとって数十年にわたる機会を生み出す。
フロンティアモデルの訓練と実行は膨大な電力を消費する。大規模言語モデルの単一の訓練実行は、数千の家が1年間に使用する電力と同じくらいの電力を消費できる。AIを駆動するデータセンターは、従来のインフラが対応できないレートでエネルギー需要の成長を推進している。同時に、次世代原子力技術(小型モジュール炉、高度な冷却システム、燃料革新)は技術的に実現可能で経済的に競争力を持つようになりつつある。両者とも長期計画、規制の明確性、継続的な資本配置を要求する。この収束は偶然ではなく、構造的である。
-
なぜこれが重要か:* 大手クラウドプロバイダーはデータセンターを原子力で駆動することを約束し、炉オペレーターと長期契約を締結した。これは従来の再生可能エネルギーだけではAIインフラ需要を確実かつ費用効果的に満たすことができないという賭けを反映している。原子力はベースロード電力を提供する。一貫した、カーボンフリーの電力であり、再生可能エネルギーだけでは保証できない。AIワークロードがスケールするにつれ、このエネルギー仲裁は競争上の優位性となる。信頼できる低炭素電力へのアクセスを持つ組織は、より低い運用コストとより強い持続可能性認証を持つだろう。
-
次の地平:* AIのためのエネルギーインフラは戦略的な差別化要因となるだろう。以下のような展開が予想される。(1)クラウドプロバイダーと原子力オペレーター間の長期電力購入契約。(2)エネルギー源の近くにコンピュートを配置する分散データセンターアーキテクチャ。(3)エネルギー可用性とコストに最適化するAIワークロードスケジューリング。(4)AIシステムのカーボン会計を義務付ける規制枠組み。(5)AI収益流によって原子力インフラに資金を供給する新しい融資モデル。(6)AIエネルギー消費の測定と報告のための標準化指標。今から信頼できる低炭素電力を確保する組織は、次の10年間、競合他社に対して構造的なコストと持続可能性の優位性を持つだろう。
-
実行可能な道筋:* 大規模でAIをデプロイする組織はエネルギー調達とカーボンフットプリントを監査すべき。プロバイダーのエネルギーミックスを理解する。持続可能性がステークホルダーにとって重要であれば、再生可能エネルギーまたは原子力を提唱する。AIエネルギー消費の測定と報告のための業界標準に参加する。インフラチームの場合、電力消費トレンドを監視する。それらは容量制約とコスト圧力を示し、価格設定と可用性を駆動する。長期電力調達をAI戦略の一部として、単なる運用経費ではなく検討すること。
体系的採用:実験から制度的能力へ
- 転換点:* フロンティアAI環境は反応的アプローチには速すぎる。明確な評価基準、運用規律、成果中心の指標を確立する組織は、リスクを管理しながら価値を抽出するだろう。AIをプラグアンドプレイ技術として扱う組織は、高くつく失敗と見落とされた機会に直面するだろう。
責任あるAI採用には、アドホックな実験から体系的な能力評価と運用成熟度への移行が必要である。これは一度限りのプロジェクトではなく、時間とともに複合化する継続的な規律である。
-
なぜこれが重要か:* 今日のAI採用をリードしている組織は共通のパターンを共有している。AI能力評価、運用準備、成果測定を事後的な考慮ではなく、中核的な能力として扱っている。評価インフラに投資し、運用規律を維持し、重要なものを測定する。故障モードを予測し、レジリエンスを構築する。エネルギー戦略をコンピュート戦略と整列させる。この体系的アプローチは複合的な優位性を生み出す。各デプロイメントは次のデプロイメントを改善する教訓を教える。各評価フレームワークはより洗練される。各運用プレイブックはより堅牢になる。
-
次の地平:* 体系的なAI採用はデータインフラやソフトウェアエンジニアリング能力に匹敵する競争上の優位性の源となるだろう。この規律を今構築する組織がリードし、他社は追従するだろう。以下のような展開が予想される。(1)AI能力評価が技術デューデリジェンスの標準部分となる。(2)AIの運用成熟度フレームワークが業界標準となる。(3)成果測定が組織全体の中核的能力となる。(4)レッドチーミングと故障モード予測が標準的実践となる。(5)エネルギー戦略がAI戦略と不可分になる。(6)AIライフサイクル管理を所有する部門横断的チームが規範となる。このプロセスを体系化する組織は、次の10年間のAI採用を定義するだろう。
-
実行可能な道筋:* 体系的な移行計画で今から始めること。
(1)現在のAIシステムを監査する。 何を測定し、なぜ測定しているのか。指標が現実世界のインパクトから乖離している箇所はどこか。調査結果を文書化する。
(2)評価能力を構築する。 独立した評価機能を確立するか、第三者と提携する。ドメイン固有のテストスイートを作成する。評価フレームワークをコードと同じくらい厳密にバージョン管理する。
(3)運用ベースラインを確立する。 インフラ準備を監査する。運用プレイブックを構築する。監視と故障復旧の明確な所有権を割り当てる。
(4)成果指標を定義する。 AI決定をビジネス目的に結びつける。ベースラインを確立する。継続的に測定する。フィードバックループを作成する。
(5)レッドチーム演習を実施する。 高リスクデプロイメントで故障モードを調査する。既知の制限を文書化する。サーキットブレーカーを実装する。
(6)エネルギー戦略を整列させる。 電力調達を監査する。カーボンフットプリントを理解する。標準化努力に参加する。
(7)文書化と共有。 制度的知識を作成する。チーム間で教訓を共有する。組織能力を構築する。
これはオーバーヘッドではなく、持続可能なAI採用の基礎である。このプロセスを体系化する組織は、リスクを管理しながらフロンティアAIから指数関数的価値を抽出するだろう。これらのステップをスキップする組織は、高くつく失敗と競争上の不利に直面するだろう。この規律を構築する時間は今である。フロンティアがまだ形成されており、計画的かつ体系的に動く者にまだ競争上の優位性が利用可能な間に。
- 図15:AI計算と原子力発電のスケーリング課題の比較*
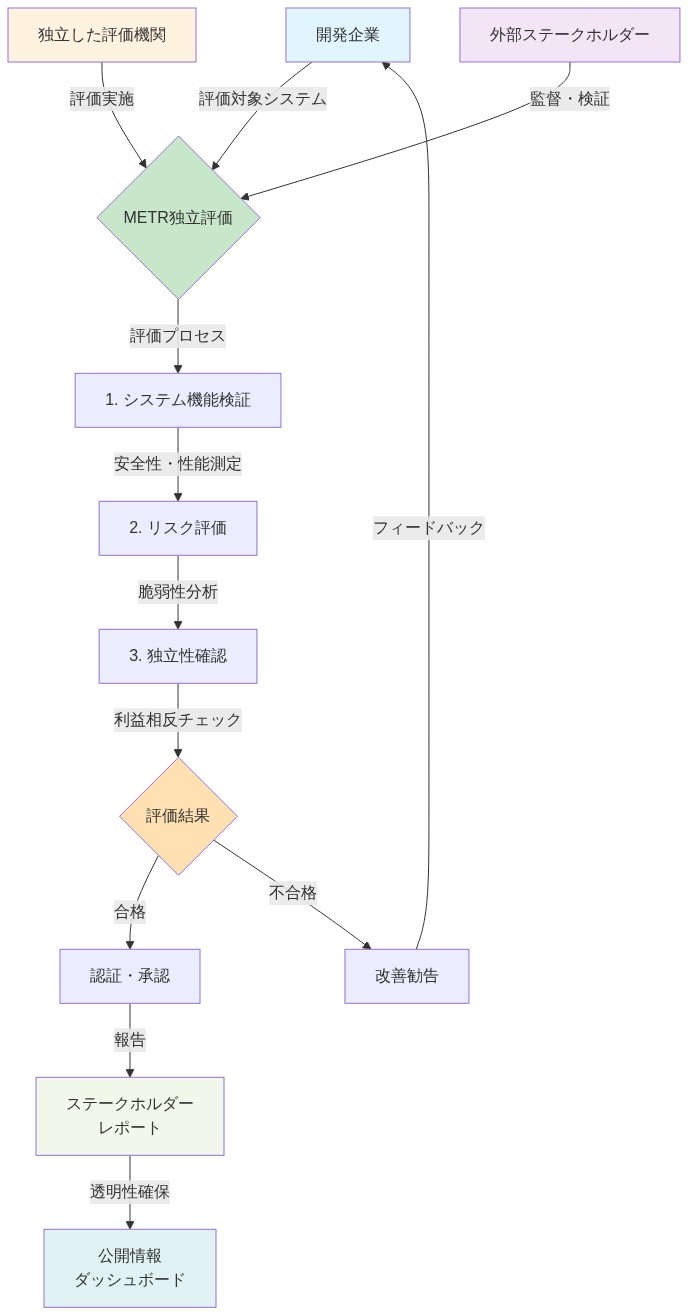
- 図5:METR独立評価フレームワークの構造(出典:METR公開資料)*
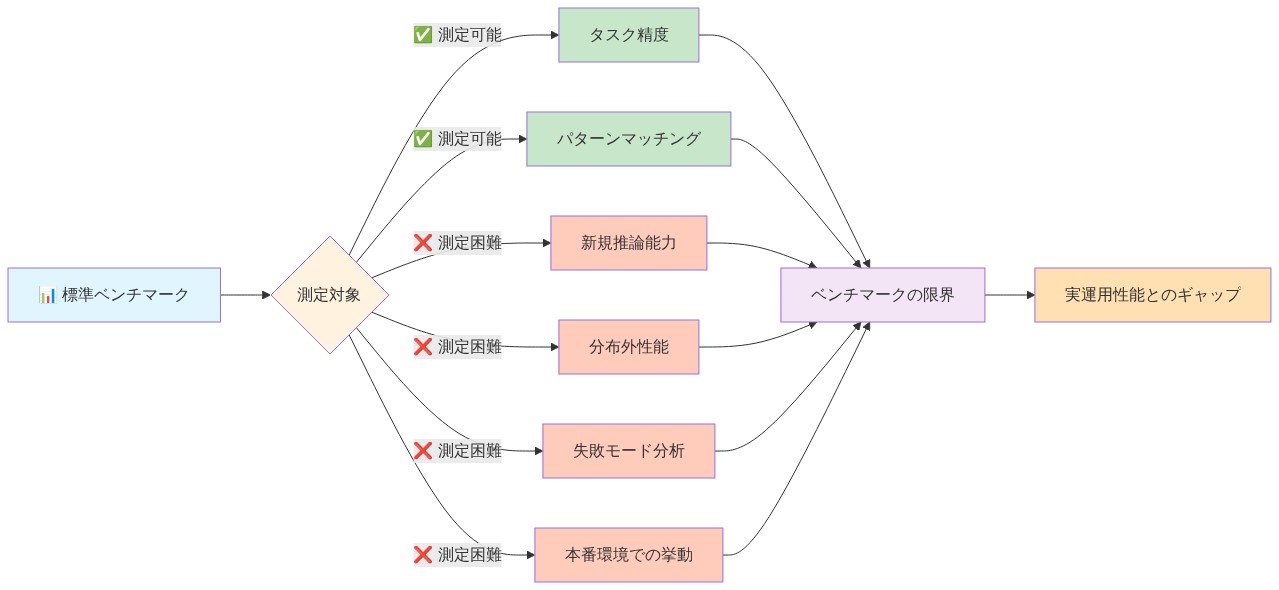
- 図3:標準ベンチマークの測定範囲と盲点*

- 図14:AI導入の成熟度モデル:実験から規律へ*