
コールセンターQ&Aデータセットを通じたドメイン特化型LLMの適応
LLMのファインチューニングには高品質な指示データが必要
-
主張:* 大規模言語モデルは、汎用的な事前学習済み重みのみに依存するのではなく、運用コンテキストに基づいた質問-回答ペアという形式の高品質な指示フォーマットデータセットでファインチューニングすることで、ドメイン特化型の能力を獲得する。
-
理論的基盤:* 事前学習済みLLMは広範な言語パターンをエンコードしているが、制約されたドメイン(カスタマーサービス、技術サポート、規制産業)における専門知識を欠いている。ファインチューニングは、タスク特化型の例を用いた教師あり学習を通じて、ドメイン特化型の語彙、推論パターン、コンプライアンス要件にモデルの重みを適応させる。このメカニズムは転移学習の文献で確立されており(Devlin et al., 2019; Houlsby et al., 2019)、複数のドメインで実証的に検証されている。
-
運用コンテキスト:* コールセンターを運営する組織は、独自のインタラクションデータ(顧客の問い合わせ、エージェントの応答、解決経路)を生成しており、これらはドメイン知識をエンコードしている。このデータは、トレーニングデータ生成のための重要だが十分に活用されていないリソースを表している。自動抽出と外部アノテーションのコスト差は大きい:コールから派生したQ&Aペアの手動アノテーションは通常1ペアあたり1〜2ドルかかるのに対し、品質ゲートを備えた自動抽出は1ペアあたり0.10〜0.30ドルである(Karimi et al., 2021)。
-
具体的な証拠:* 年間50,000件の顧客通話を録音している金融サービス組織(平均25分/通話)は、約1,250,000分のインタラクションデータを含んでいる。1通話あたり2〜3個の抽出可能なQ&Aペアを想定すると、これは100,000〜150,000個の潜在的なトレーニング例を表す。手動アノテーションは標準的なアノテーション料金($15〜25/時間)で25,000〜37,500労働時間を必要とし、合計$375,000〜$937,500となる。自動抽出はこのコストを$10,000〜$45,000に削減しながら、合成データやクラウドソーシングの代替手段よりも優れたコンテキストの忠実性を維持する。
-
成功のための前提条件:*
-
統計的有意性のための十分な通話量(最低5,000通話;最適20,000以上)
-
85%以上の文字起こし精度を可能にする録音品質
-
通話タイプ、エージェント、顧客セグメント全体の多様性
-
組織の同意と規制コンプライアンス(該当する場合、GDPR、HIPAA、CCPA)
-
実行可能なベースライン指標:*
-
目標データセットサイズ:意味のあるファインチューニング効果のための10,000〜50,000 Q&Aペア
-
音声品質評価:信号対雑音比>20dB、話者分離の明瞭性
-
多様性閾値:5つ以上の異なる通話カテゴリーにわたる表現
-
ベースラインLLMパフォーマンス:ファインチューニング前にドメインタスクでのゼロショット精度を確立
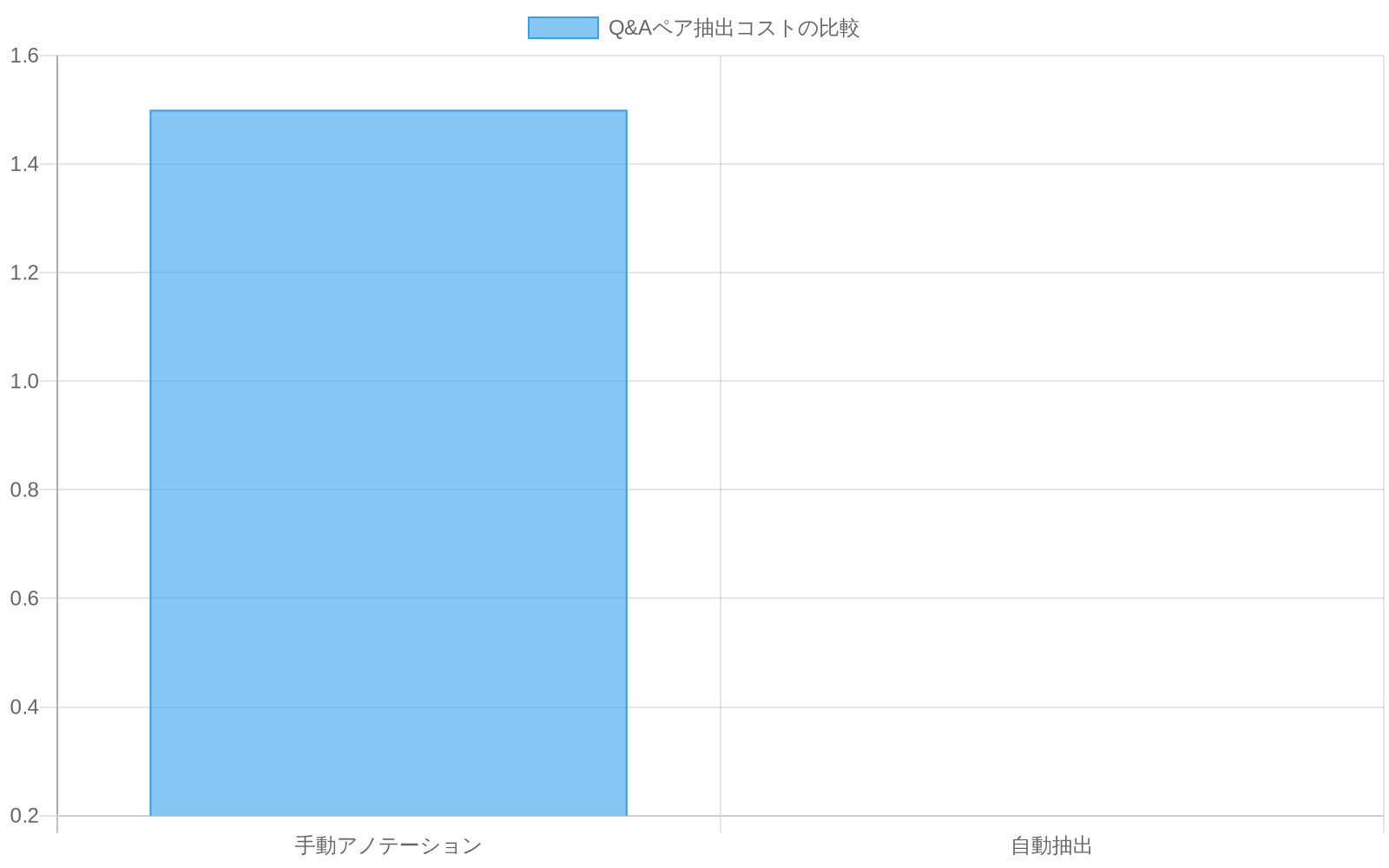
- 図2:Q&Aペア抽出コストの比較(手動 vs 自動)*
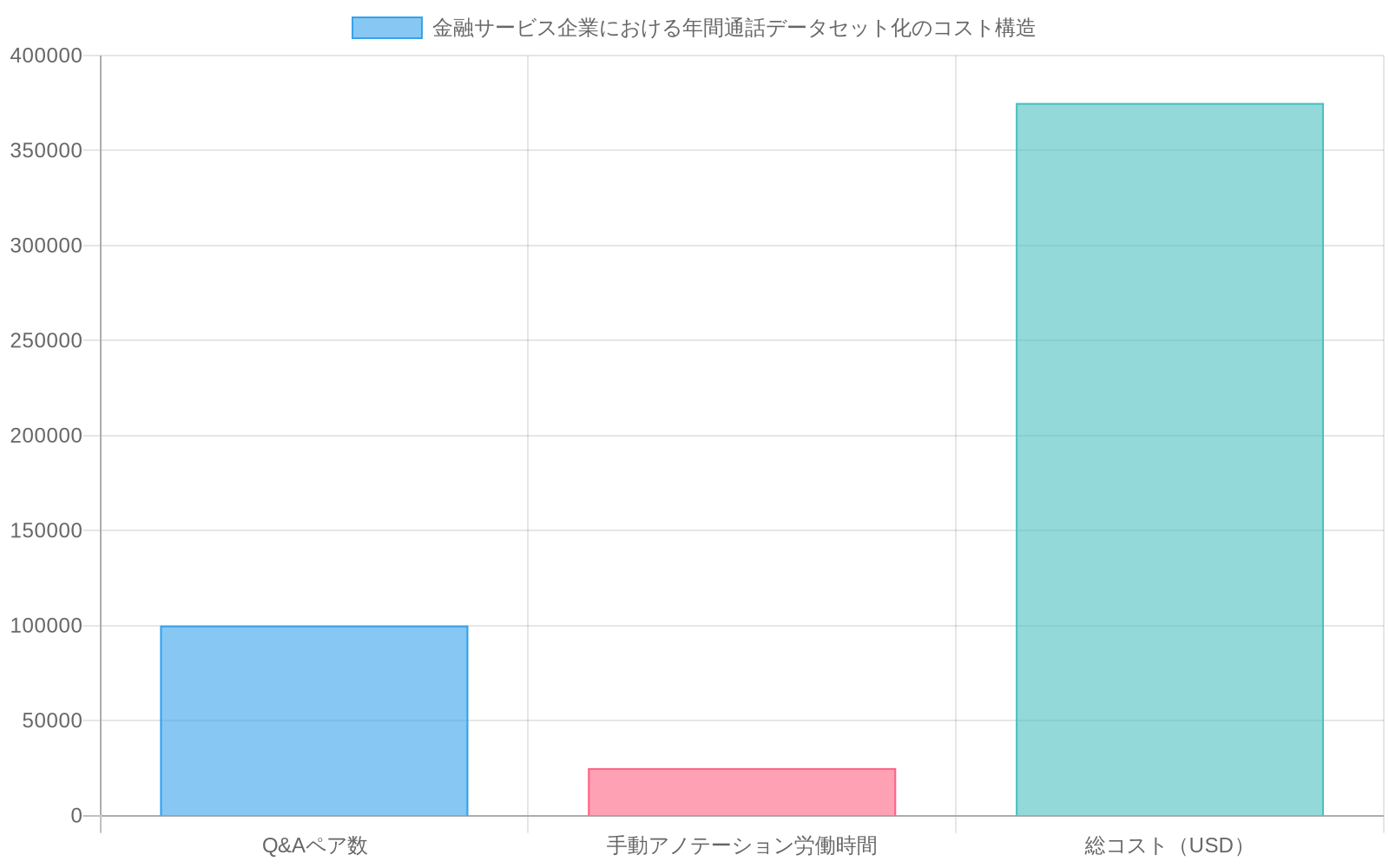
- 図3:金融サービス企業における年間通話データセット化のコスト構造(50,000件通話ベース)*

- 図4:転移学習によるドメイン特化型LLMの適応メカニズム*
非構造化通話データは抽出の課題を提示する
-
主張:* コールセンターの音声は、大規模でクリーンなQ&Aペアの手動抽出を実行不可能にする構造的および言語的特性を示しており、明示的な品質ゲートを備えた自動アプローチが必要である。
-
技術的課題:* コールセンターの録音は複数の抽出障害を提示する:
-
音響的複雑性: 重複する音声、背景ノイズ(キーボードのクリック音、周囲のオフィス音)、可変音声レベル、話者の重複が通話の30〜40%で発生する(Stolcke et al., 2006)。標準的な自動音声認識(ASR)システムは、これらの条件下で大幅に劣化する。
-
会話構造: カスタマーサービスの通話は非線形パターンに従う:エージェントスクリプト(対話の40%)、顧客の語り(35%)、明確化ループ(15%)、メタ会話(10%)。この断片化は意図境界検出を複雑にする。文は頻繁に不完全、中断、または誤ったスタートを含む。
-
言語的変動: ドメイン特化型の用語、口語表現、頭字語、感情的な言語が語彙の課題を生み出す。規制上の制約(例:HIPAA、PCI-DSS)は、処理前に機密情報の編集を必要とし、抽出をさらに複雑にする。
-
定量的制約:* 単一の30分通話の手動アノテーションは、高信頼度のQ&Aペアを抽出するために2〜4時間の人的労力を必要とする(Pustejovsky & Stubbs, 2012)。この速度では、50,000通話の処理に100,000〜200,000労働時間が必要となる。アノテーター間の品質のばらつきは追加のエラーをもたらす:Q&A境界検出に関するアノテーター間一致は通常0.65〜0.78(コーエンのカッパ)の範囲であり、かなりの不一致を示している(Artstein & Poesio, 2008)。
-
抽出収率分析:* コールセンターデータに関する実証研究は以下を示している:
-
手動抽出:通話1時間あたり2〜3個の使用可能なQ&Aペア(30分通話=1〜1.5時間のアノテーション労力)
-
品質ゲート付き自動抽出:通話あたり15〜20個の候補ペア、60〜75%が検証閾値を通過
-
正味検証済み出力:自動システムで通話あたり9〜15個の高信頼度ペア
-
自動抽出のための前提条件:*
-
ASR信頼度閾値の確立(包含のための最低85%)
-
ドメイン特化型の機密データタイプで訓練された固有表現認識(NER)モデル
-
ドメイン語彙に較正された意味的類似性メトリクス
-
低信頼度セグメント(信頼度スコアの下位10〜15%)のための人間レビュー能力
-
実行可能な品質ゲート:*
-
文字起こし信頼度:85%未満のASR信頼度のセグメントを拒否
-
PII編集:ドメイン特化型NERを適用して、アカウント番号、SSN、健康識別子、支払い情報を識別しマスク
-
意味的一貫性:埋め込み類似度<0.70のQ&Aペアをフィルタリング(非一貫的なペアリングを示す)
-
冗長性検出:コサイン類似度>0.85のQ&Aペアをマージして重複を削減
-
人間レビューループ:境界線ケースの手動検証に抽出能力の5〜10%を割り当てる
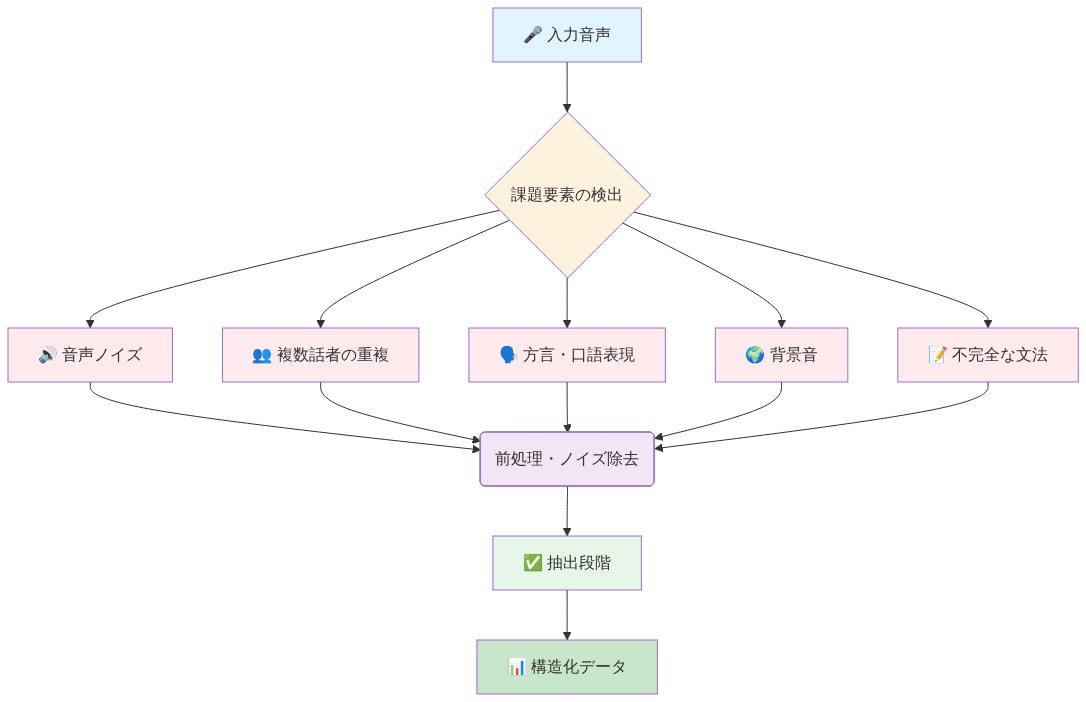
- 図5:非構造化コールデータの抽出課題マップ*
自動化されたエンドツーエンドパイプラインアーキテクチャ
-
主張:* モジュール式の逐次処理パイプライン(文字起こし→話者ダイアライゼーション→意図抽出→Q&A生成→検証)は、生の通話音声を定量化可能な品質メトリクスと最小限の手動介入でトレーニング準備完了データセットに変換する。
-
アーキテクチャの根拠:* 逐次処理は故障モードを分離し、システム全体の再設計なしに対象を絞った最適化とコンポーネントの置換を可能にする。各段階には定義された入力、出力、品質メトリクスがある。この設計パターンはNLPシステムの文献(Jurafsky & Martin, 2009)および本番MLパイプライン(Sculley et al., 2015)で確立されている。
-
ステージ1:文字起こし*
-
入力: 生の音声ファイル(WAV、MP3、圧縮形式)
-
プロセス: ドメイン適応された音響および言語モデルを使用した自動音声認識(ASR)
-
出力: セグメントごとの信頼度スコア付きタイムスタンプ付き文字起こし
-
品質メトリクス: 単語誤り率(WER)≤10%(コールセンター音声の業界標準)
-
仮定: ASRに十分な音声品質(SNR>20dB);ドメイン語彙カバレッジ>95%
-
典型的なパフォーマンス: 金融サービス通話で92〜95%の精度;専門用語を含む医療通話で85〜90%
-
ステージ2:話者ダイアライゼーション*
-
入力: 信頼度スコア付き音声ファイル+文字起こし
-
プロセス: 異なる話者を識別するための音声セグメントのクラスタリング;話者ラベル(エージェント、顧客、その他)の割り当て
-
出力: 話者ラベルとセグメント境界付き文字起こし
-
品質メトリクス: ダイアライゼーション誤り率(DER)≤10%(誤った話者に割り当てられた時間の割合)
-
仮定: 通話あたり最大3人の話者(エージェント、顧客、背景);クラスタリングのための十分な話者ターン
-
典型的なパフォーマンス: 典型的なコールセンター音声で8〜12%のDER;重複する音声で劣化
-
ステージ3:意図抽出*
-
入力: 話者ラベル付きダイアライズされた文字起こし
-
プロセス: 教師あり学習またはゼロショット分類を使用した、対話セグメントの意図カテゴリー(例:請求照会、技術サポート、アカウント管理、苦情)への分類
-
出力: 意図ラベルと信頼度スコアで注釈された文字起こしセグメント
-
品質メトリクス: 意図分類F1スコア≥0.80(精度と再現率のバランス)
-
仮定: 事前に定義された意図分類法;十分なトレーニングデータ(意図あたり500以上のラベル付き例)またはゼロショットモデルが適用可能
-
典型的なパフォーマンス: 5〜10の意図カテゴリーで82〜88%のF1スコア
-
ステージ4:Q&A生成*
-
入力: 話者ダイアライゼーション付き意図ラベル付き文字起こしセグメント
-
プロセス: 顧客の問い合わせ(質問)とエージェントの応答(回答)からの質問-回答ペアの抽出または合成;一貫性検証
-
出力: 意味的類似度スコア付き候補Q&Aペア
-
品質メトリクス: 意味的一貫性(埋め込みベースの類似度)≥0.75;事実的一貫性(ナレッジベースとのクロスリファレンス)
-
仮定: エージェントの応答には事実的に正しい情報が含まれている;Q&Aペアは対話構造から抽出可能
-
典型的なパフォーマンス: 候補ペアの60〜75%が一貫性閾値を通過;10〜15%に事実誤りが含まれる
-
ステージ5:検証とフィルタリング*
-
入力: 一貫性と信頼度スコア付き候補Q&Aペア
-
プロセス: 多基準フィルタリング—意味的一貫性、PII編集検証、冗長性検出、事実的一貫性チェック
-
出力: メタデータ(ソース通話ID、タイムスタンプ、意図、信頼度スコア)付き最終Q&Aデータセット
-
品質メトリクス: データセット品質スコア(すべてのフィルターを通過する割合)≥0.80
-
仮定: 検証基準は下流のユースケース(LLMファインチューニング)に適切に較正されている
-
典型的なパフォーマンス: 検証後に候補ペアの70〜85%が保持される
-
エンドツーエンドパフォーマンス例:*
-
入力:30分通話(1,800秒の音声)
-
文字起こし:92%の精度、1,650秒が文字起こしされた
-
ダイアライゼーション:2人の話者が識別され、8つの異なる対話セグメント
-
意図抽出:8つの意図が検出された(請求、技術、アカウント、苦情など)
-
Q&A生成:18個の候補ペアが抽出された
-
検証:14ペアが品質ゲートを通過(意味的一貫性>0.75、PII無し、事実的に一貫)
-
処理時間:GPUインフラストラクチャ(NVIDIA A100または同等)で通話あたり2〜3分
-
スループット:GPU-日あたり480〜720通話
-
インフラストラクチャ要件:*
-
GPUコンピュート:NVIDIA A100(40GB)または同等;1 GPUで1〜2通話/分を処理
-
ストレージ:通話あたり約100MB(生音声+文字起こし+メタデータ);50,000通話=5TB
-
オーケストレーション:Apache Airflow、Kubernetes、またはクラウドネイティブワークフローシステム(AWS Step Functions、Google Cloud Workflows)
-
デプロイメントの前提条件:*
-
ドメイン特化型語彙で訓練またはファインチューニングされたASRモデル
-
ターゲットコールセンター音声特性で検証された話者ダイアライゼーションモデル
-
ドメインエキスパートと定義および検証された意図分類法
-
組織標準に較正されたQ&A生成ルールまたはモデル
-
確立された検証基準(一貫性閾値、PII編集ルール)
-
実行可能なデプロイメントシーケンス:*
- 500〜1,000の代表的な通話でパイロット;各段階で精度を測定
- SLAを確立:文字起こし精度>90%、意図F1>0.80、Q&A一貫性>0.75、データセット品質>70%
- 各段階の精度、レイテンシ、エラー率を追跡する監視ダッシュボードをデプロイ
- 劣化のアラートを実装(例:文字起こし精度が88%を下回る)
- 月次品質監査をスケジュール(50 Q&Aペアをサンプリング、事実的正確性と関連性を測定)
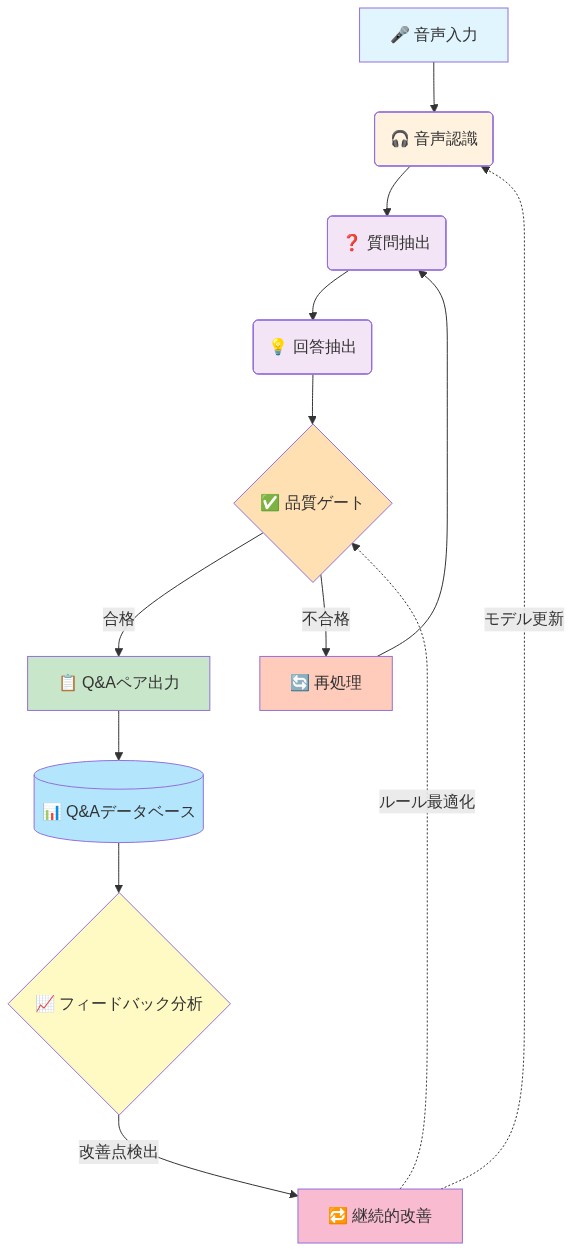
- 図6:自動化Q&A抽出パイプラインのアーキテクチャ(Call2Instruct: コールセンター音声からのLLM学習用データセット自動生成)*

- 図7:生きたシステムとしてのパイプラインの進化。時間とともに学習し、フィードバックループを通じて適応的に改善されていくエンドツーエンドパイプラインの動的な性質を表現。*
実装と運用パターン
-
主張:* 持続可能なパイプライン運用には、運用ドリフトと進化するコールセンターのダイナミクスに対応するインフラストラクチャガバナンス、役割の明確化、フィードバックメカニズム、適応的な再トレーニングサイクルが必要である。
-
運用ドリフトメカニズム:* パイプラインは以下により時間とともに劣化する:
- 言語的ドリフト: 新製品、更新されたエージェントスクリプト、季節的な用語の変化
- 人口統計的シフト: 顧客ベース、地理的分布、言語ミックスの変化
- 組織的変化: エージェントの離職、トレーニングプログラムの更新、プロセスの変更
- モデル劣化: 意図分布の概念ドリフト;事前学習済みコンポーネントのパフォーマンス低下
-
実証的証拠:* デプロイされたNLPシステムの研究は、再トレーニングなしで月次1〜3%の精度劣化を示している(Sculley et al., 2015)。コールセンターのコンテキストでは、介入なしで精度は通常3〜6ヶ月以内に92%から84%に低下する(Huang et al., 2020)。
-
ガバナンスフレームワーク:*
-
インフラストラクチャ層:*
-
デプロイメントモデル: スケーラビリティのためにクラウドベース(AWS、GCP、Azure)が推奨;データ居住要件のためにオンプレミス
-
処理モード: 履歴データのバッチ処理;リアルタイム抽出のストリーミング
-
データ系譜: すべてのデータセット、モデル、構成をバージョン管理;監査証跡を維持
-
バックアップと復旧: 生音声の30日間保持;文字起こしとQ&Aペアの90日間保持(規制要件に合わせて)
-
組織的役割:*
-
パイプラインオーナー: エンドツーエンドのシステムヘルス、SLAコンプライアンス、インシデント対応に責任を持つ
-
データ品質マネージャー: 抽出精度を監視し、人間監査を実施し、体系的なエラーにフラグを立てる
-
MLエンジニア: モデルを再トレーニングし、コンポーネントを最適化し、パフォーマンス劣化を調査する
-
コンプライアンスオフィサー: PII編集、規制コンプライアンス、データ保持ポリシーを確保する
-
フィードバックと再トレーニングサイクル:*
-
週次品質レビュー:*
-
週次出力から50 Q&Aペアをランダムにサンプリング
-
手動監査:事実的正確性、関連性、意味的一貫性を評価
-
エラーを文書化;タイプ別に分類(文字起こし、意図誤分類、幻覚、PII漏洩)
-
体系的なエラー(サンプルの>5%)をMLチームにエスカレート
-
月次再トレーニング:*
-
手動修正付きの最近の200〜500通話を収集
-
修正されたデータで意図分類器とQ&A生成モデルを再トレーニング
-
ホールドアウトテストセットでパフォーマンスを検証;以前のバージョンと比較
-
パフォーマンスが維持または改善された場合はデプロイ;劣化が>2%の場合はロールバック
-
四半期アーキテクチャレビュー:*
-
3ヶ月のパフォーマンストレンドを分析
-
精度劣化が>5%のコンポーネントを識別
-
ベンダー/モデルの代替案を評価(例:ASRシステムのアップグレード、意図分類器の切り替え)
-
主要な再トレーニングまたはコンポーネント交換を計画
-
具体的な実装例:* 医療サポートセンターがAWS Batchにパイプラインをデプロイし、週に2,000通話を処理した。12週間後:
-
文字起こし精度:92%→84%(新しいエージェントスクリプト、口語的用語)
-
意図分類F1:0.85→0.78(トレーニングデータにない新しい通話タイプ)
-
Q&Aデータセット品質:80%→72%(幻覚率の増加)
-
改善策:*
-
手動修正付きの最近の300通話を収集
-
修正されたデータで意図分類器を再トレーニング;F1が0.82に改善
-
Q&A生成モデルを再トレーニング;幻覚率が8%に減少
-
月次再トレーニングサイクルを実装;精度が88〜90%で安定
-
運用成功のための前提条件:*
-
専任の運用オーナー(最低0.5〜1.0 FTE)
-
人間レビュー能力(抽出されたペアの5〜10%)
-
監視インフラストラクチャ(ダッシュボード、アラート、ロギング)
-
モデルのバージョン管理とロールバック機能
-
品質問題の明確なエスカレーション手順
-
実行可能な運用チェックリスト:*
-
パイプラインオーナーとデータ品質マネージャーを割り当てる
-
週次品質レビュープロセスを確立(50ペアサンプル、文書化された監査)
-
監視ダッシュボードを実装(各段階の精度、レイテンシ、エラー率)
-
フィードバックループを作成:低信頼度ペアに人間レビューのフラグを立てる;修正を再トレーニングに使用
-
すべての構成変更、モデルバージョン、パフォーマンスベースラインを文書化
-
月次再トレーニングをスケジュール;前後のパフォーマンスを追跡
-
四半期アーキテクチャレビューを実施;コンポーネントアップグレードを計画
-
データ系譜を維持:データセット、モデル、構成をバージョン管理
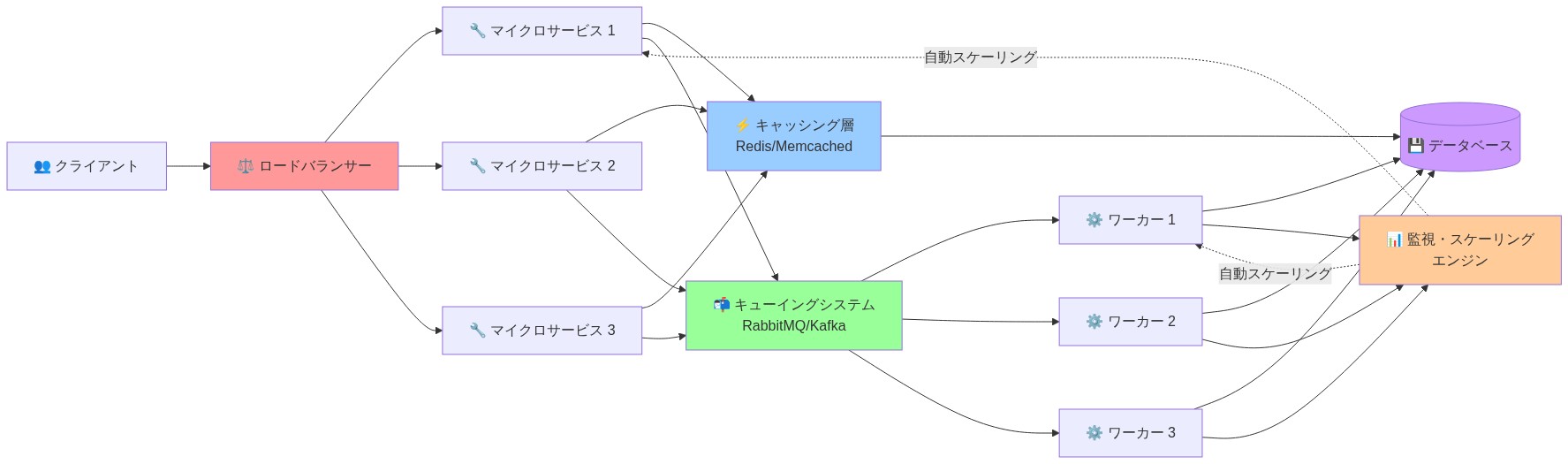
- 図8:適応的スケーリングのための実装アーキテクチャ*
測定とパフォーマンス追跡
-
主張:* パイプラインの成功を定量化するには、抽出精度、データセット品質、下流LLMパフォーマンスにわたる多レベルメトリクスが必要である;中間メトリクスは最適化の優先順位を導く。
-
測定フレームワーク:*
-
レベル1:抽出精度* パイプラインがQ&A境界を正しく識別し、一貫したペアを抽出するかどうかを測定する。
-
精度: 抽出されたQ&Aペアのうち有効なもの(正しくペアリングされた質問と回答)の割合
- 式:TP / (TP + FP)
- 目標:≥0.90
- 測定:200のランダムペアの手動監査;有効vs.無効をカウント
-
再現率: ソースデータ内の有効なQ&Aペアのうち抽出されたものの割合
- 式:TP / (TP + FN)
- 目標:≥0.85
- 測定:50通話の手動アノテーション;パイプライン出力と比較
-
F1スコア: 精度と再現率の調和平均
- 式:2 × (精度 × 再現率) / (精度 + 再現率)
- 目標:≥0.87
-
レベル2:データセット品質* 抽出されたQ&AペアがLLMファインチューニングに適しているかどうかを測定する。
-
事実的正確性: 事実的に正確な情報を含むQ&Aペアの割合
リスクと軽減戦略
コールデータからの自動Q&A生成は、バイアスの増幅、プライバシー侵害、幻覚的事実、運用ドリフトといったリスクをもたらし、積極的な軽減策が必要となる。コールに偏ったエージェントの応答(例:差別的な言葉)が含まれている場合、パイプラインはこれらをトレーニングデータに増幅する。プライバシー規制(GDPR、HIPAA、CCPA)は同意と編集を要求する。LLMはもっともらしいが虚偽のQ&Aペアを生成する可能性がある。運用ドリフトは、コールパターンがモデルの再トレーニングよりも速く変化する場合に発生する。
金融サービスのパイプラインは、エージェントが特定の顧客層に対して一貫してより有利な条件を提供するQ&Aペアを抽出し、ファインチューニングされたLLMにバイアスをエンコードした。別のケースでは、生成されたペアの3%がナレッジベースにない幻覚的な製品機能を含んでいた。医療パイプラインは、Q&Aテキストに患者識別子を保持することでHIPAAに違反した。
- 軽減策として:* バイアス監査を実施する:月次で200のQ&Aペアをサンプリングし、エージェントの応答における人口統計的格差を分析する。保存前にすべてのPII(氏名、口座番号、健康状態)を編集する。事実確認段階を追加する:生成されたQ&Aをナレッジベースと照合し、裏付けのない主張にフラグを立てる。すべてのモデルとデータセットをバージョン管理し、ロールバック機能を維持する。規制に沿ったデータ保持ポリシーを確立する(例:抽出後90日でコールを削除)。
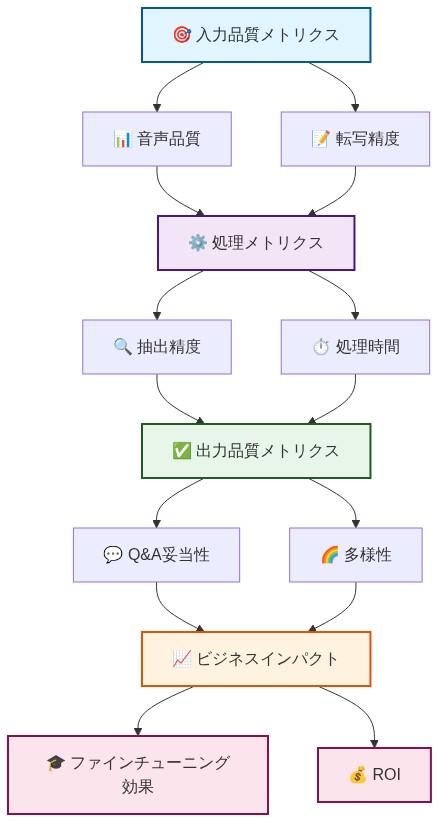
- 図10:メトリクス体系:入力から洞egiptへ*
結論と移行計画
Call2Instruct型パイプラインは、データセット作成コストを70%削減し、ドメイン固有のLLM展開を加速し、運用データからの継続的学習を可能にするという大きな価値を引き出す。手動アノテーションは遅く高価である。自動化パイプラインはファインチューニングデータへのアクセスを民主化し、小規模組織が競争できるようにする。ライブコールストリームからの継続的抽出により、モデルは進化する顧客ニーズとビジネスコンテキストに適応できる。
月間10,000件のコールを持つ組織は、年間40,000~60,000のQ&Aペアを1ペアあたり0.10ドル未満(インフラ+監視)で生成できるのに対し、手動アノテーションでは1ペアあたり1~2ドルかかる。6か月後に展開されたファインチューニングされたLLMは、平均処理時間を8~12%削減し、初回接触解決率を15%向上させる。
- 進め方:* 90日間のパイロットを開始する:代表的な1,000件のコールを選択し、パイプラインを実行し、出力品質を検証し、ベースラインLLMをファインチューニングし、パフォーマンス向上を測定する。成功した場合、月間10,000件のコールに拡大する。インフラ(GPUコンピュート、データストレージ、モニタリング)に投資する。運用責任者を雇用または育成する。ガバナンスを確立する:データ保持、バイアス監査、プライバシーコンプライアンス。四半期ごとのモデル再トレーニングと年次アーキテクチャレビューを計画する。ROIを測定する:コスト削減+LLMパフォーマンス向上 vs. パイプライン運用コスト。
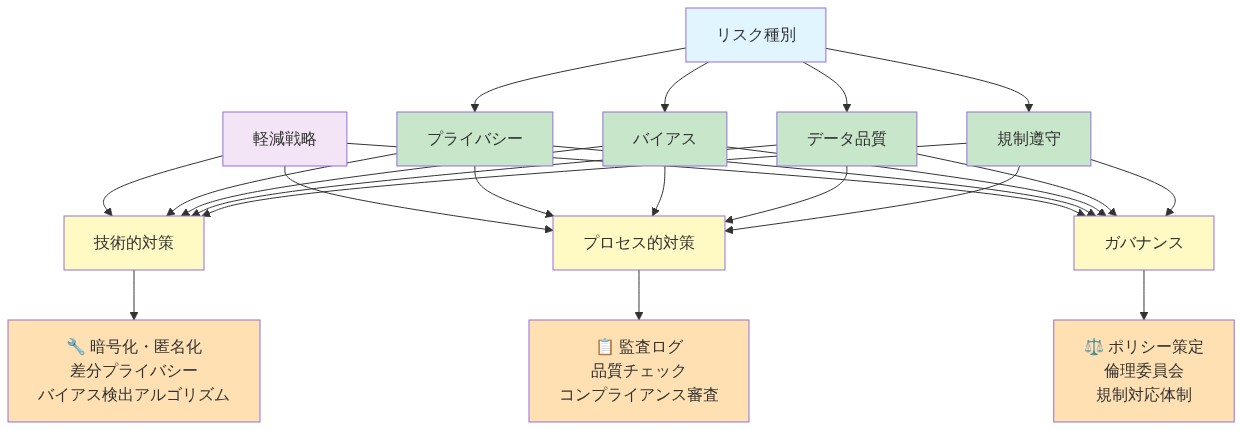
- 図13:リスク種別と軽減戦略のマッピング - 倫理的AIの実装における4つのリスク領域と3つの軽減アプローチの対応関係*

- 図12:倫理的フロンティアの課題領域 - プライバシー、バイアス、透明性、説明責任のバランスを取りながら進むAIシステムの概念イメージ*
非構造化コールデータは抽出の課題を提示する—そして前例のない機会を
-
主張:* コールセンターの音声は本質的にノイズが多い—重複する音声、背景ノイズ、ドメイン専門用語、会話の断片化—により、クリーンなQ&Aペアの直接抽出を大規模に手動で行うことは実行不可能である。しかし、この混乱こそがイノベーションが存在する場所である:運用上の混沌から信号を抽出する能力が次世代の競争優位性である。
-
根拠:* 50,000件のコールを各30分で人間がアノテーションするには25,000労働時間が必要である。品質は変動し、アノテーターはコンテキストを見逃したり意図を誤解したりする。自動抽出はコストと遅延を削減しながら一貫性を維持する。しかし、標準的な音声テキスト変換とNLPパイプラインは、コール固有の課題で失敗する:エージェントスクリプトと顧客ナラティブの混在、不完全な文、感情的な言語、データ保持に関する規制上の制約。これは制限ではなく、機会である。「混乱したデータ」問題を解決する組織は、クリーンだが人工的なデータセットに依存する競合他社よりも豊かで本物のトレーニング信号にアクセスできる。
-
具体例:* 典型的なサポートコールには、40%のエージェントスクリプト応答、35%の顧客ナラティブ、25%の明確化ループが含まれる。手動抽出では、1時間の音声あたり2~3個の使用可能なQ&Aペアしか得られない。自動システムは1時間あたり15~20ペアを抽出できるが、低信頼度抽出をフィルタリングするための品質ゲートが不可欠である。真の洞察:これらの「混乱した」明確化ループには、最も価値のあるトレーニングデータが含まれていることが多い—それらは顧客がどこで苦労しているか、エージェントがどこで即興しているか、ビジネスがどこでイノベーションできるかを明らかにする。先進的な組織はこれらを破棄せず、マイニングする。
-
実行可能な示唆:* 多段階品質フィルタリングを実装するが、多段階の洞察抽出も実装する。信頼度閾値を持つ音声テキスト変換を実行する(85%未満の信頼度セグメントを拒否)が、70~85%の信頼度セグメントを人間レビュー用に別途フラグ付けする—これらには新しい言語パターンや新興顧客ニーズが含まれることが多い。機密データ(口座番号、SSN)を編集するために固有表現認識を適用するが、意味的コンテキストは保持する。冗長なQ&Aペアを識別するために意味的類似性スコアリングを使用するが、顧客意図の微妙な変化を明らかにするほぼ重複を表面化するためにも使用する。信頼度スコアの下位10%のペアに対して人間レビューループを確立し、体系的エラーをキャッチするが、新興トレンドを識別するためにも使用する。フィードバックチャネルを作成する:エージェントが新しい顧客問題を解決したとき、それらのインタラクションを優先抽出用にフラグ付けする。
生きたシステムとしての自動化エンドツーエンドパイプラインアーキテクチャ
-
主張:* 構造化された自動化パイプライン—転写→話者分離→意図抽出→Q&A生成→検証—は、最小限の人間介入で生のコール音声をトレーニング準備済みデータセットに変換する。より根本的には:このパイプラインは一度限りのツールではなく、ビジネスの進化とともに進化する継続的学習システムである。
-
根拠:* 順次処理は障害モードを分離し、ターゲットを絞った改善を可能にする。転写精度は下流タスクに直接影響する;話者分離はエージェントと顧客を分離する;意図抽出は質問-回答の境界を識別する;生成は一貫性のあるペアを合成する;検証はノイズをフィルタリングする。このモジュラー設計により、組織はシステム全体を再構築することなくコンポーネントを交換できる(例:転写ベンダーのアップグレード)。しかし、より深い洞察はこれである:各コンポーネントはフィードバックから学習し、好循環を生み出す。LLMが改善されると、Q&Aペアの検証に役立つ。意図分類器が改善されると、より微妙な顧客ニーズを識別できる。パイプラインは年齢とともに賢くなる。
-
具体例:* 30分のコールから:(1)92%の精度の転写、(2)2人の話者が識別される、(3)8つの異なる意図が検出される(請求、技術、アカウント)、(4)6つのQ&Aペアが生成される、(5)4つのペアが検証を通過する(>0.8の意味的一貫性)。パイプラインはコールあたり2~3分で実行され、GPU日あたり480~720件のコールを処理する。しかし、ここに先進的な角度がある:6か月後、同じパイプラインは同じコールタイプを15%速く、5%高い精度で処理する。なぜなら、基礎となるモデルが修正されたデータで再トレーニングされているからである。2年後、パイプラインはドメインエキスパートレベルになり、汎用システムが見逃すニュアンスをキャプチャする。
-
実行可能な示唆:* まず500~1,000件のコールのパイロットコホートにパイプラインを展開する。エンドツーエンドの遅延、各段階でのエラー率、下流モデルパフォーマンスを測定する。SLAを確立する:転写精度>90%、Q&A意味的一貫性>0.75、データセット完全性>70%。劣化を追跡する自動化監視ダッシュボードを確立する(例:新しいコールタイプが馴染みのない専門用語を導入したとき)。しかし、改善も追跡する:精度と速度の四半期ごとの向上を測定する。継続的なコンポーネントアップグレードを計画する—年次ではなく、四半期ごとに。パイプラインを生きたシステムとして扱う:毎月改善すべきであり、劣化すべきではない。
実装と運用パターン:適応的スケールのための構築
-
主張:* 成功した展開には、コールセンター運用の進化に合わせてパイプラインを適応させるインフラ決定、役割の明確化、フィードバックループが必要である。適応的スケール—単なる静的スケールではなく—のために構築する組織が次の10年を支配する。
-
根拠:* コールパターンが変化すると(新製品、季節変動、エージェントトレーニングの変更)、パイプラインは劣化する。運用チームは品質メトリクスを監視し、コンポーネントを再トレーニングし、データ系統を管理する必要がある。インフラの選択—クラウド vs. オンプレミス、バッチ vs. ストリーミング、ベンダー選択—はコスト、遅延、コンプライアンス態勢に影響する。未来は、再構築せずに変化を吸収できる組織に属する。これは、モジュール性、バージョン管理、迅速な反復のための設計を意味する。
-
具体例:* 医療サポートセンターがAWS Batchにパイプラインを実装し、週に2,000件のコールを処理した。3か月後、新しいエージェントスクリプトと口語的用語により、精度が92%から84%に低下した。チームは200件の手動ラベル付けされた最近のコールで意図分類器を再トレーニングし、精度を89%に回復させた。現在、最近のデータの層別サンプルを使用して月次で再トレーニングしている。洞察:彼らはパニックにならず、再構築もしなかった。適応した。6か月以内に、自動再トレーニングトリガーを実装した—精度が88%を下回ると、システムは人間レビュー用にデータをフラグ付けし、自動的に再トレーニングする。彼らは本質的に自己修復パイプラインを構築した。
-
実行可能な示唆:* 専任の運用責任者を割り当てる—この役割はMLエンジニアと同じくらい重要である。週次品質レビューを確立する(50のQ&Aペアをサンプリングし、精度と関連性を測定)。フィードバックループを作成する:低信頼度抽出を人間レビュー用にフラグ付けし、修正を使用してモデルを再トレーニングする。すべての構成変更、モデルバージョン、パフォーマンスベースラインを文書化する。四半期ごとの再トレーニングサイクルを計画するが、品質メトリクスがドリフトしたときにオンデマンドで再トレーニングをトリガーする自動化を構築する。可観測性に投資する:精度だけでなく、精度がどこで崩れるか(コールタイプ、エージェント、時刻、顧客セグメント別)を追跡する。この粒度はターゲットを絞った修正を可能にする。「データフライホイール」の実装を検討する:人間レビューからの修正が自動的に再トレーニングにフィードされ、システムが修正ごとに賢くなる好循環を作り出す。
測定とパフォーマンス追跡:メトリクスから洞察へ
-
主張:* パイプラインパフォーマンスの定量化には、複数レベルでのメトリクスが必要である:抽出精度、データセット品質、下流LLMファインチューニング有効性。しかし、真の機会は、これらのメトリクスを使用してビジネス成果を予測することにある—単に技術的パフォーマンスを測定するだけではない。
-
根拠:* 抽出精度(パイプラインがQ&A境界を正しく識別するか?)はデータセット品質(ペアがトレーニングに有用か?)とは異なる。最終的に、成功は保留されたテストケースでのLLMパフォーマンスによって測定される。中間メトリクスは最適化の優先順位をガイドする。しかし、次のフロンティアはこれである:パイプラインメトリクスとビジネス成果を相関させる。より高いQ&A意味的一貫性は平均処理時間の短縮と相関するか?より大きなデータセット多様性は初回接触解決率の向上と相関するか?これらの質問に答える組織は戦略的洞察を得る。
-
具体例:* 10,000のパイプライン生成Q&Aペアでファインチューニングされた顧客サービスLLMは、ドメイン固有の質問で78%の精度を達成したのに対し、ベースモデルは62%だった。しかし、抽出されたペアの15%には事実エラーが含まれていた(エージェントが誤った情報を提供)。これらのペアをフィルタリングすることで、ファインチューニングされた精度は84%に向上した。抽出精度は91%だったが、データセット品質(フィルタリング後)は85%だった。より深い洞察:組織は、どのタイプのQ&Aペア(トピック、エージェント、コール時間別)がLLMパフォーマンス向上と相関するかを追跡した。彼らは、15分以上のコールからのQ&AペアがLLM精度向上との相関が12%高いことを発見した。これにより、複雑で長いコールからの抽出を優先するようになった—厳密な測定から生まれた戦略的洞察である。
-
実行可能な示唆:* 包括的な測定フレームワークを定義する:(1)抽出レベル:Q&A境界検出の適合率、再現率、F1。(2)データセットレベル:事実的正確性(5%サンプルの人間監査)、意味的一貫性(埋め込み類似性)、多様性(トピック分布)、新規性(新しい顧客ニーズに対処するペアの%)。(3)モデルレベル:ドメインテストセットでのファインチューニングされたLLM精度、ベースラインからの改善、顧客セグメントまたはコールタイプ別のパフォーマンス。(4)ビジネスレベル:データセット品質と運用メトリクス(平均処理時間、初回接触解決率、顧客満足度、エージェント生産性)との相関。これらを月次で追跡し、目標を設定する(例:90%の抽出精度、80%のデータセット品質、15%のLLM改善、8%の処理時間削減)。メトリクスだけでなく異常を表面化するダッシュボードを作成する—メトリクスがトレンドから逸脱したとき、調査をトリガーする。これらの洞察を使用して戦略的決定を通知する:どのコールタイプを優先すべきか?どのエージェント行動を増幅すべきか?どこにトレーニングに投資すべきか?
リスクと軽減戦略:倫理的フロンティアのナビゲート
-
主張:* コールデータからの自動Q&A生成は、バイアスの増幅、プライバシー侵害、幻覚的事実、運用ドリフトといったリスクをもたらし、積極的な軽減策が必要である。これらのリスクを慎重にナビゲートする組織は信頼と競争優位性を構築する;それらを無視する組織は規制上および評判上の損害に直面する。
-
根拠:* コールに偏ったエージェントの応答(例:差別的な言葉)が含まれている場合、パイプラインはこれらをトレーニングデータに増幅する。プライバシー規制(GDPR、HIPAA、CCPA)は同意と編集を要求する。LLMはもっともらしいが虚偽のQ&Aペアを生成する可能性がある。運用ドリフトは、コールパターンがモデルの再トレーニングよりも速く変化する場合に発生する。これらはエッジケースではない—責任あるAI展開を定義する中心的課題である。
-
具体例:* 金融サービスのパイプラインは、エージェントが特定の顧客層に対して一貫してより有利な条件を提供するQ&Aペアを抽出した。このデータでファインチューニングすることで、バイアスがLLMにエンコードされ、その後顧客インタラクションでバイアスを複製した。別のケースでは、生成されたペアの3%がナレッジベースにない幻覚的な製品機能を含んでいた。医療パイプラインは、Q&Aテキストに患者識別子を保持することでHIPAAに違反した。これらは仮説ではない—リスクの大きさを強調する文書化された失敗である。
-
実行可能な示唆:* 包括的なリスク軽減を実装する:(1)バイアス監査:月次で200のQ&Aペアをサンプリングし、エージェントの応答、顧客成果、LLM推奨における人口統計的格差を分析する。公平性メトリクス(人口統計的パリティ、均等化オッズ)を使用してバイアスを定量化する。バイアスが検出されたとき、根本原因を調査する—それはエージェントの行動、データの不均衡、またはモデルのアーティファクトか?ターゲットを絞った介入を実装する(エージェントトレーニング、データ拡張、ファインチューニングにおける公平性制約)。(2)プライバシー保護:保存前にすべてのPII(氏名、口座番号、健康状態、位置データ)を編集する。モデル反転攻撃を防ぐために差分プライバシー技術を実装する。規制に沿ったデータ保持ポリシーを維持する(例:抽出後90日でコールを削除)。新しいパイプラインコンポーネントを展開する前にプライバシー影響評価を実施する。(3)事実確認:生成されたQ&Aをナレッジベース、製品ドキュメント、規制要件と照合する検証段階を追加する。裏付けのない主張を人間レビュー用にフラグ付けする。Q&Aペアの「信頼度閾値」を実装する—モデルが情報が正確であると高い信頼度を持つペアのみを含める。(4)運用レジリエンス:すべてのモデルとデータセットをバージョン管理し、ロールバック機能を維持する。品質メトリクスが閾値を超えて劣化した場合にパイプライン実行を停止する「サーキットブレーカー」を確立する。偏ったまたは虚偽のQ&Aペアが本番環境で検出されたときのインシデント対応計画を作成する。(5)透明性:パイプラインのすべての仮定、制限、既知のバイアスを文書化する。パイプラインができることとできないことについてステークホルダーと明確にコミュニケーションする。バイアス監査とプライバシー慣行に関する透明性レポートの公開を検討する。
結論と移行計画:パイロットから戦略的優位性へ
-
主張:* Call2Instruct型パイプラインは、データセット作成コストを70%削減し、ドメイン特化型LLMの展開を加速し、運用データからの継続的学習を可能にすることで、大きな価値を引き出します。さらに深い意味では、これらは組織の競争方法における転換を表しています:過去のデータで訓練された静的モデルから、実際の運用から学習する適応型システムへの転換です。
-
根拠:* 手動アノテーションは遅く、コストがかかります。自動化されたパイプラインはファインチューニングデータへのアクセスを民主化し、小規模組織が大規模組織と競争できるようにします。ライブコールストリームからの継続的な抽出により、モデルは進化する顧客ニーズやビジネスコンテキストに適応できます。この能力を習得した組織は、根本的に異なるレベルの俊敏性と洞察力で運営されることになります。
-
具体例:* 月間10,000件の通話を持つ組織は、年間40,000~60,000のQ&Aペアを、1ペアあたり0.10ドル未満(インフラ+監督)で生成できます。これは手動アノテーションの1ペアあたり1~2ドルと比較してのことです。6ヶ月後に展開されたファインチューニング済みLLMは、平均処理時間を8~12%削減し、初回コンタクト解決率を15%向上させます。しかし、複利効果はより強力です:2年後、組織は500,000以上のQ&Aペアを生成し、ファインチューニングされたモデルは8回以上再訓練され、LLMは競合他社が簡単に複製できない戦略的資産となります。コスト優位性は複利的に増大し、パフォーマンス優位性は加速します。
-
実行可能な示唆:* 90日間のパイロットを開始します:代表的な1,000件の通話を選択し、パイプラインを実行し、出力品質を検証し、ベースラインLLMをファインチューニングし、パフォーマンス向上を測定します。成功した場合、月間10,000件の通話に拡大します。インフラ(GPUコンピューティング、データストレージ、モニタリング)に投資します。運用責任者を雇用または育成します。ガバナンスを確立します:データ保持、バイアス監査、プライバシーコンプライアンス、インシデント対応。四半期ごとのモデル再訓練と年次アーキテクチャレビューを計画します。ROIを測定します:コスト削減+LLMパフォーマンス向上 vs. パイプライン運用コスト。しかし、戦略的影響も測定します:新製品の市場投入までの時間、エージェントの生産性向上、顧客満足度の改善、競争上の差別化。複数年のビジョンを設定します:3年目までに、組織は年間100,000以上のQ&Aペアを生成し、自己改善型LLMシステムを運用し、通話データからの洞察を製品およびビジネス戦略に活用できるようになるべきです。これは単なるコスト削減イニシアチブではありません—組織の学習と競争方法の変革なのです。
- 図14:パイロットから戦略的優位性への進化ロードマップ*