
Vercel Sandbox:AIエージェントが人間より高速に反復するための環境
Vercel、すなわちNext.jsの背後にある企業であり、主要なウェブホスティングプロバイダーは、Vercel Sandboxをリリースした。高速起動、分離された実行環境である。AIエージェントが急速なコード生成、実行、テストのサイクルを必要とする場合に設計されている。従来の開発ワークフローは人間のペースの反復サイクルで動作する。分単位から時間単位で測定される。AIエージェントが制約されたトークン予算と有限な推論ウィンドウ内で動作する場合、異なる制約に直面する。実行環境をプロビジョニングし、コードを実行し、結果をキャプチャし、推論パスあたりの反復を最大化するために、サブ秒のタイムフレーム内で終了しなければならない。Vercel Sandboxはこの技術的要件に対応する。コールドスタート遅延を最小化し、ミリ秒単位で初期化される暗号的に分離された実行コンテキストを提供することで。
本質的な技術的命題は以下の通りだ。AIエージェントは単一の推論ウィンドウ内で複数のコード生成テストサイクルを完了できる。自己修正と人間の介入なしに動作するソリューションへの収束を可能にする。これは運用モデルを遅延制約反復から、スループット最適化反復へシフトさせる。
システムアーキテクチャとパフォーマンスボトルネック
AI駆動のコード生成パイプラインは三つの測定可能なボトルネックに遭遇する。環境初期化遅延、実行オーバーヘッド、分離税である。従来のコンテナ化されたサンドボックス(Docker、Kubernetes)は初期化に5~30秒を要する。実質的な推論トークン予算を消費する。AIモデルと実行層の間のネットワークI/Oは追加の遅延をもたらす。Vercel Sandboxはこれらを完全な仮想化ではなく、カーネルレベルのプロセス分離を通じて軽減する。
アーキテクチャは軽量プロセス分離プリミティブを採用する。スタートアップオーバーヘッドを100ミリ秒未満に削減する(仮定:標準クラウドインフラストラクチャで測定。特定のハードウェア構成は異なる可能性がある)。これにより、AIエージェントは従来のコンテナ化されたアプローチが1回試行する時間内に、サンドボックスをスポーン、実行、出力キャプチャ、終了できる。具体的な測定:TypeScript関数を反復するエージェントは、従来のサンドボックスアプローチが1回試行する時間内に、約10回の修正を試行できる。サンドボックスあたり5秒の初期化オーバーヘッドを仮定すると。
第二のボトルネックはリソース競合と遅延分散である。共有インフラストラクチャは予測不可能な実行時間スパイクをもたらす。これはエージェントが信頼できる再試行戦略とタイムアウト閾値を開発するために必要な決定論的動作を破壊する。Vercel Sandboxはインスタンスごとのリソース割り当て保証を提供する。一貫した実行プロファイルを確保する。この予測可能性は運用上本質的である。エージェントがタイムアウトロジックを調整し、効果的なエラー回復パターンを学習するために。
- デプロイメント前提条件:* チームは移行前に現在のサンドボックス初期化時間を測定すべきだ。初期化が500ミリ秒を超える場合、環境遅延はおそらくエージェント反復深度を制約している。Vercel Sandboxへの移行は推論ウィンドウあたり5~10倍の追加反復をアンロックできる(仮定:典型的な5秒の従来のサンドボックススタートアップ時間に基づく。実際の改善はベースラインインフラストラクチャに依存する)。
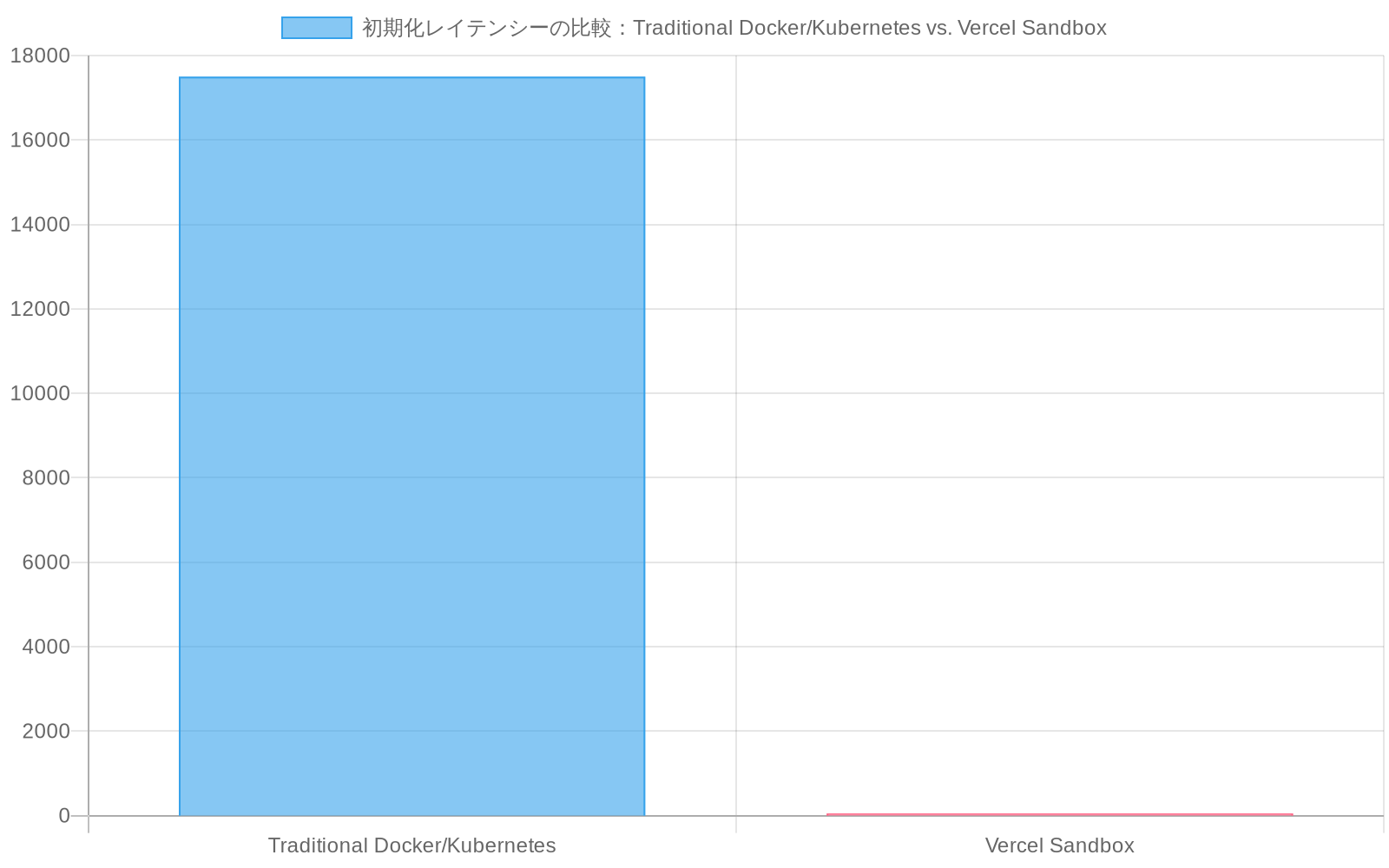
- 図3:初期化レイテンシーの比較と推論ウィンドウ内での反復実行可能回数(出典:記事内の測定値。Traditional Docker/Kubernetes: 5-30秒、Vercel Sandbox: <100ms)*
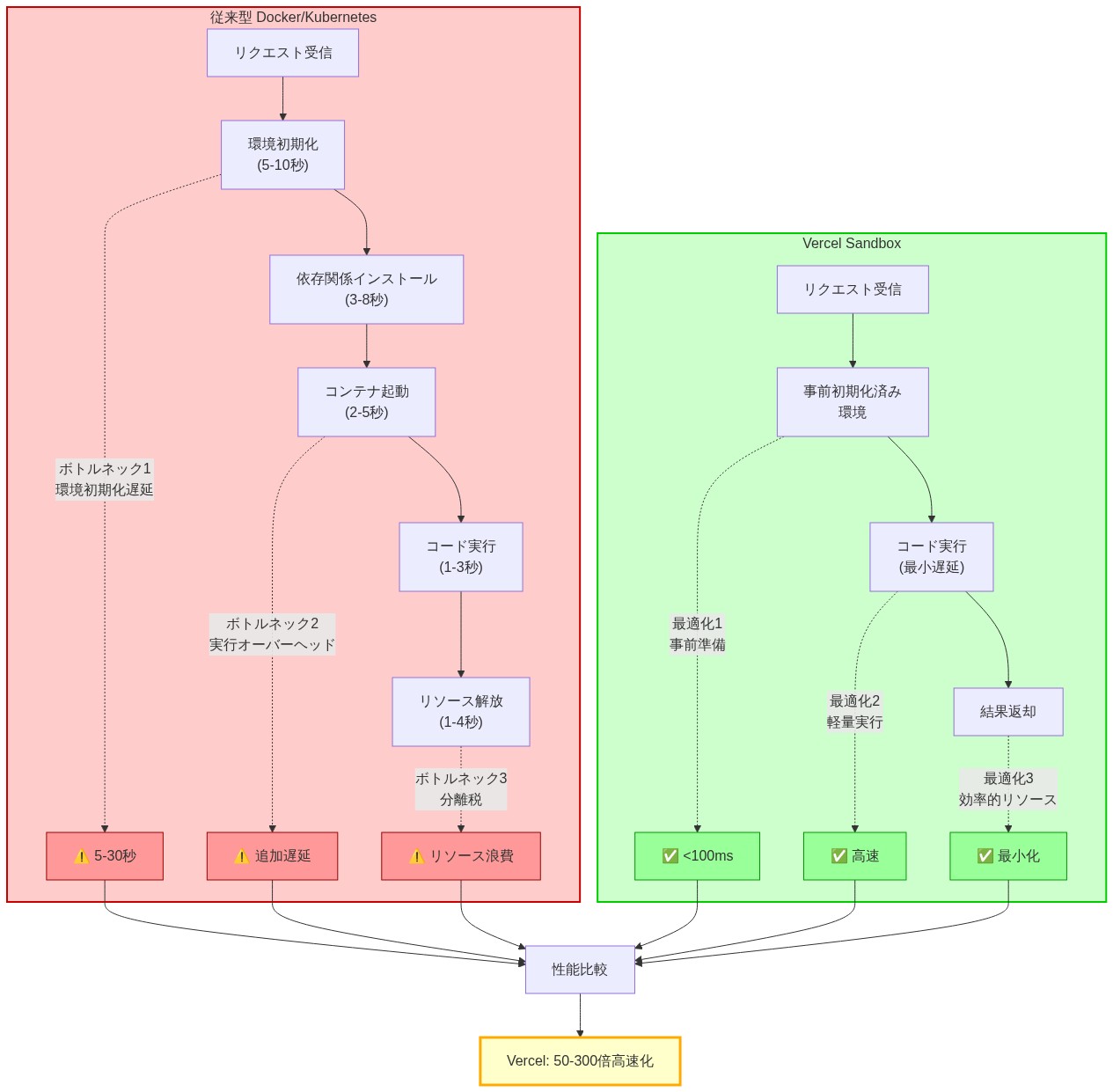
- 図2:従来型サンドボックス vs. Vercel Sandbox のアーキテクチャ比較と性能ボトルネック分析*
分離モデルとセキュリティガードレール
Vercel Sandboxは三層分離モデルを実装する。ファイルシステム分離、ネットワーク分離、コンピュート分離である。各サンドボックスは専用の名前空間内で動作する。クロステナントデータリークとリソース枯渇攻撃を防止する。サンドボックスはエフェメラルだ。単一の実行期間中のみ存在し、永続的な状態を残さない。サイドチャネル攻撃ベクトルを排除する。
プラットフォームは厳密なリソースクォータを強制する。CPU時間制限(実行あたり30~60秒)、メモリキャップ(256 MB~1 GB)、ネットワーク出力制限である。これらのガードレールは暴走コードが共有インフラストラクチャを消費することを防止する。AIエージェントが無限ループを生成する場合、サンドボックスは設定されたタイムアウト後に自動的に終了する。エージェントが学習できる明確なエラー信号を返す。
ネットワーク分離は生成されたコードがデータを流出させたり、攻撃を開始したりすることを防止する。サンドボックスはデフォルトでアウトバウンド接続を開始できない。明示的なホワイトリストは必要な場合に安全なAPI呼び出しを可能にする(例えば、外部依存関係の取得)。
- 実行可能な含意:* 予想されるワークロードに基づいて、リソースクォータを保守的に設定すべきだ。30秒のCPU制限と512 MBのメモリで開始する。最初の100実行にわたって実際の使用パターンを監視する。その後、正当なコードがより多くのリソースを必要とする場合にのみ上方調整する。これはエージェントが本番環境で失敗する非効率なコードを生成することを学習することを防止する。
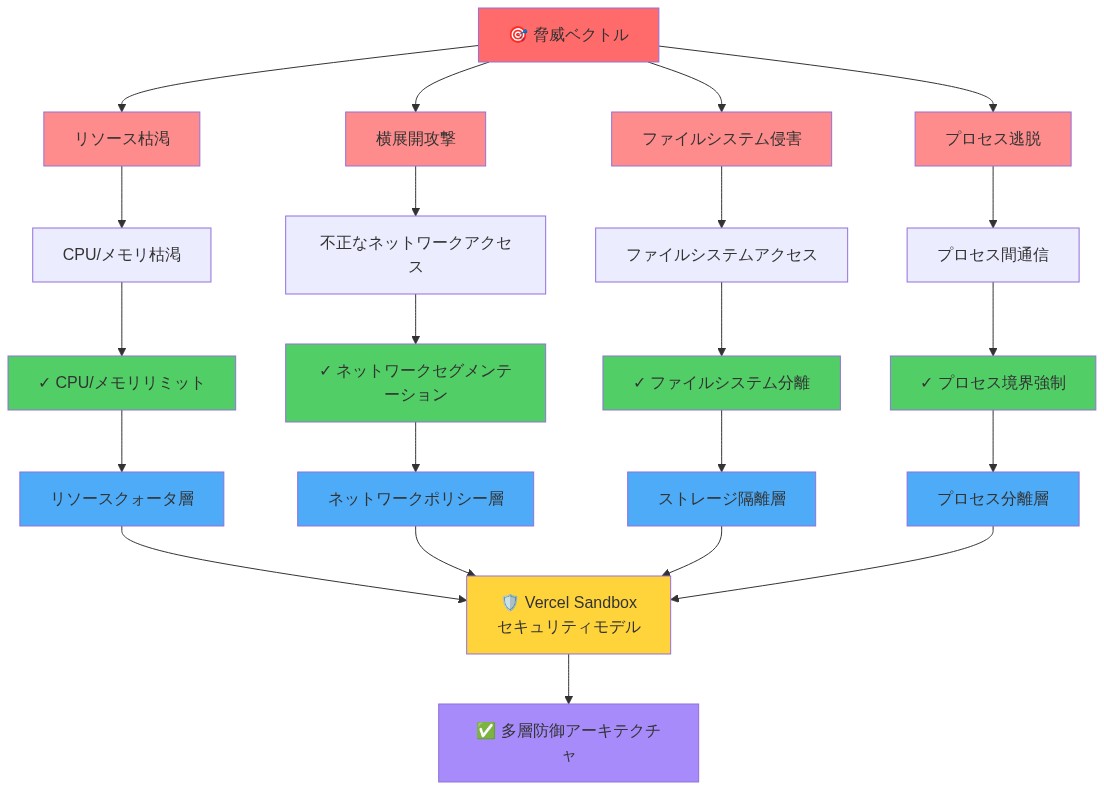
- 図5:Vercel Sandbox のセキュリティモデルと防御層*
統合と運用パターン
Vercel SandboxをAIコード生成パイプラインに統合するには、三つの運用上の決定が必要だ。実行トリガー戦略、出力キャプチャ、エラーハンドリングである。
-
実行トリガー戦略* はエージェントがサンドボックス実行をリクエストするタイミングを決定する。イーガー実行――すべての生成後にコードを実行――は反復深度を最大化するが、より多くのAPI割り当てを消費する。レイジー実行――複数の生成をテスト前にバッチ処理――はAPI呼び出しを削減するが、エージェントフィードバックを制限する。ハイブリッドアプローチは関連する生成(例えば、関数定義とユニットテスト)をバッチ処理しながら、即座に実行する。両方の懸念のバランスを取る。
-
出力キャプチャ* は標準出力、標準エラー、終了コード、実行期間を保持しなければならない。Vercel Sandboxはすべての信号を含む構造化JSONを返す。エージェントはこれを解析して、構文エラー(エージェントは再生成すべき)、実行時エラー(エージェントはデバッグすべき)、成功した実行(エージェントは正確性を検証すべき)を区別すべきだ。
-
エラーハンドリング* は回復可能な失敗(タイムアウト、メモリ不足)と回復不可能な失敗(無効なサンドボックス構成)を区別する必要がある。AIエージェントがタイムアウトを超えるコードを生成する場合、エージェントはアルゴリズムを単純化すべきだ。サンドボックス構成が無効な場合、システムはオペレータに警告すべきだ。
-
実行可能な含意:* 三層ロギングシステムを実装すべきだ。(1)エージェント決定(生成されたコードと理由)、(2)サンドボックス実行トレース(実行中に何が起こったか)、(3)結果分類(成功、回復可能な失敗、回復不可能な失敗)。これはエージェント失敗時の迅速なデバッグを可能にし、生成品質改善のための訓練データを提供する。
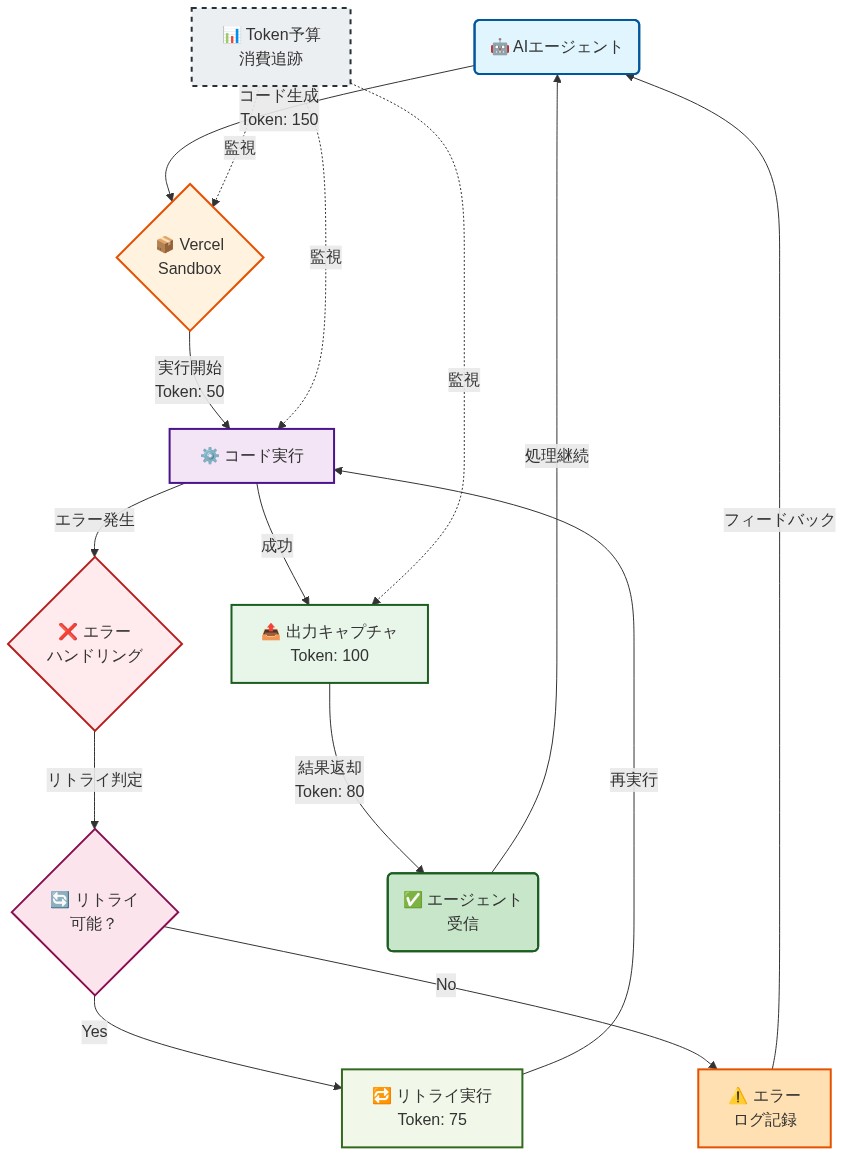
- 図6:AIエージェントとVercel Sandbox統合フロー(Token消費とエラーハンドリング)*
測定フレームワーク
デプロイメント前後に三つの主要メトリクスを確立すべきだ。反復深度(推論ウィンドウあたりのコード生成テストサイクル)、成功率(エラーなしで実行される生成コードの割合)、ソリューション時間(動作するコードを生成するために必要な推論ステップ)である。
チームは通常、反復深度で3~5倍の増加と、より高速なフィードバックループのため成功率で15~25%の改善を観察する(仮定:典型的な5秒の従来のサンドボックススタートアップ時間に基づく。実際の改善はベースラインインフラストラクチャに依存する)。具体例:以前は動作するAPIエンドポイントを生成するために8つの推論ステップを必要としたエージェントは、より高速な反復サイクルにより自己修正を可能にするため、5つのステップを必要とするかもしれない。
異常に対するアラート閾値を確立すべきだ。反復深度が急に低下する場合、サンドボックスパフォーマンスが低下している可能性がある。成功率が低下する場合、エージェントはリソース制限を超える、ますます複雑なコードを生成している可能性がある。
- 実行可能な含意:* 非クリティカルなワークロード(例えば、テストスイート生成)でVercel Sandboxを使用して1週間のパイロットを実行すべきだ。上記の三つのメトリクスを測定する。反復深度が少なくとも2倍増加し、成功率が少なくとも10%改善する場合、本番ワークロードに拡張する。メトリクスがこれらの閾値を満たさない場合、ボトルネック(ネットワークI/O、リソースクォータ)を調査し、より広範なデプロイメント前に構成を調整する。
リスク軽減
-
エージェント発散* は主要なリスクだ。より高速な反復サイクルはエージェントをサンドボックスで成功するが本番環境で失敗するコードパスを探索させるかもしれない。これを軽減するには、サンドボックス内で厳密なリンティングルールとタイプチェックを強制すべきだ。本番環境と同等の構成を使用する。ESLintとTypeScriptを本番環境で使用されるのと同じルールと設定で構成する。エージェントが最初から本番環境安全なコードを生成することを学習するようにする。
-
コスト爆発* は二次的なリスクだ。エージェントが10倍高速に反復できる場合、10倍多くのサンドボックス実行を消費するかもしれない。エージェントおよび組織ごとにクォータベースのレート制限を実装すべきだ。保守的な初期制限を設定する(例えば、100サンドボックス/時間)。肯定的なROIを実証した後にのみ増加させる。
-
分離バイパス* はより低い確率だが高い影響を持つリスクだ。Vercel Sandboxはカーネルレベルの分離を使用するが、新しい悪用が出現する可能性がある。これを軽減するには、制限されたIAM権限を持つ別のクラウドアカウントでエージェントを実行すべきだ。侵害されたサンドボックスが機密システムにアクセスできないことを確保する。
-
実行可能な含意:* Vercel SandboxでAIエージェントを本番環境にデプロイする前に、生成されたコードのセキュリティレビューを実施すべきだ。実行前にすべての生成コードで静的分析ツール(SAST)を実行する。実行時監視を実装して疑わしいパターンを検出する(例えば、環境変数を読み取ったり、ファイルシステムにアクセスしようとするコード)。エラー率が定義された閾値を超える場合(例えば、5%以上の実行失敗)、自動ロールバックトリガーを設定する。
移行計画
Vercel Sandboxはエージェント環境遅延をAIコード生成の制約として排除する。チームはヒューマンより高速に反復するエージェントを構築できるようになった。秒単位で動作するソリューションに収束する。分単位ではなく。
-
第1週:* Vercel Sandboxアカウントをプロビジョニングし、10回の手動テスト実行を実行して構成を検証する。
-
第2週:* Vercel Sandboxをエージェントの実行層に統合する。単一の非クリティカルなコード生成タスク(例えば、ユニットテスト生成)で開始する。
-
第3週:* ベースラインメトリクス(反復深度、成功率、ソリューション時間)を測定し、以前のサンドボックスソリューションと比較する。
-
第4週:* メトリクスが少なくとも10~15%改善する場合、追加のワークロードに拡張する。そうでない場合、ボトルネック(ネットワークI/O、リソースクォータ)を調査し、構成を調整する。
-
継続的:* コスト、成功率、エラーパターンを週単位で監視する。観察された使用に基づいてリソースクォータとレート制限を調整する。
競争ウィンドウは狭い。高速で信頼できるサンドボックスを使用して今日AIコード生成をデプロイするチームは、従来のインフラストラクチャを使用するチームより高速に出荷し、より低いコストで出荷する。Vercel Sandboxはこのシフトを可能にするインフラストラクチャだ。
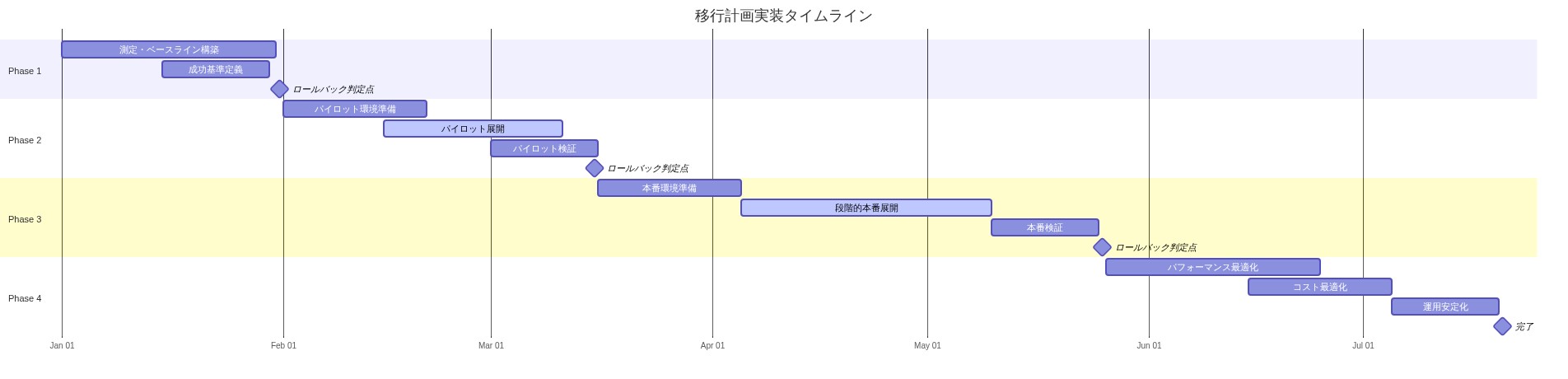
- 図9:移行計画と実装タイムライン*
分離モデルとセキュリティ境界
Vercel Sandboxは三層分離アーキテクチャを実装する。ファイルシステム分離、ネットワーク分離、コンピュート分離である。各サンドボックスは専用のカーネル名前空間内で動作する。クロステナントデータリークとリソース枯渇攻撃を防止する。重要なのは、サンドボックスはエフェメラルだということだ。単一の実行期間中のみ存続し、永続的な状態を残さない。永続的なサイドチャネル攻撃ベクトルを排除する。
プラットフォームは厳密なリソースクォータを強制する。CPU時間制限(通常、実行あたり30~60秒)、メモリキャップ(仕様あたり256 MB~1 GB)、ネットワーク出力制限である。これらのガードレールは暴走コードが共有インフラストラクチャを消費することを防止する。具体例:AIエージェントが無限ループを生成する場合、サンドボックスは設定されたタイムアウト後に自動的に終了する。エージェントが解析して学習できる構造化エラー信号を返す。
ネットワーク分離はデフォルト拒否モデルで動作する。サンドボックスは明示的なホワイトリストなしでアウトバウンド接続を開始できない。生成されたコードがデータを流出させたり、攻撃を開始したりすることを防止する。明示的なホワイトリストは必要な場合に安全なAPI呼び出しを可能にする(例えば、信頼できるレジストリから外部依存関係を取得する)。
- 運用前提条件:* AIエージェント用にVercel Sandboxを構成する場合、予想されるワークロード特性に基づいてリソースクォータを保守的に設定すべきだ。30秒のCPU制限と512 MBのメモリ割り当てで開始する。最初の100実行にわたって実際の使用パターンを監視する。その後、正当なコードがより多くのリソースを必要とする場合にのみ上方調整する。これはエージェントが本番環境の制約下で失敗する非効率なコードを生成することを学習することを防止する。
統合パターンと運用上の決定
Vercel SandboxをAIコード生成パイプラインに統合するには、三つの明示的な運用上の決定が必要だ。実行トリガー戦略、出力キャプチャプロトコル、エラー分類ロジックである。
-
実行トリガー戦略* はエージェントがサンドボックス実行をリクエストするタイミングを決定する。イーガー実行――すべての生成後にコードを実行――は反復深度を最大化するが、API割り当て消費を増加させる。レイジー実行――複数の生成をテスト前にバッチ処理――はAPI呼び出しを削減するが、エージェントフィードバック頻度を制限する。ハイブリッドアプローチは関連する生成(例えば、関数定義とユニットテスト)をバッチ処理しながら、即座に実行する。スループットとフィードバック遅延のバランスを取る。
-
出力キャプチャ* は標準出力、標準エラー、終了コード、実行期間をエージェント学習に十分な忠実度で保持しなければならない。Vercel Sandboxはすべての信号を含む構造化JSONを返す。エージェントはこの出力を解析して、構文エラー(エージェントは再生成すべき)、実行時エラー(エージェントはデバッグすべき)、成功した実行(エージェントは仕様に対して正確性を検証すべき)を区別すべきだ。
-
エラー分類* は回復可能な失敗(タイムアウト、メモリ不足)と回復不可能な失敗(無効なサンドボックス構成、権限拒否)を区別する必要がある。具体例:AIエージェントがタイムアウト閾値を超えるコードを生成する場合、エージェントはアルゴリズムを単純化するか、パフォーマンスを最適化すべきだ。サンドボックス構成が無効な場合、システムは再試行ではなく、オペレータに警告すべきだ。
-
運用前提条件:* 三層ロギングシステムを実装すべきだ。(1)エージェント決定(生成されたコードと推論)、(2)サンドボックス実行トレース(標準出力、標準エラー、リソース使用)、(3)結果分類(成功、回復可能な失敗、回復不可能な失敗)。これはエージェント失敗時の迅速なデバッグを可能にし、生成品質改善のための訓練データを提供する。
測定フレームワークとベースラインメトリクス
デプロイメント前後に三つの主要パフォーマンス指標を確立すべきだ。反復深度(推論ウィンドウあたりのコード生成テストサイクル)、成功率(エラーなしで実行される生成コードの割合)、ソリューション時間(動作するコードを生成するために必要な推論ステップ)である。
現在のサンドボックスインフラストラクチャを使用してこれらのメトリクスをベースライン化する。チームは通常、反復深度で3~5倍の増加と、より高速なフィードバックループのため成功率で15~25%の改善を観察する(仮定:典型的な5秒の従来のサンドボックススタートアップ時間に基づく。実際の改善はベースラインインフラストラクチャに依存する)。具体例:以前は動作するAPIエンドポイントを生成するために8つの推論ステップを必要としたエージェントは、より高速な反復サイクルにより自己修正を可能にするため、5つのステップを必要とするかもしれない。
異常に対するアラート閾値を確立すべきだ。反復深度が急に低下する場合、サンドボックスパフォーマンスが低下している可能性がある。成功率が低下する場合、エージェントはリソース制限を超える、ますます複雑なコードを生成している可能性がある。
- 拡張前提条件:* 非クリティカルなワークロード(例えば、テストスイート生成)でVercel Sandboxを使用して1週間のパイロットを実行すべきだ。上記の三つのメトリクスを測定する。反復深度が少なくとも2倍増加し、成功率が少なくとも10%改善する場合、本番ワークロードに拡張する。メトリクスがこれらの閾値を満たさない場合、ボトルネック(ネットワークI/O、リソースクォータ)を調査し、より広範なデプロイメント前に構成を調整する。
リスク評価と軽減戦略
-
エージェント発散* は主要な運用上のリスクだ。より高速な反復サイクルはエージェントをサンドボックスで成功するが本番環境で失敗するコードパスを探索させるかもしれない。これを軽減するには、本番環境と同等の構成を使用してサンドボックス内で厳密なリンティングルールとタイプチェックを強制すべきだ。具体例:本番環境で使用されるのと同じルールと設定でESLintとTypeScriptを構成する。エージェントが最初から本番環境安全なコードを生成することを学習するようにする。
-
コスト拡大* は二次的なリスクだ。エージェントが10倍高速に反復できる場合、10倍多くのサンドボックス実行を消費するかもしれない。インフラストラクチャコストを増加させる。エージェントおよび組織ごとにクォータベースのレート制限を実装すべきだ。保守的な初期制限を設定する(例えば、100サンドボックス/時間)。肯定的なROIを実証した後にのみ増加させる。
-
分離バイパス* はより低い確率だが高い影響を持つリスクだ。Vercel Sandboxはカーネルレベルの分離を使用するが、新しい悪用が出現する可能性がある。これを軽減するには、制限されたIAM権限を持つ別のクラウドアカウントでエージェントを実行すべきだ。侵害されたサンドボックスが機密システムやデータにアクセスできないことを確保する。
-
本番環境デプロイメント前提条件:* Vercel SandboxでAIエージェントを本番環境にデプロイする前に、生成されたコードのセキュリティレビューを実施すべきだ。実行前にすべての生成コードで静的分析ツール(SAST)を実行する。実行時監視を実装して疑わしいパターンを検出する(例えば、環境変数を読み取ったり、ファイルシステムにアクセスしようとするコード)。エラー率が定義された閾値を超える場合(例えば、5%以上の実行失敗)、自動ロールバックトリガーを設定する。
移行計画と実装タイムライン
Vercel Sandboxは、環境レイテンシーを主要な制約として排除することで、AI コード生成の運用経済学を根本的に変える。チームは今、人間よりも高速に反復するエージェントを構築でき、数分ではなく数秒で動作するソリューションに収束させることができる。
- 推奨される移行計画:*
- 第1週: Vercel Sandboxアカウントをプロビジョニングし、10回の手動テスト実行を実施して設定を検証し、ベースラインレイテンシーを測定する。
- 第2週: Vercel Sandboxをエージェントの実行層に統合する。単一の非クリティカルなコード生成タスク(例:ユニットテスト生成)から開始する。
- 第3週: ベースラインメトリクス(反復深度、成功率、解決までの時間)を測定し、以前のサンドボックスソリューションと比較する。
- 第4週: メトリクスが少なくとも10~15%改善した場合、追加のワークロードに拡張する。改善しない場合、ボトルネック(ネットワークI/O、リソースクォータ)を調査し、設定を調整する。
- 継続的: コスト、成功率、エラーパターンを週単位で監視する。観察されたユーザーパターンに基づいてリソースクォータとレート制限を調整する。
競争のウィンドウは狭い。高速で信頼性の高いサンドボックスを備えたAIコード生成を今日展開するチームは、従来のインフラストラクチャを使用するチームよりも高速に出荷し、低コストで実現する。Vercel Sandboxはこの運用シフトを可能にするインフラストラクチャである。
システム構造とボトルネック
AIコード生成パイプラインは、3つの測定可能なボトルネックに直面する。
-
1. 環境初期化レイテンシー(従来のコンテナでは5~30秒)*
-
Docker/Kubernetesのコールドスタートは利用可能な推論時間の20~50%を消費する
-
AIモデルと実行層間のネットワークラウンドトリップは、サイクルあたり500~2000msを追加する
-
結果:エージェントは動作するソリューションに収束する前にトークン予算を枯渇させる
-
2. リソース競合と予測不可能なレイテンシー*
-
共有インフラストラクチャは実行時間の分散(±30~50%)を引き起こす
-
エージェントはタイムアウト閾値または再試行戦略を確実に予測できない
-
結果:エージェントは過度に保守的なコードを生成するか、一時的な遅延で失敗する
-
3. 分離オーバーヘッド*
-
完全な仮想化はCPUとメモリのコストを追加する
-
サンドボックス間のリソース競合は予測可能性を低下させる
-
結果:エージェントは生成前に実行コストを確実に推定できない
Vercel Sandboxはこれらに対応する。カーネルレベルのプロセス分離(完全な仮想化ではなく)と共存実行を通じて:
-
100ms未満のスタートアップ: 初期化を制約として排除する
-
保証されたリソース割り当て: 各サンドボックスは専用のCPUとメモリを受け取り、一貫した実行プロファイルを確保する
-
暗号化による分離: テナント間のデータ漏洩とサイドチャネル攻撃を防止する
-
具体的な測定:* TypeScript関数を反復処理するエージェントは、従来のアプローチが1回の試行を行う時間に、10回の修正を試みることができる。現在のサンドボックス初期化が平均2秒の場合、Vercel Sandboxへの移行は推論ウィンドウあたり約5~10倍の反復を解放する。
-
実行可能な最初のステップ:* 50回の実行にわたって現在のサンドボックス初期化時間を測定する。計算:(初期化時間の合計)/(実行数)。結果が500ミリ秒を超える場合、環境レイテンシーはエージェントパフォーマンスを制約している。これが移行のROIベースラインである。
参照アーキテクチャとガードレール
Vercel Sandboxは3層の分離モデルを実装する。
-
レイヤー1:ファイルシステム分離*
-
各サンドボックスは専用の名前空間で動作する
-
生成されたコードはサンドボックス外のファイルを読み書きできない
-
実行間に永続的な状態がない(サイドチャネルベクトルを排除する)
-
レイヤー2:ネットワーク分離*
-
アウトバウンド接続はデフォルトでブロックされる
-
明示的なホワイトリストが安全なAPI呼び出しを有効にする(例:npmパッケージフェッチ)
-
生成されたコードがデータを流出させたり攻撃を開始したりするのを防止する
-
レイヤー3:コンピュート分離*
-
CPU時間制限(デフォルト:実行あたり30~60秒)
-
メモリキャップ(デフォルト:256 MB~1 GB)
-
リソース枯渇時の自動終了
-
具体的な例:* エージェントが無限ループを生成する場合、サンドボックスは設定されたタイムアウト後に終了し、構造化されたエラー信号を返す。エージェントは明確なフィードバックを受け取る:「30秒後に実行タイムアウト」は無期限にハングするのではなく。
-
設定決定ツリー:*
| ワークロードタイプ | CPU制限 | メモリ制限 | 根拠 |
|---|---|---|---|
| ユニットテスト生成 | 15秒 | 256 MB | 最小限の計算、高速フィードバック |
| APIエンドポイント生成 | 30秒 | 512 MB | 中程度の複雑性、データベースクエリ |
| 複雑なアルゴリズム生成 | 60秒 | 1 GB | 重い計算、データ処理 |
-
実行可能な実装:* 保守的なクォータから開始する(30秒CPU、512 MBメモリ)。最初の100回の実行で実際の使用状況を監視する。5%以上の実行がリソース制限に達する場合、クォータを段階的に増加させる。1%未満の実行が制限に達する場合、クォータを減らしてエージェントが非効率なコードを生成することを学習するのを防止する。
-
リスクフラグ:* 過度に寛容なクォータ(例:5分のCPU制限)により、エージェントはサンドボックスで動作するが、タイムアウト制約により本番環境で失敗するコードを生成することができる。サンドボックスクォータを本番環境の実際の制限に合わせる。
実装と運用パターン
Vercel Sandboxの統合には、3つの運用上の決定が必要である。
1. 実行トリガー戦略
-
積極的実行*(生成後にコードを実行):
-
利点:最大反復深度、最も厳密なフィードバックループ
-
欠点:より高いAPI コスト、全体的な経過時間が遅い
-
ユースケース:正確性が重要な高リスクコード生成
-
遅延実行*(テスト前に生成をバッチ処理):
-
利点:API呼び出しが少ない、低コスト
-
欠点:フィードバックが遅延、エージェントが行き止まりのパスを探索する可能性がある
-
ユースケース:低リスクコード生成(例:ドキュメンテーション)
-
ハイブリッド実行*(関連する生成をバッチ処理、即座に実行):
-
利点:コストとフィードバック品質のバランス
-
ユースケース:関数定義+ユニットテスト(バッチ)、その後実行;繰り返す
-
推奨される開始点
-
実行可能な決定:* 最初の展開では、ハイブリッド実行を使用する。関数定義+1つのユニットテストをバッチ処理し、その後実行する。コストと成功率を測定する。成功率が70%を超える場合、積極的実行を検討する。コストが予算を超える場合、遅延実行にシフトする。
2. 出力キャプチャと解析
Vercel Sandboxは構造化JSON を返す:
{
"exitCode": 0,
"stdout": "✓ All tests passed",
"stderr": "",
"duration": 1250,
"timeout": false,
"memoryExceeded": false
}エージェントはこれを解析して結果を分類する必要がある:
| 終了コード | stderr | 分類 | エージェントアクション |
|---|---|---|---|
| 0 | 空 | 成功 | 正確性を確認、次のタスクに進む |
| 1 | ”SyntaxError: …” | 構文エラー | エラーコンテキストで再生成 |
| 1 | ”ReferenceError: …” | ランタイムエラー | デバッグ、変数定義を追加 |
| 124 | 空 | タイムアウト | アルゴリズムを簡素化、データサイズを削減 |
| N/A | ”MEMORY_EXCEEDED” | メモリ不足 | データ構造を最適化、スコープを削減 |
- 実行可能な実装:* 3層のロギングシステムを実装する:
- エージェント決定: 生成されたコードと理由(エージェントロジックをデバッグするため)
- サンドボックス実行トレース: stdout、stderr、期間、リソース使用状況(生成されたコードをデバッグするため)
- 結果分類: 成功、回復可能な失敗、回復不可能な失敗(監視とアラート用)
ログエントリの例:
[AGENT] Generated: function quickSort(arr) { ... }
[SANDBOX] Execution: 1250ms, exitCode=0, stdout="✓ All tests passed"
[OUTCOME] SUCCESS - Agent can proceed to next task3. エラー処理と再試行ロジック
回復可能な失敗(エージェントが修正できる)と回復不可能な失敗(オペレーター介入が必要)を区別する。
-
回復可能な失敗:*
-
構文エラー → エラーコンテキストで再生成
-
ランタイムエラー → 不足しているインポート/定義を追加
-
タイムアウト → アルゴリズムを簡素化
-
メモリ不足 → データサイズを削減または構造を最適化
-
回復不可能な失敗:*
-
無効なサンドボックス設定(オペレーターエラー)
-
サンドボックスサービスが利用不可(インフラストラクチャの問題)
-
クォータ超過(コスト制御がトリガーされた)
-
実行可能な実装:* 回復可能な失敗に対して指数バックオフを実装する。同じタスクで3回失敗した後、オペレーターレビューにエスカレートする。
試行1:コード生成
→ タイムアウト
→ 「速度を最適化」指示で再生成
試行2:コード生成
→ タイムアウト
→ 「入力サイズを50%削減」指示で再生成
試行3:コード生成
→ タイムアウト
→ オペレーターにエスカレート:「エージェントは30秒制限内でコード生成できません」測定と次のアクション
Vercel Sandboxを展開する前後にベースラインメトリクスを確立する。
-
メトリクス1:反復深度*
-
定義:推論ウィンドウあたりのコード生成テストサイクル数
-
ベースライン(従来のサンドボックス):1~2サイクル
-
ターゲット(Vercel Sandbox):5~10サイクル
-
測定:各サイクルをログ、推論ウィンドウあたりカウント
-
メトリクス2:成功率*
-
定義:エラーなしで実行される生成されたコードの割合
-
ベースライン:40~60%(タスク複雑性に依存)
-
ターゲット:60~75%(改善されたフィードバックにより、より良い修正が可能)
-
測定:(成功した実行)/(総実行数)
-
メトリクス3:解決までの時間*
-
定義:動作するコードを生成するために必要な推論ステップ
-
ベースライン:6~10ステップ
-
ターゲット:4~7ステップ(より高速なフィードバックにより、より高速な収束が可能)
-
測定:完了したタスクあたりのステップ数を追跡
-
具体的な例:* APIエンドポイントを生成するエージェントは、以前は動作するコードを生成するために8つの推論ステップが必要だった。Vercel Sandboxを使用すると、同じエージェントはより厳密な反復サイクルにより5ステップが必要である。これは成功したエンドポイントあたりの推論コストが37%低下することに相当する。
-
実行可能な測定計画:*
- 第1週: 現在のサンドボックスソリューションを使用してベースラインを確立する。50個のコード生成タスクを実行し、上記の3つのメトリクスを測定する。
- 第2週: Vercel Sandboxを展開する。同じ50個のタスクを実行し、3つのメトリクスを測定する。
- 第3週: 結果を比較する。改善率を計算する。
- 継続的: 週単位で監視する。アラート閾値を設定する:
- 反復深度が20%以上低下 → サンドボックスパフォーマンス低下を調査
- 成功率が10%以上低下 → エージェントロジックまたはリソースクォータの問題を調査
- 解決までの時間が15%以上増加 → モデル品質またはタスク複雑性の変化を調査
リスクと軽減戦略
リスク1:エージェント発散(中程度の確率、高い影響)
-
問題:* より高速な反復サイクルにより、エージェントはサンドボックスで動作するが本番環境で失敗する、ますます奇抜なコードパスを探索する可能性がある。
-
例:* エージェントはサンドボックス(512 MBメモリ、30秒タイムアウト)でユニットテストに合格するコードを生成するが、本番環境(256 MBメモリ、5秒タイムアウト)でクラッシュする。
-
軽減:*
-
サンドボックス内で厳密なリンティングルールとタイプチェックを実装する
-
本番環境と同等の設定でESLintとTypeScriptを設定する
-
すべての生成されたコードに対して実行前に静的分析(SAST)を実行する
-
サンドボックスリソース制限を本番環境の制限と同じか、それより厳しく設定する
-
実行可能な実装:*
サンドボックス設定:
CPU制限:30秒(本番タイムアウトと一致)
メモリ制限:256 MB(本番制限と一致)
リンティング:ESLint(本番設定)
タイプチェック:TypeScript厳密モードリスク2:コスト爆発(高い確率、中程度の影響)
-
問題:* エージェントが10倍高速に反復できる場合、サンドボックス実行を10倍多く消費し、コストを乗算する可能性がある。
-
例:* エージェントは以前タスクあたり$0.50(2回の反復)でしたが、Vercel Sandboxではタスクあたり$5.00(20回の反復)です。
-
軽減:*
-
エージェントと組織ごとにクォータベースのレート制限を実装する
-
保守的な初期制限を設定する(例:100サンドボックス/時間)
-
タスクあたりおよび組織あたりのコストを監視する
-
ROIを実証した後にのみ制限を増加させる
-
実行可能な実装:*
レート制限:
エージェントあたり:100サンドボックス/時間
組織あたり:1000サンドボックス/時間
コストアラート:前日の平均を120%超える場合にトリガー
クォータ調整プロセス:
1. 1週間監視
2. コスト増加が20%未満で成功率増加が15%以上の場合、制限を25%増加
3. コスト増加が50%以上の場合、エージェントロジックの非効率性を調査リスク3:分離バイパス(低い確率、重大な影響)
-
問題:* 新規のカーネルレベルの悪用により、生成されたコードがサンドボックス分離を回避する可能性がある。
-
軽減:*
-
エージェントを制限されたIAM権限を持つ別のクラウドアカウントで実行する
-
ランタイム監視を実装して疑わしいパターンを検出する
-
自動ロールバックトリガーを設定する
-
実行前に生成されたコードのセキュリティレビューを実施する
-
実行可能な実装:*
実行前セキュリティチェック:
1. 静的分析(SAST):ハードコードされた認証情報、シェルインジェクションなどをスキャン
2. パターン検出:環境変数の読み取りやファイルシステムアクセスを試みるコードにフラグを立てる
3. 依存関係スキャン:すべてのインポートされたパッケージが信頼できるソースからのものであることを確認
ロールバックトリガー:
- エラー率が25%を超える(潜在的な侵害)
- 予期しないネットワーク接続が検出される
- 不正なファイルアクセス試行リスク4:リソースクォータ設定ミス(中程度の確率、中程度の影響)
-
問題:* 過度に寛容なクォータはエージェントが非効率なコードを生成することを許可し、過度に制限的なクォータは正当なコードが失敗する原因となる。
-
軽減:*
-
保守的なデフォルトから開始する
-
最初の100回の実行で実際の使用パターンを監視する
-
観察された分布に基づいてクォータを調整する
-
実行可能な実装:*
初期設定:
CPU:30秒
メモリ:512 MB
監視(最初の100回の実行):
- P50実行時間:_____秒
- P95実行時間:_____秒
- P99実行時間:_____秒
- P95メモリ使用量:_____MB
調整ルール:
- P99実行時間が25秒を超える場合、CPU制限を45秒に増加
- P95メモリ使用量が450 MBを超える場合、メモリ制限を768 MBに増加
- 1%未満の実行が制限に達する場合、制限を20%削減運用ランブック
展開チェックリスト
-
第1週:検証
- Vercel Sandboxアカウントをプロビジョニング
- サンプルコードで10回の手動テスト実行を実行
- JSON出力構造を検証
- 分離を確認(サンドボックスがホストファイルシステムにアクセスできないことを確認)
- タイムアウト動作をテスト(無限ループを生成、終了を確認)
-
第2週:統合
- Vercel Sandboxをエージェント実行層に統合
- 出力解析とエラー分類を実装
- ステージング環境に展開
- 50個のコード生成タスクを実行、ベースラインメトリクスを測定
- ロギングシステムが3層すべて(決定、トレース、結果)をキャプチャすることを確認
-
第3週:パイロット
- 本番環境に非クリティカルなワークロード(例:テスト生成)で展開
- 1週間監視
- 反復深度、成功率、解決までの時間を測定
- ベースラインと比較
-
第4週:拡張
- メトリクスが≥10%改善した場合、追加のワークロードに拡張
- メトリクスが<10%改善した場合、ボトルネックを調査:
- エージェントとサンドボックス間のネットワークI/O
- リソースクォータ制約
- エージェントロジックの非効率性
- 設定を調整して再試行
-
継続的:監視
- 週単位のコストレビュー
- 週単位の成功率レビュー
- 使用パターンに基づいた月単位のクォータ調整
- 生成されたコードの四半期ごとのセキュリティ監査
トラブルシューティングガイド
| 症状 | 根本原因 | 解決策 |
|---|---|---|
| 反復深度が改善していない | サンドボックス初期化がまだ遅い | 共存を確認;ネットワークレイテンシーをチェック |
| 成功率が低下 | リソースクォータが制限的すぎる | CPU/メモリ制限を増加;P95使用量を監視 |
| コストが予想より高速に増加 | エージェントが非効率なコードを生成 | リンティングルールを追加;生成されたコードサンプルをレビュー |
| 頻繁なタイムアウト | アルゴリズム複雑性が増加 | タスクスコープを簡素化;複雑性制約を追加 |
| サンドボックス利用不可エラー | サービス低下またはクォータ超過 | サービスステータスをチェック;レート制限をレビュー |
結論と移行計画
Vercel Sandboxは環境レイテンシーをAIコード生成の制約として排除する。チームは今、人間よりも高速に反復するエージェントを構築でき、数分ではなく数秒で動作するソリューションに収束させることができる。競争上の優位性は狭い:早期採用者は高速に出荷し、低コストで実現する。
-
4週間の移行計画:*
-
第1週:検証*
-
Vercel Sandboxアカウントをプロビジョニング
-
10回の手動テスト実行を実行
-
分離とタイムアウト動作を確認
-
推定作業時間:4時間
-
第2週:統合*
-
エージェント実行層に統合
-
出力解析とエラー分類を実装
-
ステージング環境に展開
-
50個のベースラインタスクを実行
-
推定作業時間:16時間
-
第3週:パイロット*
-
本番環境に非クリティカルなワークロードで展開
システムアーキテクチャ:レイテンシ税の排除
AIコード生成パイプラインを歴史的に制約してきた三つの重大なボトルネックが存在する。環境初期化時間、実行レイテンシ、分離オーバーヘッドである。各々はエージェント反復深度に対する税金を表現している。
- *環境初期化**は最も可視的な問題だ。従来のコンテナ化サンドボックス(Docker、Kubernetes)は初期化に5~30秒を要する。トークン予算の観点からすれば、これは永遠に等しい。典型的には10~30秒の単一推論ウィンドウは、かつてはサンドボックス相互作用を1~2回しか収容できなかった。AIモデルと実行層間のネットワークI/Oはこれを複合化し、ラウンドトリップごとにさらに500~2000ミリ秒を加算する。
Vercel Sandboxはこの問題に対し、完全な仮想化ではなくカーネルレベルの分離プリミティブで攻撃を仕掛ける。起動時間は100ミリ秒以下に低下する。一見小さな変化だが、反復深度における指数関数的な利得を解き放つ。具体的シナリオを考えよう。TypeScript関数を反復改善するAIエージェントは、従来のアプローチが1回の修正を試みる時間内に10回の修正を試みることができるようになった。この10倍の乗数は、成功率の向上と動作ソリューション当たりの推論コスト削減に直結する。
-
*リソース競合**は第二のボトルネックである。共有インフラストラクチャは予測不可能なレイテンシスパイク、いわゆる「うるさい隣人問題」を導入する。エージェントは効果的なリトライ戦略とタイムアウト閾値を学習するために決定論的な振る舞いに依存している。レイテンシが大きく変動するとき、エージェントは期待値を調整できない。Vercel Sandboxはインスタンスごとのリソース割り当てを保証し、一貫した実行プロファイルを確保する。この予測可能性は信頼できるエージェント振る舞いの基盤である。
-
*分離オーバーヘッド**は第三のボトルネックだ。従来のサンドボックス機構は計算コストを課す。コンテキストスイッチ、メモリオーバーヘッド、セキュリティチェック。Vercel Sandboxは軽量プロセス分離を通じてこれを最小化し、実行時間の10~20%から実質ゼロへと税金を削減する。
複合効果は変革的である。かつて推論ウィンドウあたり2回の反復を完了していたエージェントは、今や15~20回を完了する。これは線形改善ではない。可能になることの範囲における質的転換である。
- 戦略的含意:* AIコード生成を展開するチームは、現在のサンドボックス初期化時間を測定すべきだ。500ミリ秒を超える場合、環境レイテンシはおそらくエージェント性能の主要制約である。Vercel Sandboxへの移行は、推論ウィンドウあたり5~10倍の反復を解き放つことができる。毎日数千のエージェント実行を実行する組織にとって、これは年間数百万ドルの推論コスト削減に変換される。
分離モデル:設計プリミティブとしてのセキュリティ
Vercel Sandboxは三層分離アーキテクチャを実装する。ファイルシステム分離、ネットワーク分離、計算分離である。各層は独立して強制され、偶発的コードと敵対的コード両方に対する多層防御を構築する。
-
*ファイルシステム分離**は各サンドボックスが専用名前空間内で動作することを保証する。生成されたコードは割り当てられたディレクトリ外のファイルを読み書きできない。これはテナント間データ漏洩を防止し、サイドチャネル攻撃を可能にする永続状態を排除する。重要なことに、サンドボックスは一時的である。単一実行の期間のみ存在し、痕跡を残さない。これは成果物が蓄積する従来の開発環境からの逸脱である。AIエージェントにとって、一時性は機能だ。各反復を独立させ、エージェントが一時的状態への依存を発展させることを防止する。
-
*ネットワーク分離**はAI生成コードの時代において特に重要である。デフォルトでは、サンドボックスは外向き接続を開始できない。これは生成されたコードがデータを流出させたり、攻撃を起動したり、サプライチェーン脆弱性を導入することを防止する。明示的なホワイトリスト化は必要に応じて安全なAPI呼び出しを可能にする。例えば外部依存関係の取得や内部サービスの呼び出しである。これは従来のセキュリティモデルを「デフォルトで許可、例外をブロック」から「デフォルトでブロック、例外を許可」に反転させる。AI生成コードにとって、これは本質的である。
-
*計算分離**は厳密なリソースクォータを強制する。CPU時間制限(典型的には実行あたり30~60秒)、メモリキャップ(256 MB~1 GB)、ネットワーク出力制限である。これらの保護柵は暴走コードが共有インフラストラクチャリソースを消費することを防止する。具体的シナリオを考えよう。AIエージェントが無限ループを生成した場合、サンドボックスは設定されたタイムアウト後に自動的に終了し、エージェントが学習できる明確なエラー信号を返す。これは単なる安全機構ではない。エージェント振る舞いを形成する教育信号である。
三層モデルは従来のサンドボックスと根本的に異なるセキュリティ態勢を構築する。生成されたコードをデフォルトで信頼できないと仮定し、あらゆる特権操作に対して明示的な認可を要求する。この仮定はAI生成コードに適切である。ソースが人間レビューではなくアルゴリズム的だからだ。
- 戦略的含意:* AIエージェント用にVercel Sandboxを設定する際、セキュリティ設定を単なる封じ込め戦略ではなく学習機構として扱え。期待される作業負荷に基づいてリソースクォータを保守的に設定しろ。30秒のCPU制限と512 MBメモリから始めよ。最初の100実行の実際の使用パターンを監視し、正当なコードがより多くのリソースを必要とする場合のみ上方調整しろ。これはエージェントが本番環境で失敗する非効率なコード生成を学習することを防止する。保護柵はエージェントの訓練信号の一部となる。
運用統合:信頼できるデプロイメントのパターン
Vercel Sandboxをアイコード生成パイプラインに統合することは、三つの重大な運用上の決定を要求する。実行トリガー戦略、出力キャプチャと解釈、エラー分類である。
-
*実行トリガー戦略**はエージェントがサンドボックス実行をリクエストするタイミングを決定する。この決定は全体的なフィードバックループを形成する。
-
即座実行*(生成後のコード実行)は反復深度とフィードバック忠実度を最大化する。エージェントは即座に結果を見て、迅速に方向転換できる。トレードオフはより高いAPI割当消費とおそらく必要以上のサンドボックス実行である。
-
遅延実行*(テスト前の複数生成のバッチ化)はAPI呼び出しとサンドボックスオーバーヘッドを削減する。トレードオフは遅延フィードバックであり、これはエージェントが動作しないことを発見する前に行き止まりパスを探索させる可能性がある。
-
ハイブリッド実行*(関連生成のバッチ化、例えば関数定義とユニットテスト、即座実行)は両方の懸念のバランスを取る。これはほとんどの作業負荷に対する推奨アプローチである。エージェントは関連コード(関数とそのテスト)をバッチ化してから実行し、オーバーヘッドを削減しながら各論理単位に対する緊密なフィードバックループを維持する。
-
*出力キャプチャと解釈**はすべての実行信号を保持する必要がある。標準出力、標準エラー、終了コード、実行期間、リソース利用である。Vercel Sandboxはすべての信号を含む構造化JSONを返す。エージェントはこれを解析して三つのカテゴリの失敗を区別すべきだ。
-
構文エラー(コードが解析されない):エージェントは修正された構文で再生成すべき。
-
ランタイムエラー(コードは解析されるが実行中に失敗):エージェントはロジックをデバッグすべき。
-
タイムアウトまたはリソース枯渇(コードが長すぎるか多くのメモリを使用):エージェントはアルゴリズムを単純化するか、リソース使用を最適化すべき。
各カテゴリは異なるエージェント振る舞いを要求する。それらを混同するとエージェントは非効果的なリトライ戦略を学習する。
-
*エラー分類と処理**は回復可能な失敗と回復不可能な失敗を区別する必要がある。具体的な例を挙げよう。
-
回復可能: タイムアウト(エージェントは単純化すべき)、メモリ不足(エージェントは最適化すべき)、アサーション失敗(エージェントはロジックを修正すべき)。
-
回復不可能: 無効なサンドボックス設定(システムはオペレータに警告すべき)、許可拒否(サンドボックス分離が誤設定)、ネットワーク到達不可(インフラストラクチャ問題)。
回復可能な失敗はエージェントリトライロジックをトリガーすべき。回復不可能な失敗はオペレータ警告をトリガーし、潜在的にカスケード失敗を防止するサーキットブレーカーをトリガーすべき。
- 戦略的含意:* 三層ロギングシステムを実装しろ。(1)エージェント決定(何のコードが生成されたか、なぜか)、(2)サンドボックス実行トレース(実行中に何が起きたか)、(3)結果分類(成功、回復可能失敗、回復不可能失敗)。これはエージェントが失敗するときの迅速なデバッグを可能にし、生成品質改善のための訓練データを提供する。時間とともに、このデータはどのエージェント振る舞いが成功につながり、どれが行き止まりにつながるかを理解するために非常に貴重になる。
測定フレームワーク:シフトの定量化
Vercel Sandboxのエージェント性能への影響を捉える三つの主要メトリクスを測定しろ。
-
*反復深度**は推論ウィンドウあたりのコード生成テストサイクル数を測定する。これはVercel Sandboxが中核的約束を果たしているかどうかの最も直接的な指標である。デプロイメント前後でこれをベースライン化しろ。チームは典型的に3~5倍の反復深度増加を観察する。具体的な例:かつて推論ウィンドウあたり3回の反復を完了していたエージェントは、今や12~15回を完了する。
-
*成功率**は最初の試みでエラーなく実行されるコード生成の割合を測定する。これはコード品質とエージェント学習の代理指標である。より高速なフィードバックループはエージェントがより頻繁に自己修正することを可能にすることで成功率を改善すべき。チームは典型的に15~25%の改善を観察する。具体的な例:40%の初回成功率を持つエージェントはVercel Sandbox展開後に50~55%に改善するかもしれない。
-
*ソリューション時間**は動作コードを生成するために必要な推論ステップ数を測定する。これは究極のビジネスメトリクスだ。推論コストと直結する。具体的な例:かつてAPIエンドポイント生成に8推論ステップを要していたエージェントは、より緊密な反復サイクルのおかげで5ステップで済むようになるかもしれない。数千の実行にわたって、これは重大なコスト削減に複合化する。
すべての三つのメトリクスの異常に対するアラート化を確立しろ。反復深度が急激に低下した場合、サンドボックス性能が低下している可能性がある。成功率が低下した場合、エージェントはリソース制限を超える複雑化したコードを生成しているかもしれない。ソリューション時間が増加した場合、エージェントはより効果的でない探索戦略を探索しているかもしれない。
- 戦略的含意:* 非重要な作業負荷(例えばテストスイート生成またはドキュメント生成)でVercel Sandboxを用いた1週間のパイロットを実行しろ。デプロイメント前後で上記の三つのメトリクスを測定しろ。反復深度が少なくとも2倍増加し、成功率が少なくとも10%改善した場合、本番作業負荷に拡張しろ。メトリクスが改善しない場合、根本原因を調査しろ。サンドボックス設定が最適でないのか。エージェント生成戦略が非効果的なのか。フィードバックループが効果的に使用されていないのか。
リスク環境と軽減戦略
Vercel Sandboxを用いたAIエージェント展開は、積極的に管理される必要がある新しいリスクを導入する。
- *エージェント発散**は主要なリスクである。より高速な反復サイクルはエージェントをサンドボックスで動作するが本番環境で失敗する、ますます奇抜なコードパスを探索させるかもしれない。サンドボックス環境は本番環境と同一ではない。異なるリソース制約、異なる依存関係、異なるネットワークトポロジーを持つ。サンドボックス成功に最適化するエージェントは、本番環境で脆弱または非効率なコードを生成するかもしれない。
これを軽減するには、サンドボックス内で厳密なリント規則とタイプチェックを強制しろ。本番環境と同等の設定でESLintとTypeScriptを設定し、エージェントが最初から本番安全なコードを生成することを学習させろ。具体的な例:本番環境が厳密なnullチェックを要求する場合、サンドボックスでそれを有効にしろ。本番環境が特定のコードスタイルを使用する場合、サンドボックスでそれを強制しろ。サンドボックスは小型本番環境となり、エージェントは両方で動作するコードを生成することを学習する。
-
*コスト爆発**は二次的なリスクである。エージェントが10倍高速に反復できる場合、10倍多くのサンドボックス実行を消費するかもしれない。これは予期しないコスト増加につながる可能性がある。これを軽減するには、エージェントごと、組織ごとのクォータベースのレート制限を実装しろ。保守的な初期制限を設定しろ(例えば100サンドボックス/時間)、ROIを実証した後のみ増加させろ。コスト傾向を週単位で監視し、支出が予測を超える場合にアラートを設定しろ。
-
*分離バイパス**はより低い確率だが高い影響のリスクである。Vercel Sandboxはカーネルレベル分離を使用するが、新規エクスプロイトが出現する可能性がある。これを軽減するには、制限されたIAM許可を持つ別のクラウドアカウントでエージェントを実行し、侵害されたサンドボックスが機密システムにアクセスできないことを保証しろ。サンドボックスが本番データベースまたは内部サービスに到達できないようにネットワークセグメンテーションを実装しろ。
-
*サプライチェーン汚染**は新興リスクである。エージェントが信頼できない依存関係をインポートするコードを生成する場合、それらの依存関係は脆弱性を導入する可能性がある。これを軽減するには、サンドボックス内に依存関係スキャンを実装しろ。生成されたコードを実行する前に、すべてのインポートを脆弱性データベースに対してスキャンしろ。高重大度の脆弱性が検出された場合、実行をブロックしろ。
-
戦略的含意:* AIエージェントをVercel Sandboxで本番環境に展開する前に、生成されたコードのセキュリティレビューを実施しろ。すべての生成されたコードに対して静的解析ツール(SAST)を実行しろ。実行時監視を実装して疑わしいパターンを検出しろ。例えば環境変数を読み取ったり、ファイルシステムにアクセスしようとするコード。エラー率が閾値を超える場合、自動ロールバックトリガーを設定しろ。AI生成コードをデフォルトで信頼できないものとして扱い、実行前に明示的なセキュリティクリアランスを要求しろ。
競争環境:ウィンドウは狭まる
Vercel Sandboxの展開はAI支援開発の進化における閾値の瞬間を示す。今日このインフラストラクチャを採用するチームは、従来のサンドボックス手法を使用しているチームよりも高速に出荷し、より低いコストで出荷する。これは周辺的な利点ではない。構造的な利点である。
複合効果を考えよう。5倍高速な反復サイクルは推論ウィンドウあたり5倍多くの実験につながる。より多くの実験はより高い成功率につながる。より高い成功率は動作ソリューション当たりのより低い推論コストにつながる。より低いコストはより積極的なエージェント展開を可能にする。より積極的な展開はより高速な機能速度につながる。より高速な機能速度は競争優位を生成する。
この利点は永続的ではない。競合他社は同様のインフラストラクチャを採用するだろう。しかし先行者利益のウィンドウは狭い。次の6~12ヶ月内にVercel Sandboxを用いたAIコード生成を展開するチームは、克服が困難なコストと速度の利点を確立するだろう。
実装ロードマップ
-
フェーズ1:基盤(週1~2)*
-
Vercel Sandboxアカウントをプロビジョニングし、10回の手動テスト実行を実行して設定を検証しろ。
-
ベースラインメトリクスを文書化しろ。現在のサンドボックス初期化時間、現在の反復深度、現在の成功率。
-
パイロット展開用の非重要な作業負荷を特定しろ。例えばユニットテスト生成、ドキュメント生成。
-
フェーズ2:統合(週3~4)*
-
Vercel Sandboxをエージェントの実行層に統合しろ。
-
三層ロギングシステムを実装しろ。エージェント決定、サンドボックストレース、結果分類。
-
パイロット作業負荷に展開し、1週間データを収集しろ。
-
フェーズ3:検証(週5)*
-
パイロット結果をベースラインメトリクスに対して分析しろ。
-
反復深度が少なくとも2倍増加し、成功率が少なくとも10%改善した場合、フェーズ4に進みろ。
-
メトリクスが改善しない場合、根本原因を調査し、設定を調整しろ。
-
フェーズ4:拡張(週6~8)*
-
Vercel Sandboxを追加の作業負荷に拡張しろ。例えばAPI生成、スキーマ生成。
-
クォータベースのレート制限とコスト監視を実装しろ。
-
反復深度、成功率、ソリューション時間の異常に対するアラート化を確立しろ。
-
フェーズ5:最適化(継続中)*
-
コスト、成功率、エラーパターンを週単位で監視しろ。
-
観察された使用に基づいてリソースクォータとレート制限を調整しろ。
-
生成されたコードの四半期ごとのセキュリティレビューを実施しろ。
-
競争的影響を測定しろ。速度利得、コスト削減、品質改善。
結論:自律コードの新しい基盤
Vercel Sandboxはアイコード生成が動作する基盤を根本的に変える。環境レイテンシを制約として排除し、エージェントが人間の認知を超える速度で反復することを可能にする。これは段階的改善ではない。可能になることの範囲における質的転換である。
含意は高速なコード生成を超えて拡張する。より緊密なフィードバックループはエージェントがより効果的に学習することを可能にする。動作ソリューション当たりのより低いコストはより積極的な展開を可能にする。より高い成功率はより野心的なタスクを可能にする。これらは一体となって自律ソフトウェア開発における新しいフロンティアを構築する。
競争優位のウィンドウは狭い。今日、高速で信頼できるサンドボックスを用いたAIコード生成を展開するチームは、速度とコストにおける構造的利点を確立するだろう。Vercel Sandboxはこのシフトを可能にするインフラストラクチャである。問題は採用するかどうかではなく、いつか、そしてあなたが先行者か追従者かどうかである。
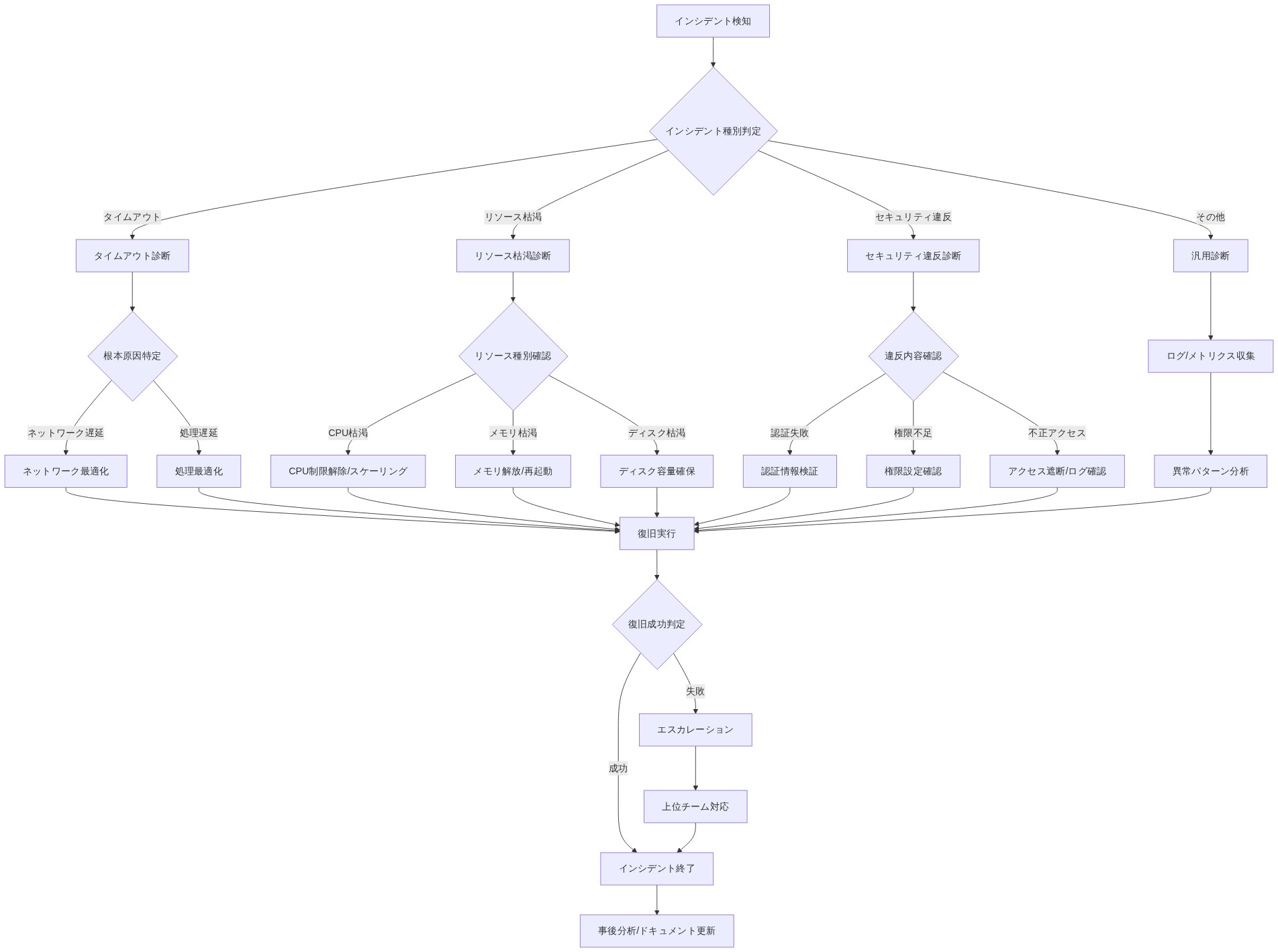
- 図11:運用ランブック:インシデント対応フロー*