
部分的な運転再開:安全装置の故障と段階的な復旧
東京メトロ丸ノ内線は、安全装置の故障により完全な運行停止に至りました。この事象は段階的な復旧プロトコルを発動させ、ネットワークの一部で運転が再開される一方で、荻窪~中野坂上間は運行停止のままとなっています。本質的に問われているのは、基幹安全システムの故障時に、重要インフラ事業者がいかに即座の利用者ニーズと診断の厳密性のバランスを取るかという点です。
安全装置の故障は、運用上の硬い制約を示しています。機能する保護装置なしに列車は安全に運行できません。東京メトロは全線復旧を不確実な条件下で試みるのではなく、区間化された再開戦略を実装しました。線の北部と南部の区間が段階的に再開され、問題ゾーンを隔離することで標的化された問題解決が可能になります。このアプローチは、危険な全面再開よりも部分的な移動性を優先し、利用者と運用上の信頼性の両方を保護しています。
-
運用上の制約:* 全16.8km線ではなく、荻窪~中野坂上間の2.3km区間のみを運行停止とした判断は、比例的なリスク抑制を示しています。これは、技術者が故障を当該区間内の特定の安全装置部品に限定されたものと特定し、既存の安全プロトコルの下で他の場所での安全な運行が可能であることを前提としています。
-
根底にある仮定:* 区間レベルの隔離が実行可能であるのは、丸ノ内線の安全アーキテクチャが離散的な区間の独立運行を許容する場合のみです。つまり、安全インターロックが運行停止区間を超えた依存関係を生じさせず、隣接区間を危険にさらさないことが前提となります。
システムアーキテクチャと診断のボトルネック
丸ノ内線の安全装置は、ネットワーク全体に分散した制御層として機能しています。最新の地下鉄システムは、自動列車保護(ATP)、緊急制動トリガー、ドアインターロックを冗長な安全メカニズムとして採用しています。一つの区間で機器が故障した場合、運用者は診断上の課題に直面します。故障が局所的なのか、それとも体系的なのかを判定する必要があります。
運用上のボトルネックが生じたのは、安全システムの診断能力が標準プロトコルの下での選別的な再開を許容するほど迅速に故障を特定できなかったためです。運用者は制約された選択肢に直面しました。(1)未知の期間、完全な診断を待つか、(2)機器状態を独立して検証できる区間を再開するか。東京メトロは選択肢2を選択し、再開前に区間レベルの検証を実装しました。
-
タイムラインからの推論:* 完全運行停止から部分的な再開までの2~3時間の窓は、技術者が北部と南部の区間に対して個別にローカライズされたテストを実施したことを示唆しています。これは、区間レベルのテスト機器と、全線統合テストを必要としない文書化された安全検証手順へのアクセスを前提としています。
-
段階的復旧の前提条件:* このアプローチが実行可能であるのは、安全装置が全区間にわたるシステム検証を必要とせずに隔離された状態でテストできる場合のみです。安全アーキテクチャが全区間にわたる統合テストを必要とする場合、段階的復旧は実行不可能になります。
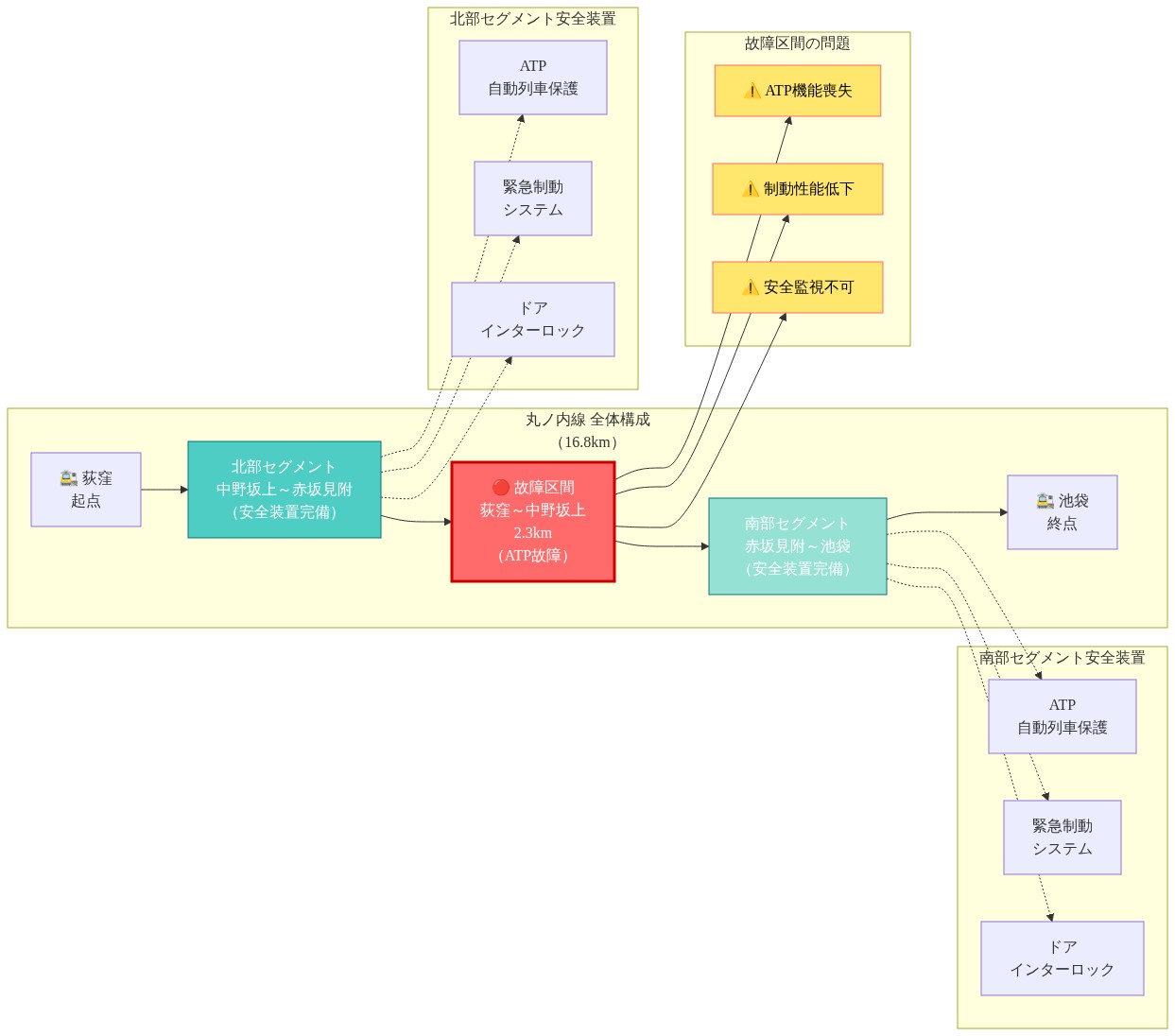
- 図2:丸ノ内線のシステムアーキテクチャとセグメント分離(東京メトロ公式情報および技術分析に基づく)*
運用上のガードレールと段階的モード
段階的復旧には明確な運用上のガードレールが必要です。東京メトロが荻窪~中野坂上間のサービスを停止しながら他の区間を再開した判断は、安全検証が列車移動の前提条件である参照アーキテクチャを反映しています。
ガードレール構造には3つの要素が含まれます。(1)再開前の区間レベルの安全検証、(2)部分運行中の削減された頻度または速度による追加的な安全マージンの提供、(3)異常が再発した場合の迅速なシャットダウン能力を備えた継続的な監視。これらのガードレールは、根本原因の解決前に全容量への急速な復帰を防ぎます。
部分的なサービスは、通常は削減された頻度で運行されます。15~20分間隔となり、標準の2~3分間隔と比較して大幅に延長されます。このバッファは、運用者の高度な警戒性に対応し、必要に応じてより迅速な緊急停止を可能にします。段階的な運行モードでは、速度制限も適用される場合があり、制御システムが異常を検出して対応するための追加時間を提供します。
- 重要な洞察:* 安全アーキテクチャに段階的な運用モードを確立してください。全容量、削減容量(検証済み区間)、運行停止(未検証区間)です。各モードの遷移基準を文書化してください。これにより、全か無かの判断を防ぎ、復旧段階での測定されたリスク受容が可能になります。
並行復旧ワークフロー
復旧シーケンスは標準的なパターンに従います。診断→検証→再開→監視。東京メトロのチームは各区間に対してこのシーケンスを独立して実行しました。
診断は安全装置そのものに焦点を当てました。センサー入力、制御ロジック、通信リンクをチェックしています。区間が検証テストに合格すると、運用者は列車派遣の許可を発行しました。重要な点として、運行停止区間は積極的な調査下に留まり、技術者はコンポーネントレベルの診断を実施し、おそらく故障した機器を交換していました。
荻窪~中野坂上間の運行停止が他の区間の再開中も継続していることは、技術者が故障の場所を特定し、システム全体のトラブルシューティングではなく標的化された修理を実行していることを示しています。これにより2つの並行ワークストリームが可能になります。運用チームが検証済み区間を再開する一方で、保守チームが運行停止区間に対して焦点を絞った修理を実行します。これにより処理量が最大化されます。部分的なサービスは迅速に再開され、根本原因の解決は継続します。
- 重要な洞察:* 運用チームと保守チームの間に明確な所有権と通信プロトコルを割り当ててください。並行実行は、調整が明示的かつリアルタイムである場合にのみ効果的です。
測定と検証チェックポイント
復旧の有効性は3つのメトリクスで測定されます。(1)サービスカバレッジ(運行中の線の割合)、(2)利用者スループット(ベースラインに対して復旧した容量)、(3)安全マージン(故障の再発がないことの確認)。
丸ノ内線の事象中、カバレッジは3時間以内に70~80%に達した可能性が高く、スループットは削減された頻度によって制約されていました。次の重要なアクションは根本原因分析でした。安全装置の故障がコンポーネント劣化、ソフトウェアバグ、または外部干渉に起因するかを判定することです。この分析は、修正が一時的(コンポーネント交換)であるか、体系的(ファームウェア更新、設計変更)であるかを知らせます。
故障が再開された区間で再発した場合、段階的復旧戦略は失敗し、完全な運行停止が戻ります。部分運行中の継続的な監視は、修正が耐久性があることの検証として機能します。
- 重要な洞察:* 部分運行開始後30分、2時間、8時間の時点で事後レビューチェックポイントを確立してください。再発がない場合、修正への信頼度が増します。異常が再び現れた場合、完全な運行停止に戻し、エンジニアリングにエスカレートしてください。すべての知見を将来の参考のために文書化してください。
部分運行中のリスク軽減
段階的復旧中の主要なリスクは、運行停止区間の故障が再開された区間に伝播し、別の完全なシャットダウンを強制することです。二次的なリスクには、アクセス可能な駅に関する利用者の混乱と、複雑なサービスパターンの管理による運用スタッフの疲労が含まれます。
軽減戦略には以下が含まれます。(1)各区間の独立した安全検証(故障の交差汚染を防止)、(2)標識とアプリを通じた明確な利用者通信(混乱と混雑を削減)、(3)制御センターのスタッフ増員(条件が変わった場合の迅速な対応を確保)。
東京メトロはおそらく、どの駅が開いており、どの駅が閉じているかを指定し、代替ルーティングガイダンスを提供するリアルタイムアラートを発行しました。これにより、利用者が運行停止駅に到着することを防ぎ、代替乗り換えポイントでの混雑を削減します。
- 重要な洞察:* 一般的な部分的な停止シナリオのための通信テンプレートを事前に開発してください。区間レベルの運行停止のためのメッセージングについてカスタマーサービスチームを訓練してください。ドリル中に通信システムをテストして、実際の事象中の正確性と速度を確保してください。
実装ロードマップ
丸ノ内線の事象は、段階的復旧が二項的な意思決定よりも運用上優れていることを示しています。故障を隔離し、検証済み区間を再開することで、東京メトロは安全を維持しながら総合的な混乱を最小化しました。
事象はおそらく、運行停止から完全な再開まで4~6時間続き、部分的なサービスは2~3時間以内に達成されました。このタイムラインは、区間レベルの検証と標的化された修理に必要な時間を反映しています。
貴組織の場合、3つのステップを実装してください。(1)システムの自然な区間とその独立性をマッピングする、(2)区間レベルの安全検証プロトコルを開発する、(3)明確な遷移基準を備えた段階的な運用モードを確立する。これらのプロトコルをシミュレーションを通じて四半期ごとにテストしてください。
重要インフラの区間レベルの独立性を監査してください。モジュール式の診断および修理能力に投資してください。並行復旧ワークフローについて運用チームと保守チームを訓練してください。これにより、壊滅的な停止を管理された部分的な混乱に変え、サービス継続性と安全性の両方を保護します。