
形式的定理証明器がなぜ莫大な計算資源を要求するのか
大規模言語モデル(LLM)は形式的定理証明タスク(Lean、Coq、Isabelleなど)において測定可能な能力を示していますが、本番環境での展開は深刻なスケーラビリティの制約に直面しています。最先端のシステムは、(1)広範なテスト時ロールアウト(定理あたり500~5,000以上の証明試行が記録されています:Thakur et al., 2024; OpenAI Codex評価)、または(2)拡張されたコンテキストウィンドウ(8K~100Kトークン)のいずれかを必要とし、これらは二次的なメモリとレイテンシペナルティを招きます。この計算需要は証明探索の根本的な性質に由来しています。タクティック適用空間は組み合わせ的に大きく、各タクティック選択は異なる証明状態を生成します。モデルは信頼できるヒューリスティックガイダンスなしにこの状態空間を探索する必要があり、冗長または意味的に等価な失敗経路につながります。
根底にあるメカニズムはアーキテクチャ的なものです。現在の証明探索システムは各ロールアウトを独立した軌跡として扱います。タクティックが失敗すると、システムはエラー信号を返します。通常は非構造化されたコンパイラ出力(スタックトレース、型診断、統一失敗)ですが、このシグナルをロールアウト全体で集約または分類しません。その結果、モデルは同じ論理的失敗モードに異なる証明試行全体で繰り返し遭遇しますが、各インスタンスを新しい問題として処理します。これにより、モデルは同じ修正洞察を何千回も再導出する必要があり、累積学習なしにトークンと実時間を消費します。
-
具体的な例*:Lean 4の証明を考えてください。タクティック適用が「application type mismatch」で失敗します。ロールアウト1は12行目で失敗、ロールアウト2は15行目で失敗、ロールアウト3は8行目で失敗します。各失敗は同じ根本的な問題に由来しています。補題は引数型
α → βを要求しますが、ゴールはγ → δを提供しています。しかし、エラーが異なる構文位置に現れ、生のコンパイラ診断として報告されるため、モデルはそれらを単一の学習可能な失敗パターンの3つのインスタンスとしてではなく、3つの独立した失敗イベントとして処理します。モデルは共有可能で再利用可能な修正を抽出することなく、3つの完全なロールアウト予算を消費します。 -
最適化の前提条件*:定理証明器を展開するチームは、まずロールアウト母集団全体で失敗シグナルをキャプチャして分類するための計測を確立する必要があります。証明探索ヒューリスティックを最適化する前に、ベースラインを測定してください。計算のどの程度の割合が繰り返される構造的に同型の失敗によって消費されていますか。この測定は圧縮機会を定量化し、下流の失敗モード集約への投資を正当化します。
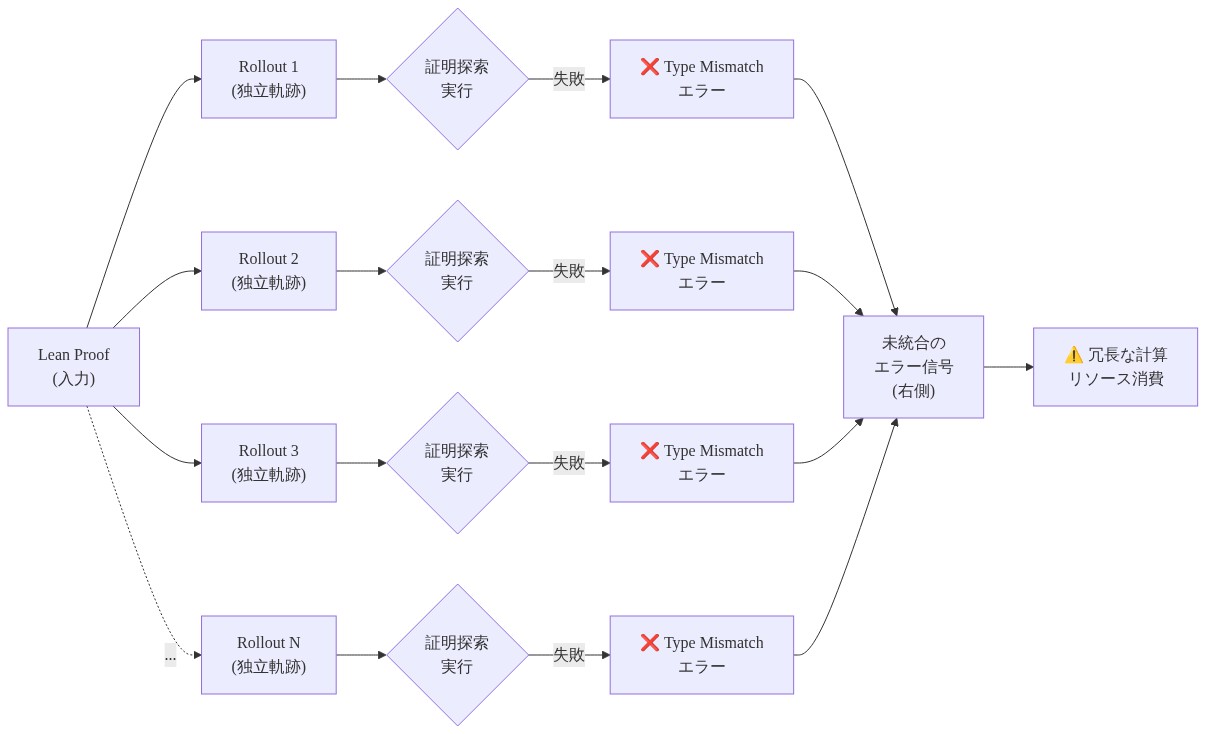
- 図2:独立したロールアウトによる冗長な失敗処理アーキテクチャ*
コンパイラ失敗に隠された構造は何か
コンパイラ(形式システムの証明チェッカーを含む)は、可能な入力の無限空間を有限で解釈可能なエラー分類セットにマップするように設計されています。例えばLean型チェッカーは、可能な証明状態の空間を約20~40の標準的な失敗モードに削減します。型不一致、欠落補題、タクティック非適用、ユニバースレベル競合、暗黙引数解決失敗などです。この削減は恣意的ではありません。証明システムの型理論とタクティックセマンティクスの論理構造を反映しています。
この圧縮は意味的に情報を与えるものです。各失敗モードは特定の修復アクションセットと確実に相関しています。
- 型不一致 → ゴールを書き換える、強制を適用する、または項を調整する
- 欠落補題 → ライブラリを検索する、証明を一般化する、または補助補題を導入する
- タクティック非適用 → ゴール状態を精緻化するか、別のタクティックを選択する
- ユニバース競合 → ユニバースパラメータを調整するか、ユニバース多型を使用する
生のエラーテキスト(フレーズング、詳細、文脈が異なる可能性があります)とは異なり、失敗モードは実行可能な構造をエンコードしています。この構造はコンパイラ診断の体系的な分類を通じて回復可能です。
意味保存圧縮の原理は、学習表現に関する最近の研究で形式化されています(例えば、BASIS:Balanced Activatio
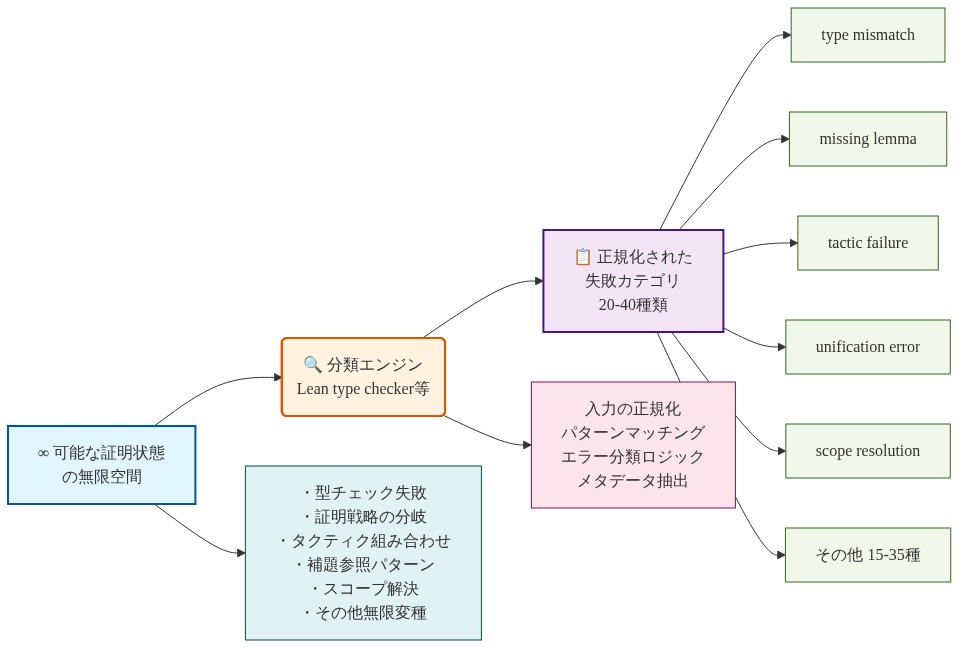
- 図4:コンパイラによる失敗の正規化プロセス — 無限の証明状態空間から有限の標準失敗カテゴリへの写像*