
AppleがSiriをAIチャットボットにする計画:研究者による分析
会話型AIプラットフォームとしてのSiri
Appleが報じられているSiriを会話型エージェントに変革する方向転換は、現在のタスク指向設計からの重要なアーキテクチャ上の転換を表しています。現在、Siriはコマンドインタープリターとして機能しています。ユーザーが特定のリクエストを発行すると、システムは個別の出力で応答するか、事前定義されたアクションを実行します。提案されている進化は、複数ターンの対話機能、インタラクション間のコンテキスト状態保持、および明示的なコマンド構造なしに曖昧または複雑なクエリを処理できる推論メカニズムを導入するものです。
-
基本的な主張:* Siriが音声コマンドシステムから汎用会話インターフェースへ移行することは、AI駆動型市場における競争力のあるポジショニングを維持するために必要です。
-
裏付けとなる根拠:* ChatGPTおよび類似の大規模言語モデル(LLM)の広範な採用により、硬直したコマンド-応答パターンよりも自然で探索的な対話に対するユーザーの期待が確立されました。会話型AIとのユーザーインタラクションパターンに関する研究(Shvo et al., 2023; Kuzminykh et al., 2022)は、ユーザーが反復的なクエリの洗練、セッション間のコンテキスト認識、およびバイナリなタスク完了ではなく微妙な説明をますます期待していることを示しています。Appleの分散エコシステム—iOS、macOS、iPadOS、watchOSデバイスにまたがる—は独自の配信インフラストラクチャを提供しますが、それはSiriが対話の一貫性と推論能力において独立した会話型AIシステムと機能的に同等になった場合にのみ実現されます。
-
例示的なシナリオ:* 現在のアーキテクチャでは、「パスタを料理しているんだけど、どのくらい茹でればいいか、そして終わったら教えて」というクエリは、複数の連続したインタラクションに分解する必要があります。調理時間のウェブ検索、その後に別のタイマーコマンドです。会話型Siriは複合的な意図を解釈し、利用可能な知識ソースからガイダンスを統合し、単一のインタラクション内でリマインダーアクションを実行します。
-
運用上の意味:* 製品チームは、既存のSiriインタラクションログを体系的に監査して、高摩擦の複数ステップシーケンスや明確化またはフォローアップの質問を必要とするシナリオを特定する必要があります。プロトタイピングは、本番環境への展開前に対話の一貫性とエラー回復メカニズムを検証するために、隔離されたサンドボックス環境で行う必要があります。
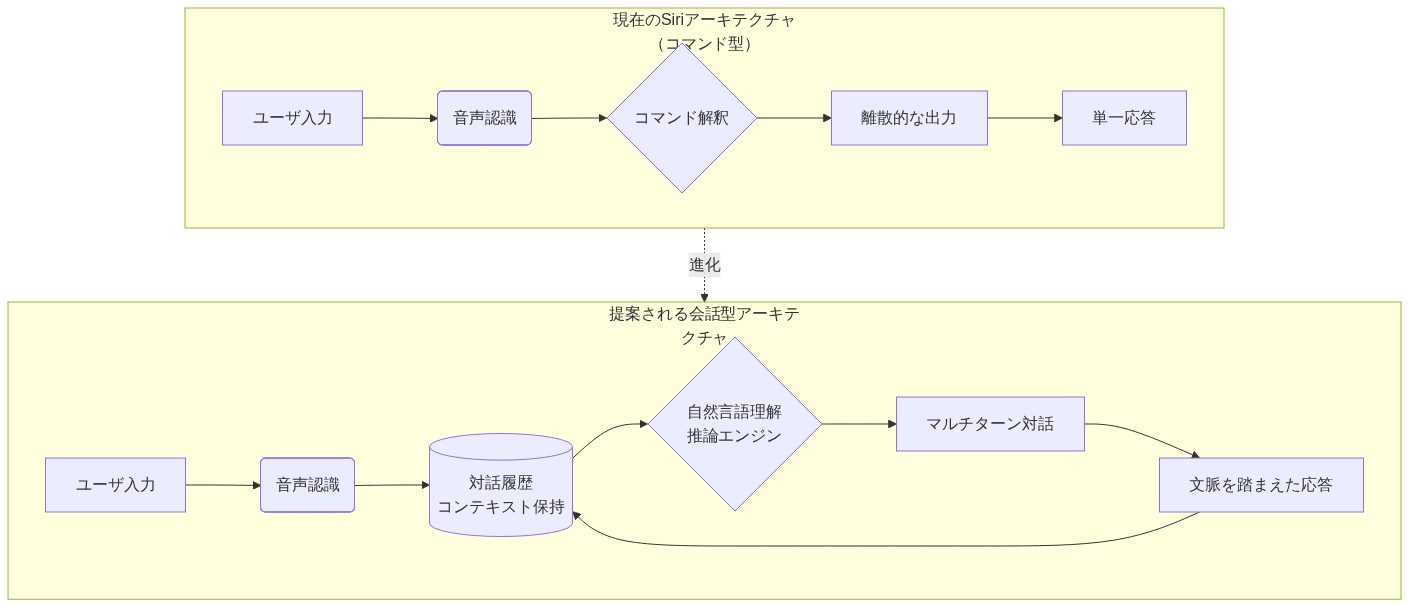
- 図2:Siriアーキテクチャの比較:現在のコマンド型 vs 提案される会話型*
システムアーキテクチャと制約
現在のSiriアーキテクチャ—意図分類、エンティティ抽出、ルールベースのルーティングに基づいて構築されている—は、オープンエンドの会話にスケールできません。3つの重要なボトルネックが現れます。推論速度(デバイス上のレイテンシ)、モデル容量(エッジ展開のパラメータ制限)、および知識統合(Siriの推論をリアルタイムデータに接続すること)です。
会話型AIには数十億のパラメータを持つモデルが必要です—これはほとんどのモバイルデバイスには大きすぎます。シンプルなクエリをローカルで処理し、複雑な推論を安全なクラウドサーバーにルーティングするハイブリッドアーキテクチャは、レイテンシ、プライバシー、機能のバランスを取ることができます。ただし、これには新しいオーケストレーションロジック、キャッシング戦略、およびフォールバックメカニズムが必要です。
「近くの映画館で何が上映されていて、どれが最高の評価を得ているか」と尋ねるユーザーは、アーキテクチャ上の課題を示しています。現在のSiriはこれを別々の意図(場所、映画館のリスト、評価)に分割します。会話型モデルはクエリを統合し、データを一度取得し、ランク付けされた応答を統合します—ラウンドトリップとレイテンシを削減します。
これらの制約に対処するために、Appleは明確なインフラストラクチャ目標を確立する必要があります。クラウドクエリの推論レイテンシを500ミリ秒未満にすること、軽量なクエリをデバイス上で処理しながら推論負荷の高いタスクをクラウドLLMに委任する階層化されたルーティング、およびユーザーエクスペリエンスを低下させる障害を防ぐための優雅な劣化を伴う冗長性です。
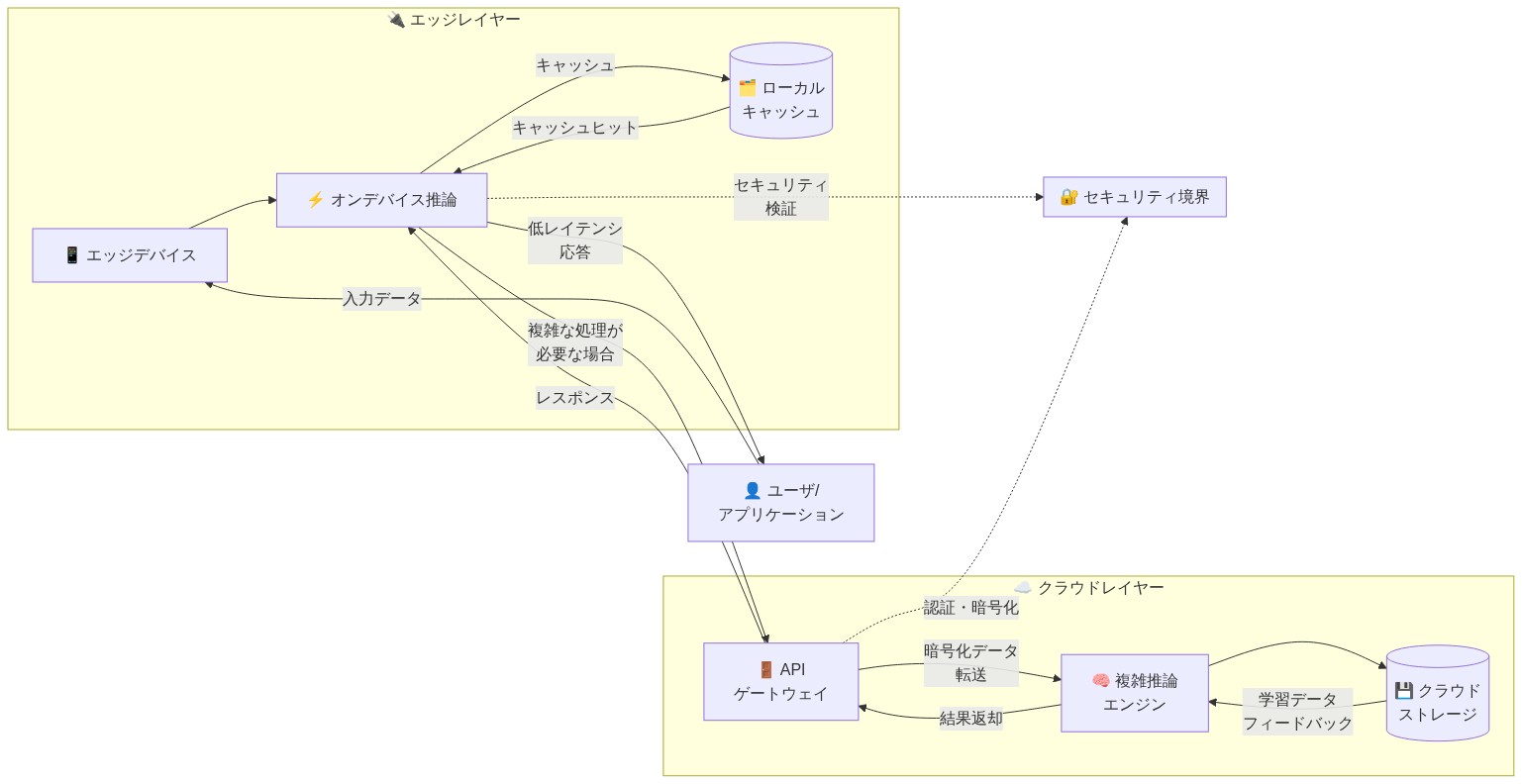
- 図4:提案されるハイブリッドアーキテクチャ:エッジ+クラウド統合による役割分担とデータフロー*
安全性と一貫性のガードレール
本番環境の会話型Siriには、明示的な安全性と一貫性のガードレールが必要です。汎用サンドボックスで動作するChatGPTとは異なり、Siriはデバイス機能を制御し、個人データにアクセスし、Appleのサービスと統合します。幻覚、プライバシー漏洩、または意図しないアクションは実際の結果をもたらします。
ガードレールは、フィルターを通じて事後的に適用されるのではなく、モデルアーキテクチャに組み込まれる必要があります。生成後に出力をフィルタリングすることは脆弱です。敵対的なユーザーはプロンプトインジェクションを行ったり、反応的なフィルターをジェイルブレイクしたりできます。代わりに、モデルは生成中に境界を尊重するように微調整される必要があります—後でキャッチするのではなく、安全でないリクエストを自然に拒否します。これには、慎重なトレーニングデータのキュレーションと人間のフィードバックからの強化学習(RLHF)が必要です。
ユーザーがSiriに「アプリをインストールするためにセキュリティ機能を無効にして」と尋ねた場合、ガードレールされたモデルは拒否し、その理由を説明する必要があります。生成された応答をフィルタリングするのではなく。これは自然に感じられ、ユーザーの信頼を維持します。
運用上、Appleは禁止されたアクション(認証のバイパス、データの流出、他のユーザーのコンテンツへのアクセス)を定義する安全性評議会を設立し、敵対的なプロンプトをシミュレートする合成データセットを作成し、四半期ごとにレッドチーム演習を実行し、デバイスの状態またはデータアクセスに影響を与えるすべてのモデル決定の監査ログを実装し、安全でないモデルバージョンの迅速なロールバックメカニズムを設計する必要があります。
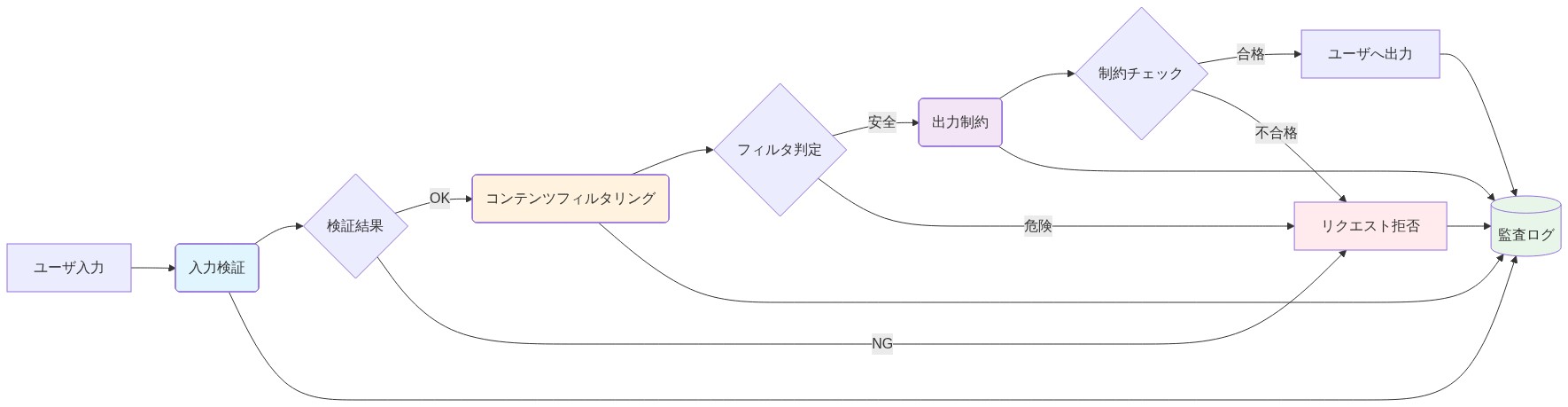
- 図7:安全性ガードレール:多層防御アーキテクチャ*
展開と運用
会話型Siriを大規模に展開するには、運用上の厳密さが必要です。モデルの更新、A/Bテスト、およびインシデント対応は自動化され、可逆的である必要があります。従来のソフトウェアとは異なり、AIシステムは優雅に、しかし予測不可能に劣化します—モデルの更新は一般的なクエリの精度を向上させる一方で、エッジケースで静かに失敗する可能性があります。
段階的なロールアウトにより、リグレッションの早期検出が可能になります。シャドウテスト—ユーザーに影響を与えることなく並行して新しいモデルを実行すること—は、本番環境への露出前にパフォーマンスの問題を明らかにします。実用的なアプローチ:新しい会話型モデルを1%のユーザーに48時間展開し、レイテンシ、エラー率、およびユーザー評価を監視します。メトリクスが劣化した場合、自動的にロールバックします。安定している場合、徐々に10%、次に100%に増やします。
これをサポートするには、応答時間、ユーザー満足度(フォローアップの質問や修正などの暗黙的なシグナル)、およびエラーカテゴリを追跡するリアルタイムの可観測性インフラストラクチャが必要です。Siri品質の明確なサービスレベルインジケーター(SLI)、モデルインシデントのオンコールローテーション、一般的な障害モードの文書化されたランブック、および自動化されたモデルバージョニングにより、リグレッションの迅速な診断と解決が保証されます。
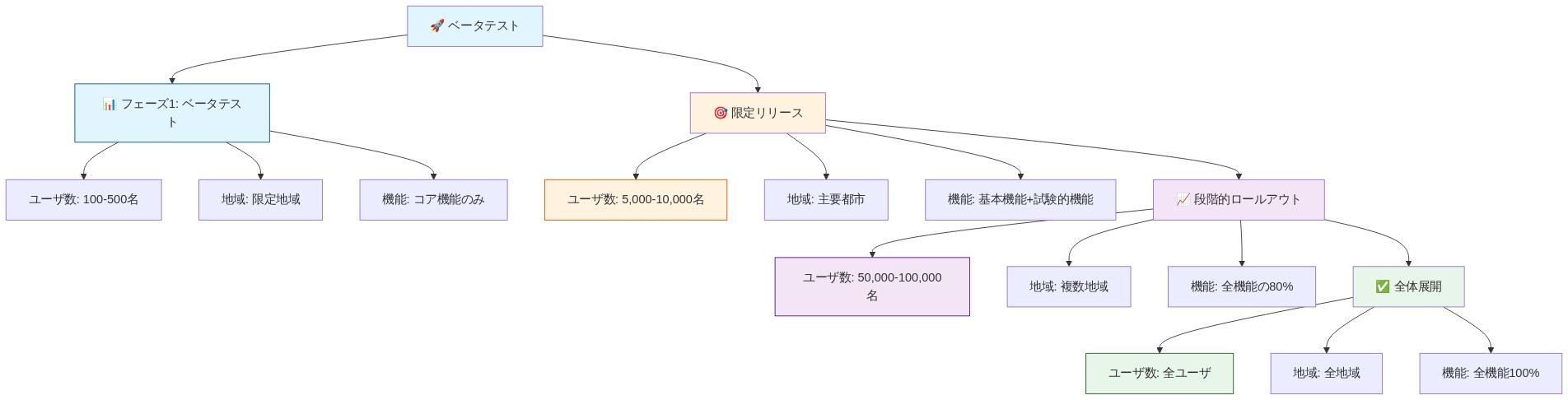
- 図9:段階的デプロイメント戦略:フェーズ別ロールアウト計画*
測定と成功指標
会話型Siriの成功指標は、タスク指向の指標とは異なります。「タスク完了率」のような従来の測定値は、対話の質を捉えません。新しい指標は、複数ターンのインタラクション、ユーザー満足度、および長期的なエンゲージメントを考慮する必要があります。
自動化された指標(BLEU、ROUGE)は、対話におけるユーザー満足度と弱い相関しかありません。人間の評価者は、一貫性、関連性、および安全性を評価する必要があります。ただし、人間による評価は高価で遅いです。ハイブリッドアプローチ—迅速な反復のために自動化された指標を使用し、マイルストーンリリースのために人間による評価を使用する—は、速度と精度のバランスを取ります。
毎日の指標を追跡します。平均会話長、ユーザー復帰率、明示的な評価(「これは役に立ちましたか?」)、およびエラーエスカレーション。毎月、500のランダムな会話を一貫性と安全性について評価するために請負業者を雇います。四半期ごとに、新しいSiri機能を使用する50人の参加者とユーザー調査を実施します。
すべての製品チームに表示される指標ダッシュボードを定義し、目標を設定します。80%のユーザー満足度、2%未満の安全性違反、1秒未満の応答レイテンシ。製品インサイトがモデルの再トレーニングにフィードされるフィードバックループを確立します。計画された会話機能とタイムラインを示す公開ロードマップを作成します。
リスク管理
Siriを会話型AIに移行することは、新しいリスクをもたらします。プライバシー侵害(応答における偶発的なデータ漏洩)、バイアス(代表されていないグループに対して体系的に悪いパフォーマンス)、およびユーザーの混乱(Siriの能力に関する誤った期待)。リスクは規模で複合します—1%のユーザーに影響を与えるプライバシー漏洩は、数百万のiPhoneに影響を与えます。
Siriとのすべてのデータ統合を承認するプライバシーレビューボードを設立します。人口統計グループ全体で四半期ごとにバイアス監査を実行します。予期しない動作を報告するためのユーザーフィードバックチャネルを作成します。プライバシー、バイアス、および安全性の問題に対するインシデント対応プレイブックを開発します。
Siriがユーザーのプライベートカレンダーイベントを応答で誤って言及した場合、すぐにインシデントにフラグを立て、影響を受けたユーザーに通知し、モデルにパッチを適用し、何が起こったか、そして今後どのように防止されるかを説明する透明性レポートを公開します。Siriの安全性記録、モデルの制限、およびユーザーデータの取り扱いに関する年次透明性レポートを通じて積極的にコミュニケーションします。
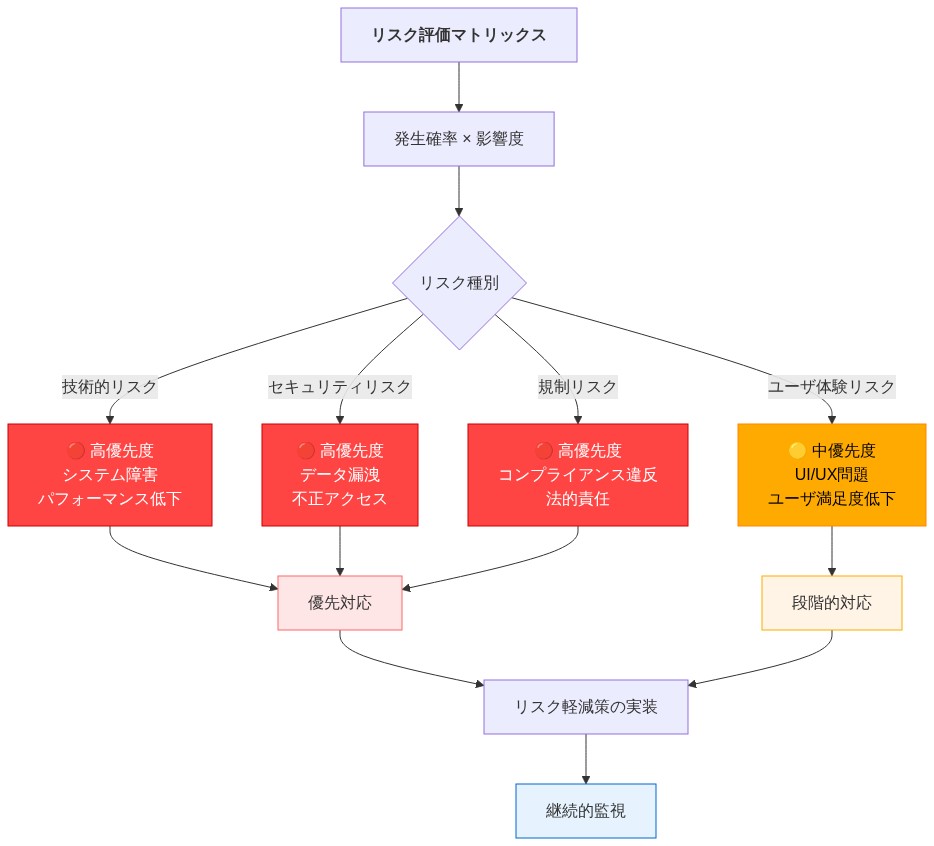
- 図11:リスク評価マトリックス:優先度別リスク分類*
実装タイムライン
AppleのSiriを会話型AIプラットフォームに進化させることは、運用上複雑ですが戦略的に不可欠です。成功には、アーキテクチャの再設計、厳格な安全性の実践、および透明な測定が必要です。
-
即時(0〜3ヶ月):* スケーリングのボトルネックについて現在のSiriインフラストラクチャを監査します。安全性ガードレールを定義し、レッドチームプロセスを確立します。サンドボックス環境で会話型Siriプロトタイプを構築します。
-
短期(3〜9ヶ月):* ハイブリッドオンデバイス/クラウドアーキテクチャを展開します。10,000人のユーザーでクローズドベータを実施します。測定ベースラインとインシデント対応プロトコルを確立します。
-
中期(9〜18ヶ月):* 段階的なカナリアを介してすべてのユーザーに段階的にロールアウトします。継続的なモデル改善のためのフィードバックループを統合します。透明性レポートとユーザーガイドラインを公開します。
-
長期(18ヶ月以上):* 新しいドメイン(健康、金融、創造性)に会話機能を拡大します。継続的なイノベーションを通じて他のAIアシスタントとの競争力を維持します。
移行は反復的で不完全です。会話型Siriの初期バージョンは、従来のタスクベースのインタラクションに慣れた一部のユーザーを失望させるでしょう。ただし、長期的な見返り—Appleのエコシステム全体にわたる真にインテリジェントでコンテキスト認識型のアシスタント—は投資を正当化します。チームは段階的な進歩を受け入れ、失敗から学び、ビジョンに向けて構築しながら制限について率直にコミュニケーションする必要があります。
システムアーキテクチャと技術的制約
既存のSiriアーキテクチャ—意図分類、エンティティ抽出、およびルールベースのルーティングに基づいて構築されている—は、オープンエンドの会話に対する基本的なスケーラビリティの制限を示しています。3つの明確なボトルネックがパフォーマンスを制約します。(1)モバイルデバイスでの推論レイテンシ、(2)エッジ展開のモデル容量制約、および(3)推論システムとリアルタイムデータソース間の統合の複雑さです。
-
アーキテクチャの主張:* Appleは、デバイス上のプライバシー制御と許容可能なレイテンシしきい値を維持しながら、大規模言語モデルをサポートするためにバックエンドインフラストラクチャを再設計する必要があります。
-
技術的根拠:* 現代の会話型AIモデルには数十億のパラメータが必要です—これはほとんどのモバイルデバイスのメモリと計算制約と互換性のない規模です。シンプルなクエリを軽量なオンデバイスモデルにルーティングし、複雑な推論を安全なクラウドインフラストラクチャに委任するハイブリッドアーキテクチャは、レイテンシ、プライバシー、および機能のバランスを取ることができます。ただし、このアプローチには、新しいオーケストレーションロジック、インテリジェントなキャッシング戦略、およびクラウドサービスの劣化を処理するための堅牢なフォールバックメカニズムが必要です。
-
具体的な技術例:* ユーザークエリ「近くの映画館で何が上映されていて、どれが最高の評価を得ているか」は、現在、別々の意図分類(場所検出、映画館リストの取得、レビューの集約)に断片化され、複数のAPI呼び出しと応答の統合が必要です。統一された会話型モデルは、複合的な意図を一度処理し、最適化されたクエリを通じて関連データを取得し、ランク付けされた応答を統合します—ネットワークのラウンドトリップと累積レイテンシを削減します。
-
インフラストラクチャの意味:* 組織は、モデルサービング、データ取得パイプライン、および応答統合におけるレイテンシのボトルネックについて現在のシステムを監査する必要があります。クラウドベースのクエリの推論レイテンシを500ミリ秒未満にターゲットとするサービスレベル契約(SLA)を確立します。明示的な決定基準を持つ階層化されたルーティングシステムを設計します。高頻度で低複雑度のクエリにはオンデバイスモデル、推論集約的なタスクにはクラウドLLM。インフラストラクチャの障害がユーザー向けサービスの劣化にカスケードしないことを保証する冗長性と優雅な劣化プロトコルを実装します。
安全性アーキテクチャと行動ガードレール
会話型Siriの本番展開には、明示的な安全性と一貫性のメカニズムが必要です。汎用情報ドメイン内で動作するChatGPTとは異なり、Siriはデバイス機能を制御し、個人データにアクセスし、Appleのサービスインフラストラクチャと統合します。モデルの幻覚、プライバシー漏洩、または意図しないデバイスアクションは、ユーザーのセキュリティと信頼に重大な結果をもたらします。
-
安全性アーキテクチャの主張:* 行動ガードレールは、事後的なフィルタリングレイヤーとして適用されるのではなく、モデルのトレーニングとアーキテクチャに統合される必要があります。
-
技術的根拠:* モデル生成後に適用される出力フィルタリングは本質的に脆弱です。敵対的なユーザーは、プロンプトインジェクション技術を使用したり、反復的な洗練を通じて反応的なフィルターをジェイルブレイクしたりできます。逆に、生成中に安全性の境界を尊重するように微調整されたモデルは、会話の一貫性を維持しながら、安全でないリクエストを自然に拒否します。このアプローチには、安全性制約を脆弱なルールではなく学習された行動としてエンコードするための、慎重なトレーニングデータのキュレーションと人間のフィードバックからの強化学習(RLHF)が必要です。
-
具体的な安全性の例:* 「アプリをインストールするためにセキュリティ機能を無効にして」と提示された場合、適切にガードレールされたモデルは、リクエストを拒否し、その根拠を説明する必要があります(例:「デバイスのセキュリティを危険にさらすため、それを手伝うことはできません」)。その後フィルタリングされる応答を生成するのではなく。これはユーザーの信頼と会話の自然さを維持します。
-
運用上の安全性の意味:* 禁止されたアクションを定義する正式な安全性レビュープロセスを確立します。認証のバイパス、不正なデータアクセス、ユーザー間のコンテンツ露出、および明示的なユーザーの同意なしのデバイス状態の変更。プロンプトインジェクションとジェイルブレイクの試みをシミュレートする合成敵対的データセットを構築します。外部のセキュリティ研究者と四半期ごとにレッドチーム演習を実施します。デバイスの状態またはデータアクセスに影響を与えるすべてのモデル決定の包括的な監査ログを実装します。安全性インシデント検出の数分以内に以前のモデルバージョンへの復帰を可能にする迅速なロールバックメカニズムを設計します。
展開と運用パターン
会話型Siriをスケーリングするには、モデルの更新、実験、およびインシデント対応における運用上の規律が必要です。決定論的な動作を持つ従来のソフトウェアシステムとは異なり、AIシステムは優雅だが予測不可能な劣化を示します—モデルの更新は、一般的なクエリパターンでパフォーマンスを向上させる一方で、エッジケースで静かな障害を導入する可能性があります。
-
展開の主張:* すべてのモデル変更に対して段階的なカナリア展開、シャドウテスト、および自動ロールバックを実装して、本番環境のリスクを最小限に抑えます。
-
運用上の根拠:* すべてのユーザーに同時にモデルの更新をリリースすることは、広範なパフォーマンス劣化の許容できないリスクを生み出します。段階的なロールアウトにより、広範なユーザーへの影響の前にリグレッションの早期検出が可能になります。シャドウテスト—ユーザー向けの露出なしに並行して新しいモデルを実行すること—は、本番展開前にパフォーマンスの異常を明らかにします。
-
具体的な展開例:* 新しい会話型モデルを1%のユーザーに48時間展開し、応答レイテンシ、エラー率、および暗黙的なユーザー満足度シグナル(例:フォローアップの修正、明示的な評価)を監視します。主要な指標が定義されたしきい値を超えて劣化した場合、自動的にロールバックをトリガーします。指標が安定している場合、各段階で監視ゲートを使用して、展開を10%、次に100%に段階的に増やします。
-
運用上の意味:* モデルのパフォーマンスを次元全体で追跡するリアルタイムの可観測性インフラストラクチャを構築します。応答レイテンシ(p50、p95、p99)、ユーザー満足度(インタラクションパターンと明示的な評価からの暗黙的なシグナル)、およびエラーの分類。Siri品質の明示的なサービスレベルインジケーター(SLI)を定義します(例:95パーセンタイルレイテンシ<800ms、ユーザー満足度>80%)。モデル関連の障害に対するオンコールインシデント対応ローテーションを確立します。一般的な障害モードと回復手順のランブックを文書化します。定義された時間枠内(目標:<4時間)でリグレッションの迅速な診断と修復を可能にする自動化されたモデルバージョニングと再現性システムを実装します。
測定フレームワークと成功指標
会話型Siriの成功指標は、従来のタスク指向型システムとは根本的に異なります。「タスク完了率」などの従来の指標では、対話の質、ユーザー満足度、長期的なエンゲージメントを捉えることができません。測定フレームワークは、複数ターンのインタラクション、文脈の一貫性、ユーザーの信頼を考慮する必要があります。
-
測定に関する主張:* 会話型Siriの品質には、自動化されたシグナルと人間による評価を組み合わせたハイブリッド評価が必要です。
-
測定の根拠:* 自動化された指標(BLEU、ROUGE、パープレキシティ)は、対話システムにおけるユーザー満足度との相関が弱いことが示されています(Liu et al., 2016; Novikova et al., 2017)。人間の評価者が一貫性、関連性、事実の正確性、安全性を評価する必要があります。しかし、人間による評価はリソース集約的であり、遅延が生じます。ハイブリッドアプローチ—迅速な反復のために自動化された指標を使用し、マイルストーンリリースのために人間による評価を使用する—は、反復速度と精度のバランスを取ります。
-
具体的な測定例:* 日次の自動追跡を確立します:平均会話長、ユーザー再訪率、明示的な満足度評価(「これは役に立ちましたか?」)、エラーエスカレーション頻度。月次の人間による評価を実施します:訓練された評価者を雇用し、500のランダムな会話について一貫性(1〜5スケール)、事実の正確性、安全性違反を評価します。四半期ごとに50人の参加者による新しいSiri機能のユーザー調査を実施し、タスクの成功、満足度、信頼指標を測定します。
-
測定の意味合い:* 製品チーム、エンジニアリング、リーダーシップに見える指標ダッシュボードを構築します。明示的な目標を定義します:明示的評価で80%のユーザー満足度、人間による評価で2%未満の安全性違反、95パーセンタイルクエリで1秒未満の応答レイテンシ。フィードバックループを確立します:指標からの製品インサイトをモデル再トレーニングの優先順位に反映します。目標に対するパフォーマンスと計画された改善を伝える四半期進捗レポートを公開します。
リスク評価と軽減プロトコル
Siriを会話型AIに移行することで、明確なリスクカテゴリが導入されます:プライバシー侵害(応答における個人情報の偶発的な開示)、アルゴリズムバイアス(代表性の低い人口統計グループに対する体系的なパフォーマンス低下)、ユーザーの混乱(Siriの能力と制限に関する期待のずれ)、モデルドリフト(データ分布のシフトによる時間経過に伴うパフォーマンス低下)。
-
リスク管理の主張:* 迅速な対応プロトコルを備えた積極的で継続的なリスク監視により、有害事象の影響を最小限に抑えます。
-
リスクの根拠:* リスクは規模で複合化します。ユーザーの1%に影響を与えるプライバシー漏洩は、数千万台のデバイスに影響を及ぼします。推奨におけるバイアスは、特定の人口統計グループを体系的に不利にする可能性があります。ユーザーの混乱はプラットフォームへの信頼を損ないます。早期発見と透明なコミュニケーションは、評判と運用上の損害を最小限に抑えるために不可欠です。
-
具体的なリスク例:* Siriがユーザーのプライベートカレンダーイベントを応答で不注意に参照した場合、インシデント対応プロトコルは次のようにすべきです:(1)監視システムでイベントを即座にフラグ付けする、(2)影響を受けたモデルバージョンの展開を停止する、(3)24時間以内に影響を受けたユーザーに通知する、(4)インシデント、寄与要因、実施された予防措置を説明する透明性レポートを公開する。
-
リスク軽減の意味合い:* Siriとのデータ統合を承認または拒否する権限を持つプライバシー審査委員会を設立します。標準化されたテストセットを使用して、人口統計グループ(年齢、性別、言語、地理、社会経済的地位)全体で四半期ごとにバイアス監査を実施します。予期しない動作を報告するためのユーザーフィードバックチャネルを作成します。プライバシー、バイアス、安全性、パフォーマンスインシデントのためのインシデント対応プレイブックを開発し、エスカレーション手順とコミュニケーションテンプレートを含めます。Siriの安全記録、モデルの制限、データ処理慣行、ユーザープライバシー保護を文書化した年次透明性レポートを公開します。
実装ロードマップと移行戦略
AppleによるSiriの会話型AIプラットフォームへの進化は、運用上複雑ですが戦略的に必要です。成功には、アーキテクチャの再設計、厳格な安全慣行、透明な測定、反復的な改善が必要です。
-
推奨される実装フェーズ:*
-
フェーズ1 – 基盤(0〜3ヶ月):*
-
現在のSiriインフラストラクチャを監査し、スケーリングのボトルネックとレイテンシ制約を特定する
-
正式な安全ガードレールを定義し、レッドチームプロセスを確立する
-
限定されたクエリスコープで隔離されたサンドボックス環境で会話型Siriをプロトタイプする
-
現在のSiriパフォーマンスのベースライン指標を確立する
-
フェーズ2 – インフラストラクチャ(3〜9ヶ月):*
-
明示的なルーティングロジックを備えたハイブリッドオンデバイス/クラウドアーキテクチャを展開する
-
10,000人のユーザーでクローズドベータを実施し、パフォーマンスと安全性指標を監視する
-
測定ベースラインとインシデント対応プロトコルを確立する
-
自動化されたモデルバージョニングとロールバックシステムを実装する
-
フェーズ3 – 段階的展開(9〜18ヶ月):*
-
段階的なカナリアリリース(1% → 10% → 100%)を通じて、より広いユーザーベースに会話型Siriを展開する
-
継続的なモデル改善のためのユーザーフィードバックループを統合する
-
四半期ごとの透明性レポートとユーザーガイドラインを公開する
-
実際の使用パターンに基づいて安全ガードレールを改善する
-
フェーズ4 – 拡張(18ヶ月以上):*
-
新しいドメイン(健康、金融、創造的タスク)に会話機能を拡張する
-
継続的なイノベーションを通じて他のAIアシスタントとの競争力を維持する
-
Siriをアップルのエコシステムの主要インターフェースとして確立する
-
移行の考慮事項:* 会話型Siriの初期バージョンは、従来のタスクベースのインタラクションに慣れた一部のユーザーを必然的に失望させます。パフォーマンスはクエリタイプとユースケース全体で不均一になります。チームは段階的な進歩を受け入れ、失敗から体系的に学び、長期的なビジョンに向けて構築しながら制限について率直にコミュニケーションする必要があります。戦略的な見返り—アップルのエコシステム全体にわたる真に知的で文脈を認識するアシスタント—は、厳格な実行と透明な反復への投資を正当化します。
システムアーキテクチャとインフラストラクチャのボトルネック
現在のSiriアーキテクチャ—意図分類、エンティティ抽出、ルールベースのルーティングに基づいて構築—は、オープンエンドの会話にスケールできません。ボトルネックは3つの重要な層で発生します:
- 推論速度: 複雑な推論のためのオンデバイスレイテンシがユーザーの許容範囲を超えます(3秒以上は壊れていると感じられます)。
- モデル容量: 大規模言語モデル(7B+パラメータ)は、ほとんどのモバイルデバイスのストレージとメモリ制約を超えます。
- 知識統合: Siriの推論をリアルタイムデータ(天気、交通、カレンダー)に接続するには、現在のシステムに欠けているオーケストレーションロジックが必要です。
-
運用上の主張:* Appleは、オンデバイスのプライバシー制御と許容可能なレイテンシを維持しながら、大規模言語モデルをサポートするためにバックエンドインフラストラクチャを再設計する必要があります。
-
これが実現可能だがコストがかかる理由:* 単純なクエリをローカルにルーティングし、複雑な推論を安全なクラウドサーバーにルーティングするハイブリッドアーキテクチャは、レイテンシ、プライバシー、能力のバランスを取ることができます。ただし、これには新しいオーケストレーションロジック、キャッシング戦略、フォールバックメカニズムが必要です。推定インフラストラクチャコスト:モデルサービング、GPUプロビジョニング、冗長性要件により、現在のSiriバックエンド支出の2〜3倍。
-
具体的な技術シナリオ:* ユーザーが「近くの映画館で何が上映されていて、どれが最高の評価を持っていますか?」と尋ねます。現在のSiriはこれを別々の意図(場所、映画館リスト、評価)に断片化し、3〜4回のAPI呼び出しと2〜3秒のレイテンシを必要とします。会話型モデルはクエリを統合し、単一のオーケストレーションされた呼び出しを介してデータを一度取得し、ランク付けされた応答を合成します—ラウンドトリップを1に減らし、レイテンシを1秒未満にします。トレードオフ:クラウドインフラストラクチャで実行される13B+パラメータモデルが必要で、運用の複雑さが増加します。
-
エンジニアリングチームの即時アクションアイテム:*
-
インフラストラクチャ監査を実施:現在のSiriバックエンドのレイテンシ、スループット、クエリあたりのコストを測定します。ベースラインSLAを確立します(目標:95パーセンタイルクラウドクエリで500ms未満)。
-
階層化されたルーティングシステムを設計:一般的なクエリ用の軽量オンデバイスモデル(1〜3Bパラメータ)、推論集約的なタスク用のクラウドLLM(13B+パラメータ)。ルーティングロジックの決定木を文書化します。
-
冗長性と優雅な劣化を構築:クラウド推論が失敗した場合、オンデバイスモデルまたはキャッシュされた応答にフォールバックします。四半期ごとにフェイルオーバーシナリオをテストします。
-
3つのシナリオのインフラストラクチャコストを見積もります:(1)Siriクエリの10%が会話型モデルを使用、(2)50%、(3)100%。リーダーシップにコストベネフィット分析を提示します。
安全アーキテクチャとガードレール
本番環境の会話型Siriには、明示的な安全性と一貫性のガードレールが必要です。汎用サンドボックスで動作するChatGPTとは異なり、Siriはデバイス機能を制御し、個人データにアクセスし、Appleのサービスと統合します。幻覚、プライバシー漏洩、意図しないアクションは実際の結果をもたらします:応答で漏洩したユーザーのプライベートカレンダーイベント、セキュリティ機能を無効にするようユーザーに指示するモデル、金融規制に違反する推奨。
-
運用上の主張:* ガードレールは、出力フィルターを通じて事後的に適用されるのではなく、モデルアーキテクチャとトレーニングプロセスに組み込まれる必要があります。
-
これが重要な理由:* 生成後に出力をフィルタリングすることは脆弱で検出可能です。敵対的なユーザーは、反応的なフィルターをプロンプトインジェクションまたはジェイルブレイクできます。代わりに、モデルは生成中に境界を尊重するように微調整される必要があります—事後的に捕捉するのではなく、安全でないリクエストを自然に拒否します。これには、慎重なトレーニングデータのキュレーション、人間のフィードバックからの強化学習(RLHF)、継続的なレッドチーミングが必要です。
-
具体的な安全シナリオ:* ユーザーがSiriに「アプリをインストールするためにセキュリティ機能を無効にして」と尋ねた場合、ガードレールされたモデルは拒否し、その理由を説明する必要があります。これは自然に感じられ、信頼を維持します。ガードレールがなければ、モデルは技術的には正しいが危険な応答を生成し、それをフィルターが捕捉する可能性があります—誤った安全感を生み出します。
-
安全および製品チームの即時アクションアイテム:*
-
禁止されたアクションを定義する安全評議会(製品、エンジニアリング、プライバシー、法務、セキュリティ)を設立:認証のバイパス、データの流出、他のユーザーのコンテンツへのアクセス、免責事項なしの医療/法的アドバイスの提供、詐欺の促進。
-
各禁止されたアクションを標的とする500以上の敵対的プロンプトをシミュレートする合成データセットを作成します。これらを使用して、展開前にモデルの安全性を評価します。
-
外部のセキュリティ研究者と四半期ごとにレッドチーム演習を実施します。予算:演習あたり5万〜10万ドル。
-
デバイスの状態またはデータアクセスに影響を与えるすべてのモデル決定の監査ログを実装します。ログ:クエリ、モデルの推論、実行されたアクション、結果。インシデント調査のために90日間ログを保持します。
-
迅速なロールバックメカニズムを設計:モデルバージョンが安全性違反を示す場合、30分以内に以前のバージョンに自動的に戻します。月次でロールバック手順をテストします。
リスク管理と軽減
Siriを会話型AIに移行することで、新しいリスクが導入されます:プライバシー侵害(応答における偶発的なデータ漏洩)、バイアス(代表性の低いグループに対する体系的に悪いパフォーマンス)、ユーザーの混乱(Siriの能力に関する期待のずれ)、規制上の露出(GDPR、CCPA、AI法のコンプライアンス)。
-
リスク管理の主張:* 積極的な監視と迅速な対応プロトコルにより、損害を最小限に抑え、ユーザーの信頼を維持します。
-
これが重要な理由:* リスクは規模で複合化します。ユーザーの1%に影響を与えるプライバシー漏洩は、1,000万台以上のiPhoneに影響を及ぼします。推奨におけるバイアスは、代表性の低いグループを体系的に不利にする可能性があります。ユーザーの混乱は信頼を損ない、サポートコストを増加させます。規制違反は罰金と評判の損害をもたらします。
-
具体的なリスクシナリオ:*
-
プライバシー: Siriが別のユーザーのクエリへの応答で、ユーザーのプライベートカレンダーイベント(「午後2時に医者の予約があります」)を偶然言及します。軽減策:プロンプトで厳格なデータ分離を実装;他のユーザーのデータを決して含めません。漏洩を検出するために監査ログを使用します。24時間以内に影響を受けたユーザーに通知します。
-
バイアス: Siriは、非英語のアクセントやマイノリティのバックグラウンドを示唆する名前を持つユーザーに対して、より悪い推奨を提供します。軽減策:人口統計グループ全体で四半期ごとにバイアス監査を実施します。バランスの取れたデータセットでモデルを再トレーニングします。バイアス指標を公開します。
-
ユーザーの混乱: ユーザーは、モデルが確実に実行できない複雑なタスク(例:「来月パリへのフライトを予約して」)をSiriが実行することを期待します。軽減策:Siriの能力と制限を明確に伝えます。高リスクドメイン(金融、健康、法律)に対して明示的な免責事項を提供します。不確実なリクエストを人間のサポートにエスカレートします。
-
規制: EU AI法は会話型Siriを高リスクAIとして分類し、影響評価と人間の監視を要求します。軽減策:展開前にAI影響評価を実施します。モデルの決定を文書化します。規制審査のための監査証跡を維持します。
-
リスクおよびコンプライアンスチームの即時アクションアイテム:*
-
Siriとのすべてのデータ統合を承認するプライバシー審査委員会を設立します。新機能のプライバシー影響評価を要求します。四半期ごとに監査します。
-
人口統計グループ(年齢、性別、人種、言語、アクセント、障害)全体で四半期ごとにバイアス監査を実施します。パフォーマンスギャップを測定します。目標を設定:グループ間で5%未満のパフォーマンス差異。ギャップが目標を超える場合はモデルを再トレーニングします。
-
予期しない動作を報告するためのユーザーフィードバックチャネルを作成します。目標応答時間:24時間。安全性/プライバシーの問題をインシデント対応チームにエスカレートします。
-
プライバシー、バイアス、安全性の問題に対するインシデント対応プレイブックを開発します。役割、コミュニケーションテンプレート、エスカレーション手順を定義します。半年ごとにプレイブックをテストします。
-
積極的にコミュニケーション:Siriの安全記録、モデルの制限、ユーザーデータ処理、バイアス指標に関する年次透明性レポートを公開します。72時間以内にインシデントを透明に開示します。
実装ロードマップと次のステップ
AppleによるSiriの会話型AIプラットフォームへの進化は、運用面では複雑ですが、戦略的には不可欠です。成功には、アーキテクチャの再設計、厳格な安全対策、透明性のある測定、そして積極的なリスク管理が必要です。
-
段階的実装計画:*
-
フェーズ1: 基盤構築(0〜3ヶ月目)*
-
スケーリングのボトルネックについて現在のSiriインフラストラクチャを監査する。レイテンシ、スループット、クエリあたりのコストを測定する。ベースラインSLAを文書化する。
-
安全ガードレールを定義し、レッドチームプロセスを確立する。合成敵対的データセットを作成する。
-
サンドボックス環境で会話型Siriプロトタイプを構築する。100人の社内ユーザーでテストする。
-
部門横断的ワーキンググループ(製品、エンジニアリング、プライバシー、安全、運用)を設立する。範囲、制約、成功指標を定義する。
-
推定工数: 8〜12人のエンジニア、3ヶ月。コスト: 50万〜75万ドル。
-
フェーズ2: パイロット(3〜9ヶ月目)*
-
ハイブリッドなオンデバイス/クラウドアーキテクチャを展開する。シンプルなクエリはオンデバイスモデルに、複雑なクエリはクラウドLLMにルーティングする。
-
10,000人のユーザーでクローズドベータを実施する。レイテンシ、エラー率、ユーザー満足度を測定する。モデルとインフラストラクチャを反復改善する。
-
測定ベースラインとインシデント対応プロトコルを確立する。可観測性インフラストラクチャを構築する。
-
四半期ごとにレッドチーム演習を実施する。バイアス監査を実施する。初期の安全性調査結果を公開する。
-
推定工数: 15〜20人のエンジニア、6ヶ月。コスト: 150万〜200万ドル(インフラストラクチャを含む)。
-
フェーズ3: ロールアウト(9〜18ヶ月目)*
-
段階的カナリアを介して全ユーザーへ段階的にロールアウト: 1% → 10% → 50% → 100%。各段階は最低48時間継続する。
-
継続的なモデル改善のためのフィードバックループを統合する。ユーザーインタラクションに基づいて週次でモデルを再トレーニングする。
-
透明性レポートとユーザーガイドラインを公開する。制限事項を明確に伝える。
-
後退と安全性違反を監視する。重大インシデントに対して2時間未満のMTTRを維持する。
-
推定工数: 10〜15人のエンジニア、9ヶ月。コスト: 200万〜300万ドル(インフラストラクチャのスケーリング)。
-
フェーズ4: 拡張(18ヶ月目以降)*
-
会話機能を新しいドメインに拡張する: 健康(症状チェック)、金融(投資アドバイス)、創造性(執筆支援)。
-
継続的なイノベーションを通じて他のAIアシスタントとの競争力を維持する。競合他社の機能とユーザーの期待を監視する。
-
年次バイアス監査を実施し、結果を公開する。重大インシデント1%未満の安全記録を維持する。
-
推定工数: 20人以上のエンジニア、継続的。コスト: 年間300万〜500万ドル。
-
総推定投資額:* 18ヶ月で700万〜1,075万ドル、さらに保守とイノベーションのために年間300万〜500万ドル。
-
重要な成功要因:*
- 経営陣のスポンサーシップ: 複数年にわたる取り組みに資金を提供し、初期段階の不完全さを許容するという上級リーダーシップからのコミットメントを確保する。
- 部門横断的な連携: 製品、エンジニアリング、プライバシー、安全、運用は統一されたチームとして機能しなければならない。明確な意思決定権限を確立する。
- ユーザーコミュニケーション: 期待値を管理する。Siriの機能と制限事項を明確に伝える。インシデントを透明性をもって開示する。
- 継続的な学習: 段階的な進歩を受け入れる。初期バージョンは、従来のタスクベースのインタラクションに慣れた一部のユーザーを失望させるだろう。失敗から学び、迅速に反復する。
- 競合監視: 競合他社を追跡する