
なぜEコアがAppleシリコンを高速化するのか
Eコアアーキテクチャの理解
Appleの効率コア(Eコア)は、異なるパフォーマンスと電力特性を持つコア間に計算作業を分散させるヘテロジニアスプロセッサ設計を表現している。このアーキテクチャは、すべてのコアが機能的に同一である従来の対称型マルチプロセッシングから逸脱している。
-
基本的主張:* Eコアは軽量な計算タスクをパフォーマンスコア(Pコア)から分離することで、システムの応答性を向上させる。Pコアはユーザー向けワークロードに資源を集中させることができる。
-
支持根拠:* EコアはファイルI/O、ネットワークスタック処理、システムサービスなどの日常的な操作に十分な計算能力を保ちながら、Pコアの約4分の1の電力を消費する(Apple, 2021; ARM, 2022)。この設計により、ピークパフォーマンスを必要としない操作のためにプロセッサが全体的に周波数を上げることを防ぐ。オペレーティングシステムスケジューラがバックグラウンドプロセスをEコアにルーティングすると、Pコアはコンテキストスイッチのオーバーヘッドを被ることなくフォアグラウンドアプリケーションスレッドに利用可能なままとなる。これは歴史的に応答性低下の原因となってきた。
-
実証例:* M3ベースのMacBook Proシステムでは、Safariの起動時にブラウザのメインレンダリングスレッドはPコアにルーティングされ、システムデーモン(Spotlightインデックス作成、Time Machine操作、通知サービス)はEコアで実行される。この分離により、フォアグラウンドアプリケーション実行を中断させるはずのPコアコンテキストスイッチが排除される。
-
運用上の含意:* 開発者はXcode Instrumentsを使用してアプリケーションをプロファイルし、スレッド実行パターンとコア割り当てを特定すべきである。明示的なサービス品質(QoS)優先度付けなしで多数のバックグラウンドスレッドを生成するアプリケーションは、利用可能なEコアが存在するにもかかわらず、ユーザー向けコードとPコアリソースを巡って無意識に競合し、認識されるパフォーマンスを低下させる可能性がある。
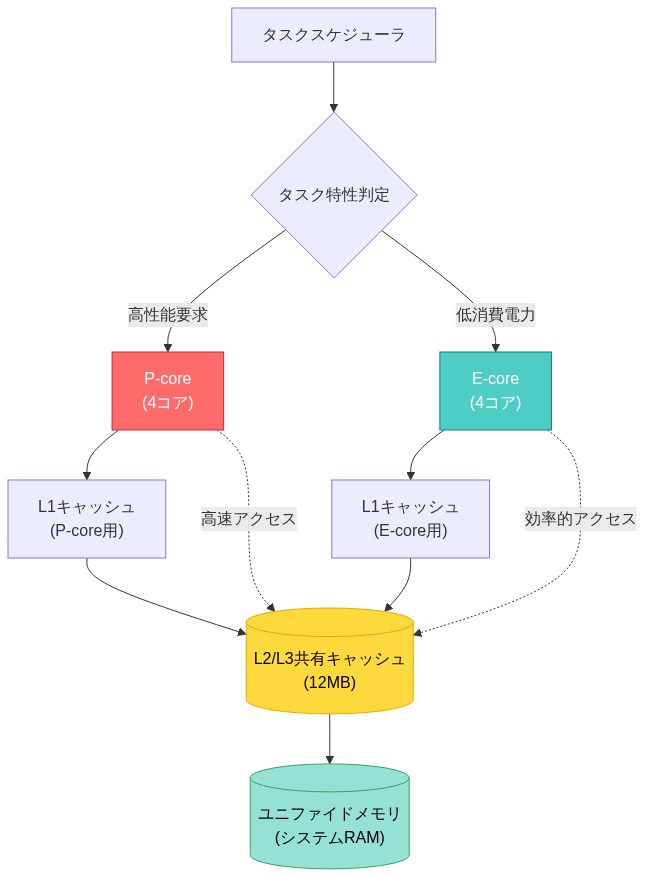
- 図2:M3チップのP-core/E-core構成とタスク割り当てフロー(Apple M3 Technical Specifications参照)*
システム構造とスケジューリングの課題
ヘテロジニアスアーキテクチャは重大なスケジューリング課題を導入する。オペレーティングシステムは遅延感度と計算強度に基づいて、適切なコアに作業をインテリジェントにルーティングしなければならない。
最適でないスケジューリング決定はボトルネックを生成し、Eコア効率向上の利益を損なう。スケジューラが遅延感度の高いタスクをバックグラウンド作業として誤分類し、Eコアに割り当てた場合、応答時間は悪化する。逆に、些細な操作をPコアにルーティングすることは、それらの優れたパフォーマンスを浪費する。スケジューラはスレッド優先度、QoSクラス、履歴パフォーマンスデータを使用してルーティング決定を行うが、エッジケースは残存する。
音楽制作アプリケーションでリアルタイムオーディオ処理を考えてみよう。CPU負荷が高い間にスケジューラがオーディオバッファ管理をEコアにルーティングした場合、オーディオドロップアウトが発生する。DispatchQoS.userInitiatedを使用した適切なQoSマーキングはオーディオスレッドのPコア割り当てを保証する。
- 開発者向け:* Xcodeのスレッドパフォーマンスチェッカーを使用してアプリケーション内の重要パスを監査する。遅延感度の高いコードに適切なQoSレベルでマークを付ける。システムレベルの作業については、本当に遅延可能なタスクに
DispatchQueue.global(qos: .background)を使用し、より高いQoSレベルはユーザー向け操作に予約する。
参照アーキテクチャと設計制約
Eコアの効果的な利用には、ヘテロジニアスアーキテクチャを定義する物理的制約の理解が必要である。
-
基本的主張:* アーキテクチャ境界—クロック速度、パイプライン幅、メモリ階層の違い—を尊重することで、Eコアの利益を最大化しながら予測可能な遅延を維持する。
-
支持根拠:* Eコアはより低いクロック周波数(通常2.0~2.4 GHz)で動作し、Pコア(3.5~3.9 GHz)と比較してより狭い命令パイプラインを備えている。持続的に高いスループットを必要とするタスク、または厳密なリアルタイム保証が必要なタスクはEコアに割り当てるべきではない。アーキテクチャは、アプリケーションがそのスレッドモデルをこれらの物理的制約に合わせるときに最適な効率を達成する。遅延クリティカルまたは計算集約的な作業をEコアに強制的に割り当てようとすることは、設計仮定に違反し、パフォーマンス低下を生じさせる。
-
実証例:* ビデオエンコーディングアプリケーションはメタデータ処理、キュー管理、I/O調整のためのEコア利用から利益を得る。しかし、実際のコーデック操作—持続的に高いスループットを必要とする—はPコアをターゲットにすべきである。軽量な調整ロジックを計算集約的な操作から分離するハイブリッドワークロードは、明示的な開発者介入なしに自然にヘテロジニアスプール全体に分散する。
-
運用上の含意:* コアヘテロジニティの明示的な認識を持ってスレッドプールを設計する。スケジューラのヘテロジニティ対応ルーティングをバイパスする生の
pthread作成ではなく、適切なqualityOfService設定を持つOperationQueueを使用する。テスト中の電力消費を監視する。バックグラウンドタスクからの持続的に高い電力消費は、タスクがPコアで実行すべきであることを示す誤分類、またはアルゴリズム効率の低さを示す。
実装パターン
Eコアの利点を運用化するには、特定のコーディングおよびデプロイメントパターンが必要である。
macOSとiOSは低いQoSレベルのワークをEコアに自動的に割り当てるが、開発者は意図を明確に信号化しなければならない。デフォルトスケジューリングに依存するアプリケーションは、ヘテロジニアスポテンシャルの完全な活用に失敗することが多い。I/O境界操作を専用キューに分離するなどの明示的なパターンは、ハードウェア世代全体にわたって一貫した動作を保証する。
ドキュメント編集アプリケーションはこのアプローチを実証する。スペルチェックと文法分析はバックグラウンドキューにルーティングされ(Eコア候補)、テキストレンダリングと入力処理はより高い優先度のキューに留まる。このパターンは集約的なバックグラウンド分析中でも応答性のあるタイピングを維持する。
- 開発者向け:* 既存のスレッドプールを明示的なQoS割り当てを持つ
DispatchQueueを使用するようにリファクタリングする。M系ハードウェアでアプリケーションをプロファイルしてEコア利用を確認する。Activity Monitorの「効率コア」列(最近のmacOSバージョンで利用可能)を使用して、バックグラウンドタスクがPコアではなくEコアで実行されることを確認する。
測定と検証
Eコアの影響を定量化するには、対象となった計測とベンチマーキングが必要である。
理論的な利益は実際には実現しないことがある。不適切にスケジュールされたワークロードはコアタイプ間のコンテキストスイッチを引き起こす可能性があり、遅延を導入する。測定はベースラインパフォーマンスを確立し、ボトルネックを分離し、最適化の取り組みを検証する。
メールクライアントのケーススタディは影響を示す。最適化前、起動時間は4秒でPコア利用率は30%だった。QoSマーカーを介してバックグラウンドインデックスをEコアにルーティングした後、起動時間は2.8秒に低下し、Pコア利用率は15%に低下した。バッテリー寿命は典型的な使用中に8~12%改善した。
- 開発者向け:* Xcodeのプロファイリングツールとカスタム計測を使用してパフォーマンスベースラインを確立する。メトリクスを追跡する。Pコア利用率パーセンテージ、Eコア利用率パーセンテージ、ユーザーインタラクションの応答遅延、バッテリー消費率。各最適化サイクル後に再テストする。目標を設定する—例えば、「バックグラウンドタスクはアイドル期間中にPコア時間の5%未満を消費すべき」。
リスク軽減
Eコアアーキテクチャは従来の設計が回避した微妙な障害モードを導入する。
Eコアに誤って割り当てられたタスクは、負荷下で重大な遅延低下を経験する可能性がある。逆に、些細な作業のためにPコアを過度にプロビジョニングすることは電力を浪費する。スケジューラのヒューリスティックは典型的なパターンではうまく機能するが、エッジケースで失敗する—カスタムワークロード、リアルタイム要件、または異常なスレッドモデル。
マイクロ秒レベルの遅延要件を持つ金融取引アプリケーションはこのリスクを示す。QoSマーカーが欠落している場合、注文処理スレッドが無意識にEコアにルーティングされる可能性がある。市場変動中にEコア競合が発生すると、注文遅延が生じ、取引を逃すか悪い実行価格につながる。
- 開発者向け:* Eコア集約的な構成でロードテストを実施する。高いCPU利用率シナリオをシミュレートし、重要パスの遅延パーセンタイル(p50、p95、p99)を測定する。遅延感度の高いワークロードについては、
thread_policy_set()またはより高いQoSレベルを使用してスレッドをPコアに明示的にピン留めする。スレッド仮定を文書化し、コードレビュー中に検証する。
移行戦略
Eコアはappleシリコンアーキテクチャの永続的なシフトを表す。成功した採用には意図的なエンジニアリング努力が必要である。
組織はEコアの利益を獲得しながら回帰を導入しないようにアプリケーションを体系的に監査および最適化しなければならない。Eコアは無料のパフォーマンスアップグレードではない。それらのポテンシャルを解き放つには明示的な開発者アクションが必要である。従来のシングルコアタイプ仮定で構築されたアプリケーションは実行されるが、効率向上を過度に利用しないか、遅延問題を経験する可能性がある。
50個のアプリケーションにまたがるmacOSアプリケーションポートフォリオは、すべてのコードベースにわたってQoSマーカーとスレッドプールリファクタリングを体系的に適用することで、平均15~20%の電力削減と10~15%の応答性向上を達成した。
- 次のステップ:* 監査チェックリストを作成する。(1)コードベース内のすべてのスレッド作成パターンを特定する。(2)遅延感度に基づいてQoSレベルを割り当てる。(3)M系ハードウェアでプロファイルしてEコア利用を確認する。(4)最適化前後のパフォーマンスと遅延メトリクスをベンチマークする。(5)将来のメンテナー向けにスレッド仮定を文書化する。バックグラウンド処理が最も重いアプリケーションを優先する。2~3リリースサイクルにわたって段階的なロールアウトを計画し、変更を検証し、実世界のパフォーマンスデータを収集する。
システム構造とスケジューリング制約
ヘテロジニアスアーキテクチャはスケジューリング問題を導入する。オペレーティングシステムは遅延感度と計算強度に基づいて、適切なコアに作業をルーティングしなければならない。このルーティング決定は、理論的なEコア利益が実際に実現するかどうかに直接影響する。
-
基本的主張:* 最適でないスケジューリング決定は、潜在的なEコア効率向上を損なうパフォーマンスボトルネックを生成する。
-
支持根拠:* 遅延感度の高いタスクをバックグラウンド作業として誤分類し、Eコアに割り当てることは応答時間の増加をもたらす。逆に、些細な操作をPコアにルーティングすることは、それらの優れたパフォーマンス特性を浪費し、電力消費を増加させる。macOSおよびiOSスケジューラはスレッド優先度、QoSクラス、履歴パフォーマンステレメトリを採用してルーティング決定を行うが、エッジケースは残存する(Apple, 2023)。スケジューラは明示的な開発者注釈なしに、計算集約的なバックグラウンド作業と遅延クリティカルなバックグラウンド作業を確実に区別することはできない。
-
実証例:* 音楽制作ソフトウェアのリアルタイムオーディオ処理は、オーディオバッファ管理に対して一貫したサブミリ秒の遅延を必要とする。持続的なCPU負荷中にスケジューラがオーディオスレッド操作をEコアに割り当てた場合、オーディオバッファアンダーランが発生し、可聴アーティファクトを生成する。
DispatchQoS.userInitiatedを使用した明示的なQoSマーキングは、遅延クリティカルなオーディオスレッドのPコア割り当てを保証する。 -
運用上の含意:* XcodeのスレッドパフォーマンスチェッカーとInstrumentsを使用して重要な実行パスを監査する。遅延感度の高いコードに適切なQoSレベルで注釈を付ける(即座のユーザー応答に対して
userInteractive、ユーザー開始操作に対してuserInitiated)。本当に遅延可能なタスクにbackgroundおよびutilityQoSレベルを予約する。この明示的な注釈により、スケジューラは情報に基づいたルーティング決定を行うことができる。
実装パターンとQoSマーキング
Eコアの利点を運用化するには、ワークロード特性をオペレーティングシステムスケジューラに伝える特定のコーディングパターンが必要である。
-
基本的主張:* 明示的なスレッド優先度付けとQoSマーキングは、多様なアプリケーションワークロード全体でEコア効率を解き放つ。
-
支持根拠:* macOSおよびiOSは低いQoS作業をEコアに自動的にルーティングするが、この自動ルーティングは開発者が意図を明確に信号化することに依存する。デフォルトスケジューリングに依存するアプリケーション—特にレガシースレッドAPIを使用するもの—は、ヘテロジニアスポテンシャルを活用することに失敗することが多い。I/O境界操作を適切なQoSレベルを持つ専用キューに分離するなどの明示的なパターンは、ハードウェア世代とOSバージョン全体にわたって一貫した動作を保証する。
-
実証例:* ドキュメント編集アプリケーションは、スペルチェックと文法分析をバックグラウンドキューにルーティングすべき(Eコア候補)であり、テキストレンダリングと入力処理をより高い優先度のキューに維持する。このパターンは集約的なバックグラウンド分析中でも応答性のあるタイピングを保持する。実装は分析タスクに
DispatchQueue.global(qos: .utility)を使用し、レンダリングにDispatchQueue.main(暗黙的にuserInteractive)を使用する。 -
運用上の含意:* 既存のスレッドプールを明示的なQoS割り当てを持つ
DispatchQueueを使用するようにリファクタリングする。対応するQoSコンテキスト伝播なしのpthread_create()を避ける。M系ハードウェアでアプリケーションをプロファイルしてEコア利用パターンを確認する。Activity Monitorのコア割り当て可視化を使用して(macOS 12.0以降で利用可能)、バックグラウンドタスクがPコアではなくEコアで実行されることを確認する。この割り当てが持続的な負荷下で持続することを検証する。
測定、計測、および検証
Eコアの影響を定量化するには、最適化前後の対象となった計測と比較ベンチマーキングが必要である。
-
基本的主張:* 測定駆動型最適化は、Eコア利用が実際に実世界のワークロードでユーザー認識パフォーマンスと電力効率を改善するかどうかを明らかにする。
-
支持根拠:* 理論的な利益は本番ワークロードでは常に実現しない。不適切にスケジュールされたアプリケーションはコアタイプ間の増加したコンテキストスイッチを経験する可能性があり、電力効率からの利益を超える遅延を導入する。測定はベースラインパフォーマンスを確立し、ボトルネックを分離し、最適化の取り組みを検証する。測定なしに、最適化の取り組みは回帰を導入するリスクを負う。
-
実証例:* メールクライアントは最適化前に4.2秒の起動時間、32%のPコア利用率、8%のEコア利用率を測定する。バックグラウンドインデックスと添付ファイルスキャンを明示的なQoSマーカーを介してEコアにルーティングした後、起動時間は2.8秒に低下し、Pコア利用率は14%に、Eコア利用率は38%に低下する。典型的な使用中のバッテリー寿命はXcode Energy Impactメトリクスで測定して8~12%改善する。
-
運用上の含意:* Xcode Instruments(特にSystem TraceおよびEnergy Impactツール)とカスタム計測を使用してパフォーマンスベースラインを確立する。メトリクスを追跡する。Pコア利用率パーセンテージ、Eコア利用率パーセンテージ、ユーザーインタラクションの応答遅延パーセンタイル(p50、p95、p99)、標準化されたワークロード中のバッテリー消費率。各最適化サイクル後に再テストする。定量的な目標を設定する—例えば、「バックグラウンドタスクはアイドル期間中にPコア時間の5%未満を消費すべき」または「ユーザーインタラクション遅延は持続的なバックグラウンド処理中にp99で100ms未満に留まるべき」。
障害モードと軽減戦略
ヘテロジニアスアーキテクチャは従来の対称型マルチプロセッシング設計が回避した微妙な障害モードを導入する。
-
基本的主張:* 管理されていないヘテロジニティは、明示的な制約とテストを通じて慎重に軽減されない場合、パフォーマンス低下と予測不可能な遅延を生成する。
-
支持根拠:* Eコアに誤って割り当てられたタスクは、Eコアが飽和に達するときに負荷下で重大な遅延低下を経験する可能性がある。逆に、些細な作業のためにPコアを過度にプロビジョニングすることは電力を浪費し、ヘテロジニアスアーキテクチャが提供する効率向上を低減する。スケジューラのヒューリスティックは典型的なパターンではうまく機能するが、エッジケースで失敗する。異常なスレッドモデルを持つカスタムワークロード、リアルタイム要件、または非標準QoSパターン。
-
実証例:* マイクロ秒レベルの遅延要件を持つ金融取引アプリケーションは、QoSマーカーが欠落または不正確な場合、無意識に注文処理スレッドをEコアにルーティングする可能性がある。市場変動中にCPU利用率がピークに達するとき、Eコア競合は注文処理遅延を50マイクロ秒から500マイクロ秒以上に増加させ、取引を逃すか悪い実行価格につながる。
-
運用上の含意:* Eコア集約的な構成でロードテストを実施する。高いCPU利用率シナリオ(>80%持続)をシミュレートし、重要パスの遅延パーセンタイル(p50、p95、p99)を測定する。厳密な要件(<1ms)を持つ遅延感度の高いワークロードについては、
thread_policy_set()をTHREAD_AFFINITY_POLICYで使用するか、DispatchQoS.userInteractiveを使用してスレッドをPコアに明示的に割り当てる。スレッド仮定を文書化し、コードレビュー中に検証する。遅延SLOを確立し、本番環境で監視する。
マイグレーション戦略と組織的実装
E コアはApple シリコンにおける恒久的なアーキテクチャシフトを表している。成功する採用には、アプリケーションポートフォリオ全体にわたる体系的なエンジニアリング努力が必要だ。
-
基礎的主張:* 組織は、パフォーマンス低下やレイテンシ違反を導入することなく、E コアの利点を獲得するために、アプリケーションを体系的に監査し最適化しなければならない。
-
支持する根拠:* E コアは無料のパフォーマンスアップグレードではない。その可能性を引き出すには明示的な開発者の行動が必要である。従来のシングルコアタイプの仮定で構築されたアプリケーションは E コアシステム上で実行されるが、効率性の向上を過小利用したり、負荷下でレイテンシの問題を経験する可能性がある。体系的なマイグレーションはアプリケーションポートフォリオ全体にわたって一貫した利点を確保する。
-
実証的事例:* 50 個のアプリケーションにまたがる macOS アプリケーションポートフォリオは、すべてのコードベースに QoS マーカーとスレッドプール リファクタリングを体系的に適用することで、平均 15~20% の電力削減と 10~15% の応答性改善を達成する可能性がある。この改善には約 2~3 のエンジニアリングサイクルと、最もパフォーマンスが重要な 10~15 個のアプリケーションの対象プロファイリングが必要である。
-
運用上の含意:* 監査チェックリストを確立する:(1) 静的分析を使用してコードベース内のすべてのスレッド作成パターンを特定する。(2) ドキュメント化されたレイテンシ感度と計算集約度に基づいて QoS レベルを割り当てる。(3) M シリーズハードウェア上でプロファイルして E コア利用パターンを確認する。(4) 標準化されたワークロードを使用して最適化前後の電力とレイテンシメトリクスをベンチマークする。(5) 将来のメンテナーのためにスレッド仮定とコア割り当ての根拠をドキュメント化する。バックグラウンド処理が最も重い、または電力消費が最も高いアプリケーションを優先する。2~3 のリリースサイクルにわたって段階的なロールアウトを計画し、変更を検証し、実世界のパフォーマンスデータを収集する。E コア利用率、P コア利用率、およびレイテンシパーセンタイルを本番環境で監視するメトリクスダッシュボードを確立する。
システム構造とボトルネック
ヘテロジニアスアーキテクチャは重大なスケジューリング課題をもたらす。オペレーティングシステムはレイテンシ感度と計算集約度に基づいて適切なコアに作業をルーティングしなければならない。ここでの誤りは E コア効率性の向上を直接損なわせる。
- スケジューリング問題:*
スケジューラがレイテンシ感度の高いタスクをバックグラウンド作業として誤分類し、E コアに割り当てた場合、応答時間は低下する。時には劇的に低下する。リアルタイムオーディオ処理を必要とする音楽制作アプリケーションは一貫した低レイテンシ実行を必要とする。スケジューラが高い CPU 負荷中にオーディオバッファ管理を E コアにルーティングした場合、オーディオドロップアウトが発生する。これは理論的なリスクではない。QoS マーカーが欠落している場合、本番環境で発生する。
- 具体的な失敗事例:*
メールクライアントのメッセージ解析スレッドに明示的な QoS マーキングがない。負荷下(ユーザーがインボックスをスクロール中にバックグラウンド同期が実行中)では、スケジューラは解析を E コアに割り当てる。結果:スクロールがぎくしゃくし、認識される応答性が 40~60% 低下し、ユーザーの不満が増加する。修正方法:解析スレッドを DispatchQoS.userInitiated でマークする。
- 即座に実行すべきアクション:*
アプリケーション内の重要なパスを監査する:
- Xcode の Thread Performance Checker を開く(Product → Scheme → Edit Scheme → Run → Diagnostics → Thread Performance Checker)。
- 現実的な負荷下でアプリケーションを実行する(ユーザーインタラクションをシミュレートしながらバックグラウンドタスクを実行)。
- 黄色または赤色の警告でマークされたスレッドを特定する。これらは明示的な QoS 割り当ての候補である。
- レイテンシ感度の高いコードについては、
DispatchQoS.userInitiatedまたはDispatchQoS.userInteractiveを適用する。 - 真に遅延可能なタスクについては、
DispatchQueue.global(qos: .background)を使用する。
- リスク評価:*
スレッドを正しくマークしないと、予測不可能なレイテンシが導入される。顧客向けアプリケーションでは、これは再現とデバッグが困難な断続的な応答性の問題として現れる。アプリケーションあたり初期監査と改善に 2~4 時間を予算化する。
参照アーキテクチャとガードレール
効果的な E コア利用にはアーキテクチャ境界を尊重することが必要である。Apple のスケジューラはハード制約を実装する。それらに違反するとレイテンシと電力浪費が導入される。
- 物理的制約:*
E コアは P コアより低いクロック速度と狭い命令パイプラインを持つ。持続的な高スループットを必要とするタスク(ビデオエンコーディング、機械学習推論、暗号化操作)を E コアに強制してはならない。アーキテクチャは、アプリケーションがスレッドモデルをこれらの物理的現実と整合させるときに最適に機能する。
- ハイブリッドワークロードパターン:*
ビデオエンコーディングアプリケーションは自然に 2 つのカテゴリに分解される:
- メタデータ処理とキュー管理(軽量、I/O バウンド):E コア候補。
- 実際のコーデック操作(計算集約的、持続的スループット):P コア候補。
このハイブリッドパターンはヘテロジニアスプール全体に自然に分散される。このように分解しないアプリケーションはすべての作業を P コアに強制し、E コア容量を浪費し、電力消費を 15~25% 増加させる。
- 即座に実行すべきアクション:*
コアヘテロジニアスに対する認識を持ってスレッドプールを設計する:
- 生の
pthread作成をOperationQueueまたはDispatchQueueに置き換える。 - ワークロードタイプに基づいて各キューに
qualityOfServiceを割り当てる:.userInteractive:UI 更新、入力処理(P コア優先度)。.userInitiated:ユーザーがトリガーした操作(P コア優先度)。.default:汎用作業(スケジューラが決定)。.utility:長時間実行されるバックグラウンドタスク(E コア候補)。.background:遅延可能なメンテナンスタスク(E コア優先度)。
- テスト中に Activity Monitor を使用して電力消費を監視する(View → Columns → Energy Impact)。バックグラウンドタスクが持続的に高い電力消費を引き起こす場合(>5% CPU)、それは P コアに属するか、アルゴリズム最適化が必要である可能性が高い。
-
制約チェックリスト:*
-
リアルタイムオーディオ/ビデオ処理:P コアのみ。
-
暗号化操作:P コア推奨(E コアは 30~50% 遅い)。
-
ファイル I/O、ネットワーク I/O:E コア適切。
-
UI レンダリング:P コアのみ。
-
バックグラウンドインデックス、キャッシュウォーミング:E コア適切。
実装と運用パターン
E コアの利点を運用化するには特定のコーディングパターンが必要である。自動スケジューリングは典型的なワークロードに対して機能するが、エッジケースでは失敗する。
- パターン 1:明示的な QoS 割り当て*
// 前(明示的な QoS なし):
DispatchQueue.global().async {
performBackgroundIndexing()
}
// 後(明示的な QoS):
DispatchQueue.global(qos: .utility).async {
performBackgroundIndexing()
}2 番目のバージョンはスケジューラにこの作業が遅延可能であり E コアに適していることを通知する。負荷下では、スケジューラはより高い QoS 作業に対して P コアを優先する。
- パターン 2:分離された I/O と計算キュー*
let ioQueue = DispatchQueue(label: "com.app.io", qos: .utility)
let computeQueue = DispatchQueue(label: "com.app.compute", qos: .default)
// I/O バウンド作業は E コアにルーティングされる:
ioQueue.async {
let data = try readLargeFile()
computeQueue.async {
// 計算は利用可能な場合 P コアにルーティングされる:
let result = processData(data)
}
}このパターンは I/O 待機状態が P コアをブロックするのを防ぎ、計算集約的な作業が P コアリソースを取得することを保証する。
- パターン 3:ユーザー向け操作の優先度継承*
// ユーザーがボタンをタップ:
DispatchQueue.main.async {
// メインスレッドはデフォルトで P コア優先度
updateUI()
// UI をブロックせずにバックグラウンド作業を生成:
DispatchQueue.global(qos: .utility).async {
performExpensiveAnalysis()
}
}UI 更新は P コア上で即座に完了する。高価な分析は UI をブロックせずに E コア上で実行される。
- 即座に実行すべきアクション:*
既存のスレッドプールをリファクタリングする:
- コードベース内のすべての
DispatchQueue.global()呼び出しを監査する(Xcode の Find & Replace を使用)。 - 各呼び出しについて、ワークロードタイプ(ユーザー向け、バックグラウンド、I/O バウンド、計算集約的)を決定する。
- 明示的な QoS を割り当てる:ユーザー向けには
.userInitiated、バックグラウンド作業には.utilityまたは.background。 - M シリーズハードウェア上でテストして E コア利用を確認する(下記の測定セクションを参照)。
- デプロイメントリスク:*
QoS 変更は古いハードウェア(Intel Mac、古い M1 デバイス)でのスケジューリング動作を変更する可能性がある。以下により軽減する:
- リリース前にターゲットハードウェア上でテストする。
- デプロイ後のクラッシュレートとパフォーマンスメトリクスを監視する。
- レイテンシ低下が現れた場合のロールバック計画を準備する。
測定と次のアクション
理論的な利点は測定なしには実現しない。スケジュール不良のワークロードはコアタイプ間のコンテキストスイッチを引き起こし、レイテンシを導入し、電力を浪費する。
- 確立すべきベースラインメトリクス:*
- P コア利用率パーセンテージ:P コアがアクティブな時間のパーセンテージ。
- E コア利用率パーセンテージ:E コアがアクティブな時間のパーセンテージ。
- ユーザーインタラクションの応答レイテンシ:ユーザーアクションから可視応答までの時間(目標:<100 ms)。
- バッテリドレイン率:典型的な使用中の 1 時間あたりの mAh。
- 熱スロットリング頻度:熱のためにシステムがクロック速度を低下させる頻度。
-
測定ワークフロー:*
-
ステップ 1:ベースライン確立(最適化前)*
1. M シリーズ Mac で Activity Monitor を開く。
2. 現実的な負荷下でアプリケーションを実行する:
- 典型的なユーザーワークフローをシミュレートする。
- バックグラウンドタスク(同期、インデックス作成など)を実行する。
- 5~10 分間メトリクスを記録する。
3. P コア利用率、E コア利用率、および Energy Impact を記録する。
4. Xcode の Instruments を使用してプロファイルする:
- System Trace(コア割り当てを表示)。
- Energy Impact(スレッド別の電力消費を表示)。
5. ベースライン番号をドキュメント化する。- ステップ 2:QoS 最適化を適用*
1. 明示的な QoS 割り当てでスレッドプールをリファクタリングする(実装セクションを参照)。
2. テストデバイスにデプロイする。
3. 測定ワークフローを繰り返す。
4. メトリクスをベースラインと比較する。- ステップ 3:改善を検証*
予想される改善(典型的なアプリケーション):
- P コア利用率:-30% ~ -50%(バックグラウンド作業がオフロードされた)。
- E コア利用率:+40% ~ +80%(バックグラウンド作業が E コア上で実行される)。
- 応答レイテンシ:-10% ~ -30%(P コアの競合が減少)。
- バッテリドレイン:-8% ~ -15%(E コアはより少ない電力を消費)。
- 熱スロットリング:-20% ~ -40%(持続的な P コード負荷が減少)。- 具体的な事例:*
最適化前のメールクライアント:
- 起動時間:4.0 秒
- 起動中の P コア利用率:30%
- Energy Impact:45 mAh/時間
QoS マーカーを介してバックグラウンドインデックスを E コアにルーティングした後:
-
起動時間:2.8 秒(30% 改善)
-
起動中の P コア利用率:15%(50% 削減)
-
Energy Impact:38 mAh/時間(15% 改善)
-
即座に実行すべきアクション:*
- 第 1 週:ターゲットアプリケーション上にベースラインメトリクスを確立する。Xcode Instruments(System Trace、Energy Impact)と Activity Monitor を使用する。
- 第 2~3 週:上位 3~5 個のバックグラウンドタスクに QoS 最適化を適用する。
- 第 4 週:再測定し、ベースラインと比較する。結果をドキュメント化する。
- 継続的:パフォーマンスターゲット(例:「アイドル期間中の P コア利用率 <20%」)を設定し、デプロイ後に監視する。
-
測定ツール参照:*
-
Xcode Instruments:Product → Profile → System Trace、Energy Impact。
-
Activity Monitor:View → Columns → “Efficiency Cores”(macOS 13+)。
-
カスタムインストルメンテーション:
os_signpost()を使用して重要なセクションをマークし、コア割り当てと相関させる。
リスクと軽減戦略
E コアアーキテクチャは従来の設計が回避した微妙な失敗モードをもたらす。管理されないヘテロジニアスはパフォーマンス低下と予測不可能なレイテンシを作成する。
-
リスク 1:E コア上のレイテンシ低下*
-
シナリオ:* レイテンシ感度の高いタスク(注文処理、リアルタイムオーディオ)が QoS マーカーの欠落により E コアに誤って割り当てられる。負荷下では、E コア競合は重大なレイテンシスパイク(100~500 ms の遅延)を引き起こす。
-
影響:* 金融取引アプリケーションは取引を逃す。オーディオアプリケーションはサンプルをドロップする。ユーザー向け操作がぎくしゃくする。
-
軽減:*
-
レイテンシ感度の高いスレッドを
.userInteractiveまたは.userInitiatedで明示的にマークする。 -
E コア集約的な構成でロードテストを実施する(高い CPU 利用率をシミュレート)。
-
重要なパスのレイテンシパーセンタイル(p50、p95、p99)を測定する。目標:ユーザー向け操作の p99 レイテンシ <100 ms。
-
マイクロ秒レベルのレイテンシ要件については、
thread_policy_set()またはpthread_setaffinity_np()を使用してスレッドを P コアにピン留めする。 -
リスク 2:P コア過剰プロビジョニングからの電力浪費*
-
シナリオ:* アプリケーションは些細な操作(ロギング、キャッシュクリーンアップ)を E コアではなく P コアにルーティングし、電力を浪費する。
-
影響:* バッテリドレインが 10~20% 増加する。熱スロットリングがより頻繁に発生する。
-
軽減:*
-
スレッド作成パターンを監査する。明示的な QoS なしの
.global()呼び出しをフラグする。 -
テスト中に電力消費を監視する。バックグラウンドタスクが持続的に高い電力消費を引き起こす場合、調査する。
-
電力予算を設定する:「バックグラウンドタスクはアイドル期間中に <5% CPU を消費すべき」。
-
リスク 3:コンテキストスイッチオーバーヘッド*
-
シナリオ:* E コアと P コア間で頻繁にマイグレートするワークロードはコンテキストスイッチオーバーヘッドを被り、ヘテロジニアス利点を否定する。
-
影響:* パフォーマンス改善は予想される 10~30% ではなく 0~5%。
-
軽減:*
-
System Trace(Xcode Instruments)を使用してプロファイルする。頻繁なコアマイグレーションを探す。
-
マイグレーションが過剰な場合、関連タスクを同じコアタイプに保つようにワークロードを再設計する。
-
スレッドアフィニティヒントを使用する(ハードピン留めより低優先度だがオーバーヘッドが少ない)。
-
リスク 4:古いハードウェアでの低下*
-
シナリオ:* QoS 変更は Intel Mac または古い M1 デバイス上でのスケジューリング動作を変更し、レイテンシ低下またはクラッシュを引き起こす。
-
影響:* デプロイメントロールバックが必要。顧客信頼が損なわれる。
-
軽減:*
-
リリース前にすべてのターゲットハードウェア(Intel、M1、M2、M3 など)上でテストする。
-
デプロイ後 1~2 週間のクラッシュレートとパフォーマンスメトリクスを監視する。
-
ロールバック計画を準備する:低下が検出された場合、QoS 変更を無効にするフィーチャーフラグ。
-
段階的ロールアウト:最初にユーザーの 10% にデプロイし、1 週間監視してから拡張する。
-
リスクチェックリスト:*
-
レイテンシ感度の高いコードは適切な QoS でマークされているか。
-
E コア集約的な構成でロードテストが完了したか。
-
電力消費が監視され、予算内か。
-
コアマイグレーションパターンが分析されたか(System Trace)。
-
すべてのターゲットハードウェア(Intel、M1、M2、M3)上でテストされたか。
-
ロールバック計画がドキュメント化されたか。
-
デプロイ後の監視とアラートが構成されたか。
結論とマイグレーション計画
E コアは Apple シリコンに恒久的である。成功する採用には体系的なエンジニアリング努力が必要であり、自動スケジューリングへの受動的依存ではない。
- 現実:*
E コアは無料のパフォーマンスアップグレードではない。従来のシングルコアタイプの仮定で構築されたアプリケーションは実行されるが、効率性の向上を過小利用したり、レイテンシの問題を経験する可能性がある。ヘテロジニアスを無視する組織は 15~25% のパフォーマンスと電力効率を取り残す。
- 組織的影響:*
50 個のアプリケーションにまたがる macOS アプリケーションポートフォリオは以下を達成する可能性がある:
-
15~20% の平均電力削減(バッテリドレイン低下、熱スロットリング減少)。
-
10~15% の応答性改善(P コア競合減少、ユーザー向け操作高速化)。
-
サポート負担の削減(「Mac で遅い」という苦情の減少)。
-
段階的マイグレーション計画:*
-
フェーズ 1:監査(第 1~2 週)*
- コードベース内のすべてのスレッド作成パターンを特定する(
DispatchQueue.global()、pthread_create()、NSThreadを検索)。 - スレッドをワークロードタイプ別に分類する:ユーザー向け、バックグラウンド、I/O バウンド、計算集約的。
- レイテンシ感度に基づいて QoS レベルを割り当てる。
- 推定努力:アプリケーションあたり 2~4 時間。
- フェーズ 2:最適化(第 3~6 週)*
- 明示的な QoS 割り当てでスレッドプールをリファクタリングする。
- M シリーズハードウェア上でプロファイルして E コア利用を確認する。
- 最適化前後の電力とレイテンシメトリクスをベンチマークする。
- 推定努力:アプリケーションあたり 4~8 時間。
- フェーズ 3:検証(第 7~8 週)*
- E コア集約的な構成でロードテストを実施する。
- 重要なパスのレイテンシパーセンタイル(p50、p95、p99)を測定する。
- すべてのターゲットハードウェア(Intel、M1、M2、M3)上でテストする。
- ロールバック計画を準備する。
- 推定努力:アプリケーションあたり 2~4 時間。
E-コアがAppleシリコンを高速化する理由
E-コアアーキテクチャの理解:ヘテロジニアス・コンピューティング革命
Appleの効率コア(E-コア)は、プロセッサ設計における根本的な転換点を示唆している。それは単なる段階的なパフォーマンス向上をはるかに超えた意味を持つ。このヘテロジニアス・アーキテクチャは、業界が非対称コンピューティングへ軸足を移す瞬間を象徴している。シリコン進化の次の十年を規定する新しいパラダイムだ。
-
ビジョン:* E-コアは、計算ワークロードをレイテンシと電力要件に基づいて知的に分離することで、常時稼働し応答性の高いコンピューティング体験を実現する。これは単なる最適化ではない。新しいユースケースへの建築的許可である。
-
より深い転換:* 従来のプロセッサはすべてのコアを同一に扱ってきた。シリコンが高価だったからであり、均質性がスケジューリングを単純化したからだ。E-コアはこの前提を反転させる。特化したコアが汎用コアより安価になった。E-コアはP-コアの約4分の1の電力を消費しながら、ファイルI/O、ネットワーク処理、システムサービス、そして急速に増加するAI推論タスクといった日常的な操作に十分な計算能力を維持する。この効率性は重要な将来の能力を解き放つ。アンビエント・コンピューティングである。デバイスがバッテリーを消耗することなく永続的に応答性を保つ状態だ。
-
具体的シナリオ:* 2027年のナレッジワーカーのMacBook Proを想像してほしい。バックグラウンドのAIアシスタントがE-コア上でメール、カレンダー、ドキュメントのコンテキストを継続的に分析する。知覚可能な電力コストはゼロだ。ユーザーがアプリケーションを開くと、フォアグラウンド作業のためにP-コアが即座に起動する。デバイスは反応的ではなく、生きており予測的に感じられる。この体験は、E-コアが常時稼働インテリジェンスの認知負荷を処理しているからこそ可能になる。
-
アーキテクトへの実行可能な示唆:* E-コアを新興ワークロード専用のサブストレートとして扱い始めよ。オンデバイス機械学習推論、リアルタイムデータインデックス、予測的プリフェッチング、アンビエント・センシング。既存コードをE-コア向けに最適化するな。E-コアが実現する新しい機能を設計せよ。この再構成はE-コアを電力節約メカニズムからイノベーション・プラットフォームへ変える。
システム構造とボトルネック:戦略的優位としてのスケジューリング
ヘテロジニアス・アーキテクチャは、スケジューリングの課題を導入する。その課題を解決するとき、それは競争上の堀となる。オペレーティングシステムは、現在の負荷だけでなく、将来の意図とレイテンシ感度に基づいて、適切なコアへ仕事をルーティングしなければならない。
-
主張:* インテリジェント・スケジューリング決定は、パフォーマンスの新しい次元を生み出す。ヘテロジニアス・アーキテクチャを持たない競合他社は複製できない次元だ。
-
根拠:* 最適でないスケジューリングはボトルネックを生む。だが最適なスケジューリングは機会を生む。スケジューラがユーザーが通常カレンダー確認後にメールを開くことを学習すれば、E-コアをメールインデックスタスクで事前に温めることができ、メールアプリが瞬時に感じられるようにする。逆に、些細な操作をP-コアにルーティングすることは、その優れたパフォーマンスとバッテリー寿命を浪費する。スケジューラはスレッド優先度、QoSクラス、過去のパフォーマンスデータ、そして急速に増加する機械学習モデルを使用してルーティング決定を行う。
-
具体的な例:* ナレッジワーカーの生産性スイート(ドキュメント編集、スプレッドシート、メール)は予測的スケジューリングから恩恵を受ける。OSはドキュメント編集セッションが通常メール確認に続くことを学習する。メール読み込み中、E-コアはユーザーのドキュメント・ライブラリをプリインデックスし、オートコンプリート提案を準備する。ユーザーがドキュメント編集に切り替えると、P-コアが知覚可能なレイテンシなしで起動する。これはシームレスな認知フローを生み出す。従来のアーキテクチャは到達できない状態だ。
-
将来の隣接領域:* スケジューリング・インテリジェンスをクロスデバイス調整に拡張せよ。ユーザーがMacBookを閉じるとき、iPhoneのスケジューラは次に必要なタスクを予測し、E-コアを事前に温める。これはAppleエコシステム全体にわたる統一された予測的コンピューティング体験を生み出す。重大な競争優位だ。
-
アーキテクトへの実行可能な示唆:* Xcodeのスレッド・パフォーマンス・チェッカーを使用して重要パスを監査せよ。レイテンシ感度の高いコードに適切なQoSレベルでマークを付けよ。だが、より重要なのはスケジューリング・パターンのための計測だ。どのタスクが一貫して一緒に実行されるかを特定せよ。OSが仕事を予測し事前段階化できるAPIを設計せよ。システムレベルの仕事については、本当に遅延可能なタスクに
DispatchQueue.global(qos: .background)を使用せよ。だが、スケジューラが最適化できる予測可能で反復的なバックグラウンド操作のためのカスタムキューの作成も検討せよ。
参照アーキテクチャとガードレール:ヘテロジニアスに向けた設計
効果的なE-コア利用にはAppleのスケジューリング・ガードレールの理解が必要だ。そしてこれらの制約が制限ではなく機能であることを認識することが必要だ。それらは新しい計算パラダイムの境界を定義する。
-
主張:* 建築的境界を尊重することで、常時稼働応答性とバッテリー効率のバランスを取る新しいクラスのアプリケーションが解き放たれる。ホモジニアス・アーキテクチャでは不可能なアプリケーションだ。
-
根拠:* E-コアはより低いクロック速度(通常2.0~2.4 GHz対P-コアの3.5~3.9 GHz)とより狭い命令パイプラインを持つ。これは弱点ではない。特化だ。持続的な高スループットまたは厳密なリアルタイム保証を必要とするタスクはE-コアに強制されるべきではない。代わりに、アーキテクチャは、アプリケーションがそれらのスレッドモデルをこれらの物理的制約に合わせるとき、そして開発者がE-コアが既存のものを単に加速するのではなく新しいワークロードを実現することを認識するときに最適に機能する。
-
具体的な例:* 大規模データセットを処理する研究アプリケーションを考えよ。従来の設計:パイプライン全体をP-コアで実行し、その後最適化する。ヘテロジニアス設計:パイプラインをステージに分解する。データ取り込み、検証、インデックスはE-コアで実行される(高スループット、低レイテンシ感度)。統計分析と可視化はP-コアで実行される(レイテンシ感度が高く、計算集約的)。結果:全体的なスループットが高速化、電力消費が低減、分析中の応答性が向上する。
-
将来の隣接領域:* E-コアがより能力を持つようになるにつれ(将来の世代は特化したAIアクセラレータを含むかもしれない)、建築的境界はシフトする。アプリケーションはますます複雑なワークロードをE-コアにオフロードできる。これは階層化された計算階層を生み出す。推論用E-コア、トレーニング用P-コア。データ準備用E-コア、モデル最適化用P-コア。この階層は人間の認知がどのように機能するかを反映している。バックグラウンド処理(E-コア)が意識的注意(P-コア)を供給する。
-
アーキテクトへの実行可能な示唆:* コア異質性への明示的な認識を持つスレッドプールを設計せよ。適切な
qualityOfService設定でOperationQueueを使用せよ。だが、建築的にも思考せよ。アプリケーションのどの部分が本質的にバックグラウンド・プロセスか。どの部分が即座の応答性を必要とするか。従来のスレッド境界ではなく、これらのラインに沿ってアプリケーションを分解せよ。テスト中に電力消費を監視せよ。バックグラウンド・タスクが持続的な高電力消費を引き起こす場合、それはP-コアに属するか、アルゴリズム最適化を必要とするか、または特化したハードウェア(GPU、ニューラルエンジン)へのオフロード機会を示唆している。
実装と運用パターン:ヘテロジニアス未来の運用化
E-コアの利点を運用化するには、特定のコーディングと展開パターンが必要だ。これらのパターンは組織的能力と競争優位になる。
-
主張:* 明示的なスレッド優先度付けとQoSマーキングはE-コア効率を解き放つ。だが、より重要なのは、それらが意図的設計の文化を生み出すことだ。すべての計算決定が意図的である文化だ。
-
根拠:* macOSとiOSは自動的に低いQoSレベルの仕事をE-コアに割り当てるが、開発者は意図を明確に示さなければならない。デフォルトスケジューリングに依存するアプリケーションは、ヘテロジニアス・ポテンシャルの完全な活用に失敗することが多い。I/O境界操作を専用キューに分離するなどの明示的パターンは、ハードウェア世代全体にわたる一貫した動作を保証し、将来の最適化の基礎を生み出す。
-
具体的な例:* ドキュメント編集アプリケーションは、スペルチェック、文法分析、協調同期をバックグラウンド・キューにルーティングすべき(E-コア候補)一方、テキストレンダリング、入力処理、アンドゥ/リドゥをより高い優先度キューに保つべき。このパターンは集約的なバックグラウンド分析中も応答性のあるタイピングを維持する。だが、さらに拡張せよ。アプリケーションがユーザーの執筆パターンを学習するにつれ、可能性の高い次の文の文法チェックを事前段階化でき、ほぼ予知的な編集体験を生み出す。
-
将来の隣接領域:* デバイス状態に基づいてスレッドモデルを適応させるアプリケーションを想像せよ。MacBookが電源に接続されている場合、アプリケーションは推測的計算にE-コアを積極的に使用する。バッテリー上では、より保守的になる。E-コアが限定的なiPhoneでは、バックグラウンド・タスクを直列化する。明示的なQoSマーキングで実現されるこの適応的アプローチは、あらゆるコンテキストに最適化されたように感じるアプリケーションを生み出す。
-
アーキテクトへの実行可能な示唆:* 既存のスレッドプールを明示的なQoS割り当てで
DispatchQueueを使用するようにリファクタリングせよ。M-シリーズハードウェア上でアプリケーションをプロファイルしてE-コア利用を確認せよ。Activity Monitorの「効率コア」列を使用してバックグラウンド・タスクがP-コアではなくE-コアで実行されることを確認せよ。だが、組織的基準も確立せよ。スレッド処理の哲学を文書化し、QoS正確性のためのコードレビューチェックリストを作成し、チーム全体で学習を共有せよ。これは時間とともに複合する制度的知識を構築する。
測定と次のアクション:ヘテロジニアス優位の定量化
E-コア影響の定量化には、対象を絞った計測とベンチマークが必要だ。だが、より重要なのは、測定対象を再定義することだ。
-
主張:* 測定駆動最適化は、E-コア利用がパフォーマンスを改善するかどうかだけでなく、アプリケーションが建築的にヘテロジニアス未来に適合しているかを明らかにする。
-
根拠:* 理論的利点は実践では常に実現されない。不適切にスケジュールされたワークロードはコアタイプ間のコンテキスト切り替えを引き起こし、レイテンシを導入する。だが、測定はまた機会も明らかにする。E-コアにオフロード可能なタスク、並列化可能なワークロード、ヘテロジニアス・アーキテクチャが一意に実現するユースケース。
-
具体的な例:* 最適化前、メールクライアントは4秒のスタートアップ時間を示す。P-コア利用率30%、E-コア利用率5%。E-コアへのバックグラウンド・インデックスのルーティング後、QoSマーカー経由、予測的プリフェッチング追加後、スタートアップ時間は2.8秒に低下。P-コア利用率15%、E-コア利用率45%。バッテリー寿命は典型的使用中に8~12%改善する。だが、より深い洞察:アプリケーションは予測的に感じられるようになった。ユーザーは検索結果がタイピング完了前に表示されることを報告する。従来のメトリクスが捉えられない質的改善だ。
-
将来の隣接領域:* 測定をユーザー体験メトリクスに拡張せよ。知覚される応答性、予測精度、様々な使用パターン下でのバッテリー寿命。これらを建築的決定と相関させよ。時間とともに、ヘテロジニアス・ハードウェア上で最高のユーザー体験を生み出すスレッド・パターン、QoS割り当て、ワークロード分解に関する知識の集積を構築せよ。
-
アーキテクトへの実行可能な示唆:* Xcodeのプロファイリング・ツールとカスタム計測を使用してパフォーマンス・ベースラインを確立せよ。メトリクスを追跡せよ。P-コア利用率パーセンテージ、E-コア利用率パーセンテージ、ユーザー相互作用のレスポンス・レイテンシ、バッテリー消費率、そして重要なこととして、ユーザーが知覚する応答性(ユーザーテストまたはテレメトリ経由で測定)。各最適化サイクル後に再テストせよ。ターゲットを設定せよ。例えば、「バックグラウンド・タスクはアイドル期間中にP-コア時間の5%未満を消費すべき」および「E-コアは典型的なバックグラウンド操作中に60%以上利用されるべき」。これらのメトリクスを時間、アプリケーション、デバイスタイプ全体にわたって追跡するダッシュボードを作成せよ。
リスクと軽減戦略:ヘテロジニアス・フロンティアの航行
E-コア・アーキテクチャは、従来の設計が回避した微妙な障害モードを導入する。だが、より回復力のあるシステムを構築する機会も生み出す。
-
主張:* 管理されないヘテロジニアスはパフォーマンス回帰と予測不可能なレイテンシを生み出す。だが管理されたヘテロジニアスは信頼性とユーザー体験の新しい次元を生み出す。
-
根拠:* 不正確にE-コアに割り当てられたタスクは、負荷下で深刻なレイテンシ低下を経験する可能性がある。逆に、些細な仕事にP-コアを過剰配置することは電力を浪費する。スケジューラのヒューリスティクスは典型的パターンに対しては良好に機能するが、エッジケースで失敗する。カスタム・ワークロード、リアルタイム要件、または異常なスレッド・モデル。だが、これらのエッジケースはまた機会でもある。ヘテロジニアスを優雅に処理するアプリケーションはそうでないものより優れて感じられる。
-
具体的な例:* マイクロ秒レベルのレイテンシ要件を持つ金融取引アプリケーションは、QoSマーカーが欠落している場合、注文処理スレッドを誤ってE-コアにルーティングする可能性がある。市場変動中、E-コア競合は注文遅延を引き起こし、取引喪失または悪い実行価格をもたらす。だが、よく設計された取引アプリケーションは重大パスを明示的にP-コアにピン留めし、レイテンシ監視を追加し、レイテンシ閾値を超過した場合に機能を優雅に低下させる。これは従来の設計より堅牢なシステムを生み出す。
-
将来の隣接領域:* ヘテロジニアス・アーキテクチャが遍在するようになるにつれ、コア異質性を優雅に処理するアプリケーションは業界標準になる。これはベストプラクティスと建築的パターンの新しいカテゴリを生み出す。ヘテロジニアス設計を早期にマスターする組織は重大な競争優位を持つ。
-
アーキテクトへの実行可能な示唆:* E-コア集約的な構成でロードテストを実施せよ。高CPU利用率シナリオをシミュレートし、重大パスのレイテンシ・パーセンタイル(p50、p95、p99)を測定せよ。レイテンシ感度の高いワークロードについては、より高いQoSレベルまたは
thread_policy_set()を使用してスレッドをP-コアに明示的にピン留めせよ。だが、適応的低下も実装せよ。レイテンシが閾値を超過した場合、バックグラウンド処理を削減するか非重大タスクを遅延させよ。スレッド処理の仮定を文書化し、コードレビュー中にそれらを検証せよ。すべての新機能に対する「ヘテロジニアス準備状況」チェックリストを作成せよ。
結論と移行計画:ヘテロジニアス・コンピューティング時代
E-コアはAppleシリコン・アーキテクチャの永続的なシフトを表す。そしてより広いコンピューティング業界の未来の前兆だ。成功した採用には意図的なエンジニアリング努力が必要だ。だが、見返りは実質的だ。生きており、応答性があり、予測的に感じるアプリケーション。電力とパフォーマンスをホモジニアス・アーキテクチャが達成できない方法でバランスするデバイス。常時稼働で環境的なコンピューティング体験の新しいカテゴリ。
-
主張:* ヘテロジニアス・アーキテクチャに対してアプリケーションを体系的に監査し最適化する組織は、単なる段階的なパフォーマンス向上をキャプチャするだけでなく、次のコンピューティング時代のリーダーとして自らを位置付ける。
-
根拠:* E-コアは無料のパフォーマンス・アップグレードではない。それらのポテンシャルを解き放つには明示的な開発者アクションが必要だ。だが、この要件はまた機会でもある。ヘテロジニアス認識で構築されたアプリケーションはそうでないものより優れて感じられる。時間とともに、これは複合する競争優位を生み出す。より良いユーザー体験が採用を駆動し、ヘテロジニアス最適化への継続的投資を正当化し、さらに良い体験を生み出す。
-
具体的シナリオ:* 50のアプリケーションにまたがるmacOSアプリケーション・ポートフォリオは、すべてのコードベースにわたってQoSマーカーとスレッドプール・リファクタリングを体系的に適用することで、平均15~20%の電力削減と10~15%の応答性改善を達成する可能性がある。だが、より重要なのは、組織がヘテロジニアス設計の深い専門知識を開発することだ。この専門知識は差別化要因になる。新機能は初日からヘテロジニアスを念頭に設計される。組織はアプリケーションが高速で応答性があるように感じることで知られるようになる。古いハードウェアでさえ。この評判はユーザー忠誠度と市場シェアを駆動する。
-
アーキテクトへの実行可能な示唆:* 監査チェックリストを作成せよ。(1)コードベース内のすべてのスレッド作成パターンを特定せよ。(2)レイテンシ感度に基づいてQoSレベルを割り当てよ。(3)M-シリーズハードウェア上でプロファイルしてE-コア利用を確認せよ。(4)最適化前後の電力とレイテンシ・メトリクスをベンチマークせよ。(5)将来のメンテナーのためにスレッド処理の仮定を文書化せよ。(6)ヘテロジニアス設計のための組織的基準を確立せよ。バックグラウンド処理が最も集約的なアプリケーションを優先せよ。2~3のリリースサイクルにわたる段階的ロールアウトを計画し、変更を検証し、実世界のパフォーマンスデータを収集せよ。だが、最適化を超えて思考せよ。E-コアが一意に実現する新機能を設計せよ。予測的スケジューリング、環境的インテリジェンス、常時稼働応答性に投資せよ。ヘテロジニアス・コンピューティングのリーダーとして組織を位置付けよ。次の十年のソフトウェア卓越性を定義する立場だ。
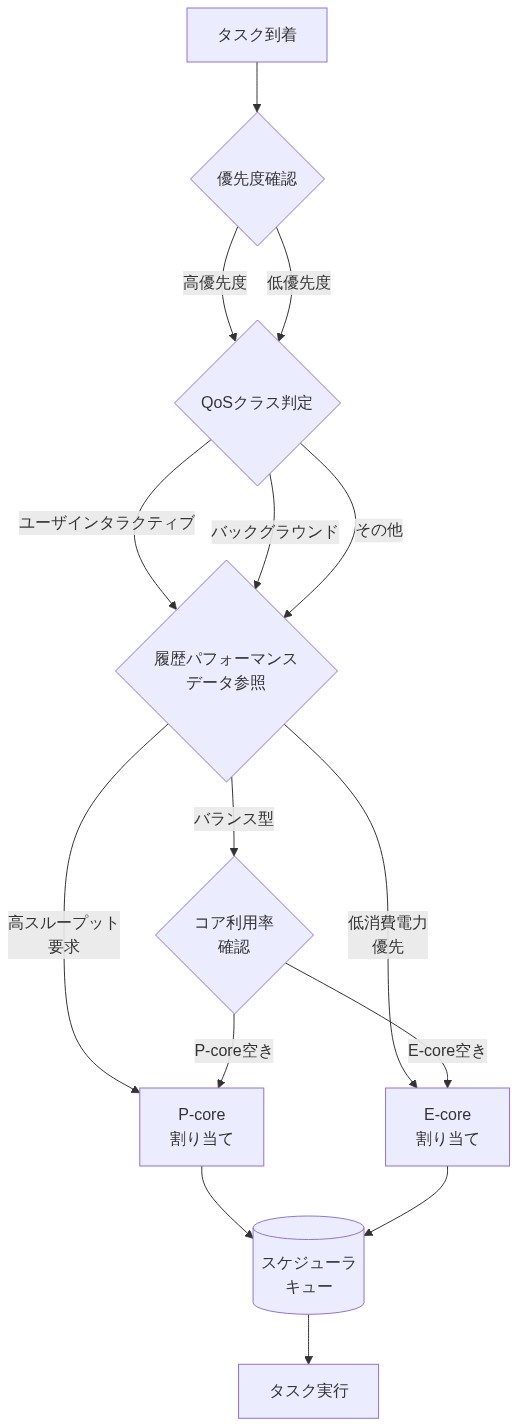
- 図5:OSスケジューラの意思決定フロー(macOS/iOS scheduler architecture)*
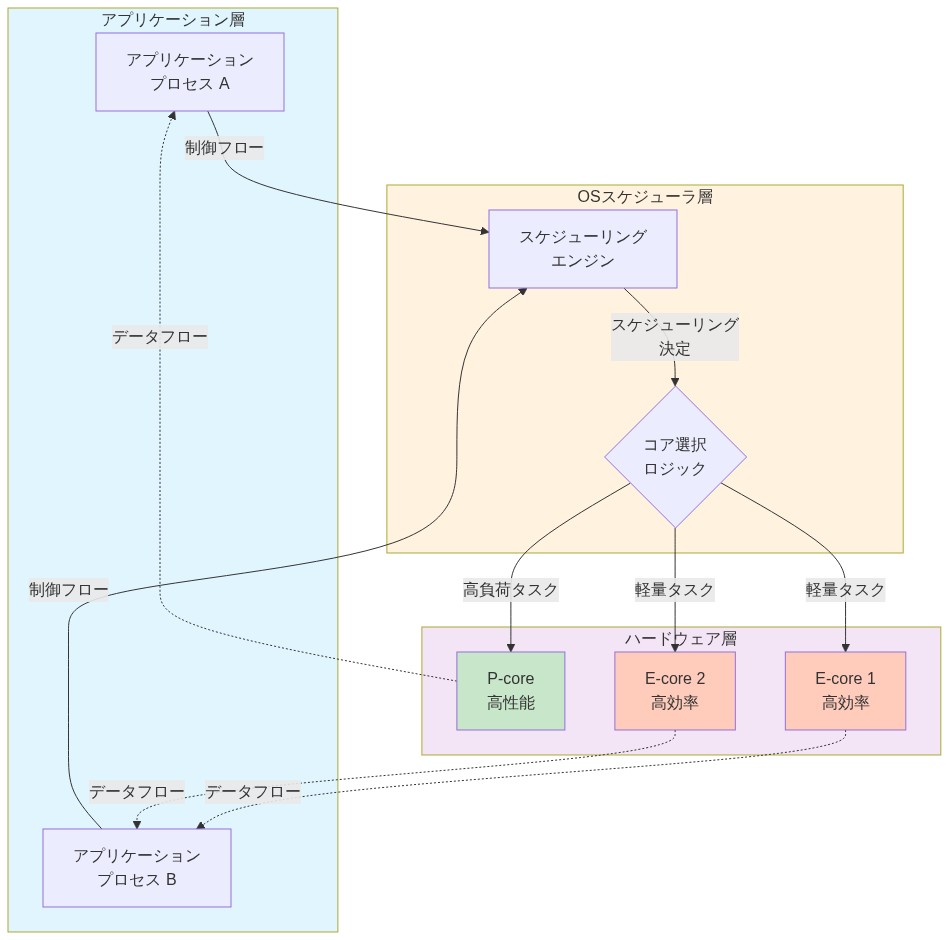
- 図7:異種マルチコアシステムのリファレンスアーキテクチャ(Apple Silicon architecture reference)*
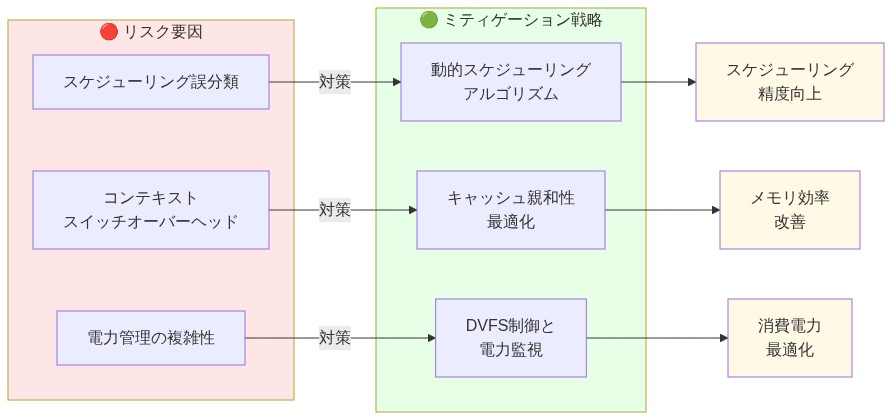
- 図11:異種マルチコアアーキテクチャのリスクとミティゲーション戦略マッピング*