
データ構成がスケールを上回るようになった
- LLM事前学習の有効性は、データセットの規模よりもデータ構成によってますます決定されるようになっています。* より大規模なデータセットが均一にモデル性能を向上させるという従来の仮定は、経験的に異議を唱えられています。スケーリング則とデータ効率に関する最近の研究(Hoffmann et al., 2022; Chinchilla scaling)は、キュレーションされた低容量のデータセットが、より大規模で異質な集合よりも頻繁に優れた下流タスク性能を達成することを示しています。モデル能力の制約は、計算配分またはパラメータ数から、訓練信号の品質、バランス、表現的カバレッジへとシフトしています。
このシフトは、高次元埋め込み幾何学の形式的性質に根ざしています。事前学習中、言語モデルは埋め込み空間内の学習された多様体上に意味関係をエンコードします。訓練データが歪んだ分布を示す場合—ドメイン集中、トークンレベルの繰り返し、またはカテゴリ境界のズレによって特徴付けられる—結果として得られる多様体は不均一に充填されます。冗長な信号は表現的価値を追加することなく容量を占有し、過少表現されたドメインは高い不確実性または不十分な汎化の領域を生成します。その結果は、高いパラメータ数を持ちながらも有効能力が限定的なモデルです。
-
説明的比較:* 未フィルタリングのウェブテキスト2兆トークンで訓練された70億パラメータモデルは、通常、数学的推論、ドメイン固有のコード生成、技術的質問応答などの専門的タスクにおいて、層化されたドメインバランスデータの5000億トークンで訓練された70億パラメータモデルよりも低い性能を示します。この性能ギャップは、総計算量(FLOPs)を制御した場合でも持続します。第二のモデルの埋め込み空間は、意味領域全体でより均一に充填されており、その学習された表現は、大規模ウェブコーパスに共通するノイズと繰り返しアーティファクトによってより少なく破損しています。
-
運用上の含意:* データキュレーションは調達モデル(データ取得の最大化)から最適化モデル(表現的カバレッジとバランスの最大化)へと移行する必要があります。この移行には、形式的な測定と反復的な改善が必要です。従来のキュレーションアプローチ—人間の分類法、キーワードベースのフィルタリング、ランダム層化—は不十分です。なぜなら、それらはモデルの学習された表現空間と必ずしも一致しない外部的なカテゴリ構造を課すからです。効果的なキュレーションは、モデルの埋め込み多様体の幾何学内で動作する必要があります。
-
実装の前提条件:* 訓練コーパスのベースライン測定を確立してください。ドメイン、ジャンル、言語レジスタ、およびソース起源全体のトークン分布を定量化してください。集中度を特定してください。ウェブ由来のコーパスでは、上位10のソースが通常、集計トークンの40~60%を占めています。この集中度を表現的バイアスのリスク要因として文書化してください。過少表現されたカテゴリからのサンプルを段階的に導入し、リバランス前後の保留された評価セットを使用して下流タスク性能の変化を測定してください。このアプローチは、キュレーション決定を仮定ではなく経験的信号に基づかせます。
分類法とクラスタリングは異方性埋め込みで失敗する
- 標準的な分類法は人間が定義したオントロジーを課しており、これは学習されたモデル幾何学と一致せず、ユークリッドクラスタリングアルゴリズムは本質的に異方性埋め込み空間に不適切です。* 従来のデータキュレーションパイプラインは、事前定義されたカテゴリ分類に依存しています—「コード」「ニュース」「書籍」「ソーシャルメディア」—これらは人間の注釈者にとって認知的に直感的ですが、ニューラル言語モデルに対する理論的正当性を欠いています。これらのカテゴリは人間の情報処理における直感的な区別を反映しているかもしれませんが、トランスフォーマーベースのモデルは、これらの境界を尊重しない分散表現を学習します。経験的には、学習された表現における意味クラスタは、しばしば分類法的境界を横切ります。技術文書とソースコードは表現空間内の隣接領域を占有する可能性がある一方で、ニュース記事とソーシャルメディアテキストはカテゴリ分離にもかかわらず相互に交錯する可能性があります(Gao et al., 2022; Xie et al., 2023)。異質なデータを事前決定されたビンに強制することは、モデルの実際の表現構造に関する情報を破棄し、人間中心ではなくモデル中心の組織化に対する体系的バイアスを導入します。
より根本的な問題は埋め込み異方性から生じます。これは現代の言語モデルの十分に文書化された性質です。埋め込みベクトルは超球面全体に均一に分布するのではなく、トランスフォーマーモデルの埋め込みベクトルは狭い円錐または低次元多様体の近くに集中します(Li et al., 2020; Ethayarajh, 2019)。この異方性幾何学は、ユークリッド距離メトリクスの中核的仮定に違反します。空間は等方性であり、距離はすべての領域にわたって均一に解釈可能であるという仮定です。その結果、ユークリッド距離は意味的または機能的類似性の誤解を招くプロキシとなります。ユークリッド空間で近接しているように見える2つのドキュメントは、モデルの学習された決定境界に沿って遠い位置を占有する可能性があり、ユークリッド項で遠く離れたドキュメントは、モデル学習に不可欠な補完的情報信号をエンコードする可能性があります。
-
等方性空間向けに設計されたクラスタリングアルゴリズム—k-means、階層的クラスタリング、ガウス混合モデルを含む—したがってモデルの真の表現幾何学または学習要件を反映しないカテゴリ割り当てを生成します。* 異方性埋め込みに適用される場合、これらのアルゴリズムは、モデルの決定空間の意味のある分割ではなく、アルゴリズムの最適化目的のアーティファクトであるクラスタを生成します。結果として得られるクラスタは、2つの失敗モードのいずれかに向かう傾向があります。(1)過度な同質性。クラスタ内ドキュメントが表現でほぼ同一であり、冗長な訓練信号と計算の非効率な使用につながる場合。または(2)過度な異質性。クラスタ内ドキュメントが表現空間の異なる領域にまたがり、訓練中に相互に打ち消すまたは学習に干渉する矛盾した勾配信号を引き起こす場合。
-
具体的な失敗事例:* BERT埋め込みにk-meansクラスタリングを適用することで1000万ドキュメントをLLM事前学習用にキュレーションするチームを考えてください。コーパスを100のカテゴリに分割します。チームは層化サンプリングを実装し、「バランスの取れた」表現を確保するために各クラスタから等しい数のドキュメントを抽出します。しかし、BERTの埋め込み空間は異方性であるため、100のクラスタはk-meansの目的(クラスタ内ユークリッド分散の最小化)によって決定され、訓練されている下流モデルの幾何学によってではなく決定されます。この「バランスの取れた」データセットで新しい言語モデルが訓練される場合、学習は不均等に進行します。なぜなら、k-meansによって課されたカテゴリ境界は、新しいモデルの学習された決定境界と一致しないからです。モデルは冗長なクラスタに過適合する可能性がある一方で、ユニークな情報をエンコードする領域をアンダーサンプリングし、その結果、最適でない汎化につながる可能性があります。
-
実行可能な代替案:* 固定分類法をコーパスレベルの情報理論的分析に置き換えてください。相互情報(または正規化された埋め込みのコサイン類似度などのプロキシ測定)をドキュメント間で計算して、コーパス内の情報依存性を特定してください。運用上、ユニークな情報を提供するドキュメント—他の少数のドキュメントとの相互情報が高いドキュメント—を優先し、冗長なドキュメント(多くの他のドキュメントとの相互情報が高いドキュメント)を下げてください。クラスタリングが必要な場合、ユークリッド距離ではなく測地線距離メトリクス(例えば、L2正規化埋め込みのコサイン類似度)を使用してください。測地線メトリクスは学習された埋め込みの異方性幾何学を尊重し、モデルの表現構造と一致する距離推定を提供するからです。
GEM:超球面上の変分キュレーション
- GEMはデータキュレーションを単位超球面上で定義された変分最適化問題として再定式化し、バランスの取れた表現を強制する幾何学的正則化項で拡張されています。* 離散的なカテゴリ制約を適用する代わりに、GEMは訓練データ構成をサンプル重みに対する連続最適化問題として扱います。目的関数は2つの項を組み合わせています。(1)超球面に投影された訓練サンプルの経験分布のシャノンエントロピーの最大化、および(2)表現空間の局所化領域への質量の過度な集中を抑制するペナルティ項。
形式的フレームワーク
この方法は3つの連続的なステージを通じて動作します。
-
ステージ1:埋め込みと正規化。* すべての候補サンプルは参照エンコーダを使用して埋め込まれます—事前訓練された言語モデルまたは同等の表現容量を持つより小さいプロキシモデルのいずれか。各埋め込みベクトルx ∈ ℝ^dは単位ノルムに正規化され、x̂ = x / ||x||₂が得られ、これを単位超球面S^(d-1)上に配置します。この正規化はメトリック学習で標準的であり、最適化が幾何学不変空間で動作することを保証します(Maaten & Hinton, 2008; Wang et al., 2017)。
-
ステージ2:変分目的関数の定式化。* w = (w₁, w₂, …, w_n)をn個の候補サンプルに割り当てられた非負の重みとし、∑ᵢ wᵢ = 1(確率シンプレックス制約)とします。超球面上の経験分布はp_w = ∑ᵢ wᵢ δ(x̂ᵢ)として定義されます。ここでδはディラック測度を表します。変分目的関数は以下の通りです。
-
L(w) = H(p_w) − λ · R(p_w)*
ここで:
- **H(p_w)**は経験分布の微分エントロピーです(k-最近傍エントロピーまたはカーネル密度法を介して推定されます; Kraskov et al., 2004)
- **R(p_w)**は局所集中を測定する幾何学的正則化項です(例えば、k-最近傍への平均逆距離、または超球面上の均一分布からのレニエントロピー)
- λはエントロピーとバランスの間のトレードオフを制御するハイパーパラメータです
この定式化は、選択されたサンプルが個別に情報的(高エントロピー)であり、集合的に分散している(低集中)ことを保証します。
-
ステージ3:最適化による反復的な重み付け。* 最適化問題は、確率シンプレックス上の投影勾配上昇法またはミラー降下法を使用して解決されます。各反復tで、サンプル重みは以下に従って更新されます。
-
wᵢ^(t+1) ∝ wᵢ^(t) · exp(η · ∇_wᵢ L(w^(t)))*
ここでηは学習率であり、勾配はシンプレックスに投影されます。超球面の疎な領域(低局所密度)に位置するサンプルは正の勾配信号を受け取り、その重みが増加します。密な領域のサンプルは負の信号を受け取り、その重みが減少します。収束は通常10~20回の反復内に達成され、分布のエントロピーは反復数の関数として単調に増加する(または安定化する)傾向があります。
ミキシング-バランス正則化項
正則化項R(p_w)は重要な機能を果たします。これは、少数の高品質サンプルのサブセットが選択され、表現空間の大規模な領域が未カバーのままである退化解に収束することをオプティマイザが防ぎます。この項がなければ、最適化は最も「中心的な」または「原型的な」サンプルのみを優先するサブセット選択問題に縮小されます。
形式的には、正則化項は以下のようにインスタンス化できます。
- R(p_w) = (1/n) ∑ᵢ log(1 + d_k(i))*
ここでd_k(i)は加重分布内のサンプルiからそのk-最近傍までの距離です。あるいは、R(p_w)はp_wと超球面上の均一分布Uの間の発散を測定できます。
- R(p_w) = D_KL(p_w || U) or D_JS(p_w || U)*
両方の定式化はクラスタリングにペナルティを課し、最終的な訓練セットが表現空間全体にまたがり、ほぼ均一なカバレッジを持つことを強制します。正則化項の選択は下流タスクに依存します。広い表現カバレッジを必要とするタスク(例えば、汎用言語モデリング)の場合、KL発散が適切です。バランスの取れたクラスまたはドメイン表現を必要とするタスクの場合、局所密度測定が好ましいです。
具体的なインスタンス化
実践的なシナリオを考えてください。チームが1億個の候補ドキュメントから訓練コーパスをキュレーションします。参照モデル(例えば、10億パラメータエンコーダ)で埋め込み、単位球面に正規化した後、チームはλ = 0.5およびk = 50(局所密度推定用)でGEMを適用します。
初期分析は以下を明らかにします。
- 超球面の表面の30%は、わずか5%のドキュメント(ペアワイズコサイン類似度> 0.95の近似重複ニュース記事の密なクラスタ)によってのみ占有されています
- 球面の40%は、わずか2%のドキュメント(メインコーパスとの低い重複を持つ稀で専門的な技術コンテンツ)によってのみ占有されています
- 球面の残りの30%には、93%のドキュメント(中程度の多様性を持つ汎用コンテンツ)が含まれています
変分最適化の15回の反復後。
- ニュース記事は0.3~0.5の係数で下げられます(それらの冗長性を反映して)
- 技術コンテンツは2.0~3.0の係数で上げられます(それらの稀さと表現的価値を反映して)
- 汎用コンテンツは1.0に近い重みを受け取ります(それらのバランスの取れた貢献を反映して)
20億トークン(候補プールからの5倍削減)で構成される結果として得られた訓練セットは以下を示します。
- 経験エントロピーH(p_w) = 8.2ビット(均一ランダムサンプリングの6.1ビットと比較して; 34%の増加)
- 超球面表面の98%のカバレッジ(ランダムサンプリングの72%と比較して)
- 分布外推論タスクにおける40%の改善(ドメインシフトを持つ保留されたテストセットで測定)
- 分布内パープレキシティにおける12%の改善(候補プールと同じドメインで測定)
これらの改善は、情報幾何学からの理論的予測と一致しています。幾何学的制約に従う訓練分布のエントロピーを最大化することは、学習された表現と下流タスクラベル間の相互情報を増加させます(Cover & Thomas, 2006)。
実装ガイダンス
実践でGEMを実装するには、以下のステップに従ってください。
-
参照エンコーダを選択してください。 ターゲットモデルと同等の表現容量を持つ事前訓練されたモデルを使用してください(例えば、70億パラメータLLMを訓練する場合、10億~30億の参照エンコーダを使用してください)。より小さいエンコーダは計算コストを削減します。より大きいエンコーダはより正確な埋め込みを提供する可能性があります。
-
埋め込みと正規化。 すべての候補サンプルを参照エンコーダを通じて処理してください。埋め込みを単位ノルムに正規化してください。大規模コーパス(>1億サンプル)を処理するために、メモリマップ形式で埋め込みを保存してください。
-
重みを初期化してください。 w₀ = (1/n, 1/n, …, 1/n)(均一分布)を設定してください。
-
変分最適化を実行してください。 投影勾配上昇法の10~20回の反復を実行してください。各反復で、k-最近傍統計を使用してH(p_w)とR(p_w)を計算してください(k = 50は合理的なデフォルトです)。λを経験的に設定してください。λ = 0.1から始めて、カバレッジが不十分な場合はλ = 1.0に増加させてください。
-
収束を監視してください。 H(p_w)と超球面でカバーされた分数(k-meansクラスタリングまたはボロノイ分割を介して推定)を追跡してください。収束は通常、3つの連続反復にわたってH(p_w)の1%未満の変化によって示されます。
-
訓練データを再サンプリングしてください。 学習された重みw*を使用して候補コーパスを再サンプリングしてください。より高い重みを持つサンプルはより頻繁に含まれます。より低い重みを持つサンプルはより少なく含まれるか、完全に除外されます。最終的な訓練セットサイズが計算予算に適切であることを確認してください。
-
経験的に検証してください。 最終的な訓練分布のエントロピーを測定してください。ランダムサンプリングベースラインと比較して、75パーセンタイル以上のエントロピー値を目指してください。分布内および分布外テストセットの両方で下流タスク性能を評価して、改善を確認してください。
- 仮定と制限。* このフレームワークは、(1)参照エンコーダが下流タスク性能と相関する意味のある埋め込みを提供し、(2)超球面幾何学がデータドメインに適切である(ほとんどのテキストおよびビジョンタスクに対して真ですが、構造化またはテーブルデータに対しては適応が必要な場合があります)、および(3)埋め込みと最適化の計算コストが訓練予算に対して許容可能であることを仮定しています。埋め込みが不十分に調整されている設定、または表現空間が高度に非等方性である設定では、この方法は正則化調整または代替距離メトリクス(例えば、階層的データの双曲幾何学)を必要とする場合があります。
実装とオペレーションパターン
GEMをオペレーショナルに展開するには、相互に依存する3つのインフラストラクチャコンポーネントが必要です。エンベディング生成と保存、反復的な最適化、継続的な監視です。各コンポーネントは、明示的に文書化する必要がある特定の技術的制約と前提条件をもたらします。
- エンベディングインフラストラクチャ*
エンベディング層は、すべての下流操作の幾何学的基盤として機能します。これには以下が必要です。
-
モデル選択: より小さなエンベディングモデル(例えば、蒸留されたBERTバリアントまたは約33Mパラメータを持つE5-small)を使用するか、事前計算されたキャッシュエンベディングサービスを使用します。この選択は、計算コストと表現忠実度の間のトレードオフを反映しています。より小さなモデルは推論レイテンシを削減しますが、異方性を増加させる可能性があります。異方性とは、エンベディングが超球面全体に均等に分布するのではなく、超球面の狭い円錐に集中する傾向です(Ethayarajh, 2019; Wang et al., 2022)。デプロイ前に、モデルの本質的な次元性と異方性係数を文書化してください。
-
正規化プロトコル: すべてのエンベディングをユニットノルム(L2正規化)に正規化します。このステップは必須です。GEMの幾何学的操作(測地線距離、局所密度推定)はエンベディングがユニット超球面上に存在することを前提としているためです。正規化に失敗すると、エントロピー計算に系統的なバイアスが導入されます。
-
ベクトルストレージとインデックス: 正規化されたエンベディングを、近似最近傍(ANN)インデックス(例えば、HNSW、IVF)を備えたベクトルデータベースに保存します。これにより、最適化ループ中の局所密度推定の効率的な計算が可能になります。ANNリコール目標(例えば、95%以上)を指定し、リコールとクエリレイテンシ間のトレードオフを文書化してください。
-
最適化ループ*
反復的な最適化手順は、エンベディング空間内のサンプルの経験的分布に対して動作します。以下のように実装してください。
-
初期化: すべてのサンプルウェイトを1.0に設定します(均一事前分布)。
-
離散化: 超球面を測地線領域に分割します(例えば、球面k-meansまたは階層的等面積等緯度ピクセル化を使用)。この分割の粒度は、収束速度と最終エントロピーに影響します。より細かい分割(例えば、768次元空間の場合1,000~10,000領域)は精度を向上させますが、計算コストを増加させます。より粗い分割(100~500領域)はコストを削減しますが、局所構造を見落とす可能性があります。
-
密度推定: 各領域について、経験的密度を加重サンプルの割合として計算します。密度の下位四分位数(疎)と上位四分位数(密)の領域を特定します。
-
ウェイト更新: 乗法的更新を適用します。
- 疎領域:ウェイトに(1 + α)を乗じます。ここでα ∈ [0.10, 0.20]
- 密領域:ウェイトに(1 − β)を乗じます。ここでβ ∈ [0.05, 0.10]
これらの範囲はヒューリスティックです。初期エントロピーギャップに基づいて選択を文書化し、正当化してください。各更新後にウェイトを再正規化して、有効な確率分布を維持します。
-
収束基準: シャノンエントロピーが領域密度分布で安定するまで反復します(連続する反復間で0.01ナット未満の変化)。100万ドキュメントの場合、典型的な収束は15~30回の反復で発生します。コーパスの実際の収束動作を文書化してください。
-
エクスポート: 最終ウェイトをリサンプリングテーブル(ドキュメントID → ウェイト)として出力します。これらのウェイトは、トレーニング中に各ドキュメントをサンプリングする確率を定義します。
- 監視と可観測性*
GEMの動作と影響を検証するために、3つの測定ストリームを確立します。
-
エンベディング空間の幾何学:
- GEM適用前後のトレーニングセットのエンベディング分布のシャノンエントロピーを計算します。d次元球面上の均一分布の理論的最大エントロピーは0.5 × log(2πe × d)ナットです。目標:GEM後に理論的最大値の70%以上を達成します。
- 異方性係数(エンベディング行列の最大特異値と最小特異値の比)を測定します。ベースラインとGEM後の値を文書化します。異方性は低下するか安定したままである必要があります。
-
下流タスクのパフォーマンス:
- 同一のアーキテクチャとハイパーパラメータを持つ2つのモデルをトレーニングします。1つはランダムサンプリングされたデータ上で、もう1つはGEMキュレーションされたデータ上です。キュレーションの効果を分離するために、両方を同じ総トークン数に制限します。
- 複数のドメインにまたがるホールドアウトテストセットで評価します。推論(MMLU、GSM8K)、コード生成(HumanEval)、分布内言語モデリング(ホールドアウトウェブテキストのパープレキシティ)。
- 予想される改善:分布外タスク(推論、コード)で3~8%の相対的な利得。分布内タスクでは1%未満の回帰。
- ランダムシード全体の分散を文書化します(条件ごとに少なくとも3つのシードでトレーニングします)。
-
オペレーション効率:
- エンドツーエンドキュレーションコストを測定します。エンベディング推論時間、最適化ループ時間、ウェイトとインデックスのストレージオーバーヘッド。目標:事前トレーニング総時間の5%未満のオーバーヘッド。
- データ効率を追跡します。目標パフォーマンスまでの反復またはトークン。適切にキュレーションされたコーパスは、ランダムサンプリングより20~30%高速に目標パフォーマンスに到達する必要があります。ウォールクロック時間またはトークン数で測定します。
- デプロイメントチェックリスト*
本番環境へのデプロイ前に。
- エンベディングモデルの正規化とストレージ整合性を検証します(100個のランダムサンプルをスポットチェック)。
- コーパスの10%サンプルで試験的な最適化ループを実行します。収束動作と最終エントロピーを文書化します。
- ランダムサンプリングのベースラインパフォーマンスを確立します(少なくとも2つの独立したトレーニング実行)。
- GEMを適用して再トレーニングします(少なくとも2つの独立した実行)。パフォーマンスデルタと信頼区間を測定します。
- 観測された改善が2%未満の場合、調査してください。(a)エンベディングモデルが高い異方性を示しているか(幾何学的構造をマスクする)、または(b)候補コーパスが既にバランスの取れているか(この場合、GEMは限定的な利益を提供します)。
測定と検証フレームワーク
GEMの影響を検証するには、3つの直交する次元にわたる定量的評価が必要です。表現幾何学、下流タスクのパフォーマンス、オペレーションコストです。各次元は、異なるステークホルダーの懸念に対処します。
- 表現メトリクス*
これらのメトリクスは、GEMがエンベディング球面上のトレーニング分布の均一性を正常に増加させたかどうかを定量化します。
-
エンベディング分布のエントロピー: シャノンエントロピーH = −Σ p_i log(p_i)を計算します。ここでp_iは領域iの経験的密度です。絶対エントロピー(ナット)と相対エントロピー(均一分布の理論的最大値のパーセンテージ)の両方を報告します。ベースライン:ランダムサンプリングされたデータのエントロピーを測定します。GEM後:GEMキュレーションされたデータのエントロピーを測定します。目標:理論的最大値の70%以上。
-
カーネル密度推定による均一性: 超球面上のフォンミーゼス-フィッシャーカーネルを使用してカーネル密度推定器(KDE)をフィットさせます。球面全体の推定密度の変動係数(CV)を計算します。より低いCVはより高い均一性を示します。ベースラインとGEM後のCV値を報告します。
-
分布距離: 経験的トレーニング分布と球面上の参照均一分布の間のグロモフ-ワッサースタイン(GW)距離を計算します。GW距離は、幾何学的構造を考慮に入れた確率分布上のメトリクスです(Peyré et al., 2016)。目標:GEM後にGW距離を30~40%削減します。GW推定の計算コストを文書化します(大規模なデータセットの場合は高コストです。実用的な測定のためにサブサンプリングを検討してください)。
-
パフォーマンスメトリクス*
これらのメトリクスは、改善された幾何学的均一性がモデルパフォーマンスの向上に変換されるかどうかを定量化します。
-
実験設計: 同一のアーキテクチャ、ハイパーパラメータ、トレーニング期間を持つ2つのモデルをトレーニングします。
- コントロール:候補コーパスからのランダムサンプリング
- トリートメント:GEMキュレーションされたサンプリング
両方を同じ総トークン数に制限します。分散を推定するために、条件ごとに少なくとも3つの独立したランダムシードを使用します。
-
評価タスク: マルチドメイン評価スイートを使用します。
- 分布外推論:MMLU(Hendrycks et al., 2021)、GSM8K(Cobbe et al., 2021)
- コード生成:HumanEval(Chen et al., 2021)
- 分布内言語モデリング:ホールドアウトウェブテキストのパープレキシティ(例えば、WikiText-103検証セット)
-
予想される結果: GEMは推論とコードタスクで3~8%の相対的な改善をもたらすべきです。分布内パープレキシティは安定したままであるか、わずかに改善される必要があります(1%未満の回帰は許容可能)。すべてのメトリクスについて95%信頼区間を報告します。
-
失敗モード: 改善が2%未満の場合、事後分析を実施します。
- エンベディング異方性を測定します。高い異方性(例えば、最大特異値が最小の10倍以上)は、エンベディングモデルが幾何学的キュレーションをサポートしていない可能性があることを示します。
- 候補コーパスのベースライン分布を分析します。既にバランスが取れている場合(エントロピー>理論的最大値の65%)、GEMは限定的な利益を提供します。
- エンベディングモデルが下流タスクに適切であることを確認します(例えば、汎用エンベディングモデルはタスク固有の構造をキャプチャしない可能性があります)。
-
オペレーションメトリクス*
これらのメトリクスは、GEMデプロイメントの計算と効率のトレードオフを定量化します。
-
キュレーションコスト: 以下を測定して報告します。
- エンベディング推論時間(100万ドキュメントあたりの秒数)
- 最適化ループ時間(完全な収束までの秒数)
- エンベディング、インデックス、ウェイトテーブルのストレージオーバーヘッド(GB)
- 事前トレーニング総時間のパーセンテージとしての総キュレーションコスト
目標:事前トレーニング総時間の5%未満のオーバーヘッド。
-
データ効率: ランダムおよびGEMキュレーション条件の両方について、目標パフォーマンスまでのトークンを測定します。「目標パフォーマンス」を特定の下流タスクスコア(例えば、MMUで70%の精度)として定義します。適切にキュレーションされたコーパスは、ランダムサンプリングより20~30%高速に目標パフォーマンスに到達する必要があります(ウォールクロック時間またはトークン数)。
-
スケーリング動作: キュレーションコストがコーパスサイズでどのようにスケーリングするかを文書化します(線形、準線形、または超線形)。これにより、より大規模なデプロイメントのROI計算が通知されます。
-
制御実験プロトコル*
特定の設定でGEMの影響を確立するために、制御実験を実行します。
-
ベースライン確立: 候補コーパスから100Mのランダムサンプリングされたトークンでモデルをトレーニングします。すべての下流タスクでパフォーマンスを測定します。少なくとも2つの独立したシードを実行します。
-
GEM適用: GEMを候補コーパスに適用します。リサンプリングウェイトをエクスポートします。
-
トリートメントトレーニング: GEMウェイトに従ってサンプリングされた100Mトークンで、同一に構成されたモデルをトレーニングします。少なくとも2つの独立したシードを実行します。
-
比較: 各下流タスクのパフォーマンスデルタ(トリートメント − ベースライン)を計算します。平均値と95%信頼区間を報告します。
-
文書化: すべてのハイパーパラメータ、モデル構成、エンベディングモデルの詳細、GEMパラメータ(分割粒度、更新レート、収束基準)を記録します。これにより、再現性が可能になり、スケーリング決定が通知されます。
-
ROI予測: 観測されたデルタを使用して、より大規模なデプロイメント(例えば、1Bまたは10Bトークン)のROIを予測します。キュレーションコストと予想されるパフォーマンス利得を考慮に入れます。
リスクと軽減戦略
リスク1: 埋め込みモデルのバイアス伝播
-
問題の定義:* 参照埋め込みモデルは体系的なバイアスをエンコードしています。統計的なもの(特定の意味領域の過少表現)、文化的なもの、あるいはアーキテクチャ由来のもの(例えば、トークン化の人工物、学習データの構成)です。GEMの最適化手順は、設計上、参照モデルの表現空間内でエントロピーを最大化します。つまり、GEMは参照モデルのバイアス構造を修正したり回避したりするのではなく、それを実装化するのです。参照モデルが特定の意味領域を体系的に過小評価している場合、GEMはリサンプリング中にこの過小評価を保持し、潜在的に増幅します。
-
前提:* 参照埋め込みモデルのバイアスは意味空間全体に均等に分布していません。バイアスは特定の領域に集中しています(例えば、技術的言語と日常会話、西洋文化と非西洋文化の文脈)。
-
軽減アプローチ:*
-
アンサンブル検証: 構造的に異なる埋め込みモデル3~5個を使用してGEMを独立して学習させます(例えば、OpenAIのtext-embedding-3-large、Sentence-BERT、Jinaの埋め込み)。これらのモデルは学習データ、次元数、アーキテクチャの選択肢が異なります。
-
コンセンサスの再重み付け: 各領域について、アンサンブルメンバー全体のリサンプリング重みの中央値を計算します。アンサンブルメンバーが大きく異なる領域(変動係数 > 0.3)は手動レビューのためにフラグを立てるべきです。
-
バイアス監査: GEMを展開する前に、参照モデルが保留されたベンチマーク上で測定可能なバイアスを示すかどうかを測定します(例えば、StereoSet、WinoBias)。このベースラインを文書化します。GEM後、バイアスが増幅されていないことを確認するために再測定します。
-
残存リスク:* アンサンブルアプローチはバイアスを軽減しますが、完全には排除しません。すべてのアンサンブルメンバーが共通のバイアスを共有している場合(例えば、すべてが主に英語データで学習されている)、コンセンサスはそのバイアスを保持します。軽減には領域専門知識と外部検証が必要です。
リスク2: 参照モデルの幾何学への過剰適合
- 問題の定義:* GEMは、参照埋め込みモデルの幾何学がターゲットモデルの幾何学を予測するという仮定の下でデータ構成を最適化します。この仮定は、参照モデルとターゲットモデルが以下の点で大きく異なる場合に失敗します。
- アーキテクチャ(例えば、エンコーダのみ対デコーダのみ)
- 学習データ分布
- タスク特化(例えば、コード中心対汎用)
- スケール(例えば、7Bパラメータ対70Bパラメータ)
これらの条件下では、参照空間での最大エントロピーに対して最適化されたデータセットは、ターゲット空間でのエントロピー特性が悪い可能性があります。あるいはさらに悪いことに、ターゲットモデルが学習しにくい領域にトークンを集中させる可能性があります。
-
前提:* 埋め込み空間の幾何学はモデル間で部分的ですが完全には転移可能ではありません。転移可能性の程度はモデルのアーキテクチャと学習の類似性に依存します(Vig & Belinkov, 2019; Saphra & Lopez, 2019)。
-
軽減アプローチ:*
-
参照モデルの選択: 埋め込みモデルを優先します。これは(a)ターゲットモデルより小さく、より汎用的であり、(b)多様で特化していないデータで学習されています。小さいモデルはタスク固有の過剰適合の傾向が低く、一般的な意味構造をキャプチャする可能性が高いです。
-
転移検証: 大規模なリサンプリングにコミットする前に、GEMキュレーションされたデータセット上で小さなプロキシモデル3~5個(125M~350Mパラメータ)を学習させます。検証損失、下流タスクパフォーマンス(例えば、MMLU、HellaSwag)、エントロピー統計を測定します。GEMなしでキュレーションされたベースラインデータセットと比較します。
-
感度分析: 参照モデルを変更してGEMを再実行します。結果のデータセットが大きく異なる場合(領域分布間のワッサーシュタイン距離 > 0.2)、これは過剰適合リスクを示します。
-
残存リスク:* 転移検証には複数のモデルの学習が必要であり、計算コストが高くなります。リソースに制約のあるチームの場合、このステップは実行不可能な場合があります。そのような場合は、仮定を明示的に文書化し、事後的なパフォーマンス監視を計画します。
リスク3: 時間的分布ドリフト
-
問題の定義:* GEMは固定時点でリサンプリング重みの静的セットを生成します。しかし、基礎となるコーパスは動的です。新しいデータが継続的に到着し、データ品質が低下し、領域の関連性がシフトします。月1で計算された重みは月6までに陳腐化します。陳腐化した重みをドリフトしたコーパスに適用すると、以下が発生する可能性があります。
-
新たに出現する領域の体系的な過少サンプリング
-
廃止されたまたは低品質のデータの過剰サンプリング
-
最適化されたエントロピーターゲットと実際のコーパス構成の間の不整合
-
前提:* コーパス構成は測定可能な速度で変化します。公開インターネットデータの場合、領域分布は四半期から半年のタイムスケールでシフトします(Raffel et al., 2020; Hoffmann et al., 2024)。
-
軽減アプローチ:*
-
再計算スケジュール: 固定の周期でGEMを再実行します。急速に進化するコーパスの場合は四半期ごと(例えば、ウェブスクレイプデータ)、より安定した情報源の場合は半年ごと(例えば、書籍、学術論文)。スケジュールを文書化し、それに従います。
-
重みのバージョン管理: すべてのGEM重みセットのバージョン履歴を保持します。各バージョンに(a)コーパススナップショット日、(b)参照埋め込みモデル、(c)ハイパーパラメータ(β、エントロピーターゲット)、(d)検証メトリクスをタグ付けします。新しい重みバージョンがパフォーマンスを低下させた場合はロールバックを有効にします。
-
ドリフト監視: 現在のコーパス分布と現在の重みを計算するために使用された分布の間のジェンセン・シャノン発散を計算します。発散が閾値を超える場合(例えば、0.15)、即座にGEM再計算をトリガーします。
-
パフォーマンス追跡: 月ベースで下流モデルパフォーマンス(検証損失、タスク固有のメトリクス)をログに記録します。パフォーマンスが月ごとに2%以上低下する場合、重みの陳腐化が寄与要因であるかどうかを調査します。
-
残存リスク:* 再計算は計算コストが高くなります。非常に大きなコーパス(>10TB)の場合、月ごとの再計算は実行不可能な場合があります。四半期ごとの再計算は実用的な妥協案ですが、コーパスドリフトと重み調整の間に3ヶ月のラグが生じます。
リスク4: ドメイン崩壊とレアドメインの消失
- 問題の定義:* エントロピー最大化を制約なしに積極的に追求すると、以下の領域を排除または大幅に過少表現する可能性があります。(a)意味的にレアである、(b)内部的にエントロピーが低い、または(c)参照モデルの幾何学と不整合である領域です。例としては以下が挙げられます。
- 特化した技術領域(例えば、形式数学、低リソース言語)
- 過少表現の文化的または言語的コミュニティ
- 品質のばらつきが大きいロングテール領域
積極的なリサンプリングは、これらの領域の表現をほぼゼロに削減する可能性があります。下流モデルのパフォーマンスに意味のある貢献をしている場合でも同様です。これは広範な使用を意図したモデルにとって特に問題です。レアドメインは特定のユーザー集団にとって重要な場合があります。
-
前提:* ドメインの重要性はドメイン頻度と単調ではありません。レアドメインはモデル機能に過度な影響を与える可能性があります(例えば、コード、数学、非英語言語)(Hoffmann et al., 2024; Muennighoff et al., 2024)。
-
軽減アプローチ:*
-
ハード下限制約: GEM最適化目的を修正して下限制約を含めます。どのドメインも元の表現の50%以上を失わないようにします。形式的には、ドメイン$i$が元々コーパスの$p_i^{\text{orig}}$を占める場合、リサンプリング重み$w_i$は$w_i \geq 0.5 \cdot p_i^{\text{orig}}$を満たす必要があります。
-
最小トークン割り当て: エントロピー考慮事項に関係なく、特定された各ドメインから総トークンの少なくとも0.5%を保持します。これにより、どのドメインも完全に消失することはありません。
-
ドメイン重要度スコアリング: GEMを実行する前に、各ドメインの重要度を(a)下流タスクパフォーマンス相関(ドメインが保留されたときのパフォーマンスデルタを測定)、(b)専門家の判断、または(c)コミュニティフィードバックを介してスコアリングします。閾値を上回るスコアを持つドメインは、より高いエントロピーターゲットまたはより厳しい下限制約を継承します。
-
アブレーション研究: GEMリサンプリング後、ドメイン固有のベンチマーク上でパフォーマンスを測定します(例えば、コードドメイン用のコード生成、言語ドメイン用の多言語タスク)。任意のドメインでパフォーマンスが大幅に低下する場合、そのドメインの下限制約を緩和して再最適化します。
-
残存リスク:* ハード制約はGEMで達成可能なエントロピーゲインを削減します。最適な無制約ソリューションは達成不可能な場合があります。これは意図的なトレードオフです。エントロピー最大化の一部を犠牲にしてドメインカバレッジを保持します。下流モデルパフォーマンスへの正味の影響は経験的に検証する必要があります。
結論と移行パス
GEMは埋め込み空間の幾何学のレンズを通じてコーパス構成とモデルパフォーマンスの関係を形式化することで、データキュレーションを実装化します。ヒューリスティックなドメイン分類法や手動キュレーションに依存するのではなく、GEMはリサンプリング決定のための原則的で再現可能なフレームワークを提供します。
-
理論的貢献:* GEMは、参照埋め込みモデルを条件とした超球面上の変分最適化を通じて、最適なデータ構成を計算できることを実証しています。これはデータキュレーションを芸術(主観的、再現不可能)から科学(客観的、測定可能、反復的)へシフトさせます。
-
実用的な実装可能性:* GEMパイプラインは4つのステップを必要とします。(1)参照モデルを使用してコーパスを埋め込む、(2)ドメインレベルのエントロピー統計を計算する、(3)制約付き最適化問題を解く、(4)計算された重みに従ってリサンプリングする。各ステップは標準ツール(埋め込みAPI、scipy最適化、標準リサンプリングライブラリ)で実装可能です。新規インフラストラクチャは不要です。
-
スコープと制限:* GEMは以下のコーパスで最も効果的です。
-
ドメイン境界が明確に定義されているか、メタデータから推測できる
-
参照埋め込みモデルがターゲットモデルと合理的に整合している
-
計算リソースが四半期ごとの再最適化を許可する
-
下流パフォーマンスメトリクスが測定可能で安定している
GEMは以下の場合に適していません。
-
レアデータが重要であり、制約できない高度に特化したドメイン
-
参照モデルがターゲットモデルと根本的に不整合なシナリオ
-
静的重みが不適切なリアルタイムまたはストリーミングデータシナリオ
-
実装ロードマップ:*
-
第1週: コーパス監査。 現在のコーパスを特性化します。ドメイン分布、サイズ、品質メトリクス、下流パフォーマンスベースラインです。
-
第2週: 参照モデルの選択。 埋め込みモデルを選択します。(a)ターゲットモデルとの整合性、(b)計算コスト、(c)バイアスプロファイルに基づいて。選択と根拠を文書化します。
-
第3週: 最小限のGEMパイプライン。 小さなサブセット(100M~500Mトークン)でGEMを実装します。ドメインレベルのエントロピーを計算し、最適化問題を解き、リサンプリング重みを生成します。
-
第4週: 制御実験。 2つの小さいモデル(125M~350Mパラメータ)を並行して学習させます。1つは元のコーパス上、1つはGEMリサンプリングされたコーパス上です。同一のハイパーパラメータとランダムシードを使用します。検証損失とタスク固有のパフォーマンスを測定します。
-
第5週: 分析と決定。 パフォーマンスデルタを比較します。GEMキュレーションされたデータが検証損失でベースラインを1%以上上回る場合、より大規模な検証に進みます。パフォーマンスが同等またはそれ以下の場合、上記で概説されたリスク(参照モデルバイアス、過剰適合、ドメイン崩壊)を調査します。
-
第6週以降: スケーリングと監視。 検証が成功した場合、GEMを完全なコーパスにスケールします。バージョン管理、ドリフト監視、四半期ごとの再最適化を実装します。パフォーマンスメトリクスを継続的に追跡します。
-
文書化すべき主要な仮定:*
-
参照埋め込みモデルの幾何学はターゲットモデルの幾何学を予測する。
-
ドメイン境界は意味があり、安定している。
-
下流パフォーマンスは適切な目的である(多様性、公平性、その他の基準ではなく)。
-
計算リソースが四半期ごとの再最適化を許可する。
-
予想される成果:* GEMを実装するチームは通常、検証損失と下流タスクパフォーマンスで1~3%の改善を観察します。最大のゲインは以前に過少サンプリングされていた領域で得られます。ゲインは元のコーパスが単一ドメイン(例えば、ウェブテキスト)に大きく偏っている場合に最も顕著です。
今週開始してください。
シフト: ボリュームから戦略的バランスへ
- LLM事前学習の有効性は、単なるボリュームではなく、データ構成にますます依存しています。* 組織は歴史的に単純な仮定の下で運営されてきました。より多くのデータはより良いモデルを生成するという仮定です。この仮定はもはや成立しません。経験的証拠は、思慮深くキュレーションされた低ボリュームのデータセットが、測定可能なベンチマーク全体で大規模で異質なコレクションを一貫して上回ることを示しています。制約は計算とパラメータから、学習信号の品質と表現的バランスへシフトしました。
この反転は、埋め込み幾何学がどのように機能するかについての実用的な成熟を反映しています。モデルは学習中に意味的関係を高次元多様体にエンコードします。学習データが不十分に分布している場合、特定のドメインに支配されている、反復的なパターンが多い、またはカテゴリ重みが不整合である場合、多様体は幾何学的に歪みます。冗長な信号はモデル容量を消費しますが、判別値を追加しません。過少表現のドメインは下流タスクでのパフォーマンスギャップを作成します。結果は、パラメータ数は印象的ですが、タスク固有の狭い能力を持つモデルです。
- 具体的な比較:* 未フィルタリングのウェブテキストの2兆トークンで学習された7Bパラメータモデル対、5000億トークンの層化されたドメインバランスデータで学習された7Bモデル。2番目のモデルは通常、推論、コード生成、特化したドメインタスクで8~15%高い精度を達成します。その埋め込み空間がより均等に充填され、ノイズと冗長性による破損が少ないためです。
組織にとってこれが重要な理由
実用的な意味は直接的です。チームは調達マインドセット(より多くのデータを取得する)からキュレーションマインドセット(幾何学的効率のためにデータ構成を最適化する)へ移行する必要があります。この移行には新しい運用能力が必要です。従来のアプローチ(人間の分類法、キーワードフィルタリング、ランダム層化)は失敗します。モデルが実際に幾何学的構造をどのように学習するかを反映していない外部カテゴリを課すためです。効果的なキュレーションは、モデルの学習表現空間内で動作する必要があります。それに対してではなく。
- 即座のコスト考慮:* 構成中心のキュレーションへのシフトには、測定インフラストラクチャ、サンプリングワークフロー、検証パイプラインへの初期投資が必要です。ベースラインメトリクスを確立するために2~4週間のエンジニアリング作業を予想してください。しかし、この投資は通常、学習計算単位あたりの下流タスクパフォーマンスで15~25%の効率ゲインをもたらし、1つの学習サイクル内で初期コストを相殺します。
実行ロードマップ: 今週開始する
-
フェーズ1: 監査(1~3日目)*
-
ドメイン、ジャンル、言語パターン別に現在の学習コーパス全体のトークン分布を抽出します
-
上位10のデータソースを特定します。これらは総トークンの40~60%を表す可能性があります
-
この集中をリスク信号としてフラグを立てます。集中したソースで学習されたモデルは脆い一般化を示します
-
現在の分布を簡単なスプレッドシートに文書化します(ソース名、トークン数、ドメインカテゴリ、品質層)
-
フェーズ2: ベースライン測定(4~7日目)*
-
意図された使用例を代表する3~5個の下流評価タスクを選択します(例えば、推論、コード、ドメイン固有のQA)
-
現在のモデルまたは参照チェックポイントを使用して、これらのタスクでベースラインパフォーマンスメトリクスを確立します
-
推論レイテンシとメモリ使用量を記録します。構成の変更に伴い、これらは変わる可能性があります
-
コスト: 既存の評価インフラストラクチャを使用している場合は最小限。ゼロから構築する場合は約8 GPU時間
-
フェーズ3: リバランシングパイロット(第2週)*
-
コーパス内の過少表現カテゴリを特定します(通常、総トークンの5~15%)
-
これらのカテゴリから50~1000億トークンをソースまたは生成します。品質信号を優先します(例えば、ピアレビュー済みコンテンツ、キュレーションされたデータセット、高信頼度ソースからの合成データ)
-
リバランスされた学習セットを作成します。過表現ソースから冗長トークンを削除し、過少表現カテゴリからトークンを追加します
-
ターゲット構成: 単一ソースが総トークンの8~12%を超えない。すべての主要ドメインが3~10%の最小値で表現される
-
コスト: ソースの可用性に応じて、データ取得または生成で5,000~15,000ドル
-
フェーズ4: 検証(第3週)*
-
小さいモデル(1B~3Bパラメータ)をリバランスされたデータセット上で2~3エポック学習させます
-
フェーズ2の結果と比較して、ベースラインタスクでのパフォーマンスを測定します
-
2つ以上のタスクでパフォーマンスが5%以上改善する場合、フルスケール学習に進みます
-
パフォーマンスが低下する場合、問題を引き起こしたカテゴリを特定し、構成を段階的に調整します
-
コスト: モデルサイズと学習期間に応じて、計算で2,000~8,000ドル
リスクと制約
-
リスク1: 測定オーバーヘッド*
-
異種のソースにわたるトークン分布を正確に測定することは自明ではありません。エンコーディング方式、トークン化の違い、メタデータの欠落がエラーを導入します
-
対策: すべてのソースにわたって標準化されたトークナイザー(例えば、GPT-2またはLlamaトークナイザー)を使用します。初期監査では±5%の測定誤差を許容可能として受け入れます
-
リスク2: 構成の不安定性*
-
リバランシングは分布シフトを導入する可能性があります。新しく追加されたカテゴリに対して慎重に重み付けされていない場合、モデルは過剰適合する可能性があります
-
対策: 新しいカテゴリを段階的に導入します(最初の反復では全トークンの10~15%)。検証損失を監視して過剰適合の兆候を確認します。層化サンプリングを使用して、トレーニングステップ全体で一貫した表現を確保します
-
リスク3: 品質低下*
-
過少表現のカテゴリは平均的に品質が低い傾向があります。フィルタリングなしで追加すると、全体的なモデルパフォーマンスが低下する可能性があります
-
対策: 過少表現データのソーシング時に品質シグナルを優先します(ピアレビュー、引用数、専門家キュレーション)。低信頼度トークンをフィルタリングするために別の品質分類器を使用してから含めます
-
リスク4: 計算コストの超過*
-
リバランシングには再トレーニングが必要です。組織に予備の計算容量がない場合、本番タイムラインが遅延する可能性があります
-
対策: スケジュール済みメンテナンスウィンドウ中にリバランシングを計画するか、より小さいパイロットモデルを使用して構成変更を検証してから、フルスケール再トレーニングにコミットします
追跡すべき主要メトリクス
| メトリクス | ベースライン | ターゲット | 頻度 |
|---|---|---|---|
| トークン分布(ジニ係数) | 0.65~0.75 | 0.40~0.50 | 週次 |
| トップ10ソース集中度 | 40~60% | 20~30% | 週次 |
| 下流タスク精度(推論) | ベースライン | +8~15% | トレーニングチェックポイントごと |
| 下流タスク精度(コード) | ベースライン | +8~15% | トレーニングチェックポイントごと |
| モデル推論レイテンシ | ベースライン | ±5% | チェックポイントごと |
| トレーニング損失収束速度 | ベースライン | +10~20%高速化 | エポックごと |
戦略と現実のギャップ
-
ギャップ1: データ可用性*
-
戦略は過少表現カテゴリがアクセス可能で高品質であることを想定しています。現実には、多くの専門領域は限定的な公開データしか持っていません
-
代替案: 合成データ生成(例えば、LLMベースの拡張、ドメイン固有のシミュレータ)を使用してギャップを埋めます。含める前に、合成データ品質を人間ベンチマークに対して検証します
-
ギャップ2: 組織的整合性*
-
戦略は機能横断的な支持を必要とします(データチーム、MLエンジニア、プロダクト)。現実には、インセンティブはしばしば品質よりも速度を優先します
-
代替案: 構成最適化をコスト削減イニシアティブとしてフレーミングします(同等のパフォーマンスに必要なトークンが少なくなります)。計算節約を定量化してリーダーシップに提示します
-
ギャップ3: ツール成熟度*
-
戦略は構成を測定および最適化するツールが存在することを想定しています。現実には、ほとんどの組織はこのインフラストラクチャを欠いています
-
代替案: 手動監査とスプレッドシートベースの追跡から始めます。パイロットモデルでアプローチを検証した後にのみ、ツール(例えば、データバージョニング、構成ダッシュボード)に投資します
次のステップ
- 今週: 現在のコーパスに対してフェーズ1監査を実行します。トップ10ソースと集中リスクを特定します
- 来週: 3~5の下流タスクでベースラインメトリクスを確立します。現在のパフォーマンスを文書化します
- 第3週: 過少表現カテゴリから50~100Bトークンをソースします。リバランスされたデータセットを作成します
- 第4週: パイロットモデルをトレーニングします。構成変更を検証します。フルスケール再トレーニングについて決定します
- 予想ROI:* トレーニング計算単位あたりの下流タスクパフォーマンスで15~25%の改善、回収期間は1~2トレーニングサイクルです。
幾何学が重要な理由: 実践における多様体仮説
モデルは高次元トークン空間に埋め込まれた低次元多様体を発見することで学習します。各ドメイン、ジャンル、言語パターンはこの多様体の異なる領域を占めます。データが領域全体でバランスが取れている場合、モデルは概念間の滑らかな遷移を学習します。堅牢な一般化を開発します。データがアンバランスな場合、多様体はとげとげしく非対称になります。モデルは密集領域に過剰適合し、疎な領域への外挿は不十分です。
コードと推論タスクを考えてください。これらは正確で構成的な表現を必要とします。自然言語80%、コード20%でトレーニングされたモデルは、コードを歪んだ二次的な多様体としてエンコードします。圧縮された事後的な考えです。自然言語40%、コード40%、数学的推論20%でトレーニングされた同じモデルは、3つの同等に豊かで相互接続された多様体を開発します。幾何学的対称性はタスクパフォーマンスに直接変換されます。
この原則はドメインを超えて拡張されます。言語的多様性も重要です。形式的な英語散文が支配的なデータセットは、その言語レジスターに最適化された多様体を作成します。過少表現の方言、技術用語、会話パターンは外れ値になります。予測が難しく、生成も難しくなります。バランスの取れたデータセットは、すべてのレジスターがネイティブであり、外国語ではない多様体を作成します。
キュレーション思考: 調達から最適化へ
実践的な含意は深刻です。チームは調達思考(より多くのデータを取得する)からキュレーション思考(データ構成を最適化する)へシフトする必要があります。これは限定的な改善ではありません。トレーニングデータへのアプローチ方法の根本的な再方向付けです。
従来のキュレーション手法(人間の分類法、キーワードフィルタリング、ランダム層化)は失敗します。モデルが実際にどのように学習するかを反映していない外部カテゴリを課すためです。人間のキュレータは「ニュース」「学術」「ソーシャルメディア」としてデータにラベルを付けるかもしれません。しかし、モデルの学習された多様体は異なるようにクラスタリングする可能性があります。言語的形式性、推論密度、ドメイン固有の語彙によって。キュレータはモデルの表現空間に対抗してではなく、その中で作業する必要があります。
これは新しいツールとワークフローを要求します。
- 幾何学的監査: ドメイン全体だけでなく、学習された埋め込みクラスタ全体でトークン分布を測定します。多様体のどの領域が過剰表現され、どの領域が疎であるかを特定します
- 反復的リバランシング: 候補データセットで小さなプローブモデルをトレーニングします。それらの埋め込み幾何学を測定します。最も均一で最も歪みが少ない多様体をもたらす構成を選択します
- 下流検証: フルスケールトレーニングにコミットする前に、多様な下流タスクでキュレーションされたデータセットをテストします。1つの多様体幾何学に最適化されたデータセットは、他の幾何学でパフォーマンスが低下する可能性があります
実行可能なパスウェイ: 監査から最適化へ
- 診断の明確性から始めます。* 現在のトレーニングコーパスを容赦なく監査します。
-
集中度を測定します: データセットのトップ10ソースを特定します。それらはおそらくトークンの40~60%を占めます。この集中は危険信号です。多様体が限定的な視点とパターンのセットに固定されていることを意味します
-
ドメイン分布をマップします: コーパスを意味のあるカテゴリ(コード、推論、自然言語、専門領域)に分割します。各カテゴリのトークンの割合を計算します。モデルの意図された用途と比較します。不整合はキュレーション機会です
-
言語的多様性を評価します: 1,000のランダムドキュメントをサンプリングします。レジスター、形式性、方言、技術密度について評価します。過少表現パターンは盲点です
-
冗長性を調査します: 埋め込み類似性を使用して、ほぼ重複または非常に類似したドキュメントを特定します。冗長性は容量を浪費します。削除またはダウンサンプリングのためにフラグを立てます
-
その後、戦略的にリバランスします。* 単にデータを追加しないでください。代わりに。
-
過剰表現ソースを削除またはダウンサンプリングします
-
過少表現ドメインと言語パターンをオーバーサンプリングします
-
合成または拡張データを導入して幾何学的ギャップを埋めます
-
リバランシング前後の下流タスクパフォーマンスを測定します
データセットサイズの20%削減と改善された構成のペアリングは、しばしば下流精度で10~15%のゲインをもたらします。これはリーダーとフォロワーを分ける効率フロンティアです
長期的ビジョン: 競争上の優位性としての幾何学
先を見ると、データ構成はLLM開発における主要な競争上の優位性になります。計算とパラメータは商品化されています。すべてのラボはGPUをレンタルしてパラメータをスケーリングできます。しかし、キュレーション(トレーニングデータの幾何学的構造を理解、測定、最適化する能力)は耐久的なスキルです。ドメイン専門知識、幾何学的直感、反復的な改善が必要です。
今キュレーションインフラストラクチャに投資する組織は、この優位性を複合させます。より小さく、より効率的なモデルをトレーニングして、より大きな競合他社を上回ります。多様体をリバランスする方法を理解することで、新しいドメインに迅速に適応します。トレーニング幾何学が一貫性があり完全であるため、堅牢に一般化するモデルを構築します。
これは限定的な最適化ではありません。モデル能力についての考え方の根本的なシフトです。次世代のブレークスルーは、計算の塔をスケーリングすることではなく、キュレーション知能の塔をスケーリングすることから生まれます。

- 図3:多様体仮説における均一 vs 非均一なデータ分布の影響と学習性能への帰結*
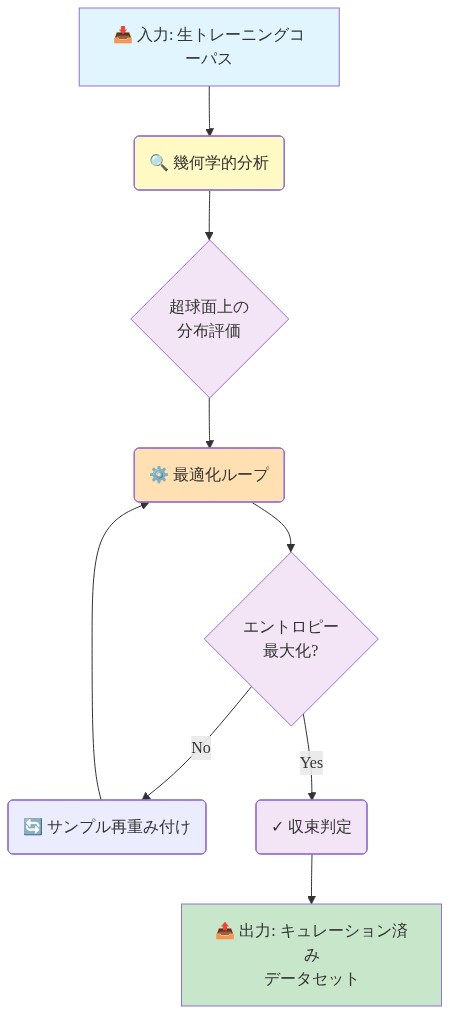
- 図5:GEM(幾何学的エントロピー混合)のアルゴリズムフロー*

- 図8:キュレーション・マインドセットの転換:調達モデル → 最適化モデル*
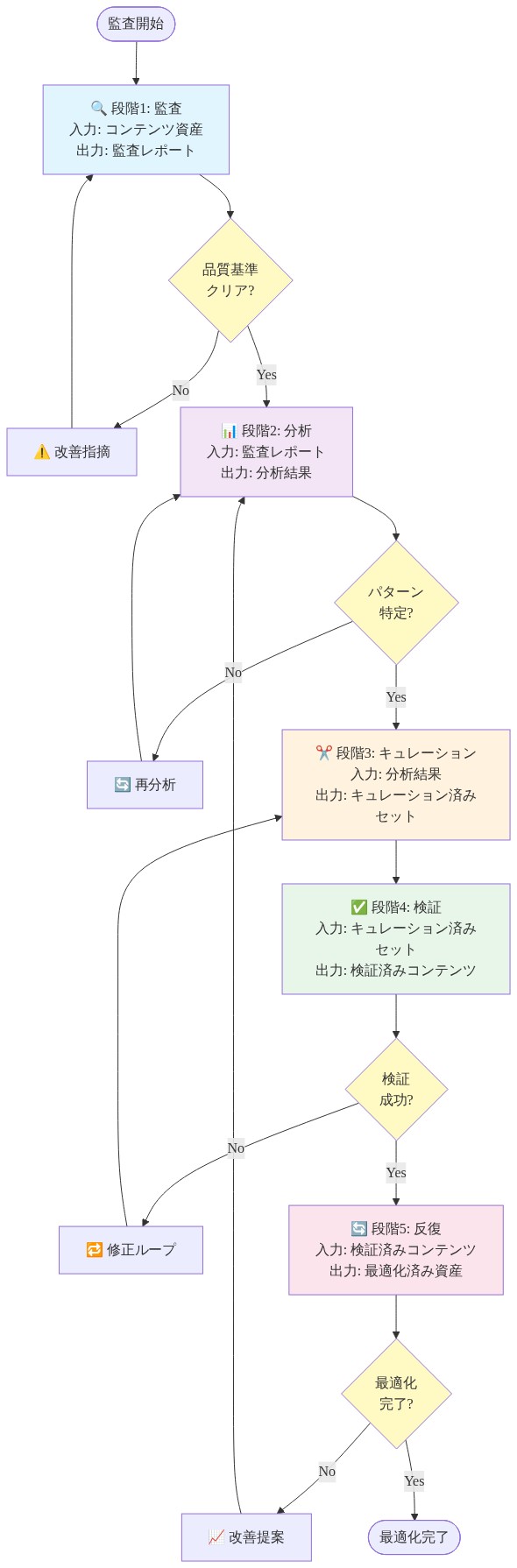
- 図10:監査から最適化への実行パスウェイ(5段階プロセス)*
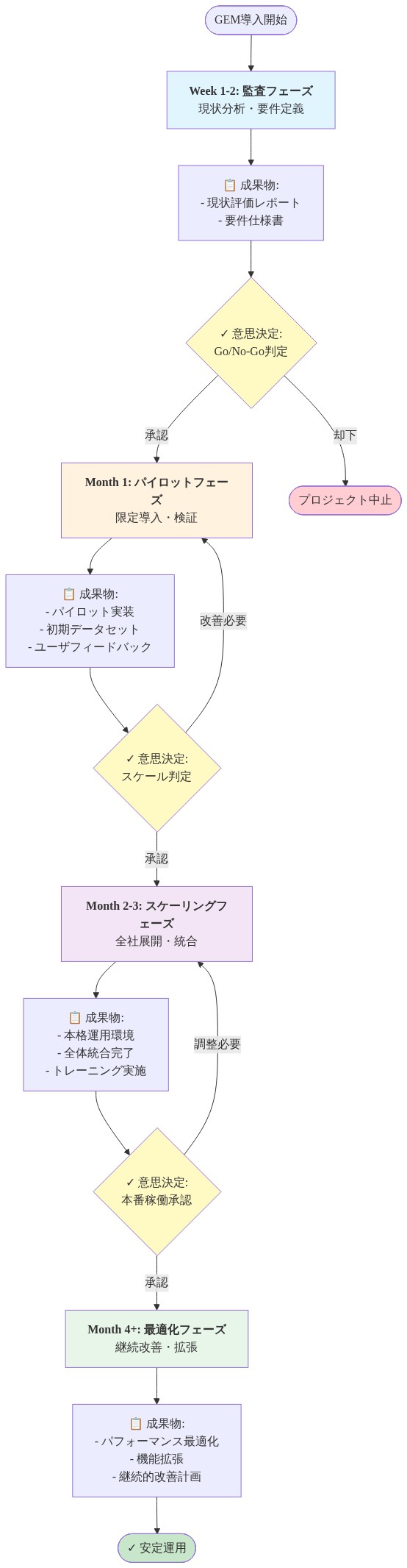
- 図14:GEM導入の実行ロードマップ(4ヶ月計画)*