
Todoistの音声タスク機能:ナレッジワーカーのための構造化分析
機能:音声を構造化タスクに変換
Todoistは、自然言語処理を通じて音声入力を構造化されたToDoアイテムに変換する音声タスク機能をリリースしました。ユーザーは「明日午後2時にベンダーに電話することをリマインド」や「金曜日にプロジェクト計画を追加」といったコマンドを話すことができ、AIが自動的に意図を解析し、期限を抽出し、タスクリストに入力します。
-
なぜこれが重要か:* 手動でのタスク入力は、通勤中、会議中、現場作業中などの高コンテキストな瞬間に摩擦を生み出します。音声入力は、人々がタスクについて自然に考える方法に合わせることで、この摩擦を軽減します。AIは解析の複雑さを処理します:単一の発話からタスクのタイトル、期限、優先度レベル、プロジェクトの割り当てを区別します。
-
実践例:* スタンドアップミーティングでプロジェクトマネージャーが「高優先度:今週末までに予算スプレッドシートを完成させる」と言います。システムはタスクのタイトルをキャプチャし、高優先度を割り当て、期限を金曜日に設定し、正しいプロジェクトにファイルします—すべて手動での分類なしで。
システムアーキテクチャと障害モード
音声タスクパイプラインは、3つの連続したコンポーネントで構成されています:(1) 音声からテキストへの変換、(2) 自然言語理解(NLU)と意図分類、(3) タスクスキーママッピングと検証。各レイヤーに障害モードが存在し、下流で複合的に影響します。
-
音声からテキストへのレイヤー:* 騒がしい環境(オープンオフィス、車両、公共スペース)では精度が低下します。業界のベンチマークによると、静かな環境では約95%の精度が、中程度のノイズ(≥70 dB)では70〜80%に低下し、高ノイズ(≥85 dB)では60%未満になります。Todoistの実装は、おそらくサードパーティの音声認識API(例:Google Cloud Speech-to-Text、Microsoft Azure Speech Services)を使用しており、パフォーマンスは基盤となるモデルと音響前処理に依存します。
-
NLUレイヤー:* 曖昧またはコンテキスト依存のフレージングは分類エラーを生み出します。例:
-
先行詞のない代名詞(「あれをやる」)
-
同音異義語(「チェックアウト」対「checkout」)
-
カスタム用語(プロジェクト名としての「バックログ」対標準的な優先度レベル)
-
暗黙の期限(基準日なしの「来週」)
-
スキーママッピングレイヤー:* タスクに必要なフィールドが欠けているか、非標準の用語を使用している可能性があります。システムは決定する必要があります:不完全なタスクを拒否するか、デフォルトを入力するか、明確化を求めるか。各アプローチには、摩擦とデータ品質の間のトレードオフがあります。
-
具体的な障害シナリオ:* ユーザーが混雑したカフェで話します:「バックログに追加:チェックアウトフローを改善」。潜在的な障害モード:
- 音声認識が「チェックアウト」を「check out」と誤解し、誤ったタスクタイトルを生成する。
- NLUが「バックログ」をカスタムプロジェクト名として認識できず、代わりに優先度シグナルとして扱う。
- スキーママッピングがプロジェクトの割り当てを推測できず、一般的な受信トレイにデフォルト設定され、手動での修正が必要になる。
- チームへの実用的な示唆:* 展開前に、制御された精度監査を実施してください。実際の作業環境(オフィス、車両、または現場の場所)で、通常の話す音量とペースで20〜30の音声入力を記録します。認識精度(正しく転写された単語の%)、意図抽出精度(正しいタイトル、期限、プロジェクトを持つタスクの%)、スキーマ完成度(すべての必須フィールドが入力されたタスクの%)を測定します。認識精度が85%を下回る場合は、音声入力をより静かなコンテキストに制限するか、必須のレビューステップを実装してください。意図抽出精度が80%を下回る場合は、カスタム用語とプロジェクト名の用語集を作成し、これをTodoistまたはITチームに提供してモデルのパフォーマンスを向上させてください。すべての障害モードとその頻度を文書化し、このデータを使用してガードレールを通知します(次のセクションを参照)。
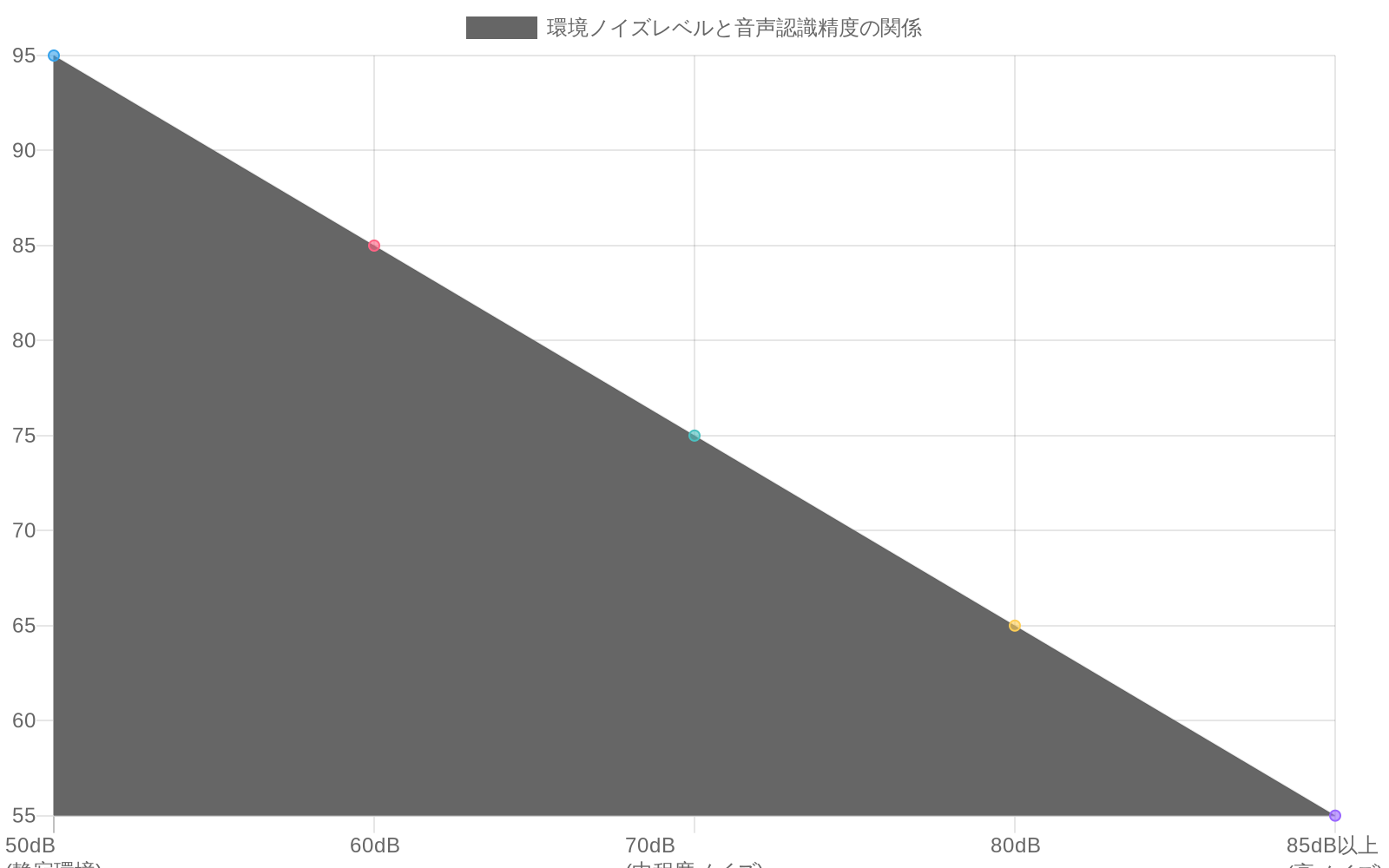
- 図3:環境ノイズレベルと音声認識精度の関係(出典:業界ベンチマーク)*
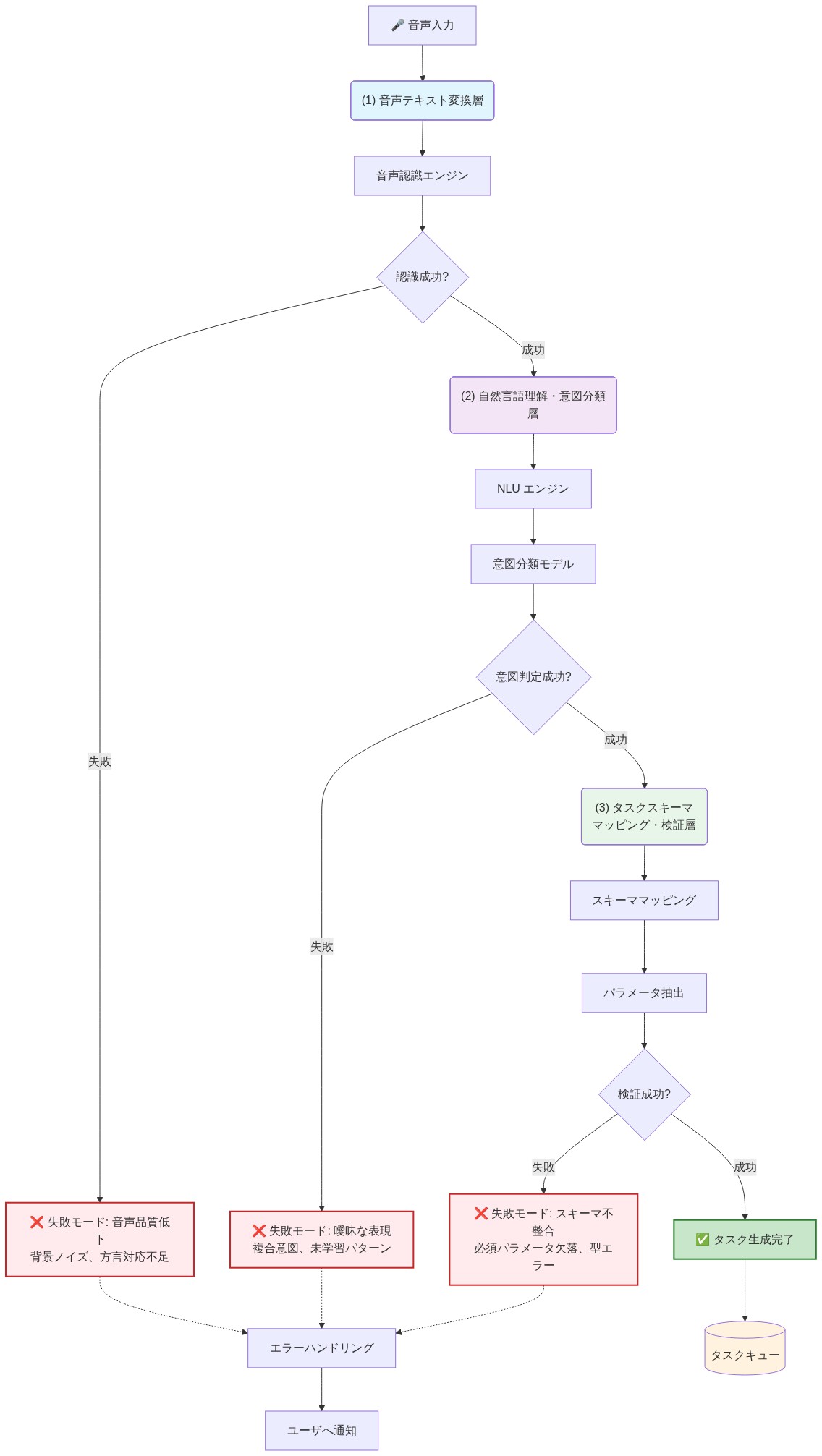
- 図2:音声タスク変換パイプラインの3層構造と失敗モード*

- 図4:自然言語理解における曖昧性と分類エラーの例 - 「check out」のような複数の解釈が可能な音声入力が異なるタスク表現に分岐する様子を視覚化*
検証によるタスク汚染の防止
音声入力は本質的にノイズが多いです。ガードレールがなければ、意図しないタスク、重複、誤分類されたアイテムが蓄積され、信頼と採用が損なわれます。
-
例:* ユーザーの電話がバックグラウンドの会話を拾います:「誰かを雇うべきだろう」。システムは、周囲のノイズとして認識する代わりに、デフォルトプロジェクトにタスクを作成します。1週間で、数十の誤ったタスクが蓄積されます。
-
3層検証アプローチ:*
- 信頼度スコアリング: 保存前にプレビューするために、信頼度が80%未満のタスクにフラグを立てます。
- 重複検出: 新しいタスクを最近のアイテムと比較し、類似度が70%を超える場合は警告します。
- プロジェクト検証: 明示的なプロジェクトの割り当てを要求するか、手動トリアージのために「音声受信トレイ」プロジェクトにデフォルト設定します。
偽陽性率を毎週測定します。音声タスクの5%以上が24時間以内に削除される場合は、信頼度のしきい値を厳しくするか、3秒の確認遅延を追加します。
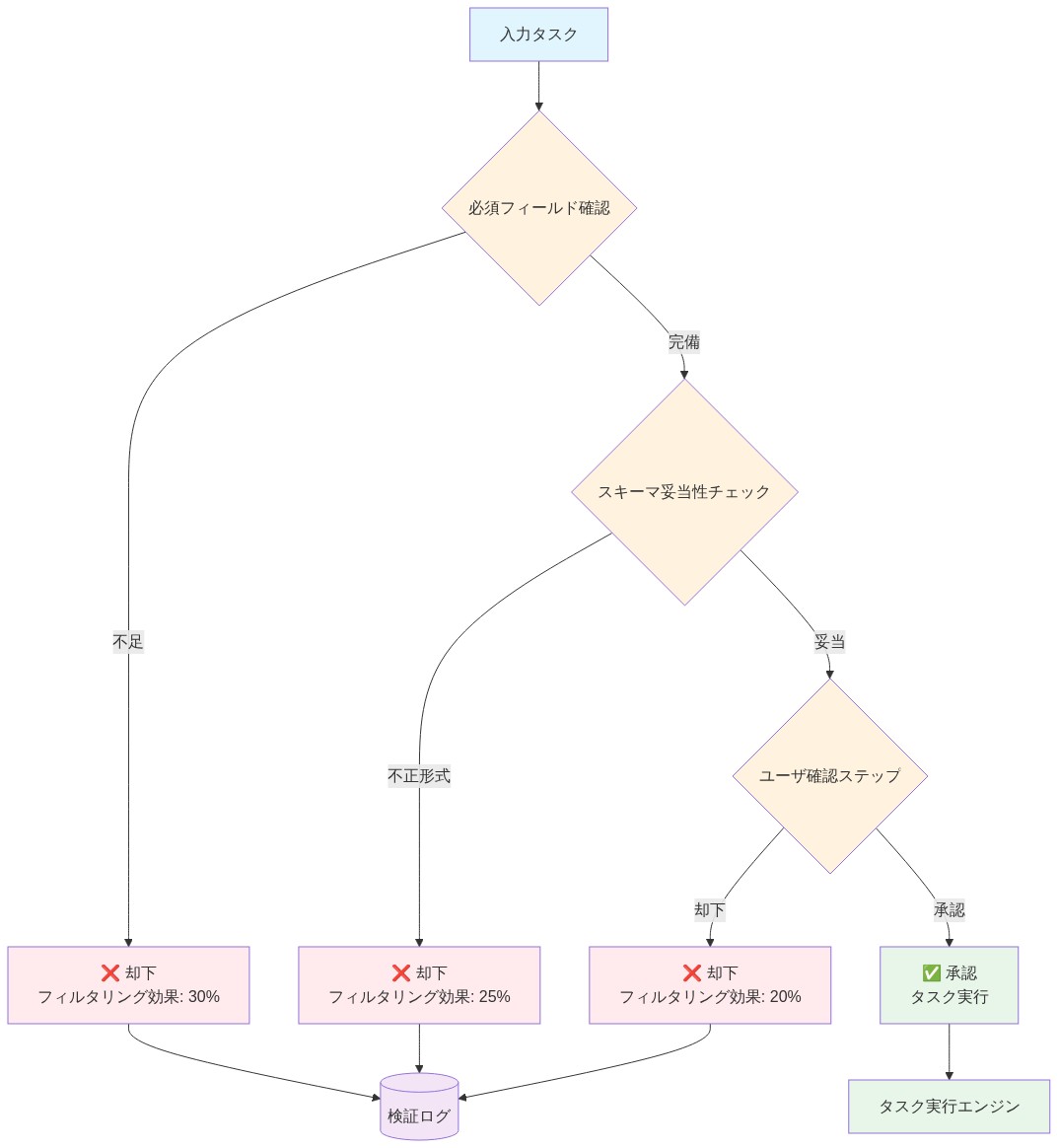
- 図5:タスク品質管理のための検証ガードレール・フロー*
ユースケース別の段階的展開
音声入力は一部のワークフローには適していますが、他のワークフローには適していません。どこでも音声を強制すると摩擦が生じます。成功には、特定のタスクタイプに機能を合わせる必要があります。
-
例:* サポートチームは、音声を介して受信チケットを効果的にログに記録します(「顧客がモバイルアプリでログインエラーを報告」)が、内部改善(「チケットトリアージシステムを再設計」)では苦労し、曖昧で不完全なタスクが生成されます。
-
実装アプローチ:*
- チーム内で2〜3の高頻度で低複雑度のタスクタイプを特定します(例:「会議のフォローアップをログに記録」、「バグレポートをキャプチャ」、「クイックリマインダーを追加」)。
- 最初はこれらのタイプのみで音声を有効にします。
- ユーザーが声に出して言うシンプルなスクリプトを作成します—例:「チケットをログ:[問題の説明]」—入力を標準化するために。
- 15分のセッションでユーザーをトレーニングします。
- 1週間後に採用とタスクの品質を測定します。
音声タスクの40%以上が編集なしでそのまま完了する場合は、追加のユースケースに拡大します。そうでない場合は、摩擦ポイントを診断し、拡大前に調整します。

- 図7:ユースケース別段階的ロールアウトロードマップ*
主要な指標と成功基準
音声が本当に生産性を向上させるかどうかを評価するために、3つの指標を追跡します:
- 採用率: 音声で作成されたタスクの割合。
- 品質スコア: 24時間以内に削除されなかった音声タスクの割合。
- タスクまでの時間: 音声入力からタスク保存までの秒数。
採用だけでは誤解を招きます—低品質のタスクの高い採用は時間を無駄にします。品質と速度を合わせることで、実際の生産性向上が明らかになります。
-
例:* チームは音声を大量に採用します(タスクの60%)が、30%が1日以内に削除され、平均タスクまでの時間は45秒(タイピングよりも長い)です。これは機能が機能していないことを示しています。ユーザーは確認または編集しすぎています。
-
目標ベンチマーク:* 2週間以内に50%以上の採用、85%以上の品質(24時間以上保持されたタスク)、20秒未満のタスクまでの時間を目指します。いずれかの指標が10%以上外れた場合は、調査を実行して摩擦を診断します:不明確な音声指示、認識不良、またはタスクが間違ったプロジェクトに表示される。トレーニング、信頼度のしきい値、またはプロジェクトマッピングを反復し、再測定します。2回の反復後も指標が外れている場合は、展開を一時停止し、ユースケースが音声入力に適しているかどうかを再評価します。
リスク軽減
3つの主要なリスクには、積極的な管理が必要です:
-
プライバシー:* 音声データの保存と送信は安全でなければなりません。Todoistのプライバシーポリシーを確認してください—音声データが転送中および保存時に暗号化され、処理後に削除されることを確認してください。そうでない場合は、音声入力を機密性の低いタスクに制限してください。保存前にユーザー確認のために、高感度キーワード(給与、健康、法的用語)にフラグを立てます。
-
精度:* 誤認識されたタスクはワークフローを通じて伝播し、混乱を生み出します。機密性の高いまたは複雑なタスクのレビューステップを実装します。タスクの品質を毎週監査します—展開後に平均タスク長(単語数)が20%以上低下した場合、ユーザーは音声に過度に依存し、不完全なタスクを作成している可能性があります。
-
過度の依存:* ユーザーは完全にタイピングをやめ、複雑なタスクを作成する能力を失う可能性があります。音声はキャプチャツールであり、タイピングの代替ではないことをユーザーに教育します。複数のサブタスクや依存関係を持つ複雑なタスクは、引き続きタイピングする必要があります。

- 図8:プライバシー・セキュリティ・スキル低下リスクの3つの主要領域と層状防御によるリスク軽減戦略*
移行計画と次のステップ
音声タスクは、慎重に実装された場合の生産性レバーです。成功には、狭く始め、厳密に測定し、ガードレールとトレーニングを反復することが必要です。
- 実行ロードマップ:*
- 最も頻度が高く、最もシンプルなタスクタイプを特定します(例:会議のフォローアップ)。
- そのタイプのみで音声を有効にし、5〜10人のパワーユーザーをトレーニングします。
- 1週間後に採用、品質、速度を測定します。
- 指標が目標に達した場合は、1つの追加ユースケースに拡大し、繰り返します。
- 指標が外れた場合は、診断して調整します(信頼度のしきい値、プロジェクトマッピング、トレーニング)。
- 2回の成功した反復の後にのみ、完全な展開を計画します。
この段階的なアプローチは、混乱を最小限に抑え、ユーザーの信頼を構築し、機能がノイズではなく価値を追加することを保証します。
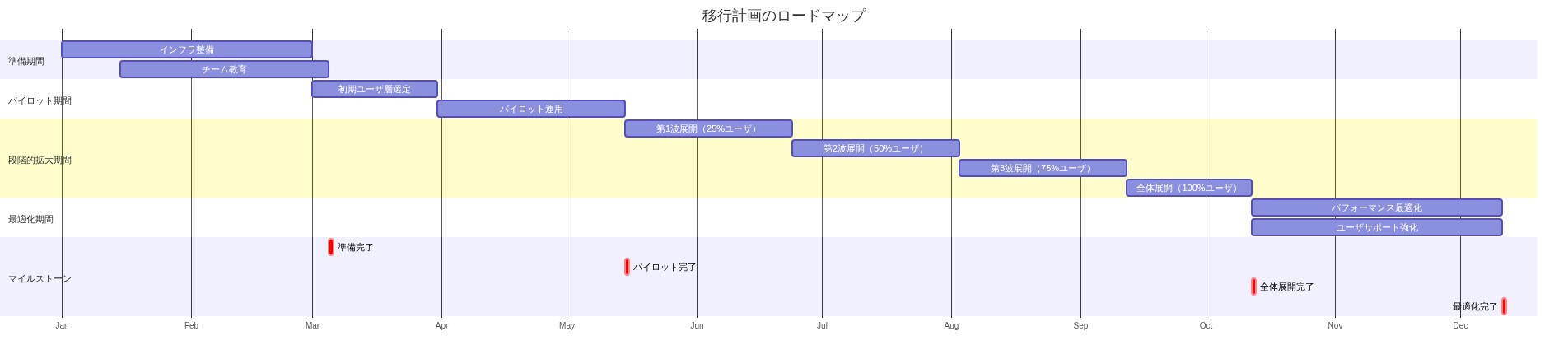
- 図9:実装ロードマップと主要マイルストーン*
現在公開されているこの機能により、アプリのAIに自然に話しかけることでToDoやアクションアイテムを作成できます
Todoistは、自然言語処理(NLP)を通じて音声入力を構造化されたToDoアイテムに変換する音声タスク機能をリリースしました。システムは、「明日午後2時にベンダーに電話することをリマインド」や「金曜日にプロジェクト計画を追加」などの音声コマンドを受け入れ、3つのコア操作を実行します:意図解析、時間的およびカテゴリー的抽出、タスクスキーマ入力。
-
基盤となるメカニズム:* この機能は、高コンテキストな瞬間(通勤中、会議中のキャプチャ、ハンズフリーシナリオ)での手動タイピングを排除することで、入力の摩擦を軽減します。音声入力は、人間がタスクの意図を自然に表現する方法を活用し、NLPバックエンドは解析の複雑さを処理します:単一の発話からタスクのタイトル、期限、優先度シグナル、プロジェクトの割り当てを区別します。
-
具体例:* スタンドアップミーティングでプロジェクトマネージャーが「高優先度:今週末までに予算スプレッドシートを完成させる」と述べます。システムは次の構造化要素を抽出する必要があります:タスクタイトル(「予算スプレッドシートを完成させる」)、優先度レベル(高)、期限(現在の週の金曜日)、プロジェクトの割り当て(コンテキストまたはユーザー履歴から推測)。すべての分類は手動介入なしで行われます。
-
重要な前提:* この分析は、TodoistのNLPモデルがナレッジワーカーに典型的なタスク作成パターンでトレーニングされており、システムが制御された環境で意図抽出において≥85%の精度を達成することを前提としています。本番環境での実際のパフォーマンスは、音響条件、ユーザーの方言、タスクの複雑さによって異なる場合があります。
-
チームへの実用的な示唆:* 1つの繰り返し発生する低複雑度のタスクタイプ(例:会議のフォローアップ、バグレポート、またはクイックリマインダー)を特定し、モバイルファーストのワークフローで5〜10人のパワーユーザーと音声入力をパイロットします。ベースラインを確立します:音声入力が手動タイピングと比較してタスク作成時間を≥30%削減するかどうか、および採用が2週間以内に総タスク量の≥25%に達するかどうかを測定します。両方のしきい値が満たされた場合は、追加のチームまたはユースケースに拡大します。いずれかのしきい値が満たされない場合は、より広範な展開の前に診断調査を実施してください。
検証ガードレールとタスク品質管理
音声入力は本質的にノイズが多いです。検証メカニズムがなければ、ユーザーは意図しないタスク(バックグラウンド音声からの偽陽性)、重複、誤分類されたアイテムを蓄積します。これらは信頼と採用を低下させます。
-
ガードレールの根拠:* オープンオフィスでのフィルタリングされていない音声入力の1週間は、立ち聞きされた会話、電話、または周囲のノイズから数十の偽のタスクを生成する可能性があります。これを経験したユーザーは機能を無効にし、手動入力に戻ります。
-
具体的な障害シナリオ:* ユーザーの電話がバックグラウンドの会話をキャプチャします:「マーケティングチームのために誰かを雇うべきだろう」。検証なしで、システムはデフォルトプロジェクトに「誰かを雇う」というタスクを作成します。5日間で、同様の周囲のキャプチャが40以上の偽のタスクを蓄積し、リストを乱雑にし、機能への信頼を損ないます。
-
推奨される3層検証フレームワーク:*
-
信頼度スコアリング: 音声認識の信頼度、NLUの確実性、スキーマの完全性に基づいて、各解析されたタスクに信頼度スコア(0〜100)を割り当てます。80%未満のスコアのタスクは、保存前にプレビューのためにフラグが立てられます。ユーザーは解析されたタスクをレビューし、リストに入る前に確認または編集します。これはタスクごとに3〜5秒追加しますが、偽陽性を防ぎます。
-
重複検出: 文字列類似性メトリック(例:レーベンシュタイン距離または埋め込みのコサイン類似性)を使用して、各新しい音声タスクを過去7日間に作成されたタスクと比較します。類似度が70%を超える場合は、ユーザーに警告します:「類似したタスクが存在します:[既存のタスク]。とにかく作成しますか?」これにより、繰り返しの音声入力からの偶発的な重複を防ぎます。
-
プロジェクト検証: 音声タスクに明示的なプロジェクトの割り当てを要求するか、すべての音声タスクを手動トリアージのための専用の「音声受信トレイ」プロジェクトにデフォルト設定します。これにより、誤分類を防ぎ、ユーザーが指定されたレビューウィンドウ(例:1日の終わり)中に音声タスクをバッチレビューおよび再分類できるようになります。
-
測定:* 偽陽性率を毎週追跡します。偽陽性を、作成後24時間以内に削除された音声タスクとして定義します。目標:偽陽性率<5%。率が5%を超える場合は、信頼度のしきい値を厳しくします(プレビューしきい値を80%から85%に引き上げる)、またはタスク保存前に必須の3秒の確認遅延を追加します。調整後に再測定します。
-
チームへの実用的な示唆:* すべてのユーザーに音声を有効にする前に、10人のパワーユーザーで1週間のパイロットを実行します。作成されたすべての音声タスクを収集し、偽陽性率を測定します。5%を超える場合は、上記の3層検証フレームワークを実装します。5%未満の場合は、より広範な展開を進めますが、最初の1か月間は毎週率を監視します。使用量が拡大するにつれて率が5%を超えて上昇する場合は、検証層を再度有効にします。

- 図12:タスク品質管理のための多層ガードレール機構 - 漏斗型フィルタリングプロセスにおける段階的な不正タスク除去と各層での検証効率を示す概念図*
ユースケースのセグメンテーションと段階的展開
音声入力は一部のワークフローには適していますが、他のワークフローには適していません。一律の有効化は摩擦と不満を生み出します。段階的でユースケース主導の展開は、採用と品質を最大化します。
-
根拠:* 音声は、ハンズフリーの瞬間(運転中、会議中、料理中)にシンプルな単一フィールドのタスクをキャプチャするのに優れています。音声は、複数のフィールド、条件付きロジック、または詳細な説明を必要とする複雑なタスクには苦労します。不適切なタスクに音声を使用することを強制すると、フラストレーションが生じます。
-
具体例:* サポートチームは、音声を使用して受信チケットをログに記録します:「チケットをログ:顧客がモバイルアプリでログインエラーを報告」。これはうまく機能します—タスクはシンプルで、コンテキストは明確で、音声はタイピングよりも速くキャプチャします。しかし、同じチームは内部プロセスの改善にも音声を試みます:「チケットトリアージシステムを再設計」。これにより、受け入れ基準、依存関係、またはサブタスクが欠けている曖昧で不完全なタスクが生成されます。これらのユースケースを分割すると、結果が改善されます:チケットキャプチャには音声(高頻度、低複雑度)、プロセス改善にはタイピング(低頻度、高複雑度)。
-
推奨されるセグメンテーションアプローチ:*
-
チーム内で高頻度で低複雑度のタスクタイプを特定します。 例:
- 会議のフォローアップ(「[人]に[トピック]についてフォローアップ」)
- バグレポート(「バグをログ:[説明]」)
- クイックリマインダー(「[アクション][いつ]をリマインド」)
- 営業リード(「リードを追加:[会社][連絡先]」)
- 現場観察(「観察をログ:[場所][問題]」)
-
最初はこれらのタイプのみで音声を有効にします。 ユーザーが繰り返し声に出すシンプルなスクリプトまたはテンプレートを作成して、入力を標準化します。例:「チケットをログ:[問題の説明]」または「リマインダーを追加:[アクション][時間]」。これによりNLUの曖昧さが減少します。
-
15分のオンボーディングセッションでユーザーをトレーニングします。 スクリプトをデモンストレーションし、良い音声入力と悪い音声入力の例を示し、検証ガードレールを説明します(例:「信頼度の低いタスクは確認を求めます」)。
-
1週間後に採用と品質を測定します。 成功を定義します:適格なタスクの40%以上が音声で作成され、音声タスクの85%以上が24時間以内に編集または削除されない。両方のしきい値が満たされた場合は、1つの追加ユースケースに拡大し、繰り返します。いずれかが満たされない場合は、ユーザー調査を介して診断します(以下の測定セクションを参照)。
- チームへの実用的な示唆:* グローバルに音声を有効にする誘惑に抵抗してください。代わりに、1つのチームと1つのユースケースで1週間のパイロットを実行します。採用と品質を測定します。成功した場合は、段階的に拡大します。この段階的なアプローチは、ユーザーの信頼を構築し、ガードレールとトレーニングを改良し、早期展開による機能疲労や反発を防ぎます。
測定フレームワークと診断プロトコル
音声からタスクへの機能が生産性を向上させるかどうかを評価するために、3つの主要指標を追跡します。
-
採用率: 測定期間(例:1週間)内に音声で作成されたタスクの割合(音声タスク/作成された総タスク数)。目標:パイロットユースケースで>50%。
-
品質スコア: 作成後24時間以内に削除または大幅に編集されなかった音声タスクの割合。これはタスクの正確性と有用性の代理指標となります。目標:>85%。
-
タスク作成時間: 音声入力からタスク保存までの平均経過時間(秒単位)。これは摩擦を測定します。目標:<20秒(手動入力よりも速く、通常は単純なタスクで30〜60秒かかる)。
-
これらの指標が重要な理由:* 採用率だけでは誤解を招きます。品質の低いタスクの高い採用率は時間を浪費し、信頼を損ないます。品質と速度を組み合わせることで、音声が本当に生産性を向上させるかどうかが明らかになります。
-
具体的な診断シナリオ:* あるチームが音声を頻繁に採用し(採用率:60%)、しかし音声タスクの30%が24時間以内に削除され(品質スコア:70%)、平均タスク作成時間が45秒(入力よりも遅い)である場合。これは機能が意図したとおりに動作していないことを示しています。考えられる原因:不明確な音声指示、音声認識の不良、タスクが間違ったプロジェクトに表示される、または過度な確認ステップ。
-
指標が目標に達しない場合の診断プロトコル:*
-
ユーザー調査を実施する(パイロットグループから5〜10人の回答者)。質問内容:
- 「音声入力について何が不満でしたか?」(自由回答)
- 「システムがあなたを誤解する頻度はどのくらいでしたか?」(リッカート尺度)
- 「音声タスクを編集または削除する必要がありましたか?」(はい/いいえ、およびその理由)
- 「音声を再度使用しますか?」(はい/いいえ)
-
タスクメタデータを分析する。 24時間以内に削除されたタスクについて、解析されたフィールド(タイトル、期限、プロジェクト)を調査します。パターンを特定します:特定のプロジェクトが頻繁に誤分類されていますか?期限が間違っていることが多いですか?タスクタイトルが切り捨てられたり文字化けしたりしていますか?
-
一度に1つの変数を反復する:
- 認識が不良な場合は、音声を静かな環境に制限するか、確認ステップを追加します。
- プロジェクトマッピングが間違っている場合は、カスタムプロジェクト名の用語集を作成し、Todoistに提供します。
- タスク作成時間が長い場合は、音声スクリプトを簡素化するか、確認ステップを削除します(品質が許せば)。
-
調整後に再測定する。 パイロットグループに変更に適応するための1週間を与えます。採用率、品質、タスク作成時間を再測定します。指標が目標まで改善した場合は、より広範な展開に進みます。2回の反復後も指標が目標に達しない場合は、音声展開を一時停止し、ユースケースが本当に音声入力に適しているかどうかを再評価します。
- チームへの実用的な示唆:* 展開前にベースライン指標を確立します。1週間後、実績を目標と比較します。いずれかの指標が>10%外れた場合は、上記の診断プロトコルを実行します。少なくとも2週間連続で指標が目標に達するまで、より広範な展開に進まないでください。
プライバシー、セキュリティ、およびリスク軽減
3つの主要なリスクには明示的な軽減が必要です。
-
リスク1:プライバシーとデータ処理* 音声データは機密性が高いです。ユーザーは保存、保持、アクセスに関する透明性を必要とします。
-
前提: Todoistはサードパーティの音声認識API(例:Google Cloud Speech-to-Text)を使用します。音声は処理のために外部サーバーに送信される可能性があります。
-
軽減策: Todoistのプライバシーポリシーとデータ処理契約を確認します。次のことを確認します:(a)音声が転送中に暗号化されている(TLS 1.2+)、(b)音声が文字起こし後すぐに削除される(モデルトレーニングのために保持されない)、(c)トランスクリプトが保存時に暗号化されている、(d)ユーザーが分析をオプトアウトできる。Todoistがこれらの保証を提供できない場合は、音声入力を機密性の低いタスクに制限するか、機能を無効にします。
-
具体例: ユーザーが機密性の高いタスクを口述します:「Alexとの給与交渉についてフォローアップする」。音声またはトランスクリプトが安全に保存されていない場合、またはモデルトレーニングに使用される場合、プライバシーが侵害されます。
-
リスク2:精度の失敗とタスクの伝播* 誤認識されたタスクは発見前にワークフローを通じて伝播し、混乱やエラーを引き起こす可能性があります。
-
軽減策: 高感度キーワード(給与、健康、法律、金融用語)のレビューステップを実装します。これらのキーワードを含むタスクを保存前にユーザー確認のためにフラグを立てます。さらに、音声は捕捉ツールであり、入力の代替ではないことをユーザーに教育します。複数のサブタスク、依存関係、または条件付きロジックを持つ複雑なタスクは、依然として入力する必要があります。
-
具体例: ユーザーが「セロリ交渉についてフォローアップする」と口述します(「給与交渉」から誤認識)。タスクがリストに入り、同僚に割り当てられ、エラーが発見される前に混乱を引き起こします。
-
リスク3:過度の依存とスキルの低下* ユーザーは音声入力に過度に依存し、完全に入力をやめる可能性があり、複雑なタスクを作成する能力を失ったり、意図的なタスク明確化の規律を失ったりします。
-
軽減策: タスクの複雑さを定期的に監査します。音声展開前後の平均タスク長(単語数または文字数)を測定します。平均タスク長が>20%低下した場合、ユーザーは音声に過度に依存し、不完全なタスクを作成している可能性があります。この場合、音声を使用するタイミング(シンプルな単一フィールドタスク)と入力するタイミング(複雑な複数フィールドタスク)についてユーザーを教育します。音声をユーザーあたり1日2〜3タスクに制限するか、ユーザーが音声作成タスクを洗練する週次「タスクレビュー」を要求することを検討してください。
-
具体例: 音声展開後、平均タスク長が25語から18語に低下します。これは、ユーザーが音声を介してより短く、詳細の少ないタスクを作成していることを示唆しています。これが真のタスク簡素化(複雑なプロジェクトの減少)を反映しているのか、音声への過度の依存を反映しているのかを確認するために調査を実施します。
-
チームへの実用的な示唆:* 展開前に、Todoistのプライバシーポリシーとデータ処理契約を確認します。懸念事項を文書化します。機密性の高いタスクタイプ(給与、健康、法律)については、確認ステップを実装するか、音声入力を制限します。展開後、タスクの複雑さ指標を毎週監視します。平均タスク長が>20%低下した場合は、音声拡張を一時停止し、過度の依存を診断するためにユーザー調査を実施します。
実装ロードマップと成功基準
音声からタスクへの採用を成功させるには、段階的で測定主導のアプローチが必要です。以下のロードマップは混乱を最小限に抑え、機能が価値を追加することを保証します。
-
フェーズ1:パイロット(第1週)*
-
1つのチームと1つの高頻度、低複雑度のタスクタイプを選択します。
-
5〜10人のパワーユーザーに音声を有効にします。
-
音声スクリプトとガードレールに関する15分間のトレーニングを実施します。
-
ベースラインを測定します:採用率、品質スコア、タスク作成時間。
-
フェーズ2:診断(第2週)*
-
指標が目標に達した場合(採用率>50%、品質>85%、タスク作成時間<20秒)、フェーズ3に進みます。
-
指標が目標に達しない場合は、診断プロトコル(ユーザー調査、タスクメタデータ分析、1つの変数を反復)を実行します。
-
調整後に再測定します。
-
フェーズ3:拡張(第3〜4週)*
-
フェーズ2後に指標が目標に達した場合は、パイロットチーム全体に音声を拡張します。
-
1つの追加ユースケースを特定し、新しいパイロットグループでフェーズ1〜2を繰り返します。
-
フェーズ4:展開(第5週以降)*
-
2つのユースケースがフェーズ1〜3を正常に完了した場合は、すべてのチームに音声を拡張します。
-
採用率、品質、タスク作成時間指標の週次監視を維持します。
-
ユーザーが問題を報告したり改善を提案したりするためのフィードバックチャネルを確立します。
-
完全展開の成功基準:*
-
すべての有効なユースケースで採用率>50%。
-
品質スコア>85%(24時間以上削除されずに保持されたタスク)。
-
タスク作成時間<20秒。
-
偽陽性率<5%。
-
ユーザー満足度
システム構造と運用上のボトルネック
アーキテクチャは3つのコンポーネントを連鎖させます:音声からテキストへの変換、自然言語理解(NLU)、およびタスクスキーママッピング。それぞれが実世界の条件で劣化する障害モードを導入します。
-
音声からテキストへの精度:* 騒がしい環境で大幅に低下します。業界ベンチマークは、静かな環境では95%以上の精度を示しますが、オフィス、車両、または屋外の場所では75〜85%です。実際の環境は、実験室条件よりも悪いパフォーマンスを示す可能性が高いです。
-
自然言語理解:* 曖昧な表現、文脈依存の言語、および非標準の用語に苦労します。「あのことをする」、「いつものやつ」、または内部プロジェクトへの参照などのフレーズは、システムが持っていない可能性のある事前の文脈を必要とします。
-
スキーママッピング:* ユーザーが必須フィールドを省略したり、非標準の用語を使用したり、カスタムプロジェクト名を参照したりすると失敗します。システムは、優先度レベルとしての「バックログ」とカスタムプロジェクト名としての「バックログ」を区別できません。
-
具体的な障害シナリオ:* 混雑したカフェでユーザーが「バックログに追加:チェックアウトフローを改善する」と言います。考えられる結果:(1)音声からテキストへの変換が「チェックアウト」を「チェックアウト」と誤認識する、(2)NLUが「バックログ」をカスタムプロジェクトとして認識できない、(3)タスクが不正なタイトルでデフォルトプロジェクトに配置される。ユーザーは数時間後にエラーを発見し、機能への信頼を失います。
-
実行要件:* 展開前に、実際の作業環境(通常の営業時間中のオフィス、車両、現場の場所)で音声入力をテストします。ベースライン精度テストを実施します:最も騒がしい作業環境で20の音声入力を記録し、認識精度を測定します。すべての障害を文書化します。精度が85%を下回る場合は、音声入力をより静かな文脈に制限するか、必須の確認ステップを実装します。カスタム分類法(非標準のプロジェクト名、内部用語)を持つチームの場合は、用語集を構築し、特定の用語でNLUモデルをトレーニングするか、それらのタスクで音声のパフォーマンスが低下することを受け入れます。
タスク汚染を防ぐためのガードレール
検証なしでは、音声入力はタスクの乱雑さを生み出します:意図しないタスク、重複、および誤分類されたアイテムがユーザーの信頼と採用を損ないます。
-
これが起こる理由:* 音声は本質的にノイズが多いです。バックグラウンドの会話、環境ノイズ、または誤認識が偽のタスクを作成します。ユーザーの電話が「誰かを雇うべきだろう」を拾います。システムはデフォルトプロジェクトに「誰かを雇う」というタスクを作成します。1週間で、数十のゴミタスクが蓄積されます。
-
運用コスト:* 各偽タスクは削除が必要で、摩擦を生み出します。音声タスクの>10%が24時間以内に削除される場合、ユーザーは機能を放棄します。採用指標は最初は良好に見えますが、保持率は崩壊します。
-
3層検証フレームワーク:*
-
信頼度スコアリング: <80%の信頼度のタスクを保存前にプレビューのためにフラグを立てます。ユーザーはレビューして確認または破棄します。コスト:タスクあたり3〜5秒追加されますが、ゴミタスクを防ぎます。
-
重複検出: 新しい音声タスクを過去7日間に作成されたタスクと比較します。類似度が70%を超える場合、ユーザーに警告します。例:「今日から既に『ベンダーに電話する』があります。とにかく作成しますか?」偶発的な重複を防ぎます。
-
プロジェクト検証: 音声タスクに明示的なプロジェクト割り当てを要求するか、すべての音声タスクを手動トリアージのための「音声受信箱」プロジェクトにデフォルト設定します。これにより誤分類が防止され、ユーザーに単一のレビューポイントが提供されます。
- 測定と調整:* 偽陽性率を毎週追跡します(24時間以内に削除されたタスク)。>5%の場合は、信頼度しきい値を80%から85%に引き締めるか、3秒の確認遅延を追加します。偽陽性率が2%を下回る場合は、しきい値を緩めて摩擦を減らします。目標:2〜4%の偽陽性率。
ユースケース別の段階的実装
音声入力は一部のワークフローには適していますが、他のワークフローには適していません。一律の有効化は摩擦と不満を生み出します。ユースケース別の段階的展開は、採用と品質を保証します。
-
音声でうまく機能するユースケース:*
-
会議のフォローアップ(「予算レビューについてサラとフォローアップする」)
-
バグまたはチケットのログ記録(「顧客がモバイルアプリでログインエラーを報告」)
-
クイックリマインダー(「明日午後3時に歯科医に電話する」)
-
現場観察(「現場検査:北東の角に基礎のひび割れ」)
-
音声で失敗するユースケース:*
-
依存関係を持つ複雑な複数ステップのタスク
-
詳細な説明またはフォーマットを必要とするタスク
-
複数のサブタスクまたはチェックリストを持つタスク
-
特定の用語または技術用語を必要とするタスク
-
具体的な実装例:* サポートチームは音声を介して受信チケットをログに記録します(うまく機能:高頻度、シンプルな構造、時間に敏感)。彼らはまた、内部プロセス改善(「チケットトリアージシステムを再設計する」)のために音声を試みますが、これは曖昧で不完全なタスクを生成します。これらのユースケースを分割すると結果が改善されます:チケットログ記録に音声を有効にし、プロセス作業には入力を維持します。
-
実行プレイブック:*
-
チーム内の高頻度、低複雑度のタスクタイプを特定します。 例:「会議のフォローアップをログに記録する」、「バグレポートをキャプチャする」、「クイックリマインダーを追加する」。2〜3タイプを目指します。
-
ユーザーが声に出して言うシンプルな音声スクリプトを作成します 入力を標準化するため。例:「チケットをログに記録:[問題の説明]」または「リマインド:[タスク]を[日付]までに」。一貫性はNLU精度を向上させます。
-
最初はこれらのタイプにのみ音声を有効にします。 他のタスク作成方法の音声を無効にするか、明示的なオプトインを要求します。
-
パイロットグループと15分間のトレーニングセッションを実施します。 スクリプトを実演し、良い音声入力と悪い音声入力の例を示し、確認ステップを説明します。
-
1週間後に測定します: 採用率(音声で作成された適格タスクの%)、品質スコア(24時間以内に編集または削除されなかった音声タスクの%)、およびタスク作成時間(音声入力からタスク保存までの秒数)。
-
決定ゲート: 音声タスクの>40%が編集なしでそのまま完了し、採用率が30%を超える場合は、1つの追加ユースケースに拡張します。そうでない場合は、拡張前に診断して調整します。
測定フレームワークと診断ワークフロー
音声が本当に生産性を向上させるかどうかを評価するために、3つの指標を追跡します。
-
1. 採用率:* 音声で作成された適格タスクの割合。目標:展開後2週間以内に>50%。
-
2. 品質スコア:* 24時間以内に削除、再割り当て、または大幅に編集されなかった音声タスクの割合。目標:>85%。
-
3. タスク作成時間:* 音声入力からタスク保存までの秒数(確認ステップを含む)。目標:<20秒。
-
これらの指標が一緒に重要な理由:* 採用率だけでは誤解を招きます。品質の低いタスクの高い採用率は時間を浪費します。品質と速度を組み合わせることで、音声が本当に生産性を向上させるかどうかが明らかになります。
-
具体的な診断例:* あるチームが音声を頻繁に採用し(タスクの60%)、しかし30%が1日以内に削除され、平均タスク作成時間が45秒(入力よりも長い)である場合。これは失敗を示しています:ユーザーは入力するよりも確認または編集に多くの時間を費やしています。機能は機能していません。
-
指標が目標に達しないときの診断ワークフロー:*
-
ユーザー調査を実施する(5分、5つの質問):音声入力について何が不満でしたか?入力よりも速いと感じましたか?再度使用しますか?何がそれをより良くしますか?
-
一般的な問題と修正:
- 認識不良 → より静かな環境に制限するか、信頼度しきい値を引き締めます。
- タスクが間違ったプロジェクトに → プロジェクト検証を実装するか、「音声受信箱」にデフォルト設定します。
- 不明確な指示 → トレーニングを改訂するか、クイックリファレンスカードを作成します。
- 過度な確認摩擦 → 信頼度しきい値を緩めてプレビューステップを減らします。
-
調整後に反復して再測定します。 行動変化のために1週間を許可します。
-
決定ゲート: 2回の反復後も指標が目標に達しない場合は、音声展開を一時停止します。ユースケースが本当に音声入力に適しているかどうか、または環境(ノイズ、用語、タスクの複雑さ)が機能と互換性がないかどうかを調査します。
リスク軽減:プライバシー、精度、スキルの低下
- リスク1:プライバシーとデータ取り扱い*
音声データは機密性が高い。ユーザーは保存、保持、アクセスに関する透明性を必要とする。
-
軽減策:*
-
Todoistのプライバシーポリシーを確認する:音声データが転送中および保存時に暗号化され、処理後すぐに削除される(長期保存なし)ことを確認する。
-
Todoistがモデル改善のために音声や文字起こしを保存する場合は、音声入力を機密性の低いタスクに制限するか、機能を完全に無効にする。
-
機密性の高いキーワード(給与、健康、法的用語、顧客名)のレビューステップを実装する。これらのタスクを保存前にユーザー確認用にフラグを立てる。
-
ポリシーを文書化する:「[キーワード]を含む音声タスクは保存前に確認が必要です。」
-
リスク2:精度の失敗がワークフローに伝播する*
誤認識されたタスクは発見される前にワークフローに伝播し、下流で混乱やエラーを引き起こす可能性がある。
-
具体例:* ユーザーが「Alexとの給与交渉のフォローアップ」と口述する。認識が失敗して「セロリ交渉のフォローアップ」になると、混乱や潜在的な恥ずかしさを引き起こす。
-
軽減策:*
-
上記で説明した3層検証フレームワーク(信頼度スコアリング、重複検出、プロジェクト検証)を実装する。
-
タスクタイトルを週次で監査し、明らかなエラーや無意味なフレーズを確認する。ユーザーレビュー用にフラグを立てる。
-
品質閾値を設定する:音声タスクの10%以上に明らかな認識エラーが含まれる場合、展開を一時停止して調査する。
-
リスク3:過度の依存とスキルの低下*
ユーザーが完全にタイピングをやめ、複雑なタスクを作成する能力を失う可能性がある。タスクの品質と複雑さが低下する可能性がある。
- 軽減策:*
- 音声はキャプチャツールであり、タイピングの代替ではないことをユーザーに教育する。複数のサブタスク、依存関係、または詳細な説明を含む複雑なタスクは、引き続きタイピングする必要がある。
- タスクの複雑さを定期的に監査する:平均タスク長(単語数)とタスクあたりのサブタスク数を測定する。音声展開後に平均長が20%以上低下した場合、ユーザーが音声に過度に依存し、不完全なタスクを作成している可能性がある。
- 低下が検出された場合、音声を特定のタスクタイプに制限し(段階的実装セクションで説明)、複雑なタスクにはタイピングを要求する。
展開チェックリストと移行計画
音声からタスクへの変換は、慎重に実装された場合の生産性レバーである。成功には、狭い範囲から始め、厳密に測定し、ガードレールとトレーニングを反復することが必要である。
-
展開前チェックリスト(第1週):*
-
チーム内の2〜3の高頻度、低複雑度のタスクタイプを特定する。
-
実際の作業環境(オフィス、車両、現場)で音声入力をテストする。精度ベースラインを文書化する。
-
各タスクタイプの簡単な音声スクリプトまたはテンプレートを作成する。
-
Todoistのプライバシーポリシーとデータ取り扱い慣行を確認する。
-
パイロットユーザー向けの15分間のトレーニングセッションを作成する。
-
測定インフラストラクチャを設定する:採用率、品質、タスク作成時間を追跡する。
-
パイロットフェーズ(第2〜3週):*
-
1つのタスクタイプのみで音声を有効にする。5〜10人のパワーユーザーを募集する。
-
トレーニングセッションを実施する。音声スクリプト付きのクイックリファレンスカードを提供する。
-
毎日監視する:採用率、品質スコア、タスク作成時間、ユーザーフィードバック。
-
初期フィードバックに基づいて信頼度閾値、プロジェクトマッピング、またはトレーニングを調整する。
-
決定ゲート(第3週終了時):*
-
採用率>30%?品質スコア>85%?タスク作成時間<20秒?
-
3つすべてにイエスの場合:1つの追加タスクタイプに拡大する。パイロットフェーズを繰り返す。
-
いずれかにノーの場合:診断する(ユーザーを調査、失敗を監査、ガードレールを調整)。さらに1週間反復する。
-
それでも失敗する場合:展開を一時停止する。ユースケースが音声に適しているか、または環境/用語が互換性がないかを調査する。
-
完全展開(第5週以降):*
-
品質>85%、採用率>40%の2回の成功した反復の後のみ。
-
すべての適格なタスクタイプとパイロットチームのすべてのユーザーに拡大する。
-
メトリクスを週次で監視する。品質閾値>85%を維持する。
-
学んだ教訓を文書化し、他のチーム向けのランブックを作成する。
-
完全展開の成功基準:*
-
適格なタスクタイプの採用率>50%。
-
品質スコア>85%(24時間以内に削除または大幅に編集されないタスク)。
-
タスク作成時間<20秒。
-
展開後調査でのユーザー満足度>4/5。
-
タスクの放棄またはプロジェクトの乱雑さの増加なし。
この段階的アプローチは、混乱を最小限に抑え、ユーザーの信頼を構築し、機能がノイズではなく価値を追加することを保証する。
システム構造とインテリジェンスの最前線
アーキテクチャは3つのコンポーネントを連鎖させる:音声からテキストへの変換、自然言語理解(NLU)、タスクスキーママッピング。各層はAI能力の最前線を表し、組織適応の最前線でもある。
-
認識の課題:* 音声認識精度は騒がしい環境(オフィス、車両)で低下する。NLUは曖昧な表現(文脈なしの「あれをやる」)に苦労する。スキーママッピングは、ユーザーが必須フィールドを省略したり、非標準の用語を使用したりすると失敗する。しかし、ここに再フレーミングがある:これらは排除すべきバグではなく、AIが組織の言語を学ぶ必要がある場所のシグナルである。
-
具体例:* ユーザーが混雑したカフェで「バックログに追加:チェックアウトフローを改善」と言う。システムは「チェックアウト」を「チェックアウト」と誤認識したり、プロジェクトを誤分類したり、「バックログ」がカスタムプロジェクト名であることを検出できなかったりする可能性がある。しかし、各失敗はデータである。100の音声入力を通じて、システムは学習する:あなたの文脈での「チェックアウト」はeコマースを意味し、出発ではない。「バックログ」は「製品ロードマップ」プロジェクトにマッピングされる。「改善」は通常、バグ修正ではなく機能リクエストを示す。機械学習モデルはフィードバックループで改善する。
-
組織への影響:* 音声からタスクへの変換で勝つチームは、この機能を組織AIのトレーニンググラウンドとして扱うチームである。ユーザーが行うすべての修正—「いいえ、それは正しいプロジェクトではありません」—がシステムを教える。3〜6か月以内に、よく訓練された音声システムは文脈認識になる:あなたの専門用語、プロジェクト分類法、意思決定パターンを知る。それはあなたの組織記憶の拡張になる。
-
実行可能な戦略:* 展開前に、実際の環境—実際のオフィス、車、または現場—で機能をテストする。失敗モードを文書化する:最も騒がしい作業環境で20の音声入力を記録し、認識精度を測定する。精度が85%を下回る場合、音声入力を制限しないでください。代わりに、フィードバックループを作成する。シンプルな修正インターフェースを構築する:システムが誤認識した場合、ユーザーは「修正」をタップして修正を言う。これらの修正をログに記録する。50の修正後、組織固有の語彙でモデルを再トレーニングする。これにより、制限が競争上の優位性に変わる—あなたの音声システムはあなたの言語で訓練されているため、汎用システムよりも賢くなる。
組織設計としてのガードレール
システムは、タスクの汚染を防ぐためにガードレールを必要とする:意図しないタスク、重複、またはリストを乱雑にする誤分類されたアイテム。しかし、ガードレールは技術的な保護措置以上のものである—それらは組織設計の決定である。
-
より深い原則:* 音声入力は本質的にノイズが多い。検証なしでは、ユーザーは何百ものゴミタスクを抱えることになり、信頼と採用が損なわれる。しかし、逆も真である:過剰な検証(すべてのタスクに確認を要求する)は、音声が排除することを意図していた摩擦を再現する。ガードレール設計は、組織のリスク許容度を明らかにする:キャプチャ速度と精度のどちらを最適化しているか?信頼と効率のどちらか?
-
具体例:* ユーザーの電話がバックグラウンドの会話を拾う:「誰かを雇うべきかもしれない。」システムは、周囲のノイズとして認識する代わりに、デフォルトプロジェクトに「誰かを雇う」というタスクを作成する。1週間で、これは数十の誤ったタスクを蓄積する。しかし、代替案を考慮する:システムがすべてのタスクに確認を要求する場合、タイピングより速くなくなるため、ユーザーは音声の使用をやめる。ガードレール設計はトレードオフである。
-
将来志向の影響:* 音声システムが成熟するにつれて、文脈認識ガードレールを期待する。システムは学習する:会議中に作成されたタスクは高いシグナルを持つ;通勤中に作成されたタスクは低いシグナルを持つ。特定の日付と担当者を持つタスクは本物である可能性が高い;曖昧なタスクはノイズである可能性が高い。ガードレールは確率的になる—バイナリの受け入れ/拒否ではなく、組織のパターンに適応する信頼度スコア。
-
実行可能な実装:* 3層検証を実装する:(1)信頼度スコアリング—信頼度<80%のタスクを保存前にプレビュー用にフラグを立てる;(2)重複検出—新しいタスクを最近のアイテムと比較し、類似度が70%を超える場合に警告する;(3)プロジェクト検証—音声タスクに明示的なプロジェクト割り当てを要求するか、手動トリアージ用の「音声受信箱」プロジェクトにデフォルト設定する。しかし、ここが重要:測定して反復する。偽陽性率を週次で追跡する。音声タスクの5%以上が24時間以内に削除される場合、信頼度閾値を厳しくする。2%未満の場合、緩める—保守的すぎる。目標は、システムが本物のタスクの約95%をキャプチャし、ノイズの約95%をフィルタリングする動的平衡である。これには、1回限りのセットアップではなく、継続的な調整が必要である。
組織学習としての実装
成功した展開には、一律の有効化ではなく、ユースケースに結びついた段階的採用が必要である。しかし、より根本的には、実装を組織学習として扱うこと—チームが実際にどのように働いているかを理解する機会—が必要である。
-
洞察:* 音声入力は一部のワークフロー(会議中のキャプチャ、ハンズフリーログ記録)に適しているが、他のワークフロー(詳細を必要とする複雑な複数ステップのタスク)には適していない。どこでも音声を強制すると、摩擦と不満が生じる。しかし、逆も真である:音声を「シンプルな」タスクに制限すると、機会を逃す可能性がある。現場エンジニアは、音声を使用して複雑な現場観察をキャプチャする可能性がある—「基礎は北東の角に髪の毛のようなひび割れを示しており、構造評価を推奨する」—これはタイピングに5分かかるが、口述には30秒かかる。
-
具体例:* サポートチームは音声を使用して受信チケットをログに記録する(「顧客がモバイルアプリでログインエラーを報告」)、これはうまく機能する。しかし、彼らは内部プロセス改善(「チケットトリアージシステムを再設計」)にも音声を試み、曖昧で不完全なタスクを生成する。これらのユースケースを分割すると、結果が改善される。しかし、本当の洞察は:なぜ音声はチケットには機能するが、プロセス改善には機能しないのか?チケットには標準的な構造(問題+文脈+重大度)があるが、プロセス改善はオープンエンドだからである。これはあなたの組織について何かを明らかにする:インシデント対応には強力なプロセスがあるが、継続的改善には弱いプロセスがある。音声はこのギャップを露呈する。
-
戦略的再フレーミング:* 音声実装を使用してタスク分類法を監査する。どのタスクタイプに明確で反復可能な構造があるか?それらは音声の候補である。どれが曖昧または文脈依存か?それらはより良い定義が必要である。この演習は、タスク管理システムが過小指定されていることをしばしば明らかにする—「良い」タスクがどのようなものかを実際に定義したことがない。音声はこの定義を強制する。
-
実行可能なアプローチ:* ワークフローでユーザーをセグメント化する。チーム内の2〜3の高頻度、低複雑度のタスクタイプを特定する(例:「会議のフォローアップをログに記録」、「バグレポートをキャプチャ」、「クイックリマインダーを追加」)。最初はこれらのタイプのみで音声を有効にする。ユーザーが声に出して言うシンプルなスクリプトまたはテンプレートを作成する—例:「チケットをログに記録:[問題の説明]」—入力を標準化する。15分間のセッションでユーザーをトレーニングする。1週間後に採用率とタスク品質を測定する。音声タスクの40%以上が編集なしでそのまま完了する場合、追加のユースケースに拡大する。しかし、特定のユースケースが機能し、他のユースケースが機能しない理由も文書化する。これは、組織がどのように考えるかについての制度的知識になる。
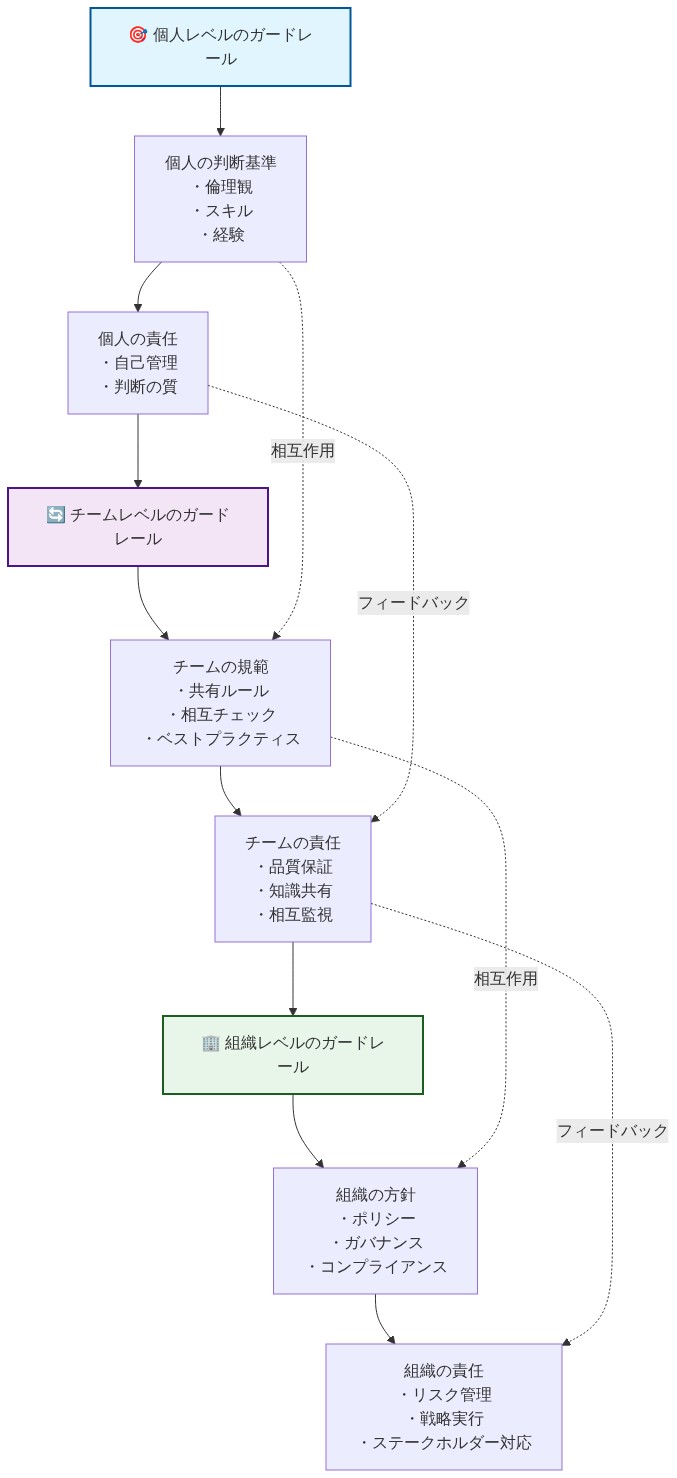
- 図13:ガードレールの階層的組織設計への統合*
戦略的洞察としての測定
3つのメトリクスを追跡する:採用率(音声で作成されたタスクの%)、品質スコア(24時間以内に削除されない音声タスクの%)、タスク作成時間(音声入力からタスク保存までの秒数)。しかし、これらのメトリクスは運用KPI以上のものである—それらは組織行動への窓である。
-
より深い読み取り:* 採用率だけでは誤解を招く—低品質のタスクの高い採用は時間を無駄にする。品質と速度を合わせると、音声が本当に生産性を向上させるかどうかが明らかになる。しかし、それらはまた、タスク管理に対する組織の関係について何かを明らかにする。高採用+高品質=チームはシステムを信頼し、意図したとおりに使用している。高採用+低品質=チームは音声をキャプチャメカニズムとして使用しているが、タスク管理システムとしては使用していない—物事を投げ込んでフォローアップしていない。低採用+高品質=チームは保守的;機能すると確信している場合にのみ音声を使用する。低採用+低品質=音声はワークフローに適合していない。
-
具体例:* チームは音声を大量に採用する(タスクの60%)が、30%が1日以内に削除され、平均タスク作成時間は45秒(タイピングより長い)である。これは機能が機能していないことを示す;ユーザーは確認または編集しすぎている可能性がある。しかし、より深く掘り下げる:なぜ彼らはタスクを削除しているのか?それらは重複か?誤分類か?それともユーザーは実際に行うつもりのないタスクをキャプチャしているのか?この区別は重要である。重複の場合、重複排除を改善する。誤分類の場合、NLUを改善する。誤ったキャプチャの場合、ユーザーは機能の目的を理解していない可能性がある—より良いトレーニングが必要か、機能がワークフローに適していない。
-
将来志向の測定:* 音声システムが成熟するにつれて、予測メトリクスを期待する。システムは学習する:どの音声タスクが完了する可能性が最も高いか?どれが削除される可能性が最も高いか?どれがフォローアップタスクにつながるか?時間の経過とともに、キャプチャ方法に基づいてタスク完了率を予測できる。これはプロジェクトの健全性の先行指標になる:「Q4計画」プロジェクトの音声タスクの完了率が40%の場合、そのプロジェクトはリソース不足または不十分に定義されている可能性がある。
-
実行可能な測定フレームワーク:* ベースラインターゲットを設定する:2週間以内に採用率>50%、品質>85%(24時間以上保持されるタスク)、タスク作成時間<20秒を目指す。いずれかのメトリクスが10%以上外れた場合、診断する:ユーザーに何が不満だったかを尋ねる調査を実行する。一般的な問題:不明確な音声指示、認識不良、または間違ったプロジェクトに表示されるタスク。トレーニング、信頼度閾値、またはプロジェクトマッピングを反復する。調整後に再測定する。2回の反復後もメトリクスが外れている場合、音声展開を一時停止し、ユースケースが本当に音声入力に適しているかどうかを調査する。しかし、何を学んだかも尋ねる。音声がチームに機能しない場合、それはワークフロー、タスク分類法、またはAI支援ツールに対する組織の準備状況に関する貴重な情報である。
組織のレジリエンスとしてのリスク軽減
3つの主要なリスク:プライバシー(音声データの保存または送信)、精度(誤認識されたタスクによる混乱の発生)、過度の依存(ユーザーがタイピングを完全にやめ、複雑なタスクを作成する能力を失う)。しかし、これらのリスクは同時に組織のレジリエンスを構築する機会でもある。
-
信頼インフラとしてのプライバシー:* 音声データは機密性が高く、ユーザーは保存と保持に関する透明性を必要とする。しかしより根本的には、プライバシーは信頼に関するものである。ユーザーが音声データの安全性を信頼しなければ、技術的な懸念からではなく、組織文化の問題として、この機能を使用しないだろう。強力なプライバシー慣行(明確なデータポリシー、定期的な監査、ユーザー教育)を持つチームは、音声機能をより迅速かつ自信を持って採用する。
-
組織学習としての精度:* 精度の失敗は複合的に影響する—誤認識されたタスクは発見される前にワークフローを通じて伝播する可能性がある。しかし、各失敗は学習の機会でもある。誤認識されたタスクは、NLUモデルの弱点を明らかにする。時間の経過とともに、システムが学習するにつれて、これらの失敗は減少する。問題は:これらの失敗を捕捉して学習しているか、それとも無視しているか?
-
スキル開発としての過度の依存:* ユーザーがタイピングを完全にやめ、複雑なタスクを作成する能力を失う可能性がある。しかし、これは必ずしも悪いことではない—それは分業である。音声は捕捉に最適化され、タイピングは詳細に最適化されている。ユーザーが適応するにつれて、自然にシフトする可能性がある:シンプルなタスクは音声で、複雑なタスクはタイピングで。これは劣化ではなく、健全な専門化である。
-
具体例:* ユーザーが機密性の高いタスクを口述する:「アレックスとの給与交渉のフォローアップ」。システムが音声や文字起こしを安全でない方法で保存すると、プライバシーが侵害される。認識が失敗してタスクが「セロリ交渉のフォローアップ」になると、混乱と潜在的な恥ずかしさが生じる。ユーザーがタイピングを完全にやめ、詳細なタスク説明を作成しなくなると、タスク管理が浅薄になる。
-
レジリエンス構築アプローチ:* (1) Todoistのプライバシーポリシーを検証する—音声データが転送中および保存時に暗号化され、処理後に削除されることを確認する。そうでない場合は、音声入力を機密性のないタスクに制限する。シンプルな分類を構築する:「給与」「健康」「法律」「機密」などのキーワードを含むタスクは確認ステップをトリガーする。(2) 精度フィードバックループを実装する—ユーザーが誤認識されたタスクを修正したときにログを記録する。50回の修正後、モデルを再トレーニングする。これにより精度の失敗がトレーニングデータに変換される。(3) タスクの複雑性についてユーザーを教育する—音声は捕捉ツールであり、タイピングの代替ではない。複数のサブタスクや依存関係を持つ複雑なタスクは、依然としてタイピングすべきである。定期的にタスクの複雑性を監査する—音声導入後に平均タスク長(単語数)が20%以上減少した場合、ユーザーが音声に過度に依存している可能性がある。トレーニングで介入する:「複雑なタスクには詳細が必要です。捕捉には音声を、設計にはタイピングを使用してください。」
展望:組織記憶としての音声
音声からタスクへの変換は、思慮深く実装された場合の生産性レバーである。しかし、それはより大きな変革への第一歩でもある:意図的で同期的なセッションではなく、思考の流れの中で非同期的に作業を捕捉する組織。
-
ビジョン:* すべてのコミットメント、アイデア、観察がリアルタイムで捕捉される組織を想像してほしい。タスクデータがプロジェクト管理システムに継続的に流れ込む場所。AIシステムがパターンを分析する—どのチームが過剰にコミットしているか、どのプロジェクトに明確性が欠けているか、どの個人がボトルネックになっているか。組織の作業がこれまでにない方法で可視化され測定可能になる場所。音声からタスクへの変換は、これを可能にするインターフェースである。
-
隣接する機会:* (1) 会議インテリジェンス—会議を聞き、アクションアイテム、決定、コミットメントを自動的に抽出する音声システム。(2) 会話駆動型ワークフロー—Slackメッセージやスレッドからタスクが作成されるSlack統合。(3) 予測的タスク管理—カレンダー、メール、過去のパターンに基づいてタスクを提案するAIシステム。(4) 組織分析—チーム全体のタスクパターンを示すダッシュボードで、ボトルネックと機会を明らかにする。
-
次のアクション:* (1) 最も頻度が高く、最もシンプルなタスクタイプを特定する(例:会議のフォローアップ)。(2) そのタイプのみで音声を有効にし、5〜10人のパワーユーザーをトレーニングする。(3) 1週間後に採用率、品質、速度を測定する。(4) メトリクスが目標に達した場合、1つの追加ユースケースに拡大して繰り返す。(5) メトリクスが目標に達しなかった場合、診断して調整する(信頼度しきい値、プロジェクトマッピング、トレーニング)。2回の成功した反復の後にのみ、完全な展開を計画する。この段階的アプローチは混乱を最小限に抑え、ユーザーの信頼を構築し、機能がノイズではなく価値を追加することを保証する。しかしより重要なのは、これが組織を学習できる位置に置くことである:ワークフロー、言語、作業パターンについて。この学習は、AI支援ツールが標準になるにつれて、競争優位性となる。