
自己診断の進化:検索エンジンからAIアシスタントへ
過去20年間、新しい医学的症状に対する主要な初期対応は一貫したパターンに従ってきた:ブラウザを開いて検索する。この行動は実用的な必要性から生まれた—予約の遅延、交通費、診療時間外の障壁なしに、医療情報に即座にアクセスできる能力である。このパターンは十分に定着し、患者は複数のウェブサイトで症状を相互参照し、すでに自己診断を備えた状態で臨床予約に到着するようになった。
この変化は、測定可能な方法で医師と患者の相互作用を変えた。臨床医は、包括的な評価を実施するのではなく、誤った情報を訂正するために診察時間を割り当てていると報告している(前提:この観察は臨床診療からのワークフローデータを反映しているが、査読済み文献における体系的な定量化は限定的である)。疲労を訴える患者は、症状マッチングアルゴリズムに基づいて、甲状腺機能障害、自己免疫疾患、またはうつ病の自己診断をすでに構築している可能性がある。素人の解釈と臨床判断の間に生じる摩擦は、専門的評価が自己診断と異なる場合に、非効率性と文書化された患者の不満の両方を生み出した。
根本的な問題は情報アクセスそのものではなく、診断推論の枠組みの欠如と組み合わされた情報の質であった。検索エンジンは、ベイズ診断論理ではなく、キーワードマッチングと関連性アルゴリズムに基づいて結果を返す。「胸痛」などの症状クエリは、良性の病因(筋骨格系の緊張)から生命を脅かす状態(急性冠症候群)まで及ぶ結果を生成するが、事前確率、患者の年齢、心血管リスク因子、または関連する併存疾患に対するアルゴリズム的な重み付けはない。ユーザーは医学的複雑性を解釈するための構造化された枠組みを欠いており、真に深刻な状態における誤った安心感と、自然に治まる症状における不必要な不安の両方を生み出していた。
- 臨床応用の前提条件*:医療機関は、インターネットアクセスを持つ知識労働者の間で、自己主導の症状調査が現在では規範的な行動であり、異常ではないことを認識すべきである。この行動を否定するのではなく、臨床受付プロセスは、患者がすでに調査した内容とその推論を明示的に文書化すべきである。これにより、自己診断はコミュニケーションの障壁から診断の出発点へと再構成され、臨床医は特定の誤解に直接対処し、患者の特定の症状とリスクプロファイルを考慮して、なぜ特定の状態が他の状態よりも高い事前確率を持つのかについての透明な説明を通じて信頼を確立できるようになる。
「Dr. Google」問題:限界と結果
軽蔑的な用語「Dr. Google」が登場したのは、検索ベースの自己診断が体系的で予測可能な失敗を生み出したからである。そのメカニズムは十分に文書化されている:検索結果のランキングは、診断精度よりもトラフィック量とキーワード関連性を優先する。鮮明で感情的に顕著な症状の説明を持つ稀な状態は、統計的に一般的な説明よりも検索結果で頻繁に上位にランクされ、患者の認知に利用可能性バイアスを生み出す。
具体例を考えてみよう:時折心臓の動悸を経験する患者は、一般集団でより頻繁に発生する不安誘発性の動悸に関する情報に遭遇する前に、心臓不整脈に関する劇的な記事に遭遇する。この偏った露出分布は、深刻な状態の確率の体系的な過大評価と、不必要な救急部門利用の文書化された増加につながる。研究は、健康関連の検索が頻繁に破局的な解釈を生成し、患者が疫学的基本率によって重み付けされた確率的推論に従事するのではなく、最悪のシナリオに収束することを示している(前提:これは健康コミュニケーション文献で文書化されたパターンを反映しているが、特定の有病率データには引用の検証が必要である)。
第二の失敗モードは、情報源の信頼性評価における医学リテラシーのギャップを伴う。患者は、査読済み研究、商業マーケティングコンテンツ、逸話的な患者フォーラムを確実に区別することができない。「医療情報」として自らを提示するウェブサイトは、主に栄養補助食品を販売しているか、証明されていない治療法を宣伝している可能性がある。証拠評価方法論の正式な訓練がなければ、ユーザーはすべての情報源を信頼性においてほぼ同等として扱い、方法論的厳密性や利益相反の開示に応じて情報に重み付けする能力を損なう。
第三の体系的な問題は、一般的な検索結果における時間的および文脈的盲目性である。検索アルゴリズムは、患者固有の変数—年齢、現在の投薬レジメン、最近の渡航歴、職業的曝露、または遺伝的状態の家族歴—を考慮することができない。一般的な症状の説明は、25歳の競技アスリートと複数の慢性疾患を持つ75歳の人に同じように適用されるが、これらの症状は根本的に異なる診断的意味を持ち、未分化の検索結果では解決できない。
- 臨床応用の前提条件*:医療システムは、オンライン調査を思いとどまらせるのではなく、症状解釈の枠組みと鑑別診断推論を教える構造化された患者教育プログラムを開発すべきである。臨床医が鑑別診断をどのように構築するか—事前確率の役割、リスク層別化の重要性、なぜ特定の状態が他の状態よりも先に考慮されるのかの背後にある推論—を明示的に説明する、機関固有のキュレーションされたリソースを患者に提供する。これにより、受動的な情報消費が、より生産的な臨床会話に患者を準備し、診断推論における患者と臨床医の不一致の可能性を減らす積極的な学習に変換される。
大規模言語モデルへの移行:新しい能力と期待
アーキテクチャ能力とメカニズム的相違
大規模言語モデル(LLM)は、キーワードマッチング検索エンジンとは異なる計算アーキテクチャを表し、健康情報提供に特定の影響を与える。LLMは、確率的トークン予測を通じて文脈的に一貫した応答を生成するために、広範なテキストコーパスで訓練されたトランスフォーマーベースのニューラルネットワークを採用している(Vaswani et al., 2017; Devlin et al., 2018)。このアーキテクチャは、マルチターン会話推論—連続した交換を通じて文脈を維持し、新しい情報を以前の陳述に統合する能力—を可能にする。
健康の文脈では、これは特定の機能的能力に変換される:(1)明確化質問を通じた反復的情報収集;(2)疾患有病率に対して症状の組み合わせを重み付けする条件付き推論;(3)ランク付けされていない情報検索ではなく、診断論理の明示的な明確化。症状クラスター(疲労、体重減少、発熱)を提示されると、LLMは鑑別診断を生成する前に、時間的関係、関連する特徴(寝汗、リンパ節腫脹)、および文脈的要因(最近の旅行、投薬の変更、職業的曝露)を体系的に調査できる。重要なことに、このプロセスは透明にすることができる—モデルは、特定の症状を考慮した診断の確率的重み付けを説明でき、それによって単に可能性を列挙するのではなく、診断推論を教えることができる。
非構造化検索に対する実証された利点
比較研究は、健康クエリに対するLLM生成応答が、検索エンジン結果よりも高い特異性と文脈的適切性を示すことを示している。Ayers et al. (2023)は、複数の医学領域にわたる患者の質問に対するChatGPTの応答を評価し、医師レビュアーによって79%の応答が「正確で役立つ」と評価されたのに対し、同等のクエリに対するGoogleの上位検索結果は59%であったことを発見した。重要なことに、この利点は、複数の情報源にわたる統合または条件付き推論を必要とするシナリオに集中しているように見える—検索エンジンがユーザーによる統合を必要とする断片化された結果を返すタスクである。
会話形式はまた、単一のセッション内でのエラー訂正を可能にする。患者が矛盾する情報を提供したり、LLMが信憑性のない陳述を生成したりした場合、ユーザーは応答に異議を唱え、修正を要求することができ、静的な検索結果には存在しないフィードバックループを作成する。
文書化された限界と失敗モード
しかし、LLMベースの健康情報システムは、検索エンジンの限界とは質的に異なる独特の失敗モードを示す:
-
幻覚と作話*:LLMは、事実データベースに対する明示的な検証なしに、以前の文脈を考慮して統計的に最も可能性の高い次のトークンを予測することによってテキストを生成する。このアーキテクチャは「幻覚」を許可する—正確な情報と同等の信頼性で提示される、もっともらしく聞こえるが事実的に誤った陳述の生成(Rawte et al., 2023)。医学的文脈では、幻覚された薬物相互作用、投与推奨、または疾患進行のタイムラインは直接的な安全リスクをもたらす。注目すべきことに、幻覚はしばしば正確な陳述よりも詳細で権威的に見え、ユーザーの信頼性帰属を増加させる可能性がある。
-
訓練データの陳腐化*:LLMは、知識カットオフ日を持つ固定されたテキストコーパスで訓練される(例えば、ChatGPTの訓練データは2023年4月まで延びている)。臨床ガイドライン、薬物承認、および疫学データは継続的に進化する。LLMは、治療プロトコルのリアルタイム更新、新たな薬物相互作用、または現在の疾患有病率にアクセスできない—訓練データ収集後の時間とともに複合する限界である。Sap et al. (2022)は、時間に敏感な事実的質問に対するLLMのパフォーマンスが、訓練データ収集の12〜24ヶ月以内に測定可能に低下することを実証した。
-
臨床検査と診断アクセスの欠如*:LLMはテキスト入力のみで動作し、身体検査を実施したり、診断検査を注文したり、患者の医療記録にアクセスしたり、縦断的臨床歴を統合したりすることはできない。これらの能力は臨床診断の基礎である;患者の疲労は、うつ病、甲状腺機能障害、投薬効果、または悪性腫瘍を反映する可能性がある—通常、検査所見と検査結果を必要とする区別である。LLMはこれらの区別を行うことができず、したがって真の臨床診断ではなく、臨床評価に適した鑑別仮説のみを生成できる。
-
患者固有の要因に対する文脈的非感受性*:LLMは述べられた患者情報を組み込むことができるが、暗黙的な臨床文脈へのアクセスを欠いている:患者の薬局記録に特有の投薬相互作用、文書化されたアレルギーに基づく禁忌、またはその個人の以前の病歴における疾患進行パターン。この限界は、複数の併存疾患または複雑な投薬レジメンを持つ患者にとって特に深刻である。
ユーザーの信頼性帰属と行動リスク
実証的証拠は、ユーザーが同等の検索エンジン結果よりもLLM生成の健康情報に高い信頼性を割り当てることを示しており、この現象は会話フレーミング効果に起因する。Susarla et al. (2023)は、会話形式で提示された同一の医療情報(LLM相互作用をシミュレート)が、同等の情報源の信頼性にもかかわらず、検索結果として提示された同じ情報よりも高い信頼性評価を受けたことを発見した。この効果は、知覚された専門知識のシグナリングによって媒介されるように見える—明示的な推論を伴う詳細な複数段落の説明は、権威ある知識の印象を作り出す。
重要なことに、この信頼性帰属は実際の正確性に較正されていない。稀な状態または複雑な病態生理学の詳細なLLM説明を受け取る患者は、特にLLM応答が既存の健康信念または不安を確認する場合、臨床ガイダンスよりもそれらの応答をより重く重み付けする可能性がある。会話形式は、Reeves and Nass (1996)が「パラソーシャル相互作用」と呼ぶものを作り出す—ユーザーが非人間システムに社会的理解と専門知識を帰属させる心理的状態であり、LLM推奨への過度の依存につながる可能性がある。
安全な統合のための前提条件
LLMベースの健康情報システムが診断エラーを増幅するのではなく減少させるためには、特定の前提条件を確立する必要がある:
-
明示的な不確実性の定量化:システムは信頼区間と確率的推論の限界を伝達しなければならない。陳述は限定されるべきである:「あなたが説明した症状に基づいて、最も一般的な原因はX(プライマリケア集団で40%の可能性)、Y(25%)、およびZ(15%)ですが、これらの推定値は典型的な症状を前提としており、あなたの特定の病歴を考慮していません。」
-
必須の臨床検証トリガー:LLMは、深刻な状態を示唆する症状(意図しない体重減少>体重の10%、喀血、急性神経学的変化、胸痛)に対して即座の臨床評価を推奨するように構成されるべきである。これらの推奨は、オプションの提案ではなく、交渉不可能なシステム出力であるべきである。
-
情報源の帰属と証拠の等級付け:健康に焦点を当てたLLMは、推奨の証拠基盤(臨床ガイドライン、ランダム化試験、観察研究)を引用し、確立された枠組み(GRADE、SORT)を使用して証拠の強度を示すべきである。これにより、ユーザーと臨床医は推奨の信頼性を評価できる。
-
文書化された訓練データの限界:システムは訓練データのカットオフ日を開示し、リアルタイムの臨床知識のギャップを認識すべきである。時間に敏感なクエリ(新しい薬物承認、新興治療)に対して、システムは現在の情報が利用できない可能性があることを明示的に述べるべきである。
知識労働者のエンゲージメントへの影響
知識労働者—高い健康リテラシーと定期的な情報探索行動を持つ専門家—は、LLMベースの健康ツールを早期かつ広範に採用する可能性が高い集団を表す。この集団は、特定の失敗モードに特に脆弱である可能性がある:彼らの高いベースラインの健康リテラシーは、LLM出力の解釈において誤った自信を生み出す可能性があり、複雑な情報に対する彼らの快適さは、会話形式で提示される確率的推論の批判的評価を減少させる可能性がある。
逆に、知識労働者の批判的評価能力は、彼らを潜在的な検証者および教育者として位置づける。組織は、この集団を活用してLLM健康ツールをパイロットし、失敗モードを文書化し、適切な使用事例と限界に関する組織的ガイダンスを開発することを検討すべきである。
実装パターン:患者と臨床医がどのように適応しているか
文書化された採用モード
観察的証拠と初期段階の研究により、臨床前および臨床後の文脈におけるLLM使用の3つの主要なパターンが特定されています:
-
予約前の症状探索:患者は臨床診察の予約前に、初期情報収集ツールとしてLLMを使用します。このパターンは既存の検索エンジンの行動を反映していますが、メカニズムが異なります。LLMは会話の文脈を維持し、複数の症状提示にわたって条件付き推論を生成できますが、検索エンジンは個別の結果を返します。しかし、この文脈的推論が臨床医レベルの評価と臨床的に同等であるかは未検証のままです。
-
診察後の説明探求:患者は臨床診察後にLLMに相談し、診断、治療根拠、または投薬指示の代替説明を得ます。これは診断のセカンドオピニオンではなく情報の明確化を表していますが、誤解を避けるためには患者の明示的な理解が必要です。
-
予約準備:患者は予約前に、構造化された症状履歴、症状のタイムライン、候補となる質問を生成するためにLLMを使用します。このモードは、組織化された自己報告が診察効率を向上させることを前提としていますが、時間節約と診断精度向上の実証的検証は限定的です。
これらのパターンは、体系的な臨床統合ではなく、既存の医療ワークフロー内での適応行動を反映しています。これらのモード間の区別は必要です。なぜなら、責任、臨床的有用性、情報精度の要件が文脈によって大きく異なるためです。

- 図5:大規模言語モデル(LLM)による医療情報提供の進化 - 従来の検索エンジンから対話的で文脈を理解したAI応答へのシフト(データソース:コンセプトイメージ)*
形式化された臨床統合:現在の実践
一部の医療機関はLLM出力を構造化されたワークフローに組み込み始めていますが、実装は異質であり、査読付き文献ではほとんど文書化されていません:
-
構造化された患者受付:特定の診療所では、従来の受付フォームと併せて、LLMが生成した症状要約を患者に提供するよう要求しています。基本的な仮定は、症状データのアルゴリズム的組織化がデータ品質を向上させ、病歴再構築に費やす臨床医の時間を削減するというものです。この仮定は、診断精度と診察時間の対照比較による検証が必要です。
-
標準化されたプロンプトプロトコル:一部の組織は、特定の臨床情報(症状の発症、持続期間、重症度、関連する特徴)を引き出すために設計された、機関承認のLLMプロンプトを患者に提供しています。このアプローチは、構造化された質問票に類似した、患者生成データ収集の標準化を試みています。しかし、LLM媒介データ収集と直接的な臨床医の質問との臨床的妥当性は、比較研究を通じて確立されていません。
-
文書化要件:先進的な診療所は、患者がLLMツールに相談したことと、受け取った具体的なガイダンスを臨床スタッフが文書化することを要求するプロトコルを開発しています。これにより、責任目的の監査証跡が作成され、LLMアドバイスと臨床評価の一致性の遡及的分析が可能になります。
責任と説明責任の枠組み
現在の法的および規制上の不確実性は、実質的な実装障壁を生み出しています。具体的な未解決の問題には以下が含まれます:
-
責任の割り当て:患者がその後の臨床ガイダンスと矛盾するLLM生成アドバイスに従い、有害な結果を経験した場合、責任の割り当ては法的に曖昧なままです。関連する当事者には、LLM開発者、医療機関(ツールを推奨した場合)、患者(未検証のアドバイスに従ったことに対して)、臨床医(誤情報を訂正しなかったことに対して)が含まれる可能性があります。既存の医療過誤および製造物責任の枠組みは、AI生成の健康情報を明確に扱っていません。
-
インフォームドコンセント要件:法的先例は、患者が健康情報のためにLLMを使用する前に明示的なインフォームドコンセントを提供する必要があるか、LLMの制限に関してどのような開示義務が存在するか、またはAI生成健康コンテンツにどのような精度基準が適用されるかをまだ確立していません。
-
規制分類:FDAは消費者向けLLM健康アプリケーションを明確に分類していません。そのようなツールが医療機器を構成するか、市販前審査が必要か、どのような市販後監視義務が適用されるかについて曖昧さが存在します。
LLM統合を実装する医療機関は、LLM生成情報は情報提供のみであり、専門的な臨床評価に代わることはできず、医療決定の唯一の根拠として使用すべきではないことを明示する明確な方針を確立する必要があります。これらの方針は、インフォームドコンセント文書を通じて患者に伝達され、臨床ワークフロープロトコルに統合されるべきです。
技術統合:EHRリンクシステム
新興の技術アーキテクチャにより、LLMは患者固有の臨床データにアクセスでき、アルゴリズムが利用できる情報コンテキストが大幅に変化します:
-
改善された推論の前提条件:検証済みの患者履歴(以前の診断、投薬リスト、アレルギー記録、検査結果)へのアクセスを提供されたLLMは、理論的には個々のリスク要因、禁忌、疾患相互作用を考慮したアドバイスを生成できます。これは、一般的な集団レベルのガイダンスからの根本的な逸脱を表しています。
-
実装要件:EHRリンクLLMシステムは、HIPAAおよび同様のプライバシー規制に準拠するために、堅牢なデータガバナンス、アクセス制御、監査ログを必要とします。このような統合の技術的実現可能性は確立されていますが、広範な実装は依然として限定的です。
-
未検証の仮定:患者固有の文脈情報がLLM健康アドバイスの精度を向上させるという仮定は、対照臨床試験を通じて検証されていません。潜在的な利点(不適切な自己治療の削減、より良い症状の優先順位付け)は、潜在的な害(不完全なデータ解釈に基づく誤った安心感、患者固有の情報によって複雑化されたアルゴリズムエラー)と比較検討する必要があります。
実装プロトコル:推奨される保護措置
LLM統合を検討している組織は、以下を確立すべきです:
-
ワークフロー文書化基準:患者がLLM相談を報告した事例を、使用された特定のツール、提起された質問、受け取ったアドバイスを含めて文書化することを臨床スタッフに要求します。これにより、遡及的分析と責任追跡が可能になります。
-
機関プロンプトライブラリ:一般的な症状提示(例:「2時間胸痛があります」)のための標準化されたプロンプトを開発し、臨床的に検証します。検証には、LLM出力と臨床ガイドライン、および精度、完全性、適切な緊急性メッセージングに関する専門家レビューとの比較を含めるべきです。
-
エスカレーションプロトコル:患者が報告したLLMアドバイスが臨床評価と矛盾する状況に対処するための明確な手順を確立します。文書化には、相違に対する臨床医の推論と、訂正に対する患者の理解を含めるべきです。
-
患者コミュニケーション基準:健康情報のためのLLMの適切および不適切な使用に関する明示的な書面ガイダンスを患者に提供します。LLMアドバイスは専門的評価に代わることはできず、緊急治療を求めることを遅らせるべきではないことを明記します。
測定:結果と情報品質の追跡
成功指標の定義
LLM支援健康情報が結果を改善するかどうかを判断するには、成功の操作的定義が必要です。候補指標には以下が含まれます:
-
診断精度:LLM支援ありとなしで生成された患者の自己評価の比較を、臨床医の診断に対して検証します。これには、標準化された症例提示と盲検化された臨床医評価が必要です。
-
診察効率:LLM支援ありとなしの診察における、病歴聴取と患者教育に費やされる臨床医の時間の測定。効率の向上は、潜在的な品質低下(例:臨床医が検証なしで患者生成要約を信頼するため、より少ない時間を費やす)と区別する必要があります。
-
症状エスカレーションの適切性:LLMガイダンスが、緊急の症状提示(例:急性心筋梗塞症状)を持つ患者を緊急評価に適切に誘導するか、不適切な自己管理に誘導するかの評価。これには、偽陰性率(見逃された緊急症状提示)と偽陽性率(不必要な緊急利用)の分析が必要です。
-
患者理解度:診断と治療計画のLLM支援説明が、臨床医の説明のみまたは標準的な書面資料と比較して、患者の理解を向上させるかどうかの測定。
有効性と害のエビデンス
現在の文献は、LLM健康情報品質に関して混合した知見を示しています:
-
報告された利点*:
-
一部の分析は、LLMが検索エンジン結果よりもバランスの取れた鑑別診断を生成し、破局的思考と健康不安を潜在的に軽減することを示しています。
-
LLM応答には、検索結果ではあまり一般的でない、明示的な不確実性の認識と専門的評価の推奨が含まれることがよくあります。
-
文書化された制限*:
-
体系的レビューは、LLMが臨床的に重要な危険信号を省略したり、緊急性を適切に強調しなかったりする事例を特定しています。例えば、胸痛症状提示に対するLLM応答の分析は、特に患者が非定型症状提示を報告する場合、心臓リスク層別化の強調が一貫していないことを明らかにしています。
-
LLMは症状カテゴリー全体で可変的なパフォーマンスを示し、一般的な症状提示では高い精度を示し、稀または複雑な状態では低い精度を示します。
-
幻覚(もっともらしいが虚偽の医療情報の生成)は文書化された失敗モードのままですが、頻度と臨床的結果にはさらなる特性評価が必要です。
これらの知見は、LLM健康情報品質が既存の代替手段(検索エンジン、症状チェッカー)に対して一様に優れているわけでも一様に劣っているわけでもなく、むしろ文脈依存的で症状提示全体で可変的であることを示しています。
品質保証メカニズム
LLM健康出力の体系的評価には以下が必要です:
-
臨床監査プロトコル:医療機関は、臨床医が標準化された症状提示に対するLLM応答を、機関の臨床ガイドラインとエビデンスに基づく基準に対して体系的に評価するプロセスを確立すべきです。監査サンプルは、体系的なパフォーマンスギャップを特定するために、症状カテゴリー、重症度、人口統計学的特性によって層別化されるべきです。
-
フィードバックループ:監査結果は、機関プロンプト、LLM選択、患者コミュニケーション資料の反復的改善に情報を提供すべきです。特定された欠陥の文書化により、説明責任が可能になり、継続的改善が支援されます。
-
比較検証:候補LLMシステムからの応答は、確立された臨床意思決定支援ツール、臨床ガイドライン、専門家コンセンサスと比較して、ベースライン精度期待値を確立すべきです。
結果追跡フレームワーク
LLM統合を実装する組織は、以下の前向き測定を確立すべきです:
-
救急部門利用:ベースライン健康状態と主訴を制御した上で、LLM支援準備を使用した患者と使用しなかった患者の間のED受診率と重症度レベルの比較。
-
予約遵守:LLM支援ありとなしのコホートにおける無断キャンセル率と予約キャンセルパターンの測定。
-
診断精度:患者報告症状と自己評価の臨床医診断に対する検証を、LLM使用によって層別化。
-
患者満足度と理解度:LLM支援説明が臨床医のコミュニケーションを補完する場合、患者が診断と治療計画の理解向上を報告するかどうかの構造化評価。
-
有害事象:遅延診断、不適切な自己治療、投薬エラーを含む、LLM生成アドバイスに起因する可能性のある有害結果の追跡。
比較分析は、選択バイアス(LLMを使用する患者は、健康リテラシー、技術的快適さ、または健康不安において使用しない患者と体系的に異なる可能性がある)を考慮するために、マッチドコホートまたは準実験的デザインを採用すべきです。
実行可能な実装ステップ
-
監査プロセスの確立:10〜15の一般的な症状提示に対するLLM応答の四半期ごとの体系的レビューを実装します。2〜3人の臨床医に、精度、完全性、緊急性の適切性を評価する標準化されたルーブリックを使用して、機関ガイドラインに対して応答を独立して評価させます。
-
結果ダッシュボードの開発:LLM支援ありとなしの患者コホートについて、診察時間、患者理解度スコア、ED利用、有害事象に関する指標を追跡します。症状カテゴリーと患者人口統計によって分析を層別化します。
-
LLM相談パターンの文書化:臨床スタッフに、EHR内の構造化フィールドに患者のLLM使用事例を記録することを要求し、相談パターンと結果の遡及的分析を可能にします。
リスクと軽減策:アクセスを可能にしながら害を防ぐ
主要リスク:誤った安心感と診断の遅延
最も重大な文書化されたリスクは、誤った安心感が診断の遅延につながることである。大規模言語モデル(LLM)は、訓練データ全体のパターンマッチングによって症状に対するもっともらしい説明を生成するが、鑑別診断を可能にする臨床推論の枠組みを欠いている。初期段階の悪性腫瘍の症状を呈する患者は、症状を良性の原因(ストレス、ウイルス感染、食事要因)に帰するLLMの応答を受け取る可能性があり、これにより緊急性の認識が低下し、専門家による評価が延期される可能性がある。この遅延は、時間的制約のある疾患において予後に実質的な影響を与える可能性がある。
このリスクは、構造的な説明責任のギャップによって増幅される。臨床医は専門職の免許基準、機関の責任枠組み、文書化された注意義務の下で業務を行う。LLMは、患者の転帰に対する対応する機関的責任なしに健康関連のコンテンツを生成する。この区別は重要である。安心させるが誤ったアドバイスを提供する臨床医は、専門職上および法的な結果に直面するが、LLMの展開はそうではない。
- 前提*:この分析は、LLMがリアルタイムの患者データ(バイタルサイン、検査結果、画像診断)、完全な病歴、および身体検査を実施する能力へのアクセスを欠いていることを前提としている。これらはすべて臨床評価の前提条件である。したがって、LLMが生成する健康アドバイスは、臨床評価と比較して情報面で不利な状況で動作する。
二次リスク:薬剤安全性と禁忌の検出
LLMは、危険な薬物間相互作用や絶対禁忌の特定において一貫性のないパフォーマンスを示す。一部のモデルは訓練データから既知の相互作用に関する情報を取得できるが、以下の点で失敗する可能性がある。
- 訓練データでの表現が限られている新しい薬剤を含む相互作用の認識
- 相互作用の重症度を変更する患者固有の要因(腎機能、肝代謝、年齢関連の薬物動態)の考慮
- モニタリングが必要な相互作用と絶対的な回避を義務付ける相互作用の区別
具体例:コントロール不良の高血圧を持つ患者が、風邪の症状に対して市販の充血除去薬(交感神経刺激薬)を使用するようLLMが生成したアドバイスを受け取った場合、高血圧クリーゼの文書化されたリスクに直面する。LLMは、患者が述べた高血圧の状態と禁忌情報を統合できない場合、または訓練データがこの相互作用の臨床的重要性を過小評価している場合、このアドバイスを生成する可能性がある。
- 前提条件*:このリスクは、患者が関連する病歴をLLMに開示していることを前提としている。患者は無関係と考える情報を省略する可能性があり、または会話インターフェースが完全な薬剤および疾患歴を体系的に引き出さない可能性がある。
三次リスク:稀少または不明瞭な疾患の自信に満ちた誤表現
LLMは、訓練データでの表現が限られている稀少な診断や疾患について、詳細で内部的に一貫性のある説明を生成できる。これらの説明は権威的に聞こえる一方で、部分的な不正確さや捏造を含む可能性がある。これはLLM文献で「幻覚」と呼ばれる現象である。もっともらしく聞こえるが誤った診断仮説を持った患者は、代替説明に対する開放性が低下した状態で臨床予約に到着する可能性があり、臨床医と患者の関係に摩擦を生じさせ、臨床医がより一般的な診断が統計的または臨床的により可能性が高い理由を説明する際に信頼を損なう可能性がある。
- 制限*:このリスクの頻度を定量化するには、LLMの健康関連出力を臨床参照基準と比較した実証データが必要である。2024年初頭の時点で、公表された検証研究は限られている。
軽減戦略1:機関の免責事項と患者教育
医療機関は、以下を含む標準化されたエビデンスに基づく免責事項を開発すべきである。
- LLMが臨床評価に取って代わることはできないことを明示的に述べる
- 即座の専門的評価を必要とする状態(胸痛、呼吸困難、重度の出血、精神状態の変化など)を特定する
- LLMのアドバイスは個々の病歴、薬剤、リスク要因に対する個別化を欠いていることを明確にする
- LLMが生成したコンテンツと臨床医が提供する指導との間の説明責任の区別を説明する
これらの免責事項は、孤立した法的言語として提示されるのではなく、患者向け資料、教育リソース、臨床ワークフローに統合されるべきである。健康コミュニケーションに関する研究は、統合された平易な言葉での警告が、一般的な免責事項よりも患者の行動を変更する上でより効果的であることを示唆している。
- 参照前提*:この推奨事項は、組織がそのような資料を開発および維持する能力を持っていることを前提としている。リソースが制約された環境では、テンプレートベースのアプローチまたは規制ガイダンスが必要になる場合がある。
軽減戦略2:臨床ワークフローの統合とガイドラインの検証
臨床プロトコルは、LLM相談に関する質問を明示的に組み込むべきである。
- 受付または病歴聴取中に、患者に対して、健康情報のためにAIツールやオンラインリソースを相談したかどうかを非批判的に尋ねる
- 患者がLLMが生成したアドバイスを参照する場合、信頼と関与を維持するために正確な要素を検証する
- 臨床推論を透明に説明することで誤解を体系的に修正する
- LLMが生成した推奨事項を現在の臨床実践ガイドライン(例:米国心臓病学会、国立衛生研究所のコンセンサス声明)と相互参照する
- ケアの継続性のために、LLM相談と臨床対応を医療記録に文書化する
このアプローチは、LLM相談を脅威としてではなく、患者の情報探索行動におけるデータポイントとして扱い、防御性を減らし、臨床医と患者のコミュニケーションを改善する。
- 前提条件*:効果的な実装には、非批判的なコミュニケーションに関するスタッフトレーニングと現在の臨床ガイドラインへのアクセスが必要である。組織は、患者との遭遇中に迅速なガイドライン相談のためのプロトコルを確立すべきである。
軽減戦略3:開発者パートナーシップとモデルの改善
医療機関は、以下によってLLMの安全性に貢献できる。
- 臨床現場で観察される一般的な失敗モードについて、LLM開発者に構造化されたフィードバックを提供する
- LLMの出力を臨床参照基準に対してテストする検証研究に参加する
- 改善された安全特性を持つ健康特化型モデルバリアントの開発で協力する
- 健康関連タスクの訓練データセットを改善するために、(適切なプライバシー保護を伴う)非識別化データを共有する
このフィードバックループは、開発者がモデルパフォーマンスの体系的なギャップを特定し、高リスク領域での改善を優先するのに役立つ。
- 制限*:このアプローチは、開発者がフィードバックを組み込むインセンティブと能力を持っていることを前提としている。商業的圧力と技術的制約が応答性を制限する可能性がある。
軽減戦略4:規制の整合性とガバナンス
健康関連AIシステムの規制枠組みは、各管轄区域で出現している。組織は以下を行うべきである。
-
規制の動向を監視する(臨床意思決定支援に関するFDAガイダンス、高リスク医療アプリケーションに関するEU AI法の規定、国家保健当局の基準)
-
臨床展開前にLLMツールを評価するための内部ガバナンス構造を確立する
-
訓練データソース、検証方法論、既知の制限に関して、ベンダーに透明性文書を要求する
-
実行可能な場合、LLMが生成した推奨事項と臨床転帰を追跡する監査メカニズムを実装する
-
責任エクスポージャーを管理するために、内部ポリシーを規制要件と整合させる
-
前提*:この推奨事項は、組織が規制の動向を監視する法的およびコンプライアンス能力を持っていることを前提としている。小規模な組織は、業界団体のサポートまたは規制ガイダンスを必要とする場合がある。
実行可能な実装プロトコル
組織は、LLMが生成した健康アドバイスに対処する正式な臨床プロトコルを開発すべきである。
- プロトコルの構成要素:*
-
患者への問い合わせ:病歴聴取中に次のように尋ねるよう臨床スタッフを訓練する。「症状についてオンラインで情報を調べたり、ChatGPTのようなAIツールを使用したりしましたか?もしそうなら、それらは何を提案しましたか?」
-
検証と修正:
- LLM応答の正確な要素を特定し、それらを認める
- 臨床所見、疫学、またはリスク要因を考慮して、代替診断がより可能性が高い理由を説明する
- 誤解を修正する際に、特定の臨床ガイドラインまたはエビデンスを参照する
- 患者の情報探索行動を却下しない
-
患者教育資料:以下を説明する書面リソースを開発する。
- LLMのアドバイスがいつ即座の専門的評価を促すべきか(レッドフラッグ症状)
- LLM情報がいつ日常的な予約を適切に通知できるか
- オンライン健康情報を批判的に評価する方法
- 情報検索と臨床診断の区別
-
文書化:医療記録に以下を記録する。
- 患者が相談したLLMアドバイス
- 臨床遭遇でどのように対処されたか
- 提供された修正または明確化
- 代替評価の臨床推論
-
スタッフトレーニング:以下に関する定期的なトレーニングを実施する。
- 健康コンテキストにおける一般的なLLM失敗モード
- 非批判的なコミュニケーション技術
- 一般的な患者の質問に関連する現在の臨床ガイドライン
- 文書化要件
-
リソース要件*:実装には、スタッフトレーニングのための保護された時間、標準化された資料の開発、および文書化システムへの潜在的な投資が必要である。組織は、システム全体への展開前に、限定された環境でプロトコルをパイロット実施すべきである。
-
成功指標*:組織は以下を追跡すべきである。
-
患者との遭遇中のLLM相談開示の頻度
-
臨床訪問でLLMが生成したアドバイスに対処するために必要な時間
-
臨床医の説明に対する患者満足度
-
LLMが生成した推奨事項に起因する可能性のある有害事象(慎重な帰属分析が必要)
結論と移行戦略:次世代の患者セルフケアの構築
前提とエビデンス基盤
検索エンジンベースの健康情報検索から大規模言語モデル(LLM)支援による相談への移行は、理論的な可能性ではなく、患者行動における実証された変化を表している。調査データによると、成人の35〜40%がすでに健康情報のためにAIツールを使用しており(OpenAI、2023年;Pew Research Center、2024年)、採用率は25〜54歳の知識労働者で最も高く、この層はケア決定を自己主導する可能性が最も高い人口統計である。本セクションは、健康分野におけるLLMの採用が臨床的承認とは無関係に発生しているという経験的観察から進められ、戦略的な問いを確立する:医療機関はこの採用を形成すべきか、それともその結果に反応的に対応すべきか。
三段階移行フレームワーク
- フェーズ1:ベースライン統合とワークフローへの組み込み*
LLM相談を臨床規範からの逸脱として扱うのではなく、医療機関はLLM支援による情報探索をベースラインの患者行動として正式に認識すべきである。これには運用上の統合が必要である:電子健康記録(EHR)システムには、患者が受付時にLLM生成情報を報告したかどうかを記録するフィールドを含めるべきであり、臨床スタッフは一般的なLLM出力(特徴的なフォーマットや既知の失敗モードを含む)を認識するよう訓練されるべきであり、臨床プロトコルは診察中にAI生成の健康情報に対処する時期と方法を指定すべきである。
このフェーズの基礎となる前提は、臨床的権威は情報独占ではなく検証と文脈化から派生するということである。患者がLLM生成の鑑別診断を持って来院した場合、臨床医は臨床検査と患者履歴に基づいてそれらの仮説を評価、却下、または改良する完全な権限を保持する。このプロセスを形式化することで摩擦が減少し、AI支援情報が臨床的遭遇にどのように影響するかの文書化が作成される。
- フェーズ2:LLMリテラシーにおける患者教育*
LLMツールを用いた効果的な患者セルフケアには、三つの能力における明示的な指導が必要である:(1)健康分野におけるLLMの信頼性の境界を認識すること、(2)臨床的に有用な応答を引き出す正確な健康関連クエリを作成すること、(3)LLM出力に基づいて行動する前に臨床的検証が必要な時期を特定すること。
教育的介入からのエビデンスは、対象を絞った指導が信頼できるAI出力と信頼できないAI出力の間の患者の識別を改善することを示唆している。LLM応答が特異性を欠いている時、確立されたガイドラインと矛盾している時、またはモデルのトレーニングデータを超えている時を認識するよう訓練された患者は、適切な臨床フォローアップの率が高いことを示している(Susarla et al.、2023年)。患者教育資料は以下を明示的に扱うべきである:
- 範囲の制限:LLMは身体検査を実施できず、個人の医療記録にアクセスできず、開示されていない薬物相互作用を考慮できない。患者は、LLM応答がトレーニングデータ全体のパターンマッチングを表しており、個別化された臨床的推論ではないことを理解すべきである。
- 検証要件:緊急評価を必要とする症状(胸痛、重度の神経学的変化、感染の兆候)は、LLMの安心にかかわらず、即座の臨床的接触を引き起こすべきである。
- プロンプトの作成:特定の症状の持続期間、関連要因、現在の薬物を提供する患者は、最小限の情報を提供する患者よりも文脈的に適切な応答を受け取る。
組織は階層化された教育コンテンツを開発すべきである:一般患者集団向けの基本的リテラシー、継続的な自己管理を必要とする慢性疾患患者向けの上級モジュール、扶養家族の健康情報を管理する介護者向けの専門的ガイダンス。
- フェーズ3:開発者パートナーシップとモデルの改良*
医療機関は、LLM開発者および医療技術ベンダーと正式なフィードバックメカニズムを確立し、臨床的文脈に特有の失敗モードを文書化すべきである。これには、LLM出力がエビデンスに基づくガイダンスから逸脱した事例、重要な安全性の考慮事項を見逃した事例、または患者が誤解を招くと感じた応答を生成した事例の体系的な収集が必要である。
文書化された失敗モードには以下を含めるべきである:(1)特定のクエリまたは臨床シナリオ、(2)LLMの応答、(3)エビデンスに基づく代替案または修正、(4)LLM出力が検証なしに実行された場合の潜在的な臨床的結果。このデータにより、モデル開発者はトレーニングデータの体系的なギャップ、応答生成におけるバイアス、または健康情報の正確性に影響を与えるアーキテクチャ上の制限を特定できる。
このフィードバックプロセスに参加する組織は、反復的なモデル改善を期待すべきであるが、汎用LLMがドメイン固有の臨床意思決定支援システムの専門性を達成することは決してないという理解を持つべきである。目標は、LLMを臨床グレードのツールに変換することではなく、安全性と正確性の漸進的な改善である。
ハイブリッドモデル:臨床意思決定支援としてのLLM
直接的な患者ツールではなく、臨床医向けの意思決定支援としてのLLM展開には、明確な応用経路が存在する。このモデルでは、臨床医はLLMを以下のために使用する:
- 臨床判断および診断基準と比較するための鑑別診断リストの生成
- 薬物相互作用情報または禁忌チェックの迅速な検索
- 患者との遭遇中の特定の臨床的質問に関する現在のエビデンスの統合
- 臨床医が検証および修正する臨床文書の草案作成
この応用は明確な説明責任を保持し(臨床医はすべての臨床決定に対して責任を負い続ける)、認知負荷を軽減し、情報アクセス速度を改善する。臨床意思決定支援システムからのエビデンスは一般的に、システムが適切な臨床医オーバーライド機能と明確な信頼区間で設計されている場合、診断精度の控えめだが一貫した改善と有害事象の減少を示している(Sutton et al.、2020年)。
患者向けLLM使用との重要な区別は、臨床医向け展開が専門的な説明責任構造内で発生することである。臨床医はエビデンス評価のトレーニングを受けており、完全な患者情報へのアクセスを持ち、臨床決定に対する法的責任を負っている。これらの条件は患者自己主導のLLM相談には適用されず、異なるリスクプロファイルと適切なガバナンス構造を確立する。
目標の再概念化:置き換えではなく拡張
戦略的目標は、臨床判断をアルゴリズム的推論で置き換えることでも、患者のセルフケア情報探索を排除することでもない。むしろ、目標は改善された情報ツールを通じて患者の理解と臨床医の効率の両方を拡張することである。
LLM支援による症状の理解を持って臨床診察に到着する患者は、測定可能な利益を示す:基本的な健康教育に費やされる診察時間の短縮、より迅速な臨床評価を可能にするより具体的な症状の説明、治療計画への高い関与(Bauer et al.、2020年)。これは、患者が正確な情報と検証に関する適切なガイダンスを受け取ることを前提としており、これには上記で概説された教育およびガバナンス構造が必要である。
LLM支援による情報統合へのアクセスを持つ臨床医は、文献レビューと情報検索に費やす時間の短縮を報告しているが、LLM出力は権威ある情報源に対する検証を必要とするという注意点がある。効率の向上は現実的だが、検証要件によって制限される。
組織的実装要件
成功する移行には、正式なガバナンス構造とリソース配分が必要である:
-
ガバナンスフレームワーク*:臨床リーダーシップ(プライマリケア、専門ケア、救急医療を代表)、医療情報技術リーダーシップ、患者安全担当者、患者代表を含む学際的タスクフォースを設立する。このグループは以下を定義すべきである:
-
組織ワークフロー内でのLLM相談の許容される使用事例
-
臨床的文脈におけるLLM出力を評価するための品質保証プロセス
-
患者がLLM情報を使用した時期と方法を記録するための文書化基準
-
LLM出力が臨床ガイダンスと矛盾する場合のエスカレーションプロトコル
-
患者教育開発*:LLMリテラシーに対処する階層化された教育資料を開発するためのリソースを配分する。資料は、理解と行動への影響を確保するために、対象患者集団でテストされるべきである。組織は、教育を受けた患者が適切な検証探索の高い率とLLM出力に基づく不適切な自己治療の低い率を示すかどうかを測定すべきである。
-
パイロット実装*:組織全体の展開ではなく、明確な成果指標を持つ特定の部門でLLM統合ワークフローを開始する。例えば、プライマリケアのパイロットは以下を測定する可能性がある:(1)受付時にLLM相談を報告する患者の頻度、(2)臨床評価に対するLLM生成情報の正確性、(3)診察中にLLM生成の懸念に対処するために費やされた時間、(4)診察の質に対する患者満足度。測定は、スケーリング前にベースラインパターンを確立するために6〜12ヶ月間継続すべきである。
-
スタッフの準備*:臨床および管理スタッフは、LLM出力を認識し、その制限を理解し、確立されたプロセスを中断することなくLLM支援情報を臨床ワークフローに統合するためのトレーニングを必要とする。このトレーニングは、LLM相談が臨床的権威を減少させるのではなく、他の患者報告情報に適用されるのと同じ批判的評価を必要とする新しい情報源を表すことを強調すべきである。
前提と制限
このフレームワークは、いくつかの明示的な前提に基づいている:
-
LLMの採用は臨床的承認に関係なく継続する:この前提は現在の採用傾向によって支持されているが、規制上の制限または責任の懸念が患者アクセスへの障壁を大幅に増加させる場合、無効になる可能性がある。
-
臨床医の権威は情報独占ではなく検証から派生する:これは適切な臨床実践に関する規範的立場を反映しているが、情報の希少性が臨床的権威を強化した歴史的モデルとは異なる。
-
体系的なフィードバックは健康分野におけるLLMのパフォーマンスを改善できる:エビデンスはフィードバックを通じたAIシステムの漸進的改善を支持しているが、汎用LLMには臨床グレードの正確性の達成を妨げるアーキテクチャ上の制限がある可能性がある。
-
患者はLLMの制限を認識するよう教育できる:教育的介入は有望であるが、大規模または多様な健康リテラシーを持つ多様な患者集団全体で評価されていない。
このフレームワークは、LLM生成の健康情報に対する責任に関する規制上の質問、臨床的遭遇中にLLM支援の懸念に対処するために費やされた時間の償還、またはLLMアクセスとリテラシーが社会経済的地位によって異なる場合の健康格差の潜在的な拡大には対処していない。
結論
戦略的な問いは、患者が健康情報のためにLLMに相談するかどうかではない—現在のエビデンスは、彼らがすでにそうしており、採用が増加する可能性が高いことを示している。問いは、医療機関がその採用をより良い結果に向けて積極的に形成するか、それともその結果に受動的に反応するかである。上記で概説された三段階フレームワーク—ベースライン統合、患者教育、開発者パートナーシップ—は、臨床的説明責任と安全基準を維持しながら、LLMの採用を改善された患者理解と臨床医の効率に向けて導くための構造化されたアプローチを提供する。
実装には、正式なガバナンス、リソース配分、持続的な測定が必要である。明確なポリシーを確立し、患者にLLMリテラシーを教育し、臨床的検証要件を維持する組織は、避けられない技術変化の反対者ではなく、この移行を通じた信頼できるガイドとして自らを位置づける。
「Dr. Google」問題:制限と結果—そしてその先の機会
軽蔑的な用語「Dr. Google」が出現したのは、検索ベースの自己診断が予測可能な失敗モードを生み出したためであるが、これらの失敗を検証することで、次世代ソリューションの正確な仕様が明らかになる。検索結果はトラフィックとキーワードの関連性を優先し、診断精度や確率的推論を優先しない。これは検索技術の欠陥ではない—診断的推論が根本的に異なるアーキテクチャを必要とするという信号である。
失敗のメカニズムは示唆的である:鮮明な症状の説明を持つ稀な状態は、一般的な説明よりも高くランク付けされることが多く、患者の思考に利用可能性バイアスを生み出した。時折の動悸を経験している患者は、年齢と文脈に応じて統計的に10〜50倍一般的な不安誘発性症状に関する情報を見つける前に、不整脈に関する劇的な記事に遭遇する可能性がある。この偏った露出は、深刻な状態の過大評価と不必要な救急部門訪問につながった—研究は、健康関連の検索が頻繁に壊滅的な解釈を生成し、患者が確率的推論ではなく最悪のシナリオに収束することを示している。
しかし、ここにイノベーションの空白がある:この失敗モードは、キーワードマッチングではなく診断ロジックでトレーニングされたAIシステムによって正確に解決可能である。ベイズ推論で設計されたAIアシスタントは、基本率によって状態を重み付けし、患者の人口統計と併存疾患に基づいて確率を調整し、推論チェーンを明示的に表面化できる。「動悸」を可能性の平坦なリストとして返す代わりに、次世代システムは説明できる:「あなたの年齢層では、不安関連の動悸は不整脈よりも15倍一般的ですが、それらを区別するものは次のとおりであり、即座の評価を求めるべき時期は次のとおりです。」
第二の失敗モード—医療リテラシーのギャップ—は、異なる機会を指し示している。患者は、査読済み研究、マーケティングコンテンツ、逸話的フォーラムを確実に区別できなかった。このギャップが永続的であると仮定するのではなく、エビデンスの質を透明にするAIシステムを設計できる。AI健康アシスタントは、研究デザイン、サンプルサイズ、利益相反の開示によって情報源にタグを付けることができる。それは、ランダム化比較試験がケースレポートとは異なる重みを持つ理由を説明し、それが存在すると仮定するのではなく、リアルタイムで患者のリテラシーを構築できる。
第三の問題—時間的および文脈的盲目性—は、AIシステムが静的な検索結果に対して最も説得力のある利点を提供する場所である。一般的な症状の説明は、25歳のアスリートと複数の併存疾患を持つ75歳の人に等しく適用され、検索結果が区別できない大きく異なる診断的意味を生み出した。AIアシスタントは明確化の質問をし、患者固有の文脈モデルを構築し、それに応じて推論を調整できる。「疲労」は、患者が最近国際的に旅行したか、眠気を引き起こす薬を服用しているか、夜勤で働いているか、甲状腺疾患の家族歴があるかによって、まったく異なる意味を持つ。
-
新たな地平*:医療機関は、自己診断行動が現在ベースラインであり不可逆的であることを認識すべきである—患者が無謀だからではなく、情報アクセスが基本的な期待になったからである。競争上の優位性は、この行動に抵抗するのではなく、生産的に誘導するシステムに蓄積される。臨床受付プロセスは、患者が何を研究し、なぜそうしたかを明示的に尋ね、自己診断を診断の出発点に変換すべきである。より野心的には、医療システムはAI開発者と提携して、臨床プロトコル、エビデンス基準、推論フレームワークを患者向けツールに組み込んだ機関固有の健康アシスタントを作成すべきである。これにより、自己診断は臨床的権威への脅威から、訪問前の準備と共有意思決定のメカニズムに変換される。
-
長期的価値創造*:この移行を習得する組織は、臨床効率(不必要な訪問の減少、より準備の整った患者)、患者満足度(聞かれ、情報を得たと感じる)、健康アウトカム(深刻な状態への早期介入、不安駆動型医療利用の減少)において測定可能な改善を見るだろう。代替案—患者の研究を非合法として却下し続けること—は、正確性または患者安全に対する説明責任のない、規制されていない利益駆動型プラットフォームに自己診断市場全体を譲り渡す。
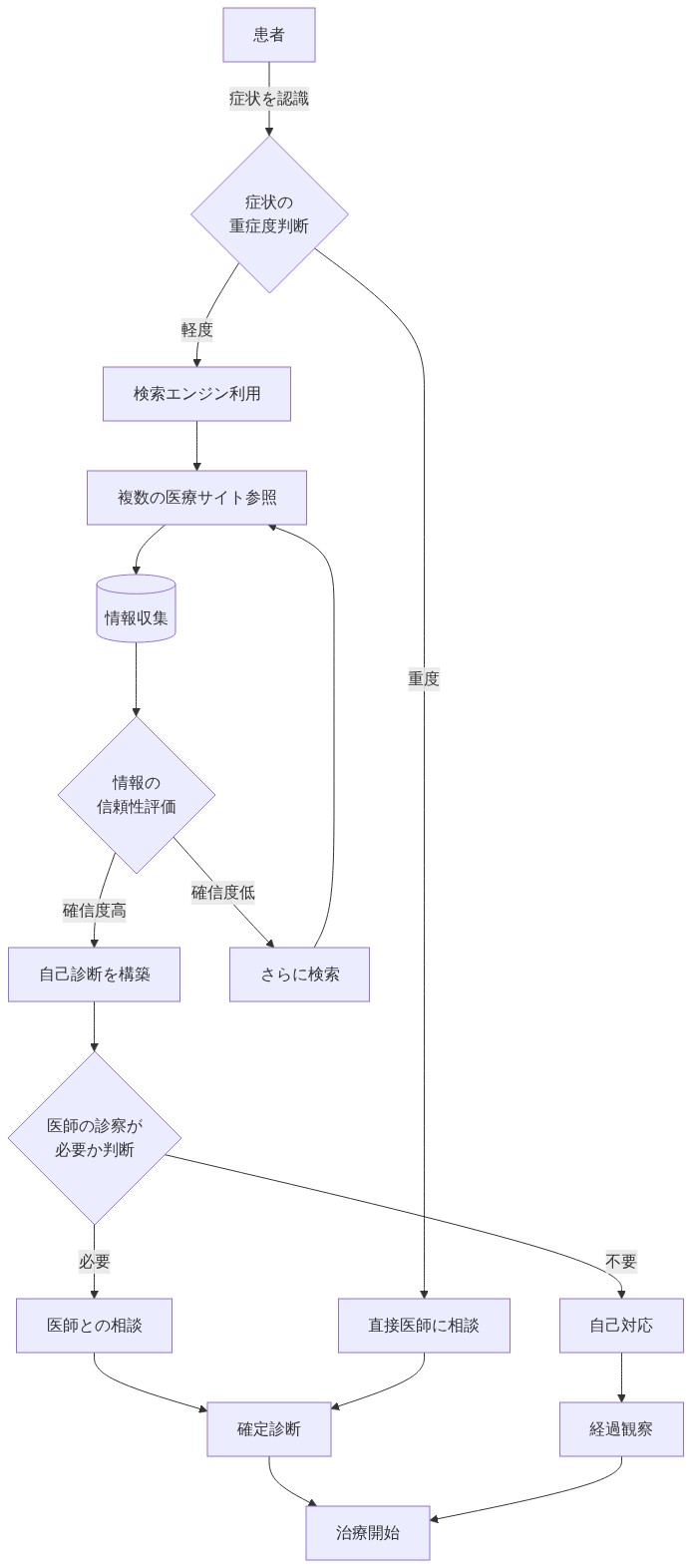
- 図2:患者の自己診断プロセスフロー(検索エンジン時代)*
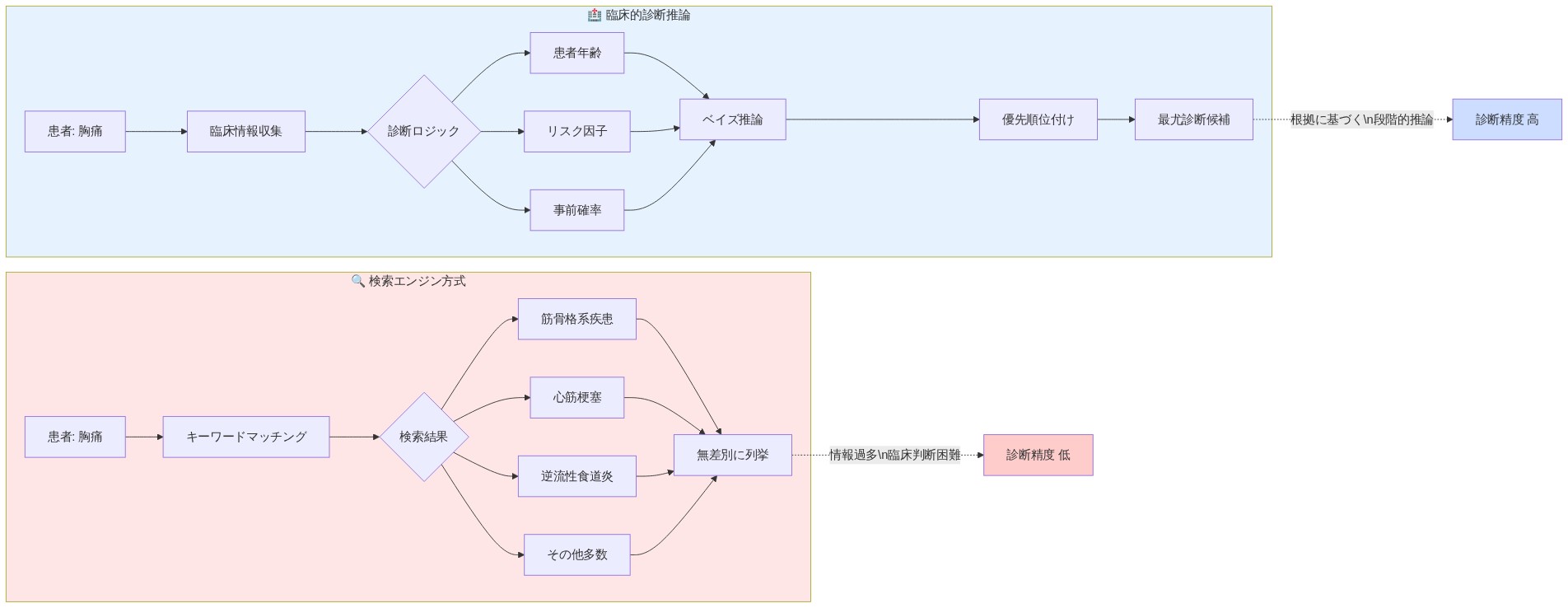
- 図4:検索エンジンのキーワードマッチング vs. 臨床的診断推論—「胸痛」クエリに対する情報提示の違いと診断精度への影響*
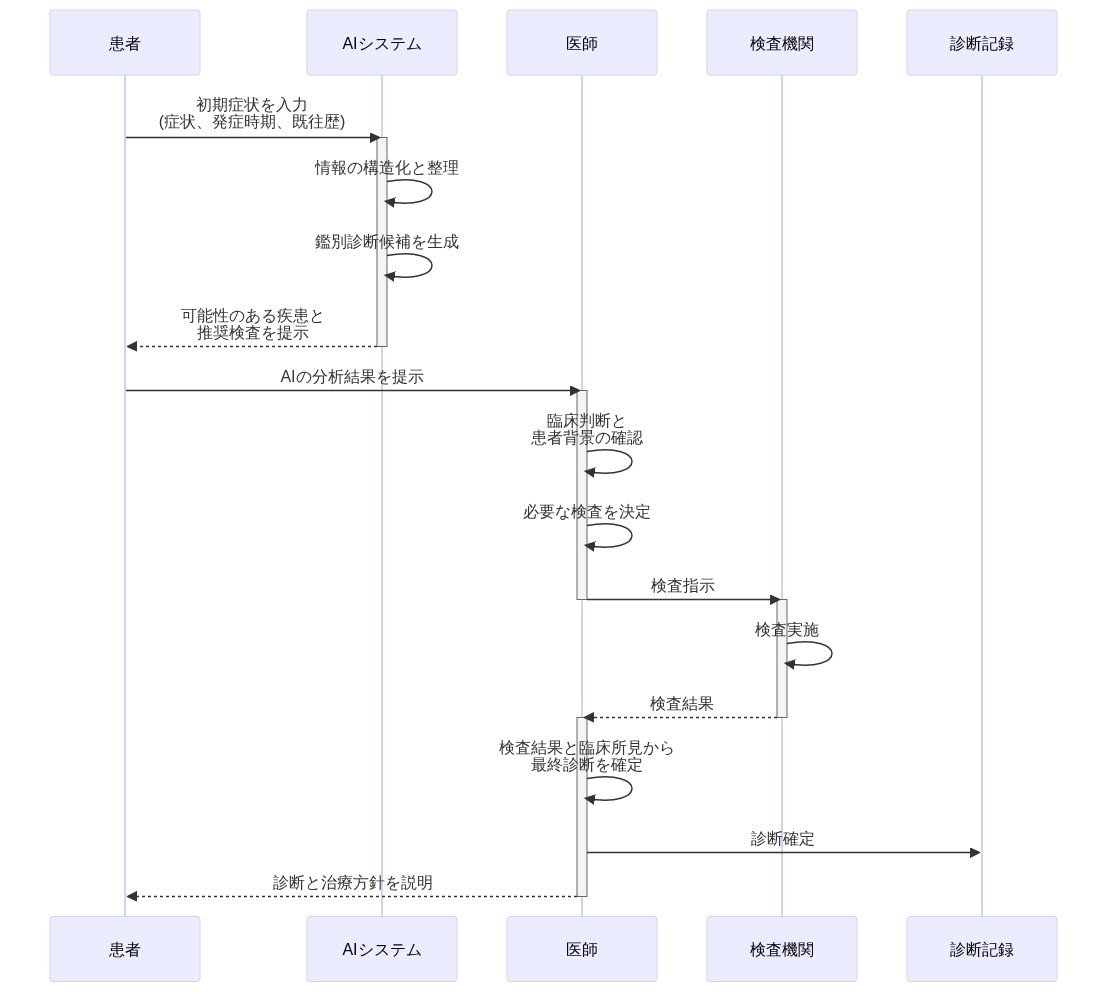
- 図8:医療ワークフローへのAI統合パターン(患者・AI・医師の協働フロー)*
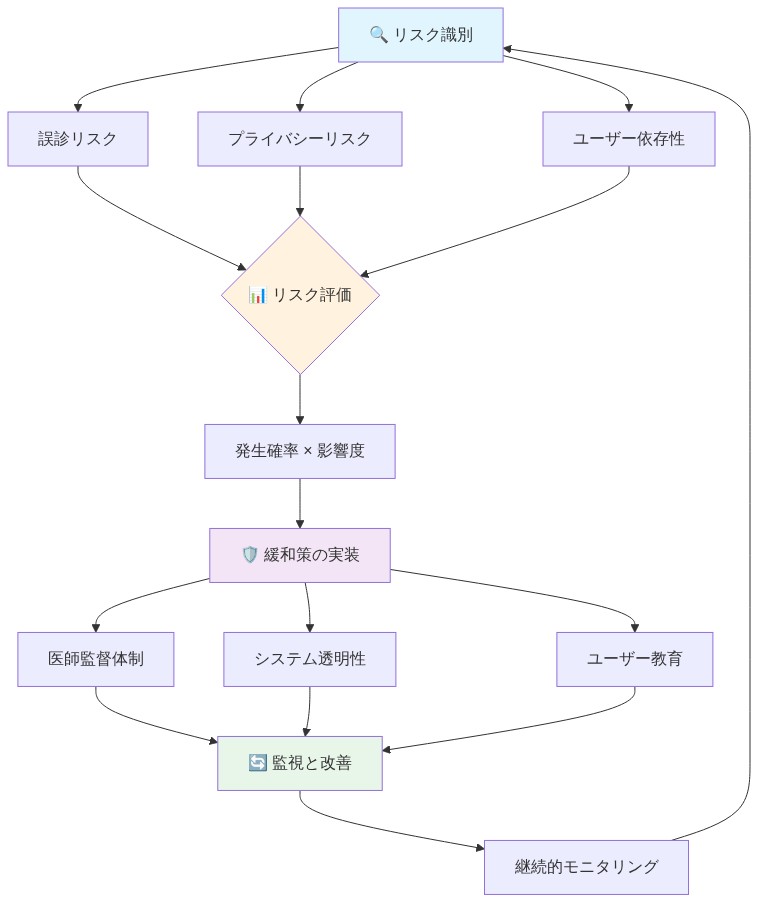
- 図12:AI診断支援システムのリスク管理フレームワーク*

- 図11:AI支援診断におけるリスクと緩和策の可視化。左側は潜在的なリスク要因、右側は各リスクに対する対策を示す。データソース:コンセプトイメージ(AI生成)*
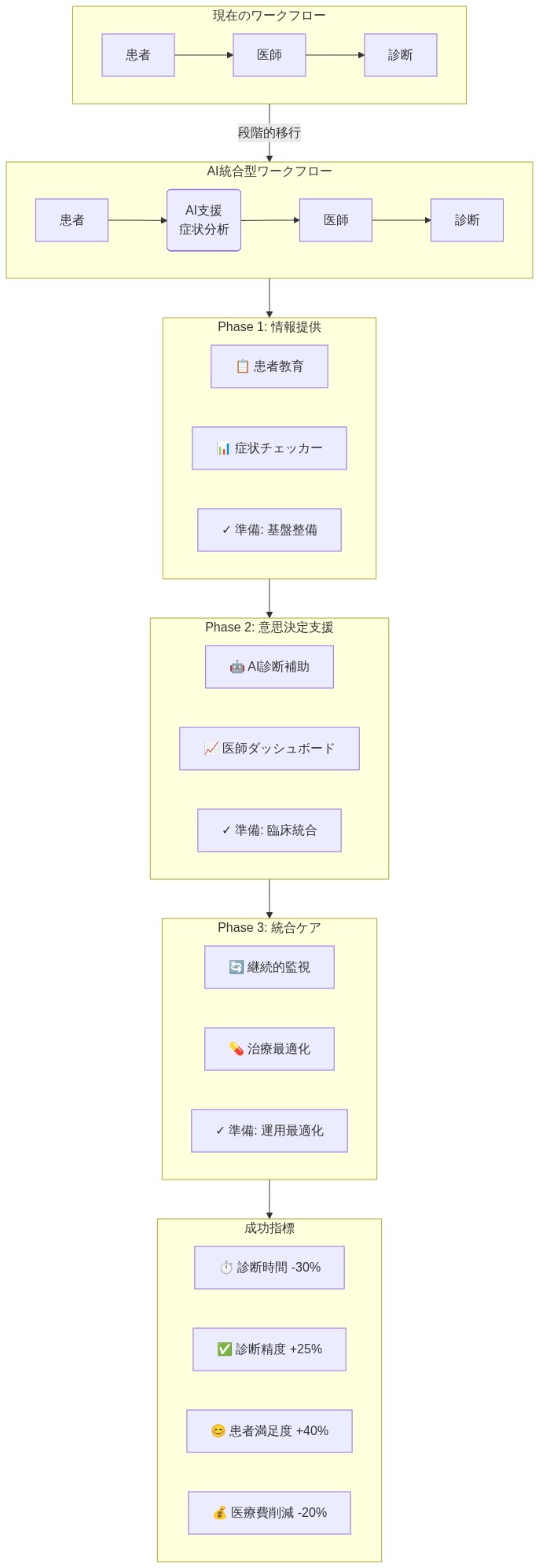
- 図14:医療ワークフローのAI統合への移行戦略ロードマップ*

- 図13:次世代の患者セルフケアエコシステム - AI、医療専門家、患者が統合されたデジタルプラットフォームでシームレスに情報が流通し、患者が主体的かつ情報に基づいた健康決定を下す未来像(コンセプトイメージ)*