
大規模言語モデルのための二段階オプティマイザ認識型オンラインデータ選択
オフライングラディエント選択とオンラインの現実
グラディエントベースのデータ選択手法は、LLM ファインチューニング時のサンプル有用性を推定するための原理的な基盤を確立しています。理論的根拠は堅牢です。各訓練例のグラディエントと検証性能目標との整合性を計算し、整合性の高いサンプルを優先するというアプローチです。このアプローチは、完全なデータセットが事前に利用可能であり、選択フェーズと訓練フェーズ全体でオプティマイザの状態が一定に保たれるオフライン設定で有効性を示します。
オンラインファインチューニングは、これらの仮定から実質的な乖離をもたらします。データは順序立てて到着し、サンプル有用性は時間依存的になります。有用性はサンプルの本質的な特性とモデルの学習状態の両方の関数です。形式的には、訓練ステップ t におけるサンプル s の有用性 U(s, t) は、ステップ t’ > t における U(s, t’) と異なります。s が変わらない場合でもです。ステップ 1,000 で検証損失を大幅に削減するサンプルは、ステップ 2,000 では以前に学習した表現との冗長性により、限定的な周辺利益しか提供しないかもしれません。
標準的なグラディエントベース選択のもう一つの重要な制限は、適応的オプティマイザへの対応です。Adam のような手法は、パラメータごとの学習率、または同等に二次モーメント推定から導出されたパラメータごとのスケーリング係数を保持します。標準的なグラディエントベース有用性スコアは g^T v を計算します。ここで g はグラディエント、v は検証目標であり、すべてのグラディエント方向を等しい重みで扱います。しかし、実際のパラメータ更新は Δθ ∝ α_i · g_i です。ここで α_i はパラメータ i の適応的学習率です。このスケーリングを無視すると、体系的誤差が生じます。低学習率パラメータの大きなグラディエントは、高学習率パラメータの小さなグラディエントより小さな更新を生成するかもしれません。この不一致を無視する選択手法は、グラディエント大きさと実際のパラメータ移動を混同します。
-
具体例:* 事実知識例と推論例から構成されるデータセットを考えます。初期訓練フェーズ(ステップ 1~10,000)では、事実例がモデルの基本知識の欠如により急速な損失削減を駆動します。訓練が進行するにつれ(ステップ 50,000~100,000)、モデルは事実知識を統合し、推論例は汎化に対してより価値が高くなります。オフライン選択手法は完全なデータセット上で有用性スコアを一度計算し、訓練全体を通じて静的ランキングを適用します。相対的有用性の変化を検出できません。オンライン手法は、事実有用性が減少し推論有用性が増加するタイミングを認識する必要があります。そしてこの認識を、リアルタイムデータ到着レートと互換性のある遅延で実行する必要があります。
-
実行可能な示唆:* 現在のファインチューニングパイプラインが完全なデータセットからグラディエントベースのスコアを事前計算し、静的ランキングを適用している場合、訓練の後期段階で冗長な選択を経験し、オプティマイザ状態の進化に伴ってのみ高有用性になるサンプルを見落としている可能性があります。静的有用性スコアと動的訓練ダイナミクスの間のこの不一致は、オンライン設定における訓練非効率性の定量化可能な源を表しています。
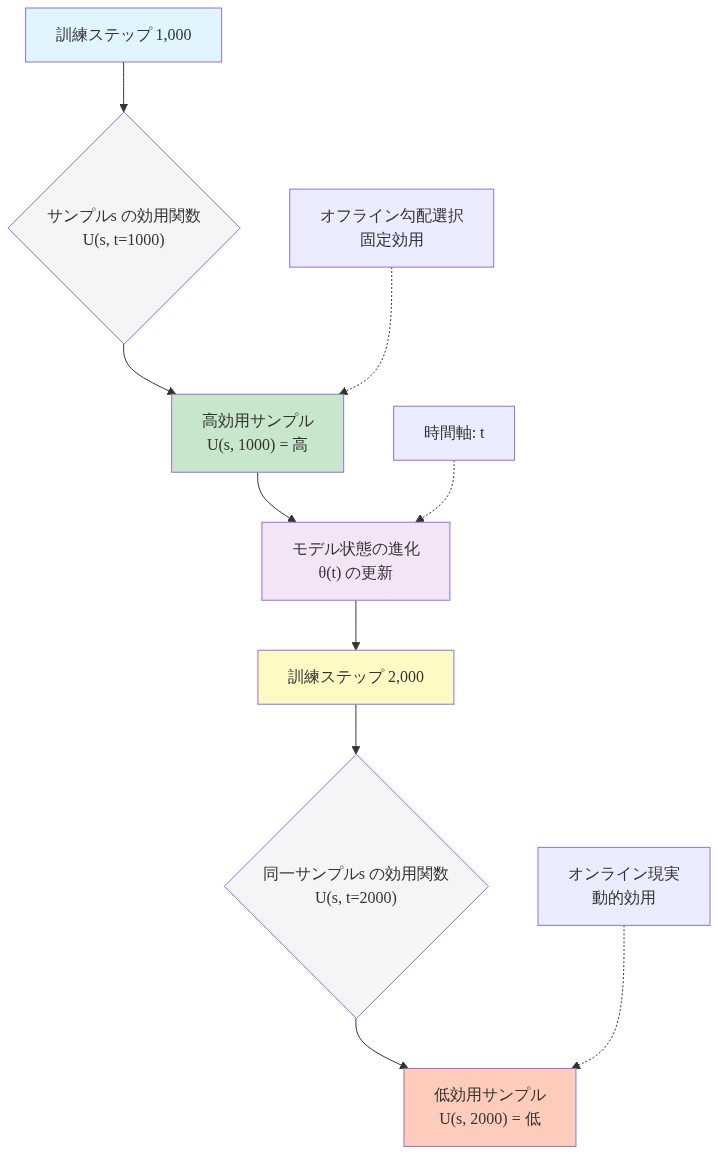
- 図2:訓練進行に伴うサンプル効用の時間依存性(オフライン勾配選択 vs オンライン現実)*
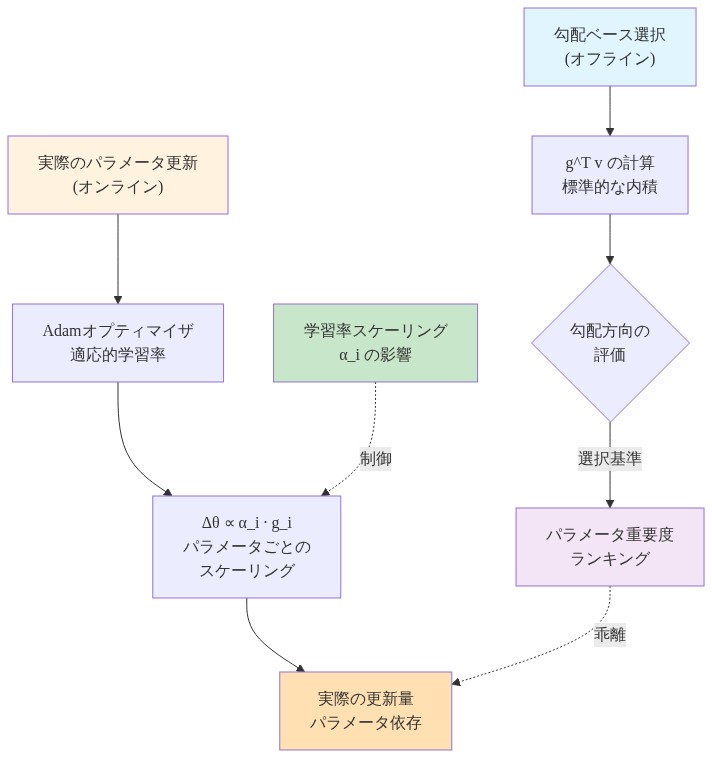
- 図3:適応的オプティマイザにおける勾配と実パラメータ更新の乖離*
二段階オプティマイザ認識型フレームワーク
提案されたフレームワークは、グラディエントベース有用性推定とオプティマイザ状態の明示的な組み込みを結合する二段階アーキテクチャを通じて、これらの制限に対処します。
-
ステージ 1:オプティマイザ認識型有用性推定。* グラディエント情報と現在のオプティマイザの適応的パラメータを組み合わせてサンプル有用性を計算します。g_s をサンプル s の検証目標に関するグラディエント、α_i(t) をステップ t におけるパラメータ i の適応的学習率(例えば、Adam の二次モーメント推定から導出)とします。オプティマイザ認識型有用性スコアは以下の通りです。
-
U_opt(s, t) = Σ_i α_i(t) · (g_s,i)^2*
または同等に、スケーリングされたグラディエントとそれ自身のドット積です。この定式化は、有用性推定がグラディエント大きさだけでなく、パラメータ更新の有効大きさを考慮することを保証します。
- ステージ 2:オンライン受け入れ/拒否判定。* オプティマイザ認識型有用性スコアを使用して、リアルタイム受け入れ/拒否判定を行うか、訓練バッチ内のサンプルを再重み付けします。各ステップ t で、各到着サンプル s に対して、U_opt(s, t) を計算し、閾値またはパーセンタイルと比較します。閾値を超えるサンプルを受け入れ、その他を拒否または下重み付けします。閾値は静的または適応的(例えば、目標受け入れ率を維持)です。
重要な洞察は、サンプルのモデルパラメータへの真の影響がそのグラディエントとオプティマイザの現在の状態の両方に依存することです。選択基準にオプティマイザ状態を組み込むことで、フレームワークは有用性推定を実際のパラメータ軌跡と整合させます。
-
具体例:* Adam オプティマイザを使用して 7B パラメータモデルをファインチューニングすることを考えます。グラディエント分散により、初期層パラメータは通常、より小さな二次モーメント推定を発展させ、したがってより小さな適応的学習率を持ちます。初期層に大きなグラディエントを持つサンプルは、標準的なグラディエントベース選択の下では高有用性に見えますが、限定的な実際のパラメータ更新を生成します。オプティマイザ認識型手法はこの不一致を検出します。スケーリングされたグラディエント大きさは、大きな生グラディエントにもかかわらず小さいです。この手法はサンプルを下優先順位付けし、高学習率パラメータ(通常は後期層またはグラディエント履歴が安定しているパラメータ)のグラディエントが整合するサンプルのための計算予算を確保します。
-
実行可能な示唆:* 選択時にオプティマイザ状態を読み取る有用性スコアリングを実装します。Adam を使用する PyTorch 実装の場合、
optimizer.state_dict()['state']経由でパラメータごとの二次モーメントを抽出し、適応的学習率を α_i = lr / (√m_i + ε) として計算します。ここで m_i は二次モーメント、ε はイプシロン項です。その後、グラディエントを要素ごとにスケーリングします。この変更には約 10~20 行のコードが必要で、無視できる計算オーバーヘッド(ウォールクロック時間の 1% 未満の増加)が発生します。
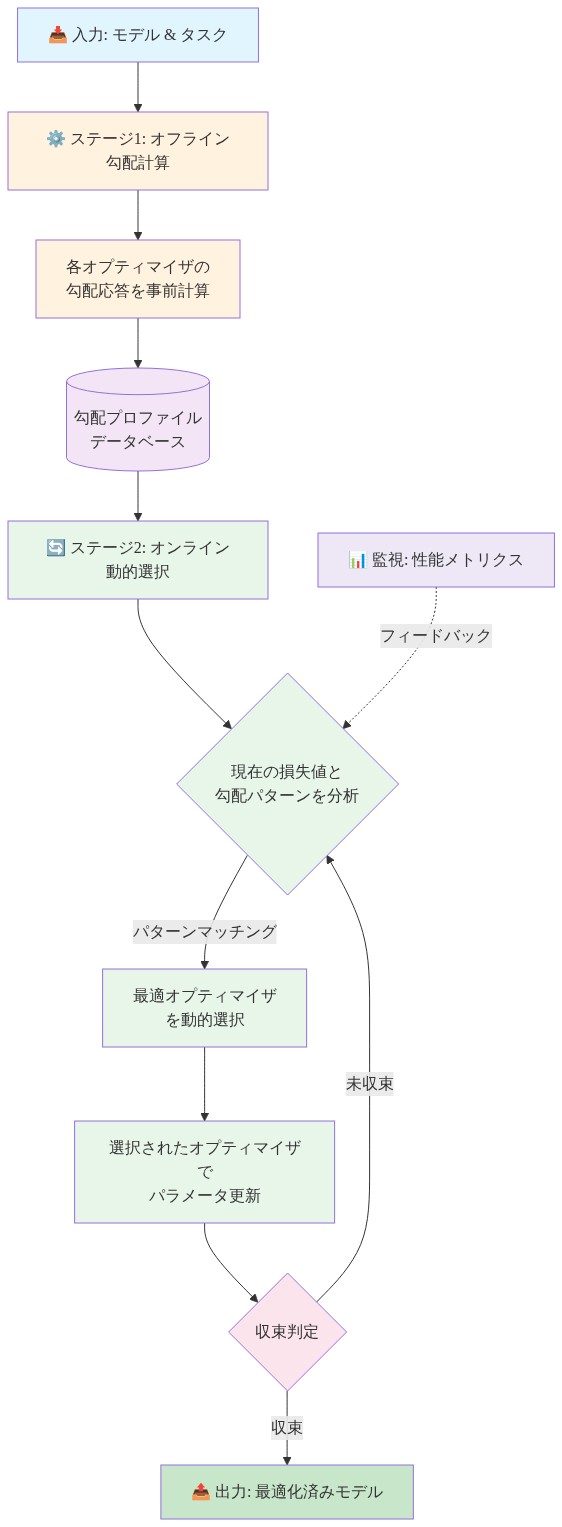
- 図5:2段階オプティマイザ認識型フレームワークのアーキテクチャ*
実装と運用パターン
オプティマイザ認識型選択を運用化するには、3 つの設計判定が必要です。選択粒度(バッチレベルまたはサンプルレベル)、有用性計算効率、およびオーバーヘッド管理。

- 図7:オンライン選択の実装フロー(バッチ処理・キャッシング・遅延補正含む)*
選択粒度
-
*バッチレベル選択**は、到着サンプルのグループ(例えば、バッチあたり 32~256 サンプル)の有用性を評価します。このアプローチはサンプルごとの計算オーバーヘッドを削減し、データが自然にマイクロバッチで到着するストリーミングパイプラインに適しています。バッチレベル選択はベクトル化操作も可能にし、ウォールクロック時間を削減します。
-
*サンプルレベル選択**は各サンプルを個別に評価し、独立した受け入れ/拒否判定を行います。これはより細かい粒度を提供し、オプティマイザ状態の変化により迅速に適応できますが、判定ごとの低遅延を要求します(本番環境では通常、サンプルあたり 10 ミリ秒未満)。サンプルレベル選択は、個別のサンプルをバッファリングなしで即座に受け入れまたは拒否できる場合に適切です。
有用性計算効率
すべてのサンプルの完全なグラディエント計算は、計算上禁止的です。実用的な実装は、2 つの近似のいずれかを使用します。
-
キャッシュされた検証グラディエントアプローチ: 固定検証セット(例えば、500~2,000 例)を保持します。エポックごと、または N 訓練ステップごとに 1 回、その勾配を計算します。各到着訓練サンプルについて、キャッシュされた検証グラディエントとの整合性を計算することで、その有用性を推定します。形式的には、U_opt(s, t) ≈ α_i(t) · (g_s,i · g_val,i) を近似します。ここで g_val はキャッシュされた検証グラディエントです。これはサンプルごとに順伝播とドット積操作のみを必要とし、コストを 10~100 倍削減します。
-
低ランク勾配近似: グラディエントを低ランク基底に投影します(例えば、最近のグラディエントの上位 k 主成分)。低ランク空間で有用性を計算します。これはメモリと計算をさらに削減しますが、近似誤差を導入します。経験的には、7B~70B パラメータモデルに対して k = 50~200 がしばしば十分です。
オプティマイザ状態の組み込みは無視できるコストを追加します。グラディエント(またはその近似)の適応的学習率による単一の要素ごとの乗算です。
-
具体例:* チームは 1 日あたり 10M トークンを使用してバッチレベル選択でファインチューニングします。彼らは 500 例の検証セットを保持し、100 訓練ステップごと(ウォールクロック時間で約 2 時間ごと)にその勾配を計算します。64 サンプルの各到着バッチについて、彼らはグラディエント(バッチあたり 1 つの順伝播)を計算し、オプティマイザ学習率で乗算し、結果のスコアでランク付けします。総選択オーバーヘッド:訓練時間の約 5% 増加。下流利益:目標検証損失に到達するために必要なサンプルの 15~20% 削減。
-
実行可能な示唆:* キャッシュされた検証グラディエントを使用するバッチレベル選択から始めます。グラディエント計算遅延とオプティマイザ状態アクセス時間を測定します。オーバーヘッドが訓練時間の 10% を超える場合、低ランク近似を実装するか、検証グラディエント再計算の間隔を増やします。ほとんどの本番環境では、キャッシュされた検証グラディエントは効率と精度の有利なトレードオフを提供します。
測定と検証シグナル
オプティマイザ認識型選択の有効性を測定するには、3 つの独立したシグナルを追跡する必要があります。受け入れ率ダイナミクス、下流タスク性能、および計算効率。
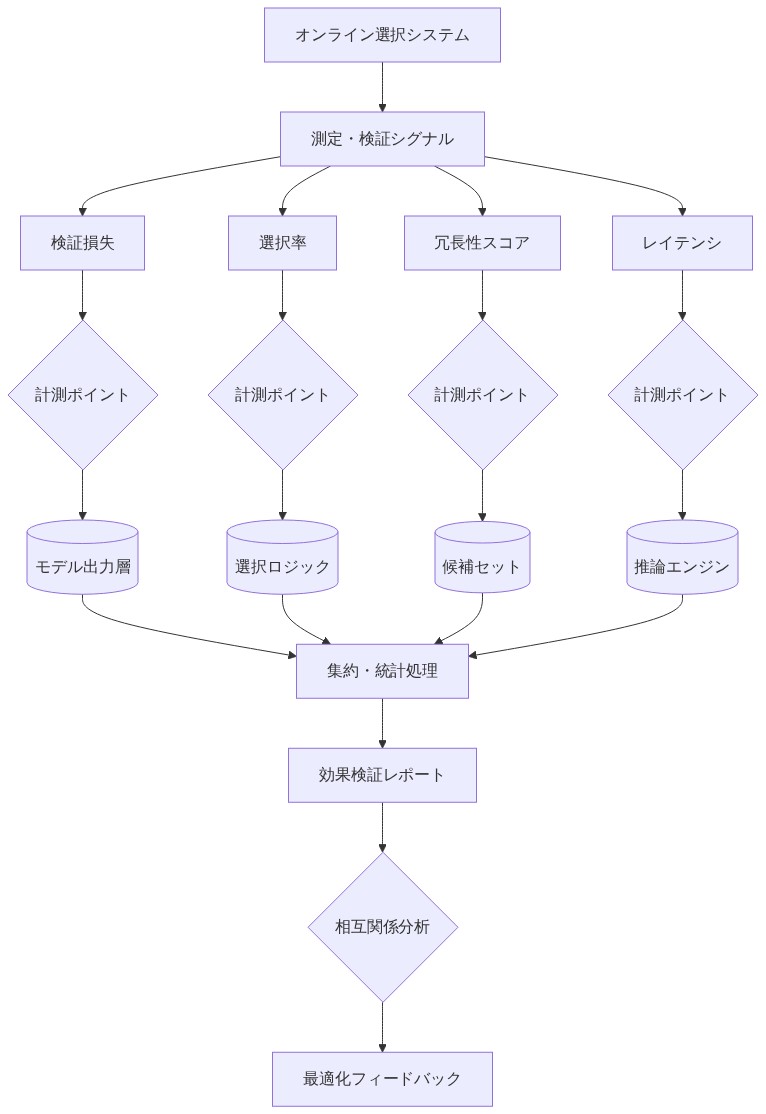
- 図9:オンライン選択効果の測定・検証シグナル体系*
受け入れ率ダイナミクス
受け入れ率(訓練のために選択されたサンプルの割合)は、訓練の過程全体を通じて非定常的な動作を示すべきです。初期訓練フェーズは通常、70~85% のサンプルを受け入れます(大きなグラディエント大きさと急速な損失削減による高有用性密度)。訓練が進行し、モデルが収束するにつれ、受け入れ率は通常 20~40% に低下します(グラディエントが減少し冗長性が増加するため、低有用性密度)。訓練全体を通じた静的受け入れ率は、この手法がオプティマイザ状態進化に適応していないことを示唆し、設定エラーを示す可能性があります。
形式的には、定期的な間隔で A(t) = |{s : U_opt(s, t) > threshold}| / |batch| を追跡します。訓練ステップ上で A(t) をプロットします。期待される動作:A(t) は訓練フェーズに対応する可能性のあるプラトーを伴う減少傾向を示します。
下流タスク性能
検証損失、下流ベンチマーク精度、またはタスク固有のメトリクス(例えば、翻訳の BLEU、QA の完全一致)を測定します。主要な仮説は、オプティマイザ認識型選択がベースライン手法より少ないサンプルで目標性能を達成することです。典型的な目標は、同じ検証損失または下流性能に到達するために必要なサンプルの 10~15% 削減です。
形式的には、2 つの訓練実行を比較します。(1) ベースライン手法(例えば、均一サンプリングまたは静的グラディエントベース選択)および (2) オプティマイザ認識型選択。各手法について、収束までのステップ T_baseline と T_opt を測定します。効率向上は (T_baseline - T_opt) / T_baseline です。10~15% の向上は典型的です。20% を超える向上は、強いオプティマイザ・データ相互作用またはサブ最適なベースライン設定を示唆しています。
計算効率
ウォールクロック時間、GPU メモリ利用率、およびデータスループットを組み合わせます。オプティマイザ認識型選択はバッチごとのオーバーヘッド(グラディエント計算、オプティマイザ状態アクセス、有用性スコアリング)を導入しますが、より少ないサンプルを必要とすることで総訓練時間を削減します。純利益は、バッチごとの遅延ではなく、収束までの端末間時間に現れます。
形式的には、T_total = T_selection + T_training を測定します。ここで T_selection は累積選択オーバーヘッド、T_training は累積訓練時間です。手法全体で T_total を比較します。オプティマイザ認識型選択は、T_selection(opt) > 0 にもかかわらず T_total(opt) < T_total(baseline) の場合に有益です。
-
具体例:* チームは 13B パラメータモデルの 10 日間のファインチューニング実行全体でこれらのメトリクスを追跡します。受け入れ率はステップ 10,000 で 75% から低下し、ステップ 100,000 で 25% に達し、その後 22% で安定します。検証損失は、オプティマイザ認識型選択で目標(0.85)に到達します。ステップ 95,000 対均一サンプリングでステップ 110,000。ステップの 14% 削減です。総ウォールクロック時間は、バッチごとの 5% オーバーヘッドにもかかわらず 8% 低くなります。全体的に処理されるサンプルが少ないためです。これら 3 つのシグナルは、この手法が設計通りに機能していることの証拠を一緒に提供します。
-
実行可能な示唆:* 訓練ループをインストルメント化して、受け入れ率、検証性能、および選択遅延を定期的な間隔(例えば、1,000 ステップごと、または 10 分のウォールクロック時間ごと)でログします。これらを構造化形式(例えば、JSON または CSV)に保存します。受け入れ率を時間経過でプロットして、この手法が適応しているかを検出します。検証性能をプロットして効率向上を確認します。選択遅延をプロットしてボトルネックを特定します。受け入れ率が平坦のままである場合(50,000 ステップ上で ±5% 以内)、オプティマイザ状態統合を再検討し、適応的学習率が時間経過で変化していることを確認します。
リスクと軽減戦略
実務では 3 つの主要なリスクが生じます。選択バイアス、オプティマイザ結合脆弱性、および遅延スパイク。
選択バイアス
この手法は、特定のデータ型(例えば、特定のドメイン、言語、またはタスクカテゴリ)が一貫して低いオプティマイザ認識型有用性スコアを持つ場合、それらのデータ型を体系的に下優先順位付けする可能性があります。これは、オプティマイザの適応的学習率がデータ型と相関する場合に発生します(例えば、コード例が一貫して小さなグラディエントを持ち、したがってスケーリングされた有用性が低い場合)。チェックされないと、選択バイアスはカバレッジを削減し、過小表現されたデータ型の下流性能を害する可能性があります。
- 軽減:* 検証データをドメイン、言語、またはタスクカテゴリで層別化します。層別ごとの受け入れ率を計算し、不均衡を監視します。1 つの層別の受け入れ率が他の層別より 2 倍以上高い、または低い場合、スコアリング関数を調整して明示的な多様性項を含めます。例えば、有用性スコアを U_adjusted(s, t) = U_opt(s, t) + λ · D(s) に変更します。ここで D(s) は多様性ボーナス(例えば、層別が過小表現されている場合は +1、そうでない場合は 0)、λ は調整可能な重みです。経験的には、λ = 0.1~0.3 がしばしば有用性と多様性のバランスを取るのに十分です。
オプティマイザ結合脆弱性
この手法は、オプティマイザ状態に関する仮定を組み込みます(例えば、Adam の二次モーメント推定)。オプティマイザを切り替える場合(例えば、Adam から SGD with momentum、または別の適応的オプティマイザに)、状態抽出ロジックがオプティマイザの実際の動作と一致しなくなるため、この手法は失敗するか、サブ最適な結果を生成する可能性があります。
- 軽減:* オプティマイザ状態統合をパラメータ化して、オプティマイザ型に適応するようにします。初期化時に、オプティマイザクラスを検出し(例えば、
type(optimizer).__name__経由)、適切な状態抽出ロジックを適用します。Adam の場合、二次モーメントを抽出します。SGD with momentum の場合、モーメンタムバッファを抽出するか、均一スケールを使用します。他のオプティマイザの場合、グラディエント大きさのみにフォールバックします。これをモジュール関数として実装します。
def get_adaptive_scales(optimizer, model):
if isinstance(optimizer, torch.optim.Adam):
# Extract Adam second moments
scales = [...]
elif isinstance(optimizer, torch.optim.SGD):
# Extract momentum buffers or use uniform scales
scales = [...]
else:
# Fallback: uniform scales
scales = [1.0] * num_parameters
return scalesこのアプローチは、オプティマイザ変更全体で手法が機能的なままであることを保証します。
遅延スパイク
検証グラディエント計算またはオプティマイザ状態アクセスがボトルネックになる場合、選択オーバーヘッドは禁止的になる可能性があります。遅延スパイクは、(1) 検証グラディエント計算が償却されない場合(例えば、すべてのバッチについて再計算)、(2) オプティマイザ状態アクセスが分散訓練全体で同期を必要とする場合、または (3) 有用性スコアリングがベクトル化されない場合に発生します。
-
軽減:* (1) 検証グラディエント計算をバッチ処理し、複数の選択判定全体で結果をキャッシュします(例えば、すべてのバッチではなく、100 バッチごとに再計算)。(2) グローバルに同期するのではなく、各デバイスでローカルにオプティマイザ状態をキャッシュします。(3) ループではなく、ベクトル化操作(例えば、PyTorch の要素ごとの乗算)を使用します。(4) 訓練フレームワークが非同期操作をサポートする場合、訓練をブロックしないように、別のスレッドまたはプロセスで選択を実行します。
-
具体例:* チームはオプティマイザ認識型選択をデプロイし、検証損失が 15% 低下することを観察しますが、命令チューニングデータが 60% の時間で拒否され、コードデータが 40% の時間で受け入れられることを発見します。彼らは検証データをドメイン別に層別化し、ドメインごとの受け入れ率を計算し、不均衡を観察します。彼らは多様性制約を追加します。U_adjusted(s, t) = U_opt(s, t) + 0.2 · I(domain(s) = instruction-tuning) ここで I は指示関数です。これは、選択されたサンプルの少なくとも 30% が命令チューニングデータであることを保証し、全体的な有用性向上を維持しながら、バランスの取れたカバレッジを回復します。
-
実行可能な示唆:* 完全な本番環境デプロイメント前に、代表的なデータセットのサブセット(例えば、典型的な日次ボリュームの 10~20%)で 2 週間のパイロットを実行します。ドメインごとの受け入れ率、ドメインごとの下流性能、および選択遅延を監視します。受け入れ率不均衡または遅延のいずれかが許容可能なしきい値を超える場合、本番環境にスケーリングする前に、対応する軽減を実装します。
結論と移行パス
本質的に問われているのは、勾配ベースの効用推定という原則的なアプローチと、逐次的で適応的な訓練という運用上の現実をいかに橋渡けするかという点です。オプティマイザ認識型オンラインデータ選択は、既存のオフライン手法に取って代わるものではなく、データがオンラインで到着し、訓練中にオプティマイザの状態が大きく変化する設定に対する補完的なアプローチです。
このフレームワークが最も有効なのは、以下の条件が揃った場合です。第一に、ファインチューニングの実行が100万ステップを超える場合で、オプティマイザの状態が実質的に進化する余地があります。第二に、データが逐次的またはストリーミング形式で到着する場合です。第三に、データ効率がコストに直結する場合、例えばトークン単位の課金が行われるクラウドベースの訓練環境です。第四に、モデルとオプティマイザが安定している場合、つまり選択フェーズと訓練フェーズの間で変更されない場合です。
見落とされがちですが、より短い実行期間(10万ステップ未満)やデータセット全体が事前に利用可能なオフライン設定では、より単純な勾配ベースの選択手法でも同等の効果を提供でき、実装の複雑性が低くなります。
移行ステップ
-
現在のパイプラインの監査: オンライン選択がデータ量を削減できるファインチューニングジョブを特定します。50万ステップ以上かつトークン単位のコストが高いジョブを優先します。
-
訓練ループへの計測機能の組み込み