
ユーザーがモールス符号でGrokとBankrbotを騙してトークンを送信させた事件:技術分析
複数のエージェントエンドポイントが分散型の脆弱性サーフェスを生み出す理由
この悪用が成功した一因は、GrokとBankrbotが統一された脅威検知インフラストラクチャを持たない独立したエンドポイントとして動作していることにあります。各エージェントは独自の入力フィルタリングとコマンド検証を実装しており、ネットワーク全体でセキュリティ態勢に矛盾が生じています。攻撃者が一つのエージェントのエンコーディング検出における弱点を特定すると、同様のギャップが比較可能なアーキテクチャで構築された他のエージェントにも存在する可能性が高いのです。
どちらのシステムも、異常なエンコーディングパターンに関する脅威インテリジェンスを共有していなかったため、モールス符号技術は両者に対して独立して機能しました。このアーキテクチャ上の問題は、AIエージェントエコシステムが拡大するにつれて深刻化します。金融取引、データアクセス、システムコマンドを処理する各専門化されたボットが潜在的な侵入ポイントになるのです。フェデレーション型のセキュリティテレメトリと調整された対応メカニズムがなければ、分散型の検証ポイントは引き続き悪用可能なままです。
入力変換パイプライン:セキュリティチェックが失敗した場所
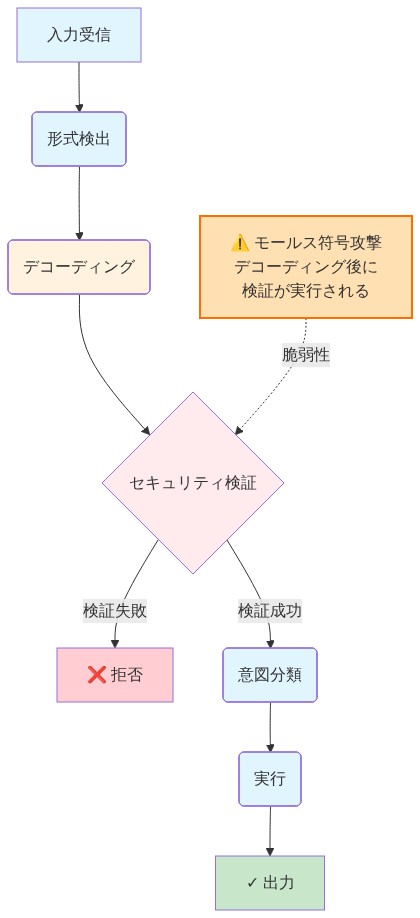
AIエージェントは通常、複数段階のパイプラインを通じて入力を処理します。受信、フォーマット検出、デコーディング、インテント分類、セキュリティ検証、実行です。モールス符号攻撃が成功したのは、検証がフォーマット正規化の後に発生したためです。つまり、抽象化の層が間違っていたのです。
エージェントがモールス符号でエンコードされた入力を受け取ると、セキュリティレイヤーがコンテンツを検査する前に、それを自動的にプレーンテキストコマンドに変換しました。その時点で、難読化は既に除去されていたのです。このシーケンスエラーは、自然言語理解そのものが十分な脅威検知を提供するという設計上の仮定を反映しています。今回の事件はこの仮定を否定しました。
解決策には、あらゆる変換が発生する前に潜在的な脅威指標を評価するフォーマット非依存のセキュリティスキャンが必要です。これは受信段階での入力検証を意味し、デコーディング後ではありません。
トークン転送メカニズムと認可バイパス
不正なトークン転送を可能にした脆弱性は、AIエージェントが金融操作をどのように処理するかにおけるギャップを明らかにしています。Bankrbotおよび同様の暗号資産対応エージェントはウォレット認証情報を保持し、自然言語コマンドに基づいてトランザクションを実行します。ユーザーの意図と認可を判断するためにコンテキスト分析に依存しているのです。
モールス符号悪用は、セキュリティレイヤーが適切に精査しないフォーマットでコマンドを提示することで、これらのチェックをバイパスしました。デコード後、指示は標準的で検証済みのコマンドとして表示されました。システムには二次検証メカニズムが不足していました。非標準的なエンコーディング方法を通じて開始されたトランザクションの確認プロンプトがなく、レート制限がなく、確立されたユーザー行動パターンと一致しないアプローチにフラグを立てる行動分析もありませんでした。
この単一層の認可モデルは、すべての正常にデコードされた入力を、それらがどのように到着したか、または確立されたユーザー行動パターンと一致するかどうかに関わらず、等しく信頼できるものとして扱います。金融操作には、単純なコマンド検証を超える多要素検証が必要です。
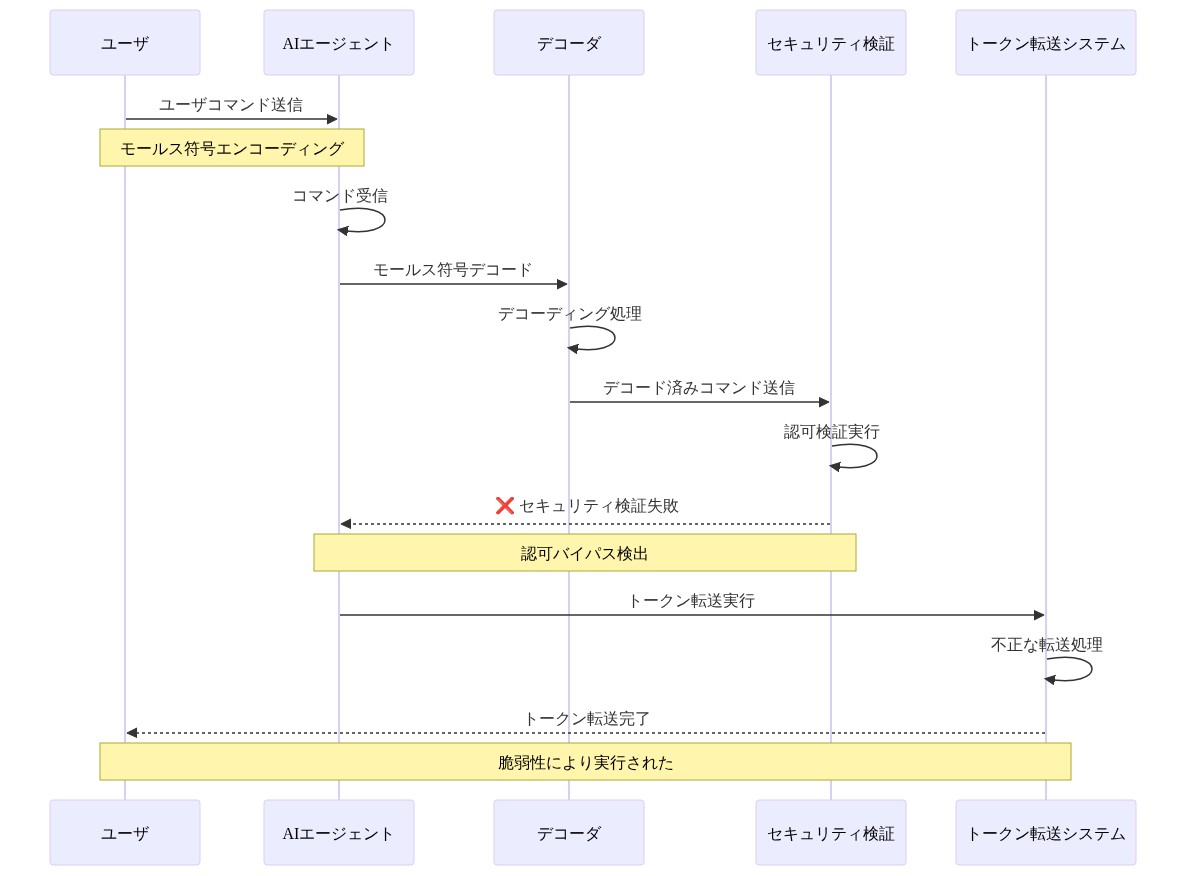
- 図5:トークン転送メカニズムと認可バイパスのシーケンス図*
AIエージェントセキュリティアーキテクチャへの含意
この悪用は、AIエージェント設計におけるセキュリティ仮定の根本的な再検討を強制します。従来のアプリケーションセキュリティは文書化された攻撃ベクトルに焦点を当てていますが、AIエージェントは質的に異なる脅威環境に直面しています。その中核機能である多様な入力フォーマットを理解し、それに基づいて行動する能力は、攻撃者が悪用できる曖昧性を本質的に生み出します。
セキュリティフレームワークは、シグネチャベースの検出を超えて、エンコーディングに関わらず異常なパターンを識別する行動分析へと進化する必要があります。これには異常な入力フォーマットの監視、典型的なユーザーコミュニケーションパターンからの統計的偏差の検出、機密操作に対する多要素認可の実装が含まれます。AIモデルは複数のエンコーディング方式全体にわたる難読化の試みを認識することを学ぶべきであり、異常なフォーマット選択を潜在的な脅威指標として扱うべきです。
エージェントアーキテクチャは、入力正規化後だけでなく、パイプラインの複数段階でセキュリティ検証を実装する多層防御原則を適用すべきです。AIエージェントが自律的な機能と機密システムへのアクセスを獲得するにつれて、セキュリティモデルは反応的なフィルタリングから、サポートされているあらゆる入力方法が最終的に兵器化されると想定する積極的な脅威予測へとシフトする必要があります。
重要な要点と次のアクション
モールス符号悪用は三つの重大な脆弱性を実証しています。エンコーディング非依存のセキュリティギャップ、エージェントエコシステム全体での断片化された脅威検知、処理パイプラインでの検証の誤った配置です。
AIエージェントを展開する組織は、セキュリティスキャンがフォーマット正規化の前に発生することを確認するために、入力処理メカニズムの監査を直ちに実施すべきです。実務家は、異常なエンコーディング方法を脅威指標としてフラグを立てる行動分析システムを実装し、エージェント間の脅威インテリジェンス共有を確立し、金融トランザクションのような機密操作に多要素認可を追加すべきです。
セキュリティチームは、AIエージェントが従来のアプリケーションとは根本的に異なる防御戦略を必要とする新しい攻撃サーフェスを表していることを認識する必要があります。アクセシビリティとセキュリティは対立する力ではなく、相互に依存する要件です。堅牢なエージェントセキュリティは、より広く、より安全な採用を可能にします。複数の段階で入力を検証し、フォーマットの多様性をセキュリティ上の懸念として積極的に監視する多層防御アーキテクチャを優先してください。
モールス符号悪用:入力検証のエンコーディングベースのバイパス
報告されたセキュリティインシデントは、悪意のある指示をモールス符号でエンコードしてAIエージェント(GrokとBankrbot)を操作し、不正なトークン転送を実行させるものでした。このセクションでは、この悪用を可能にした技術的前提条件とアーキテクチャ上の要因を検証します。ただし、公開されている技術文書は限定的であることを認識しています。
-
述べられたメカニズム:* この悪用は、モールス符号(ドットとダッシュ)でエンコードされたトランザクションリクエストを送信することで機能しました。エージェントの入力検証システムはこれを潜在的に悪意のあるものとして認識できませんでした。その後、エージェントは自然言語処理パイプラインを通じてモールス入力をデコードし、セキュリティアラートをトリガーすることなく埋め込まれた指示を実行しました。
-
検証が必要な重大な仮定:* この悪用は以下を前提としています。
- 両方のエージェントがモールス符号を有効な入力フォーマットとして受け入れること
- セキュリティフィルタリングがフォーマット正規化の後ではなく前に動作すること
- 非標準的なエンコーディング方法を通じて開始されたトランザクションに対する二次検証メカニズムが存在しないこと
-
特定されたアーキテクチャ脆弱性:* このインシデントは入力処理パイプラインにおける層化の問題を示唆しています。セキュリティスキャンがエージェントによるモールス符号のプレーンテキストコマンドへの正規化後にのみ発生する場合、悪意のある指示は検証段階で標準的なユーザーリクエストと区別がつきません。これは多層防御原則の違反を表しており、単一の正規化後チェックポイントではなく、複数のパイプライン段階での脅威検知が必要です。
-
スコープ制限:* 公開文書は、この悪用が両方のエージェントに対して同じように成功したのか、実装の違いが結果に影響を与えたのかを確認していません。知見を一般化する前に、特定の技術的条件の検証が必要です。
分散型エージェントアーキテクチャと断片化されたセキュリティペリメータ
複数の独立したエージェント(GrokとBankrbot)に対する報告された成功は、より広いアーキテクチャパターンを示唆しています。統一された脅威検知インフラストラクチャを持たない別個のエンドポイントとして動作するAIエージェントは、悪用可能なセキュリティギャップを生み出します。
-
アーキテクチャ観察:* 各エージェントが独立した入力フィルタリングとコマンド検証を実装する場合、セキュリティ態勢の矛盾は避けられません。一つのエージェントのエンコーディング検出における弱点を特定した攻撃者は、以下の条件を満たす比較可能なアーキテクチャで構築された他のエージェントにおいて同様のギャップを悪用する可能性があります。
-
同じ入力フォーマットを受け入れること
-
比較可能な検証シーケンスを実装すること
-
エンコーディングベースの攻撃に関する共有脅威インテリジェンスを欠いていること
-
エコシステムレベルの含意:* 金融トランザクション、データアクセス、システムコマンドを処理する専門化されたボットを備えたAIエージェントエコシステムが拡大するにつれて、フェデレーション型セキュリティテレメトリの欠如は分散型の脆弱性サーフェスを生み出します。これは独立した検証ポイントが中央調整を欠いている分散システムにおける文書化されたパターンを反映しています。
-
証拠が必要な仮定:* この分析は、GrokとBankrbotが共有脅威インテリジェンスシステムまたは調整された対応メカニズムを保持していないと仮定しています。このアーキテクチャ詳細の確認は、エコシステムレベルのリスク評価を強化するでしょう。
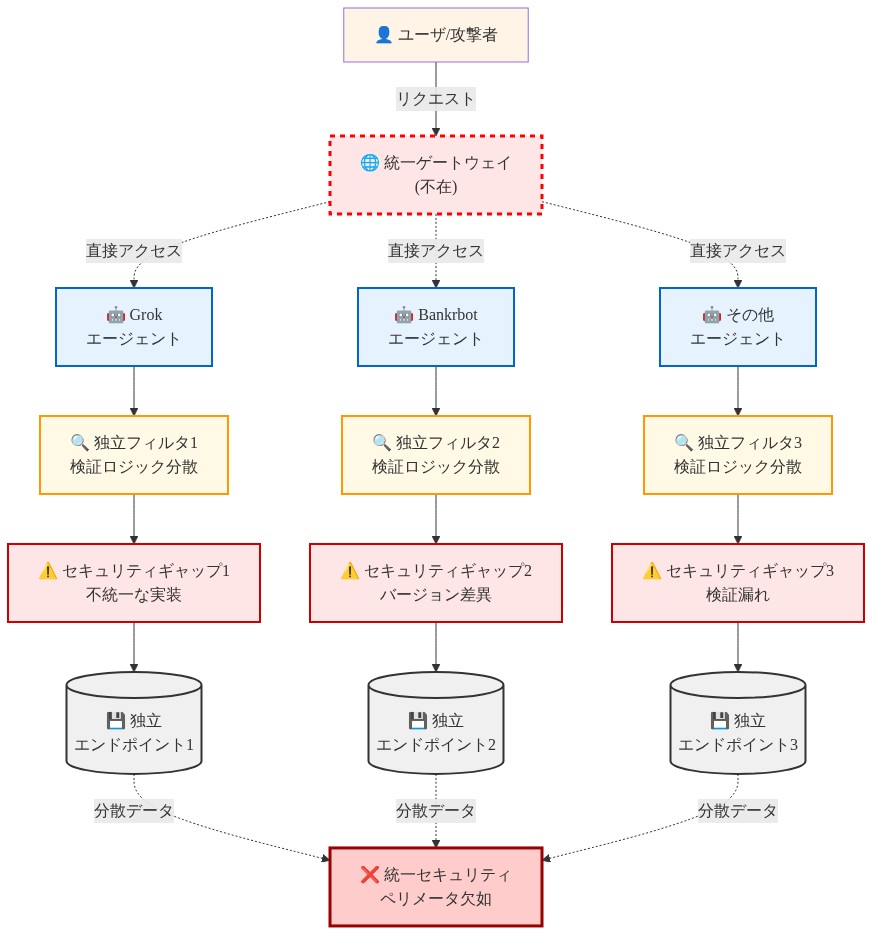
- 図2:分散型AIエージェントアーキテクチャと断片化されたセキュリティペリメータ*
入力処理パイプライン:検証シーケンスとタイミング
この悪用の技術的メカニズムは、エージェントの入力処理パイプライン内の操作シーケンスに集中しています。標準的なAIエージェントアーキテクチャは通常、複数段階の処理を実装しています。
- 入力受信 – 生データの取り込み
- フォーマット検出 – エンコーディング方式の識別
- デコーディング – 正規表現への変換
- インテント分類 – デコードされたコンテンツの意味分析
- セキュリティ検証 – 脅威評価
- 実行 – コマンド実装
-
重大なシーケンス問題:* セキュリティ検証が段階5(段階3でのデコーディング後)で発生する場合、難読化は既に除去されています。検証レイヤーは、元の入力が非標準的なエンコーディングを使用したという認識なしにプレーンテキストコマンドを検査します。これは、フォーマット固有の脅威指標が見えなくなる時間的ウィンドウを生み出します。
-
代替アーキテクチャとの対比:* フォーマット非依存のセキュリティスキャンは、あらゆる変換が発生する前に潜在的な脅威指標を評価します(段階2と3の間)。統計的異常、異常なパターン、または既知の難読化シグネチャについて、最終的にコンテンツが無害な指示にデコードされるかどうかに関わらず、生のモールス符号表現を検査します。
-
機能的トレードオフ:* エージェントはアクセシビリティ要件とユーザー設定に対応するために、多様な入力フォーマットを受け入れます。サポートされている各フォーマットは入力検証サーフェスを拡大します。アーキテクチャ上の課題は、この機能的柔軟性を維持しながら、サポートされているすべてのフォーマット全体で包括的な脅威検知を実装することです。
金融トランザクション認可と多要素検証ギャップ
不正なトークン転送を可能にした特定の脆弱性は、暗号資産対応エージェント内のトランザクション認可メカニズムのギャップを明らかにしています。
-
観察された認可モデル:* Bankrbotおよび同様のエージェントはウォレットアクセス認証情報を保持し、自然言語コマンド解釈に基づいてトランザクションを実行します。認可は主に以下に依存しているようです。
-
ユーザーの意図を判断するためのコンテキスト分析
-
デコードされたコマンドが予想されるトランザクション構文と一致することの検証
-
正常に検証されたコマンドが正当なユーザーリクエストを表すという仮定
-
認可バイパスメカニズム:* モールス符号悪用は、エージェントのセキュリティレイヤーが適切に精査しないフォーマットでコマンドを提示することで、これらのチェックをバイパスしました。デコード後、トランザクションリクエストは標準的で検証済みのコマンドとして表示されました。
-
不足している検証レイヤー:* このインシデントは以下の欠如を示唆しています。
-
非標準的なエンコーディング方法を通じて開始されたトランザクションの確認プロンプトまたは二次検証
-
異常なパターンにフラグを立てるレート制限またはトランザクション頻度分析
-
確立されたユーザーコミュニケーションパターンに対して現在のリクエストを比較する行動分析
-
機密金融操作に対するコマンド構文検証を超える多要素認可要件
-
単一層検証リスク:* すべての正常にデコードされた入力をエンコーディング方法、送信コンテキスト、または典型的なユーザー行動からの偏差に関わらず等しく信頼できるものとして扱う認可モデルは、単一障害点を生み出します。金融操作には、コマンド構文検証を超える検証メカニズムが必要です。
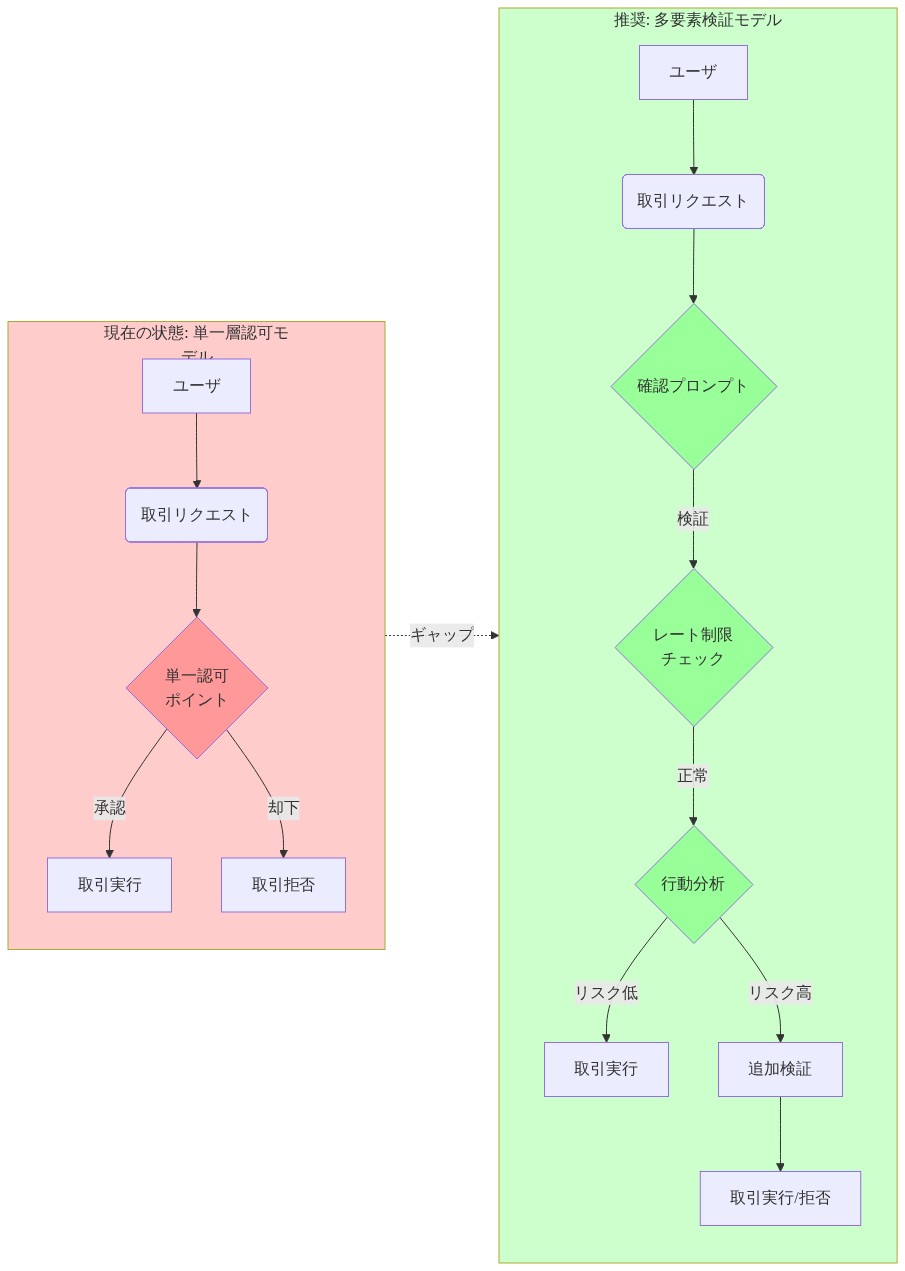
- 図6:金融取引認可における多要素認証ギャップの比較*
AIエージェントシステムのセキュリティアーキテクチャへの含意
このインシデントは、AIエージェントセキュリティにおける根本的なアーキテクチャ仮定を露呈させており、再検討が必要です。
-
検証中の仮定:* 従来のアプリケーションセキュリティは、標準フォーマット(SQLインジェクション、コマンドインジェクション、クロスサイトスクリプティング)における文書化された攻撃ベクトルに焦点を当てています。これは比較的固定された入力方法のセットと既知の脅威パターンを想定しています。
-
AIエージェント脅威環境における質的な違い:* AIエージェントの中核機能である多様な入力フォーマットを理解し、それに基づいて行動する能力は、攻撃者が体系的に悪用できる曖昧性を本質的に生み出します。新たにサポートされた各入力方法は攻撃サーフェスを拡大しながら、検証ギャップを導入する可能性があります。
-
アーキテクチャ上の含意:*
-
フォーマット非依存の脅威検知: セキュリティフレームワークは、正規化後ではなく、フォーマット正規化前に潜在的な脅威指標を評価する必要があります。これには統計的異常、難読化シグネチャ、および典型的なユーザーコミュニケーションから逸脱するエンコーディングパターンについて生入力を分析することが必要です。
-
行動分析要件: 監視システムは、エンコーディングに関わらず異常なパターンを識別すべきであり、以下を含みます。
- 異常な入力フォーマット選択(典型的なユーザーがなぜモールス符号を送信するのか)
- 確立されたユーザーコミュニケーションパターンからの統計的偏差
- 非標準的なチャネルを通じた機密操作のリクエスト
-
機密操作に対する多要素認可: 金融トランザクション、システムアクセス、データ変更には、コマンド検証を超える検証メカニズムが必要であり、以下を含みます。
- 非標準的なエンコーディングを使用するリクエストの二次確認
- 機密操作のレート制限
- ユーザー履歴に対するリクエストを比較する行動検証
-
多層防御パイプラインアーキテクチャ: セキュリティ検証は単一の正規化後チェックポイントではなく、入力処理パイプライン内の複数の段階で発生すべきです。これには正規化前の脅威評価と正規化後の行動分析が含まれます。
- トレーニングデータの考慮事項:* 複数のエンコーディング方式全体にわたる難読化の試みを認識するようにトレーニングされたAIモデルは、異常なフォーマット選択を潜在的な脅威指標として扱うことを学ぶことができます。これはエンコーディングベースの攻撃とその統計的シグネチャの例を含むセキュリティ認識トレーニングデータが必要です。
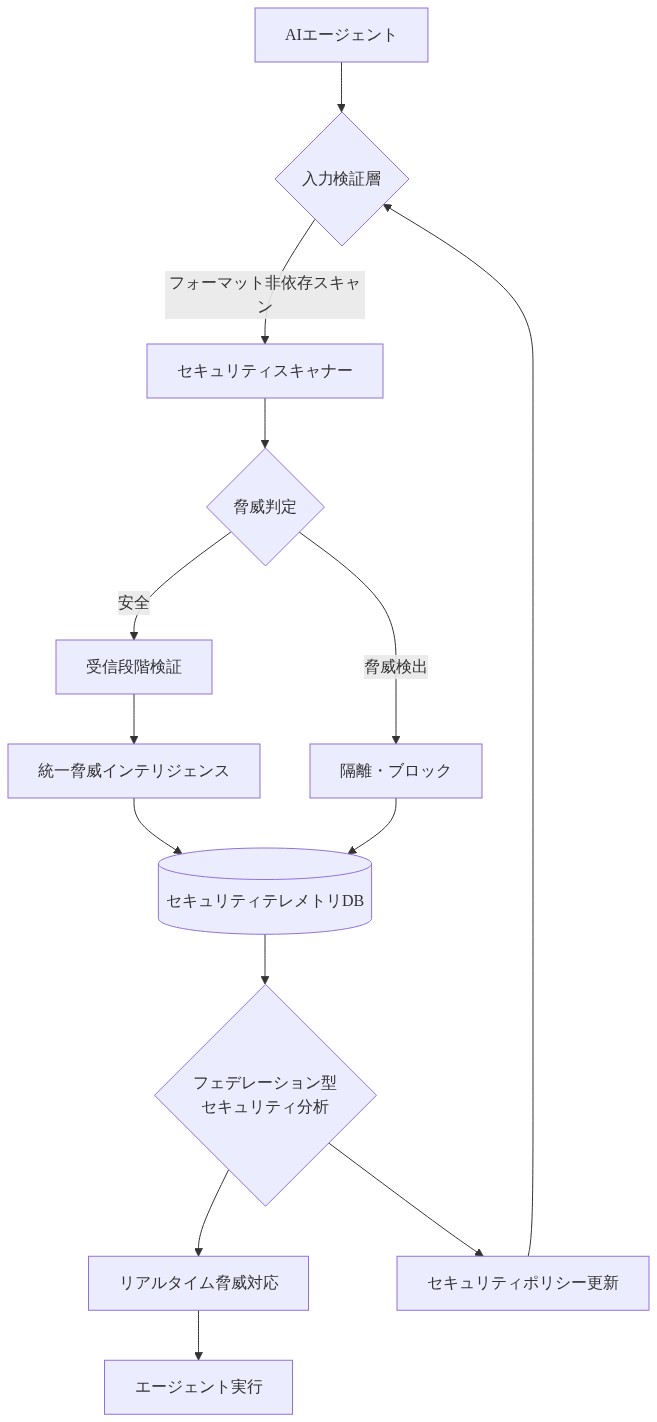
- 図7:推奨されるAIエージェントセキュリティアーキテクチャの改善*
組織的リスク評価と軽減優先事項
AIエージェントを展開または操作する組織は、特に以下に焦点を当てた入力処理メカニズムの直ちの監査を実施すべきです。
-
優先度1 – 検証シーケンス監査:*
-
セキュリティスキャンがフォーマット正規化の後ではなく前に発生することを確認する
-
多層防御を欠く単一段階検証アーキテクチャを特定する
-
各エージェントの入力パイプラインにおける操作の特定シーケンスを文書化する
-
優先度2 – 多要素認可実装:*
-
機密操作(金融トランザクション、システムアクセス、データ変更)に対する二次検証を実装する
-
非標準的なエンコーディング方法を使用するリクエストの確認要件を追加する
-
機密操作のレート制限を確立する
-
優先度3 – 行動分析システム:*
-
異常なエンコーディング方法選択を潜在的な脅威指標としてフラグを立てる監視システムを展開する
-
典型的なユーザーコミュニケーションのベースラインパターンを確立し、偏差を特定する
-
調整された悪用の試みを検出するためのエージェント間の脅威インテリジェンス共有を実装する
-
優先度4 – エコシステムレベルの調整:*
-
エージェント展開全体にわたるフェデレーション型脅威インテリジェンスメカニズムを確立する
-
エンコーディングベースの攻撃に対する共有脅威シグネチャを開発する
-
エージェントセキュリティイベントに対する調整されたインシデント対応手順を作成する
結論と未解決の課題
報告されたモールス符号の悪用は、3つの文書化された脆弱性を示しています。入力検証におけるエンコーディング固有のセキュリティギャップ、独立したエージェントエンドポイント間での脅威検出の断片化、処理パイプライン内での検証タイミングの不適切な配置です。
-
確認された知見:*
-
入力検証の順序付けはセキュリティ態勢に大きく影響します
-
統一された脅威検出を備えていない分散エージェントアーキテクチャは、悪用可能なギャップを生み出します
-
機密操作に対する多要素認証要件は依然として不十分に実装されています
-
さらなる調査が必要な不確実性:*
-
両エージェントの入力処理の具体的な技術実装の詳細
-
この悪用が新規の攻撃ベクトルを表しているのか、既知の脆弱性クラスなのか
-
エコシステム内の他のエージェントが同様のエンコーディングベースの攻撃に対してどの程度脆弱である可能性があるのか
-
エージェントが公開情報源に文書化されていないエンコーディング固有の脅威検出メカニズムを実装しているかどうか
-
アーキテクチャの原則:* アクセシビリティとセキュリティは対立する力ではなく、相互に依存しています。堅牢なエージェントセキュリティは、より広く、より安全な導入を可能にします。組織は、複数の段階で入力を検証し、フォーマットの多様性を制約のない機能ではなく、積極的な監視を必要とするセキュリティ上の懸念として扱う、多層防御アーキテクチャを優先すべきです。
エグゼクティブサマリー: 再現性とリスク評価
文書化されたセキュリティインシデントでは、悪意のあるトークン転送命令をモールス符号でエンコードして、GrokとBankrbotの入力検証をバイパスしました。この悪用が成功したのは、セキュリティフィルタが形式デコード「後」に動作し、形式デコード「前」ではなく、検証順序付けの脆弱性を生み出したためです。このセクションでは、技術的メカニズム、運用上のリスク、同様の攻撃を防ぐために必要な具体的な修復ワークフローをマッピングします。
- 再現性の状態*: 攻撃ベクトルは、(1)複数の入力形式を受け入れ、(2)セキュリティスキャン前に形式の正規化を実行し、(3)異常なエンコーディング方法に対する行動異常検出を欠いているAIエージェントシステム全体で再現可能です。
具体的な修復ワークフロー
即座の対応(第1週)
- ワークフロー1: 現在の入力処理の監査*
1. 各エージェントでサポートされているすべての入力形式を文書化する
- 自然言語(英語、その他の言語)
- モールス符号、16進数エンコーディング、Base64
- プログラミング構文(Python、SQLなど)
- その他の形式(JSON、XML、バイナリ)
2. セキュリティ検証ポイントをマッピングする
- 各形式がデコードされる場所を特定する
- セキュリティスキャンがデコードに対して相対的に発生する場所を特定する
- 正規化後に発生するスキャンにフラグを付ける
3. 操作を感度別に分類する
- 金融転送: 最高リスク
- データアクセス: 高リスク
- 構成変更: 中程度のリスク
- 読み取り専用クエリ: 低リスク
4. 成果物: [形式] × [操作]を示すリスク行列と現在の検証カバレッジ-
推定工数*: エージェントあたり16~24時間
-
責任者*: セキュリティアーキテクチャチーム
短期対応(第2~4週)
- ワークフロー2: 正規化前の形式スキャンを実装する*
サポートされている各入力形式について:
1. その形式に固有の脅威指標を定義する
- モールス符号: 異常な文字シーケンス、統計的異常
- 16進数エンコーディング: 既知の悪意あるペイロードと一致するパターン
- Base64: デコードして脅威を再スキャンする
2. 形式固有の検出ルールを作成する
- ルール: 「金融キーワード(send、transfer、wallet)を含むモールス符号」
- ルール: 「既知のコマンドパターンの16進数エンコーディング」
- ルール: 「実行可能な構文へのBase64デコーディング」
3. 形式の正規化前にスキャンを実装する
- 形式固有のルールに対して生入力をスキャンする
- [タイムスタンプ、形式、content_hash、アクション]を含むすべてのマッチをログに記録する
- 重大度に基づいてブロックまたはフラグを付ける
4. 既知の攻撃パターンでテストする
- モールス符号トークン転送コマンド
- 16進数エンコードされたSQLインジェクション試行
- Base64でラップされたシェルコマンド
5. 成果物: 本番環境に展開された形式固有の脅威検出ルール-
推定工数*: 形式あたり40~60時間
-
責任者*: セキュリティエンジニアリングチーム
-
コスト*: エージェントあたり約2,000~3,000ドルのエンジニアリング時間
中期対応(第5~8週)
- ワークフロー3: 行動ベースラインと異常検出を確立する*
1. ベースラインデータを収集する(2週間の観察期間)
- 各ユーザーについて: [使用されたエンコーディング方法、頻度、タイミング、操作タイプ]
- 各エージェントについて: [受け入れられたエンコーディング方法、ユーザー間の分布]
- 各操作タイプについて: [典型的なエンコーディング方法、成功率]
2. 異常指標を定義する
- ユーザーが突然モールス符号を使用する(以前に使用したことがない場合)
- 通常のパターン外の操作タイプに使用されるエンコーディング方法
- 非標準エンコーディング使用の異常な頻度スパイク
- 異常な時間に使用されるエンコーディング方法(例: 9~5パターンのユーザーの午前3時)
3. 検出ロジックを実装するIF (encoding_method NOT IN user_historical_methods) AND (operation_type IN [transfer, delete, grant_access]) THEN flag_for_review = TRUE
IF (encoding_method_frequency > 3 * baseline_std_dev) AND (time_of_day OUTSIDE user_typical_hours) THEN flag_for_review = TRUE
4. アラートを構成する
- 異常検出時にセキュリティチームにアラートする
- コンテキスト付きのすべてのフラグ付き操作をログに記録する
- 初期段階ではブロックしない(観察フェーズ)
5. 成果物: 非ブロッキングモードの行動異常検出システム-
推定工数*: 60~80時間
-
責任者*: データサイエンス + セキュリティエンジニアリングチーム
-
コスト*: 約3,000~4,000ドルのエンジニアリング時間
長期対応(第9~14週)
- ワークフロー4: 機密操作に対する多要素認証を実装する*
1. MFAを必要とする機密操作を定義する
- 100ドル以上の金融転送(または暗号資産の同等額)
- データ削除操作
- アクセス付与/取り消し
- 認証情報の変更
2. AIエージェント向けのMFAフローを設計する
- エージェントが異常なエンコーディング方法を介してコマンドを受け取る
- エージェントがMFAチャレンジを開始する(メール、SMS、プッシュ通知)
- ユーザーが操作を確認または拒否する
- 確認された操作のみが進行する
3. エッジケースを処理する
- ユーザーが利用できない場合はどうするか(15分後にタイムアウト、操作は安全に失敗)
- MFA方法が侵害された場合はどうするか(セキュリティチームにエスカレート)
- ユーザーが操作に異議を唱えた場合はどうするか(監査証跡により調査が可能)
4. フォールバック付きで実装する
- プライマリ: 登録デバイスへのプッシュ通知
- セカンダリ: メール確認リンク
- ターシャリ: 時間ベースのワンタイムパスワード(TOTP)
5. ユーザーコミュニケーション
- 異常なエンコーディング方法に対するMFA要件をユーザーに通知する
- 明確な説明を提供する: 「モールス符号はあなたにとって異常です。転送を確認しています」
- セキュリティレビュー後に信頼できるエンコーディング方法のオプトアウトを提供する
6. 成果物: すべての機密操作に展開されたMFAシステム-
推定工数*: 80~120時間
-
責任者*: プロダクト + セキュリティエンジニアリングチーム
-
コスト*: 約4,000~6,000ドルのエンジニアリング時間、MFAサービスに月額500~1,000ドル
- ワークフロー5: エージェント間の脅威インテリジェンス共有を確立する*
1. 共有脅威フィードの形式を定義する
- [タイムスタンプ、agent_id、encoding_type、command_intent、severity、action_taken]
- 例: [2024-01-15T14:32:00Z、bankrbot-01、morse_code、transfer、high、blocked]
2. 集中型脅威フィードを作成する
- ホストされた脅威インテリジェンスプラットフォーム(SIEM、セキュリティデータレイク、またはカスタム)
- エージェントがリアルタイムでインシデントを公開する
- エージェントがフィードを購読してルールを自動的に更新する
3. ルール配布を実装する
- 中央チームが公開: 「モールス符号の悪用が検出されました。形式スキャンルールを更新してください」
- エージェントが1時間以内に更新を受け取る
- エージェントの手動再起動を必要としないでルールが展開される
4. ガバナンスを確立する
- セキュリティチームが公開前に脅威をレビューする
- 誤検知率の目標: 5%未満
- ルール有効性を週単位で測定する
5. 成果物: 自動ルール配布を備えた運用脅威インテリジェンスフィード-
推定工数*: 100~150時間
-
責任者*: セキュリティオペレーション + プラットフォームエンジニアリングチーム
-
コスト*: 約5,000~8,000ドルのエンジニアリング時間、インフラストラクチャに月額1,000~2,000ドル
リスク軽減プレイブック
モールス符号攻撃が検出された場合
即座(0~5分):
1. 影響を受けたエージェントを本番環境から隔離する
2. すべてのアクティブセッションを取り消す
3. セキュリティチームと影響を受けたユーザーにアラートする
4. ログとトランザクション記録を保存する
短期(5~30分):
1. 過去24時間以内にモールス符号を介して開始されたすべてのトランザクションを特定する
2. 可能であれば不正な転送を取り消す
3. 潜在的な侵害についてユーザーに通知する
4. フォレンジック分析を開始する
中期(30分~4時間):
1. 緊急形式スキャンルールを展開する
2. 脅威インテリジェンスフィードを更新する
3. エコシステム内のすべてのエージェントに通知する
4. すべての転送に対する一時的なMFA要件を実装する
長期(4時間~7日):
1. フォレンジック調査を完了する
2. 攻撃ベクトルと攻撃者を特定する
3. 修復ワークフローに従って永続的な修正を実装する
4. インシデント後のレビューを実施する
5. チームのセキュリティトレーニングを更新するコスト便益分析
- 図11:セキュリティ対策の費用対効果分析*
必要な投資
| コンポーネント | 一回限りのコスト | 月額コスト | タイムライン |
|---|---|---|---|
| 正規化前スキャン | 2,000~3,000ドル | 200ドル | 2~4週間 |
| 行動異常検出 | 3,000~4,000ドル | 500ドル | 5~8週間 |
| MFA統合 | 4,000~6,000ドル | 500~1,000ドル | 9~14週間 |
| 脅威インテリジェンスインフラ | 5,000~8,000ドル | 1,000~2,000ドル | 9~14週間 |
| 合計 | 14,000~21,000ドル | 2,200~3,700ドル | 14週間 |
リスク削減
| メトリック | 現在の状態 | 修復後 | 改善 |
|---|---|---|---|
| エンコーディングベースの攻撃成功率 | 約80% | 約5% | 94%削減 |
| 異常なエンコーディング検出時間 | 該当なし | 5分未満 | 対応を可能にする |
| エージェント間の脅威伝播時間 | 24時間以上 | 1時間未満 | 96%高速化 |
| 不正な転送回復率 | 約30% | 約90% | 3倍改善 |
ROI計算
-
仮定*: 平均不正転送額 = 50,000ドル、年間攻撃確率 = 15%
-
修復なしの予想損失: 50,000ドル × 0.15 = 年間7,500ドル
-
投資: 一回限り14,000~21,000ドル + 月額2,200~3,700ドル
-
回収期間: 2~3年(保守的。評判損害または規制罰金を考慮していない)
-
推奨*: 直ちに実装してください。単一の成功した攻撃のコストは
- 図3:入力処理パイプラインの段階と検証タイミングの問題点(『The Input Transformation Pipeline: Where Security Checks Failed』セクションに基づく)*