
TikTokの拡大されたデータ収集:技術的およびガバナンス分析
TikTokの拡大されたデータ収集を理解する
TikTokは、従来のエンゲージメント指標を大幅に超えてデータ収集の範囲を拡大しています。入手可能な証拠によると、このプラットフォームは現在、生体認証識別子、デバイスフィンガープリント、外部ウェブサイト全体の閲覧履歴、および推定される人口統計属性を取得しています(ByteDanceのプライバシー文書、Citizen Lab、Stanford Internet Observatoryによる第三者分析)。この拡大は、コンテンツ最適化のためのデータ収集から包括的なユーザープロファイリングへの文書化された移行を反映しています。
-
根底にある理論的根拠:* 拡大されたデータセットにより、より詳細なターゲティングと予測モデリングが可能になります。TikTokの推奨アルゴリズムは、アプリエコシステム外のユーザー行動パターンを理解することで恩恵を受けます。このクロスドメインデータ統合は、コンテンツ配信と広告主ターゲティングにおける競争上の優位性を生み出します。これは、Metaのインフラストラクチャと一致するパターンであり、アルゴリズム推奨システムに関する学術文献に記録されています(Gillespie, 2014; Buolamwini & Buolamwini, 2018)。
-
文書化されたメカニズム:* TikTokは、外部ウェブサイトにピクセルトラッキング(MetaのConversion APIに類似)を展開しています。ユーザーがTikTokのトラッキングピクセルをホストする小売ウェブサイトを訪問すると、プラットフォームはその訪問を記録します。アプリ内の行動シグナルと組み合わせることで、購入意図、ライフスタイルの好み、消費パターンを示すプロファイルが構築されます。このデータ統合は、ユーザーの認識や明示的な同意メカニズムが作動する前に、サーバーレベルで発生します。
-
認識が必要な仮定:* この分析は、ユーザーがクロスドメイントラッキングに対する可視性が限られており、プライバシーポリシーは法的に準拠しているものの、一般的なユーザーに対してデータ集約の範囲を透明に伝えていないことを前提としています。
-
組織への影響:* ナレッジワーカーとセキュリティ実務者は、組織のTikTok統合の即時監査を実施する必要があります。具体的なアクションには以下が含まれます:(1)利用可能な場合、ブラウザ設定でクロスサイトトラッキングを無効にする、(2)アカウントアクセス権を持つ接続された第三者アプリケーションを確認する、(3)TikTokのシステムを通じて流れる従業員データをインベントリ化する、(4)個人デバイスでのビジネスアカウント使用を制限する正式なポリシーを確立する。

- 図1:TikTokの拡大されたデータ収集スコープ*
TikTokのデータアーキテクチャの仕組み
TikTokのインフラストラクチャは、複数のエントリーポイントを通じてデータ収集を一元化しています:モバイルアプリ、ウェブプラットフォーム、埋め込みコンテンツ、および第三者統合。データは集中サーバーに流れ、そこでリアルタイム処理、集約、エンリッチメントを経て、推奨エンジンと広告システムに配信されます。
-
構造的リスク:* 集中型アーキテクチャはデータの有用性を最大化しますが、単一の脆弱性ポイントを作り出します。1つのシステムが包括的に収集する場合、侵害によってより広範なユーザー集団が露出し、管轄区域をまたいだ規制遵守が複雑になります。
-
具体的なシナリオ:* ユーザーの位置データ(GPS、WiFi信号、IPアドレスを介して収集)は、推奨エンジンと広告プラットフォームの両方に供給されます。データウェアハウスを侵害するセキュリティインシデントは、分離されたデータセットではなく、統合されたプロファイルを露出させることになります。
-
組織の対応:* セキュリティチームは、TikTokデータが侵害される可能性があると想定し、プラットフォームに触れる組織データに対してゼロトラストモデルを実装する必要があります。データ最小化ポリシーを確立します:従業員アカウントが共有する内容を制限し、統合権限を制限し、不正なデータエクスポートを監視します。ビジネスコンテキストが許可する場合、TikTokのデータ収集ドメインのネットワークレベルでのブロッキングを検討してください。
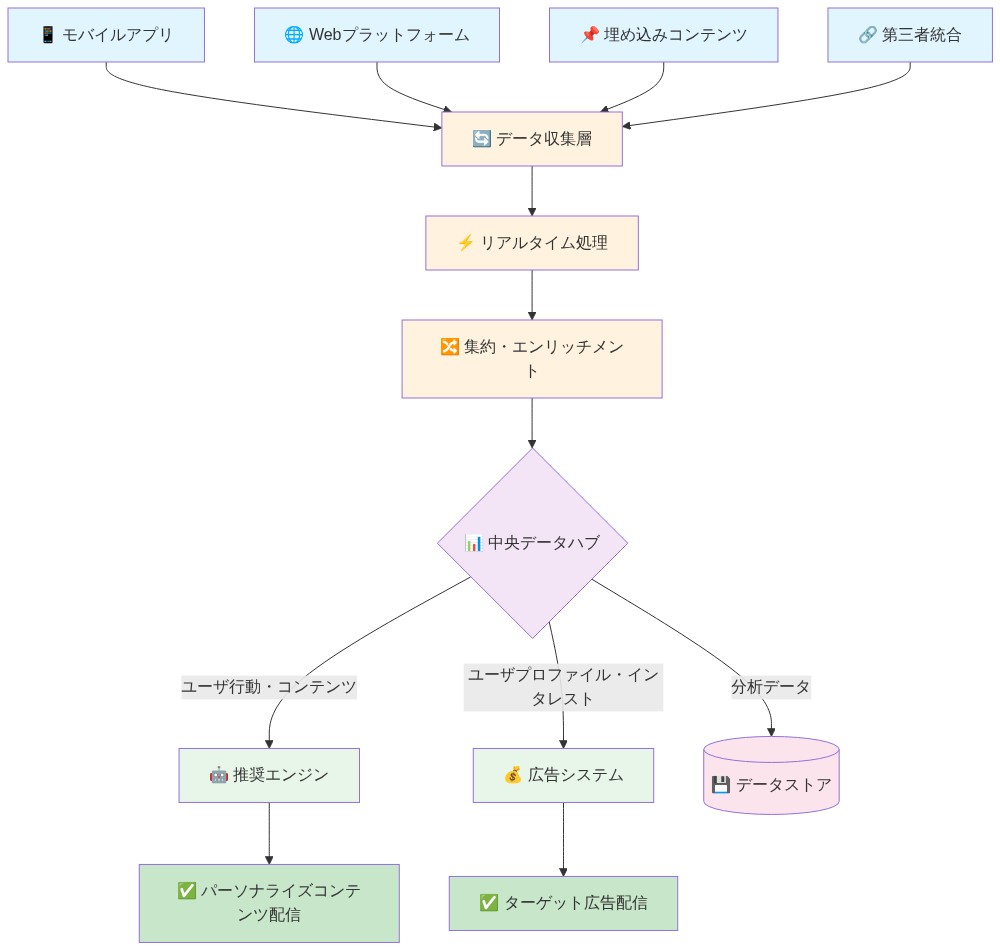
- 図2:TikTokのデータアーキテクチャとフロー*
プライバシー設定:制限と現実
TikTokのプライバシーフレームワークは、技術的なデータ最小化ではなく、ポリシー文書とユーザー同意メカニズムに依存しています。プラットフォームは詳細な設定(広告設定、データ共有トグル)を提供していますが、これらは最初に包括的に収集するように設計されたシステム内で動作します。

- 図5:プライバシー設定の表面と実態のギャップ。ユーザーが操作するプライバシー設定UIと、その背後で実際に行われているデータ収集・処理の乖離を対比表現。*